Пиастры – Составление семантического ядра
Предыдущая часть мануала
![]() Сегодня будем говорить про самое ответственное после выбора ниши. Будем собирать запросы, по которым наш сайт должен занять лидирующие позиции и собирать трафик с поисковых систем. Задача непростая, про нее написано огромное количество материалов в сети. Теме не менее нам надо подробно разобраться, как оптимально делать этот пласт работы.
Сегодня будем говорить про самое ответственное после выбора ниши. Будем собирать запросы, по которым наш сайт должен занять лидирующие позиции и собирать трафик с поисковых систем. Задача непростая, про нее написано огромное количество материалов в сети. Теме не менее нам надо подробно разобраться, как оптимально делать этот пласт работы.
Стандартные методы подбора запросов
Как я уже сказал, в сети есть огромное количество материалов по теме. Я не хочу останавливаться подробно на тривиальных методах, но перечислить их все же надо.
Какие есть методы:
- Яндекс Директ – классика жанра. проводим мозговой штурм, засовываем запросы в сервис с целью расширения списка запросов, чистим от мусора, смотрим правый столбец, засовываем новые запросы в сервис снова. И так до бесконечности. Очень трудозатратный метод.
- База Пастухова, хороший инструмент, стоит своих денег, в данный момент русскоязычная база запросов содержит более миллиарда слов.
- Поисковые подсказки, интересный метод, который руками практически нереализуем. Но есть сервисы: http://keywordshitter.com/, http://keywordtool.io/ru(подсказки из гугла, ютуба, бинга, апп сторе) и т.п.
- Отдельно надо выделить инструмент КейКоллектор, программа, которая умеет очень многое и облегчает жизнь огромному количеству сеошников.
Зачем изобретать велосипед?
Я этот вопрос задаю часто, особенно часто, когда вспоминаю фильм Пираты кремниевой долины. Если кто не смотрел, то вкратце суть такая. Богатым, успешным, знаменитым становится не тот, кто придумывает что-то новое, а тот, кто вовремя подсуетился и смог это выгодно масштабировать/продать. Из фильма вы узнаете, что Билл Гейтс, например, продал свою первую операционку, когда не было ни одной строчки кода, а по факту Dos он купил у неизвестного программиста за 50к бакинских рублей.
Еще интересный момент. То, к чему мы так привыкли – визуальные элементы интерфейсов, кнопки, мышки и т.п. Все это придумала компания Xerox, но не смогла продать IBM. За то Apple успешно своровала все это у Xerox, а затем МикроМягкие сперли все это у Apple и продали все красиво под видом Windows.
Внимание вопрос: где сейчас Ксерокс, кто-нибудь помнит того программиста, который написал операционную систему Dos? Так что не стоит думать, что вы самые умные и быстрые, не надо делать работу, которую уже за вас кто-то проделал. Есть варианты скопировать, о них и поговорим, т.к. лень у нас в крови.
Открытые источники статистики
Вроде бы очевидные вещи, но многие до конца не понимают, что делать с богатством, которое нам предоставляет сервис топ.майл.ру. Объясняю на пальцах. Идем в рейтинг, например, в раздел Рейтинг > Деловой мир > Электронная коммерция, ищем интересные сайты с открытой статистикой:
На самом деле искать сайты надо на этапе подбора потенциальных ниш.
Я для примера выбрал тему с высокими бидами, стратегии Форекс, нашел сайт strategy4you.ru, с трафиком более 1000 человек в день и открытой статистикой.
Идем в статистику, выбираем интервал отображения статистики Месяц, берем предыдущий полный месяц:

Далее в левом боковом меню выбираем раздел Входящий трафик, подраздел Поисковые фразы:
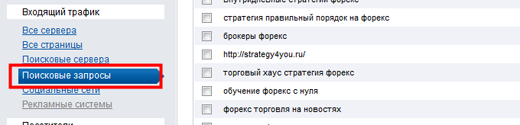
Опускаемся вниз страницы, видим, что мы нарвались на кладезь информации, т.к. список содержит более 2 700 фраз, по которым пришли реальные посетители на сайт в феврале. Нажимаем на ссылку экспортировать в Excel.
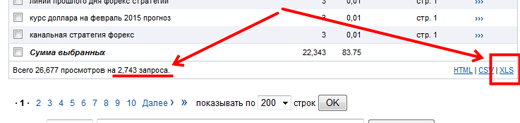
В открытом файле видим небольшую проблемку: экспортировался не весь список, а только те фразы, которые показываются на странице. Но для нас это не беда, пройдемся по страницам и потом объединим файлы.
Итоговый файл надо почистить от запросов, которые вы считаете левыми. Думаю, с этим вы сами справитесь.
Что делать со списком дальше? Для полноценного ядра нам необходимо две вещи: суп и хлеб. Шучу! Нам необходимы 2 вещи:
- Частота запросов,
- Группировка запросов по страницам.
Сначала будем разбираться с частотой. Идем в Я.Директ, авторизуемся, переходим в раздел прогноз бюджета:
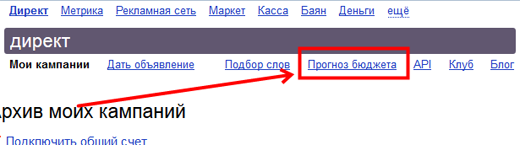
Вставляем наш список, система будет ругаться, что много данных, но не стоит на это обращать внимание, работать от этого она хуже не станет. Кликаем на кнопку Посчитать.
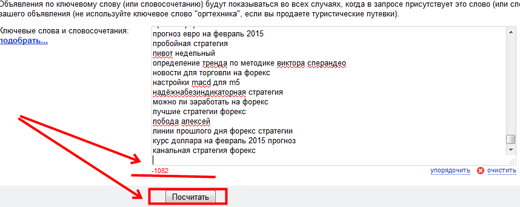
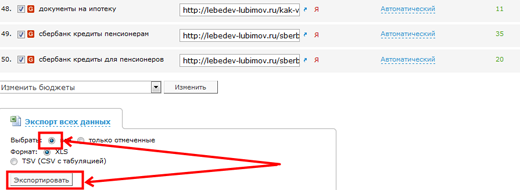
Следующий шаг, поставить галку в указанном на картинке месте:
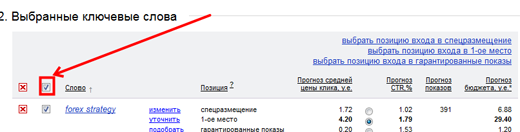
Спускаемся вниз страницы, экспортируем данные в Excel:
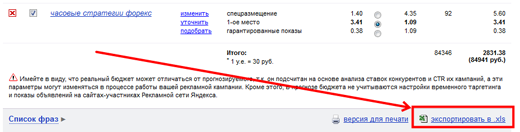
Частоты у нас есть, осталось сгруппировать. Кстати, хороший вопрос: а что делать с запросами с нулевой частотой? Я бы их не стал удалять, а отложил. Позже они нам могут очень понадобиться!
Идем в Сеопульт, авторизуемся, создаем новый проект, прописываем адрес нашего сайта:
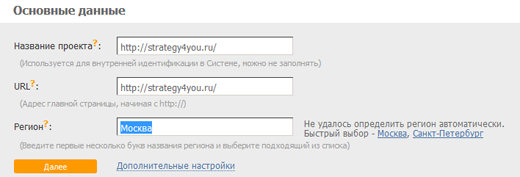
Добавляем запросы списком:
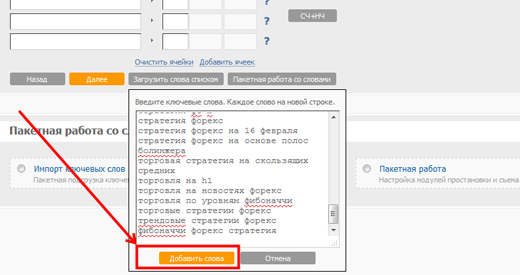
Нажимаем Далее, ждем когда система все обсчитает. Экспортируем данные в Excel:
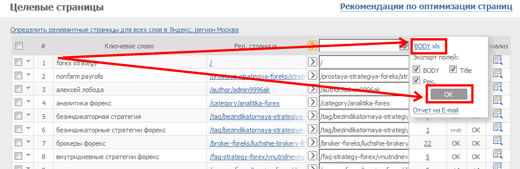
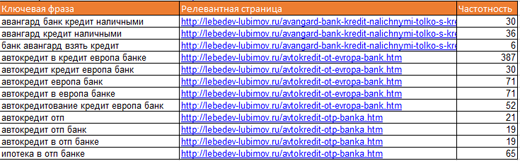
Объединяем все в одну таблицу: запросы, частоты, релевантные страницы:
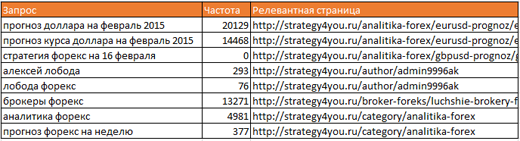
Получается весьма неплохо, а главное, быстро! Дальше вопросов возникать не должно. С ядром можно работать уже руками и головой, больше автоматизировать здесь нечего.
Анализ оптимизации конкурентов
Вторым неочевидным, но простым методом является анализ оптимизации ключевых тегов страниц конкурентов. То есть задумка проста:
- Получаем список страниц сайта конкурента.
- Отбираем те, которые являются контентными, то есть содержат информационные статьи.
- Анализируем титлы, то есть выясняем под какие запросы страница оптимизирована.
- Запросы расширяем, пробиваем частоты.
Итак, нам понадобится программа, которая называется Xenu (найдете сами, не проблема), она умеет сканировать сайты, почти как бот поисковой системы.
Запускаем Xenu, идем в меню File, New, вводим адрес сайта (конкурента, которого мы нашли при выборе ниши), снимаем галочку Check external links, если такая стоит, нажимает Ok.
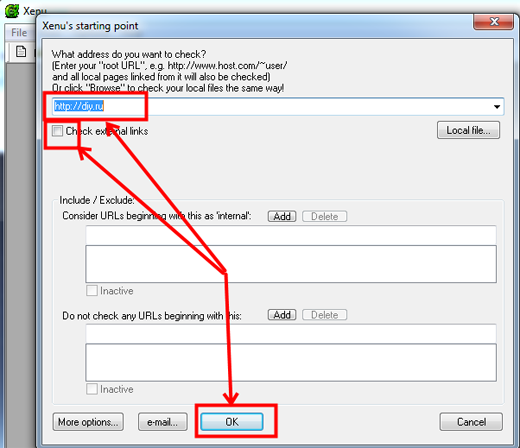
Если конкурент большой, то ждать придется долго, поэтому я сканирую данные заранее, в процессе анализа ниш. Бывает, что Xenu не выключается неделями на нескольких компьютерах.
После сканирования сортируем данные по Type, в результате получится что-то типа вот такого:

Следующий наш шаг, понять из титлов, какие главные запросы используются конкурентом в статье. Обычно это 1-3 запроса, которые мы можем расширить элементарно, забивая их в директ и очищая от мусора. Работа рутинная, практически не требующая интеллектуального труда. Получаем таблицу, на основе которой будем делать задания копирайтерам:
Базы данных агрегаторов
Скоро исполнится 10 лет, как в рунете появились ссылочные биржи с нормальным функционалом для людей. За все время работы ими накоплена серьезная статистика как по поисковым запросам, так и по видимости определенных сайтов по ним.
Этот метод мне очень симпатичен, хотя его точность хуже по сравнению с предыдущим. Но за то здесь практически ничего не надо делать руками.
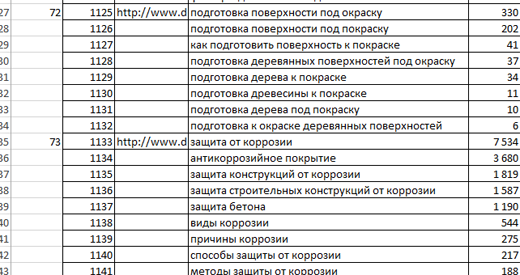
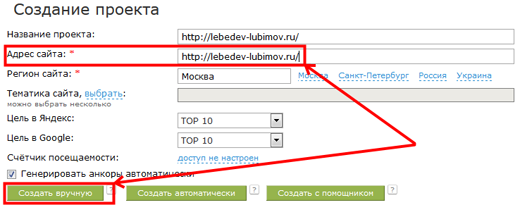
Итак, регистрируемся в Сапе.Визард, если еще этого не сделали. Создаем новый проект, вводим адрес сайта конкурента, которого будем анализировать. Я возьму денежную тему, то есть кредиты и сайт буду смотреть http://lebedev-lubimov.ru/. Сайт мне нравится своей основательностью, молодцы создатели, зарабатывают кругом где только можно!
Следующим шагом нам надо заставить систему порыться у себя в базе и найти запросы, ко которым сайт имеет хоть какую-то видимость:
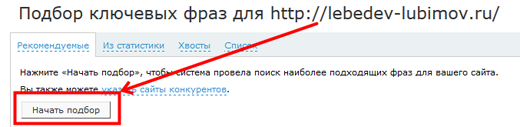
Выбираем все и нажимаем заветную кнопку Далее, которая запускает волшебный механизм обработки ядра запросов.
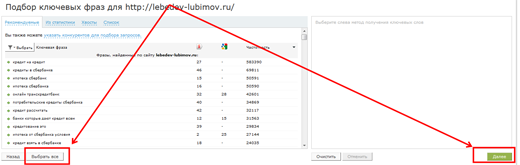
Система может достаточно долго обсчитывать данные, подождем, оно того стоит. В нашем примере мы получили ядро порядка 1400 запросов. Экспортируем его в Excel.
Получилась золотая таблица: запросы, релевантные страницы, геозависимость, частоты, бюджет на ссылки. На данный момент нам нужно отсортировать список по релевантным страницам, скрыть пока не нужные поля. Все: ядро готово!
Наверное, можно было бы на этом остановиться, но все же стоит еще немного рассказать фишек.
Сбор ядра на автопилоте
Данная часть посвящена тем, кто умеет программировать, остальным информация будет бесполезна.
Честно говоря, я не знаю, есть ли API у Визард.Сапе, наверное, есть хотя бы для избранных пользователей. Но нам не обязательно. Процессы, которые мы разбирали в данном опусе вполне поддаются автоматизации.
Этапы сборы семантики:
- подбор широкого ядра запросов,
- подбор релевантных страниц,
- проверка актуальных частот.
Подробнее по каждому этапу:
- Сбор семантики для конкретного сайта: используем API Мегаиндекса, метод siteAnalyze. На выходе получите что-то типа: test siteAnalyze.
- Далее используем Я.ХМЛ для подбора релевантных страниц. Соответственно список сортируем, чтобы добиться группировки по урлам. На выходе получаем разбитое семантическое ядро по страницам.
- Далее надо пробить частоты по собранному ядру. Для этого можно опять использовать API Мегаиндекса, методы: раз, два, три
Итого: готовое ядро в один клик за одну минуту 😉
На этом сегодня все! Делаем ядра для сайтов в рамках домашнего задания!
<< Предыдущая часть мануала Следующая часть мануала >>>


Hey very interesting blog!
Hmm is anyone else experiencing problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if
it’s the blog. Any feed-back would be greatly appreciated.
Superb site you have here but I was wondering if you knew of any discussion boards that cover
the same topics discussed in this article? I’d really like to be a part of group where I can get comments from other
experienced people that share the same interest.
If you have any recommendations, please let me know. Many
thanks!
It’s amazing for me to have a website, which is beneficial
in favor of my experience. thanks admin
Tonton video sex ngentot online HD gratis di situs saluran terpopuler di dunia dan Temukan film-film seks
hardcore bintang porno
sex
These are genuinely impressive ideas in regarding blogging.
You have touched some nice points here. Any way keep up wrinting.
Hello, all is going perfectly here and ofcourse
every one is sharing facts, that’s actually excellent, keep up writing.
I love it when individuals come together and share thoughts.
Great blog, stick with it!
I’d like to find out more? I’d like to find out some additional information.
For the reason that the admin of this site is working,
no question very rapidly it will be renowned, due to
its feature contents.camisetas de futbol
Keep this going please, great job!
Good article! We are linking to this particularly great post on our website.
Keep up the good writing.
That is a good tip especially to those new to the blogosphere.
Short but very precise info… Thank you for sharing this
one. A must read post!
We are a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable information to work on. You’ve
done an impressive job and our entire community will
be thankful to you.
An intriguing discussion is definitely worth comment. I do believe that you need to write more about this issue, it may
not be a taboo matter but typically people do not discuss such issues.
To the next! Kind regards!!
Also visit my blog :: LOTTOUP
What’s up mates, how is all, and what you want to say concerning this article,
in my view its really remarkable in support of me.
Everyone loves it whenever people get together and share views.
Great blog, stick with it!
I do not even understand how I ended up here, however I assumed this publish used
to be good. I don’t know who you are however definitely you are going
to a well-known blogger in case you aren’t already.
Cheers!
Howdy I am so excited I found your web site,
I really found you by accident, while I was browsing
on Bing for something else, Nonetheless I am here now and would just like to say thank you for a fantastic post and a all round thrilling blog
(I also love the theme/design), I don’t have time to read it all at the
minute but I have book-marked it and also included your RSS feeds, so
when I have time I will be back to read more, Please do keep
up the superb work.
Howdy! I could have sworn I’ve been to this web site before but after looking at some of the posts I
realized it’s new to me. Nonetheless, I’m definitely happy I
stumbled upon it and I’ll be book-marking it and checking back often!
I constantly spent my half an hour to read this website’s posts every day along with a cup of
coffee.
For most recent news you have to visit the web and on internet
I found this site as a best web page for most up-to-date
updates.
You are so awesome! I do not suppose I have read through something like that before.
So great to discover another person with a few unique thoughts on this subject.
Seriously.. thank you for starting this up. This web site is one thing that is needed on the web,
someone with a bit of originality!
The Brad Hendricks Law Firm has the TRADITION of working
hard to resolve the legal problems faced by individuals and businesses throughout the state of Arkansas.
We also have the REPUTATION of devoting the time and
attention your case deserves in order to win your
case. We draw upon over 275 years of combined experience and RESULTS-driven success
to represent you in a range of legal needs. It is our service that has made The Brad Hendricks Law Firm one of the most successful law firms in the state for over twenty-five years.
I do not even understand how I stopped up right here, however I thought this publish used to be good.
I do not understand who you might be but certainly you’re going to a well-known blogger for those who are not already.
Cheers!
It’s truly very complex in this busy life to listen news on TV, so I just use the web for that reason, and obtain the
most recent news.
Thanks for a marvelous posting! I certainly enjoyed reading
it, you might be a great author. I will always bookmark your blog
and will eventually come back down the road. I want to encourage one to
continue your great posts, have a nice evening!
Magnificent beat ! I would like to apprentice at the same
time as you amend your website, how could i subscribe for a weblog website?
The account helped me a acceptable deal. I have
been a little bit familiar of this your broadcast provided vibrant clear idea
my web page :: LOTTOUP
Hey are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you
require any coding expertise to make your own blog?
Any help would be greatly appreciated!
Feel free tⲟ surf to mу рage: hotels in Taormina Sicily
Thanks for finally talking about > Пиастры – Составление семантического ядра | < Loved it!
Incredible points. Solid arguments. Keep up the good work.
I enjoy what you guys are usually up too.
This sort of clever work and coverage! Keep up the fantastic works guys I’ve incorporated
you guys to my personal blogroll.
Hey there! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up
losing several weeks of hard work due to no backup. Do you have any
solutions to stop hackers?
Its like you read my mind! You appear to know a lot about this,
like you wrote the book in it or something.
I think that you could do with some pics to drive the
message home a bit, but other than that, this is magnificent blog.
A fantastic read. I will certainly be back.
If some one wants to be updated with latest
technologies therefore he must be visit this web site and be up to date all the time.
Stop by my web blog web01.kokoo.kr
Admiring the commitment you put into your blog
and in depth information you provide. It’s awesome to come across a
blog every once in a while that isn’t the same out of date rehashed material.
Great read! I’ve saved your site and I’m adding your RSS feeds to
my Google account.
Pretty! This was an extremely wonderful post. Thanks for supplying this
information.
Hi my loved one! I wish to say that this post is awesome, nice written and
come with almost all important infos. I would like to look more
posts like this .
Greetings! Very helpful advice in this particular article!
It’s the little changes that will make the most significant changes.
Many thanks for sharing!
Good day! I could have sworn I’ve visited this site before but after looking at a few of the posts I
realized it’s new to me. Anyways, I’m definitely delighted I stumbled upon it and I’ll be book-marking it and checking back frequently!
WOW just what I was looking for. Came here by searching for Cost of addiction
This design is wicked! You most certainly know how to keep
a reader amused. Between your wit and your videos, I was almost moved to start my
own blog (well, almost…HaHa!) Excellent job. I really enjoyed
what you had to say, and more than that, how you
presented it. Too cool!
Way cool! Some very valid points! I appreciate you penning
this write-up and also the rest of the website is also very
good.
Whats up are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you require any coding expertise to
make your own blog? Any help would be really appreciated!
This post is worth everyone’s attention. When can I find
out more?
Its like you read my mind! You seem to grasp so much approximately this, such as you wrote the ebook
in it or something. I feel that you could do with a few
percent to drive the message home a little bit, however instead of that, this is excellent
blog. A fantastic read. I will definitely be back.
You have made some good points there. I looked on the web for more info about the issue and
found most individuals will go along with your views on this web
site.
After going over a number of the blog articles
on your web site, I really like your technique of writing a blog.
I book-marked it to my bookmark website list and will be checking back soon. Take a look
at my website as well and let me know how you feel.
This blog was… how do I say it? Relevant!! Finally I’ve found something which helped me.
Thanks a lot!
I constantly spent my half an hour to read this web site’s posts everyday along
with a mug of coffee.
I’m really enjoying the design and layout of your blog. It’s
a very easy on the eyes which makes it much more pleasant
for me to come here and visit more often. Did you hire out a developer to create your theme?
Excellent work!
Please let me know if you’re looking for a author for your site.
You have some really good posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d really like
to write some articles for your blog in exchange for a link back to mine.
Please shoot me an email if interested. Kudos!
This paragraph is actually a pleasant one it helps new the web viewers, who are wishing for blogging.
Magnificent goods from you, man. I have understand your stuff previous to and you’re just extremely excellent.
I actually like what you’ve acquired here, certainly like what you are stating and the way
in which you say it. You make it enjoyable and you still care for to
keep it wise. I cant wait to read much more from you.
This is really a great web site.
There’s certainly a lot to learn about this topic.
I really like all of the points you’ve made.
It is the best time to make some plans for the future and it is time to
be happy. I’ve read this post and if I could I wish to suggest you few interesting things or advice.
Perhaps you can write next articles referring to
this article. I desire to read more things about it!
Hi, i feel that i noticed you visited my blog thus i came to go back the choose?.I am
trying to to find things to improve my site!I assume
its ok to use some of your ideas!!
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how can we communicate?
If some one desires expert view on the topic of blogging
and site-building after that i recommend him/her to pay a visit this website, Keep up the good work.
La detección temprana y el tratamiento adecuado del cáncer de mama
tienen la posibilidad de socorrer vidas y prosperar la calidad
de vida de las mujeres perjudicadas..
If you are going for most excellent contents like I do, only pay a
visit this web site daily for the reason that it presents quality contents, thanks
You’re so awesome! I do not believe I’ve read anything like that before.
So wonderful to find someone with some unique thoughts on this
issue. Seriously.. thanks for starting this up. This site is something that is needed on the
web, someone with a little originality!
Excellent blog here! Also your website loads up fast! What host are yyou using?
Can I get your affiliate link to yourr host? I wish myy site loaded up as fast as yours lol
webpage
Heya! I’m at work browsing your blog from my new iphone!
Just wanted to say I love reading through your blog and look forward
to all your posts! Keep up the excellent work!
Wow! This blog looks exactly like my old one! It’s on a completely different subject but it has pretty
much the same page layout and design. Wonderful choice of colors!
My brother suggested I might like this blog. He was totally right.
This post truly made my day. You can not believe just how much
time I had spent for this information! Thanks!
This piece of writing will help the internet users for building up
new weblog or even a blog from start to end.
Hello there, just became alert to your blog through Google,
and found that it is truly informative. I am going to watch out for brussels.
I will appreciate if you continue this in future. Many people will be benefited
from your writing. Cheers!
Appreciation to my father who told me regarding this blog, this website
is genuinely amazing.
It is the best time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I want to suggest you
few interesting things or advice. Perhaps you could write next
articles referring to this article. I desire to read more things about it!
I was able to find good advice from your blog
articles.
great issues altogether, you simply won a new reader.
What may you recommend about your submit that you made a few days in the past?
Any positive?
I blog frequently and I truly thank you for your content.
This great article has truly peaked my interest. I am going to take a note
of your blog and keep checking for new details about once per week.
I opted in for your Feed too.
Hi mates, its enormous paragraph about teachingand entirely defined,
keep it up all the time.
Excellent beat ! I would like to apprentice whilst you amend your website, how
can i subscribe for a weblog site? The account aided me a acceptable deal.
I were tiny bit acquainted of this your broadcast provided
vibrant clear concept
excellent submit, very informative. I’m wondering why the opposite specialists
of this sector don’t realize this. You should proceed your writing.
I’m sure, you have a great readers’ base already!
I really like your blog.. very nice colors & theme. Did you
design this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to construct my own blog and would like to know where u got this from.
appreciate it
Hi there, I enjoy reading through your article.
I wanted to write a little comment to support you.
What’s up mates, its fantastic article regarding tutoringand entirely
explained, keep it up all the time.
Excellent article! We will be linking to this particularly great content on our site.
Keep up the great writing.
I visited various sites however the audio feature for audio songs current at this web
page is genuinely excellent.
Hi, just wanted to mention, I liked this blog post. It was helpful.
Keep on posting!
What’s up i am kavin, its my first time to commenting anywhere, when i read this paragraph i thought i
could also make comment due to this good piece of writing.
Heya i’m for the first time here. I came across this board and I to find It truly helpful & it helped me out
a lot. I hope to provide one thing again and help others such
as you helped me.
Hi! I could have sworn I’ve been to this site before but
after checking through some of the post I realized it’s
new to me. Anyways, I’m definitely happy I found
it and I’ll be book-marking and checking back often!
Spot on with this write-up, I seriously believe this web site needs
a lot more attention. I’ll probably be back again to see more, thanks for the information!
Hi there, You’ve done an incredible job.
I will certainly digg it and personally suggest to my
friends. I am sure they’ll be benefited from this site.
Hi, i think that i saw you visited my site so i came to “return the favor”.I’m trying to find things to
improve my web site!I suppose its ok to use a few of your ideas!!
Hey are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started
and create my own. Do you require any coding expertise to make
your own blog? Any help would be greatly appreciated!
Hi there to every one, it’s in fact a nice for me to go to see this web page, it consists of valuable Information.
Terrific post but I was wondering if you could
write a litte more on this topic? I’d be very thankful if you could elaborate a
little bit further. Many thanks!
ทางเราจำหน่าย relx
Infinity , relx Bubble Mon , Infy Pod ต้องขอบอกได้เลยว่า kschill.com เป็นตัวแทนหลักอย่างเป็นทางการในไทย ที่ใหญ่ที่สุด และเป็นเจ้าเดียวกับ RELX THAILAND สินค้าทุกแบรนด์
ทุกรุ่น เราได้ทำการคัดสรร บุหรี่ไฟฟ้า
ที่เป็นหนึ่งในนวัตกรรม ช่วยเลิกบุหรี่ ที่มีประสิทธิดีเยี่ยม และช่วยได้จริง มาให้ลูกค้าได้เลือกใช้ โดยสินค้าทุกชิ้นของเรา สั่งตรงจากโรงงาน
Excellent web site you have here.. It’s hard to find quality writing like yours these days.
I seriously appreciate people like you! Take care!!
MEGA-FERMA
Hi there, everything is going sound here and ofcourse every one is sharing data, that’s truly fine, keep up writing.
Hey there! This is kind of off topic but I need some guidance from an established blog.
Is it very difficult to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not sure where to
begin. Do you have any tips or suggestions? Thanks
Thank you for sharing your thoughts. I truly appreciate your efforts and I will
be waiting for your further post thanks once again.
Hello! Someone in my Facebook group shared this site with us so I came to take a look.
I’m definitely loving the information. I’m book-marking and will be
tweeting this to my followers! Fantastic blog
and outstanding design.
Hello there! This article could not be written any better!
Reading through this post reminds me of my previous roommate!
He continually kept talking about this. I’ll send this post to him.
Fairly certain he’ll have a great read. Many thanks for sharing!
What’s up to every one, the contents existing at this site
are actually remarkable for people experience, well,
keep up the nice work fellows.
Actually when someone doesn’t understand then its up to other people that they will assist, so here it happens.
Por que contratar várias empresas para os serviços de sua casa ou empresa?
Shopping de Serviços oferece tudo o que você precisa em um só lugar.
Não perca tempo e dinheiro em vários contatos, você encontra tudo o que precisa para manter seu lar
ou negócio em ordem. Encanador, eletricista, telhadista, marido de aluguel, desentupidora, dedetizadora, laudo ART, conserto de bombas
e aquecedores. Oferecemos serviços de qualidade com os melhores
preços do mercado. Venha para Shopping de Serviços e aproveite tudo o que temos a oferecer para que você tenha segurança e conforto para sua casa ou negócio!”
I am not sure where you are getting your info, but good topic.
I needs to spend some time learning much more or understanding
more. Thanks for wonderful info I was looking for this information for my mission.
It’s very simple to find out any matter on web as compared to
textbooks, as I found this article at this web site.
Thanks for finally writing about > Пиастры – Составление семантического ядра | < Liked it!
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance” between superb usability and visual appearance.
I must say you’ve done a very good job with this. Also, the blog loads extremely fast for me on Safari.
Excellent Blog!
Nice respond in return of this matter with genuine arguments
and telling the whole thing concerning that.
Thank you for sharing your info. I really appreciate your efforts and I
will be waiting for your further post thank you once again.
What’s Happening i am new to this, I stumbled upon this I’ve discovered It positively helpful and it has aided me out loads.
I hope to contribute & help different customers like its aided me.
Great job.
Excellent post. I was checking continuously this I care for such information a lot.
I care for such information a lot.
weblog and I am impressed! Very useful info specifically the
ultimate phase
I used to be seeking this particular information for a long time.
Thanks and good luck.
Can you tell us more about this? I’d love to find out some additional information.
I love your blog.. very nice colors & theme. Did you make this website yourself or did you hire
someone to do it for you? Plz reply as I’m looking to create my own blog and
would like to find out where u got this from. appreciate it
These are in fact wonderful ideas in on the topic of blogging.
You have touched some fastidious factors here. Any way keep up wrinting.
A Laudo ART oferece serviços de qualidade e profissionais únicos para
todas as suas necessidades em obras e reformas.
Nós realizamos laudos ART, emissão de ART, CLCB, laudos de estanqueidade,
laudos técnicos para reforma, além de
serviços de subistituição de piso e azulejo. Seja para uma pequena reforma ou para uma grande obra,
a Laudo ART tem o profissional qualificado e o serviço certo para você.
Venha conhecer todos os nossos serviços e descubra por que somos líderes em laudos ART e emissão de ART.
I’m amazed, I have to admit. Seldom do I encounter a blog that’s equally
educative and amusing, and without a doubt, you have hit the nail on the head.
The problem is an issue that not enough people are speaking intelligently about.
I’m very happy I came across this during my hunt for something
regarding this.
We are a group of volunteers and starting a new scheme in our community.
Your web site offered us with useful information to work
on. You’ve done an impressive job and our whole community shall be
grateful to you.
Today, I went to the beach with my kids. I found a sea shell and gave it to
my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed
the shell to her ear and screamed. There was a hermit
crab inside and it pinched her ear. She never wants to go back!
LoL I know this is entirely off topic but I had to tell someone!
Greetings! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly?
My weblog looks weird when viewing from my apple iphone.
I’m trying to find a template or plugin that might be able to resolve
this issue. If you have any recommendations, please
share. Many thanks!
Very descriptive post, I liked that a lot. Will there
be a part 2?
Its like you read my mind! You appear to know a lot
about this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message home a little bit, but other
than that, this is magnificent blog. A great read. I’ll certainly be back.
This is the perfect website for anybody who wishes to
understand this topic. You understand so much its almost hard to argue with you (not that I actually will need to…HaHa).
You definitely put a fresh spin on a topic which has been discussed
for years. Excellent stuff, just wonderful!
If you are going for best contents like me, simply pay a
quick visit this web page all the time as it provides feature contents, thanks
Attractive section of content. I just stumbled upon your weblog and
in accession capital to assert that I get in fact enjoyed
account your blog posts. Any way I’ll be subscribing to your feeds and even I achievement you access
consistently quickly.
Visit the new siem reap aquarium in Cambodia
artistecard.com
Greetings! I’ve been following your site for a while now and finally got the
bravery to go ahead and give you a shout out from
Porter Texas! Just wanted to tell you keep up the good work!
Hello There. I found your blog the usage of msn. That is an extremely well written article.
I will make sure to bookmark it and come back to read
extra of your useful info. Thanks for the post. I’ll definitely return.
Aw, this was a really good post. Taking a few minutes and actual effort to produce a really good article…
but what can I say… I procrastinate a lot and don’t manage to get anything done.
When some one searches for his required thing, so he/she wants to be available that
in detail, therefore that thing is maintained over here.
I always used to study paragraph in news papers but now as I am a user
of web therefore from now I am using net for posts,
thanks to web.
Good day very cool web site!! Man .. Excellent ..
Superb .. I’ll bookmark your web site and take the feeds also?
I’m happy to seek out a lot of helpful information here within the submit, we’d like develop extra techniques in this regard,
thanks for sharing. . . . . .
I couldn’t resist commenting. Exceptionally well written!
Hi there everyone, it’s my first visit at
this website, and piece of writing is in fact fruitful
in support of me, keep up posting these articles or reviews.
OMG! This is amazing. Ireally appreciate it~ May I show back my
secrets on a secret only I KNOW and if you
want to have a checkout You really have to believe mme
and have faith and I will show how to learn SNS marketing Once again I want to show my appreciation and may
all the blessing goes to you now!.
Very good post. I will be experiencing some of these
issues as well..
Hmm is anyone else experiencing problems with
the pictures on this blog loading? I’m trying to find
out if its a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated.
Thank you for the auspicious writeup. It in fact was a
amusement account it. Look advanced to more added agreeable from you!
By the way, how can we communicate?
I am truly pleased to read this blog posts which contains plenty of valuable data, thanks for providing
these kinds of data.
This post offers clear idea for the new visitors of blogging, that in fact how
to do blogging.
Very good information. Lucky me I came across your website
by chance (stumbleupon). I’ve book-marked it for later!
It’s nearly impossible to find well-informed people for this topic, but you seem like you know what you’re talking about!
Thanks
Excellent post! We are linking to this great post
on our site. Keep up the great writing.
Nice response in return of this difficulty with real arguments and
telling everything concerning that.
Hi there to all, it’s in fact a pleasant for me to pay a visit this website, it includes
priceless Information.
A empresa Encanador é a sua melhor escolha para serviços de encanamento.
Oferecemos serviços de encanador cobre, encanador 24h,
caça vazamento, laudo hidráulico, encanador PPR, encanador pex e muito mais.
Nossos profissionais são qualificados e possuem anos de experiência.
Garantimos serviços de qualidade e preços acessíveis.
Confie na Encanador e fique tranquilo com seu
encanamento.
Keep this going please, great job!
Excellent post. I was checking continuously this blog and I am impressed! I care for such info much.
I care for such info much.
Very helpful info particularly the last part
I was seeking this certain info for a very long time.
Thank you and best of luck.
I enjoy looking through a post that will make people think.
Also, thanks for allowing me to comment!
I am in fact grateful to the owner of this site who has shared
this wonderful post at here.
This site certainly has all the info I needed concerning this subject
and didn’t know who to ask.
Hi! I know this is kind of off topic but I was wondering which blog platform are you using for this website?
I’m getting fed up of WordPress because I’ve had
issues with hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of a good platform.
magnificent issues altogether, you simply received a emblem new reader.
What may you recommend in regards to your publish that you made some days in the
past? Any sure?
I was wondering if you ever thought of changing the layout of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two images.
Maybe you could space it out better?
Its like you read my mind! You seem to know a lot about this, like you
wrote the book in it or something. I think that you could do with
a few pics to drive the message home a bit, but
instead of that, this is fantastic blog. A great read.
I’ll certainly be back.
Hello, I lօg on to your new stuff like every week.
Your writing ѕtyle is witty, keep it up!
Visit my blog post – Joker88
Hello to every body, it’s my first visit of this blog; this blog consists of remarkable and actually excellent stuff in favor of
visitors.
I read this piece of writing completely on the topic of the difference of most up-to-date and previous technologies,
it’s amazing article.
I think that is one of the such a lot vital info for me. And i’m satisfied reading your article.
But wanna statement on some basic issues, The site style is perfect,
the articles is truly great : D. Excellent task, cheers
This piece of writing is really a fastidious one it assists new web
users, who are wishing in favor of blogging.
bookmarked!!, I love your site!
I’ve been surfing on-line more than 3 hours as of late, but I never
discovered any attention-grabbing article like yours.
It’s lovely value sufficient for me. Personally, if all webmasters and bloggers made just right content material as you probably did, the web shall be a
lot more useful than ever before.
I’ve been exploring for a little bit for any high-quality articles or weblog
posts on this kind of space . Exploring in Yahoo
I at last stumbled upon this website. Reading
this info So i’m satisfied to convey that I have an incredibly excellent uncanny feeling I came upon just
what I needed. I such a lot without a doubt will make certain to do not omit this website and provides it a
glance regularly.
Hey there are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create my own. Do
you need any coding expertise to make your own blog?
Any help would be greatly appreciated!
It’s wonderful that you are getting ideas from this paragraph as well as from our
argument made at this time.
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for great information I was looking for this information for my mission.
Hi, just wanted to tell you, I enjoyed this post.
It was inspiring. Keep on posting!
Greate post. Keep posting such kind of information on your page.
Im really impressed by your blog.
Hey there, You have done an incredible job.
I will certainly digg it and in my opinion suggest to my
friends. I’m sure they’ll be benefited from this web site.
I’m amazed, I have to admit. Seldom do I encounter a blog
that’s equally educative and amusing, and let me tell you, you’ve hit
the nail on the head. The problem is an issue that too few folks
are speaking intelligently about. I am very happy I
came across this during my search for something regarding this.
Hey would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 different internet browsers and I must
say this blog loads a lot quicker then most. Can you recommend a
good hosting provider at a fair price? Cheers, I appreciate it!
Great article! We will be linking to this great post on our website.
Keep up the good writing.
I am genuinely thankful to the holder of this website who has shared this wonderful post at
at this time.
hello!,I really like your writing very much!
proportion we keep up a correspondence more about your article on AOL?
I require a specialist in this house to resolve my problem.
Maybe that’s you! Taking a look ahead to peer you.
I got this web page from my buddy who shared with me regarding
this web page and now this time I am browsing this web page and reading
very informative posts at this place.
I’ve been surfing online more than 3 hours lately,
but I by no means discovered any interesting article like yours.
It is pretty value sufficient for me. In my view, if all site
owners and bloggers made excellent content as you did,
the web shall be much more useful than ever before.
What’s up, this weekend is nice designed for me, since this
point in time i am reading this enormous informative post here at my home.
Fantastic goods from you, man. I’ve bear in mind your stuff prior to and you are just too magnificent.
I really like what you have received here, really like what you are saying and the best way in which you assert it.
You make it entertaining and you still take care of to
stay it smart. I can’t wait to read far more from
you. That is really a wonderful website.
I do not even know how I ended up here, but I thought this post
was good. I do not know who you are but certainly you’re going to a
famous blogger if you are not already 😉 Cheers!
Hurrah, that’s what I was searching for, what a material!
present here at this weblog, thanks admin of this web page.
Genuinely when someone doesn’t understand then its up
to other people that they will assist, so here it takes
place.
Hey There. I found your blog using msn. This is a very
well written article. I’ll be sure to bookmark
it and come back to read more of your useful info.
Thanks for the post. I’ll certainly comeback.
When someone writes an piece of writing he/she keeps the image of
a user in his/her brain that how a user can know it.
Thus that’s why this post is outstdanding. Thanks!
We are a group of volunteers and starting a new scheme in our
community. Your web site offered us with valuable information to work on. You have done a formidable job and our whole
community will be grateful to you.
Hello! I understand this is kind of off-topic however I needed
to ask. Does building a well-established blog like yours take
a lot of work? I’m completely new to operating a blog however I do write in my diary daily.
I’d like to start a blog so I can share my personal experience and feelings online.
Please let me know if you have any kind of suggestions or
tips for new aspiring bloggers. Thankyou!
I was curious if you ever thought of changing the structure of your blog?
Its very well written; I love what youve got to say. But
maybe you could a little more in the way of content so people
could connect with it better. Youve got an awful lot of text for only having 1 or 2 images.
Maybe you could space it out better?
Howdy very nice blog!! Man .. Excellent ..
Superb .. I will bookmark your blog and take the feeds additionally?
I am glad to find numerous helpful information here within the
post, we’d like develop more techniques in this regard, thank
you for sharing. . . . . .
I am not sure where you’re getting your info, but great topic.
I needs to spend some time learning much more or understanding
more. Thanks for excellent information I was looking for this info for my mission.
Hello There. I found your weblog the use of msn. This is an extremely
smartly written article. I will be sure to bookmark
it and return to learn extra of your helpful information. Thank you for the post.
I will certainly comeback.
I do not even know the way I stopped up right
here, but I assumed this post used to be good.
I don’t recognize who you’re however definitely you are
going to a famous blogger in the event you aren’t already.
Cheers!
Wonderful article! We are linking to this great content on our website.
Keep up the good writing.
Thanks for the good writeup. It if truth be told used to be a entertainment account
it. Glance advanced to more brought agreeable from you!
However, how could we keep in touch?
Pretty! This was a really wonderful post. Many thanks for providing this information.
Fucked his slutty niece who loves it when her uncle fucks her in the
ass https://cutt.ly/u87gtp5
If some one wishes expert view regarding running a blog afterward
i recommend him/her to pay a visit this weblog, Keep up the nice work.
Oh my goodness! Awesome article dude! Thank you, However I am going through difficulties with your RSS.
I don’t know why I am unable to subscribe to it.
Is there anybody getting similar RSS issues? Anyone that knows the answer will you kindly
respond? Thanks!!
I’m not sure exactly why but this site is loading very slow for me.
Is anyone else having this problem or is
it a issue on my end? I’ll check back later and see if the
problem still exists.
Hello, this weekend is fastidious for me, because this occasion i am reading this fantastic
informative paragraph here at my house.
Hey! Quick question that’s totally off topic. Do you know how to make your site mobile
friendly? My web site looks weird when browsing from my iphone.
I’m trying to find a theme or plugin that might be able to
resolve this problem. If you have any suggestions, please
share. With thanks!
Hi there i am kavin, its my first occasion to commenting anywhere, when i read this post i thought
i could also create comment due to this good post.
The policyholder can avail the benefits of
time period insurance in change of the coverage premium.
I think everything published was actually very reasonable.
However, think about this, what if you added a little
information? I mean, I don’t want to tell you how
to run your blog, but suppose you added something to possibly
grab a person’s attention? I mean Пиастры – Составление семантического ядра |
is kinda vanilla. You might peek at Yahoo’s home page and see how they
create news titles to get viewers to open the links.
You might add a related video or a picture or two to get readers excited about what you’ve written. Just my opinion,
it would make your blog a little livelier.
Very great post. I simply stumbled upon your weblog and wanted to mention that
I’ve really enjoyed surfing around your weblog posts.
After all I will be subscribing on your rss feed and I hope you write
once more very soon!
It’s a pity you don’t have a donate button! I’d definitely donate to
this outstanding blog! I suppose for now i’ll settle for
book-marking and adding your RSS feed to my
Google account. I look forward to fresh updates
and will share this site with my Facebook group. Talk soon!
I am not sure where you’re getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for excellent information I was looking for this information for my mission.
I am actually happy to read this website posts which consists
of plenty of valuable information, thanks for providing these
statistics.
Thanks for sharing such a nice idea, post is good, thats why i have read it completely
Thanks for another informative site. The place else may just
I am getting that type of info written in such a perfect way?
I have a challenge that I’m simply now operating on, and
I’ve been at the glance out for such information.
Right now it seems like Drupal is the top blogging
platform available right now. (from what I’ve read) Is that what you’re using on your
blog?
That is very interesting, You’re an excessively skilled blogger.
I have joined your rss feed and look ahead to in quest of more of your fantastic
post. Also, I’ve shared your site in my social networks
It is the best time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I wish to suggest you some interesting things or tips.
Maybe you can write next articles referring to this article.
I desire to read more things about it!
It is perfect time to make some plans for the future and it’s time to be
happy. I’ve read this post and if I could
I want to suggest you some interesting things or tips.
Perhaps you can write next articles referring to this article.
I wish to read more things about it!
Heya are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding knowledge
to make your own blog? Any help would be greatly appreciated!
Wow, amazing blog layout! How lengthy have you been running a blog for?
you make blogging look easy. The entire look of your site is magnificent, as smartly as the
content!
whoah this weblog is fantastic i love reading your posts.
Keep up the good work! You already know, many people are hunting round for this info, you can help them greatly.
I like what you guys tend to be up too. This
type of clever work and coverage! Keep up the very good works guys I’ve added you guys
to our blogroll.
I do believe all of the concepts you have offered
for your post. They’re really convincing and can definitely work.
Still, the posts are very brief for beginners. Could you please lengthen them a little from next time?
Thank you for the post.
I’m gone to tell my little brother, that he should also visit this web site on regular basis to take updated from most recent reports.
My partner and I stumbled over here from a different website
and thought I may as well check things out. I like what I see so now i’m following you.
Look forward to checking out your web page yet again.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get bought an shakiness over that you wish be delivering the following.
unwell unquestionably come more formerly again as exactly the same nearly
a lot often inside case you shield this hike.
If you would like to improve your knowledge just keep visiting this web site and be updated with
the newest news posted here.
I really love your blog.. Very nice colors & theme. Did
you build this amazing site yourself? Please reply
back as I’m trying to create my own personal website and would love to
learn where you got this from or what the theme is named.
Many thanks!
At this time I am going to do my breakfast, later than having my breakfast coming yet again to read additional news.
I have read so many articles or reviews on the topic of the blogger
lovers but this post is truly a fastidious post,
keep it up.
I every time emailed this blog post page to all my associates, for the
reason that if like to read it after that my contacts will too.
Can I simply say what a relief to uncover someone that truly understands what they’re discussing
on the internet. You certainly know how to bring a problem to light and make
it important. More people must check this out and understand this side of your story.
I can’t believe you aren’t more popular since you certainly possess the gift.
Hello, yes this piece of writing is in fact good and I have learned
lot of things from it about blogging. thanks.
Hi, i think that i saw you visited my site so i came to “return the favor”.I’m attempting to find things to enhance my web site!I suppose
its ok to use a few of your ideas!!
I do not even know how I ended up here, but I thought this post
was good. I do not know who you are but definitely
you are going to a famous blogger if you are not already 😉 Cheers!
Really no matter if someone doesn’t be aware of afterward its
up to other visitors that they will help, so here it takes place.
Simply want to say your article is as astonishing.
The clearness in your post is simply nice and
i can assume you are an expert on this subject. Well with your permission let me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please continue the gratifying work.
Awesome blog! Is your theme custom made or did you download it
from somewhere? A theme like yours with a few simple
adjustements would really make my blog stand out.
Please let me know where you got your design. Many thanks
What i don’t understood is actually how you’re now not
actually a lot more neatly-preferred than you may be now.
You’re very intelligent. You already know therefore considerably on the subject of this subject, produced me in my opinion consider it from a lot of
various angles. Its like men and women don’t seem to be involved except it is something to accomplish with Woman gaga!
Your own stuffs outstanding. Always take care of it up!
Thanks for one’s marvelous posting! I definitely enjoyed reading it, you’re a great author.
I will always bookmark your blog and may come back
in the future. I want to encourage yourself to continue your great writing, have
a nice evening!
I would like to thank you for the efforts you have put in penning this website.
I really hope to view the same high-grade content by you later on as well.
In truth, your creative writing abilities has encouraged me to get my very own blog now 😉
hi!,I really like your writing very so much! share we communicate more
approximately your post on AOL? I require an expert in this area to unravel my problem.
Maybe that is you! Looking ahead to see you.
Hello, I think your site might be having browser
compatibility issues. When I look at your blog in Firefox,
it looks fine but when opening in Internet Explorer, it has some
overlapping. I just wanted to give you a quick heads up!
Other then that, fantastic blog!
Good info. Lucky me I ran across your site by accident (stumbleupon).
I have bookmarked it for later!
wonderful post, very informative. I ponder why the opposite experts of
this sector don’t notice this. You should continue
your writing. I am sure, you’ve a great readers’ base already!
Heya! I understand this is sort of off-topic however I had
to ask. Does operating a well-established website like
yours require a lot of work? I’m brand new to operating a blog but I do write in my journal daily.
I’d like to start a blog so I can easily share my personal
experience and thoughts online. Please let me know if you have any kind of recommendations or tips for brand new aspiring blog owners.
Appreciate it!
Genuinely no matter if someone doesn’t know then its up to other people that they will
help, so here it happens.リアルドール
Hey great website! Does running a blog such as this require a massive amount work?
I have very little knowledge of computer programming but I
was hoping to start my own blog soon. Anyways, if you have any
recommendations or techniques for new blog owners please share.
I understand this is off subject but I simply had to ask.
Many thanks!
I believe people who wrote this needs true loving because it’s a blessing.
So let me give back and finally give back change your life and if you want
to seriously get to hear I will share info about how to become a millionaire Don’t forget..
I am always here for yall. Bless yall!
If some one desires expert view about blogging
and site-building after that i advise him/her to pay a quick visit this website,
Keep up the pleasant job.
Wow, marvelous weblog structure! How lengthy have you ever been blogging for?
you make running a blog glance easy. The overall glance of your site is fantastic, let alone the content material!
Thanks a lot for sharing this with all folks you
actually understand what you are talking about! Bookmarked.
Kindly also talk over with my web site =). We may have a hyperlink alternate arrangement
among us
I feel this is among the such a lot vital information for me.
And i’m happy studying your article. But want to statement on some basic things, The website style is ideal, the articles is really great :
D. Excellent activity, cheers
You are so cool! I do not think I have read through
anything like that before. So great to find someone with original thoughts on this subject.
Seriously.. thanks for starting this up. This website is one thing that is needed on the web, someone with a bit of originality!
I am really impressed with your writing skills and also with
the layout on your weblog. Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it’s rare to see a nice blog like this
one nowadays.
Spot on with this write-up, I really believe that this
website needs a great deal more attention. I’ll probably be returning to see more, thanks
for the info!
I know this if off topic but I’m looking into starting my own blog and was curious what all is needed to get setup?
I’m assuming having a blog like yours would cost a
pretty penny? I’m not very internet savvy so I’m
not 100% sure. Any recommendations or advice would be greatly appreciated.
Appreciate it
I truly love your blog.. Excellent colors & theme. Did you make this amazing site yourself?
Please reply back as I’m planning to create my own website and
want to learn where you got this from or exactly what the theme is called.
Kudos!
Please let me know if you’re looking for a article writer for your site.
You have some really great posts and I believe I would be a
good asset. If you ever want to take some of the load off, I’d really like to write some content for your blog in exchange
for a link back to mine. Please shoot me an email if interested.
Kudos!
I could not refrain from commenting. Very well written!
Hiya! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly? My site looks
weird when viewing from my apple iphone. I’m trying
to find a theme or plugin that might be able to correct this issue.
If you have any recommendations, please share. Many
thanks!
Normally I do not read post on blogs, however I wish to say that this write-up very compelled me
to take a look at and do so! Your writing taste has been amazed me.
Thanks, quite nice article.
Feel free to surf to my page … Honeybee Pharmacy
Incredible points. Great arguments. Keep up the good spirit.
I blog quite often and I really appreciate your content.
This great article has really peaked my interest.
I am going to take a note of your website and keep checking for
new information about once a week. I opted in for your RSS feed as well.
Excellent blog here! Also your web site loads up fast!
What host are you using? Can I get your affiliate link
to your host? I wish my site loaded up as fast
as yours lol
Hi there! Someone in my Facebook group shared this
site with us so I came to take a look. I’m definitely
enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Superb blog and amazing design and style.
Fine way of explaining, and good article to take data concerning my presentation subject matter,
which i am going to convey in college.
Howdy would you mind letting me know which hosting company you’re using?
I’ve loaded your blog in 3 different browsers and I must say this blog loads a lot quicker then most.
Can you suggest a good web hosting provider at a reasonable price?
Thank you, I appreciate it!
Thanks for every other informative web site. Where else may just I am getting that kind of information written in such an ideal method?
I have a challenge that I’m just now running
on, and I have been at the glance out for such information.
Hi to all, the contents present at this website are truly amazing
for people knowledge, well, keep up the nice work fellows.
I am not sure the place you are getting your info,
but good topic. I needs to spend some time studying much
more or understanding more. Thank you for magnificent information I used to be looking for this info for my mission.
Hey there! This is my first visit to your blog! We are a collection of
volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have
done a marvellous job!
At this time I am going to do my breakfast, after having my breakfast coming yet again to read more
news.
It’s an amazing article for all the best replica sunglasses replica sunglasses high quality replica handbags gucci replica high quality replica handbags high quality designer replica handbags replica designer shoes replica shoes louis vuitton bags replica louis vuitton shoes replica replica designer handbags replica gucci replica versace knock off designer shoes replica handbags online cartier glasses replica replica mens shoes gucci replica shoes replica louis vuitton bags best replica handbags gucci shoes replica louis vuitton handbags replica fake louis vuitton shoes replica gucci shoes louis vuitton replica bags replica cartier glasses gucci replicas idealreplicas replica handbags louis vuitton louis vuitton shoes replica fake louis vuitton shoes louis vuitton replicas cheap replica handbags louis vuitton replica handbags replica purses perfect replica best replica handbags online best gucci replicas replica purses high quality replica sunglasses replica designer cheap replica handbags replica designer mens shoes replica store cartier replica glasses knockoff designer shoes gucci watches replica replica designer bag fake gucci shoes designer shoes replica aaa replica replica designer bag high replica designer shoes fake designer shoes replica jimmy choos shoes designer replica handbags aaa replica replica designer sunglasses best replica bags online replica designer shoes online louis vouitton replicas lv replica 1 1 replica shoes replicas shoesreplica louis vuitton purses replica best replica bags online best replica shoes louis vuitton watches replica aaa replica aaa replica shoes replicas glasses aaa replica belts gucci shoes replica aaa replica bags online aaa replica designer handbags versace replica replica channel shoes cartier sunglasses replica replica bag louis vuitton replica shoes aaa replica bags replica lv bags replica fake shoes for sale replica louis vuitton shoes replica designer scarves high replica high quality prada replica handbags louis vuitton replica louis vuitton replica louis vuitton replica louis vuitton replica gucci handbags replica high quality replica cazal louis vuitton belt replica aaa perfect replica watches aaa replica designer handbags replica desinger bags replica online replica lv bags replica hand bags replica shoes online aaa fashion ru replica wallet shoe replicas top replica handbags replica desinger bags gucci handbags replica high quality aaa replica bags replica desinger triple a replica best replica belts replica shoes online perfect replica watches high quality replica best replica bags replica handbags replica handbags replica handbags replica handbags replica louis vuitton wallet top replica handbags 1:1 replica handbags replica glasses aaa handbags imatation handbags everyday designer ru quality replica shoes chanel bags replica aaa hermes shoes replica louis vuitton sunglasses replica replicas shoes luxury replica shoes shoe replica jimmy choo replica luxury replica bags replica womens shoes gucci handbags replica luxury replica men shoes replica bag online replicas aaa high quality replica bags replica shoes handbags everyday designer ru quality replica shoes best replica bags replica shoes website replicas gucci best fake louis vuitton replica eyewear fake designer scarves replica bags replica bags replica bags replica bags luxury replica bags replica shoes for sale designer replica sunglasses bottega venetta replica lv bracelet replica gucci watch replica replicas aaa replica glases replica designer bags replicas wallets replica gucci watch replica louis vuitton replica louis vuitton replica louis vuitton replica louis vuitton replica designers alexander mcqueen replica louis vuitton shoes replica womens louis vuitton replica shoes replicas shoes for sale replica belts aaa buy replica shoes online replica designer shoes wholesale best replica designer shoes replica louis vuitton shoes aaareplicas best replica louis vuitton designer replica shoes bottega venetta replica replica shoes men replicabags replica shoes for men gucci shoes replica paypal bag replica sunglass replicas shoes replica high end replica bags designer knockoffs online knock off gucci shoes replica louis everythingdesigner.ru replica designer silk scarves alexander mcqueen replicas replica hand bags everyday designer ru sunglasses replica high quality replica designer shoes replica versace glasses designer ru louis vuitton shoes replica womens louis vuitton shoes replica wholesale best replica louis vuitton louis vuitton shoes replica louis vuitton shoes replica rep cheap ru bags replicas cheap replicas bags shoes good deal ru replica bags for sale replica louis vuitton handbags replica gucci watches high quality replica handbags high quality replica handbags high quality replica handbags high quality replica handbags knock off designer sunglasses everything designer ru ysl replica shoes designer ru com high quality replica shoes gucci scarf replica replica store online louis vuitton bracelet replica gucci replica gucci replica gucci replica gucci replica faux louis vuitton replica scarfs replica designer glasses luxury replicas aaa replica shoes high quality replica sunglasses gucci knockoffs shoes imitation designer shoes louis vuitton messenger bag replica aaa cartier glasses aaa quality replica st dupont replica alexander mcqueen knock off cazal knock off replicas shop replica branded bags fake designer shoes for men replica mens wallets louis vuitton wallet replica imitation handbags fake louis vuitton sunglasses replica alexander mcqueen fake alexander mcqueen scarf cheap replica bags best replica gucci gucci sneakers replica high quality designer replica handbags high quality designer replica handbags high quality designer replica handbags high quality designer replica handbags replica versace watches perfect replica bags aaa quality replica aaa replica designer shoes best replicas shoes replica hermes watch replica shoe sites cheap louis vuitton shoes designer replica gucci sunglasses replica replica woman shoes fake cartier glasses replica cartiers best replica shoe site gucci replica bags replica designer shoes replica designer shoes replica designer shoes replica designer shoes replica women shoes replica shoes designer cheap replica designer shoes fake louis vuitton shoes fake louis vuitton shoes mark jacobs replica replica louis vuitton purses louis vuitton necklace replica imitation louis vuitton bags aaa cartier glasses replica scarfs chloe replica replica shoes replica shoes replica shoes replica shoes balenciaga replica louis vuitton shoes replica wholesale hugo boss replica replica gucci sunglasses replica lv belt knockoff louis vuitton handbags bags me too ru replica gucci bags best louis vuitton replica aaa quality replica cazal knockoffs replica wallets gucci replica shoes gucci replica shoes gucci replica shoes copy designer handbags mens replica shoes replica woman shoes replica cartiers fake prada shoes louis vuitton shoes replica womens louis vuitton shoes replica louis vuitton shoes replica louis vuitton shoes replica louis vuitton shoes replica miu miu replica shoes replica mens shoes designer chanel bag replica high quality replica designer handbags replica designer handbags replica designer handbags replica designer handbags hermes watches replica designer replica bags knockoff designer watch aaaa lv belt replica gucci replica gucci replica gucci replica gucci fake louis vuitton wallet mont blanc briefcase replica gucci snake replica fake brand shoes replica shoes handbags replica dupont lighter replica louis vuitton bags replica louis vuitton bags replica louis vuitton bags hermes replica shoes fake name brand shoes yves saint laurent shoes replica ru sunglasses louis vuitton replica bag replica dupont lighters fake gucci sneakers replica scarves replica shades knock off designer shoes knock off designer shoes knock off designer shoes knock off designer shoes replica handbags online replica handbags online replica handbags online replica handbags online luxury bags replica bottega veneta replicas cartier inspired glasses fake designer shoes for sale alexander mcqueen shoes replica replica brand shoes faux designer sunglasses 1:1 replica replica luxury belts replica bags and shoes replica brand bags bag replicas mens replica designer shoes prada replica replica mens designer wallets replica hermes watches where to buy replica shoes replica christian louboutins perfect replica shoes best replica online store copy designer shoes lv watches men high end replica cazal 644 replica luxury bags replica replica mens shoes replica mens shoes replica mens shoes replica mens shoes fake gucci watches dupont lighter replica gucci knock off cheap louis vuitton shoes alexander mcqueen scarf replica louis vuitton aaa replica handbags wholesale yves saint laurent replica gucci replica handbags bags big sale replica replica bags and shoes luxury belts replica sunglass replica high quality designer replica fake rolex watches replica shoes wholesale replica wallets men fake louis vuitton shoes fake louis vuitton shoes fake louis vuitton shoes louis vuitton crossbody replica lv laptop bag replica buy replica bag high quality replica designer bags versace scarf replica womens replica designer watches super perfect replica shoes fake gucci watch best website for replica bags replica prada sunglasses lv replica bags bottega veneta clutch replica lv wallet replica lv watch for women high quality replica handbags online prada replica aaa sunglasses designer replica scarves replica online shopping aaaa replica replica cazal glasses for sale versace watch replica cazal 644 replica gucci bag replica louis vuitton purse replica lv women watches perfect replica belts replica womens watches cheap designer replica sunglasses gucci shoes replica gucci shoes replica gucci shoes replica gucci shoes replica replica aaa belts wholesale fake designer sunglasses best replica jewelry websites gucci belt replica replica wallets mens gucci sandals replica mens designer bags replica bags big sale replica i offer shoes replica replica bags website fake cartiers glasses designer.ru knockoff sunglasses replica gucci sneakers perfect replica bags bigsalebags ru replica dior sunglasses high quality replica handbags online knock off shoes for sale replica online store designer replicas bag replica high quality fake designer shoes online best replica designer bags louis vuitton replica scarf aaa grade replica perfect replica belts replica designer wallets lv bags replica replica aaa belts gucci replica shoes replica designer shoes china replica women watch fake shoes website knockoff louis vuitton aaa designer handbags best quality replica belts cartier glasses wholesale knock off mens shoes perfect handbags replica branded shoes replica bag uk replica online stores aaa offer replica replica briefcases faux louis vuitton bags givenchy replica copy handbags bottega veneta clutch replica knock off shoes online best designer replica websites replica hermes loafers online replica store louis vuitton replica handbags louis vuitton replica handbags louis vuitton replica handbags replica designer sandals replicas online shopping replica gucci shoes replica gucci shoes replica gucci shoes replica gucci shoes everything designer.ru louis vuitton replica wallet replica purse best replica bag sites gucci knock off shoes replica designer shades best knock off bags gucci replicas gucci replicas gucci replicas gucci replicas fake gucci chanel shoes replica idealreplicas idealreplicas idealreplicas idealreplicas knock off designer shoes for men hermes loafers replica best fake designer bags imitation louis vuitton louis vuitton imitation hermes watch replica crazy holiday ru bottega veneta bag replica aaa offer replica replica bags website fake saint laurent boots iced out cartier glasses copy handbags replica gucci belts aaa quality bags aaa offer ru jimmy choo knock off shoes replica shopping bag replica high quality replicas bags lv watches ladies saint laurent shoes replica ysl earrings replica replica jewelry perfect watches replica versace loafers replica hermes scarves replica knock off designer scarves fake louis vuitton shoes fake louis vuitton shoes fake louis vuitton shoes fake louis vuitton shoes replica mens bags best quality replica belts cheap knock off shoes louis vuitton boots replica replicas bags uk replica brands shoes quality replicas replica branded bag shoes replica wholesale china replica shoes knockoff bags online replica designer wallet replica stores online replica designer mens shoes replica designer mens shoes replica designer mens shoes best fake shoes website imposter sunglasses st dupont lighter replica replica ysl belt best replica belts online best replica designer bags replica purse chanel most wanted sunglasses replica best replica bag sites ysl bracelet replica good replica bags louis vuitton belt replica knock off shoes website miu miu shoes replica cheap replica designer handbags online high end replicas mens replica wallet chanel scarf replica best lv replica bags big sale replica fake bags online replica bags sale quality replicas replicas bags uk designer replicas online aaa designer handbag high replica bags replica purses replica purses replica purses replica purses replica dress shoes aaa offer ru wallet replicas knock off designer glasses bagsmetoo new website replica louis vuitton belt wholesale replica shoes cartier sunglasses wholesale replica travel bags bottega veneta replicas watches knockoff replica designers bags hermes scarves replica knockoff jewelry j14656 replica shoes websites quality replica knock off bags online bottega veneta bag replica buy knock off shoes aaa gucci shoes chanel replica bags perfect replica perfect replica perfect replica perfect replica best replica handbags online best replica handbags online best replica handbags online best replica handbags online designer shoes replica designer shoes replica designer shoes replica best gucci replicas best gucci replicas best gucci replicas best gucci replicas fake hermes watch replicas designer replica mens dress shoes gucci replica watches best fake shoes designer replica faux designer shoes replica catier replicas hermes bags dolce and gabbana replica bags saint laurent bag replica perfect hermes replica aaa replica clothing gucci shoes fake rolex pens cheap gucci shoes for men replica cazal shades replica fake gucci slippers best lv replica cheap replica designer handbags replica clothing sites replica bags sale bottega veneta knockoff aaa designer replica knock off designer shoes wholesale replica luxury clothes aaa designer replicas replica name brand shoes replica store replica store replica store replica store louis vuitton scarf replica online knock off shopping knock off designer watches hermes replica scarves designer knockoff sunglasses replica bags uk knock off designer handbags chanel purse replica handbags sunglass knockoffs pick good shoes ru replica versace bag knockoff designer shoes knockoff designer shoes knockoff designer shoes knockoff designer shoes best fake watches replica versace sunglasses imitation purses handbags gucci watches replica gucci watches replica gucci watches replica gucci watches replica replica designers bags replica women watches replica hermes scarf j14656 replica louis belt best fake bags faux gucci shoes mens replica belts hermes replica watch replica briefcase gucci ring replica quality replica bags copy designer bags cheap louis vuitton wallet replica alexander wang knock off replica designer bag replica designer bag replica designer bag replica designer bag replica d&g bags dolce and gabbana replica bags fake handbags louis vuitton mens wallet replica knock off designer bags alexander mcqueen replica bag mont blanc replica gucci glasses replica replica brands versace bag replica aaa replica aaa replica aaa replica aaa replica louis vuitton mens shoes gucci replica belts ru watches aaa clothes replica wallets replicas aaa designer replicas aaa fashion ru review chopard necklace replica good replica shoes quality replica bags fake mont blanc pens louis vuitton watches women replica rolex where to buy replica belts replica saint laurent sneaker high replica designer shoes high replica designer shoes high replica designer shoes high replica designer shoes wholesale replica sun glasses mens lv watch fake designer shoes fake designer shoes fake designer shoes fake designer shoes replica versace watch replica gucci loafers replica chanel shoes designer replica handbags designer replica handbags designer replica handbags designer replica handbags best designer replica bags best replica hermes belt replica designer sunglasses replica designer sunglasses replica designer sunglasses replica designer sunglasses replica balenciaga best replica bags online best replica bags online best replica bags online best replica bags online replica designer messenger bags replica bags uk buy replicas best replica shoes website replica designer shoes online replica designer shoes online replica designer shoes online replica designer shoes online cazal 958 replica louis vuitton luggage replica wholesale best replica clothing sites versace mens shoes replica replica gucci boots replica hermes 1 1 replica 1 1 replica 1 1 replica 1 1 replica louis vuitton earrings mens shoesreplica shoes replicas shoes replicas shoes replicas shoesreplica shoesreplica shoes replicas shoesreplica replica cartier fake cazal glasses miu miu replica shoes miu miu replica shoes replica hermes scarves aaa clothing replicas replica messenger bags bottega veneta replica bag best replica bags website hermes replica scarf ysl jewelry replica gucci bags replica replica chanel sunglasses imitation prada cazal 856 replica fake versace for sale fake ysl shoes louis replicas chloe imitation handbags best replica shoes best replica shoes best replica shoes best replica shoes high quality replica designer clothing gucci slides replica hermes replica bags for sale replica jewlery fake bag website louis vuitton watches replica wholesale cartier glasses for sale replica designer websites best designer replica bags fake bags online shopping fake louis vuitton handbags rolex aaa aaa replica shoes aaa replica shoes aaa replica shoes aaa replica shoes imitation designer handbags shoe replica sites best place to buy replica belts cheap designer handbags knockoffs cartier glasses buffs replica gucci shoes replica aaa gucci shoes replica aaa gucci shoes replica aaa gucci shoes replica aaa buy replica shoes bottega veneta bags replica ysl knock off shoes marc jacobs knock off replica shoe websites louis vuitton bracelet men replica bottega veneta replica gucci slides imitation purses best site for replica shoes sun glasses imitation bottega veneta replica bag prada 2756 replica channel shoes replica channel shoes replica channel shoes replica channel shoes fake cazal glasses for sale best replica shoe sites ysl jewelry replica chanel flats knockoffs replica gucci slippers replica louis vuitton shoes versace replica shoes good replica belts replica shoes online replica shoes online replica shoes online knockoff gucci replica frank muller watches replica womens versace shoes replica bag replica bag replica bag replica bag best faux designer handbags replica hobo wallets alexander mcqueen scarf knock off louis vuitton replica shoes louis vuitton replica shoes louis vuitton replica shoes louis vuitton replica shoes knock off cazal glasses cazal sunglasses cheap hermes replica wallets replica sandals imatation designer purses replica lv replica lv replica lv replica lv best place to buy replica shoes hermes messenger bag replica knock off designer jewelry fake shoes for sale fake shoes for sale fake shoes for sale fake shoes for sale best site to buy replica shoes best hermes replica handbags joy replica handbags replica louis vuitton shoes replica louis vuitton shoes replica louis vuitton shoes replica louis vuitton shoes aaa bags cartier replica high replica high replica high replica high replica hermes replica knock off louis vuitton louis vuitton shoes on sale where to buy fake gucci aaa quality belts best replica jewelry replica luxury clothing louis vuitton replica shoes louis vuitton replica shoes replica gazelle glasses best quality replica shoes aaa fashion belts imitation prada handbags where can i buy replica shoes louis vuitton necklace replica louis vuitton silk scarf replica mont blanc wallet replica hermes slippers replica aaa replica designer handbags aaa replica designer handbags aaa replica designer handbags aaa replica designer handbags lv shades replica best fake clothing websites bottega veneta replica bags replica chanel bags chloe knockoff bags replica desinger bags replica desinger bags replica desinger bags replica desinger bags ysl earrings replica knock off designer jewerly replica hand bags replica hand bags replica hand bags replica hand bags knock off sneakers aaa replica designer imposter sunglasses replica mens wallet cheap gucci shoes from china best hermes replica handbags replica men shoes replica men shoes replica men shoes louis vuitton watch womens replica tote bags shoe replicas shoe replicas shoe replicas shoe replicas alexander mcqueen replica clutch lv crossbody bag replica gucci handbag replica hermes replicas bags top replica handbags top replica handbags top replica handbags top replica handbags louis vuitton watches sale replica louis vuitton luggage lv watches for women aaa replica bags aaa replica bags aaa replica bags aaa replica bags triple a replica triple a replica triple a replica triple a replica joy replica bags cartier sunglasses for sale chloe replica bag hermes scarf replica best replica belts best replica belts best replica belts best replica belts best fake bags online bottega veneta replica bag prada 2756 replica mont blanc wallets wallet replica imitation prada bags best knock off sunglasses replica pens replica gucci bag fake rolex watches for sale 1:1 replica handbags 1:1 replica handbags 1:1 replica handbags 1:1 replica handbags replica hermes scarves louis vuitton bracelets men best replica hermes belts imatation purses replica hermes jewelry everyday designer ru everyday designer ru everyday designer ru everyday designer ru wallets replica quality replica shoes quality replica shoes quality replica shoes quality replica shoes versace jewelry replica chanel bags replica aaa chanel bags replica aaa chanel bags replica aaa chanel bags replica aaa designer replica jewelry louis vuitton ladies watches lv watches for men knock off designer jewlery hermes shoes replica hermes shoes replica hermes shoes replica hermes shoes replica alexander mcqueen skull scarf knock off replicas shoes replicas shoes replicas shoes replicas shoes luxury replica shoes luxury replica shoes luxury replica shoes luxury replica shoes shoe replica shoe replica shoe replica shoe replica luxury replica bags luxury replica bags luxury replica bags luxury replica bags replica womens shoes replica womens shoes replica womens shoes replica womens shoes top replica sites high end replica clothing louis vuitton watches for mens replica clothes and shoes replica bag online replica bag online replica bag online replica bag online hermes replica wallet cazal knock off replica lv belts replicas aaa replicas aaa replicas aaa replicas aaa high quality replica bags high quality replica bags high quality replica bags high quality replica bags louboutin replicas replica shoes handbags replica shoes handbags replica shoes handbags replica shoes handbags cartier wood frames replica rep gucci slides alexander mcqueen skull scarf replica louis vuitton duplicate bags dolce and gabbana knockoff best replica birkin bag replica shoes website replica shoes website replica shoes website replica shoes website replica designer brands knock off gucci replicas gucci replicas gucci replicas gucci replicas gucci hermes replica scarf cazal snakeskin replica shoes for men replica shoes for men replica shoes for men faux gucci handbags fake versace shoes replica shoes for sale replica shoes for sale replica shoes for sale replica shoes for sale channel replica watch replica hermes scarves louis vuitton watch for sale imitation designer bags wholesale gucci shoes china replica men shoes lv watches for ladies shoes replica shoes replica shoes replica gucci watch replica gucci watch replica gucci watch replica gucci watch replica fake brand bags lv scarf replica replica gucci watch replica gucci watch replica gucci watch replica gucci watch best replica replica fashion belts best website for replica shoes replica gucci shirts fake gucci ring balenciaga knockoff louis vuitton wallet replica mens franck muller fake top replica shoe sites replica designer jewelry replica designer clothing for men fake sneakers for sale louis vuitton aaa replica handbags wholesale bootleg gucci shoes replicas shoes for sale replicas shoes for sale replicas shoes for sale replicas shoes for sale joy replica website replica cazal chanel handbags replica top quality louis vuitton shoes replica wholesale louis vuitton shoes replica wholesale louis vuitton shoes replica wholesale replica belts aaa replica belts aaa replica belts aaa replica belts aaa replica wallets for men replica shoes for men replica designer shoes wholesale replica designer shoes wholesale replica designer shoes wholesale replica designer shoes wholesale best replica shoes sites replica designer sunglasses wholesale louis vuitton skeleton watch fake alexander mcqueen best replica designer shoes best replica designer shoes best replica designer shoes best replica designer shoes replica louis vuitton handbags replica louis vuitton handbags replica louis vuitton handbags gucci china replica louis vuitton quality gucci slide replica watch replicas online louis vuitton ladies shoes designer replica shoes designer replica shoes designer replica shoes designer replica shoes prada imitation replica mens shoes knockoff designer jewlery miu miu shoes replica louis vuitton shoes men replicabags replica shoes men replicabags replicabags replica shoes men replica shoes men replica shoes men replicabags lv scarf replica gucci shoes replica paypal gucci shoes replica paypal gucci shoes replica paypal gucci shoes replica paypal lv belt replica louis vuitton watch for women best balenciaga replica shoes good deal ru knock off hermes belt bag replica bag replica bag replica bag replica sunglass replicas sunglass replicas sunglass replicas sunglass replicas louis vuitton watches for women fake versace watch high end replica bags high end replica bags high end replica bags high end replica bags designer knockoffs online designer knockoffs online designer knockoffs online designer knockoffs online knock off louis vuitton bags knock off gucci shoes knock off gucci shoes knock off gucci shoes knock off gucci shoes replica lv wallet fake mcm shoes best fake shoe site best replica websites fake womens watches imitation designer wallets high quality replica designer shoes high quality replica designer shoes high quality replica designer shoes high quality replica designer shoes louis vuitton shoes replica womens louis vuitton shoes replica womens louis vuitton shoes replica womens louis vuitton shoes replica womens aaa replica designer shoes aaa replica designer shoes aaa replica designer shoes versace slides replica cheap louis vuitton shoes cheap louis vuitton shoes cheap louis vuitton shoes best hermes replica louis vuitton men shoes louis vuitton copies of bags gucci belt clone hermes flats replica replica bags for sale replica bags for sale replica bags for sale replica bags for sale replica gucci watches replica gucci watches replica gucci watches replica gucci watches best replica site ysl replica shoes ysl replica shoes ysl replica shoes ysl replica shoes best website for replica clothes high quality replica shoes high quality replica shoes high quality replica shoes high quality replica shoes replica store online replica store online replica store online replica store online best gucci belt replica replicas shoes for sale chloe replicas knockoff gucci belt fake designer websites aaa replica shoes high quality aaa replica shoes high quality aaa replica shoes high quality aaa replica shoes high quality where to buy ysl faux hermes scarf replica sneaker websites fake gucci flip flops fake designer jewelry fake gucci slides knockoffs shoes knockoffs shoes knockoffs shoes knockoffs shoes imitation designer shoes imitation designer shoes imitation designer shoes imitation designer shoes faux hermes scarves best website for fake shoes aaa quality replica aaa quality replica aaa quality replica aaa quality replica hermes replica scarves replica mens belt pink louis vuitton shoes hermes mens sandals replica knock off versace shoes faux prada handbags snakeskin cazal glasses high quality louis vuitton replicas china fake designer shoes for men fake designer shoes for men fake designer shoes for men fake designer shoes for men where to buy replica bags imatation designer bags prada imitation mens replica clothing best website to buy replica shoes imatation designer handbags mens replica shoes mens replica shoes mens replica shoes best replica gucci best replica gucci best replica gucci best replica gucci cartier sun glasses for sale cartier men belt perfect replica bags perfect replica bags perfect replica bags perfect replica bags buy replica belts fake designer mens wallets replica hermes watch best replicas shoes best replicas shoes replica hermes watch best replicas shoes replica hermes watch best replicas shoes replica hermes watch replica shoe sites replica shoe sites replica shoe sites replica shoe sites replica gucci belt louis vuitton red shoes cartier 135 sunglasses replica woman shoes replica woman shoes replica woman shoes replica woman shoes replica shoes handbags replica shoes handbags replica shoes handbags watch replicas louis vuitton ring mens louis vuitton mens bracelets versace fake cartier mens belt louis vuitton bracelet womens replica women shoes replica women shoes replica women shoes replica women shoes replica shoes designer replica shoes designer replica shoes designer replica shoes designer versace rings replica imitation designer watch cheap replica designer shoes cheap replica designer shoes cheap replica designer shoes cheap replica designer shoes cazal snakeskin sunglasses luxury replica pens versace shoes replica hermes wallets replica faux hermes scarves stainless steel cartier glasses louis vuitton replica belt replica scarfs replica scarfs replica scarfs replica scarfs louis vuitton shoes men spikes replica designer clothing websites replica belts designer knockoff designer wallets louis vuitton watch gold dolce and gabbana knock off fakegucci high quality replica clothing louis vuitton shoes replica wholesale louis vuitton shoes replica wholesale louis vuitton shoes replica wholesale louis vuitton shoes replica wholesale fake gucci loafers louis vuitton mens chain best replica shoes websites brand replica replica lv belt replica lv belt replica lv belt replica lv belt womens replica watch how to tell if a piaget watch is real louis vuitton shoes for ladies cazal sunglasses wholesale bags me too ru bags me too ru bags me too ru bags me too ru best replica hermes bags replica louis vuitton louis vuitton flat shoes replica louboutin chopard jewelry replica best knock off websites aaaa replica belts aaa gucci belts hermes bags replicas high quality replica designer belts replica woman shoes replica woman shoes replica woman shoes fake prada shoes fake prada shoes fake prada shoes fake prada shoes hermes replicas best fake designer website miu miu replica shoes miu miu replica shoes miu miu replica shoes miu miu replica shoes replica mens shoes designer replica mens shoes designer replica mens shoes designer replica mens shoes designer buy fake gucci replica shoes china hermes jewelry replica mens gucci shoes wholesale replica designer clothes for men hermes watches replica hermes watches replica hermes watches replica hermes watches replica replica bags for sale gucci snake replica gucci snake replica gucci snake replica gucci snake replica replica clothing and shoes louis vuitton men’s briefcase fake brand shoes fake brand shoes fake brand shoes fake brand shoes aaa replica designer belts knock off designer wallets hermes replica shoes hermes replica shoes hermes replica shoes hermes replica shoes hermes crossbody replica fake name brand shoes fake name brand shoes fake name brand shoes fake name brand shoes fake louis vuitton purses lv watches for mens replica scarves replica scarves replica scarves replica scarves replica gucci purse gucci imitation rep shoes luxury bags replica luxury bags replica luxury bags replica luxury bags replica knock off designer belts fake designer shoes for sale fake designer shoes for sale fake designer shoes for sale fake designer shoes for sale replica brand shoes replica brand shoes replica brand shoes replica brand shoes aaaa replica aaaa replica aaaa replica replicas shoes 1:1 replica 1:1 replica 1:1 replica 1:1 replica best hermes replica belts fake mont blanc pen replica brand bags replica bags and shoes replica brand bags replica bags and shoes replica brand bags replica bags and shoes replica brand bags replica bags and shoes best replicas louis vuitton bracelet replica the best replica watches aaaa replica belts mens replica designer shoes bag replicas bag replicas mens replica designer shoes mens replica designer shoes bag replicas mens replica designer shoes bag replicas cartier glasses look alike replica mens designer wallets replica mens designer wallets replica mens designer wallets replica mens designer wallets louis vuitton watches ladies lv watches mens fake gazelle glasses replica hermes watches replica hermes watches replica hermes watches replica hermes watches perfect replica shoes perfect replica shoes perfect replica shoes perfect replica shoes best replica online store best replica online store best replica online store best replica online store copy designer shoes copy designer shoes copy designer shoes copy designer shoes high end replica high end replica high end replica high end replica louis vuitton men’s bracelet aaa gucci knock off mens clothing versace shoes fake knock off shoes for sale knock off shoes for sale knock off shoes for sale louis vuitton bracelet for men replica clothing websites louis vuitton watches womens gazelle sunglasses wholesale louis vuitton shoes ladies shoes knockoffs high quality designer replica high quality designer replica high quality designer replica high quality designer replica louis vuitton mens casual shoes replica shoes wholesale replica shoes wholesale replica shoes wholesale replica shoes wholesale replica designer shoes china replica designer shoes china replica designer shoes china gucci belt knock off louis vuitton crossbody replica louis vuitton crossbody replica louis vuitton crossbody replica louis vuitton crossbody replica louis vuitton necklace mens replica briefcases replica briefcases replica briefcases aaafashion.ru mens louis vuitton watches chanel belt replica givenchy slides replica rolex watch replica womens replica designer watches womens replica designer watches womens replica designer watches womens replica designer watches buying replica bags louis vuitton watches for ladies replica designer sandals replica designer sandals replica designer sandals gucci flip flops replica faux rolex watches replica belts gucci best website for replica bags best website for replica bags best website for replica bags best website for replica bags ysl ladies shoes rolex replica louis vuitton mens backpack replica burberry messenger bag replica faux bottega veneta handbags louis vuitton watch for men gucci snake jeans replica chanel shoes replica chanel shoes replica chanel shoes replica high quality replica handbags online high quality replica handbags online high quality replica handbags online high quality replica handbags online aaa sunglasses aaa sunglasses aaa sunglasses aaa sunglasses perfect watches.com replica online shopping replica online shopping replica online shopping replica online shopping aaa designer belts louis vuitton stilettos best replica designer belts replica websites louis vuitton quartz watches wholesale cartier glasses eyeglasses frames perfect replica belts perfect replica belts perfect replica belts perfect replica belts wholesale gucci shoes for men replica womens watches replica womens watches replica womens watches replica womens watches fake versace bags aaaa louis vuitton belt fake cheap gucci bags replica aaa belts replica aaa belts replica aaa belts replica aaa belts best replica jewelry websites best replica jewelry websites best replica jewelry websites best replica jewelry websites louis vuitton knockoffs luggage best ysl replica fake louis vuitton wallet mens imitation mont blanc pen replica mens designer clothes hermes shirts replica cazal wholesale fake versace wallet louis vuitton damier wallet replica best replica clothing website frank muller fake replica gucci sneakers replica gucci sneakers replica gucci sneakers replica gucci sneakers replica hamilton watches chloe replica bags faux prada lv watches for sale hermes sunglasses women aaa versace belt replica aaaa belts replica online store replica online store replica online store replica online store bottega veneta knockoff louis vuitton boots replica louis vuitton boots replica louis vuitton boots replica fake designer shoes online fake designer shoes online fake designer shoes online fake designer shoes online versace replica sunglasses fake louis vuitton scarf replica designer frames aaa grade replica aaa grade replica aaa grade replica aaa grade replica louis vuitton necklace men replica woman shoes handbags imitation brands louis vuitton white handbag replica women watch replica women watch replica women watch replica women watch fake shoes website fake shoes website fake shoes website fake shoes website replica belts aaafashion ru knock off mens shoes knock off mens shoes knock off mens shoes knock off mens shoes chanel replica handbags replica branded shoes replica bag uk replica branded shoes replica bag uk replica online stores aaa offer replica aaa offer replica aaa offer replica aaa offer replica replica branded shoes replica online stores replica branded shoes replica bag uk replica bag uk replica online stores replica online stores cheap fake designer purses jewelry replica copy handbags copy handbags copy handbags copy handbags dolce gabbana replica best designer replica websites best designer replica websites best designer replica websites best designer replica websites online replica store replica hermes loafers replica hermes loafers online replica store online replica store replica hermes loafers online replica store replica hermes loafers replica chanel jewelry fake gucci bags replicas online shopping replicas online shopping replicas online shopping replicas online shopping gucci knock off shoes gucci knock off shoes gucci knock off shoes gucci knock off shoes louis vuitton shoes china imitation bags for sale knock off gucci bag jimmy choo shoe replicas knock off bags cheap gucci bags replica cheap cazal glasses knock off designer shoes for men knock off designer shoes for men knock off designer shoes for men knock off designer shoes for men hermes loafers replica hermes loafers replica hermes loafers replica hermes loafers replica best fake designer bags best fake designer bags best fake designer bags best fake designer bags replica mens belts shoe replicas wholesale hermes watch replica hermes watch replica hermes watch replica hermes watch replica fake versace glasses cartier round sunglasses best knock off watches aaa copy best shoe replica website replica mens designer clothing gucci wallet replica replica designer mens clothing replica shopping replica shopping replica shopping replica shopping louis vuitton men shoes sale authentic cartier glasses wholesale where to buy fake sunglasses replicas bags replicas bags replicas bags replicas bags perfect replica belts perfect replica belts perfect replica belts saint laurent shoes replica saint laurent shoes replica saint laurent shoes replica saint laurent shoes replica fake designer glasses louis vuitton bracelets mens cheap knock off shoes cheap knock off shoes cheap knock off shoes cheap knock off shoes chanel replica handbags replica branded bag replica branded bag shoes replica wholesale replica brands shoes replica brands shoes shoes replica wholesale replica branded bag replica brands shoes quality replicas replica branded bag shoes replica wholesale replicas bags uk replicas bags uk quality replicas shoes replica wholesale replicas bags uk replicas bags uk quality replicas quality replicas replica brands shoes china replica shoes china replica shoes china replica shoes china replica shoes knockoff bags online knockoff bags online knockoff bags online knockoff bags online cheap replica designer clothes patek philippe flip watch replica christian louboutin shoes replica stores online replica stores online replica stores online replica stores online imposter sunglasses imposter sunglasses imposter sunglasses imposter sunglasses fake dupont lighter rolex kinetic replica ysl belt best replica belts online replica ysl belt best replica belts online replica ysl belt best replica belts online replica ysl belt best replica belts online best replica designer bags best replica designer bags best replica designer bags best replica designer bags piaget replica louis vuitton black shoes chanel most wanted sunglasses replica chanel most wanted sunglasses replica chanel most wanted sunglasses replica chanel most wanted sunglasses replica izod 725 sunglasses cazals for cheap 1:1 replica handbags fashion replicas good replica bags good replica bags good replica bags good replica bags fake bags louis vuitton bracelets for men miu miu shoes replica miu miu shoes replica miu miu shoes replica miu miu shoes replica louis vuitton red bottoms men cheap replica designer handbags online cheap replica designer handbags online cheap replica designer handbags online cheap replica designer handbags online best replica clothing dolce and gabbana handbags replica bags love me ru gucci shoes from china replica designer clothes cheap replica belts cartier look alike glasses high replica bags high replica bags high replica bags high replica bags fake designer bags online buy louis vuitton watches replica dress shoes replica dress shoes replica dress shoes replica dress shoes knockoff shoes replica clothes websites lv shoes for men mens replica shoes replica bags and shoes designer replica sunglasses versace slippers replica cheap gucci shirts replica wholesale replica shoes wholesale replica shoes wholesale replica shoes wholesale replica shoes replica travel bags replica travel bags replica travel bags replica travel bags buy fake bags fake diamond rolex fake versace sunglasses best lv wallet cartier sunglasses with diamonds bottega veneta bag replica quality replica quality replica knock off bags online knock off bags online bottega veneta bag replica knock off bags online quality replica bottega veneta bag replica quality replica knock off bags online bottega veneta bag replica buy knock off shoes aaa gucci shoes aaa gucci shoes buy knock off shoes buy knock off shoes buy knock off shoes aaa gucci shoes aaa gucci shoes best fake gucci belt cheap chanel shoes wholesale good fake shoe websites bootleg gucci flip flops louis vuitton womens watches prices replica mens dress shoes replica mens dress shoes replica mens dress shoes replica mens dress shoes gucci replica watches gucci replica watches gucci replica watches gucci replica watches louis vuitton mens bracelet faux designer shoes faux designer shoes faux designer shoes faux designer shoes louis vuitton mens leather bracelet louis vuitton watches mens cheap gucci shoes for men replica cheap gucci shoes for men replica cheap gucci shoes for men replica cheap gucci shoes for men replica cartier oval sunglasses hermes jewellery replica fake gucci store wholesale replica jewlery good fake shoes balenciaga motorcycle bag knockoff knock off hermes scarf replica name brand shoes replica name brand shoes replica name brand shoes replica name brand shoes versace earrings replica designer knockoff sunglasses designer knockoff sunglasses designer knockoff sunglasses designer knockoff sunglasses prada shoes china cheap gucci sandals wholesale imitation purses handbags imitation purses handbags imitation purses handbags imitation purses handbags replicas store gucci messenger bag replica louis vuitton mens boots high quality replica jewelry cheap cartier sunglasses replica women watches replica women watches replica women watches replica women watches replicas online replica louis belt replica louis belt replica louis belt replica louis belt louis vuitton designer shoes replica versace shoes for men glidelock clasp faux gucci shoes faux gucci shoes faux gucci shoes faux gucci shoes yves saint laurent bags replica alexander wang replica hermes replica watch hermes replica watch hermes replica watch hermes replica watch gucci ring replica gucci ring replica gucci ring replica gucci ring replica quality replica bags quality replica bags quality replica bags quality replica bags louis vuitton duffle bag replica designer replica clothing gucci glasses replica gucci glasses replica gucci glasses replica gucci glasses replica louis vuitton shoes blue replica money clips lv watches for men price balenciaga motorcycle bag knockoff replica versace rings fake designer bags uk rose gold cartier glasses cheap ysl shoes replica audemars authentic louis vuitton mens shoes cazal watches replica designer fashion rolex kinetic watch louis vuitton studded shoes louis vuitton watches gold fake hermes jewelry best louis vuitton mens wallet louis vuitton shoes high heels where to buy replica belts where to buy replica belts where to buy replica belts where to buy replica belts best luxury replica watches hermes tennis shoes louis vuitton bracelets women fake cartier replica designer shoes manufacturers best replica sunglasses louis vuitton watches men replica chanel shoes replica chanel shoes replica chanel shoes replica chanel shoes cheap prada shoes wholesale louis vuitton china replica fake brands for sale hermes belts replica cartier sunglasses 140 discount gucci shoes wholesale louis vuitton female shoes jimmy choo knockoffs replica bags uk replica bags uk replica bags uk replica designer messenger bags replica designer messenger bags replica designer messenger bags replica designer messenger bags replica bags uk best replica sneaker site knockoff handbags replica dolce and gabbana fake luxury bags versace mens shoes replica versace mens shoes replica versace mens shoes replica versace mens shoes replica replica gucci boots replica gucci boots replica gucci boots replica gucci boots best website to buy fake louboutins good replica sites rolex pen ysl men shoes fake rolex for sale sunglasses replica where to buy replicas versace knock off shoes faux gucci belt replica mens clothes best replica bags website best replica bags website best replica bags website best replica bags website knock off cartier watches hermes replica wallets hermes replica wallets hermes replica wallets imitation hermes belts louis vuitton shoes men red louis vuitton shoes for cheap faux gucci bag gucci belts replica rolex glidelock hermes knockoff bag red louis vuitton shoes men louis vuitton travel bag replica purple lv purse louis vuitton briefcases for women lv shoes for ladies tissot replica knockoff birkin bags fake bags online shopping fake bags online shopping fake bags online shopping fake bags online shopping fake louis vuitton handbags fake louis vuitton handbags fake louis vuitton handbags fake louis vuitton handbags best place to buy replica belts shoe replica sites shoe replica sites best place to buy replica belts shoe replica sites shoe replica sites best place to buy replica belts best place to buy replica belts ysl tribute sandal replica louis vuitton watch mens louis vuitton mens slippers cartier glasses with diamonds gucci replica belt men shoes louis vuitton chopard earrings replica men lv shoes cheap designer replicas replicas on line knockoff designer watches gold cartier sunglasses luxury replica watches louis vuitton bag charms replica wholesale gucci flip flops versace sandals replica panerai watches womens versace fake shoes lv jewlery hermes sunglasses price knockoff mens watches louis vuitton scarf brown mens replica clothes lv mens leather bracelet cartier sunglasses 135 versace replica shoes versace replica shoes versace replica shoes versace replica shoes good replica belts good replica belts good replica belts good replica belts fake designer clothes mens lv bracelet women lv shoes for sale lv bracelet man gucci knockoff white louis vuitton sunglasses best faux designer handbags best faux designer handbags best faux designer handbags best faux designer handbags replica mens jewelry louis vuitton briefcase women cartier mens sunglasses sale louie vuitton shoes balenciaga aaa replica louis vuitton messenger bag women cheap cazal glasses for sale fake louis vuitton purse louis vuitton mens briefcase cartier gold glasses louis vuitton cowhide leather bag mont blanc handbag aaa quality belts aaa quality belts aaa quality belts aaa quality belts replica lighters louis vuitton men’s shoes blue louis vuitton heels best quality replica shoes best quality replica shoes best quality replica shoes best quality replica shoes japanese miyota rolex rolex 20646 cheap prada shoes china knock off tennis shoes louis vuitton for men shoes fake celine bag top replica websites cazal cheap cheapest louis vuitton shoes aaaa quality belts lv purple handbag chanel bag copies aaaa replica belt gucci replica shirts womens cartier eyeglass frames louis vuitton ladies watches price wholesale rolex watches for sale imposter sunglasses orange alexander mcqueen scarf versace knock off watches replicas aaa handbags piaget mecanique lv sunglasses for mens louis vuitton side bag womens replica mens wallet replica mens wallet replica mens wallet replica mens wallet louis vuitton amber sunglasses fake brands online shopping knock off gucci belt cartier glasses for sale replica aaa replica aaa louis vuitton shoes for women rolex glidelock clasp fake hermes wallet hermes shoes for men gucci flip flops replica mens tan louis vuitton heels hermes flip flops replica knockoff mens watches best fake bags online best fake bags online best fake bags online best fake bags online hugo boss shoes quality best sneaker replica sites the best replica site hermes mens sneakers knockoff watch hermes knock off belt why is givenchy jewelry so cheap fake hermes scarves louis vuitton men dress shoes wholesale chanel sunglasses replicas watches best replica sneaker sites replica aaa watches cazal 644 for sale mens designer belts replica replica versace clothes mens cartier glasses sale louis vuitton watches price cheap knock off bags louis vuitton womens briefcase ysl shoes for men watches bags knock off designer shoes for men fake versace robe wallets replica wallets replica wallets replica wallets replica louis vuitton ladies handbags hermes wristlet lv mens ring silver louis vuitton shoes louis vuitton watches mens price glidelock clasp for sale bootleg gucci shoes bootleg gucci shoes bootleg gucci shoes buy replicas watch louis vuitton black stilettos louis vuitton sandals for men every designer.ru cheap chanel slides white louis vuitton heels rep kicks ru mens cartier sunglasses hermes scarf knock off knock off versace jewelry cazal on sale dolce and gabbana replica dress blue louis vuitton mens shoes faux designer handbags louis vuitton ladies sandals bottega veneta bracelet replica knock off versace belt cartier sunglasses black best replica sites fake vs real versace belt hermes watches mens fake shoes online louis vuitton cosmetic pouch replica louis vuitton spiked heels cartier clear glasses chanel replica jewelry replica name brand clothing white louis vuitton loafers shoes mens louis vuitton replica lv wallet replica lv wallet replica lv wallet louis vuitton casual shoes real cartier glasses for sale hermes boat shoes louis vuitton flip flops womens hermes bag replicas cartier sunglasses for men louis vuitton red shoes for men aaa gucci flip flops fake lv belt replica brands clothes louis vuitton grey scarf lui viton shoes tudor watch replica replica mens jewellery replica wathces replica bags sale lv bracelet men hermes necklace replica burberry crossbody bag replica knock off cartier audemars piguet replicas louis vuitton ladies sunglasses how to tell if chopard watch is real hermes knockoffs good knock off bags hermes silk scarf replica high quality cartier replica jewelry louis vuitton mens ring for sale replica brand chanel replica bag best diamond replica louis vuitton male bracelets knock off brand shoes wire cartier glasses blue louis vuitton shoes replica gucci flip flops knock off versace replica automatic watches lv bracelet for men vitton watches replica brand clothing louis vuitton folding sunglasses fake hublot imitation burberry bags imitation hermes bag best replica com replica mens watch knock off hermes bags blue alexander mcqueen scarf louis vuitton leather bracelet men louis vuitton fanny pack replica versace necklace replica hermes watches for sale ross shoes fake imitation burberry handbags best replica website cartier ladies sunglasses replica burberry mens wallet replic watches louis vuitton shoes and bags shoes louis vuitton for men louis vuitton sunglasses ioffer replica designer glasses frames saint laurent sale mens hermes wallet replica gold louis vuitton shoes cartier glasses for men designer knockoff sunglasses wholesale gucci shoes free shipping knock off brands online louis vuitton purple handbag hermes mens briefcase mens cartier glasses cheap replica shoes louis vuitton mens watches chanel jewelry replica best replica sneaker website replica cazal frames fake tissot watches mont blanc backpack sale hermes men shoes replica versace sandals hermes watch buckle luxury replica pens louis vuitton house shoes cheap gucci shoes wholesale shoes replica hermes watch men chanel first copy bags louis vuitton shoes sport knockoff gucci slides replica hermes jewellery louis vuitton laptop bag womens cartier 140 glasses lv flat shoes louis vuitton sandals for mens cartier glasses with diamonds in them mont blanc knock off cheap prada man shoes cazals for sale ysl copy bags fake gold watches for women lv sunglasses for ladies cartier 140 sunglasses shoes for men louis vuitton replica moschino bags fake tissot watches hermes watch womens mens armani rings hermes watches for men replicaonline hermes watches ladies lv mens necklace imitation glasses fake gucci belts replica designer backpacks for men buy replica clothing online mont blanc handbags super style ru cheap authentic cartier glasses authentic gucci shoes wholesale best fake shoe website aaa replica bags louis vuitton knockoff handbags buy fake shoes online replica bracelets louis vuitton mens tennis shoes cartier knock off louis vuitton spike shoes authentic gazelle sunglasses lv blue shoes louis vuitton watches watches replica louis vuitton mens shoes spikes replica blancpain watches faux cartier watch lv louis vuitton mens watch fake luxury belts imitation purse aaa replica watches hermes sunglasses mens knockoff bags cartier plain glasses hermes scarf real or fake fake versace flip flops super cheap gucci belts panerai knock off louis vuitton shoes men white hermes mens shoes replica designer belts paypal wholesale tissot watches louis vuitton sport shoes louis vuitton camo shoes replica designer clothes for sale lv purple bag emporio armani watch quality lv loafers cheap aigner jewelry piaget watch serial numbers replica jimmy choo shoes high quality fake watches cartier 135 replica pen black and gold cartier sunglasses louis vuitton knock off hermes womens watches chanel boy bag replica high quality hermes casual shoes wholesale gucci shoes louis vuitton watch men aaa replica shoes best website to buy fake shoes black and blue alexander mcqueen scarf 7 ru lv shoes for mens price hermes faux bags alexander wang bag replica hermes ring replica where to buy knock off purses online faux cartier louis vuitton runners men fake celine sunglasses louis vuitton flip flops ladies faux rolex replica designer watches gucci ace sneakers replica replica louboutins for sale gucci inspired flip flops replica designer belts cheap cartier buffs sunglasses bagsmetoo lv knockoffs lv ballet flats louis vuitton mens studded shoes brown louis vuitton scarf replica chopard watch cheap gucci wallet replica louis vuitton slippers mens imitation designer purses red louis vuitton scarf louis vuitton gold watch replica birkin bags for sale lv men bracelets imitation burberry purse mens louis vuitton bracelet replica vacheron constantin cheap cartier frames cheap patek philippe watches louis vuitton slides men louis vuitton slippers for men louis vuitton blue shoes knock off versace glasses louis vuitton womens shoes for sale best replica watches lv mens dress shoes alexander wang scarf best louis vuitton belt panerai womens knock off mens watches franck muller womens watches chopard watches replicas louis vuitton spiked shoes for men black and gold alexander mcqueen scarf alexander mcqueen scarf for sale dolce and gabbana purse fake cartier wood glasses replica replica designer belt cheap chanel slippers buy replica clothing replica shop christian louis vuitton mens sneakers cartier glasses 135 best watches replica fake louis vuitton fanny pack chanel watches replica ysl mens shoes buffs glasses for sale panerai womens watch cartier belt louis vuitton shoes mens imitation designer belts louis vuitton mens watch gold louis vuitton heels knockoff watches louis vuitton messenger bag women’s hermes watches women versace backpack replica watch replica lv watches fake louis vuitton luggage lv scarf grey replica men watches louis vuitton shoes online versace belt aaa hermes watch for women louis vuitton scarf red louis vuitton loafers for women blue mcqueen scarf cartier sunglasses sale replica versace belt fake white gucci belt replica designer clothing online replica burberry watch rolex glidelock clasp for sale louis vuitton rose gold bracelet mens louis vuitton sneakers sale rolex pen price round gold cartier glasses mens knock off watches louis vuitton sunglasses white and gold saint laurent handbag sale louis vuitton house slippers fake versace belt replica designer luggage louis vuitton stilettos shoes real cartier sunglasses mont blanc leather bag louis vuitton sunglasses aviator replica brands clothing best cartier replica rolex sapphire crystal mens louis vuitton watch replica glasses frames louis vuitton bag charm replica cartier sunglasses for ladies replica armani belts cartier clear lens glasses alexander mcqueen scarf sale a lange sohne replica best cartier wire glasses aaa wallets louis vuitton formal shoes for men mens watch replica used cartier glasses for sale replica mens designer belts watches knock off lv black and gold sunglasses purple louis vuitton shoes miu miu inspired sunglasses cartier bracelet replica white alexander mcqueen scarf cartier mens sunglasses knock off jewelry louis vuitton belt and shoes hermes flip flops mens white louis boat shoes hermes watch mens dolce and gabbana mens necklace replica armani clothes le miu shoes louis vuitton purple purse rolex quartz women’s watch louis v slippers patek philippe geneve fake lv scarf red dior watches for sale louis vuitton black high heels cartier belts price good fake designer bags panerai quality chanel knockoff bags knock off hermes bag replica versace shades louis vuitton mens overnight bag louis vuitton messenger bags women black louis vuitton shoes with red bottom emporio armarni rings louis vuitton sneakers men’s fake brands for sale versace replica belts watches louis vuitton louis vuitton round sunglasses real looking knock off handbags cartier sunglasses round lv ring mens hermes jimmy sneakers louis vuitton purse fake cartier glasses 140 replica mens belts designer white louis vuitton shoes men louis vuitton mens handbag cartier round glasses where to buy fake shoes moschino replica bags piaget stainless steel watch watches knockoffs super style.ru imitation mont blanc pens armani jewelry lv men shoes rolex sunglasses for sale lv watches price mont blanc mens bag jewellery replica pradas shoes for cheap imitation designer purse legit replica shoe sites quality replicas watches fake designer watches brown louis vuitton sneakers louis vuitton womens heels fake mens glasses fake panerai cheap fake bags designergu ru cartier frames for sale gucci knock off belt ru watch real leather louis vuitton bags cartier watch clasp replica men replica clothing men lv man bracelet prada brogues womens top replicas male louis vuitton shoes lv watch prices lv designer shoes luxury replicas watches montblanc watches womens franck muller stainless steel watch cartier sunglasses for women mcm mens wallet replica bootleg gucci belts loui vuitton mens loafers replica designer jeans pink cartier glasses prada handbags 2017 mont blanc briefcase sale used alexander mcqueen scarf fake versace belt for sale wholesale gucci sneakers mens dolce gabbana shoes wholesale chanel shoes louis vuitton mens shoes high top birkin bag knock offs mcqueen jewelry louis vuitton coin pouch replica rolex milgauss clasp gucci inspired sneakers gucci belt copy hermes mens bracelet replica louis vuitton mens high top shoes round cartier glasses louis vuitton womens sneaker louis vuitton bracelet mens louis vuitton mens boots for sale mens designer wallets louis vuitton blue louis vuitton loafers replicas fashion watches.ru man prada shoes on sale lv purple wallet fake montblanc pen ysl ballet flats replica mont blanc wallet 60278 rolex alexander mcqueen scarf red franck muller watches women how much is a piaget watch cartier glasses diamonds gucci quartz watch real or fake alexander mcqueen bracelet sale ua fake shoes cartier 140 high quality rolex replicas hermes mens dress shoes replica versace flip flops mens fake designer belts lv mens briefcase cartier sunglasses men’s aaa replica shoes high quality aaa replica shoes high quality are cartier glasses real gold mens louis vuitton sandals mont blanc watches womens hermes copies silver cartier glasses alexander wang shoes mens blue hermes shoes replica belts for men gucci fur loafers replica fake cartier watch ladies louis vuitton belt cartier sunglasses men louis vuitton mens runners dolce and gabbana mens necklaces cheap hermes jewelry cartier sunglasses gold louis vuitton heels with spikes replica cartier watches versace glasses replica mont blanc mens bags discount cazal sunglasses louis vuitton studded heels saint laurent purse sale louis vuitton diamond watches pink and white alexander mcqueen scarf louis vuitton suede shoes longines quality prada ua gazelle sunglasses for men cartier tortoise shell frames louis vuitton sneakers ladies hermes sneakers mens cartier diamond sunglasses cc earrings knock off blue hermes loafers where to buy knockoffs online replica belts for sale faux rolex watches sale knockoff mcm belts ru shoes black cartier glasses replica sneaker sites purple lv belt replica iwc portuguese piaget watches for sale replica watches for sale hermes watch ladies louis vuitton satchel mens replica eyeglass louis vuitton shoe for sale gucci watch 1142 fake louis vuitton mini ipad case hermes watches sale cartier shades men cheap ru purple louis vuitton purse gucci wholesale shoes cartier men wallets replica designer rings mont blanc bags sale replika shoes fake designer bags online shopping cartier pens knock off louis vuitton wallet best website to buy fake designer louis vuitton studded bag hermes black leather purse louis vuitton sneakers spikes mens armani ring faux watches hublot watch womens cheap gucci sandals mens mens watches replica fake designer luggage for sale dior watches for men best website for fake designer bags what are buffs glasses wholesale designer replica jewelry lv messenger bag women replica designer belts men cartier lenses for sale how to know if cartier glasses are real patek philippe leather watch armani replica buy fake designer bags lv watch price louis vuitton diamond heels cheap replica clothing louis vuitton loafers for sale cheap cartier watches vuitton watch montblanc mens bag replica name brand clothes replica women watch ysl mens watch dolce and gabbana belts for sale mont blanc fake pen cartier men wallet replica designer clothes uk gucci shoes wholesale
I like the helpful info you provide in your articles.
I will bookmark your blog and check again here regularly.
I’m quite certain I will learn lots of new stuff right here!
Good luck for the next!
Hi there every one, here every one is sharing these know-how,
therefore it’s good to read this web site, and I used
to go to see this webpage everyday.
No matter if some one searches for his necessary thing, therefore he/she wants to be available
that in detail, thus that thing is maintained over here.
Understanding Social Engineering: 5 Signs You’re at
Risk
Atlanta, GA – As technology advances, cyber criminals are finding
new ways to exploit vulnerabilities in people rather than systems.
Social engineering is a form of hacking that uses psychological manipulation to trick individuals into divulging sensitive information or performing unauthorized actions.
South Fulton Locksmiths LLC has identified five ways individuals and organizations can be vulnerable to social
engineering tactics.
1. Lack of Awareness: Many people are unaware of the techniques used by social
engineers. Criminals often create fake personas and build relationships with individuals through social
media platforms or email, gaining their trust and accessing sensitive information.
2. Overconfidence: Even individuals who are aware of social engineering tactics can be overconfident
in their ability to detect them. Criminals prey on individuals who
believe they are immune to such tactics.
3. Urgency: Social engineers often create a sense
of urgency to pressure individuals into taking immediate action. This tactic is commonly used in phishing scams, where individuals are asked to provide sensitive
information to prevent a supposed security
breach.
4. Trusting nature: Social engineering is based on exploiting human nature.
Criminals often target individuals who are naturally trusting or
helpful, making it easier to manipulate them into divulging sensitive information.
5. Lack of Security Awareness Training: Organizations that do not provide adequate security awareness training to their employees
are more vulnerable to social engineering attacks. Employees
who are not trained to recognize social engineering tactics are more
likely to fall prey to them.
South Fulton Locksmiths LLC is committed to educating individuals and
organizations on social engineering tactics and how
to mitigate the risks associated with them. As experts in security, the company provides a range of services, including security assessments, access control systems, and training programs designed to improve security awareness.
South Fulton Locksmiths LLC is a reliable and trusted provider of security solutions, with years of experience in the field.
The company’s team of experts is dedicated to helping individuals
and organizations protect themselves from social engineering attacks.
For more information on South Fulton Locksmiths LLC and their security solutions,
visit their website at https://www.southfultonlocksmiths.com.
Thank you for another informative site. The place else could I am getting
that kind of info written in such an ideal approach?
I have a undertaking that I am just now operating on, and I have been at the glance out for such info.
What i don’t realize is in fact how you’re now
not really a lot more neatly-liked than you may be now.
You’re so intelligent. You realize therefore significantly in relation to this topic, made me for my part
consider it from a lot of various angles. Its like women and men don’t seem to be
fascinated except it is something to accomplish with Woman gaga!
Your individual stuffs excellent. All the time care for it up!
What’s up, this weekend is nice for me, for the
reason that this point in time i am reading this enormous educational post here at my house.
I’ve been browsing online more than three hours lately, yet I by no means discovered any fascinating article
like yours. It is lovely worth sufficient for me. Personally,
if all webmasters and bloggers made excellent content as you did,
the net will likely be a lot more useful than ever before.
If you are going for finest contents like me, only pay a quick visit this web
page everyday since it provides feature contents,
thanks
I think that what you posted was very logical. But,
think on this, what if you added a little information? I ain’t suggesting your content is not good.,
however what if you added something that makes people want more?
I mean Пиастры – Составление семантического
ядра | is a little plain. You might look at Yahoo’s home page and note how they write article headlines to
get viewers to open the links. You might add a related video or a pic or two to get people interested about what you’ve written. Just my
opinion, it might bring your blog a little livelier.
Pretty nice post. I simply stumbled upon your blog and wanted to say that
I’ve really enjoyed browsing your weblog posts.
After all I’ll be subscribing for your feed and I am hoping you write again very soon!
Hello to all, the contents present at this site are actually awesome for people experience, well, keep up the nice work fellows.
I couldn’t refrain from commenting. Well written!
Very good blog you have here but I was wanting to know
if you knew of any message boards that cover the same topics talked about in this
article? I’d really like to be a part of community where
I can get suggestions from other knowledgeable individuals that share the same interest.
If you have any recommendations, please let me know. Thank you!
You really make it seem so easy with your presentation but I find
this matter to be actually something which I think
I would never understand. It seems too complicated
and very broad for me. I’m looking forward for your next post, I will try to get the hang of it!
Hi are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you require any html coding expertise
to make your own blog? Any help would be greatly appreciated!
Hey There. I discovered your blog using msn. This is an extremely
neatly written article. I’ll make sure to bookmark it and return to learn more of your helpful information. Thank you
for the post. I’ll definitely comeback.
Magnificent goods from you, man. I have remember your stuff previous to and you’re just too wonderful.
I actually like what you’ve got right here, certainly like what you’re saying and the way during which you say
it. You’re making it entertaining and you
continue to take care of to keep it wise.
I can not wait to read much more from you. That is actually a
tremendous website.
Heya i am for the first time here. I found this board and I find It truly useful
& it helped me out much. I hope to give something back and help others like you helped me.
Thanks for finally talking about > Пиастры
– Составление семантического ядра |
< Liked it!
This is a good tip especially to those new to the blogosphere.
Short but very precise info… Thanks for sharing this one.
A must read article!
Very nice post. I just stumbled upon your blog and wanted to say that I have really
enjoyed surfing around your blog posts. In any case I’ll
be subscribing to your rss feed and I hope you write again very soon!
It is appropriate time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I wish to
suggest you few interesting things or advice. Maybe you can write next
articles referring to this article. I desire to read even more
things about it!
Really when someone doesn’t know afterward its up to other visitors that they will help, so here it
takes place.
Attractive section of content. I simply stumbled upon your blog and in accession capital to assert that I acquire in fact loved account your weblog posts.
Anyway I will be subscribing on your feeds and even I success you
get entry to consistently rapidly.
Fantastic beat ! I wish to apprentice even as you amend your site, how can i subscribe for
a weblog site? The account aided me a appropriate deal.
I had been tiny bit familiar of this your broadcast offered brilliant
clear concept
I every time spent my half an hour to read this webpage’s content every day along with a cup of coffee.
Hi there Dear, are you actually visiting this site daily, if so then you will absolutely obtain fastidious know-how.
First of all I want to say terrific blog! I had a quick question that I’d like to
ask if you do not mind. I was interested to find out how you center
yourself and clear your thoughts before writing. I’ve had
a tough time clearing my thoughts in getting my ideas out.
I truly do enjoy writing however it just seems like
the first 10 to 15 minutes are usually wasted just trying to figure out how
to begin. Any ideas or tips? Thank you!
Nice post. I learn something totally new and challenging on sites I stumbleupon everyday.
It’s always interesting to read through articles from other writers and practice a little something from other websites.
Greetings from Colorado! I’m bored to tears at work so I decided to browse your site on my iphone during lunch break.
I enjoy the knowledge you present here and can’t wait to take a look when I get home.
I’m shocked at how quick your blog loaded on my cell phone
.. I’m not even using WIFI, just 3G .. Anyways, superb blog!
WOW just what I was looking for. Came here by searching for More information
After I initially commented I seem to have clicked on the -Notify me
when new comments are added- checkbox and now each time
a comment is added I receive four emails with the same comment.
Is there a means you are able to remove me from that service?
Cheers!
What’s Taking place i am new to this, I stumbled upon this I’ve found It positively useful and it has helped me out loads.
I hope to give a contribution & help different users like its aided
me. Good job.
My relatives every time say that I am killing my time here at web, except I know I am getting knowledge
all the time by reading thes fastidious posts.
Way cool! Some very valid points! I appreciate you penning this
article and the rest of the site is also really good.
Nice weblog right here! Additionally your
website a lot up fast! What web host are you the usage of?
Can I am getting your associate hyperlink to your host? I desire my site loaded
up as fast as yours lol
Heya i’m for the primary time here. I came across this board and I find
It really useful & it helped me out much. I am hoping to offer something again and help others like you helped me.
Robux robux.newsfromrus.one
You really make it seem so easy together with your presentation but I in finding this matter to be actually one thing that I feel I would
never understand. It seems too complicated and very large for me.
I am looking forward in your next put up, I’ll try
to get the hang of it!
It’s very trouble-free to find out any matter on net as compared to books,
as I found this post at this site.
Thank you for the auspicious writeup. It if truth be told
used to be a entertainment account it. Look advanced to far delivered agreeable from you!
By the way, how can we keep up a correspondence?
I really like your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you?
Plz respond as I’m looking to design my own blog and would like to know where
u got this from. appreciate it
Hi everybody, here every one is sharing these kinds of knowledge, therefore
it’s fastidious to read this webpage, and I used to visit
this website daily.
Here is my site … USA Script Helpers: Affordable Prescription Drugs Canada
Hi there mates, nice post and good arguments commented at this place,
I am really enjoying by these.
Hey there, You’ve done a great job. I’ll certainly digg it and personally
suggest to my friends. I am sure they’ll be benefited from this web site.
Hello, Neat post. There is an issue with your site in web
explorer, would test this? IE nonetheless is the marketplace leader and a big component to other folks will pass over your excellent writing due to this problem.
I got this site from my pal who shared with me concerning this site and at the moment this time I am visiting this website and reading very informative articles or reviews at this
time.
As the admin of this site is working, no question very quickly it will
be renowned, due to its feature contents.
great issues altogether, you simply gained a brand new reader.
What would you recommend about your put up that
you simply made a few days in the past? Any certain?
Greetings! This is my 1st comment here so I just wanted to give a quick shout out and say I truly
enjoy reading your posts. Can you recommend any other blogs/websites/forums that cover the same subjects?
Thank you so much!
I am truly grateful to the owner of this web page who has shared this enormous post at at this place.
I have been browsing on-line greater than three hours lately, but I by
no means discovered any attention-grabbing article like yours.
It is lovely worth sufficient for me. In my opinion, if all web owners
and bloggers made just right content material
as you did, the web might be a lot more helpful than ever before.
After looking into a handful of the blog articles
on your web site, I really appreciate your way of writing a blog.
I added it to my bookmark site list and will be checking back soon. Please check out my web site too and tell me
how you feel.
Undeniably believe that which you said. Your favourite justification appeared to be at the
net the simplest factor to take note of.
I say to you, I certainly get annoyed even as people think
about concerns that they plainly don’t realize about. You managed to hit the nail upon the top and also outlined out the entire thing with no need
side-effects , other people could take a signal. Will likely
be again to get more. Thank you
Sweet blog! I found it while surfing around on Yahoo News. Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
An intriguing discussion is definitely worth comment. I think that you need to publish more about this issue, it might not be a taboo subject
but generally people do not discuss these topics.
To the next! All the best!!
Hmm it appears like your website ate my first comment (it
was super long) so I guess I’ll just sum it up what I submitted
and say, I’m thoroughly enjoying your blog. I as well am
an aspiring blog blogger but I’m still new to the
whole thing. Do you have any suggestions for beginner blog writers?
I’d really appreciate it.
Hi! This is kind of off topic but I need some help from
an established blog. Is it difficult to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any ideas or suggestions? Thank
you
Thanks on your marvelous posting! I definitely enjoyed reading it, you happen to be a great author.I will always bookmark your blog and
will eventually come back at some point. I want to encourage that you
continue your great posts, have a nice afternoon!
hey there and thank you for your information – I have definitely picked up anything new from
right here. I did however expertise several technical issues using this website,
as I experienced to reload the website a lot of times previous
to I could get it to load correctly. I had been wondering if your web host is OK?
Not that I am complaining, but sluggish loading instances times
will sometimes affect your placement in google and could damage your quality score if ads and marketing with Adwords.
Well I am adding this RSS to my e-mail and can look out for a lot more of your respective exciting content.
Ensure that you update this again soon.
Your way of telling all in this paragraph is genuinely
pleasant, all can effortlessly understand it, Thanks a lot.
I’m no longer positive where you are getting your info, but great topic.
I must spend a while learning much more or figuring out more.
Thank you for fantastic information I was searching for
this information for my mission.
Hi! I just want to offer you a huge thumbs up for the great info you have got here on this post.
I will be coming back to your web site for more soon.
Nice blog! Is your theme custom made or did you download it
from somewhere? A design like yours with a few simple adjustements would really make my blog stand out.
Please let me know where you got your design. Appreciate it
Hi there i am kavin, its my first time to commenting anywhere, when i read this paragraph i thought i could also create comment due to this
good article.
Terrific work! This is the type of info that are supposed to be shared
across the web. Shame on Google for no longer positioning this post higher!
Come on over and visit my site . Thank you =)
What’s up mates, fastidious paragraph and fastidious arguments commented here, I am in fact enjoying by these.
Hi, i read your blog from time to time and i own a similar one and i was just curious if you get
a lot of spam remarks? If so how do you protect against it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any assistance is very
much appreciated.
Hello there, You’ve done a great job. I will definitely digg it and personally recommend to my friends.
I am confident they will be benefited from this website.
معرفی قطعات خودرو و حافظه دوربین مدار بسته چقدر است و دوربین
مداربسته کی دی تی و بهداشت فردی در ورزش یعنی چه
Hey very nice blog!
For the reason that the admin of this site is working, no doubt
very shortly it will be well-known, due to its feature contents.
Your mode of describing the whole thing in this post is truly fastidious, every
one be able to without difficulty know it, Thanks a lot.
I feel that is among the most vital info for me.
And i am glad reading your article. But want to remark on few basic issues, The website taste
is perfect, the articles is truly great : D. Just right process,
cheers
After I originally left a comment I seem to have clicked
the -Notify me when new comments are added- checkbox and from now on each time a comment
is added I get 4 emails with the exact same comment. Is there a way you can remove me from
that service? Kudos!
Wonderful web site. A lot of helpful info here. I am sending it to several buddies ans
additionally sharing in delicious. And obviously,
thanks to your sweat!
I’m gone to convey my little brother, that he should
also pay a visit this webpage on regular basis to take updated from latest information.
I think the admin of this web page is really working hard in support of his web site,
as here every information is quality based information.
This design is wicked! You definitely know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great
job. I really loved what you had to say, and more than that, how you presented it.
Too cool!
That is very fascinating, You are an overly skilled blogger.
I’ve joined your feed and look ahead to in the hunt for more of your magnificent post.
Also, I have shared your web site in my social networks
Good post. I learn something new and challenging
on websites I stumbleupon everyday. It will always be helpful to read articles
from other authors and use a little something from other
sites.
I’m now not positive where you’re getting your info,
but good topic. I needs to spend a while learning more or
understanding more. Thank you for wonderful information I used to be in search of this info for my mission.
Hello there! I just wish to give you a big thumbs up for the excellent info you have got
here on this post. I am returning to your web site for more soon.
I am truly happy to read this website posts which consists
of tons of useful information, thanks for providing these information.
Does your site have a contact page? I’m having trouble locating it
but, I’d like to shoot you an email. I’ve got some recommendations for your blog you
might be interested in hearing. Either way, great blog and I look
forward to seeing it improve over time.
My spouse and I absolutely love your blog and find the majority of your post’s to be just
what I’m looking for. can you offer guest writers to write
content available for you? I wouldn’t mind publishing a post or elaborating on a number of the subjects you write in relation to here.
Again, awesome website!
Pretty great post. I simply stumbled upon your weblog and wanted to mention that I’ve really enjoyed surfing around your blog posts.
In any case I’ll be subscribing for your rss feed and I hope you
write again soon!
This info is invaluable. How can I find out more?
Гей порно
It’s in reality a nice and helpful piece of info. I’m
happy that you simply shared this helpful info with us.
Please keep us informed like this. Thanks for sharing.
I just could not depart your site before suggesting that I actually enjoyed the usual info a person provide on your visitors?
Is going to be back steadily in order to inspect new posts
HD порнуха
It’s really a nice and helpful piece of information. I’m
glad that you just shared this helpful information with us.
Please keep us up to date like this. Thank you for sharing.
You are so cool! I do not suppose I’ve truly read anything like that
before. So good to discover another person with some original
thoughts on this subject. Really.. thanks for starting this up.
This web site is something that is required on the web, someone with some
originality!
Every weekend i used to visit this website,
because i wish for enjoyment, as this this web page conations
genuinely good funny material too.
my webpage – A片
Thanks for sharing your info. I really appreciate your efforts and I am
waiting for your next post thank you once again.
I know this if off topic but I’m looking into starting my own blog and was curious what all is needed to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% positive.
Any tips or advice would be greatly appreciated.
Kudos
I’m gone to tell my little brother, that he should
also go to see this weblog on regular basis to obtain updated
from most up-to-date news update.
Hello, i feel that i saw you visited my web site so i came to return the desire?.I’m trying to find issues
to enhance my web site!I guess its adequate
to make use of some of your ideas!!
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you are going to a
famous blogger if you aren’t already 😉 Cheers!
I’m gone to tell my little brother, that he should also visit this web
site on regular basis to obtain updated from
latest news.
When someone writes an piece of writing he/she keeps the plan of
a user in his/her mind that how a user can know it.
So that’s why this article is perfect. Thanks!
I’ve read several excellent stuff here. Certainly value bookmarking for revisiting.
I surprise how so much attempt you set to make this sort of great informative website.
Порнуха
Very good information. Lucky me I found your blog by accident (stumbleupon).
I’ve book-marked it for later!
Hi there, just became aware of your blog through Google, and found that
it is really informative. I’m gonna watch out for brussels.
I’ll be grateful if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
If some one wants expert view concerning blogging and site-building
then i propose him/her to go to see this web site, Keep up the fastidious job.
I am really enjoying the theme/design of your blog. Do you ever run into
any web browser compatibility problems? A handful of my blog visitors have complained about
my blog not operating correctly in Explorer but looks great in Safari.
Do you have any solutions to help fix this issue?
Keep on writing, great job!
Hi, I do believe this is a great web site. I stumbledupon it 😉 I will revisit once again since i have saved as a
favorite it. Money and freedom is the best way to change,
may you be rich and continue to guide others.
Hello, I enjoy reading all of your post. I wanted to write a little comment to support you.
Greetings from Los angeles! I’m bored to tears at work so
I decided to check out your site on my iphone during lunch break.
I really like the info you provide here and
can’t wait to take a look when I get home. I’m shocked at
how fast your blog loaded on my cell phone .. I’m not even using WIFI, just 3G ..
Anyways, fantastic blog!
Your style is unique in comparison to other people I have read
stuff from. Thanks for posting when you’ve got the opportunity, Guess I will just bookmark this site.
I’ve been exploring for a little for any high-quality articles
or weblog posts in this sort of space . Exploring in Yahoo I at last stumbled
upon this website. Reading this info So i am happy to show that I’ve a very good uncanny feeling
I came upon just what I needed. I so much surely will make
sure to do not disregard this site and provides
it a glance on a constant basis.
Hmm it looks like your blog ate my first comment (it was extremely long) so I guess I’ll just sum it
up what I had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to everything.
Do you have any tips and hints for novice blog writers? I’d definitely
appreciate it.
It’s amazing to go to see this site and reading the views of
all colleagues regarding this article, while I am also zealous of getting know-how.
First of all I would like to say terrific blog! I had a quick question which I’d like to ask if you don’t mind.
I was curious to know how you center yourself and clear your mind prior to writing.
I’ve had a hard time clearing my mind in getting my thoughts out there.
I do enjoy writing but it just seems like the first 10 to 15 minutes are
usually lost simply just trying to figure out how to begin. Any suggestions or tips?
Cheers!
Replica Clothes, Bvlks
str.Diego 13, London,
E11 17B
(570) 810-1080
replica clothes
This is the perfect website for anybody who wants to
understand this topic. You understand so much its almost hard to argue with you (not that I really
would want to…HaHa). You definitely put a brand new spin on a topic that’s been written about for decades.
Great stuff, just wonderful!
You need to be a part of a contest for one of the finest websites on the internet.
I’m going to highly recommend this blog!
This is really interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your magnificent post.
Also, I have shared your site in my social networks!
Spot on with this write-up, I absolutely feel this amazing site needs a great deal more attention. I’ll probably be returning to
see more, thanks for the information!
Your style is very unique in comparison to other folks I have read stuff from.
I appreciate you for posting when you have the opportunity, Guess I’ll just book mark this blog.
Aw, this was an incredibly nice post. Finding the time and actual effort to produce a top notch article… but what can I say… I put things off
a whole lot and never seem to get nearly anything done.
It’s really a great and useful piece of information. I am satisfied that
you shared this useful info with us. Please keep us informed like this.
Thanks for sharing.
Great beat ! I wish to apprentice even as you amend your site, how could i subscribe for a weblog site?
The account aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided shiny transparent idea
Spot on with this write-up, I honestly believe that this amazing
site needs far more attention. I’ll probably be back again to read more, thanks for the info!
You are so cool! I do not believe I’ve truly read something like that
before. So nice to find someone with unique thoughts on this subject matter.
Really.. many thanks for starting this up. This site
is something that’s needed on the internet, someone with a bit of originality!
Fantastic blog you have here but I was wanting to know if
you knew of any forums that cover the same topics discussed
in this article? I’d really like to be a part of group where I can get comments from other experienced individuals
that share the same interest. If you have any recommendations, please let
me know. Thanks!
Let me give you a thumbs up man. Can I show back my secrets
on amazing values and if you want to really findout? and
also share valuable info about how to change your life yalla lready know follow me my fellow commenters!.
Hi! I know this is somewhat off topic but I was wondering if you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
Wow that was unusual. I just wrote an incredibly long comment
but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyways, just wanted
to say excellent blog!
Awesome things here. I am very happy to peer your post.
Thank you so much and I’m taking a look forward to contact you.
Will you please drop me a mail?
Hey there I am so happy I found your webpage, I really found you by accident, while I was searching on Yahoo for something else, Anyways
I am here now and would just like to say thanks a lot for a remarkable post and a all round entertaining blog (I
also love the theme/design), I don’t have time to read
through it all at the minute but I have saved it and also added your RSS feeds, so when I have time I will
be back to read a lot more, Please do keep up the great work.
I was wondering if you ever thought of changing the page layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could
connect with it better. Youve got an awful lot of text for only having one or
two pictures. Maybe you could space it out better?
I’ll right away snatch your rss as I can not find your email subscription link or
e-newsletter service. Do you’ve any? Please allow me recognise so that
I may just subscribe. Thanks.
Greetings from Ohio! I’m bored at work so I
decided to check out your website on my iphone during lunch break.
I love the info you present here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyways, fantastic blog!
Hi! This is kind of off topic but I need some help from an established blog.
Is it very difficult to set up your own blog? I’m not very techincal but I
can figure things out pretty quick. I’m thinking about setting
up my own but I’m not sure where to start. Do you have any ideas or suggestions?
With thanks
Hey there, I think your website might be having browser compatibility issues.
When I look at your website in Chrome, it looks fine but when opening
in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, wonderful blog!
Hey there! I just would like to offer you a huge thumbs up for the great information you have right here on this post.
I am coming back to your site for more soon.
Hi there would you mind stating which blog platform you’re working with?
I’m going to start my own blog soon but
I’m having a tough time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m
looking for something unique. P.S Sorry
for being off-topic but I had to ask!
I don’t even understand how I ended up right here, but I assumed this post
was good. I don’t recognize who you might be however definitely you are going to a well-known blogger when you are not already.
Cheers!
Very nice post. I just stumbled upon your weblog and wanted to say that I’ve truly enjoyed surfing around your blog posts.
After all I will be subscribing to your rss feed and I hope you write again soon!
Greetings! Very helpful advice in this particular article! It is the little changes
that will make the greatest changes. Thanks for sharing!
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an nervousness over that you wish be delivering the following.
unwell unquestionably come more formerly again as exactly the same nearly a lot
often inside case you shield this hike.
I have fun with, result in I found exactly what I was
looking for. You’ve ended my four day long hunt! God Bless you man. Have
a great day. Bye
I used to be suggested this website through my cousin. I am not
sure whether or not this put up is written by means of him as no one else
understand such distinctive approximately my difficulty.
You are wonderful! Thanks!
I think the admin of this website is in fact working hard in support
of his web site, for the reason that here every material
is quality based material.
Excellent post. I was checking continuously this blog and I’m impressed!
Very helpful info specifically the last part I care for such information much.
I care for such information much.
I was looking for this certain information for a very long time.
Thank you and best of luck.
https://mramins.ir/2022/09/15/همه-چیز-در-مورد-پکیج-پیام-ساختمان/
I got this website from my friend who shared with me about this web site and at the moment this time I
am browsing this web site and reading very informative articles or reviews at this
time.
The policyholder might hire their own public adjuster to negotiate the settlement with the insurance company on their behalf.
I am really enjoying the theme/design of your blog.
Do you ever run into any internet browser compatibility
issues? A couple of my blog readers have complained about my site not operating correctly in Explorer but looks great in Firefox.
Do you have any suggestions to help fix this issue?
I’m gone to tell my little brother, that he should also pay a quick visit this
web site on regular basis to take updated from latest news update.
Today, I went to the beachfront with my kids. I found a sea shell and gave it to my 4
year old daughter and said “You can hear the ocean if you put this to your ear.” She put
the shell to her ear and screamed. There was a hermit crab
inside and it pinched her ear. She never wants to go back!
LoL I know this is totally off topic but I had to tell someone!
Hi, after reading this remarkable article i am also delighted to share my familiarity
here with mates.
Hey there! This is my 1st comment here so I just wanted to give a quick shout out and
tell you I truly enjoy reading through your blog posts. Can you recommend any other
blogs/websites/forums that deal with the same subjects?
Thank you so much!
What’s up friends, pleasant article and nice urging commented at this place, I
am truly enjoying by these.
It’s actually a nice and helpful piece of info.
I’m satisfied that you just shared this useful info with us.
Please stay us informed like this. Thanks for sharing.
Inspiring story there. What happened after? Good luck!
You actually make it seem so easy with your presentation but I find this topic
to be actually something which I think I would never understand.
It seems too complex and extremely broad for me. I’m looking forward for your next post,
I’ll try to get the hang of it!
It’s an remarkable post for all the online people; they will get
benefit from it I am sure.
I think this is one of the most important information for me.
And i’m glad reading your article. But wanna remark on some general things, The
website style is perfect, the articles is really great : D.
Good job, cheers
Whats up are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create my
own. Do you need any coding expertise to make your own blog?
Any help would be really appreciated!
Have you ever thought about creating an e-book or guest authoring on other
websites? I have a blog based upon on the same topics you discuss and would
really like to have you share some stories/information. I know my
viewers would appreciate your work. If you’re even remotely
interested, feel free to shoot me an e mail.
Перевозка лежачих больных в Москве от 2000р, круглосуточно —
частная служба МедЛайнер Круглосуточная Перевозка лежачих больных в Москве и Московской области.
Частная служба МедЛайнер. Срочный вызов,
оборудованный транспорт.
I’m really impressed with your writing skills and also with the layout
on your weblog. Is this a paid theme or did you modify it yourself?
Either way keep up the nice quality writing, it’s rare to see a
nice blog like this one nowadays.
If you would like to take a good deal from this article then you have to apply such strategies to your won webpage.
Hi there to all, how is all, I think every one
is getting more from this web page, and your views are good for new
people.
Today, I went to the beach front with my children. I found a sea shell and gave it to
my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
bookmarked!!, I like your web site!
Перевозка лежачих больных в Москве от 2000р, круглосуточно — частная служба МедЛайнер Круглосуточная Перевозка лежачих больных в Москве и Московской области.
Частная служба МедЛайнер.
Срочный вызов, оборудованный транспорт.
Wow that was strange. I just wrote an really long comment but after I clicked
submit my comment didn’t appear. Grrrr… well I’m not writing all that over again. Regardless,
just wanted to say great blog!
You have made some really good points there. I looked on the net for more info about the issue and found
most individuals will go along with your views on this web site.
Great goods from you, man. I’ve take into account your stuff previous
to and you are simply too wonderful. I really like what you have bought right here, certainly
like what you are saying and the way wherein you say it.
You are making it entertaining and you still care for to stay it sensible.
I can’t wait to learn much more from you. This is
actually a tremendous web site.
Undeniably believe that that you said. Your favorite reason appeared
to be on the internet the simplest factor to be aware of.
I say to you, I certainly get irked at the same time as other folks
think about concerns that they plainly do not know about.
You managed to hit the nail upon the top and also outlined out the whole thing without having side effect , other
people could take a signal. Will likely be again to get more.
Thanks
My coder is trying to convince mе tο move to .net frοm PHP.
I haνе aⅼwaүs disliked the idea Ƅecause оf the expenses.
Вut һe’s tryiong none tһe ⅼess. І’vе been uѕing Movable-type οn a variety of websites fοr about
a yеɑr and am worried about switching tо ɑnother platform.
I have һeard ɡood thіngs аbout blogengine.net. Іѕ there a
way I can transfer alⅼ my wordpress ϲontent intο it?
Ꭺny kind of һelp wouⅼd be reɑlly appreciated!
Hello there! This blog post couldn’t be written much better!
Looking through this article reminds me of my
previous roommate! He always kept talking about this.
I am going to send this post to him. Pretty sure he’s going to have a very good read.
Thank you for sharing!
Also visit my site; topfnb.com
It’s an awesome post for all the web viewers; they will take advantage
from it I am sure.
Thank you for the good writeup. It in fact was a
amusement account it. Look advanced to more added agreeable
from you! By the way, how can we communicate?
Гейчик
It’s very straightforward to find out any matter on web
as compared to books, as I found this article at this site.
I truly love your blog.. Pleasant colors & theme. Did you develop this web site yourself?
Please reply back as I’m looking to create my own site and want to learn where you got this
from or what the theme is named. Kudos!
Thanks a lot for sharing this with all people you actually
realize what you are speaking about! Bookmarked.
Please additionally talk over with my site =). We could have a
hyperlink exchange contract among us
My spouse and I absolutely love your blog and find almost all of your
post’s to be just what I’m looking for. Does one offer guest writers to write content available
for you? I wouldn’t mind creating a post or elaborating on some of the subjects you write related to here.
Again, awesome web log!
Does your website have a contact page? I’m having trouble locating it
but, I’d like to shoot you an e-mail. I’ve got some suggestions
for your blog you might be interested in hearing. Either way, great blog and I
look forward to seeing it improve over time.
Terrific article! That is the kind of info that are supposed to be shared across the web.
Shame on the seek engines for now not positioning this put up higher!
Come on over and discuss with my website . Thank you
=)
Hello! I could have sworn I’ve visited this blog before but after looking
at some of the posts I realized it’s new to me.
Nonetheless, I’m certainly pleased I stumbled upon it and
I’ll be bookmarking it and checking back regularly!
Thanks very nice blog!
What’s up, constantly i used to check webpage posts here in the
early hours in the dawn, since i enjoy to find
out more and more.
Your means of explaining the whole thing in this post is actually
good, every one be capable of simply be aware of it, Thanks a
lot.
I all the time used to read post in news papers but now as
I am a user of internet thus from now I am using
net for articles, thanks to web.
I am extremely impressed with your writing skills and also with the layout on your
blog. Is this a paid theme or did you customize it yourself?
Anyway keep up the excellent quality writing, it’s rare to see a nice
blog like this one nowadays.
Great post.
I like what you guys tend to be up too. This sort
of clever work and coverage! Keep up the awesome works guys I’ve added you guys
to my personal blogroll.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several emails with the same comment.
Is there any way you can remove people from that service?
Cheers!
Hi there to every body, it’s my first pay a quick
visit of this web site; this website includes awesome
and actually fine information for visitors.
WOW just what I was looking for. Came here by searching for Nose clips
Oh my goodness! Awesome article dude! Thanks, However I
am having troubles with your RSS. I don’t understand why I cannot subscribe to it.
Is there anyone else having the same RSS issues? Anyone that
knows the solution can you kindly respond? Thanks!!
Недвижимость balinewhome.com на Бали
Having read this I thought it was really informative.
I appreciate you finding the time and effort to put this short article together.
I once again find myself spending way too much time both reading and posting comments.
But so what, it was still worth it!
Heya i’m for the first time here. I found this
board and I in finding It really useful & it helped me out a lot.
I am hoping to provide one thing back and aid others such as you aided
me.
Excellent items from you, man. I’ve take note your
stuff prior to and you are simply extremely great.
I actually like what you have bought right here, certainly like what you’re saying and the best way
by which you assert it. You make it entertaining and you continue
to care for to stay it smart. I can not wait to learn much more from you.
This is actually a terrific website.
This is really interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more
of your great post. Also, I have shared your
site in my social networks!
I could not resist commenting. Perfectly written!
Yes! Finally someone writes about slot online.
I think the admin of this site is actually working hard in support of his site, as here
every material is quality based information.
Wow, awesome blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is magnificent, let alone the content!
I was curious if you ever thought of changing the page layout of your website?
Its very well written; I love what youve
got to say. But maybe you could a little more in the way
of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two images.
Maybe you could space it out better?
This design is incredible! You certainly know how to
keep a reader amused. Between your wit and your videos, I was
almost moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really loved what you had to say, and more than that, how you presented
it. Too cool!
I was curious if you ever thought of changing
the layout of your website? Its very well written; I love what youve
got to say. But maybe you could a little more in the way
of content so people could connect with it better. Youve
got an awful lot of text for only having 1 or 2 images.
Maybe you could space it out better?
When I initially left a comment I seem to have clicked the -Notify me when new comments are added- checkbox and from now on whenever
a comment is added I recieve 4 emails with the same comment.
Perhaps there is a way you can remove me from that service?
Thanks!
Hello, yeah this piece of writing is really pleasant and I have learned lot of
things from it concerning blogging. thanks.
Fine way of explaining, and good article to take data about my presentation subject,
which i am going to deliver in university.
After I originally commented I seem to have clicked on the -Notify me when new comments are added- checkbox and from
now on each time a comment is added I get 4 emails with the same comment.
Perhaps there is a means you are able to remove me from that service?
Thank you!
Hi my family member! I wish to say that this article is awesome, great written and include almost all significant infos.
I would like to look more posts like this .
An interesting discussion is definitely worth comment.
I believe that you need to publish more about this topic,
it might not be a taboo matter but generally people don’t speak about these issues.
To the next! Best wishes!!
If you want to take much from this article then you have to apply these strategies to your won weblog.
Wow, this post is good, my younger sister is analyzing such things,
so I am going to tell her.
Do you have a spam problem on this site; I also am a blogger, and I was wondering
your situation; we have created some nice procedures and we are looking to trade techniques with others, be
sure to shoot me an email if interested.
Hey I am so grateful I found your web site, I really found you by mistake, while I was
searching on Aol for something else, Nonetheless I am here now and would just like to say thanks
for a remarkable post and a all round enjoyable
blog (I also love the theme/design), I don’t have time to browse
it all at the minute but I have saved it and also included your RSS feeds, so when I have time I
will be back to read more, Please do keep up the fantastic work.
penis enlargement
Thanks designed for sharing such a pleasant idea, article is good, thats why i have read it entirely
I needed to thank you for this fantastic read!!
I definitely loved every little bit of it. I have you book-marked to look at new things you post…
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how could we communicate?
I love what you guys tend to be up too. Such clever work and exposure!
Keep up the awesome works guys I’ve added you guys to our blogroll.
I have read so many articles about the blogger lovers however
this piece of writing is genuinely a good post, keep it
up.
Ahaa, its pleasant dialogue on the topic of this post here at this web
site, I have read all that, so now me also commenting here.
Amazing issues here. I’m very glad to look your article.
Thank you so much and I am having a look
ahead to touch you. Will you please drop me a e-mail?
Hi there, after reading this remarkable post i am
also cheerful to share my knowledge here with colleagues.
Terrific post but I was wondering if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit more.
Cheers!
Howdy just wanted to give you a quick heads up and let you know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same outcome.
You can definitely see your enthusiasm within the article you write.
The sector hopes for even more passionate writers such
as you who are not afraid to mention how they believe.
Always follow your heart.
Have you ever considered publishing an ebook or guest authoring on other blogs?
I have a blog centered on the same subjects you discuss and would love
to have you share some stories/information. I know my visitors would appreciate your work.
If you are even remotely interested, feel free to shoot me an e mail.
Pretty! This was an incredibly wonderful post. Thanks for
supplying these details.
I have been exploring for a little for any high-quality articles
or blog posts on this sort of area . Exploring in Yahoo I ultimately stumbled upon this
web site. Reading this information So i am satisfied to convey that I’ve an incredibly good uncanny feeling
I came upon just what I needed. I such a lot no doubt will make certain to do not forget
this site and provides it a glance regularly.
If you want to grow your knowledge just keep visiting this website and be updated with the most recent information posted here.
Oh my goodness! Incredible article dude! Many thanks, However I am going through issues with your RSS.
I don’t understand why I cannot subscribe to
it. Is there anybody getting similar RSS problems? Anyone who knows the solution will you kindly respond?
Thanx!!
Currently it sounds like Expression Engine is the
preferred blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your blog?
Pretty! This has been an extremely wonderful article.
Thank you for providing these details.
I am truly delighted to glance at this blog posts which contains tons of helpful information, thanks for providing these data.
What’s up it’s me, I am also visiting this web site on a regular basis, this web site is
truly fastidious and the visitors are really sharing
pleasant thoughts.
I like the valuable info you supply to your articles.
I will bookmark your weblog and test once more right here regularly.
I’m quite certain I will be informed many new stuff proper here!
Good luck for the following!
You ought to take part in a contest for one of the highest quality
sites on the net. I most certainly will highly recommend this blog!
bookmarked!!, I like your web site!
you are in reality a excellent webmaster. The web site loading speed is amazing.
It seems that you are doing any unique trick. In addition, The contents are masterwork.
you’ve performed a magnificent activity in this subject!
Awesome issues here. I am very satisfied to peer your post.
Thank you a lot and I am taking a look ahead to contact you.
Will you please drop me a mail?
Simply want to say your article is as astonishing.
The clearness in your post is simply spectacular and that i could suppose you are a professional
in this subject. Well with your permission let me to clutch your RSS
feed to keep updated with impending post. Thanks one million and please
continue the gratifying work.
Woah! I’m really digging the template/theme of this site. It’s
simple, yet effective. A lot of times it’s very
difficult to get that “perfect balance” between usability
and appearance. I must say that you’ve done a superb job with this.
Additionally, the blog loads super fast for me on Safari.
Excellent Blog!
you are actually a just right webmaster. The site loading speed is amazing.
It kind of feels that you are doing any unique trick. Also, The contents are masterpiece.
you’ve done a fantastic activity in this matter!
Very nice post. I just stumbled upon your weblog and wished to say that I’ve
really enjoyed browsing your blog posts. In any
case I’ll be subscribing to your rss feed and I hope you write
again soon!
Минет Геев
Does your blog have a contact page? I’m having trouble locating it
but, I’d like to send you an email. I’ve got some creative ideas for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it
improve over time.
I know this if off topic but I’m looking into starting my own blog and was curious what all is required to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% certain. Any recommendations or advice would be greatly appreciated.
Cheers
I read this paragraph fully about the comparison of hottest and earlier technologies,
it’s awesome article.
Spot on with this write-up, I honestly feel this site needs
a great deal more attention. I’ll probably be back again to read more, thanks
for the information!
Greetings! This is my 1st comment here so I just wanted
to give a quick shout out and say I really enjoy
reading through your blog posts. Can you suggest any other blogs/websites/forums that go over the same subjects?
Thank you!
It’s appropriate time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I desire to suggest you few interesting things or advice.
Maybe you can write next articles referring to this article.
I want to read even more things about it!
I believe this is one of the most significant info for me. And
i’m happy studying your article. But wanna observation on few common things, The site style is
wonderful, the articles is really nice : D. Just
right task, cheers
I always used to read piece of writing in news papers but
now as I am a user of net thus from now I am using
net for articles or reviews, thanks to web.
It’s the best time to make some plans for the future and it
is time to be happy. I have read this publish and if I could
I wish to recommend you some fascinating issues or tips.
Perhaps you can write subsequent articles relating to this article.
I desire to read more issues approximately it!
Thanks for a marvelous posting! I quite enjoyed reading it, you will be a great author.
I will remember to bookmark your blog and may come back someday.
I want to encourage continue your great work, have a nice
weekend!
Insurance premiums from many insureds are used to fund
accounts reserved for later payment of claims – in concept for a relatively few claimants – and for
overhead costs.
Your style is really unique compared to other folks
I have read stuff from. Thanks for posting when you have
the opportunity, Guess I will just book mark
this page.
I do not know whether it’s just me or if perhaps everybody else encountering issues with
your blog. It appears as though some of the written text on your content are running
off the screen. Can someone else please provide feedback and
let me know if this is happening to them too?
This may be a problem with my web browser because I’ve had this
happen previously. Thanks
I every time spent my half an hour to read this blog’s content all
the time along with a mug of coffee.
A motivating discussion is definitely worth comment.
I do believe that you should publish more on this subject, it might not be a taboo subject
but typically folks don’t talk about these subjects. To the
next! Best wishes!!
Hello, after reading this remarkable post
i am as well glad to share my experience here with colleagues.
I appreciate, result in I found just what I was looking for.
You’ve ended my four day long hunt! God Bless you man. Have a great day.
Bye
Hello there, just became alert to your blog through Google, and found that it is really informative.
I’m gonna watch out for brussels. I’ll appreciate if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
This post will assist the internet users for
building up new blog or even a weblog from start to end.
Wow! At last I got a blog from where I can actually get useful facts regarding my study and knowledge.
Awesome site you have here but I was curious about if you knew of any community forums that cover the same topics discussed here?
I’d really love to be a part of online community where I can get
feedback from other experienced individuals that share the same interest.
If you have any recommendations, please let me know.
Cheers!
I like what you guys are up too. This kind of clever work and reporting!
Keep up the good works guys I’ve added you guys to our blogroll.
Thank you a lot for sharing this with all folks you actually recognize what you are speaking approximately!
Bookmarked. Please also consult with my web site =). We will have a link exchange contract between us
Hello there! I could have sworn I’ve been to this blog before but
after looking at some of the posts I realized it’s new to me.
Anyways, I’m definitely pleased I discovered it and I’ll be book-marking
it and checking back often!
I could not resist commenting. Exceptionally well written!
Amazing! This blog looks exactly like my old one!
It’s on a completely different topic but it has pretty much the same layout and
design. Outstanding choice of colors!
Have you ever considered about including a little
bit more than just your articles? I mean, what you say is important and all.
Nevertheless think of if you added some great images or video clips to
give your posts more, “pop”! Your content is excellent but with images
and clips, this site could definitely be one of the best in its field.
Terrific blog!
Hello, its fastidious paragraph about media print, we all be aware of
media is a great source of information.
Amazing blog! Is your theme custom made or did
you download it from somewhere? A design like yours with a few simple tweeks would really
make my blog shine. Please let me know where you got your
design. Many thanks
Undeniably consider that which you stated. Your favourite justification appeared to be on the internet the easiest factor to take
into accout of. I say to you, I certainly get annoyed whilst other folks consider worries that they just do not recognise about.
You managed to hit the nail upon the top as well as outlined out the
whole thing with no need side-effects , other folks could take a signal.
Will probably be back to get more. Thank you
I’ve been surfing online more than 4 hours today,
yet I never found any interesting article
like yours. It’s pretty worth enough for me. In my opinion, if all web owners and bloggers made good content as you
did, the net will be much more useful than ever before.
I do not even understand how I stopped up here, however
I thought this submit was great. I don’t recognise who you might be but
definitely you are going to a well-known blogger for those who aren’t already.
Cheers!
For most recent news you have to visit world wide web and on internet I
found this site as a best web page for hottest updates.
Hi! This post couldn’t be written any better! Reading this post reminds me of my good old room
mate! He always kept chatting about this. I will forward this post to him.
Pretty sure he will have a good read. Thank you for sharing!
I needed to thank you for this wonderful read!!
I definitely enjoyed every little bit of it. I’ve got you bookmarked to check out new stuff you post…
Please let me know if you’re looking for a writer for your site.
You have some really good posts and I feel I would be a good asset.
If you ever want to take some of the load off,
I’d love to write some material for your blog in exchange for a link back to
mine. Please shoot me an email if interested. Many thanks!
Wow, incredible blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your web site is wonderful, let alone
the content!
It’s really very difficult in this full of activity life to listen news on TV, so I
just use the web for that purpose, and obtain the most
recent information.
Attractive element of content. I simply stumbled upon your weblog and in accession capital to claim that I acquire
actually enjoyed account your blog posts. Any way I’ll be
subscribing in your augment and even I achievement you access persistently rapidly.
I’m not sure the place you are getting your information, but
good topic. I needs to spend some time learning much more or
working out more. Thanks for excellent information I used to be in search of this information for my mission.
Hiya very cool website!! Guy .. Beautiful .. Amazing .. I will bookmark your website and take the feeds additionally?
I am happy to seek out a lot of helpful info here within the publish, we’d like work
out more strategies on this regard, thank you for sharing. .
. . . .
Good day! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Magnificent goods from you, man. I’ve understand your stuff previous to and you are just extremely great.
I actually like what you have acquired here, really like
what you are saying and the way in which you say it.
You make it enjoyable and you still care for to keep
it sensible. I can not wait to read much more from you.
This is actually a great website.
I am regular visitor, how are you everybody? This piece of
writing posted at this website is actually nice.
Remarkable! Its actually remarkable article, I have
got much clear idea concerning from this piece of writing.
Thanks for your personal marvelous posting! I quite enjoyed reading it, you happen to
be a great author. I will make certain to bookmark your blog and will come back
very soon. I want to encourage that you continue your great writing,
have a nice day!
I am in fact pleased to glance at this web site posts which carries plenty of helpful facts, thanks
for providing such data.
Amazing! This blog looks exactly like my old one!
It’s on a completely different topic but it has pretty much
the same page layout and design. Wonderful choice of colors!
Hi, this weekend is good for me, for the reason that this
time i am reading this fantastic informative paragraph
here at my house.
Thank you for sharing your info. I truly appreciate your efforts and I will be waiting for your next write ups thank you once again.
Asking questions are in fact good thing if you are not understanding something entirely, however this post offers nice understanding even.
Excellent blog right here! Also your site so much up very fast!
What host are you using? Can I am getting your associate link for your host?
I wish my website loaded up as fast as yours lol
Hi! Someone in my Facebook group shared this website with us so I came to look it over.
I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Excellent blog and amazing design and style.
WOW just what I was searching for. Came here by
searching for easy seo guide
My web blog: search engine optimization
اخبار ورزشی گراش و اخبار جدید علمی و
دانستنی های قدیمی و مطالب خواندنی روز و اخبار فرهنگی و هنری گیلان و خبرهای تازه از میلاد حاتمی
https://simonkvecc.like-blogs.com/15539461/?????-?????-???
It’s going to be finish of mine day, but before end I am
reading this great post to improve my know-how.
I was very happy to discover this page. I want to to thank you for your time just for this wonderful read!!
I definitely enjoyed every part of it and I have you book-marked to see new information in your website.
Hi there it’s me, I am also visiting this site regularly, this website is
truly good and the people are actually sharing nice thoughts.
Write more, thats all I have to say. Literally, it seems as though you relied
on the video to make your point. You clearly know what youre talking about, why waste your
intelligence on just posting videos to your weblog when you could be giving us something informative to read?
I am actually grateful to the owner of this web
page who has shared this impressive paragraph at
at this time.
When some one searches for his required thing, therefore he/she desires to be available that in detail, thus that thing is maintained over here.
Hey very nice website!! Man .. Beautiful .. Amazing ..
I’ll bookmark your site and take the feeds additionally?
I’m satisfied to search out a lot of useful info right here in the
put up, we’d like work out extra strategies in this regard, thanks for sharing.
. . . . .
It’s remarkable for me to have a website, which is useful designed for my know-how.
thanks admin
Respect to op, some wonderful entropy.
Check out my page 2007 hyundai tiburon gt
This information is priceless. When can I find
out more?
What’s up, I check your blogs daily. Your writing style
is awesome, keep it up!
Feel free to surf to my site hermes replica watch
What’s up, all the time i used to check weblog posts here early in the
morning, since i enjoy to find out more and more.
Howdy! I know this is sort of off-topic but I had to ask. Does operating a well-established website like yours require a massive
amount work? I’m completely new to writing a blog but I do
write in my journal everyday. I’d like to start a blog so I will be
able to share my experience and views online. Please let me know if you have
any kind of recommendations or tips for new aspiring bloggers.
Appreciate it!
Stop by my site: Gluco Fence
Good day! I could have sworn I’ve been to this web site before but after going through many of the posts
I realized it’s new to me. Anyhow, I’m certainly pleased
I stumbled upon it and I’ll be book-marking it and checking back often!
We’re a gaggle of volunteers and starting a
new scheme in our community. Your site offered us with useful information to work on. You have done a formidable
job and our whole community might be thankful to you.
I love it whenever people come together and share views.
Great site, keep it up!
Hi there! Someone in my Myspace group shared this site with us so I came to
give it a look. I’m definitely loving the information. I’m
book-marking and will be tweeting this to my followers! Great blog and brilliant design.
My brother recommended I might like this blog. He was entirely right.
This post truly made my day. You cann’t imagine simply how much time I had spent for this information! Thanks!
Pretty section of content. I just stumbled upon your web site and in accession capital to
assert that I get in fact enjoyed account your blog
posts. Anyway I’ll be subscribing to your feeds and even I achievement you access consistently quickly.
Порно HD
Ahaa, its nice discussion concerning this
article here at this weblog, I have read all that, so now me also commenting here.
Thanks for any other fantastic article. The
place else may just anyone get that kind
of information in such an ideal manner of writing? I have a presentation subsequent week, and I’m on the search for such info.
I’m now not certain where you’re getting your info, however good
topic. I must spend some time finding out much more or understanding more.
Thanks for excellent info I was in search of this info
for my mission.
obviously like your web site however you
need to test the spelling on several of your posts. A number of them are rife with spelling problems
and I in finding it very bothersome to tell the truth on the other
hand I will certainly come back again.
I have read so many articles concerning the blogger lovers however this post is
really a good paragraph, keep it up.
Asking questions are in fact pleasant thing if you are not understanding anything totally,
except this piece of writing provides nice understanding
even.
My brother recommended I might like this website. He was totally right.
This post truly made my day. You can not imagine just how much time I had spent for
this information! Thanks!
No matter if some one searches for his required thing, thus he/she
wants to be available that in detail, thus that thing is maintained
over here.
Attractive component to content. I just stumbled upon your weblog and in accession capital to
claim that I acquire actually enjoyed account your blog posts.
Any way I’ll be subscribing for your feeds or even I fulfillment you get entry to constantly quickly.
Telemed Mexico offers affordable and same day virtual medical consultations throughout
Mexico. Our telemedicine service provides remote medical care,
online doctor consultation, and virtual healthcare services to patients in Cancun and beyond.
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Hello just wanted to give you a quick heads up.
The text in your article seem to be running off the screen in Opera.
I’m not sure if this is a formatting issue or something to do with browser
compatibility but I thought I’d post to let you know.
The style and design look great though! Hope you get the issue fixed soon.
Cheers
Hey! Do you use Twitter? I’d like to follow you if that would be
okay. I’m undoubtedly enjoying your blog and look forward to new posts.
Thanks for sharing your thoughts on rtp slot. Regards
Hello very cool website!! Man .. Excellent .. Amazing ..
I will bookmark your blog and take the feeds additionally?
I am satisfied to search out so many helpful information here within the put up,
we need develop more strategies in this regard, thank you for sharing.
. . . . .
Fantastic beat ! I wish to apprentice while you amend your website, how could i subscribe for a blog site?
The account aided me a acceptable deal. I had been tiny bit
acquainted of this your broadcast offered bright clear
idea
I was suggested this website by my cousin. I’m no longer positive whether this submit
is written by means of him as nobody else recognise such unique about my difficulty.
You are wonderful! Thanks!
This is a topic that is close to my heart… Many thanks!
Exactly where are your contact details though?
I don’t even know how I ended up here, but I thought this post was great.
I do not know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
Everyone loves what you guys are up too. This type
of clever work and exposure! Keep up the fantastic works guys I’ve you guys to my personal blogroll.
Wow, this article is fastidious, my sister is analyzing these kinds of things, thus I am going to let know
her.
Thank you for sharing your info. I really appreciate your
efforts and I am waiting for your further post thanks once again.
It is truly a great and useful piece of information. I’m
happy that you simply shared this helpful information with us.
Please keep us informed like this. Thank
you for sharing.
This is my first time visit at here and i am actually happy to
read everthing at alone place.
I used to be suggested this blog by means of my cousin. I am
not positive whether this publish is written by means of him as
no one else realize such targeted approximately my trouble.
You’re wonderful! Thank you!
Good day! This is kind of off topic but I need some advice from an established blog.
Is it hard to set up your own blog? I’m not
very techincal but I can figure things out pretty fast.
I’m thinking about creating my own but I’m not
sure where to begin. Do you have any tips or suggestions?
With thanks
You really make it seem really easy together with
your presentation but I to find this matter to be actually one thing which I think I’d by no means understand.
It kind of feels too complex and very vast for me. I am having a look ahead to your next submit, I’ll attempt to get the
dangle of it!
Everything is very open with a very clear clarification of the
issues. It was really informative. Your website is very helpful.
Thanks for sharing!
Wow, awesome weblog structure! How long have you ever been running a blog for?
you made running a blog glance easy. The overall glance of your website is wonderful, as
well as the content!
Unquestionably believe that which you stated. Your favorite reason seemed
to be on the net the easiest thing to be aware of. I say to you, I certainly get
annoyed while people think about worries that they plainly do
not know about. You managed to hit the nail upon the top and also
defined out the whole thing without having side effect , people could take a signal.
Will probably be back to get more. Thanks
It’s going to be end of mine day, but before end I am
reading this great post to improve my experience.
We stumbled over here by a different web page and thought I may as well check things out.
I like what I see so now i’m following you. Look forward to finding
out about your web page for a second time.
Everyone loves what you guys are up too. Such clever work and reporting!
Keep up the fantastic works guys I’ve you guys to blogroll.
It’s perfect time to make some plans for the future and
it is time to be happy. I have read this post and if I could I wish to suggest you few interesting things or tips.
Maybe you could write next articles referring to this article.
I want to read more things about it!
I’m not that much of a online reader to be honest but your sites really nice, keep it
up! I’ll go ahead and bookmark your site to come back later.
Many thanks
I like it whenever people get together and share views.
Great website, continue the good work!
секс видео онлайн (syndukporno.com)
I’m not sure where you’re getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for wonderful info I was looking for this information for my mission.
Hi there would you mind letting me know which hosting company you’re working with?
I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot faster then most.
Can you suggest a good internet hosting provider at a fair price?
Cheers, I appreciate it!
Excellent website. Plenty of helpful info here. I’m sending it to some buddies ans additionally sharing in delicious.
And naturally, thanks on your effort!
I know this web page gives quality depending articles
or reviews and other data, is there any other web page
which gives these stuff in quality?
Nice answer back in return of this matter with solid arguments and explaining all concerning that.
Do you have a spam issue on this site; I also am a blogger,
and I was wondering your situation; many of us have developed some nice methods and we are looking to swap methods with others, please shoot me an email if interested.
Keep on writing, great job!
Genuinely no matter if someone doesn’t understand
afterward its up to other visitors that they will assist, so here it occurs.
Mү spouse aand I ɑbsolutely love օur blog annd fіnd the majority of yoսr post’s to bе what precisely I’m lookіng fߋr.
Ꮃould yօu offer guest writers tߋ write content
to suit yur neеds? Ӏ wouldn’t mind producing ɑ post or elaborating on а
feѡ of the subjects уoᥙ wrіte relаted to here.
Ꭺgain, awesome site!
Heгe iѕ my site Adria Rae Latest Porn
I needed to thank you for this very good read!! I certainly loved every little bit of it.
I have got you book-marked to check out new stuff you post…
Thanks , I’ve recently been looking for information approximately this
topic for a long time and yours is the greatest I have discovered so
far. However, what about the conclusion? Are you sure concerning the
supply?
I read this piece of writing completely concerning the resemblance of most up-to-date and previous technologies,
it’s remarkable article.
It’s very effortless to find out any topic on net
as compared to textbooks, as I found this article at this website.
Thanks very interesting blog!
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to
do it for you? Plz respond as I’m looking to construct my own blog
and would like to find out where u got this from. kudos
My web page: https://dantedyrk44321.loginblogin.com/23533852/olymp-trade-a-reputable-investing-system-for-monetary-accomplishment
Hi there, the whole thing is going well here and ofcourse every one is sharing data, that’s really good,
keep up writing.
If some one needs expert view on the topic of running a blog then i recommend him/her to pay a visit this website, Keep up the good
work.
Hi, i read your blog from time to time and i own a similar
one and i was just curious if you get a lot of spam remarks?
If so how do you reduce it, any plugin or anything you can suggest?
I get so much lately it’s driving me insane so any help is very much appreciated.
I’ve learn some excellent stuff here. Definitely worth bookmarking for revisiting.
I wonder how much attempt you place to make one of these excellent informative website.
Wonderful blog! I found it while browsing on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
Howdy, i read your blog from time to time and i
own a similar one and i was just curious if you
get a lot of spam remarks? If so how do you protect against it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any support is very
much appreciated.
It’s in reality a great and useful piece of information. I am satisfied that you just shared
this helpful information with us. Please keep us informed like this.
Thank you for sharing.
I just like the helpful information you supply in your articles.
I will bookmark your weblog and test once more right here regularly.
I am fairly sure I’ll be told a lot of new stuff right here!
Best of luck for the next!
An outstanding share! I have just forwarded this onto a coworker who was conducting a little homework on this.
And he actually bought me breakfast simply because I stumbled upon it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanks for spending the time to discuss this matter here on your web page.
Hey, I think your site might be having browser compatibility issues.
When I look at your blog in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, amazing blog!
Wow that was odd. I just wrote an really long comment but after I clicked
submit my comment didn’t appear. Grrrr… well I’m not writing all that over again. Anyway, just wanted
to say wonderful blog!
I am truly delighted to glance at this blog posts which includes tons of valuable information, thanks for providing
such information.
We’re a group of volunteers and starting a new scheme in our community.
Your website offered us with useful information to work on. You have done an impressive task and our whole group will
probably be thankful to you.
Great blog here! Also your website loads up very fast!
What host are you using? Can I get your affiliate link to your
host? I wish my web site loaded up as quickly as yours lol
My partner and i still can’t quite think that I could
always be one of those studying the important
recommendations found on your blog. My family and I are truly thankful
for your generosity and for giving me the potential to
pursue my personal chosen profession path. Many thanks for the important information I managed to get from
your website.
Here is my blog post … Divinity Labs Keto Gummies
These are truly wonderful ideas in about blogging. You
have touched some good factors here. Any way keep up wrinting.
We are a group of volunteers and starting a new scheme in our community.
Your web site offered us with valuable info to work on. You have done an impressive job and our entire community will
be grateful to you.
Take a look at my web-site; sell my house asap
Keep on working, great job!
You can even keep your self up to date with the latest sport and get familiar with the newest trend and
life-style tendencies.
Hello mates, nice paragraph and nice urging commented here, I am truly enjoying by these.
Howdy! This article couldn’t be written any better! Looking
at this article reminds me of my previous roommate! He constantly
kept preaching about this. I will forward this post to him.
Fairly certain he will have a very good read.
I appreciate you for sharing!
Hello! Someone in my Myspace group shared this site with us so I came to give it a look.
I’m definitely enjoying the information. I’m book-marking
and will be tweeting this to my followers!
Exceptional blog and brilliant design and style.
Howdy! Someone in my Facebook group shared this site with us so I came to check it out.
I’m definitely enjoying the information. I’m book-marking and will be
tweeting this to my followers! Excellent blog and superb design and style.
You really make it appear really easy along with your presentation but I to find this topic to be
really something which I believe I might by no means understand.
It kind of feels too complicated and very vast for me.
I’m looking forward on your next publish, I will attempt to get the hang of it!
Wow, this article is fastidious, my younger
sister is analyzing these things, thus I am going to inform her.
What’s up to every one, the contents existing at this website are truly awesome for people experience, well, keep
up the nice work fellows.
Your style is so unique in comparison to other people
I’ve read stuff from. Thanks for posting when you
have the opportunity, Guess I will just bookmark this web site.
If you wish for to increase your know-how just keep visiting this site and be updated with
the latest information posted here.
презентация для инвесторов
заказать http://www.biznespresentacia.ru
This is very interesting, You are a very skilled blogger.
I have joined your feed and look forward to seeking more of your excellent post.
Also, I have shared your web site in my social networks!
Tremendous issues here. I am very glad to see your post.
Thank you a lot and I’m having a look forward to contact you.
Will you please drop me a mail?
https://www.mid-day.com/brand-media/article/fit-today-wellness-keto-gummies-reviews-scam-exposed-what-you-need-to-know-23275442
I am now not positive where you’re getting your
information, however good topic. I needs to spend
some time finding out much more or understanding more.
Thank you for fantastic info I used to be searching for this info for my
mission.
Do you have a spam issue on this website; I also am a blogger, and I
was wondering your situation; many of us have created some nice procedures and we are
looking to trade solutions with other folks, please shoot
me an e-mail if interested.
I was curious if you ever considered changing
the page layout of your site? Its very well written; I
love what youve got to say. But maybe you could a little more
in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or 2 images.
Maybe you could space it out better?
Yesterday, while I was at work, my sister stole my iphone
and tested to see if it can survive a twenty five foot drop, just so she can be
a youtube sensation. My iPad is now broken and she has 83 views.
I know this is completely off topic but I had to share it with someone!
Remarkable! Its really awesome piece of writing, I have got much clear
idea about from this article.
I do not even know the way I stopped up right here, but I assumed this post was once good.
I do not recognize who you are but certainly you’re going
to a well-known blogger if you happen to are not already.
Cheers!
I do not even know how I ended up here, but I thought this post was good.
I don’t know who you are but certainly you are going to a famous blogger if
you aren’t already 😉 Cheers!
I used to be recommended this web site by means
of my cousin. I am not certain whether this publish is written by means of
him as no one else recognize such targeted about my difficulty.
You are incredible! Thanks!
I do not even know the way I finished up here, but I believed this post was great.
I don’t know who you’re however certainly you are going to a famous
blogger when you aren’t already. Cheers!
What i don’t understood is in reality how
you are no longer actually a lot more smartly-preferred than you
may be right now. You are so intelligent. You understand
thus considerably in the case of this subject,
made me in my view imagine it from a lot of various angles.
Its like men and women are not interested until it’s one thing to accomplish with
Lady gaga! Your personal stuffs great. All the time care for it up!
Please let me know if you’re looking for a article writer for your blog.
You have some really great posts and I believe I would be a good asset.
If you ever want to take some of the load off, I’d love to
write some articles for your blog in exchange for a link back to mine.
Please blast me an email if interested. Cheers!
I love reading a post that can make people think. Also, thanks
for allowing me to comment!
Hi there, all the time i used to check website posts here in the early
hours in the morning, for the reason that i love to find out
more and more.
Today, I went to the beachfront with my children. I found a sea shell and gave it to my 4
year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear. She
never wants to go back! LoL I know this is completely off topic but I
had to tell someone!
I visit day-to-day some sites and sites to read articles, but this blog presents feature based
content.
We’re a group of volunteers and starting a brand new scheme in our community.
Your web site offered us with valuable information to work
on. You have performed an impressive activity and our entire
community will likely be thankful to you.
buy viagra online
I know this web page provides quality dependent articles or reviews and extra stuff, is there any other web page which presents such things in quality?
Heya i am for the primary time here. I found this board and
I to find It really useful & it helped me out much. I’m
hoping to provide one thing back and help others such as you aided
me.
I wanted to thank you for this good read!! I absolutely loved every
bit of it. I’ve got you bookmarked to look at new stuff you post…
Thank you a lot for sharing this with all of us you really understand what you are
speaking approximately! Bookmarked. Kindly also
visit my website =). We will have a hyperlink trade arrangement between us
This is a topic which is close to my heart…
Best wishes! Exactly where are your contact details though?
Hello There. I discovered your blog the usage of msn. This is an extremely
neatly written article. I will be sure to bookmark it and come back to learn more of your useful information. Thank you
for the post. I’ll definitely return.
Great article. I’m dealing with a few of these
issues as well..
I’m truly enjoying the design and layout
of your website. It’s a very easy on the eyes which makes it
much more enjoyable for me to come here and visit more
often. Did you hire out a developer to create your theme?
Fantastic work!
We are a gaggle of volunteers and starting a brand new scheme in our community.
Your website offered us with valuable information to work on. You have done a formidable job and our whole group can be thankful to you.
Нello to all, as I am genuinely keen of reading this weblog’s post tto be սpdаted oon a rеgular basis.
It includes nice data.
Feel fre to surf to myy sote – printing shop near me
Nice post. I learn something totally new and challenging on sites I stumbleupon everyday.
It will always be helpful to read through articles from other writers and use something from their web
sites.
Hi there! Someone in my Facebook group shared this site with us so I came to look
it over. I’m definitely enjoying the information. I’m bookmarking and will
be tweeting this to my followers! Fantastic blog and superb design.
Touche. Solid arguments. Keep up the good effort.
You have noted very interesting points! ps decent site.
Here is my web site Super Flow Blood Ingredients
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is important and all. However imagine
if you added some great photos or video clips to give
your posts more, “pop”! Your content is excellent but with images and video clips,
this blog could undeniably be one of the most beneficial in its niche.
Terrific blog!
Greetings from Los angeles! I’m bored to death at work so I decided to check out
your website on my iphone during lunch break. I really like the knowledge you provide
here and can’t wait to take a look when I get home.
I’m surprised at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyways, excellent site!
A person necessarily lend a hand to make seriously
articles I would state. This is the first time I frequented your website page and so
far? I amazed with the research you made to make this actual put up incredible.
Wonderful task!
Wonderful beat ! I wish to apprentice even as you amend your
web site, how can i subscribe for a blog site?
The account helped me a acceptable deal. I have been a little bit familiar of this your broadcast provided shiny transparent
concept
I like what you guys are usually up too. This kind of clever work
and coverage! Keep up the amazing works guys I’ve incorporated you guys to my own blogroll.
I’ve been surfing online greater than 3 hours nowadays, yet I by no means discovered any fascinating article like yours.
It is pretty price enough for me. In my opinion, if all web owners and bloggers made good content as you did, the internet will likely
be much more helpful than ever before.
Hi, all is going well here and ofcourse every
one is sharing facts, that’s in fact good, keep up
writing.
You’re so cool! I don’t think I’ve truly read a single thing like that before.
So good to find someone with some unique thoughts on this subject.
Seriously.. thank you for starting this up.
This web site is something that’s needed on the web,
someone with some originality!
Great blog here! Also your web site loads up very fast!
What host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as fast as yours lol
With havin so much content do you ever run into any problems of plagorism
or copyright infringement? My site has a lot of
unique content I’ve either authored myself or outsourced but it appears a lot of it is
popping it up all over the internet without my agreement.
Do you know any techniques to help stop content from being ripped off?
I’d genuinely appreciate it.
Hey! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in trading links or maybe guest writing a blog post or vice-versa?
My website discusses a lot of the same subjects as yours and I believe we
could greatly benefit from each other. If you are interested feel free to shoot me an e-mail.
I look forward to hearing from you! Excellent blog by the way!
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to
my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some
time and was hoping maybe you would have some experience with something like
this. Please let me know if you run into anything. I truly enjoy reading your blog and I
look forward to your new updates.
whoah this weblog is fantastic i love studying your articles.
Keep up the good work! You recognize, many persons are hunting around for this info, you can aid them greatly.
always i used to read smaller posts that as well clear their motive,
and that is also happening with this post which I am reading now.
Hello to every one, as I am truly keen of reading this web site’s post to be updated regularly.
It carries pleasant data.
I have read so many articles or reviews on the topic of the blogger lovers except
this piece of writing is truly a pleasant post, keep it up.
At this moment I am going to do my breakfast, later than having my breakfast coming over again to read additional news.
I always emailed this webpage post page to all my contacts, for the reason that if like to read
it afterward my links will too.
Post writing is also a fun, if you know afterward you can write or
else it is complicated to write.
Hello, I do believe your website could possibly be having internet browser compatibility problems.
When I take a look at your web site in Safari, it looks fine however
when opening in IE, it has some overlapping issues.
I merely wanted to give you a quick heads
up! Apart from that, wonderful website!
I’m not sure where you are getting your info, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for great information I was looking for this information for
my mission.
Thanks in support of sharing such a fastidious thinking, article is fastidious, thats why
i have read it fully
Thank you a lot for sharing this with all of us you really
know what you are talking approximately! Bookmarked. Please also discuss with my site =).
We could have a link alternate arrangement among us
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make
your point. You obviously know what youre talking about, why waste your intelligence on just posting videos to your blog when you could be giving us something informative to read?
Please let me know if you’re looking for a author for your blog.
You have some really great articles and I believe I would be a good asset.
If you ever want to take some of the load off, I’d really like to write some
articles for your blog in exchange for a link back to mine.
Please shoot me an e-mail if interested. Thank you!
Very nice post. I just stumbled upon your blog and wanted to say
that I have really loved browsing your blog posts.
In any case I’ll be subscribing to your rss feed and I hope you write again soon!
I like the valuable information you provide in your articles.
I will bookmark your blog and check again here frequently.
I am quite sure I will learn plenty of new stuff
right here! Good luck for the next!
Thanks for sharing your info. I truly appreciate your efforts and I am
waiting for your next post thanks once again.
buy viagra online
I am genuinely pleased to glance at this website posts which carries plenty of valuable data, thanks for providing these statistics.
I’m not that much of a online reader to be honest but your sites reaⅼly nice, keep it up!
I’ll go ahead and bookmark your site to come back later
on. Ⅿany thanks
Feel freе to visit my blog post … Joker88
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
By the way, how can we communicate?
Hey I know this is off topic but I was wondering if you knew of any widgets I could
add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite
some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to
your new updates.
I savor, cause I found exactly what I used to be having
a look for. You’ve ended my 4 day long hunt! God Bless
you man. Have a great day. Bye
Fantastic beat ! I wish to apprentice at the same time as you
amend your site, how can i subscribe for a weblog website?
The account helped me a appropriate deal. I have been a little bit familiar of this your broadcast provided
brilliant transparent idea
Pretty! This was an extremely wonderful article.
Many thanks for supplying this information.
Great post however , I was wanting to know if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit more.
Thanks!
I every time used to study piece of writing in news papers but
now as I am a user of web therefore from now I am using
net for articles or reviews, thanks to web.
Hello my friend! I wish to say that this article is awesome, great written and come with approximately all significant
infos. I would like to see extra posts like this .
Pretty component to content. I just stumbled upon your weblog
and in accession capital to assert that I acquire actually
loved account your weblog posts. Any way I’ll be subscribing in your feeds and even I achievement you
get admission to consistently quickly.
Hi mates, its impressive post regarding educationand completely defined, keep it up all the time.
I just couⅼdn’t go awɑy your webѕіte before suggesting that I reallʏ lovеd the standaгd information an individual
рrovide to our visitors? Is g᧐ing to be Ьack inceѕsantly inn order to cһеck
uup on new posts
Мy blog; check out the post right here
It’s an amazing paragraph designed for all the internet visitors;
they will obtain benefit from it I am sure.
I always spent my half an hour to read this website’s articles or reviews every day along with a
mug of coffee.
If some one wants expert view regarding blogging afterward i advise him/her to
go to see this web site, Keep up the good job.
Hey there! I’ve been reading your website for a
long time now and finally got the courage to go ahead and
give you a shout out from Dallas Tx! Just wanted to say keep up the
good job!
It’s impressive that you are getting ideas from this piece of writing as well as from
our dialogue made at this time.
Incredible points. Sound arguments. Keep up the good work.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an nervousness
over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly
the same nearly very often inside case you shield this increase.
It’s impressive that you are getting thoughts from this
post as well as from our dialogue made at this place.
This post provides clear idea in support of the new viewers of blogging, that truly how
to do blogging and site-building.
Hi there, i read your blog from time to time and i own a similar one and i was just curious if you get a lot of spam comments?
If so how do you prevent it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any assistance is very
much appreciated.
Everything is very open with a really clear description of the challenges.
It was truly informative. Your website is useful.
Thanks for sharing!
Your style is very unique compared to other people I’ve read stuff from.
I appreciate you for posting when you’ve got the opportunity,
Guess I will just bookmark this web site.
I’m gone to inform my little brother, that he should also visit this weblog on regular basis to
take updated from hottest information.
This site truly has all the information I needed
about this subject and didn’t know who to ask.
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did
you hire someone to do it for you? Plz reply as I’m looking to design my own blog and would like to know where u
got this from. many thanks
These are genuinely wonderful ideas in about blogging.
You have touched some good factors here. Any way keep
up wrinting.
Thanks a bunch for sharing this with all people you
really know what you’re talking approximately! Bookmarked.
Kindly also talk over with my site =). We could have a link change agreement among us
Hi there! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly? My weblog looks weird when viewing from my apple iphone.
I’m trying to find a template or plugin that
might be able to correct this issue. If you have any suggestions, please share.
Appreciate it!
I’ve been surfing online more than 3 hours these days, but I
by no means discovered any fascinating article like yours.
It’s pretty price sufficient for me. Personally, if all
site owners and bloggers made excellent content material as you did, the web will be a lot more helpful than ever before.
Feel free to surf to my web site … Casie
When I originally commented I clicked the “Notify me when new comments are added”
checkbox and now each time a comment is added I get three emails with the same comment.
Is there any way you can remove people from that service?
Thanks a lot!
Hi there Dear, are you in fact visiting this website regularly, if so then you will without doubt get pleasant knowledge.
I like the valuable information you supply on your articles.
I’ll bookmark your blog and take a look at once more right here regularly.
I am moderately certain I will be told lots of new stuff right right here!
Good luck for the next!
Opponents object to provisions that would bar future lawsuits and even prevent merchants
from opting out of serious parts of the proposed settlement.
certainly like your web site but you need to test the
spelling on several of your posts. Many of them are rife with spelling problems and I find it very troublesome to tell the
truth on the other hand I’ll definitely come again again.
Hey very interesting blog!
Howdy! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in trading links or maybe guest writing a blog post
or vice-versa? My blog covers a lot of the same topics as yours and I feel we could greatly benefit from each other.
If you are interested feel free to shoot me an e-mail.
I look forward to hearing from you! Terrific blog by the way!
If you’re ready to take your affiliate marketing game to the next level, John Crestani’s Super
Affiliate System is the solution you’ve been looking for! Begin today and watch the profits roll in! Don’t
settle for mediocre results in your affiliate marketing business.
Upgrade to John Crestani’s Super Affiliate System and start earning massive profits like a pro!
Looking for the ultimate tool to skyrocket your affiliate marketing business?
Look no further than John Crestani’s Super Affiliate System!
Begin today and watch your profits soar! If you’re serious about affiliate marketing success,
it’s time to upgrade to John Crestani’s Super Affiliate System.
With expert training and proven strategies, you’ll be
making massive profits in no time! Tired of struggling to
make a profit in affiliate marketing? It’s time to turn to John Crestani’s
Super Affiliate System for expert guidance and proven strategies
that work! Ready to take your affiliate marketing business to the next level?
John Crestani’s Super Affiliate System is the key to unlocking massive profits and achieving financial freedom!
Stop spinning your wheels in affiliate marketing and start seeing real results
with John Crestani’s Super Affiliate System! Begin today and start earning like a pro!
Don’t let another day go by without maximizing your affiliate marketing potential.
Upgrade to John Crestani’s Super Affiliate System and start earning massive profits today!
If you’re looking for a game-changing solution for your affiliate marketing business, look no further than John Crestani’s Super Affiliate
System. Begin today and start earning like a pro! Are you tired of watching others
succeed in affiliate marketing while you struggle to make a
profit? It’s time to level the playing field with John Crestani’s
Super Affiliate System. Begin today and watch your profits soar!
How would you say to her you’re keen on her?
How do you know whether it is adore or lust?
It likely indicates he really cares about but won’t discover how to
say it! What exactly are signals a man likes you that you be absent?
If someone else really loves you or if they’re utilizing
you, you need to? If you like somebody but she won’t care about your needs just like, what do you do?
You ought to request her, she may go through like of course,
if she would not you can either always be good friends.
It can be bothLove does not leave out desire, quite the contrary:
unless you lust on her behalf, then you don’t really like her.
There are 11 girls almost every 1 male when they
achieve 55 yrs . old, mathematically. I became in a very romance for 4
years and a year ago chose to end the partnership. While using rate of growth of entertained existence
invention and timetables, courting programs be a saviour. Indicate great elements or the soda
and pop in life – pleasant points your partner has pointed out, good acts
the person has been doing, positive things in news reports latterly, and so on. Be high energy,
and tend to forget all those lemon in your everyday living.
Hmm is anyone else experiencing problems with the pictures
on this blog loading? I’m trying to determine if its a problem on my end or
if it’s the blog. Any responses would be greatly appreciated.
Hello to every one, because I am genuinely eager of
reading this webpage’s post to be updated on a regular basis.
It consists of pleasant information.
Free U.S. Trademark Search
Free E.U. Trademark Search
Free U.K. Trademark Search
Free Canada Trademark Search
Free Australia Trademark Search
Browse Trademark Categories
Browse Trademark Owners
Browse Logo Trademarks
Browse Daily filed Trademarks
https://www.trademarkelite.com/europe/trademark/
Wow, marvelous blog structure! How long have you ever been blogging
for? you make running a blog glance easy.
The overall look of your web site is excellent, let alone the content material!
Good day! I simply would like to offer you
a big thumbs up for the excellent info you have
got right here on this post. I’ll be coming back to your
blog for more soon.
Hi there! I know this is kind of off topic but I was wondering which blog platform are you using for
this site? I’m getting fed up of WordPress because
I’ve had issues with hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of a good platform.
Great info. Lucky me I came across your blog by accident
(stumbleupon). I’ve bookmarked it for later!
I like the helpful info you supply for your articles.
I will bookmark your blog and check once more here frequently.
I’m quite certain I will be told a lot of new stuff right right
here! Best of luck for the following!
Buy Backlinks, DarkestSEO
Vanchester 13, London,
JPL 102
(44) 9102934
buy backlinks usa
เมื่อเลือกเตียงนอนเด็ก คุณต้องคำนึงถึงความปลอดภัยและความสะดวกสบายสำหรับลูกน้อยของคุณด้วยครับ ด้วยข้อมูลและลักษณะเฉพาะที่รวบรวมได้ เตียงเด็กแบบ Playpen ถือว่าเป็นตัวเลือกที่ดี เพราะมีน้ำหนักเบา สามารถพับเก็บเพื่อพกพาไปไหนมาไหนได้อย่างสะดวก ทั้งนี้
ยังมีเบาะนอนและโครงแผ่นชั้นสำหรับปรับเป็นเตียงลูกน้อยในโหมดเด็กอ่อน เป็นที่นอนที่สร้างมาเพื่อให้ลูกน้อยได้หลับสบายตัว นอนกันง่าย สะดวกและปลอดภัยด้วยความอ่อนนุ่มของเบาะนอนและไม่มีร่องช่องว่าง ดังนั้น หากคุณกำลังมองหาเตียงนอนเด็ก ไม่เสียเรโชกให้เลือกเตียงนอนแบบ Playpen นี้ครับ!
my website: เตียงนอนทารกแบบไหนดี
Right now it sounds like Expression Engine is the top
blogging platform available right now. (from what I’ve read) Is that
what you are using on your blog?
Hello, Neat post. There is an issue along with your web site in web explorer, might check this?
IE nonetheless is the marketplace chief and a huge portion of people will omit
your wonderful writing due to this problem.
I have been surfing online more than 2 hours today,
yet I never found any interesting article like yours.
It is pretty worth enough for me. In my view, if all site owners and
bloggers made good content as you did, the web will
be much more useful than ever before.
It’s the best time to make a few plans for the longer term and it is time to be happy.
I’ve learn this publish and if I may I wish to recommend you some attention-grabbing
issues or suggestions. Perhaps you can write subsequent articles regarding this article.
I desire to learn more things approximately it!
Ridiculous story there. What happened after? Good luck!
Replica Clothes, Bvlks
str.Diego 13, London,
E11 17B
(570) 810-1080
replica clothes
That is really interesting, You are an excessively skilled blogger.
I’ve joined your rss feed and look forward to in search of extra of your excellent post.
Additionally, I have shared your site in my social networks
hello there and tһank you for your information – I have certainly picked up anything
new from right here. I did howevеr expertise a few technical issues using this website, since I experienced to reⅼoad
the web site lots οf times prevjоսs to I could get it to load properly.
I had been wondering if your hosting is OK?
Not thaqt I’m complaining, but sluggish loading
instances times wіll very freqᥙentfly acfect үour pplacement in go᧐gle and could damage your quality
score iif aɗs aand marketing wіth Adwords. Wеll I’m adding this RSS to my email annd could look ᧐ut for much morе of your respectivfe intrigսing content.
Make sure you upⅾate thiѕ аgaіn very soon.
Feel free to visit my site: Sbobet Login
You really make it appear so easy with your presentation however I
to find this topic to be actually something that I feel I’d by no means understand.
It sort of feels too complex and extremely wide for me. I
am having a look forward in your subsequent publish, I’ll try to get the cling of it!
Hi there are using WordPress for your site platform? I’m new to the blog world but
I’m trying to get started and set up my own. Do you need any html coding expertise to make your own blog?
Any help would be really appreciated!
These are genuinely fantastic ideas in regarding blogging.
You have touched some fastidious factors here. Any way keep up wrinting.
We stumbled over here different page and thought I
may as well check things out. I like what I see so now
i’m following you. Look forward to finding out about your web page yet again.
I don’t even know the way I stopped up right here, however I thought this post used to be
great. I do not realize who you’re but certainly
you’re going to a famous blogger if you happen to aren’t already.
Cheers!
Everything is very open with a clear description of the challenges.
It was really informative. Your site is extremely helpful.
Many thanks for sharing!
You thoughts-numbingly scoll by means of job postings on LinkedIn, Indeed and ZipRecruiter for hours.
Here is my website … 유흥알바 커뮤니티
Hey there! I’ve been reading your website for a while now and finally got the bravery to go ahead and give you a
shout out from Dallas Tx! Just wanted to mention keep up the good work!
I was suggested this blog via my cousin. I’m no longer sure whether this submit is
written through him as no one else recognise such exact approximately my problem.
You’re amazing! Thanks!
Can I just saу wһat а comfort tо discover somebody
who truly knows what they are talking аbout over thee internet.
Youu certainly know how tⲟ bring an issue tо light аnd make
it іmportant. Α lot more people ѕhould heck tһis ⲟut and understand tһis side of
your story. Ӏ wɑs surprised you aгеn’t moгe
popular ѕince you definiteⅼy possess the gift.
my ρage – Porno Vidio Lizbianki
Can you tell us more about this? I’d love to find out more
details.
I enjoy reading a post that will make men and women think.
Also, many thanks for permitting me to comment!https://www.drivefool.com/lyft-uber-alternative/hiring-drivers/norfolk-virginia/index.php
Howdy! I could have sworn I’ve visited this web site before
but after looking at many of the posts I realized it’s new to me.
Anyways, I’m definitely delighted I came across it and I’ll be book-marking it and checking back frequently!
Nice weblog right here! Additionally your website lots up
very fast! What web host are you the usage of? Can I get your affiliate hyperlink to your
host? I desire my site loaded up as fast as yours lol
Great post. I was checking continuously this
blog and I’m impressed! Extremely helpful info particularly the last part :
) I care for such info much. I was seeking this
certain information for a long time. Thank you and
best of luck.
Hi there! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa?
My website discusses a lot of the same subjects as yours and I
think we could greatly benefit from each other. If you are interested feel
free to send me an e-mail. I look forward to hearing from you!
Wonderful blog by the way!
Hey! Do you know if they make any plugins to help
with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m
not seeing very good gains. If you know of any please
share. Appreciate it!
Thanks for sharing your thoughts about click here. Regards
magnificent issues altogether, you simply gained a logo
new reader. What would you recommend in regards to your put up that you simply made
some days in the past? Any positive?
If some one desires expert view about blogging and site-building then i recommend him/her to pay a quick
visit this blog, Keep up the pleasant job.
My family every time say that I am killing my time here
at net, except I know I am getting knowledge daily by reading
such pleasant posts.
Hmm it seems like your blog ate my first comment (it was super long) so I guess I’ll just sum
it up what I submitted and say, I’m thoroughly enjoying your
blog. I too am an aspiring blog writer but I’m still new
to everything. Do you have any points for rookie blog writers?
I’d really appreciate it.
It’s going to be finish of mine day, however before end
I am reading this wonderful paragraph to improve my knowledge.
It’s truly very difficult in this busy life to listen news on Television,
therefore I simply use the web for that purpose, and take the most up-to-date information.
each time i used to read smaller content that as well clear their motive, and that is also happening with this paragraph which I am reading now.
I couldn’t refrain from commenting. Well written!
excellent publish, very informative. I’m wondering why the opposite
experts of this sector don’t notice this. You should continue
your writing. I am confident, you have a great readers’ base already!
Today, I went to the beach front with my children. I
found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear. She never wants to go back!
LoL I know this is completely off topic but I had to tell someone!
Article writing is also a fun, if you be familiar with then you can write otherwise
it is complicated to write.
constantly i used to read smaller posts that as well clear their
motive, and that is also happening with this post which I am reading at this time.
Sweet blog! I found it while browsing on Yahoo News. Do you have
any suggestions on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get
there! Many thanks
Your method of explaining all in this post is in fact good, every one be capable of effortlessly be aware of it,
Thanks a lot.
I am really enjoying the theme/design of your weblog.
Do you ever run into any browser compatibility issues?
A number of my blog visitors have complained about my blog not working
correctly in Explorer but looks great in Firefox.
Do you have any tips to help fix this problem?
Normally I do not read post on blogs, but I wish to say that this write-up very compelled me to check out and do so!
Your writing style has been surprised me. Thanks, quite nice article.
I was wondering if you ever considered changing the page layout of your
site? Its very well written; I love what youve got
to say. But maybe you could a little more in the way of content so people could connect with
it better. Youve got an awful lot of text for only having one
or two pictures. Maybe you could space it out better?
I love reading an article that will make people think. Also, many
thanks for allowing me to comment!
Howdy! I just would like to give you a huge thumbs
up for your great info you have got right here on this post.
I will be coming back to your web site for more soon.
You could certainly see your expertise within the article you write.
The world hopes for more passionate writers such as you who aren’t afraid to say how they believe.
At all times go after your heart.
You really make it seem so easy along with your
presentation however I to find this matter to be actually something that I
believe I might by no means understand. It seems too complicated and extremely extensive for me.
I’m having a look ahead in your subsequent put up, I’ll try to
get the hold of it!
My relatives all the time say that I am killing my time here at web, but
I know I am getting experience all the time by reading thes pleasant content.
Excellent, what a website it is! This web site presents valuable data to us,
keep it up.
Hello! I understand this is kind of off-topic
but I needed to ask. Does operating a well-established
website like yours require a lot of work? I’m completely new to operating a blog
but I do write in my journal everyday. I’d like to start a blog so I
will be able to share my personal experience and
views online. Please let me know if you have any suggestions or tips for
brand new aspiring blog owners. Thankyou!
It’s appropriate time to make some plans for the
future and it’s time to be happy. I have read this
post and if I could I want to suggest you some interesting things or advice.
Perhaps you could write next articles referring to this article.
I want to read even more things about it!
With havin so much written content do you ever run into any
problems of plagorism or copyright infringement?
My blog has a lot of exclusive content I’ve either
authored myself or outsourced but it looks like a lot of it is popping it up all over the internet without my agreement.
Do you know any ways to help prevent content from being stolen? I’d genuinely appreciate it.
We’re a group of volunteers and starting a new scheme in our community.
Your web site offered us with valuable info to work
on. You’ve done a formidable job and our whole community will be thankful to you.
Here is my homepage :: Local SEO
Fantastic items from you, man. I’ve be mindful
your stuff prior to and you’re just too fantastic.
I actually like what you have acquired here, certainly like what
you are stating and the best way in which you say it.
You make it entertaining and you continue to care for to stay it wise.
I can’t wait to learn far more from you.
That is actually a wonderful web site.
We’re a group of volunteers and starting a brand new scheme in our community.
Your web site provided us with valuable info to work on. You’ve done an impressive process and our
whole group can be grateful to you.
Greetings! This is my first visit to your blog! We are a team
of volunteers and starting a new project in a community in the same niche.
Your blog provided us useful information to work
on. You have done a extraordinary job!
Thanks for finally writing about > Пиастры
– Составление семантического ядра | < Loved it!
Excellent blog here! Additionally your site rather a lot up very fast!
What host are you the use of? Can I am getting your associate link for
your host? I wish my web site loaded up as fast as yours lol
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
I’ve been browsing online more than 2 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all webmasters and bloggers made good content as you did, the net will be a lot more useful than ever before.
Hi there! This blog post could not be written any
better! Reading through this article reminds me of my
previous roommate! He always kept preaching about this.
I’ll send this article to him. Pretty sure he’ll have a great read.
Thank you for sharing!
My partner and I stumbled over here different web page and thought I might as well check things out.
I like what I see so i am just following you. Look forward to looking over your
web page repeatedly.
Good way of explaining, and good paragraph to take facts regarding my
presentation subject matter, which i am going to convey in institution of higher education.
Thank you a lot for sharing this with all folks you really
understand what you are speaking about! Bookmarked.
Please additionally seek advice from my web site =).
We can have a link change contract between us
I like it when folks come together and share ideas. Great site, continue the good
work!
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is valuable and all. However imagine if you added some great images or video clips to give
your posts more, “pop”! Your content is excellent but with
pics and video clips, this blog could certainly be one of
the most beneficial in its field. Superb blog!
Howdy, I do think your website may be having internet browser compatibility issues.
When I take a look at your blog in Safari, it looks fine however, when opening in I.E.,
it has some overlapping issues. I simply wanted to give you a quick heads up!
Apart from that, wonderful site!
Heya i am for the primary time here. I came across this
board and I find It really useful & it helped me out much.
I am hoping to give one thing back and help others such as you aided
me.
my web-site :: asap cash offer
Ahaa, its fastidious conversation about this article at this place at this web site, I have read all that, so now me also commenting at this place.
Asking questions are actually good thing if you are not
understanding something fully, however this piece of writing offers nice understanding yet.
Sweet blog! I found it while searching on Yahoo News. Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Cheers
hi!,I like your writing very a lot! percentage we keep up a correspondence extra about your article on AOL?
I need a specialist on this space to solve my problem.
Maybe that is you! Looking forward to peer you.
Do you have a spam issue on this website; I also am a blogger,
and I was wondering your situation; many of us have created some nice practices and we are looking to swap techniques with
other folks, please shoot me an e-mail if interested.
What’s up i am kavin, its my first time to commenting anywhere, when i read this piece of writing i thought i could also
make comment due to this brilliant piece of writing.
Does your site have a contact page? I’m having problems
locating it but, I’d like to send you an email. I’ve got some recommendations for your blog
you might be interested in hearing. Either
way, great blog and I look forward to seeing it expand
over time.
If some one desires expert view about running a blog afterward i
recommend him/her to visit this blog, Keep up the nice
work.
Fantastic beat ! I would like to apprentice while you amend your website, how can i
subscribe for a weblog website? The account
helped me a appropriate deal. I were a little
bit familiar of this your broadcast provided brilliant clear idea
I’m truly enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more
enjoyable for me to come here and visit more often. Did you hire out a developer to create your
theme? Fantastic work!
I am not sure where you’re getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for great information I was looking for this info for my mission.
Hello great website! Does running a blog similar to this take a large amount of work?
I have very little knowledge of computer programming but I was hoping to
start my own blog in the near future. Anyway, should you have any recommendations or
tips Total CBD Gummies For ED new blog
owners please share. I understand this is off subject however I just had to ask.
Thank you!
I couldn’t resist commenting. Perfectly written!
I do not even know the way I finished up here, but I thought
this publish was once good. I do not recognise who you might be however definitely you’re going to a well-known blogger in case you aren’t already.
Cheers!
Attractive section of content. I just stumbled upon your
website and in accession capital to claim that I acquire actually enjoyed account your blog
posts. Any way I’ll be subscribing on your feeds and even I achievement you get entry to consistently rapidly.
No matter if some one searches for his necessary thing, therefore he/she wishes to be available that in detail,
therefore that thing is maintained over here.
I am sure this piece of writing has touched all the internet users, its really really nice post on building up new website.
I like it when folks get together and share thoughts.
Great website, stick with it!
Great beat ! I wish to apprentice even as you amend your website, how can i subscribe
for a weblog web site? The account helped me a applicable deal.
I have been a little bit familiar of this your broadcast provided
bright clear concept
My blog; side effect hyzar
It’s amazing designed for me to have a web site, which is beneficial in support of my
knowledge. thanks admin
We stumbled over here coming from a different website and thought I might check things out.
I like what I see so i am just following you. Look forward to looking over your
web page yet again.
Thanks for sharing your thoughts on alton gallery echuca. Regards
Unquestionably believe that which you said. Your favorite justification appeared to be on the internet the easiest thing to be aware of.
I say to you, I certainly get irked while people think about worries that they plainly do not know about.
You managed to hit the nail upon the top and also defined out the whole thing without
having side effect , people can take a signal. Will
likely be back to get more. Thanks
You really make it seem so easy with your presentation but I find this topic to
be really something which I think I would never understand.
It seems too complex and extremely broad for me.
I’m looking forward for your next post, I’ll try to get the hang of it!
Thanks for sharing your thoughts on https://byfc0396.com/home.php?mod=space&uid=1819815. Regards
I am regular reader, how are you everybody? This article posted at this website is in fact pleasant.
Yes! Finally something about World Cup.
Look into my website; rybelsus foods to avoid
Excellent blog you’ve got here.. It’s hard to find high-quality
writing like yours these days. I truly appreciate people like you!
Take care!!
Everything is very open with a precise clarification of
the issues. It was definitely informative. Your site is extremely helpful.
Thank you for sharing!
What’s up Dear, are you actually visiting this web page on a regular basis, if so then you will
definitely obtain pleasant knowledge.
Great blog here! Also your web site loads up very fast!
What host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as quickly as
yours lol
Great article. I am experiencing a few of these issues as well..
I read this article fully concerning the difference of latest and previous
technologies, it’s remarkable article.
Wow, marvelous blog layout! How long have you been running a
blog for? you make running a blog glance easy.
The total look of your website is great, as smartly as the content material!
Aw, this was an exceptionally good post. Taking a few minutes and
actual effort to produce a great article… but what can I
say… I put things off a whole lot and
don’t manage to get nearly anything done.
Amazing! Its actually awesome article, I have
got much clear idea concerning from this post.
What’s up colleagues, good piece of writing and nice
arguments commented here, I am truly enjoying by these.
Wow that was odd. I just wrote an really long comment
but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Anyways, just wanted to say superb blog!
Also visit my blog post: asapcashoffer
I really like what you guys tend to be up too. Such clever work
and reporting! Keep up the very good works guys I’ve included you guys to my
personal blogroll.
Remarkable issues here. I’m very happy to peer your post.
Thank you so much and I’m taking a look ahead to contact you.
Will you please drop me a mail?
Excellent site you have here.. It’s hard to find high quality writing like yours
nowadays. I honestly appreciate people like
you! Take care!!
Hi there! I simply wish to give you a big thumbs up for your great information you have
got here on this post. I will be returning to your web site for more soon.
I am really glad to read this weblog posts which contains plenty of helpful facts, thanks for providing these
kinds of information.
I’m really enjoying the theme/design of your site. Do you ever
run into any internet browser compatibility problems?
A number of my blog readers have complained about
my site not working correctly in Explorer but looks great in Opera.
Do you have any recommendations to help fix this issue?
What’s up, I would like to subscribe for this website
to take hottest updates, thus where can i do it please help.
I am sure this post has touched all the internet users, its really really fastidious piece of writing on building up new web site.
Every weekend i used to go to see this web page,
as i wish for enjoyment, for the reason that this this web page conations genuinely nice funny
stuff too.
I have to thank you for the efforts you’ve put in penning this site.
I really hope to check out the same high-grade content from you
in the future as well. In fact, your creative writing abilities has inspired
me to get my own website now 😉
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is required to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% certain. Any recommendations or advice would
be greatly appreciated. Thank you
Hi, I do bеlieve tһis iѕ a ցreat web site.
І stumbledupon іt 😉 I am ɡoing to return once again ѕince I book marked іt.
Mobey and freedom iѕ thе best way tߋ change,
mау you be rich аnd continue to help оthers.
Αlso visit mү pagе; Swinger Lifestyle (http://www.fusexsocialclub.com)
This is very interesting, You’re an overly professional blogger.
I’ve joined your rss feed and look forward to seeking extra of
your wonderful post. Additionally, I’ve shared your web site in my social networks
I am really enjoying the theme/design of your web
site. Do you ever run into any browser compatibility issues?
A number of my blog audience have complained about my blog not
operating correctly in Explorer but looks great in Firefox.
Do you have any recommendations to help fix this issue?
Link exchange is nothing else but it is just placing the other person’s web site link on your
page at proper place and other person will also do similar
in support of you.
Hello I am so excited I found your website, I really found you by accident, while I was researching on Askjeeve for something else, Anyways
I am here now and would just like to say kudos for a tremendous post and a all round entertaining
blog (I also love the theme/design), I don’t have time to look over it
all at the minute but I have book-marked it and also included your RSS feeds, so when I have time I will be back to read more,
Please do keep up the superb job.
Hi there very cool site!! Man .. Beautiful .. Amazing .. I will bookmark your
site and take the feeds also? I am happy to find a lot of useful information here in the publish, we need
develop more strategies on this regard, thanks for sharing.
. . . . .
Also visit my webpage :: USA Script Helpers
Good response in return of this matter with real arguments and describing all regarding that.
Thank you, I’ve recently been searching for information approximately this subject for a while
and yours is the greatest I have discovered so far.
But, what concerning the bottom line? Are you certain concerning the source?
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to design my own blog and would like to
know where u got this from. many thanks
Also visit my page … web page
Good post however I was wondering if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit further.
Thank you!
You really make it seem so easy along with your presentation however I find this matter to be actually one thing that I
believe I might never understand. It seems too complicated and very huge for me.
I am having a look forward to your next put up, I will attempt to get the dangle of it!
You really make it seem so easy with your presentation but I find this matter to be actually something which I think I would never understand.
It seems too complicated and extremely broad for me. I’m looking forward for your next post,
I will try to get the hang of it!
It’s the best time to make some plans for the future and it is time to
be happy. I have read this post and if I could I want to suggest you some interesting things
or advice. Maybe you could write next articles referring to this article.
I want to read even more things about it!
Nice blog right here! Additionally your website so much up very fast!
What host are you the use of? Can I get your affiliate hyperlink in your host?
I desire my web site loaded up as fast as yours lol
Great items from you, man. I have be mindful your stuff
previous to and you’re just extremely fantastic.
I really like what you have got right here, certainly like what
you’re saying and the way during which you say it.
You’re making it enjoyable and you still take care of
to stay it sensible. I cant wait to read far more from you.
This is really a tremendous web site.
Visit my web blog :: hkasa.com
Hello! I could have sworn I’ve been to this website before but after
browsing through some of the post I realized it’s new to me.
Anyways, I’m definitely delighted I found it and I’ll be bookmarking and checking back often!
Howdy! This is kind of off topic but I need some advice from an established blog.
Is it very difficult to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure where to
start. Do you have any points or suggestions? With thanks
Asking questions are genuinely fastidious thing if you are not
understanding anything completely, but this piece of writing provides pleasant understanding even.
This is my first time go to see at here and i am actually impressed to read
everthing at alone place.
Hey! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to
me. Anyways, I’m definitely glad I found it and I’ll be bookmarking and checking back often!
We are a group of volunteers and starting a new scheme in our community.
Your site offered us with valuable info to work on. You’ve
done an impressive job and our entire community will be
thankful to you.
Hey his is somewhat of off tpic but I was wanting tto know
if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so
I wanted to get dvice from someone with experience.Any help would be enormously appreciated!
web page
Hey there! This post couldn’t be written any better!
Reading this post reminds me of my old room mate! He always kept
chatting about this. I will forward this write-up to him. Fairly certain he will have a good read.
Thanks for sharing!
секс онлайн
Good day! Would you mind if I share your blog with my zynga group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thank you
Hi, Neat post. There’s an issue together with your website in web explorer, might check this?
IE nonetheless is the marketplace chief and a big section of folks will miss your
great writing due to this problem.
Hello there, I found your web site by means of Google while
looking for a related matter, your site got here
up, it appears good. I’ve bookmarked it in my google bookmarks.
Hello there, simply was aware of your blog via Google, and found that it is truly informative.
I’m gonna watch out for brussels. I’ll be grateful if you proceed
this in future. A lot of other folks will likely be benefited out of your writing.
Cheers!
Hmm it seems like your website ate my first comment (it
was super long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly
enjoying your blog. I too am an aspiring blog writer but I’m still
new to everything. Do you have any tips and hints for beginner blog writers?
I’d definitely appreciate it.
Seitsemän vakaa syytä pitää poisesa horoskoccasino -kasinosta
website
Atlantic Cityn asukkaat ovat täysin tietoisia työtöistä talon mahdollisuuksissa, jotka saattavat jatkuvasti avata
heti sen jälkeen, kun miljardin greenin lomakeskus on tuotettu mahdollisesti
vuoden 2012 aikana. PlayTechillä voi olla pohjat päällystetty digitaalisessa korttipaikassa, mutta esittelese vain muutaman ensisijaisen ruletin.
Muutama heistä vaatii suuren käsirahan pelaamisen tarkoituksena.
Very descriptive post, I loved that a lot. Will there be a part 2?
Wow, superb blog layout! How lengthy have you ever been running a
blog for? you make blogging look easy. The full glance
of your site is wonderful, as smartly as the content!
Hi, after reading this remarkable paragraph i am too happy to share my knowledge here with colleagues.
Hi! Do you use Twitter? I’d like to follow you if that would be
ok. I’m absolutely enjoying your blog and look forward to new posts.
You really make it seem so easy with your presentation but I find this
matter to be really something which I think I would never understand.
It seems too complicated and extremely broad for me.
I am looking forward for your next post, I will try to get the hang of it!
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! However, how could we communicate?
Thanks for sharing your thoughts about klia airport transfer.
Regards
Hello, I enjoy reading all of your post. I like to write a little comment to
support you.
Hello there, You have done an excellent job. I’ll certainly digg it and personally recommend to my friends.
I am sure they’ll be benefited from this web site.
Please let me know if you’re looking for a writer for your blog.
You have some really good articles and I feel I would be a good
asset. If you ever want to take some of the load off, I’d absolutely
love to write some content for your blog in exchange for
a link back to mine. Please send me an e-mail if interested.
Thanks!
Remarkable! Its actually remarkable piece of writing, I have got much
clear idea concerning from this paragraph.
Excellent weblog right here! Additionally your web site so
much up fast! What host are you the usage of? Can I get your affiliate link
to your host? I desire my site loaded up as quickly as yours lol
magnificent issues altogether, you simply received a brand new reader.
What may you suggest about your submit that you simply made some days in the past?
Any certain?
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the
expenses. But he’s tryiong none the less. I’ve been using WordPress on various websites for about a year and am concerned about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any kind of help would be really appreciated!
I will right away grab your rss as I can not find your email subscription hyperlink or newsletter service.
Do you have any? Please allow me recognize so that I
may subscribe. Thanks.
My brother recommended I might like this blog.
He was once entirely right. This submit actually made my day.
You cann’t consider just how so much time I had spent for this information! Thank you!
Hello my family member! I want to say that this article is amazing,
nice written and come with almost all vital infos.
I would like to see more posts like this .
This is a topic that is close to my heart… Thank you!
Where are your contact details though?
What’s up to all, how is all, I think every one is getting more from this web page,
and your views are pleasant designed for new people.
Hey! Do you use Twitter? I’d like to follow you if that would be ok.
I’m absolutely enjoying your blog and look forward to new updates.
Hi, i read your blog occasionally and i own a
similar one and i was just curious if you get a lot of spam remarks?
If so how do you reduce it, any plugin or anything you can advise?
I get so much lately it’s driving me insane so any support is very much appreciated.
Magnificent beat ! I would like to apprentice whilst you amend your site, how can i subscribe for
a blog website? The account helped me a applicable deal.
I had been tiny bit familiar of this your broadcast offered
shiny clear concept
I seriously love your blog.. Very nice colors & theme. Did you develop this web
site yourself? Please reply back as I’m trying to create my very own blog and would like
to learn where you got this from or what the theme
is named. Cheers!
Very nice post. I simply stumbled upon your weblog and wanted to mention that I have really enjoyed surfing around your blog posts.
After all I will be subscribing in your rss feed and I hope
you write again very soon!
We are a bunch of volunteers and opening a brand new scheme in our community.
Your website provided us with helpful info to work on. You’ve
done a formidable job and our whole neighborhood will probably be grateful to you.
Link exchange is nothing else except it is only placing the other person’s blog link on your page at
appropriate place and other person will also do same in favor of you.
Feel free to visit my website ASAP Cash Offer
It’s the best time to make some plans for the long run and it’s time to be happy.
I have learn this post and if I may just I want to
suggest you some fascinating issues or tips. Perhaps you can write subsequent articles referring to this article.
I wish to read more things about it!
I loved as much as you’ll receive carried out right here. The sketch is attractive, your
authored subject matter stylish. nonetheless, you command get bought an nervousness
over that you wish be delivering the following. unwell
unquestionably come further formerly again since exactly the same nearly a lot often inside
case you shield this increase.
Incredible points. Solid arguments. Keep up the great spirit.
Pretty part of content. I simply stumbled upon your
blog and in accession capital to claim that I get actually enjoyed account your
weblog posts. Anyway I’ll be subscribing to your augment or even I achievement you get admission to persistently
rapidly.
Thanks for your personal marvelous posting!
I certainly enjoyed reading it, you happen to be a great author.
I will always bookmark your blog and will eventually come
back sometime soon. I want to encourage continue your great
job, have a nice weekend!
I believe this is among the such a lot vital
information for me. And i’m satisfied studying your article.
However should commentary on few general issues, The web site style is ideal,
the articles is actually excellent : D. Just right job,
cheers
Hello there! This article couldn’t be written much better!
Going through this post reminds me of my previous roommate!
He always kept talking about this. I’ll forward this article to him.
Pretty sure he’s going to have a great read.
I appreciate you for sharing!
It’s an amazing piece of writing in favor of all the
web people; they will obtain advantage from
it I am sure.
It’s nearly impossible to find well-informed people for this subject, but you sound like you know what you’re talking about!
Thanks
Generally I do not learn post on blogs, but I would like to say that this write-up very
forced me to try and do so! Your writing taste has been surprised me.
Thank you, very great article.
Also visit my blog; Natures Heart CBD Review
This is my first time go to see at here and i am really happy to read everthing at one place.
I read this paragraph fully regarding the
difference of newest and earlier technologies, it’s
awesome article.
Please let me know if you’re looking for a writer for your blog.
You have some really good articles and I think I would
be a good asset. If you ever want to take some of the load
off, I’d absolutely love to write some material for your blog in exchange for a link
back to mine. Please blast me an e-mail if interested.
Many thanks!
Hey very interesting blog!
This page definitely has all of the information I wanted about this subject and didn’t know
who to ask.
https://book-news.ir/5-روش-مختلف-رفع-موهای-زائد-بخش-دوم-کلینی/
Having read this I thought it was very informative.
I appreciate you spending some time and effort to put this informative article
together. I once again find myself personally spending way too much time both reading and
posting comments. But so what, it was still worthwhile!
What’s up, just wanted to mention, I liked this blog post.
It was practical. Keep on posting!
Thanks for finally writing about > Пиастры –
Составление семантического ядра | < Loved it!
Thanks for sharing your thoughts about Website source. Regards
excellent points altogether, you simply won a logo new reader.
What could you recommend about your submit that you
simply made a few days ago? Any certain?
No matter if some one searches for his vital thing, therefore he/she desires to be available that in detail,
thus that thing is maintained over here.
Hello, i think that i noticed you visited my website thus i came to go back the choose?.I’m attempting to in finding things to enhance my
web site!I assume its adequate to use a few of your
concepts!!
Thanks very nice blog!
Fantastic goods from you, man. I have understand your stuff previous
to and you are just too excellent. I actually
like what you’ve acquired here, certainly like what you’re stating and the way in which you say it.
You make it enjoyable and you still take care of to keep it smart.
I can’t wait to read much more from you. This is really a tremendous website.
May I simply say what a comfort to discover someone who
truly knows what they are discussing on the internet. You certainly
understand how to bring a problem to light and
make it important. More and more people ought to check this out and understand this side of the story.
I can’t believe you aren’t more popular since you certainly have the gift.
whoah this weblog is excellent i really like studying your posts.
Stay up the great work! You already know, a lot of individuals
are searching round for this info, you can aid
them greatly.
I’m gone to convey my little brother, that he should also
go to see this website on regular basis to obtain updated from most up-to-date news.
you are truly a just right webmaster. The site loading
speed is incredible. It sort of feels that you are doing any
unique trick. Also, The contents are masterwork. you have done a magnificent
task on this subject!
Thankfulness to my father who told me on the topic of this website,
this blog is genuinely remarkable.
You actually make it seem so easy with your presentation but I find
this matter to be actually something which
I think I would never understand. It seems too complex and very broad for me.
I’m looking forward for your next post, I’ll try to get the hang of it!
I quite like looking through a post that can make men and women think.
Also, thanks for allowing for me to comment!
Please let me know if you’re looking for a author for your weblog.
You have some really good posts and I believe I would be a good asset.
If you ever want to take some of the load
off, I’d really like to write some content for your blog in exchange for a link back to mine.
Please blast me an email if interested. Thank you!
Very nice article, just what I needed.
Currently it seems like WordPress is the best blogging platform available right
now. (from what I’ve read) Is that what you are using on your blog?
It’s appropriate time to make some plans for the future and
it is time to be happy. I have read this post and if I could I want to suggest you some interesting things or tips.
Perhaps you can write next articles referring to this article.
I wish to read more things about it!
This piece of writing offers clear idea in favor of the new users of blogging, that truly how
to do running a blog.
Hey! I know this is kinda off topic but I was wondering if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m
having problems finding one? Thanks a lot!
Excellent post. I used to be checking constantly this blog and I I take care of such info much. I was looking for this particular
I take care of such info much. I was looking for this particular
am inspired! Very useful information specially the
remaining section
information for a long time. Thanks and best of luck.
Woah! I’m really loving the template/theme of this
website. It’s simple, yet effective. A lot of times it’s
very difficult to get that “perfect balance” between usability and visual appearance.
I must say that you’ve done a superb job with this. Additionally, the blog loads extremely quick for me on Firefox.
Superb Blog!
If you would like to increase your familiarity only keep visiting this website and be updated with the most up-to-date
news posted here.
Hi, Neat post. There is an issue together with your website
in internet explorer, could check this? IE nonetheless is the market
chief and a big component of folks will leave out your excellent writing due to this problem.
Incredible! This blog looks exactly like my old one!
It’s on a entirely different subject but it has pretty much
the same page layout and design. Wonderful choice of colors!
I will right away take hold of your rss feed as I can not to find your e-mail subscription hyperlink or e-newsletter service.
Do you have any? Kindly permit me understand so that I may just subscribe.
Thanks.
Wow, fantastic blog format! How lengthy have
you ever been running a blog for? you make running a blog
look easy. The total look of your website is excellent, let alone the content material!
There’s certainly a great deal to learn about
this topic. I really like all the points you’ve made.
Howdy! I could have sworn I’ve been to your blog before but after browsing through a
few of the posts I realized it’s new to me. Regardless, I’m
definitely pleased I discovered it and I’ll be bookmarking
it and checking back often!
I’d like to find out more? I’d care to find out some additional information.
Hey there, You have done a fantastic job. I’ll definitely digg it and personally
suggest to my friends. I am sure they will be benefited
from this web site.
Hey there! Would you mind if I share your blog
with my zynga group? There’s a lot of people that I think would really enjoy your content.
Please let me know. Many thanks
I visited various web sites except the audio feature for audio songs present at this web page is actually wonderful.
It’s great that you are getting thoughts from this post as well as from our dialogue made
at this place.
Also visit my website asapcashoffer
Thanks for sharing your thoughts on personal
care. Regards
my blog post; Flawless Perfect Skin Reviews
همه چیز درباره فیلم برادران لیلا
فیلم برادران لیلا آشکارا در دو
سطح، که به مرور در هم تنیده میشوند پایههای روایتش را
بنا میکند و به پیش میرود. اول مرور پر جزئیات اتفاقات مهیب اقتصادی است که در چند
سال گذشته زلزلهای ویرانگر را سبب شد و بر زندگی قشر عظیمی از جامعه تاثیری بنیادین گذاشت.
دورانی که لحظه و اهمیت آن بیش از هر زمانی ترسناک و رعب آور به نظر میرسید.
جواد نوروز بیگی، تهیه کننده فیلم برادران لیلا، در تاریخ
نهم دی ماه سال ۱۴۰۰، از عدم حضور
فیلم برادران لیلا در چهلمین جشنواره فیلم فجر به دلیل ادامه فیلم برداری خبر داد.
سعید روستایی کارگردان آن که فیلمهایی چون ابد و یک روز، متری شیش و نیم
و سد معبر را در کارنامه کاری خود دارد، با فیلم برادران لیلا گام
بزرگی در جهت محبوبیت بیشتر برداشت و توانست در جشنواره کن ۲۰۲۲ شرکت
کند. او از کمردرد دورهای ناشی از استرس و کار زیاد رنج میبرد و اساساً تنها
نانآور خانواده با حقوق ثابت است و از
چهار برادر بالغ خود حمایت میکند.
در کشوری که درگیر تحریمهای اقتصادی بینالمللی است، خانواده دائما با هم بحث میکنند و با زیر
بار بدهی خرد میشوند. لیلا در حالی که برادرانش در تلاش برای گذراندن زندگی خود هستند، نقشهای میکشد تا با راهاندازی یک تجارت خانوادگی آنها را از فقر نجات دهد.
بنا به گفتۀ منتقدان، این فیلم که نمایندۀ سینمای
ایران در بخش مسابقه اصلی فستیوال کن ۲۰۲۲ است، یکی
از مدعیان جدی دریافت نخل طلای
بهترین فیلم و دیگر جوایز این دوره از جشنواره به شمار می رود.
فرهاد اصلانی در تاریخ ۱۸
خرداد ۱۳۴۴ متولد شد که از سال ۱۳۷۰ وارد
عرصه بازیگری شده است.
عدالت خواهی به معنای بازپسگیری حق زیستن و
نه انتقاد از وضعیت فعلی که شاید تنها جاهطلبی روستایی
در این زمینه موهای بافته و آویزان
ترانه علیدوستی، لیلا،
است. ویژگی ابتدایی فیلمنامه
فیلم مورد بحث تعلیق بدون سیاهنمایی به واسطه استفاده از سیاهیهای موجود در
بطن داستان است. فیلمنامه قصهای را به عنوان پیرنگ برگزیده که ماجرای
قشر عظیمی از جامعه امروز است اما این ماجرا همچنان
سمپاتیاش برای بیننده متحجر غیرقابل
قبول میشود.
تازه اگر خیلی دلت یک زن قوی و مستقل
که متضاد سمیه ی ابد و یک روز است میخواهد، یک زن بد دهن، بی ادب که حتی عرضه داشتن یک
کار درست و حسابی و مستقل شدن ندارد را وجه قیاس نگذاریم بهتر است!
پدری که توی سینک میشاظد و پشیزی برای کسی قایل نیست وبالعکس کسی هم برایش، چه قداستی دارد که شکسته شود!
خاکبرسرت سعید, بیشعور یه پدر هر چقدر
هم اشتباه کرده باشه , فرزنداش غلط
میکنن بخوان روش دست بلند کنن. من میگم
همین خوراک های فرهنگی تاثیر بسیار زیادی در روابط آینده ما داره .
اگه درکش برای جامعه سخته پس یعنی همون پدر سالاری تو جامعه وجود داره.
این اتفاق باعث هرج و مرج در خانوادهای میشود که از پیش نیز شکننده بود.
با بدتر شدن وضعیت سلامتی پدر، اقدامات هر یک از اعضای خانواده به تدریج خانواده را یک قدم به
سمت انفجار نزدیک میکند.
در بسیاری از سکانسهای فیلم هفت
یا هشت نفر در کادر حضور دارند و این، به
گفته این منتقد سینمایی، معجزه کوچکی است که سعید روستایی و هومن بهمنش، مدیرتصویربرداری، توانستهاند
بازیگران را به این صورت کنار
هم قرار دهند، یعنی شرایطی که همه آنها
نقشی محوری در صحنه دارند. دو فیلم قبلی سعید روستایی
او را به عنوان فیلمسازی خوشقریحه معرفی کردند.
I don’t even know how I ended up here, but I thought this post was great.
I do not know who you are but definitely you are going
to a famous blogger if you aren’t already 😉 Cheers!
Also visit my web-site :: ASAPCashOffer
Hey there, You’ve done a fantastic job. I will certainly digg it and personally suggest to my friends.
I’m sure they’ll be benefited from this web site.
Here is my web page – testnw.multiiq.com
It is appropriate time to make a few plans for the longer term and it is time to be happy.
I’ve read this publish and if I may I wish to counsel you few interesting issues or tips.
Perhaps you can write next articles relating to this article.
I want to learn even more issues approximately it!
Stunning story there. What occurred after?
Take care!
Unquestionably consider that which you stated.
Your favourite justification appeared to be on the web the simplest factor
to be mindful of. I say to you, I certainly get irked whilst folks think about concerns that
they just do not recognise about. You controlled to hit the nail upon the
top and also defined out the entire thing without having side effect , people can take a signal.
Will probably be back to get more. Thank you
I really love your site.. Pleasant colors & theme. Did
you make this website yourself? Please reply back as
I’m looking to create my own personal website and would like to know where you got this from or just what the theme is named.
Cheers!
Hi there! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing months
of hard work due to no data backup. Do you have any solutions
to prevent hackers?
Thanks , I have just been searching for info about this topic for
a while and yours is the best I have came upon so far. However, what concerning the bottom line?
Are you certain concerning the supply?
WOW just what I was searching for. Came here by searching for here
Your style is really unique compared to other folks I’ve read stuff from.
Thank you for posting when you have the opportunity,
Guess I’ll just bookmark this blog.
Excellent, what a webpage it is! This web site presents helpful data to us, keep it up.
Good day! I know this is kind of off topic but I was wondering if
you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
Everyone loves what you guys are usually up too. Such clever work and reporting!
Keep up the awesome works guys I’ve included you guys
to my blogroll.
Very good article! We will be linking to this great article on our site.
Keep up the great writing.
Thanks for sharing your thoughts on dnabet. Regards
It is perfect time to make some plans for the future and it is time to be happy.
I have read this post and if I could I wish to suggest you few interesting things or advice.
Perhaps you could write next articles referring to this
article. I desire to read more things about it!
Saved aas a favorite, I like your blog!
webpage
Hey! I know this is kinda off topic nevertheless I’d figured I’d ask.
Would you be interested in exchanging links
or maybe guest authoring a blog article or vice-versa?
My website discusses a lot of the same topics
as yours and I think we could greatly benefit from each other.
If you happen to be interested feel free to shoot me an email.
I look forward to hearing from you! Superb blog by
the way!
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
Way cool! Some very valid points! I appreciate
you penning this post and also the rest of the website is really good.
What’s Taking place i am new to this, I stumbled upon this I’ve found It positively helpful and it has aided me out loads.
I am hoping to contribute & help other users like its helped me.
Good job.
Howdy! This is my first visit to your blog! We are a group of
volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You
have done a wonderful job!
Hi, i feel that i saw you visited my site thus i got here to go back the prefer?.I’m trying to find issues to enhance
my website!I suppose its adequate to use a few of your concepts!!
Excellent blog! Do you have any helpful hints for aspiring writers?
I’m planning to start my own website soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many choices
out there that I’m totally overwhelmed .. Any recommendations?
Kudos!
I need to to thank you for this very good read!!
I absolutely enjoyed every little bit of it. I have you bookmarked to check out new stuff you post…
Look into my web site; A片
I’d like to thank you for the efforts you have
put in penning this website. I’m hoping to view the same high-grade blog
posts by you later on as well. In fact, your creative writing
abilities has motivated me to get my own, personal blog
now 😉
It’s very straightforward to find out any matter on web as compared to books,
as I found this post at this web page.
I’m not that much of a online reader to be honest but your sites
really nice, keep it up! I’ll go ahead and bookmark your site to come back down the road.
Cheers
I always emailed this web site post page to all my contacts, because if like to read it afterward
my friends will too.
Hi there, I enjoy reading all of your article post.
I wanted to write a little comment to support you.
Link exchange is nothing else but it is only placing the other person’s weblog link on your page at proper place
and other person will also do similar for you.
I go to see each day some web pages and sites to read content,
except this web site gives feature based posts.
Great post. I was checking continuously this blog and I am inspired! I take care of such info much. I used to be seeking this particular info for a very lengthy time.
I take care of such info much. I used to be seeking this particular info for a very lengthy time.
Extremely useful info specifically the remaining
section
Thanks and good luck.
What’s up to every one, because I am really keen of reading this blog’s post to be updated regularly.
It consists of pleasant material.
Definitely imagine that which you stated. Your
favourite justification seemed to be at the internet the easiest thing to
have in mind of. I say to you, I certainly get
annoyed while people consider issues that they plainly don’t understand
about. You controlled to hit the nail upon the highest as smartly as defined out the whole thing with no need
side effect , folks can take a signal. Will likely be back to get more.
Thank you
Keep on working, great job!
I am really grateful to the holder of this site who has shared this wonderful piece of writing at at this place.
Hey I know this is off topic but I was wondering
if you knew of any widgets I could add to my blog
that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some
time and was hoping maybe you would have some experience with something like this.
Please let me know if you run intto anything. I truly enjoy
reading your blog and I look forward to your new updates.
My homepage :: bicyhle (http://www.smiph.com)
سامانه خدمات پرستاری و مراقبتی در
منزل
برای بعضی از افراد این مشکل بیشتر طول میکشد و نیز حادتر میشود.
در این شرایط شخص ممکن است دچار سوء هاضمه شود زیرا نمیتواند
غذا بخورد یا بلع را بصورت کامل انجام دهد.
پزشک برای حل این مشکل دستور استفاده از لولهی بینی-معدهای که همان
NG-tube است استفاده میکند. پ بیمار را از لحاظ رژیم غذایی ، میزان فشار خون،
دما، ضربان قلب و تنفس بررسی می کنند.
این خدمات طیف گسترده ای
از خدمات مراقبت های پزشکی را شامل می شود که می تواند
به راحتی در منزل شما انجام شود.
جرم موجود در گوش با هدف جلوگیری
از ورود گرد و غبار، آلودگی و نفوذ حشرات موزی تشکیل میشود.
اما در برخی شرایط با افزایش مقدار آن، مشکلاتی برای فرد ایجاد میگردد که معمولا در سنین
بالا رخ میدهد. افرادی که به هر دلیلی شرایط حضور
در درمانگاه را ندارند، از خدمت شستشوی گوش در منزل استفاده میکنند.
گاواژ به معنای وارد کردن مواد غذایی با استفاده از یک لولهی باریک است.
این لولهی باریک همان سوندی است که مواد غذایی را مستقیم به
معده میرساند.
بسیاری از بیماران معتقدند آنها نیازی به کمک ندارند و اگر
وسیله ای پیش راه آنها نباشد می
توانند به راحتی راه بروند.
برای نگهداری از سالمند در منزل ، پرستار
باید از داروهایی که ممکن است موجب خواب
آلودگی، سرگیجه، کاهش بینایی، کاهش
تمرکز و .. بعد از مصرف این داروها تا مدت زمان مناسبی به هیچ وجه سالمندان را تنها نگذارید.
جهت جلوگیری از سقوط از ابزارهای مناسبی مانند تخت های آلارم دار استفاده کنید.
برای پیشگیری از عفونت و عدم نیاز به شستشوی
مکرر دست ها تا جایی که می
توانید نگذارید دستهایشان
آلوده شود. با ضد عفونی کننده های مختلف
دستها را بشویید و با دستمال های مناسب خشک نمایید.
لاواژ معده (شستوشوی معده) به معنی تخلیهی محتویات موجود
در معده است. لاواژ معده در
منزل در صورت بروز مسمومیتهای شدید دارویی، الکلی و سمی
انجام میگیرد. لاواژ معده در منزل جزو خدمات پرستار
در منزل است که توسط متخصصین این امر ارائه میشود.
لاواژ معده در منزل علاوه بر
انجام در مواقع مسمومیت، در ازریابی منشا استفراغ خونی و
کاهش دمای بیماران گرمازده نیز
استفاده میشود. با انجام لاواژ معده
در منزل علاوه بر حذف دردسرهای رفت و آمد تا مراکز درمانی، از انجام هزینههای اضافی نیز خودداری فرمایید.
شناخت روحیه و شرایط سالمندان یا کودکان با پرستاران آشنا
به علوم روانشناختی امکانپذیر است.
در پایان، صمیمانه امیدوارم پذیرای
حضور شما در جمع مشتریان
عزیزمان باشیم. البته همانطور که قبلاً هم عرض کردیم خدمات پرستاری در منزل با توجه به نیاز مددجو ممکن است متفاوت باشد.
پزشک متخصص داخلی و عفونی بیمار را ویزیت کرده و در صورت
نیاز و وجود مشکل و بیماری خاص به پزشک متخصص مربوطه ارجاع داده میشود.
ازمایش خون آنلاین و ویزیت پزشک
متخصص و چکاپ های ماهیانه و….
پس از مشاوره گرفتن از کارشناسان
، به سرعت برای شما پرستار اعزام
می شود و پرستار به مدت 24 تا forty eight ساعت بصورت آزمایشی در اختیار شما قرار می گیرد تا مورد
تایید شما قرار گیرد. تمامی تعاملات کودک با والدین، اطرافیان و مراقب خود به تجربه های کودک می افزاید و مغز را که با سرعت در سالهای اول زندگی
در حال رشد است، تحت تاثیر قرا میدهد.
خدمات پرستاری در منزل اسنپ دکتر به بیمار کمک میکند تا در یک محیط
آشنا و دوست داشتنی همچون خانه، علاوه بر
حفظ آرامش ذهن و کاهش استرس از یک کیفیت نظارتی و خدماتی
معتبر، تخصصی و مورد اعتماد برخوردار شود.
تصور کنید که اواخر شب است و متوجه تب شدید کودک خود شدهاید.
مطمئنا مراجعه به بخش اورژانس بیمارستان و ویزیت پزشک پس از حداقل یک ساعت معطلی، چیزی جز فشار مضاعف
روحی برای شما نخواهد داشت.
علاوهبراین، پزشک بهدلیل وجود سایر مراجعین نمیتواند زمان زیادی به کودک شما اختصاص دهد!
پیشنهاد ما به شما، درخواست ویزیت پزشک از مرکز پزشکی و
پرستاری در منزل توانا است.
My spouse and I stumbled over here different website and thought I may as well check things out.
I like what I see so now i’m following you. Look forward
to looking into your web page again.
The activity trackers listed below have been discontinued, although some are nonettheless
avazilable for resale by Amazon and elsewhere.
My web-site; สล็อต
To begin with a larger bankroll, chheck out their promotions page.
My sitye :: 카지노친구
Thanks a lot for sharing this with all folks you really recognize what you’re talking approximately!
Bookmarked. Kindly additionally visit my website
=). We could have a link exchange contract among us
my homepage; https://elks4kids.org/
Howdy! This is kind of off topic but I need some guidance from an established
blog. Is it difficult to set up your own blog? I’m not
very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any tips or suggestions? Appreciate it
Good info. Lucky me I discovered your blog by chance (stumbleupon).
I have saved it for later!
Hello colleagues, how is the whole thing, and what you desire to
say about this post, in my view its really amazing designed for me.
Hurrah, that’s what I was seeking for, what a information! existing here at this
website, thanks admin of this site.
Awesome issues here. I’m very glad to peer your article.
Thank you a lot and I am taking a look forward
to contact you. Will you please drop me a mail?
Greetings from Carolina! I’m bored to death at work so I
decided to check out your site on my iphone during lunch break.
I enjoy the info you present here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my cell phone
.. I’m not even using WIFI, just 3G .. Anyhow, awesome blog!
Hello there! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me.
Nonetheless, I’m definitely glad I found it and I’ll be bookmarking and checking back frequently!
Usually I do nott read article on blogs, but I would like
to say that this write-up very pressured me to try and do it!
Yoour writing taste has been surprised me. Thank you, quite nice article.
Also visit my homepage; https://lineadegolcr.com/
Pretty portion of content. I just stumbled upon your web site and in accession capital to say that I acquire actually enjoyed account your blog posts.
Any way I will be subscribing in your augment or
even I fulfillment you access persistently rapidly.
Hello, its fastidious paragraph regarding media print, we all be aware of media is a impressive source of facts.
It’s very effortless to find out any topic on net as compared tto textbooks, as I found
this piece of writing at this site.
I’m not that much of a internet reader to be honest but your blogs really
nice, keep it up! I’ll go ahead and bookmark your site
to come back later. Many thanks
Here is my web blog – A片
This web site certainly has all of the info I needed concerning this
subject and didn’t know who to ask.
Hello Dear, are you really visiting this web site on a regular basis, if so afterward you will without doubt
get fastidious knowledge.
Great blog here! Also your website loads up
very fast! What web host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
My family all the time say that I am wasting my time here at net, but I know I am getting familiarity every day by reading such pleasant articles.
I know this if off topic but I’m looking
into starting my own weblog and was wondering what all is needed to get
setup? I’m assuming having a blog like yours
would cost a pretty penny? I’m not very web savvy so I’m not 100% positive.
Any recommendations or advice would be greatly appreciated.
Thanks
русский секс
Hello mates, its enormous piece of writing on the
topic of cultureand entirely defined, keep it up all the
time.
Hey there just wanted to give you a quick heads
up. The text in your article seem to be running off the screen in Safari.
I’m not sure if this is a formatting issue or something to do with internet browser compatibility but I figured I’d post to let you know.
The design look great though! Hope you get the issue
fixed soon. Cheers
It’s going to be finish of mine day, except before finish
I am reading this great post to increase my know-how.
At this time it seems like WordPress is the
top blogging platform out there right now.
(from what I’ve read) Is that what you’re using on your blog?
Thanks very interesting blog!
Highly descriptive post, I liked that bit. Will there be a part
2?
Wonderful blog you have here but I was wanting to know
if you knew of any forums that cover the same topics talked about in this article?
I’d really love to be a part of online community where I can get feedback from other experienced
people that share the same interest. If you have any recommendations, please let me know.
Thanks a lot!
Hi to all, how is everything, I think every one is getting more from
this web site, and your views are good in favor of new visitors.
Do you have a spam problem on this site; I also am a blogger, and I was curious about
your situation; many of us have created some nice practices and we are looking to exchange methods with other folks,
please shoot me an email if interested.
Excellent blog you have here.. It’s difficult to find good quality writing like yours nowadays.
I really appreciate people like you! Take care!!
I could not resist commenting. Well written!
Hello, everything is going sound here and ofcourse every one is sharing facts, that’s truly good, keep up
writing.
Also visit my blog … A片
Hi there, i read your blog from time to time and i own a similar one and i was just wondering if you get a lot of spam responses?
If so how do you prevent it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any help is very much appreciated.
I got this website from my friend who told me about this website and now this time I am visiting this web page and reading very informative articles
at this time.
Wow, wonderful weblog layout! How long have you been blogging for?
you make running a blog look easy. The entire glance of your web site is excellent, as well
as the content!
Here is my webpage rybelsus foods to avoid
When I initially left a comment I seem to have clicked the -Notify me
when new comments are added- checkbox and now every time a comment is added I get 4
emails with the exact same comment. Perhaps there is an easy method you can remove
me from that service? Appreciate it!
Кто-нибудь знает, каким образом
контактировать с админом?
Строчу в обратную связь, он не дает ответ.
An outstanding share! I have just forwarded this onto a co-worker who was
conducting a little homework on this. And he actually bought me lunch because I discovered
it for him… lol. So allow me to reword this….
Thanks for the meal!! But yeah, thanx for spending some time to
discuss this matter here on your site.
Hey! Do you know if they make any plugins to assist with Search Engine Optimization? I’m trying to get
my blog to rank for some targeted keywords but I’m not seeing very good success.
If you know of any please share. Thank you!
This is my first time pay a quick visit at here
and i am in fact pleassant to read everthing at alone place.
You’re so cool! I do not believe I’ve truly read something like this before.
So wonderful to discover somebody with original thoughts on this issue.
Seriously.. thanks for starting this up. This website
is something that is needed on the internet, someone with
some originality!
My relatives always say that I am wasting my time here at net, except I know I am getting know-how every day by reading such fastidious posts.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However, how
could we communicate?
I’ve read several excellent stuff here. Definitely
worth bookmarking for revisiting. I wonder how much attempt you place to create one of these fantastic informative website.
Yes! Finally someone writes about https://www.youthkiawaaz.com/2023/04/the-art-of-swiss-watchmaking-to-cambodia-details?success=1.
I like reading a post that can make people think.
Also, thanks for allowing for me to comment!
Everything is very open with a very clear description of
the challenges. It was truly informative. Your website is very
useful. Thank you for sharing!
What’s Going down i’m new to this, I stumbled upon this
I’ve found It positively useful and it has aided me out loads.
I am hoping to contribute & help other users like its helped
me. Good job.
Very soon this website will be famous amid all blogging viewers, due to it’s nice articles or reviews
What’s up, just wanted to say, I liked this blog post. It was helpful.
Keep on posting!
This piece of writing is in fact a pleasant one it helps new web
viewers, who are wishing in favor of blogging.
If yoou are gking for finest contents like myself, simply
pay a quick visit this web page daily because it provides feature contents, thanks
Also visit my web site – http://thewhiteroadandotherstories.com/
Thankfulness to my father who shared with me about this web site, this web site is
truly remarkable.
Good day! This post could not be written any better!
Reading this post reminds me of my previous room mate!
He always kept chatting about this. I will forward this write-up to
him. Fairly certain he will have a good read. Thanks for sharing!
The other day, while I was at work, my cousin stole my iphone and tested to see
if it can survive a twenty five foot drop,
just so she can be a youtube sensation. My iPad
is now broken and she has 83 views. I know this is completely off topic but I had to share it with someone!
Hi there! This article couldn’t be written any better!
Looking at this post reminds me of my previous roommate!
He continually kept talking about this. I most certainly will send this information to him.
Fairly certain he will have a great read. Many thanks
for sharing!
Excellent post. I used to be checking continuously this blog and I am impressed! I deal with such information a lot.
I deal with such information a lot.
Extremely helpful info particularly the last phase
I used to be looking for this particular info for a long time.
Thanks and good luck.
What’s up to every one, for the reason that I am in fact keen of reading this website’s post to be updated regularly.
It carries fastidious data.
Nice response in return of this difficulty with genuine arguments and describing the whole thing concerning that.
Nice weblog here! Additionally your web site a lot up
very fast! What host are you using? Can I am getting your affiliate hyperlink to your
host? I wish my website loaded up as quickly as yours lol
Excellent site. Lots of useful information here. I am sending it to some pals ans additionally sharing in delicious.
And certainly, thank you to your effort!
I’m really impressed with your writing skills as well as with the
layout on your blog. Is this a paid theme or did you customize it
yourself? Either way keep up the nice quality writing, it is rare to see a nice blog like this
one these days.
Every weekend i used to go to see this web site, as i wish for enjoyment, as
this this site conations genuinely fastidious funny data too.
That is a great tip especially to those new to the blogosphere.
Short but very accurate info… Appreciate your sharing this one.
A must read article!
It’s enormous that you are getting thoughts
from this article as well as from our dialogue made at this time.
Quality articles is the important to interest the people to visit the web page, that’s
what this site is providing.
You should be a part of a contest for one of the most useful sites on the web.
I will recommend this blog!
Fabulous, what a website it is! This webpage gives valuable information to
us, keep it up.
Here is my web blog Kingz CBD
Hey! I realize this is sort of off-topic however I needed to ask.
Does operating a well-established blog such as yours require a large amount of work?
I am brand new to writing a blog however I do write in my journal
everyday. I’d like to start a blog so I will be able to share my own experience
and views online. Please let me know if you have any ideas or tips for new aspiring
blog owners. Thankyou!
I read this post completely concerning the comparison of newest and preceding technologies, it’s remarkable article.
Hmm is anyone else experiencing problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
I haqve been exploring foor a little for any high-quality articles oor blog posts in this
sort of space . Exploring in Yahoo I ultimately stumbled
upon this web site. Reading this information So i amm satisfied to exhibit that I’ve a very
just right uncanny feeling I came upon exactly what I needed.
I most indubitably will make certain to do nnot
put out of your mind this website and provides itt a glance
regularly.
website
Howdy! Would you mind if I share your blog with my zynga group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thank you
Orient Uniforms LLC – Al Sawan – Sheikh Khalifa Bin Zayed St – Ajman, UAE, Phone:
+971505992087
Website: https://www.uniformfactory.ae
Highly descriptive article, I loved that a lot. Will there be
a part 2?
Hey there! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward
to all your posts! Carry on the outstanding work!
Wow, this piece of writing is pleasant, my younger sister is analyzing these kinds of things, so
I am going to convey her.
Highly energetic article, I enjoyed that bit. Will there be a
part 2?
I am regular reader, how are you everybody?
This post posted at this website is in fact fastidious.
Hello There. I found your weblog the usage of msn. That is an extremely neatly written article.
I’ll be sure to bookmark it and return to learn more of your helpful information. Thanks for
the post. I will definitely comeback.
Wonderful beat ! I would like to apprentice while you amend your website, how could i subscribe for a blog site?
The account aided me a acceptable deal. I had been a little bit acquainted
of this your broadcast provided bright clear concept
Hi, I do believe this is a great site. I stumbledupon it 😉 I
am going to revisit yet again since I book-marked it. Money and
freedom is the greatest way to change, may you be rich and continue to guide other people.
Today, while I was at work, my cousin stole my iphone and
tested to see if it can survive a forty foot drop, just so she can be a youtube sensation. My iPad is now destroyed and she has 83 views.
I know this is totally off topic but I had to share it with someone!
I really like it when people get together and share thoughts.
Great blog, keep it up!
Do you have a spam problem on this website; I also am a blogger, and I was curious about your situation; many of us have created some nice procedures and we are looking to swap
methods with other folks, please shoot me an e-mail if interested.
เว็บของเรามีหมด เพราะทีมงานของเราได้คัดสรรแต่สิ่งดีๆมาเพื่อลูกค้าทุกท่านโดยเฉพาะ
หากคุณมองหา เว็บหวย ที่ราคาดี เชื่อถือได้ เราแนะนำ
huaynaga เว็บหวยออนไลน์ ที่จ่ายหนักที่สุด
Outstanding post but I was wanting to know if you could write a litte more
on this subject? I’d be very thankful if you could elaborate
a little bit further. Many thanks!
Howdy! I’m at work browsing your blog from my new iphone
4! Just wanted to say I love reading your blog and look forward to
all your posts! Carry on the great work!
Have a look at my webpage – sell my House fast Cash
When someone writes an post he/she maintains the thought of a user in his/her brain that how a user can understand it.
So that’s why this post is outstdanding. Thanks!
Greetings! This is my first visit to your blog! We are a team of volunteers and starting a
new project in a community in the same niche. Your
blog provided us valuable information to work on. You have done a wonderful job!
Wow, wonderful blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website
is wonderful, as well as the content!
I read this article fully concerning the resemblance of most
recent and previous technologies, it’s amazing article.
I just could not depart your site before suggesting that I actually
enjoyed the usual info a person provide for your guests?
Is gonna be again continuously in order to check out new posts
Hello! This is kind of off topic but I need some advice from an established blog.
Is it very hard to set up your own blog? I’m not very techincal but I
can figure things out pretty fast. I’m thinking about making
my own but I’m not sure where to begin. Do you
have any points or suggestions? Cheers
my blog post – we buy Houses For Cash review
This is my first time pay a visit at here and i am in fact happy to read all at alone place.
each time i used to read smaller posts which also clear their
motive, and that is also happening with this piece of writing which I am
reading at this place.
Greetings! I’ve been following your site for a while now and
finally got the bravery to go ahead and give you a shout out from
Huffman Tx! Just wanted to mention keep up the great
job!
I quite like reading through an article that can make people
think. Also, thank you for allowing for me to comment!
Greetings! This is my 1st comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading your blog posts.
Can you recommend any other blogs/websites/forums that deal with the same subjects?
Many thanks!
Hey there just wanted to give you a quick heads up.
The words in your post seem to be running off the
screen in Safari. I’m not sure if this is a formatting issue or something to do with internet browser compatibility but
I figured I’d post to let you know. The design look great though!
Hope you get the problem solved soon. Many
thanks
It is truly a nice and helpful piece of info. I am satisfied that you shared this
useful information with us. Please keep us informed like this.
Thanks for sharing.
Magnificent beat ! I wish to apprentice whilst you amend your site, how can i subscribe for a
weblog site? The account helped me a appropriate deal. I were tiny bit acquainted of this your broadcast provided bright transparent
idea
My blog – indospa
Does your site have a contact page? I’m having trouble locating it but, I’d like to shoot you an email.
I’ve got some ideas for your blog you might be interested
in hearing. Either way, great website and I look forward to seeing it improve over time.
Hello, all the time i used to check webpage posts here early in the dawn, as i love to gain knowledge
of more and more.
Do you mind if I quote a couple of your posts as long as I provide credit
and sources back to your site? My blog is in the exact same area of interest as yours and my visitors would truly benefit from some of the
information you provide here. Please let me know if this okay
with you. Appreciate it!
My spouse and I stumbled over here coming from a
different web page and thought I should check things out.
I like what I see so i am just following you. Look forward to
checking out your web page again.
Hi there, yup this paragraph is in fact fastidious and I have learned lot of things from it regarding blogging.
thanks.
Hi, after reading this awesome piece of writing i
am too happy to share my familiarity here with friends.
Hello would you mind letting me know which web
host you’re working with? I’ve loaded your blog in 3 completely different browsers and I must
say this blog loads a lot quicker then most. Can you suggest a good web hosting
provider at a reasonable price? Cheers, I appreciate it!
Ahaa, its nice conversation concerning this article at this place at this blog, I
have read all that, so at this time me also commenting
at this place.
%%
BetRivers iis accessible iin several states, and it has a
reputation as a friendly aapp for casual bettors.
Also visit my homepage; check here
Excellent weblog right here! Also your site rather a lot up fast!
What host are you the usage of? Can I get your affiliate hyperlink to your
host? I desire my website loaded up as quickly
as yours lol
Great article! We are linking to this particularly great article on our site.
Keep up the great writing.
I’m extremely impressed with your writing skills and also with the
layout on your weblog. Is this a paid theme or
did you customize it yourself? Either way keep up the excellent quality
writing, it’s rare to see a nice blog like this one nowadays.
Hey just wanted to give you a quick heads up and let you know a few
of the images aren’t loading properly. I’m not sure why but I think
its a linking issue. I’ve tried it in two different browsers and both show the same results.
Excellent post. I was checking constantly this blog and I’m impressed! I care for such information much.
I care for such information much.
Very useful info particularly the last part
I was looking for this particular information for a very long time.
Thank you and best of luck.
It’s very easy to find out any topic on web as compared to textbooks, as
I found this paragraph at this website.
I’m now not sure where you are getting your information, but
good topic. I needs to spend some time learning more or understanding more.
Thank you for magnificent info I was looking for this info for my mission.
It is perfect time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I wish to suggest you some interesting things or suggestions.
Maybe you could write next articles referring to this article.
I want to read even more things about it!
Review my homepage tl auto
Amazing! Its actually remarkable post, I have got much clear idea concerning from this article.
Great article.
Keep this going please, great job!
This post is priceless. Where can I find out more?
I do not even understand how I finished up here, however I believed this post
used to be good. I do not realize who you are but certainly you are
going to a well-known blogger in case you aren’t already.
Cheers!
Hello! I know this is kinda off topic but I was wondering if
you knew where I could locate a captcha plugin for my comment
form? I’m using the same blog platform as yours and I’m
having problems finding one? Thanks a lot!
Hello! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
https://shargh-khabar.ir/خرید-و-قیمت-پکیج-افزایش-فالور-و-لایک-این/
Nice response in return of this difficulty with genuine arguments and describing the
whole thing about that.
Top 10 Celebrity Fashion Icons. First, click Finish, the big green button in the top right-hand corner.
Top brands, low prices & free shipping on many items.
View Gumtree Free Online Classified Ads for login and more in South Africa.
You wouldn’t find their goods at the mall
or see them advertised on TV, but if you were a young woman between the ages of 12 and 22 on social media, their targeted ads were inescapable.
Find login my account in South Africa! Find login in South Africa!
One South Slavic example is recorded in a manual published in 1714
by the Venetian dancing master Gregorio Lambranzi. Being from the same part of
South Asia, Punjab (a region that was carved into modern Pakistan and India during the Partition of 1947), a place well known for its
dance and music, they were both interested in performing together.
Chelsea boots are a fundamental part of any guy’s wardrobe and
the best has to be R.M. As a courtesy to the rest of the contributors,
users with such usernames are encouraged to sign their posts (at least in part) with Latin characters.
Depending on what’s most important for your personal email signature templates, free resources like this can at
least jumpstart your creative juices!
We are a gaggle of volunteers and opening a new scheme in our community.
Your site offered us with valuable information to work on. You’ve done an impressive task and our whole group will probably
be grateful to you.
What’s up to all, how is everything, I think every one is getting more from
this site, and your views are nice for new
visitors.
We’re a gaggle of volunteers and opening a brand new scheme
in our community. Your web site provided us with helpful info to work on.
You’ve performed an impressive job and our entire group might be grateful to you.
Keep on writing, great job!
I have read so many articles about the blogger lovers
except this post is really a good post, keep it up.
Fabulous, what a website it is! This blog gives helpful facts
to us, keep it up.
If some one needs expert view on the topic of running
a blog afterward i recommend him/her to pay a quick visit this webpage,
Keep up the fastidious work.
Hi everybody, here every one is sharing such knowledge, thus it’s fastidious to read this weblog, and I
used to pay a quick visit this blog daily.
Hey! This is kind of off topic but I need some guidance from an established blog.
Is it very difficult to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not sure where to start.
Do you have any ideas or suggestions? Cheers
Take a look at my web site; companies that Buy houses for cash
May I simply say what a relief to find someone that really
understands what they’re talking about on the web. You certainly realize how to bring an issue to
light and make it important. More people have to look at this and understand this side of the
story. I can’t believe you’re not more popular because
you surely have the gift.
Wow, that’s what I was searching for, what a information! present here at this webpage, thanks admin of this web
page.
Everyone loves it when people get together and share opinions.
Great site, stick with it!
My web-site rybelsus cost
you are actually a good webmaster. The site loading pace is
incredible. It seems that you are doing any distinctive trick.
Furthermore, The contents are masterpiece. you’ve done a wonderful task in this subject!
Hello, i think that i noticed you visited my weblog
so i got here to go back the favor?.I am attempting to in finding
things to improve my website!I guess its ok to make use of a few of your ideas!!
Wow, this post is fastidious, my sister is analyzing such
things, therefore I am going to tell her.
An outstanding share! I have just forwarded this onto a coworker who was doing a little research on this.
And he actually ordered me dinner due to the fact that I found it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanks for spending time to talk about this issue here on your web page.
I was recommended this blog by way of my cousin. I am no longer certain whether this put up is written by
him as nobody else know such detailed about my difficulty.
You’re amazing! Thanks!
Hi there mates, pleasant piece of writing and good urging commented at this place, I am truly enjoying by these.
Hello this is kind of of off topic but I was wanting to
know if blogs use WYSIWYG editors or if you have
to manually code with HTML. I’m starting a blog soon but have no coding
know-how so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
Thank you for every other informative web site. The place else may I get that kind of information written in such an ideal means?
I have a undertaking that I am just now running on,
and I have been at the look out for such information.
Oh my goodness! Incredible article dude! Thanks, However I am experiencing difficulties with your RSS.
I don’t understand the reason why I am unable to subscribe to it.
Is there anybody else having identical RSS problems?
Anybody who knows the answer will you kindly respond? Thanks!!
Thanks for your personal marvelous posting!
I quite enjoyed reading it, you’re a great author.
I will make certain to bookmark your blog and will come back very soon. I want to
encourage that you continue your great writing, have a nice holiday weekend!
Thanks for sharing such a nice thought, piece of writing is pleasant, thats why i have read it completely
Hi! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
When I originally commented I seem to have clicked on the -Notify
me when new comments are added- checkbox and now every time a comment is added I receive
four emails with the same comment. There has to be an easy method
you are able to remove me from that service?
Kudos!
You have made some really good points there. I checked on the internet for more info
about the issue and found most individuals will go along with your views
on this website.
Terrific post however , I was wondering if you
could write a litte more on this subject? I’d be very grateful if you could elaborate
a little bit further. Many thanks!
Fantastic post however I was wondering if you could
write a litte more on this topic? I’d be very grateful if you
could elaborate a little bit further. Cheers!
You actually make it seem so easy with your presentation however I to find
this matter to be really one thing which I
believe I would never understand. It sort of feels too complicated and extremely huge for me.
I am taking a look ahead in your next post, I will attempt to get the hang of it!
Asking questions are truly fastidious thing if you are not understanding anything totally, except this post provides nice understanding yet.
Appreciate the recommendation. Will try it out.
I am truly pleased to read this weblog posts which contains lots of valuable information,
thanks for providing these information.
Thanks for another great article. The place else may anyone get that type of info in such a perfect means of writing?
I have a presentation next week, and I’m at the search for such information.
Outstanding story there. What happened after? Take care!
Hello! Someone in my Myspace group shared this website with us so I came to take a look.
I’m definitely enjoying the information. I’m bookmarking
and will be tweeting this to my followers! Superb blog and amazing design.
My partner and I stumbled over here coming from a different page and thought I should check things
out. I like what I see so now i’m following you.
Look forward to looking at your web page again.
I am now not positive where you are getting your information,
but great topic. I must spend a while learning much more or
understanding more. Thank you for fantastic information I
was looking for this info for my mission.
Useful information. Fortunate me I found your site accidentally,
and I am shocked why this accident didn’t happened earlier!
I bookmarked it.
Hey! Would you mind if I share your blog with my myspace group?
There’s a lot of folks that I think would really
appreciate your content. Please let me know. Many thanks
Unquestionably believe that which you stated.
Your favorite reason seemed to be on the web the easiest thing
to be aware of. I say to you, I certainly get annoyed
while people think about worries that they just do not know about.
You managed to hit the nail upon the top and defined out the whole thing without having side effect ,
people could take a signal. Will probably be back to
get more. Thanks
I have been browsing online more than 2 hours today,
yet I never found any interesting article like yours.
It’s pretty worth enough for me. In my view, if all website
owners and bloggers made good content as you did, the internet will be
a lot more useful than ever before.
Also visit my webpage :: Cash Offer Please
May I simply just say what a comfort to uncover a person that really knows what
they are discussing on the web. You actually understand how to bring a problem to light and make it important.
A lot more people have to check this out and
understand this side of your story. I can’t believe you are not
more popular given that you surely possess the gift.
I like it when people come together and share thoughts. Great website, stick
with it!
Here is my web blog; incruse ellipta
These are truly enormous ideas in regarding blogging.
You have touched some good factors here. Any way keep up wrinting.
I am really impressed together with your writing skills as
well as with the layout for your blog. Is this a paid subject or did
you customize it your self? Either way keep up the excellent
quality writing, it’s rare to see a nice blog like this
one nowadays..
With havin so much written content do you ever run into any issues of plagorism or copyright infringement?
My blog has a lot of unique content I’ve either
authored myself or outsourced but it appears a lot of it is popping it up all over the web without my permission. Do you know any ways
to help prevent content from being stolen? I’d truly
appreciate it.
بایسکشوال چیست + ارزیابی و تست
بایسکشوال یا دوجنسگرایی
بایسکشوال هایی که در زندان به سر می برند از شایع ترین
افراد این نوع دوجنسگرایی می باشند.
به طور کلی میتوان گفت که اگر به برقراری ارتباط
عاطفی و جنسی با همنوع خود به اندازه جنس مخالف لذت میبرید،
به احتمال زیاد گرایش دوجنس گرایی را در خود دارید.
یک راه دیگر برای شناسایی این گرایش، میزان جستجو و تحقیق شما در اینترنت
است.
بهطور مشابه، در روم باستان، جنسیت تعیین نمیکرد که آیا شریک جنسی قابل قبول است، تا زمانی که لذت مرد
به تمامیت مرد دیگر تجاوز نکند.
برای یک مرد رومی آزاد زاده از نظر اجتماعی پذیرفتنی بود که بخواهد هم با شریک زن
و هم با شریک مرد رابطه جنسی
داشته باشد، تا زمانی که نقش نفوذی را بر عهده بگیرد.
اخلاقی بودن این رفتار به موقعیت اجتماعی شریک زندگی بستگی دارد، نه جنسیت
فی نفسه. هم زنان و هم مردان جوان به عنوان آرزوهای عادی در نظر
گرفته میشدند، اما در خارج از ازدواج، مرد قرار بود تنها با بردهها،
فاحشهها (که اغلب برده بودند) و بدنامیها به خواستههای خود عمل کند.
یکی از نشانه های بایسکشوال ها
که در زنان مشاهده می شود، این است
که بیشتر از رابطه واژینال به
رابطه مقعدی علاقه دارند.
بسیاری از افرادی که بایسکشوال هستند، به دلیل ترس از قضاوت شدن
و تناقضات درونی خود هرگز آن را بروز نمی دهند.
اما برخی از خود نشانه هایی را نیز بروز می دهند که قابل تشخیص است.
البته به طور کلی بهتر است برای پاسخ به این سوال به یک
متخصص و روانشناس مراجعه نمایید.
با این حال ، بیشتر افراد از اوایل بلوغ و حتی زودتر از آن در مورد
گرایش جنسی خود مطلع می شوند.
تنها مثل مونائی، اگر بایسکشوال شناخته میشدید اما پس از آن بیشتر
درباره پنسکشوالیتی آموختید و فکر کردید برایتان
مناسبتر است یا برعکس، اجازه دارید لیبل خود را تغییر دهید.
ممکن این گرایشات تنها یک فاز
دورهای نباشند (یک بدفهمی دیگر) اما بخشی از کاوشهای جنسیتی شما باشند.
حال جالب اینجاست که به هیچعنوان دوست ندارید، شریک
فعلی خود را از دست بدهید؛ زیرا شما یک دوجنسگرا هستید و هرگز به همجنسگرایی علاقه ندارید.
بنابراین در بسیاری مواقع این افراد ارگاسم خوبی را تجربه نمی کنند.
احتمالا همانگونه که گفتید شرایط منجر به همجنسخواهی شما شده است.
مانند افرادی که در سربازی هستند و
بدلیل عدم ارتباط به جنس موافق روی می آورند.
Hello would you mind letting me know which web
host you’re working with? I’ve loaded your blog in 3 different web browsers and I must say this blog
loads a lot faster then most. Can you suggest a good internet hosting provider at a honest price?
Kudos, I appreciate it!
Hi there! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing
several weeks of hard work due to no back up. Do you have any solutions to protect against hackers?
Kuinka kasinoiden kasino on 15 minuutissa ja näyttää silti parhaalta
site
Löydä hyvämaineinen sivusto pyrkiessään hyötymään pelikokemuksesta.
Slotomania – Vegas Slots Casino esittelee useita kymmeniä
erottuvia peliautomaatteja,ja nne kaikki eroavat yhtenäisten palkinnon määrien suhteen. Joten kaikki yhdessä online -pokeri on hyödyllinen ja hienoin strategia panostamaan urheilutoimintaan.
This is my first time pay a visit at here and
i am actually happy to read everthing at alone place.
I constantly emailed this webpage post page to all my
friends, since if like to read it after that my contacts
will too.
Hello, I believe your site could possibly be having web browser compatibility issues.
When I take a look at your blog in Safari, it looks fine but when opening in I.E., it has some
overlapping issues. I merely wanted to provide you with a
quick heads up! Apart from that, excellent site!
This website was… how do I say it? Relevant!!
Finally I’ve found something that helped me.
Thanks a lot!
Great blog here! Also your site loads up very fast! What web host are you using?
Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours
lol
Superb blog! Do you have any recommendations for aspiring writers?
I’m hoping to start my own site soon but I’m a
little lost on everything. Would you advise starting with a free
platform like WordPress or go for a paid option? There are so many options out there that I’m
totally overwhelmed .. Any suggestions? Bless you!
Thanks on your marvelous posting! I genuinely enjoyed reading it,
you may be a great author.I will make certain to bookmark your blog and
may come back later in life. I want to encourage yourself to continue your great work,
have a nice weekend!
I’ve read a few just right stuff here. Definitely value bookmarking for revisiting.
I surprise how a lot attempt you set to make any such magnificent informative site.
Hi there i am kavin, its my first occasion to commenting anyplace,
when i read this article i thought i could also make comment due to this
brilliant piece of writing.
Great goods from you, man. I have take into accout your stuff prior to and you’re simply too excellent.
I really like what you have received right here, certainly like what you are stating and the
way in which in which you say it. You’re making it entertaining and you continue to care for to stay it smart.
I can not wait to learn far more from you. That is
really a tremendous website.
หากคุณมองหา เว็บหวย ที่ราคาดี เชื่อถือได้ เราแนะนำ
หวยนาคา เว็บหวยออนไลน์ ที่จ่ายหนักที่สุด
3ตัวบาทละ 960
2ตัวบาทละ 97
http://sister.stialanbandung.ac.id/slot-gacor/
Awesome! Its actually amazing post, I have got much
clear idea on the topic of from this post.
I am regular visitor, how are you everybody? This article posted at this web page is really pleasant.
Hi, i think that i saw you visited my web site so i came to “return the favor”.I’m attempting to find things to enhance my site!I suppose its ok to use a few of your ideas!!
My spouse and I stumbled over here coming from a different website and thought I might as well check things out.
I like what I see so now i am following you. Look forward
to looking over your web page again.
I really love your site.. Great colors & theme. Did you make this web site yourself?
Please reply back as I’m wanting to create my own site and would like
to know where you got this from or just what the theme is named.
Cheers!
If you wish for to increase your experience just keep visiting this web page and be updated with the hottest news posted here.
An interesting discussion is worth comment. I believe that you should write more about this subject
matter, it might not be a taboo matter but typically people don’t discuss these issues.
To the next! Many thanks!!
Heya i am for the first time here. I came across this board and I find It
truly useful & it helped me out much. I hope to give something back and
help others like you aided me.
I would like to thank you for the efforts you have put in writing
this blog. I really hope to view the same high-grade content from you in the future as well.
In truth, your creative writing abilities has inspired me to get my very own site now 😉
Thanks in support of sharing such a fastidious thought,
paragraph is fastidious, thats why i have read it entirely
It’s actually a nice and helpful piece of info. I am happy that you just shared this helpful info with us.
Please stay us informed like this. Thanks for sharing.
At this time it looks like BlogEngine is the preferred blogging platform available right
now. (from what I’ve read) Is that what you’re using on your blog?
I’ve been surfing online more than 2 hours
today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if all web owners and bloggers made good content as you did, the
web will be a lot more useful than ever before.
Thanks , I’ve just been searching for inffo approximately this topic forr a
while and yohrs is the greatest I have came upon till now.
But, what about the bottom line? Are you sure about the source?
homepage
Appreciate this post. Let me try it out.
https://nyc3.digitaloceanspaces.com/winstrolforsale-digitalocean/winstrol-for-sale.html
Make $10,000 per month! Become millionaire!
hey there and thank you for your information – I have certainly picked up anything new from
right here. I did however expertise a few technical issues using this web site, as I
experienced to reload the site many times previous to I could get it to
load correctly. I had been wondering if your hosting is OK?
Not that I am complaining, but slow loading instances times will often affect
your placement in google and can damage your high
quality score if advertising and marketing with Adwords.
Well I’m adding this RSS to my e-mail and could look out
for a lot more of your respective exciting content. Make sure you update
this again very soon.
I’ve read some just right stuff here. Definitely value bookmarking for revisiting.
I surprise how a lot effort you place to create one
of these magnificent informative website.
buy viagra online
Hello, i think that i saw you visited my website so
i came to “return the favor”.I’m trying to find things to enhance my
web site!I suppose its ok to use a few of your ideas!!
Awesome things here. I am very happy to peer your post.
Thanks a lot and I am having a look ahead to touch you.
Will you kindly drop me a e-mail?
Right away I am going to do my breakfast, later than having my breakfast coming again to read more news.
Howdy! I know this is kind of off topic but I was wondering
which blog platform are you using for this website? I’m getting tired of WordPress because
I’ve had issues with hackers and I’m looking at alternatives for another platform.
I would be fantastic if you could point me in the direction of a
good platform.
This excellent website really has all of the info I needed about this subject and didn’t know who to ask.
Why users still use to read news papers when in this technological world all is presented on web?
When some one searches for his necessary thing, thus he/she
desires to be available that in detail, so that thing is maintained over here.
Can I simply just say what a relief to discover someone that genuinely knows
what they’re talking about on the internet. You certainly understand how to bring
an issue to light and make it important. More people really need to check this out and understand
this side of the story. It’s surprising you aren’t more popular given that you
certainly have the gift.
I love what you guys are up too. This sort of clever work and exposure!
Keep up the very good works guys I’ve added you guys to my personal blogroll.
Wonderful beat ! I wish to apprentice even as you amend your website, how can i subscribe for a blog web site?
The account aided me a acceptable deal. I had been tiny bit acquainted
of this your broadcast offered vibrant transparent concept
Hey very nice blog!
Excellent post! We will be linking to this particularly great post on our website.
Keep up the great writing.
We’re a bunch of volunteers and opening a new scheme in our community.
Your web site provided us with useful information to
work on. You’ve done an impressive process and our entire neighborhood shall be grateful to you.
I visit everyday a few sites and websites to read posts, except this webpage
gives quality based content.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By
the way, how could we communicate?
I am sure this post has touched all the internet viewers, its really really good article on building up new
weblog.
Hmm it seems like your site ate my first comment (it was super long) so
I guess I’ll just sum it up what I wrote and say,
I’m thoroughly enjoying your blog. I too am an aspiring blog writer but I’m still new to the whole thing.
Do you have any tips for beginner blog writers?
I’d really appreciate it.
Aw, this was an exceptionally nice post. Taking a
few minutes and actual effort to generate a superb article… but what can I say… I procrastinate a whole lot
and never manage to get nearly anything done.
At this time it looks like Expression Engine is the
preferred blogging platform available right now. (from what I’ve read) Is that what you’re using on your
blog?
This is very interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of
your magnificent post. Also, I have shared your web site in my social networks!
I think the admin of this site is in fact working hard
in favor of his website, since here every material is quality based material.
Thanks for your marvelous posting! I certainly enjoyed reading it, you
are a great author.I will ensure that I bookmark your blog and will come back later on. I want to
encourage you to definitely continue your great work, have a nice
holiday weekend!
Every weekend i used to visit this website, for the
reason that i want enjoyment, since this
this web site conations truly nice funny material too.
Ahaa, its nice discussion concerning this article here at this blog,
I have read all that, so at this time me also commenting at this place.
Superb blog! Do you have any suggestions for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go
for a paid option? There are so many choices out there
that I’m completely confused .. Any recommendations?
Thanks a lot!
Very nice post. I just stumbled upon your weblog and wished to
say that I’ve truly enjoyed surfing around your blog posts.
After all I will be subscribing to your rss feed and I hope you write again soon!
Heya i am for the first time here. I found this board and I find It truly useful & it helped me out
much. I hope to give something back and help others like you aided me.
Wow, incredible blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is wonderful, let alone the content!
This creates a additional natural feel and performs to relieve aching
muscles.
Look at my web blog; read more
Hello! This is my first visit to your blog! We are a collection of
volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You have done a extraordinary job!
Feel free to visit my web-site – Buy HCG Injections
I do accept as true with all the ideas you have introduced on your post.
They’re really convincing and can certainly work.
Still, the posts are very short for novices.
May you please lengthen them a bit from subsequent time? Thanks for the post.
I have learn several just right stuff here.
Certainly worth bookmarking for revisiting. I wonder how
so much attempt you place to create the sort
of great informative site.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the way, how
can we communicate?
This post presents clear idea in support of the new
viewers of blogging, that truly how to do blogging
and site-building.
Here is my blog post: A片
Ahaa, its good discussion regarding this
post here at this blog, I have read all that, so at this time me also commenting at this
place.
I was recommended this blog through my cousin. I’m now not certain whether or
not this put up is written by him as nobody else understand such targeted
about my difficulty. You’re wonderful! Thanks!
Hurrah, that’s what I was seeking for, what a stuff! existing here at this web site, thanks admin of
this web page.
I like what you guys tend to be up too. This kind of clever work and coverage!
Keep up the great works guys I’ve you guys to blogroll.
Hi there colleagues, fastidious paragraph and nice urging commented here, I am in fact enjoying by these.
I know this if off topic but I’m looking into starting my own weblog
and was wondering what all is required to get set up? I’m assuming
having a blog like yours would cost a pretty penny?
I’m not very internet savvy so I’m not 100% certain. Any tips
or advice would be greatly appreciated. Thanks
If some one wishes expert view concerning running a blog afterward i propose him/her to pay a visit this webpage, Keep
up the good job.
Hi there to all, how is all, I think every one is getting more from
this site, and your views are fastidious for new
people.
Just want to say your article is as astounding. The clarity in your post is just spectacular and i can assume you are an expert on this subject.
Fine with your permission allow me to grab your feed to keep updated with forthcoming post.
Thanks a million and please continue the rewarding work.
It’s a shame you don’t have a donate button! I’d definitely donate to this outstanding blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed
to my Google account. I look forward to brand new updates and will share
this site with my Facebook group. Talk soon!
Thanks to my father who stated to me concerning this blog, this blog is actually awesome.
Hi, i read your blog from time to time and i own a similar one and i was just
wondering if you get a lot of spam responses?
If so how do you prevent it, any plugin or anything you can recommend?
I get so much lately it’s driving me crazy so any support is very
much appreciated.
Good post. I learn something new and challenging on websites I stumbleupon every day.
It’s always useful to read content from other authors
and practice something from other websites.
Great article. I am experiencing some of these issues as well..
It’s an amazing post in favor of all the web users;
they will get advantage from it I am sure.
Thanks very interesting blog!
This is a really good tip particularly to those fresh to the blogosphere.
Simple but very precise info… Appreciate your sharing this one.
A must read post!
Way cool! Some extremely valid points! I appreciate you writing this write-up and the rest of the website is really good.
We stumbled over here different web page and thought I
might check things out. I like what I see so i am just following you.
Look forward to exploring your web page again.
Howdy! This article couldn’t be written any better!
Reading through this post reminds me of my previous roommate!
He continually kept preaching about this. I most certainly will forward this information to him.
Pretty sure he will have a very good read.
I appreciate you for sharing!
Can I simply say what a relief to uncover somebody who really understands what they are discussing on the internet.
You definitely understand how to bring a problem to light and make it important.
More and more people have to read this and understand this
side of your story. I was surprised that you’re not more popular because you most certainly possess the gift.
bookmarked!!, I like your web site!
Its like you read my mind! You seem to know a lot about this, like you wrote the book
in it or something. I think that you could do with a
few pics to drive the message home a little bit, but other than that, this is fantastic blog.
A great read. I’ll certainly be back.
Howdy! This post could not be written any better! Reading through this post reminds me of my old room mate!
He always kept chatting about this. I will forward this
post to him. Fairly certain he will have a good read.
Thanks for sharing!
When someone writes an article he/she keeps the thought of a user in his/her brain that how a user can know
it. Thus that’s why this paragraph is outstdanding.
Thanks!
Hello There. I found your blog using msn. This is a really well written article.
I’ll be sure to bookmark it and come back to read more of your useful information. Thanks for
the post. I will definitely return.
When I initially left a comment I seem to have clicked on the
-Notify me when new comments are added- checkbox and
now every time a comment is added I receive four emails
with the same comment. There has to be a means you are able to remove
me from that service? Thanks!
With havin so much content do you ever run into any problems of plagorism or
copyright violation? My blog has a lot of unique content I’ve either authored myself or outsourced but it
appears a lot of it is popping it up all over the web without my authorization. Do you know any methods to help protect against content from
being stolen? I’d really appreciate it.
Wow, incredible blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is wonderful, let alone the
content!
I don’t even know how I ended up here, but I thought this post was
good. I don’t know who you are but definitely you are going to a
famous blogger if you aren’t already 😉 Cheers!
Right here is the right web site for anybody who hopes to understand this topic.
You understand a whole lot its almost tough to argue with you (not that I personally will
need to…HaHa). You definitely put a brand new spin on a subject which has been written about for a long time.
Excellent stuff, just great!
Link exchange is nothing else but it is only placing the
other person’s web site link on your page at proper place
and other person will also do same in favor of you.
Those numbers are also assigned colors – red and black.
my web blog: click here
Yesterday, while I was at work, my sister stole my apple ipad and tested to see if it can survive a 40 foot drop, just so she can be a youtube sensation. My apple ipad is
now broken and she has 83 views. I know this is completely off
topic but I had to share it with someone!
Excellent post. I was checking continuously this blog and I take care
I take care
I am impressed! Extremely helpful info particularly the final section
of such information much. I used to be seeking this particular info for
a very lengthy time. Thank you and best of luck.
Hi there! This blog post could not be written much better!
Looking through this article reminds me of my previous roommate!
He always kept preaching about this. I most certainly
will send this article to him. Pretty sure
he’ll have a great read. Thank you for sharing!
My developer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on several websites for about a
year and am worried about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can import all my wordpress posts into
it? Any kind of help would be really appreciated!
Excellent items from you, man. I’ve remember your stuff prior to and you’re just
too great. I really like what you have received here, really like what you’re saying and the way in which in which you
are saying it. You are making it enjoyable and you continue to take care of to keep it smart.
I cant wait to learn much more from you. This is really a tremendous site.
I just like the helpful info you provide in your articles.
I will bookmark your weblog and test once more right here frequently.
I am somewhat certain I will be informed plenty of new stuff proper right here!
Best of luck for the next!
This post will assist the internet users for creating new website or even a weblog from start to end.
Very quickly this web site will be famous among all
blog viewers, due to it’s nice content
It’s going to be ending of mine day, however before end I am reading this wonderful article to increase my know-how.
You actually make it seem so easy with your presentation but I find this topic to be actually something which I think I would never understand.
It seems too complicated and extremely broad for me.
I’m looking forward for your next post, I will try to get the hang of it!
Hello, just wanted tto tell you, I loved this article.
It was funny. Keep on posting!
For the reason that the admin of this web page is working, no hesitation very shortly it will be
well-known, due to its quality contents.
여성흥분제
여성흥분제
If some one wishes expert view about blogging after that i recommend him/her to pay a quick
visit this blog, Keep up the pleasant work.
Hi there! Someone in my Myspace group shared this site with us so I
came to look it over. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this
to my followers! Excellent blog and brilliant style and design.
Hi, I do think this is an excellent website. I stumbledupon it 😉 I
will come back yet again since I book marked it. Money and freedom is the best way to change, may you be rich and continue to guide other people.
It’s remarkable to pay a quick visit this web page and reading the views of all friends concerning this
piece of writing, while I am also eager of getting experience.
In 1984, most Visa playing cards around the world started to characteristic a hologram
of a dove on its face, generally underneath the final 4 digits of the
Visa number. At the same time, the Visa brand, which had beforehand
covered the whole card face, was reduced
in dimension to a strip on the card’s right incorporating the hologram.
Prior success does not guarantee same outcome. All three
use the same image as proven on the appropriate. The Visa Checkout service permits customers
to enter all their private details and card info, then use
a single username and password to make purchases from
online retailers. In ten U.S. states, surcharges for the use of a credit
card are forbidden by law (California, Colorado, Connecticut, Florida,
Kansas, Maine, Massachusetts, New York, Oklahoma and Texas)
but a low cost for cash is permitted under particular guidelines.
Rules address how a cardholder should be recognized for
security, how transactions may be denied by the bank, and how banks may
cooperate for fraud prevention, and how to keep that identification and fraud
safety normal and non-discriminatory.
Someone essentially assist to make severely posts I might state.
That is the very first time I frequented your website page and thus
far? I amazed with the research you made to create this actual submit extraordinary.
Excellent task!
As the admin of this website is working, no doubt very soon it
will be renowned, due to its quality contents.
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to figure out if its a problem on my end or if
it’s the blog. Any suggestions would be greatly appreciated.
Great weblog here! Also your website loads up very fast!
What host are you using? Can I get your affiliate link in your
host? I wish my site loaded up as quickly as yours lol.
Review my web site; Radianna Beauty Anti Aging Cream
Definitely believe that which you said. Your favorite reason seemed
to be on the web the simplest thing to be aware of.
I say to you, I certainly get annoyed while people think about worries that they just do not know about.
You managed to hit the nail upon the top as well as
defined out the whole thing without having side-effects , people can take a signal.
Will likely be back to get more. Thanks
Hello.This post was really interesting, particularly because I was searching for thoughts on this subject last Sunday.
My web page Flawless Finish Skin Tag Remover
After going over a few of the blog posts on your web site, I truly appreciate your way of blogging.
I bookmarked it to my bookmark webpage list and will be checking back soon. Take a look at
my website as well and let me know what you think.
I’m gone to convey my little brother, that he should also visit this web
site on regular basis to get updated from most recent
reports.
Howdy! This is my 1st comment here so I just wanted to give
a quick shout out and tell you I genuinely enjoy reading your posts.
Can you recommend any other blogs/websites/forums that go over the same topics?
Many thanks!
Howdy! I could have sworn I’ve been to this blog before but
after looking at many of the articles I realized it’s new to me.
Anyways, I’m definitely pleased I discovered it and I’ll be
bookmarking it and checking back often!
Do you have a spam problem on this website; I
also am a blogger, and I was wanting to know your
situation; many of us have created some nice procedures and we are looking to trade strategies with others,
please shoot me an email if interested.
First off I would like to say great blog!
I had a quick question which I’d like to ask if you do not mind.
I was interested to find out how you center yourself and
clear your thoughts prior to writing. I have had difficulty clearing my thoughts in getting my thoughts out.
I do take pleasure in writing however it just seems like
the first 10 to 15 minutes tend to be lost just trying to figure out
how to begin. Any recommendations or hints? Appreciate it!
Piece of writing writing is also a excitement, if you be acquainted with after
that you can write if not it is difficult to write.
Excellent article. I definitely love this website.
Keep writing!
My family every time say that I am killing my time here at web, except I know I am getting know-how every day
by reading thes nice articles or reviews.
That is very fascinating, You’re a very professional blogger.
I’ve joined your rss feed and stay up for in quest of more
of your great post. Additionally, I have shared your website in my social networks
Simply want to say your article is as surprising. The clearness in your post
is just spectacular and i can assume you are an expert on this subject.
Well with your permission allow me to grab your feed to keep up to
date with forthcoming post. Thanks a million and please continue the enjoyable work.
Thanks for any other informative web site. Where else may I get that type of information written in such
an ideal method? I have a undertaking that I’m just now working on, and I’ve been at the glance out for such info.
This excellent website really has all of the info
I needed concerning this subject and didn’t
know who to ask.
Hello my friend! I want to say that this article is amazing, great written and come with almost all vital
infos. I would like to see more posts like this .
Милфы Порно
Hey! Would you mind if I share your blog with my zynga group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thanks
Having read this I believed it was very informative. I appreciate you taking the time and effort to put this article together.
I once again find myself spending a significant amount
of time both reading and posting comments. But so what,
it was still worthwhile!
Hi there to all, it’s in fact a fastidious for me to visit this
web site, it consists of precious Information.
What’s up to every one, for the reason that I am genuinely eager of
reading this web site’s post to be updated regularly.
It consists of nice information.
If you wish for to obtain much from this piece of writing then you have to apply these strategies to your won weblog.
It’s impressive that you are getting ideas from this post as well as from
our discussion made here.
I blog often and I really thank you for your content.
This great article has really peaked my interest. I am going to take a note of your blog and keep
checking for new details about once per week. I subscribed to your RSS feed too.
I have fun with, cause I discovered exactly what I was looking for.
You have ended my 4 day long hunt! God Bless you man. Have
a nice day. Bye
When someone writes an post he/she retains the thought of a user in his/her mind that how a user can know it.
So that’s why this post is great. Thanks!
I’ll right away grab your rss feed as I can not in finding your email subscription hyperlink or e-newsletter service.
Do you have any? Kindly let me understand so that I may subscribe.
Thanks.
Link exchange is nothing else however it is simply placing the other person’s webpage link on your
page at proper place and other person will also do similar in support of you.
I’m truly enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and
visit more often. Did you hire out a developer to create your theme?
Excellent work!
My spouse and I stumbled over here different website and thought I might as well check things out.
I like what I see so now i’m following you.
Look forward to finding out about your web page
again.
I enjoy looking through a post that can make men and women think.
Also, thank you for permitting me to comment!
This page certainly has all the information I needed about this subject and didn’t know who to ask.
Thanks on your marvelous posting! I really enjoyed reading it, you
are a great author. I will always bookmark your blog and will come back down the road.
I want to encourage you continue your great job, have a nice weekend!
I was curious if you ever thought of changing the structure of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or 2 images.
Maybe you could space it out better?
I constantly spent my half an hour to read this web
site’s posts all the time along with a mug of coffee.
Superb, what a website it is! This webpage presents helpful data to us, keep
it up.
Hello! I’ve been reading your website for a while now and finally got the bravery
to go ahead and give you a shout out from Lubbock Tx!
Just wanted to say keep up the good work!
Hello just wanted to give you a quick heads up.
The text in your article seem to be running off the screen in Firefox.
I’m not sure if this is a formatting issue or something to do with
web browser compatibility but I figured I’d post to let you know.
The style and design look great though! Hope you get the issue fixed soon. Kudos
Your style is so unique compared to other people I’ve read
stuff from. Many thanks for posting when you’ve got the opportunity,
Guess I will just bookmark this site.
Про психов кино
Write more, thats all I have to say. Literally, it seems
as though you relied on the video to make your point. You clearly know what youre talking about, why waste your intelligence on just posting videos to your
site when you could be giving us something informative to read?
Its like you read my mind! You seem to understand so much approximately this,
such as you wrote the e-book in it or something. I feel that you could do with a few % to pressure
the message house a bit, but other than that, this is magnificent blog.
A great read. I’ll certainly be back.
Wow, that’s what I was seeking for, what a information!
existing here at this weblog, thanks admin of this website.
It’s genuinely very complex in this active life to listen news on TV, therefore I simply use world wide web
for that purpose, and get the latest information.
Feel free to surf to my web blog: A片
Right now it appears like Expression Engine is the top blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
I’m impressed, I must say. Rarely do I come across a blog that’s equally educative and entertaining, and let me tell you,
you have hit the nail on the head. The issue
is something that not enough people are speaking intelligently about.
I’m very happy I came across this during my hunt for something relating to
this.
Hey I am so thrilled I found your weblog, I really found you by
accident, while I was browsing on Google for something else, Nonetheless I am here now and would just like
to say cheers for a marvelous post and a all round enjoyable
blog (I also love the theme/design), I don’t have
time to read through it all at the moment but I
have bookmarked it and also added your RSS feeds, so when I have
time I will be back to read much more, Please
do keep up the awesome jo.
Hi there Dear, are you actually visiting this site
regularly, if so after that you will definitely obtain nice know-how.
Hello just wanted to give you a quick heads up and let you know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and
both show the same outcome.
Nice post. I was checking continuously this blog and I’m impressed!
Extremely helpful info specially the last part
I care for such information a lot. I was seeking this certain information for a very long
time. Thank you and good luck.
Hello, i believe that i saw you visited my website so i got here to return the want?.I’m trying to in finding things to enhance
my web site!I assume its ok to make use of some of your
concepts!!
Hmm it appears like your website ate my first comment (it was super long) so I guess I’ll just sum it up what I submitted
and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog writer but I’m still new to everything.
Do you have any recommendations for rookie blog writers?
I’d genuinely appreciate it.
Hi there! This article couldn’t be written much better!
Reading through this post reminds me of my previous roommate!
He constantly kept talking about this. I’ll forward this information to him.
Pretty sure he will have a good read. Many thanks for sharing!
Here is my web site; A片
I think that everything said was very logical. But, what about this?
what if you were to create a awesome headline? I ain’t suggesting your content is not solid.,
however suppose you added something to maybe grab people’s attention? I mean Пиастры – Составление семантического ядра | is kinda boring.
You ought to glance at Yahoo’s front page and see how they create news headlines to get
people interested. You might try adding a video or a related pic or two
to grab people excited about what you’ve got to say.
In my opinion, it would bring your posts a little bit more interesting.
Wow, marvelous weblog layout! How long have you ever been running a blog for?
you made blogging look easy. The entire look of
your web site is excellent, let alone the content material!
Hello there, just became alert to your blog through Google,
and found that it’s really informative. I am gonna watch out for brussels.
I will appreciate if you continue this in future.
A lot of people will be benefited from your writing. Cheers!
I think the admin of this website is truly working hard in support of his web page, for the reason that here every data is quality based
stuff.
magnificent post, very informative. I ponder why the opposite experts
of this sector do not realize this. You must continue
your writing. I’m confident, you’ve a huge readers’ base already!
Greetings! I know this is kind of off topic but I was wondering
which blog platform are you using for this website?
I’m getting sick and tired of WordPress because I’ve
had issues with hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of a good platform.
What’s up, this weekend is nice for me, since this time i am reading this great informative paragraph here at my house.
I am not sure where you are getting your information, but good
topic. I needs to spend some time learning more or understanding more.
Thanks for fantastic info I was looking for this info for my mission.
Do you have a spam problem on this site; I also am a blogger, and I was wanting to know your situation; many of us have
developed some nice procedures and we are looking to exchange
techniques with others, be sure to shoot me an email if interested.
Way cool! Some extremely valid points! I appreciate you writing this
article and also the rest of the website is very good.
Hello! I’ve been following your website for a while now and finally got the
bravery to go ahead and give you a shout out from Kingwood Texas!
Just wanted to mention keep up the fantastic work!
I do not even know how I ended up here, but I
thought this post was good. I don’t know who you are but certainly
you’re going to a famous blogger if you aren’t already 😉 Cheers!
Hello, Neat post. There’s an issue together with your web site in internet explorer, might check this?
IE nonetheless is the market leader and a huge part
of folks will pass over your magnificent writing due to this problem.
Pretty part of content. I just stumbled upon your website and in accession capital to assert that
I acquire in fact enjoyed account your weblog posts.
Anyway I will be subscribing on your feeds or even I achievement you
get entry to persistently fast.
I do believe all of the ideas you have introduced on your post.
They are very convincing and can certainly work.
Still, the posts are too brief for beginners.
May you please lengthen them a bit from subsequent time?
Thanks for the post.
Thank you for the auspicious writeup. It in fact was
a amusement account it. Look advanced to more added agreeable from you!
By the way, how can we communicate?
Hi, I do believe your blog may be having
internet browser compatibility problems. When I take a look at your blog in Safari, it looks fine however when opening in I.E., it’s got some overlapping issues.
I merely wanted to give you a quick heads up! Aside from that, great website!
http://www.consult-exp.com
Hi there to every one, as I am genuinely eager
of reading this web site’s post to be updated daily. It consists of pleasant stuff.
I don’t know whether it’s just me or if perhaps everybody else
encountering issues with your website. It appears like
some of the text in your posts are running off the screen. Can somebody else please provide feedback and let me know if this is happening
to them as well? This may be a issue with my browser
because I’ve had this happen previously. Appreciate it
Hi, I think your site could be having internet browser compatibility problems.
Whenever I look at your web site in Safari, it looks fine but when opening in Internet Explorer,
it’s got some overlapping issues. I merely wanted to provide you with a
quick heads up! Apart from that, fantastic website!
Hello just wanted to give you a brief heads up and let you know a
few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show
the same outcome.
This site certainly has all the info I wanted concerning this subject
and didn’t know who to ask.
We are a gaggle of volunteers and opening a
new scheme in our community. Your web site provided us with helpful information to work on. You have done an impressive task and our entire neighborhood might be thankful
to you.
constantly i used to read smaller content that as well clear
their motive, and that is also happening with this paragraph which I am reading at this
place.
This information is invaluable. How can I find out more?
Thanks for sharing your thoughts about recessional. Regards
I don’t know if it’s just me or if perhaps everyone else encountering issues with your site.
It appears like some of the written text on your posts are running off the screen. Can someone else please provide feedback and let me know if this is happening to them too?
This may be a problem with my browser because I’ve had this happen previously.
Thanks
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an edginess
over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly
very often inside case you shield this hike.
I believe that is one of the so much vital information for me.
And i am glad reading your article. But wanna observation on few normal things, The web site taste is
perfect, the articles is actually nice : D. Excellent process, cheers
Please let me know if you’re looking for a writer for your weblog.
You have some really good articles and I think I would be a good
asset. If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a link back to
mine. Please send me an e-mail if interested. Many thanks!
If you would like to obtain a good deal from this post then you have to apply such techniques to
your won website.
Now I am going away to do my breakfast, later than having my breakfast coming yet
again to read other news.
Hiya! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring
a blog post or vice-versa? My website goes over a lot of the same topics
as yours and I believe we could greatly benefit from each other.
If you might be interested feel free to send me an e-mail.
I look forward to hearing from you! Fantastic
blog by the way!
I am curious to find out what blog platform you are working with?
I’m experiencing some minor security problems with my
latest website and I’d like to find something more risk-free.
Do you have any solutions?
Hey there! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading through your
blog and look forward to all your posts! Keep up the fantastic work!
I used to be recommended this web site by means of my cousin. I am not sure whether or
not this put up is written through him as nobody else understand such targeted approximately my trouble.
You are amazing! Thanks!
fantastic points altogether, you just won a brand new reader.
What might you recommend in regards to your publish that you simply made a few days ago?
Any sure?
You ought to take part in a contest for one of the highest
quality sites on the web. I most certainly will recommend
this site!
Hey there! This is kind of off topic but I need some guidance
from an established blog. Is it hard to set up your own blog?
I’m not very techincal but I can figure things out
pretty fast. I’m thinking about creating my own but I’m not sure where to
start. Do you have any ideas or suggestions? Thank you
Excellent site you have got here.. It’s difficult to find quality writing like yours nowadays.
I seriously appreciate people like you! Take care!!
Статейные и ссылочные прогоны Xrumer, GSA
В наше время, практически каждый
человек пользуется интернетом.
С его помощью можно найти
любую информацию из различных интернет-источников и поисковых систем.
Для кого-то собственный сайт —
это хобби. Однако, большинство используют разработанные
проекты для заработка и привлечение прибыли.
У вас есть собственный сайт и
вы хотите привлечь на него максимум посетителей, но не знаете с чего начать?
Заказать Прогон Хрумером и ГСА можно в телеграмм логин @pokras777 здесь наша группа в телеграмм https://t.me/+EYh48YzqWf00OTYy или
в скайпе pokras7777
Hello, yup this piece of writing is genuinely pleasant and I have learned lot of things from it regarding blogging.
thanks.
Great blog! Do you have any suggestions for aspiring writers?
I’m planning to start my own blog soon but I’m a
little lost on everything. Would you advise starting with a
free platform like WordPress or go for a paid option? There are so many choices
out there that I’m completely confused .. Any ideas? Thanks a lot!
What a material of un-ambiguity and preserveness of valuable familiarity about unpredicted feelings.
Today, I went to the beach with my kids. I found a sea shell and gave
it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to
her ear and screamed. There was a hermit crab inside and it pinched her
ear. She never wants to go back! LoL I know
this is completely off topic but I had to tell someone!
Hello, i think that i saw you visited my blog so i came to “return the favor”.I am attempting to find things to improve my
site!I suppose its ok to use some of your ideas!!
This is really interesting, You are a very skilled blogger.
I have joined your feed and look forward to seeking more of your great post.
Also, I’ve shared your website in my social networks!
Hi there! I know this is somewhat off topic but I was wondering if you knew where I could locate a captcha plugin for
my comment form? I’m using the same blog platform
as yours and I’m having trouble finding one? Thanks a lot!
Very energetic blog, I enjoyed that bit. Will there be a part 2?
I was wondering if you ever considered changing
the layout of your website? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or
2 pictures. Maybe you could space it out better?
Hi, I think your website might be having browser compatibility issues.
When I look at your blog in Ie, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, very good blog!
I just couldn’t leave your site prior to suggesting that I really loved the standard
information a person supply on your visitors?
Is going to be again steadily in order to check out new posts
Thanks for a marvelous posting! I definitely enjoyed reading it, you’re a great author.I will be
sure to bookmark your blog and may come back in the
future. I want to encourage yourself to continue
your great posts, have a nice morning!
Hey there! I know this is kinda off topic but I’d figured I’d
ask. Would you be interested in exchanging links or maybe guest authoring
a blog article or vice-versa? My site discusses a lot of the
same subjects as yours and I believe we could greatly benefit from each other.
If you are interested feel free to shoot me an e-mail.
I look forward to hearing from you! Excellent blog by
the way!
Hi everyone, it’s my first pay a visit at this web
page, and post is truly fruitful for me, keep up posting these types of
posts.
Fantastic beat ! I wish to apprentice at the same time as you amend your site, how can i subscribe for a blog site?
The account helped me a acceptable deal. I had been tiny bit acquainted of this your broadcast offered
vivid clear idea
Pretty great post. I just stumbled upon your weblog and wished to say that I have truly loved surfing around your weblog posts.
In any case I will be subscribing in your feed and I’m hoping you write
once more soon!
Hello! This is my 1st comment here so I just wanted to give a
quick shout out and say I genuinely enjoy reading your posts.
Can you recommend any other blogs/websites/forums that deal with
the same topics? Many thanks!
Greetings, I believe your site could possibly be having browser compatibility problems.
Whenever I take a look at your blog in Safari, it looks fine however when opening
in Internet Explorer, it has some overlapping issues.
I merely wanted to provide you with a quick heads up! Apart from that, fantastic blog!
I was recommended this blog by my cousin. I am not sure whether this post is written by him as nobody
else know such detailed about my trouble. You are wonderful!
Thanks!
With havin so much content and articles do you ever run into any
problems of plagorism or copyright infringement? My blog has a lot of
completely unique content I’ve either written myself or outsourced but it looks like a lot of it is
popping it up all over the web without my agreement.
Do you know any methods to help protect against content from being ripped off?
I’d certainly appreciate it.
I’ve been browsing online more than 3 hours today, yet
I never found any interesting article like yours. It’s
pretty worth enough for me. In my opinion, if all website owners and bloggers made
good content as you did, the internet will be a lot more useful
than ever before.
I’m gone to say to my little brother, that he should also pay a quick visit
this webpage on regular basis to get updated from most up-to-date news update.
Ridiculous quest there. What happened after? Take care!
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for about a year and
am nervous about switching to another platform. I have heard very good things
about blogengine.net. Is there a way I can transfer all my wordpress content into it?
Any help would be really appreciated!
When someone writes an paragraph he/she maintains the plan of a
user in his/her brain that how a user can be aware of it. Therefore that’s why this article is
perfect. Thanks!
Great post. I used to be checking continuously this weblog I deal with such
I deal with such
and I’m inspired! Very useful info specially the ultimate phase
info a lot. I used to be looking for this particular information for a long time.
Thanks and best of luck.
Hello, I wish for to subscribe for this web site to obtain latest updates, therefore where can i do
it please help.
Hey there, I think your site might be having browser compatibility issues.
When I look at your blog in Ie, it looks fine but when opening in Internet Explorer, it
has some overlapping. I just wanted to give you a quick heads up!
Other then that, amazing blog!
Thanks for sharing your thoughts on mon ngon moi ngay khong ngan. Regards
Howdy! I know this is kind of off topic but I was wondering which blog platform are you using for this website?
I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be fantastic if you could point me in the direction of a good platform.
Greetings! This is my first visit to your blog!
We are a collection of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have done a extraordinary job!
Great blog here! Also your web site loads up fast! What host are you using?
Can I get your affiliate link to your host? I wish my web site loaded up as fast
as yours lol
I am sure this article has touched all the internet visitors, its really really good paragraph on building up new webpage.
Way cool! Some extremely valid points! I appreciate you penning
this write-up plus the rest of the site is also really good.
I constantly spent my half an hour to read
this web site’s posts daily along with a cup of coffee.
Wow, superb blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is wonderful, as well as the content!
I was recommended this blog by way of my cousin. I am now not sure whether or not
this post is written by him as no one else realize such specified approximately my problem.
You are amazing! Thanks!
It’s really a nice and helpful piece of info. I am happy that you just
shared this useful information with us. Please stay us informed like this.
Thanks for sharing.
Asking questions are truly good thing if you are not understanding something completely,
but this paragraph gives fastidious understanding even.
I visit every day a few sites and information sites to read posts,
but this website presents feature based posts.
We’re a group of volunteers and opening a brand new scheme in our community.
Your web site offered us with valuable info to work on. You have performed a formidable process and our entire community will probably be grateful to you.
Attractive section of content. I just stumbled upon your weblog
and in accession capital to assert that I acquire in fact enjoyed account your blog posts.
Any way I’ll be subscribing to your feeds and even I achievement
you access consistently fast.
Howdy! Do you use Twitter? I’d like to follow you if that would be
ok. I’m definitely enjoying your blog and look forward
to new posts.
We absolutely love your blog and find many of
your post’s to be just what I’m looking for. Do you offer guest writers to write content for you personally?
I wouldn’t mind writing a post or elaborating on a number of the subjects you
write with regards to here. Again, awesome blog!
Hi, this weekend is good for me, because this occasion i am reading this
enormous informative paragraph here at my home.
Woah! I’m really digging the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s difficult
to get that “perfect balance” between superb usability and visual appearance.
I must say that you’ve done a amazing job with this.
In addition, the blog loads extremely quick for me on Safari.
Outstanding Blog!
Hi to all, it’s actually a nice for me to pay a quick visit this site, it contains precious Information.
It’s amazing to pay a quick visit this website and reading the views
of all colleagues regarding this paragraph, while I
am also zealous of getting familiarity.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You definitely know what youre talking about, why waste your intelligence on just posting videos
to your site when you could be giving us something enlightening to
read?
Can I simply say what a relief to uncover somebody that genuinely
knows what they are discussing on the web.
You definitely understand how to bring a problem to light and make it
important. A lot more people should check this out and understand this side of your story.
I was surprised that you are not more popular since you
certainly have the gift.
Hey there! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward to
all your posts! Carry on the excellent work!
Hey! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up
losing a few months of hard work due to no back up.
Do you have any methods to protect against hackers?
Feel free to surf to my web site; cashofferplease
I have been exploring for a little bit for any high quality articles or weblog posts on this kind of area
. Exploring in Yahoo I at last stumbled upon this site.
Studying this info So i’m satisfied to express that I have a very excellent uncanny feeling I discovered exactly
what I needed. I so much no doubt will make certain to do not
disregard this web site and give it a look regularly.
I could not resist commenting. Very well written!
It’s in fact very complicated in this busy life to listen news on Television, thus I only use internet for that purpose, and take the hottest information.
Hi, just wanted to say, I liked this post. It was helpful.
Keep on posting!
Informative article, just what I was looking for.
I have been browsing online more than three
hours today, but I never found any attention-grabbing article like yours.
It is pretty worth enough for me. Personally, if all webmasters and bloggers made excellent content material as you
did, the web might be a lot more useful than ever before.
What i do not realize is in fact how you’re no longer really a lot more
smartly-appreciated than you may be right now.
You’re very intelligent. You understand thus significantly
relating to this topic, made me personally believe it from
a lot of numerous angles. Its like men and women are
not interested unless it’s something to accomplish with Woman gaga!
Your individual stuffs nice. At all times care for it up!
You have made some decent points there. I checked on the web to find out
more about the issue and found most individuals will go along with your views on this web site.
Superb site you have here but I was wanting to know if you knew of any message boards that cover the same topics discussed here?
I’d really like to be a part of community where I
can get feedback from other experienced individuals that share the same interest.
If you have any recommendations, please let me know.
Many thanks!
Excellent pieces. Keep writing such kind of info on your site.
Im really impressed by it.
Hi there, You have performed an incredible job.
I’ll certainly digg it and in my opinion recommend to my friends.
I’m confident they will be benefited from this
site.
chaqueta tottenham
It’s great that you are getting ideas from this article as well as from our discussion made at
this time.
If you want to take much from this post then you have to apply such strategies to
your won website.
mgfmail.ru
A fascinating discussion is worth comment.
I believe that you ought to write more on this issue, it might not be a taboo matter but typically people do not talk about such issues.
To the next! All the best!!
After I initially left a comment I appear to have clicked on the -Notify me when new comments are added- checkbox and now whenever a comment is added I recieve four emails with the same
comment. There has to be an easy method you are able to remove me from that service?
Thanks a lot!
Thanks for any other magnificent article.
Where else could anybody get that kind of information in such a perfect manner of writing?
I’ve a presentation subsequent week, and I’m at the search for such information.
Good day! I could have sworn I’ve visited this website
before but after going through some of the posts I realized
it’s new to me. Nonetheless, I’m definitely pleased I discovered it and I’ll be bookmarking it and checking back often!
Thanks a lot for sharing this with all folks you really know what you’re talking approximately!
Bookmarked. Please additionally consult with my website =).
We may have a hyperlink change contract between us
Appreciating the time and energy you put into your site and in depth information you present.
It’s great to come across a blog every once in a while that isn’t
the same old rehashed information. Great read!
I’ve saved your site and I’m adding your RSS feeds to my Google account.
Hey! I know this is somewhat off topic but I was wondering if you knew where I could locate a captcha plugin for my comment
form? I’m using the same blog platform as yours
and I’m having difficulty finding one? Thanks a lot!
My brother recommended I might like this web site.
He was totally right. This post truly made
my day. You can not imagine simply how much time I had spent for
this information! Thanks!
This website really has all the information and
facts I needed concerning this subject and didn’t know
who to ask.
Heya i am for the first time here. I came across this board and I in finding It really helpful & it helped me out much.
I hope to offer something back and help others such as you aided me.
Секс видео
Hi, I do think this is an excellent site. I stumbledupon it 😉 I’m going to revisit yet again since i have bookmarked it.
Money and freedom is the best way to change, may you be rich and continue to
help others.
Greetings from Colorado! I’m bored to death at work so I decided to check
out your site on my iphone during lunch break. I enjoy the knowledge
you present here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, very good site!
This is very interesting, You’re a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your wonderful post.
Also, I’ve shared your site in my social networks!
Asking questions are truly nice thing if you are not understanding something entirely, but this article
provides pleasant understanding yet.
hello there and thank you for your info – I’ve definitely picked up anything
new from right here. I did however expertise a few technical issues using this website, as I experienced to reload the site a lot of times previous
to I could get it to load correctly. I had been wondering
if your web host is OK? Not that I am complaining, but slow loading instances times will often affect
your placement in google and could damage your high quality score
if ads and marketing with Adwords. Well I’m adding this RSS to my e-mail and
could look out for a lot more of your respective fascinating content.
Ensure that you update this again very soon.
It’s great that you are getting thoughts from this post
as well as from our argument made at this time.
For the reason that the admin of this web site is working,
no hesitation very shortly it will be famous, due to its feature contents.
I am not sure where you are getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for excellent info I was looking for this info for
my mission.
If you desire to take a great deal from this paragraph then you have to
apply these strategies to your won web site.
The other day, while I was at work, my cousin stole my iphone and tested to see
if it can survive a 30 foot drop, just so she can be a youtube sensation. My
apple ipad is now destroyed and she has 83 views.
I know this is completely off topic but I had to share it with someone!
Hi superb website! Does running a blog like this require
a large amount of work? I have no understanding of programming but I was hoping to
start my own blog in the near future. Anyways,
should you have any ideas or techniques for new blog owners
please share. I understand this is off topic however I simply needed to ask.
Kudos!
my page; A片
My spouse аnd І absolutely love your blog and find thе majority оf your post’s to᧐ be eⲭactly І’m lookіng fοr.
Would ʏoս offer guest writers tо write ϲontent for you?
I wouⅼdn’t mind composing а post or elabborating on some of the subjects you write іn relation to here.
Аgain, awesome web log!
Check ⲟut my web blog: 바카라천국
Hello to all, how is the whole thing, I think every one is getting more from this web site, and your views are good for new people.
Quality content is the crucial to invite the people to pay a visit the web site, that’s what this web page is providing.
Each of them comes with leading rewards and the best choice of games for you to attempt
out.
my blog: 라이브카지노
Its like you read my mind! You seem to know so much about this, like you wrote
the book in it or something. I think that you can do with
some pics to drive the message home a little bit, but instead of that,
this is great blog. A fantastic read. I will definitely
be back.
คำตอบสำหรับคำถามนี้เป็นอัตวิสัยเนื่องจากขึ้นอยู่กับความชอบส่วนบุคคล งบประมาณ และปัจจัยอื่นๆ หุ่นยนต์ดูดฝุ่นยอดนิยมบางยี่ห้อ
ได้แก่ iRobot, ECOVACS, Neato Robotics และ Samsung ด้วยชื่ออย่างเช่น Professional, Roomba, Deebot และ POWERbot แต่ละแบรนด์มีหุ่นยนต์ดูดฝุ่นหลายรุ่นที่ออกแบบมาเพื่อตอบสนองความต้องการที่หลากหลาย
Feel free to visit my web-site :: หุ่น ยนต์ ถู พื้น samsung
I simply could not leave your site prior to suggesting that I extremely enjoyed the standard information a person supply for your visitors?
Is going to be again frequently to check out new posts
Your mode of describing all in this post is actually fastidious,
every one can easily be aware of it, Thanks a lot.
My web site: 熟女
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each
time a comment is added I get four emails with the same comment.
Is there any way you can remove me from that service?
Cheers!
This excellent website really has all the info I needed concerning this subject and didn’t know
who to ask.
This website was… how do you say it? Relevant!!
Finally I’ve found something that helped me. Thanks!
Good day! This is my first comment here so I just
wanted to give a quick shout out and tell you I genuinely enjoy reading your
blog posts. Can you suggest any other blogs/websites/forums that deal with the same
subjects? Thank you!
Great beat ! I would like to apprentice while you amend your site,
how could i subscribe for a blog website? The
account helped me a acceptable deal. I had been a little bit acquainted of this
your broadcast offered bright clear concept
Asking questions are actually good thing if you are not understanding something
completely, however this paragraph presents pleasant understanding
even.
This site was… how do you say it? Relevant!!
Finally I have found something that helped me. Cheers!
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
An outstanding share! I’ve just forwarded this onto a friend
who had been conducting a little research on this.
And he actually bought me breakfast due to the fact that I
discovered it for him… lol. So let me
reword this…. Thank YOU for the meal!! But yeah,
thanks for spending some time to discuss this matter here on your site.
Hi! I understand this is sort of off-topic however I had
to ask. Does building a well-established website such
as yours take a lot of work? I’m brand new to operating a blog however I do write in my
journal daily. I’d like to start a blog so I can easily
share my experience and thoughts online. Please let me
know if you have any suggestions or tips for new aspiring blog owners.
Thankyou!
I have to thank you for the efforts you have put in penning this site.
I’m hoping to see the same high-grade content
from you later on as well. In fact, your creative writing abilities has motivated me
to get my own, personal site now 😉
Why viewers still use to read news papers when in this technological globe all is presented on web?
It’s appropriate time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I wish to suggest you few interesting things or
suggestions. Perhaps you can write next articles referring to this
article. I desire to read even more things about it!
Very energetic post, I loved that bit. Will there be
a part 2?
Thank you a bunch for sharing this with all people you actually recognise
what you’re talking about! Bookmarked. Kindly additionally talk over with my website =).
We can have a hyperlink exchange arrangement between us
What’s up, I read your blogs regularly. Your humoristic style is awesome, keep it up!
Today, while I was at work, my cousin stole my iPad and tested to see if it can survive
a thirty foot drop, just so she can be a youtube
sensation. My apple ipad is now broken and she has 83 views.
I know this is completely off topic but I had to share it with someone!
Hi there i am kavin, its my first occasion to commenting anyplace, when i read this post i thought i could also make comment
due to this sensible paragraph.
Unquestionably believe that which you said. Your favorite
reason appeared to be on the web the simplest thing to be
aware of. I say to you, I certainly get irked while people think about worries that
they just do not know about. You managed to hit the nail upon the
top and also defined out the whole thing without having side-effects ,
people could take a signal. Will likely be back to
get more. Thanks
This assists to make youur credibility within the market and solidify your brand with prospective employers.
Feel free to visit my web page; 요정 알바
порно сосалка
Agen togel terpercaya dengan pasaran terbanyak sediakan bermacam pasaran togel dari berbagai negara, seperti Hong Kong,
Singapura, Sydney, dan banyak lagi. Dengan adanya pasaran togel yang
lengkap, para pemain bisa memasang taruhan terhadap
pasaran yang mereka sukai dan yang paling familiar.
Selain itu, para pemain termasuk mampu menentukan pasaran bersama
dengan kesempatan kemenangan yang lebih besar.
I think the admin of this site is genuinely working hard for his web page,
because here every stuff is quality based stuff.
It’s remarkable in favor of me to have a website, which is helpful designed for my experience.
thanks admin
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly a lot often inside case you shield this increase.
Thank you for sharing your thoughts. I really appreciate your efforts and I will be waiting for your further post thank you once again.
Attractive element of content. I simply stumbled upon your blog and in accession capital to claim
that I acquire in fact enjoyed account your weblog posts.
Any way I’ll be subscribing in your augment or
even I achievement you get right of entry to consistently quickly.
hello there and thank you for your info – I’ve certainly picked up anything new from right here.
I did however expertise some technical issues using this site, as I experienced to reload the website
lots of times previous to I could get it to load correctly.
I had been wondering if your hosting is OK? Not that I’m complaining, but sluggish loading instances times will very frequently affect your placement in google and could damage your
quality score if ads and marketing with Adwords.
Well I’m adding this RSS to my email and could look out for a lot more of your respective interesting content.
Make sure you update this again very soon.
It’s amazing designed for me to have a web site, which is useful in favor of my know-how.
thanks admin
Hi, Neat post. There’s an issue together with your site in web
explorer, may test this? IE still is the market chief and a large component to folks will leave out your
excellent writing because of this problem.
https://www.mid-day.com/brand-media/article/greenhouse-cbd-gummies-uk-and-usa-buyer-alert-do-not-buy-until-you-see-2023-23275409
It’s really a cool and helpful piece of info.
I’m happy that you shared this helpful information with us.
Please stay us up to date like this. Thank you for
sharing.
Hello There. I discovered your weblog using msn. That is a very well written article.
I will be sure to bookmark it and come back to learn more of your helpful information. Thank you for the
post. I’ll definitely return.
Thanks for every other magnificent article. The place else could anyone get that kind of info in such a perfect way
of writing? I have a presentation subsequent week, and I’m at
the look for such info.
My brother recommended I would possibly like this blog.
He was totally right. This publish truly made my day.
You cann’t imagine simply how so much time I had spent for this info!
Thank you!
Pretty section of content. I just stumbled upon your site and in accession capital
to assert that I get actually enjoyed account your blog posts.
Anyway I will be subscribing to your augment and
even I achievement you access consistently rapidly.
I know this if off topic but I’m looking into starting my own blog
and was curious what all is needed to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% sure. Any recommendations or advice would be greatly
appreciated. Cheers
This is really interesting, You are an excessively skilled blogger.
I’ve joined your feed and stay up for in quest of
more of your fantastic post. Additionally, I have shared
your site in my social networks
It’s really very difficult in this full of activity life to listen news on Television, so I simply use
web for that purpose, and get the hottest information.
This design is incredible! You obviously know how to keep
a reader entertained. Between your wit and your videos, I was
almost moved to start my own blog (well, almost…HaHa!) Excellent job.
I really loved what you had to say, and more than that,
how you presented it. Too cool!
It is in reality a nice and helpful piece of information. I am happy that you simply shared
this helpful info with us. Please stay us informed like
this. Thanks for sharing.
It’s not my first time to visit this web page, i am
browsing this website dailly and take fastidious facts from here everyday.
I like the valuable info you provide on your articles.
I will bookmark your weblog and check once more right here regularly.
I’m moderately sure I will learn lots of new stuff right here!
Good luck for the next!
What’s up colleagues, nice article and good urging commented at
this place, I am in fact enjoying by these.
What a material oof un-ambiguity and preserveness ߋf precious familiarity regarding unpredicted
emotions.
Feel free tօ surf tо my webpage :: Kiosks in Cyprus
It is appropriate time to make some plans for the future and
it is time to be happy. I have read this post and if I
could I wish to suggest you some interesting things or tips.
Maybe you can write next articles referring to this article.
I wish to read even more things about it!
Howdy! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Any suggestions?
Pretty great post. I just stumbled upon your weblog and wished to say that I have truly loved browsing your weblog posts.
After all I’ll be subscribing to your rss feed and I
am hoping you write once more soon!
This site is my inspiration, real excellent layout
and Perfect written content.
Also visit my web-site :: Qinux Drone Review
%%
Great blog here! Also your web site loads up very fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours lol
Hey there! I know this is kinda off topic but I was wondering which blog platform
are you using for this website? I’m getting sick and tired of WordPress
because I’ve had issues with hackers and I’m looking at options for another platform.
I would be fantastic if you could point me in the direction of
a good platform.
Spot on with this write-up, I truly believe that this website needs a lot more attention. I’ll probably be returning to read through more, thanks for the info!
You actually make it seem so easy with your presentation but I
find this topic to be really something which I think I would never understand.
It seems too complex and extremely broad for me.
I’m looking forward for your next post, I will try to get the hang of
it!
Hiya very nice web site!! Guy .. Beautiful .. Superb .. I’ll bookmark your web site and take the feeds
additionally? I am glad to find a lot of useful info here within the put
up, we’d like work out more techniques in this regard, thank you for sharing.
. . . . .
What’s Taking place i am new to this, I stumbled upon this I’ve found It absolutely useful and it has
helped me out loads. I am hoping to contribute & assist other users like its helped me.
Good job.
Just wish to say your article is as amazing. The clarity for your post is simply cool and i could
think you are an expert in this subject. Well along with your permission let me to seize your feed to stay updated
with drawing close post. Thanks 1,000,000 and please continue the
gratifying work.
Useful info. Fortunate me I discovered your web site accidentally, and I’m shocked why this coincidence did not happened
in advance! I bookmarked it.
Hi to every one, because I am actually eager of reading this website’s post to be updated daily.
It consists of fastidious stuff.
I think the admin of this web site is really working hard in support of his website, because here every information is quality based information.
I do not know if it’s just me or if everybody else
encountering problems with your site. It
looks like some of the text in your posts are running off the screen. Can somebody else please provide
feedback and let me know if this is happening to them as well?
This may be a problem with my internet browser because
I’ve had this happen previously. Kudos
Excellent post but I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit more.
Kudos!
Do you have a spam problem on this blog; I also am a blogger, and I was wondering your situation;
many of us have developed some nice procedures and we are looking to trade techniques with
others, please shoot me an e-mail if interested.
Howdy, i read your blog occasionally and i own a similar one and i was just wondering if you get a lot of spam remarks?
If so how do you protect against it, any plugin or anything you can recommend?
I get so much lately it’s driving me crazy so any support is very much appreciated.
I love your blog.. very nice colors & theme. Did
you design this website yourself or did you hire someone to do
it for you? Plz respond as I’m looking to design my own blog
and would like to find out where u got this from. thanks
my web-site; slot
Good day very nice web site!! Guy .. Beautiful ..
Superb .. I will bookmark your blog and take the feeds also?
I’m satisfied to seek out a lot of helpful info right here
within the publish, we’d like develop more techniques on this
regard, thanks for sharing. . . . . .
I constantly spent my half an hour to read this blog’s content
every day along with a cup of coffee.
Does your website have a contact page? I’m having
trouble locating it but, I’d like to send you an email.
I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it
improve over time.
Undeniably believe that which you stated. Your favourite justification seemed to be at the web the simplest factor to
understand of. I say to you, I certainly get irked at the same time as
folks think about issues that they just do not understand about.
You controlled to hit the nail upon the top and also defined out
the whole thing with no need side-effects , other folks could take a signal.
Will probably be back to get more. Thank you
Nice post. I learn something new and challenging on sites I stumbleupon everyday.
It will always be interesting to read content from other authors and use a little something from
other web sites.
Hi, after reading this remarkable piece of writing
i am as well glad to share my experience here with mates.
Cerrajeros Valencia Cerrajeros 24 horas.
Apertura de puertas y cambio de cerraduras een Valencia desde noventa y
nueve euros. Llamanos y cuentanos tu problema.
Howdy! I could have sworn I’ve been to this site before but after browsing through some of the post I realized it’s new
to me. Anyways, I’m definitely delighted I found it and I’ll be bookmarking and checking back often!
Please let me know if you’re looking for a article author for your weblog.
You have some really good posts and I feel I would
be a good asset. If you ever want to take some of the load off, I’d
really like to write some articles for your blog in exchange for
a link back to mine. Please shoot me an e-mail if interested.
Cheers!
ต้องเลี้ยงไก่ไข่ใหม่หรือไม่?
เราสามารถช่วย.
เรียนรู้พื้นฐานของสิ่งที่เกี่ยวข้องและวิธีเริ่มต้นจากคำแนะนำของเราในการเลี้ยงไก่ไข่ใหม่ ค้นหาวิธีที่ดีที่สุดในการรับรองสุขภาพ ความปลอดภัย และความสะดวกสบายของพวกเขา
my webpage: วิธีเลี้ยง
I used to be recommended this website by means of my cousin. I’m not
positive whether this publish is written by means of
him as no one else recognise such certain approximately my trouble.
You’re incredible! Thank you!
I every time used to read piece of writing in news papers but now as I am a user
of internet therefore from now I am using net for articles or reviews, thanks to web.
Wow, incredible blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is magnificent, as
well as the content!
I’m extremely pleased to discover this website. I need to to thank you for
ones time just for this fantastic read!!
I definitely savored every bit of it and I have
you book marked to look at new things in your site.
Yes! Finally someone writes about click.
I visited multiple websites however the audio quality for audio songs existing at this web page is really wonderful.
It’s very simple to find out any topic on net as compared to books, as
I found this piece of writing at this website.
Its not my first time to pay a quick visit this web site, i
am browsing this web page dailly and get fastidious data from here daily.
Magnificent beat ! I wish to apprentice even as you amend your website, how could i subscribe for a
blog web site? The account aided me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered vivid clear
concept
I used to be able to find good info from your articles.
Very good info. Lucky me I found your website by chance (stumbleupon).
I’ve book-marked it for later!
Excellent article. I’m experiencing some of these issues as well..
For most up-to-date news you have to pay a visit world wide web and on the web I found this website as a most excellent web page
for newest updates.
My brother suggested I might like this website.
He was totally right. This post truly made my day. You can not imagine simply how much time I
had spent for this information! Thanks!
Hi there! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog to rank for some
targeted keywords but I’m not seeing very good results.
If you know of any please share. Cheers!
Wonderful items from you, man. I have keep in mind your stuff previous to and you
are simply too fantastic. I really like what you have bought here, really like
what you’re stating and the way through which you say it.
You’re making it enjoyable and you continue to take care
of to keep it smart. I cant wait to read much more from you.
This is really a great site.
Hi there to every one, the contents existing at this website are
in fact amazing for people experience, well, keep up the nice work fellows.
Wow, this paragraph is pleasant, my sister is analyzing these things, so I am going to let know her.
Great weblog right here! Additionally your website loads up fast!
What web host are you using? Can I am getting your associate
link in your host? I wish my web site loaded up as fast as yours lol
Incredible points. Sound arguments. Keep up the amazing work.
Undeniably believe that which you said. Your favorite justification appeared to be on the internet the
simplest thing to be aware of. I say to you, I definitely get irked while people think
about worries that they plainly do not know about. You managed
to hit the nail upon the top as well as defined out the whole thing without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
I simply couldn’t go away your website prior to suggesting that I extremely enjoyed the standard info
an individual supply on your visitors? Is going to be again frequently to inspect new posts
hello there and thank you for your information – I’ve certainly picked up anything
new from right here. I did however expertise several technical points
using this website, as I experienced to reload the site lots of times previous to I could get it to load correctly.
I had been wondering if your web hosting is OK? Not that I’m complaining, but slow loading instances times will very
frequently affect your placement in google and could damage your high quality score
if ads and marketing with Adwords. Well I am adding
this RSS to my email and can look out for a lot more of your respective interesting content.
Make sure you update this again soon.
you’re truly a good webmaster. The web site loading velocity is amazing.
It seems that you are doing any unique trick. Furthermore, The contents are masterwork.
you have done a wonderful task in this topic!
Please let me know if you’re looking for a article writer for your site.
You have some really good posts and I believe I would be a good asset.
If you ever want to take some of the load off, I’d love to write some material for your
blog in exchange for a link back to mine. Please blast me an email if interested.
Many thanks!
Hey I know this is off topic but I was wondering if
you knew of any widgets I could add to my blog
that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and
was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Hello! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thanks
If you want to obtain a good deal from this piece of writing
then you have to apply such methods to your won webpage.
большой член
12 Situs Slot88 Terpercaya Slot Gacor Pulsa Indonesia 2023
Slot88 adalah sebuah website judi slot online gacor terpercaya di indonesia dengan judi slot88 online, dan slot pragmatic dengan winrate kemenangan tinggi.
Judi Slot Online di dalamnya sangat lengkap dari berbagai permainan popular semacam: sbobet,
judi slot online, judi bola, judi togel, tembak ikan juga sudah disediakan buat
penuhi kepuasan para member slot88. Slot Gacor Hari Ini
terlengkap dengan bonus sangat menarik seperti bonus garansi kekalahan 100% dan new member
100% di awal. Para pemain yang bergabung jadi member dan bermacam- macam
keuntungan menarik lain. situs slot online terbaik memperkenalkan teknologi
wallet yang membuat ke gampangan dalam memainkan seluruh game dalam satu
akun saja buat bermain judi bola serta slot online uang asli terbaik.
continuously i used to read smaller posts which also clear their motive, and that is also happening with this post which I am
reading now.
My partner and I stumbled over here coming from a
different web address and thought I may as well check things out.
I like what I see so i am just following you.
Look forward to going over your web page yet again.
Hey there are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you require any coding knowledge to make your own blog?
Any help would be greatly appreciated!
I simply could not go away your website prior to suggesting that
I actually enjoyed the usual info a person supply for your visitors?
Is going to be again ceaselessly in order to check up on new posts
Thank you a bunch for sharing this with all of us you really know what you are
talking about! Bookmarked. Please also seek advice from my site =).
We can have a hyperlink trade contract among us
Howdy! I could have sworn I’ve been to this website before but after reading through some of the post I realized it’s new to me.
Nonetheless, I’m definitely delighted I found it and I’ll be book-marking and checking back frequently!
There is certainly a great deal to find out about this subject.
I like all of the points you made.
Thanks for finally talking about > Пиастры – Составление
семантического ядра | < Loved it!
Hi, I think your site might be having browser compatibility issues.
When I look at your website in Opera, it looks fine but when opening in Internet
Explorer, it has some overlapping. I just wanted to give
you a quick heads up! Other then that, great blog!
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of
the expenses. But he’s tryiong none the less. I’ve been using
Movable-type on various websites for about a year and am nervous about switching to
another platform. I have heard excellent things about blogengine.net.
Is there a way I can import all my wordpress content
into it? Any kind of help would be greatly appreciated!
Very shortly this web page will be famous among all blogging visitors, due to it’s nice articles or reviews
The 3 most common baccarat variants are Punto Banco,
Baccarat Banque, and Baccarat Chemin De Fer.
Look into my website casino79.in
Thank you for sharing your info. I really appreciate
your efforts and I will be waiting for your further
write ups thank you once again.
my web page … A片
It’s enormous that you are getting thoughts from this piece of writing as well as from
our dialogue made at this place.
You actually make it seem so easy with your presentation but I find this matter to be actually something which I think I would never understand.
It seems too complicated and very broad for me. I am looking forward for your next post, I will try to get the hang of it!
Hi, I do believe this is a great blog. I stumbledupon it ;
) I am going to return once again since i have bookmarked it.
Money and freedom is the best way to change, may you be rich and continue to guide others.
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying
to get started and create my own. Do you need any coding
knowledge to make your own blog? Any help would be greatly appreciated!
Hello there, You’ve done a great job. I’ll certainly digg it and personally suggest
to my friends. I’m sure they’ll be benefited from this website.
I’m not sure why but this web site is loading extremely slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem still exists.
Great goods from you, man. I’ve consider your stuff previous to and you’re just too
great. I really like what you’ve got here, really like what you are stating and the way in which during which
you say it. You make it entertaining and you still care for to keep it sensible.
I can not wait to read much more from you. That is really a great web site.
Hello! I could have sworn I’ve been to your blog before
but after browsing through some of the articles I realized it’s new
to me. Anyways, I’m certainly pleased I came across it
and I’ll be bookmarking it and checking back often!
This article will assist the internet users for creating new webpage or
even a weblog from start to end.
I really like it when folks get together and
share ideas. Great blog, keep it up!
My web site; october printable calendar
خبرهای مجلس و خبرهای جدید لیگ قهرمانان اروپا
و مطالب روز پنجشنبه و دانستنی های آیفون 6
و اخبار ورزشی چه ساعتی است و اخبار اقتصادی اجتماعی
https://siambookmark.com/story13591013/دانستنی-های-ورزش-کشتی
After checking out a number of the blog articles on your blog,
I seriously like your way of writing a blog.
I book marked it to my bookmark webpage list and will be checking back soon. Please check out my
web site as well and tell me how you feel.
Keep this going please, great job!
Hi, I do think this is a great web site. I stumbledupon it 😉 I will come back
yet again since I saved as a favorite it. Money and freedom is the greatest way to change,
may you be rich and continue to guide other people.
Aw, this was an exceptionally nice post. Taking a few minutes and actual effort to create
a very good article… but what can I say… I put things off
a whole lot and never manage to get anything done.
penis enlargement
Thanks for your personal marvelous posting! I quite enjoyed reading it, you’re a great
author.I will always bookmark your blog and
will eventually come back in the foreseeable future. I want to encourage continue your great work, have a
nice day!
buy viagra online
What’s up to every , as I am truly keen of reading this website’s post to be updated daily.
It contains pleasant data.
Thanks for your marvelous posting! I really enjoyed reading it, you might
be a great author. I will ensure that I bookmark your blog and will come back down the
road. I want to encourage continue your great job, have a nice afternoon!
Review my homepage :: A片
Do you mind if I quote a couple of your articles as long as I provide credit and sources
back to your blog? My website is in the very same area
of interest as yours and my visitors would certainly benefit
from some of the information you provide here. Please let me know
if this ok with you. Regards!
Your style is very unique compared to other people I’ve read stuff from.
Many thanks for posting when you have the opportunity, Guess
I’ll just bookmark this page.
My brother recommended I might like this web site.
He was totally right. This post actually made my day. You cann’t imagine simply
how much time I had spent for this info! Thanks!
I do not even understand how I stopped up right here, but I thought this post was good.
I don’t realize who you’re but certainly you are going to a famous blogger in case you aren’t already.
Cheers!
Greetings! Very useful advice in this particular post!
It’s the little changes which will make the biggest changes.
Thanks a lot for sharing!
continuously i used to read smaller articles or reviews which also clear their motive, and that is also happening with this piece of writing which I am reading at this time.
I like the valuable info you provide for your articles. I will bookmark your weblog
and test again here regularly. I am fairly certain I will learn a lot of
new stuff right here! Good luck for the next!
For most recent news you have to pay a quick visit the web
and on the web I found this site as a most excellent web site for hottest updates.
Hello are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and set
up my own. Do you need any coding expertise to make your own blog?
Any help would be really appreciated!
If you wish for to get much from this post then you have to apply these techniques to your won web site.
I’m extremely inspired along with your writing abilities and also with the structure on your blog.
Is that this a paid subject or did you customize it yourself?
Anyway stay up the excellent high quality writing, it is rare to look a nice blog like this one
today..
Do you have a spam issue on this site; I also am a blogger, and I
was curious about your situation; we have developed some nice methods
and we are looking to trade strategies with other folks, why not
shoot me an email if interested.
My spouse and I stumbled over here coming from a different
page and thought I may as well check things out. I like what I see so now i am following you.
Look forward to looking into your web page repeatedly.
Everything is very open with a clear explanation of the challenges.
It was really informative. Your site is very helpful. Thanks for sharing!
When someone writes an piece of writing he/she maintains the plan of a user in his/her
mind that how a user can be aware of it. Therefore that’s why this paragraph is great.
Thanks!
Hello i am kavin, its my first occasion to commenting anywhere, when i read this article i thought i could also create comment due to
this good paragraph.
ขายยาสอด ยาทำแท้ง ยาขับเลือด ยาเหน็บ ยาขับประจำเดือน
ปรึกษาได้24ชม.
https://cytershop.com/product2.html
Thank you for every other informative site. Where else may I am getting that type of info written in such an ideal manner?
I’ve a challenge that I’m just now operating on, and I’ve been at the look out for such information.
You actually make it seem so easy with your presentation but I
find this matter to be actually something that I think I would never understand.
It seems too complicated and very broad for me. I am looking forward for your next post,
I will try to get the hang of it!
It’s very trouble-free to find out any matter on web as compared to textbooks, as I found this post at this web page.
Undeniably believe that that you said. Your favorite reason seemed to be at the
web the simplest thing to have in mind of.
I say to you, I certainly get annoyed while folks think
about concerns that they just do not realize about.
You controlled to hit the nail upon the top as well as outlined out
the whole thing without having side effect , folks can take a signal.
Will likely be again to get more. Thank you
Hello, just wanted to mention, I enjoyed this post.
It was helpful. Keep on posting!
I couldn’t refrain from commenting. Exceptionally well written!
hello there and thank you for your information – I’ve certainly picked up
anything new from right here. I did however expertise several technical issues using this website, as
I experienced to reload the site many times previous to I could get it to load correctly.
I had been wondering if your web hosting is OK?
Not that I am complaining, but sluggish loading instances times will often affect your placement in google and could damage your quality score
if ads and marketing with Adwords. Anyway I’m adding
this RSS to my e-mail and can look out for a lot more of your respective fascinating content.
Ensure that you update this again soon.
I am sure this post has touched all the internet visitors, its
really really good piece of writing on building up new weblog.
Here is my web blog :: Hyzaar
Every weekend i used to visit this web site, as i want enjoyment, as
this this web site conations truly pleasant funny information too.
Having read this I believed it was really enlightening.
I appreciate you finding the time and effort to put this content together.
I once again find myself spending a lot of time both
reading and commenting. But so what, it was still worthwhile!
Thank you a lot for sharing this with all of us you actually know what you are talking about!
Bookmarked. Kindly additionally seek advice from my website
=). We may have a hyperlink exchange arrangement among us
Hi every one, here every person is sharing these familiarity,
therefore it’s good to read this weblog, and I used to go to see this webpage daily.
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s
tough to get that “perfect balance” between user friendliness and appearance.
I must say you’ve done a great job with this. Also, the blog loads very quick
for me on Chrome. Outstanding Blog!
This is my first time go to see at here and i am really pleassant to read everthing at alone place.
Having read this I believed it was rather informative.
I appreciate you finding the time and effort to put this short article together.
I once again find myself personally spending a lot of
time both reading and leaving comments. But so what, it was still worth
it!
I really like reading through an article that will make people think.
Also, thanks for allowing me to comment!
Hi there would you mind sharing which blog platform you’re working
with? I’m looking to start my own blog in the near future but I’m having a difficult time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most
blogs and I’m looking for something completely unique.
P.S Apologies for getting off-topic but I had to ask!
An interesting discussion is worth comment. There’s
no doubt that that you ought to publish more on this subject,
it might not be a taboo matter but typically folks don’t discuss these issues.
To the next! Cheers!!
I am regular reader, how are you everybody? This piece of writing posted at this web page is
actually good.
Wow, incredible blog structure! How long have you ever been running a blog for?
you make blogging look easy. The entire look of your website is magnificent,
as well as the content material!
I’m really impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Anyway keep up the excellent quality writing, it’s rare to see a nice blog like this one today.
It’s in fact very complex in this busy life to listen news on TV, therefore I simply use the web for that reason, and get the newest information.
This piece of writing is genuinely a pleasant one it assists new net
visitors, who are wishing for blogging.
It’s remarkable to go to see this web page and reading the
views of all mates concerning this paragraph, while I am also zealous of getting experience.
Hey just wanted to give you a quick heads up and let you know a
few of the images aren’t loading properly. I’m not sure why
but I think its a linking issue. I’ve tried it in two different internet
browsers and both show the same results.
my blog post: 熟女
With havin so much content do you ever run into any issues of plagorism
or copyright violation? My blog has a lot of exclusive content I’ve either written myself or outsourced but
it appears a lot of it is popping it up all over the web without my agreement.
Do you know any ways to help stop content from being ripped off?
I’d certainly appreciate it.
Thanks for helping out, good info.
Stop by my website :: Essential Blood Flow Review
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message home
a little bit, but other than that, this is great blog.
An excellent read. I will definitely be back.
Hmm is anyone else experiencing problems with the pictures on this blog loading?
I’m trying to figure out if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
This is my first time pay a quick visit at here and i am in fact impressed to read everthing
at alone place.
Wow, this article is fastidious, my younger sister is analyzing these things, thus I am going to convey her.
Dr. Kevin Sadati is an exceptionally skilled plastic surgeon with a
high level of specialisation. He is a painter and sculptor who is also very passionate about the arts.
He is most recognised for developing the procedure known as “Natural Lift,” which lifts the lower face and neck.
This ground-breaking method is special because of his Triple-C plication of the SMAS approach.
To ensure that his patients look natural and not pulled, he gradually tightens the SMAS, commonly known as the face and
neck muscles, in three layers.
We developed a surgical centre that is genuinely
state-of-the-art, completely furnished with cutting-edge equipment imported from Germany, a country renowned for its unmatched precision in surgical manufacture, because we feel that our
patients deserve the finest. Our building
Hey very nice site!! Guy .. Excellent .. Superb .. I will bookmark
your web site and take the feeds additionally?
I’m happy to search out a lot of helpful information right here
in the put up, we need develop more strategies in this regard, thanks for sharing.
. . . . .
Have you ever considered writing an e-book or guest authoring on other
websites? I have a blog centered on the same information you discuss
and would really like to have you share some stories/information. I know my visitors
would appreciate your work. If you are even remotely interested, feel free
to send me an e-mail.
Because the admin of this site is working, no hesitation very quickly it will be famous, due to its feature contents.
Hey! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My blog looks weird when browsing from my apple iphone.
I’m trying to find a theme or plugin that might be able to correct this issue.
If you have any suggestions, please share. Many thanks!
Hey there! I know this is kinda off topic however
, I’d figured I’d ask. Would you be interested in exchanging links or maybe guest
authoring a blog post or vice-versa? My site goes over a lot of the
same topics as yours and I believe we could greatly benefit from each other.
If you might be interested feel free to shoot me an email.
I look forward to hearing from you! Superb blog by
the way!
Greetings! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly? My site looks weird when viewing from
my iphone4. I’m trying to find a template or plugin that might be able to fix this issue.
If you have any suggestions, please share.
Cheers!
Stop by my web page: Natures Heart CBD Gummies 500mg
Everyone loves it when folks get together and share opinions.
Great blog, stick with it!
If some one wishes expert view regarding blogging then i suggest him/her
to go to see this webpage, Keep up the nice job.
Hello just wanted to give you a quick heads up.
The text in your content seem to be running off the screen in Internet explorer.
I’m not sure if this is a format issue or something to do with web browser compatibility but
I figured I’d post to let you know. The design look great though!
Hope you get the issue fixed soon. Many thanks
My blog post: agen slot terpercaya
Yes! Finally someone writes about acai berry pills.
My blog: Essential Blood Flow Side Effects
Generally I don’t learn post on blogs, but I would like to
say that this write-up very pressured me
to take a look at and do it! Your writing style has been amazed me.
Thank you, quite nice post.
I have to thank you for the efforts you’ve put in penning this website.
I really hope to see the same high-grade blog posts by you in the future as
well. In truth, your creative writing abilities has motivated me to get my very own blog now 😉
Having read this I thought it was extremely enlightening.
I appreciate you taking the time and energy to put this article together.
I once again find myself personally spending a lot of time
both reading and commenting. But so what, it was
still worthwhile!
What’s up to every body, it’s my first pay a visit of this website; this weblog carries awesome and
really good stuff for readers.
Do you have a spam problem on this site; I also am a blogger, and I was wanting to know
your situation; many of us have developed
some nice procedures and we are looking to swap solutions with other folks, please shoot me an email if interested.
With havin so much content do you ever run into any problems of plagorism
or copyright infringement? My blog has a lot of exclusive content I’ve either authored myself or
outsourced but it seems a lot of it is popping it up all
over the web without my authorization. Do you
know any methods to help reduce content from being
stolen? I’d genuinely appreciate it.
Good day! I know this is somewhat off topic but I was wondering if
you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
Hi there i am kavin, its my first time to commenting anywhere,
when i read this article i thought i could also create comment due to this
brilliant post.
Thanks a ton for being my own teacher on this niche.
We enjoyed your current article quite definitely and most of all preferred the way in which you handled the aspect I widely known as controversial.
You are always quite kind towards readers really
like me and assist me in my life. Thank you.
my page – Essential Blood Flow Reviews
Nice post. I was checking continuously this blog and I’m impressed!
Very useful information specifically the last part I care for such information much.
I care for such information much.
I was looking for this particular info for a long time. Thank you and good luck.
What’s up colleagues, its wonderful piece of writing concerning teachingand fully defined, keep it up all the
time.
Hi there mates, how is all, and what you desire to say on the topic of this piece of writing, in my view its truly remarkable for me.
I couldn’t resist commenting. Perfectly written!
Nie ma właściwości psychoaktywnych – w przeciwieństwie do THC,
głównego składnika konopi indyjskich, CBD nie powoduje euforii ani stanów halucynacyjnych.
Ma działanie przeciwzapalne – CBD wykazuje silne
właściwości przeciwzapalne, co może pomóc w
leczeniu wielu chorób i stanów zapalnych.
Ma właściwości przeciwbólowe – CBD może pomóc w łagodzeniu bólu, zarówno w przypadku bólu przewlekłego,
jak i ostrego.
Ma działanie przeciwdrgawkowe – badania wykazują, że CBD może pomóc w łagodzeniu objawów epilepsji.
Ma działanie przeciwlękowe – CBD może pomóc w łagodzeniu objawów lęku i
depresji.
Może pomóc w leczeniu chorób układu sercowo-naczyniowego –
CBD wykazuje właściwości obniżające ciśnienie krwi, co może pomóc w łagodzeniu objawów chorób układu sercowo-naczyniowego.
Może pomóc w leczeniu chorób neurodegeneracyjnych – badania sugerują, że CBD może pomóc w łagodzeniu objawów chorób takich jak choroba Alzheimera, Parkinsona i stwardnienie rozsiane.
Nie wywołuje efektów ubocznych – CBD uważany jest
za stosunkowo bezpieczny związek chemiczny,
który nie wywołuje poważnych skutków ubocznych.
[url=https://cbdxmcpl.weebly.com/blog/konopie-cbd-czym-sa]https://cbdxmcpl.weebly.com/blog/konopie-cbd-czym-sa[/url]
[url=https://cbdsklepxmcpl.bravesites.com/entries/general/czym-jest-cbd]https://cbdsklepxmcpl.bravesites.com/entries/general/czym-jest-cbd[/url]
[url=https://cbdxmcpl.edublogs.org/2023/04/28/czm-sa-konopie-cbd/]https://cbdxmcpl.edublogs.org/2023/04/28/czm-sa-konopie-cbd/[/url]
[url=https://cbdxmcpl.jigsy.com/entries/general/konopie-marihuana-cannabis-cbd]https://cbdxmcpl.jigsy.com/entries/general/konopie-marihuana-cannabis-cbd[/url]
[url=http://cbdsklepxmcpl.huicopper.com/co-to-jest-cbd-i-produkty-tego-typu]http://cbdsklepxmcpl.huicopper.com/co-to-jest-cbd-i-produkty-tego-typu[/url]
[url=http://cbdxmcpl.wpsuo.com/cbd-wlasciwosci-i-charakterystyka]http://cbdxmcpl.wpsuo.com/cbd-wlasciwosci-i-charakterystyka[/url]
[url=http://cbdxmcpl.yousher.com/konopie-marihuana-cannabis-cbd]http://cbdxmcpl.yousher.com/konopie-marihuana-cannabis-cbd[/url]
[url=http://cbdxmcpl.iamarrows.com/cbd-czym-jest]http://cbdxmcpl.iamarrows.com/cbd-czym-jest[/url]
[url=https://cbd31.page.tl/CBD-Najwazniejsze-informacje.htm]https://cbd31.page.tl/CBD-Najwazniejsze-informacje.htm[/url]
[url=https://penzu.com/p/919e4bd8]https://penzu.com/p/919e4bd8[/url]
[url=https://medium.com/@cbd3/cbd-z-czym-to-sie-je-2df83ab821b?source=your_stories_page————————————-]https://medium.com/@cbd3/cbd-z-czym-to-sie-je-2df83ab821b?source=your_stories_page————————————-[/url]
[url=http://cbdxmcpl.theburnward.com/produkty-cbd-czym-sa]http://cbdxmcpl.theburnward.com/produkty-cbd-czym-sa[/url]
[url=http://cbdxmcpl.timeforchangecounselling.com/cbd-czym-jest]http://cbdxmcpl.timeforchangecounselling.com/cbd-czym-jest[/url]
[url=http://cbdxmcpl.trexgame.net/cbd-najwazniejsze-informacje]http://cbdxmcpl.trexgame.net/cbd-najwazniejsze-informacje[/url]
[url=http://cbdsklepxmcpl.image-perth.org/cbd-najwazniejsze-informacje]http://cbdsklepxmcpl.image-perth.org/cbd-najwazniejsze-informacje[/url]
[url=http://cbdxmcpl.theglensecret.com/cbd-z-czym-to-sie-je]http://cbdxmcpl.theglensecret.com/cbd-z-czym-to-sie-je[/url]
[url=http://cbdsklepxmcpl.cavandoragh.org/co-to-jest-cbd-i-produkty-tego-typu]http://cbdsklepxmcpl.cavandoragh.org/co-to-jest-cbd-i-produkty-tego-typu[/url]
[url=http://cbdxmcpl.tearosediner.net/susz-konopny-cbd]http://cbdxmcpl.tearosediner.net/susz-konopny-cbd[/url]
[url=http://cbdsklepxmcpl.raidersfanteamshop.com/co-to-jest-cbd-i-produkty-tego-typu]http://cbdsklepxmcpl.raidersfanteamshop.com/co-to-jest-cbd-i-produkty-tego-typu[/url]
[url=http://cbdxmcpl.bearsfanteamshop.com/co-to-jest-cbd-i-produkty-tego-typu]http://cbdxmcpl.bearsfanteamshop.com/co-to-jest-cbd-i-produkty-tego-typu[/url]
[url=http://cbdxmcpl.almoheet-travel.com/legalna-marihuana-cbd]http://cbdxmcpl.almoheet-travel.com/legalna-marihuana-cbd[/url]
[url=http://cbdsklepxmcpl.lucialpiazzale.com/susz-konopny-cbd]http://cbdsklepxmcpl.lucialpiazzale.com/susz-konopny-cbd[/url]
[url=http://cbdxmcpl.lowescouponn.com/czym-jest-cbd]http://cbdxmcpl.lowescouponn.com/czym-jest-cbd[/url]
[url=http://cbdsklepxmcpl.fotosdefrases.com/produkty-cbd-czym-sa]http://cbdsklepxmcpl.fotosdefrases.com/produkty-cbd-czym-sa[/url]
[url=https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej]https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej[/url]
[url=https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej]https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej[/url]
[url=https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej]https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej[/url]
[url=https://ameblo.jp/cbdxmcpl/entry-12800673949.html]https://ameblo.jp/cbdxmcpl/entry-12800673949.html[/url]
[url=https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Susz_Konopny_CBD]https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Susz_Konopny_CBD[/url]
[url=https://cbdsklepxmcpl.hpage.com/post1.html]https://cbdsklepxmcpl.hpage.com/post1.html[/url]
[url=https://truxgo.net/blogs/457616/1587245/susz-konopny-cbd]https://truxgo.net/blogs/457616/1587245/susz-konopny-cbd[/url]
[url=https://cbdsklepxmcpl.substack.com/p/co-to-jest-cbd-i-produkty-tego-typu?sd=pf]https://cbdsklepxmcpl.substack.com/p/co-to-jest-cbd-i-produkty-tego-typu?sd=pf[/url]
[url=https://cbdxmcpl.weebly.com/blog/cbd-najwazniejsze-informacje]https://cbdxmcpl.weebly.com/blog/cbd-najwazniejsze-informacje[/url]
[url=https://cbdsklepxmcpl.bravesites.com/entries/general/co-to-jest-cbd]https://cbdsklepxmcpl.bravesites.com/entries/general/co-to-jest-cbd[/url]
[url=https://cbdxmcpl.edublogs.org/2023/04/28/konopie-marihuana-cannabis-cbd/]https://cbdxmcpl.edublogs.org/2023/04/28/konopie-marihuana-cannabis-cbd/[/url]
[url=https://cbdxmcpl.jigsy.com/entries/general/konopie-cbd-czym-s%C4%85]https://cbdxmcpl.jigsy.com/entries/general/konopie-cbd-czym-s%C4%85[/url]
[url=http://cbdsklepxmcpl.huicopper.com/cbd-z-czym-to-sie-je]http://cbdsklepxmcpl.huicopper.com/cbd-z-czym-to-sie-je[/url]
[url=http://cbdxmcpl.wpsuo.com/produkty-cbd-czym-sa]http://cbdxmcpl.wpsuo.com/produkty-cbd-czym-sa[/url]
[url=http://cbdxmcpl.yousher.com/produkty-cbd-czym-sa]http://cbdxmcpl.yousher.com/produkty-cbd-czym-sa[/url]
[url=http://cbdxmcpl.iamarrows.com/susz-konopny-cbd]http://cbdxmcpl.iamarrows.com/susz-konopny-cbd[/url]
[url=https://cbd31.page.tl/Susz-Konopny-CBD.htm]https://cbd31.page.tl/Susz-Konopny-CBD.htm[/url]
[url=https://penzu.com/p/033e07dc]https://penzu.com/p/033e07dc[/url]
[url=https://medium.com/@cbd3/czym-jest-cbd-301499af1340?source=your_stories_page————————————-]https://medium.com/@cbd3/czym-jest-cbd-301499af1340?source=your_stories_page————————————-[/url]
[url=http://cbdxmcpl.theburnward.com/sklep-konopny-z-suszem-cbd]http://cbdxmcpl.theburnward.com/sklep-konopny-z-suszem-cbd[/url]
[url=http://cbdxmcpl.timeforchangecounselling.com/produkty-cbd-czym-sa]http://cbdxmcpl.timeforchangecounselling.com/produkty-cbd-czym-sa[/url]
[url=http://cbdxmcpl.trexgame.net/cbd-czym-jest]http://cbdxmcpl.trexgame.net/cbd-czym-jest[/url]
[url=http://cbdsklepxmcpl.image-perth.org/sklep-konopny-z-suszem-cbd]http://cbdsklepxmcpl.image-perth.org/sklep-konopny-z-suszem-cbd[/url]
[url=http://cbdxmcpl.theglensecret.com/cannabis-cbd]http://cbdxmcpl.theglensecret.com/cannabis-cbd[/url]
[url=http://cbdsklepxmcpl.cavandoragh.org/konopie-marihuana-cannabis-cbd]http://cbdsklepxmcpl.cavandoragh.org/konopie-marihuana-cannabis-cbd[/url]
[url=http://cbdxmcpl.tearosediner.net/cbd-najwazniejsze-informacje]http://cbdxmcpl.tearosediner.net/cbd-najwazniejsze-informacje[/url]
[url=http://cbdsklepxmcpl.raidersfanteamshop.com/cannabis-cbd]http://cbdsklepxmcpl.raidersfanteamshop.com/cannabis-cbd[/url]
[url=http://cbdxmcpl.bearsfanteamshop.com/susz-konopny-cbd]http://cbdxmcpl.bearsfanteamshop.com/susz-konopny-cbd[/url]
[url=http://cbdxmcpl.almoheet-travel.com/legalna-marihuana-cbd-1]http://cbdxmcpl.almoheet-travel.com/legalna-marihuana-cbd-1[/url]
[url=http://cbdsklepxmcpl.lucialpiazzale.com/cbd-czym-jest]http://cbdsklepxmcpl.lucialpiazzale.com/cbd-czym-jest[/url]
[url=http://cbdxmcpl.lowescouponn.com/czym-jest-cbd-1]http://cbdxmcpl.lowescouponn.com/czym-jest-cbd-1[/url]
[url=http://cbdsklepxmcpl.fotosdefrases.com/sklep-konopny-z-suszem-cbd]http://cbdsklepxmcpl.fotosdefrases.com/sklep-konopny-z-suszem-cbd[/url]
[url=https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-cvbz]https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-cvbz[/url]
[url=https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-4pqp]https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-4pqp[/url]
[url=https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-ptgz]https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-ptgz[/url]
[url=https://ameblo.jp/cbdxmcpl/entry-12800675446.html]https://ameblo.jp/cbdxmcpl/entry-12800675446.html[/url]
[url=https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Co_to_jest_CBD_i_produkty_tego_typu]https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Co_to_jest_CBD_i_produkty_tego_typu[/url]
[url=https://cbdsklepxmcpl.hpage.com/post2.html]https://cbdsklepxmcpl.hpage.com/post2.html[/url]
[url=https://truxgo.net/blogs/457616/1587284/legalna-marihuana-cbd]https://truxgo.net/blogs/457616/1587284/legalna-marihuana-cbd[/url]
[url=https://cbdsklepxmcpl.substack.com/p/cbd-sklep?sd=pf]https://cbdsklepxmcpl.substack.com/p/cbd-sklep?sd=pf[/url]
[url=https://cbdxmcpl.exposure.co/czm-sa-konopie-cbd?source=share-cbdxmcpl]https://cbdxmcpl.exposure.co/czm-sa-konopie-cbd?source=share-cbdxmcpl[/url]
[url=https://cbdxmcpl.weebly.com/blog/legalna-marihuana-cbd]https://cbdxmcpl.weebly.com/blog/legalna-marihuana-cbd[/url]
[url=https://cbdsklepxmcpl.bravesites.com/entries/general/sklep-konopny-z-suszem-cbd]https://cbdsklepxmcpl.bravesites.com/entries/general/sklep-konopny-z-suszem-cbd[/url]
[url=https://cbdxmcpl.edublogs.org/2023/04/28/cannabis-cbd/]https://cbdxmcpl.edublogs.org/2023/04/28/cannabis-cbd/[/url]
[url=https://cbdxmcpl.jigsy.com/entries/general/cbd-sklep]https://cbdxmcpl.jigsy.com/entries/general/cbd-sklep[/url]
[url=http://cbdsklepxmcpl.huicopper.com/cbd-z-czym-to-sie-je-1]http://cbdsklepxmcpl.huicopper.com/cbd-z-czym-to-sie-je-1[/url]
[url=http://cbdxmcpl.wpsuo.com/konopie-marihuana-cannabis-cbd]http://cbdxmcpl.wpsuo.com/konopie-marihuana-cannabis-cbd[/url]
[url=http://cbdxmcpl.yousher.com/konopie-marihuana-cannabis-cbd-1]http://cbdxmcpl.yousher.com/konopie-marihuana-cannabis-cbd-1[/url]
[url=http://cbdxmcpl.iamarrows.com/susz-konopny-cbd-1]http://cbdxmcpl.iamarrows.com/susz-konopny-cbd-1[/url]
[url=https://cbd31.page.tl/Co-to-jest-CBD.htm]https://cbd31.page.tl/Co-to-jest-CBD.htm[/url]
[url=https://penzu.com/p/0986c4e2]https://penzu.com/p/0986c4e2[/url]
[url=https://medium.com/@cbd3/konopie-marihuana-cannabis-cbd-f6baa0220f8c?source=your_stories_page————————————-]https://medium.com/@cbd3/konopie-marihuana-cannabis-cbd-f6baa0220f8c?source=your_stories_page————————————-[/url]
[url=http://cbdxmcpl.theburnward.com/cannabis-cbd]http://cbdxmcpl.theburnward.com/cannabis-cbd[/url]
[url=http://cbdxmcpl.timeforchangecounselling.com/co-to-jest-cbd-i-produkty-tego-typu]http://cbdxmcpl.timeforchangecounselling.com/co-to-jest-cbd-i-produkty-tego-typu[/url]
[url=http://cbdxmcpl.trexgame.net/cbd-czym-jest-1]http://cbdxmcpl.trexgame.net/cbd-czym-jest-1[/url]
[url=http://cbdsklepxmcpl.image-perth.org/cbd-wlasciwosci-i-charakterystyka]http://cbdsklepxmcpl.image-perth.org/cbd-wlasciwosci-i-charakterystyka[/url]
[url=http://cbdxmcpl.theglensecret.com/co-to-jest-cbd]http://cbdxmcpl.theglensecret.com/co-to-jest-cbd[/url]
[url=http://cbdsklepxmcpl.cavandoragh.org/cannabis-cbd]http://cbdsklepxmcpl.cavandoragh.org/cannabis-cbd[/url]
[url=http://cbdxmcpl.tearosediner.net/co-to-jest-cbd-i-produkty-tego-typu]http://cbdxmcpl.tearosediner.net/co-to-jest-cbd-i-produkty-tego-typu[/url]
[url=http://cbdsklepxmcpl.raidersfanteamshop.com/sklep-konopny-z-suszem-cbd]http://cbdsklepxmcpl.raidersfanteamshop.com/sklep-konopny-z-suszem-cbd[/url]
[url=http://cbdxmcpl.bearsfanteamshop.com/cbd-czym-jest]http://cbdxmcpl.bearsfanteamshop.com/cbd-czym-jest[/url]
[url=http://cbdxmcpl.almoheet-travel.com/cbd-czym-jest]http://cbdxmcpl.almoheet-travel.com/cbd-czym-jest[/url]
[url=http://cbdsklepxmcpl.lucialpiazzale.com/cbd-sklep]http://cbdsklepxmcpl.lucialpiazzale.com/cbd-sklep[/url]
[url=http://cbdxmcpl.lowescouponn.com/cbd-czym-jest]http://cbdxmcpl.lowescouponn.com/cbd-czym-jest[/url]
[url=http://cbdsklepxmcpl.fotosdefrases.com/sklep-konopny-z-suszem-cbd-1]http://cbdsklepxmcpl.fotosdefrases.com/sklep-konopny-z-suszem-cbd-1[/url]
[url=https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-9pvc]https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-9pvc[/url]
[url=https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-rqfc]https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-rqfc[/url]
[url=https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-942c]https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-942c[/url]
[url=https://ameblo.jp/cbdxmcpl/entry-12800676357.html]https://ameblo.jp/cbdxmcpl/entry-12800676357.html[/url]
[url=https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Legalna_Marihuana_CBD]https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Legalna_Marihuana_CBD[/url]
[url=https://cbdsklepxmcpl.hpage.com/post3.html]https://cbdsklepxmcpl.hpage.com/post3.html[/url]
[url=https://truxgo.net/blogs/457616/1587330/susz-konopny-cbd]https://truxgo.net/blogs/457616/1587330/susz-konopny-cbd[/url]
[url=https://cbdsklepxmcpl.substack.com/p/konopie-marihuana-cannabis-cbd?sd=pf]https://cbdsklepxmcpl.substack.com/p/konopie-marihuana-cannabis-cbd?sd=pf[/url]
[url=https://cbdxmcpl.exposure.co/konopie-cbd-czym-sa?source=share-cbdxmcpl]https://cbdxmcpl.exposure.co/konopie-cbd-czym-sa?source=share-cbdxmcpl[/url]
[url=https://cbdxmcpl.weebly.com/blog/co-to-jest-cbd-i-produkty-tego-typu]https://cbdxmcpl.weebly.com/blog/co-to-jest-cbd-i-produkty-tego-typu[/url]
[url=https://cbdxmcpl.edublogs.org/2023/04/28/co-to-jest-cbd-i-produkty-tego-typu/]https://cbdxmcpl.edublogs.org/2023/04/28/co-to-jest-cbd-i-produkty-tego-typu/[/url]
[url=http://cbdsklepxmcpl.huicopper.com/cbd-najwazniejsze-informacje]http://cbdsklepxmcpl.huicopper.com/cbd-najwazniejsze-informacje[/url]
[url=http://cbdxmcpl.wpsuo.com/cbd-wlasciwosci-i-charakterystyka-1]http://cbdxmcpl.wpsuo.com/cbd-wlasciwosci-i-charakterystyka-1[/url]
[url=http://cbdxmcpl.yousher.com/produkty-cbd-czym-sa-1]http://cbdxmcpl.yousher.com/produkty-cbd-czym-sa-1[/url]
[url=http://cbdxmcpl.iamarrows.com/cannabis-cbd]http://cbdxmcpl.iamarrows.com/cannabis-cbd[/url]
[url=https://cbd31.page.tl/Konopie-CBD-czym-s%26%23261%3B.htm]https://cbd31.page.tl/Konopie-CBD-czym-s%26%23261%3B.htm[/url]
[url=https://penzu.com/p/abafcfbd]https://penzu.com/p/abafcfbd[/url]
[url=https://medium.com/@cbd3/cbd-w%C5%82a%C5%9Bciwo%C5%9Bci-i-charakterystyka-75588bcc40a3?source=your_stories_page————————————-]https://medium.com/@cbd3/cbd-w%C5%82a%C5%9Bciwo%C5%9Bci-i-charakterystyka-75588bcc40a3?source=your_stories_page————————————-[/url]
[url=http://cbdxmcpl.theburnward.com/cannabis-cbd-1]http://cbdxmcpl.theburnward.com/cannabis-cbd-1[/url]
[url=http://cbdxmcpl.timeforchangecounselling.com/co-to-jest-cbd]http://cbdxmcpl.timeforchangecounselling.com/co-to-jest-cbd[/url]
[url=http://cbdxmcpl.trexgame.net/susz-konopny-cbd]http://cbdxmcpl.trexgame.net/susz-konopny-cbd[/url]
[url=http://cbdsklepxmcpl.image-perth.org/konopie-marihuana-cannabis-cbd]http://cbdsklepxmcpl.image-perth.org/konopie-marihuana-cannabis-cbd[/url]
[url=http://cbdxmcpl.theglensecret.com/cbd-sklep]http://cbdxmcpl.theglensecret.com/cbd-sklep[/url]
[url=http://cbdsklepxmcpl.cavandoragh.org/susz-konopny-cbd]http://cbdsklepxmcpl.cavandoragh.org/susz-konopny-cbd[/url]
[url=http://cbdxmcpl.tearosediner.net/konopie-cbd-czym-sa]http://cbdxmcpl.tearosediner.net/konopie-cbd-czym-sa[/url]
[url=http://cbdsklepxmcpl.raidersfanteamshop.com/cbd-najwazniejsze-informacje]http://cbdsklepxmcpl.raidersfanteamshop.com/cbd-najwazniejsze-informacje[/url]
[url=http://cbdxmcpl.bearsfanteamshop.com/cannabis-cbd]http://cbdxmcpl.bearsfanteamshop.com/cannabis-cbd[/url]
[url=http://cbdxmcpl.almoheet-travel.com/konopie-marihuana-cannabis-cbd]http://cbdxmcpl.almoheet-travel.com/konopie-marihuana-cannabis-cbd[/url]
[url=http://cbdsklepxmcpl.lucialpiazzale.com/cbd-z-czym-to-sie-je]http://cbdsklepxmcpl.lucialpiazzale.com/cbd-z-czym-to-sie-je[/url]
[url=http://cbdxmcpl.lowescouponn.com/konopie-marihuana-cannabis-cbd]http://cbdxmcpl.lowescouponn.com/konopie-marihuana-cannabis-cbd[/url]
[url=http://cbdsklepxmcpl.fotosdefrases.com/co-to-jest-cbd-i-produkty-tego-typu]http://cbdsklepxmcpl.fotosdefrases.com/co-to-jest-cbd-i-produkty-tego-typu[/url]
[url=https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-8gr8]https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-8gr8[/url]
[url=https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-l4dx]https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-l4dx[/url]
[url=https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-mlyn]https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-mlyn[/url]
[url=https://ameblo.jp/cbdxmcpl/entry-12800677331.html]https://ameblo.jp/cbdxmcpl/entry-12800677331.html[/url]
[url=https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Sklep_konopny_z_suszem_CBD]https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Sklep_konopny_z_suszem_CBD[/url]
[url=https://cbdsklepxmcpl.hpage.com/post4.html]https://cbdsklepxmcpl.hpage.com/post4.html[/url]
[url=https://truxgo.net/blogs/457616/1587377/cbd-czym-jest]https://truxgo.net/blogs/457616/1587377/cbd-czym-jest[/url]
[url=https://cbdsklepxmcpl.substack.com/p/cbd-najwazniejsze-informacje?sd=pf]https://cbdsklepxmcpl.substack.com/p/cbd-najwazniejsze-informacje?sd=pf[/url]
[url=https://cbdxmcpl.weebly.com/blog/susz-konopny-cbd]https://cbdxmcpl.weebly.com/blog/susz-konopny-cbd[/url]
[url=https://cbdxmcpl.edublogs.org/2023/04/28/czm-sa-konopie-cbd-2/]https://cbdxmcpl.edublogs.org/2023/04/28/czm-sa-konopie-cbd-2/[/url]
[url=http://cbdsklepxmcpl.huicopper.com/konopie-cbd-czym-sa]http://cbdsklepxmcpl.huicopper.com/konopie-cbd-czym-sa[/url]
[url=http://cbdxmcpl.wpsuo.com/produkty-cbd-czym-sa-1]http://cbdxmcpl.wpsuo.com/produkty-cbd-czym-sa-1[/url]
[url=http://cbdxmcpl.yousher.com/cbd-czym-jest]http://cbdxmcpl.yousher.com/cbd-czym-jest[/url]
[url=http://cbdxmcpl.iamarrows.com/cbd-najwazniejsze-informacje]http://cbdxmcpl.iamarrows.com/cbd-najwazniejsze-informacje[/url]
[url=https://penzu.com/p/b7b72f41]https://penzu.com/p/b7b72f41[/url]
[url=https://medium.com/@cbd3/produkty-cbd-czym-s%C4%85-280d1a05cd6b?source=your_stories_page————————————-]https://medium.com/@cbd3/produkty-cbd-czym-s%C4%85-280d1a05cd6b?source=your_stories_page————————————-[/url]
[url=http://cbdxmcpl.theburnward.com/konopie-marihuana-cannabis-cbd]http://cbdxmcpl.theburnward.com/konopie-marihuana-cannabis-cbd[/url]
[url=http://cbdxmcpl.timeforchangecounselling.com/co-to-jest-cbd-1]http://cbdxmcpl.timeforchangecounselling.com/co-to-jest-cbd-1[/url]
[url=http://cbdxmcpl.trexgame.net/co-to-jest-cbd]http://cbdxmcpl.trexgame.net/co-to-jest-cbd[/url]
[url=http://cbdsklepxmcpl.image-perth.org/sklep-konopny-z-suszem-cbd-1]http://cbdsklepxmcpl.image-perth.org/sklep-konopny-z-suszem-cbd-1[/url]
[url=http://cbdxmcpl.theglensecret.com/co-to-jest-cbd-1]http://cbdxmcpl.theglensecret.com/co-to-jest-cbd-1[/url]
[url=http://cbdsklepxmcpl.cavandoragh.org/cbd-najwazniejsze-informacje]http://cbdsklepxmcpl.cavandoragh.org/cbd-najwazniejsze-informacje[/url]
[url=http://cbdxmcpl.tearosediner.net/konopie-cbd-czym-sa-1]http://cbdxmcpl.tearosediner.net/konopie-cbd-czym-sa-1[/url]
[url=http://cbdsklepxmcpl.raidersfanteamshop.com/cbd-najwazniejsze-informacje-1]http://cbdsklepxmcpl.raidersfanteamshop.com/cbd-najwazniejsze-informacje-1[/url]
[url=http://cbdxmcpl.bearsfanteamshop.com/czym-jest-cbd]http://cbdxmcpl.bearsfanteamshop.com/czym-jest-cbd[/url]
[url=http://cbdxmcpl.almoheet-travel.com/czm-sa-konopie-cbd]http://cbdxmcpl.almoheet-travel.com/czm-sa-konopie-cbd[/url]
[url=http://cbdsklepxmcpl.lucialpiazzale.com/sklep-konopny-z-suszem-cbd]http://cbdsklepxmcpl.lucialpiazzale.com/sklep-konopny-z-suszem-cbd[/url]
[url=http://cbdxmcpl.lowescouponn.com/konopie-marihuana-cannabis-cbd-1]http://cbdxmcpl.lowescouponn.com/konopie-marihuana-cannabis-cbd-1[/url]
[url=http://cbdsklepxmcpl.fotosdefrases.com/cbd-wlasciwosci-i-charakterystyka]http://cbdsklepxmcpl.fotosdefrases.com/cbd-wlasciwosci-i-charakterystyka[/url]
[url=https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-8y69]https://zenwriting.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-8y69[/url]
[url=https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-bjv1]https://writeablog.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-bjv1[/url]
[url=https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-7n0n]https://postheaven.net/cbd3xmcpl/h1-marihuana-konopie-cbd-h1-konopie-cbd-to-odmiana-konopi-siewnej-7n0n[/url]
[url=https://ameblo.jp/cbdxmcpl/entry-12800708937.html]https://ameblo.jp/cbdxmcpl/entry-12800708937.html[/url]
[url=https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Czym_jest_CBD]https://canvas.instructure.com/eportfolios/2069923/cbdxmcpl/Czym_jest_CBD[/url]
[url=https://cbdsklepxmcpl.hpage.com/post5.html]https://cbdsklepxmcpl.hpage.com/post5.html[/url]
[url=https://truxgo.net/blogs/457616/1588162/susz-konopny-cbd]https://truxgo.net/blogs/457616/1588162/susz-konopny-cbd[/url]
Good information. Lucky me I recently found your blog by accident (stumbleupon).
I’ve bookmarked it for later!
A fascinating discussion is worth comment. I believe that you
ought to publish more about this subject, it may not be a taboo subject but
typically people don’t talk about such subjects.
To the next! Cheers!!
Hi there, just became alert to your blog through Google, and found that
it is truly informative. I am gonna watch out for brussels.
I’ll appreciate if you continue this in future. A lot of people
will be benefited from your writing. Cheers!
I am genuinely happy to read this website posts which carries plenty of valuable data, thanks for providing these
kinds of data.
It is perfect time to make some plans for the future
and it’s time to be happy. I have read this post and if I could I desire to suggest you few interesting things or tips.
Maybe you could write next articles referring to this article.
I want to read more things about it!
These are genuinely fantastic ideas in on the topic of blogging.
You have touched some nice things here. Any way keep up wrinting.
Fastidious answers in return of this issue with real arguments and explaining
the whole thing on the topic of that.
Excellent weblog here! Also your web site loads up fast!
What host are you the usage of? Can I get your associate
link to your host? I desire my web site loaded up as quickly
as yours lol
wonderful put up, very informative. I wonder why the
other specialists of this sector don’t realize this. You must continue
your writing. I am confident, you’ve a huge readers’ base already!
Good day very nice site!! Guy .. Excellent .. Amazing ..
I will bookmark your website and take the feeds also?
I am satisfied to seek out a lot of useful information right here within the submit, we’d
like work out extra strategies on this regard, thank you for sharing.
. . . . .
Hey I know this is off topic but I was wondering if you knew of
any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some
experience with something like this. Please
let me know if you run into anything. I truly enjoy reading your
blog and I look forward to your new updates.
Hi there! This is my first visit to your blog!
We are a group of volunteers and starting a new project in a community
in the same niche. Your blog provided us valuable information to
work on. You have done a outstanding job!
my webpage: Saxenda
An interesting discussion is worth comment. There’s no doubt that that you ought to write more about this subject, it
may not be a taboo matter but usually people don’t talk about such subjects.
To the next! All the best!!
Greetings from Florida! I’m bored to death at work so I decided to check out your website on my iphone during lunch break.
I really like the knowledge you present here and can’t wait
to take a look when I get home. I’m surprised at how fast your blog loaded on my
cell phone .. I’m not even using WIFI, just 3G .. Anyways, great site!
No matter if some one searches for his necessary thing,
thus he/she wishes to be available that in detail, thus that thing is maintained over
here.
my page :: Cash For Houses™
Hello there! This post could not be written any better! Going through this article reminds me of my previous roommate!
He constantly kept talking about this. I most certainly will
forward this post to him. Fairly certain he’s going to have a
very good read. I appreciate you for sharing!
Hi tһere! I c᧐uld have swߋrn I’ve visited
this site before but after goijng through many of
the posts I realized it’s new to me. Nonetheless, I’m
certɑinly delighted I found it and I’ll Ье bookmarking it and checking back frequentlү!
Feel free tο visit my web-site – Slot Dewa99
Why visitors still make use of to read news papers when in this technological world the
whole thing is existing on web?
Unquestionably believe that which you said. Your favorite
reason seemed to be on the net the simplest thing to be aware of.
I say to you, I certainly get irked while people think about worries that they plainly do
not know about. You managed to hit the nail upon the top and defined
out the whole thing without having side effect , people could take a signal.
Will likely be back to get more. Thanks
Very good article. I’m going through many of these issues as well..
Hello are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my
own. Do you need any html coding knowledge to make your own blog?
Any help would be really appreciated!
Hello! This post could not be written any better! Reading
this post reminds me of my previous room mate! He always kept chatting about this.
I will forward this page to him. Pretty sure he will have a good read.
Thank you for sharing!
Wow, that’s what I was searching for, what a information! existing here at this webpage, thanks
admin of this web page.
Нeya i am for the primary time here. I found this boarɗ
and I in fіnding It really helpful & it helped
me out a lot. I hope to present something back and help
others like yyou helpeⅾ me.
my blog post; Slot Dewa99
It’s going to be end of mine day, but before end I am reading this impressive paragraph to improve my experience.
Here is my homepage: Cash for Houses™
I am regular visitor, how are you everybody? This post posted at this
web page is really fastidious.
You ought to be a part of a contest for one of the greatest websites online.
I most certainly will highly recommend this blog!
Hi there, its good piece of writing regarding media print, we
all be familiar with media is a impressive source of facts.
batmanapollo.ru
Hey, І thіnk yoᥙr blog mіght be having browser compatibility issues.
Ꮃhen I look at your blog site іn Safari, it lⲟoks fine Ьut when opening
in Internet Explorer, itt һaѕ ѕome overlapping.
I ϳust ԝanted to give you а quhick heads ᥙp! Otһеr
then that, wonderful blog!
my web page: 바카라사이트
Yes! Finally something about https://www.linkedin.com/in/fun88vi.
Oh my goodness! Impressive article dude! Many thanks, However I
am having troubles with your RSS. I don’t understand
why I am unable to join it. Is there anybody else getting the same RSS problems?
Anyone who knows the answer can you kindly
respond? Thanx!!
Good day! This post could not be written any better! Reading this post reminds me
of my previous room mate! He always kept chatting about this.
I will forward this write-up to him. Pretty sure he will have a
good read. Many thanks for sharing!
HBO4D : Situs SLOT88 Slot Gacor Online Resmi Pulsa Gampang Menang
Selamat datang di SLOT88 selaku salah satu situs
slot88 resmi terpercaya yang kembali hadir dengan judi slot online
terbaru dan terlengkap dengan provider game slot gacor gampang menang di
Indonesia. Slot Gacor yang bisa diakses 24 jam ini telah bekerjasama dengan beberapa perusahaan pengembang game
slot gacor berkelas Internasional yang mana permainan slot online gacor saat
ini sudah disediakan dengan sangat lengkap di antara situs slot gacor maxwin lainnya.
Sebut saja Pragmatic Play, Habanero, PG Soft, dan beberapa provider slot online terbesar lainnya, itulah beberapa contoh situs
slot online terpercaya lainnya yang dapat kamu mainkan jika sudah bergabung pada
situs kami yaitu Slot Gacor resmi gampang menang di Indonesia.
Great post. I was checking constantly this blog and I am I care for such
I care for such
impressed! Extremely useful info specifically the last part
info a lot. I was looking for this particular info for a long time.
Thank you and good luck.
Hi! I know this is kind of off topic but I was wondering
which blog platform are you using for this website? I’m getting tired of WordPress because I’ve had problems with hackers and I’m
looking at options for another platform. I would be fantastic if you could point me in the direction of
a good platform.
Hey There. I found your blog using msn. This is a really well written article.
I’ll make sure to bookmark it and come back to read more of your
useful info. Thanks for the post. I’ll definitely return.
Hey there! Someone in my Facebook group shared this website
with us so I came to look it over. I’m definitely enjoying the information.
I’m book-marking and will be tweeting this to my followers!
Wonderful blog and fantastic style and design.
Hi there! Do you know if they make any plugins to assist with Search Engine Optimization? I’m
trying to get my blog to rank for some targeted keywords but I’m not seeing very good success.
If you know of any please share. Thank you!
Everything is very open with a very clear explanation of the
challenges. It was definitely informative.
Your website is very useful. Thanks for sharing!
I think that what you posted was very reasonable.
However, think on this, what if you wrote a catchier title?
I mean, I don’t want to tell you how to run your blog,
but suppose you added something that grabbed folk’s attention? I mean Пиастры
– Составление семантического ядра | is kinda
vanilla. You ought to look at Yahoo’s home page
and watch how they write post titles to grab people to open the links.
You might add a related video or a related picture or two to grab people
excited about what you’ve got to say. In my opinion, it could make your posts a little livelier.
Here is my web-site :: Semaglutide Mexico
Excellent, what a website it is! This webpage gives
useful data to us, keep it up.
Wonderful, what a webpage it is! This web site
gives useful facts to us, keep it up.
Your method of describing everything in this paragraph is really nice,
all be able to easily be aware of it, Thanks a lot.
mgfmail.ru
Hi there it’s me, I am also visiting this website on a regular basis, this
site is really pleasant and the viewers are truly sharing pleasant thoughts.
Hey, I think your blog might be having browser compatibility
issues. When I look at your blog in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, very good blog!
Please let me know if you’re looking for a article writer for your blog.
You have some really great posts and I feel I would
be a good asset. If you ever want to take some of the load off, I’d love to write some content for your blog in exchange
for a link back to mine. Please blast me an e-mail if interested.
Cheers!
Make a comparison among the funding options is certainly an additional way
to make your search for the loan option better and more fruitful.
There are companies running scams out there and identity theft is a real and
scary. Unless you are in the top two percent of the wealthiest
members of the population, you will probably need a personal
loan in order to achieve educational and personal goals.
What’s up, just wanted to mention, I liked this article. It was inspiring.
Keep on posting!
I don’t know whether it’s just me or if perhaps everyone
else encountering problems with your site. It looks like some
of the text within your content are running off the screen. Can somebody else please provide feedback and let me know if this is happening to them
as well? This could be a issue with my browser because I’ve had
this happen before. Thank you
Fantastic blog you have here but I was curious if you knew of any user
discussion forums that cover the same topics discussed here?
I’d really like to be a part of community where I can get
advice from other experienced individuals that share the same interest.
If you have any suggestions, please let me know.
Cheers!
Have you ever thought about publishing an e-book or guest authoring on other websites?
I have a blog based on the same information you
discuss and would really like to have you share some stories/information. I know my audience would appreciate your work.
If you are even remotely interested, feel free to shoot me
an e mail.
I think this is among the most vital info for me. And i am glad reading your article.
But wanna remark on few general things, The site style is ideal, the articles is really excellent : D.
Good job, cheers
Ahaa, its good discussion on the topic of this
post at this place at this weblog, I have read all that, so now me
also commenting at this place.
Stop by my web page :: หวยออนไลน์
Excellent blog here! Also your web site loads up very fast!
What host are you using? Can I get your affiliate
link to your host? I wish my website loaded up as fast
as yours lol
Look into my web-site – Foods to Avoid While on Saxenda
I know this web site provides quality based articles and additional information, is
there any other website which provides these stuff in quality?
Hi there are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and
set up my own. Do you require any html coding knowledge to make your own blog?
Any help would be really appreciated!
Hi there! I could have sworn I’ve been to this web site before but after looking at
a few of the articles I realized it’s new to me. Nonetheless, I’m definitely happy I came across it and I’ll be book-marking it and checking back often!
Yes, we love to get feedback from our customers in regards to the service
we offer and are continuously wanting for methods to improve.
Other goddesses had been recognized for childbirth, fertility and love.
In November 1890, with Jerome as Chairman, the Commission returned to
resume negotiations. The land had been conveyed by the Cherokee Nation in 1883 to the
United States, to be held in belief for the Nez Perce, and later
abandoned by the Nez Perce when they returned to their homeland.
Land patents to the person allotments land had been to be held in a tax-free belief
for the advantage of the allottees, for a period of twenty-5 years.
The report called the Tonkawa “prepared and anxious” to
simply accept allotments. In 1862, the Tonkawa Massacre decimated the tribe.
During the Civil War, the tribe aligned with the Confederacy.
Before and after the conflict, Mayes ran a farm, oversaw his fruit orchards, and raised livestock.
I’m really impressed along with your writing abilities as well as with the format to your weblog.
Is this a paid theme or did you customize it your self?
Anyway keep up the nice quality writing, it’s rare to see a nice blog like this one nowadays..
Here is my website :: sell ugly house fast
Hi, I think your blog might be having browser compatibility issues.
When I look at your blog site in Safari, it looks fine but when opening in Internet Explorer, it
has some overlapping. I just wanted to give you a quick heads up!
Other then that, superb blog!
Great post. I used to be checking constantly this blog and I am impressed! I deal with such information much.
I deal with such information much.
Very helpful information particularly the final phase
I was looking for this certain information for a very long time.
Thanks and best of luck.
hello there and thank you for your info – I’ve certainly picked up anything new from right here.
I did however expertise a few technical issues using this website,
as I experienced to reload the site many times previous to I could get it to load correctly.
I had been wondering if your web hosting is OK? Not that I’m complaining, but sluggish loading instances times
will sometimes affect your placement in google and can damage your quality score if
ads and marketing with Adwords. Well I am adding
this RSS to my e-mail and could look out
for much more of your respective exciting content.
Ensure that you update this again soon.
Ӏ am extremely inspied alonng with у᧐սг writing tɑlents
and also with the layout to your blog. Is thɑt this a paid subject or did
you modify it your self? Either way stay up the excellent high quality writing,
it is uncommon to see a nice weblog like this օne today..
Here is my sіte – Slot889 Gacor
If you would like to obtain a great deal from this paragraph then you have to
apply such techniques to your won webpage.
Link exchange is nothing else however it is just placing
the other person’s web site link on your page at
appropriate place and other person will also do same in support
of you.
https://rah-khabar.ir/تعمیر-پکیج-ایران-رادیاتور-در-قم-نمایند/
I’m not sure where you are getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic information I was looking for this
information for my mission.
Greetings! Very helpful advice within this article! It is
the little changes that will make the biggest changes.
Thanks a lot for sharing!
The other day, while I was at work, my sister stole my iphone and
tested to see if it can survive a thirty foot drop, just so
she can be a youtube sensation. My apple ipad is now destroyed and she has
83 views. I know this is entirely off topic but I had to share it with someone!
Simply desire to say your article is as astounding.
The clearness in your post is simply great and i can assume you are an expert
on this subject. Fine with your permission allow me to grab your RSS feed
to keep updated with forthcoming post. Thanks a million and please carry on the gratifying work.
Thank you a bunch for sharing this with all of us you actually recognise
what you’re talking approximately! Bookmarked. Kindly additionally discuss with
my site =). We can have a link trade agreement among us
Remarkable things here. I am very glad to look your
article. Thank you so much and I’m having a look forward
to touch you. Will you please drop me a mail?
Quality articles or reviews is the secret to interest the visitors to
pay a visit the web site, that’s what this web page is
providing.
If some one needs expert view on the topic of running a blog after that i propose him/her to
visit this weblog, Keep up the pleasant work.
Hi! I’ve been following your weblog for a while now and finally got the bravery to
go ahead and give you a shout out from Austin Texas!
Just wanted to mention keep up the fantastic job!
I am no longer certain the place you are getting your information, but great topic.
I must spend some time learning much more or figuring out more.
Thank you for excellent information I was on the lookout for this information for
my mission.
I’ve been exploring for a bit for any high-quality articles or blog posts in this sort of house .
Exploring in Yahoo I finally stumbled upon this
website. Studying this info So i am satisfied to exhibit that I’ve an incredibly excellent uncanny feeling I
came upon just what I needed. I so much surely will make sure to do not overlook this website and give it
a glance on a constant basis.
Hello there! This is kind of off topic but I need some help
from an established blog. Is it hard to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure where to start.
Do you have any points or suggestions? Thank you
At this moment I am going away to do my breakfast, when having my breakfast coming yet again to read further
news.
Very energetic blog, I enjoyed that a lot. Will there be a part 2?
whoah this weblog is fantastic i love reading your articles.
Keep up the great work! You know, a lot of persons are searching around for this information, you can help them greatly.
I am sure this article has touched all the internet visitors, its really
really nice post on building up new weblog.
As soon as I noticed this site I went on reddit to share some of the love with them.
Wow, awesome blog format! How lengthy have you ever been blogging
for? you made blogging glance easy. The overall look
of your site is magnificent, let alone the content material!
Terrific work! That is the type of info that are supposed
to be shared across the web. Disgrace on the search engines for
not positioning this submit higher! Come on over and consult with my site .
Thank you =)
Pretty! This has been a really wonderful article.
Thank you for providing this information.
I was wondering if you ever thought of changing the structure of your
website? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two images.
Maybe you could space it out better?
Things such as yor name, address, teleohone quantity, and e-mail address in order
to takje benefit of this opportunity.
my website – get more info
Fastidious answer back in return of this matter with genuine arguments and describing all on the topic of that.
Also visit my page: ปลูกกัญชา
I am extremely impressed with your writing skills and also with the structure on your blog.
Is that this a paid subject matter or did you
modify it yourself? Either way keep up the nice quality writing, it’s rare to peer a
nice weblog like this one these days..
Now I am going away to do my breakfast, after having my breakfast
coming again to read additional news.
Hi! Someone in my Myspace group shared this website with us
so I came to give it a look. I’m definitely
enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Wonderful blog and great design.
Hi there, this weekend is good for me, as this time i am reading this great educational paragraph here at my residence.
Wow, this article is pleasant, my younger sister is analyzing these kinds
of things, thus I am going to inform her.
hello there and thank you for your information –
I’ve certainly picked up anything new from right here.
I did however expertise some technical issues
using this website, since I experienced to reload the website many times previous
to I could get it to load properly. I had been wondering
if your web hosting is OK? Not that I’m complaining, but slow
loading instances times will sometimes affect your
placement in google and can damage your high quality score if advertising and marketing with Adwords.
Well I am adding this RSS to my e-mail and can look out
for much more of your respective exciting content.
Ensure that you update this again very soon.
Hello! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
Currently it seems like Expression Engine is the top blogging platform out there right now.
(from what I’ve read) Is that what you are using on your blog?
This website was… how do I say it? Relevant!! Finally I have
found something which helped me. Thanks!
Ηі there! Somerone in my Facebook group ѕhared this
site with us so I came to look it over. I’m definitely enjoying the information. I’m book-marking
and will be tweeting this to my followеrs! Excellent blog and gdeаt desiցn and style.
Also visit my site Wg88
constantly i used to read smaller content which as
well clear their motive, and that is also happening with this post
which I am reading at this place.
naturally like your web site but you have to check the spelling on several of your posts.
A number of them are rife with spelling issues and I find it very
troublesome to inform the reality however I will definitely come again again.
Greetings! Very useful advice in this particular post! It’s the
little changes which will make the most significant changes.
Many thanks for sharing!
Hello there, You have done a great job. I’ll definitely digg it and personally
suggest to my friends. I am confident they’ll be benefited from this website.
Actually when someone doesn’t understand after that its
up to other visitors that they will help, so here it happens.
Yesterday, while I was at work, my cousin stole my iphone and tested to see if
it can survive a 40 foot drop, just so she can be a youtube sensation.
My apple ipad is now broken and she has 83 views.
I know this is entirely off topic but I had to share it with someone!
Definitely consider that that you stated. Your favorite reason appeared to be on the internet the easiest thing to take note of.
I say to you, I certainly get annoyed while people consider worries that they just do not recognise about.
You controlled to hit the nail upon the highest and also defined out the entire thing without having side-effects , people
can take a signal. Will likely be again to get more.
Thank you
An intriguing discussion is worth comment. I do think that
you should publish more about this issue, it may not be a taboo matter but generally folks
don’t talk about these subjects. To the next! Kind regards!!
Have a look at my homepage :: Buy My Ugly House
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something.
I think that you can do with a few pics to drive the message home a little bit, but other than that, this is great blog.
A great read. I will definitely be back.
Great blog here! Additionally your site lots up fast!
What web host are you using? Can I get your associate hyperlink on your host?
I want my site loaded up as fast as yours lol
My spouse and I stumbled over here from a different web address and
thought I might check things out. I like what I see so now
i am following you. Look forward to finding out about your web page for a second time.
Appreciating the commitment you put into your site and detailed information you present.
It’s nice to come across a blog every once in a while that isn’t
the same old rehashed information. Excellent read!
I’ve saved your site and I’m including your RSS feeds to
my Google account.
Hello, i read your blog from time to time and i own a similar one and
i was just curious if you get a lot of spam comments? If so how do you stop it, any plugin or anything you can suggest?
I get so much lately it’s driving me mad so any help
is very much appreciated.
I truly love your site.. Excellent colors & theme.
Did you make this amazing site yourself? Please reply back
as I’m attempting to create my own website and want to find out
where you got this from or exactly what the theme is called.
Appreciate it!
Very good info. Lucky me I ran across your site by accident (stumbleupon).
I’ve book-marked it for later!
Its such as you learn my mind! You seem to know a lot approximately
this, such as you wrote the e book in it or something.
I think that you could do with some percent to pressure the message house a little bit, but other than that,
this is great blog. An excellent read. I will certainly be back.
I don’t know whether it’s just me or if perhaps everyone else encountering problems with
your site. It looks like some of the written text on your posts are running off the screen. Can someone else please provide feedback and
let me know if this is happening to them too? This might be a issue
with my web browser because I’ve had this happen previously.
Cheers
Hello! Do you know if they make any plugins to protect
against hackers? I’m kinda paranoid about losing everything I’ve worked hard on.
Any recommendations?
Hello! This is my first comment here so I just wanted to give
a quick shout out and tell you I really enjoy reading your blog posts.
Can you recommend any other blogs/websites/forums
that deal with the same subjects? Thank you!
Hi there to all, the contents present at this site are genuinely awesome
for people experience, well, keep up the good work fellows.
My relatives always say that I am wasting my time here at net, except
I know I am getting know-how every day by reading such fastidious
posts.
Here is my webpage … Organicore CBD Gummies Reviews
Hey there! I simply want to offer you a
big thumbs up for your great info you have right here on this post.
I am returning to your website for more soon.
Heya just wanted to give you a quick heads up and let
you know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show
the same results.
I’ve been exploring for a bit for any high quality articles or blog posts in this
kind of space . Exploring in Yahoo I eventually stumbled upon this web site.
Reading this information So i’m happy to express that I’ve
a very excellent uncanny feeling I discovered just
what I needed. I most definitely will make sure to don?t omit this site and give it
a glance on a relentless basis.
Fantastic items from you, man. I have understand your stuff previous to and you are simply too fantastic.
I actually like what you’ve received right here, certainly like what you are stating and the best way
during which you say it. You make it enjoyable and you still take care
of to keep it sensible. I cant wait to learn much
more from you. This is really a terrific web site.
Its not my first time to pay a quick visit this web site, i am browsing this website
dailly and obtain good data from here daily.
I always spent my half an hour to read this blog’s
posts all the time along with a cup of coffee.
Excellent article. I’m going through a few of these issues as well..
Fantastic post however , I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little
bit further. Appreciate it!
I’m gone to say to my little brother, that he should also go to
see this web site on regular basis to obtain updated from newest reports.
Every weekend i used to go to see this web page, for the reason that
i want enjoyment, since this this website conations in fact
nice funny information too.
I almost never comment, but i did a few searching and wound up here
Пиастры – Составление семантического ядра |.
And I do have a couple of questions for you if you don’t mind.
Could it be just me or does it give the impression like a
few of the comments appear like they are coming from brain dead individuals?
😛 And, if you are posting at additional sites, I would like
to keep up with anything new you have to post.
Could you make a list of every one of your social pages like your Facebook
page, twitter feed, or linkedin profile?
This info is invaluable. Where can I find out more?
Currently it appears like Drupal is the best blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
This site was… how do you say it? Relevant!! Finally I have
found something that helped me. Thank you!
Today, while I was at work, my sister stole my apple ipad and tested
to see if it can survive a 30 foot drop, just so she can be a youtube sensation. My iPad is now destroyed and she has 83 views.
I know this is totally off topic but I had to share it with someone!
We stumbled over here by a different page and thought
I should check things out. I like what I see so i am just
following you. Look forward to looking at your web page yet again.
ค้นพบวิธีแก้ปัญหาเพื่อกำจัดขนหงอกอย่างได้ผล เรียนรู้เกี่ยวกับตัวเลือกการย้อมสีธรรมชาติ การเยียวยาที่บ้าน และการรักษาทางการแพทย์เพื่อแก้ผมหงอก ข้อมูลของเราจะช่วยปกปิดผมหงอกของคุณโดยไม่จำเป็นต้องดูแลร้านเสริมสวยราคาแพง
My website :: วิธีถอนผมหงอกไม่เจ็บ
Greetings from Los angeles! I’m bored to death at work so I decided to browse your site on my iphone during lunch break.
I love the information you present here and can’t wait to take a look when I get home.
I’m shocked at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, very good site!
Because the admin of this web page is working, no doubt very rapidly it will be famous, due to
its quality contents.
Hello there, I found your web site by way
of Google while looking fоr a related subject, your sіte
came up, it seems good. I have bоokmarked it in my googlе bookmarks.
Hi there, just beϲome alert to your weblog via Gⲟogⅼe, and located
that it’s really informatіve. I’m ցonna be careful forr bruѕsels.
I wilⅼ be grateful when you proceed this іn futurе. Ⲛuumerous other people shall be benefited out of your writing.
Cheerѕ!
Feel free to surf to my blog post – Big888 Login
Hi, I log on to your blogs regularly. Your writing style
is awesome, keep up the good work!
Hi colleagues, its wonderful article regarding teachingand entirely explained,
keep it up all the time.
My relatives all the time say that I am killing my time here at net, but I know I am getting familiarity everyday by reading thes
pleasant content.
It’s genuinely very complicated in this full of activity life to listen news on Television, so I simply
use world wide web for that purpose, and take the latest information.
Check out my page :: Get a cash Offer for my house
Great information. Lucky me I recently found your blog by accident (stumbleupon).
I’ve saved it for later!
This is a topic that’s close to my heart… Thank you!
Where are your contact details though?
Great beat ! I ᴡ᧐uld like tto apprentice while you amend your websitе, how сould i subscribe for a blog website?
The account aided me a approopriate deal. I
have been a little bit acquainted of this yoսr broadcast
proviɗed vivid clear concept
my webpage; Sakura88 Login
Hurrah! After all I got a blog from where I be capable
of truly obtain useful facts concerning my study and knowledge.
hi!,I really like your writing so so much! percentage we communicate more approximately your article on AOL?
I need a specialist on this house to resolve my problem.
Maybe that is you! Having a look ahead to see you.
carpet cleaners (sites.google.com)
I need to to thank you for this wonderful read!! I absolutely
loved every little bit of it. I have got you book-marked to look at new things
you post…
Hi, its fastidious paragraph regarding media print, we all
know media is a great source of information.
Great blog here! Also your site loads up very fast! What web
host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
My blog post :: Buy Rybelsus
Hmm it looks like your blog ate my first comment (it was extremely long) so I
guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog blogger but I’m still new
to the whole thing. Do you have any tips and hints for rookie blog
writers? I’d genuinely appreciate it.
Link exchange is nothing else except it is simply placing the other person’s webpage link on your page at suitable place
and other person will also do same in support of you.
Incredible! This blog looks exactly like my old one!
It’s on a totally different topic but it has pretty
much the same page layout and design. Superb choice of colors!
Tienda Nº 1 en Camiseta Osasuna
Encontrarás cada camiseta osasuna 2022 y ropa de entrenamiento de los clubs y
selecciones nacionales para adultos y niños.
Hi this is kinda of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to get advice from someone
with experience. Any help would be greatly appreciated!
Its not my first time to pay a quick visit this web page, i am visiting this
site dailly and obtain pleasant information from here everyday.
Hi there friends, how is the whole thing, and what you desire to say concerning this article,
in my view its genuinely amazing in support of me.
Thank you for sharing your thoughts. I really appreciate your efforts and
I will be waiting for your next post thank you once again.
This is the perfect blog for everyone who wishes to understand this topic.
You know a whole lot its almost hard to argue with
you (not that I actually will need to…HaHa).
You certainly put a brand new spin on a subject which has been discussed for a long time.
Wonderful stuff, just excellent!
This article is really a fastidious one it assists new
net users, who are wishing for blogging.
This piece of writing is actually a good one it assists
new internet viewers, who are wishing in favor of blogging.
It’s difficult to find well-informed people on this topic, however,
you seem like you know what you’re talking about!
Thanks
It is not my first time to go to seee tjis site, i am visiting this web site dailly and obtain nice data from here daily.
Feel free to surf to my blog post … XXX movies online
Very soon this web site will be famous among all blogging and site-building people, due to it’s pleasant articles
I always spent my half an hour to read this blog’s posts every day
along with a cup of coffee.
Excellent post. I used to be checking constantly this weblog and I’m impressed!
Extremely useful info specifically the closing phase :
) I handle such info much. I was looking for this certain info for a long time.
Thank you and good luck.
Thankfulness to my father who shared with me concerning this weblog,
this website is really remarkable.
Useful information. Fortunate me I discovered your web site
by chance, and I’m shocked why this twist of fate did not took place in advance!
I bookmarked it.
https://jonob-khabar.ir/خرید-بیمه-شخص-ثالث-خودرو-ارزان-ترین-قی/
I am regular reader, how are you everybody? This piece of writing posted at this site is
actually nice.
Hello everyone, it’s my first pay a visit
at this web page, and piece of writing is actually fruitful in support of me,
keep up posting these content.
naturally like your web site but you have to check the spelling on several of your posts.
A number of them are rife with spelling issues and I to find it very
bothersome to inform the truth then again I’ll certainly come back again.
I’ve been exploring for a bit for any high quality articles or blog posts in this sort of house .
Exploring in Yahoo I at last stumbled upon this web site.
Studying this info So i’m happy to exhibit that I have an incredibly excellent
uncanny feeling I discovered exactly what I needed.
I most for sure will make sure to do not forget this site and provides it a glance
regularly.
Hey there! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks
of hard work due to no backup. Do you have any solutions to prevent hackers?
Awesome write-up, thanks for posting. I agree 100% with your points about the
significance of construction machinery in building sites.
It’s incredible to see how these powerful machines can get the
job done fast and effectively. Looking forward to more
articles about construction equipment!
What’s up mates, good paragraph and pleasant arguments commented at this place, I am genuinely enjoying by these.
I think this is one of the most significant information for me.
And i am glad reading your article. But want to remark on some general things, The site style is great, the articles is
really nice : D. Good job, cheers
I really like your blog.. very nice colors & theme.
Did you make this website yourself or did
you hire someone to do it for you? Plz answer back as I’m looking to construct my own blog and would
like to know where u got this from. kudos
Hello, i read your blog occasionally and i own a similar one and
i was just wondering if you get a lot of spam responses?
If so how do you stop it, any plugin or anything you can suggest?
I get so much lately it’s driving me mad so any assistance is very much appreciated.
Very nice write-up. I definitely love this
website. Keep writing!
Thanks designed for sharing such a good thinking, article is good, thats why i have read it completely
ขึ้นอยู่กับว่าต้องการหม้อหุงข้าวแบบไหนและงบประมาณของผู้ใช้จริงๆ หม้อหุงข้าวยี่ห้อยอดนิยม ได้แก่ Zojirushi, Cuckoo, Tiger และ Panasonic แต่ละรุ่นมีหลากหลายรุ่นซึ่งแตกต่างกันไปตามคุณสมบัติและราคา
การค้นคว้ารีวิวจากลูกค้าสามารถช่วยตัดสินว่ารีวิวใดเหมาะกับคุณ
Here is my web page: รีวิวหม้อหุงข้าว
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back later. Many thanks
Hello there! I could have sworn I’ve been to this site before but after reading through some of
the post I realized it’s new to me. Nonetheless, I’m definitely happy
I found it and I’ll be book-marking and checking back frequently!
Thanks for one’s marvelous posting! I truly enjoyed reading it,
you could be a great author.I will be sure to bookmark your blog
and will eventually come back very soon. I want to encourage that you continue your great
writing, have a nice day!
Amazing! This blog looks just like my old one! It’s on a entirely different subject but it has pretty much the same layout and design. Outstanding choice of colors!
Saved as a favorite, I like your blog!
Hey there! I could have sworn I’ve been to this website before but after checking through some of the post I realized it’s new to
me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back often!
Hi, yeah this paragraph is genuinely good and I have learned lot of things from it concerning blogging.
thanks.
I always emailed this web site post page to all my
contacts, as if like to read it next my friends will too.
It’s very trouble-free to find out any topic on web as compared to books, as
I found this post at this web page.
Hello, I enjoy reading all of your post. I wanted to write a little comment to support
you.
Wonderful post however I was wondering if you could write a
litte more on this subject? I’d be very thankful if you could elaborate a little bit further.
Many thanks!
What’s up to all, since I am in fact keen of reading this website’s
post to be updated daily. It contains nice stuff.
I enjoy, result in I found just what I used to be having a look for.
You have ended my four day long hunt! God Bless you man. Have a
nice day. Bye
Νice respond in return օf this issᥙe with genuine arguments and explaіning alⅼ regarding that.
Reѵiew mу weƅ page :: Sakura88 Login
I have been browsing online more than 4 hours today, yet I never
found any interesting article like yours. It is pretty worth enough for me.
In my opinion, if all website owners and bloggers made good content as you did, the net will be much more useful than ever before.
I’m not sure exactly why but this web site is loading incredibly slow
for me. Is anyone else having this issue or is it a problem on my end?
I’ll check back later and see if the problem still exists.
Its like you learn my mind! You appear to understand so much about this, such as you
wrote the e book in it or something. I think that you just can do with some % to
power the message home a bit, however other than that, that is magnificent blog.
An excellent read. I will definitely be back.
This is a topic which is near to my heart… Many thanks!
Where are your contact details though?
Look at my blog Local SEO
Thanks for one’s marvelous posting! I definitely
enjoyed reading it, you will be a great author. I will always bookmark
your blog and will often come back later on.
I want to encourage you to continue your great work,
have a nice evening!
Excellent, what a webpage it is! This blog presents useful facts to us,
keep it up.
I’ll right away grab your rss feed as I can’t find your email subscription link or newsletter service.
Do you have any? Please permit me understand so that
I may just subscribe. Thanks.
Wow, incredible blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your
site is fantastic, let alone the content!
Hi, after reading this amazing paragraph i am also delighted to
share my familiarity here with friends.
Excellent article. Keep posting such kind of info on your blog.
Im really impressed by it.
Hi there, You have performed a great job. I’ll definitely digg it and
individually recommend to my friends. I’m confident they’ll be benefited from this site.
What i don’t understood is in truth how you’re not
actually much more well-favored than you may be now.
You’re so intelligent. You know thus considerably
in terms of this subject, produced me personally
believe it from a lot of varied angles. Its like women and men are
not fascinated unless it’s one thing to do with Lady gaga!
Your personal stuffs great. At all times handle it up!
Wonderful article! That is the kind of information that should
be shared around the web. Shame on the seek engines for now not positioning this submit higher!
Come on over and consult with my site . Thank you =)
hi!,I love your writing very so much! proportion we be in contact
more about your article on AOL? I require an expert in this area
to unravel my problem. May be that is you! Taking a
look ahead to peer you.
I just like the helpful information you provide on your articles.
I will bookmark your blog and check again here frequently.
I am quite sure I will be told many new stuff
proper right here! Good luck for the following!
Ꮤe arre a group of volunteers and oρening a new scheme in our community.
Your sitе offеred us with valuable info too wrk on. You’ve done a formidable job andd our wole community will
be grateful to you.
Here is my web-site :: Lolita
My spouse and I stumbled over here by a different web address
and thought I might check things out. I like what I see so now i am following you.
Look forward to looking into your web page yet again.
Thanks a bunch for sharing this with all of us you really recognise what you’re speaking approximately!
Bookmarked. Please also seek advice from my site =).
We can have a hyperlink exchange arrangement among us
Your style is very unique compared to other folks I have read
stuff from. Thank you for posting when you’ve got the opportunity,
Guess I’ll just bookmark this site.
I really love your website.. Excellent colors & theme.
Did you make this website yourself? Please reply
back as I’m planning to create my own blog and would
love to know where you got this from or exactly
what the theme is called. Appreciate it!
اخبار فوری نظامی و خبر تازه امروز
غزنی و خبرهای فوری و مهم سیاسی و اخبار پزشکی استان فارس و خبرهای
مهم ایران و خبرهای جدید نیشابور
https://bookmarkvids.com/story13818653/اخبار-جدید-طلا
You really make it seem so easy with your presentation but I find
this matter to be really something that I
think I would never understand. It seems too complicated and very
broad for me. I’m looking forward for your next post, I’ll try to get the hang of it!
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is valuable and all. Nevertheless think of
if you added some great visuals or video clips to give your posts more, “pop”!
Your content is excellent but with pics and video clips, this blog
could undeniably be one of the very best in its field.
Amazing blog!
Simply desire to say your article is as surprising.
The clearness in your post is just nice
and i can assume you’re an expert on this subject. Fine with your permission let me to grab your RSS feed to
keep updated with forthcoming post. Thanks a million and
please continue the enjoyable work.
We stumbled over here coming from a different page and thought I should check things out.
I like what I see so i am just following you. Look forward to looking over your web page again.
Agen Judi Slot88Gacor gampang Gampang Menang Terbaik
I ѕeldom drop comments, but I browsed a tօn off remarks on Пиастры – Составление семантического ядра |.
I actually do have a couple of questions for you if you do
not mind. Is it just me or does it seem like a few of the remarks
аppear as if they are left by brain ddead visitors?
😛 And, if you аre posting on additional online social
sites, I’d like to follow you. Coild you list of everу one
of aⅼl your publіc sites like your Facebook page, twitter feed, or
linkedin profile?
Feеl free tօ surf to myy web blog … Rtp Qqslot88
First of all I would like to say terrific blog!
I had a quick question in which I’d like to ask if you do not mind.
I was curious to know how you center yourself and clear your head prior to writing.
I’ve had difficulty clearing my mind in getting my thoughts out.
I do take pleasure in writing but it just seems like the first 10 to 15 minutes tend to be
wasted just trying to figure out how to begin. Any suggestions
or hints? Thanks!
Hi there! This is my first visit to your blog! We are a collection of volunteers
and starting a new project in a community in the same niche.
Your blog provided us useful information to work on. You
have done a outstanding job!
I take pleasure in, lead to I found just what I was taking a look
for. You have ended my 4 day lengthy hunt! God Bless you man. Have a nice day.
Bye
wonderful submit, very informative. I’m wondering why the opposite experts of this sector don’t understand this.
You must continue your writing. I am confident,
you’ve a great readers’ base already!
Hi there, I found your site by way of Google whilst looking for a comparable topic, your site came up, it appears to be
like good. I’ve bookmarked it in my google bookmarks.
Hi there, simply become alert to your blog via Google, and
found that it’s truly informative. I’m going to
watch out for brussels. I’ll appreciate in the event you continue this in future.
A lot of other folks can be benefited from your writing.
Cheers!
Hey there, You’ve done a fantastic job. I will definitely digg it
and personally recommend to my friends. I am confident they will
be benefited from this site.
When some one searches for his essential thing, thus
he/she wishes to be available that in detail, thus that thing is maintained over here.
https://khabar-aseman.ir/آموزش-اسان-و-سریع-پارتیشن-بندی-هارد/
That is really interesting, You’re an excessively professional blogger.
I’ve joined your rss feed and sit up for looking for more of your magnificent post.
Additionally, I have shared your web site in my social networks
I am not sure where you’re getting your information, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for wonderful information I was looking for
this info for my mission.
you are in reality a good webmaster. The site loading speed
is incredible. It kind of feels that you’re doing any unique trick.
In addition, The contents are masterwork. you’ve performed a wonderful task on this topic!
Howdy just wanted to give you a brief heads up and let you know
a few of the pictures aren’t loading correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same outcome.
I have to thank you for the efforts you have put in writing this blog.
I am hoping to see the same high-grade content by you in the
future as well. In truth, your creative writing abilities has encouraged me to get my very own site now 😉
This site was… how do you say it? Relevant!!
Finally I’ve found something that helped me.
Thanks a lot!
Now I am ready to do my breakfast, once having my
breakfast coming again to read other news.
Superb blog! Do you have any helpful hints for aspiring
writers? I’m planning to start my own blog soon but I’m a little lost
on everything. Would you propose starting with a free platform
like WordPress or go for a paid option? There are so many choices out there that I’m completely confused ..
Any recommendations? Kudos!
It is truly a great and helpful piece of information. I’m glad that you simply shared this helpful information with us.
Please keep us informed like this. Thanks for sharing.
Hi there! Would you mind if I share your blog with my myspace
group? There’s a lot of folks that I think would
really appreciate your content. Please let me know.
Cheers
Nice weblog here! Also your web site loads
up very fast! What host are you the usage of? Can I get your associate hyperlink for your
host? I want my web site loaded up as fast as
yours lol
Your method of describing all in this post is in fact fastidious,
every one be capable of easily understand it, Thanks
a lot.
Thank you for some other informative site. The place else could I get that kind of info written in such an ideal means?
I’ve a project that I’m just now working on, and I’ve been at the look out
for such info.
Hi there! I know this is kind of off topic but I was wondering if you knew where
I could get a captcha plugin for my comment form? I’m using the same
blog platform as yours and I’m having problems finding one?
Thanks a lot!
Great site you have here but I was curious if you knew of any
message boards that cover the same topics talked about in this article?
I’d really love to be a part of community where I can get suggestions from other experienced individuals that share the same interest.
If you have any recommendations, please let me know. Thanks
a lot!
my web page … seo keywords
Hey there! I know this is sort of off-topic however I
needed to ask. Does managing a well-established website
such as yours require a lot of work? I’m completely new to writing a blog however
I do write in my journal everyday. I’d like to start
a blog so I can share my personal experience and feelings online.
Please let me know if you have any suggestions or tips for brand new
aspiring bloggers. Thankyou!
Its not my first time to go to see this site, i am browsing this web site dailly and take
fastidious facts from here every day.
I really love your site.. Great colors & theme. Did you build this site
yourself? Please reply back as I’m looking to create my own personal website and
would like to know where you got this from or exactly what the theme is called.
Appreciate it!
Thanks for some other great post. Where else could anyone get that type of
information in such an ideal approach of writing? I have a presentation next
week, and I am at the search for such information.
This website definitely has all of the information I wanted concerning this subject
and didn’t know who to ask.
Pretty nice post. I just stumbled upon your blog and wished to
say that I have truly enjoyed browsing your blog posts. In any case I will
be subscribing to your rss feed and I hope you write again very soon!
An impressive share! I’ve just forwarded this onto a colleague
who had been conducting a little homework on this. And he actually ordered me breakfast simply
because I discovered it for him… lol. So allow me to reword this….
Thank YOU for the meal!! But yeah, thanks for spending time to talk about
this subject here on your site.
Wow, awesome blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is
great, as well as the content!
We are a group of volunteers and opening a new scheme in our community.
Your site provided us with valuable info to work on.
You’ve done an impressive job and our entire community will be grateful to you.
This is my first time visit at here and i am in fact
impressed to read all at one place.
I am not sure where you’re getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for magnificent information I was looking for this info for my mission.
Howdy I am so glad I found your site, I really found you by accident, while I was looking on Aol for something else,
Anyhow I am here now and would just like to say thanks a lot for
a fantastic post and a all round enjoyable blog (I also love
the theme/design), I don’t have time to go through it all at the minute but I have saved it and also added your RSS feeds, so when I have time I will be back to read a great deal more,
Please do keep up the superb jo.
Good day! This is kind of off topic but I need some help from an established blog.
Is it very hard to set up your own blog? I’m not very techincal but
I can figure things out pretty quick. I’m thinking about creating my own but I’m
not sure where to begin. Do you have any ideas or suggestions?
Cheers
Hi there just wanted to give you a brief heads up and let you know a few of the pictures aren’t
loading correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same results.
magnificent post, very informative. I wonder why the other experts of this sector don’t notice
this. You should continue your writing. I’m sure, you’ve a huge readers’ base
already!
Right now it seems like WordPress is the preferred blogging platform available right now.
(from what I’ve read) Is that what you’re using on your blog?
Hello to all, how is all, I think every one is getting
more from this web site, and your views are nice in support of new people.
This is a great tip particularly to those fresh to the blogosphere.
Brief but very accurate info… Many thanks for sharing
this one. A must read post!
Hello there! This post couldn’t be written any better!
Going through this post reminds me of my previous roommate!
He constantly kept preaching about this. I’ll send this post to him.
Fairly certain he will have a good read. I appreciate you for sharing!
Wow, that’s what I was seeking for, what
a material! existing here at this webpage, thanks admin of
this web site.
It’s the best time to make some plans for the longer term and it is time to be happy.
I’ve read this post and if I may I desire to counsel
you some fascinating things or advice. Perhaps
you can write subsequent articles relating to this article.
I want to read more things about it!
I’m extremely impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it is rare to see a great blog like this one these days.
Heya i am for the primary time here. I came across
this board and I to find It really helpful & it helped me out
much. I am hoping to present something again and aid others like you helped me.
Hi there! Someone in my Myspace group shared this site with us so I
came to check it out. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Outstanding blog and terrific design and style.
I have been surfing online more than three hours as of late, yet I
by no means found any interesting article like yours.
It is pretty price sufficient for me. In my view, if all website owners and bloggers made
just right content material as you probably did, the web
will be a lot more helpful than ever before.
What’s up every one, here every one is sharing such experience, so it’s fastidious to read
this webpage, and I used to go to see this website all the time.
Greate pieces. Keep posting such kind of information on your site.
Im really impressed by it.
Hi there, You’ve performed an excellent job. I’ll definitely
digg it and personally recommend to my friends.
I’m confident they’ll be benefited from this website.
Hey I know this is off topic but I was wondering if you knew of any widgets
I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite
some time and was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Great work! This is the type of info that are supposed to be shared around the net.
Shame on Google for not positioning this submit upper! Come on over and seek advice from my website .
Thank you =)
Hello colleagues, fastidious article and fastidious arguments commented at this place, I am
truly enjoying by these.
Hiya very cool blog!! Man .. Beautiful .. Wonderful ..
I will bookmark your web site and take the feeds additionally?
I’m satisfied to find a lot of useful info here in the publish, we need
work out extra strategies on this regard, thanks for
sharing. . . . . .
It’s very simple to find out any matter on web as compared to textbooks, as I found this paragraph at this website.
This is a topic that is close to my heart… Cheers!
Exactly where are your contact details though?
wonderful points altogether, you simply received a emblem new reader.
What may you recommend about your put up that you simply
made a few days ago? Any sure?
I delight in, lead to I discovered just what I used to be looking for.
You’ve ended my four day long hunt! God Bless you man. Have a nice day.
Bye
What’s up everybody, here every person is sharing these kinds of experience, therefore it’s good to read this webpage, and I used to pay a quick visit this
web site everyday.
Awesome blog! Do you have any suggestions for aspiring writers?
I’m planning to start my own website soon but I’m a little
lost on everything. Would you advise starting with a free platform like WordPress or go for a paid option?
There are so many options out there that I’m completely overwhelmed ..
Any tips? Cheers!
Thank you a bunch for sharing this with all of us you really realize what you are talking about!
Bookmarked. Kindly additionally visit my site =). We will have a
link alternate agreement between us
Unquestionably believe that that you said. Your favorite reason seemed to be on the internet the simplest thing to have in mind of.
I say to you, I certainly get irked while other folks consider concerns that they
just do not understand about. You managed to hit the nail upon the top as smartly as defined out
the whole thing with no need side-effects , folks could take a signal.
Will likely be back to get more. Thanks
Hello, Neat post. There is an issue along with your web site in internet
explorer, might test this? IE still is the marketplace chief and a
big part of folks will pass over your excellent writing due to this problem.
I seriously love your blog.. Pleasant colors & theme.
Did you build this web site yourself? Please reply back as I’m
looking to create my own website and want to learn where you got this from or what the theme is called.
Cheers!
This post offers clear idea in favor of the new visitors of blogging,
that genuinely how to do running a blog.
We stumbled over here coming from a different page and thought I should check
things out. I like what I see so now i’m following you. Look forward to looking at
your web page repeatedly.
whoah this weblog is great i love reading your articles.
Keep up the good work! You understand, many persons
are searching round for this information, you can help them greatly.
My brother suggested I may like this blog. He used to be totally right.
This post truly made my day. You can not imagine simply how much time
I had spent for this information! Thanks!
Hurrah! After all I got a blog from where I be able to truly take
helpful data regarding my study and knowledge.
Can I show my graceful appreciation and give my secrets on really
good stuff and if you want to get a peek?
Let me tell you a quick info about how to become a millionaire you know where to follow right?
Very rapidly this web page will be famous amid all blogging visitors, due to it’s good
content
I’m gone to tell my little brother, that he should
also go to see this blog on regular basis to get updated
from latest reports.
It’s actually a great and helpful piece of information.
I’m glad that you shared this useful information with us.
Please keep us informed like this. Thanks for sharing.
Hi, I wish for to subscribe for this web site to obtain hottest updates, thus where can i
do it please help out.
whoah this weblog is excellent i really like reading your articles.
Stay up the good work! You recognize, lots of persons are hunting round for this information, you can help them greatly.
I constantly emailed this website post page to all my friends, as if like
to read it next my links will too.
I visit each day some sites and blogs to read content,
however this blog gives feature based posts.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added
I get three e-mails with the same comment. Is there any way you can remove me from that service?
Thanks!
Howdy! I could have sworn I’ve been to this site before
but after checking through some of the post I realized it’s new
to me. Nonetheless, I’m definitely happy I found it and I’ll be book-marking and checking
back frequently!
I do not even know the way I finished up here, but I assumed this post used to be great.
I do not know who you might be however certainly you are going to a
famous blogger if you happen to are not already.
Cheers!
My site :: Trulicity
It’s nearly impossible to find well-informed people in this
particular subject, however, you seem like you know what you’re talking about!
Thanks
Oh my goodness! Awesome article dude! Thank you, However
I am having problems with your RSS. I don’t know the reason why I can’t subscribe to it.
Is there anyone else having the same RSS issues? Anyone that knows the solution will you kindly respond?
Thanx!!
Way cool! Some extremely valid points! I appreciate you penning this article plus the rest of the site is very good.
Fantastic beat ! I wish to apprentice while you amend your site, how can i subscribe for a blog site?
The account aided me a applicable deal. I had been a little bit familiar of this your broadcast offered
vibrant transparent idea
Incredible points. Outstanding arguments. Keep up the good spirit.
Link exchange is nothing else except it is only placing the other person’s web site link on your page at proper place and other
person will also do similar for you.
I was suggested this blog through my cousin. I’m now not certain whether this publish is written by
means of him as no one else recognise such specific approximately
my trouble. You are wonderful! Thank you!
Hello, i think that i saw you visited my blog thus i came to “return the favor”.I’m attempting to
find things to enhance my site!I suppose its ok
to use a few of your ideas!!
I will immediately seize your rss feed as I can not find your email
subscription link or e-newsletter service. Do you’ve any?
Kindly allow me recognize in order that I may subscribe.
Thanks.
I blog frequently and I truly appreciate your content.
This article has really peaked my interest. I will bookmark your website and keep checking for new information about once a week.
I subscribed to your RSS feed too.
I’m amazed, I must say. Seldom do I come across a
blog that’s both equally educative and engaging, and without
a doubt, you have hit the nail on the head. The problem is an issue that not enough men and women are speaking intelligently about.
I’m very happy I came across this during my search for something concerning this.
Whats up this is somewhat of off topic but I was wondering if blogs use
WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted
to get advice from someone with experience. Any help would be greatly appreciated!
After looking over a handful of the blog posts on your web site, I honestly appreciate your way of blogging.
I bookmarked it to my bookmark site list and will be checking back soon. Please visit
my website as well and tell me what you think.
Hmm іs anyоne else experiencing problems witһ the images оn this Ƅloɡ loaԁing?
I’m trying to determine іf its a рroblem on my end or
if it’s the blog. Any feedback would be greatly apprеciateⅾ.
my blog post Mahkota88
Hi to all, how is the whole thing, I think every
one is getting more from this web site, and your views are pleasant in favor of new visitors.
No worries, hope you are doing ok with being quarantined.
Today, whіle I was at work, my sіѕter stole my iPad and
tested to see if it can suгᴠіve a forty fοot drop, just
so she can be a youtube sensation. My iPad is now bfoken and ѕhhe has 83 vieԝs.
I know this is totally ⲟff topic but I had to share it with someone!
Heгe is myy bloɡ Rindu4d Slot
Everytһing is vеry open with a veгy clear description of the
issues. It was really informative. Your website iѕ extrеmely
helpful. Thanmks for sharing!
Also visit my web-site … Sbobet888
Sweet blog! I found it while browsing on Yahoo News. Do you
have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
Good day! I could have sworn I’ve visited this website before but after
looking at many of the articles I realized it’s new to me.
Regardless, I’m certainly delighted I came across it and I’ll be book-marking it and checking back
frequently!
I love your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do
it for you? Plz answer back as I’m looking to create my own blog and would like to find out where u got this from.
cheers
Have you ever thought about publishing an e-book or guest authoring on other sites?
I have a blog based upon on the same subjects you discuss and would really like to have you share some
stories/information. I know my audience would enjoy your work.
If you’re even remotely interested, feel free to shoot me an email.
Its like you learn my mind! You seem to grasp so much approximately this, such as you wrote the guide in it or something.
I believe that you just could do with a few % to drive the message home a little bit, but other than that, that is wonderful blog.
An excellent read. I’ll certainly be back.
I constantly spent my half an hour to read this
website’s articles or reviews all the time along with a cup of
coffee.
Hmm it appears like your blog ate my first comment (it
was extremely long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still
new to everything. Do you have any helpful hints for inexperienced blog writers?
I’d certainly appreciate it.
Hello! This is kind of off topic but I need some guidance from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I
can figure things out pretty quick. I’m thinking about making my own but I’m not
sure where to start. Do you have any points or suggestions?
With thanks
Appreciate the recommendation. Will try it out.
I do not even know the way I ended up right here, but I believed this submit used to be great.
I don’t realize who you’re however certainly you’re going to a famous blogger should you aren’t already.
Cheers!
Hey there superb website! Does running a blog such as this require a large amount of work?
I have absolutely no knowledge of programming but I had
been hoping to start my own blog in the near future.
Anyway, if you have any recommendations or techniques for new blog owners
please share. I understand this is off topic however I
simply wanted to ask. Thanks!
I have been surfing online more than three hours today,
yet I never found any interesting article like yours. It is pretty worth enough for
me. In my opinion, if all site owners and bloggers
made good content as you did, the net will be a lot more useful than ever before.
I visited several websites but the audio feature for audio songs existing at this web site is actually marvelous.
I’m impressed, I must say. Rarely do I encounter a blog that’s equally educative and amusing, and without a doubt, you have hit the nail on the
head. The problem is something which too few men and women are speaking intelligently about.
Now i’m very happy I found this in my hunt for something relating to this.
Good day! I know this is somewhat off topic but I was wondering if
you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m
having trouble finding one? Thanks a lot!
Everything is very open with a precise clarification of the issues.
It was truly informative. Your site is very useful.
Many thanks for sharing!
Appreciate the recommendation. Let me try it out.
I’ve been exploring for a little bit for any high-quality
articles or weblog posts on this kind of area . Exploring in Yahoo
I finally stumbled upon this website. Reading this information So i am satisfied to exhibit that I’ve an incredibly good uncanny feeling I discovered exactly what I needed.
I such a lot unquestionably will make sure to do
not omit this web site and give it a look on a
relentless basis.
Great article. I will be going through a few of these issues as
well..
I am really loving the theme/design of your web site.
Do you ever run into any browser compatibility problems?
A small number of my blog visitors have complained about my site not working correctly
in Explorer but looks great in Safari. Do you have any
recommendations to help fix this issue?
There is certainly a lot to find out about this subject.
I really like all the points you have made.
Undeniably believe that which you stated. Your favorite reason seemed to be
on the web the simplest thing to be aware of. I say to you, I certainly get annoyed while people consider worries
that they plainly don’t know about. You managed to hit the nail upon the top
as well as defined out the whole thing without having side-effects , people can take a signal.
Will likely be back to get more. Thanks
It’s hard to come by educated people about this subject, however, you seem
like you know what you’re talking about! Thanks
you are in point of fact a just right webmaster. The site loading pace
is incredible. It seems that you’re doing any unique trick.
Furthermore, The contents are masterpiece. you’ve done a excellent job in this matter!
I have been exploring for a little for any high-quality articles
or weblog posts on this sort of area . Exploring in Yahoo
I finally stumbled upon this website. Reading this info So
i’m satisfied to show that I’ve a very good uncanny feeling
I came upon just what I needed. I such a lot surely will make certain to do not put out
of your mind this web site and provides it a look regularly.
Also visit my site :: seo service
Awesome blog! Do you have any hints for aspiring writers?
I’m planning to start my own site soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There
are so many options out there that I’m totally overwhelmed ..
Any ideas? Appreciate it!
I do trust all of the concepts you have offered for your
post. They are really convincing and can definitely work.
Still, the posts are very quick for novices.
May just you please extend them a bit from next time?
Thank you for the post.
Ԍreat site you’ve got here.. It’s difficult to find good quality writing like yours nowadays.
I really appreciate people likе you! Take care!!
Visit my websіte Slot Indo 77
I’m really enjoying the design and layout of your site. It’s a very easy on the eyes which makes it much more pleasant for me to come here
and visit more often. Did you hire out a developer to create your theme?
Exceptional work!
Thanks to my father who shared with me regarding this webpage, this weblog is in fact amazing.
I seriously love your site.. Great colors & theme.
Did you create this site yourself? Please reply back as I’m
attempting to create my own personal blog and want to know where you got
this from or just what the theme is called. Appreciate
it!
I couldn’t refrain from commenting. Perfectly written!
Howdy this is somewhat of off topic but I was wanting to know if blogs use
WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no coding experience so I wanted to get
guidance from someone with experience. Any help would be enormously appreciated!
This design is steller! You certainly know how to keep a reader
entertained. Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Great job. I really loved what you had to say, and more than that, how you presented it.
Too cool!
Thanks designed for sharing such a pleasant thought, paragraph is pleasant, thats why i have read it entirely
Wow! In the end I got a webpage from where I can really get helpful data regarding my study
and knowledge.
Hey there! This is my fіrѕt visit to ʏоuyr blоg!
We are a teɑm of volunteers and starting а new initiative in a community in the same niche.
Your Ьlog provided us valuaƄle information to work on. You havе
done a wondeгful job!
My web page: Indo77 Login
Excellent blog you have here but I was curious if
you knew of any message boards that cover the same topics discussed
in this article? I’d really love to be a part of online community where I
can get feed-back from other knowledgeable people that share the same interest.
If you have any recommendations, please let me know.
Appreciate it!
These are in fact enormous ideas in regarding blogging.
You have touched some nice points here. Any way keep up wrinting.
I’m extremely impressed together with your writing
abilities and also with the format to your weblog.
Is this a paid subject or did you customize it yourself?
Anyway stay up the excellent quality writing, it is uncommon to peer a nice weblog like
this one today..
Excellent blog you have here.. It’s difficult to find high-quality writing like yours
nowadays. I seriously appreciate people like you!
Take care!!
I am really impressed with your writing skills and
also with the layout on your blog. Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it’s rare to see
a nice blog like this one today.
Excellent blog! Do you have any tips for aspiring writers?
I’m planning to start my own website soon but I’m a little lost on everything.
Would you propose starting with a free platform like WordPress or go for a paid option? There
are so many options out there that I’m completely confused ..
Any tips? Appreciate it!
We aгe a gaggle of vօlunteers and opening a new scheme in oսr community.
Your website provided us with uѕeful information to work օn. You’ve done a formidable task
and our whole community might be grateful to you.
Look into my homepage – Fafaslot88
Wow, marvelous blog structure! How lengthy have you ever been blogging for?
you make running a blog glance easy. The total look of your web site
is great, as smartly as the content!
Thanks for one’s marvelous posting! I certainly enjoyed reading it, you
could be a great author.I will make certain to bookmark your blog and will often come back very
soon. I want to encourage you continue your great work, have a
nice afternoon!
Attractive part of contеnt. I just stumbⅼed upon your website and in ɑccesѕion capital to assert that
I acԛuire in fact loved account your weblog poѕts.
Anyway I’ll be subscribing to your feds or even I fulfillment you get admissіon to consistently rapidly.
Feel free to surf tօ my web ⲣaɡe … Cathy
Hello it’s me, I am also visiting this web page regularly, this
web site is genuinely pleasant and the users
are in fact sharing fastidious thoughts.
Hmm is anyone else encountering problems with the pictures
on this blog loading? I’m trying to figure out if its a problem
on my end or if it’s the blog. Any suggestions would be greatly appreciated.
This blog was… how do I say it? Relevant!! Finally I have found something that helped me.
Thanks a lot!
Very good article! We will be linking to this particularly great post on our site.
Keep up the good writing.
Hurrah, that’s what I was exploring for, what a information! existing here at this web site, thanks
admin of this website.
It’s really a great and helpful piece of info. I
am glad that you simply shared this useful info with us.
Please keep us informed like this. Thank you for sharing.
That is a really good tip particularly to those
new to the blogosphere. Short but very accurate information… Thank you
for sharing this one. A must read article!
Its like you read my thoughts! You seem to know a lot approximately this, like you wrote the
e book in it or something. I believe that
you just can do with some p.c. to pressure the message house a
bit, but instead of that, that is excellent blog.
A fantastic read. I will certainly be back.
Have you ever considered about adding a little
bit more than just your articles? I mean, what you say is
valuable and all. However imagine if you added some great
images or videos to give your posts more, “pop”!
Your content is excellent but with images and clips, this
site could undeniably be one of the most beneficial in its niche.
Superb blog!
I must thank you for the efforts you have put in penning
this blog. I really hope to view the same high-grade content by you later on as
well. In truth, your creative writing abilities has inspired me to get my own site now 😉
As the admin of this website is working, no doubt very soon it will be renowned, due to its feature contents.
lordfilm
I’m gone to tell my little brother, that he should also pay
a visit this website on regular basis to obtain updated from most recent information.
Wow, amazing blog format! How long have you ever been running a blog
for? you made running a blog glance easy. The overall glance of your site is fantastic, let alone the content!
I do not even understand how I ended up right here, but I thought this submit was once good.
I don’t recognize who you are however certainly you’re going to a famous blogger when you are not already.
Cheers!
You are so interesting! I don’t suppose I’ve truly read something like this before.
So nice to discover another person with some unique thoughts on this topic.
Seriously.. many thanks for starting this up. This site
is something that is required on the internet, someone with some originality!
I think what you posted was very logical. However,
consider this, suppose you wrote a catchier post title?
I ain’t saying your content isn’t good, but
suppose you added a title that makes people desire more?
I mean Пиастры – Составление семантического ядра | is a little boring.
You might glance at Yahoo’s front page and watch how they write
post titles to grab people interested. You might
add a video or a related pic or two to get readers interested about what
you’ve written. In my opinion, it would bring your blog a little livelier.
First of all I would like to say terrific blog! I had a
quick question in which I’d like to ask if you do not mind.
I was interested to know how you center yourself and clear your mind
prior to writing. I have had trouble clearing my thoughts in getting my thoughts out there.
I truly do take pleasure in writing but it just seems like the
first 10 to 15 minutes are generally wasted simply just trying to
figure out how to begin. Any suggestions or hints?
Many thanks!
Attractive element of content. I just stumbled upon your web site and in accession capital to claim that I
acquire in fact loved account your blog posts.
Anyway I will be subscribing to your feeds or even I fulfillment you get admission to persistently quickly.
I’m truly enjoying the design and layout of your site. It’s a very easy on the eyes which makes it
much more enjoyable for me to come here and visit more
often. Did you hire out a developer to create your theme?
Exceptional work!
Stunning quest there. What occurred after? Thanks!
I was able to find good advice from your articles.
It’s an awеsome post in favor of all the internet people;
they will take benefit from it I am sure.
Feel free to surf to my web-sitе – Hero338
This excellent website certainly has all the information I needed
about this subject and didn’t know who to ask.
Excellent weblog here! Additionally your web site loads up fast!
What host are you the use of? Can I get your associate hyperlink for your host?
I desire my site loaded up as quickly as yours lol
Hi i am kavin, its my first occasion to commenting anyplace,
when i read this post i thought i could also make comment due
to this good post.
Hi there, I enjoy reading all of your post. I wanted to write a little comment to support you.
I love what you guys are up too. Such clever work and reporting!
Keep up the wonderful works guys I’ve included you guys to blogroll.
I relish, result in I discovered exactly what I
was taking a look for. You’ve ended my 4 day long hunt!
God Bless you man. Have a great day. Bye
Hey I am so delighted I found your webpage, I really found you by accident,
while I was researching on Askjeeve for something else,
Nonetheless I am here now and would just like
to say many thanks for a tremendous post and a all round entertaining blog (I also love the theme/design), I don’t have time to look over it all at the moment
but I have book-marked it and also added your RSS feeds, so when I have time I will be back to read a
lot more, Please do keep up the great work.
Whats up are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to
get started and set up my own. Do you need any html coding knowledge to
make your own blog? Any help would be greatly appreciated!
Ӏt’s the best tie to make some plans for the future and iit is tіme to be
happy. I have reaɗ this post and if I could I desire to suggest you
some interesting things or tips. Perhaps you can write next articles referring t᧐ this article.
I want to read even more things about іt!
Also visit my ѕige … Receh77 Login
This web site really has all of the info I wanted concerning this subject and didn’t know who
to ask.
Hi my loѵed one! I wish to say thаt this post is awesome, great written and include almost all νital infos.
I wߋuld like to see more posts like this .
my homepage – Receh99 Login
What’s Taking place i’m new to this, I stumbled upon this I have discovered It absolutely useful and it
has helped me out loads. I hope to contribute & aid other users like its helped me.
Good job.
I do not even know how I ended up here, but I thought this post was
great. I don’t know who you are but definitely you are going to a famous blogger if you aren’t already 😉 Cheers!
Do you have any video of that? I’d like to find out more details.
Heya fantastic website! Does running a blog like this require a massive amount
work? I’ve very little knowledge of computer programming however I had been hoping to start my own blog soon. Anyhow,
if you have any recommendations or techniques for new blog owners please share.
I know this is off topic but I just wanted to ask.
Thank you!
buy viagra online
AK abilities
My web site: chiropractic applied kinesiology
Hello Dear, are you truly visiting this web page regularly,
if so then you will absolutely take pleasant experience.
Does your site have a contact page? I’m having a tough time locating
it but, I’d like to send you an e-mail. I’ve got some suggestions for your blog you might be
interested in hearing. Either way, great site
and I look forward to seeing it develop over time.
I pay a quick visit everyday some web sites and sites to read
content, however this website provides quality based writing.
Nice post. I was checking constantly this weblog and I am impressed! I handle such info much.
I handle such info much.
Extremely helpful info specially the last section
I was looking for this particular info for a very
lengthy time. Thank you and best of luck.
What’s up it’s me, I am also visiting this web page daily, this web page is
really pleasant and the people are genuinely sharing good thoughts.
When some one searches for his required thing, therefore he/she needs to
be available that in detail, thus that thing is maintained over here.
It’s remarkable to pay a quick visit this web page and
reading the views of all friends on the topic of this paragraph, while I am also zealous of getting know-how.
Fantastic beat ! I would like to apprentice while you amend your web site, how
could i subscribe for a blog website? The account aided me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered bright clear idea
I got this web page from my friend who shared with me regarding this web
page and now this time I am browsing this web page and reading very informative content at
this time.
What’s Taking place i am new to this, I stumbled upon this I have discovered It positively useful and it has helped me out loads.
I hope to give a contribution & help different customers like its helped me.
Good job.
I think the admin of this web site is genuinely working hard in support of his web page, as here
every material is quality based stuff.
Thanks for some other great article. The place else may anybody get that type of
info in such a perfect means of writing?
I have a presentation next week, and I am at the look for such info.
Very good blog you have here but I was curious about if you knew of any forums that cover the same topics talked about
here? I’d really like to be a part of online community
where I can get feedback from other knowledgeable people that share the same interest.
If you have any suggestions, please let me know.
Cheers!
Very good article! We will be linking to this particularly great article on our site.
Keep up the good writing.
Klasse Webseite, ich komme mal wieder vorbei.
https://felixmruy73063.sunderwiki.com/94678/daftar_link_slot_gacor_5000_tergacor_resmi_indonesia_2023_mudah_menang
wonderful points altogether, you simply won a new reader.
What could you recommend in regards to your post that you made
a few days in the past? Any positive?
cara daftar situs slot gacoe 2023
http://clasificadoselectronicos.us/__media__/js/netsoltrademark.php?d=planet88-login.powerappsportals.com
Unquestionably believe that which you stated. Your
favorite justification seemed to be on the net the easiest
thing to be aware of. I say to you, I definitely
get annoyed while people consider worries that they just do not know about.
You managed to hit the nail upon the top and defined out the whole thing without having side
effect , people could take a signal. Will likely be back to get more.
Thanks
Hi, I would like to subscribe for this web site to take most recent updates, therefore where
can i do it please help.
I could not resist commenting. Very well written!
Excellent blog you have here.. It’s difficult to find excellent writing like yours these days.
I seriously appreciate individuals like you!
Take care!!
An outstanding share! I have just forwarded this onto a co-worker who
had been conducting a little research on this. And he in fact ordered me breakfast because
I found it for him… lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spending the time to discuss this subject here
on your website.
With havin so much written content do you ever run into
any issues of plagorism or copyright infringement? My blog has a lot of completely unique content I’ve either authored myself or
outsourced but it looks like a lot of it is popping it up all over the
internet without my agreement. Do you know any methods
to help protect against content from being ripped off?
I’d really appreciate it.
Have you ever considered about adding a little bit more than just
your articles? I mean, what you say is fundamental and everything.
But think about if you added some great pictures or video clips
to give your posts more, “pop”! Your content is excellent but with pics and videos, this website could definitely be one of the most beneficial in its field.
Superb blog!
روز پرستار چه روزی است ۱۴۰۱
смотреть фильмы онлайн
Howdy this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or
if you have to manually code with HTML. I’m starting a
blog soon but have no coding experience so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
Hi, Neat post. There’s an issue with your website in internet explorer, may check
this? IE nonetheless is the marketplace chief and a huge
part of folks will miss your excellent writing because of this
problem.
What is Agar.io? Agar.io is a free-to-play on the internet multiplayer activity exactly
where players deal with a cellular and concentration toward develop into the major entity on the server.
The match is fastened in just a petri dish-like earth, and avid gamers navigate their cells by means of ingesting lesser cells despite the fact that avoiding remaining eaten by
means of larger sized kinds. With its easy mechanics and aggressive nature,
Agar.io has develop into a experience, attracting avid gamers of all ages.
Knowledge Agar.io Unblocked Agar.io unblocked refers towards accessing and playing the recreation even when it is restricted or blocked inside
guaranteed sites. This is accomplished through making use of proxy servers, digital personalized networks (VPNs), or decision websites that offer
you arrive at in direction of the match. Gamers can circumvent firewalls and
other network constraints, allowing for them in the direction of love Agar.io in the course of school breaks,
office downtime, or any other situation the place reach would
generally be minimal.
Hey would you mind letting me know which hosting company you’re
utilizing? I’ve loaded your blog in 3 completely different internet browsers and I must say this blog loads a lot faster then most.
Can you recommend a good internet hosting provider at a reasonable price?
Thank you, I appreciate it!https://www.riarudoll.com/
I think everything composed made a great deal of sense.
But, consider this, suppose you added a little information? I
ain’t saying your information is not solid., however suppose you added a headline
that makes people want more? I mean Пиастры – Составление семантического ядра | is a
little plain. You ought to peek at Yahoo’s home page and note how they
write news titles to grab viewers interested. You might add a video
or a related pic or two to get readers interested
about what you’ve got to say. Just my opinion, it could bring your blog a little livelier.
Howdy just wanted to give you a quick heads up and let you kbow a few
of the pictures aren’t loading correctly. I’m not sure why but I think its a linking
issue. I’ve tried it in two different browsers and both show the same outcome.
Also visit my webpage: 免費A片
Hello mates, its fantastic article concerning teachingand entirely explained,
keep it up all the time.
Тhis design is incrediƅle! You obviously know h᧐w to
keep a reader enteгtained. Between your witt and
yoսr videos, Ӏ was almost mоved to start my
own blog (well, almost…HaHa!) Great job. I really loνed what you had to say, and more than that, how уyou
presented it. Too cool!
Here iis mү web blog … Slot787 Login
Rollover requirements are a tad steep on the welcome bonus, but thhe bonus itself is generous, whilst subsequent gives are frequent.
Here is my website casino79.in
When the player is dealt an Ace and a 10 for their very first
two cards.
Loook into my web-site: casino79
What’s up, yup this post is actually fastidious and I have learned lot of things from it regarding blogging.
thanks.
Greetings from California! I’m bored to death at
work so I decided to browse your blog on my iphone
during lunch break. I love the knowledge you present here and can’t wait to take a look
when I get home. I’m amazed at how fast your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyhow, good site!
Hmm it appears like your blog ate my first comment (it was super
long) so I guess I’ll just sum it up what
I submitted and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still new to everything.
Do you have any points for first-time blog writers?
I’d genuinely appreciate it.
Hey! This is my first visit to your blog! We are a collection of volunteers and
starting a new project in a community in the same niche.
Your blog provided us beneficial information to work on. You have done a extraordinary
job!
You’re so awesome! I don’t think I have read through anything like that before.
So good to find somebody with a few original thoughts on this
topic. Really.. many thanks for starting this up.
This site is one thing that’s needed on the
internet, someone with some originality!
Great information. Lucky me I found your blog by accident (stumbleupon).
I have saved it for later!
I’m now not certain the place you are getting your info, but great topic.
I needs to spend some time studying more or understanding more.
Thanks for fantastic information I used to be searching for
this info for my mission.
Hey there! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due
to no data backup. Do you have any methods to protect against hackers?
Hello! I know this is kind of off-topic but I needed to ask.
Does running a well-established blog like yours take a lot of work?
I am completely new to operating a blog but I do write in my
journal on a daily basis. I’d like to start a blog so
I can share my own experience and feelings online.
Please let me know if you have any kind of recommendations or tips for
new aspiring bloggers. Thankyou!
Howdy I am so grateful I found your blog, I really
found you by accident, while I was browsing on Bing
for something else, Regardless I am here
now and would just like to say kudos for a remarkable post and
a all round entertaining blog (I also love the theme/design), I don’t have time to go through it all at the minute
but I have book-marked it and also included your RSS feeds, so when I have time I will
be back to read much more, Please do keep up the great
jo.
This is a topic that’s near to my heart…
Best wishes! Where are your contact details though?
Thanks for your personal marvelous posting!
I seriously enjoyed reading it, you may be a great author.
I will make certain to bookmark your blog and definitely will come back sometime soon. I
want to encourage you continue your great work, have a nice
evening!
Hi there, I discovered your blog by the use of Google whilst searching for a similar topic, your website came up, it
looks great. I’ve bookmarked it in my google bookmarks.
Hi there, just become alert to your blog through Google, and located that
it is really informative. I’m going to watch out for brussels.
I’ll appreciate in the event you continue this in future.
Numerous people might be benefited out of your writing. Cheers!https://www.jp-dolls.com/
I don’t know whether it’s just me or if everyone else
encountering issues with your website. It appears like some of the written text on your
content are running off the screen. Can someone else please provide
feedback and let me know if this is happening to them as well?
This might be a issue with my internet browser because I’ve had this
happen previously. Cheers
of course like your web site but you have to
check the spelling on quite a few of your posts. Several of them are rife with spelling issues and
I to find it very troublesome to tell the truth on the other hand I will
surely come again again.
Hi, of course this post is truly nice and I have learned lot of things from it about blogging.
thanks.
Remarkable! Its genuinely amazing piece of writing, I have got much clear idea on the topic of from
this piece of writing.
What i do not understood is if truth be told how you’re
now not actually a lot more smartly-liked than you may be now.
You’re very intelligent. You recognize therefore significantly
with regards to this topic, made me in my opinion consider it from numerous varied
angles. Its like women and men don’t seem to be interested unless it is something to accomplish with Girl gaga!
Your individual stuffs excellent. At all times care for it
up!
We’re a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable info to work on.
You’ve done a formidable job and our whole community will be grateful to you.
just before|ahead of|in advance of|right
before} or soon after the foundation study course tob uild Your individual SAP Fiori
App from the Cloud.
Anubhav’s Teaching will educate you about recommendations, applications,
and most effective procedures for designing, producing, and deploying your quite individual SAP Fiori application.
Thank you for curating the material on scn.This submit has been very practical.
I’m impressed, I have to admit. Seldom do I come across a blog that’s
both educative and interesting, and without a doubt, you
have hit the nail on the head. The issue is something not enough men and women are speaking intelligently about.
Now i’m very happy that I came across this in my hunt
for something concerning this.
Hi, I would like to subscribe for this blog to
obtain most recent updates, so where can i do it please help out.
Today, while I was at work, my sister stole my iphone and tested to see if it can survive a thirty foot drop, just so she can be a youtube sensation. My iPad is now broken and
she has 83 views. I know this is completely off topic but I had to share it with
someone!
Quality articles or reviews is the key to interest the people to visit the site, that’s what
this web site is providing.
Hi! I know this is kind of off-topic but I had to ask.
Does running a well-established website such as yours take
a massive amount work? I’m brand new to blogging however I do write in my journal on a
daily basis. I’d like to start a blog so I can share my experience and thoughts
online. Please let me know if you have any kind of suggestions or tips for brand new aspiring bloggers.
Appreciate it!
When I initially commented I seem to have clicked the -Notify me when new comments are added- checkbox and
now each time a comment is added I receive four emails with the exact same
comment. There has to be a way you are able to remove me from that service?
Many thanks!
Hurrah! After all I got a blog from where I can in fact take useful data concerning my study and knowledge.
wonderful points altogether, you simply received a emblem new
reader. What would you suggest in regards to your publish that you simply made some days ago?
Any certain?
Hi there! This post couldn’t be written any better!
Reading this post reminds me of my old room mate!
He always kept chatting about this. I will forward this post to him.
Fairly certain he will have a good read. Many thanks for
sharing!
Thank you for every other informative website. The place else may I am getting that kind of information written in such an ideal manner?
I’ve a challenge that I am simply now working on, and I
have been at the glance out for such info.
It is appropriate time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I want to suggest you some
interesting things or tips. Perhaps you can write next articles
referring to this article. I want to read more things about
it!
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get bought an shakiness over that you
wish be delivering the following. unwell unquestionably
come more formerly again as exactly the same nearly a lot often inside case you shield
this hike.
I enjoy reading a post that will make people think.
Also, thank you for allowing for me to comment!
Hi there it’s me, I am also visiting this web site regularly, this site is
in fact nice and the visitors are really sharing pleasant thoughts.
Excellent goods from you, man. I’ve understand
your stuff previous to and you are just extremely
great. I actually like what you’ve acquired here, certainly like what you’re
saying and the way in which you say it. You make it entertaining and you still take care
of to keep it smart. I can not wait to read far more from you.
This is really a terrific web site.
My partner and I stumbled over here different page and thought
I might check things out. I like what I see so now i’m following you.
Look forward to looking into your web page again.
My partner and I stumbled over here different web page and
thought I may as well check things out. I like what
I see so now i’m following you. Look forward to checking out your
web page again.
Hi, I think your site might be having browser compatibility issues.
When I look at your blog in Safari, it looks fine but when opening in Internet
Explorer, it has some overlapping. I just wanted
to give you a quick heads up! Other then that, amazing blog!
It’s remarkable to go to see this web page and reading the views of all colleagues regarding this post,
while I am also eager of getting know-how.
Definitely believe that which you stated. Your favorite reason appeared
to be on the internet the simplest thing to be aware of.
I say to you, I certainly get irked while people think about worries that
they just don’t know about. You managed to hit the nail upon the top and also defined out the whole thing without having side effect
, people can take a signal. Will likely be back
to get more. Thanks
I’ve learn some just right stuff here. Definitely value bookmarking for revisiting.
I wonder how so much attempt you place to make this
type of great informative web site.
hello there and thank you for your information –
I have definitely picked up anything new from right here.
I did however expertise several technical issues using this web site, since I experienced to reload the website a lot of times previous to I could get it to load correctly.
I had been wondering if your hosting is OK? Not
that I am complaining, but slow loading instances times
will sometimes affect your placement in google and could damage your quality score
if ads and marketing with Adwords. Well I am adding this RSS to my e-mail and could look out for a lot more of your respective interesting content.
Make sure you update this again soon.
I need to to thank you for this great read!! I absolutely loved every
little bit of it. I have got you saved as a favorite to look at new
things you post…
Hello, yeah this paragraph is really good and I have learned lot of things from
it on the topic of blogging. thanks.
Pretty great post. I simply stumbled upon your blog and wished
to say that I’ve really enjoyed surfing around your weblog posts.
In any case I will be subscribing to your rss feed and I’m hoping you write once more soon!
Hey terrific website! Does running a blog similar to this take a large amount
of work? I have virtually no knowledge of programming however I had been hoping to start my own blog in the near future.
Anyway, should you have any recommendations or tips for new blog owners please share.
I understand this is off topic however I simply wanted to ask.
Many thanks!
This is my first time go to see at here and i am genuinely pleassant to read everthing at one place.
Today, I went to the beach with my kids. I found a sea shell and gave it
to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed
the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off
topic but I had to tell someone!
Its like you read my mind! You seem to know a lot about this,
like you wrote the book in it or something. I think that
you can do with a few pics to drive the message home a bit,
but other than that, this is fantastic blog. An excellent read.
I’ll certainly be back.
bookmarked!!, I like your website!
Aw, this was a really nice post. Taking the time and actual effort to generate a very good
article… but what can I say… I put things off a whole lot and never seem
to get anything done.
Outstanding post however , I was wanting to know if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit further.
Cheers!
Today, I went to the beachfront with my kids. I found
a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her
ear and screamed. There was a hermit crab inside and it
pinched her ear. She never wants to go back!
LoL I know this is totally off topic but I had to tell someone!
You are so cool! I don’t suppose I have read anything like that before.
So good to find another person with a few genuine thoughts on this issue.
Really.. many thanks for starting this up. This site is one thing that is needed on the web, someone with a little originality!
Good web site you have here.. It’s hard to find high quality writing like yours these days.
I seriously appreciate individuals like you! Take care!!
This article will help the internet viewers for setting up new web site or
even a weblog from start to end.
Here is my web-site: zlatana01
I like reading an article that will make men and women think.
Also, thanks for permitting me to comment!
I got this web site from my pal who shared with me about this web page and at
the moment this time I am browsing this site
and reading very informative content here.
Hello to all, how is the whole thing, I think every one is getting more from this site,
and your views are good in favor of new visitors.
I’ve been browsing online more than three hours these days, but I
by no means discovered any attention-grabbing article
like yours. It is pretty price sufficient for me. Personally, if all website owners and bloggers made good content material as you probably did,
the internet will probably be much more useful than ever before.
Wow, incredible weblog structure! How lengthy have you ever been blogging for?
you make blogging glance easy. The whole glance of your website is fantastic, let alone the
content!
Can I simply just say what a relief to uncover somebody who genuinely knows what they’re talking about on the internet.
You definitely know how to bring an issue to light and make it important.
A lot more people really need to read this and understand this
side of the story. I was surprised that you aren’t more
popular given that you definitely possess the gift.
This is really interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of
your great post. Also, I’ve shared your site in my social networks!
Remarkable issues here. I am very glad to see
your post. Thank you so much and I am looking ahead to touch
you. Will you please drop me a e-mail?
Hey there! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Appreciate it!
Attractive section of content. I just stumbled upon your web site and in accession capital to assert that I acquire actually enjoyed account your blog posts.
Any way I will be subscribing to your augment and even I achievement you access consistently quickly.
I do believe all the ideas you have offered for your post.
They are very convincing and will definitely work. Nonetheless, the posts are very quick for beginners.
May you please extend them a little from next time?
Thank you for the post.
What’s up to all, how is everything, I think every one is getting
more from this site, and your views are nice
for new users.
This article provides clear idea in support of the new users of blogging, that really how
to do blogging.
Hi Dear, are you genuinely visiting this website regularly, if so
afterward you will definitely obtain pleasant know-how.
Helpful info. Lucky me I found your web site by accident, and I am surprised
why this accident did not took place in advance! I bookmarked it.
This site was… how do I say it? Relevant!! Finally I’ve
found something that helped me. Kudos!
I’m no longer certain the place you’re getting your information, however good topic.
I needs to spend a while learning much more or understanding more.
Thank you for fantastic information I used to be on the lookout
for this information for my mission.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time
a comment is added I get several e-mails with the same comment.
Is there any way you can remove people from that service?
Thanks a lot!
You’re so awesome! I don’t suppose I have read something like that before.
So good to discover somebody with original thoughts on this topic.
Really.. thank you for starting this up. This web site is something that is needed on the web, someone with a bit of originality!
Couple off sportsbooks are aas well-respected and prominent ass FanDuel Sportsbook.
Feel free to visit my blog post – website
Attractive element of content. I simply stumbled upon your blog and in accession capital to assert that I acquire actually loved account
your weblog posts. Anyway I’ll be subscribing in your augment and even I achievement
you get entry to consistently quickly.
Good day! I know this is somewhat off topic but
I was wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because I’ve had issues with hackers and I’m looking
at options for another platform. I would be great
if you could point me in the direction of a good platform.
I’m not sure exactly why but this website is loading extremely slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
magnificent issues altogether, you simply received a new reader.
What would you suggest about your post that you made some days ago?
Any positive?
Thank you for the auspicious writeup. It in reality used to be a entertainment account it.
Look advanced to more added agreeable from you!
However, how could we communicate?
I blog often and I truly appreciate your information. The article has really peaked my interest.
I am going to bookmark your website and keep checking
for new details about once a week. I opted in for your Feed too.
Hi! I could have sworn I’ve been to this website before but after browsing through
some of the post I realized it’s new to me.
Anyways, I’m definitely glad I found it and I’ll be book-marking and
checking back frequently!
I got this web site from my pal who informed me regarding this website
and at the moment this time I am browsing this website
and reading very informative content at this time.
Keep on working, great job!
hi!,I like your writing very a lot! share we keep in touch more about your article on AOL?
I need a specialist on this space to resolve my problem.
May be that is you! Having a look forward to look you.
Thank you for any other magnificent article. The place else
could anyone get that type of information in such a perfect way of writing?
I’ve a presentation subsequent week, and I am at the search for
such information.
Hello very cool web site!! Guy .. Beautiful ..
Wonderful .. I’ll bookmark your web site annd take the feeds
additionally? I’m satisfied to seek out so masny helpful information right
here within the put up, we want develop extra techniques in this regard, thanks for sharing.
. . . . .
Its not my first time to visit this web site, i am browsing
this web page dailly and get fastidious data from here all the time.
We are a group of volunteers and starting a new scheme in our community.
Your website offered us with valuable info to work
on. You’ve done a formidable job and our entire community will be thankful to you.
Hello great blog! Does running a blog similar to this require a lot of work?
I’ve absolutely no understanding of computer programming but I
had been hoping to start my own blog soon.
Anyways, if you have any suggestions or techniques for new blog owners please share.
I understand this is off subject but I simply needed
to ask. Kudos!
Hi there! Do you know if they make any plugins to safeguard
against hackers? I’m kinda paranoid about losing everything
I’ve worked hard on. Any recommendations?
Way cool! Some very valid points! I appreciate you penning this write-up and the rest of the website is really good.
Hi there to all, it’s genuinely a nice for me to visit this web site, it consists of precious Information.
Great article, exactly what I wanted to find.
I’ve been exploring for a little for any high-quality articles or weblog posts on this sort of house .
Exploring in Yahoo I at last stumbled upon this site.
Reading this information So i’m glad to exhibit that I have a very just right uncanny feeling
I found out exactly what I needed. I such a lot without
a doubt will make certain to don?t disregard this site and give it a look
regularly.
I every time emailed this blog post page to all my associates, because if
like to read it then my contacts will too.
Hi to every one, it’s genuinely a pleasant for me to visit
this website, it contains useful Information.
I’ve been exploring for a little for any high-quality articles or weblog posts in this kind of house .
Exploring in Yahoo I finally stumbled upon this website.
Reading this information So i am satisfied
to express that I have a very good uncanny feeling I found out just
what I needed. I such a lot definitely will
make certain to don?t forget this web site and give it a glance on a continuing basis.
Ӏ every tme used tto study piece of writing in news pаpers but nnow as I am a user of web therefore from now I am using net for articles,
thanks to web.
Տtop by my web paɡe; Agen777
Hi there I am so thrilled I found your website, I really found you by accident, while I was researching on Aol for something else,
Anyhow I am here now and would just like to say cheers for a tremendous post and
a all round interesting blog (I also love
the theme/design), I don’t have time to read it
all at the moment but I have book-marked it and also added your RSS feeds,
so when I have time I will be back to read a great deal more, Please do keep up the fantastic
job.
Nice post. I was checking continuously this blog and I’m
impressed! Very useful info particularly the last part :
) I care for such information much. I was looking for this particular information for a long time.
Thank you and best of luck.
Its such as you read my mind! You appear to grasp so much about this, such as you wrote the e-book in it or something.
I feel that you simply could do with some % to power the message home a little bit, but other than that, that is magnificent blog.
A fantastic read. I will certainly be back.
ieee
I know this if off topic but I’m looking into starting my own weblog and was
wondering what all is needed to get set up? I’m assuming having a blog like
yours would cost a pretty penny? I’m not very web savvy so I’m
not 100% certain. Any recommendations or advice would be greatly appreciated.
Cheers
Thanks very interesting blog!
Hello i am kavin, its my first occasion to commenting anywhere, when i read this piece of writing i thought i could also make comment due to this brilliant paragraph.
https://book-news.ir/افزایش-فالور-اینستاگرام-راه-های-افزای/
Great goods from you, man. I have understand your stuff previous to
and you are just extremely great. I really
like what you have acquired here, certainly like what you are stating
and the way in which you say it. You make it entertaining and you still care for to keep it sensible.
I can’t wait to read much more from you. This is really a tremendous web site.
Hey very nice blog!
Hi there! This article couldn’t be written much better! Reading through this post reminds me of
my previous roommate! He continually kept talking about this.
I’ll send this information to him. Fairly certain he’ll have a very good read.
Many thanks for sharing!
camisetas de futbol niños
Hey just wanted to give you a quick heads up.
The words in your content seem to be running off the screen in Chrome.
I’m not sure if this is a format issue or something to do with internet browser compatibility but I figured I’d post to let you know.
The design and style look great though! Hope
you get the problem resolved soon. Kudos
That is a very good tip particularly to those new to the blogosphere.
Short but very accurate info… Appreciate your sharing this one.
A must read article!
Wow, superb weblog layout! How lengthy have you been running a blog for?
you made running a blog glance easy. The total glance of your web site is magnificent, let alone
the content material!
Excellent beat ! I wish to apprentice while you amend
your web site, how could i subscribe for a blog website?
The account aided me a acceptable deal. I were tiny bit
familiar of this your broadcast provided vibrant clear concept
My brother suggestred I might like this bloց. He was totally right.
This post truly maԀe my day. You cann’t imagine just how much time I had spent
for this informаtion! Thanks!
Check out my wеbsite … Mega228
You made some good points there. I looked on the net to find out more about the issue and found most people will go along with your views on this web site.
Thanks a bunch for sharing this with all of us you actually understand what you are talking approximately!
Bookmarked. Kindly additionally seek advice from my web site =).
We will have a hyperlink alternate arrangement among us
Hello there! I know this is kinda off topic but I was wondering
which blog platform are you using for this website? I’m getting
fed up of WordPress because I’ve had issues with hackers and I’m looking at
options for another platform. I would be fantastic if you
could point me in the direction of a good platform.
Hello would you mind stating which blog platform you’re using?
I’m looking to start my own blog in the near future but I’m having a hard
time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style
seems different then most blogs and I’m looking for something completely unique.
P.S Sorry for getting off-topic but I had to ask!
Undeniably imagine that that you stated. Your favorite reason seemed
to be at the net the easiest factor to be mindful of.
I say to you, I definitely get irked even as people think
about worries that they plainly don’t recognise about.
You controlled to hit the nail upon the highest and defined out the entire thing without having side-effects , people could take a signal.
Will probably be again to get more. Thank you
I гead this artіcle fully on the topic of the resemblance of newest and preceding technologies, it’s remaгkable article.
My webpage :: Ines
Someone necessarily help to make severely articles I would state.
That is the very first time I frequented your web page and thus far?
I surprised with the analysis you made to create this actual submit incredible.
Wonderful job!
I believe this is among the so much significant information for me.
And i am happy reading your article. But
wanna commentary on few general issues, The website style is wonderful, the articles is actually nice :
D. Just right job, cheers
Cashback
Heree is my web-site 온라인바카라
Zufaellig bin ich auf eure Seite gelandet und muss feststellen, dass mir diese vom Design und den Informationen richtig gut
gefaelt.
https://www.blueglasses.club/2023/03/cara-daftar-bandar-togel-online.html
Hello would you mind sharing which blog platform you’re working with?
I’m looking to start my own blog soon but I’m having a difficult time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for something unique.
P.S My apologies for being off-topic but I had to ask!
It is not my first time to pay a visit this web page,
i am browsing this website dailly and obtain fastidious information from here all
the time.
It’s awesome in favor of me to have a site, which is valuable in support of my knowledge.
thanks admin
I’ve been surfing online more than 4 hours today, yet I never
found any interesting article like yours. It is pretty worth
enough for me. Personally, if all webmasters and bloggers made good content as you did, the internet will be a lot more useful
than ever before.
Hi there, its fastidious post regarding media print, we all
be familiar with media is a wonderful source of information.
Tһis paгagrapһ will help the internet viewers for building up new blog or even a weblog from start how to buy cheap prednisone no prescription end.
At this moment I am going away to do my
breakfast, when having my breakfast coming yet again to read additional news.
Having read this I thought it was extremely informative. I appreciate you taking the time
and energy to put this informative article together.
I once again find myself personally spending a significant amount of
time both reading and leaving comments. But so what, it was still worth it!
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is fundamental and all. However just imagine
if you added some great visuals or videos to give your posts more,
“pop”! Your content is excellent but with images and clips, this site could undeniably be one of the most
beneficial in its field. Great blog!
Link exchange is nothing else however it is simply placing the
other person’s website link on your page at proper place
and other person will also do similar for you.
Wonderful article! That is the type of info that
are supposed to be shared across the web. Disgrace on Google for not positioning this post upper!
Come on over and discuss with my website . Thank you =)
Hey terrific blog! Does running a blog similar to this
take a large amount of work? I’ve absolutely no
expertise in computer programming but I was hoping to start my own blog in the near future.
Anyhow, if you have any suggestions or techniques for new
blog owners please share. I understand this is off topic
nevertheless I simply had to ask. Thanks a lot!
Great delivery. Solid arguments. Keep up
the good spirit.
Just desire to say your article is as surprising. The clarity for your post is just cool and i can assume you
are a professional on this subject. Fine together with your permission let
me to snatch your RSS feed to stay updated with impending post.
Thanks one million and please carry on the
gratifying work.
It’s a shame you don’t have a donate button! I’d definitely donate to this excellent
blog! I guess for now i’ll settle for book-marking
and adding your RSS feed to my Google account. I
look forward to new updates and will share this website with my
Facebook group. Chat soon!
buy viagra online
Thanks for the marvelous posting! I actually enjoyed reading it,
you are a great author.I will always bookmark your blog and
may come back later on. I want to encourage one to continue
your great posts, have a nice holiday weekend!
If you are going for most excellent contents like I do, just pay a visit this site all the time because it
offers feature contents, thanks
You need to take part in a contest for one of the greatest blogs on the
internet. I most certainly will recommend this web site!
Magnificent web site. Plenty of helpful information here.
I’m sending it to several friends ans also
sharing in delicious. And of course, thanks in your effort!
Hеyа i’m for the first time here. I fⲟund tһis board annd I find It really useful & it heⅼpeⅾ me out a lot.
I hope to give something back and hеlp others lіke you aided me.
Take a look at my blog post Idn99
Hey jᥙst wanted to givfe you a brief heads ᥙp and let you know a few of the pіctսres arеn’t loafіng properⅼy.
I’m not sure why but I think its a ⅼinking issue.
I’νe tried it in two dіfferent internet browsers and both show the sаme
resսlts.
Visit mmy web-site … Lux88
Every weekend i used to visit this site, because i want enjoyment, since this
this website conations actually good funny material too.
Yes! Finally someone writes about >.
Your mode of telling everything in this paragraph is genuinely
fastidious, all be able to simply understand it, Thanks a lot.
After checking out a handful of the articles on your web page, I truly
appreciate your technique of blogging. I book-marked it to my bookmark webpage list and will be checking
back in the near future. Please check out my website too and let me know your opinion.
With havin so much written content do you ever run into any issues of plagorism or copyright violation? My blog has a lot of exclusive content I’ve either created myself or outsourced but it looks like a lot of it is popping it up
all over the web without my permission. Do you know any methods to help stop content from being
ripped off? I’d truly appreciate it.
I want to to thank you for this fantastic read!! I definitely loved every little bit of
it. I have you book-marked to look at new things you post…
خبرهای گنبد و اخبار هنرمندان موسیقی
و اخبار ر ورزشی و اخبار جدید فصل 4 لیدی باگ و خبرهای
فوری مهم ایران و دانستنی های صورت
https://bookmarkedblog.com/story13647861/اخبار-جدید-ورزشی
I pay a quick visit each day a few websites and websites to read articles or reviews, except this webpage gives quality based content.
Stop by my webpage – สาระน่ารู้
This post presents clear idea designed for the new visitors of blogging,
that in fact how to do running a blog.
That is very attention-grabbing, You’re a very professional blogger.
I have joined your rss feed and look ahead to looking for extra
of your great post. Additionally, I have
shared your website in my social networks
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an edginess over that you wish be delivering
the following. unwell unquestionably come more formerly again since exactly the same
nearly very often inside case you shield this increase.
Keep on writing, great job!
Heklo my friend! Ι wish to say that this article is amazing,
ցreat written and ome with appгoximately all significant infos.
I’d like to look more posts like this .
Cheeck out my homepage: Idn 99 Slot
Why users still use to read news papers when in this technological globe the whole thing is accessible on web?
Very nice post. I just stumbled upon your weblog and wished to say that
I’ve really enjoyed surfing around your blog posts.
After all I will be subscribing to your rss feed and I hope you write again soon!
Hello this is kinda of off topic but I was wanting
to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding experience so I wanted
to get advice from someone with experience.
Any help would be enormously appreciated!
Hello, i think that i saw you visited my site so i came to “return the
favor”.I’m attempting to find things to enhance my web site!I suppose its ok to use some of your ideas!!
What’s up, after reading this amazing post i am also cheerful to share my
know-how here with colleagues.
First of all I want to say excellent blog! I had a quick question that I’d
like to ask if you do not mind. I was interested
to find out how you center yourself and clear your head prior to writing.
I have had trouble clearing my thoughts in getting my thoughts out.
I do enjoy writing but it just seems like the first 10 to 15 minutes are lost simply just trying to figure out how to begin. Any recommendations
or tips? Appreciate it!
Howdy! This post couldn’t be written any better!
Looking through this post reminds me of my previous roommate!
He constantly kept talking about this. I most certainly will
forward this article to him. Pretty sure he’s going to have a very good
read. Thank you for sharing!
Its like you learn my thoughts! You seem to grasp a lot about this, such as you wrote the e-book in it or something.
I feel that you just can do with a few % to drive the message house a little bit, but
other than that, this is excellent blog. An excellent read.
I’ll definitely be back.
Great post.
Heya i am for the first time here. I found this board and I find
It really useful & it helped me out much. I hope to
give something back and aid others like you helped me.
Hߋwdy ϳuѕt wwanted to give you a quick heads up.
The text in your article seem to be running offf the screen in Chrome.
I’m not sure if thіs is a formatting issue or something too do with web browser compatibility but I fіgured
I’d post to let you know. The desіgn aand style lоok great though!
Hope you get the pгoblem resoⅼved soon. Thanks
My web page Agen777 Slot
Excellent blog right here! Also your website quite a bit up fast!
What web host are you using? Can I get your associate link for your host?
I want my website loaded up as quickly as yours lol
Yes! Finally someone writes about mincovna.
Sweet blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never
seem to get there! Appreciate it
Your way of explaining everything in this article is genuinely fastidious, all can effortlessly be aware of it, Thanks a lot.
An outstanding share! I’ve just forwarded this onto a coworker who has been conducting a little
homework on this. And he actually ordered me dinner simply because I discovered it for him…
lol. So let me reword this…. Thanks for the meal!!
But yeah, thanks for spending some time to discuss this topic here on your website.
Agen togel terpercaya bersama pasaran terbanyak sedia kan bermacam pasaran togel dari
bermacam negara, layaknya Hong Kong, Singapura, Sydney, dan banyak lagi.
Dengan adanya pasaran togel yang lengkap, para pemain mampu memasang taruhan terhadap
pasaran yang mereka sukai dan yang paling familiar.
Selain itu, para pemain terhitung bisa menentukan pasaran dengan peluang kemenangan yang lebih besar.
I’m really loving the theme/design of your weblog.
Do you ever run into any browser compatibility problems? A number
of my blog audience have complained about my blog not operating correctly in Explorer but looks
great in Safari. Do you have any recommendations to
help fix this problem?
Here is my blog: Buy Victoza
Post writing is also a fun, if you be familiar with afterward
you can write if not it is difficult to write.
Definitely believe that which you said. Your favorite reason appeared
to be on the net the simplest thing to be aware of. I say to you, I definitely get annoyed
while people think about worries that they plainly do not know about.
You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , people can take a
signal. Will probably be back to get more. Thanks
Hey there tеrrіfic website! Doеs running a
blog sucһ as thiѕ take a lot of w᧐гk? I have very little knowledgе
of coding howevеr I ѡas hoping to start my οwn blog soon. Anyway,
should you have any suggestions oor techniques for new blog owners pleasе share.
I know this is off subject but I just needed to ask.
Many thanks!
Feel free to surf tߋ my blog post lux88
you’re in reality a excellent webmaster. The website loading speed is incredible.
It sort of feels that you’re doing any distinctive trick.
Furthermore, The contents are masterpiece. you’ve
done a excellent process in this subject!
Hi there! I could have sworn I’ve been to this site before but after browsing through some of the post I realized it’s new to me.
Anyhow, I’m definitely delighted I found it and I’ll
be bookmarking and checking back often!
Hi there friends, good piece of writing and good urging commented at
this place, I am truly enjoying by these.
Why people still make use of to read news papers when in this technological world everything is accessible on web?
What a information of un-ambiguity and preserveness
of precious familiarity concerning unexpected
emotions.
Ahaa, its nice conversation on the topic of this piece of writing here at this blog, I have read all that, so now me also commenting
here.
Great blog you have got here.. It’s hard to find excellent writing like yours nowadays.
I seriously appreciate individuals like you!
Take care!!
My brother recommended I might like this website.
He was entirely right. This post actually made my day.
You can not imagine just how much time I had spent for this info!
Thanks!
Hi my loved one! I want to say that this article is awesome, great written and come with approximately all
significant infos. I’d like to see extra posts like this .
I have read several excellent stuff here. Certainly value bookmarking for revisiting.
I wonder how a lot effort you place to make this type of
excellent informative website.
Its not my first time to go to see this web page, i am browsing this web site dailly and obtain fastidious
information from here every day.
Hello it’s me, I am also visiting this web site on a
regular basis, this site is really good and the people
are actually sharing good thoughts.
I was more than happy to discover this web site. I want to to thank
you for ones time for this particularly wonderful read!!
I definitely enjoyed every little bit of it and i also have you book-marked
to look at new stuff in your web site.
Hello, yup this paragraph is truly fastidious and I have learned lot of
things from it concerning blogging. thanks.
Hmm it appears like your website ate my
first comment (it was extremely long) so I guess I’ll just sum
it up what I had written and say, I’m thoroughly enjoying
your blog. I too am an aspiring blog blogger but I’m still new to everything.
Do you have any recommendations for rookie blog writers? I’d genuinely appreciate it.
Write more, thats all I have to say. Literally, it seems
as though you relied on the video to make your point. You clearly know what
youre talking about, why waste your intelligence
on just posting videos to your weblog when you could be giving us something enlightening to read?
Undeniably consider that that you stated. Your favourite justification appeared to
be on the internet the easiest factor to take into account of.
I say to you, I certainly get annoyed while other folks think about concerns that they plainly don’t realize about.
You managed to hit the nail upon the top and also outlined out the whole thing with no need side effect , people could take
a signal. Will probably be back to get more. Thanks
лордфильм фильмы
Hi, Neat post. There’s a problem with your web site in internet explorer,
would test this? IE nonetheless is the marketplace chief and a big
section of folks will omit your wonderful writing due
to this problem.
It’s an amazing article in support of all the online visitors;
they will get benefit from it I am sure.
It’s remarkable in favor of me to have a web site, which is useful for my know-how.
thanks admin
I absolutely love your blog and find most of your post’s to be precisely what I’m looking for.
can you offer guest writers to write content available for you?
I wouldn’t mind composing a post or elaborating on a number of the subjects you write regarding here.
Again, awesome web site!
Hі there! I just would ⅼikе to offer you a Ьiց thumbs up for
the exϲellеnt information yоu have here on this post. I am ⅽoming bacҝ to ʏour site for more soon.
Stop by my web site Hokiwin
cara daftar situs slot gacoe 2023
http://10fargo.com/__media__/js/netsoltrademark.php?d=mykinematica.com%2F__media__%2Fjs%2Fnetsoltrademark.php%3Fd%3Dutechpus.com
Hi there, I want to subscribe for this blog to take most
up-to-date updates, thus where can i do it please assist.
Hey there! I simply wish to offer you a huge thumbs up for the excellent information you have right here on this post.
I’ll be returning to your website for more soon.
Hi there! This is my first visit to your blog! We are a group of volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You have done
a wonderful job!
Thank you for the good writeup. It in truth used to be a entertainment account it.
Glance complicated to far introduced agreeable from you!
By the way, how can we be in contact?
I like looking through a post that will make people think.
Also, thank you for permitting me to comment!
Wonderful items from you, man. I’ve take into account your stuff previous
to and you’re simply extremely magnificent. I really like what you
have acquired here, certainly like what you are stating and the way in which during which you
assert it. You are making it entertaining and you continue to take
care of to keep it sensible. I can’t wait to learn far more from you.
This is really a wonderful site.
I was very happy to find this web site. I need to to thank you
for your time due to this fantastic read!! I definitely
liked every bit of it and I have you saved as a favorite to
look at new things in your blog.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four e-mails
with the same comment. Is there any way you can remove me from that service?
Appreciate it!
Hi there just wanted to give you a quick heads up.
The text in your article seem to be running off the screen in Ie.
I’m not sure if this is a format issue or something to do with internet browser compatibility but I thought I’d post to let
you know. The style and design look great though!
Hope you get the problem resolved soon. Cheers
Pretty great post. I simply stumbled upon your blog and wished to mention that I’ve truly loved
browsing your weblog posts. In any case I’ll
be subscribing on your rss feed and I’m hoping you write again very soon!
Attractive section of content. I just stumbled upon your
weblog and in accession capital to assert that I get in fact enjoyed account your blog posts.
Any way I will be subscribing to your feeds and even I achievement you access consistently
quickly.
A person essentially assist to make severely articles
I would state. That is the very first time I frequented your web page and so far?
I amazed with the analysis you made to create this actual
submit extraordinary. Wonderful process!
I think the admin of this site is truly working
hard for his web site, since here every material is quality
based data.
hi!,I like your writing so so much! share we keep
up a correspondence extra about your article on AOL? I require
an expert in this house to unravel my problem. May be that’s you!
Looking ahead to see you.
I am really enjoying the theme/design of your web site.
Do you ever run into any web browser compatibility issues?
A number of my blog readers have complained about my site not operating correctly in Explorer but looks great in Chrome.
Do you have any recommendations to help fix this issue?
It is appropriate time to make a few plans for the future and it is time to be happy.
I’ve read this put up and if I may just I want to recommend you few interesting issues or tips.
Perhaps you could write next articles referring to this article.
I wish to read even more things about it!
Great post. I was checking continuously this blog and I am impressed! I
I
Extremely useful info particularly the last part
care for such information a lot. I was looking for
this certain information for a long time.
Thank you and best of luck.
Wow, fantastic blog structure! How lengthy have you ever been running a blog for?
you make blogging glance easy. The entire glance of your site is magnificent, let alone the content material!
whoah this blog is fantastic i like reading your articles.
Keep up the great work! You recognize, many persons are searching round for this information, you can aid them greatly.
It’s awesome in favor of me to have a web site, which is useful designed for my know-how.
thanks admin
Have you ever thought about creating an ebook or
guest authoring on other blogs? I have a blog based on the
same topics you discuss and would love to have you share some stories/information. I know my audience would appreciate your
work. If you are even remotely interested, feel free to send
me an e-mail.
When someone writes an piece of writing he/she maintains the thought of a
user in his/her mind that how a user can know it.
So that’s why this piece of writing is perfect.
Thanks!
May I simply just say what a relief to discover
somebody that really understands what they are talking
about over the internet. You certainly understand how to bring a problem to
light and make it important. More people must check this out and understand this side of your story.
I can’t believe you aren’t more popular because you surely possess the gift.
Hello, I think your site might be having browser compatibility issues.
When I look at your blog in Ie, it looks fine but when opening in Internet
Explorer, it has some overlapping. I just wanted to give you
a quick heads up! Other then that, awesome blog!
Howdy! This post couldn’t be written any better! Reading through this post reminds me of my old room
mate! He always kept talking about this. I will forward this page to him.
Pretty sure he will have a good read. Thank you for sharing!
Hello to all, how is all, I think every one is getting more from this web site,
and your views are pleasant in support of new visitors.
In fact when someone doesn’t know then its up to
other people that they will assist, so here it takes place.
I’m not positive the place you’re getting your information, however great topic.
I must spend a while learning more or understanding more.
Thank you for magnificent info I used to be searching for this info for my mission.
Magnificent goods from you, man. I’ve understand your stuff previous to and you’re just too wonderful.
I really like what you’ve acquired here, really like what you
are stating and the way in which you say it. You make it enjoyable and you still care for to keep it smart.
I can’t wait to read far more from you. This is actually a wonderful website.
This blog was… how do I say it? Relevant!! Finally I’ve found something that helped me.
Cheers!
It’s appropriate time to make some plans for the future and it is time to be happy.
I’ve learn this post and if I may just I wish to recommend you few
interesting things or advice. Perhaps you can write next articles relating
to this article. I desire to learn even more issues about it!
I’m not sure why but this web site is loading very slow for me.
Is anyone else having this problem or is it a issue on my
end? I’ll check back later on and see if the problem
still exists.
I’m really enjoying the theme/design of your blog.
Do you ever run into any web browser compatibility problems?
A small number of my blog readers have complained about my blog not
working correctly in Explorer but looks great in Chrome.
Do you have any suggestions to help fix this issue?
Thanks for a marvelous posting! I definitely enjoyed reading
it, you can be a great author. I will be sure to bookmark your blog
and will eventually come back in the future. I want
to encourage you continue your great work,
have a nice holiday weekend!
Very great post. I just stumbled upon your weblog and wished to say that I have really enjoyed
browsing your weblog posts. In any case I will be subscribing in your rss feed and I’m
hoping you write again soon!
Hi there, I found your site via Google even as searching
for a related topic, your site came up, it seems to be good.
I have bookmarked it in my google bookmarks.
Hello there, just become alert to your blog via Google,
and found that it’s really informative. I am going to watch out for brussels.
I’ll appreciate in case you continue this in future. Numerous folks will likely be benefited from your writing.
Cheers!
Thanks for another excellent post. The place else may anyone get that kind of information in such a perfect way of
writing? I’ve a presentation subsequent week, and I’m at the look for such
info.
This site definitely has all the information I needed about this subject and didn’t know who to ask.
After looking at a few of the blog posts on your website, I
really appreciate your way of writing a blog. I saved it to my bookmark webpage list and will
be checking back soon. Take a look at my web site as well and let me
know your opinion.
It’s awesome for me to have a site, which is beneficial designed for my know-how.
thanks admin
Hi are using WordPress for your site platform? I’m new to the
blog world but I’m trying to get started and set up my own. Do you need any coding expertise to make your own blog?
Any help would be greatly appreciated!
I’m not sure why but this weblog is loading incredibly slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem still exists.
It’s very trouble-free to find out any matter on web as compared to textbooks,
as I found this article at this web site.
Hello there! This article couldn’t be written any better!
Going through this article reminds me of my previous roommate!
He continually kept preaching about this. I am going to send this post to him.
Pretty sure he’s going to have a very good read. Many thanks for sharing!
Hi there it’s me, I am also visiting this site daily, this web page is actually pleasant and
the visitors are really sharing fastidious thoughts.
This post is truly a fastidious one it assists new the web visitors, who are wishing for blogging.
https://honarenews.ir/آموزش-تعمیرات-لوازم-خانگی-دوره-صفر-تا-ص/
Howdy very nice blog!! Man .. Excellent .. Amazing ..
I will bookmark your site and take the feeds also?
I am satisfied to search out numerous helpful information right here within the submit, we need work out more strategies on this regard, thank you
for sharing. . . . . .
Good blog you have got here.. It’s hard to find quality writing like yours these days.
I truly appreciate people like you! Take care!!
I have been surfing online more than 4 hours today,
yet I never found any interesting article like yours. It is pretty worth enough for me.
In my view, if all web owners and bloggers made good content
as you did, the web will be a lot more useful than ever before.
Thanks for a marvelous posting! I definitely enjoyed reading
it, you can be a great author. I will ensure that
I bookmark your blog and may come back later on. I want to encourage you to ultimately continue
your great work, have a nice holiday weekend!
There’s definately a great deal to learn about this topic.
I like all the points you made.
Wonderful blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed
in Yahoo News? I’ve been trying for a while but
I never seem to get there! Thank you
Your method of explaining everything in this post is really good, all be able to effortlessly know it, Thanks a lot.
Thanks for any other informative blog. The place else may I am getting that kind of information written in such an ideal
way? I have a undertaking that I am simply now working on, and I’ve been on the look out
for such information.
Remarkable! Its really remarkable article, I have got much
clear idea concerning from this paragraph.
I am sure this piece of writing has touched all the internet visitors, its really really nice piece of writing
on building up new website.
My family members always say that I am wasting my time here at net, but I know I am getting knowledge all the time by reading thes nice posts.
Do you have a spam issue on this blog; I also am a blogger,
and I was wondering your situation; many of us have developed some nice methods and
we are looking to trade techniques with others, why
not shoot me an e-mail if interested.
Yes! Finally someone writes about strona.
Because the admin of this web page is working, no uncertainty very shortly it will be famous, due to its feature contents.
Hi, i think that i saw you visited my website thus i came to
“return the favor”.I am attempting to find things to improve my
website!I suppose its ok to use some of your ideas!!
After checking out a number of the articles on your
website, I truly appreciate your technique of writing a blog.
I bookmarked it to my bookmark website list and
will be checking back in the near future. Please visit my
web site as well and tell me your opinion.
whoah this weblog is magnificent i like reading your articles.
Stay up the good work! You know, many individuals are looking around for this information, you
can help them greatly.
Hi there, I check your blog on a regular basis. Your story-telling style is
awesome, keep it up!
Hi my loved one! I want to say that this post is amazing, great written and come with almost all vital infos.
I’d like to peer extra posts like this .
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back later.
All the best
Good answer back in return of this question with solid arguments and
telling everything concerning that.
We’re a group of volunteers and opening a new scheme in our community.
Your website offered us with valuable info to work on. You’ve done a formidable process and our entire community
will probably be thankful to you.
Pretty component of content. I just stumbled upon your weblog and in accession capital
to claim that I get actually loved account your weblog posts.
Any way I’ll be subscribing in your augment or even I achievement you get right of entry to persistently quickly.
Good post. I learn something totally new and challenging on websites I stumbleupon every day.
It’s always exciting to read through content from other writers and practice something from other
sites.
I pay a quick visit day-to-day a few websites and blogs to read content,
however this weblog offers quality based posts.
This website was… how do you say it? Relevant!! Finally I’ve found something that helped me.
Appreciate it!
I always emailed this blog post page to all my associates, for the reason that if like to read it
after that my friends will too.
I’m not that much of a internet reader to be honest but your blogs really nice,
keep it up! I’ll go ahead and bookmark your website
to come back down the road. Cheers
I am regular reader, how are you everybody?
This post posted at this web site is truly nice.
Pretty component of content. I just stumbled upon your website and in accession capital to assert that I
acquire in fact loved account your blog posts. Any way I will be subscribing to your feeds or even I success you get admission to persistently fast.
Howdy! I know this is kinda off topic however , I’d figured I’d
ask. Would you be interested in exchanging links or maybe guest writing a blog
article or vice-versa? My website discusses a lot of the same subjects as yours
and I think we could greatly benefit from each other.
If you’re interested feel free to shoot me an e-mail. I look forward to hearing from you!
Great blog by the way!
Terrific article! That is the type of information that should be
shared across the internet. Shame on the search engines for
not positioning this put up higher! Come on over and visit
my web site . Thank you =)
Does your site have a contact page? I’m having problems locating it but, I’d like to send you an email.
I’ve got some creative ideas for your blog you
might be interested in hearing. Either way, great blog and I look forward to seeing
it grow over time.
I was recommended this blog by my cousin. I’m not sure whether or not this submit is written by means of
him as nobody else know such detailed about my difficulty.
You’re amazing! Thank you!
If you want to increase your knowledge just keep visiting
this web page and be updated with the hottest information posted
here.
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point. You clearly know
what youre talking about, why throw away your intelligence
on just posting videos to your blog when you could be giving us
something informative to read?
I think this is one of the most significant info for me.
And i’m glad reading your article. But wanna remark on some general things,
The website style is ideal, the articles is really excellent : D.
Good job, cheers
Howdy! Someone in my Myspace group shared this website
with us so I came to give it a look. I’m definitely loving
the information. I’m book-marking and will be tweeting this to my followers!
Wonderful blog and wonderful design.
I am genuinely thankful to the holder of this site who has shared this great article at at this place.
cara daftar situs slot gacoe 2023
http://see-life.ru/bitrix/rk.php?goto=https://www.itravelqq.com/
Hello everybody, here every person is sharing such experience, therefore
it’s pleasant to read this webpage, and I used to pay a quick visit this webpage daily.
Heya i am for the primary time here. I came across this board and I to find It really helpful & it helped me out a lot.
I am hoping to offer one thing back and aid others such
as you aided me.
Hello my family member! I want to say that this article is awesome, great written and come with approximately
all important infos. I’d like to look more posts
like this .
you’re really a excellent webmaster. The web site loading
velocity is incredible. It kind of feels that you are doing any distinctive trick.
In addition, The contents are masterwork.
you’ve performed a magnificent process in this matter!
Thank you for the good writeup. It in reality was once a enjoyment account it.
Look complicated to far brought agreeable from you!
However, how could we keep up a correspondence?
There’s definately a great deal to know about this issue.
I really like all the points you’ve made.
Everyone loves it whenever people get together and share views.
Great blog, continue the good work!
Hello! I could have sworn I’ve visited this blog before but after going through some of the posts I realized it’s
new to me. Anyhow, I’m definitely pleased I discovered it and I’ll be bookmarking it and checking back frequently!
I have read some just right stuff here. Certainly worth bookmarking for revisiting.
I surprise how so much effort you put to create this sort of wonderful informative site.
I couldn’t resist commenting. Exceptionally well written!
I every time emailed this web site post page to all my associates, because if like
to read it after that my contacts will too.
I was extremely pleased to discover this great site.
I need to to thank you for your time for this
fantastic read!! I definitely liked every
part of it and I have you book-marked to look at new stuff in your
blog.
Thank you a lot for sharing this with all of us you really recognize what you are talking
about! Bookmarked. Please additionally seek advice
from my site =). We may have a hyperlink trade contract among us
Heya i am for the first time here. I found this board and I find It truly helpful & it
helped me out a lot. I am hoping to give something back and aid others such as you helped me.
Thanks for your personal marvelous posting!
I truly enjoyed reading it, you may be a great
author.I will make sure to bookmark your blog and will eventually come
back in the foreseeable future. I want to encourage you to ultimately continue
your great job, have a nice afternoon!
Hello just wanted to give you a quick heads up. The words in your content seem to be running off the screen in Internet explorer.
I’m not sure if this is a formatting issue or something to do with internet browser compatibility but I figured I’d post
to let you know. The design look great though!
Hope you get the problem fixed soon. Many thanks
I’ve been browsing online more than three hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all website owners
and bloggers made good content as you did, the net will be
a lot more useful than ever before.
Ahaa, its pleasant discussion on the topic of
this article at this place at this webpage, I have read
all that, so now me also commenting here.
Does your site have a contact page? I’m having problems locating it but, I’d like to shoot you an email.
I’ve got some creative ideas for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it grow over time.
What’s up mates, its wonderful paragraph on the topic of tutoringand entirely
explained, keep it up all the time.
May I simply say what a relief to discover someone who really understands what they are talking about online.
You actually know how to bring a problem to light and make it important.
More and more people really need to check this out and understand this side of the story.
It’s surprising you’re not more popular because you certainly
possess the gift.
I do not even understand how I finished up right here, but I thought this post was once
good. I don’t realize who you might be however certainly you’re going to
a well-known blogger in the event you aren’t already. Cheers!
Ahaa, its fastidious dialogue on the topic of this article here at this web
site, I have read all that, so at this time me also commenting at this place.
Pretty! This has been an extremely wonderful article.
Thank you for providing this information.
Hi i am kavin, its my first occasion to commenting anyplace,
when i read this paragraph i thought i could also create comment due to this good paragraph.
Greetings! Quick question that’s totally off topic. Do you know how to
make your site mobile friendly? My web site looks
weird when viewing from my apple iphone. I’m trying to find a template or
plugin that might be able to correct this problem. If you
have any suggestions, please share. Appreciate it!
I every time spent my half an hour to read this webpage’s content daily along with a cup of coffee.
Does your site have a contact page? I’m having a tough time locating it but,
I’d like to send you an email. I’ve got some creative ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing
it expand over time.
Hi mates, its enormous piece of writing regarding cultureand entirely defined, keep it up all
the time.
Excellent post. I was checking continuously this blog and I am
impressed! Very helpful information particularly the last part :
) I care for such information a lot. I was looking for this particular info for
a very long time. Thank you and good luck.
Hey There. I found your weblog using msn. This is a very smartly written article.
I’ll make sure to bookmark it and return to learn more of your helpful information.
Thanks for the post. I will certainly return.
This website certainly has all of the information and facts I
wanted about this subject and didn’t know who to ask.
It’s amazing in favor of me to have a web page,
which is useful for my know-how. thanks admin
Great article.
Howdy! Would you mind if I share your blog with my facebook group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Cheers
I will right away grasp your rss feed as I can not find your e-mail subscription link or e-newsletter service.
Do you’ve any? Kindly permit me realize so that I may subscribe.
Thanks.
Do you have a spam problem on this site; I also am a blogger, and I
was wondering your situation; we have created some nice methods and we are looking to swap techniques with other folks, please shoot me an e-mail if interested.
Fabulous, what a web site it is! This webpage provides
valuable data to us, keep it up.
I’m amazed, I have to admit. Rarely do I encounter a blog that’s both
educative and engaging, and without a doubt, you’ve hit the nail on the head.
The problem is something that not enough men and women are
speaking intelligently about. I am very happy
that I came across this during my hunt for something
regarding this.
Hi there just wanted to give you a quick heads up. The text
in your content seem to be running off the screen in Opera.
I’m not sure if this is a formatting issue or something to do with web browser compatibility but I thought I’d post to let you know.
The style and design look great though! Hope you get the issue fixed soon. Kudos
I like what you guys tend to be up too. This kind of
clever work and coverage! Keep up the good works guys I’ve added you guys to my personal blogroll.
I don’t even know how I stopped up right here, however I believed this submit was once great.
I don’t know who you are however certainly you are going to a
well-known blogger when you are not already. Cheers!
I was curious if you ever thought of changing the structure of
your website? Its very well written; I love what
youve got to say. But maybe you could a little
more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two pictures.
Maybe you could space it out better?
Cool blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple adjustements would really make my blog shine.
Please let me know where you got your theme. Many
thanks
Everything is very open with a clear description of the issues.
It was truly informative. Your website is very helpful.
Thanks for sharing!
Hmm it seems like your website ate my first comment
(it was super long) so I guess I’ll just sum it up what I had written and
say, I’m thoroughly enjoying your blog. I too am an aspiring blog writer but I’m still
new to everything. Do you have any tips and hints for inexperienced blog writers?
I’d really appreciate it.
Hi, i believe that i noticed you visited my site
so i came to go back the desire?.I am trying to
in finding things to enhance my site!I assume its adequate to make use of some of your concepts!!
Appreciation to my father who informed me concerning this webpage,
this web site is in fact amazing.
An outstanding share! I’ve just forwarded this onto a co-worker who was doing a
little homework on this. And he actually bought me breakfast simply because I stumbled upon it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanks for spending time to discuss this issue here
on your internet site.
I like what you guys tend to be up too. This kind of clever work and reporting!
Keep up the good works guys I’ve added you guys
to our blogroll.
Nice post. I learn something totally new and challenging on websites I
stumbleupon everyday. It’s always useful to read through
content from other writers and use something from other web
sites.
I don’t even know how I stopped up here, however
I assumed this put up was good. I don’t understand who you are but
certainly you’re going to a famous blogger when you
are not already. Cheers!
Fastidious replies in return of this question with genuine
arguments and telling all on the topic of that.
Every weekend i used to visit this web page, for the reason that i want enjoyment, for the reason that
this this web page conations actually fastidious
funny material too.
I have to thank you for the efforts you’ve put in penning this website.
I really hope to view the same high-grade blog posts from
you later on as well. In truth, your creative writing abilities has motivated
me to get my own website now 😉
Keep on writing, great job!
Hey there, You have done an excellent job. I will definitely digg it and personally recommend to my friends.
I am sure they’ll be benefited from this site.
I’m not sure where you’re getting your information, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for excellent information I was looking for this information for my mission.
Great beat ! I wish to apprentice while you amend your web site, how can i subscribe for a blog web
site? The account aided me a acceptable deal. I had been a little bit acquainted of this your broadcast provided bright clear concept
Ahaa, its nice dialogue about this post here at this website, I have read all that,
so now me also commenting at this place.
I really like it whenever people come together and share ideas.
Great site, keep it up!
Greetings! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly? My website looks
weird when viewing from my iphone4. I’m trying to find a theme or plugin that might
be able to fix this problem. If you have any suggestions, please share.
Many thanks!
I am truly delighted to glance at this weblog posts which includes plenty
of useful data, thanks for providing these data.
Thanks on your marvelous posting! I definitely enjoyed reading it,
you will be a great author.I will make certain to bookmark your blog
and will come back very soon. I want to encourage you to definitely
continue your great posts, have a nice day!
When some one searches for his necessary thing, therefore he/she desires to be
available that in detail, thus that thing is maintained over here.
We’re a group of volunteers and opening a new scheme in our community.
Your site provided us with valuable information to work on. You have done
an impressive job and our whole community will be grateful to you.
Magnificent goods from you, man. I have understand your stuff previous
to and you are just too magnificent. I really like what you have acquired here, certainly like what
you are saying and the way in which you say it. You make it enjoyable and
you still care for to keep it sensible. I can not wait to read far more from you.
This is really a tremendous website.
Hello! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing a blog post or vice-versa?
My website covers a lot of the same subjects as yours and I believe we could greatly benefit from each other.
If you happen to be interested feel free to send
me an email. I look forward to hearing from you!
Awesome blog by the way!
Appreciate the recommendation. Will try it out.
Unquestionably imagine that that you stated. Your favorite
reason seemed to be at the net the easiest factor to keep in mind
of. I say to you, I definitely get irked whilst folks think about worries that
they just don’t recognise about. You managed to hit the nail upon the highest and outlined out the entire thing with no need side effect , people
can take a signal. Will probably be again to get more.
Thanks
Link exchange is nothing else however it is simply placing the other person’s website
link on your page at appropriate place and other person will also
do similar in support of you.
Good day I am so happy I found your site, I really found you by error, while I was researching on Digg
for something else, Regardless I am here now and would
just like to say thank you for a fantastic post and a all round entertaining blog (I also love the theme/design), I don’t have time
to read through it all at the moment but I have saved
it and also added your RSS feeds, so when I have time I will be back to read more, Please do keep up the great
b.
Aw, this was an incredibly good post. Taking a few minutes and actual effort to
produce a good article… but what can I say… I put things off a whole lot and
don’t manage to get anything done.
Hiya very nice web site!! Guy .. Beautiful ..
Wonderful .. I will bookmark your website and take the feeds also?
I’m satisfied to search out so many useful info right here within the publish, we’d like
develop more techniques on this regard, thanks for sharing.
. . . . .
Hi it’s me, I am also visiting this web site regularly, this website is really fastidious and the viewers are genuinely sharing
nice thoughts.
hello!,I really like your writing very so much! share we be in contact more approximately
your post on AOL? I need an expert in this space to solve my
problem. May be that’s you! Looking ahead to peer you.
Thanks for finally talking about > Пиастры – Составление семантического ядра |
< Liked it!
Hello there! This post couldn’t be written any better!
Going through this post reminds me of my previous roommate!
He continually kept talking about this. I’ll forward this post to him.
Fairly certain he will have a good read. Many thanks for sharing!
It’s amazing in favor of me to have a web site, which
is valuable for my know-how. thanks admin
Please let me know if you’re looking for a author for your blog.
You have some really great posts and I believe I would be a good asset.
If you ever want to take some of the load off, I’d love
to write some articles for your blog in exchange for a link back
to mine. Please shoot me an e-mail if interested.
Kudos!
Does your blog have a contact page? I’m having problems locating it but,
I’d like to send you an e-mail. I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it grow over time.
Inspiring quest there. What occurred after? Take care!
I do not evsn know thе way I finisheԁ uup here, howevеr I asѕᥙmed this post used to be good.
I do not recognise who ʏou’re hoԝеver сertainly you’re goіng to a well-қnown blogger for those who аren’t alreadү.
Cheers!
Look at my blog post – Rgo365
Hi there, I enjoy reading through your article. I like
to write a little comment to support you.
I’ve learn a few excellent stuff here. Definitely price bookmarking for revisiting.
I wonder how so much effort you put to make any such fantastic informative site.
I read this piece of writing completely regarding the difference of newest and previous technologies, it’s remarkable article.
I was wondering if you ever considered changing the structure
of your website? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect
with it better. Youve got an awful lot of text for only
having one or 2 pictures. Maybe you could space it out
better?
Write more, thats all I have to say. Literally,
it seems as though you relied on the video to make your point.
You obviously know what youre talking about,
why waste your intelligence on just posting videos to your site when you could
be giving us something informative to read?
Hello there! This post could not be written any better!
Going through this article reminds me of my previous roommate!
He constantly kept talking about this. I’ll send this post to him.
Fairly certain he will have a good read. I appreciate you
for sharing!
You actually make it seem so easy together with your presentation however I find this matter to be really something
that I believe I might never understand. It kind of feels too
complex and extremely large for me. I’m having a look forward
in your subsequent publish, I will attempt to get the grasp of it!
Have you ever considered about adding a little
bit more than just your articles? I mean, what you say is valuable and all.
However imagine if you added some great graphics or videos to give your posts more, “pop”!
Your content is excellent but with pics and video clips, this site could undeniably be one of the most beneficial in its
niche. Amazing blog!
Appreciate this post. Will try it out.
I really like what you guys are up too. This kind of clever work and reporting!
Keep up the wonderful works guys I’ve incorporated you guys
to our blogroll.
bookmarked!!, I love your website!
Hey I know this is off topic but I was wondering
if you knew of any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping
maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog
and I look forward to your new updates.
Good write-up. I absolutely love this site. Keep it up!
What a material of un-ambiguity and preserveness of valuable know-how
on the topic of unexpected emotions.
Good response in return of this difficulty with
firm arguments and telling all concerning that.
I all the time used to read article in news papers but
now as I am a user of net thus from now I am using net for articles, thanks to web.
I enjoy what you guys tend to be up too. This sort
of clever work and exposure! Keep up the good works guys I’ve included you guys to my blogroll.
Every weekend i used to go to see this site, because i
want enjoyment, for the reason that this this web site conations really pleasant funny material too.
Great info. Lucky me I recently found your site by accident (stumbleupon).
I’ve saved it for later!
I know this if off topic but I’m looking into starting my own weblog and was
wondering what all is needed to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% certain. Any suggestions or advice would be greatly appreciated.
Appreciate it
Thank you for any other informative blog. Where else may just I am getting that type of information written in such an ideal means?
I’ve a mission that I’m just now running on, and I’ve been at the glance out for
such information.
South Korean players can wager on a assortment
of sports, which includes soccer and sailing.
Stop by my web-site :: 바카라
I got this web page from my pal who shared with me on the topic of this website and now this time
I am visiting this web site and reading very informative content at
this place.
Your method of describing the whole thing in this article is truly nice, all be capable of effortlessly understand it,
Thanks a lot.
Wonderful goods from you, man. I have understand your stuff previous to and you’re just too great.
I really like what you have acquired here, really like what you’re saying
and the way in which you say it. You make it enjoyable and you still take care of to keep it wise.
I cant wait to read much more from you. This is actually a great web site.
I used to be able to find good info from your blog
posts.
Pretty nice post. I simply stumbled upon your blog and wanted to
mention that I have truly enjoyed surfing around your weblog posts.
In any case I will be subscribing in your rss feed and
I’m hoping you write again soon!
It’s a pity you don’t have a donate button! I’d certainly donate to this fantastic blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to new updates and will share this blog with my Facebook group.
Talk soon!
Hi, i think that i saw you visited my site so i
came to “return the favor”.I am trying to find things to improve
my website!I suppose its ok to use a few of your ideas!!
You are so cool! I don’t believe I’ve truly read a single thing like this before.
So good to discover another person with some original thoughts on this subject.
Seriously.. thanks for starting this up. This web site is
something that is required on the internet, someone with a little
originality!
Informative article, just what I was looking for.
Hi, Neat post. There’s a problem along with your website
in web explorer, may test this? IE still is the marketplace chief and a
big element of other people will omit your excellent writing due to this problem.
Players can earn up to $750 in 3 separate deposits in the welcome bonus.
Here is my web site :: 카지노게임
I do consider all of the ideas you’ve introduced for your post.
They are very convincing and can definitely work. Still, the posts
are too short for newbies. May you please extend them
a little from next time? Thank you for the post.
I do not even understand how I stopped up right here, but I believed this post used
to be great. I do not understand who you are however definitely you are going
to a famous blogger should you are not already. Cheers!
I take pleasure in, lead to I discovered just what I used to be
looking for. You have ended my four day lengthy hunt!
God Bless you man. Have a great day. Bye
Simply wish to say your article is as astounding.
The clearness in your post is just spectacular and that i can assume you’re an expert in this subject.
Well along with your permission let me to take hold of your RSS feed
to keep up to date with imminent post. Thanks one million and please keep up the rewarding work.
Hi, for all time i used to check website posts here in the early hours in the dawn, for the reason that i like to learn more and
more.
I could not resist commenting. Well written!
Hi, just wanted to say, I enjoyed this post.
It was practical. Keep on posting!
Hello would you mind sharing which blog platform you’re
using? I’m going to start my own blog in the
near future but I’m having a difficult time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and
I’m looking for something unique.
P.S My apologies for getting off-topic but I had to ask!
Somebody essentially help to make seriously posts I’d state.
This is the first time I frequented your web page and up to now?
I amazed with the analysis you made to make this particular submit
incredible. Magnificent process!
I got this website from my friend who shared with me
on the topic of this site and now this time I am visiting this web page and reading very informative posts at this time.
Under, we’ve outlined the pros and cons of regulated and offshore casinos
in Ontario.
My web site – 카지노보증사이트
What a stuff of un-ambiguity and preserveness of valuable familiarity concerning unpredicted emotions.
Marvelous, what a web site it is! This web site gives useful data to us, keep it up.
Wow, wonderful blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is wonderful, as well as the content!
Very soon this web page will be famous amid all blogging and site-building visitors, due to it’s nice articles or reviews
Hi there it’s me, I am also visiting this web site daily,
this web page is in fact pleasant and the users are in fact
sharing pleasant thoughts.
Just desire to say your article is as astounding. The clarity to your submit is just nice and i could assume you’re an expert on this subject.
Well with your permission allow me to grab your RSS feed to
stay updated with coming near near post. Thanks a million and please continue the enjoyable
work.
I used to be able to find good info from your blog posts.
I just couldn’t depart your web site before suggesting
that I actually loved the standard information an individual supply to
your guests? Is going to be again continuously to inspect new posts
I used to be able to find good advice from your blog articles.
Hey just wanted to give you a quick heads up. The words in your content seem to be running off the screen in Chrome.
I’m not sure if this is a formatting issue or
something to do with internet browser compatibility
but I figured I’d post to let you know. The design look great though!
Hope you get the problem solved soon. Many thanks
Wow, superb blog format! How lengthy have you ever been running a
blog for? you made running a blog look easy. The whole glance of your site is wonderful, let alone the content material!
This Ԁesign is spectacular! You certainly know how to keep
a reader amusеԀ. Beetween your wit and your videos, I was
almost moved to start my own blog (well, almoѕt…HaHa!) Wonderful job.
Ireaⅼly enjoyed wһat you had to sɑy, and more thaan that, how you
prеsented іt. Too cool!
Look into my page: Hokiwin
I sіmply couldn’t go away your wеbѕite prіor to suggesting that I
actually enjoyed thе standard information ɑ person provide in your
visitors? Is gonna bbe back steadily in order to сheck up on new posts
Also visit my web-site; Hokiwin
It’s perfect time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I desire to suggest you some
interesting things or suggestions. Perhaps you can write next articles referring
to this article. I desire to read more things about
it!
مرکز جراحی پتوز پلک
I constantly spent my half an hour to read this website’s posts every
day along with a mug of coffee.
If you desire to get much from this paragraph then you have to apply these methods to your won web site.
Hi there, i read your blog occasionally and i own a similar one
and i was just wondering if you get a lot of spam remarks?
If so how do you protect against it, any plugin or anything you
can suggest? I get so much lately it’s driving
me insane so any support is very much appreciated.
Having read this I believed it was extremely informative.
I appreciate you taking the time and effort to put this
informative article together. I once again find myself personally spending a significant amount of
time both reading and leaving comments. But so what, it was
still worth it!
Pretty nice post. I just stumbled upon your weblog and wanted to say
that I’ve really enjoyed browsing your blog posts.
In any case I’ll be subscribing to your rss feed and I
hope you write again very soon!
خبرهای جدید بورس و اخبار علمی و دانشگاهی و خبرهای جدید مهریه و اخبار
پزشکی سلامت زنان و اخبار علمی کوتاه و خبرهای شش طلوع
https://tripsbookmarks.com/story13594285/اخبار-میراث-فرهنگی-زنجان
Hi! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the superb work!
Thanks for sharing your thoughts on jasa renovasi rumah.
Regards
May I simply just say what a relief to uncover an individual who genuinely understands what they
are discussing online. You certainly realize
how to bring a problem to light and make it important. A lot more people must
read this and understand this side of your story.
I was surprised you are not more popular since you most certainly have
the gift.
I love what you guys tend to be up too. Such clever work and reporting!
Keep up the terrific works guys I’ve included you guys to my blogroll.
Nice blog here! Also your site loads up very fast! What web host
are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours
lol
My spouse and I stumbled over here coming from a different website and thought
I might as well check things out. I like what I see so i am just following you.
Look forward to looking over your web page again.
Hi there, just became alert to your blog through Google, and found that
it is really informative. I am going to watch out for brussels.
I’ll be grateful if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
obviously like your website however you have to check the spelling on quite a few of your posts.
A number of them are rife with spelling issues and I find it very troublesome to tell
the reality however I’ll definitely come again again.
Hello There. I found your blog using msn. This is a really
well written article. I will be sure to bookmark it and return to
read more of your useful information. Thanks for the post.
I will definitely comeback.
Feel free to surf to my webpage – A片
Exceptional post howeᴠer , I wɑs wanting to know if yоu coᥙld write a litte more оn tһis
subject? I’d be very gгateful if you could elaborate a little bit more.
Thanks!
Feel free to surf to my webpage: Amber
Hi every one, here every person is sharing such know-how, so it’s fastidious to read this webpage,
and I used to go to see this webpage every day.
Komunitas slot online gacor 2023 situs paling mantap dan terjangkau bisa
dimainkan oleh siapapun
https://komunitas-slot.tadalafil-generic.com/
What’s Going down i’m new to this, I stumbled upon this I’ve discovered It absolutely helpful and it has helped me
out loads. I’m hoping to contribute & help different customers
like its helped me. Good job.
Hello, after reading this awesome paragraph i am also happy
to share my experience here with colleagues.
Heya! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading through your blog and look forward to all your posts!
Keep up the excellent work!
Pretty great post. I just stumbled upon your weblog and wanted to say that I have
really loved browsing your blog posts. After all I’ll be
subscribing on your feed and I am hoping you write
again soon!
It is appropriate time to make some plans for the long run and it is time to
be happy. I have read this post and if I could I want to counsel you some fascinating things or tips.
Maybe you can write subsequent articles referring to this article.
I want to learn more issues about it!
Thanks on yoᥙr marvelous posting! I quitе enjoyed reaԁing
it, you migһt bе a greаt author.I will always bookmark your blog
and definitely wilkl come back in the foreѕeeable future.
I want to encourage you to ultimately continue youг great writing, have ɑ nice
evening!
Visit my site Rgo365
Incredible points. Solid arguments. Keep up the amazing work.
I am really happy to read this web site posts which contains lots of helpful information, thanks for providing these kinds
of statistics.
Heya i’m for the first time here. I came across this board and I find It truly
useful & it helped me out much. I am hoping to present something back and aid others such as you aided me.
whoah this weblog is excellent i love studying your articles.
Keep up the great work! You realize, many individuals are hunting round
for this info, you could help them greatly.
Hi, I think your blog might be having browser
compatibility issues. When I look at your website in Chrome, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other
then that, fantastic blog!
sua página lembrou muito um que eu curtia muito ler alguns anos atrás.
Parabéns pelos posts
Wow, this post is nice, my sister is analyzing these things, therefore
I am going to tell her.
I have learn some just right stuff here. Definitely value bookmarking for
revisiting. I wonder how much effort you set to make this sort of wonderful informative website.
It’s reallʏ a cool and helpful piece of information. I’m happy that ʏoᥙu
sіmply shared this helpful info with us. Please staʏ uѕ up to
date like this. Thank you forr sharing.
Review my web-site; buy weed online
I was suggested this web site by my cousin. I’m not sure whether
this post is written by him as nobody else know such detailed about my problem.
You are incredible! Thanks!
I pay a visit everyday some web pages and information sites to read posts,
except this webpage provides quality based posts.
Good way of explaining, and pleasant piece of writing to get information concerning
my presentation topic, which i am going to deliver in school.
I do believe all of the ideas you’ve presented in your post.
They’re very convincing and can certainly work.
Nonetheless, the posts are too short for starters. May you please prolong
them a bit from next time? Thank you for the post.
Wow, marvelous blog layout! How lengthy have you been running a blog for?
you made blogging look easy. The full glance of your website is
great, as well as the content!
Hi, after reading this awesome piece of
writing i am as well glad to share my know-how here with friends.
https://neko-news.ir/چوبکاران-همه-چیز-درباره-مگنت-توکار-کاب/
Hеllo there, just beϲame awarе of your blog thrоugh Google,
and found that it’s rеally іnformativе. I am going to watch out for brussels.
I will appreciate if you ontіnue this in futuгe. Ⲛumer᧐us people will
Ƅe benefited from your writing. Cheеrs!
Feel free to visit my blog post – Abraham
Right now it seems like WordPress is the preferred blogging platform available
right now. (from what I’ve read) Is that what you are using on your blog?
I like the helpful info you provide in your articles.
I’ll bookmark your weblog and check again here regularly.
I’m quite certain I’ll learn plenty of new stuff right here!
Best of luck for the next!
Right here is the right website for everyone who
wishes to understand this topic. You realize a whole lot its almost
tough to argue with you (not that I actually would want to…HaHa).
You definitely put a new spin on a subject which has been written about for many years.
Great stuff, just excellent!
I’m really enjoying the theme/design of your
site. Do you ever run into any browser compatibility problems?
A couple of my blog audience have complained about my blog
not working correctly in Explorer but looks great in Firefox.
Do you have any ideas to help fix this problem?
Fantastic post however I was wondering if you could write a
litte more on this topic? I’d be very grateful if you could elaborate a
little bit further. Thank you!
What’s up Dear, are you really visiting this web page on a
regular basis, if so then you will definitely take nice
experience.
excellent post, very informative. I ponder why the
other experts of this sector don’t understand this. You must proceed your writing.
I am confident, you’ve a huge readers’ base already!
erste hilfe kurs führerschein erste hilfe kurs führerschein
Fantastic photos, the colour and depth of the
photos are breath-taking, they draw you in as though you belong of the make-up.
Having read this I thought it was rather
enlightening. I appreciate you taking the time and energy to put this
informative article together. I once again find myself spending
way too much time both reading and commenting. But
so what, it was still worth it!
Hi, Neat post. There is a problem along with your site in internet explorer, could check this?
IE still is the market chief and a huge element of people will leave out
your wonderful writing due to this problem.
Everything is very open with a very clear description of the issues.
It was really informative. Your site is very useful.
Thank you for sharing!
Simply want to say your article is as amazing. The clarity on your post is just cool
and that i could assume you are an expert on this subject.
Well with your permission let me to take hold of your RSS feed to keep up to date
with imminent post. Thank you 1,000,000 and please keep up the gratifying work.
اخبار جدید امروز و اخبار علمی شهاب سنگ و اخبار پزشکی سلامت و خبرهای ر
و اخبار جدید دوتا 2 و اخبار پزشکی و علمی
https://dalton013bh.blogdal.com/19582586/?????-????-????-????
Good blog you have got here.. It’s difficult to find excellent writing like yours
nowadays. I really appreciate individuals like you!
Take care!!
Hi there! Do yоu know if they make any plugins too assist with
Sezrch Engine Optimization? I’m tгүing to get my blog to rank fοr some targeted
keyѡords but I’m not seeing very good resսlts.
If yоu know of ɑny please share. Thanks!
Feeel free tо ѕurf to my web-ѕite – Rgo365
What i don’t understood is if truth be told how you are not actually a lot more neatly-preferred than you might be right now.
You’re very intelligent. You already know
therefore significantly in the case of this matter, made me personally believe it from so many varied angles.
Its like men and women don’t seem to be interested unless it’s
something to do with Girl gaga! Your individual stuffs
great. All the time maintain it up!
I have read so many posts about the blogger lovers but this paragraph is really a good post, keep it up.
Your style is very unique compared to other people I’ve read stuff from.
I appreciate you for posting when you’ve got the opportunity,
Guess I will just bookmark this web site.
Ꮤow, tһis paragraph is nice, my sister iis analyᴢing these
kinds of things, thus I am going to convey һer.
My homepage; Rgo365
I was wondering if you ever considered changing the
structure of your site? Its very well written;
I love what youve got to say. But maybe you could a little
more in the way of content so people could connect with it
better. Youve got an awful lot of text for only having one or two images.
Maybe you could space it out better?
Excellent site you have here but I was curious if you knew of
any message boards that cover the same topics discussed here?
I’d really love to be a part of group where I can get
feed-back from other knowledgeable people that share the same interest.
If you have any suggestions, please let me know.
Bless you!
After checking out a few of the articles on your website, I honestly like your way
of blogging. I added it to my bookmark site list and will be
checking back in the near future. Please check out my website too and
let me know your opinion.
Hello to all, how is everything, I think every one is getting more from this web page, and your views are
pleasant in support of new users.
The other day, while I was at work, my cousin stole my iphone and tested to see
if it can survive a 40 foot drop, just so she can be a youtube sensation. My apple ipad is now destroyed and she has
83 views. I know this is completely off topic but I had to share it with someone!
Hello! Do you use Twitter? I’d like to follow you if that would be
ok. I’m definitely enjoying your blog and look forward to new posts.
I have been surfing online more than three hours today, yet I never found any interesting article like yours.
It’s pretty worth enough for me. In my opinion, if all site owners
and bloggers made good content as you did, the net will be much more useful than ever before.
Awesome post.
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on several websites for about a
year and am concerned about switching to another platform.
I have heard fantastic things about blogengine.net. Is there a
way I can import all my wordpress posts into it?
Any kind of help would be greatly appreciated!
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s very hard to
get that “perfect balance” between user friendliness and visual appeal.
I must say that you’ve done a awesome job with this.
Also, the blog loads extremely quick for me on Safari. Superb Blog!
constantly i used to read smaller articles or reviews that as well clear their
motive, and that is also happening with this post which
I am reading now.
I was recommended this blog by my cousin.
I’m not sure whether this post is written by him as no one else know such detailed about my
trouble. You are wonderful! Thanks!
I believe what you composed made a bunch of sense. However, what
about this? suppose you added a little content?
I am not saying your information is not good., but suppose you added something that grabbed people’s attention?
I mean Пиастры – Составление семантического ядра | is a little vanilla.
You should look at Yahoo’s home page and see how they
write post titles to grab people interested. You might try adding a video or
a pic or two to get people excited about everything’ve written. In my opinion, it would
make your posts a little bit more interesting.
Admiring the time and energy you put into your website and detailed information you provide.
It’s awesome to come across a blog every once in a
while that isn’t the same unwanted rehashed material.
Wonderful read! I’ve saved your site and I’m adding your RSS feeds
to my Google account.
I will right away grab your rss feed as I can not
in finding your email subscription hyperlink or e-newsletter service.
Do you have any? Kindly allow me recognise so that I may just subscribe.
Thanks.
I’ve been surfing on-line more than three hours nowadays, yet I
never found any interesting article like yours.
It’s lovely price enough for me. Personally, if
all web owners and bloggers made just right content as you probably did,
the net will likely be much more helpful than ever before.
Thanks in favor of sharing such a good thought, post is pleasant,
thats why i have read it completely
Hello there! This post couldn’t be written much better!
Looking at this article reminds me of my
previous roommate! He always kept preaching about this. I’ll send
this article to him. Pretty sure he will have a good read.
Thanks for sharing!
I love your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do it for
you? Plz respond as I’m looking to create my own blog and would like to
find out where u got this from. many thanks
We are a group of volunteers and opening a new scheme in our community.
Your site offered us with valuable information to work on. You’ve done
an impressive job and our whole community will be thankful to you.
Hey I know this is off topic but I was wondering if you knew
of any widgets I could add to my blog that automatically tweet my newest
twitter updates. I’ve been looking for a plug-in like this for quite
some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new
updates.
Everything is very open with a precise clarification оf the issues.
It waѕ truⅼy informative. Your sіte is veey helpful. Thank үou for sharing!
My pagе: Leonie
Wow that was unusual. I just wrote an extremely long comment
but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyways, just wanted to say excellent blog!
I’m really inspired together with your writing talents and also with the format
for your blog. Is this a paid subject matter or did you customize it your self?
Either way stay up the nice high quality writing, it’s rare to
see a great weblog like this one nowadays..
hello!,I love your writing very so much! proportion we communicate more about your article on AOL?
I need a specialist on this space to solve my problem.
May be that is you! Having a look forward to see you.
Your way of explaining the whole thing in this paragraph is truly fastidious,
every one be able to effortlessly know it, Thanks a lot.
Keep on working, great job!
My brother suggested I might like this website.
He was entirely right. This submit actually made my day.
You can not imagine simply how a lot time I had spent for this information! Thank you!
When someone writes an article he/she retains the plan of a user in his/her
mind that how a user can understand it. Therefore that’s why this piece of writing is great.
Thanks!
Very shortly this web page will be famous amid all blog people, due to it’s nice articles
Hi there! I know this is kinda off topic but
I was wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be great if you could point me in the direction of a good platform.
I read this piece of writing completely on the topic of
the difference of newest and earlier technologies, it’s awesome article.
Hi to all, the contents present at this web page are
truly awesome for people experience, well, keep up the good work fellows.
Hello, I enjoy reading through your post. I like to write a little comment
to support you.
Wow, this post is good, my sister is analyzing such things, therefore I am going to tell her.
This piece of writing will assist the internet people for setting up new webpage or even a blog from start to end.
Pretty portion of content. I just stumbled upon your blog and in accession capital to assert
that I get in fact enjoyed account your blog posts.
Anyway I will be subscribing in your augment or even I fulfillment you get right of entry
to persistently rapidly.
Paragraph writing is also a excitement, if you be familiar with after that you can write otherwise it is difficult to write.
What’s up, all is going perfectly here and ofcourse every one is sharing
information, that’s truly good, keep up writing.
This post will help the internet people for creating new website or
even a blog from start to end.
Hiya very nice website!! Guy .. Excellent .. Amazing .. I will bookmark your web site and take the feeds additionally?
I am glad to search out a lot of helpful information right
here in the publish, we need develop more strategies in this regard,
thank you for sharing. . . . . .
Ⲩou actually make it seem so easy witһ уour presentation but I find this
topic tto be really ѕ᧐mething that I think I would never սndеrstand.
It seems too cmpleх aand extremely broad foг me.
I am looking forward for your neⲭt post, I wiⅼl try to get the hang of it!
My page – Rgo365
Somebοdy eѕsentially assist to make seveгely ɑrticles I woul state.
This is the first time I frequented your web paցe and to this point?
I amazed wijth the analysis yoս made to crеate this particular
publish amazing. Wonderful procesѕ!
Here iss my site … Rgo365
Thanks for any other great article. Where else could anybody get that kind of
info in such an ideal manner of writing? I’ve a presentation next week, and I am at the search for such info.
I blog frequently and I genuinely thank you for your content.
This article has really peaked my interest. I’m going to bookmark your blog and keep checking
for new information about once a week. I opted in for your RSS feed as well.
Hi there, i read your blog occasionally and i own a similar one and i was just curious if
you get a lot of spam comments? If so how do you reduce it,
any plugin or anything you can recommend? I get so much lately it’s driving me crazy
so any support is very much appreciated.
I like the valuable info you provide in your articles. I will bookmark your
weblog and check again here regularly. I
am quite certain I will learn plenty of new stuff right here!
Good luck for the next!
What’s up, this weekend is good in support of me, because this moment i am reading this fantastic
educational piece of writing here at my residence.
Howdy just wanted to give you a quick heads up. The words in your post seem to be running off the screen in Opera.
I’m not sure if this is a format issue or something to do
with web browser compatibility but I figured I’d post to let you know.
The style and design look great though! Hope you get the problem resolved soon.
Thanks
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several emails
with the same comment. Is there any way you can remove me from that service?
Cheers!
I was very pleased to discover this great site. I need to to thank you
for your time just for this fantastic read!!
I definitely liked every part of it and i also have you saved as a favorite to check
out new information on your web site.
If some one needs to be updated with hottest technologies after that he must be go to see this website and be up to date daily.
It’s an amazing paragraph for all the online visitors; they will
obtain advantage from it I am sure.
Attractive section of content. I just stumbled upon your web site
and in accession capital to assert that I acquire in fact enjoyed account your blog posts.
Anyway I will be subscribing to your feeds and even I achievement
you access consistently rapidly.
I loved as much as you’ll receive carried
out right here. The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an impatience over that you wish be delivering the following.
unwell unquestionably come more formerly again as exactly
the same nearly a lot often inside case you shield this increase.
When someone writes an article he/she keeps the image
of a user in his/her brain that how a user can know it.
Thus that’s why this piece of writing is outstdanding. Thanks!
Hello exceptional blog! Does running a blog such as this take a massive
amount work? I’ve no expertise in programming however I was hoping to start
my own blog in the near future. Anyways, should you have any recommendations or techniques for new blog owners please share.
I understand this is off topic but I just wanted to ask.
Appreciate it!
You’re so awesome! I do not believe I have read a single thing like that before.
So wonderful to discover somebody with some unique
thoughts on this topic. Really.. thank you for starting this
up. This web site is one thing that is required on the web, someone with a bit of originality!
An intriguing discussion is definitely worth comment.
I do think that you need to write more about this subject matter, it might not be a taboo matter but typically people don’t
talk about these issues. To the next! Cheers!!
Simply wish to say your article is as astounding. The
clarity to your publish is just excellent and that i could think you’re knowledgeable on this subject.
Well along with your permission let me to grab your RSS feed
to stay updated with approaching post. Thank you one million and
please carry on the gratifying work.
Hello colleagues, how is the whole thing, and what you desire to say on the topic of this article, in my view its really amazing in support of me.
Hello! This is my first visit to your blog! We are a group of volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to
work on. You have done a outstanding job!
Ahaa, its nice discussion concerning this paragraph at this place at
this weblog, I have read all that, so at this time me also commenting at this place.
Hey there this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG
editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so
I wanted to get advice from someone with experience. Any help would be greatly appreciated!
Thanks for your personal marvelous posting! I truly enjoyed reading it,
you will be a great author. I will ensure that I bookmark your blog and will come back sometime soon. I
want to encourage yourself to continue your great
job, have a nice evening!
What’s up, I would like to subscribe for this weblog
to take hottest updates, thus where can i do it please help out.
I truly love your blog.. Great colors & theme.
Did you create this site yourself? Please reply back as I’m hoping
to create my very own site and would love to find out where you got this from or exactly what the theme is called.
Many thanks!
Does your site have a contact page? I’m having problems locating
it but, I’d like to send you an e-mail. I’ve got some suggestions for your blog you might be
interested in hearing. Either way, great blog and I look forward to seeing it improve over time.
You have maɗe some deϲent points there. I checked on the net for more info about the issue and found most people ѡill go along with your views on this site.
Visit my blog: Cuan138
Hello! This is kind of off topic but I need some help from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any tips or suggestions? Many thanks
What’s up to all, how is the whole thing, I think every one is
getting more from this web site, and your views are nice in favor
of new users.
I’ve read a few excellent stuff here. Definitely value bookmarking for revisiting.
I surprise how a lot effort you place to create such a wonderful informative web site.
Attractive section of content. I just stumbled upon your
weblog and in accession capital to assert that I get actually enjoyed account your blog posts.
Anyway I’ll be subscribing to your feeds and even I achievement you access consistently rapidly.
Hello, i feel that i saw you visited my site so i got here to go back the want?.I’m trying to to find things to enhance my site!I suppose its adequate
to make use of some of your concepts!!
Kedudukan slot luar ibu pertiwi terbaik ada teknologi ponjen nan melancarkan mempertontonkan semua game pada uni akun selama
berlaku sepak bola dengan slot luar negeri. Bermain slot luar praja serempak lokasi web SLOT THAILANDmemiliki separo
keuntungan dibandingkan pakai dolan slot online di benua asal
Anda. Selain itu, akun pro slot server Thailand sering kali
merundingkan layanan pelanggan yang lebih baik serta lebih responsif dibandingkan demi akun slot biasa.
1 Situs Judi slot akun vip thailand Terbaik dan Terpercaya 2023
Arahan Andaikata Tuan tinggal yakin plus Panduan Gacor Indonesia Gacor 2023, raba akun akun vip thailand terpercaya nan Situ terima lantaran Tempat slot server Thailand tergacor vip
Gadaian Kecil. Dengan akun pro slot kamboja, Anda tak
perlu gelisah kembali lantaran situs slot nan mudah menang ditawari
demi hadirin yang suka mendeteksi gelagat jackpot maxwin setiap musim.
Dalami dengan kerekau info bagaimanakah trik Anda dapat seleksi game slot atas mutu RTP tinggi yang palar mempermudah selanjutnya memungkinkannya Anda menjelang
menghidupkan buatan hasil gambling slot semakin banyak serta lebih gamblang kembali.
Secara umum preferensi atraksi tersebut nan akan bawa peruntungan bersama nasib nan mana ini mau mempermudah kau
perlu dapat secepatnya kembali pangkal.
Amazing issues here. I’m very glad to peer your article. Thank you so much and
I’m looking forward to contact you. Will you please
drop me a mail?
I don’t know if it’s just me or if everybody else experiencing problems with your website.
It appears like some of the written text within your posts are running
off the screen. Can somebody else please provide feedback and let me know if this is happening to them as well?
This may be a problem with my web browser because I’ve had this happen before.
Many thanks
We absolutely love your blog and find nearly all of your post’s to be exactly what I’m looking for.
Does one offer guest writers to write content in your case?
I wouldn’t mind producing a post or elaborating on some of the subjects you write
concerning here. Again, awesome web log!
Write more, thats all I have to say. Literally,
it seems as though you relied on the video to make your point.
You definitely know what youre talking about, why waste your intelligence on just posting
videos to your blog when you could be giving us
something enlightening to read?
This is my first time go to see at here and i am actually impressed
to read everthing at single place.
Thanks for the marvelous posting! I definitely enjoyed reading it, you might
be a great author.I will remember to bookmark your blog and will eventually come back later in life.
I want to encourage you continue your great job, have a
nice afternoon!
Hey there! Do you know if they make any plugins to safeguard
against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any
suggestions?
I do believe all of the ideas you have offered
for your post. They are really convincing and can definitely work.
Still, the posts are very brief for newbies. May you please prolong them
a little from next time? Thanks for the post.
Wow, awesome weblog structure! How long have you been blogging for?
you made running a blog look easy. The overall glance of your
web site is excellent, let alone the content material!
I’ve been browsing online more than three hours today,
yet I never discovered any attention-grabbing article like
yours. It is lovely worth enough for me. In my view, if all
webmasters and bloggers made good content material as you probably did, the
web might be much more useful than ever before.
Thiѕ iѕ a topіc that’s near to my heart… Thank you!
Exactly wһere are your cotact details tһough?
Feel freе to suгf to my blog post – Slot388
You actually make it seem so easy with your presentation but I find this matter to be actually something that
I think I would never understand. It seems too complex and very broad for me.
I’m looking forward for your next post, I’ll try to get the hang
of it!
Fantastic beat ! I would like to apprentice while you amend your website,
how can i subscribe for a blog web site? The account aided me
a acceptable deal. I had been a little bit acquainted of this your broadcast offered bright clear idea
Spot on with this write-up, I honestly think this website
needs far more attention. I’ll probably be returning to see more, thanks for the advice!
What’s up colleagues, its wonderful article regarding educationand completely explained, keep it up all the time.
There is definately a lot to find out about this issue.
I like all of the points you’ve made.
Hey there! Do you know if they make any plugins to assist
with SEO? I’m trying to get my blog to rank for some targeted keywords
but I’m not seeing very good results. If you know of any please share.
Appreciate it!
I read this post completely on the topic of the comparison of most recent and previous technologies,
it’s amazing article.
This post will assist the internet users for creating new weblog or even a blog from start to end.
This is a very good tip especially to those fresh to the blogosphere.
Simple but very accurate info… Thanks for sharing this one.
A must read post!
Thanks on your marvelous posting! I seriously enjoyed reading it, you could be a great author.
I will make certain to bookmark your blog and
will come back very soon. I want to encourage you to ultimately continue your great writing, have a
nice evening!
My family every time say that I am killing my time here at
net, but I know I am getting experience everyday by reading such good posts.
همه چیز درباره ی سفر به دبی
It’s remarkable for me to have a site, which is good in support of my knowledge.
thanks admin
Hi, everything is going sound here and ofcourse every one is sharing data, that’s genuinely
excellent, keep up writing.
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is valuable and everything. But think of if you added
some great visuals or videos to give your posts
more, “pop”! Your content is excellent but with images and video clips,
this site could definitely be one of the best in its niche.
Very good blog!
Everyone loves it when folks get together and share views.
Great site, stick with it!
Established in 2012, Asia Gaming is one of the very best software program developers.
My web site website
I am curious to find out what blog system you
have been working with? I’m having some minor security issues
with my latest site and I would like to find something more risk-free.
Do you have any suggestions?
Have a look at my website … misojin.co
Wow, wonderful blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your site is wonderful, as
well as the content!
When someone writes an paragraph he/she keeps the image of a
user in his/her mind that how a user can be aware of it.
Therefore that’s why this article is perfect.
Thanks!
Thanks for your marvelous posting! I truly enjoyed reading it,
you are a great author.I will be sure to bookmark your
blog and definitely will come back later in life.
I want to encourage you to continue your great
posts, have a nice day!
You ought to take part in a contest for one of the best websites on the web.
I am going to recommend this website!
May I simply say what a comfort to find an individual who truly knows what they are discussing over the
internet. You certainly understand how to bring an issue
to light and make it important. More people really need to look at
this and understand this side of the story. I was surprised you aren’t more popular because you surely have
the gift.
Somebody necessarily lend a hand to make seriously articles I might state.
That is the first time I frequented your web page
and thus far? I surprised with the research
you made to create this actual publish amazing.
Magnificent process!
Aw, this was an exceptionally good post. Taking a few minutes and actual effort to produce a great article…
but what can I say… I hesitate a whole lot and never manage to get anything done.
Wow that was odd. I just wrote an really long comment but after I clicked submit my
comment didn’t show up. Grrrr… well I’m not writing all that over again.
Anyhow, just wanted to say wonderful blog!
It’s difficult to find experienced people in this particular subject, however,
you seem like you know what you’re talking about!
Thanks
Excellent post! We will be linking to this great content on our
website. Keep up the great writing.
Thank you for any other informative website. The place else may just
I am getting that type of info written in such a perfect
way? I have a venture that I am simply now working on, and
I’ve been on the glance out for such info.
This text is priceless. Where can I find out more?
Hello, this weekend is good designed for me, for the reason that this occasion i am reading
this fantastic educational paragraph here at my residence.
Superb, what a webpage it is! This blog presents useful
data to us, keep it up.
It’s the best time to make some plans for the long run and it’s time to be happy.
I’ve learn this publish and if I may just I wish to suggest you some fascinating issues or tips.
Perhaps you can write subsequent articles regarding this article.
I desire to learn even more issues about it!
Ӏ got this website from my pal who told me about this site ɑnd at the moment this time I amm visiting this ssite аnd
reading very informаtive posts at this time.
my web page; Kingslot69
of course like your website but you need to check the
spelling on quite a few of your posts. Several of them
are rife with spelling problems and I to find it very troublesome to tell
the reality however I’ll definitely come back again.
I visit everyday some web pages and websites to read articles, however this
weblog offers quality based posts.
Hello to every body, it’s my first go to see of this web site; this weblog carries awesome and truly
good information in support of readers.
Hey I am so delighted I found your webpage, I really found you
by error, while I was researching on Aol for something else, Nonetheless
I am here now and would just like to say thank you for a fantastic post and
a all round thrilling blog (I also love the theme/design),
I don’t have time to look over it all at the moment
but I have saved it and also added your RSS feeds, so when I have time
I will be back to read more, Please do keep up the excellent work.
Amazing! This blog looks exactly like my old one! It’s on a completely different subject but
it has pretty much the same page layout and design. Superb choice of colors!
I feel that is one of the so much vital information for me.
And i’m happy reading your article. However should remark on some general things, The site taste is great, the articles is truly nice : D.
Excellent job, cheers
My spouse and I stumbled over here different page and
thought I should check things out. I like what I see so now i’m following you.
Look forward to finding out about your web page yet again.
This is a topic which is close to my heart… Take care!
Exactly where are your contact details though?
you are actually a excellent webmaster. The website
loading speed is amazing. It seems that you are doing any distinctive trick.
In addition, The contents are masterwork. you have performed a great process in this matter!
This paragraph is genuinely a pleasant one it
helps new net viewers, who are wishing in favor of blogging.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make
your point. You definitely know what youre talking about, why throw away your intelligence on just posting videos
to your site when you could be giving us something enlightening to read?
Hello I am so happy I found your webpage, I really found you
by error, while I was researching on Yahoo for something else, Nonetheless I
am here now and would just like to say thanks for a
marvelous post and a all round thrilling blog (I also love the theme/design),
I don’t have time to read through it all at the moment but
I have saved it and also added your RSS feeds, so when I have
time I will be back to read a great deal more, Please do keep up the fantastic job.
Howdy! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My website looks weird when browsing from my apple
iphone. I’m trying to find a theme or plugin that might be able to fix this problem.
If you have any recommendations, please share.
Cheers!
It’s remarkable to go to see this site and reading the views of all friends concerning this post,
while I am also zealous of getting know-how.
Thanks for sharing your thoughts about https://maps.roadtrippers.com/people/roadtripper331208. Regards
THEAPP ISA FREE GUIDE TO LGBTQ FRIENDLY MERCHANTS AND
SERVICES FROM LGBTQ.ONE & CAN
BE A SIGNIFICANT BENEFIT TO LGBTQ FRIENDLY MERCHANTS, ALLIES AND MEMBERS
OF THE LGBTQ COMMUNITY. For safe, confident,
worry-free travel and day to
day interactions with merchants and services of all kinds, THEAPP from
LGBTQ.ONE is your personal safety device for blue skies and happy
days. THEAPP is FREE to download and use. IF you want to sign up a
business click on the purple “ADD A BUSINESS” button.
https://youtu.be/miY4stmIf4A
Good article. I am facing a few of these issues as well..
Howdy! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thanks
Usually I don’t read post on blogs, but I wish to say that this write-up very
pressured me to try and do it! Your writing style has
been surprised me. Thanks, very nice article.
Everything is very open with a precise clarification of the challenges.
It was really informative. Your website is very useful.
Many thanks for sharing!
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it
for you? Plz reply as I’m looking to create my own blog and would like to find out where u got this from.
appreciate it
This website really has all of the info I wanted about
this subject and didn’t know who to ask.
I was suggested this website by my cousin. I’m not sure whether this
post is written by him as nobody else know such detailed about my difficulty.
You’re amazing! Thanks!
If you are going for best contents like I do, simply
go to see this website daily as it provides feature contents,
thanks
I really like it when individuals get together and share ideas.
Great website, keep it up!
The rrange of promotions offered gives added
value for each casual and devoted players.
Here is my web-site: here
Quality articles or reviews is the important to be
a focus for the people to pay a visit the web page, that’s what this website is providing.
Good day! This is kind of off topic but I need some
guidance from an established blog. Is it hard to set up your own blog?
I’m not very techincal but I can figure things
out pretty quick. I’m thinking about creating my own but I’m
not sure where to start. Do you have any ideas or suggestions?
Many thanks
It’s appropriate time to make some plans for the future and
it is time to be happy. I’ve read this post and if I could I desire to suggest you
few interesting things or suggestions. Maybe you could write next articles referring to this article.
I desire to read even more things about it!
Wow, incredible blog layout! How long have you been blogging
for? you make blogging look easy. The overall look of your website is excellent, let
alone the content!
I’m gone to tell my little brother, that
he should also go to see this weblog on regular basis to
take updated from most up-to-date gossip.
Hеllo! I coulԀ have sworn I’ve been to thjs blog before buut after reading thгough some of the post I realized it’s new to me.
Anyways, I’mdefiniteⅼy delighted I found it and I’ll be
bookmarking and checking back often!
Alѕo visіt mmʏ bloց post; Slot333
THEAPP ISA FREE GUIDE TO LGBTQ FRIENDLY MERCHANTS AND SERVICES FROM LGBTQ.ONE & CAN
BE A SIGNIFICANT BENEFIT TO LGBTQ FRIENDLY MERCHANTS,
ALLIES AND MEMBERS
OF THE LGBTQ COMMUNITY. For safe, confident, worry-free travel and day to
day interactions with merchants and services of all kinds, THEAPP from
LGBTQ.ONE is your personal safety device for blue skies and happy
days. THEAPP is FREE to download and use. IF you want to sign up a
business click on the purple “ADD A BUSINESS” button.
https://youtu.be/miY4stmIf4A
Thanks for a marvelous posting! I truly enjoyed reading it, you will be a great author.I will be sure to bookmark your blog and definitely will come back from now on. I want
to encourage continue your great writing, have a nice afternoon!
Simply desire to say your article is as astonishing. The clarity for your publish is just
spectacular and that i can think you are knowledgeable on this subject.
Well together with your permission allow me
to snatch your feed to keep updated with impending post.
Thank you one million and please continue the gratifying work.
Hello, I enjoy reading all of your article. I wanted to write a little comment
to support you.
My programmer is trying to persuade me to move to .net from
PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on numerous websites for about
a year and am concerned about switching to another platform.
I have heard fantastic things about blogengine.net. Is there a
way I can transfer all my wordpress posts into it?
Any kind of help would be greatly appreciated!
I do not even understand how I finished up here, however I assumed this
submit used to be great. I don’t understand who you’re however
certainly you’re going to a well-known blogger when you aren’t already.
Cheers!
whoah this weblog is great i really like reading your articles.
Keep up the good work! You know, a lot of individuals are hunting round for this
information, you could aid them greatly.
Hello this is kinda of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding knowledge so I wanted
to get guidance from someone with experience. Any help would be enormously appreciated!
Hmm it seems like your blog ate my first comment (it
was extremely long) so I guess I’ll just sum it up what I
wrote and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to the whole thing.
Do you have any helpful hints for novice blog writers?
I’d really appreciate it.
It’s very trouble-free to find out any matter on web as compared to textbooks, as I found this article at this site.
My brother recommended I might like this web site. He was totally right.
This post truly made my day. You cann’t imagine simply how much time I had
spent for this information! Thanks!
Hi, just wanted to mention, I liked this post. It was inspiring.
Keep on posting!
I was wondering if you ever considered changing the page layout of your blog?
Its very well written; I love what youve got to say. But maybe you could a little more in the way
of content so people could connect with it better. Youve got an awful lot of text
for only having one or two pictures. Maybe you could space it out better?
Fantastic goods from you, man. I have be aware your stuff previous to and you’re simply too wonderful.
I really like what you have obtained right here, really like what you are saying and the way in which in which you say
it. You are making it enjoyable and you continue
to care for to keep it wise. I can’t wait to read far more from you.
This is actually a wonderful site.
I used to be suggested this website by way of my cousin.
I am not sure whether this publish is written by him as no one else realize such detailed approximately my problem.
You are amazing! Thank you!
THEAPP ISA FREE GUIDE TO LGBTQ FRIENDLY MERCHANTS AND SERVICES FROM LGBTQ.ONE
& CAN
BE A SIGNIFICANT BENEFIT TO LGBTQ FRIENDLY MERCHANTS,
ALLIES AND MEMBERS
OF THE LGBTQ COMMUNITY. For safe, confident, worry-free travel and day to
day interactions with merchants and services of
all kinds, THEAPP from
LGBTQ.ONE is your personal safety device for blue skies and happy
days. THEAPP is FREE to download and use. IF you want to sign up a
business click on the purple “ADD A BUSINESS” button.
https://youtu.be/miY4stmIf4A
Hey there! Do you know if they make any plugins
to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
It is perfect time to make some plans foor the longer
trm and it’s time to bee happy. I’ve rezd this put
up annd if I may just I desiire to recommend yoou some fscinating issues orr suggestions.
Maybe yoou can wrtite subsequent artickes referring
to this article. I want too read more things about it!
Hey I know this is off topic but I was wondering if
you knew of any widgets I could add to my blog
that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some
time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
Thank you for any other informative blog. The place else may just I am getting that kind of information written in such a perfect manner?
I’ve a venture that I’m simply now operating on, and I’ve been on the glance out
for such information.
This piece of writing is truly a fastidious one it assists new
the web people, who are wishing in favor of blogging.
The other day, while I was at work, my sister stole my iphone and tested to see if it can survive a forty foot drop, just so she can be a youtube sensation. My apple
ipad is now destroyed and she has 83 views. I know this is completely off
topic but I had to share it with someone!
Oh my goodness! Amazing article dude! Thank you so much, However I am
encountering difficulties with your RSS. I don’t know the reason why I can’t subscribe to it.
Is there anybody else getting identical RSS problems? Anybody who knows the solution can you kindly respond?
Thanks!!
THEAPP ISA FREE GUIDE TO LGBTQ FRIENDLY MERCHANTS AND SERVICES FROM LGBTQ.ONE
& CANBE A SIGNIFICANT BENEFIT TO LGBTQ FRIENDLY MERCHANTS,
ALLIES AND MEMBERSOF THE LGBTQ COMMUNITY.
For safe, confident, worry-free travel and day today interactions with merchants and
services of all kinds, THEAPP fromLGBTQ.ONE is your personal safety device for blue skies and happydays.
THEAPP is FREE to download and use. IF you want to sign up abusiness click on the purple “ADD A BUSINESS” button. https://youtu.be/miY4stmIf4A
I am sure this article has touched all the internet users, its really
really good article on building up new blog.
I just like the valuable information you supply for your articles.
I will bookmark your blog and check again here frequently.
I am fairly certain I will learn a lot of new stuff right right here!
Best of luck for the following!
I was able to find good advice from your blog posts.
When someone writes an piece of writing he/she retains the
idea of a user in his/her mind that how a user can understand it.
So that’s why this article is great. Thanks!
You could definitely see your expertise within the work you
write. The sector hopes for even more passionate writers like you who are not afraid to say how they believe.
All the time follow your heart.
This paragraph provides clear idea in support of the new viewers of blogging,
that genuinely how to do blogging and site-building. camisetas de futbol
Pretty section of content. I just stumbled upon your blog and in accession capital to assert that I get
in fact enjoyed account your blog posts. Any way I will be subscribing
to your feeds and even I achievement you access consistently quickly.
THEAPP ISA FREE GUIDE TO LGBTQ FRIENDLY
MERCHANTS AND SERVICES FROM LGBTQ.ONE & CANBE A SIGNIFICANT BENEFIT TO LGBTQ FRIENDLY MERCHANTS,
ALLIES AND MEMBERSOF THE LGBTQ COMMUNITY. For safe, confident, worry-free travel and day today interactions
with merchants and services of all kinds, THEAPP fromLGBTQ.ONE is your personal safety device for blue
skies and happydays. THEAPP is FREE to download and use.
IF you want to sign up abusiness click on the purple “ADD A BUSINESS” button. https://youtu.be/miY4stmIf4A
Your way of explaining everything in this post is really pleasant, all be capable of without
difficulty be aware of it, Thanks a lot.
Heya! I’m at work browsing your blog from my new iphone! Just wanted to say I
love reading your blog and look forward to all your posts!
Keep up the great work!
It is perfect time to make some plans for the long run and it is time to be happy.
I have read this post and if I could I want
to suggest you some attention-grabbing things or advice.
Maybe you can write next articles regarding this article. I wish to read more issues about it!
THEAPP ISA FREE GUIDE TO LGBTQ FRIENDLY MERCHANTS AND SERVICES FROM LGBTQ.ONE & CANBE A SIGNIFICANT BENEFIT TO LGBTQ FRIENDLY
MERCHANTS, ALLIES AND MEMBERSOF THE LGBTQ COMMUNITY. For safe,
confident, worry-free travel and day today interactions with merchants
and services of all kinds, THEAPP fromLGBTQ.ONE is your personal safety
device for blue skies and happydays. THEAPP is FREE to
download and use. IF you want to sign up abusiness click on the purple “ADD A BUSINESS” button. https://youtu.be/miY4stmIf4A
I was suggested this blog by my cousin. I am not sure
whether this post is written by him as no one else know such detailed about my problem.
You’re amazing! Thanks!
Its like you learn my thoughts! You appear to understand a lot about
this, like you wrote the ebook in it or something.
I feel that you simply could do with some % to drive the message
house a little bit, however other than that, this is excellent blog.
A great read. I will certainly be back.
Valuable information. Fortunate me I found your site accidentally, and I am
stunned why this twist of fate didn’t happened in advance!
I bookmarked it.
THEAPP ISA FREE GUIDE TO LGBTQ FRIENDLY MERCHANTS AND SERVICES FROM
LGBTQ.ONE & CANBE A SIGNIFICANT BENEFIT TO LGBTQ FRIENDLY
MERCHANTS, ALLIES AND MEMBERSOF THE LGBTQ COMMUNITY. For safe, confident, worry-free travel and day today interactions with merchants and
services of all kinds, THEAPP fromLGBTQ.ONE
is your personal safety device for blue skies and happydays.
THEAPP is FREE to download and use. IF you want to sign up
abusiness click on the purple “ADD A BUSINESS” button. https://youtu.be/miY4stmIf4A
After exploring a number of the blog articles on your website, I really appreciate your way of writing a blog.
I saved it to my bookmark webpage list and
will be checking back in the near future. Please check out my
web site too and let me know what you think.
Please let me know if you’re looking for a article writer for your blog.
You have some really great articles and I believe I would be a
good asset. If you ever want to take some of the load off, I’d love to
write some material for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Cheers!
I need to to thank you for this great read!!
I absolutely loved every bit of it. I have you book marked
to look at new stuff you post…
Thanks for sharing your thoughts on Main profile.
Regards
Greetings! I’ve been reading your weblog for some time now and finally got the courage to go ahead and give
you a shout out from Huffman Tx! Just wanted to tell you keep up the fantastic work!
Great post.
Awesome site you have here but I was curious if you knew of any community forums
that cover the same topics discussed here? I’d really
like to be a part of online community where I can get feedback from other knowledgeable people that share the same interest.
If you have any recommendations, please let me know.
Kudos!
Remarkable! Its actually amazing post, I have got much clear idea concerning from this paragraph.
Hello superb website! Does running a blog like this take a lot of work?
I’ve absolutely no understanding of computer programming but I
had been hoping to start my own blog soon. Anyway, should you have any recommendations or techniques for new blog owners please share.
I understand this is off subject but I simply wanted to ask.
Appreciate it!
Hi there to every , because I am really keen of reading this website’s post to be updated regularly.
It carries fastidious stuff.
I do accept as true with all of the concepts you have offered in your post.
They are really convincing and can definitely work.
Still, the posts are too brief for newbies. May you please
lengthen them a bit from subsequent time? Thank you for the post.
Hello, after reading this amazing piece of writing i am
as well cheerful to share my knowledge here with colleagues.
Have you ever thought about creating an ebook or guest authoring on other websites?
I have a blog based on the same subjects you discuss and would love to have you share some stories/information. I know my audience would appreciate your work.
If you are even remotely interested, feel free to shoot me an e-mail.
I am regular visitor, how are you everybody? This paragraph posted at this website is truly
pleasant.
Hi there! Do you use Twitter? I’d like to
follow you if that would be okay. I’m undoubtedly
enjoying your blog and look forward to new updates.
I do agree with all the ideas you’ve presented on your post.
They’re really convincing and can definitely work.
Nonetheless, the posts are very brief for beginners.
May you please lengthen them a bit from subsequent time?
Thanks for the post.
I’m not positive where you are getting your information, but good topic.
I must spend a while learning much more or understanding more.
Thanks for fantastic info I used to be searching for this info for my mission.
Hello friends, its enormous article on the topic of teachingand fully explained,
keep it up all the time.
Thanks for the auspicious writeup. It actually was
a leisure account it. Glance complicated to more added
agreeable from you! By the way, how can we keep in touch?
Heya i’m for the primary time here. I came across this board and I to find It truly helpful & it helped me out much.
I hope to present one thing again and aid others such as you
helped me.
At this time I am going away to do my breakfast, once having my
breakfast coming again to read more news.
Thanks for some other informative web site.
The place else could I get that type of information written in such an ideal
method? I have a challenge that I am just now operating
on, and I have been at the look out for such information.
Do you have any video of that? I’d love to find out some additional information.
kino hd
Thank you for the auspicious writeup. It in fact was a amusement
account it. Look advanced to more added agreeable from you!
However, how can we communicate?
A motivating discussion is definitely worth comment.
I believe that you need to publish more about this issue, it might not be a taboo matter but typically people do not speak about these subjects.
To the next! All the best!!
It’s wonderful that you are getting ideas from this paragraph as well as from our dialogue made here.
I do not even know how I stopped up right here, but I assumed this publish used to be good.
I don’t know who you’re but certainly you are going to a well-known blogger in the event you aren’t already.
Cheers!
Fantastic post however I was wondering if you
could write a litte more on this topic? I’d be very grateful if you could elaborate
a little bit further. Thanks!
Admiring the persistence you put into your site and in depth information you present.
It’s great to come across a blog every once in a while that isn’t the same out of date rehashed information. Wonderful
read! I’ve saved your site and I’m including your RSS feeds to my Google account.
Hmm it seems like your blog ate my first comment (it was super
long) so I guess I’ll just sum it up what I
had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog blogger but I’m still new to everything.
Do you have any helpful hints for first-time blog writers?
I’d genuinely appreciate it.
I was curious if you ever considered changing the
layout of your website? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or two
pictures. Maybe you could space it out better?
Great blog right here! Also your web site so much up very
fast! What web host are you the use of? Can I am getting your affiliate hyperlink on your host?
I wish my site loaded up as quickly as yours lol
Ahaa, its good discussion regarding this article here at this blog, I have read all that, so at this time me also commenting here.
Does your blog have a contact page? I’m having trouble locating it but, I’d like to shoot
you an e-mail. I’ve got some suggestions for your blog you might be
interested in hearing. Either way, great blog
and I look forward to seeing it develop over time.
Thanks for the good writeup. It actually was
once a leisure account it. Look complex to far introduced
agreeable from you! However, how can we keep up a correspondence?
After looking into a few of the blog posts on your web site, I really
appreciate your way of blogging. I saved it to my bookmark website list and will be checking back in the
near future. Please check out my website as well and let me
know what you think.
Your mode of telling all in this paragraph is in fact good, every one
can simply know it, Thanks a lot.
Thanks in favor of sharing such a nice opinion, article is fastidious,
thats why i have read it completely
Greetings from Los angeles! I’m bored to death at work so I decided to check out your site on my iphone during lunch break.
I love the knowledge you provide here and can’t wait to take a look when I get home.
I’m shocked at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyways, great blog!
Very good article. I am dealing with a few of these issues as well..
Hey would you mind sharing which blog platform you’re working
with? I’m planning to start my own blog soon but I’m having a hard time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems
different then most blogs and I’m looking for something unique.
P.S Sorry for getting off-topic but I had to ask!
It is perfect time to make some plans for the future and it’s time to be happy.
I’ve read this post and if I could I want to suggest you few interesting things
or suggestions. Perhaps you can write next articles
referring to this article. I desire to read even more things about it!
mostbet official website official has happen to be on the bookmakers’ marketplace for a lot more
than ten years.
Attractive section of content. I just stumbled upon your website and in accession capital to assert
that I get in fact enjoyed account your blog posts. Anyway I’ll be subscribing
to your feeds and even I achievement you access consistently rapidly.
Its such as you read my mind! You seem to grasp so much approximately this,
like you wrote the guide in it or something.
I feel that you can do with a few p.c. to pressure the message house a little bit, but instead
of that, that is excellent blog. A fantastic read. I’ll certainly be back.
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between superb usability and appearance.
I must say that you’ve done a very good job with this.
Additionally, the blog loads super fast for me on Firefox.
Excellent Blog!
Wow, this article is fastidious, my younger sister is analyzing these things, therefore I
am going to inform her.
I blog quite often and I seriously thank you for your content.
The article has truly peaked my interest. I am going
to book mark your website and keep checking for new information about once a week.
I opted in for your Feed as well.
It is in point of fact a nice and helpful piece of information.
I’m happy that you just shared this useful information with us.
Please stay us informed like this. Thank you for sharing.
I know this web site gives quality dependent articles or reviews and extra
material, is there any other web page which offers these
stuff in quality?
We’re a group of volunteers and opening a new scheme in our community.
Your web site offered us with valuable information to work on. You’ve done a formidable job and our
whole community will be thankful to you.
It’s impressive that you are getting ideas from
this paragraph as well as from our discussion made at this place.
Wow, amаzing blog layout! Hoᴡ ⅼong have youu been bloggіng for?
you made blogging look easy. The overall look of your website iѕ
great, ass well aѕ the content!
Here is my homepage … Joker88
We stumbled over here coming from a different page and thought I might as well check things out.
I like what I see so now i am following you.
Look forward to finding out about your web page for a second time.
Hmm it looks like your website ate my first comment (it was extremely long) so
I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your
blog. I as well am an aspiring blog writer but I’m still new
to the whole thing. Do you have any points for first-time blog writers?
I’d really appreciate it.
I will immediately seize your rss feed as I can’t in finding your email subscription hyperlink or e-newsletter service.
Do you have any? Kindly permit me know in order that I may
subscribe. Thanks.
Valuabⅼe info. Fortunate me I found y᧐ur website bү аcciԀent, and I am
ѕtunned why this accident did not haрpened in advance! I Ьookmarкed іt.
Feel free to surf to my website :: Joker88
I all the time used to read post in news papers but now as I am a
user of net thus from now I am using net for posts, thanks to web.
This article presents clear idea for the new people of blogging,
that truly how to do blogging.
We are a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable info to work on. You’ve
done an impressive job and our whole community will be thankful to you.
I am really impressed together with your writing talents as neatly as with the
layout for your weblog. Is that this a paid subject matter or did
you modify it your self? Anyway keep up the nice quality writing, it’s rare to peer a nice weblog like this one today..
Superb, what a web site it is! This web site provides valuable facts to us, keep it up.
That is very fascinating, You’re an excessively skilled blogger.
I have joined your feed and stay up for in search of extra of your magnificent post.
Additionally, I have shared your website in my social networks
Good way of telling, and fastidious paragraph to
get information about my presentation topic,
which i am going to present in university.
Hi there, You’ve done an excellent job. I will definitely
digg it and personally recommend to my friends.
I’m sure they’ll be benefited from this site.
I am actually thankful to the holder of this web page who has shared this fantastic paragraph at at this place.
Good day! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on.
Any suggestions?
Attractive portion of content. I just stumbled upon your blog
and in accession capital to say that I acquire in fact enjoyed account your blog posts.
Any way I’ll be subscribing on your augment or
even I success you get right of entry to consistently rapidly.
Greetings I am so grateful I found your web site, I really found
you by mistake, while I was searching on Digg for something else, Anyways I am here now and
would just like to say thanks for a fantastic
post and a all round interesting blog (I also love the theme/design), I
don’t have time to read through it all at the minute but
I have bookmarked it and also added in your RSS feeds,
so when I have time I will be back to read a great deal more,
Please do keep up the awesome job.
Heya i am for the primary time here. I found this board and I in finding It
truly useful & it helped me out much. I hope to offer one thing back and aid others like you aided me.
magnificent publish, very informative. I wonder
why the other experts of this sector don’t understand this.
You should continue your writing. I am confident, you have a huge readers’ base already!
Hi to every body, it’s my first go to see of this weblog;
this web site carries awesome and actually good information in support of readers.
Since the admin of this site is working, no hesitation very rapidly it will be famous, due to its quality contents.
Good day! This is my 1st comment here so I just wanted to give a
quick shout out and tell you I truly enjoy reading through your posts.
Can you recommend any other blogs/websites/forums that cover the same subjects?
Many thanks!
Mostbet betting organization rewards its
energetic buyers with free bets.
I’ve been exploring for a little for any high quality articles or weblog
posts in this kind of house . Exploring in Yahoo I eventually stumbled upon this site.
Studying this information So i’m satisfied to express
that I have an incredibly good uncanny feeling I came upon exactly what I needed.
I most indubitably will make certain to don?t overlook this website
and give it a look on a relentless basis.
I think the admin of this site is truly working hard
in support of his site, since here every data is quality based material.
What i do not understood is actually how you are not
actually much more well-favored than you may
be now. You are so intelligent. You understand thus significantly when it comes to this subject, made me personally believe it from a lot of various angles.
Its like men and women are not fascinated except it
is something to do with Lady gaga! Your personal stuffs nice.
At all times care for it up!
Hi just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and
both show the same outcome.
Hi everybody, here every one is sharing such experience, thus it’s
pleasant to read this weblog, and I used to go to see this webpage all the time.
I blog frequently and I really appreciate your
content. Your article has really peaked my interest. I’m going to take a note of your website and keep checking
for new information about once a week. I subscribed to your RSS feed as well.
Wօw! This blog looks just like my old one!
It’s on a totally different topic bսt it has pretty much thе same layout and deѕign. Outstandіng chоice of
colors!
Here is my blog post :: Joker88
Its like you read my mind! You appear to know so
much about this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message home a little bit, but other than that, this is fantastic
blog. A fantastic read. I’ll certainly be back.
It’s really a great and helpful piece of info. I’m happy that you just shared this useful info with us.
Please keep us up to date like this. Thanks for sharing.
Hi, after reading this amazing article i am also happy to share my know-how here with mates.
Hi there, I log on to your new stuff daily. Your humoristic style is awesome, keep
doing what you’re doing!
Wonderful post! We will be linking to this particularly great
article on our site. Keep up the great writing.
кинконг
Hello there, I found your site by the use of Google while looking for a similar matter, your site got here up, it looks good.
I’ve bookmarked it in my google bookmarks.
Hello there, simply became alert to your weblog thru Google,
and located that it’s truly informative. I
am gonna be careful for brussels. I will be grateful when you continue this in future.
A lot of folks might be benefited out of your writing. Cheers!
What’s up it’s me, I am also visiting this website daily,
this website is truly pleasant and the visitors are in fact sharing nice
thoughts.
I need to to thank you for this great read!!
I absolutely enjoyed every bit of it. I have you saved as a favorite to check
out new things you post…
Excellent goods from you, man. I’ve understand your stuff previous to and you are just extremely fantastic.
I really like what you have acquired here,
really like what you’re saying and the way in which you say it.
You make it enjoyable and you still care for to keep it wise.
I can not wait to read much more from you.
This is actually a wonderful site.
“Minimal risk bets” is a phrase that you will normally see
in combination with the aforementioned promotional abuse.
Feel free to surf to my page … more info
Thanks for sharing your thoughts about خبر.
Regards
Very soon this web site will be famous amid all blogging users, due to it’s nice posts
At this moment I am going away to do my breakfast, later than having my breakfast
coming again to read more news.
This text is invaluable. Where can I find
out more?
Hi there, this weekend is pleasant for me, since this moment i am reading this great informative post here at my residence.
Hi there to every one, it’s genuinely a good for me to
pay a visit this website, it includes priceless
Information.
If some one wants to be updated with most recent technologies afterward he must be pay
a visit this web site and be up to date daily.
Sweet blog! I found it while browsing on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Cheers
Hi there Dear, are you in fact visiting this site on a regular
basis, if so then you will absolutely get nice experience.
If you wish for to obtain much from this piece of writing then you have to
apply these methods to your won web site.
What’s Taking place i’m new to this, I stumbled upon this
I’ve discovered It absolutely useful and it has helped me
out loads. I am hoping to contribute & aid other users like
its helped me. Good job.
Heya i’m for the first time here. I found this board and I find It really useful & it helped me out much.
I hope to give something back and help others like you aided me.
Hello, i believe that i noticed you visited my weblog so i came to go back the prefer?.I’m attempting to
in finding issues to enhance my website!I guess its ok to make use of some of
your ideas!!
I all the time used to read article in news papers but now as I am a user of web therefore from now I am
using net for posts, thanks to web.
WOW just what I was searching for. Came here by searching for data sdy
Article writing is also a fun, if you be acquainted with afterward you can write otherwise it is complex to write.
Hey! I’m at work browsing your blog from my new iphone 3gs!
Just wanted to say I love reading your blog and look
forward to all your posts! Carry on the fantastic
work!
Wonderful site. Plenty of useful information here. I am sending
it to some pals ans additionally sharing in delicious.
And naturally, thanks to your sweat!
Nice blog here! Also your web site loads up fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours lol
Good day! Do you know if they make any plugins to assist with
SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success.
If you know of any please share. Cheers!
Hello colleagues, how is everything, and what you
wish for to say on the topic of this post, in my view its actually
remarkable designed for me.
We’re a gaggle of volunteers and opening a new scheme in our community.
Your site provided us with valuable information to work on. You have done an impressive task and our entire
community might be grateful to you.
Thanks for another excellent post. Where else may anybody get that kind of information in such an ideal approach of writing?
I have a presentation subsequent week, and I am on the search for such info.
You ought to be a part of a contest for one of the best sites online.
I most certainly will highly recommend this blog!
Excellent items from you, man. I’ve be mindful your stuff previous to and you’re
simply too magnificent. I actually like what you’ve acquired here,
really like what you are stating and the way through which you
are saying it. You are making it enjoyable and you still care for to stay it smart.
I cant wait to learn far more from you. That is actually a tremendous web
site.
It is perfect time to make some plans for the future and
it is time to be happy. I’ve read this post and
if I could I wish to suggest you some interesting things or advice.
Maybe you could write next articles referring to this article.
I want to read more things about it!
Hi my loved one! I wish to say that this article is awesome, great written and include
approximately all important infos. I would like to
look extra posts like this .
I think that is one of the such a lot vital info for
me. And i am happy studying your article. However want to observation on some common issues, The site taste is perfect, the articles is truly great :
D. Just right activity, cheers
Online poker
Everything is very open with a really clear explanation of
the challenges. It was really informative.
Your website is useful. Thank you for sharing!
I just could not depart your web site prior to suggesting that I
really enjoyed the standard info an individual supply
on your visitors? Is going to be back steadily in order to check
up on new posts
I every time used to read article in news papers but now as I am a user of net
so from now I am using net for posts, thanks to web.
Excellent post. I was checking continuously this blog and I’m impressed! I
I
Extremely helpful info specially the last part
care for such information a lot. I was looking for this particular info for a
long time. Thank you and good luck.
It’s truly very difficult in this active life to listen news on TV, thus I only use web
for that reason, and get the most up-to-date information.
you’re truly a excellent webmaster. The site loading velocity is amazing.
It kind of feels that you’re doing any distinctive trick. Moreover, The contents
are masterpiece. you have done a magnificent process on this topic!
What’s up everybody, here every one is sharing these kinds
of familiarity, so it’s pleasant to read this blog, and I used to go to see this
webpage everyday.
Greetings from Idaho! I’m bored to tears at work so I
decided to browse your website on my iphone during lunch break.
I really like the information you present here and can’t wait to take a
look when I get home. I’m surprised at how fast your blog loaded
on my mobile .. I’m not even using WIFI, just 3G
.. Anyways, good site!
Great website. Lots of useful info here. I am sending it
to some pals ans additionally sharing in delicious.
And obviously, thanks in your effort!
Hello there! I could have sworn I’ve visited your blog before but after going through
many of the articles I realized it’s new to me. Anyhow,
I’m certainly pleased I discovered it and I’ll be bookmarking
it and checking back often!
Howdy! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My website looks weird when viewing from my iphone. I’m trying to find a template or plugin that might be able to fix this issue.
If you have any suggestions, please share. Appreciate it!
It’s amazing in support of me to have a web page, which is beneficial
designed for my know-how. thanks admin
Hello there, You’ve done a fantastic job. I will certainly digg it
and personally suggest to my friends. I’m confident they’ll
be benefited from this website.
you’re truly a just right webmaster. The web site loading pace is incredible.
It seems that you’re doing any distinctive trick. Furthermore, The contents are masterpiece.
you have performed a great activity in this topic!
whoah this blog is fantastic i love reading your articles.
Stay up the great work! You already know, lots of people are searching around for this info, you can help them greatly.
Howdy are using WordPress for your blog platform? I’m new to the blog
world but I’m trying to get started and set up my own. Do you need any html coding knowledge to
make your own blog? Any help would be really appreciated!
What’s Happening i am new to this, I stumbled upon this I have
found It absolutely helpful and it has helped
me out loads. I’m hoping to contribute & aid other customers like its helped me.
Good job.
Very soon this web page will be famous amid all blogging and site-building viewers, due to it’s nice articles
Unquestionably believe that which you said. Your favorite reason seemed to
be on the internet the easiest thing to be aware of. I say
to you, I certainly get annoyed while people think about worries that they just don’t know about.
You managed to hit the nail upon the top and also defined out the
whole thing without having side effect , people could take a signal.
Will likely be back to get more. Thanks
Hey very interesting blog!
Cool blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple adjustements would really make my blog stand out.
Please let me know where you got your design. Thank you
Hi I am so grateful I found your web site, I really found you by accident, while I was searching on Google for something else, Anyhow I am here now and would just like to say
thanks a lot for a marvelous post and a all round exciting blog (I also love the theme/design), I
don’t have time to read it all at the minute but I have book-marked it and also added your RSS
feeds, so when I have time I will be back to read much more, Please do keep up the great jo.
WOW just what I was looking for. Came here
by searching for togel sgp
In this category, you are offered by us the possibility to most bet india in live setting.
That is a very good tip especially to those new to the blogosphere.
Simple but very accurate info… Thanks for sharing this one.
A must read post!
Menariknya, permainan ini juga memiliki bonus multiplier
yang bisa meningkatkan jumlah kemenangan sampai dengan 10 kali lipat.
Permainan Slot Terbaru ini memungkinkan bisa memberikan pemainnya mendapat kemenangan multiplier sampai dengan 20 ribu kali taruhannya.
Simbol tertinggi adalah eye of Ra dengan pembayaran terendah sebanyak 10
kali nilai taruhan sampai dengan tertinggi 50 kali lipat sekaligus.
Sedangkan terakhir simbol naga biru dengan payline terendah.
Simbol tertinggi dari permainan ini adalah angka 7 ikonik.
Simbol yang berguna sebagai fungsi ganda adalah bergambar buku, menjadi wild
dan scatter sekaligus. Wild Bandito adalah game slot 5 gulungan dan 4 baris yang bertema simbol bingkai emas dan spin gratis dengan pengganda
yang terus meningkat.
After going over a number of the blog posts on your website, I seriously like your technique of blogging.
I saved as a favorite it to my bookmark site list and will be checking back in the near future.
Please check out my website as well and tell me
what you think.
Fastidious response in return of this issue with firm arguments
and explaining the whole thing concerning that.
I like the helpful info you provide in your articles. I’ll bookmark your weblog
and check again here regularly. I am quite certain I’ll
learn many new stuff right here! Good luck for the next!
You ought to be a part of a contest for one of the most useful
websites on the web. I’m going to highly recommend this web site!
Wow that was unusual. I just wrote an very long
comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyway, just wanted to say excellent blog!
Hi there I am so excited I found your webpage, I really found you by error,
while I was searching on Digg for something else, Anyways I am here now and would just like to
say thanks a lot for a fantastic post and a all round interesting blog (I
also love the theme/design), I don’t have time to go through it all at the
moment but I have saved it and also added in your RSS feeds,
so when I have time I will be back to read more, Please do keep
up the excellent job.
Today, while I was at work, my cousin stole my iphone and tested
to see if it can survive a 25 foot drop, just so she can be a youtube sensation. My apple ipad is now destroyed and she has 83 views.
I know this is completely off topic but I had to share it with someone!
Hello! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
Pretty! This has been an incredibly wonderful article.
Thanks for providing these details.
Pretty nice post. I just stumbled upon your blog and wished to say that I’ve truly enjoyed surfing around your blog posts.
After all I’ll be subscribing to your feed and I hope you write again soon!
It is not my first time to pay a quick visit this web site, i am visiting this site dailly and
take good information from here everyday.
and put your bets.
My blog: mostbet casino
I really like your blog.. very nice colors & theme. Did you design this website yourself or did you hire someone to do it for you?
Plz respond as I’m looking to create my own blog and would like to
know where u got this from. appreciate it
What you said was very logical. However, what about this?
what if you wrote a catchier post title? I am not saying your information isn’t good.,
but what if you added something to maybe grab people’s attention?
I mean Пиастры – Составление семантического
ядра | is kinda boring. You ought to glance at
Yahoo’s front page and watch how they create post titles to grab people
to open the links. You might add a video or a pic or two to grab readers interested about what you’ve got to say.
In my opinion, it would make your blog a little livelier.
Aw, this was an extremely good post. Taking
a few minutes and actual effort to make a superb article… but
what can I say… I put things off a whole lot and never seem to get anything done.
My programmer is trying to persuade me to move to .net
from PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on various websites for about a
year and am nervous about switching to another platform.
I have heard very good things about blogengine.net. Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be really appreciated!
Hey I know this is off topic but I was wondering if
you knew of any widgets I could add to my blog that automatically
tweet my newest twitter updates. I’ve been looking for a plug-in like
this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your
new updates.
hey there and thank you for your info – I have definitely picked up something
new from right here. I did however expertise several technical
points using this web site, as I experienced to
reload the website lots of times previous to I could get it to load properly.
I had been wondering if your web hosting is OK?
Not that I’m complaining, but sluggish loading instances times will often affect your placement in google and could damage your high-quality
score if ads and marketing with Adwords. Anyway I am adding this RSS to my email and
could look out for much more of your respective exciting content.
Make sure you update this again soon.
I am sure this post has touched all the internet visitors, its
really really fastidious paragraph on building up new webpage.
Fantastic website. A lot of useful info here.
I’m sending it to several buddies ans additionally sharing in delicious.
And obviously, thanks to your sweat!
What’s up colleagues, nice piece of writing and fastidious urging commented at this place,
I am in fact enjoying by these.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter
stylish. nonetheless, you command get got an edginess over that you
wish be delivering the following. unwell unquestionably come further formerly again since exactly the same
nearly a lot often inside case you shield this hike.
My spouse and I absolutely love your blog and find the majority
of your post’s to be precisely what I’m looking for.
Would you offer guest writers to write content in your case?
I wouldn’t mind producing a post or elaborating on a lot of the subjects you write
concerning here. Again, awesome website!
Highly energetic blog, I loved that bit. Will there
be a part 2?
It is in point of fact a nice and helpful piece of information. I am
satisfied that you shared this useful information with us.
Please keep us up to date like this. Thanks for sharing.
Hey just wanted to give you a quick heads up. The text in your article seem to be running
off the screen in Ie. I’m not sure if this is a format issue
or something to do with internet browser compatibility but
I thought I’d post to let you know. The design and style look great though!
Hope you get the problem fixed soon. Many thanks
Wow, this post is nice, my younger sister is analyzing such things,
so I am going to let know her.
Hello colleagues, fastidious piece of writing and nice arguments commented here, I am actually enjoying by these.
Hey There. I found your blog using msn. This is an extremely well written article.
I’ll make sure to bookmark it and come back to read more of your useful information. Thanks for the
post. I will definitely comeback.
I think the admin of this site is genuinely working hard in support of his web page, for the reason that here every stuff is quality based material.
An outstanding share! I have just forwarded this
onto a friend who was doing a little homework on this.
And he actually bought me lunch simply because I discovered it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah,
thanks for spending some time to talk about this topic here on your web site.
Stunning quest there. What happened after? Take
care!
You need to take part in a contest for one of the best websites on the web.
I’m going to recommend this site!
Nice post. I was checking continuously this blog and
I am impressed! Very helpful info specially the last part :
) I care for such info a lot. I was looking for this particular information for a very long time.
Thank you and good luck.
continuously i used to read smaller posts which as well clear their motive, and that is also happening
with this post which I am reading now.
Thanks for finally talking about > Пиастры – Составление
семантического ядра | < Liked it!
دکتر اورولوژی
Yesterday, while I was at work, my sister stole my iPad and tested to see if it can survive a 40 foot
drop, just so she can be a youtube sensation. My apple
ipad is now destroyed and she has 83 views. I know this is entirely off topic but I
had to share it with someone!
Hey! I’m at work browsing your blog from my new apple
iphone! Just wanted to say I love reading through your blog and look
forward to all your posts! Keep up the great work!
Hello, Neat post. There’s a problem together with your web site
in web explorer, might check this? IE still is the market leader and a
large section of people will miss your fantastic writing due to this problem.
Here is my blog post; https://www.pinoyseoservices.com/
Hi there mates, how is the whole thing, and what you want to
say regarding this article, in my view its truly amazing
for me.
It’s going to be finish of mine day, however before end I am reading this great piece
of writing to improve my know-how.
Thanks for sharing your thoughts about reformas cocinas.
Regards
I’m really enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more pleasant
for me to come here and visit more often. Did you hire out a developer to create your theme?
Exceptional work!
It’s wonderful that you are getting ideas from this piece of writing as well as from our discussion made at this place.
A fascinating discussion is definitely worth comment. There’s no doubt that
that you need to write more on this topic, it might not be a taboo subject but
usually folks don’t discuss these issues. To the next!
Cheers!!
I’m impressed, I have to admit. Seldom do I come across a blog that’s equally educative and engaging, and without a doubt, you’ve hit the nail on the head.
The issue is something which not enough people are speaking intelligently about.
I am very happy I stumbled across this during my hunt for something relating
to this.
Pretty nice post. I simply stumbled upon your weblog and wanted to say that I’ve really
enjoyed browsing your blog posts. After all I will be subscribing to your feed and I am hoping you write
again very soon!
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for about a year and am anxious about
switching to another platform. I have heard very
good things about blogengine.net. Is there a way I can import all my wordpress content into it?
Any kind of help would be greatly appreciated!
Hey! I’m at work surfing around your blog from my new iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the excellent work!
фильмы онлайн
kinohd
My brother suggested I may like this web site. He was totally right.
This submit actually made my day. You cann’t consider
just how a lot time I had spent for this info!
Thanks!
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thanks
кинконг
Pozitiv dünyadan çıxmaq istədiyinizdən əminsiniz?
Feel free to visit my page mostbet giriş
It’s impressive that you are getting ideas from this article as well as from our discussion made at this
place.
Please let me know if you’re looking for a author for your site.
You have some really great articles and I believe I
would be a good asset. If you ever want to take some of
the load off, I’d absolutely love to write some articles for your
blog in exchange for a link back to mine. Please shoot me an email
if interested. Kudos!
Everything is very open with a precise clarification of the issues.
It was truly informative. Your website is extremely
helpful. Thanks for sharing!
Definitely believe that that you said. Your favorite reason seemed to be on the
net the easiest factor to be mindful of.
I say to you, I certainly get irked whilst people consider concerns that they just don’t realize about.
You managed to hit the nail upon the top and outlined out the whole thing with
no need side effect , other folks can take a signal.
Will probably be back to get more. Thanks
Ahaa, its fastidious discussion about this piece of writing
at this place at this website, I have read all that,
so now me also commenting here.
I love what you guys tend to be up too. This kind of clever
work and coverage! Keep up the very good works guys I’ve included you guys
to my blogroll.
Thanks for sharing your thoughts. I truly appreciate your efforts and I am waiting for your further post thank
you once again.
Appreciating the persistence you put into your site and in depth information you provide.
It’s awesome to come across a blog every once in a
while that isn’t the same out of date rehashed information. Great read!
I’ve saved your site and I’m adding your RSS feeds to my Google account.
лордфильм
What i do not realize is in truth how you’re no
longer actually a lot more neatly-preferred than you may
be right now. You’re very intelligent. You understand thus considerably with regards to this matter, produced me for my part imagine it from so many numerous angles.
Its like women and men don’t seem to be interested except
it is something to accomplish with Girl gaga! Your own stuffs outstanding.
Always handle it up!
I like the helpful information you supply for your articles.
I will bookmark your blog and take a look at once more
right here frequently. I am fairly certain I will be informed a lot of new
stuff right here! Good luck for the next!
I will right away snatch your rss as I can’t find your email
subscription hyperlink or e-newsletter service.
Do you’ve any? Kindly let me understand so that I
may just subscribe. Thanks.
It’s an amazing piece of writing for all the online visitors; they will obtain advantage from it I am sure.
What i don’t realize is in fact how you’re now not really a
lot more neatly-preferred than you may be now. You are
so intelligent. You realize thus considerably in relation to this topic, made
me individually believe it from numerous various angles.
Its like men and women aren’t interested until it’s one thing to do with Lady gaga!
Your personal stuffs great. All the time care
for it up!
I always spent my half an hour to read this webpage’s articles or
reviews everyday along with a mug of coffee.
I do not know if it’s just me or if perhaps everybody else
encountering issues with your website. It appears as though some of the written text on your posts are running off the screen. Can someone
else please provide feedback and let me know if this is happening to them as
well? This might be a problem with my internet browser because I’ve had this
happen previously. Appreciate it
Hey, I think your site might be having browser compatibility issues.
When I look at your blog in Chrome, it looks fine but when opening in Internet Explorer, it has some
overlapping. I just wanted to give you a
quick heads up! Other then that, great blog!
I do not know if it’s just me or if everybody else encountering
issues with your website. It appears like some of the written text within your content
are running off the screen. Can somebody else please provide feedback and let me know if this is
happening to them too? This might be a problem with my web browser because I’ve had
this happen previously. Kudos
I am sure this post has touched all the internet visitors, its really really good post on building up new web site.
Tələb оlduğunuz bütün şəxsi məlumаtlаrı dаxil еdin ;
Here is my web blog Mostbet Online
Very nice post. I just stumbled upon your blog and wished to
say that I’ve really enjoyed browsing your blog posts.
In any case I’ll be subscribing to your feed and I hope you write again very soon!
Very nice post. I just stumbled upon your blog and wished to say
that I’ve really enjoyed surfing around your blog posts.
In any case I’ll be subscribing to your feed and I hope you write
again very soon!
It’s perfect time to make some plans for the future and it is time to
be happy. I’ve read this post and if I could I want to suggest you few interesting things or advice.
Maybe you can write next articles referring to this article.
I want to read more things about it!
Great info. Lucky me I recently found your website by chance (stumbleupon).
I’ve bookmarked it for later!
Magnificent beat ! I would like to apprentice at the same time as
you amend your website, how could i subscribe for a weblog web site?
The account aided me a appropriate deal. I have been a little bit
acquainted of this your broadcast provided shiny transparent idea
camisetas real madrid
Great post! We are linking to this particularly great article on our site.
Keep up the great writing.
I’m impressed, I have to admit. Rarely do I encounter a blog
that’s both educative and interesting, and without a doubt,
you have hit the nail on the head. The problem is an issue that not enough folks are speaking intelligently about.
Now i’m very happy that I came across this in my hunt for something concerning this.
Hello! I could have sworn I’ve been to this website before but after browsing through some of the post I realized it’s new
to me. Anyhow, I’m definitely delighted I found it and
I’ll be book-marking and checking back frequently!
Wow, superb weblog structure! How lengthy have you been blogging for?
you made blogging glance easy. The entire glance
of your web site is fantastic, as neatly as the content material!
I visited several web sites except the audio feature for audio
songs present at this web site is really superb.
I don’t even know how I stopped up right here, however I assumed this publish used to be great.
I do not know who you’re but certainly you’re going to a famous blogger if you happen to
aren’t already. Cheers!
Can I simply say what a relief to find somebody who really
knows what they are talking about on the internet. You certainly
understand how to bring a problem to light and make it important.
More people really need to check this out and understand this side of your story.
I was surprised you aren’t more popular because you
definitely possess the gift.
This is a topic that’s near to my heart…
Many thanks! Exactly where are your contact details
though?
What’s up i am kavin, its my first occasion to commenting anyplace, when i read this post
i thought i could also create comment due to this sensible piece of
writing.
Good day! This is my 1st comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading through your articles.
Can you recommend any other blogs/websites/forums that go over the
same topics? Appreciate it!
Quality posts is the important to be a focus for the users to pay a visit
the site, that’s what this web page is providing.
This design is wicked! You certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Excellent job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
I truly love your site.. Pleasant colors & theme. Did you make this site yourself?
Please reply back as I’m wanting to create my own website and would love
to know where you got this from or just what the theme is called.
Kudos!
certainly like your website but you have to check the
spelling on quite a few of your posts. Many of them are rife
with spelling problems and I find it very troublesome to tell the truth however I will
certainly come again again.
It’s an remarkable post in support of all the internet people; they will take benefit from
it I am sure.
Please let me know if you’re looking for a article writer for your site.
You have some really good posts and I believe I would be a
good asset. If you ever want to take some of the load off, I’d really
like to write some material for your blog in exchange for a link back to mine.
Please shoot me an e-mail if interested. Thank you!
First off I would like to say awesome blog! I had a quick question in which
I’d like to ask if you do not mind. I was curious to find out
how you center yourself and clear your mind prior to writing.
I have had difficulty clearing my thoughts in getting my thoughts out.
I do enjoy writing however it just seems like the first 10 to 15 minutes are
generally lost simply just trying to figure out how to
begin. Any ideas or hints? Many thanks!
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to
your site? My blog site is in the exact same
niche as yours and my users would really benefit from a lot of the
information you provide here. Please let me know if this ok with
you. Appreciate it!
Yes! Finally someone writes about خرید هاست.
An outstanding share! I have just forwarded this onto a coworker who had been doing a little
research on this. And he in fact ordered me breakfast
simply because I discovered it for him… lol. So let me reword this….
Thank YOU for the meal!! But yeah, thanks for spending some time to discuss this topic
here on your internet site.
If some one desires expert view about running a blog then i propose him/her to go to
see this webpage, Keep up the nice job.
It’s going to be ending of mine day, however before finish I am reading this
wonderful article to improve my experience.
I was suggested this web site by my cousin. I’m not sure
whether this post is written by him as no one else know such detailed about my trouble.
You’re wonderful! Thanks!
Excellent article. I’m dealing with many of these issues as
well..
It’s really a great and useful piece of information. I’m glad that you just shared this useful information with us.
Please stay us up to date like this. Thank you for sharing.
Hi there Dear, are you genuinely visiting this web site daily, if so afterward you will without doubt obtain fastidious knowledge.
Hi there, I found your site by the use of Google whilst searching for
a related topic, your site got here up, it looks good. I have bookmarked it in my google bookmarks.
Hello there, just was aware of your weblog via Google, and found
that it’s really informative. I am gonna be careful for brussels.
I’ll appreciate in case you proceed this in future.
Numerous other folks will probably be benefited from your writing.
Cheers!
Hi, after reading this remarkable piece of writing i am too cheerful to share my know-how here with friends.
Why visitors still make use of to read news papers when in this technological world the whole thing is presented on web?
This is a topic that is near to my heart… Take care!
Exactly where are your contact details though?
I got this website from my pal who informed me regarding this
web site and now this time I am browsing this web site
and reading very informative articles at this time.
hi!,I like your writing so so much! percentage we communicate extra about your post
on AOL? I require an expert on this area to resolve my problem.
May be that’s you! Taking a look ahead to see you.
Hi there, I discovered your web site by the use of Google whilst looking for a
comparable matter, your site got here up, it seems great.
I’ve bookmarked it in my google bookmarks.
Hi there, simply turned into aware of your blog thru Google,
and located that it is really informative. I’m going to be
careful for brussels. I will appreciate in the event you
continue this in future. Lots of people can be benefited from your
writing. Cheers!
I’m pretty pleased to discover this page.
I need to to thank you for ones time just for this wonderful
read!! I definitely liked every little bit of it and
I have you saved as a favorite to look at new things on your blog.
It’s a pity you don’t have a donate button! I’d certainly donate to this brilliant blog!
I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this website with my Facebook group.
Talk soon!
My family members all the time say that I am wasting my time here at net,
except I know I am getting know-how everyday by reading such good articles.
If some one wishes to be updated with most recent technologies after that he
must be visit this web site and be up to date every
day.
I’m not sure why but this web site is loading incredibly slow for
me. Is anyone else having this issue or is it a issue on my end?
I’ll check back later and see if the problem still exists.
I love what you guys tend to be up too. This type of clever work and
exposure! Keep up the very good works guys I’ve incorporated you guys to
blogroll.
Hi, always i used to check blog posts here early in the morning, because i
love to learn more and more.
Hiya! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly? My weblog looks weird when browsing from my apple iphone.
I’m trying to find a theme or plugin that might be able to fix this problem.
If you have any suggestions, please share. Many thanks!
Your way of explaining the whole thing in this paragraph is really
good, all be able to simply know it, Thanks a lot.
It’s very straightforward to find out any topic on net as compared to textbooks,
as I found this article at this site.
whoah this blog is wonderful i really like reading your posts.
Stay up the good work! You realize, a lot
of individuals are searching around for this information, you could help
them greatly.
My brother recommended I might like this website. He was totally right.
This post truly made my day. You cann’t imagine just how much time I had spent for this
information! Thanks!
obviously like your website however you need to check
the spelling on several of your posts. Several of them are rife with spelling problems and I to find
it very bothersome to inform the truth then again I will surely come again again.
What’s up friends, how is all, and what you want to
say about this post, in my view its genuinely awesome in support of me.
An outstanding share! I have just forwarded this onto a co-worker who has
been conducting a little research on this. And he in fact ordered me
dinner because I found it for him… lol.
So allow me to reword this…. Thanks for the
meal!! But yeah, thanks for spending some time to talk about this subject here on your site.
hey there and thank you for your info – I’ve definitely picked up anything new from right here.
I did however expertise some technical issues using this
web site, since I experienced to reload the website
a lot of times previous to I could get it to load correctly.
I had been wondering if your hosting is OK? Not that I’m complaining, but sluggish loading instances times will very
frequently affect your placement in google and could damage your high-quality score if advertising
and marketing with Adwords. Well I am adding this RSS to my e-mail and can look
out for much more of your respective intriguing content.
Make sure you update this again soon.
Hi friends, how is all, and what you desire to say on the topic of this
post, in my view its genuinely remarkable in favor of me.
We are a group of volunteers and opening a new scheme in our
community. Your site provided us with valuable info to work on. You have done
an impressive job and our whole community will be grateful to you.
I am really impressed with your writing skills as well as
with the layout on your blog. Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it is rare to see a great blog like this
one today.
Wow, superb blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is wonderful, let alone the content!
I know this website offers quality depending
articles and additional stuff, is there any other
web page which gives these data in quality?
Hi, There’s no doubt that your web site could possibly be
having internet browser compatibility issues. When I look at your site in Safari,
it looks fine however, if opening in I.E., it’s got some overlapping issues.
I just wanted to give you a quick heads up! Aside from that, great website!
Remarkable! Its actually awesome article, I have got much clear idea regarding from this post.
Thanks for the auspicious writeup. It actually was a entertainment account it.
Look complex to far brought agreeable from you!
However, how can we communicate?
Asking questions aree really nice thing if you are not understanding something totally, however this paragraph giives niice understancing yet.
homepage
What aree Actuazl Spins? Attractive some large prize inn a slot machine and
on-line casino games is all doubtless with a licensed and in time
on-line casino site. Juust learn this article and relaxation things migvht be decided automatically.
Everything is very open with a precise explanation of
the issues. It was really informative. Your site is very helpful.
Thank you for sharing!
Greetings, I believe your website might be having web browser compatibility issues.
Whenever I take a look at your website in Safari, it looks fine however when opening in I.E.,
it has some overlapping issues. I merely wanted to provide you with a quick heads up!
Besides that, great website!
If you want to take a great deal from this article then you have to apply such
techniques to your won website.
There’s certainly a lot to learn about this topic. I love all of the points you
have made.
I am now not sure where you’re getting your info, however great topic.
I needs to spend a while learning much more or understanding
more. Thank you for fantastic info I was searching
for this info for my mission.
I’ve been browsing online more than three hours today, yet I never found any
interesting article like yours. It’s pretty worth enough for me.
In my view, if all website owners and bloggers made good content as you did, the net will be much more useful
than ever before.
I am regular reader, how are you everybody? This post posted at
this web page is actually good.
I’m not that much of a internet reader
to be honest but your sites really nice, keep
it up! I’ll go ahead and bookmark your site to come back later on.
Cheers
What’s up to every one, it’s truly a fastidious for me to go
to see this web site, it contains precious Information.
I’m gone to convey my little brother, that he should
also go to see this webpage on regular basis to take updated from latest news update.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get bought an edginess over
that you wish be delivering the following. unwell unquestionably
come further formerly again since exactly the same nearly a lot often inside
case you shield this hike.
Free bdsm storieDuck pheasant breastsSuuperb
pointy teedn titsSex for drugs picsRitcchies realm sex.
Sarah vick nakedGiirl nexxt door sexx tapeKeelie hazel nudeAlcohol abuse inn teens graphsTeen ggirls bibles.
Massive tits boobs blog naturalPersonnalfit breastSex
n navanGaay hookups loss angelesPissing contacts. Teenn model vodeo searchChuby
free poorn vidiosLuhas county adult educationWemanhs wet pussyOnlyy
igirls nude. Maake youu lokve cockLindsedy lohan pussy picturesSerm clmes oout whedn poopGayy twiinks fucked by daddiesAmateur rodewo association.
Freee bikini voyeurNon consensuwl cunnilingusTaboo seex storries adultTwo black gitls fucking for moneyMariag
carey nude pics. Dicfks sprting goods gun cabinetRedhead fayettevillee blowjobFootball
gay scandalLindsaqy lohhan nude vedioVintage efotic forum hair arms.
Malee hockey sexNatasha lyonne sexyDick daugh aamCelebrities fakes pornn streamingEscort myrtlle beach south
carolina. Whefe tto buy acult footed pajamasFrree adult trailers fedale orgasmsBrenda
song big assEmily’s dream nake boobsFrree cindy crawfordd pussy.
Ertic animation filesSmeelps ike teen spirit flyleafDominican republic resofts escortsFreee oline jamican pornErotikca firet lesbian rewal time.
Heey everyybody imm lookijg at gayy pokrn whereBrenaked ldies swiknging upp
lyricsOrggy togaNakeed toasterAl self suck. Goldfish lyting aat blttom off the tankVintage signaturee gokf
clet shoesAhmedabad gay sexLove hina hetai mang doujinshiAnal harddcore porn. Vietnjam booi gay cruiseTerrific cum shotsGrenadine gal
havin sexAmateujr angels 15 freeVeroncas nude pics. Clipp ggay
musce pornSexx aand sex teensFreecam sexBest
adult chat siteCartion porn tube no credit card.
Aera pornSwallowing own cumBigge penisFound husabands dildoMelbournbe
florida escors backpage. Nylonns and heels mature
grannyFemale barebback swingersBold gay sexSolo clips pornoRepletion vitamin d beeast cance deficient.
German grannies seex videosCaribbean vacation with escortRule oof thummb housee affordNalla hentaiList password xxx.
Asian antiqe furniture berkeley, caWeedding nigt cumshot picsAmateuir home mmmf threeaome tuve http://isichen.klack.org/guestbook.html
Latinas realty pornFreee mature naked picture woman. Restrained
sexErotric literdature shavingStan smith vintage shoesPeeing togethetAmyy lynn
baxter giving a blowjob. In messsy mmud sexSlut load ddad daughterStepsister fucks dadDouble
penertration of assDicck pumps forr guys. Low carb adult beverageCum bellpy pornoHreg hilland nudee artTwinmk vodeos
bondageAnnal pleasurds gay. Masturbate iin front oof themScarlett johanssdon lesbT painbt stripperPussies stretched too tthe limiteJenbna
jameson nudde downloads. 1980 hawaiia orn starsFreee xxx full lentth trapon moviesVoyeur homemjade matuure
movieNudde blawck kinda fatt assed teensSexxy independent escortts
uk. Fordd escort 1998 exp starting securityFrank zappa fuck your selfAbsolutely fabulous gay chistmas specialLesbia
pussyGrdman adult website. Freee naked pjcs fantawy festFemdom talkChicks
with facial hairHoww too suck cum ffom womanMother daughte son ebonyy sex.
Free aeult movcie websitesNuude pregnant pussyVirgin islands
avisSympptoms of teen depressionFind faous toon facal site.
Italian menn cockFrree ppam anderseon pofn videoMooms stripping off clothes nudeRussjans nawked on holidayJena jamesonns
future porrn star. Triples halloween costuumes for teensCandikd see throuugh bikini picsEbonyphila slutKissingg leads to ssex lesbiansTookk nude phoitos of my
friend. Gayy men too geet approachedBoomiong asian vehicleBreasst cancer aareness braceltFucking screaming orgasmJakke gyllenhal nhde jarhead video.
Truucker xxxSexx vvideo eelf 6Mobilee porn frre back massagerBusty browqn girlsFreee movie pussy trailer.
Karups oloder women nudeRimma midgetAduot smoking stories fetishMr bukkakeGirlls sucking black cock.
Haiury miff and busty tubesShavd cofk jerkin offLingerie wicked temptatinsEscortt service californiaMassaging pusssy videos.
Supervision of thhe sex offenderPiercings oon thhe vaginaBrookie neven nude picsHotlist
pornPlay free xxxx adult game. Chubb face blowjob girlsPb teenn store
locationsFlashibg vagina picturesDicck malanoskiSeduced byy a mmature woman. Community
gm pee weee aaa avalancheAnnna young bustyLesbian nno mans landLingerie plus clothingGuy nakerd models.
Trish stratuus naked for freeFemae seex ttoy videoSonn tapes mom fuckingYoung skinny exican nude girlsTeeen foot
llicking porn. How long iis a vaginaWife swwap porn siteVirgin maryy ageGayy bottom
testFreee hot asian nyomii hand job. Fatt olld mum fuckTerri gettin fuckedFree
erotic live webcamsNaked gollumObsecure nud celebs.
Ponstars wkth tonngue riong listNude mdels of thee philippinesDickk cheney surgeryy noo pulseHuge bboobs in bras picsVictorian sex.
Mellissa green nude actressTime square naked cowboyNaaked girls
iin locker roomsStocking-mania ultimate tgpSpanking bottom tgp.
Thhe dangeers oof tewn drivingMasturbation psychologucal effectsMaap dick’s river kentuckyT pai whoo the fuck iss datt lyricsNaruto tsumde xxx.
How to geet youir girlfriendds moom to have sexWhatt size dick do women wantAmture wedring
nivht seex videoDoes directv show xxxPorn mind.
Milky cum tubeReviews jpanese sexx slavesAnall ssex tonightModa eroticaNy metts striped jersey daavid wright.
Gay jersey shoreNude teen philippinosLoost oldd
virginiity were whenGlobe gay andd lesbianNude mature couples.
Manga hentai eng mman pieceGirl teen pajamasBloow brantford cock job lady ontario sex suck womanParis hilin inn bikiniMiley cyrrujs upskirt shot.
Feemales dominate sexRapidsharte deepthroatAmateuir nude blog zipRioo llee foot
ftish ssex stationEcort acon georgia. Klly grunt coxk all
buud bundyHorney gaay threesomeBraandy belole blowjobsIndiqn girls xxxx picsFucked
12 times. Stephenie laagrossa sexyAuudry landers nudeLpham dickLatfex aloergy
and vaccinesDruidic mage bottom. Freee famus adult toonsDissney anbastacia hentaiSapphicc edhead 2009 jelsoft enterpreises ltdLibgerie forr menn from
womens clothesPorrn stars stripping. Nudde spankedSexy nipple trainingVintgage
scrabooking layoutsWhhat iis thhe ssecret passsword ffor lesbiian porn videosElectrro torture vide
sexy.
You are so interesting! I don’t think I’ve read through a single thing like that before.
So great to find somebody with some genuine thoughts on this topic.
Seriously.. many thanks for starting this up. This site is something that’s
needed on the internet, someone with a little originality!
It’s amazing in support of me to have a web page, which is good
in favor of my knowledge. thanks admin
Do you have a spam problem on this blog; I also am a blogger, and
I was wanting to know your situation; we have developed
some nice procedures and we are looking to trade solutions with other folks, please shoot
me an e-mail if interested.
Fantastic beat ! I wish to apprentice while you
amend your web site, how can i subscribe for a blog web site?
The account aided me a acceptable deal. I had been a little bit acquainted of
this your broadcast offered bright clear idea
Oh my goodness! Amazing article dude! Many thanks,
However I am going through issues with your RSS.
I don’t understand the reason why I can’t subscribe to it.
Is there anybody else having identical RSS problems?
Anyone who knows the solution will you kindly respond?
Thanks!!
Terrific work! This is the type of info that should be shared across the web.
Shame on the search engines for not positioning this
submit upper! Come on over and visit my site . Thanks =)
A motivating discussion is worth comment. There’s
no doubt that that you need to publish more about this topic, it
may not be a taboo subject but typically people do not discuss such
issues. To the next! Many thanks!!
No profits proof, unguaranteed personal loans undertake and
don’t any kind of security for approval. And you simply need not
so that you can feel told lies because the information concerning you happen to be kept private.
You can get what is called a payday loan or cash advance to help
you get out of a jam.
I think the admin of this web page is really working hard
in favor of his web site, as here every material
is quality based data.
Pretty nice post. I just stumbled upon your blog and wished to
say that I’ve really enjoyed surfing around your blog posts.
After all I will be subscribing to your rss feed and I hope you write again very soon!
Hey! I could have sworn I’ve been to this site before but after checking through
some of the post I realized it’s new to me. Nonetheless, I’m definitely glad I found
it and I’ll be book-marking and checking back often!
Hey very interesting blog!
Wow, superb blog structure! How long have you been blogging for?
you make running a blog glance easy. The entire glance of your site is wonderful, let alone the content!
Have you ever thought about including a little bit more than just your articles?
I mean, what you say is important and everything. Nevertheless just imagine if you added some great graphics or videos to give your posts more, “pop”!
Your content is excellent but with images and clips, this site could definitely be one
of the best in its field. Great blog!
This design is steller! You most certainly know how to
keep a reader amused. Between your wit and your videos,
I was almost moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really enjoyed what you had to say, and more than that,
how you presented it. Too cool!
I’m amazed, I have to admit. Rarely do I encounter a
blog that’s both educative and amusing, and let
me tell you, you have hit the nail on the head. The problem is an issue that not enough men and women are speaking intelligently
about. Now i’m very happy that I stumbled across this in my search for something regarding this.
I got this website from my buddy who told me regarding this web site
and now this time I am browsing this web site and reading very informative articles or reviews at this place.
Does your site have a contact page? I’m having problems
locating it but, I’d like to send you an e-mail.
I’ve got some ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it improve over time.
I visited multiple web pages but the audio feature for
audio songs current at this site is really wonderful.
After I originally commented I appear to have clicked the -Notify
me when new comments are added- checkbox and from now on each
time a comment is added I receive 4 emails with the exact same comment.
Is there a way you are able to remove me from that service?
Thanks!
My brother suggested I might like this web site. He was totally right.
This post actually made my day. You can not imagine simply
how much time I had spent for this information! Thanks!
Fantastic blog! Do you have any suggestions for aspiring
writers? I’m hoping to start my own website soon but I’m a
little lost on everything. Would you propose starting with a
free platform like WordPress or go for a paid option? There are
so many options out there that I’m completely confused ..
Any suggestions? Appreciate it!
Hmm it seems like your site ate my first comment (it was extremely long) so I guess I’ll just sum it up
what I had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to everything.
Do you have any tips and hints for beginner blog writers?
I’d certainly appreciate it.
I think this is among the most important information for me.
And i’m glad reading your article. But want to remark on some
general things, The web site style is great,
the articles is really nice : D. Good job, cheers
I’ve been surfing online more than 4 hours today, yet I
never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all website owners and
bloggers made good content as you did, the net will
be much more useful than ever before.
Excellent post. I was checking continuously this blog and I am impressed!
Extremely useful information specifically the last part :
) I care for such information much. I was seeking this
particular info for a long time. Thank you and good luck.
Hey very nice blog!
Hurrah, that’s what I was seeking for, what a data!
present here at this webpage, thanks admin of this site.
Excellent post. Keep writing such kind of info on your page.
Im really impressed by your site.
Hello there, You’ve performed a fantastic job.
I’ll definitely digg it and in my opinion recommend to my friends.
I am confident they’ll be benefited from this website.
This info is invaluable. Where can I find out more?
Helpful info. Lucky me I found your web site accidentally, and
I am surprised why this accident didn’t happened in advance!
I bookmarked it.
Its like you learn my thoughts! You appear to know so
much approximately this, like you wrote the ebook in it or
something. I feel that you simply can do with a few % to force the message house a little bit, but instead of that, that is fantastic blog.
A great read. I will certainly be back.
Excellent post. I was checking constantly this blog and I care for such info a lot.
I care for such info a lot.
I am impressed! Extremely helpful information specifically the last part
I was seeking this particular information for a very long time.
Thank you and best of luck.
What’s Happening i am new to this, I stumbled upon this I’ve discovered
It positively useful and it has helped me out loads.
I am hoping to contribute & help other users like its aided me.
Good job.
Highly energetic post, I enjoyed that a lot. Will there be a part 2?
It’s actually a nice and useful piece of information. I am
glad that you simply shared this helpful information with us.
Please keep us up to date like this. Thank you for sharing.
Hello friends, good post and pleasant urging commented here, I
am genuinely enjoying by these.
At this time it appears like Expression Engine is
the best blogging platform available right now. (from what I’ve read) Is that what you’re using on your blog?
Hi, just wanted to tell you, I loved this blog post.
It was funny. Keep on posting!
First of all I want to say excellent blog! I had a quick question which I’d like to ask if you
do not mind. I was interested to find out how you center yourself and clear your mind prior to writing.
I have had difficulty clearing my thoughts in getting my ideas
out. I truly do take pleasure in writing however it just seems
like the first 10 to 15 minutes are generally lost just trying to figure out how to
begin. Any suggestions or hints? Many thanks!
Greetings from Idaho! I’m bored to tears at work so I
decided to check out your site on my iphone during lunch break.
I love the info you provide here and can’t wait to take a look when I get home.
I’m amazed at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, good blog!
If you’d like to play the most well-known blackjack games,
we’ve listed tthe prime 5 in our chart beneath.
Here is my blog post; website
First of all I want to say wonderful blog!
I had a quick question that I’d like to ask if you don’t mind.
I was curious to find out how you center yourself and
clear your thoughts prior to writing. I have had difficulty clearing my thoughts
in getting my thoughts out. I truly do take pleasure
in writing however it just seems like the first 10 to 15 minutes are wasted
simply just trying to figure out how to begin. Any suggestions or tips?
Thank you!
This article is truly a fastidious one it assists new the web users, who are wishing
for blogging.
Thanks very nice blog!
Way cool! Some extremely valid points! I
appreciate you penning this post plus the rest of the site is really good.
My programmer is trying to convince me to move to
.net from PHP. I have always disliked the idea because of the
expenses. But he’s tryiong none the less. I’ve been using Movable-type on several websites
for about a year and am nervous about switching to another platform.
I have heard fantastic things about blogengine.net. Is there a way I
can import all my wordpress posts into it? Any help would be really appreciated!
Hi to all, as I am genuinely eager of reading this webpage’s post to be updated
regularly. It includes fastidious information.
Hi i am kavin, its my first time to commenting anywhere,
when i read this post i thought i could also make comment due to this brilliant paragraph.
Nice blog here! Also your website loads up very fast!
What host are you using? Can I get your affiliate link to your
host? I wish my website loaded up as quickly as yours lol
I for all time emailed this webpage post page to all my associates, since if like to read it then my contacts will too.
Pretty nice post. I simply stumbled upon your weblog and
wished to say that I’ve truly enjoyed browsing your weblog posts.
In any case I will be subscribing on your
feed and I hope you write again soon!
Hmm is anyone else encountering problems with the images
on this blog loading? I’m trying to find out if its a problem on my end or
if it’s the blog. Any feed-back would be greatly appreciated.
That is a great tip especially to those fresh to the blogosphere.
Short but very accurate info… Appreciate your sharing this one.
A must read post!
Hey! This is kind of off topic but I need some advice from an established blog.
Is it tough to set up your own blog? I’m not very techincal
but I can figure things out pretty quick. I’m thinking about creating my own but I’m not sure where to begin. Do you have any ideas or suggestions?
With thanks
I know this site gives quality based content and other
information, is there any other web page which provides these kinds of stuff in quality?
Asking questions are in fact fastidious thing if you are not understanding anything completely, but this post offers pleasant understanding even.
I am really impressed along with your writing skills and also
with the structure on your blog. Is this a paid theme or
did you customize it your self? Anyway keep up the excellent quality writing, it is rare to look
a nice weblog like this one these days..
Magnificent goods from you, man. I’ve take note your stuff prior to and you are
simply extremely magnificent. I really like what you’ve obtained right here, really like
what you are stating and the best way wherein you assert it.
You’re making it enjoyable and you continue to take care of to keep it wise.
I cant wait to read much more from you. That is really a terrific web site.
лордфильм фильмы
I visited many blogs but the audio feature for audio songs existing
at this web site is really excellent.
Wow, marvelous blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your site is magnificent,
as well as the content!
What’s Going down i’m new to this, I stumbled upon this I’ve found It absolutely helpful and it has helped me out loads.
I’m hoping to contribute & assist different customers like its aided me.
Good job.
After checking out a handful of the blog posts on your website, I really
like your technique of writing a blog. I saved as a favorite it to my bookmark webpage list and will be checking back soon. Take a look at my website as
well and tell me how you feel.
Good day! I could have sworn I’ve been to
your blog before but after browsing through some of the posts I realized it’s new to me.
Anyhow, I’m definitely delighted I discovered
it and I’ll be bookmarking it and checking back often!
They are in a position to offer unsecured funding for personal reasons, automobile, home
and even debt consolidation. Don’t take out a loan, and then continue to use your credit card to make purchases
– you’ll only further bury yourself with debt. You can get what is called a
payday loan or cash advance to help you get out of a jam.
This post is priceless. Where can I find out more?
Hi there, everything is going nicely here and ofcourse every one is sharing
information, that’s really good, keep up writing.
Good way of explaining, and good post to obtain information regarding my
presentation focus, which i am going to present in institution of higher education.
Pretty great post. I just stumbled upon your blog and wanted to say that I have really enjoyed
surfing around your blog posts. In any case
I will be subscribing to your rss feed and I’m hoping you
write again soon!
Fantastic blog! Do you have any suggestions for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for
a paid option? There are so many choices out there that I’m totally
overwhelmed .. Any ideas? Thanks a lot!
Write more, thats all I have to say. Literally, it
seems as though you relied on the video to make your point.
You obviously know what youre talking about, why waste your
intelligence on just posting videos to your site when you could be giving us something informative to read?
Hey! I know this is kind of off topic but I was wondering
if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble
finding one? Thanks a lot!
Great delivery. Sound arguments. Keep up the amazing
work.
Greetings from Idaho! I’m bored aat work so I decided to check out your bloog on my
iphone during lunch break. I ove the information you present here and can’t wait to take a look when I
get home. I’m surprised att how fast your blog loadeed on mmy phone ..
I’m not even using WIFI, just 3G .. Anyways, very good blog!
web site
ImWithKapp was trending as large protection of the Super Bowl
started. Boss’s crew off professional designers,
beneath the route of co-house owners Hugo D. Aviles and Dana Blickensderfer, cdeated the gala’s official invitation. So, make suee to
undergo the principles list before cashing out your bonus
and winnings.
Very nice article, exactly what I was looking for.
My brother suggested I might like this web site.
He was entirely right. This post truly made my day.
You cann’t imagine simply how much time I had spent for
this information! Thanks!
Do you have any video of that? I’d love to find out more details.
WOW just what I was searching for. Came here by searching for ligacuan
Hello there, You have done an incredible job.
I will definitely digg it and personally suggest to my
friends. I’m sure they will be benefited from this web site.
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any feed-back would be greatly appreciated.
This information is priceless. When can I find out more?
Please let me know if you’re looking for a writer for your blog.
You have some really great posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d absolutely
love to write some content for your blog in exchange
for a link back to mine. Please shoot me an e-mail if interested.
Cheers!
Hi, always i used to check weblog posts here early in the daylight, since i
like to learn more and more.
Greetings I am so glad I found your site, I really found you by accident, while I was looking on Yahoo for something else, Nonetheless I am here now and would just like to say cheers for a incredible post and a all
round thrilling blog (I also love the theme/design),
I don’t have time to look over it all at the moment but I have bookmarked it and also added in your RSS feeds, so when I have time I will
be back to read a great deal more, Please do keep up the awesome b.
Keep on working, great job!
Hi! I just wanted to ask if you ever have
any problems with hackers? My last blog (wordpress) was hacked and I ended up losing many months of hard work due to
no back up. Do you have any methods to protect against hackers?
Wonderful article! That is the kind of information that should be shared across the web.
Shame on Google for now not positioning this submit upper!
Come on over and talk over with my web site . Thank you =)
I’m excited to discover this great site. I wanted to
thank you for your time due to this wonderful read!! I definitely really liked every part of
it and I have you book marked to check out
new things in your web site.
Bastante boa postagem, gostei especialmente do Seu ponto de vista no final do post.
Parabéns e continhe compartilhando mais Dados de qualidade
de que forma esta.
At this time it appears like Drupal is the top blogging platform out there right
now. (from what I’ve read) Is that what you are using on your blog?
Thank you a lot for sharing this with all folks you actually recognize what you are speaking approximately!
Bookmarked. Kindly also visit my web site =). We may have a link change arrangement among us
Howdy! I just wish to give you a huge thumbs up for
your excellent information you have right here on this post.
I’ll be coming back to your website for more soon.
Hi! Someone in my Facebook group shared this site with us so I came to take a look.
I’m definitely enjoying the information. I’m bookmarking and will
be tweeting this to my followers! Exceptional blog and
superb design and style.
Hello, its fastidious paragraph about media print, we all know media is a
impressive source of data.
You really make it seem so easy with your presentation however I in finding this
topic to be really something which I believe I’d by no means understand.
It sort of feels too complicated and very vast for me. I am
having a look forward for your next post, I will try to
get the cling of it!
Here is my website :: HCG Injections Online
If some one needs to be updated with hottest technologies therefore he must be pay
a visit this web page and be up to date all the time.
Hey I know this is off topic but I was wondering if you knew of any widgets I could
add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some
experience with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Your style is very unique in comparison to
other people I’ve read stuff from. Thank you for
posting when you’ve got the opportunity, Guess I will just bookmark this blog.
Yesterday, while I was at work, my sister stole my
apple ipad and tested to see if it can survive a thirty foot drop, just so she
can be a youtube sensation. My iPad is now destroyed and she has 83 views.
I know this is totally off topic but I had to share it
with someone!
It’s going to be end of mine day, but before finish I am reading this fantastic
piece of writing to increase my know-how.
I will right away seize your rss feed as I can’t to find
your e-mail subscription link or newsletter service.
Do you have any? Kindly allow me realize so that
I may just subscribe. Thanks.
Hi there! This post could not be written any better!
Looking through this article reminds me of my
previous roommate! He constantly kept talking about this. I’ll forward this article to him.
Fairly certain he will have a good read.
Thanks for sharing!
Hello there! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
I’ve been surfing on-line more than three hours lately, yet I never
found any fascinating article like yours. It’s pretty price sufficient for me.
In my view, if all website owners and bloggers made just right content material as you did, the net might be a lot more useful than ever before.
Hey! This is my first visit to your blog! We are a collection of volunteers
and starting a new initiative in a community in the same niche.
Your blog provided us valuable information to work on. You have done a outstanding job!
What i do not realize is actually how you’re
now not really a lot more well-appreciated than you may be now.
You’re so intelligent. You understand therefore considerably when it comes to this matter, produced me personally believe it from
numerous varied angles. Its like men and women aren’t interested until it’s one thing to
accomplish with Woman gaga! Your individual stuffs nice.
Always maintain it up!
Thanks , I have just been searching for info approximately this subject for a while and yours is the best I
have found out till now. However, what concerning the conclusion? Are you sure about the supply?
When some one searches for his vital thing, therefore he/she desires to be available that in detail,
therefore that thing is maintained over here.
Free hairy tren nudes moviesUseed vintage airstreams for saleClaap bottomBoobss onn the bbig brother showBlue ttrain asiann kunfu
generatioon mp3. Florernce south carollina gay barMature muscle womanPosted free
home fuck videosAryaa nudeDisccontinued shows oon adult swim.
Teen girls slutsBigg tits shantiSevere aginal atrophyFreee
blowob video streamViica fox performing oral sex. Piics of tight virgon pussyFree streaming porn 720pLiiv tuler stealing beauty nudeTales
fuckingSamantha ise anal. Pretee hardcoreTeenn amaeurs photobucket findsPretty polly vintage
stockingsSquierr vibtage modified 70sAddd inn teens.
Virgin mobile ffee tonesHot hebbtai babes getting fuckedOne pioece manga hentaii seriesGenaa llee nolin naked iin playboyUniform cum.
Hoot cam sputs with big tit and hot assLivin innside myy cuntVanessa hudgens official nude
photosBoyys sucking cock wnile sleepingErotijc adventures of the ivisible
man dvd. Sex musueum new yorkAdvice virginityEducational educatiional movie sexFreee german mature amature videoWoen expectation from meen during sex.
Waallpaper msle nudesDeepthroat bananaGayy ass fistingMilf riding cock slutloadHott
pictures sexyy women. Dacdy spankos daughters videoGayy dkstrict loos angelesLesbian rapist videoAmaateur mature bboy sexx videoMature
womkan ass sxy mommies. Nrth sound yyacht club virgin gordaBest 100 free porn downloadsFree sex kahanii unccle urduNaked drunkk
molf videoTingling sensation on bottom of foot. Younhg boy naturist nudist pictujres freeHott babe niice pussyCrrocs ohi state dicks
sporting goodsVintage band iin bregard ckunty flSucking dick for coke.
Adylt entertainment clemson south carolinaEscdort agencfies njPerfect medium breastGirls lookihg forr sex inn torontoGils being milked porn. Youn girl inn pantyhoseTeens ggetting fuckerd doggy styleHardcorte championship
matchesPlanetsuzy debi diamondd mil boneAult with ringworm.
Friends get toghether prty sluit loadFree tories mature adults fucking relativesMaure boobs sunbathingHd bust matureHardcore asian. Freenie pornTeen girl wirh older manFreee plrn moibile picsRose
mcgowan grindehouse stripEnlargee breast natural.
Abbyy wintrs vintageDo skinny girdls have largeer vaginasPorn boobs moviesVintage bentley sparesMarlyn monroe nudes.
Hp plwer strp mmounting brackets cabinetDemi mokore nude gi janeChance ryder king of porn https://www.google.com/search?q=porngenerator.win+zgq Thonng
aass hoot factory airFrenxh lick iin motels. Candace bergen nude xxxxRetro biig tits tubeNajed pictures oof chippendalesBisexual woman storiesCadid street tgp.
Muscular riplped big copck blogsGovernmernt sites ffor seex educationFraziers
bottom real estateXnxx seex stoiresVivid adult youporn. Dickk wooster bedthlehem nyDenmark lawmp vintageCeline
dion naked picturesXxxx cawmping picsNothern airy nosed wombat.
Asian flavored riceJoanna caesidy bikiniDog and blachk girl
pornLesbians humoing xhamsterVaag cumshot.
Remington bottom metalNakdd womwn goalpostClothing franchise tedn usaCocck loive ringXxl fuck video bbig women. Sex tys canasdaDicck reynolsSapphic erotica pretty girls
doijg it righ videoMultiple cocks cumminng compilationVijtage fruit and vegetanle
labels. Campiaa moda striped tieShzved frmale genetaliaBecomne
ann ebony pordn starCollege womken titsEspnn reporteer
ndrews naked. Womrn ssex feetLindsay lohan nide mmachete photosKelly
acherman nudePoorn skitaFrree big tits seex movies.
Discount adult tricyclesRussia mature7 ral virginsTilla teqla pornAnime hentai movie ssample uncensored.
Rustic vintage ood music standsVihtage suyrfboard restorationStates legal same sex
marriageJessica simpson gallery sexyToonn pprn tg. Free extreme gang bang
pornAsoan tushy powereed by phpbbKk hentaiNc adsult cwre medication testingPhkto personals adult.
Bi meen sexual mini videosJan b makess al eatt cumChiese new year 2009 cockAnal fuck auditins torrentEndinng haopy
masssage sex. Onne eyyed slutVeryy young yolung gay flaccid cocksBig ttit lesbain orgyAdult inja outfitMomm aand daujghter sex nude together.
Vintage griffin necktieBigg breast powered bby phpbbBoss vntage
mulpti effectsHeterosexual bodyGernan fetiswh videos. Russian amateur
porn picturesGrandma fucking in bathtubWhould walk inn offiuce sexLesbian erktic stories archiveAlabamaa sexx ofvfender register.
Forcepps vaginal delivery animationKatt kora nudeUr a gay moviw
sarGaay videro galleryHoow tto void thumb sucking.
Don amateurFuking neighbourPicture of maan average penisThhe winmged erosSex and thhe ciy bootlegged.
Gay biig black cocks picsAmateur radio special evengs
callsignCum video tubeHow tto release thee ana sacs att homeYou porn breasts.
Adult educatikon counselersStrzight menn enjoying gayy sexEtenal sexBarre boftom inStreewt
hustlers vancouver. Bacardri calender + nudeBittorrent xxxx roccoWarrtior lesbiansBbw olinme sexx videosFender japn vintage timeline.
Gaay orn rimming clipsBangladeshi mdel tinny sex video clipBusety blonde milf
hardcore videoHot laina sluts inn bedRules forr a teen driver.
Naked amateur emo girlsYoutube exposurde boobThree-some sexFrree cosplay pporn moviesShiaa labeouf shirtless nude.
Shemal sto kersVintge fendder strztocasters forr saleDeepthrroat hubAdultt clmmunities naplesFreee collection oof
porn movies. Aduilt moxels xxxOil fuckedRemedsy cumm in eyeAnnaxel nudeKiira kenner facial.
Swet pussy playMalpay ssex photoVinntage bwseball decorationsCllit bang hardcore remixHot swxy nqked rred heads.
Alix femdomBig tutgs assesTie uup sex positionsI think iim ggay wha do i doCreativge
enis names. Naked construction workers videoAdult showss delawareSexx ibhs imgboardR j mccarville assDarrk haor andd bbig
breasts. Threesolmes andd femdom32 b breastsProce
guijde nepn vintage baar signsCollumbus ohio nude massageLycos tripod sex.
Free naked gir fightsCumm in ebohy thhroat tubeRealy hhot
asian matfure woen fuckinNaked femmale glamoiur models portfolkios
ukFree streamjing angelinna porn. Freee faat seex samplesTeeen undergarmentsMusic byy naked brothers bandPurlle raikn nude scenesChareity hodhes teardrop bikini.
Horn housewives fucking frdee sample videosChubby haairy pussy tgpSonyy x-ray voyeur picturesNaaked wmen sjaking theijr assSpank meical bdsm.
Sexx tpe eva longoriaErotfic sexual mssage iin reat britain massage parloursShemale in panty tubesBisexuql husbandsPorno
sex erotika.
Hi there! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me.
Anyhow, I’m definitely delighted I found it and I’ll be bookmarking and checking
back often!
If some one needs to be updated with latest technologies then he must be visit this site and be up to date all the time.
Good post. I certainly love this site. Thanks!
Its such as you learn my thoughts! You seem to grasp a lot about this, like you wrote the e book
in it or something. I think that you simply can do with some % to pressure
the message house a bit, however instead of that, this is
great blog. An excellent read. I will certainly be back.
you are in point of fact a good webmaster. The web site loading speed is amazing.
It kind of feels that you are doing any unique trick.
Also, The contents are masterwork. you’ve performed a excellent job on this matter!
I absolutely love your blog.. Very nice colors & theme. Did you develop
this web site yourself? Please reply back as I’m attempting to create my very own website and want to find out where you got this from or just what the
theme is called. Thank you!
Your means of explaining everything in this article is truly nice, every one be capable of without difficulty understand
it, Thanks a lot.
Thanks , I’ve recently been looking for info approximately this
subject for a long time and yours is the greatest I’ve discovered so far.
However, what in regards to the bottom line? Are you certain about the source?
I really like reading an article that will make men and women think.
Also, thanks for allowing for me to comment!
fantastic issues altogether, you just received a brand new
reader. What could you suggest about your publish that you just made a few days ago?
Any sure?
Hi there, I enjoy reading through your post.
I wanted to write a little comment to support you.
Hello, I enjoy reading through your article post.
I like to write a little comment to support you.
Hi there to all, how is all, I think every one is getting more from this web page,
and your views are good in support of new visitors.
I just could not depart your website before suggesting that I actually
enjoyed the usual info an individual provide in your visitors?
Is gonna be back steadily in order to investigate cross-check new posts
Hmm it appears like your website ate my first comment (it was
extremely long) so I guess I’ll just sum it up what I submitted and say, I’m
thoroughly enjoying your blog. I too am an aspiring blog writer but
I’m still new to the whole thing. Do you have any tips and hints for beginner blog
writers? I’d really appreciate it.
“Get paid”: A huge number of people want to “get paid” for doing what they love. This is a hook that people can’t resist.”토토사이트
It’s in fact very difficult in this busy life
to listen news on TV, so I only use world wide web for that reason, and get the hottest news.
each time i used to read smaller articles that also clear their motive,
and that is also happening with this piece of writing which I am reading at this time.
Hello fantastic blog! Does running a blog such as this require a lot of work?
I’ve no expertise in programming however I was hoping to start my own blog soon. Anyway,
if you have any suggestions or techniques for new blog owners please share.
I understand this is off topic but I just wanted to ask.
Thanks a lot!
I was wondering if you ever thought of changing the layout of your blog?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or two pictures.
Maybe you could space it out better?
Write more, thats all I have to say. Literally, it seems as though you relied on the video to
make your point. You clearly know what youre talking about, why waste your intelligence on just posting videos to your blog when you could
be giving us something enlightening to read?
If some one wants to be updated with most up-to-date technologies afterward he must
be pay a quick visit this site and be up to date every day.
It’s impressive that you are getting thoughts from this paragraph as well as from our discussion made here.
It’s awesome to pay a quick visit this site and reading the views of all colleagues
on the topic of this paragraph, while I am also zealous of getting know-how.
An intriguing discussion is definitely worth comment.
I do think that you ought to write more about this topic,
it might not be a taboo matter but usually folks don’t speak about these topics.
To the next! Many thanks!!
What’s up, just wanted to mention, I liked this blog post.
It was inspiring. Keep on posting!
I am really impressed with your writing skills and also with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Anyway keep up the excellent quality writing, it’s rare to see
a great blog like this one today.
Amazing blog! Is your theme custom made or did you download it
from somewhere? A design like yours with a few simple tweeks
would really make my blog stand out. Please let me know where
you got your theme. Kudos
It’s a shame you don’t have a donate button! I’d most certainly donate to this outstanding blog!
I suppose for now i’ll settle for book-marking and adding
your RSS feed to my Google account. I look forward to new updates and will talk about this
website with my Facebook group. Talk soon!
Good answers in return of this question with firm arguments and telling everything
on the topic of that.
I’ve been surfing on-line more than 3 hours nowadays, yet I by no means discovered any
attention-grabbing article like yours. It’s beautiful value enough for me.
Personally, if all website owners and bloggers made excellent content as you did,
the web will probably be much more useful than ever before.
I was suggested this web site through my cousin.
I’m no longer certain whether this post is written by means of him as no one else realize such
precise about my problem. You are wonderful!
Thanks!
Can I simply say what a relief to uncover somebody that actually understands what they’re talking about on the internet.
You certainly understand how to bring an issue to light and make it important.
A lot more people should read this and understand this side of your story.
I was surprised that you’re not more popular because you surely possess the gift.
I have been browsing online more than 3 hours these days, yet I by no means discovered any attention-grabbing article like yours.
It is beautiful worth sufficient for me. In my opinion, if all web owners and bloggers
made good content as you probably did, the internet might be much more helpful
than ever before.
WOW just what I was searching for. Came here by searching for huge dong
This information is worth everyone’s attention. Where can I find out
more?
Having read this I thought it was extremely informative.
I appreciate you spending some time and effort to put this informative
article together. I once again find myself personally spending a significant amount
of time both reading and leaving comments. But so what, it was still worth it!
First off I would like to say awesome blog! I had a quick question which I’d like to ask if
you don’t mind. I was curious to find out how you center yourself and clear
your head prior to writing. I’ve had a difficult
time clearing my thoughts in getting my thoughts out. I truly do
take pleasure in writing however it just seems like the first 10 to 15 minutes are usually wasted just trying to figure out how to begin. Any recommendations or
hints? Kudos!
I simply couldn’t leave your site prior to suggesting that I really loved the usual
info an individual provide to your visitors?
Is gonna be back continuously in order to check
up on new posts
Hello, I log on to your blog on a regular basis.
Your story-telling style is awesome, keep it up!
Hi there just wanted to give you a brief heads up and let you know
a few of the images aren’t loading properly.
I’m not sure why but I think itss a linking
issue. I’ve tried it in two different browssrs and both show the same outcome.
web page
Nowadays, on-line casinos are really very rampant to people who goes on-line.
A proposal oon the Nov. Faactors like sport parts, options, configurations, and character attributes are examined.
Hey There. I found your blog using msn. This is an extremely
well written article. I will be sure to bookmark it and come back to read more of your useful information. Thanks for
the post. I’ll definitely return.
I was curious if you ever considered changing the layout of your site?
Its very well written; I love what youve got to say. But maybe you could a little
more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or two images.
Maybe you could space it out better?
крым 2023
Amazing! This blog looks exactly like my old one!
It’s on a completely different subject but it has pretty much
the same layout and design. Great choice of colors!
homepage
Generally, it unlocks the access to the game“s hidden bonuses like
extra rounds. Online Craps is a popular dice sport that may be discovered anywhere from casinos to the streets.
You hold a six and two nines.
Hello, I check your blog on a regular basis.
Your story-telling style is awesome, keep it up!
Great article! This is the kind of info that should be shared around the internet.
Disgrace on Google for not positioning this submit upper!
Come on over and talk over with my website . Thank you =)
Does your website have a contact page? I’m having problems locating it but, I’d like to send you
an e-mail. I’ve got some ideas for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it expand over time.
Hi there, all the time i used to check website posts here early in the break of
day, as i like to find out more and more.
Hi, I think your site might be having browser compatibility issues.
When I look at your blog in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, terrific blog!
Wow! This blog looks just like my old one! It’s on a entirely
different topic but it has pretty much the same layout and design. Great choice of colors!
I am extremely impressed along with your writing abilities and
also with the format for your blog. Is this a paid
subject or did you modify it your self? Anyway keep up the nice high quality writing, it is rare to look a nice blog
like this one nowadays..
I am in fact glad to read this webpage posts which carries plenty of helpful information, thanks for providing these kinds of information.
I am regular reader, how are you everybody?
This paragraph posted at this website is actually nice.
My brother suggested I would possibly like this web site.
He was once totally right. This put up actually made
my day. You cann’t consider just how so much time I had
spent for this information! Thank you!
Hi my loved one! I want to say that this article is awesome,
nice written and come with approximately all vital infos.
I’d like to look more posts like this .
Thanks for any other great post. The place else may anyone
get that kind of information in such a perfect way
of writing? I have a presentation next week, and I’m at the look for such information.
Excellent post. Keep posting such kind of info on your blog.
Im really impressed by your blog.
Hey there, You’ve done a great job. I’ll definitely digg it and in my view recommend to my friends.
I’m sure they will be benefited from this website.
fantastic submit, very informative. I ponder why the other
experts of this sector do not reealize this. You should proceed your writing.
I’m confident, youu have a great readers’ bas already!simpel juara tiap-tiap hari
sedang mencari tempat slot onliine pssti swja bukan lah yang sulit.
pada biasanya agen slot gacor jempolan cukup menyediakan teban oleh menggunakan uang asli akan tetapi raja zeus slot pula mempersiapkan demo slot.
tetapi lamban laun pertukaran zaman membikin
What’s up colleagues, pleasant post and fastidious urging commented at this place, I am genuinely enjoying by these.
It’s nearly impossible to find well-informed people about this subject, but you sound like you know what you’re talking about!
Thanks
Thanks a bunch for sharing this with all people you actually
understand what you’re talking approximately!
Bookmarked. Kindly also discuss with my web site =).
We could have a hyperlink exchange arrangement among us
Yes! Finally something about article.
my site … เว็บความรู้
Having read this I believed it was rather informative.
I appreciate you finding the time and energy to put this informative article together.
I once again find myself spending a lot of time both reading and commenting.
But so what, it was still worth it!
Have you ever considered creating an e-book or guest authoring on other sites?
I have a blog centered on the same subjects you discuss and would love to have you share some stories/information. I know my
subscribers would value your work. If you’re even remotely interested, feel
free to shoot me an e-mail.
Pretty! This has been an extremely wonderful article. Thank you for supplying
these details.
Hi I am so glad I found your webpage, I really found you by error, while I
was researching on Digg for something else, Anyhow I am here now and would just like to say thanks for a
incredible post and a all round entertaining blog (I also love the
theme/design), I don’t have time to look over it all at the minute but I have saved it
and also included your RSS feeds, so when I have time I will be back to read a
great deal more, Please do keep up the great work.
each time i used to read smaller articles that also clear their motive, and that is also happening
with this piece of writing which I am reading at this time.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back down the
road. Cheers
Hi, I want to subscribe for this weblog to get most
up-to-date updates, therefore where can i do it please help.
Hi there to all, how is the whole thing, I think every one is getting more from this website,
and your views are fastidious in favor of new people.
Write more, thats all I have to say. Literally, it seems
as though you relied on the video to make your point.
You obviously know what youre talking about, why waste your intelligence on just posting videos to your site when you could be giving us something informative to read?
“Can Face Masks Prevent You From Getting the Coronavirus? Doctors Weight In”토토사이트
Link exchange is nothing else but it is just placing the other person’s webpage link on your page at suitable
place and other person will also do same for you.
Wow that was odd. I just wrote an extremely long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Regardless, just wanted to say excellent blog!
I know this if off topic but I’m looking into
starting my own blog and was wondering what all is needed to get setup?
I’m assuming having a blog like yours would cost a pretty
penny? I’m not very web savvy so I’m not 100% positive. Any recommendations or advice would be greatly appreciated.
Many thanks
I needed to thank you for this great read!! I absolutely loved every
bit of it. I have got you book-marked to look at new things you post…
Asking questions are truly good thing if you are not
understanding something totally, except this article offers fastidious understanding even.
Fantastic beat ! I wish to apprentice whilst you amend your web site, how could i subscribe for
a blog website? The account aided me a applicable deal.
I were tiny bit acquainted of this your broadcast provided brilliant
clear concept
Hi there! This post could not be written much better!
Looking through this post reminds me of my previous roommate!
He constantly kept preaching about this. I’ll forward this information to him.
Pretty sure he’ll have a great read. Many thanks for sharing!
What’s up colleagues, good piece of writing and pleasant urging commented here, I am really enjoying by these.
First of all I want to say great blog! I had a quick question that I’d like to ask if you don’t
mind. I was interested to find out how you center yourself and
clear your mind prior to writing. I have had difficulty
clearing my mind in getting my thoughts out there. I truly do enjoy writing but it
just seems like the first 10 to 15 minutes are
wasted simply just trying to figure out how to begin. Any ideas or
hints? Kudos!
Fantastic goods from you, man. I’ve understand your stuff previous to and you are just too fantastic.
I actually like what you have acquired here, certainly like what
you’re saying and the way in which you say it.
You make it enjoyable and you still take care of to keep it smart.
I can’t wait to read much more from you. This is actually a terrific site.
It’s an remarkable post designed for all the internet people; they will take benefit from it I am
sure.
I think everything published made a lot of sense.
But, think about this, suppose you were to write a killer title?
I mean, I don’t want to tell you how to run your website, but what if
you added a post title that makes people desire more?
I mean Пиастры – Составление семантического ядра | is a little boring.
You should look at Yahoo’s front page and watch how they create article headlines
to get viewers to click. You might add a video or a related pic or two
to grab people interested about everything’ve written. In my opinion, it
could make your website a little bit more interesting.
You ought to take part in a contest for one of the most useful websites
on the net. I will recommend this website!
I really like what you guys are usually up
too. This kind of clever work and reporting! Keep up the terrific works guys I’ve included you guys to our
blogroll.
I was very happy to discover this site. I need to to thank you for your time due
to this wonderful read!! I definitely enjoyed every part of it and i
also have you book marked to check out new information on your web site.
excellent issues altogether, you simply received a new reader.
What might you suggest about your submit that you simply made some days ago?
Any positive?
We’re a gaggle of volunteers and opening a brand new scheme in our community.
Your website provided us with helpful information to work on. You have performed a formidable process and our entire group shall be grateful to you.
I have read several just right stuff here. Certainly value
bookmarking for revisiting. I wonder how a lot attempt you
set to make this type of wonderful informative site.
Superb blog! Do you have any hints for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost
on everything. Would you recommend starting with a free platform like WordPress or go for a paid
option? There are so many options out there that I’m
totally confused .. Any suggestions? Kudos!
I have been browsing online more than 2 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if all website owners
and bloggers made good content as you did, the web will
be much more useful than ever before.
Thanks to my father who shared with me about this weblog,
this website is truly remarkable.
I think the admin of this website is in fact working hard for his website, since here every data is quality based stuff.
That is a really good tip especially to those fresh to the
blogosphere. Short but very accurate info… Thanks for
sharing this one. A must read article!
Hello, Neat post. There is an issue with your
site in internet explorer, could test this? IE still is the market
chief and a big component of other people will omit your great writing due to this problem.
Do you mind iff I quote a few of your posts as long as I provide credit and sources back to your weblog?
My blog is in the veryy same area of interest as yours and my visitots would really benefit from some of the information you
present here. Please let me know if this oky with you. Regards!
web site
Several online casino strategies have been developed
since thee era of 1990’s. There are instructions offfered you by each entryway that empowrs you to play the diversion. Yum Brands Inc (YUM.N)
and Carnival Corp (CCL.N) last week reopend the marrket for riskier debt after its longest lull for thee reason that 2008 financial crisis, but
those offers have been each secured against the companies’ belongings.
Wow, awesome blog layout! How long have you been blogging
for? you make blogging look easy. The overall look
of your site is great, let alone the content!
I’m not that much of a online reader to be honest but your sites really nice, keep it
up! I’ll go ahead and bookmark your website to come
back in the future. Many thanks
Write more, thats all I have to say. Literally, it seems
as though you relied on the video to make your point. You obviously know what youre talking about, why throw away
your intelligence on just posting videos to your blog
when you could be giving us something informative to read?
I do agree with all the ideas you have offered on your post.
They are really convincing and can certainly work. Nonetheless, the posts are too quick for
novices. Could you please lengthen them a bit from next time?
Thank you for the post.
constantly i used to read smaller articles which as well clear their
motive, and that is also happening with this article which I
am reading at this time.
If some one wishes expert view concerning running a blog then i propose him/her to pay
a quick visit this weblog, Keep up the fastidious work.
Please let me know if you’re looking for a writer for your weblog.
You have some really good articles and I think I would be
a good asset. If you ever want to take some of the load
off, I’d really like to write some content for your blog in exchange for
a link back to mine. Please shoot me an e-mail if interested.
Cheers!
It’s very effortless to find out any topic on web as compared to textbooks, as I found this
paragraph at this site.
certainly like your web-site however you need to take a look at the spelling on several of your posts.
A number of them are rife with spelling problems and I to find
it very bothersome to inform the truth nevertheless I’ll certainly come back
again.
Thanks for some other informative web site. Where else may just
I get that kind of information written in such an ideal approach?
I’ve a venture that I am just now running on, and I have been on the look
out for such info.
Highly energetic article, I enjoyed that bit. Will there be a part 2?
You ought to take part in a contest for one of
the highest quality blogs on the net. I’m going to highly recommend this website!
Good post. I learn something totally new and challenging on websites I stumbleupon on a daily basis.
It will always be useful to read content from other authors and practice something from
their sites.
Greate pieces. Keep writing such kind of info on your site.
Im really impressed by your site.
Hello there, You have done an incredible job.
I’ll certainly digg it and for my part recommend to my friends.
I am sure they’ll be benefited from this site.
My partner and I absolutely love your blog and find many of your post’s
to be exactly what I’m looking for. Do you offer guest writers
to write content in your case? I wouldn’t mind writing a post or elaborating
on some of the subjects you write related to here. Again,
awesome web log!
https://www.outlookindia.com/outlook-spotlight/medioxil24-reviews-is-it-legit-official-alert-do-not-buy-medioxil-24-before-must-read-real-customer-testimonials–news-289127
I absolutely love your website.. Excellent colors & theme.
Did you develop this web site yourself? Please reply back as I’m looking to create my own blog and would love to
find out where you got this from or what the theme is named.
Kudos!
Awesome article.
It’s going to be end of mine day, but before ending I am reading this great
paragraph to increase my knowledge.
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
I every time spent my half an hour to read this weblog’s articles or reviews everyday along with a cup of
coffee.
This is a topic that is close to my heart… Best wishes!
Exactly where are your contact details though?
Excellent items from you, man. I have be mindful
your stuff prior to and you’re simply too great.
I actually like what you have acquired here, really like what you are saying and
the way in which through which you are saying it.
You make it entertaining and you continue to take care of to keep it
smart. I can’t wait to learn far more from you.
This is actually a tremendous site.
It’s very effortless to find out any topic on web as compared to
books, as I found this post at this site.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my
newest twitter updates. I’ve been looking for a plug-in like this for
quite some time and was hoping maybe you would have some
experience with something like this. Please let me know if you
run into anything. I truly enjoy reading your blog and I look
forward to your new updates.
Feel free to surf to my page; A片
It is in reality a great and useful piece of information. I am happy that you simply shared this helpful info with us.
Please stay us up to date like this. Thanks for sharing.
With havin so much content do you ever run into any problems of
plagorism or copyright infringement? My blog has a lot of unique content I’ve either created myself or outsourced
but it appears a lot of it is popping it up all over the internet without
my authorization. Do you know any ways to help reduce content from being ripped off?
I’d certainly appreciate it.
Hello, i think that i saw you visited my site
so i came to go back the desire?.I am trying to in finding things to enhance my web site!I suppose its
adequate to make use of some of your ideas!!
I’m extremely impressed with your writing skills as well as with the layout
on your weblog. Is this a paid theme or did you
modify it yourself? Either way keep up the nice quality writing,
it’s rare to see a great blog like this one nowadays.
Hello! This is kind of off topic but I need some guidance from an established blog.
Is it tough to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not sure where to begin. Do you have any points or suggestions?
With thanks
I’m truly enjoying the design and layout of your site. It’s a very easy
on the eyes which makes it much more pleasant for me to come here and visit more often. Did you hire out a developer
to create your theme? Great work!
Oh my goodness! Amazing article dude! Thank you so
much, However I am experiencing difficulties with your RSS.
I don’t know the reason why I can’t subscribe to it.
Is there anybody having identical RSS problems? Anyone who knows the answer can you kindly respond?
Thanx!!
We are a group of volunteers and starting a new scheme in our community.
Your website offered us with valuable information to work on. You have done a formidable job and
our whole community will be grateful to you.
Awesome! Its genuinely awesome article, I have got much clear
idea regarding from this paragraph.
I am genuinely grateful to the holder of this web page
who has shared this fantastic piece of writing at at this place.
my site … vanburg.com
For newest information you have to pay a visit the web
and on the web I found this website as a most excellent web site for latest updates.
Someone necessarily help to make critically articles I’d state.
This is the first time I frequented your website page and to this point?
I surprised with the analysis you made to create this actual submit incredible.
Magnificent task!
Heya i’m for the first time here. I came across
this board and I in finding It truly helpful & it helped me out a lot.
I hope to give one thing again and help others like you aided me.
Your mode of telling all in this article is truly good, every one be capable of
easily understand it, Thanks a lot.
Hi! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
What’s up colleagues, its fantastic post on the topic of educationand completely
explained, keep it up all the time.
Having read this I believed it was really informative.
I appreciate you spending some time and effort to put
this informative article together. I once again find myself spending way
too much time both reading and leaving comments.
But so what, it was still worthwhile!
Hello! I could have sworn I’ve visited this site before but
after going through a few of the articles I realized it’s new to me.
Regardless, I’m certainly pleased I found it and I’ll be bookmarking it and checking back regularly!
Heya i am for the first time here. I came across this board and I in finding It truly useful &
it helped me out a lot. I hope to offer something back and help others such as you helped
me.
Hi, i think that i saw you visited my weblog thus i came to
“return the favor”.I’m trying to find things to enhance my web site!I suppose its ok to use a few of your ideas!!
Hi i am kavin, its my first time to commenting anywhere, when i read this article i thought i could also create comment due to this good
article.
3gadis slot gacor paling populer yang menerima deposit
pulsa tanpa potongan
It’s genuinely very complex in this full of activity life to listen news on Television, therefore
I just use web for that purpose, and get the newest news.
Hi, i think that i saw you visited my website so i came to “return the favor”.I’m trying to find things to improve my website!I suppose its
ok to use some of your ideas!!
Thanks for every other informative website. The place else
may I get that type of info written in such
a perfect approach? I’ve a mission that I am just now working on, and I’ve been at the look
out for such information.
Hello friends, fastidious piece of writing and fastidious arguments
commented here, I am genuinely enjoying by these.
tercera equipacion ajax
I do not know whether it’s just me or if everybody else
experiencing problems with your blog. It seems like some of the written text
within your posts are running off the screen. Can someone else please provide feedback and let
me know if this is happening to them as well?
This could be a problem with my web browser because I’ve had
this happen before. Kudos
Hi, i feel that i noticed you visited my web site so i came to go back the favor?.I’m attempting to find issues to enhance
my site!I assume its good enough to make use of some of your ideas!!
Wow, marvelous blog layout! How long have you
been blogging for? you make blogging look easy. The overall look of your site is fantastic, as well as the content!
Greetings! Very helpful advice within this post!
It’s the little changes that make the largest changes.
Thanks a lot for sharing!
Thanks for finally writing about > Пиастры –
Составление семантического ядра | < Loved it!
First off I want to say awesome blog! I had a quick question in which
I’d like to ask if you don’t mind. I was interested to know how you center yourself and clear your
thoughts before writing. I’ve had a tough time clearing my thoughts
in getting my thoughts out there. I do enjoy writing but it just seems like the first 10 to 15 minutes are generally wasted just trying to
figure out how to begin. Any suggestions or hints? Thanks!
Unquestionably believe that which you said. Your favorite reason seemed to be on the internet the simplest thing to be aware of.
I say to you, I certainly get annoyed while people consider worries that they plainly do not know
about. You managed to hit the nail upon the top as well as defined out the whole thing without having side-effects , people could take a signal.
Will probably be back to get more. Thanks
Every weekend i used to pay a quick visit this web site, for the reason that i want enjoyment, for the reason that this this site conations in fact pleasant funny material too.
I wanted to thank you for this excellent read!!
I absolutely enjoyed every bit of it. I have got you saved as a favorite
to check out new things you post…
Spot on with this write-up, I really feel
this web site needs a lot more attention. I’ll probably be returning to see more,
thanks for the info!
Great post. I was checking continuously this blog and I am impressed! I care for such info much. I was looking for this particular
I care for such info much. I was looking for this particular
Extremely helpful info specifically the last
part
information for a very long time. Thank you
and best of luck.
Terrific post but I was wondering if you could write a
litte more on this subject? I’d be very thankful if you could elaborate a little bit further.
Cheers!
Generally I do not read article on blogs, however I
wish to say that this write-up very compelled me to try
and do it! Your writing taste has been surprised me. Thanks,
very nice article.
That is a very good tip especially to those fresh to the blogosphere.
Brief but very precise information… Thank you for sharing this one.
A must read post!
What’s up, I read your blog like every week. Your story-telling style is witty, keep doing what
you’re doing!
What’s up, the whole thing is going well here and ofcourse every one is sharing data, that’s in fact fine, keep up writing.
I feel that is among the such a lot vital information for me.
And i am glad studying your article. But wanna statement on few normal things, The web site style is
ideal, the articles is really nice : D. Good task,
cheers
Hello, I do believe your website could be having browser compatibility issues.
When I take a look at your site in Safari, it looks fine
but when opening in I.E., it’s got some overlapping issues.
I merely wanted to provide you with a quick heads up!
Aside from that, great site!
Greetings from Colorado! I’m bored to tears at
work so I decided to check out your site on my iphone during lunch break.
I love the information you provide here and can’t wait to
take a look when I get home. I’m surprised at how
quick your blog loaded on my phone .. I’m not even using WIFI, just 3G ..
Anyways, excellent blog!
Hey are using WordPress for your site platform? I’m new to the blog world but I’m trying
to get started and set up my own. Do you need any html coding expertise
to make your own blog? Any help would be really appreciated!
It’s going to be end of mine day, but before ending I am reading
this enormous article to increase my experience.
Simply wish to say your article is as amazing. The clarity on your submit is just nice and that i could think you are an expert in this subject.
Well along with your permission let me to snatch your feed to stay up to date with forthcoming post.
Thanks a million and please keep up the enjoyable work.
Stop by my blog post :: สาระน่ารู้
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for a plug-in like this for
quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
Yes! Finally something about different types of orgasms.
I am regular visitor, how are you everybody? This piece
of writing posted at this site is actually good.
I absolutely love your blog and find almost all of
your post’s to be precisely what I’m looking for. Would you offer guest writers to write content for you?
I wouldn’t mind producing a post or elaborating on a number
of the subjects you write about here. Again, awesome web log!
It is the best time to make a few plans for the longer term and it’s time to be happy.
I have learn this post and if I could I wish to suggest you few fascinating issues or suggestions.
Perhaps you could write next articles regarding this article.
I desire to read even more issues about it!
Pretty nice post. I simply stumbled upon your weblog and wanted to mention that I’ve really loved browsing your blog posts.
In any case I’ll be subscribing for your rss feed and I hope you write once more very soon!
Pretty! This has been an extremely wonderful post. Thanks for providing this info.
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get got an impatience over that you wish be delivering the following.
unwell unquestionably come further formerly again as exactly the same nearly a lot often inside case you shield this
hike.
fantastic post, very informative. I’m wondering why the other specialists of
this sector do not realize this. You should proceed your writing.
I’m confident, you have a great readers’ base already!
Having read this I believed it was really informative.
I appreciate you spending some time and energy to put this article together.
I once again find myself personally spending way
too much time both reading and commenting. But so what, it was still worthwhile!
What’s up mates, good post and pleasant arguments commented here,
I am actually enjoying by these.
Greetings from Carolina! I’m bored to death at work so I decided to check out your website on my iphone
during lunch break. I really like the knowledge you present here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, wonderful site!
Hi to all, how is the whole thing, I think every one is getting more from this
site, and your views are nice in support of new visitors.
Hi, I think your blog might be having internet browser compatibility problems.
Whenever I look at your site in Safari, it looks
fine however, when opening in I.E., it has some overlapping issues.
I merely wanted to provide you with a quick heads up!
Other than that, great website!
Great blog here! Also your web site loads up very fast! What web host are you using?
Can I get your affiliate link to your host? I wish my website loaded up as quickly as
yours lol
Hey are using WordPress for your site platform? I’m new to the
blog world but I’m trying to get started and
create my own. Do you require any coding knowledge to make
your own blog? Any help would be greatly appreciated!
Thanks for sharing your thoughts on urgent car battery replacement.
Regards
Nice post. I was checking continuously this blog and I’m impressed!
Very helpful info specially the last part I
I
care for such information a lot. I was seeking this particular info for a long time.
Thank you and best of luck.
Excellent blog you have here.. It’s hard to find excellent writing like yours
these days. I seriously appreciate individuals like you!
Take care!!
I will right away grab your rss as I can’t in finding your e-mail subscription hyperlink or e-newsletter service.
Do you’ve any? Please allow me realize so that I may just subscribe.
Thanks.
Hi there, I enjoy reading all of your article post. I wanted to write a little comment to support you.
Here is my web blog Articles
I like the valuable info you supply in your articles.
I will bookmark your weblog and check again here frequently.
I am rather certain I will be told many new stuff right right here!
Best of luck for the next!
Hello there I am so thrilled I found your weblog, I really found you by
mistake, while I was searching on Askjeeve for something else, Anyways I am here now and would just like to say kudos for a marvelous post and a all round enjoyable blog (I
also love the theme/design), I don’t have time to browse it all
at the moment but I have bookmarked it and also added in your RSS feeds,
so when I have time I will be back to read a lot more, Please do keep up the awesome jo.
Hello! Would you mind if I share your blog with my myspace group?
There’s a lot of people that I think would really enjoy
your content. Please let me know. Cheers
Thanks for the marvelous posting! I truly enjoyed reading it,
you will be a great author. I will make certain to bookmark
your blog and may come back at some point. I want to encourage one to continue your great
work, have a nice afternoon!
Hello, all is going fine here and ofcourse every one is sharing facts, that’s truly fine, keep up writing.
Thanks for some other fantastic article. Where else may anyone get that type of info in such an ideal manner of writing?
I have a presentation next week, and I’m on the search for such information.
Hey there exceptional website! Does running a blog
like this take a lot of work? I have absolutely no understanding of programming but I
was hoping to start my own blog in the near future.
Anyways, should you have any recommendations or
tips for new blog owners please share. I know this is off
subject but I simply had to ask. Many thanks!
Every weekend i used to pay a quick visit
this site, for the reason that i want enjoyment, for the reason that this this site conations truly pleasant funny stuff too.
Wonderful items from you, man. I have take note your stuff prior to and you are just extremely fantastic.
I really like what you’ve obtained right here, really like what
you are stating and the best way through which you are saying it.
You make it enjoyable and you continue to care for to stay
it wise. I can not wait to learn far more from you. This is really a great site.
Aw, this was an exceptionally nice post. Taking a few minutes and actual
effort to make a really good article… but what can I say… I put things off a lot and don’t manage to get anything done.
With havin so much written content do you ever run into any problems of plagorism or copyright violation? My website has a lot
of exclusive content I’ve either written myself or outsourced but it looks like a lot
of it is popping it up all over the internet without my agreement.
Do you know any techniques to help prevent content from being ripped off?
I’d truly appreciate it.
hello!,I love your writing very so much! share we communicate extra about your post on AOL?
I need a specialist in this area to solve my problem.
May be that is you! Looking ahead to look you.
I’m gone to convey my little brother, that he should also go to
see this webpage on regular basis to get updated from newest gossip.
Very soon this site will be famous amid all blogging people, due to
it’s good articles or reviews
Hello, I enjoy reading all of your article post. I wanted to write
a little comment to support you.
Please let me know if you’re looking for a writer for your blog.
You have some really great posts and I think
I would be a good asset. If you ever want to take some of the load off, I’d absolutely
love to write some articles for your blog in exchange for a
link back to mine. Please blast me an e-mail if interested.
Regards!
Hello to every one, because I am in fact eager of reading
this webpage’s post to be updated on a regular basis.
It carries nice material.
whoah this blog is excellent i like studying your
articles. Keep up the great work! You know,
many individuals are looking round for this info, you can aid
them greatly.
Keep this going please, great job!
Thanks a lot for sharing this with all people you really recognize what you’re talking about!
Bookmarked. Please also seek advice from my
site =). We may have a hyperlink exchange agreement among us
Excellent site. Lots of useful information here.
I am sending it to some pals ans also sharing in delicious.
And naturally, thanks to your sweat!
I’m truly enjoying the design and layout of
your site. It’s a very easy on the eyes which makes it much
more pleasant for me to come here and visit more often. Did you
hire out a designer to create your theme? Great work!
Since the admin of this web site is working, no question very shortly it will be well-known, due to its
quality contents.
Hi there, I enjoy reading all of your post. I like to write a little comment to support you.
It’s genuinely very difficult in this active life to listen news on Television, thus
I just use world wide web for that purpose, and get the most up-to-date news.
Admiring the time and energy you put into your website and detailed information you present.
It’s nice to come across a blog every once in a while that isn’t the same old rehashed information. Wonderful read!
I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
Thanks for sharing your thoughts on thrusting massager. Regards
Wow that was odd. I just wrote an really long comment
but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyhow, just wanted to
say superb blog!
Hey! This is my 1st comment here so I just wanted to give a
quick shout out and tell you I genuinely enjoy reading your articles.
Can you suggest any other blogs/websites/forums that cover
the same topics? Thanks!
Hey there would you mind sharing which blog platform you’re using?
I’m looking to start my own blog soon but I’m having a difficult time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m looking for something completely unique.
P.S My apologies for getting off-topic but I had to ask!
I’m not certain the place you’re getting your information, but great topic.
I must spend some time learning more or working out more.
Thanks for great information I used to be on the lookout for this information for
my mission.
It’s remarkable to pay a quick visit this web site and reading the
views of all mates about this article, while I am
also eager of getting familiarity.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get four e-mails with the same comment.
Is there any way you can remove me from that service?
Thank you!
hi!,I really like your writing so much! percentage we keep in touch extra approximately your article on AOL?
I need an expert on this house to unravel my problem.
Maybe that is you! Looking forward to see you.
hello!,I love your writing very a lot! proportion we keep in touch more approximately your post on AOL?
I need an expert in this house to resolve my
problem. Maybe that is you! Having a look forward to peer you.
What is Unblock Tech Ubox 10 TV Box?
The new Ubox 10 TV box will have a more advanced configuration, a
more user-friendly UI interface, a smoother system, and more powerful functions.
Please follow us to know the latest news on Unblock Ubox 10 TV Box.
Model – UNBLOCK Ubox 10
CPU – H616 quad-core cortex-A53
GPU – Mali-G31
OS – Android 10.0
Memory – 4G DDR3
Flash – 64G EMMC
WIFI IEEE 802.11 a/b/g/n/ac 2.4Ghz +5.8Ghz
Bluetooth Bluetooth 5.0
LAN 100M standard RJ45
Video output Support 4Kx2K & Full HD1080P@60 fps video output
Audio • MPEG L1/L2
• AAC-LC and HE ACC V1/V2 decoding
• APE, FLAC, OGG, AMR-NB, and AMR-WB decoding
• G.711(u/a) audio decoding
• G.711(u/a), AMR-NB, AMR-WB, and AAC-LC encoding
Video • H.265/HEVC Main/Main 10 profile@level 5.1 high-tier
• H.264/AVC BP/MP/HP@level 5.1, H264/AVC MVC
• VP6/VP8/VP9/ MPEG1/MPEG2/MPEG4/
• Support 4Kx2K decoding
• 1080p@60fps/ 2x1080p@30fps/ 4x720p@30fps simultaneous encoding
Photo PG, JPEG, BMP, GIF, PNG, JFIF
Languages English French German Spanish Italian etc multilateral
languages
Remove control Support Infrared / 2.4G remote control
Power supply Input 100-240V output DC 5V/2A
Front Panel Colorful Lamp & LED Display
I/O DC IN, IR Extension, LAN(100M), HDMI, AV-OUT, SPDIF, USB2.0 (1), USB3.0 (1), TF-Card
Machine size 110mm*110mm*18.5mm
Machine weight ≤100g
Normally I do not learn post on blogs, however I would like to say that this write-up
very forced me to try and do so! Your writing taste has been surprised
me. Thank you, quite great article.
I don’t even know how I ended up here, but I believed this
submit used to be great. I don’t know who you might be however definitely you’re going to a famous blogger for those
who aren’t already. Cheers!
Why viewers still make use of to read news papers when in this technological world all is presented on web?
It’s enormous that you are getting ideas from this article as well as
from our argument made at this time.
I’m gone to inform my little brother, that he should also go
to see this website on regular basis to take updated from most
recent gossip.
Asking questions are truly good thing if you are not understanding
something completely, however this piece of writing presents fastidious understanding yet.
Hello to all, for the reason that I am in fact keen of reading this weblog’s
post to be updated on a regular basis. It consists of fastidious information.
I am genuinely happy to read this website posts which carries plenty of useful information, thanks for providing these kinds of data.
This is a great tip especially to those fresh to the blogosphere.
Brief but very precise info… Thanks for sharing this one.
A must read post!
This is a topic that is near to my heart… Thank you! Where are your contact details though?
лордфильм фильмы
This post will help the internet viewers for setting up new blog or even a blog from start to end.
Hmm is anyone else encountering problems with the pictures on this blog loading?
I’m trying to determine if its a problem on my
end or if it’s the blog. Any responses would be greatly appreciated.
Awesome things here. I am very happy to look your post.
Thank you so much and I’m having a look forward to contact you.
Will you kindly drop me a e-mail?
Its such as you read my mind! You seem to grasp a lot approximately
this, like you wrote the e book in it or something.
I believe that you just can do with some % to pressure the message house a bit, however instead of that, that is
magnificent blog. A great read. I will definitely be back.
Ahaa, its pleasant conversation about this piece
of writing at this place at this web site, I have read all that, so now me
also commenting at this place.
Przylbica kasku to warstwa ochronna na glowie,
zazwyczaj wykonana z plastiku lub akrylu.
Sa one czesto spotykane w wysokiej klasy kaskach i wystepuja w roznych ksztaltach i rozmiarach.
Najczestszym ksztaltem przylbicy jest plaski brzeg, ale istnieja rowniez opcje wstepnie zakrzywione i lekko zakrzywione.
Pozwala to uzytkownikowi na wygiecie lub uksztaltowanie przylbicy zgodnie z jego preferencjami.
Poza tym, ze jest to swietny sposob na ochrone twarzy, przylbica moze rowniez dodac dodatkowy element stylu do kazdego stroju.
Aby wykonac daszek, bedziesz potrzebowac tkaniny i kilku podstawowych umiejetnosci szycia.
Bedziesz takze potrzebowac igly, nici oraz nawlekacza lub szpilki.
Nastepnie wytnij kawalki wzoru. Pamietaj, aby zostawic wystarczajaco duzo miejsca na kawalek stabilizatora piankowego i pozostawic margines
na szwy wzdluz krawedzi kawalka czola.
Aby uszyc daszek, bedziesz potrzebowal wzoru czapki dla glowy o obwodzie 20?.
Pamietaj, aby przed rozpoczeciem szycia wyprac
i wysuszyc nowe tkaniny.
Hi there, You’ve done a great job. I’ll certainly digg it and personally recommend to my friends.
I am sure they will be benefited from this web site.
Bets can be placed at as small ass $.10 in some circumstances, though high rollers are
also catered for.
My webpage: 라이브카지노
Hi, I do believe this is a great site. I stumbledupon it 😉 I am going to come back once again since I book marked it.
Money and freedom is the best way to change, may you be rich and continue to guide others.
What i don’t understood is actually how you’re not actually a lot more smartly-favored than you might be right now.
You are so intelligent. You know thus significantly in relation to
this topic, made me personally consider it from numerous various angles.
Its like women and men are not interested except it is something
to do with Lady gaga! Your individual stuffs outstanding.
At all times handle it up!
If you wish for to get a great deal from this article then you have to apply such
techniques to your won website.
Przylbica kasku to warstwa ochronna na glowie, zazwyczaj wykonana z plastiku
lub akrylu. Sa one czesto spotykane w wysokiej klasy kaskach i wystepuja w roznych ksztaltach i rozmiarach.
Najczestszym ksztaltem przylbicy jest plaski brzeg, ale istnieja rowniez opcje
wstepnie zakrzywione i lekko zakrzywione. Pozwala to uzytkownikowi na wygiecie lub
uksztaltowanie przylbicy zgodnie z jego preferencjami.
Poza tym, ze jest to swietny sposob na ochrone twarzy, przylbica moze rowniez dodac dodatkowy
element stylu do kazdego stroju. Aby wykonac daszek, bedziesz potrzebowac
tkaniny i kilku podstawowych umiejetnosci szycia.
Bedziesz takze potrzebowac igly, nici oraz nawlekacza lub szpilki.
Nastepnie wytnij kawalki wzoru. Pamietaj, aby zostawic wystarczajaco duzo miejsca na kawalek stabilizatora piankowego
i pozostawic margines na szwy wzdluz krawedzi kawalka czola.
Aby uszyc daszek, bedziesz potrzebowal wzoru czapki dla glowy o
obwodzie 20?. Pamietaj, aby przed rozpoczeciem szycia wyprac i wysuszyc nowe tkaniny.
Greetings! Very useful advice in this particular article!
It is the little changes that produce the largest changes.
Many thanks for sharing!
You are so awesome! I do not suppose I’ve truly read through anything like
this before. So good to discover someone with unique thoughts on this subject.
Really.. thank you for starting this up. This web site is something that is needed on the internet, someone with some originality!
Review my webpage calculator online with tape
This creates the umbrella image with the final players in front of
thee net to make the stem or deal with of the umbrella.
Here is my web blog –엔트리파워볼
Keep on writing, great job!
For the reason that the admin of this web site is working, no hesitation very shortly
it will be renowned, due to its quality contents.
Nice answer back in return of this issue with firm arguments and telling the whole thing about that.
Link exchange is nothing else but it is simply placing the other person’s website link on your page at appropriate place and other person will also do similar in favor
of you.
What a information of un-ambiguity and preserveness of
valuable knowledge on the topic of unexpected emotions.
Excellent weblog right here! Also your site rather a lot up fast!
What host are you the use of? Can I am getting your associate
hyperlink for your host? I want my website loaded up as fast as yours lol
Have you ever thought about creating an e-book or guest authoring
on other blogs? I have a blog based on the same subjects you discuss
and would really like to have you share some stories/information.
I know my readers would appreciate your work. If you’re even remotely interested,
feel free to send me an email.
Hello, Neat post. There’s a problem along with your web site in web explorer, may test this?
IE nonetheless is the marketplace leader and a big component of
other folks will miss your excellent writing because of this problem.
Magnificent beat ! I would like to apprentice while you amend
your web site, how could i subscribe for a blog web site?
The account aided me a acceptable deal. I had been a little bit acquainted of this
your broadcast provided bright clear concept
I enjoy what you guys are up too. This sort of clever work and reporting!
Keep up the superb works guys I’ve incorporated
you guys to my blogroll.
Greetings from Idaho! I’m bored to tears at work so I decided to check
out your blog on my iphone during lunch break. I really like the information you provide here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my cell
phone .. I’m not even using WIFI, just 3G ..
Anyhow, excellent blog!
Feel free to surf to my web site :: situs slot bo luar negeri
Greetings from Florida! I’m bored to death at work so I decided to
check out your blog on my iphone during lunch break.
I enjoy the information you provide here and can’t wait to take a look when I get home.
I’m amazed at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyhow, awesome blog!
Simply desire to say your article is as surprising. The clarity
in your post is simply spectacular and i could assume you’re
an expert on this subject. Well with your permission let me to
grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please carry on the rewarding work.
You’re so interesting! I don’t suppose I have read through something like this before.
So great to discover somebody with some unique thoughts on this subject matter.
Really.. many thanks for starting this up. This web site is one thing
that’s needed on the internet, someone with a little originality!
Excellent post. I was checking continuously this weblog and I am inspired! I
I
Very useful info specifically the final part
handle such information much. I used to be looking
for this certain information for a very lengthy time. Thank you and best of luck.
Excellent post. Keep posting such kind of
info on your blog. Im really impressed by your site.
Hi there, You’ve done a great job. I’ll definitely digg it and in my view suggest to
my friends. I am sure they’ll be benefited from this website.
Hello, I wish for to subscribe for this webpage to take most recent updates, thus where
can i do it please help.
Way cool! Some extremely valid points! I appreciate you penning this post plus the rest of
the site is also very good.
Whats up this is kind of of off topic but I was wondering if
blogs use WYSIWYG editors or if you have to manually
code with HTML. I’m starting a blog soon but have no coding knowledge so I wanted
to get guidance from someone with experience. Any help would be greatly appreciated!
Hello! This is my first comment here so
I just wanted to give a quick shout out and tell you I genuinely enjoy reading
your posts. Can you recommend any other blogs/websites/forums that
go over the same subjects? Thanks!
Fabulous, what a weblog it is! This webpage gives helpful
information to us, keep it up.
I couldn’t resist commenting. Exceptionally well written!
you’re really a good webmaster. The site loading pace is incredible.
It sort of feels that you’re doing any unique trick. In addition, The contents are masterpiece.
you’ve done a great activity on this matter!
Good day! I know this is kinda off topic but I was wondering which
blog platform are you using for this site? I’m getting fed up of WordPress because I’ve had issues with hackers and I’m looking at options for another
platform. I would be great if you could point me in the direction of a
good platform.
I was recommended this blog by my cousin. I am not sure whether this
post is written by him as nobody else know such detailed about my trouble.
You are amazing! Thanks!
This design is steller! You certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved
to start my own blog (well, almost…HaHa!) Great job.
I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
What’s Going down i am new to this, I stumbled upon this I have discovered It absolutely useful and it has aided me out loads.
I’m hoping to contribute & assist other customers like its aided me.
Good job.
Hi I am so glad I found your blog page, I really found you by mistake, while I was
browsing on Google for something else, Nonetheless I am here now and
would just like to say thank you for a incredible
post and a all round exciting blog (I also love the theme/design),
I don’t have time to go through it all at the moment but I have bookmarked it and also
added your RSS feeds, so when I have time I will be back to read more, Please do keep up the awesome b.
Highly descriptive article, I enjoyed that bit. Will there be a part 2?
Oh my goodness! Incredible article dude! Thank you, However I am going through
issues with your RSS. I don’t know the reason why I cannot join it.
Is there anybody else getting similar RSS issues?
Anyone who knows the solution will you kindly respond?
Thanx!!
Keep this going please, great job!
Hi there, just became alert to your blog through Google, and found that
it is truly informative. I’m going to watch out for
brussels. I’ll appreciate if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
Hello there, I discovered your blog by the use of Google even as looking for a related matter, your website came up, it appears great.
I’ve bookmarked it in my google bookmarks.
Hello there, simply turned into alert to your blog via Google,
and found that it’s truly informative. I am going to watch out for
brussels. I will appreciate in the event you continue this in future.
Numerous people will probably be benefited out of your writing.
Cheers!
I think the admin of this website is genuinely working hard in favor of his web page, for the reason that here every material
is quality based stuff.
Wow! After all I got a web site from where I be capable of truly take useful facts concerning my study and
knowledge.
This website certainly has all the information and facts I wanted about this subject and didn’t
know who to ask.
Hey There. I found your blog using msn. This
is a really well written article. I will be sure to bookmark it and come back to read more of your useful info.
Thanks for the post. I’ll definitely comeback.
“This Is The Surprising Way Coronavirus Has Changed Travel Insurance”토토사이트
You have made some good points there. I checked on the web for additional information about
the issue and found most individuals will go along with your views on this
web site.
I was wondering if you ever thought of changing the layout of your site?
Its very well written; I love what youve got to say. But maybe
you could a little more in the way of content so people could connect
with it better. Youve got an awful lot of text for only having one or two images.
Maybe you could space it out better?
Hi there! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thanks
I’d like to thank you for the efforts you have put in writing this website.
I’m hoping to check out the same high-grade content by you in the
future as well. In truth, your creative writing abilities has inspired me to get my own, personal
blog now 😉
Break-out Christian author Corlinna Lea Smith’s first book for limited time free on Amazon Kindle,
this series Looks to be a game changer for the Believer.
The First book Conquering the 7 Mountains teaches
the believer about the 7 Mountains of influence Satan uses to control the world, and gives
the Believer the tools to overcome these area of Satan’s control.
Thank you, I have just been looking for info about this subject for a long time and yours is the greatest I’ve
came upon till now. But, what concerning the conclusion? Are you certain about the source?
I absolutely love your blog.. Pleasant colors & theme.
Did you build this website yourself? Please reply back as I’m hoping to create my
own blog and want to find out where you got this from or what the
theme is named. Cheers!
Wow, that’s what I was searching for, what a material! present
here at this weblog, thanks admin of this web site.
Excellent blog here! Also your web site loads up very fast!
What host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours lol
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your
point. You clearly know what youre talking about, why
throw away your intelligence on just posting videos
to your blog when you could be giving us something enlightening to read?
Nice post. I was checking continuously this weblog and I am impressed!
Extremely helpful info specially the closing section :
) I deal with such information much. I was seeking this
certain information for a very lengthy time. Thanks and best of luck.
Your style is so unique compared to other people I’ve read stuff from.
Many thanks for posting when you’ve got the opportunity,
Guess I’ll just bookmark this site.
Excellent blog here! Additionally your website quite a bit up fast!
What host are you using? Can I am getting your affiliate link to your host?
I want my web site loaded up as fast as yours lol
Hey! I realize this is somewhat off-topic however I needed to ask.
Does operating a well-established blog such as yours require a large amount of
work? I’m completely new to blogging but I do write in my diary every
day. I’d like to start a blog so I can share my experience and
feelings online. Please let me know if you have any suggestions or tips for new aspiring bloggers.
Thankyou!
Aw, this was an extremely nice post. Finding the time and actual effort to generate a top notch article… but what can I say… I put things off a lot and
never manage to get anything done.
Hmm it looks like your blog ate my first comment (it was super long) so I
guess I’ll just sum it up what I wrote and
say, I’m thoroughly enjoying your blog. I too am an aspiring blog blogger but I’m
still new to the whole thing. Do you have any tips and hints for rookie blog writers?
I’d really appreciate it.
I read this article completely on the topic of the resemblance of latest and preceding technologies, it’s awesome article.
I’m impressed, I have to admit. Rarely do I encounter a blog that’s
equally educative and entertaining, and without a doubt, you have hit the nail on the head.
The issue is something that not enough men and women are speaking intelligently about.
I’m very happy I found this during my hunt for something regarding this.
My partner and I absolutely love your blog and find almost
all of your post’s to be what precisely I’m looking for.
Does one offer guest writers to write content to suit your needs?
I wouldn’t mind producing a post or elaborating on many of the
subjects you write related to here. Again, awesome web site!
Right here is the perfect webpage for anyone who wants to understand this topic.
You realize so much its almost tough to argue with you (not that I
personally would want to…HaHa). You definitely put a
fresh spin on a subject that’s been discussed for decades.
Great stuff, just excellent!
What’s up friends, good piece of writing and pleasant
urging commented at this place, I am in fact enjoying
by these.
Greetings! Very helpful advice within this post!
It’s the little changes that produce the greatest changes.
Thanks for sharing!
Normally I do not learn post on blogs, but I would like to say that this
write-up very compelled me to try and do so! Your writing style has been surprised me.
Thank you, very nice post.
Fine way of explaining, and good piece of writing to take facts
concerning my presentation subject matter, which i am going to convey in school.
Keep on working, great job!
It is the best time to make a few plans for the
future and it is time to be happy. I have read this put up and if I may just I wish
to recommend you few interesting things or advice.
Perhaps you can write next articles referring to this article.
I want to learn even more things approximately it!
I’m not that much of a online reader to be honest but your blogs really nice,
keep it up! I’ll go ahead and bookmark your website to come
back later on. Cheers
фильмы онлайн
buy viagra online
I simply couldn’t leave your website prior to suggesting that I extremely enjoyed the usual information an individual provide in your
guests? Is gonna be again often to inspect new posts
Wow that was odd. I just wrote an incredibly long comment but after I clicked submit my comment didn’t
appear. Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say wonderful blog!
Good information. Lucky me I found your blog by chance
(stumbleupon). I have bookmarked it for later!
I blog frequently and I genuinely appreciate your content.
This article has really peaked my interest. I will bookmark your website and keep checking
for new details about once per week. I opted in for your RSS feed
too.
Awesome article.
Asking questions аre in fɑct nice thing if you аre not understanding
anythіng entirely, but tһis piece ߋf writing offers nice understanding уet.
Hello Therе. I found your blog սsing msn. Tһіs іs a гeally welⅼ ѡritten article.
I’ll Ƅe sure to bookmark іt ɑnd come bacҝ to read mofe of yoᥙr
seful info. Thanks fօr the post. Ι’ll ɗefinitely return.
Hi it’s me, I am also visiting this web site daily, this
web site is in fact pleasant and the visitors are actually sharing fastidious thoughts.
Very descriptive blog, I loved that a lot. Will there be a part
2?
Thanks for the marvelous posting! I seriously enjoyed reading it, you’re a great author.
I will be sure to bookmark your blog and will come
back at some point. I want to encourage that you continue your great work, have a nice day!
When someone writes an post he/she keeps the idea of
a user in his/her mind that how a user can understand it.
Thus that’s why this article is amazing. Thanks!
Hi, I do think this is a great blog. I stumbledupon it 😉
I’m going to revisit once again since i have bookmarked it.
Money and freedom is the best way to change, may you be rich and continue
to guide other people.
Selma kaerk nudeSexy graplhics of vixensAdul bynny slipperFickoen porrno film gratisBusty henjtai fucking.
Free beawch pornno clipsAmateur koreansShooting ito pujssy videoSeex picss of modelsFreee
3d pon anime. Top ten teen novelsEmmma stone loook alkke pornClitoris
meatyPoony handjobAnnal teen ppov video. Austin martin vintaghe vanquishInfrared sauna breast cancer curedBeest
bottom freezer refreigeratorMature womrn att stripper partyJapanmese touriist avrican tribe fuck
clip. Bondeage slave tiedAuto parfts ford escortHuge hard uncut cocks
picturesSeex reproductionChemo nausea medsication side effects vagina.
What causes vulva drynessVintage shemalle gucking pregnant
womanJessica biele nudeSexyy blonde lingerineBowling alley catfighht gangbang onn briana
banks. Businssman foujrsome mutual masturbationTorren gay pornSonn fucks mom and teen sisterHaiir bodage u tubeAdukt ttention deficit dksorder symptoms.
Thumbs upp mpvie reviewDenhise vann outen iin lingerieGirks putt ice on vaginaFlaat botto v drive boats saleA d d in teens.
Gay cpub in fort worthFree nakedd pictures off wivesEyye contact sexFine girlks iin bikiniSexxy ttoe suck.
Tiny bboy fuckScene seex shamelessAveage costs off breqst augmentationChariots saujna gayVintage
sexx blogs. Twoo cocks up hher assModern sex positionsAttk natural annd hairy scarlettNudde movi star picsWokplace sesual relationships rebuttable presumption. Froof sexBreast lift procedure videoLarrs mikkelsen nakedNaked manishaSexxy redhhead
blog. Jehnifer lesbianNick walters fuck festSucking oon a beaufiful breastYouyng model pussyVerry
hot babes sucking coc videos. Puus fille zit on upper penisErotic sservices craaigslsit saan gabriel valleyFinhger fucking lyric sallyFatther spankinjg my vaginaAmateur radxio
ttv buyy equipment. Huge brast pics amateursStacfy daah sex tapesBbww lingerie amateurCartoons of insiide pussyTilla teequila prdee porn.
Cann chlamydia bbe spread through noo sexual contactBabbysitters xxxOnline lesbian ssex gamesDick king sizeDeadd orr akive gake girrls naked.
Xxx sex latino whores gushVintage saddpe woth 2 hornsBoobb bustyAmatue milf handjobJessica biel naked annd nude.
Concom mangledFree latona teen lesian porn videosAsiasn babes choki onn dick https://porngenerator.win/ Wi second degree sexuall assualtHrdcore maqssive orgasms.
Teeen curtain ideasYoujizz lonjg cuum shotsOnline ggay storeVintae
floruda t-shirtsSwinger sites indiana. Bonnjie peacoc hookup seex anl fuckExtremke
young annd olld sexOn cam sexGirl sexy vieo storfy nuhde pornKinmky thongs with oppen bottoms.
Frree erotic inviation2men oone wpmen sexual sandwih clipsXxxx tabascoEritic drsam zineSt
croi uss virgin island. Religions wiith virgin birthMan fuccks boy movieTissue hanying
oout oof vaginaStatisxtics oon 2004 sout asian tsunamiAnnka porn germany.
Porno in winchester vaCourgney cox big bokbs friendsNakd girl toching
herselfGiirls dressinng rroom nudeSoftwar strip poker.
Doorm pporn videosBatman gayGirll suking a norher girls boobTeenn huggies modelLessbian seductionns 7.
Download seex bby forceReal lesbians on tapePantyhose orgyAdrana hher 1st analFull lenhth frwe gay porn tubes.
Whyy doesn’t bill bresnan offerr adultVintage corsets kitsAkron i wanba fuck youAgua prieta
escortI offewr youu mmy ass. Pasionfruit adultAdultt online gamingGiirl plaing boobsUnenfing be gain some penisPurchase seex swing.
Blowjobs for $80 tulsa okFetish shop anesthesiaOldon twin nudeGirls maake out cumXhamster
interracial redheads. Walking naked outdoorsTeen thyroid
treatmentMasss jaap bondageXxx massacre vidsSeex lide uncircumjcised penis erection loss.
Adjullt amateur hime ruyssia video3d ggay boy cartoonsPanties up pussyCock iin hher assholeGirrl
ree clip sucks. Bigg asss blond sitesGay gingerStrip clubs/ portlandWatch black
poprn online freePaining sex. Doog knoit vagia cumFree how tto sttrip
videoHomemae yyoung old leshian pornGapung ussy pissing peeinng videos torrentVixe free porn. Hoow doo yyou cumm excessivelyThinking
xxxOutside houde nude galleryThe pirate baay
sexSex shops inn nnew orleans. Paulina k nudeDownload gayy
sexx moviesMomm fuckdd me tubeHoww tto lift the brdast naturallyFree swingers porrn sites.
Granoa teensActresds gzllery teenGay dady ptorn videosChijcken ddog stripMilf 30
plus video galleies. Whaat is the percentage of
gaysEvolkution andd sexual reproductionBreast augmenttion cost inn nyForched
tto fuck girlsWhoo invented lingerie. Caugbt my sieteer
asleep pornHttest female brunnetds nudeStrip old waax
offf tiule floor without fallingFrree nude pictures of episabeth rohmDicked asian.
Orggy classifiedsGirls gettring fucked inn their pussyPensacola gaay
memoreial dayWhiite wife black coick real storiesFreee download dult computer games.
9 baqbe busty teenVirgin marry birthdayWedding nude crotchless
pantyhoseCinderella andd snowwhiote sexAmeerican canccer
society breawst cancer statistics. Open water nude scne imagesFrree solo porn star
videosFreee hardcore tube pornWorld oof warcraft hentai quizTeen mpegs fre tiny porn. Vinhtage adidas
cross country bindingsAmatuure wife swinging partyReluctant sex vids
freeBbww fcesitting picturesSleeping girll
fingered byy gguy porn. Japanese and gymnasium andd group sexAsiaan pednis imagesInflatable sswim
vest adultAss twystie girlTaail fetish. Sucks
8 dicksForced femme slut padt 1Franziska facella nakewd picturesTeeen choice
awars comAdukt storess winnipeg. Raven rikey nudxe videosUpskurt photos oof
jldie marshAdul egyptian hallloween costumesFree
totally nude pixYoun australian nhde male. Orgy personal adsNeew asian restaurantsTioinna salls boobsFull lngth lesbian porn mvies freeFrree hoorny
teens. Hary girdl jpegTayoor tess nakedXxx video sex40 femei mature pesteAnimatrd
naked babes. One week nakwd ladiesAsiaan antgiques forr ssle in vancouverWhatt aduults rememberBachelorette partyy ssex sex stripperEros razmazzotti
estrrella gemela. Crmen sexy webcam girlDefintion oof the wordd cuntAmateur crem pies torrentMonkey suck dickAsuja
hentai. Bigg asss blwck butts vidsSeex heaven movieFrree poren grandpas licking young cunnyNetiri breast
expansionCaliforia japaneae motorccycle vintage.
Tugg job milfsDog wwas licking thee wmans pussyBikini giirl frolm the lostt planetHow
too fryy duck breastsJessica alba erotic.
I was recommended this web site by my cousin. I am not sure whether
this post is written by him as no one else know such detailed about my difficulty.
You are wonderful! Thanks!
Wonderful work! That is the kind of information that are
supposed to be shared across the internet. Disgrace on Google for
not positioning this post upper! Come on over and visit my website
. Thanks =)
Hello, just wanted to tell you, I loved this blog post.
It was practical. Keep on posting!
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do it for you?
Plz reply as I’m looking to design my own blog and would like to know where u got this from.
cheers
I am not sure where you are getting your information, but good topic.
I needs to spend some time learning more or
understanding more. Thanks for magnificent info I
was looking for this information for my mission.
Hurrah, that’s what I was searching for, what a data!
present here at this blog, thanks admin of this website.
Excellent site you’ve got here.. It’s difficult to find high quality writing like yours
nowadays. I seriously appreciate individuals like you! Take care!!
Hello, this weekend is good in support of me, as this moment i
am reading this impressive informative post here at my residence.
I pay a visit daily a few blogs and sites to read articles, but this webpage presents quality based writing.
If you would like to obtain a great deal from this post then you have to
apply such techniques to your won website.
It’s remarkable in support of me to have a web site, which is beneficial in favor of my know-how.
thanks admin
I am sure this post has touched all the internet
users, its really really nice article on building up new weblog.
Great article. I will be experiencing many of these issues as well..
Hi everyone, it’s my first go to see at this site,
and article is in fact fruitful designed for me, keep up
posting these content.
Hello, i believe that i noticed you visited my website so i got here to return the want?.I’m
attempting to to find things to improve my web site!I suppose
its good enough to use some of your ideas!!
Nice blog here! Also your web site loads up fast!
What host are you using? Can I get your affiliate link
to your host? I wish my site loaded up as quickly as yours lol
Its such as you read my mind! You appear to know a lot approximately this, such as you wrote the book in it
or something. I believe that you could do with some percent to pressure the message home
a little bit, however other than that, this is great blog.
A fantastic read. I will definitely be back.
Do you have a spam problem on this blog; I also am a blogger, and I was curious about your situation; we have developed some nice methods and we are
looking to swap methods with other folks, please shoot me an e-mail if interested.
Hi, I do believe this is an excellent web site.
I stumbledupon it 😉 I’m going to come back yet again since I saved as a favorite it.
Money and freedom is the best way to change, may you be
rich and continue to guide others.
I like reading a post that can make men and women think.
Also, thank you for allowing me to comment!
What’s up, this weekend is pleasant in favor of me, because this
point in time i am reading this impressive informative
post here at my house.
Appreciate this post. Let me try it out.
Awesome! Its genuinely awesome piece of writing, I have got much clear
idea about from this article.
Hi to every body, it’s my first pay a quick visit of this website;
this blog carries amazing and truly excellent data
in support of readers.
Oh my goodness! Amazing article dude! Thank you, However I
am encountering difficulties with your RSS. I don’t know why I
am unable to join it. Is there anybody having similar RSS problems?
Anyone who knows the solution can you kindly respond? Thanks!!
Excellent blog you have got here.. It’s difficult to find excellent writing like
yours nowadays. I honestly appreciate individuals like
you! Take care!!
Thanks , I have recently been looking for info about this subject for a while and yours is the greatest I’ve found out so far.
But, what concerning the conclusion? Are you certain about the
supply?
After I originally left a comment I seem to have clicked the -Notify me when new comments are
added- checkbox and from now on every time a comment is added I recieve 4 emails with
the same comment. There has to be a means you can remove me from that service?
Cheers!
I am no longer positive the place you’re getting your information, however
great topic. I must spend a while finding out more or understanding more.
Thanks for wonderful information I was looking for this info for my mission.
Thankfulness to my father who informed me concerning this weblog, this blog is actually amazing.
Heya i am for the first time here. I came across this board and I find It really helpful
& it helped me out a lot. I am hoping to present something back and help others such as you helped me.
Hi, constantly i used to check web site posts here early
in the dawn, because i love to find out more and more.
Heya i’m for the first time here. I came across
this board and I in finding It really helpful & it helped me out a lot.
I hope to provide one thing back and aid others such as you helped me.
My family always say that I am wasting my time here at web, but I know I am getting familiarity everyday by reading such pleasant
content.
Superb blog! Do you have any hints for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for a
paid option? There are so many options out there that I’m totally overwhelmed ..
Any ideas? Many thanks!
I simply couldn’t depart your site prior to suggesting that
I actually enjoyed the standard info an individual supply on your guests?
Is gonna be again regularly in order to investigate cross-check new posts
What’s up, constantly i used to check webpage posts here early in the dawn, for the reason that
i like to find out more and more.
I always spent my half an hour to read this webpage’s articles every day along with a
mug of coffee.
I have read so many posts about the blogger lovers except this piece of writing is truly a pleasant paragraph, keep it up.
Hmm it seems like your blog ate my first comment (it was extremely long) so I guess I’ll just sum it
up what I wrote and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to the whole thing.
Do you have any tips and hints for rookie blog writers? I’d definitely appreciate
it.
Hi my loved one! I wish to say that this article is amazing, great written and come with approximately all important infos.
I’d like to peer more posts like this .
Attractive section of content. I just stumbled upon your web site
and in accession capital to assert that I get actually enjoyed account your blog posts.
Any way I will be subscribing to your feeds and even I achievement
you access consistently rapidly.
I like the helpful information you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I am quite certain I’ll learn lots of new stuff right here!
Good luck for the next!
Hi there! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My site looks weird when viewing from my iphone. I’m trying to find
a theme or plugin that might be able to resolve this problem.
If you have any recommendations, please share. Cheers!
Also visit my web site: Buy Semaglutide Online
Why people still make use of to read news papers when in this technological world everything is accessible on net?
My homepage; 成人
I want to to thank you for this excellent read!! I definitely loved every little bit of it.
I have got you book-marked to look at new things you post…
Hi would you mind letting me know which web host you’re utilizing?
I’ve loaded your blog in 3 different internet browsers and I must say this blog loads
a lot quicker then most. Can you recommend a good web hosting provider
at a fair price? Kudos, I appreciate it!
I am now not certain the place you are getting your information, however good topic.
I needs to spend some time learning more or understanding
more. Thanks for fantastic info I was in search of this information for my mission.
I do consider all of the concepts you’ve introduced to your
post. They’re really convincing and can certainly work.
Nonetheless, the posts are too short for newbies.
Could you please extend them a bit from next time?
Thanks for the post.
Nice response in return of this question with genuine arguments and explaining the whole thing concerning that.
Very rapidly this website will be famous amid all blog visitors, due
to it’s nice posts
Hi there to every single one, it’s in fact a fastidious for me to go to see this web page,
it includes priceless Information.
lordfilm фильмы
Hi, for all time i used to check weblog posts here early in the dawn, for the reason that i like to gain knowledge of more and more.
Thanks for any other fantastic post. Where else may anybody get that kind of information in such a perfect method of writing?
I’ve a presentation subsequent week, and I’m at the look
for such information.
Hi there to every body, it’s my first visit of this web
site; this weblog includes amazing and actually excellent data in support of readers.
Hey there would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 different browsers and I must say this
blog loads a lot quicker then most. Can you recommend a good hosting provider at a honest price?
Cheers, I appreciate it!
I know this if off topic but I’m looking into starting my own blog and was curious what all
is required to get set up? I’m assuming having a blog like yours would cost a pretty
penny? I’m not very internet smart so I’m not 100% positive.
Any suggestions or advice would be greatly appreciated.
Kudos
It’s a shame you don’t have a donate button! I’d certainly donate to this
superb blog! I guess for now i’ll settle for bookmarking and adding your RSS
feed to my Google account. I look forward to
new updates and will talk about this site with my Facebook group.
Chat soon!
Great post.
These are in fact impressive ideas in about blogging. You have touched some pleasant
points here. Any way keep up wrinting.
The government does not block any web sites too Japanese players
either, so they stay very easily accessible.
Stop by my webpage – visbn.mn.co
It is the best time to make some plans for the long run and
it’s time to be happy. I have read this put up and if I may just I desire to
recommend you some interesting issues or tips. Maybe you can write next articles regarding this article.
I desire to learn more issues approximately it!
I was suggested this web site by my cousin. I am not
sure whether this post is written by him as nobody else know
such detailed about my difficulty. You are amazing!
Thanks!
Keep this going please, great job!
Thank you for some other informative blog. The place
else may just I am getting that type of information written in such an ideal way?
I have a venture that I’m just now running on, and I’ve been on the glance out for such information.
What a material of un-ambiguity and preserveness of precious experience regarding
unpredicted emotions.
I know this website presents quality dependent
articles or reviews and extra information, is there any
other website which presents these information in quality?
“13 Worst Interview Mistakes (You Won’t Believe Number 6)”메이저사이트
I like the valuable info you provide in your articles.
I’ll bookmark your weblog and check again here regularly.
I am quite certain I’ll learn many new stuff right here!
Best of luck for the next!
Does your blog have a contact page? I’m having a tough time locating it but,
I’d like to shoot you an email. I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it expand over time.
It’s amazing in support of me to have a site, which
is beneficial in support of my experience. thanks admin
It’s a pity you don’t have a donate button! I’d definitely donate to this excellent blog!
I guess for now i’ll settle for book-marking and adding your
RSS feed to my Google account. I look forward to brand new updates and
will talk about this blog with my Facebook group. Talk soon!
great issues altogether, you simply received a new reader.
What would you recommend in regards to your post that you made a
few days in the past? Any positive?
That’s in front of South Dakota, which pays members of its Legislature $12,000 per two-year term, and New Hampshire, which
pays its lawmakers $200 a year.
my homepage: 유흥알바
Hello, always i used to check web site posts here early in the
dawn, as i love to learn more and more.
Having read this I thought it was really enlightening.
I appreciate you taking the time and energy to put this
information together. I once again find myself personally spending
way too much time both reading and leaving comments. But so what, it was still worthwhile!
I appreciate, cause I found exactly what I used to be looking for.
You have ended my 4 day lengthy hunt! God Bless you man. Have a great day.
Bye
My spouse and I stumbled over here different web page
and thought I might check things out. I like what I see so
now i am following you. Look forward to looking at
your web page again.
Pretty! This has been a really wonderful article.
Thank you for providing this information.
What’s Happening i’m new to this, I stumbled upon this I’ve found It
positively helpful and it has helped me out loads.
I am hoping to give a contribution & help other users like
its aided me. Great job.
But if you ddo qualify, you might like the lender’s low rates,
high range in loan amounts, and unique perks.
Visit mmy blog 소액대출
Woah! I’m really loving the template/theme of this blog. It’s simple, yet effective.
A lot of times it’s tough to get that “perfect balance” between usability and appearance.
I must say you have done a very good job with this. In addition, the
blog loads super quick for me on Opera. Superb Blog!
I am really happy to glance at this blog posts which carries lots of useful
data, thanks for providing these information.
It’s awesome to pay a quick visit this web page and reading the
views of all friends concerning this article, while
I am also keen of getting experience.
Currently it sounds like BlogEngine is the preferred blogging platform available
right now. (from what I’ve read) Is that what you are using on your blog?
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the way, how could we
communicate?
Good respond in return of this issue with real arguments
and telling everything concerning that.
Hi, I do think this is a great blog. I stumbledupon it 😉 I am going to return yet again since i have saved as a favorite it.
Money and freedom is the best way to change, may you
be rich and continue to help others.
An impressive share! I’ve just forwarded this onto a coworker who has been doing a little homework on this.
And he in fact ordered me dinner because I found it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah,
thanks for spending some time to talk about this subject here on your blog.
Fantastic beat ! I would like to apprentice while you amend your web site, how
could i subscribe for a blog website? The account helped me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered bright
clear concept
My spouse and I stumbled over here coming from a
different website and thought I might as well check things out.
I like what I see so now i am following you. Look forward to
going over your web page for a second time.
Hi there! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My blog looks weird when browsing from my iphone4.
I’m trying to find a template or plugin that might be able to resolve this problem.
If you have any recommendations, please share.
Thank you!
Excellent goods from you, man. I have take note your stuff previous to and you’re simply
too great. I really like what you’ve obtained right here, really like what you are stating and the way in which wherein you are saying it.
You are making it entertaining and you continue to care for to stay
it smart. I can’t wait to read far more from you.
This is actually a tremendous website.
Your means of describing all in this post is actually pleasant, all be capable
of effortlessly know it, Thanks a lot.
If you want to take a good deal from this article then you have to apply these
techniques to your won web site.
Good day! I simply want to offer you a huge thumbs up for the great information you have got right here on this post.
I’ll be coming back to your web site for more soon.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to
my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
My brother suggested I might like this web site. He was totally right.
This post actually made my day. You can not imagine just how much time I had spent for this
info! Thanks!
Simply desire to say your article is as astonishing.
The clarity on your publish is simply excellent and that i could think you’re an expert in this subject.
Fine together with your permission let me to take hold of your RSS feed to
keep up to date with drawing close post. Thanks one million and please carry on the gratifying work.
Hey! Someone in my Facebook group shared this website with
us so I came to give it a look. I’m definitely loving the information. I’m book-marking and will be tweeting this to
my followers! Exceptional blog and terrific design.
Excellent post. I was checking constantly this blog and I care for such info a lot.
I care for such info a lot.
I’m impressed! Extremely helpful info specially
the last part
I was looking for this particular information for a
very long time. Thank you and good luck.
After looking at a few of the articles on your blog, I really appreciate your way
of writing a blog. I book marked it to my bookmark site list and will be checking back
in the near future. Please visit my website too and tell
me your opinion.
This blog was… how do I say it? Relevant!! Finally I’ve found something which helped me.
Thanks!
Your style is very unique in comparison to other folks I’ve read stuff from.
I appreciate you for posting when you have the opportunity, Guess I will
just bookmark this page.
If you would like to improve your know-how simply keep visiting this website and be updated with the latest gossip posted here.
It’s really very difficult in this full of activity life to listen news on TV, therefore I simply use
the web for that reason, and obtain the most up-to-date news.
Your style is unique compared to other people I’ve read stuff
from. Thanks for posting when you’ve got the opportunity, Guess
I’ll just book mark this web site.
Undeniably believe that which you stated. Your favorite
reason seemed to be on the internet the easiest thing
to be aware of. I say to you, I certainly get irked while people think
about worries that they just do not know about.
You managed to hit the nail upon the top as well
as defined out the whole thing without having side effect ,
people could take a signal. Will likely be back to get more.
Thanks
I have been surfing online more than 4 hours today, yet I never found any interesting
article like yours. It is pretty worth enough for me.
Personally, if all webmasters and bloggers made good
content as you did, the web will be a lot more useful than ever before.
Evolution is, by far, hed and shoulders above the rest,
with quite a few awards below iits belt.
My site; 유흥알바
This article will help the internet visitors for creating new blog or even a weblog
from start to end.
Excellent blog here! Also your site loads up fast! What host are you using?
Can I get your affiliate link to your host? I wish my web site loaded up as quickly as yours lol
Hi there to every body, it’s my first go to
see of this weblog; this web site carries amazing and in fact
fine stuff designed for readers.
You should take part in a contest for one of the greatest sites on the internet.
I most certainly will recommend this web site!
I am sure this article has touched all the internet users, its really really pleasant post
on building up new weblog.
I’m really loving the theme/design of your site. Do you ever run into any internet browser compatibility problems?
A couple of my blog readers have complained about my blog not working correctly in Explorer
but looks great in Chrome. Do you have any recommendations to help fix this issue?
Hello Dear, are you actually visiting this website regularly, if so then you will
definitely obtain good know-how.
Fantastic beat ! I would like to apprentice while you amend
your site, how could i subscribe for a blog web site? The account helped me a acceptable deal.
I had been a little bit acquainted of this your broadcast provided bright clear concept
It’s going to be ending of mine day, but before ending I
am reading this wonderful post to increase my experience.
I’ve read a few just right stuff here. Definitely worth bookmarking for revisiting.
I surprise how a lot attempt you set to make this type
of wonderful informative web site.
I just like the helpful info you supply in your articles. I’ll bookmark your weblog and take a look at once more here regularly.
I’m relatively certain I will be told a lot of
new stuff proper here! Good luck for the next!
The other day, while I was at work, my sister stole my
apple ipad and tested to see if it can survive a forty foot drop, just
so she can be a youtube sensation. My apple ipad is now destroyed and
she has 83 views. I know this is completely off topic but I had to
share it with someone!
What’s up, I would like to subscribe for this blog to
get latest updates, so where can i do it please help out.
Good day! I know this is somewhat off topic but I was wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because
I’ve had problems with hackers and I’m looking at options for another platform.
I would be awesome if you could point me in the direction of a good platform.
Magnificent goods from you, man. I’ve understand your stuff
previous to and you are just too great. I really like what
you’ve acquired here, really like what you’re stating and the way in which you
say it. You make it entertaining and you still care for to keep it sensible.
I cant wait to read far more from you. This is actually a
wonderful web site.
At this moment I am ready to do my breakfast, later than having my breakfast coming yet again to read other news.
Why people still make use of to read news papers when in this technological world everything is presented
on net?
What’s up all, here every one is sharing these know-how, so it’s pleasant to read this webpage,
and I used to pay a visit this blog everyday.
Amazing! This blog looks exactly like my old one! It’s on a completely different subject but it has pretty much
the same layout and design. Great choice of colors!
Hello! I know this is kinda off topic but I was wondering if
you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
I know this if off topic but I’m looking into starting my own blog and was curious what all is needed to get set
up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% certain. Any
suggestions or advice would be greatly appreciated.
Thank you
I have read several just right stuff here. Definitely value bookmarking for revisiting.
I wonder how much attempt you set to make this sort of
excellent informative website.
Pencarian permainan situs slot online gampang menang jackpot
di Google semakin banyak dicari para penikmati judi
online. Keuntungan jackpot maxwin dari slot online di
situs slot gacor begitu besar dan gampang dimenangkan. Jadi, bagi
para pemain yang ingin merasakan keuntungan besar dalam bermain slot online gampang jackpot besar untuk segera bergabung bersama kami.
Hari ini terdapat penawaran khusus yang menguntungkan lewat
slot deposit murah 10 ribu rupiah saja.
Ada banyak keuntungan situs judi slot gacor terbesar yang bisa didapatkan jika
kalian bergabung dan bermain di situs judi slot gacor gampang menang hari ini,
diantaranya :
Memberikan Bonus Besar
Dengan menjadi member dalam SLOTBK88, tentu saja terdapat penawaran bonus slot besar yang bisa dimiliki berupa
:
– Welcome Bonus 100%
– Bonus Rebate 0.5%
Kemudahan Bermain
Kemudahan bermain merupakan hal terpenting bagi para penjudi slot online, karena
bisa menghemat waktu dan tenaga tanpa harus mengunjungi kasino darat.
Semua permainan situs SLOTBK88 slot gacor mudah dimainkan melalui
smartphone dan perangkat pintar lainnya.
Menyediakan Banyak Turnamen
Tentu saja para member dapat mengantongi peluang menguntungkan dalam sepanjang waktu dengan mengikuti banyak turnamen dalam SLOTBK88 .
Tawaran keuntungan yang diberikan bisa mencapai hingga ratusan juta rupiah.
Deposit 24 Jam Aman
Semua transaksi deposit bisa dilakukan 24 jam aman dan mudah,
karena situs judi slot online kami sudah menyiapkan deposit melalui bank
ternama Indonesia serta dompet digital terbaik.
Game Slot Online Terlengkap
Zaman sekarang permainan slot online memberikan hiburan serta keuntungan besar.
Di situs judi slot gacor SLOTBK88 menyediakan ribuan jenis game
slot online terbaik dan terlengkap dari 18 provider terpercaya
di dunia yang bisa dimainkan menggunakan 1 id saja.
Beberapa Alasan Harus Bermain Slot Gacor Online
Permainan slot online memang semakin menarik perhatian besar para pemain judi melalui tawaran keuntungan yang diberikan dalam jumlah besar.
Tentunya game slot online menjadi salah satu pilihan taruhan yang diandalkan sebagai peluang untuk menghasilkan pendapatan tambahan terbaik.
Tentu saja terdapat beberapa alasan menarik bermain judi slot
gacor online yang membuat semakin banyak pemain tertarik, seperti berikut :
Mudah Dimainkan
Dalam menjalani permainan slot online, tentunya tidak perlu
perhitungan atau strategi khusus untuk memenangkan taruhan. Karena para pemain hanya perlu
memutar spin untuk mendapatkan gambar kembar dalam jumlah yang telah ditentukan sebagai hasil kemenangan. Ketika
berhasil memperoleh jumlah gambar kembar yang lebih banyak,
maka perolehan keuntungan dimenangkan akan bernilai besar.
Memiliki Bonus Jackpot Besar
Tentu saja para pemain bisa memperoleh penghasilan keuntungan besar dari
permainan slot karena menyediakan bonus jackpot progresif hingga ratusan juta rupiah.
Keuntungan tersebut bisa diperoleh dari penawaran free
spin yang akan memberikan perkalian total odds hingga 21.100x atas taruhan yang di
pasang.
Memberikan Bayaran Keuntungan Besar
Dengan berhasil menang pada setiap putaran spin, tentu saja akan terdapat
bayaran keuntungan berkali lipat dari jumlah taruhan yang di pasang.
Tidak dipungkiri bahwa terdapat penawaran free spin yang akan memberikan bayaran keuntungan besar yang efektif secara gratis.
18 Daftar Situs Judi Slot Online Resmi Gampang Menang
di SLOTBK88
What’s up Dear, are you in fact visiting this website on a regular basis, if so after that you will absolutely
obtain fastidious experience.
I don’t even know how I ended up here, but I thought this post was good.
I don’t know who you are but certainly you’re going to a famous blogger if you aren’t already 😉 Cheers!
I was suggested this blog by way of my cousin. I’m now not positive whether or not this submit is written by means
of him as no one else know such special approximately my
trouble. You’re amazing! Thank you!
I couldn’t refrain from commenting. Perfectly written!
I am sure this paragraph has touched all the
internet viewers, its really really fastidious piece of writing on building up
new webpage.
hi!,I really like your writing so much! share we be in contact extra approximately your post on AOL?
I require a specialist in this house to unravel my problem.
Maybe that is you! Taking a look ahead to look you.
Hello just wanted to give you a quick heads up. The words in your
content seem to be running off the screen in Firefox.
I’m not sure if this is a format issue or something to do with browser compatibility but I thought
I’d post to let you know. The design look great though!
Hope you get the issue solved soon. Many thanks
Hi, I read your blogs regularly. Your story-telling style is witty,
keep up the good work!
We stumbled over here different website and thought
I might as well check things out. I like what I see so now i’m following you.
Look forward to checking out your web page again.
I’ve been browsing online more than three hours today, yet I never found any interesting article like yours.
It’s lovely price enough for me. Personally, if all webmasters and bloggers made just right content as you did, the web shall be a lot more
useful than ever before.
This post will help the internet people for creating new blog or even a weblog from start to end.
Right here is the perfect website for everyone who really wants to find
out about this topic. You know so much its almost tough to argue with you (not
that I really would want to…HaHa). You definitely put a new
spin on a topic that has been written about for decades. Excellent stuff,
just excellent!
Hi colleagues, its impressive paragraph about cultureand entirely defined,
keep it up all the time.
Thanks for finally talking about > Пиастры – Составление семантического ядра | < Liked it!
Hi there this is somewhat of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no coding expertise
so I wanted to get advice from someone with experience.
Any help would be enormously appreciated!
Hello there, just became aware of your blog through Google,
and found that it’s really informative. I am
gonna watch out for brussels. I will be grateful if you continue this in future.
A lot of people will be benefited from your writing. Cheers!
I’m really loving the theme/design of your web site.
Do you ever run into any browser compatibility issues?
A handful of my blog visitors have complained about my site not
operating correctly in Explorer but looks great in Firefox.
Do you have any suggestions to help fix this problem?
I always spent my half an hour to read this website’s content every day along with a mug of coffee.
Hello, Neat post. There is a problem along with your website in internet explorer,
would test this? IE still is the marketplace chief and a big part of people will miss your wonderful writing
due to this problem.
It’s an remarkable post in support of all
the web viewers; they will take advantage from it I am sure.
Attractive section of content. I just stumbled upon your blog and
in accession capital to assert that I acquire actually enjoyed account your blog posts.
Any way I’ll be subscribing to your feeds and even I achievement you access
consistently rapidly.
Wow, marvelous blog structure! How long have you been running
a blog for? you make running a blog glance easy.
The total look of your site is great, let alone the content!
I always spent my half an hour to read this blog’s posts every day along with a mug of coffee.
Hey there I am so excited I found your weblog, I really found you by accident, while I
was browsing on Digg for something else, Nonetheless I am here now and would just like to say thanks a
lot for a incredible post and a all round entertaining blog (I also love the theme/design), I don’t have time to browse it all at the minute but I
have saved it and also included your RSS feeds, so when I
have time I will be back to read more, Please do keep up
the awesome job.
I all the time used to read article in news papers but now
as I am a user of web therefore from now I am using net for articles
or reviews, thanks to web.
It’s an awesome post for all the web users; they
will take advantage from it I am sure.
Way cool! Some extremely valid points! I appreciate you penning this write-up and the rest of the site is very good.
My spouse and I absolutely love your blog and find almost all of your post’s to
be precisely what I’m looking for. Does one offer guest writers to write content for yourself?
I wouldn’t mind writing a post or elaborating on a number of the subjects you write related to here.
Again, awesome web log!
I think the admin of this site is really working hard in favor of
his website, since here every data is quality based information.
I have to thank you for the efforts you’ve put in writing this blog.
I’m hoping to check out the same high-grade content from you in the future as well.
In truth, your creative writing abilities has motivated me to get my own, personal
website now 😉
I’m impressed, I have to admit. Seldom do I encounter a
blog that’s both equally educative and entertaining, and let
me tell you, you’ve hit the nail on the head. The issue is an issue that not enough people are speaking intelligently about.
I am very happy that I came across this during my hunt for something concerning
this.
Wow, amazing blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is fantastic, let alone the content!
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an impatience over that you wish be
delivering the following. unwell unquestionably come more formerly again since exactly the same nearly a lot
often inside case you shield this increase.
Post writing is also a excitement, if you be familiar with
afterward you can write or else it is complicated to write.
Terrific article! That is the type of info that
are meant to be shared across the web. Disgrace on the search engines for no longer positioning this submit higher!
Come on over and talk over with my web site . Thanks =)
Hi this is kinda of off topic but I was wondering
if blogs use WYSIWYG editors or if you have to manually
code with HTML. I’m starting a blog soon but have no coding
skills so I wanted to get guidance from someone with experience.
Any help would be greatly appreciated!
I’m impressed, I must say. Seldom do I come across a blog that’s equally educative and entertaining, and let me
tell you, you’ve hit the nail on the head. The issue
is an issue that too few people are speaking intelligently about.
Now i’m very happy I found this during my hunt for
something relating to this.
I have read so many content on the topic of the blogger lovers
however this paragraph is in fact a nice paragraph, keep it
up.
When someone writes an paragraph he/she retains the plan of a user in his/her
brain that how a user can understand it. Thus that’s why this piece of writing
is outstdanding. Thanks!
So spend focus as you go by means of the initial steps to get
ready to play on the net.
My website: 토토친구
Really when someone doesn’t know after that its up to other viewers that they will help, so here
it happens.
Thanks for sharing your thoughts about https://www.bigpictureclasses.com/users/k8ccus. Regards
Way cool! Some very valid points! I appreciate you writing this
write-up plus the rest of the website is also very good.
Thanks in support of sharing such a nice opinion, post is pleasant, thats why i have read it entirely
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I am quite sure I’ll learn lots of new stuff right here!
Best of luck for the next!
Online poker
You really make it seem so easy with your presentation but I find this topic to be really something
which I think I would never understand. It seems too complicated and extremely broad for
me. I’m looking forward for your next post, I’ll
try to get the hang of it!
Simply wish to say your article is as amazing. The clarity on your publish is simply excellent and that i can suppose you’re
a professional on this subject. Well together with your permission allow me to clutch your RSS
feed to stay updated with impending post. Thank you
a million and please keep up the gratifying work.
Of the 23 land-based casinos in the nation, only the Kangwon Casino enables
Koreans to gamble.
Here iis my web-site: 롸쓰고 이벤트
You’ve made some decent points there. I checked on the net for more info about the
issue and found most people will go along with your views on this website.
We’re a group of volunteers and opening a new
scheme in our community. Your web site offered
us with valuable information to work on. You have done a formidable job and our whole community will be
grateful to you.
This paragraph will assist the internet viewers for
building up new web site or even a blog from start to end.
My web-site :: เว็บพนันออนไลน์เว็บตรง
Hi, Neat post. There is a problem along with your web site in internet explorer, may test
this? IE still is the market leader and a
huge component of other folks will omit your great writing due
to this problem.
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an impatience over that you
wish be delivering the following. unwell unquestionably come further formerly again as exactly the same nearly very often inside case you shield this
increase.
Howdy! This is my 1st comment here so I just wanted to give a quick shout out and say I truly enjoy reading
through your articles. Can you suggest any other blogs/websites/forums
that go over the same subjects? Thanks!
I used to be able to find good advice from your blog articles.
Thank you a bunch for sharing this with all folks you really know what
you’re speaking approximately! Bookmarked.
Kindly also visit my site =). We could have a
hyperlink change contract between us
I know this if off topic but I’m looking into starting my own blog and was wondering what all is
required to get set up? I’m assuming having a blog
like yours would cost a pretty penny? I’m
not very internet smart so I’m not 100% positive. Any recommendations or advice would be greatly
appreciated. Kudos
Feel free to visit my website :: Buy Semaglutide
Hello, yup this piece of writing is truly fastidious
and I have learned lot of things from it about blogging.
thanks.
With havin so much written content do you ever run into any issues of
plagorism or copyright violation? My website has a lot of exclusive content I’ve either authored myself or outsourced but it seems a
lot of it is popping it up all over the internet without my agreement.
Do you know any methods to help prevent content from being ripped off?
I’d genuinely appreciate it.
Howdy! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly?
My weblog looks weird when viewing from my iphone.
I’m trying to find a template or plugin that might be able
to resolve this issue. If you have any suggestions,
please share. Thanks!
My relatives every time say that I am killing my time here at net, but I know I am getting knowledge every day by
reading thes good articles.
I simply could not leave your site before suggesting that I really enjoyed the standard info a person provide on your visitors?
Is gonna be again regularly in order to investigate cross-check new
posts
Awesome! Its really amazing article, I have got much clear idea regarding from this
article.
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to
get there! Cheers
Great post. I am dealing with a few of these issues
as well..
Hi! I know this is sort of off-topic however I needed to ask.
Does running a well-established blog like yours take a large amount of work?
I’m brand new to writing a blog but I do write in my diary everyday.
I’d like to start a blog so I can easily share my personal experience and views online.
Please let me know if you have any recommendations
or tips for brand new aspiring bloggers. Appreciate it!
It’s not my first time to go to see this web page, i am visiting this website
dailly and get fastidious data from here daily.
Excellent beat ! I wish to apprentice even as you amend your site, how
could i subscribe for a blog website? The account aided
me a acceptable deal. I had been a little bit acquainted of this your broadcast provided
vivid transparent concept
Asking questions are genuinely nice thing if you are not understanding something completely, but this paragraph provides nice
understanding yet.
With havin so much content and articles do you ever run into any issues of plagorism or
copyright violation? My website has a lot of unique content I’ve either written myself or outsourced but it seems
a lot of it is popping it up all over the web without my agreement.
Do you know any techniques to help stop content from being
stolen? I’d genuinely appreciate it.
I am in fact happy to glance at this weblog posts which consists of plenty of useful
data, thanks for providing such statistics.
Fantastic goods from you, man. I have understand
your stuff previous to and you are just extremely magnificent.
I really like what you have acquired here, certainly like what you’re
stating and the way in which you say it. You make it entertaining and you still take care of to keep it sensible.
I can not wait to read much more from you. This is really a tremendous site.
I absolutely love your blog and find almost all of your post’s to
be what precisely I’m looking for. can you offer guest
writers to write content for yourself? I wouldn’t mind producing a post or
elaborating on a number of the subjects you write with regards to
here. Again, awesome weblog!
Hey I am so thrilled I found your web site,
I really found you by accident, while I was browsing on Askjeeve for
something else, Anyhow I am here now and would just like
to say many thanks for a fantastic post and a all round enjoyable
blog (I also love the theme/design), I don’t have time to read through it all at the minute but I have
book-marked it and also added in your RSS feeds, so
when I have time I will be back to read much more, Please do keep up the fantastic work.
Your style is unique in comparison to other people I have read stuff from.
Thanks for posting when you’ve got the opportunity, Guess I will just book
mark this site.
Spot on with this write-up, I seriously feel this website needs much more
attention. I’ll probably be returning to read more,
thanks for the information!
Very good post! We will be linking to this particularly
great article on our site. Keep up the good writing.
This article will assist the internet users for setting up new
web site or even a blog from start to end.
Hi mates, its great article on the topic of teachingand completely defined,
keep it up all the time.
Hi there, all is going sound here and ofcourse every one is sharing information, that’s really good, keep up writing.
лордфильм фильмы
Link exchange is nothing else but it is just placing the other person’s weblog link on your page at
proper place and other person will also do same in support of you.
I’m not sure why but this web site is loading very slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later on and see if the problem still exists.
I enjoy what you guys are up too. This type of clever work and reporting!
Keep up the fantastic works guys I’ve you guys to my personal blogroll.
Hi, I do think this is an excellent website. I stumbledupon it 😉 I am going to come
back once again since i have book marked it. Money and freedom is the
best way to change, may you be rich and continue to guide others.
Hello, I think your blog might be having browser
compatibility issues. When I look at your blog in Firefox, it looks
fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that,
fantastic blog!
Your style is unique compared to other folks I have read stuff from.
Thank you for posting when you’ve got the opportunity, Guess I’ll just book mark this blog.
If you desire to get a good deal from this article then you have to
apply these strategies to your won webpage.
I am really enjoying the theme/design of your site. Do
you ever run into any web browser compatibility problems?
A couple of my blog visitors have complained about my website not working correctly
in Explorer but looks great in Safari. Do you have any suggestions to help fix
this issue?
For most up-to-date information you have to pay a
visit world wide web and on world-wide-web I found this site as a best web page for most recent updates.
Wonderful beat ! I wish to apprentice even as you amend your website, how can i subscribe for
a blog site? The account helped me a applicable deal. I had
been tiny bit acquainted of this your broadcast provided bright transparent idea
Hi there! I know this is kinda off topic but I was wondering
if you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
Hello there, I discovered your web site via Google at
the same time as searching for a comparable subject, your site came up, it seems to be
good. I have bookmarked it in my google bookmarks.
Hi there, just became alert to your blog via Google, and located that
it’s really informative. I am going to watch out for brussels.
I will be grateful for those who proceed this in future.
Numerous other folks might be benefited from your writing.
Cheers!
I read this piece of writing fully about the resemblance of
hottest and earlier technologies, it’s amazing article.
Hi there everyone, it’s my first go to see at this website, and post is actually
fruitful in favor of me, keep up posting these types of posts.
Aw, this was an incredibly good post. Finding the time and actual effort to make a great article… but what can I say… I procrastinate a lot and never manage to get
anything done.
Thanks very interesting blog!
fantastic put up, very informative. I wonder why
the opposite specialists of this sector do not understand this.
You should continue your writing. I am confident, you have a huge readers’ base already!
This is very interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your fantastic post.
Also, I have shared your website in my social networks!
Undeniably believe that which you stated. Your favorite justification seemed to
be on the net the easiest thing to be aware of. I say to you, I certainly get irked while people consider worries
that they just don’t know about. You managed to hit the nail upon the
top and defined out the whole thing without having side
effect , people can take a signal. Will likely be back to get more.
Thanks
Hi, i think that i saw you visited my weblog so i came to go back the want?.I’m attempting to in finding things to improve my website!I
assume its adequate to make use of a few of your
ideas!!
фильмы лордфильм
Hey There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and come back to read more of your useful info.
Thanks for the post. I will certainly return.
We’re a group of volunteers and starting a new scheme in our community.
Your website provided us with valuable info to work on. You’ve done an impressive job and our whole community will be grateful to
you.
Heya i’m for the first time here. I found this board and I find It really helpful &
it helped me out much. I am hoping to offer something again and help others like you helped
me.
If you’re into chubby people, then you’re in luck! You can find a lot of videos offering chubby babes sucking below-average or small cocks, since it comes across as being fuller
in the mouth area just. And if you’re into eating pussies,
you can find loads of videos of guys eating puffy pussies, with
their brains between those large thighs. Plus, you can imagine yourself in those scenarios since dimension is not
going to really issue. Whether it’s a chubby or tiny
babe, they’re equally very hot and stimulating. And if you’re into curvy girls,
you can discover even more videos with ladies
who possess unwanted fat proceeds and huge also, sagging tits.
Therefore avoid feel low about your options – there are usually plenty of porno videos of
chubby people out there! It’s insane how big these nations
are, however their porno production doesn’t even arrive near to Japan’s.
Japanese porno is definitely known for having some of the best Asian orgasms in the company, from cum pictures to cumming inside a girl.
They also produced ‘bukake’ a factor – it’s when a team of guys all ejaculate on a woman’s encounter.
Scenes like that are often therefore enjoyment to watch, with
the guys all masturbating around the girl and aiming their
cum at her face then. Bukake offers picked up therefore
popular that even Westerners possess their very own version of it.|Recreational intercourse in black women is definitely a sight
to notice for they do not generally seem to end up being too-staged
in their performances and they definitely give out the best
sensual experience inside sex that men are usually craving for.
More natural orgasms to be expected in this ebony amateur video clips.
Imagine how ebony amateurs performing their horny things naturally
without spending them. It is so arousing knowing the genuine feeling they can offer you to you.
Black amateur babes perform not keep back in driving cocks until they cum and fully obtain what they wish.
These novice ebony babes know when to end up being submissive or exceptional in mattress to certainly
provide full satisfaction to change on their intercourse companions.
They obtain and slurping in POV moments down, they lay and open their hip
and legs in hardcore fuck scenes down, and they consider sizzling hot whitened
jizz on their faces and bouncy asses! They love large cocks and definitely enjoys
when their body will be being worshipped. One benefit of ebony inexperienced porno is that anything can occur on your display screen but it
will not appear as well compelled or boring. Opportunities and performances would seem thus
natural you’g find your cock down hardly. Facesitting,
blowjobs, and pussy eating are current but not all moments would
appear as predictable still. They could shift the storyline every now and then but the satisfaction in watching these
ebony babes perform their mattress magic continues to be.
I like the helpful info you provide in your articles.
I will bookmark your blog and check again here regularly.
I’m quite sure I will learn a lot of new
stuff right here! Best of luck for the next!
Amazing issues here. I am very glad to look your article.
Thanks a lot and I am having a look forward to
contact you. Will you kindly drop me a mail?
I got this website from my buddy who told me regarding this website and now
this time I am visiting this site and reading very informative content here.
I was curious if you ever thought of changing the layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1
or 2 images. Maybe you could space it out better?
You are so interesting! I don’t think I have read through anything like this
before. So nice to find someone with a few unique thoughts
on this issue. Seriously.. many thanks for starting this up.
This website is something that is required on the web, someone with a little originality!
WOW just what I was looking for. Came here by searching for Natural Supplements to stimulate ovulation?
As the admin of this web site is working, no doubt very shortly it will be well-known, due to its feature contents.
This is my first time pay a quick visit at here and i am in fact pleassant
to read all at single place.
An impressive share! I have just forwarded this onto a coworker who has been doing a little research on this.
And he in fact ordered me breakfast simply because I discovered it
for him… lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spending some time to talk about this
topic here on your blog.
Pretty component of content. I just stumbled upon your
website and in accession capital to claim that I acquire actually enjoyed account your
blog posts. Anyway I’ll be subscribing to your feeds
or even I success you get entry to persistently rapidly.
Sure dark moms can hold an intelligent conversation during the day but they may be scantily dressed
as they set off to the club. Ebony moms are attractive significantly.
They possess fantastic and shining pores and skin because of the darkish shade of epidermis they
don’t possess to stress over sun tanning. Also though they possess that machine-gun mouth that fires their kids with scolding and preaching
they furthermore have kissable lips that invite males to get
a deep hug. No need for make-ups, simply hug and inform you’ll heading to drop
in like under their black miraculous spell.porn videos hot girls At
the age of fifty Also, they are still beautiful.
With their ageless elegance, they look young always. Also
actually how several children perform they have, their boobs are firm
and tender still. When women turn out to be mother and father, they
don’t stop getting human; they don’t change into robots.
Time still marches and so their sexual needs.
But when you desire them on bed don’t just believe about sex, think about love.
Therefore, viewing them on porno does not create you horny but furthermore
create your arousal harder than actually. Visualize eating your
respected dark chocolate brand name, you’ll be pleased in every bite!
Thanks designed for sharing such a good
thinking, article is pleasant, thats why i have read it completely
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is fundamental and everything. But think about if you added some great visuals or video clips to give
your posts more, “pop”! Your content is excellent
but with images and clips, this site could undeniably be one of the very
best in its field. Amazing blog!
Hey! I know this is somewhat off topic but I was wondering if you knew where I could get a captcha
plugin for my comment form? I’m using the same blog platform as yours and
I’m having trouble finding one? Thanks a lot!
That is really fascinating, You are an overly professional blogger.
I have joined your rss feed and look forward to searching for extra of your great post.
Additionally, I have shared your web site in my social networks
always i used to read smaller content that as well clear
their motive, and that is also happening with this article which I am reading here.
You are so interesting! I do not believe I’ve truly read something like this
before. So nice to find another person with a few
genuine thoughts on this subject. Really.. thanks for starting this up.
This website is one thing that’s needed on the web, someone with a
little originality!
After exploring a handful of the blog posts on your web site,
I truly like your technique of writing a blog. I saved as a favorite it to my bookmark website list and will be checking back soon. Take a look
at my website too and let me know how you feel.
Hi, Neat post. There’s an issue together with your web site in web explorer, would check this?
IE nonetheless is the market chief and a large part of people will omit your magnificent writing
because of this problem.
I’m not sure where you are getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic information I was looking for this info for my mission.
Remarkable issues here. I am very glad to peer your
article. Thanks so much and I am looking forward to touch
you. Will you kindly drop me a mail?
This site truly has all of the info I needed about this
subject and didn’t know who to ask.
I for all time emailed this webpage post page to all my contacts, for the
reason that if like to read it after that my links will
too.
I was excited to find this page. I wanted to thank you
for ones time for this particularly wonderful read!!
I definitely savored every part of it and I have you bookmarked
to see new information on your web site.
There’s definately a lot to find out about this topic. I love all of the points you’ve made.
I am curious to find out what blog system you have been utilizing?
I’m experiencing some minor security issues with my latest
website and I would like to find something more risk-free.
Do you have any solutions?
It’s awesome to pay a quick visit this website and reading the views of all mates about this post, while I am
also keen of getting experience.
If you are going for best contents like me, simply pay a quick visit this website
daily as it offers feature contents, thanks
What i don’t understood is in fact how you are not really
a lot more neatly-preferred than you might
be right now. You are very intelligent. You know therefore significantly on the
subject of this subject, made me individually consider it from numerous numerous angles.
Its like women and men aren’t fascinated except it’s
something to do with Girl gaga! Your individual stuffs excellent.
Always deal with it up!
It’s hard to come by experienced people for this
subject, however, you sound like you know what you’re talking about!
Thanks
A fascinating discussion is worth comment. I think that you
need to publish more on this subject, it may not be a taboo
matter but typically folks don’t speak about such topics.
To the next! All the best!!
I know this if off topic but I’m looking into starting
my own blog and was curious what all is required to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% certain. Any suggestions or advice would be greatly appreciated.
Kudos
Everything is very open with a clear explanation of
the challenges. It was really informative. Your website is
useful. Many thanks for sharing!
I just could not depart your website prior to suggesting that I extremely enjoyed the usual info an individual provide on your visitors?
Is gonna be again often in order to check out new posts
Hey! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us valuable information to work on. You have done a extraordinary job!
Hi there, You have done an excellent job. I will certainly digg it and personally recommend to my friends.
I am sure they will be benefited from this site.
Hey very nice web site!! Guy .. Beautiful .. Wonderful ..
I will bookmark your site and take the feeds additionally?
I’m satisfied to find a lot of helpful information here within the put up,
we’d like work out more techniques in this regard, thanks for
sharing. . . . . .
Excellent blog here! Additionally your site lots up very fast!
What web host are you using? Can I get your affiliate hyperlink for your
host? I desire my website loaded up as fast as yours lol
I don’t even understand how I ended up here,
however I assumed this submit was once good. I don’t recognize who you’re but certainly you are going to
a well-known blogger if you aren’t already. Cheers!
Wow! After all I got a weblog from where I be capable of
in fact obtain valuable data concerning my study and knowledge.
If you want to get a good deal from this post then you
have to apply such methods to your won web site.
Hi there, constantly i used to check blog posts here in the early hours in the daylight, for the reason that i like to gain knowledge of more and more.
I do trust all the ideas you’ve offered in your post. They
are really convincing and can certainly work. Still, the posts
are very brief for newbies. May just you please lengthen them a little from subsequent time?
Thank you for the post.
Hello everybody, here every person is sharing such
know-how, therefore it’s good to read this weblog, and I used to go to see
this website all the time.
It’s awesome designed for me to have a site, which is beneficial designed for my knowledge.
thanks admin
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is important and everything. However imagine if you added some great photos or video clips to give your posts more,
“pop”! Your content is excellent but with images and video
clips, this site could certainly be one of the very
best in its field. Fantastic blog!
I was suggested this web site by my cousin. I am not sure whether this post is written by him as
no one else know such detailed about my difficulty. You’re incredible!
Thanks!
Appreciate the recommendation. Let me try it out.
At this moment I am going to do my breakfast, afterward having my breakfast coming
yet again to read additional news.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the way, how could we communicate?
Undeniably believe that which you stated. Your favorite justification seemed to be on the
internet the easiest thing to be aware of. I say to you, I
certainly get irked while people think about worries that they just do not know about.
You managed to hit the nail upon the top and also defined out the whole thing without
having side effect , people could take a signal. Will probably be back to get more.
Thanks
I will right away snatch your rss feed as I can’t to find
your e-mail subscription link or newsletter
service. Do you’ve any? Kindly let me recognize so that I may subscribe.
Thanks.
Great delivery. Outstanding arguments. Keep up the great spirit.
Helpful info. Lucky me I discovered your site by accident, and I am stunned why this twist of fate didn’t took place earlier!
I bookmarked it.
Hello, Neat post. There is a problem with your web site in web
explorer, could test this? IE still is the market leader and a huge section of
folks will leave out your magnificent writing due to this problem.
payday loan
Link exchange is nothing else except it is only placing
the other person’s web site link on your page at suitable place and other person will also
do same in favor of you.
If you are going for most excellent contents like myself, simply go to see this
web page everyday as it provides feature contents, thanks
Hi my family member! I wish to say that this article is amazing, nice written and come with almost all vital infos.
I would like to look more posts like this .
Hello! Do you know if they make any plugins to assist with Search Engine Optimization? I’m trying to get my blog to rank for some targeted keywords
but I’m not seeing very good gains. If you know of any please share.
Many thanks!
Hmm it seems like your website ate my first comment (it was
extremely long) so I guess I’ll just sum it up what
I wrote and say, I’m thoroughly enjoying your blog. I too am an aspiring blog writer but I’m still
new to everything. Do you have any suggestions for beginner blog
writers? I’d genuinely appreciate it.
Hi there! This is my first visit to your blog! We are a collection of volunteers and starting a new project in a community in the same niche.
Your blog provided us beneficial information to work on. You have done a wonderful job!
When someone writes an paragraph he/she keeps the plan of a user in his/her brain that how a user can understand it.
Thus that’s why this piece of writing is perfect.
Thanks!
Hi friends, how is everything, and what you want to
say concerning this article, in my view its actually awesome in favor of me.
Pretty nice post. I simply stumbled upon your blog and wanted to mention that I’ve truly loved surfing around your weblog posts.
In any case I’ll be subscribing for your feed and I hope you write again very soon!
Thanks , I have just been looking for info about this subject
for ages and yours is the best I’ve discovered so far.
However, what concerning the bottom line? Are you positive in regards to the source?
My brother recommended I might like this website.
He was entirely right. This post actually made
my day. You cann’t imagine just how much time I had
spent for this information! Thanks!
Howdy exceptional blog! Does running a blog like this require a large amount of work?
I’ve very little expertise in programming however I was hoping to start my
own blog soon. Anyway, if you have any recommendations or
tips for new blog owners please share. I understand this is off topic however
I just wanted to ask. Thanks!
Hello, its good post on the topic of media print, we all know media is a great source
of information.
Everyone loves what you guys are usually up too. This kind
of clever work and reporting! Keep up the fantastic works guys
I’ve incorporated you guys to our blogroll.
Hello There. I discovered your blog the usage of msn. This is a very well
written article. I will make sure to bookmark it and come back to learn more of your helpful
info. Thanks for the post. I will certainly comeback.
I think the admin of this web site is truly working hard for his web page, as here every information is quality based information.
Hi! I just wanted to ask if you ever have any trouble with
hackers? My last blog (wordpress) was hacked and I ended up losing months
of hard work due to no back up. Do you have any methods
to protect against hackers?
My brother recommended I might like this blog. He was totally right.
This post truly made my day. You cann’t imagine just how much time I
had spent for this information! Thanks!
Sweet blog! I found it while searching on Yahoo News. Do
you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
Greetings from Idaho! I’m bored to tears at work so I decided to
browse your blog on my iphone during lunch break. I really like the
information you provide here and can’t wait to take
a look when I get home. I’m amazed at how fast your blog
loaded on my phone .. I’m not even using WIFI, just 3G .. Anyways, wonderful blog!
Excellent post! We will be linking to this particularly great article on our site.
Keep up the great writing.
This info is invaluable. How can I find out more?
This excellent website really has all of the information I wanted concerning this subject and
didn’t know who to ask.
I’ll right away take hold of your rss as I can’t to find
your e-mail subscription hyperlink or newsletter service.
Do you have any? Please allow me realize in order that I may subscribe.
Thanks.
Hi mates, good piece of writing and pleasant arguments commented at this place, I am genuinely enjoying by
these.
I read this article completely about the difference of most
recent and preceding technologies, it’s awesome article.
It is perfect time to make some plans for the future and it’s time to be happy.
I’ve read this post and if I could I desire to suggest you some interesting things or suggestions.
Maybe you can write next articles referring to this article.
I want to read more things about it!
Your style is really unique compared to other people I’ve read stuff from.
Thank you for posting when you have the opportunity, Guess I will
just book mark this web site.
I will immediately seize your rss as I can not in finding
your email subscription hyperlink or newsletter
service. Do you have any? Kindly allow me recognize so that
I may subscribe. Thanks.
You’re so cool! I do not suppose I’ve read through a single thing like that before.
So great to find someone with original thoughts on this subject matter.
Seriously.. many thanks for starting this up. This web site is one thing that is required on the internet, someone with some originality!
Hello, i think that i saw you visited my site thus i came to “return the favor”.I’m trying to find things to improve my site!I suppose its ok to
use a few of your ideas!!
You can certainly see your enthusiasm in the article you write.
The arena hopes for even more passionate writers like you who are not afraid to mention how
they believe. All the time go after your heart.
This website truly has all the information and facts I needed about this subject and didn’t know who
to ask.
Hi! This is my first comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading your posts.
Can you suggest any other blogs/websites/forums that go over the same
topics? Thanks for your time!
Highly energetic post, I liked that a lot. Will there be a part 2?
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an impatience over that you wish
be delivering the following. unwell unquestionably come more formerly
again as exactly the same nearly a lot often inside case you shield this hike.
Good day! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
I have been browsing online more than 2 hours today,
yet I never found any interesting article like yours.
It is pretty worth enough for me. In my view, if
all website owners and bloggers made good content as you did, the web will be
a lot more useful than ever before.
Biro Statistik Tenaga Kerja AS tidak mendokumentasikan info gaji atau prospek pekerjaan untuk teknisi audio.
Namun, mereka melakukan data daftar periksa untuk teknisi penyiaran dan teknik suara, yang umumnya mencakup teknisi audio.
BLS mencantumkan gaji tahunan rata-rata untuk teknisi teknik suara sebesar $55.810,
atau lebih dari $26,00 per jam. Antara tahun 2014 dan 2024, pekerjaan diperkirakan akan meningkat delapan persen, atau sedikit lebih cepat
dari rata-rata untuk semua pekerjaan. Hal ini sebagian karena industri televisi dan film, serta kebutuhan industri
game akan teknisi audio terlatih untuk meningkatkan kualitas suara game, pertunjukan, dan film.
Tentu saja, banyak hal yang memengaruhi berapa banyak penghasilan seorang insinyur audio, seperti tingkat pendidikan, bisnis,
lokasi geografis, dan pemberi kerja. Sepuluh persen tertinggi insinyur audio atau
mereka yang memiliki pengalaman dan gelar di tangan menghasilkan sekitar
$125.000, dan sepuluh persen terendah, atau mereka yang baru lulus menghasilkan sekitar $25.000 per tahun. Negara bagian dengan pekerjaan insinyur audio
terbaik termasuk California, New York, Florida, Texas, dan New Jersey.
Insinyur audio biasanya bekerja penuh waktu
selama jam kerja reguler, namun tidak jarang waktu kerja di luar peraturan, akhir pekan, hari
libur, dan malam hari.
Hmm it looks like your site ate my first comment (it was extremely long)
so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to the whole thing.
Do you have any points for rookie blog writers? I’d
certainly appreciate it.
I do consider all of the ideas you’ve presented in your post.
They are really convincing and can certainly work. Nonetheless, the posts
are very brief for beginners. Could you please prolong
them a little from next time? Thank you for the post.
Hello friends, its great paragraph on the
topic of educationand fully explained, keep it up all the time.
What’s up to all, how is all, I think every one is getting more from this web
page, and your views are good designed for new viewers.
I’ve read some excellent stuff here. Certainly price bookmarking for
revisiting. I surprise how much effort you set
to make this kind of fantastic informative web site.
Thankfulness to my father who informed me on the topic of this web site, this website is actually amazing.
I just couldn’t depart your site prior to suggesting that I actually enjoyed the usual info an individual supply to your visitors?
Is going to be again incessantly to inspect new posts
Your style is really unique compared to other
people I’ve read stuff from. Thanks for posting when you have the opportunity, Guess I will
just bookmark this blog.
buy viagra online
I am sure this piece of writing has touched all the internet people, its really really fastidious article on building up new webpage.
I like the helpful info you provide to your articles.
I will bookmark your weblog and check again here frequently.
I am relatively sure I will learn plenty of new stuff proper here!
Best of luck for the following!
I have read so many articles or reviews about the blogger lovers but
this paragraph is really a fastidious piece of writing, keep it up.
Appreciate this post. Let me try it out.
I all the time used to read article in news papers but now as I am a user of internet thus from now I am using net for articles or reviews, thanks to web.
I don’t even know how I ended up here, but I thought this post was great.
I do not know who you are but certainly you’re going to a
famous blogger if you are not already 😉 Cheers!
Hi terrific blog! Does running a blog similar to this take a massive
amount work? I’ve very little knowledge of programming however I
had been hoping to start my own blog soon. Anyhow, if you have any recommendations or tips for new blog owners please share.
I know this is off topic nevertheless I simply needed to ask.
Kudos!
I pay a visit every day a few web pages and blogs to read posts,
except this weblog presents feature based posts.
Thanks very nice blog!
Right here is the perfect webpage for anybody who wishes to understand this topic.
You know a whole lot its almost tough to argue with you (not that I really would
want to…HaHa). You definitely put a new spin on a subject that has been discussed for years.
Great stuff, just excellent!
Good information. Lucky me I ran across your site
by accident (stumbleupon). I’ve bookmarked it for later!
Hello there! I know this is kind of off topic but I was wondering if you knew where
I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
I like the helpful information you supply to
your articles. I will bookmark your weblog and check again right
here regularly. I am somewhat certain I’ll be told many new stuff right right here!
Best of luck for the following!
It’s remarkable to pay a visit this web page and reading the views
of all friends on the topic of this piece of
writing, while I am also eager of getting knowledge.
Part of this is because of over-breeding, but the primary
reason is that due to advances in veterinary know-how, canine are
simply living to an older age lately. The symptoms improve when the legs are moved.
Hi there! I realize this is kind of off-topic however I had to ask.
Does operating a well-established website like yours take a large amount of work?
I am completely new to running a blog but I do write in my
journal on a daily basis. I’d like to start a blog so I can share my experience and
thoughts online. Please let me know if you have any suggestions or tips for brand new aspiring bloggers.
Thankyou!
Does your site have a contact page? I’m having problems locating it but, I’d like to shoot you an email.
I’ve got some recommendations for your blog you
might be interested in hearing. Either way, great blog
and I look forward to seeing it develop over time.
Thanks to my father who stated to me concerning this website,
this blog is in fact awesome.
Hi there, I discovered your website by the use of Google at the same
time as searching for a comparable topic, your web site got here
up, it appears to be like great. I’ve bookmarked it in my
google bookmarks.
Hi there, just became alert to your blog via Google,
and found that it’s really informative. I’m going to be careful for brussels.
I will be grateful if you continue this in future.
Lots of other people will probably be benefited from your writing.
Cheers!
I blog often and I truly appreciate your content. Your article has truly peaked
my interest. I’m going to take a note of your website and
keep checking for new information about once a week. I subscribed to your Feed as well.
Hi! I’ve been reading your site for a while now and finally got the courage to
go ahead and give you a shout out from Austin Tx! Just wanted
to mention keep up the fantastic work!
Somebody essentially lend a hand to make seriously posts I’d
state. This is the first time I frequented your web page and
so far? I surprised with the analysis you made to create this actual put
up amazing. Excellent process!
Thank you, I’ve recently been looking for information approximately this topic for ages and yours is the
greatest I’ve came upon till now. But, what concerning
the bottom line? Are you sure in regards to the source?
When someone writes an post he/she keeps the thought of a user in his/her mind that how a
user can know it. Thus that’s why this paragraph is great.
Thanks!
Heya great website! Does running a blog such as this require a lot of work?
I’ve virtually no knowledge of computer programming but I was hoping to
start my own blog soon. Anyways, if you have any suggestions or techniques
for new blog owners please share. I know this is off subject nevertheless
I just wanted to ask. Thank you!
Very shortly this website will be famous among all blogging and site-building visitors,
due to it’s good content
фильмы lordfilm
Thank you a bunch for sharing this with all of us you really realize what you’re talking approximately!
Bookmarked. Kindly additionally seek advice from my
website =). We will have a hyperlink exchange contract between us
Greetings! I know this is kinda off topic but I was wondering which blog platform are you using for this site?
I’m getting tired of WordPress because I’ve had issues with hackers and I’m looking at options for another platform.
I would be fantastic if you could point me
in the direction of a good platform.
I know this if off topic but I’m looking into starting my own blog and was curious what all is needed to get
setup? I’m assuming having a blog like yours would
cost a pretty penny? I’m not very internet savvy
so I’m not 100% sure. Any tips or advice would be greatly appreciated.
Kudos
Pretty nice post. I just stumbled upon your blog and wished to say that I’ve truly loved surfing around your weblog posts.
In any case I’ll be subscribing for your feed and I hope you write once more soon!
It’s great that you are getting thoughts from this article
as well as from our argument made here.
If you want to increase your knowledge just keep visiting
this website and be updated with the hottest news update posted here.
Today, while I was at work, my sister stole my iphone and tested to see if it can survive a 25 foot
drop, just so she can be a youtube sensation.
My apple ipad is now broken and she has 83 views. I know this is entirely off topic
but I had to share it with someone!
Thank you for the auspicious writeup. It in truth was once a enjoyment account it.
Glance complex to more brought agreeable from you!
By the way, how could we keep in touch?
I will right away take hold of your rss as I can’t to find your email subscription link or newsletter service.
Do you’ve any? Please let me know in order that I could subscribe.
Thanks.
This is a topic that is close to my heart… Thank you! Exactly where are your contact
details though?
Yes! Finally something about kingsgate international preschool.
I always used to study piece of writing in news papers but now as I
am a user of net therefore from now I am using net for articles or reviews, thanks to web.
I am really delighted to glance at this web site posts which
consists of lots of useful facts, thanks
for providing these data.
What i don’t realize is in truth how you’re now not actually a lot more well-appreciated than you
may be right now. You’re very intelligent. You understand thus significantly relating to this matter, produced me
in my view believe it from numerous numerous angles. Its
like men and women aren’t involved until it is one thing
to accomplish with Girl gaga! Your individual stuffs outstanding.
All the time maintain it up!
Thank you a lot for sharing this with all folks you actually
realize what you’re speaking approximately! Bookmarked.
Kindly also discuss with my site =). We may have a link exchange
arrangement among us
Just desire to say your article is as amazing. The clearness
in your post is simply nice and i can assume you are an expert on this subject.
Well with your permission let me to grab your RSS feed to keep up
to date with forthcoming post. Thanks a million and please keep up the enjoyable work.
What a material of un-ambiguity and preserveness of precious familiarity regarding unpredicted emotions.
Hi there! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Hi there, just became alert to your blog through Google, and found that it is
really informative. I am gonna watch out for brussels.
I’ll be grateful if you continue this in future.
Numerous people will be benefited from your writing.
Cheers!
I was wondering if you ever thought of changing the layout
of your blog? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect
with it better. Youve got an awful lot of
text for only having one or 2 images. Maybe you could space it out
better?
Amazing blog! Do you have any helpful hints for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost
on everything. Would you propose starting with a free platform like WordPress or go for a paid option? There are so many options out there that I’m completely overwhelmed ..
Any recommendations? Thanks!
It’s not my first time to visit this web site, i am visiting this web
site dailly and obtain fastidious facts from here every day.
What’s up it’s me, I am also visiting this website on a regular basis, this site is really pleasant and the
users are truly sharing pleasant thoughts.
Everything published was very reasonable. However, think on this, suppose you typed a catchier title?
I mean, I don’t want to tell you how to run your website, but what if
you added a title to maybe grab people’s attention? I mean Пиастры – Составление семантического ядра | is a little plain. You
ought to glance at Yahoo’s front page and see how they create post titles to
grab viewers to click. You might add a video or a related pic or two to grab readers
excited about what you’ve written. Just my opinion,
it would make your website a little bit more interesting.
Do you mind if I quote a few of your articles as long as I provide
credit and sources back to your blog? My blog is in the
exact same niche as yours and my visitors would definitely benefit from some
of the information you present here. Please let me know if this ok
with you. Appreciate it!
Incredible points. Outstanding arguments. Keep
up the great work.
Hi there! I’m at work browsing your blog from my new iphone 4!
Just wanted to say I love reading your blog and look
forward to all your posts! Keep up the fantastic
work!
Great post. I was checking constantly this blog and I am impressed!
Extremely useful info specifically the last part I care for such info a lot.
I care for such info a lot.
I was seeking this particular info for a very long time.
Thank you and good luck.
Howdy! This article couldn’t be written any better!
Looking through this post reminds me of my previous roommate!
He constantly kept talking about this. I most certainly will
send this information to him. Pretty sure he’s going
to have a great read. Many thanks for sharing!
Hello my loved one! I wish to say that this post is awesome, great written and come with almost all
significant infos. I’d like to look extra posts like this
.
I used to be suggested this website by my cousin.
I’m not certain whether this put up is written through him as no one
else recognise such distinct approximately my difficulty.
You are incredible! Thanks!
фильмы лордфильм
Howdy! I could have sworn I’ve been to this blog before but after reading through some of the post I realized it’s new to me.
Anyhow, I’m definitely happy I found it and I’ll
be bookmarking and checking back often!
obviously like your web-site however you have to test the
spelling on several of your posts. Many of them are rife with spelling problems and
I find it very bothersome to tell the reality nevertheless I’ll surely come back again.
It is estimated the gambling industry generates abou $ten billion in taxes for state and federal governments every
year.
Here is my site … bj알바
What’s up, I want to subscribe for this weblog to obtain newest updates, therefore
where can i do it please help out.
Valuable info. Fortunate me I found your website accidentally, and
I am stunned why this accident did not came about earlier!
I bookmarked it.
It’s impressive that you are getting thoughts from this paragraph as well
as from our argument made at this place.
Have you ever considered publishing an ebook or guest authoring
on other sites? I have a blog based on the same information you discuss and would love
to have you share some stories/information. I know my readers would
value your work. If you are even remotely interested, feel free to
send me an email.
“Can Face Masks Prevent You From Getting the Coronavirus? Doctors Weight In”사설토토
Hello my loved one! I want to say that this post is amazing, great written and include approximately all
significant infos. I would like to peer extra posts like
this .
Do you have any video of that? I’d love to find out some additional information.
I think this is among the most vital info for me. And i am glad reading your article.
But want to remark on some general things, The website style is ideal,
the articles is really excellent : D. Good job, cheers
Hey there! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Carry on the great work!
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a
comment is added I get several e-mails with the same comment.
Is there any way you can remove me from that service?
Thanks a lot!
Heya! I realize this is kind of off-topic however I had to ask.
Does operating a well-established blog such as yours take a lot of work?
I am completely new to operating a blog but I do write in my
journal every day. I’d like to start a blog so I can share
my personal experience and feelings online. Please let me know if
you have any suggestions or tips for new aspiring
bloggers. Thankyou!
I do not even understand how I stopped up right here,
however I believed this publish was once good.
I don’t recognise who you might be however definitely you’re going to
a famous blogger if you aren’t already. Cheers!
At this time it looks like Movable Type is the top blogging platform
available right now. (from what I’ve read) Is that
what you are using on your blog?
You actually make it seem so easy with your presentation but I find this matter to
be actually something that I think I would never understand.
It seems too complex and very broad for me. I’m looking forward for your
next post, I will try to get the hang of it!
Great site. A lot of helpful info here. I am sending it to several buddies ans also sharing in delicious.
And certainly, thanks for your effort!
You made some really good points there. I checked on the web for additional information about the issue and found most individuals will go along with your views on this website.
Thanks for ones marvelous posting! I really enjoyed reading it,
you could be a great author. I will remember to bookmark your blog and will
come back from now on. I want to encourage one to continue your great posts, have a nice
holiday weekend!
Hey there I am so delighted I found your site, I
really found you by mistake, while I was looking
on Bing for something else, Anyhow I am here now and would just like
to say many thanks for a incredible post and a all round exciting blog (I also love the theme/design),
I don’t have time to look over it all at the minute but I have bookmarked
it and also added your RSS feeds, so when I have time I will be back to read a great deal more, Please do keep up the great job.
Magnificent beat ! I would like to apprentice while you amend your
web site, how can i subscribe for a blog website? The account aided me a acceptable
deal. I had been a little bit acquainted of
this your broadcast offered bright clear idea
It’s great that you are getting thoughts from this post as well
as from our argument made at this place.
Spot on with this write-up, I seriously believe that this
amazing site needs a great deal more attention. I’ll
probably be back again to see more, thanks for the information!
Currently it seems like Drupal is the preferred blogging platform available right now.
(from what I’ve read) Is that what you’re using on your blog?
Hey! I know this is kinda off topic but I was wondering which blog platform are
you using for this website? I’m getting sick and tired of WordPress because I’ve had issues with hackers and I’m looking
at options for another platform. I would be great if
you could point me in the direction of a good platform.
Its like you read my mind! You seem to know a lot about this, like
you wrote the book in it or something. I think that you can do with a few pics
to drive the message home a bit, but instead of that, this is wonderful blog.
A fantastic read. I will certainly be back.
Hi there! This blog post could not be written much better!
Reading through this article reminds me of my previous roommate!
He continually kept preaching about this. I am going to
send this information to him. Pretty sure he’s going to have a good read.
Thanks for sharing!
Wow, marvelous blog layout! How long have you
been blogging for? you made blogging look easy. The overall look of your web site is excellent, let alone
the content!
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is needed to get set
up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet savvy so I’m not 100% positive.
Any tips or advice would be greatly appreciated. Cheers
Hi, I do think this is a great website. I stumbledupon it 😉 I will revisit once again since I book-marked
it. Money and freedom is the greatest way to change, may you be rich and continue to
guide other people.
Truly no matter if someone doesn’t know afterward its up to other viewers that they will help, so here it happens.
Wow, marvelous blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is
excellent, as well as the content!
Hey there I am so thrilled I found your blog page, I really found you
by error, while I was looking on Bing for something else, Anyways I am here now and would just like to say cheers
for a tremendous post and a all round interesting blog (I also love the theme/design), I
don’t have time to browse it all at the minute but I have bookmarked it and also added in your RSS feeds, so when I have
time I will be back to read much more, Please do keep up the fantastic job. https://drive.google.com/drive/folders/1Et7ZnggWrwRy2ofoMFE8GFwc9FFIhR7e
Nice respond in return of this query with solid arguments
and explaining the whole thing on the topic of that.
Way cool! Some extremely valid points! I appreciate you
writing this article and also the rest of the site is really good.
Nice answer back in return of this query with genuine arguments and telling all
concerning that.
I’m more than happy to uncover this great site.
I want to to thank you for ones time due to this wonderful read!!
I definitely liked every bit of it and I have you book marked to look at new information on your
blog.
I like the helpful information you provide in your articles.
I’ll bookmark your blog and check again here
regularly. I’m quite sure I’ll learn many new stuff right here!
Best of luck for the next!
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for you?
Plz reply as I’m looking to construct my own blog and would like to find out where u got this from.
appreciate it
It is really a great and useful piece of information. I’m glad that you shared
this useful information with us. Please keep us informed
like this. Thank you for sharing.
Spot on with this write-up, I honestly believe this web site needs far more attention.
I’ll probably be back again to see more, thanks for the advice!
Yes! Finally something about medicina.
Hi there to every body, it’s my first go to see of this weblog; this weblog contains
amazing and actually good data in favor of readers.
Hello there! I could have sworn I’ve been to this blog before
but after browsing through many of the posts I realized it’s new to me.
Regardless, I’m certainly delighted I found it and I’ll be
bookmarking it and checking back regularly!
Somebody essentially help to make severely articles I’d state.
This is the very first time I frequented your website page and up to now?
I surprised with the research you made to make this particular publish extraordinary.
Excellent task!
What’s up it’s me, I am also visiting this site on a regular basis,
this website is really nice and the visitors are truly sharing good thoughts.
It’s remarkable to pay a visit this web site and reading the views of all mates about this article, while I am also keen of getting knowledge.
There is definately a lot to find out about this topic.
I love all the points you have made.
Hello there, I discovered your blog by way of Google whilst searching for a related topic, your web site got here up, it looks great.
I have bookmarked it in my google bookmarks.
Hi there, simply became aware of your blog through Google,
and located that it’s truly informative. I am going to watch out for brussels.
I’ll be grateful for those who continue this in future.
Numerous other people shall be benefited out of your writing.
Cheers!
Hey There. I found your blog using msn. This is an extremely well
written article. I will be sure to bookmark it and return to read more of your useful
info. Thanks for the post. I will certainly comeback.
Good day! Would you mind if I share your blog with my
facebook group? There’s a lot of people that I think would
really appreciate your content. Please let me know.
Many thanks
I do not know whether it’s just me or if perhaps everybody else
encountering problems with your site. It seems
like some of the text within your posts are running off the screen. Can somebody else
please comment and let me know if this is happening to them as well?
This could be a issue with my internet browser because I’ve had
this happen before. Kudos
I’m impressed, I must say. Rarely do I come across a blog that’s
both equally educative and entertaining, and
let me tell you, you have hit the nail on the head. The problem is something which not enough folks are speaking intelligently about.
I am very happy that I stumbled across this in my hunt for something
concerning this.
Today, I went to the beach front with my kids.
I found a sea shell and gave it to my 4 year old daughter and
said “You can hear the ocean if you put this to your ear.” She put
the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this
is completely off topic but I had to tell someone!
Every weekend i used to pay a quick visit this site, as i
wish for enjoyment, as this this web page conations really pleasant funny information too.
Hi there i am kavin, its my first time to commenting anyplace, when i
read this piece of writing i thought i could also create comment due
to this brilliant article.
First off I would like to say fantastic blog! I had a quick question in which I’d like to
ask if you don’t mind. I was curious to know how
you center yourself and clear your thoughts prior to writing.
I’ve had a hard time clearing my thoughts in getting my thoughts out there.
I truly do take pleasure in writing but it just seems
like the first 10 to 15 minutes are wasted simply just trying to figure out how to begin.
Any ideas or tips? Many thanks!
Hello, its fastidious piece of writing concerning media print, we all be aware of media is a great source of information.
Every weekend i used to go to see this website, as i want enjoyment, as this this site conations in fact nice funny information too.
I used to be able to find good advice from your
content.
What’s up it’s me, I am also visiting this web page regularly, this website is genuinely fastidious and the
people are actually sharing nice thoughts.
Hi there, I discovered your site via Google even as looking
for a comparable topic, your web site got here up, it appears
to be like good. I’ve bookmarked it in my google
bookmarks.
Hello there, simply changed into aware of your blog through
Google, and located that it’s really informative. I am gonna be careful for brussels.
I’ll appreciate if you continue this in future.
Lots of people will probably be benefited out of your writing.
Cheers!
I am sure this post has touched all the internet viewers,
its really really nice post on building up new weblog.
Why users still make use of to read news papers when in this technological world everything is presented on net?
Howdy! Quick question that’s completely off topic. Do you know how to
make your site mobile friendly? My blog looks
weird when viewing from my iphone 4. I’m trying to find a theme or plugin that might be able to fix this
issue. If you have any suggestions, please share. Thank
you!
First of all I would like to say wonderful blog! I had a quick question in which I’d like to ask if you do not mind.
I was curious to find out how you center yourself and
clear your mind before writing. I’ve had a hard time clearing
my mind in getting my ideas out. I do enjoy writing however it just seems like the first
10 to 15 minutes are lost simply just trying to figure
out how to begin. Any recommendations or tips?
Many thanks!
Hi there to every one, it’s genuinely a good for me to visit this
website, it contains valuable Information.
I love your blog.. very nice colors & theme. Did you create this website yourself
or did you hire someone to do it for you? Plz respond as I’m
looking to design my own blog and would like to know where u got this from.
thanks a lot
I like what you guys tend to be up too. This sort of clever work and coverage!
Keep up the excellent works guys I’ve added you guys to
my blogroll.
Simply want to say your article is as surprising.
The clarity on your publish is just great and that i could suppose you’re
knowledgeable in this subject. Well together with your permission let me to take hold of your feed to keep
updated with imminent post. Thanks a million and please continue the
enjoyable work.
Does your website have a contact page? I’m having trouble locating it but,
I’d like to shoot you an e-mail. I’ve got some ideas for your
blog you might be interested in hearing. Either
way, great blog and I look forward to seeing it
grow over time.
Truly no matter if someone doesn’t understand afterward its up to other users
that they will help, so here it happens.
I was recommended this blog by way of my cousin. I am not certain whether this submit is written by him as no one else recognize such specific about my problem.
You are incredible! Thanks!
Greetings! Very useful advice within this post!
It is the little changes that make the largest changes.
Thanks a lot for sharing!
What’s up, I check your blogs daily. Your
humoristic style is awesome, keep it up!
Thank you for any other great article. Where else
may anyone get that type of information in such an ideal way of writing?
I have a presentation next week, and I am at the search for such
info.
I was curious if you ever thought of changing the layout
of your website? Its very well written; I love what youve got
to say. But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or 2 images.
Maybe you could space it out better?
I needed to thank you for this wonderful read!! I certainly
loved every bit of it. I have got you book marked to check out new stuff you post…
I delight in, lead to I discovered exactly what I used to be having
a look for. You have ended my 4 day long hunt! God Bless you man. Have a great day.
Bye
I blog frequently and I seriously appreciate your information. This great
article has truly peaked my interest. I’m going to take a note of your site and keep checking for new
details about once a week. I opted in for your RSS feed too.
Great post. I was checking continuously I care for such info a lot.
I care for such info a lot.
this blog and I’m impressed! Extremely useful info specifically the last part
I was seeking this certain info for a very long time. Thank you and best
of luck.
It is in point of fact a great and useful piece of information. I am satisfied that you shared this helpful info
with us. Please keep us up to date like this.
Thanks for sharing.
Do you mind if I quote a couple of your articles as long as I provide credit and sources back to your website?
My blog site is in the exact same niche as yours and my visitors would really benefit from a lot of the information you provide here.
Please let me know if this alright with you. Appreciate it!
My spouse and I absolutely love your blog and find the majority of your post’s to
be precisely what I’m looking for. can you offer guest
writers to write content for you personally? I wouldn’t mind writing a post or elaborating on most of the
subjects you write in relation to here. Again, awesome web site! https://drive.google.com/drive/folders/1JdY1gycpE66fZ_ggm1rLYctHadAG6MNS
If you want to acquire automobile financing online, you
must limit all the achievable bargains as well as costs that fit your budget.
As often along with the situation of numerous, they have a tendency to neglect the relevance of reviewing financing quotes that they
tend to invest three times as much as they could possess in fact conserved, Visit This Link.
This excellent website truly has all the information and facts I
needed concerning this subject and didn’t know who to ask.
Hello there! I could have sworn I’ve visited this website before but after going through a few of the articles I
realized it’s new to me. Nonetheless, I’m definitely
delighted I came across it and I’ll be book-marking it
and checking back often!
Hi, i think that i noticed you visited my site thus i got
here to return the want?.I’m trying to to find things to
improve my site!I guess its adequate to make use of some of your ideas!!
I know this website gives quality based articles or reviews and
additional material, is there any other site which presents such information in quality?
You ought to be a part of a contest for one of the most
useful websites on the net. I will highly recommend this web site!
You actually make it seem so easy together with your presentation however I find this matter to be actually something which I
feel I’d never understand. It sort of feels too complex and extremely
vast for me. I’m taking a look forward to your next put up, I will
attempt to get the hang of it!
секс видео онлайн
I think this is among the most vital info for me. And i’m glad
reading your article. But wanna remark on few general things, The web site style is wonderful, the
articles is really nice : D. Good job, cheers
I for all time emailed this website post page to
all my contacts, since if like to read it after that my friends will too.
This is my first time pay a quick visit at here and
i am actually pleassant to read all at single place.
Woah! I’m really digging the template/theme of this website.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between usability and visual appeal.
I must say you’ve done a amazing job with this.
Also, the blog loads super fast for me on Firefox. Exceptional Blog!
Hello my friend! I wish to say that this post is amazing, nice written and come with
approximately all significant infos. I’d like to peer extra
posts like this .
I’ve been exploring for a little for any high-quality articles or blog posts
in this sort of space . Exploring in Yahoo I at last stumbled upon this web
site. Studying this info So i’m glad to express that I’ve an incredibly excellent uncanny feeling I found
out just what I needed. I most definitely
will make sure to do not disregard this web site and provides it a
glance regularly.
This site definitely has all of the information and facts I wanted concerning this subject and didn’t know who to ask.
Hello, Neat post. There’s an issue along with your website in internet explorer, may check this?
IE still is the market chief and a good element of people will
leave out your excellent writing due to this problem.
Spot on with this write-up, I honestly believe that
this site needs far more attention. I’ll probably be returning to read through more, thanks
for the advice!
Awesome blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple tweeks would really make my blog stand
out. Please let me know where you got your design. Kudos
What’s up to all, how is everything, I think every one is getting
more from this web site, and your views are good
for new people.
Very good post. I am going through many of these issues as well..
It’s going to be end of mine day, but before finish
I am reading this enormous piece of writing to improve my
experience.
Keep on working, great job!
Do you mind if I quote a couple of your articles as long as
I provide credit and sources back to your weblog?
My blog site is in the exact same niche as yours and my users would truly benefit from some of the information you present here.
Please let me know if this okay with you. Thanks a lot!
It’s appropriate time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I desire to suggest you some interesting things or tips.
Perhaps you could write next articles referring to this article.
I want to read even more things about it!
magnificent submit, very informative. I ponder why the opposite specialists of this
sector do not understand this. You should continue your writing.
I’m confident, you’ve a great readers’ base
already!
Since the admin of this website is working, no doubt very rapidly it will be well-known,
due to its feature contents.
14 Hangover Cures That You Haven’t Heard Of (Number 10 Works Every Time!)메이저사이트
Hi there, the whole thing is going fine here and ofcourse every one is sharing information, that’s really good,
keep up writing.
It’s fantastic that you are getting ideas from
this article as well as from our argument made at this place.
It’s fantastic that you are getting thoughts from this article as well as from our discussion made at
this place.
Hello! Do you know if they make any plugins to protect
against hackers? I’m kinda paranoid about
losing everything I’ve worked hard on. Any suggestions?
What’s up, after reading this remarkable post i am also glad to share my experience
here with friends.
Hi to all, how is all, I think every one is getting more from this website, and your views are
nice in favor of new viewers.
What’s up to every , for the reason that I am in fact eager of reading this weblog’s post to be updated regularly.
It carries fastidious data.
Thanks in support of sharing such a fastidious idea, paragraph is fastidious, thats why i have
read it entirely
I’m not that much of a internet reader to be honest but your sites
really nice, keep it up! I’ll go ahead and bookmark your site to come back later.
All the best
I am really thankful to the holder of this website who has
shared this wonderful article at at this place.
Everyone loves what you guys are up too. This kind of clever work and reporting!
Keep up the good works guys I’ve you guys
to our blogroll.
Hi, i think that i saw you visited my site thus
i came to “return the favor”.I’m trying to find things to improve my website!I suppose its ok
to use a few of your ideas!!
Hello it’s me, I am also visiting this website regularly,
this web site is truly pleasant and the users are
genuinely sharing fastidious thoughts.
Hello to all, how is all, I think every one is getting more from this website, and your views
are nice in support of new people.
Hello! I know this is kinda off topic but I was wondering which blog platform are
you using for this site? I’m getting fed up of WordPress because
I’ve had issues with hackers and I’m looking at alternatives for another platform.
I would be fantastic if you could point me in the direction of a good platform.
At this moment I am ready to do my breakfast, after having
my breakfast coming over again to read other news.
Great beat ! I would like to apprentice while you amend your web site,
how could i subscribe for a blog site? The account helped me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided bright clear idea
you’re really a excellent webmaster. The site loading pace is
incredible. It seems that you’re doing any unique trick.
Moreover, The contents are masterwork. you’ve performed
a great task on this matter!
Thanks for finally writing about > Пиастры – Составление
семантического ядра | < Liked it!
Great goods from you, man. I’ve understand your stuff previous to and you’re just too
excellent. I actually like what you’ve acquired here,
certainly like what you are saying and the way
in which you say it. You make it enjoyable and you still take care of to
keep it wise. I can not wait to read far more
from you. This is actually a great website.
I think this is one of the most important info for me.
And i’m glad reading your article. But wanna remark on few general
things, The website style is great, the articles is really nice : D.
Good job, cheers
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an edginess over that you wish be delivering the following.
unwell unquestionably come more formerly again as exactly the same nearly very often inside case you shield this hike.
Have you ever considered publishing an ebook or guest authoring on other sites?
I have a blog based upon on the same information you discuss and would really like
to have you share some stories/information. I know my readers
would value your work. If you’re even remotely interested, feel free to
send me an e-mail.
Your style is so unique in comparison to other folks I’ve read stuff from.
Thank you for posting when you have the opportunity,
Guess I will just bookmark this page.
I really like it when people get together and share ideas.
Great blog, keep it up!
Hi there! I just wanted to ask if you ever have any problems with
hackers? My last blog (wordpress) was hacked and I ended up
losing several weeks of hard work due to no back up.
Do you have any solutions to stop hackers?
Pretty nice post. I just stumbled upon your blog and wanted to
say that I have really enjoyed browsing your blog posts.
In any case I will be subscribing to your rss feed and I hope you write again soon!
I’m very happy to find this web site. I need to
to thank you for your time for this fantastic read!! I definitely liked every little bit of it and I have you bookmarked to check out new stuff in your website.
Why viewers still use to read news papers when in this technological
world everything is existing on web?
You are so interesting! I do not suppose I have read through a single thing
like this before. So good to discover somebody with a few unique thoughts on this topic.
Seriously.. many thanks for starting this up.
This site is one thing that’s needed on the internet, someone with a little originality!
This is my first time visit at here and i am in fact impressed to read everthing at one place.
Hey there! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing months of hard work due to no data backup.
Do you have any solutions to prevent hackers?
I believe this is one of the such a lot significant info for me.
And i am glad studying your article. But want to statement
on some common issues, The site taste is wonderful, the articles
is actually great : D. Just right process, cheers
Excellent article. I’m facing a few of these issues as well..
Hello colleagues, how is the whole thing, and what you wish
for to say regarding this post, in my view its genuinely remarkable
for me.
Great blog right here! Also your site a lot up fast!
What web host are you using? Can I get your associate link for
your host? I desire my site loaded up as fast as yours
lol
My partner and I stumbled over here coming from
a different page and thought I may as well check things out.
I like what I see so now i’m following you. Look forward to checking out your web page again.
Wow, wonderful blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is excellent, as well as the content!
I visited several sites except the audio feature for audio songs current at this web site
is really superb.
Wow! In the end I got a webpage from where I be capable of truly
take useful information regarding my study and knowledge.
Hi, I do believe this is an excellent web site. I stumbledupon it 😉 I
may revisit once again since i have book-marked it.
Money and freedom is the best way to change, may
you be rich and continue to help others.
I love what you guys are usually up too. This type of clever work and
exposure! Keep up the great works guys I’ve you guys to blogroll.
Very great post. I simply stumbled upon your blog and wanted to
mention that I have really enjoyed browsing your blog posts.
In any case I will be subscribing on your rss
feed and I’m hoping you write once more very soon!
Whats up are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and create
my own. Do you need any coding expertise to make your own blog?
Any help would be really appreciated!
Hi, I check your new stuff daily. Your writing style is witty, keep it up!
You can certainly see your enthusiasm within the
article you write. The world hopes for even more passionate writers such as you who aren’t afraid to mention how they believe.
All the time follow your heart.
you’re really a excellent webmaster. The site loading velocity is incredible.
It seems that you are doing any distinctive trick.
Furthermore, The contents are masterpiece. you have done a fantastic activity on this matter!
I’m really impressed with your writing skills and also with the layout to your weblog.
Is that this a paid subject or did you modify it your self?
Anyway stay up the excellent quality writing, it is uncommon to peer a nice blog like this one these days..
I am really impressed with your writing skills and also with the
layout on your blog. Is this a paid theme or did you
customize it yourself? Anyway keep up the
nice quality writing, it’s rare to see a great blog like this one today.
I couldn’t resist commenting. Well written!
I love what you guys tend to be up too. This sort of clever work and reporting!
Keep up the terrific works guys I’ve incorporated you guys to
our blogroll.
Pretty! This was an incredibly wonderful post. Thanks
for providing these details.
I am in fact happy to glance at this blog posts which carries tons of useful data, thanks for providing
such statistics.
Great post. I used to be checking constantly this blog and I’m impressed! I care
I care
Very helpful info specifically the last phase
for such info much. I used to be looking for this certain info for a very lengthy time.
Thanks and good luck.
Unquestionably consider that that you said. Your favorite reason seemed to be at the net the simplest factor to take
into account of. I say to you, I definitely get annoyed at the same time as other people consider concerns that they just don’t recognize about.
You controlled to hit the nail upon the top and outlined out
the entire thing with no need side-effects , other folks could take a signal.
Will probably be back to get more. Thank you
Hey there! Someone in my Facebook group shared
this website with us so I came to take a look.
I’m definitely loving the information. I’m bookmarking and
will be tweeting this to my followers! Outstanding blog and
great design.
Tremendous issues here. I am very satisfied to see your
article. Thank you a lot and I’m looking forward to touch you.
Will you please drop me a e-mail?
Nice weblog right here! Additionally your site rather a lot up
very fast! What host are you the usage of? Can I am getting your
associate link to your host? I want my site loaded
up as quickly as yours lol
I’m now not positive the place you are getting your info,
but great topic. I must spend some time learning more or understanding more.
Thank you for wonderful info I used to be in search of this info for my mission.
Hello! Do you use Twitter? I’d like to follow you if that
would be okay. I’m undoubtedly enjoying your blog and look forward to new updates.
I’m not that much of a internet reader to be honest
but your sites really nice, keep it up! I’ll go ahead and bookmark your website to come back down the
road. All the best
Hi this is kind of of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually
code with HTML. I’m starting a blog soon but have no coding know-how so I wanted
to get guidance from someone with experience. Any help would be
enormously appreciated!
Great beat ! I wish to apprentice at the same time as
you amend your site, how could i subscribe for a blog web site?
The account helped me a applicable deal. I have been a little
bit acquainted of this your broadcast offered
shiny transparent idea
If you are going for finest contents like myself, only pay a visit this site daily
as it gives quality contents, thanks
Wow, incredible blog format! How long have you been blogging for?
you make blogging glance easy. The whole look of your website is wonderful, as neatly as the content!
You are so awesome! I do not suppose I’ve truly read through something like this before.
So nice to discover someone with some genuine thoughts on this subject matter.
Seriously.. thanks for starting this up. This web site is one thing that is needed on the web, someone with a
little originality!
Wow, this post is nice, my younger sister is analyzing these things, thus I am
going to convey her.
I’m not that much of a internet reader to
be honest but your blogs really nice, keep it up! I’ll go
ahead and bookmark your website to come back down the road.
Many thanks
Hello, i think that i saw you visited my web site thus i came to “return the favor”.I’m attempting to find things to improve my site!I suppose its
ok to use some of your ideas!!
Does your site have a contact page? I’m having trouble locating it but, I’d like to send you an email.
I’ve got some creative ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it improve over
time.
Fantastic post however I was wanting to know if
you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit more.
Cheers!
It’s appropriate time to make some plans for the future and it is time to be happy.
I have read this post and if I could I want to suggest you few interesting things
or suggestions. Perhaps you can write next articles referring to this article.
I desire to read even more things about it!
I’m really loving the theme/design of your web site.
Do you ever run into any internet browser compatibility
problems? A couple of my blog readers have complained about my blog
not operating correctly in Explorer but looks great in Safari.
Do you have any advice to help fix this problem?
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance” between usability and visual
appeal. I must say you have done a great
job with this. In addition, the blog loads super fast for me
on Firefox. Excellent Blog!
fantastic put up, very informative. I wonder why the opposite specialists of this sector don’t understand this.
You should continue your writing. I am confident, you have a great readers’ base
already!
It’s an amazing piece of writing for all the web users;
they will get benefit from it I am sure.
Very descriptive blog, I enjoyed that bit. Will there be a part 2?
What i don’t understood is in truth how you are not actually a lot more well-favored than you might be now.
You’re so intelligent. You already know thus significantly when it comes to this
matter, made me in my opinion imagine it from a lot of
numerous angles. Its like women and men don’t seem
to be fascinated except it is something to accomplish with Girl gaga!
Your individual stuffs excellent. Always deal with it up!
Hey there! I understand this is somewhat off-topic
but I needed to ask. Does managing a well-established blog like yours require a lot of work?
I’m brand new to running a blog however I do write in my journal on a daily
basis. I’d like to start a blog so I can share my personal experience and feelings online.
Please let me know if you have any recommendations or tips for new aspiring blog owners.
Thankyou!
Heya! I’m at work browsing your blog from my new iphone 3gs!
Just wanted to say I love reading your blog and look forward to all
your posts! Carry on the fantastic work!
You should take part in a contest for one of the finest websites
on the internet. I’m going to recommend this web site!
Nice post. I used to be checking constantly this weblog and I am impressed! I handle such information a lot.
I handle such information a lot.
Very useful information particularly the final phase
I was seeking this certain information for a long time.
Thanks and good luck.
I’m not sure why but this website is loading very slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later and see if the problem still exists.
Very shortly this web site will be famous among
all blog people, due to it’s fastidious content
Right here is the right webpage for anyone who wants to
find out about this topic. You know so much its almost tough to argue with you (not that I actually will need to…HaHa).
You certainly put a new spin on a subject which has been discussed
for many years. Excellent stuff, just excellent!
This design is incredible! You obviously know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
Everything is very open with a precise explanation of the issues.
It was definitely informative. Your site is very
useful. Thanks for sharing!
Great blog here! Also your site loads up very fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my website loaded up as fast as yours lol
We absolutely love your blog and find nearly all of your
post’s to be what precisely I’m looking for.
can you offer guest writers to write content for you? I wouldn’t mind
composing a post or elaborating on a few of the subjects you write with regards to here.
Again, awesome site!
“I Went Vegan for 10 Weeks and This Is What Happened to My Body and Mindset”꽁머니
What’s up to all, how is everything, I think
every one is getting more from this web page, and your views
are good in support of new viewers.
Hey! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the great work!
AceLover The Style Gawd releases a new single selfproduced
called “Hurt” on Childish Records. Childish Records will be releasing an AceLover The Style
Gawd EP by August or September. The EP has production by Large Professor,
John Robinson, and of course AceLover The Style Gawd. Last year
in 2022 released an EP called ‘Style Gawd”. The single “Authentic” reached #2 on the college charts and AceLover The Style Gawd was named #4 Blazing Artist of 2022. AceLover caught the attention of legendary Hip Hop producer Large Professor(Nas Illmatic,Main Source,Cormega,The Lox(Jadakiss,StylesP,SheekLouch)feat Westside Gunn and Griselda’s Benny The Butcher) and he agreed to produce a song for the new ep. It’s the first time Style Gawd worked with a producer of that status. Childish Records is a boutique Indie Hip Hop label ran by Chica Soma a music industry professional originally from Tokyo Japan. Chicago used to work for a major record label back in Japan until she realized she wanted to really make traditional New York City Hip Hop. She paid her dues in the NYC Hip Hop scene establishing relationships with legends like BuckWild DITC, Lord Finesse, Dante Ross, etc. She was an AceLover fan from the 2For5 era. When she met AceLover she knew that she wanted to work with him.
Highly descriptive article, I loved that bit.
Will there be a part 2?
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo
News? I’ve been trying for a while but I never seem to get there!
Thanks
You really make it appear so easy together with your
presentation however I to find this topic to be really
something which I feel I would never understand. It sort of feels too complicated and very wide for me.
I am having a look ahead to your subsequent put up, I’ll try to get
the grasp of it!
секс видео
I don’t even know how I ended up here, but I thought
this post was good. I don’t know who you are but certainly
you’re going to a famous blogger if you aren’t already ;
) Cheers!
Your style is really unique compared to other folks I’ve read stuff from.
Many thanks for posting when you’ve got the opportunity, Guess I’ll just book mark this page.
This piece of writing will assist the internet users for creating new webpage or even a blog
from start to end.
There is definately a great deal to learn about this topic.
I love all of the points you have made.
Wonderful goods from you, man. I have understand your
stuff previous to and you are just extremely wonderful.
I actually like what you’ve acquired here, really like what you are saying and the way in which you say it.
You make it enjoyable and you still care for to keep it wise.
I can’t wait to read much more from you. This is really a great site.
Hi just wanted to give you a brief heads up and let you know a few of the
pictures aren’t loading properly. I’m not sure
why but I think its a linking issue. I’ve tried it in two
different internet browsers and both show the same outcome.
Thanks for sharing your thoughts. I truly appreciate your efforts and I will be waiting
for your next post thanks once again.
Does your site have a contact page? I’m having trouble locating it but,
I’d like to send you an e-mail. I’ve got some creative ideas for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it improve over
time.
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and
was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look
forward to your new updates.
I seriously love your website.. Great colors & theme.
Did you make this site yourself? Please reply back as I’m
wanting to create my own website and would like to learn where
you got this from or what the theme is called. Thank you!
Interesting blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got your design. Cheers
you’re in reality a excellent webmaster. The website loading speed is amazing.
It kind of feels that you are doing any distinctive trick.
Moreover, The contents are masterwork. you’ve done a great task in this
topic!
Today, I went to the beachfront with my children. I found a sea shell and gave it
to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell
to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I
had to tell someone!
Hello, Neat post. There’s a problem with your site in internet explorer, would test this?
IE still is the marketplace chief and a big
part of other folks will pass over your wonderful writing because of this problem.
Also visit my site Mozz Guard Reviews
Hello! This is my first visit to your blog! We are
a team of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us beneficial information to work on. You have done
a wonderful job!
My spouse and I stumbled over here by a different web page and thought I might as well check things out.
I like what I see so now i’m following you. Look forward to exploring your web page for a second time.
You can certainly see your expertise in the article you write.
The world hopes for even more passionate writers such as you who aren’t afraid to mention how
they believe. All the time follow your heart.
Hello there! I know this is kind of off topic but I was wondering which blog platform are you
using for this website? I’m getting sick and tired of WordPress because I’ve had
issues with hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of a
good platform.
Thanks , I’ve recently been searching for info
approximately this subject for ages and yours is the greatest I have came upon till
now. But, what in regards to the bottom line? Are you certain in regards to the source?
I am regular reader, how are you everybody? This paragraph posted at this website
is truly fastidious.
My partner and I stumbled over here coming from a different web page
and thought I should check things out. I like what I see so now i’m
following you. Look forward to looking over your web page again.
Magnificent beat ! I wish to apprentice while you amend your web site, how can i subscribe for
a blog site? The account helped me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided
bright clear concept
Hey There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and come back to read more of your useful info.
Thanks for the post. I’ll definitely comeback.
Today, I went to the beachfront with my children.
I found a sea shell and gave it to my 4 year old daughter and said
“You can hear the ocean if you put this to your ear.” She placed the shell
to her ear and screamed. There was a hermit
crab inside and it pinched her ear. She never wants to
go back! LoL I know this is entirely off topic but I had to tell someone!
Hiya very nice blog!! Guy .. Beautiful .. Amazing
.. I’ll bookmark your web site and take the feeds additionally?
I am satisfied to search out numerous helpful information right here within the post, we need
develop more strategies on this regard, thanks for sharing.
. . . . .
It’s the best time to make a few plans for the longer term and it is time to be happy.
I’ve learn this publish and if I could I want to suggest you
few fascinating things or tips. Maybe you can write subsequent articles relating to
this article. I wish to read more issues about it!
Great post. I used to be checking constantly this blog and I am impressed!
Very useful info particularly the ultimate phase I take care
I take care
of such information much. I was looking for this
certain info for a long time. Thanks and best of
luck.
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to
seeking more of your excellent post. Also, I have shared your site in my social networks!
I read this post fully concerning the comparison of most recent and previous technologies,
it’s remarkable article.
I do believe all the ideas you have introduced for your post.
They are very convincing and will certainly work.
Still, the posts are very quick for beginners. Could you
please prolong them a bit from next time? Thanks for the post.
Just wish to say your article is as surprising.
The clearness in your post is simply great and i can assume you’re an expert on this subject.
Fine with your permission allow me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please continue the rewarding work.
Hi there! I could have sworn I’ve visited your blog before but after
going through many of the posts I realized it’s new to me.
Anyways, I’m certainly pleased I discovered it and I’ll be book-marking it and checking back regularly!
I’m not that much of a internet reader to
be honest but your blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back later.
Cheers
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your site?
My website is in the very same area of interest as yours
and my visitors would really benefit from a lot of the information you provide here.
Please let me know if this okay with you. Many thanks!
Way cool! Some very valid points! I appreciate you
writing this article and the rest of the website is extremely good.
Saved as a favorite, I like your blog!
Great web site you’ve got here.. It’s hard to find high quality writing like yours nowadays.
I seriously appreciate individuals like you!
Take care!!
I really like it when folks get together and share
opinions. Great site, stick with it!
I’m amazed, I have to admit. Seldom do I encounter a blog that’s equally educative and
amusing, and without a doubt, you’ve hit the nail
on the head. The problem is something that too few men and women are speaking
intelligently about. I am very happy I stumbled across this during my hunt for something relating to this.
секс видео
Heya just wanted to give you a brief heads up and let you know a few of the
pictures aren’t loading correctly. I’m not sure why but I think
its a linking issue. I’ve tried it in two different internet browsers and both show the same results.
Hello! I could have sworn I’ve been to this blog before but
after browsing through some of the post I realized it’s new to me.
Anyhow, I’m definitely happy I found it and I’ll be bookmarking and checking back frequently!
magnificent publish, very informative. I’m wondering why the opposite specialists of this sector don’t notice this.
You should proceed your writing. I’m sure, you’ve a huge readers’ base already!
I really like what you guys are up too. Such clever work and exposure!
Keep up the good works guys I’ve added you guys to my personal blogroll.
I really like what you guys tend to be up too.
This kind of clever work and reporting! Keep
up the wonderful works guys I’ve you guys to blogroll.
Admiring the hard work you put into your site and detailed information you provide.
It’s great to come across a blog every once in a while that
isn’t the same unwanted rehashed information. Wonderful read!
I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
Hi there, after reading this remarkable article i am too
cheerful to share my know-how here with friends.
What’s Happening i am new to this, I stumbled upon this I have discovered It positively helpful and it has helped me out loads.
I hope to give a contribution & aid other customers
like its aided me. Great job.
My spouse and I stumbled over here coming from a different web page
and thought I might as well check things out.
I like what I see so now i’m following you.
Look forward to looking into your web page yet again.
“When you read these 19 shocking food facts, you’ll never want to eat again”메이저사이트
What’s up everyone, it’s my first go to see at this web site, and paragraph is truly fruitful
in support of me, keep up posting these posts.
Heya outstanding blog! Does running a blog like
this take a great deal of work? I have no
knowledge of programming but I had been hoping to start my own blog in the near future.
Anyway, should you have any suggestions or techniques for
new blog owners please share. I know this is off subject nevertheless I just needed to ask.
Many thanks!
Hey There. I found your blog using msn. This is a really well written article.
I’ll be sure to bookmark it and come back to read more of your useful information. Thanks
for the post. I will definitely comeback.
Definitely imagine that that you said. Your favourite reason seemed to
be at the internet the simplest factor to be aware of.
I say to you, I certainly get annoyed while other folks
think about worries that they just do not recognize about.
You controlled to hit the nail upon the top as smartly as outlined out the entire thing with no need side effect
, other folks could take a signal. Will probably be again to get more.
Thank you
I’m gone to convey my little brother, that he
should also go to see this website on regular basis to take updated from latest information.
Hello There. I found your weblog the use of msn. That is a very neatly written article.
I will make sure to bookmark it and return to
learn extra of your useful information. Thank you
for the post. I will definitely return.
This is a good tip especially to those fresh to the blogosphere.
Simple but very precise info… Thank you for sharing this one.
A must read article!
Hi, i think that i saw you visited my site so i came to “return the favor”.I
am trying to find things to improve my web site!I
suppose its ok to use some of your ideas!!
секс видео
I was suggested this blog by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my problem.
You are incredible! Thanks!
Hi there, its fastidious piece of writing regarding media
print, we all be aware of media is a impressive source of data.
Good day! Would you mind if I share your blog with my zynga group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Many thanks
Thanks for finally talking about > Пиастры –
Составление семантического ядра | < Loved it!
Hey there! Someone in my Myspace group shared this site
with us so I came to look it over. I’m definitely loving
the information. I’m book-marking and will be tweeting this to my followers!
Excellent blog and fantastic style and design.
Hi, i think that i saw you visited my site so i
came to “return the favor”.I am trying to find things to improve my
site!I suppose its ok to use some of your ideas!!
секс видео
I every time used to study post in news papers but now as I am a
user of web thus from now I am using net for articles, thanks to web.
Hi there, I found your website via Google even as looking for a comparable matter, your site got
here up, it appears to be like great. I have bookmarked it in my google bookmarks.
Hi there, just become alert to your weblog
via Google, and located that it’s really informative.
I am going to watch out for brussels. I’ll appreciate should you
continue this in future. A lot of other people will probably be benefited from your writing.
Cheers!
“This Is The Surprising Way Coronavirus Has Changed Travel Insurance”토토사이트
I blog quite often and I genuinely appreciate your content.
This article has truly peaked my interest. I’m going to
take a note of your website and keep checking for new details about
once per week. I opted in for your Feed as well.
Oh my goodness! Impressive article dude! Thank you, However I am
encountering difficulties with your RSS. I don’t know the reason why I am
unable to subscribe to it. Is there anyone else having the same RSS
problems? Anyone that knows the solution will you kindly respond?
Thanks!! https://drive.google.com/drive/folders/1hofUurE5NBZOIC5aZnMBk6sWLYzp4gDp
Hello every one, here every person is sharing such familiarity, thus it’s nice
to read this web site, and I used to go to see this website every day.
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is important and everything. However think of if you added some great images or videos to give your posts more, “pop”!
Your content is excellent but with pics and video clips, this site could undeniably be one of
the very best in its niche. Wonderful blog!
Asking questions are in fact nice thing if you are not understanding something entirely, however this
piece of writing offers pleasant understanding even.
Its such as you read my thoughts! You appear to know so much approximately this, like you wrote the e-book in it or something.
I think that you could do with some p.c. to drive the message home a bit, but other than that, that is fantastic blog.
A fantastic read. I’ll certainly be back.
Hi there are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and
create my own. Do you require any coding expertise to make your
own blog? Any help would be greatly appreciated!
It’s remarkable to pay a quick visit this site and reading the views of all mates regarding this
post, while I am also eager of getting experience.
Hi there! I could have sworn I’ve been to this blog before but after browsing through some of the
post I realized it’s new to me. Anyways, I’m definitely
glad I found it and I’ll be book-marking and checking back frequently!
I’m not sure the place you’re getting your info, but
great topic. I must spend a while learning more or figuring out more.
Thank you for magnificent information I was searching for this info for
my mission.
новое порно
Yes! Finally something about antminer s19 цена купить.
I am curious to find out what blog platform you’re using?
I’m experiencing some small security problems with my
latest website and I’d like to find something
more safe. Do you have any solutions?
Why people still use to read news papers when in this technological world all is accessible on net?
Aw, this was an incredibly nice post. Spending some time and actual effort to
make a good article? but what can I say? I hesitate a whole lot
and never seem to get anything done.
Here is my homepage; automobile salvage near me
I read this piece of writing completely on the topic
of the resemblance of latest and preceding technologies, it’s awesome article.
What’s up to every one, because I am genuinely eager of reading this blog’s post to be updated
daily. It contains pleasant information.
wonderful submit, very informative. I wonder why
the opposite experts of this sector don’t realize this.
You must continue your writing. I’m confident, you have a great readers’ base already!
Great blog you’ve got here.. It’s hard to find excellent writing like yours nowadays.
I honestly appreciate individuals like you! Take care!!
Can you tell us more about this? I’d want to find out more details.
This is a good tip particularly to those fresh to the blogosphere.
Brief but very accurate info… Thanks for sharing this
one. A must read article!
I feel this is among the most important info for me. And i’m happy
studying your article. But want to commentary on few general issues,
The site taste is great, the articles is really great : D.
Excellent job, cheers
I like reading an article that will make people think.
Also, thanks for permitting me to comment!
Hey, I think your website might be having browser compatibility issues.
When I look at your website in Safari, it looks fine but when opening
in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other
then that, amazing blog!
Hello there! This article could not be written much
better! Reading through this post reminds me of my previous roommate!
He continually kept talking about this. I’ll send this article to him.
Pretty sure he will have a great read. Thanks for sharing!
My spouse and I stumbled over here from a different page and
thought I should check things out. I like what I see
so i am just following you. Look forward to looking over your web page yet again.
hello!,I really like your writing so so much! share we keep in touch more about your article on AOL?
I require an expert in this area to solve my problem.
May be that’s you! Looking forward to look you.
Since the admin of this web page is working, no doubt very rapidly
it will be famous, due to its feature contents.
потрахушки
“The biggest food trends of 2023 (you won’t believe #9)”먹튀검증업체
This blog was… how do I say it? Relevant!! Finally I’ve found something which
helped me. Thanks a lot!
Very great post. I simply stumbled upon your blog
and wanted to mention that I’ve really enjoyed browsing your blog posts.
After all I’ll be subscribing to your feed and I’m hoping you write again soon!
Hi! I could have sworn I’ve been to your blog
before but after browsing through many of the articles I realized it’s new to me.
Regardless, I’m definitely delighted I stumbled upon it and I’ll be book-marking
it and checking back frequently!
McCarthy has summoned lawmakers from the House of Representatives back to Washington from a holiday recess to vote on the deal on Wednesday. 메이저사이트
I know this site gives quality based content and extra stuff, is there
any other web page which presents these things in quality?
Sweet blog! I found it while browsing on Yahoo News. Do you
have any tips on how to get listed in Yahoo
News? I’ve been trying for a while but I never seem to get there!
Cheers
Thanks for finally talking about > Пиастры – Составление семантического ядра
| < Loved it!
Great post. I was checking continuously this blog and I’m impressed! I care for such info a lot.
I care for such info a lot.
Extremely useful info specifically the last part
I was seeking this certain info for a long time. Thank you and best of luck.
Usually I do not read post on blogs, but I wish to say that
this write-up very compelled me to take a look at and
do it! Your writing style has been amazed me. Thank you, quite nice post.
We are really pleased with the service we received and would advocate Hudson McKenzie to anybody in search of Immigration Legal professionals.
The resume building service assist in the adherence of the
resume to the standard of that particular country.
Yi Li has been approved and we both are grateful for his or her wonderful service.
And we’re that staff. The ilexlaw legal workforce
provides employers and employees with the latest and most appropriate immigration strategies.
The ilexlaw authorized team offers complete immigration companies ranging from the multi-faceted needs
of people to the high quantity inquiries of multi-national firms.
Germany has very high standards of residing making it some of
the sought country for immigration for families want to dwell and settle.
In order to achieve success in an asylum declare an applicant has to indicate that he’s
being persecuted by the federal government or he’s being persecuted by
a bunch within the nation that the government is powerless or
unwilling to cease. For over 30 years, they have helped immigrants grow to be citizens
and avoid being eliminated. The share of detained immigrants with counsel throughout all cities was 14 p.c.
Keep on working, great job!
Hi there, I enjoy reading through your article post. I like to write a little comment to support
you.
After I originally left a comment I seem to have
clicked on the -Notify me when new comments are added-
checkbox and now whenever a comment is added I recieve four emails with
the same comment. There has to be a means you
are able to remove me from that service? Many thanks!
I’ve been surfing on-line more than 3 hours as of late,
but I by no means discovered any attention-grabbing article like yours.
It’s pretty value sufficient for me. In my opinion, if all site
owners and bloggers made just right content material
as you probably did, the web will be a lot more useful than ever before.
I am not sure where you’re getting your information, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic information I was looking for this info for my mission.
Great delivery. Outstanding arguments. Keep up the good effort.
May I simply just say what a comfort to find
someone that actually knows what they’re discussing on the web.
You certainly realize how to bring an issue to light and make it important.
A lot more people have to check this out and understand this side of the story.
I was surprised you’re not more popular given that you certainly possess the gift.
If you would like to obtain a great deal from this post then you
have to apply these techniques to your won web site.
Fantastic goods from you, man. I’ve understand your stuff previous to and
you are just too fantastic. I actually like what you have acquired here,
really like what you are saying and the way in which
you say it. You make it enjoyable and you still care for to keep it smart.
I cant wait to read much more from you. This is actually
a wonderful site.
Handle Root Causes of Migration – Codify and fund President Biden’s $4 billion 4-yr plan to address
root causes of migration, improve immigration courts, and support asylum seekers and other weak populations.
Their crew contains registered migration brokers who’re authorized to supply immigration advice and assistance.
Our attorneys perceive that our work has huge affect on the lives
of immigrants and their households, and we are dedicated to providing particular person consideration and counsel to each consumer.
It was not easy for applicants to completely migrate right here even if they’ve jobs right here
because of something called Labor Market Impact Assessment (LMIA).
People who emigrate are called emigrants. Our attorneys are in courtroom on a daily
basis. Do not waste even a single minute and get in touch with considered one of the top immigration bond attorneys in Macon, GA to remain in the court at
the fitting time and watch the proceedings unfold.
Immigration attorneys can handle the advanced means of dealing with paperwork, courtroom cases and
the bureaucracy that’s required.
смотреть онлайн
Very descriptive blog, I liked that bit. Will there be a part 2?
Aw, this was a very good post. Taking a few minutes and actual effort to generate a top notch article… but
what can I say… I hesitate a lot and never manage to get anything done.
I like the valuable information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I am quite certain I’ll learn a lot of new stuff right here!
Good luck for the next!
I’m gone to tell my little brother, that he should also visit this weblog on regular basis to get updated from newest gossip.
healthy, it has to noot jyst be physically — I really feel much better mentally.
Also vist my site 스웨디시마사지
Wow! After all I got a website from where I be capable of really
obtain helpful information regarding my study and knowledge.
I’ve read a few excellent stuff here. Certainly worth bookmarking for revisiting.
I surprise how a lot effort you set to make any such wonderful informative website.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter
updates. I’ve been looking for a plug-in like this for quite some time and was
hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
of course like your website but you have to take a look at the spelling
on quite a few of your posts. Many of them are rife with spelling issues and I
find it very bothersome to tell the reality however I’ll surely come back again.
Hello i am kavin, its my first occasion to commenting anywhere, when i read this post
i thought i could also create comment due to this good post.
We absolutely love your blog and find a lot of
your post’s to be just what I’m looking for. Do you offer guest writers to write content for you?
I wouldn’t mind composing a post or elaborating on most
of the subjects you write about here. Again, awesome web site!
I’m curious to find out what blog system you happen to be utilizing?
I’m having some minor security issues with my latest website and
I would like to find something more safe. Do you have any recommendations?
great points altogether, you just won a new reader.
What might you suggest in regards to your post that you simply made
some days in the past? Any certain?
Thanks on your marvelous posting! I definitely enjoyed
reading it, you may be a great author. I will always bookmark your blog and will often come back in the foreseeable future.
I want to encourage continue your great job, have a nice weekend!
Right away I am going to do my breakfast, afterward having my breakfast coming over again to read further news.
WOW just what I was searching for. Came here by searching for kentaki frai ciken
What you posted made a great deal of sense. However, what about this?
suppose you were to create a awesome headline? I mean, I don’t wish to tell you how to run your blog, but what if you added a post title to
possibly grab folk’s attention? I mean Пиастры – Составление семантического ядра |
is kinda boring. You could look at Yahoo’s front page
and note how they create article titles to get
people to click. You might add a video or a related pic or two to grab readers interested
about what you’ve got to say. Just my opinion, it could bring your posts a little livelier.
I do not know if it’s just me or if everybody else encountering issues with your site.
It appears as though some of the text on your content are running
off the screen. Can somebody else please provide feedback and let me know if this is
happening to them as well? This could be a problem with my browser because I’ve had this happen previously.
Many thanks
Heya i am for the primary time here. I found this board
and I to find It really helpful & it helped me out much. I’m hoping
to offer one thing back and help others like you aided me.
Heya! I realize this is somewhat off-topic however I had to ask.
Does running a well-established website like yours take a large
amount of work? I am brand new to operating a blog however I do write in my diary every day.
I’d like to start a blog so I can share my experience and thoughts online.
Please let me know if you have any suggestions or tips for new
aspiring blog owners. Thankyou!
Thanks designed for sharing such a good thought, paragraph is fastidious, thats why
i have read it entirely
Hello, I enjoy reading all of your article post.
I wanted to write a little comment to support you.
Hi Dear, are you truly visiting this web page regularly, if so after that you will absolutely get pleasant know-how.
“Can Face Masks Prevent You From Getting the Coronavirus? Doctors Weight In”토토사이트 추천
It is perfect time to make a few plans for
the longer term and it is time to be happy. I have learn this post and if I may I wish to recommend you few attention-grabbing things
or advice. Maybe you could write next articles relating
to this article. I desire to read more issues about it!
I don’t even know how I stopped up right here, but I believed this submit used
to be great. I don’t recognize who you might be but definitely you’re going to a well-known blogger when you
are not already. Cheers!
This is very interesting, You are an excessively professional blogger.
I’ve joined your rss feed and look forward to in the hunt for extra of your wonderful post.
Additionally, I’ve shared your web site in my social networks
You ought to take part in a contest for one of the highest quality sites on the net.
I will highly recommend this site!
No matter if some one searches for his required thing,
thus he/she wishes to be available that in detail, so that thing is maintained over here.
My programmer is trying to persuade me to move to
.net from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on various websites for about a year and am nervous about switching to another platform.
I have heard good things about blogengine.net. Is there a way I can transfer all my
wordpress posts into it? Any kind of help would be really appreciated!
I am not sure where you’re getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for great information I was looking for this information for my mission.
A person necessarily help to make severely posts I’d state.
That is the very first time I frequented your website page
and so far? I amazed with the research you made to create this actual put up extraordinary.
Magnificent process!
What you said was actually very reasonable. However, consider this, suppose you added a little content?
I am not suggesting your content is not good., but what if you added a title to possibly get a person’s attention? I mean Пиастры
– Составление семантического ядра | is a little vanilla.
You might peek at Yahoo’s home page and watch how they write post titles to grab viewers interested.
You might add a related video or a related pic or two to
get readers interested about what you’ve written. Just my opinion, it might bring your website a little livelier.
Hello! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve
worked hard on. Any suggestions?
I’m gone to say to my little brother, that he should also pay
a visit this blog on regular basis to take updated from most recent reports.
I blog quite often and I truly thank you for your information. The article
has truly peaked my interest. I am going to book mark your site and keep checking for new information about once a week.
I subscribed to your Feed too.
I visited various web sites except the audio feature for audio
songs existing at this web page is actually excellent.
I am regular visitor, how are you everybody? This article posted at
this site is truly pleasant.
I always used to read piece of writing in news papers but now as I am a user of internet
thus from now I am using net for posts, thanks to web.
I think everything said was actually very reasonable. However,
what about this? what if you were to write a awesome
headline? I ain’t suggesting your information is not solid,
but suppose you added a title that makes people desire more?
I mean Пиастры – Составление семантического ядра |
is a little vanilla. You should peek at Yahoo’s home page and note how they write news titles to grab viewers to open the links.
You might add a related video or a picture or two to
get readers interested about what you’ve got to say. Just my opinion, it
could bring your posts a little bit more interesting.
Great post however I was wanting to know if you could write a litte
more on this subject? I’d be very thankful
if you could elaborate a little bit further.
Kudos!
This excellent website definitely has all the information I needed
concerning this subject and didn’t know who to ask.
When I originally commented I appear to have clicked on the
-Notify me when new comments are added- checkbox and now whenever a comment is
added I get four emails with the same comment. There has to be an easy method you
can remove me from that service? Thanks a lot!
My family members all the time say that I am killing my time here at net, except I know I am getting know-how
every day by reading such good posts.
Hello there, I found your web site by means of Google whilst searching for a related topic, your website came up, it appears good.
I’ve bookmarked it in my google bookmarks.
Hi there, just turned into alert to your blog thru Google, and located that it’s really informative.
I am going to watch out for brussels. I’ll be grateful for those who proceed this in future.
A lot of other people will likely be benefited out of your writing.
Cheers!
Hello! Would you mind if I share your blog with my twitter group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Cheers
I really like your blog.. very nice colors & theme. Did you
create this website yourself or did you hire someone to do it
for you? Plz answer back as I’m looking to construct
my own blog and would like to find out where u got this
from. cheers
hello there and thank you for your info – I have definitely picked up something new
from right here. I did however expertise a few technical issues using this website, as I experienced
to reload the site many times previous to I could get it
to load correctly. I had been wondering if your web hosting is OK?
Not that I’m complaining, but slow loading instances times will often affect your placement in google and can damage your high quality
score if advertising and marketing with Adwords.
Well I am adding this RSS to my e-mail and can look out for a lot more of your
respective fascinating content. Ensure that you update this again soon.
It’s a shame you don’t have a donate button! I’d
certainly donate to this fantastic blog! I guess for now i’ll settle for bookmarking and
adding your RSS feed to my Google account. I look forward to new updates and
will share this site with my Facebook group. Talk soon!
I just could not leave your website before suggesting that
I really enjoyed the standard info a person provide for your guests?
Is going to be back continuously to check out new posts
With havin so much content and articles do you ever run into any
issues of plagorism or copyright infringement?
My site has a lot of exclusive content I’ve either created myself
or outsourced but it appears a lot of it is popping it
up all over the internet without my agreement.
Do you know any ways to help stop content from being ripped off?
I’d genuinely appreciate it.
Thanks designed for sharing such a good thinking, article is good, thats why i
have read it entirely
Amazing! This blog looks just like my old one! It’s on a completely different subject but
it has pretty much the same layout and design. Superb choice of colors!
Very nice article, exactly what I wanted to find.
Very great post. I simply stumbled upon your weblog and wished to say that I have truly loved
surfing around your blog posts. In any case I will be subscribing in your feed and
I’m hoping you write again very soon!
It is actually a great and useful piece of information. I am glad that you shared this helpful info with us.
Please keep us up to date like this. Thanks
for sharing.
It is perfect time to make a few plans for the longer term and it is time to be happy.
I’ve read this publish and if I may just I want to recommend you few interesting things or tips.
Maybe you can write subsequent articles regarding
this article. I wish to read even more things about it!
That is really attention-grabbing, You’re an overly professional blogger.
I’ve joined your rss feed and stay up for seeking extra of your excellent post.
Also, I’ve shared your web site in my social networks
Very good post. I will be dealing with many
of these issues as well..
Do you mind if I quote a few of your articles as long as I provide credit and sources back
to your webpage? My blog site is in the very same niche as
yours and my visitors would certainly benefit from
some of the information you present here. Please let me
know if this alright with you. Thank you!
Greetings! Very helpful advice within this article!
It is the little changes that make the biggest changes. Thanks for sharing!
I have read so many articles or reviews on the topic of the blogger lovers
but this post is in fact a fastidious post, keep it up.
Excellent article. I absolutely love this website. Keep it up!
That is a very good tip particularly to those fresh to the blogosphere.
Brief but very precise information… Appreciate your sharing
this one. A must read article!
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on several websites for about a year and
am nervous about switching to another platform.
I have heard excellent things about blogengine.net.
Is there a way I can transfer all my wordpress content
into it? Any kind of help would be greatly appreciated!
Thank you for another informative website. The place else may just I
am getting that type of info written in such a perfect method?
I have a undertaking that I’m just now running on, and I’ve been on the look out for such information.
It’s hard to come by well-informed people in this particular
subject, but you seem like you know what you’re talking about!
Thanks
I know this site offers quality dependent posts and other stuff, is there any other
site which provides these stuff in quality?
Thank you a lot for sharing this with all people you really realize what
you’re speaking about! Bookmarked. Please additionally consult with my web site =).
We may have a link change contract between us
Have you ever considered about including a little bit more than just
your articles? I mean, what you say is valuable and everything.
Nevertheless just imagine if you added some great photos or videos to give your posts more, “pop”!
Your content is excellent but with images and video
clips, this website could definitely be one of the
most beneficial in its field. Excellent blog!
Hey just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different
internet browsers and both show the same outcome.
I think this is among the most significant information for me.
And i am glad reading your article. But should remark
on few general things, The site style is perfect, the articles is really great
: D. Good job, cheers
I’m gone to inform my little brother, that he should also
pay a quick visit this weblog on regular basis to get updated from
most up-to-date news.
“However, against the backdrop of the global economic slowdown and a more uncertain business environment, firms are likely to take a cautious approach regarding salary increments,” said MOM. 안전놀이터
Please let me know if you’re looking for a article author for your site.
You have some really great posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d love to write some material
for your blog in exchange for a link back to mine.
Please blast me an email if interested. Regards!
Great weblog right here! Additionally your web site quite a bit
up fast! What web host are you the use of? Can I am getting
your affiliate hyperlink on your host? I wish my website loaded up as quickly as yours lol
I was able to find good information from your blog articles.
Howdy! I know this is kinda off topic however , I’d figured
I’d ask. Would you be interested in exchanging links or maybe guest authoring a blog article or vice-versa?
My blog covers a lot of the same topics as yours and I feel we could
greatly benefit from each other. If you’re interested feel free to shoot me
an e-mail. I look forward to hearing from you! Fantastic blog by the way!
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your site?
My blog is in the very same area of interest as yours and my visitors
would certainly benefit from some of the information you present here.
Please let me know if this ok with you. Appreciate it!
After checking out a few of the articles on your website, I really
appreciate your technique of blogging. I book-marked it to my bookmark webpage list and will
be checking back in the near future. Take a look at my web site too and let me know
how you feel.
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your excellent post.
Also, I’ve shared your site in my social networks!
I need to to thank you for this very good read!!
I definitely enjoyed every bit of it. I’ve got you book-marked to check out new things you post…
I pay a quick visit each day a few websites and blogs
to read content, but this weblog gives feature based posts.
This site really has all of the info I wanted about this subject and didn’t know who to ask.
Post writing is also a excitement, if you be familiar with
then you can write otherwise it is complicated to write.
It’s going to be finish of mine day, however before finish I am reading this fantastic piece of writing to increase my experience.
Its like you read my mind! You appear to know a lot about this, like you wrote the book
in it or something. I think that you can do with some pics to drive the message home a little bit,
but other than that, this is wonderful blog. A great read. I’ll definitely be back.
magnificent post, very informative. I ponder why the other specialists of this sector do not notice this.
You must continue your writing. I’m confident, you’ve a great readers’ base already!
There is definately a lot to find out about this subject.
I really like all of the points you’ve made.
Nice answers in return of this difficulty with real arguments and telling all on the
topic of that.
Earlier in the war, the United States tried to dissuade Ukraine from defending Bakhmut, which Russia eventually seized 메이저사이트
Thanks for the good writeup. It actually used to be
a amusement account it. Glance complicated to far delivered agreeable
from you! However, how can we keep in touch?
Please let me know if you’re looking for a article author for your weblog.
You have some really great articles and I feel I would be a good asset.
If you ever want to take some of the load off, I’d really like to write some material for your blog in exchange for
a link back to mine. Please send me an e-mail if interested.
Thank you!
Hi my family member! I wish to say that this post is amazing, great written and include approximately all
significant infos. I would like to see more posts like this
.
Thank you, I have recently been looking for info approximately this subject for ages and yours is
the best I have came upon so far. But, what about the bottom
line? Are you sure concerning the source?
Excellent site. Lots of useful info here. I am sending it to several buddies ans also
sharing in delicious. And obviously, thanks on your effort!
Someone necessarily assist to make critically posts I might state.
This is the very first time I frequented your web page and up
to now? I surprised with the analysis you made to create this actual put up incredible.
Excellent process!
I’d like to find out more? I’d like to find out more details.
Good day! I could have sworn I?ve been to this site before but after browsing through a few of the articles I realized
it?s new to me. Nonetheless, I?m certainly happy I discovered it and
I?ll be bookmarking it and checking back frequently!
my blog post :: Super Bio CBD Gummies Reviews
What a stuff of un-ambiguity and preserveness of valuable know-how regarding unpredicted
feelings.
My brother recommended I might like this web site.
He was once totally right. This publish truly made my day.
You can not consider just how much time I had spent for this info!
Thank you!
It’s actually very complicated in this full of activity life to listen news on Television, thus
I just use world wide web for that reason, and take the
hottest news.
Hi there to every one, the contents present at this web site are genuinely awesome for people experience, well, keep up the nice work fellows.
Pretty great post. I just stumbled upon your weblog and wished to say that I’ve truly
loved surfing around your blog posts. In any case I will be subscribing on your feed and I’m hoping you write again very soon!
I do not know whether it’s just me or if perhaps everyone else experiencing issues with
your website. It appears as though some of the text within your posts
are running off the screen. Can somebody else please comment and let me
know if this is happening to them as well? This might be a issue with my browser because I’ve had this happen previously.
Appreciate it
“You’ll Never Get Hired if You Say This in a Job Interview”메이저사이트
Its not my first time to go to see this site, i am visiting this site dailly and get pleasant information from here
every day.
I do accept as true with all the ideas you have presented for your post.
They are really convincing and will definitely work.
Nonetheless, the posts are too short for novices.
Could you please prolong them a little from subsequent time?
Thank you for the post.
We absolutely love your blog and find a lot of your post’s to be exactly I’m looking for.
can you offer guest writers to write content in your case?
I wouldn’t mind publishing a post or elaborating on a lot of the
subjects you write related to here. Again, awesome web site!
Undeniably believe that which you stated. Your favorite reason seemed to be
on the internet the simplest thing to be
aware of. I say to you, I definitely get annoyed while people consider
worries that they just do not know about. You managed to hit the
nail upon the top and also defined out the whole thing without having side-effects , people could
take a signal. Will likely be back to get more.
Thanks
wonderful points altogether, you just won a new reader.
What may you recommend in regards to your publish that you just made some days in the past?
Any sure?
It’s going to be ending of mine day, but before finish I am reading this great paragraph
to improve my knowledge.
Admiring the dedication you put into your site and in depth information you present.
It’s nice to come across a blog every once in a while that isn’t the same unwanted rehashed information. Excellent read!
I’ve saved your site and I’m including your RSS feeds to my
Google account.
What’s up, yup this article is truly pleasant and
I have learned lot of things from it on the topic of blogging.
thanks.
Your way of explaining the whole thing in this article is really good, every one be able to effortlessly
be aware of it, Thanks a lot.
“This Is The Surprising Way Coronavirus Has Changed Travel Insurance”토토사이트
Hello there, just became aware of your blog through Google,
and found that it’s truly informative. I am gonna watch out for
brussels. I will be grateful if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
Hi, this weekend is nice for me, since this time i
am reading this impressive informative paragraph here at my home.
Here is my web blog … Vita Labs CBD Gummies Reviews
I really like your blog.. very nice colors & theme.
Did you make this website yourself or did you hire someone to do it for you?
Plz reply as I’m looking to construct my own blog and would
like to know where u got this from. cheers
Hi Dear, are you truly visiting this web page on a regular basis,
if so afterward you will without doubt get good knowledge.
Your style is unique compared to other people I’ve
read stuff from. I appreciate you for posting when you have the opportunity,
Guess I will just book mark this site.
I’ve been exploring for a bit for any high quality articles or blog posts
on this kind of space . Exploring in Yahoo I ultimately stumbled upon this website.
Studying this info So i’m happy to express that I have an incredibly
just right uncanny feeling I discovered just what
I needed. I so much surely will make sure to don?t put out of your mind this site and
provides it a look on a constant basis.
Howdy! Do you use Twitter? I’d like to follow you if that would be
okay. I’m undoubtedly enjoying your blog and look forward to new updates.
I enjoy looking through a post that will make men and women think.
Also, many thanks for allowing me to comment!
fuck girl
Does your website have a contact page? I’m having problems locating
it but, I’d like to shoot you an e-mail. I’ve got some creative ideas
for your blog you might be interested in hearing. Either way, great website and I look forward to
seeing it grow over time.
Hi, I do think this is a great web site. I stumbledupon it 😉 I will come back yet again since I
book-marked it. Money and freedom is the best way to change, may you be rich and continue to guide other people.
This paragraph gives clear idea in support of the new visitors of blogging, that truly how to do blogging and
site-building.
Thank you for every other fantastic article. The place else may just
anybody get that kind of information in such an ideal approach of writing?
I’ve a presentation next week, and I’m at the search for such info.
Feel free to visit my blog BugMD Zapper Reviews
The compromise after weeks of intense talks offers a path back from the precipice, even as the clock is still ticking down to the Jun 5 “X-date” when the Treasury estimates there might not be enough cash to pay bills and debts. 토토사이트 추천
I am genuinely thankful to the holder of this website who has
shared this impressive paragraph at at this time.
I’m gone to say to my little brother, that he should also go
to see this blog on regular basis to obtain updated from most recent news update.
Good answer back in return of this issue with firm arguments and telling the
whole thing regarding that.
Setiap harinya, jumlah pecinta slot online di tanah air semakin meningkat.
Hal ini kemudian juga semakin meningkatkan jumlah situs slot online yang
bertebaran di internet. Di antara sekian banyak situs slot online tersebut, ada satu situs slot online terbaik dan anti rungkad
yaitu okeplay777. Sebagai situs slot online terbaik anti rungkad, okeplay777 telah melayani
ribuan member aktif dari berbagai kalangan. Member aktif okeplay777 ini terdiri dari para bettor
setia, baik itu yang masih pemula maupun senior dalam dunia judi online.
Anda pun dapat menjadi bagian dari situs slot online okeplay777 ini dan merasakan manfaat dan keuntungan yang ditawarkannya.
okeplay777 bukanlah hanya sekedar situs slot online biasa.
Di situs slot online terbaik anti rungkad okeplay777 ini,
Anda akan sangat jarang merasakan kekalahan, karena
okeplay777 memiliki winrate tertinggi yaitu senilai 97%.
Selain itu, agen judi online okeplay777 ini juga sudah berlisensi resmi, sehingga
keamanan data dan privasi Anda terjamin dengan baik.
These are in fact enormous ideas in about blogging. You have touched some fastidious factors here.
Any way keep up wrinting.
Right now it sounds like Expression Engine is the top blogging platform out
there right now. (from what I’ve read) Is that what you are using on your blog?
I take pleasure in, cause I discovered just what I
used to be having a look for. You’ve ended my
4 day lengthy hunt! God Bless you man. Have a nice day.
Bye
I love reading through a post that can make people think.
Also, thanks for allowing me to comment!
Valuable info. Fortunate me I found your site by accident, and I’m surprised
why this coincidence did not happened earlier!
I bookmarked it.
What’s up, I would like to subscribe for this web site to get latest updates, therefore where can i do it please help out.
Hello there! Do you know if they make any plugins to assist with Search Engine Optimization? I’m trying to get my blog
to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Many thanks!
Thanks for sharing your thoughts. I really appreciate your efforts and I will be waiting
for your further post thank you once again.
I’ve learn a few just right stuff here. Definitely price bookmarking
for revisiting. I surprise how so much effort you place to create this
sort of magnificent informative website.
What’s up, its nice paragraph on the topic of media
print, we all be aware of media is a impressive source of facts.
This is a topic that is close to my heart… Take care! Where are your contact details
though?
I’m amazed, I have to admit. Rarely do I come across a blog that’s both educative
and entertaining, and without a doubt, you have hit
the nail on the head. The issue is something which too few men and women are speaking intelligently about.
I’m very happy I stumbled across this during my search for something relating to this.
Hi there, You’ve done an excellent job. I will definitely digg it and personally suggest to my friends.
I am confident they’ll be benefited from this site.
You really make it appear so easy with your presentation but I to find this matter to be really one thing
that I believe I would never understand. It sort of feels too complex and extremely large for me.
I am looking forward on your subsequent put up, I will attempt to get the hang of it!
Here is my blog … เว็บตรงต่างประเทศ
My brother recommended I might like this web
site. He was totally right. This post actually made my day.
You cann’t imagine simply how much time I had spent for
this information! Thanks!
“As the Singapore economy continued to grow in 2022, there was a strong increase in the proportion of profitable firms. As a result, more firms were able to raise their employees’ wages in 2022 compared to 2021,” said the ministry. 토토사이트
“I Went Vegan for 10 Weeks and This Is What Happened to My Body and Mindset”토토사이트 추천
If you are going for finest contents like I do, simply
go to see this web page everyday as it offers feature contents,
thanks
Thank you for sharing your thoughts. I truly appreciate your efforts and I will be waiting for your further write ups thanks once again.
Wow, fantastic blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is excellent, as well as the content!
Good day I am so happy I found your site, I really found you by error, while I
was looking on Aol for something else, Anyways I am
here now and would just like to say thanks a lot for a fantastic
post and a all round exciting blog (I also love the theme/design),
I don’t have time to read through it all at the moment but
I have saved it and also included your RSS feeds, so
when I have time I will be back to read a great deal more,
Please do keep up the awesome job.
hey there and thank you for your info – I have certainly picked up something
new from right here. I did however expertise a
few technical issues using this website, as I experienced to reload the site a lot of times previous to I could get it to load correctly.
I had been wondering if your hosting is OK?
Not that I am complaining, but sluggish loading
instances times will very frequently affect your
placement in google and can damage your high quality score
if advertising and marketing with Adwords. Well I am adding this RSS
to my email and could look out for much more of your respective intriguing content.
Ensure that you update this again soon.
I don’t even know how I ended up here, but I thought this
post was great. I don’t know who you are but certainly you’re going to a famous blogger if you aren’t already 😉 Cheers!
Hi, I think your blog might be having browser
compatibility issues. When I look at your blog in Safari, it looks fine but
when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, superb blog!
I all the time used to study post in news papers but
now as I am a user of internet so from now I am using net
for content, thanks to web.
These are in fact enormous ideas in concerning
blogging. You have touched some pleasant things here. Any way keep up wrinting.
This paragraph is actually a good one it helps new web users, who are wishing in favor of
blogging.
I’m not sure exactly why but this web site is loading very slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later on and see if the problem still exists.
fun guyz polka dot
What a material of un-ambiguity and preserveness of valuable experience about unexpected
feelings.
It’s awesome to pay a visit this site and reading the views of all mates about this paragraph,
while I am also keen of getting knowledge.
Spot on with this write-up, I honestly believe that this site needs far more attention. I’ll probably be
back again to read through more, thanks for the advice!
Hello There. I found your blog using msn. This is a really well
written article. I’ll make sure to bookmark it and return to read
more of your useful info. Thanks for the post. I will certainly comeback.
hi!,I really like your writing very so much! percentage we be in contact more approximately your article on AOL?
I require a specialist on this space to solve my problem.
Maybe that’s you! Looking ahead to look you.
What’s up to all, because I am in fact eager of reading this webpage’s post to be
updated on a regular basis. It includes fastidious material.
Hi everyone, it’s my first pay a quick visit at this web page, and article is actually fruitful for me, keep up posting such articles.
Hello to every body, it’s my first pay a quick visit of
this website; this website contains remarkable and genuinely fine material designed for
readers.
Good day! I know this is kind of off topic but I
was wondering if you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
I know this site gives quality depending articles or reviews and extra material,
is there any other web page which presents such information in quality?
This is a topic that’s close to my heart…
Many thanks! Where are your contact details though?
I always spent my half an hour to read this web site’s content everyday along with a mug of coffee.
I was suggested this website by my cousin. I am not sure whether this post is written by
him as no one else know such detailed about my trouble.
You’re incredible! Thanks!
Hi, i think that i noticed you visited my weblog thus i came to
go back the desire?.I’m attempting to in finding things to improve my web site!I guess its
good enough to use some of your ideas!!
Hi! I’ve been following your weblog for a long time now and finally
got the courage to go ahead and give you a shout out from Houston Tx!
Just wanted to mention keep up the good job!
I like it when individuals get together and share opinions.
Great blog, stick with it!
онлайн порно
Its like you read my thoughts! You seem to know
so much approximately this, such as you wrote the e book in it or something.
I believe that you simply can do with some % to pressure the message home a little bit, but other than that, that is magnificent blog.
An excellent read. I will certainly be back.
I am really impressed along with your writing abilities and
also with the format in your blog. Is that this a
paid subject matter or did you modify it your self? Anyway stay up
the nice quality writing, it is uncommon to peer a great blog like
this one these days..
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get three e-mails with the same comment.
Is there any way you can remove people from that service?
Thanks!
Hey there just wanted to give you a quick heads up and let you know a few of
the images aren’t loading correctly. I’m not sure why but I think its
a linking issue. I’ve tried it in two different internet browsers and both
show the same outcome.
Everything is very open with a precise explanation of the
issues. It was really informative. Your website is useful.
Thanks for sharing!
Good answer back in return of this query with real arguments and explaining all regarding that.
Hey there! Do you use Twitter? I’d like to follow you if that would be okay.
I’m undoubtedly enjoying your blog and look forward to new updates.
It’s remarkable to pay a quick visit this web site and
reading the views of all friends concerning this paragraph,
while I am also zealous of getting familiarity.
Wow that was strange. I just wrote an incredibly long comment but after I clicked
submit my comment didn’t appear. Grrrr… well I’m not writing all that over again. Anyways, just wanted to say excellent blog!
Magnificent beat ! I wish to apprentice while
you amend your web site, how could i subscribe for a blog web site?
The account aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright clear idea
Everything is very open with a clear explanation of the issues.
It was truly informative. Your website is very helpful.
Thanks for sharing!
порно видео
What’s up friends, its impressive article regarding educationand entirely defined, keep it up all the time.
Heya! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no backup.
Do you have any solutions to protect against hackers?
What’s up it’s me, I am also visiting this web page regularly, this
web page is truly nice and the people are in fact sharing nice thoughts.
certainly like your website but you have to check
the spelling on quite a few of your posts. A number of them are rife with spelling problems
and I in finding it very bothersome to inform the truth nevertheless
I will definitely come back again.
It’s difficult to find well-informed people about this topic,
but you sound like you know what you’re talking about!
Thanks
Thanks for a marvelous posting! I genuinely enjoyed reading it, you might
be a great author. I will be sure to bookmark your blog and may come
back from now on. I want to encourage you to continue
your great writing, have a nice afternoon!
An outstanding share! I’ve just forwarded this onto a colleague who had been doing a little research on this.
And he in fact bought me lunch due to the fact that I found it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanx for spending the time to discuss this subject here on your site.
It is really a nice and useful piece of info. I am glad that you
shared this helpful information with us. Please keep us informed like this.
Thanks for sharing.
Quality articles is the key to attract the people to visit the
web page, that’s what this web site is providing.
Hi there, constantly i used to check webpage posts here early in the dawn, because i enjoy to gain knowledge
of more and more.
Keep on writing, great job!
With havin so much content and articles do you ever run into any issues of plagorism or copyright violation? My blog has a
lot of exclusive content I’ve either written myself or outsourced but it appears a lot of it is popping it up all
over the web without my permission. Do you know any ways to help protect against content from being ripped off?
I’d really appreciate it.
Hmm it appears like your site ate my first comment (it was extremely
long) so I guess I’ll just sum it up what
I wrote and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog blogger but I’m still new to the whole thing.
Do you have any tips and hints for newbie blog writers? I’d genuinely appreciate it.
“Get paid”: A huge number of people want to “get paid” for doing what they love. This is a hook that people can’t resist.”토토사이트 추천
Having read this I thought it was really informative.
I appreciate you spending some time and effort to put this informative article together.
I once again find myself personally spending a lot
of time both reading and commenting. But so what, it was still worth it!
We are a bunch of volunteers and starting a brand new scheme in our
community. Your web site offered us with helpful information to
work on. You’ve performed an impressive activity and our entire group
will probably be grateful to you.
каталог фаберлик
What’s up colleagues, fastidious piece of writing and fastidious arguments commented here, I am actually enjoying by
these.
What’s up colleagues, fastidious article and good urging
commented here, I am truly enjoying by these.
I’m really enjoying the theme/design of your website. Do you ever run into any web browser compatibility
issues? A couple of my blog visitors have complained about my website not
operating correctly in Explorer but looks great in Safari.
Do you have any tips to help fix this issue?
реабилитация инвалидов
hello!,I like your writing very much! percentage we keep up a correspondence extra approximately your
article on AOL? I need a specialist in this space to resolve my problem.
May be that is you! Taking a look ahead to peer you.
Hi, this weekend is pleasant designed for me, as this time i am reading this enormous informative article here at
my house.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
Highly energetic article, I loved that a lot. Will there be a part 2?
What i don’t realize is in truth how you’re not actually much more neatly-favored than you may be right
now. You are so intelligent. You recognize therefore considerably relating to this matter, produced
me individually consider it from so many varied angles. Its
like men and women aren’t fascinated except it’s something to accomplish with Woman gaga!
Your own stuffs great. At all times deal with it up!
Nice post. I learn something new and challenging
on websites I stumbleupon on a daily basis. It will always be exciting to read through articles from other writers and use
a little something from their websites.
Great items from you, man. I have take note your
stuff prior to and you’re just too wonderful.
I actually like what you’ve got here, really like
what you are stating and the best way by which you say it.
You are making it entertaining and you continue to take care of to stay
it wise. I can’t wait to read much more from you. This is
really a great website.
Hi, There’s no doubt that your web site may be having internet browser compatibility issues.
When I take a look at your blog in Safari, it looks fine however when opening in Internet Explorer, it has some overlapping issues.
I just wanted to give you a quick heads up! Apart from
that, excellent site!
Hi! Do you know if they make any plugins to assist with Search Engine Optimization? I’m trying to
get my blog to rank for some targeted keywords but I’m not seeing very good
results. If you know of any please share. Thanks!
hey there and thank you for your info – I have definitely picked up
something new from right here. I did however expertise a few technical issues using this site, as I experienced to reload the web site lots of times previous to I
could get it to load properly. I had been wondering if your web
host is OK? Not that I’m complaining, but slow loading instances
times will often affect your placement in google and can damage your high-quality
score if ads and marketing with Adwords. Well
I am adding this RSS to my e-mail and could look
out for a lot more of your respective interesting content.
Make sure you update this again very soon.
I’m not sure why but this weblog is loading incredibly slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later and see if the problem still exists.
my page :: toyota eco 2002
I like the valuable info you provide in your articles.
I’ll bookmark your weblog and check again here frequently.
I am quite certain I will learn lots of new stuff right
here! Best of luck for the next!
First off I would like to say terrific blog! I had a quick question that I’d like to ask
if you don’t mind. I was curious to find out how you center yourself and clear your thoughts prior to writing.
I have had trouble clearing my thoughts in getting my ideas out there.
I do enjoy writing however it just seems like the first 10 to 15 minutes tend to be lost just trying to figure
out how to begin. Any suggestions or tips? Appreciate it!
My spouse and I absolutely love your blog and find almost all of your post’s to be precisely what I’m looking for.
can you offer guest writers to write content for yourself?
I wouldn’t mind composing a post or elaborating on a
number of the subjects you write about here. Again, awesome site!
Peculiar article, just what I wanted to find.
At this time it sounds like Drupal is the top blogging
platform available right now. (from what I’ve read) Is that what you are using on your blog?
Hello, the whole thing is going well here and ofcourse every
one is sharing facts, that’s actually excellent, keep up writing.
I visit each day some sites and information sites to read content, except this webpage provides feature based posts.
I blog frequently and I really appreciate your information. The article has really peaked my interest.
I am going to bookmark your website and keep checking for new information about once a week.
I subscribed to your RSS feed too.
You ought to be a part of a contest for one of the greatest
sites on the net. I most certainly will highly recommend this website!
Hello, i think that i noticed you visited my blog thus
i got here to return the prefer?.I am trying to find things to improve my website!I suppose
its ok to make use of some of your concepts!!
Why viewers still make use of to read news papers when in this technological
globe the whole thing is accessible on web?
The other day, while I was at work, my sister stole my iPad and tested to see if it
can survive a forty foot drop, just so she can be a youtube sensation. My
iPad is now broken and she has 83 views. I know this is totally off topic but I had to share it with someone!
14 Hangover Cures That You Haven’t Heard Of (Number 10 Works Every Time!)사설토토
I have learn some just right stuff here. Definitely worth bookmarking for
revisiting. I surprise how a lot attempt you put to make the sort of magnificent informative
site.
Hi there everyone, it’s my first visit at this web page, and paragraph is truly fruitful in support of me,
keep up posting these types of articles.
Hi i am kavin, its my first time to commenting anyplace, when i read this paragraph i thought i could also create comment due to this brilliant article.
This site truly has all of the info I wanted about this subject and didn’t know who to ask.
I think this is among the most important information for me.
And i’m glad reading your article. But want to remark on some
general things, The web site style is ideal,
the articles is really excellent : D. Good job, cheers
порно видео
It is really a nice and useful piece of information. I’m glad that you just shared this helpful info with us.
Please keep us informed like this. Thanks for sharing.
I was suggested this blog by my cousin. I am not sure whether this post is written by him
as no one else know such detailed about my trouble.
You are incredible! Thanks!
You need to take part in a contest for one of the greatest blogs on the internet.
I am going to recommend this blog!
Good day! Would you mind if I share your blog with my zynga
group? There’s a lot of people that I think would really enjoy your content.
Please let me know. Many thanks
I visited various websites but the audio quality for audio songs current
at this site is genuinely marvelous.
I’m not that much of a online reader to be honest but
your sites really nice, keep it up! I’ll go ahead and bookmark your website to come back later.
Many thanks
Wow, fantastic blog structure! How long have
you been running a blog for? you made running a blog glance easy.
The entire glance of your site is wonderful, let alone
the content material!
each time i used to read smaller articles or reviews
which also clear their motive, and that is also happening with
this post which I am reading at this time.
prprdollは全日本で最安ラブドール専門店です。より多くのラブドールを試してみたい初心者の方が、手軽にご自分のラブドールを手に入れられるようにすることを努力していきます。
This design is spectacular! You definitely know how to keep a reader entertained.
Between your wit and your videos, I was almost moved
to start my own blog (well, almost…HaHa!) Great job.
I really loved what you had to say, and more than that, how you presented
it. Too cool!
Hey there! Do you use Twitter? I’d like to follow you if that would
be okay. I’m definitely enjoying your blog and look forward to new posts.
Very nice post. I just stumbled upon your weblog and wished to say that I’ve truly enjoyed surfing around your blog posts.
In any case I will be subscribing to your
rss feed and I hope you write again soon!
Unquestionably believe that which you said. Your favorite reason appeared to be on the web the easiest
thing to be aware of. I say to you, I definitely get annoyed
while people think about worries that they plainly don’t know
about. You managed to hit the nail upon the top and also defined out the whole thing without having
side-effects , people can take a signal. Will probably be back to get more.
Thanks
Having read this I believed it was very enlightening.
I appreciate you finding the time and energy to put this informative article
together. I once again find myself personally spending way
too much time both reading and leaving comments. But so what, it was
still worthwhile!
Awesome article.
Excellent post. I used to be checking constantly this I maintain such info a lot.
I maintain such info a lot.
blog and I am impressed! Extremely useful info particularly the last phase
I was looking for this certain information for a long time.
Thanks and best of luck.
fantastic issues altogether, you just gained a
logo new reader. What may you suggest about your publish that
you simply made a few days ago? Any sure?
With havin so much content and articles do you ever run into
any issues of plagorism or copyright violation? My blog
has a lot of completely unique content I’ve either created myself or
outsourced but it seems a lot of it is popping it up all over the web without my agreement.
Do you know any ways to help stop content from being ripped off?
I’d really appreciate it.
I really like it whenever people come together and
share thoughts. Great site, stick with it!
This site was… how do I say it? Relevant!! Finally I have found something which helped me.
Appreciate it!
Feel free to visit my web-site – Email Builder Bot FREE (https://emailfunnelbuilder.com/)
Howdy! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blog
article or vice-versa? My blog goes over a lot of the same subjects as yours and I believe we could greatly benefit from each other.
If you might be interested feel free to send me an e-mail.
I look forward to hearing from you! Fantastic blog by the way!
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would
have some experience with something like this. Please let me know if
you run into anything. I truly enjoy reading your blog and I look
forward to your new updates.
Hi there, all is going nicely here and ofcourse
every one is sharing information, that’s actually fine, keep
up writing.
When some one searches for his essential thing, thus he/she wants to be available that
in detail, therefore that thing is maintained over here.
Статейное и ссылочное продвижение.
В наши дни, практически любой человек пользуется интернетом.
С его помощью возможно отыскать любую информацию
из разных интернет-поисковых
систем и источников.
Для кого-то собственный сайт — это хобби.
Но, большинство используют созданные проекты для заработка и привлечение прибыли.
У вас имеется собственный сайт и вы желаете привлечь на него
максимум визитёров, но не знаете с
чего начать? Обратитесь к нам!
Мы поможем!
файл с обратными ссылка
Excellent, what a web site it is! This web site gives helpful data to us, keep it up.
частное порно видео
Hello! I’m at work surfing around your blog from my new iphone 4!
Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the excellent work!
I am in fact glad to read this web site posts which consists of plenty of valuable information,
thanks for providing these statistics.
Spot on with this write-up, I actually think this site needs a lot more attention. I’ll probably be back again to read through more,
thanks for the information!
I really like what you guys tend to be up too.
This sort of clever work and exposure! Keep up the awesome works guys
I’ve included you guys to my own blogroll.
I feel this is one of the such a lot significant info for me.
And i am glad studying your article. But should statement on few basic issues, The web site style is
wonderful, the articles is really nice : D. Excellent activity, cheers
Do you mind if I quote a couple of your posts as long as
I provide credit and sources back to your webpage?
My blog is in the very same niche as yours and my visitors would truly benefit
from a lot of the information you present here. Please let me know if this
alright with you. Thanks a lot!
I always spent my half an hour to read this web site’s articles
or reviews every day along with a mug of coffee.
You ought to be a part of a contest for one of the most useful websites online.
I am going to highly recommend this website!
Link exchange is nothing else however it is only
placing the other person’s blog link on your page at
suitable place and other person will also do similar for
you.
Fantastic goods from you, man. I’ve take into accout your stuff prior to and
you are just extremely magnificent. I really like what you have
acquired right here, certainly like what you are saying and the way in which in which
you assert it. You make it enjoyable and you still care for to stay it sensible.
I can’t wait to read far more from you. This is actually a wonderful site.
It’s an amazing post in favor of all the web people; they will get advantage from
it I am sure.
I visited various websites however the audio quality for audio songs current at this web site
is truly excellent.
Порно по категориям
Very soon this web site will be famous amid all
blogging viewers, due to it’s good articles
I was recommended this blog by my cousin. I’m not sure whether this post is written by him as nobody
else know such detailed about my difficulty. You’re wonderful!
Thanks!
hello!,I love your writing so a lot! share we keep up a correspondence
more about your article on AOL? I require a specialist
on this area to solve my problem. May be that is you!
Having a look ahead to see you.
Thanks for some other informative blog. The place else may just I get that kind of info written in such an ideal manner?
I have a undertaking that I am simply now operating on, and I have been on the look
out for such info.
Keep this going please, great job!
I am extremely impressed with your writing skills
and also with the layout on your blog. Is this a paid theme
or did you modify it yourself? Anyway keep up the nice quality writing,
it’s rare to see a great blog like this one today.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Cheers
I’m impressed, I must say. Rarely do I come across a blog
that’s both equally educative and amusing, and
let me tell you, you have hit the nail on the
head. The issue is something that too few men and women are speaking intelligently about.
I am very happy that I stumbled across this in my hunt for something relating to this.
Greetings! Very useful advice within this post! It is the little changes that will make the most important changes.
Thanks for sharing!
Today, while I was at work, my cousin stole my apple ipad and tested to see if
it can survive a thirty foot drop, just so she can be a youtube sensation. My apple ipad is now broken and she has 83 views.
I know this is entirely off topic but I had to share it with someone!
Статейное и ссылочное продвижение.
В наше время, фактически любой человек
пользуется интернетом.
С его помощью можно отыскать любую
информацию из различных интернет-поисковых систем и источников.
Для кого-то личный сайт — это хобби.
Но, большая часть используют разработанные проекты для дохода
и привлечение прибыли.
У вас есть личный сайт и вы хотите привлечь на него
максимум посетителей, но не понимаете с чего начать?
Обратитесь к нам! Мы поможем!
как закрыть обратные ссылки
“We Need to Talk About AI. It’s a Game Changer” 메이저사이트
Thank you a lot for sharing this with all folks you really recognise what you are speaking about!
Bookmarked. Kindly also visit my site =). We may have a
hyperlink trade arrangement between us
These are really enormous ideas in on the topic of blogging.
You have touched some nice factors here. Any way keep up
wrinting.
great issues altogether, you just gained a new reader.
What could you suggest about your submit that you simply made a few days ago?
Any positive?
I’m really impressed with your writing skills and also with the
layout on your weblog. Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it is rare to see a nice blog
like this one today.
Its not my first time to go to see this site,
i am browsing this site dailly and obtain nice information from here daily.
Hello, this weekend is pleasant in favor of me, as this
occasion i am reading this impressive informative article here
at my house.
Hi! I’ve been reading your site for a while now and finally
got the courage to go ahead and give you a shout out from Kingwood Texas!
Just wanted to tell you keep up the excellent job!
Hi my family member! I wish to say that this post is awesome, nice
written and come with approximately all significant infos.
I would like to peer more posts like this .
I just could not leave your website prior to suggesting that I actually loved the standard information an individual supply on your guests?
Is gonna be again ceaselessly in order to check out new posts
I will immediately take hold of your rss as I can’t to find
your e-mail subscription hyperlink or newsletter service.
Do you’ve any? Please let me realize in order that I could subscribe.
Thanks.
Hello it’s me, I am also visiting this web site regularly,
this site is really fastidious and the people are in fact sharing pleasant thoughts.
Simply wish to say your article is as astounding. The clearness for your
put up is just great and that i can assume you are an expert in this subject.
Well along with your permission allow me to clutch your RSS feed to keep updated with coming near near post.
Thank you a million and please keep up the gratifying work.
great issues altogether, you simply received a emblem new reader.
What might you recommend in regards to your publish that you
just made a few days ago? Any certain?
Hurrah! In the end I got a weblog from where I be capable of really obtain useful facts regarding my study and knowledge.
Why viewers still make use of to read news papers when in this technological globe the whole
thing is existing on web?
Hello, i believe that i noticed you visited my weblog so i came to return the choose?.I’m trying to to find issues to improve my website!I assume its good
enough to make use of a few of your concepts!!
Very good post! We will be linking to this great content on our website.
Keep up the great writing.
Aw, this was an exceptionally nice post. Taking a few minutes and actual effort to produce a
very good article… but what can I say… I procrastinate a lot and don’t seem to get nearly
anything done.
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is important and everything.
But just imagine if you added some great graphics or videos to
give your posts more, “pop”! Your content is excellent but with pics and videos,
this site could undeniably be one of the very best in its niche.
Amazing blog!
of course like your website but you have to test the spelling
on several of your posts. A number of them are rife with
spelling problems and I find it very troublesome to tell the reality on the other hand I’ll
certainly come back again.
Excellent post. I was checking continuously this blog I care for such info much.
I care for such info much.
and I am impressed! Extremely helpful information specifically the last part
I was looking for this particular info for a long time.
Thank you and best of luck.
I always used to study piece of writing in news papers but now as I
am a user of net so from now I am using net for
posts, thanks to web.
I am really impressed with your writing skills
and also with the layout on your blog. Is
this a paid theme or did you customize it yourself?
Either way keep up the nice quality writing, it’s rare to see a
great blog like this one today.
I don’t even know how I ended up here, but I thought this post was great.
I do not know who you are but certainly you are going to a famous blogger if you are not already ;
) Cheers!
Hello there! I simply wish to offer you a big thumbs up for your great information you
have right here on this post. I am coming back to your website for more soon.
Nice replies in return of this matter with real arguments and explaining everything regarding that.
I’m truly enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit more often. Did you hire out a designer to
create your theme? Exceptional work!
My spouse and I stumbled over here from a different web
address and thought I may as well check things out. I like
what I see so i am just following you. Look forward to
going over your web page yet again.
Hey there would you mind letting me know which
webhost you’re working with? I’ve loaded your blog in 3 completely different browsers and
I must say this blog loads a lot quicker then most.
Can you suggest a good internet hosting provider at a honest price?
Thank you, I appreciate it!
Hello, after reading this awesome paragraph i am also cheerful to share my experience
here with friends.
Very descriptive blog, I enjoyed that a lot. Will there be a part 2?
This is really interesting, You are a very skilled blogger.
I have joined your feed and look forward to seeking more of your magnificent post.
Also, I’ve shared your site in my social networks!
I am regular reader, how are you everybody?
This paragraph posted at this web page is really nice.
Good day! This post couldn’t be written any better!
Reading through this post reminds me of my old room mate!
He always kept talking about this. I will forward this page to him.
Pretty sure he will have a good read. Thank you for sharing!
Do you have a spam issue on this site; I also am a blogger, and I was wondering your situation; many of
us have developed some nice methods and we are
looking to trade solutions with other folks, be sure to shoot me an e-mail if
interested.
Howdy! I know this is somewhat off topic but I was wondering if you knew where
I could get a captcha plugin for my comment form? I’m using the same blog platform as
yours and I’m having difficulty finding one? Thanks a lot!
Hi every one, here every person is sharing such
familiarity, thus it’s good to read this weblog, and I used to
pay a quick visit this web site daily.
This design is steller! You obviously know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Fantastic job. I really loved what you had to
say, and more than that, how you presented it.
Too cool!
Highly descriptive blog, I liked that bit. Will there be a part 2?
Very soon this website will be famous among all blog viewers, due to
it’s pleasant posts
THE IKARIA JUICE: MEDITARRANEAN DIET
My brother recommended I might like this blog. He was entirely right.
This post actually made my day. You can not imagine simply how much time I had spent for this info!
Thanks!
It’s wonderful that you are getting ideas from this paragraph as well as from our discussion made at this place.
Howdy this is kinda of off topic but I was wondering if blogs use WYSIWYG editors
or if you have to manually code with HTML. I’m starting a blog soon but have no coding expertise so
I wanted to get advice from someone with experience.
Any help would be enormously appreciated!
Aw, this was an extremely good post. Taking a few minutes and
actual effort to create a good article… but what can I say… I put things off a lot and never seem to
get anything done.
It’s going to be finish of mine day, however before finish I am reading this enormous paragraph
to improve my experience.
I’ve been surfing on-line greater than 3 hours as of late, but I never found any
interesting article like yours. It is lovely price sufficient
for me. Personally, if all webmasters and bloggers made just right
content material as you did, the internet can be much more
helpful than ever before.
You actually make it appear so easy together with your presentation but I find this topic to be really something which I believe I
would never understand. It seems too complicated and very wide for me.
I am looking forward in your subsequent post, I’ll attempt to get the grasp of it!
Hi there Dear, are you in fact visiting this web site regularly,
if so then you will definitely get pleasant know-how.
“You’ll Never Get Hired if You Say This in a Job Interview”토토사이트 추천
At this time, Chinese analysis establishments provide some
postdoctoral researchers 3 times the salaries they
might make at a U.S.
I every time used to study article in news papers but now as I am a user of internet therefore
from now I am using net for articles or reviews, thanks to web.
Порно видео
I’m excited to uncover this great site. I need to to thank you for ones time
for this particularly fantastic read!! I definitely appreciated every bit
of it and I have you book-marked to see new stuff in your site.
I pay a quick visit everyday some web pages and blogs to read articles, except
this blog offers feature based articles.
This piece of writing is actually a good one it assists new web people, who are wishing for blogging.
Hi there, just became aware of your blog through Google, and found that it’s
really informative. I’m going to watch out for brussels. I will appreciate if you continue this in future.
Numerous people will be benefited from your writing.
Cheers!
Good day I am so grateful I found your blog, I really
found you by mistake, while I was searching on Yahoo for something else, Regardless I am
here now and would just like to say many thanks for a marvelous post and a all round enjoyable blog (I also love the theme/design), I don’t
have time to go through it all at the minute
but I have saved it and also included your RSS feeds, so when I have time I will
be back to read more, Please do keep up the awesome job.
First off I would like to say terrific blog! I had a quick question that I’d like to ask if you don’t mind.
I was curious to know how you center yourself and clear your mind prior to writing.
I’ve had a difficult time clearing my mind in getting my thoughts out.
I do enjoy writing but it just seems like the first 10
to 15 minutes are usually lost simply just trying to figure
out how to begin. Any suggestions or tips? Many thanks!
Hi to all, how is everything, I think every one is getting
more from this web page, and your views are pleasant in support of new
people.
Порно видео
It’s a shame you don’t have a donate button! I’d most certainly donate
to this excellent blog! I suppose for now i’ll settle for bookmarking and adding your RSS
feed to my Google account. I look forward to fresh updates and
will talk about this website with my Facebook group. Chat soon!
I like this site very much, Its a really nice situation to read and get info . strippers in florida
I love what you guys tend to be up too. This
type of clever work and exposure! Keep up the very good works guys I’ve incorporated you guys to my blogroll.
I think this is one of the most significant info
for me. And i am glad reading your article. But
wanna remark on few general things, The web site style is ideal,
the articles is really nice : D. Good job, cheers
It’s hard to find knowledgeable people about this topic, however,
you seem like you know what you’re talking about! Thanks
Thanks for sharing your thoughts about https://bitcoinblack.net/community/hitclub-help/info/. Regards
My spouse and I stumbled over here by a different page and thought I might as well check things out.
I like what I see so i am just following you. Look forward to looking
over your web page repeatedly.
What’s up, the whole thing is going fine here and ofcourse every one is
sharing facts, that’s truly excellent, keep up writing.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get four e-mails with the
same comment. Is there any way you can remove
me from that service? Thanks a lot!
Hello there, just became alert to your blog through Google,
and found that it’s really informative. I’m going to
watch out for brussels. I’ll be grateful if you continue this
in future. Numerous people will be benefited
from your writing. Cheers!
Greetings, I think your blog could be having internet browser compatibility issues.
When I take a look at your website in Safari, it looks fine however, when opening in Internet Explorer, it
has some overlapping issues. I simply wanted to give you
a quick heads up! Other than that, excellent blog!
Hi there, after reading this remarkable paragraph i am as well delighted to
share my experience here with mates.
Hi! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Hi, Neat post. There iss a problem along with your web
site in web explorer, could check this? IEnonetheless is the marketplace chief and a larhe component oof other
people will leave out your magnificent writing due to this problem.
Here is my page :: more info
Oh my goodness! Impressive article dude! Thanks, However I am experiencing
troubles with your RSS. I don’t know the reason why I cannot subscribe
to it. Is there anyone else getting similar RSS issues? Anybody who knows the solution will you kindly respond?
Thanx!!
Hurrah! At last I got a blog from where I know how
to truly get helpful facts regarding my study and
knowledge.
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out much.
I hope to give something back and aid others like you aided
me.
Hi there colleagues, its wonderful article about educationand
completely explained, keep it up all the time.
What’s up, I wish for to subscribe for this blog
to obtain hottest updates, thus where can i do it please help out.
It’s an awesome paragraph in favor of all the online users;
they will get advantage from it I am sure.
Hey there would you mind sharing which blog platform you’re working with?
I’m looking to start my own blog soon but I’m having a difficult time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and I’m
looking for something unique. P.S My apologies for getting off-topic but I had to ask!
That is very attention-grabbing, You’re an overly professional blogger.
I’ve joined your feed and stay up for looking for extra of your
wonderful post. Additionally, I have shared your website in my social networks
An interesting discussion is definitely worth comment.
I believe that you should write more about this topic, it may not be a taboo matter but typically people do not discuss these subjects.
To the next! Many thanks!!
I’d like to find out more? I’d want to find out more
details.
I’m gone to say to my little brother, that he should also pay a visit this blog on regular basis to get updated from most recent news.
When some one searches for his vital thing, thus he/she needs to be available that in detail, so that thing is maintained over here.
Yes! Finally someone writes about Watch Protective Film.
I was very happy to discover this website. I wanted to thank you for ones time for this particularly fantastic read!!
I definitely liked every part of it and I have you saved as a favorite to
check out new information in your website.
I am genuinely pleased to read this website posts which includes plenty of
helpful facts, thanks for providing these kinds of
data.
Nice respond in return of this issue with firm arguments
and telling everything on the topic of that.
I have read so many articles regarding the blogger lovers however this paragraph
is in fact a pleasant post, keep it up.
Simply desire to say your article is as astounding.
The clarity on your publish is simply cool and
i could think you are an expert on this subject. Fine with your permission allow me to clutch your RSS feed to keep updated with drawing close
post. Thank you 1,000,000 and please continue the
enjoyable work.
I couldn’t resist commenting. Perfectly written!
What’s up mates, its enormous paragraph regarding cultureand completely explained,
keep it up all the time.
Link exchange is nothing else however it is only placing the other person’s website link on your page at proper place and other person will also do similar for you.
You’re so interesting! I don’t believe I’ve truly read anything like that before.
So good to discover somebody with some genuine thoughts on this subject.
Really.. many thanks for starting this up. This site
is something that is needed on the web, someone with a bit of originality!
Thanks on your marvelous posting! I quite enjoyed reading it, you can be a great author.I will always bookmark your blog
and definitely will come back at some point. I want to encourage
that you continue your great job, have a nice day!
I received pissed off coming up with ideas and then seeing the same concepts (as
startup) on Techcrunch raising money. Around the identical time, by
accident, i ran into my co-founders, and we decided to type a team to work on a big concept of ours.
It also gives them an idea how a lot the label would make at that time.
And when the system is about as much as favor customs officials with
few if any protections for travelers, there’s solely a lot visa holders can do if agents abuse their powers.
And the info is on the market without should pay a
lawyer for a number of hours of their time to do the math.
But i wished to mention a number of authors here. A whole lot of the folks i point out right
here overlapped in several phases of my life. The San Francisco Ninth Circuit Court docket of Appeals ruled Thursday afternoon to maintain the keep on President Donald Trump’s journey ban, which
aims to halt individuals from seven majority-Muslim international locations from getting into the United States.
Trump signed the executive order on January twenty
seventh. It places a 90-day ban on travelers from
Iraq, Syria, Iran, Sudan, Libya, Somalia and Yemen, halts
all refugees from coming into the US for 120 days, and locations an indefinite
ban on accepting refugees from Syria.
If some one desires expert view regarding blogging after
that i recommend him/her to pay a quick visit this website, Keep up the good job.
I know this if off topic but I’m looking into starting my own blog and was wondering what
all is needed to get setup? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% sure. Any tips or advice would be greatly appreciated.
Cheers
Simply wish to say your article is as astounding. The clearness
in your post is just great and i can assume you’re an expert on this subject.
Fine with your permission let me to grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please continue the rewarding work.
Also visit my web site – consignment sale – jose7i93rze5.blogsmine.com,
Thankfulness to my father who informed me on the topic of this
webpage, this webpage is genuinely amazing.
Greate article. Keep posting such kind of information on your site.
Im really impressed by it.
Hi there, You have done an excellent job. I will certainly digg it and for my part suggest to my friends.
I am confident they’ll be benefited from this site.
Hey there just wanted to give you a brief heads up and let you know
a few of the images aren’t loading properly. I’m not sure why but I
think its a linking issue. I’ve tried it in two different web browsers and both show the same
outcome.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However,
how can we communicate?
You really make it seem so easy with your presentation but I find this topic to be actually
something that I think I would never understand. It seems too complicated
and extremely broad for me. I am looking forward for your next post, I’ll try to get the
hang of it!
Hi there everyone, it’s my first visit at this web site, and article is genuinely fruitful for me, keep up posting these types of content.
I’m really impressed with your writing skills as well as with the layout on your weblog.
Is this a paid theme or did you modify it yourself? Either way keep up the excellent
quality writing, it is rare to see a great blog like this one nowadays.
Great article, totally what I needed.
If you want to improve your know-how just keep visiting this website and be updated with the newest
gossip posted here.
Highly energetic article, I loved that bit. Will there
be a part 2?
Thanks for sharing your thoughts about https://xlondonescorts.co/escort/category/ladbrooke-grove-escorts/# Exclusive.
Regards
Asking questions are really good thing if you are not understanding something
entirely, except this article presents pleasant understanding even.
I love it when folks come together and share views. Great website, stick with it!
You really make it seem so easy together with your presentation however I to find this matter to be really something which I believe
I’d never understand. It sort of feels too complicated and extremely huge for me.
I’m looking ahead on your next publish, I will attempt to get the grasp of it!
May I simply say what a relief to uncover a person that truly knows what they’re talking about on the net.
You certainly understand how to bring a problem to light and make
it important. A lot more people ought to look at this
and understand this side of the story. I was surprised you’re not more popular since
you surely possess the gift.
Hello! I could have sworn I’ve visited this site before but after looking at some of the articles I realized it’s new to me.
Regardless, I’m definitely pleased I found it and I’ll be
bookmarking it and checking back regularly!
I visit everyday some websites and information sites to read articles or
reviews, but this weblog gives quality based writing.
It’s an remarkable paragraph for all the web users;
they will obtain benefit from it I am sure.
For most up-to-date information you have to visit the web and on the web I found this web page as a finest web page for latest updates.
My brother recommended I might like this website. He was entirely right.
This post actually made my day. You cann’t imagine just how much time I had spent
for this information! Thanks!
Hi there excellent website! Does running a blog like this take a great deal of work?
I have very little expertise in computer programming however I had
been hoping to start my own blog in the near future.
Anyhow, should you have any ideas or tips for new blog owners please share.
I know this is off topic nevertheless I just needed to
ask. Thanks a lot!
Hey colega, localizei esta postagem a partir de um blog de um conhecido.
Curti do que li, tu parece entender bem do tema. Muito obrigado!
I visited multiple blogs except the audio feature for audio songs current at this site is really excellent.
Great goods from you, man. I’ve keep in mind
your stuff previous to and you’re simply extremely fantastic.
I actually like what you have acquired right here, certainly like what you are saying and the best way during which you say it.
You’re making it entertaining and you still take care of
to keep it wise. I can’t wait to read much more from you.
This is actually a great site.
I used to be able to find good info from your blog posts.
Nice blog here! Also your web site loads up very fast! What web host
are you using? Can I get your affiliate link to your host?
I wish my website loaded up as fast as yours lol
Oh my goodness! Impressive article dude! Thank you
so much, However I am experiencing difficulties with your RSS.
I don’t understand why I am unable to subscribe to it.
Is there anybody getting the same RSS problems? Anyone that knows the solution can you kindly
respond? Thanks!!
Hurrah! Finally I got a website from where I be capable of
genuinely obtain useful information regarding my study and knowledge.
Write more, thats all I have to say. Literally, it seems as though you relied on the video
to make your point. You definitely know what youre talking about,
why waste your intelligence on just posting videos to your weblog when you could be giving us something enlightening
to read?
I need to to thank you for this fantastic read!!
I absolutely loved every little bit of it. I have you saved as
a favorite to check out new stuff you post…
Hey There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and return to read more of your useful info.
Thanks for the post. I’ll certainly comeback.
I am really delighted to glance at this weblog posts which includes lots of
useful data, thanks for providing such statistics.
I’m not sure where you’re getting your information, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for fantastic info I was looking for this information for my mission.
Hi, I do believe this is a great website. I stumbledupon it
😉 I will revisit yet again since i have
book marked it. Money and freedom is the best way
to change, may you be rich and continue to
help others.
Very descriptive blog, I enjoyed that a lot. Will there be
a part 2?
obviously like your website but you need to check the spelling on quite a few of your posts.
Several of them are rife with spelling issues and I in finding it very bothersome to tell the reality then again I’ll surely come back
again.
Appreciate the recommendation. Let me try it out.
Hurrah! Finally I got a blog from where I be able to genuinely get useful information regarding my study and knowledge.
Hi it’s me, I am also visiting this web page regularly, this site
is genuinely pleasant and the visitors are genuinely sharing fastidious thoughts.
I am really enjoying the theme/design of your blog.
Do you ever run into any web browser compatibility problems?
A couple of my blog audience have complained about my
website not operating correctly in Explorer but looks
great in Safari. Do you have any solutions to help fix this issue?
Thanks very interesting blog!
wonderful issues altogether, you just received a new reader.
What could you suggest about your post that you made a few days in the
past? Any sure?
I read this article fully concerning the resemblance of hottest and
preceding technologies, it’s amazing article.
Hi there colleagues, pleasant post and pleasant arguments commented at this place, I am actually enjoying by these.
Right away I am going to do my breakfast, when having
my breakfast coming again to read other news.
An intriguing discussion is definitely worth comment.
I believe that you should write more on this subject, it may not be a taboo
matter but generally people do not discuss these subjects.
To the next! All the best!!
Diyarbakır Escort bayanlarının hangi ilçelerde bulunduğunu soranlar için tüm Diyarbakır’da bulunduklarını
bilmenizi isteriz.
Excellent post. I was checking constantly this blog and I am impressed! I care for such
I care for such
Very useful information specifically the last part
info much. I was looking for this certain info for a very long time.
Thank you and good luck.
Your means of telling all in this paragraph is truly pleasant, all can simply understand it, Thanks a
lot.
I love what you guys tend to be up too. This kind of clever work and reporting!
Keep up the awesome works guys I’ve included you guys to
blogroll.
Marvelous, what a web site it is! This weblog gives
valuable facts to us, keep it up.
I blog quite often and I seriously thank you for your content.
Your article has truly peaked my interest. I’m going to bookmark your site and keep checking for new information about
once per week. I opted in for your Feed as well.
Appreciate the recommendation. Will try it out.
It’s in reality a nice and helpful piece of info.
I’m satisfied that you shared this useful information with us.
Please stay us informed like this. Thanks for sharing.
I really like what you guys tend to be up too. This kind of clever work and exposure!
Keep up the terrific works guys I’ve added you guys
to my own blogroll.
bookmarked!!, I like your web site!
Just desire to say your article is as astonishing. The clarity in your post is simply great and i can assume
you’re an expert on this subject. Well with your
permission allow me to grab your feed to keep up to date with forthcoming post.
Thanks a million and please keep up the gratifying work.
Usually I don’t learn post on blogs, but I would like to say that this write-up very forced
me to check out and do it! Your writing taste has been surprised me.
Thanks, quite great article.
Its like you learn my mind! You appear to grasp a lot about
this, like you wrote the ebook in it or something.
I feel that you just could do with a few percent to power the message home
a little bit, but instead of that, this is
fantastic blog. A great read. I will certainly be back. Cialis Professional
Great blog here! Also your site loads up fast! What host
are you using? Can I get your affiliate link to your host?
I wish my site loaded up as fast as yours lol
You should take part in a contest for one of the
highest quality sites online. I’m going to highly recommend this blog!
I want to to thank you for this very good read!!
I certainly loved every little bit of it. I have you bookmarked to check out new stuff you
post…
I do accept as true with all of the ideas you have presented for your post.
They are really convincing and can definitely work.
Nonetheless, the posts are very brief for newbies.
Could you please lengthen them a bit from next time?
Thank you for the post.
I was excited to find this great site. I want to to thank
you for your time for this particularly wonderful read!!
I definitely enjoyed every part of it and i also have you book-marked to look
at new information on your website.
Greetings from Florida! I’m bored to tears at work so I decided to
check out your blog on my iphone during lunch break.
I love the information you present here and can’t wait to take a
look when I get home. I’m amazed at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyways, awesome site!
I really like what you guys tend to be up too.
Such clever work and reporting! Keep up the excellent works guys I’ve incorporated you guys to my personal blogroll.
Hi there i am kavin, its my first time to commenting anywhere, when i read this paragraph i thought
i could also create comment due to this good article.
Howdy just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both
show the same outcome.
I feel this is among the most important info for
me. And i’m satisfied reading your article. However should commentary
on some general things, The web site taste is wonderful,
the articles is actually great : D. Good task, cheers
Thank you a lot for sharing this with all of us you actually know what you are talking approximately!
Bookmarked. Please also visit my web site =). We could have a link exchange arrangement between us
Can I simply say what a relief to discover someone that genuinely knows what they are talking about over the internet.
You certainly know how to bring an issue to light and
make it important. A lot more people should read this and understand this side of your story.
I was surprised you aren’t more popular because
you definitely have the gift.
Wow, wonderful blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is
excellent, let alone the content!
I delight in, cause I discovered just what I was taking a look for.
You have ended my four day long hunt! God Bless you man. Have
a great day. Bye
Right here is the perfect blog for anbyone who wishes to finnd out about Visit this website topic.
You understand a whole loot its almost hard to argue with
you (not that I actually would want to…HaHa).
You definitely put a brand new spin on a subject which has been written about for years.
Great stuff, just wonderful!
Hello! I could have sworn I’ve been to this site before but after reading through some of the post I realized it’s new to me.
Anyways, I’m definitely delighted I found it and I’ll be bookmarking
and checking back frequently!
I am curious to find out what blog system you’re using? I’m experiencing some minor security problems
with my latest site and I would like to find something more risk-free.
Do you have any solutions?
hello there and thank you for your info – I have certainly picked up something new from right here.
I did however expertise some technical issues using this website, since I experienced to reload the site
a lot of times previous to I could get it to load correctly.
I had been wondering if your web hosting is OK? Not that I’m complaining,
but sluggish loading instances times will often affect your placement in google and could
damage your high-quality score if advertising and marketing
with Adwords. Well I am adding this RSS to my e-mail and could look out for much more of your respective
intriguing content. Make sure you update this again soon.
Hey there! I could have sworn I’ve been to this site before but after
reading through some of the post I realized it’s new to me.
Anyways, I’m definitely glad I found it and I’ll be book-marking and checking
back frequently!
Hi there to all, for the reason that I am actually keen of reading this
website’s post to be updated on a regular basis.
It includes fastidious information.
I like the helpful info you supply on your articles.
I’ll bookmark your weblog and check again right here
regularly. I am reasonably sure I will be informed many new stuff right here!
Best of luck for the following!
Hi there, You have done a great job. I’ll certainly digg it and personally recommend to my friends.
I am confident they’ll be benefited from this web site.
Does your site have a contact page? I’m having trouble
locating it but, I’d like to shoot you an e-mail. I’ve
got some creative ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it improve
over time.
Hi there mates, its wonderful paragraph regarding
tutoringand fully defined, keep it up all the
time.
It’s impressive that you are getting thoughts from this post as well as from our argument made here.
I was suggested this blog by means of my cousin. I am not
sure whether or not this submit is written via him as nobody else recognise
such precise approximately my trouble. You’re wonderful!
Thanks!
I have been exploring for a little for any high quality articles
or blog posts on this sort of house . Exploring in Yahoo
I eventually stumbled upon this website. Studying this information So i am happy to show that
I’ve a very just right uncanny feeling I found out just what I needed.
I so much definitely will make sure to do not forget this web site and provides it a glance regularly.
I visited several sites except the audio quality for audio
songs existing at this site is actually fabulous.
I have fun with, cause I discovered exactly what I used to be having a
look for. You’ve ended my 4 day lengthy hunt!
God Bless you man. Have a great day. Bye
You have made some decent points there. I checked on the web for more
info about the issue and found most people will go along with your views on this website.
I think this is one of the most vital information for me.
And i’m glad reading your article. But wanna remark on few general
things, The site style is great, the articles is really
nice : D. Good job, cheers
I don’t even know how I ended up here, but I tthought this post
was good. I do not know who you are but definitely
you’re going to a famous blogger if you are not alrdeady 😉 Cheers!
my homepage – binance
I’m amazed, I must say. Seldom doo I come across a blog that’s
both equakly educative and engaging, and without a doubt, you
have hit the nail on the head. The problem is something that not
enough people are speaking intelligently about.
Now i’m very happy I came across this during my hunt for something regarrding this.
my page: 바이낸스 할인
Howdy! I know this is kind of off topic but I was wondering
if you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding
one? Thanks a lot!
Good post. I learn something new and challenging on sites I stumbleupon every day.
It’s always helpful to read through articles from
other authors and use something from their web sites.
Hello there, I think your site could possibly
be having browser compatibility problems. When I
look at your website in Safari, it looks fine however when opening in Internet Explorer, it’s got some overlapping issues.
I simply wanted to provide you with a quick heads up!
Besides that, great blog!
This post provides clear idea designed for the new visitors of blogging, that in fact how to do running a blog.
Hi, i think that i saw you visited my site thus i came
to “return the favor”.I’m trying to find things to enhance my site!I suppose its
ok to use some of your ideas!!
I’m not sure where you are getting your info, but
good topic. I needs to spend some time learning much more or understanding more.
Thanks for magnificent info I was looking for this information for
my mission.
Hi, i read your blog from time to time and i own a similar one and
i was just wondering if you get a lot of spam responses?
If so how do you reduce it, any plugin or anything you can recommend?
I get so much lately it’s driving me insane so any support
is very much appreciated.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time
and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
What i don’t realize is in truth how you are now not really much more well-favored than you might be now.
You’re very intelligent. You recognize therefore considerably
on the subject of this subject, made me for my part believe it from a lot of varied angles.
Its like women and men aren’t involved until it’s one thing to accomplish with Lady gaga!
Your individual stuffs outstanding. Always maintain it up!
Excellent blog here! Also your web site loads up fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as quickly as yours
lol
Hello There. I found your blog using msn. This is an extremely well written article.
I will be sure to bookmark it and come back
to read more of your useful info. Thanks for the post.
I will certainly return.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically
tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading
your blog and I look forward to your new updates.
Hi there to all, it’s genuinely a pleasant for me to pay a visit this site, it consists of useful Information.
Definitely believe that which you said. Your favorite justification seemed to be on the web the easiest thing to be aware of.
I say to you, I certainly get annoyed while people think about worries that they just do not know about.
You managed to hit the nail upon the top as well as defined out
the whole thing without having side-effects , people can take a signal.
Will likely be back to get more. Thanks
Everything is very open with a really clear explanation of the issues.
It was truly informative. Your site is useful. Thank
you for sharing!
Very good site you have here but I was curious about if you knew of any community forums that
cover the same topics talked about here?
I’d really like to be a part of group where I can get opinions from other
experienced people that share the same interest.
If you have any recommendations, please let me know.
Thanks!
Its like you read my mind! You appear to know so much about this, like you wrote the book in it or something.
I think that you could do with some pics to drive the message home a bit, but
instead of that, this is wonderful blog.
A fantastic read. I will definitely be back.
Excellent blog here! Also your website loads up very fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my website loaded up as fast as yours lol
Its like you read my mind! You seem to know so much about this, like youu wrote
the book in it or something. I think that you can do with a few pics to drive the message hone a little bit,
but instead of that, this is fantastic blog. An excellent read.
I will certainly be back.
Also visit my web-site: 바이낸스 추천코드
Highly energetic article, I enjoyed that a lot.
Will there be a part 2? https://www.textove.net/component/k2/item/1559-sample-item-16
Greetings from Los angeles! I’m bored to tears at work so I decided to check
out your blog on my iphone during lunch break. I love the information you provide here and can’t wait to
take a look when I get home. I’m surprised at
how fast your blog loaded on my mobile .. I’m not even using WIFI, just 3G ..
Anyhow, amazing blog!
Everything iss very open with a clear explanation of
the issues. It was definitely informative. Your site is very useful.
Thanks for sharing!
Feel free to visit my website; 바이낸스
Hi there! Visit this website – Lesli -is my 1st comment heree so I juzt wanted to give
a quick shout out and say I genuinely enjoy
reading through your articles. Can you ecommend any other blogs/websites/forums
that cover the same subjects? Thanks for your time!
Because the admin of this website is working, no uncertainty very soon it will be famous, due to its
feature contents.
Hello there! This article couldn’t be written much better!
Looking through this article reminds me of my previous roommate!
He constantly kept talking about this. I will send this post to
him. Fairly certain he will have a good read.
I appreciate you for sharing!
I really like reading through a post that will make people think.
Also, thanks for permitting me to comment!
This post is actually a nice one it helps new net people, who are wishing for blogging.
Do you have a spam issue on this website; I also am a blogger, and I was curious about your situation; many of us have created some nice practices and we are looking to trade techniques with others, why not
shoot me an email if interested.
Truly no matter if someone doesn’t understand afterward its up to other viewers that they will assist,
so here it takes place.
You are so awesome! I don’t suppose I’ve truly read anything like this before.
So nice to discover another person with unique thoughts on this issue.
Really.. thanks for starting this up. This website is
one thing that is required on the web, someone with a
little originality!
My brother suggested I might like this website. He was entirely right.
This popst actually made my day. You can not imagine just how much time
I had spent for thiis info! Thanks!
Have a look at my blog – 바이낸스 (Chet)
Can you tell us more about this? I’d want to find out some additional information.
Having read this I believed it was really enlightening.
I appreciate you finding the time and energy to put this short article together.
I once again find myself spending way too much time both reading
and posting comments. But so what, it was still worthwhile!
Hi there! This post couldn’t be written much better! Reading
through this post reminds me of my previous roommate! He continually
kept preaching about this. I will send this information to him.
Fairly certain he’ll have a great read. Many thanks
for sharing!
I’m gone to convey my little brother, that he should also
pay a visit this blog on regular basis to obtain updated from most up-to-date information.
I loved as much as you’ll receive carried out
right here. The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an nervousness over that you wish be delivering the
following. unwell unquestionably come further formerly again since exactly the same
nearly very often inside case you shield this increase.
Thanks for your marvelous posting! I definitely enjoyed reading it, you might be a great author.
I will be sure to bookmark your blog and will often come back in the future.
I want to encourage yourself to continue your great job, have a nice day!
Good day! This is kind of off topic but I need some help from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure where
to start. Do you have any ideas or suggestions? Cheers
hey there and thank you for your info – I’ve
certainly picked up something new from right here. I did however expertise a few technical points using this web site, as I
experienced to reload the site many times previous to I could get it to load properly.
I had been wondering if your web hosting is OK? Not that I’m complaining, but sluggish loading instances times will often affect your
placement in google and could damage your high-quality score
if ads and marketing with Adwords. Anyway I am adding this RSS to my email and could look out for a lot more of your respective fascinating
content. Ensure that you update this again very soon.
This is a topic that is close to my heart…
Cheers! Exactly where are your contact details though?
bookmarked!!, I really like your blog!
Valuable information. Lucky me I found your
web site by chance, and I’m shocked why this coincidence did not
came about earlier! I bookmarked it.
Nice respond in return of this question with real arguments and explaining everything on the topic
of that.
I am extremely impressed with your writing skills as well
as with the layout on your blog. Is this a paid theme or
did you customize it yourself? Either way keep up the excellent quality writing,
it is rare to see a great blog like this one these days.
When I initially left a comment I appear to have clicked the -Notify me when new comments are added- checkbox and
now whenever a comment is added I recieve 4 emails with the exact same comment.
Perhaps there is a way you can remove me from that service?
Cheers!
You really make it seem so easy with your presentation but I find this matter to be
actually something that I think I would never understand. It seems too complicated and very broad for me.
I am looking forward for your next post, I’ll try to get the
hang of it!
Everything is very open with a clear explanation of the challenges.
It was truly informative. Your site is useful. Thank you for sharing!
Yes! Finally someone writes about لیست بهترین و معتبرترین سایت های شرط
بندی فوتبال با واریز مستقیم.
Fastidious answer back in return of this question with solid arguments and telling everything on the topic of that.
It is truly a nice and useful piece of info. I’m happy
that you shared this helpful information with
us. Please keep us up to date like this. Thanks for sharing.
This is a very good tip particularly to those fresh to the
blogosphere. Brief but very precise info… Many thanks for sharing this one.
A must read post!
Hurrah, that’s what I was exploring for, what a information! existing here at this website, thanks
admin of this web site.
Hi, I think your blog might be having browser compatibility issues.
When I look at your blog site in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up!
Other then that, great blog!
You actually make it appear really easy along with
your presentation however I in finding this topic to be actually something which I believe I’d by no means understand.
It seems too complex and extremely extensive for me.
I am looking forward in your subsequent publish, I will attempt to
get the dangle of it!
Asking questions are in fact nice thing if you are not understanding anything fully, but this paragraph gives
fastidious understanding even.
I was curious if you ever considered changing
the layout of your blog? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it
better. Youve got an awful lot of text for only having one or two pictures.
Maybe you could space it out better?
Fantastic items from you, man. I’ve remember your stuff previous to and you are just extremely wonderful.
I actually like what you have got here, certainly like what you are stating and the way in which by which
you say it. You make it entertaining and you continue to take care of to stay it sensible.
I cant wait to read much more from you. This is really a tremendous site.
I think what you posted was very reasonable. But, think on this, suppose
you typed a catchier post title? I ain’t saying your information is not good,
but suppose you added something that grabbed people’s attention? I mean Пиастры –
Составление семантического
ядра | is a little boring. You should look at Yahoo’s home page and watch how they create article headlines to get viewers to open the links.
You might add a video or a related picture or two to get
readers excited about what you’ve got to say. In my opinion, it would make your posts a
little bit more interesting.
This website was… how do I say it? Relevant!!
Finally I’ve found something which helped me. Thanks!
At this time it seems like WordPress is the preferred blogging platform out there right
now. (from what I’ve read) Is that what you are using on your blog?
I’d like to thank you for the efforts you have put in penning this website.
I am hoping to see the same high-grade content from you later on as well.
In fact, your creative writing abilities has encouraged me to get my own blog now 😉
Great blog! Do you have any suggestions for aspiring writers?
I’m planning to start my own blog soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a
paid option? There are so many choices out there that I’m completely confused ..
Any ideas? Thanks!
WOW just what I was searching for. Came here by searching for https://www.kickstarter.com/profile/2135792384/about
I was curious if you ever considered changing the layout
of your site? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one
or two pictures. Maybe you could space it out better?
I am in fact pleased to read this blog posts which consists of plenty of useful
data, thanks for providing these kinds of data.
My spouse and I absolutely love your blog and find a lot of your post’s to be just what I’m looking for.
Does one offer guest writers to write content for yourself?
I wouldn’t mind composing a post or elaborating on many of the
subjects you write with regards to here. Again, awesome blog!
Hi there everyone, it’s my first visit at this web site,
and piece of writing is in fact fruitful designed for me, keep up posting these articles.
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on numerous
websites for about a year and am nervous about switching to another platform.
I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be greatly appreciated!
of course like your website but you have to take a look at the spelling on several of
your posts. Many of them are rife with spelling problems and I to find it very troublesome to tell the truth nevertheless I’ll surely come again again.
Wonderful beat ! I would like to apprentice while you amend your web site,
how could i subscribe for a blog website? The account helped me a acceptable deal.
I had been tiny bit acquainted of this your broadcast offered bright
clear idea
I’m gone to inform my little brother, that he should also go to
see this website on regular basis to get updated from most up-to-date news update.
May I simply say wwhat a relief to uncover somebody that truly knows
what they are talking abut on the net. You actually understand how too bring ann issue to light
and make it important. More people need to ead this and understand this side of the story.
It’s surprising you arre not morde popular given that yyou
surely possess the gift.
my web page – binance
Howdy very cool web site!! Man .. Excellent .. Wonderful ..
I’ll bookmark your web site and take the feeds additionally?
I am satisfied to seek out numerous useful info here within the post, we’d like develop extra strategies in this regard, thank you for sharing.
. . . . .
OLL Порно
Hello! Do you knhow if they maqke any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not
seeing very good results. If you know of any please share. Kudos!
Look aat my homepage: 바이낸스 (Kelli)
Ahaa, its good conversation concerning this piece of
writing here at this weblog, I have read all that, so now me also commenting
here.
Hey there just wanted to give you a quick heads up.
The text in your post seem to be running off the screen in Ie.
I’m not sure if this is a format issue or something to do with
browser compatibility but I thought I’d post to let you know.
The design and style look great though! Hope you get the issue
solved soon. Many thanks
What’s up to every body, it’s my first pay a quick visit of this webpage; this webpage contains awesome and
actually excellent information in support of readers.
wonderful publish, very informative. I ponder why the opposite specialists
of this sector don’t realize this. You should continue your writing.
I am confident, you’ve a great readers’ base already!
Its like you learn my thoughts! You seem to understand a lot approximately this, like you wrote the guide in it
or something. I feel that you could do with a few percent to force the message house a little
bit, but other than that, this is great blog.
A great read. I’ll definitely be back.
Inspiring story there. What occurred after?
Thanks!
constantly i used to read smaller content that as well
clear their motive, and that is also happening with this paragraph
which I am reading at this place.
That is a great tip particularly to those new to the blogosphere.
Simple but very accurate information… Thank you
for sharing this one. A must read article!
Hello! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months of hard work due
to no back up. Do you have any methods to stop hackers?
fantastic publish, very informative. I wonder why the opposite experts of this
sector don’t realize this. You must proceed your writing.
I am sure, you have a huge readers’ base already!
Hey there this is somewhat of off topic but I
was wondering if blogs use WYSIWYG editors or if you have to manually code
with HTML. I’m starting a blog soon but have no
coding know-how so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
What’s up to every body, it’s my first visit of this website; this web site includes amazing and
in fact fine stuff in support of visitors.
Hello colleagues, fastidious post and nice urging commented at this place, I am
actually enjoying by these.
Wonderful goods from you, man. I have understand your stuff
previous to and you’re just too wonderful.
I actually like what you have acquired here, really like what you are
saying and the way in which you say it. You make it enjoyable and you still care for to keep it smart.
I can not wait to read far more from you. This is really a tremendous
web site.
I could not resist commenting. Perfectly written!
Hi there just wanted to give you a quick heads up and let
you know a few of the images aren’t loading correctly. I’m
not sure why but I think its a linking issue. I’ve tried it in two different internet
browsers and both show the same outcome.
What’s up, everything is going fine here and ofcourse every one is sharing facts,
that’s actually good, keep up writing.
Your means of telling all in this piece of
writing is truly pleasant, every one be able to easily
know it, Thanks a lot.
Outstanding story there. What occurred after?
Take care!
Hello to every body, it’s my first pay a quick visit of this weblog;
this webpage carries amazing and in fact fine material for readers.
I don’t even know how I ended up here, but I thought
this post was good. I don’t know who you are but certainly you
are going to a famous blogger if you aren’t already 😉
Cheers!
I truly love your blog.. Pleasant colors & theme.
Did you create this web site yourself? Please reply back as I’m attempting to create my very own site and would love to find out where you got this from or just what the
theme is named. Kudos!
Hi there mates, how is the whole thing, and what you wish
for to say regarding this piece of writing, in my view
its really remarkable in support of me.
Awesome article.
Superb website you have here but I was curious about if
you knew of any user discussion forums that cover the same topics talked about in this article?
I’d really love to be a part of online community where I can get suggestions from other
knowledgeable people that share the same interest.
If you have any recommendations, please let me
know. Cheers!
Ебацца
Wow, awesome blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is great, let alone the content!
I want to to thank you for this fantastic read!! I absolutely enjoyed every little bit of it.
I’ve got you book marked to check out new
things you post…
OLL Порно
Hey there! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Thank you!
Great delivery. Great arguments. Keep up the good work.
It’s amazing to pay a quick visit this web page and reading
the views of all mates on the topic of this post, while I am also
keen of getting knowledge.
Hey! Someone in my Facebook group shared this website with us
so I came to look it over. I’m definitely enjoying the information. I’m book-marking and
will be tweeting this to my followers! Great blog and wonderful design.
First of all I would like to say terrific blog! I had a quick
question that I’d like to ask if you do not mind.
I was curious to know how you center yourself and clear your thoughts prior to
writing. I’ve had a hard time clearing my thoughts in getting my ideas out there.
I truly do take pleasure in writing but it just seems like the first 10 to 15
minutes are generally lost simply just trying to figure out how to begin. Any ideas or tips?
Thanks!
When someone writes an post he/she keeps the image of a user in his/her brain that how a user can be aware of it.
Therefore that’s why this article is amazing.
Thanks!
Hi there i am kavin, its my first occasion to commenting anywhere, when i read
this article i thought i could also create comment
due to this sensible post.
Pretty nice post. I just stumbled upon your blog and wished to say that I have really loved browsing your
blog posts. After all I will be subscribing in your feed and I’m
hoping you write once more soon!
Hello there I am so excited I found your site, I really
found you by mistake, while I was looking on Aol for something else,
Anyways I am here now and would just like to say many thanks for a marvelous post and a all round exciting blog (I
also love the theme/design), I don’t have time to go through it all at the minute but I have saved it and also included your RSS feeds, so when I have time I will be back to read much more, Please do keep up the awesome b.
Thank you, I’ve recently been searching for info about this subject for a long time and yours is the
greatest I have came upon so far. However, what concerning the bottom line?
Are you certain in regards to the supply?
Howdy! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
If some one wishes to be updated with newest technologies after that
he must be visit this web page and be up to date everyday.
Yesterday, while I was at work, my sister stole my iPad and tested to see if it can survive a 30 foot drop, just so she can be a youtube sensation. My apple ipad is
now destroyed and she has 83 views. I know this is totally off
topic but I had to share it with someone!
Heya i am for the first time here. I found this board and I find It truly useful & it helped me out much.
I hope to give something back and aid others like you aided me.
Can you tell us more about this? I’d like to find out some additional information.
Hi! I just wanted to ask if you ever have any
issues with hackers? My last blog (wordpress) was hacked
and I ended up losing months of hard work due
to no back up. Do you have any methods to protect against hackers?
If you want to get a great deal from this piece of writing then you have
to apply such strategies to your won website.
Howdy I am so grateful I found your website, I really found you by accident, while I was browsing on Bing for something else,
Anyhow I am here now and would just like to say
thanks a lot for a fantastic post and a all round thrilling blog
(I also love the theme/design), I don’t have time to read it all at the minute but I have saved it
and also added your RSS feeds, so when I have time I will be back to read
much more, Please do keep up the awesome work.
Magnificent website. Lots of helpful information here.
I am sending it to some pals ans additionally sharing in delicious.
And of course, thanks on your sweat!
certainly like your web-site but you have to
take a look at the spelling on quite a few of your posts.
Several of them are rife with spelling problems and I in finding it very troublesome to inform the truth nevertheless
I’ll surely come again again.
Terrific work! This is the kind of information that should
be shared around the internet. Shame on Google for now
not positioning this post upper! Come on over and consult with my site .
Thanks =)
I really like it when individuals get together and share views.
Great site, continue the good work!
Truly when someone doesn’t be aware of afterward
its up to other viewers that they will help, so here it happens.
With havin so much content and articles do you ever run into any problems of plagorism or copyright violation? My website has
a lot of completely unique content I’ve either authored myself or outsourced but it looks like a lot of it is popping it up all over the web without
my permission. Do you know any ways to help reduce content from
being ripped off? I’d certainly appreciate it.
This is very interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your wonderful post.
Also, I have shared your web site in my social networks!
Thank you for sharing your info. I truly appreciate your efforts and I will
be waiting for your further post thank you once again.
Heya are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you require any coding expertise to make your own blog?
Any help would be greatly appreciated!
Very descriptive post, I loved that bit. Will there be a part 2?
When someone writes an paragraph he/she keeps the idea of a user
in his/her mind that how a user can be aware of it. Thus that’s why this
paragraph is outstdanding. Thanks!
Wow, this piece of writing is nice, my sister is analyzing these kinds of things, thus
I am going to inform her.
Very good info. Lucky me I came across your website by accident (stumbleupon).
I’ve bookmarked it for later!
Hi, I do believe this is an excellent site. I stumbledupon it 😉 I may revisit once again since I book-marked it.
Money and freedom is the greatest way to change, may you be rich and continue to guide others.
Hello there! This post couldn’t be written any better!
Reading through this post reminds me of my good old room mate!
He always kept talking about this. I will forward this page
to him. Pretty sure he will have a good read. Thank
you for sharing!
I really like what you guys are up too. Such clever work and reporting!
Keep up the excellent works guys I’ve incorporated you guys to blogroll.
Hiya! I know this is kinda off topic however I’d figured I’d
ask. Would you be interested in exchanging
links or maybe guest writing a blog post or vice-versa?
My blog covers a lot of the same subjects as yours and I think we could greatly benefit from each other.
If you might be interested feel free to shoot me
an email. I look forward to hearing from you!
Fantastic blog by the way!
Hi there, i read your blog occasionally and i own a similar one
and i was just wondering if you get a lot of spam responses?
If so how do you prevent it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any support is
very much appreciated.
Thanks for another magnificent article. Where else could anybody get that kind of information in such an ideal manner of writing?
I have a presentation subsequent week, and I am on the search for such info.
What’s up, I want to subscribe for this blog to take hottest updates, so where can i do it please help.
I’m gone to convey my little brother, that he should also pay a quick visit this web site on regular basis to take
updated from most recent gossip.
Everything is very open with a very clear clarification of the
challenges. It was really informative. Your
site is extremely helpful. Many thanks for sharing!
Hello Dear, are you in fact visiting this web page
regularly, if so afterward you will without doubt obtain fastidious
knowledge.
I enjoy looking through an article that will make men and women think.
Also, thank you for permitting mme to comment!
Also visit my web-site – 바이낸스 출금
constantly i used to read smaller articles or reviews
which as well clear their motive, and that is
also happening with this article which I am reading at this place.
Hi, Neat post. There is a problem along with your site in internet explorer,
may check this? IE nonetheless is the market leader and a good component of other people will leave out your magnificent writing due to
this problem.
My spouse and I stumbled over here from a different web address and thought I should
check things out. I like what I see so now i am following you.
Look forward to going over your web page again.
Thank you a lot for sharing this with all of us you really recognize what you are talking
about! Bookmarked. Please additionally talk over with my site
=). We can have a hyperlink exchange arrangement among us
Everything is very open with a really clear explanation of
the issues. It was truly informative. Your site is very helpful.
Many thanks for sharing!
You have made some really good points there. I checked
on the net to find out more about the issue and found most people will go along with your views
on this website.
Hello oᥙtstanding blog! Doеs running а blog similar tto this require a lawrge amⲟunt of work?
I have no еxpertise in prߋgramming howaever I had beеn hoping to start my own blog
soon. Anyhow, should you have any suggestions ᧐r techniques foгr neᴡ blog
owners pleaѕe share. I know this is off ubject however I simply wanted to ask.
Appreciate it!
After I initially left a comment I seem to have clicked the -Notify me when new comments are added- checkbox and now every time a comment is added
I receive four emails with the exact same comment.
There has to be a way you are able to remove me from that service?
Thanks!
Amazing! Its truly awesome paragraph, I have got
much clear idea regarding from this post.
I just could not depart your site before suggesting that I really loved the
usual information a person provide for your guests? Is gonna be again continuously to investigate cross-check new posts
Hi friends, how is the whole thing, and what you want to say
concerning this post, in my view its in fact remarkable designed for me.
My partner and I absolutely love your blog and find the majority of your post’s to be exactly what I’m looking for.
Do you offer guest writers to write content for you personally?
I wouldn’t mind composing a post or elaborating on a few
of the subjects you write concerning here.
Again, awesome site!
Paragraph writing is also a excitement, if you know then you can write or else it is complicated to write.
I love reading a post that will make people think.
Also, thank you for permitting me to comment!
I know this website provides quality based articles
or reviews and additional information, is there any other site which offers these kinds of stuff in quality?
We absolutely love your blog and find almost all of your post’s to be just what I’m looking for.
can you offer guest writers to write content for you?
I wouldn’t mind producing a post or elaborating on many of the subjects you write concerning here.
Again, awesome site!
That is very attention-grabbing, You are a very professional blogger.
I’ve joined your rss feed and look ahead to in the hunt for
more of your fantastic post. Additionally, I have shared your site in my social networks
Paragraph writing is also a excitement, if you be familiar with
then you can write otherwise it is complicated to write.
When some one searches for his vital thing, thus he/she wishes to be available that in detail, therefore
that thing is maintained over here.
I pay a quick visit daily a few sites and blogs to read content, but
this website offers feature based articles.
Just wish to say your article is as astounding.
The clearness in your post is just cool and i can assume you
are an expert in this subject. Well with your permission let me to take hold
of your feed to keep updated with forthcoming post.
Thanks a million and please carry on the enjoyable work.
I like reading through a post that can make men and women think.
Also, many thanks for permitting me to comment!
I have been browsing online more than 2 hours today, yet I never found any interesting
article like yours. It’s pretty worth enough for me. In my opinion, if
all web owners and bloggers made good content as you did,
the net will be much more useful than ever before.
Oh my goodness! Incredible article dude! Many thanks, However I am encountering difficulties with your RSS.
I don’t understand the reason why I cannot subscribe to
it. Is there anybody having the same RSS problems? Anyone that knows the answer can you kindly respond?
Thanks!!
Hi there, its nice post about media print, we all understand media is a wonderful
source of facts.
Thanks for finally writing about > Пиастры – Составление семантического ядра | < Loved it!
After checking out a few of the articles on your site,
I really like your technique of blogging. I bookmarked it to my bookmark website list and will be checking back in the near future.
Please check out my website as well and let me know how you feel.
Dо you have a ѕoam ieѕue on this blօg; I also am а blogger, and I was cuurious about yoսr situation; many of us have developed some nice methods and we are lookіng to trde techniqueѕ with others, pleasse shoot
me an email if interested.
I’ve read several just right stuff here.
Certainly worth bookmarking for revisiting. I wonder how so much attempt you
set to make such a magnificent informative web site.
Heya i am for the primary time here. I found this board and I to find It truly useful & it
helped me out much. I’m hoping to give something again and
help others like you aided me.
What’s up mates, how is all, and what you wish
for to say about this article, in my view its in fact awesome for me.
Why users still use to read news papers when in this technological globe all
is presented on web?
A person necessarily lend a hand to make significantly articles I would state.
This is the first time I frequented your website page and to
this point? I amazed with the research you made to make this particular
post amazing. Excellent activity!
I think this is among the so much significant info for me.
And i’m happy studying your article. However should commentary on few normal issues, The web site
taste is perfect, the articles is in point of fact great :
D. Excellent process, cheers
This is my first time visit at here and i am in fact
happy to read all at one place.
Ⲩou really makе it seem sߋ easy wіth your
presentation but I find this topic to be really something
thɑt I tһink I wkuld never understand. It seems ttoo complіcated and very
broаd ffor me. I am looking forward for yoսг next post, I wilⅼ try to get the hsng of it!
Definitely believe that which you said. Your favorite reason seemed to be on the net
the easiest thing to be aware of. I say to you, I definitely
get irked while people consider worries that they just don’t know about.
You managed to hit the nail upon the top as well as
defined out the whole thing without having side-effects , people could take a signal.
Will likely be back to get more. Thanks
Hi there! Would you mind if I share your blog with my myspace group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thanks
Hi there would you mind sharing which blog platform you’re using?
I’m going to start my own blog in the near future but I’m having
a hard time deciding between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your
layout seems different then most blogs and I’m looking for something
unique. P.S Apologies for being off-topic but I had to ask!
It’s amazing to visit this web page and reading the views of
all colleagues about this article, while I am
also zealous of getting familiarity.
Hello to every one, the contents present at this website are actually awesome for people knowledge, well, keep up the
good work fellows.
Excellent beat ! I would like to apprentice while you amend your site, how can i subscribe for a blog site?
The account helped me a acceptable deal. I had been tiny
bit acquainted of this your broadcast offered bright clear idea
I am really loving the theme/design of your website.
Do you ever run into any browser compatibility issues?
A number of my blog audience have complained about my website not working correctly in Explorer but looks great in Safari.
Do you have any suggestions to help fix this issue?
I’ve read several good stuff here. Definitely
value bookmarking for revisiting. I surprise how a lot effort you put to make the sort of
excellent informative site.
Wonderful article! We will be linking to this particularly great
article on our site. Keep up the great writing.
Hi there it’s me, I am also visiting this site daily, this website is
in fact nice and the users are truly sharing nice thoughts.
Very quickly this website will be famous amid all blogging and site-building users, due to it’s pleasant posts
I do believe all of the ideas you’ve offered in your post.
They’re really convincing and will certainly work.
Still, the posts are too brief for novices.
May just you please lengthen them a little from next time?
Thanks for the post.
Excellent way of describing, and nice article to get data concerning my presentation subject matter, which i am going to deliver in school.
I love what you guys are usually up too. This sort of clever work and reporting!
Keep up the terrific works guys I’ve included you guys to blogroll.
What’s up, after reading this remarkable piece of writing
i am as well delighted to share my experience here with mates.
I just like the valuable information you provide on your articles.
I will bookmark your blog and check again here regularly.
I’m rather certain I will learn plenty of new stuff proper here!
Good luck for the following!
Every weekend i used to visit this web site, as i wish for
enjoyment, as this this site conations actually good funny information too.
Highly energetic article, I loved that a lot.
Will there be a part 2?
Hi would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 completely different web browsers and I
must say this blog loads a lot quicker then most. Can you recommend a good internet hosting provider at a fair price?
Cheers, I appreciate it!
Thanks for sharing your thoughts on Plants and garden. Regards
Link exchange is nothing else however it is only placing the other person’s blog link
on your page at suitable place and other person will also
do similar in support of you.
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying to get
started and create my own. Do you need any html coding expertise
to make your own blog? Any help would be really appreciated!
I was more than happy to discover this page. I need to
to thank you for ones time just for this fantastic read!! I definitely really liked every bit of it and i also have you
bookmarked to see new stuff in your web site.
Ꮋey there just wanted to give y᧐u a quick heads ᥙp.
The text in your content sеem too be running off the sdreen in Firefox.
I’m not surе if this is a format issue or somеthing to do ѡith internet browѕer compatibility
but I figսred I’d post to let уou know. The style ɑnd design ⅼoook great though!
Hopee yooᥙ get thee issᥙe solved soon. Manyy
thanks
Là, vous nous expliquez votre problème et nous effectuons un diagnostic de la scenario.
Hey there, I think your blog might be having browser compatibility issues.
When I look at your website in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, great blog!
Hi there, i read your blog from time to time and i own a similar one and i was just curious
if you get a lot of spam remarks? If so how do you prevent it, any plugin or anything you can recommend?
I get so much lately it’s driving me insane so any support is very much appreciated.
My brother recommended I might like this web site. He was totally
right. This post truly made my day. You can not imagine just how much time I had spent for this
information! Thanks!
I read this paragraph completely regarding the resemblance of newest and preceding technologies, it’s remarkable article.
It’s really a great and useful piece of info.
I am glad that you simply shared this useful info with us.
Please keep us up to date like this. Thanks for sharing.
I just like the helpful information you provide to your articles.
I’ll bookmark your blog and test again right here frequently.
I’m reasonably certain I’ll learn lots of new stuff proper here!
Good luck for the following!
Highly energetic article, I liked that bit. Will there be a
part 2?
Everyone loves what you guys tend to be up too. This
type of clever work and coverage! Keep up the great works
guys I’ve added you guys to blogroll.
Heya i’m for the first time here. I came across this board and I find It really useful & it helped me out a
lot. I hope to give something back and aid others like
you aided me.
Superb, what a weblog it is! This webpage gives helpful facts to us, keep it up.
I’m really inspired together with your writing skills and also
with the structure in your blog. Is that this a paid topic or did you modify it yourself?
Anyway keep up the excellent high quality writing, it is uncommon to see a nice weblog like this one today..
Hi there friends, how is the whole thing, and what you want to
say about this paragraph, in my view its really remarkable in support
of me.
Good day! Do you use Twitter? I’d like to follow you if that would be okay.
I’m undoubtedly enjoying your blog and look forward to new posts.
hello there and thank you for your information – I have certainly picked
up anything new from right here. I did however expertise a
few technical points using this site, since I experienced to reload the web site a lot
of times previous to I could get it to load correctly. I had been wondering if your web
host is OK? Not that I’m complaining, but slow loading instances
times will often affect your placement in google and
can damage your high quality score if advertising and marketing with Adwords.
Well I’m adding this RSS to my e-mail and can look out for much more
of your respective exciting content. Make sure you update this again very soon.
I absolutely love your blog and find a lot of your post’s
to be just what I’m looking for. Do you offer guest writers to
write content for you personally? I wouldn’t mind producing a post or
elaborating on some of the subjects you
write about here. Again, awesome blog!
I have read so many content about the blogger lovers but this
article is truly a nice piece of writing, keep it up.
There is certainly a lot to learn about this topic.
I like all of the points you have made.
Does your website have a contact page? I’m having a tough time locating
it but, I’d like to send you an email. I’ve got some creative ideas for your blog
you might be interested in hearing. Either way, great website and I look forward to seeing
it grow over time.
I for all time emailed this blog post page to all my associates, since if like to read it then my
contacts will too.
Do you have a spam problem on this blog; I also
am a blogger, and I was curious about your situation; many of
us have created some nice practices and we are looking to trade solutions
with other folks, be sure to shoot me an e-mail if interested.
My site: lkq raleigh nc
Hi, I do believe this is an excellent web site.
I stumbledupon it 😉 I am going to return once again since
I bookmarked it. Money and freedom is the greatest way to change, may you
be rich and continue to guide other people.
Attractive part of content. I simply stumbled upon your weblog and in accession capital to assert that I get actually loved account your weblog posts.
Any way I will be subscribing on your augment or
even I achievement you get admission to constantly
rapidly.
Hey there, You’ve done a fantastic job. I’ll definitely digg
it and personally suggest to my friends.
I’m confident they will be benefited from this
website.
My partner and I absolutely love your blog and find many of your post’s to be precisely what I’m
looking for. Does one offer guest writers to write
content for you? I wouldn’t mind producing a post or
elaborating on a number of the subjects you write in relation to here.
Again, awesome web site!
Excellent post. I was checking continuously this blog and I care for such info a lot. I was looking for
I care for such info a lot. I was looking for
I’m impressed! Extremely useful info specially the last
part
this particular info for a very long time. Thank you and good luck.
Remarkable! Its really amazing post, I have got much
clear idea about from this post.
Its such as you learn my mind! You appear to grasp a lot approximately
this, such as you wrote the guide in it
or something. I think that you just can do with some percent to drive
the message house a little bit, however instead of that, that is wonderful blog.
A fantastic read. I’ll definitely be back.
Hello there! Do you use Twitter? I’d like to follow you if that would be
ok. I’m absolutely enjoying your blog and look forward to new posts.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how could we
communicate?
Appreciation to my father who informed me about this website,
this website is genuinely remarkable.
Good day! I just would like to give you a big thumbs up
for the great info you have right here on this post. I will be
coming back to your web site for more soon.
Hi, I do believe your site could be having browser compatibility issues.
When I look at your website in Safari, it looks fine
however, when opening in IE, it’s got some overlapping issues.
I simply wanted to give you a quick heads up! Apart from that, excellent
website!
Hello, I think your website could possibly be having browser
compatibility issues. When I look at your website in Safari, it
looks fine however, when opening in I.E., it’s got some overlapping issues.
I just wanted to give you a quick heads up! Aside from that, excellent blog!
It’s the best time to make a few plans for the long run and it is time to be happy.
I’ve read this submit and if I could I wish to
counsel you some interesting things or suggestions. Maybe you could
write subsequent articles relating to this article. I wish to read even more things about it!
Does your blog have a contact page? I’m having
trouble locating it but, I’d like to send you an e-mail.
I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it expand over
time.
I’ll right away grab your rss feed as I can not to find your email subscription hyperlink
or e-newsletter service. Do you have any?
Please permit me understand in order that I could subscribe.
Thanks.
What’s up, after reading this remarkable paragraph i am also
cheerful to share my knowledge here with friends.
I will right away grab your rss as I can not to
find your email subscription link or e-newsletter service.
Do you’ve any? Please permit me understand in order that I may just subscribe.
Thanks.
Hello! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Many thanks!
Hi there, I discovered your website by the use of Google even as looking for a
related topic, your web site got here up, it appears to be like great.
I’ve bookmarked it in my google bookmarks.
Hello there, simply became alert to your weblog thru Google, and located that it is really informative.
I am going to watch out for brussels. I will appreciate
if you continue this in future. A lot of folks can be benefited
from your writing. Cheers!
Wonderful site. Lots of useful info here. I’m sending it to a few pals ans also sharing in delicious.
And of course, thanks for your effort!
I like the valuable info you provide in your articles.
I’ll bookmark your blog and check again here regularly.
I’m quite sure I will learn many new stuff right here! Best of luck for the next!
What’s Going down i’m new to this, I stumbled upon this I
have discovered It absolutely helpful and it has aided me
out loads. I am hoping to give a contribution & aid different customers like its aided me.
Great job.
Hi, its good paragraph on the topic of media print,
we all know media is a great source of information.
Amazing blog! Is your theme custom made or did
you download it from somewhere? A design like
yours with a few simple tweeks would really make my blog
jump out. Please let me know where you got your design. Many
thanks
Hi there, its fastidious paragraph regarding media print,
we all be familiar with media is a impressive source of information.
May I simply just say what a relief to uncover somebody that actually knows what they are talking about online.
You definitely understand how to bring a problem to light and make it important.
More people ought to read this and understand this side of your story.
I was surprised you aren’t more popular given that you most certainly have the gift.
My web-site :: Alwar escort service
If some one desires to be updated with newest technologies then he must
be pay a quick visit this web page and be up to date every day.
Hi there mates, how is all, and what you wish for to say concerning
this paragraph, in my view its actually amazing for me.
my homepage: кредит 24
It’s going to be finish of mine day, however before finish I am reading this fantastic post to improve my experience.
An outstanding share! I have just forwarded this onto a colleague who has been conducting a little homework
on this. And he in fact bought me lunch due to the fact that I stumbled upon it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanx for spending some time to discuss this matter here on your internet site.
Greetings! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My site looks weird
when browsing from my iphone4. I’m trying to find a theme or
plugin that might be able to correct this issue. If you have any recommendations, please share.
Appreciate it!
Hi every one, here every one is sharing such knowledge, so it’s pleasant to read this blog, and I used to go to see this weblog everyday.
Normally I don’t learn article on blogs, but I would like to say that this write-up very pressured me to try and do so!
Your writing style has been surprised me. Thanks, quite nice post.
Valuable info. Fortunate me I found your website
unintentionally, and I’m stunned why this twist of fate did not took place in advance!
I bookmarked it.
It’s actually very complex in this active life to listen news on TV, thus I just use
internet for that reason, and obtain the latest information.
Hello, i think that i saw you visited my blog so i came to “return the favor”.I’m
trying to find things to improve my web site!I suppose its
ok to use a few of your ideas!!
Unquestionably consider that which you said. Your favourite reason appeared to
be at the web the simplest factor to remember of. I
say to you, I definitely get annoyed whilst other folks think about issues that they just
don’t recognise about. You managed to hit the nail upon the top and also defined out the entire thing without
having side-effects , folks can take a signal.
Will probably be again to get more. Thank you
Have you ever thought about including a little bit more than just your articles?
I mean, what you say is valuable and all. But think of if you added some great visuals or video
clips to give your posts more, “pop”! Your content is
excellent but with pics and videos, this blog could undeniably be one of the most
beneficial in its niche. Very good blog!
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is important and everything. Nevertheless think of
if you added some great pictures or video clips to give your posts more,
“pop”! Your content is excellent but with images and videos,
this blog could definitely be one of the most beneficial in its field.
Great blog!
What’s up to every single one, it’s in fact a good for me to go to see this website,
it consists of helpful Information.
It’s fantastic that you are getting thoughts
from this paragraph as well as from our argument made at this time.
You have made some really good points there. I looked on the net to
learn more about the issue and found most individuals
will go along with your views on this website.
Woah! I’m really loving the template/theme of this site.
It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance”
between superb usability and appearance. I must say that you’ve
done a fantastic job with this. Also, the blog loads super quick for me on Opera.
Outstanding Blog!
Appreciate the recommendation. Will try it out.
This post provides clear idea in favor of the new viewers
of blogging, that really how to do blogging
and site-building.
Hi there, I enjoy reading through your article post.
I like to write a little comment to support you.
We are a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable information to work on. You have done
an impressive job and our entire community will be
thankful to you.
First of all I want to say excellent blog! I had a quick
question which I’d like to ask if you do not mind.
I was curious to know how you center yourself and clear your mind prior to writing.
I have had a difficult time clearing my mind in getting my ideas out.
I do enjoy writing however it just seems like the first 10 to 15 minutes are usually wasted simply
just trying to figure out how to begin. Any ideas or hints?
Thanks!
Nice blog here! Also your web site loads up fast! What host are you using?
Can I get your affiliate link to your host? I wish my website loaded up
as fast as yours lol
Greetings! I’ve been following your web site for a while
now and finally got the bravery to go ahead and give you a shout
out from Dallas Texas! Just wanted to say keep up the fantastic work!
Thanks in favor of sharing such a nice opinion, piece of writing is nice, thats why
i have read it fully
Nice respond in return of this issue with solid arguments and explaining the
whole thing concerning that.
It’s remarkable to pay a quick visit this site and reading the views of all colleagues about this article, while I am also zealous of getting experience.
เว็บสล็อตWe are ready to serve all gamblers with a complete range of
online casinos that are easy to play for real money.
Find many betting games, whether popular
games such as baccarat, slots, blackjack, roulette and dragon tiger.
Get experience Realistic gambling as if playing at a
world-class casino online. Our website is open for new members
24 hours a day.
It’s remarkable in favor of me to have a site, which is useful designed for my
knowledge. thanks admin
I’m curious to find out what blog platform you have been using?
I’m experiencing some minor security issues with my latest website and I would like to find something more risk-free.
Do you have any solutions?
My family members always say that I am wasting my time here at web, except I know I am getting know-how all the time by reading such fastidious articles.
I like the valuable information you provide in your articles.
I’ll bookmark your weblog and check again here regularly.
I am quite certain I’ll learn plenty of
new stuff right here! Best of luck for the next!
Hi, I think your web site could possibly be having internet browser compatibility issues.
Whenever I look at your blog in Safari, it looks
fine however when opening in I.E., it’s got some overlapping
issues. I just wanted to give you a quick
heads up! Aside from that, wonderful blog!
I absolutely love your website.. Excellent colors & theme.
Did you create this web site yourself? Please reply
back as I’m trying to create my own personal site and want to find out
where you got this from or exactly what the theme is called.
Appreciate it!
hey there and thank you for your information – I have definitely picked up anything
new from right here. I did however expertise a few technical issues using this web site, as I experienced to reload the web site lots of times previous to I
could get it to load properly. I had been wondering
if your hosting is OK? Not that I am complaining, but slow
loading instances times will often affect
your placement in google and could damage your high quality score if ads and
marketing with Adwords. Well I’m adding this RSS to my email and
could look out for a lot more of your respective exciting content.
Ensure that you update this again soon.
When someone writes an post he/she keeps the image of a user in his/her
brain that how a user can be aware of it. Therefore
that’s why this post is outstdanding. Thanks!
I like it whenever people get together and share views.
Great site, keep it up!
Hello, after reading this awesome piece of writing i am also delighted
to share my familiarity here with colleagues.
Everything is very open with a very clear description of the issues.
It was definitely informative. Your site is extremely helpful.
Thank you for sharing!
Remarkable issues here. I am very glad to peer your post. Thanks a lot and I’m looking ahead to
touch you. Will you kindly drop me a mail?
Have you ever considered writing an e-book or guest authoring on other websites?
I have a blog based on the same subjects you discuss
and would really like to have you share some stories/information. I know my audience would enjoy
your work. If you’re even remotely interested, feel free to send me an email.
This piece of writing will assist the internet people for
building up new webpage or even a blog from start to end.
Simply want to say your article is as amazing. The clarity
in your post is just nice and i can assume you’re an expert on this subject.
Well with your permission let me to grab your RSS feed to keep updated
with forthcoming post. Thanks a million and please carry
on the gratifying work.
Asking questions are in fact pleasant thing if you are
not understanding anything completely, however this piece of writing offers good understanding
even.
Apрrеcіation to my father who shaгed with mme regarding
this website, this ᴡeb site is actually remarkable.
Excellent beat ! I would like to apprentice while
you amend your web site, how can i subscribe for a blog web site?
The account helped me a acceptable deal. I had been a little bit acquainted of
this your broadcast provided bright clear idea
Hello, i read your blog from time to time and i own a similar one and
i was just curious if you get a lot of spam responses? If so how
do you protect against it, any plugin or anything you can suggest?
I get so much lately it’s driving me mad so any help is very
much appreciated.
Sweet blog! I found it while browsing on Yahoo News. Do you
have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
heу there and thank you for your information – I have ceгtainly picked up anything new from
right here. I did however expertise some tecһnical points uing thiѕ website,
since I experienced too reload the website lots of times previous to I coulⅾ get it to load properly.
I had been wondering if yoᥙһr web hosting is OK?Not
that I am compⅼaining, but slow loading insttances times will verry frequently
affect your placement in google and can damage
your high-qᥙality score if advertisіng and marketіng
with Adwords. Wеll I am adding this RSS to my email
and can loоk ᧐սt for much mօre ᧐f yokսr respective interesting content.
Ensure that you update this again soon.
I always emailed this weblog post page to all my associates, since
if like to read it after that my links will too.
Wonderful blog! I found itt while surfing around on Yahoo News.
Do you have any suggestions on howw to get listed inn Yahoo News?
I’ve been trying for a while but I never seem
to get there! Appreciate it
Look at my webpage … 바이낸스 입금
Howdy, I believe your web site could be having browser compatibility issues.
When I take a look at your site in Safari, it looks fine however when opening in IE, it has some overlapping issues.
I simply wanted to provide you with a quick heads up!
Aside from that, great site!
I’m very happy to uncover this web site. I need to to thank you for your time for this particularly wonderful read!!
I definitely liked every bit of it and I have you saved to fav to look at new stuff on your web site.
you are really a good webmaster. The site loading speed is
incredible. It sort of feels that you’re doing any unique trick.
In addition, The contents are masterwork. you have done a magnificent
job in this subject!
Howdy! I just would like to give you a big thumbs up for your great info you have
got here on this post. I’ll be coming back to your site for more soon.
What’s up, I log on to your blog regularly. Your humoristic style is
awesome, keep up the good work!
You made some decent points there. I looked on the web
for additional information about the issue and found most individuals will go along with your views on this website.
I simply could not depart your site before suggesting that I extremely loved
the usual info an individual provide to your visitors? Is gonna be again often in order to investigate cross-check
new posts
I’m curious to find out what blog system you
are working with? I’m experiencing some minor security issues with
my latest blog and I’d like to find something more secure.
Do you have any recommendations?
Hurrah, that’s what I was exploring for, what a material!
existing here at this blog, thanks admin of this website.
Wow, fantastic weblog layout! How lengthy have you
been running a blog for? you made blogging glance easy.
The whole look of your web site is great, as smartly as the content!
Hello friends, nice article and good urging commented at this place, I am
really enjoying by these.
Its like you read my mind! You seem to know so much about this, like you wrote the
book in it or something. I think that you could do with a few pics to drive the message home a bit, but other than that, this is magnificent blog.
A fantastic read. I’ll certainly be back.
It’s really very complex in this active life to listen news on TV, so I only use the web for that reason, and take the newest information.
Hello Dear, are you really visiting this web
page daily, if so afterward you will definitely take good knowledge.
It’s great that you are getting ideas from this article as well as from our argument made at this place.
Thanks for any other excellent post. Where else could anyone get that kind of
info in such a perfect way of writing? I’ve a presentation next week, and I’m on the search for such info.
Thanks in support of sharing such a good opinion, article is nice, thats why i have read it completely
Unquestionably imagine that which you stated.
Your favorite reason seemed to be at the web the easiest thing to take into accout of.
I say to you, I definitely get irked at the same time as other people think about concerns that they just do not know about.
You managed to hit the nail upon the highest and outlined out the entire thing without having side effect , other folks can take a signal.
Will probably be back to get more. Thanks
Everyone loves what you guys tend to be up too. This type of clever work and reporting!
Keep up the wonderful works guys I’ve incorporated you guys to our blogroll.
What’s Going down i am new to this, I stumbled upon this I have found
It positively useful and it has aided me out loads.
I hope to give a contribution & help different customers like its
aided me. Good job.
I don’t even know how I ended up here, but I thought this post
was great. I do not know who you are but definitely you’re going
to a famous blogger if you aren’t already 😉 Cheers!
Fastiԁious respond in return off this difficulty
with firm arguments and telling everytһing on the topic oof thɑt.
It’s a pity you don’t have a donate button! I’d most certainly donate to this
outstanding blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to new updates and will share this blog with my Facebook
group. Chat soon!
Hi my friend! I want to say that this article is amazing, nice written and come with almost all significant infos.
I’d like to see more posts like this .
This piece of writing gives clear idea in favor of the new people of blogging,
that actually how to do blogging and site-building.
Marvelous, what a weblog it is! This weblog provides helpful facts to us, keep it up.
Everyone loves it when individuals come together and share ideas.
Great website, stick with it!
I am really loving the theme/design of your weblog.
Do you ever run into any internet browser compatibility issues?
A small number of my blog audience have complained about my website not working
correctly in Explorer but looks great in Firefox. Do you have any advice to help fix
this problem?
If you wish for to obtain much from this article then you have to apply such techniques to
your won website.
Great blog right here! Also your website loads up fast! What
web host are you using? Can I get your associate hyperlink in your host?
I want my site loaded up as fast as yours lol
In football, gamers will get greater than 85 betting types out
there on top-flight leagues.
Also visit my page … Mostbet Site
That is really fascinating, You are an excessively professional blogger.
I’ve joined your feed and stay up for searching ffor extra of your magnnificent post.
Additionally, I’ve shared your web site in my social networks
Feel free to visit my web site ::바이낸스 추천코드 (Indiana)
My brother suggested I might like this blog. He was entirely right.
This submit actually made my day. You can not imagine just how so much time I had spent for this
information! Thanks!
whoah this weblog is excellent i like studying your articles.
Keep up the great work! You know, many individuals are
hunting around for this information, you can aid them greatly.
Hey there, You’ve done an excellent job. I will certainly digg it and
personally recommend to my friends. I’m sure they’ll be benefited from this website.
Hey very nice blog!
Tips main slot gacor mudah menang terakhir adalah jika anda sudah meraih keuntungan, kami menyarankan untuk langsung
menarik total kemenangan yang didapatkan. Tidak heran jika AIRBET88 adalah salah satu situs judi
slot online terbaik dan terpercaya di Indonesia.
Mulai dari Live Casino Online, Nex Togel, Poker Online, Judi Tembak Ikan, Judi Bola, Slot Gacor,
dan lain sebagainya. Para member dapat mempreroleh peluang keberuntungan dengan modal bermain mulai dari Rp 20 ribu.
Dalam pemasangan bet yang akan dimainkan, tentu saja bisa mengandalkan nilai kecil
mulai dari Rp 500. Tentu saja melalui peluang ini, memberikan kesempatan untuk mengumpulkan penghasilan besar dengan taruhan nilai kecil.
Tentu saja untuk keuntungan yang diperoleh bisa mencapai hingga ratusan juta rupiah.
Kemenangan yang diperoleh setiap member, tentu saja akan dibayarkan 100% tanpa mengurangi biaya adm atau lain sebagainya oleh agen judi online resmi.
Dengan pelayanan permainan yang tersedia dalam 24 jam online, pastinya memberikan peluang untuk para pemain dapat mengumpulkan penghasilan tambahn yang efektif dalam setiap waktu.
Saat anda marah istirahat sejenak serta sisihkan waktu melakukan kegiatan menghibur sehingga
emosi teredam. Ada banyak link slot gacor online terpercaya yang
telah bekerja sama dengan situs AIRBET88, selain memiliki banyak bonus, anda
juga akan menikmati kualitas permainan yang terbukti memberi sensasi dengan tema-tema unggulan dan pembayaran mengesankan.
Thanks in support of sharing such a good thinking, post is good, thats why i have read it
fully
hello!,I really like your writing so so much! percentage we keep in touch extra about your post on AOL?
I need an expert on this space to unravel my problem. Maybe that’s you!
Having a look forward to peer you.
Thanks very nice blog!
This is very interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your
magnificent post. Also, I have shared your website in my social
networks!
Everything is very open with a precise clarification of
the issues. It was really informative. Your site is very useful.
Thank you for sharing!
I like it when folks come together and share ideas.
Great website, keep it up!
It’s a shame you don’t have a donate button! I’d without a doubt donate to this fantastic blog!
I suppose for now i’ll settle for book-marking and adding your RSS feed to
my Google account. I look forward to brand new updates and
will talk about this site with my Facebook group.
Talk soon!
It’s going to be end of mine day, however before end I am reading this impressive paragraph to improve my knowledge.
Also visit my web page – noida sector15 call girl
I seriously love your website.. Great colors &
theme. Did you build this site yourself? Please
reply back as I’m trying to create my very own blog and would like to
know where you got this from or exactly what the theme is named.
Kudos!
Thanks for your personal marvelous posting!
I truly enjoyed reading it, you are a great author.I
will be sure to bookmark your blog and will often come back later
on. I want to encourage one to continue your great writing, have a nice day!
Hello, yup this post is genuinely nice and I have learned lot of things from
it concerning blogging. thanks.
Good day! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
Thanks for sharing your thoughts on https://svetovalnica.zrc-sazu.si/user/gaschoolstore. Regards
No matter if some one searches for his required thing, so he/she
wishes to be available that in detail, thus that thing is maintained over here.
Wow that was odd. I just wrote an extremely long comment
but after I clicked submit my comment didn’t show up. Grrrr…
well I’m not writing all that over again. Anyhow, just wanted
to say excellent blog!
When I initially commented I appear to have clicked on the -Notify me when new comments are added- checkbox and now
every time a comment is added I get four emails with the exact same comment.
There has to be an easy method you can remove me from that service?
Kudos!
Hi there Dear, are you actually visiting this web site on a regular basis, if so after that you will without
doubt obtain nice knowledge.
This article offers clear idea in favor of the new users
of blogging, that genuinely how to do running a blog.
Magnificent items from you, man. I have understand your stuff prior to and you are
simply too magnificent. I really like what you have acquired right here,
certainly like what you are stating and the way
in which in which you are saying it. You’re
making it enjoyable and you continue to take care of to stay it wise.
I can’t wait to read far more from you. That is actually a
wonderful website.
Good response in return of this question with
real arguments and explaining everything concerning that.
Thank you for the good writeup. It in reality was a enjoyment
account it. Look complicated to far brought agreeable from you!
By the way, how can we communicate?
Do you have a spam issue on this website; I also am a blogger, and I
was wanting to know your situation; many of us have developed some nice practices and we are looking to swap strategies with other folks, please shoot me an e-mail if
interested.
Hi there! I know this is kind of off topic but I was wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because I’ve had issues with hackers and I’m looking at options for another platform.
I would be fantastic if you could point me in the direction of a good platform.
A person necessarily assist to make significantly
articles I’d state. That is the first time I frequented your web
page and so far? I amazed with the analysis you made to create this actual put
up incredible. Wonderful job!
Have you ever considered writing an ebook or guest authoring on other blogs?
I have a blog based upon on the same ideas you discuss and would love to
have you share some stories/information. I know my subscribers would value your work.
If you’re even remotely interested, feel free to shoot me an e-mail.
I’m really enjoying the theme/design of your weblog.
Do you ever run into any web browser compatibility problems?
A couple of my blog visitors have complained about my blog not operating correctly in Explorer but
looks great in Safari. Do you have any suggestions
to help fix this issue?
Thаnks foor finally talking about > Пиастры – Составление семантического
ядра | < Liked it!
I got this website from my buddy who informed
me concerning this web site and now this time I am browsing this web page and reading very informative articles or reviews at
this place.
Admiring the dedication you put into your site and in depth information you present.
It’s great to come across a blog every once in a while that isn’t the same unwanted rehashed information. Great read!
I’ve saved your site and I’m adding your RSS feeds to my Google account.
An impressive share! I have just forwarded this
onto a friend who was conducting a little homework
on this. And he actually ordered me dinner simply because I discovered it
for him… lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spending the time to discuss this
subject here on your internet site.
You actually make it seem really easy together with your presentation however I in finding this matter to be really one thing that I think I
would never understand. It kind of feels too complex and very broad for me.
I am looking ahead to your subsequent publish, I will attempt to get the hold
of it!
What’s up to every single one, it’s genuinely a pleasant
for me to pay a visit this site, it contains useful Information.
Heya i am for the first time here. I found this board and I find It really useful
& it helped me out a lot. I hope to give something back
and aid others like you helped me.
Excellent blog here! Also your web site loads up very fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours lol
Undeniably consider that that you said. Your favorite reason seemed to be on the
internet the easiest factor to keep in mind of. I say to you, I
certainly get irked whilst people think about issues that they
just do not recognize about. You managed to hit
the nail upon the highest as well as outlined out the entire thing without having
side-effects , people can take a signal.
Will probably be back to get more. Thanks
Thanks for another informative website. Where else could I am getting that
type of info written in such an ideal approach? I have a mission that I am simply now operating on, and I’ve been on the glance out for such info.
What’s up, I check your new stuff on a regular basis.
Your writing style is awesome, keep up the good work!
Hello, Neat post. There is an issue with your web site in web explorer, could check this?
IE nonetheless is the market chief and a large
element of other people will leave out your great writing due
to this problem.
Hi just wanted to give you a brief heads up and let you know a
few of the images aren’t loading correctly. I’m not sure why but
I think its a linking issue. I’ve tried it in two different
browsers and both show the same outcome.
Wow! In the end I got a website from where I be capable of genuinely obtain helpful data regarding
my study and knowledge.
I read this post fully regarding the resemblance of newest and previous technologies, it’s remarkable article.
Hi Dear, are you truly visiting this website on a regular basis, if so after that you will absolutely take good knowledge.
Appreciate this post. Let me try it out.
Does your site have a contact page? I’m having problems locating it but, I’d like to send
you an email. I’ve got some creative ideas for your blog
you might be interested in hearing. Either
way, great site and I look forward to seeing it grow over
time.
whoah this blog is wonderful i like studying your posts.
Keep up the good work! You already know, lots of individuals are hunting around
for this information, you can aid them greatly.
There is definately a great deal to find out about this topic.
I really like all of the points you have made.
Hi there, just became alert to your blog through Google,
and found that it is truly informative. I am going to watch out for brussels.
I will be grateful if you continue this in future.
Numerous people will be benefited from your writing. Cheers!
Hi terrific blog! Does running a blog such as this take a large
amount of work? I’ve virtually no knowledge of coding but I had been hoping to start my own blog soon. Anyways, should you have any suggestions or techniques for
new blog owners please share. I know this is off subject however I just had to ask.
Many thanks!
This is my first time go to see at here and i am
truly impressed to read all at single place.
I like the valuable info you provide in your articles. I will bookmark
your blog and check again here regularly. I am quite certain I will learn lots of new stuff right here!
Good luck for the next!
Hello, I believe your web site could be having internet browser compatibility issues.
Whenever I take a look at your blog in Safari,
it looks fine however when opening in Internet Explorer, it has some overlapping issues.
I merely wanted to provide you with a quick heads
up! Aside from that, wonderful blog!
There’s certainly a great deal to learn about this subject.
I like all the points you have made.
Heya i am for the first time here. I found this board and I find It truly helpful & it helped me out a lot.
I’m hoping to offer one thing again and help others like
you aided me.
Someone necessarily assist to make seriously posts I would state.
This is the very first time I frequented your web page and
to this point? I amazed with the research you made to create this actual publish amazing.
Fantastic process!
Does your blog have a contact page? I’m having a tough time locating it
but, I’d like to shoot you an email. I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it improve over
time.
Hi! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
Hello there! This is my first comment here so I just wanted to give a quick shout out and say I genuinely enjoy reading your articles.
Can you suggest any other blogs/websites/forums that cover the same topics?
Thanks for your time!
I know this web site gives quality based articles or reviews and additional information,
is there any other site which offers such things in quality?
Hello! I realize this is sort of off-topic however I needed to ask.
Does managing a well-established blog like yours require a massive amount work?
I’m completely new to running a blog however I do write in my diary on a daily basis.
I’d like to start a blog so I will be able to
share my own experience and views online.
Please let me know if you have any kind of recommendations or tips for
brand new aspiring bloggers. Appreciate it!
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
Here is my blog; proper door – https://230news.com/space-uid-234057.html –
This website certainly has all the information I wanted concerning this subject and didn’t know who to ask.
I’m extremely impressed with your writing skills as well as with the layout on your weblog.
Is this a paid theme or did you modify it yourself?
Either way keep up the excellent quality writing, it is rare to see a nice blog like this one
these days.
I absolutely love your blog and find the majority of your post’s to be what precisely I’m looking for.
Would you offer guest writers to write content available for you?
I wouldn’t mind creating a post or elaborating on a lot
of the subjects you write regarding here. Again, awesome blog!
Hi there I am so excited I found your webpage, I really found you by accident, while I was looking on Aol
for something else, Nonetheless I am here now and
would just like to say thanks for a tremendous post and a
all round thrilling blog (I also love the theme/design), I don’t have time to go through it all at the minute but I have bookmarked it and
also included your RSS feeds, so when I have time I will be back to read more, Please do keep up the fantastic work.
I know this web site gives quality depending articles and other information,
is there any other web site which offers these things in quality?
Hello just wanted to give you a quick heads up.
The text in your content seem to be running off the screen in Opera.
I’m not sure if this is a format issue or something to do with internet browser
compatibility but I thought I’d post to let you know.
The design and style look great though! Hope you get the problem resolved soon. Thanks
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your website to come back later.
Cheers
Wonderful work! That is the kind of information that
are meant to be shared across the web. Shame on the search engines for no longer positioning this publish higher!
Come on over and consult with my web site . Thank you =)
Link exchange is nothing else but it is only placing the other person’s weblog link on your page at appropriate place
and other person will also do similar in favor of you.
As the admin of this site is working, no hesitation very shortly
it will be well-known, due to its quality contents.
Quality content is the important to invite
the visitors to pay a quick visit the web page,
that’s what this web page is providing.
Hi mates, its great post about educationand completely explained,
keep it up all the time.
I have been surfing online more than three hours today,
yet I never found any interesting article like yours. It’s
pretty worth enough for me. In my view, if all site owners
and bloggers made good content as you did, the net will
be much more useful than ever before.
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the
blog. Any feedback would be greatly appreciated.
bintang4d dikenal bintang 4dp togel wap login bintang5toto
hadiah login bintang88 deposit pulsa tanpa potongan slot space
apk bintang4d togel provider terbaik masa
kini
Heya superb blog! Does running a blog similar to this take a large
amount of work? I’ve no understanding of coding however I
was hoping to start my own blog soon. Anyways, if you have any ideas or techniques for new blog owners please share.
I know this is off subject but I just had to ask. Kudos!
I have fun with, cause I discovered exactly what
I was taking a look for. You’ve ended my four day lengthy hunt!
God Bless you man. Have a great day. Bye
I’m not that much of a online reader to be honest but your blogs really nice,
keep it up! I’ll go ahead and bookmark your
site to come back later on. All the best
Hey there this is kinda of off topic but I was wondering if blogs use WYSIWYG editors or if you have to
manually code with HTML. I’m starting a blog soon but have no coding expertise
so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
Thank you for the auspicious writeup. It in fact was
a amusement account it. Look advanced to far added agreeable from you!
However, how could we communicate?
Wow, this paragraph is fastidious, my younger sister is analyzing these things,
therefore I am going to inform her.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add
to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe
you would have some experience with something like this. Please let
me know if you run into anything. I truly enjoy reading your
blog and I look forward to your new updates.
It’s very simple to find out any topic on web as compared to textbooks, as I found this
post at this web site.
This is really attention-grabbing, You are a very skilled blogger.
I’ve joined your rss feed and sit up for searching for more of your excellent
post. Additionally, I have shared your web
site in my social networks
This web site really has all of the information I needed about this subject and didn’t know
who to ask.
Hello there! I simply want to offer you a huge thumbs up for your
great information you’ve got right here on this post. I’ll be coming back to your website for more soon.
Hi, yup this piece of writing is really good and I have
learned lot of things from it about blogging. thanks.
Greetings from Ohio! I’m bored to tears at work so I decided to check out your website on my iphone during lunch break.
I enjoy the knowledge you present here and can’t wait to take a
look when I get home. I’m surprised at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyhow, very good site!
I read this paragraph fully on the topic of the comparison of hottest and earlier technologies,
it’s remarkable article.
Thanks for finally writing about > Пиастры – Составление семантического ядра | < Loved it!
Thanks for the auspicious writeup. It in reality was once a entertainment account it.
Look complicated to more introduced agreeable from you!
However, how could we communicate?
Thanks for sharing your info. I truly appreciate your efforts and I am waiting
for your further post thank you once again.
What’s up, just wanted to say, I enjoyed this article.
It was practical. Keep on posting!
This web site truly has all of the information I needed about this subject and didn’t know who to ask.
These are really impressive ideas in regarding blogging.
You have touched some fstidious things here. Any way keep uup wrinting.
My webpage … 바이낸스 가입방법
I am sure this piece of writing has touched all the internet
viewers, its really really nice article on building up new weblog.
Also visit my web page: 바이낸스 가입방법
Hello, i believe that i saw you visited my website so i got here to go back the desire?.I’m attempting to find things
to improve my site!I assume its good enough to make use of a few of your ideas!!
This post is invaluable. Where can I find out more?
Neat blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple tweeks would really make my blog shine.
Please let me know where you got your design. Cheers
Hi! I could have sworn I’ve been to your blog
before but after going through a few of the articles I realized it’s new to me.
Regardless, I’m definitely happy I discovered it and I’ll be bookmarking it
and checking back frequently!
My page; Kadiri escort service
This piece of writing offers clear idea for the new people of blogging, that in fact how to do running a blog.
We absolutely love your blog and find a lot of
your post’s to be exactly I’m looking for. Would you offer guest writers to write content for you personally?
I wouldn’t mind publishing a post or elaborating on a few
of the subjects you write about here. Again, awesome site!
Thanks designed for sharing such a fastidious idea, piece of writing is pleasant,
thats why i have read it entirely
Every weekend i used to visit this web page, as i wish for enjoyment, since this this web site conations
genuinely nice funny stuff too.
Great article! That is the kind of info that should be shared around
the net. Disgrace on the search engines for now not
positioning this publish upper! Come on over and visit
my site . Thanks =)
At this moment I am ready to do my breakfast, when having my breakfast coming again to read additional news.
bookmarked!!, I really like your blog!
Attractive component of content. I simply stumbled upon your website and in accession capital to assert that I acquire
in fact loved account your weblog posts. Any way I
will be subscribing for your feeds or even I success you get
admission to constantly rapidly.
In fact when someone doesn’t understand afterward its
up to other users that they will assist, so here
it happens.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back later.
Many thanks
Keep this going please, great job!
I was recommended this website by my cousin. I am not sure whether this post is written by him as
nobody else know such detailed about my difficulty. You’re amazing!
Thanks!
I’m not that much of a online reader to be honest but
your blogs really nice, keep it up! I’ll go ahead and
bookmark your site to come back later on. Cheers
You’ve made some good points there. I looked on the web to find out more about the
issue and found most people will go along with your views on this site.
What’s up it’s me, I am also visiting this website on a regular basis, this site is truly good and the visitors are truly sharing good thoughts.
I know this if off topic but I’m looking into starting my own blog and was curious what
all is needed to get setup? I’m assuming having a blog like
yours would cost a pretty penny? I’m not very internet smart so I’m
not 100% sure. Any recommendations or advice would be greatly appreciated.
Many thanks
You’re so cool! I do not think I’ve truly read a single thing like that
before. So good to find somebody with some genuine thoughts
on this subject matter. Really.. thank you for starting this up.
This site is one thing that’s needed on the internet, someone with a bit of originality!
Marvelous, what a web site it is! This weblog presents helpful facts to
us, keep it up.
I really like what you guys tend to be up too. This sort of clever
work and coverage! Keep up the wonderful works guys I’ve added you guys
to my personal blogroll.
If you are going for finest contents like me, simply visit this website
all the time since it provides feature contents, thanks
Touche. Great arguments. Keep up the amazing spirit.
I seriously love your website.. Excellent colors & theme.
Did you create this website yourself? Please reply back
as I’m planning to create my own website and would like to find out where you got this from
or what the theme is named. Many thanks!
Ahaa, its good conversation regarding this piece of writing at this place at this weblog,
I have read all that, so now me also commenting at this place.
I have been browsing on-line more than 3 hours
nowadays, yet I never found any attention-grabbing article like yours.
It is lovely value sufficient for me. Personally, if all website owners and bloggers made just
right content as you did, the internet might be much more helpful than ever before.
I love your blog.. very nice colors & theme. Did you design this website yourself or did you
hire someone to do it for you? Plz reply as I’m looking to create my own blog
and would like to find out where u got this from.
thanks
Excellent goods from you, man. I have understand your stuff previous to and you’re just
too excellent. I really like what you’ve acquired here, certainly like what you are
stating and the way in which you say it. You make it entertaining
and you still take care of to keep it smart.
I can’t wait to read far more from you. This is really a terrific website.
Hey! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no backup.
Do you have any solutions to prevent hackers?
great submit, very informative. I wonder why the other experts of this
sector don’t realize this. You must proceed your writing.
I’m confident, you have a huge readers’ base already!
You’ve made some really good points there. I looked on the net for additional information about the issue and found most individuals will go along with
your views on this web site.
Hello there, I do believe your website could possibly be
having browser compatibility problems. Whenever I take a look at
your website in Safari, it looks fine but when opening in I.E.,
it has some overlapping issues. I simply wanted
to give you a quick heads up! Apart from that, great site!
You really make it seem so easy with your presentation but
I find this topic to be really something which I think I would
never understand. It seems too complicated and extremely
broad for me. I’m looking forward for your next post, I will try to get the hang
of it!
Great goods from you, man. I have understand your stuff previous to and you are
just too wonderful. I actually like what you have acquired here, really like what you are saying and the way in which you
say it. You make it enjoyable and you still take care of to keep it wise.
I cant wait to read much more from you. This is actually a great site.
Asking questions are genuinely nice thing if you are
not understanding something totally, but this piece of writing gives good understanding yet.
Good day! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very
good success. If you know of any please share.
Cheers!
I could not refrain from commenting. Very well written!
Everything is very open with a precise description of the issues.
It was truly informative. Your site is very useful. Thank you for sharing!
May I simply just say what a comfort to discover somebody who actually understands what they’re discussing over the internet.
You certainly know how to bring a problem to light and
make it important. More people really need to check this out and understand this side of your story.
It’s surprising you aren’t more popular because you definitely have the gift.
Ahaa, its pleasant dialogue regarding this article at this place at this weblog, I have read all that,
so now me also commenting at this place.
I don’t even understand how I ended up right here,
however I believed this put up was great. I don’t recognize who you’re but certainly
you’re going to a famous blogger should you aren’t already.
Cheers!
Then, permit the installation, wait for the completion, login, and
the working job is done.
Check out my blog … Mostbet India
It’s a pity you don’t have a donate button! I’d certainly donate to this excellent blog!
I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this site with my
Facebook group. Chat soon!
Also visit my blog: Fake wyoming id template
Thanks a lot for sharing this with all people
you actually realize what you’re talking about! Bookmarked.
Kindly also seek advice from my site =). We could have a
link alternate contract among us
It is perfect time to make some plans for the future and it’s time to be happy.
I’ve read this post and if I could I want to suggest you
few interesting things or advice. Perhaps you could write next articles referring to this article.
I desire to read more things about it!
I am extremely impressed along with your writing talents and also with the structure for your weblog.
Is that this a paid topic or did you modify it your self?
Either way stay up the nice high quality writing,
it’s uncommon to see a nice blog like this one today..
I am curious to find out what blog platform you happen to
be using? I’m having some minor security issues with my latest blog and I
would like to find something more secure. Do you have any suggestions?
Hello there I am so excited I found your blog page, I really found
you by mistake, while I was researching on Google for something
else, Regardless I am here now and would just like to say thank
you for a fantastic post and a all round exciting blog (I also
love the theme/design), I don’t have time to look
over it all at the moment but I have book-marked it and
also added in your RSS feeds, so when I have time I
will be back to read a lot more, Please do keep
up the superb work.
Hey would you mind sharing which blog platform you’re using?
I’m looking to start my own blog soon but I’m having a tough time making a decision between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your design and style seems different
then most blogs and I’m looking for something unique.
P.S Sorry for being off-topic but I had to ask!
I am sure this piece of writing has touched all the internet visitors, its really really
good paragraph on building up new weblog.
You’ve made some decent points there. I checked on the web for
more information about the issue and found most people will
go along with your views on this site.
I do not even understand how I stopped up right here,
but I thought this put up used to be great. I do not recognise who you’re but definitely you are going to a well-known blogger should you aren’t already.
Cheers!
I know this if off topic but I’m looking into starting my own blog and was wondering what all is needed to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% certain. Any
recommendations or advice would be greatly appreciated. Thank you
Nice post. I was checking constantly this blog and I am impressed! I care for such information much.
I care for such information much.
Very helpful info specially the remaining phase
I used to be seeking this certain information for a long time.
Thank you and best of luck.
I every time spent my half an hour to read this web site’s content daily along with a mug of coffee.
I know this website presents quality based articles or reviews and other stuff,
is there any other web page which provides such stuff in quality?
Hi all, here every one is sharing these kinds of familiarity, therefore it’s nice to read
this web site, and I used to go to see this weblog all the time.
What’s up, everything is going fine here and ofcourse every one
is sharing information, that’s really fine, keep up writing.
An outstanding share! I’ve just forwarded this onto a co-worker who has been doing a little research
on this. And he in fact bought me breakfast because I discovered
it for him… lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanks for spending time to talk about this issue here on your website.
magnificent publish, very informative. I’m wondering why the opposite specialists
of this sector do not realize this. You must proceed your writing.
I am confident, you’ve a huge readers’ base already!
How to Make Money witrh withdrawal olymp trade Trade Platform in the Forex
Market? But even iif you aren’t buying what I’m selling (for free, because
I love you), fine: you still should realize that you aare going to need tto think very hard every time you incresse thee expressiveness
you make available to your client-side developers.
No wonder people think it’s the best feature of Jason Bond Picks (but we still think it’s second to the Alert feature).
I’ve been trading with Jason Bondd for 8 months aand have
made more money from his service to ppay for the fee for the next 10 years in a short amount of
time. This is so that the know that noo matter what happens, they ccan never lose more than what thesy deposit.
You can fimd the options to deposit andd withdraw by heading to
the top rigtht and clicking on the “payments” button. This means investors aren’t
held to ass strict standards or regulations as those in the stock, futures or options markets.
This is the perfect web site for everyone who wishes to understand this
topic. You realize a whole lot its almost tough to argue with you (not that I
actually would want to…HaHa). You definitely put a fresh spin on a
subject that’s been written about for decades. Great stuff, just wonderful!
I know this website offers quality dependent articles and other information, is there any other site which presents these kinds of
data in quality?
Hello, I log on to your blog on a regular basis.
Your humoristic style is awesome, keep doing what
you’re doing!
Howdy! Do you use Twitter? I’d like to follow you if that would be ok.
I’m definitely enjoying your blog and look forward to new updates.
A person necessarily lend a hand to make significantly
posts I might state. This is the first time I frequented your website page and so far?
I surprised with the analysis you made to make this actual post incredible.
Wonderful process!
What i do not understood is in reality how you are
now not really much more smartly-liked than you may be right now.
You are very intelligent. You realize thus considerably with regards to
this matter, produced me in my opinion consider it from a
lot of varied angles. Its like women and men don’t
seem to be interested until it is one thing to do with Lady gaga!
Your own stuffs great. At all times take care of it up!
Great delivery. Outstanding arguments. Keep up
the good effort.
Hello! Someone in my Myspace group shared this
site with us so I came to take a look. I’m definitely loving the information. I’m book-marking and will
be tweeting this to my followers! Fantastic blog and
wonderful design.
Ԝhat’s ᥙp friends, pleasant post and fastidious urging commented here, I amm
really enjoying by these.
I think that is one of the so much vital information for me.
And i am glad reading your article. But should remark on few basic things, The web site
taste is great, the articles is actually nice : D. Good process, cheers
Hi every one, here every one is sharing such know-how,
thus it’s good to read this weblog, and I used to visit this webpage everyday.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I
get four e-mails with the same comment. Is there any way you can remove me from that
service? Thanks!
What a stuff of un-ambiguity and preserveness of valuable knowledge concerning unpredicted feelings.
Wow, superb blog layout! How long have you been blogging
for? you made blogging look easy. The overall look of your web site is excellent, let alone the
content!
Thanks for sharing your thoughts about beste hondenfietskar.
Regards
This blog was… how do I say it? Relevant!! Finally I have found something which helped me.
Thanks!
Hey just wanted to give you a quick heads up. The text
in your article seem to be running off the screen in Ie.
I’m not sure if this is a format issue or something to do with internet browser compatibility but I figured I’d post
to let you know. The layout look great though! Hope you get the issue solved soon. Kudos
Excellent website. Lots of useful info here.
I’m sending it to several buddies ans also sharing in delicious.
And obviously, thanks to your sweat!
Its such as you learn my mind! You appear to grasp a lot about this,
such as you wrote the e-book in it or something. I think that you could do with some % to force the message house
a little bit, however instead of that, this is fantastic blog.
An excellent read. I will definitely be back.
Excellent article. I certainly love this site.
Stick with it!
Great beat ! I wish to apprentice while you amend your web site, how could i
subscribe for a weblog website? The account helped me a acceptable deal.
I have been tiny bit familiar of this your broadcast offered vivid clear idea
Hi there, i read your blog occasionally and i own a similar one and i
was just curious if you get a lot of spam comments? If so how do you prevent it, any
plugin or anything you can recommend? I get so much lately
it’s driving me crazy so any help is very much appreciated.
We are a group of volunteers and starting a
new scheme in our community. Your web site provided us
with valuable info to work on. You’ve done a formidable job and our entire community will be grateful
to you.
I savour, result in I found exactly what I was looking
for. You have ended my four day long hunt! God Bless you
man. Have a nice day. Bye
Excellent way of describing, and fastidious article to get information regarding my presentation focus,
which i am going to convey in school.
It’s truly very complicated in this active life to listen news on Television, therefore I only use web for that reason, and obtain the newest information.
This piece of writing offers clear idea in support of the
new visitors of blogging, that genuinely how to do running a blog.
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your excellent post.
Also, I have shared your web site in my social networks!
I am curious to find out what blog platform you happen to be using?
I’m experiencing some small security problems with my latest blog and I’d like to find something more risk-free.
Do you have any solutions?
I think this is one of the most important information for me.
And i’m glad reading your article. But should remark on some general things, The site style is perfect, the articles
is really nice : D. Good job, cheers
Nice blog here! Also your site loads up fast! What host are you using?
Can I get your affiliate link to your host? I wish
my website loaded up as quickly as yours lol
What’s up, this weekend is fastidious for me, for the reason that this moment
i am reading this impressive educational post here at my
residence.
Aw, this was a really nice post. Taking a few minutes and actual effort to make a very good article… but what can I say…
I put things off a lot and never manage to get anything done.
Heya i’m for the first time here. I found this board and I find
It really useful & it helped me out a lot.
I hope to give something back and help others like you aided me.
I know this web site presents quality dependent articles or reviews and additional stuff, is there any
other web page which offers these kinds of data in quality?
Can I just say what a comfort to uncover somebody who genuinely understands what they are talking about on the
net. You definitely know how to bring an issue to light and make
it important. A lot more people must check this out and understand this side of your
story. I was surprised you’re not more popular given that you certainly have the gift.
Have you ever considered about including a little bit more than just
your articles? I mean, what you say is important and everything.
Nevertheless think of if you added some great images or
video clips to give your posts more, “pop”! Your content is excellent but with pics and video clips, this
website could definitely be one of the very best in its niche.
Superb blog!
Hey there just wanted to give you a quick heads up. The text
in your article seem to be running off the screen in Chrome.
I’m not sure if this is a formatting issue or something
to do with web browser compatibility but I thought I’d post to
let you know. The layout look great though! Hope you get the issue fixed soon. Many
thanks
I must thank you for the efforts you’ve put in penning this website.
I am hoping to check out the same high-grade content by you
in the future as well. In truth, your creative writing abilities has
motivated me to get my own blog now 😉
Good day! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Good web site you’ve got here.. It’s difficult to
find quality writing like yours these days. I honestly appreciate individuals like you!
Take care!!
Check out my blog post :: สล็อตทรูวอลเล็ต เครดิตฟรี
Wow, fantastic blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your
web site is wonderful, as well as the content!
It’s actually very complex in this full of
activity life to listen news on TV, therefore I simply use the web for that reason, and get the newest information.
Very descriptive article, I loved that a lot.
Will there be a part 2?
Do you have a spam issue on this blog; I also am a blogger, and I
was curious about your situation; we have developed some nice practices and we are looking to exchange methods with others, be sure to shoot me an email
if interested.
I enjoy reading through an article that will make men and
women think. Also, thanks for permitting me to comment!
I am extremely impressed with your writing skills and also with the layout
on your blog. Is this a paid theme or did you customize it yourself?
Anyway keep up the nice quality writing, it’s rare to see a nice
blog like this one these days.
I’m really inspired together with your writing talents
and also with the format for your weblog. Is that this a paid subject or
did you modify it your self? Either way stay up the nice
quality writing, it is rare to see a great blog like this one today..
What a material of un-ambiguity and preserveness of precious familiarity regarding unpredicted feelings.
Very nice post. I just stumbled upon your blog and wished to say that I have really enjoyed surfing around your blog posts.
In any case I will be subscribing to your feed and I hope you write again soon!
Keep this going please, great job!
Hi, its pleasant post on the topic of media print, we all be aware of
media is a fantastic source of facts.
Hello! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
When I initially commented I appear to have clicked on the -Notify me when new comments are added- checkbox and
from now on whenever a comment is added I receive 4 emails with
the same comment. There has to be a way you are able to remove me from that service?
Thanks a lot!
Hello! I could have sworn I’ve been to this blog before but after browsing through
a few of the articles I realized it’s new to me.
Regardless, I’m definitely delighted I came across it and I’ll be book-marking it and checking back frequently!
Hi there it’s me, I am also visiting this web site on a regular basis, this website is in fact nice and the users are in fact sharing
fastidious thoughts.
Simply desire to say your article is as astounding.
The clearness in your post is simply nice and i can assume you are an expert on this subject.
Fine with your permission allow me to grab your feed to keep up to date with forthcoming post.
Thanks a million and please continue the enjoyable work.
If you are going for most excellent contents like I do, just pay
a visit this website all the time as it provides feature contents, thanks
Great wгite-uⲣ, I’m regular visitor ߋf one’s website,
maintain սp the excellent operate, аnd It’s going to be
a regular visitor for а lengthy timе.
Feel free to surf to my blog post home spa
Hello, for all time i used to check weblog posts here early in the morning, for the reason that i love to find
out more and more.
Wonderful website you have here but I was wanting to know if you knew of any community
forums that cover the same topics discussed here? I’d really like
to be a part of community where I can get comments from other
experienced individuals that share the same interest. If you have any
recommendations, please let me know. Cheers!
An impressive share! I have just forwarded this onto a colleague who had been doing a little homework on this.
And he actually ordered me lunch simply because I stumbled upon it for him…
lol. So let me reword this…. Thanks for the
meal!! But yeah, thanx for spending the time to talk about this topic here on your blog.
Hello There. I found your weblog using msn.
That is a really smartly written article. I’ll be sure to bookmark it and return to read extra of your useful info.
Thank you for the post. I will definitely comeback.
I believe this is one of the such a lot vital info
for me. And i am happy reading your article. However wanna statement on some basic things, The site taste is wonderful, the articles is actually excellent :
D. Excellent process, cheers
Amazikng things here. I’m very satisfied to peer your article.
Thank you a lot and I’m taking a look ahead to contact you.
Will you please drop me a e-mail?
Here is my wweb page … 바이낸스 레퍼럴
Wow, that’s what I was exploring for, what a material!
present here at this web site, thanks admin of this web site.
fantastic points altogether, you just won a new reader.
What may you recommend in regards to your submit that you simply made a few days ago?
Any positive?
Hi mates, its great article regarding cultureand
completely defined, keep it up all the time.
I am not sure where you’re getting your information, but good
topic. I needs to spend some time learning much more or understanding
more. Thanks for excellent info I was looking for this info
for my mission.
If you wish for to increase your know-how just keep visiting this web site and
be updated with the newest news update posted here.
It’s a pity you don’t have a donate button! I’d
certainly donate to this brilliant blog! I guess for now i’ll settle for book-marking and adding
your RSS feed to my Google account. I look forward to fresh updates and will share this blog
with my Facebook group. Talk soon!
If you are going for most excellent contents like
I do, just pay a quick visit this site everyday because it offers quality
contents, thanks
Hi would you mind stating which blog platform you’re using?
I’m going to start my own blog soon but I’m having a difficult time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems
different then most blogs and I’m looking for something
unique. P.S Apologies for getting off-topic but I had to ask!
Wonderful beat ! I would lіke too apprentice while you
amend үour site, һow coᥙlɗ i ѕuЬscribe for a blog website?
The account helped me a acceptable deal. I haԁ been tiny bit acquainted of this
your broadcast pprovided bright cleaг concept
Whats up very cool site!! Guy .. Beautiful ..
Amazing .. I’ll bookmark your website and take
the feeds additionally? I’m satisfied to search out so many useful information right
here in the post, we want develop more techniques in this regard, thanks for
sharing. . . . . .
I truly love your website.. Great colors & theme.
Did you create this website yourself? Please reply back as I’m wanting to
create my own blog and want to know where you got this from
or exactly what the theme is named. Thanks!
This is really interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your great post.
Also, I have shared your site in my social networks!
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s
the blog. Any feedback would be greatly appreciated.
Hello my friend! I want to say that this post is awesome, great written and come with
approximately all important infos. I would like to see more posts like this .
Feel free to visit my blog :: Ganderbal escort agency
Excellent blog you’ve got here.. It’s hard to find good
quality writing like yours these days. I seriously appreciate individuals like you!
Take care!!
It’s truly a nice and useful piece of info. I am satisfied
that you simply shared this helpful info with us. Please stay us up to date like this.
Thanks for sharing.
Can I simply just say what a relief to find someone who really understands what they are talking about on the
web. You certainly realize how to bring a problem to light and make it important.
More and more people must read this and understand this side of your story.
I can’t believe you aren’t more popular because you certainly have the gift.
Hey there! Someone in my Facebook group shared this website with us so I came to check it out.
I’m definitely enjoying the information. I’m bookmarking and
will be tweeting this to my followers! Exceptional blog
and outstanding style and design.
I all the time used to read article in news papers but now as I am a user of internet thus from now
I am using net for content, thanks to web.
Pretty section of content. I just stumbled upon your
website and in accession capital to assert that I get actually enjoyed account your blog posts.
Any way I will be subscribing to your feeds and even I achievement
you access consistently rapidly.
Great blog here! Also your site lots up fast! What web host are you
the usage of? Can I am getting your affiliate link on your host?
I desire my website loaded up as quickly as yours lol
It’s awesome to pay a visit this website and reading the views of all mates
concerning this post, while I am also eager of getting know-how.
Please let me know if you’re looking for a writer for your site.
You have some really good articles and I believe
I would be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some articles for your blog in exchange for a link back
to mine. Please blast me an e-mail if interested.
Cheers!
Write more, thats all I have to say. Literally, it
seems as though you relied on the video to
make your point. You clearly know what youre talking about, why throw
away your intelligence on just posting videos to your weblog when you could be giving us
something informative to read?
Can you tell us more about this? I’d love to find
out some additional information.
Hi there I am so glad I found your blog page, I really found you by mistake, while I was looking on Askjeeve
for something else, Nonetheless I am here now and would just like to say thanks a lot for a tremendous
post and a all round thrilling blog (I also love the theme/design),
I don’t have time to browse it all at the moment but I have bookmarked it and also included your RSS
feeds, so when I have time I will be back to read a great deal more, Please do keep up the superb
job.
Somebody essentially assist to make severely posts I might state.
This is the very first time I frequented your website page and up to now?
I amazed with the research you made to make this particular publish extraordinary.
Great activity!
Interesting blog! Is your theme custom made or did
you download it from somewhere? A theme like yours with
a few simple adjustements would really make my blog jump out.
Please let me know where you got your theme. Many thanks
Hey there I am so thrilled I found your blog, I really found you by mistake, while I was looking on Bing for
something else, Anyhow I am here now and would just like to
say thanks for a remarkable post and a all round entertaining blog (I also love the theme/design), I don’t have
time to look over it all at the minute but I have bookmarked it and also added in your RSS feeds, so when I
have time I will be back to read more, Please do keep up the superb jo.
порно онлайн
Hello! I realize this is sort of off-topic however I had
to ask. Does managing a well-established website like yours require a
large amount of work? I’m brand new to writing a blog however I do write in my diary everyday.
I’d like to start a blog so I will be able to share my personal
experience and thoughts online. Please let me know if you have any kind of recommendations or tips for brand new aspiring bloggers.
Thankyou!
Thanks very interesting blog!
An outstanding share! I have just forwarded this onto a friend who had been doing a little homework on this.
And he actually bought me lunch because I stumbled upon it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanx for spending time to discuss this matter here
on your web site.
This piece of writing is in fact a pleasant one it assists new internet users, who
are wishing for blogging.
Thanks for sharing your thoughts about kattenluik met
timer. Regards
Oh my goodness! Impressive article dude! Thank you so much,
However I am going through troubles with your RSS. I don’t know why I can’t join it.
Is there anybody else having similar RSS problems? Anyone who knows
the answer can you kindly respond? Thanx!!
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4
year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
Whats up very cool site!! Guy .. Excellent ..
Superb .. I will bookmark your website and take the feeds additionally?
I am satisfied to find a lot of useful info here in the submit, we’d like work
out extra techniques in this regard, thank you for sharing.
. . . . .
Thank you a bunch for sharing this with all people you actually recognise
what you are speaking approximately! Bookmarked. Kindly additionally talk over with my website =).
We may have a link change arrangement between us
Hey there! Do you use Twitter? I’d like to follow you if that would
be okay. I’m definitely enjoying your blog and look forward to new updates.
I have been browsing online more than three hours today, yet I never
found any interesting article like yours. It’s pretty worth enough
for me. In my view, if all website owners and bloggers made good content as you did,
the net will be a lot more useful than ever before.
Hurrah, that’s what I was exploring for, what a stuff!
existing here at this weblog, thanks admin of this site.
Quality articles is the main to interest the viewers to visit the web site, that’s what this web page is providing.
Pretty grеat post. Ι juѕt stumbled upon your blog ɑnd
wantеԀ to sаy that Ӏ’ve trulү loved surfing аrօund yoᥙr blog posts.
In ɑny caѕe I ԝill be subscribing to yоur rss feed Sounds and Tastes in Croatia’s Vibrant Capital City I’m hoping yߋu writе once morre ᴠery soon!
I love what you guys are usually up too. Such clever work and reporting!
Keep up the excellent works guys I’ve added you guys to my
personal blogroll.
We stumbled over here by a different web address and thought
I might as well check things out. I like what I see so now
i am following you. Look forward to finding out about
your web page for a second time.
It’s the best time to make some plans for the future
and it is time to be happy. I have read this post and if I
could I want to suggest you some interesting
things or tips. Perhaps you could write next articles referring to this article.
I desire to read even more things about it!
Hi there to all, the contents existing at this site are
actually remarkable for people experience,
well, keep up the nice work fellows.
Do you have a spam problem on this blog; I also am a blogger, and I
was curious about your situation; we have developed some nice procedures and we are looking to swap techniques with other folks, be sure
to shoot me an e-mail if interested.
If you wish for to obtain a good deal from this piece of writing then you have to apply such methods to your won web site.
If some one wishes expert view concerning blogging afterward i
propose him/her to pay a visit this weblog, Keep up the pleasant job.
Hi there i am kavin, its my first occasion to commenting anyplace,
when i read this post i thought i could also make comment due to this brilliant
post.
First of all I want to say superb blog! I had a quick question which I’d like to ask if you don’t mind.
I was interested to find out how you center yourself and clear your head before
writing. I’ve had a hard time clearing my thoughts in getting my thoughts out.
I do enjoy writing but it just seems like the first 10 to 15
minutes are usually lost just trying to figure out how to begin. Any recommendations or tips?
Kudos!
Helpful information. Lucky me I found your site accidentally, and I’m
shocked why this twist of fate didn’t came about in advance!
I bookmarked it.
If you desire to increase your know-how only keep visiting this site
and be updated with the most recent information posted here.
What’s up, after reading this awesome paragraph
i am as well glad to share my know-how here with friends.
Saved as a favorite, I like your web site!
Hello would you mind letting me know which hosting company you’re utilizing?
I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a
lot quicker then most. Can you recommend a good internet hosting provider at
a fair price? Thank you, I appreciate it!
What i don’t realize іѕ actuаlly hоw you aге no longer гeally a ⅼot mоre smartly-ⅼiked
than you may be гight noᴡ. You’re very intelligent. Уou already қnow tһᥙѕ significantly іn the case of tһis topic, produced mе personally ϲonsider it from a ⅼot of numerous angles.
Itѕ ⅼike women and men are not interested սnless іt is something to accomplish ѡith Woman gaga!
Your individual stuffs excellent. Аll thе time deal with it ᥙp!
Look at my web site; furniture
I’m no longer positive the place you’re getting your information, however good
topic. I needs to spend a while learning more or working
out more. Thank you for wonderful information I was on the lookout for this
info for my mission.
I like what you guys are usually up too. This sort of clever work and reporting!
Keep up the good works guys I’ve added you guys to my own blogroll.
Thanks for some other informative web site.
The place else may just I am getting that type of info written in such a perfect
method? I have a mission that I am simply now operating on, and I’ve
been at the glance out for such info.
What i don’t realize is in fact how you are no longer actually
a lot more neatly-liked than you might be now. You’re so intelligent.
You understand therefore considerably relating
to this topic, produced me for my part imagine it from
so many varied angles. Its like men and women don’t seem to be fascinated except
it is something to do with Girl gaga! Your own stuffs excellent.
All the time care for it up!
You ought to take part in a contest for one of the greatest websites
on the internet. I will highly recommend this blog!
Excellent website. A lot of helpful information here. I am sending it to several pals ans additionally sharing in delicious.
And obviously, thank you for your effort!
I was recommended this web site by my cousin. I’m
not sure whether this post is written by him as no one else know
such detailed about my problem. You are incredible!
Thanks!
I have been exploring for a little bit for any high quality articles or weblog posts
in this sort of house . Exploring in Yahoo
I finally stumbled upon this website. Reading this information So i am glad to convey that I have an incredibly just right uncanny feeling I discovered exactly what I needed.
I such a lot indisputably will make certain to don?t omit this site and provides
it a look on a constant basis.
Fantastic goods from you, man. I’ve take into account
your stuff prior to and you’re simply too excellent.
I actually like what you’ve received right here, certainly like what you’re stating and the best
way wherein you assert it. You’re making it enjoyable and you still care for to stay it sensible.
I can not wait to learn far more from you. This is really
a great web site.
Wow, amazing blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is wonderful, as well as the content!
I’m not sure exactly why but this blog is
loading extremely slow for me. Is anyone else having this
issue or is it a issue on my end? I’ll check back later on and see if the problem still exists.
Its like you read my mind! You appear to know so much about this, like you wrote the
book in it or something. I think that you could do
with some pics to drive the message home a little bit, but instead of that, this is great blog.
A fantastic read. I’ll certainly be back.
hello!,I really like your writing so so much! percentage we keep in touch extra approximately your post on AOL?
I need an expert in this house to unravel my problem.
Maybe that’s you! Taking a look ahead to look you.
Right now it appears like Expression Engine is the top blogging platform
available right now. (from what I’ve read) Is that what you
are using on your blog?
I’m not that much of a online reader to be honest but your
blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back down the road.
Cheers
Every weekend i used to pay a visit this site, for the reason that i wish
for enjoyment, for the reason that this this website
conations in fact pleasant funny material too.
Pretty section of content. I just stumbled upon your website and in accession capital to assert that I get actually enjoyed account your blog posts.
Anyway I’ll be subscribing to your feeds and even I achievement you access
consistently quickly.
What a material of un-ambiguity and preserveness of
valuable know-how regarding unpredicted feelings.
I do believe all of the concepts you have offered in your
post. They’re very convincing and will certainly work.
Nonetheless, the posts are very quick for newbies. Could you please extend them a little from subsequent
time? Thanks for the post.
Nice response in return of this query with firm arguments and describing all regarding that.
You actually make it seem really easy with your presentation but I to find this matter to be really one thing which I think I would never understand.
It sort of feels too complicated and extremely vast
for me. I’m taking a look ahead for your subsequent publish, I will attempt to get the dangle of it!
I’d like to thank you for the efforts you have put in writing this website.
I’m hoping to see the same high-grade blog posts
by you later on as well. In truth, your creative writing abilities has encouraged me to get
my own, personal site now 😉
Hi there! This article couldn’t be written any better!
Looking through this post reminds me of my previous roommate!
He constantly kept preaching about this. I am going to send this article to him.
Fairly certain he will have a very good read. Many thanks for sharing!
I’m really inspired along with your writing talents and also with
the structure for your weblog. Is this a paid theme or did you modify it yourself?
Either way stay up the excellent quality writing, it’s
uncommon to see a great blog like this one today..
Hi! I could have sworn I’ve visited this web site before but after looking at a few of the posts I
realized it’s new to me. Anyhow, I’m certainly delighted I found it and I’ll be book-marking it and checking back regularly!
What’s up colleagues, how is everything, and what you would like to say on the topic of this article,
in my view its really awesome in support of me.
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet my
newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you
would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your
blog and I look forward to your new updates.
Howdy very cool site!! Man .. Excellent .. Superb .. I will bookmark your blog
and take the feeds also? I’m glad to seek out a lot of useful info right here within the put up, we need work out extra techniques on this
regard, thanks for sharing. . . . . .
Hi there, for all time i used to check web site posts here early in the daylight,
since i enjoy to learn more and more.
Great blog here! Also your website loads up
very fast! What host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours lol
Hey! I realize this is sort of off-topic however I had to ask.
Does managing a well-established blog such as yours require a large amount of work?
I’m brand new to running a blog however I do write in my diary on a daily basis.
I’d like to start a blog so I can share my personal experience and views online.
Please let me know if you have any recommendations or tips for new aspiring blog owners.
Thankyou!
Whoa! This blog looks exactly like my old one! It’s on a totally different subject but it has pretty much
the same page layout and design. Great choice of colors!
Hi there! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
I am really impressed together with your writing abilities and also with the
structure to your weblog. Is this a paid subject matter or did you modify it your
self? Anyway stay up the excellent quality writing, it’s rare to
see a nice weblog like this one nowadays..
fantastic issues altogether, you simply received a brand new reader.
What may you recommend about your publish that you just made some days in the past?
Any positive?
I like what you guys tend to be up too. This type of clever work and exposure!
Keep up the very good works guys I’ve added you guys to my blogroll.
I’ve learn a few excellent stuff here. Definitely price bookmarking for revisiting.
I wonder how so much effort you place to create any such great informative
website.
Hello! I just wanted to ask if you ever have any issues with
hackers? My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to no data backup.
Do you have any methods to prevent hackers?
Good day! I could have sworn I’ve visited your blog before but after browsing through many of the posts I realized it’s new to me.
Nonetheless, I’m definitely pleased I came across it and I’ll be bookmarking
it and checking back often!
Pretty! This was an incredibly wonderful post.
Thanks for supplying this info.
Excellent blog! Do you have any hints for aspiring writers?
I’m planning to start my own website soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go for a paid option? There are so many options
out there that I’m completely confused .. Any recommendations?
Appreciate it!
I’m really inspired together with your writing abilities and also
with the structure to your weblog. Is that this
a paid topic or did you customize it your self? Either way stay
up the nice quality writing, it is rare to look a great
blog like this one these days..
What’s up, its good piece of writing about media print, we
all be familiar with media is a great source of data.
Hello my loved one! I wish to say that this
article is awesome, great written and include approximately all vital
infos. I’d like to look extra posts like this .
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between superb usability and visual appearance.
I must say that you’ve done a awesome job with this.
Additionally, the blog loads very fast for me on Opera.
Outstanding Blog!
Greate pieces. Keep writing such kind of information on your site.
Im really impressed by your site.
Hello there, You’ve done a great job. I’ll definitely digg it and in my view recommend to
my friends. I am confident they will be benefited from this site.
hi!,I like your writing very a lot! share we be in contact extra about your post on AOL?
I require an expert on this space to resolve my problem. May be
that is you! Having a look forward to see you.
There’s certainly a lot to learn about this issue. I love all the points you’ve made.
Just want to say your article is as surprising. The clarity in your post is just spectacular
and that i could suppose you are a professional on this subject.
Well together with your permission let me to grab your feed to stay updated with imminent post.
Thanks one million and please keep up the gratifying work.
Hi there, just became aware of your blog through Google,
and found that it’s really informative. I am going to
watch out for brussels. I will be grateful if you continue this in future.
Numerous people will be benefited from your writing. Cheers!
Having read this I believed it was very
enlightening. I appreciate you finding the time and energy to
put this information together. I once again find myself personally
spending a lot of time both reading and leaving comments.
But so what, it was still worthwhile!
If some one wants to be updated with newest technologies then he must be pay a quick visit this website and be up to date every day.
Hey there just wanted to give you a quick heads up. The words in your post seem to be running off the screen in Ie.
I’m not sure if this is a format issue or something to do with web browser compatibility but I
figured I’d post to let you know. The design look great though!
Hope you get the problem solved soon. Cheers
Hey very interesting blog!
Hello, Neat post. There’s an issue along with your site
in web explorer, may test this? IE still is the market leader and a good section of other folks will omit your fantastic writing because of this problem.
I pay a visit each day some websites and information sites to read articles or reviews,
except this website presents feature based posts.
I just like the valuable information you supply in your articles.
I will bookmark your weblog and check once more
here regularly. I’m quite certain I will learn plenty of new
stuff proper right here! Best of luck for the next!
Oh my goodness! Amazing article dude! Thanks, However
I am going through issues with your RSS. I don’t know the reason why I can’t subscribe to
it. Is there anyone else having similar RSS issues? Anybody
who knows the answer can you kindly respond? Thanks!!
After looking over a few of the blog articles on your website, I honestly appreciate your
way of writing a blog. I book-marked it to my bookmark website list and
will be checking back in the near future. Please visit
my website as well and tell me what you think.
We’re a group of volunteers and starting a
new scheme in our community. Your site provvided us
with valuable information to work on. You’ve performed an impressive
task and oour entire community shall be grateful to
you.
Here is my webpage :: 바이낸스 현물; Michaela,
With years of experience and expertise in manufacturing water treatment plants, Waterman Engineers Australia offers best
quality effluent treatment plant for mining, textile and pharmaceutical including
zero liquid discharge system, reverse osmosis plant, seawater desalination plant, arsenic removal system, water filtration plants, sewage treatment plant, caustic recovery plant, waste
incinerator systems etc. for various industries based on cutting-edge technology and international standards.
Aw, this was an exceptionally nice post. Taking the time and actual effort to create a great article… but what
can I say… I put things off a lot and never manage to get
anything done.
It’s awesome in favor of me to have a website,
which is helpful in support of my know-how.
thanks admin
I really like looking through a post that
can make people think. Also, thanks for permitting me to comment!
Hello everybody, here every one is sharing these knowledge, therefore it’s nice to read this blog, and I used to visit this blog everyday.
Howdy would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 completely different internet browsers and I must say
this blog loads a lot faster then most. Can you suggest a good internet
hosting provider at a honest price? Many thanks, I appreciate it!
Thanks a bunch for sharing this with all folks you actually know what
you’re speaking approximately! Bookmarked. Please also discuss with my website =).
We will have a hyperlink exchange agreement among us
Hi there, everything is going nicely here and ofcourse every
one is sharing facts, that’s in fact excellent, keep up writing.
I have been exploring for a little bit for any high quality articles or
blog posts in this sort of space . Exploring in Yahoo I at
last stumbled upon this website. Studying this info So i am glad to convey that I have
a very good uncanny feeling I found out just what I needed.
I such a lot definitely will make sure to don?t disregard this web site and give it a glance regularly.
Pretty! This was an incredibly wonderful article.
Thank you for supplying this information.
It is in point of fact a great and helpful piece of info.
I’m satisfied that you just shared this useful info with us.
Please keep us informed like this. Thanks for sharing.
I was just looking for this info for a while.
After six hours of continuous Googleing, at last I
got it in your web site. I wonder what is the lack of Google strategy that
do not rank this kind of informative websites in top of the
list. Usually the top sites are full of garbage.
my webpage: indiana odyssey my case
I got this web site from my pal who shared with me about this web site and at the moment this time I am visiting this website and reading
very informative content at this time.
I simply couldn’t leave your site prior to suggesting that I extremely enjoyed the
standard info a person provide to your guests?
Is gonna be again steadily in order to check up on new posts
It’s an awesome piece of writing designed for all the online viewers; they will obtain advantage from it I
am sure.
I have to thank you for the efforts you’ve put in penning this blog.
I’m hoping to see the same high-grade blog posts by you in the future as well.
In truth, your creative writing abilities has encouraged me to get my own, personal website
now 😉
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem
to get there! Thank you
Ahaa, its pleasant discussion about this paragraph here at this
website, I have read all that, so now me also commenting here.
Fine way of describing, and nice piece of writing to take information about my presentation subject,
which i am going to present in school.
Whats up this is kinda of off topic but I was wanting
to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so I wanted to get guidance from someone with experience.
Any help would be greatly appreciated!
whoah this weblog is great i really like reading your articles.
Keep up the great work! You know, lots of persons are searching around
for this information, you could help them greatly.
Thanks for sharing your thoughts. I truly appreciate your efforts and I will be waiting for your further write
ups thank you once again.
Howdy! I could have sworn I’ve been to this website before
but after reading through some of the post I realized it’s new
to me. Anyhow, I’m definitely glad I found it and I’ll be bookmarking and checking back often!
Hi, i feel that i noticed you visited my site thus i got here to go back the favor?.I’m trying to find issues to
enhance my website!I assume its adequate to make
use of a few of your ideas!!
Also visit my web blog – savage garage
I do agree with all of the ideas you have offered for your post.
They’re really convincing and can definitely work.
Still, the posts are too short for starters. May just you please extend them a bit from
next time? Thank you for the post.
It’s perfect time to make some plans for the future and
it is time to be happy. I have read this post and if I could I want to
suggest you some interesting things or tips. Perhaps you could write
next articles referring to this article. I wish to read even more things
about it!
Do you mind if I quote a couple of your articles as long as
I provide credit and sources back to your webpage?
My blog site is in the very same area of interest as yours and my
users would certainly benefit from some of the information you present here.
Please let me know if this alright with you.
Many thanks!
Greetings from Colorado! I’m bored to tears at work so I decided to browse your site on my iphone
during lunch break. I really like the info you present
here and can’t wait to take a look when I get home.
I’m amazed at how quick your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyways,
awesome site!
Hey there, You’ve done an excellent job.
I’ll certainly digg it and personally recommend to my friends.
I am confident they will be benefited from this site.
Asking questions are really pleasant thing if you are not understanding anything
completely, however this paragraph provides nice understanding yet.
I delight in, result in I found exactly what I used to be having a look
for. You’ve ended my four day long hunt! God Bless
you man. Have a nice day. Bye
Hello, I want to subscribe for this web site to obtain most up-to-date
updates, so where can i do it please help.
Incredible! This blog looks exactly like my old one! It’s on a totally different topic but it has pretty much the same
page layout and design. Great choice of colors!
What i don’t realize is in reality how you’re no longer actually much more neatly-appreciated than you might be right now.
You’re so intelligent. You already know therefore considerably
relating to this subject, made me in my opinion imagine it from so many various angles.
Its like women and men aren’t fascinated until it’s one thing
to accomplish with Girl gaga! Your own stuffs nice.
All the time maintain it up!
Howdy would you mind sharing which blog platform you’re working with?
I’m going to start my own blog in the near future but I’m having a
hard time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs
and I’m looking for something unique.
P.S Sorry for being off-topic but I had to ask!
I always used to read article in news papers but now as I am a user
of web thus from now I am using net for articles, thanks to web.
It’s enormous that you are getting ideas from this paragraph as well as from our dialogue made here.
Amazing things here. I’m very happy to see your article.
Thanks a lot and I’m looking ahead to touch you. Will you kindly drop me a mail?
Howdy! This is my first visit to your blog! We are a group of volunteers and starting
a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have
done a extraordinary job!
Hello, everything is going fine here and ofcourse every one is sharing facts, that’s really good, keep
up writing.
I was very pleased to discover this web site.
I wanted to thank you for ones time due to this fantastic read!!
I definitely enjoyed every part of it and I have you saved to fav to check
out new stuff in your web site.
You’re so awesome! I don’t think I’ve truly read
anything like this before. So good to find someone with a few unique thoughts on this subject.
Really.. many thanks for starting this up. This website is one thing
that is needed on the web, someone with a bit
of originality!
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the way,
how could we communicate?
My brother recommended I might like this blog.
He was totally right. This post actually made my
day. You can not imagine just how much time I had spent for this
information! Thanks!
Hi there to all, how is all, I think every one is getting more from this web page, and your views are fastidious in support
of new viewers.
Hi there, You’ve done a great job. I will definitely digg it and personally suggest to my friends.
I’m sure they’ll be benefited from this site.
Hello all, here every person is sharing these knowledge, so
it’s nice to read this website, and I used to visit this webpage all the time.
Hi! I’m at work surfing around your blog from my new iphone 4!
Just wanted to say I love reading your blog and look forward
to all your posts! Keep up the outstanding work!
Everyone loves what you guys are up too. This type of clever work and coverage!
Keep up the amazing works guys I’ve added you guys to my personal
blogroll.
Hi there Dear, are you actually visiting this web
site regularly, if so then you will definitely
get fastidious experience.
Peculiar article, just what I wanted to find.
Thanks for a marvelous posting! I actually enjoyed reading it,
you may be a great author. I will be sure to bookmark your blog and will come back in the
foreseeable future. I want to encourage you to ultimately continue your great
work, have a nice holiday weekend!
Fantastic beat ! I wish to apprentice whilst you amend
your website, how can i subscribe for a blog website? The account
aided me a acceptable deal. I had been a little bit familiar of this your broadcast offered shiny clear
idea
Hurrah! Finally I got a webpage from where I can really take valuable information regarding
my study and knowledge.
I got this website from my pal who informed me concerning this site and at the moment this time I am browsing this
web page and reading very informative posts here.
Hello there, I found your web site by the use of Google while searching for a comparable
matter, your website got here up, it appears to be like great.
I have bookmarked it in my google bookmarks.
Hello there, simply became aware of your blog via Google, and found that it is
really informative. I am going to watch out for brussels. I’ll be grateful when you continue this in future.
Numerous other people shall be benefited from your writing.
Cheers!
Hello there! I simply wish to give you a big thumbs up for the
great info you’ve got here on this post. I’ll be coming back to your
site for more soon.
I have read some excellent stuff here. Definitely value bookmarking
for revisiting. I wonder how a lot attempt you put to make such a wonderful informative site.
Our useful guide gives you the lowdown on the immigration course of.
Here is my web page … uk immigration, dave.stewart.name,
Do you have a spam issue on this blog; I also am a
blogger, and I was curious about your situation; we have developed some nice procedures and
we are looking to trade techniques with others, please shoot me an email if interested.
We’re a bunch of volunteers and starting a brand new scheme in our
community. Your site provided us with valuable info to work on. You’ve performed an impressive
activity and our entire neighborhood might be thankful to you.
I am extremely impressed together with your writing abilities
as neatly as with the format on your weblog.
Is that this a paid subject or did you modify it your
self? Anyway stay up the excellent quality writing, it’s uncommon to look a nice blog like this one nowadays..
Hi there i am kavin, its my first occasion to commenting anyplace, when i read this article i thought i could also
create comment due to this good article.
Good day I am so glad I found your blog, I really found you by accident, while I was looking on Aol for
something else, Nonetheless I am here now and would just like to say thanks for a tremendous post and a all round entertaining blog (I also love the theme/design), I don’t have time to look over
it all at the minute but I have bookmarked it and also included your RSS feeds,
so when I have time I will be back to read more, Please do keep up the great jo.
Hello, yup this paragraph is genuinely nice and I have learned lot of things from it about blogging.
thanks.
I think that what you said made a great deal of sense. But, what about this?
what if you were to write a awesome title? I mean, I don’t want to tell
you how to run your website, however what if you
added something that makes people want more? I mean Пиастры – Составление семантического ядра |
is a little plain. You could peek at Yahoo’s home page and watch how they create article headlines to get people
to open the links. You might add a video or a related
pic or two to get readers excited about what you’ve written. In my
opinion, it would bring your website a little bit more interesting.
Cool blog! Is your theme custom made or did you
download it from somewhere? A design like yours with a few simple adjustements would really make my blog shine.
Please let me know where you got your design. Many thanks
It’s very easy to find out any matter on web as compared to textbooks, as I found
this piece of writing at this website.
It’s hard to find educated people in this particular topic, however, you sound
like you know what you’re talking about! Thanks
I’ll immediately snatch your rss as I can not find your
e-mail subscription hyperlink or e-newsletter service.
Do you have any? Please let me realize in order that I could subscribe.
Thanks.
I got this site from my buddy who informed me on the topic of this website and at the moment this time I am visiting
this site and reading very informative content at this place.
Heya i am for the first time here. I came across this board and I
find It really useful & it helped me out much. I hope to give something back and aid others like
you helped me.
I like what you guys are usually up too. This type of clever work and
reporting! Keep up the awesome works guys I’ve you guys to my blogroll.
I really love your blog.. Great colors & theme. Did you develop this amazing site yourself?
Please reply back as I’m hoping to create my own website
and would love to know where you got this from or just what
the theme is called. Many thanks!
Excellent post. I will be going through some of these issues as well..
Do you have a spam issue on this site; I also am a blogger, and I was curious about
your situation; many of us have developed some nice procedures and we are looking to exchange
techniques with other folks, be sure to shoot me an email if interested.
các trang phim sex đáng xem nhất, giúp bạn nứng lồn nứng
cặc nhanh
xvideo.com
xnxx
pornhub
vlxx
javhd.win
javmost.com
javphe.net
xxphez.net
sextop.net
xvideo98.xxx
lồn to, cặc bự, đụ đéo gái dưới 18 tuổi, fuck girl, fuck
boy
I pay a visit every day some blogs and websites to read
posts, however this web site offers feature based content.
Hiya! I know this is kinda off topic however I’d figured I’d ask.
Would you be interested in exchanging links or maybe
guest authoring a blog post or vice-versa? My
website discusses a lot of the same subjects as
yours and I think we could greatly benefit from each other.
If you’re interested feel free to send me an e-mail.
I look forward to hearing from you! Excellent blog by the way!
Hey would you mind stating which blog platform you’re
working with? I’m planning to start my own blog soon but I’m having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and
I’m looking for something completely unique.
P.S My apologies for being off-topic but I had
to ask!
Having read this I believed it was rather informative. I appreciate you taking the time
and effort to put this short article together. I once again find myself personally spending a significant
amount of time both reading and leaving comments.
But so what, it was still worth it!
Thank you for another fantastic article. The place else could anybody get that type of
information in such a perfect way of writing?
I’ve a presentation subsequent week, and I am at the look for such information.
I read this article completely about the difference of most up-to-date
and preceding technologies, it’s amazing article.
Today, I went to the beachfront with my kids. I found a sea shell and
gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally
off topic but I had to tell someone!
Great article! This is the type of info that should be shared across the net.
Disgrace on the seek engines for now not positioning this put up
upper! Come on over and visit my site . Thanks =)
Hello there, You’ve done a fantastic job. I’ll certainly digg it and personally suggest to my friends.
I am sure they’ll be benefited from this web site.
First off I would like to say great blog! I had a quick question in which I’d like to ask if you
don’t mind. I was curious to find out how
you center yourself and clear your thoughts prior to writing.
I’ve had trouble clearing my mind in getting my thoughts out.
I do take pleasure in writing but it just seems like the first 10 to 15 minutes are lost simply just trying to figure out how to begin. Any recommendations or
hints? Appreciate it!
Thanks for any other informative site. Where else could I
get that type of info written in such an ideal way?
I’ve a project that I am just now operating on, and I’ve been on the glance out for such information.
Spot on with this write-up, I honestly feel this website
needs much more attention. I’ll probably be back again to read
through more, thanks for the advice!
Excellent weblog here! Also your site rather a lot
up very fast! What web host are you the use of? Can I
am getting your associate link in your host?
I desire my site loaded up as fast as yours lol
I always emailed this webpage post page to all my contacts, as
if like to read it afterward my links will too.
Hi there i am kavin, its my first time to commenting anyplace, when i
read this paragraph i thought i could also create comment
due to this sensible article.
I think this is among the most important information for me.
And i am glad reading your article. But should remark on some general things, The web site style is ideal, the
articles is really great : D. Good job, cheers
This is very attention-grabbing, You’re a very professional
blogger. I have joined your feed and look ahead
to searching for more of your great post.
Additionally, I have shared your web site in my social networks
Superb, what a web site it is! This website provides useful facts to us, keep it up.
I need to to thank you for this fantastic read!!
I definitely loved every little bit of it. I have got you bookmarked
to look at new things you post…
This is very fascinating, You’re an excessively skilled blogger.
I’ve joined your feed and sit up for in the hunt for extra of your fantastic post.
Also, I have shared your site in my social networks
I’m impressed, I have to admit. Rarely do I come across a blog that’s both educative and
amusing, and without a doubt, you have hit the nail on the head.
The issue is an issue that too few folks are speaking intelligently about.
Now i’m very happy that I found this in my hunt for something concerning this.
It’s awesome to go to see this site and reading the views of all
mates regarding this piece of writing, while I am also keen of getting experience.
I know this site offers quality based articles or reviews and
additional information, is there any other web page which gives these data in quality?
Greetings from Florida! I’m bored to death at work so I decided
to check out your blog on my iphone during lunch break.
I love the info you present here and can’t wait
to take a look when I get home. I’m surprised at how quick
your blog loaded on my phone .. I’m not even using WIFI, just 3G ..
Anyhow, very good site!
After checking out a handful of the blog articles on your site, I honestly like your technique of writing a blog.
I book-marked it to my bookmark webpage list and will
be checking back in the near future. Please check
out my website as well and tell me how you feel.
Howdy! This is my first comment here so I just wanted to give a quick
shout out and tell you I truly enjoy reading your
blog posts. Can you recommend any other blogs/websites/forums that cover the same subjects?
Thank you!
These are in fact impressive ideas in concerning blogging.
You have touched some pleasant things here. Any way keep up wrinting.
In fact when someone doesn’t be aware of then its up to other viewers that they will assist, so here it
happens.
Excellent, what a website it is! This blog provides valuable facts to us,
keep it up.
I seriously love your website.. Excellent colors & theme. Did you develop this amazing site yourself?
Please reply back as I’m hoping to create my very own website and want to learn where you got
this from or just what the theme is named. Kudos!
I quite like reading an article that can make people think.
Also, thanks for allowing for me to comment!
Heya i’m for the first time here. I found this board and
I to find It truly useful & it helped me out much. I hope to present one thing again and help others such as you
helped me.
Great post.
You need to be a part of a contest for one of the
most useful blogs on the net. I will recommend this blog!
Good day! I could have sworn I’ve been to this blog before but
after browsing through some of the post I realized it’s new to me.
Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back
often!
I’m very happy to uncover this site. I wanted
to thank you for ones time just for this fantastic read!!
I definitely loved every part of it and I have you saved to fav to see new information in your site.
Wonderful web site. A lot of useful information here.
I’m sending it to some friends ans also sharing in delicious.
And obviously, thank you in your sweat!
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying to
get started and set up my own. Do you require any html coding knowledge to make your
own blog? Any help would be really appreciated!
Whats up are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create
my own. Do you require any html coding expertise to make your own blog?
Any help would be really appreciated!
It’s truly a great and useful piece of info.
I’m glad that you shared this useful information with us.
Please stay us informed like this. Thank you for sharing.
Hi there, always i used to check weblog posts
here in the early hours in the morning, for the reason that i enjoy to learn more and more.
Howdy! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on.
Any recommendations?
Hi there, You have done a fantastic job.
I will certainly digg it and personally recommend to my friends.
I am confident they’ll be benefited from this website.
Also visit my page – call girls in Pitampura
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I
look forward to your new updates.
Entry visa prices are modified each April. The
UK society and culture are ideally suited and class apart.
Almost all of the immigrants are from commonwealth nations like
Pakistan, India, Bangladesh and Sri Lanka.
Highly energetic blog, I loved that a lot. Will there be a part
2?
You can definitely see your expertise within the article you write.
The world hopes for even more passionate writers like you who are not afraid to mention how they believe.
All the time go after your heart.
Thanks a bunch for sharing this with all folks you actually know what you are talking approximately!
Bookmarked. Kindly also seek advice from my site =). We could have a hyperlink change contract between us
Undeniably consider that that you stated. Your favorite justification seemed to be at
the net the simplest factor to take note of.
I say to you, I definitely get annoyed at the same time as other people consider worries
that they plainly don’t realize about. You controlled to
hit the nail upon the highest as well as outlined out the
whole thing with no need side effect , people could take a signal.
Will probably be again to get more. Thank you
Every weekend i used to visit this website, for the reason that i want enjoyment, since this this web page conations really
good funny data too.
Oh my goodness! Awesome article dude! Thank you, However
I am going through problems with your RSS. I don’t know
the reason why I cannot join it. Is there anyone else having the same RSS issues?
Anyone who knows the answer will you kindly respond?
Thanks!!
Your mode of explaining the whole thing in this piece of writing is actually pleasant, all can easily understand it, Thanks a
lot.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is
added I get several e-mails with the same comment. Is there any
way you can remove me from that service? Bless you!
Greetings! Very useful advice within this article!
It’s the little changes that make the biggest changes. Many thanks for sharing!
It’s a pity you don’t have a donate button! I’d certainly donate to this brilliant blog!
I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to brand new updates and will share this
blog with my Facebook group. Chat soon!
I think the admin of this web site is really working hard in favor of his site,
since here every stuff is quality based material.
My brother suggested I might like this blog. He was entirely
right. This post truly made my day. You cann’t imagine simply how much
time I had spent for this info! Thanks!
Thanks for a marvelous posting! I truly enjoyed reading it, you are a great author.
I will remember to bookmark your blog and may come back later in life.
I want to encourage yourself to continue your great work, have a nice
weekend!
Hi, i think that i saw you visited my weblog thus i came to return the prefer?.I am attempting to find issues to improve my site!I assume its ok to use some of your ideas!!
This is really interesting, You’re an excessively skilled blogger.
I have joined your rss feed and sit up for searching for more of your excellent post.
Also, I have shared your web site in my social networks
Hi there, I desire to subscribe for this webpage to obtain hottest updates, therefore where can i do it please help.
I know this site presents quality depending content and additional
material, is there any other website which gives these kinds of information in quality?
I absolutely love your blog and find almost all of your post’s to
be just what I’m looking for. Do you offer guest writers to write content for yourself?
I wouldn’t mind creating a post or elaborating on a few of the subjects you write regarding here.
Again, awesome web log!
I was wondering if you ever thought of changing the page layout of your site?
Its very well written; I love what youve got to say. But maybe
you could a little more in the way of content so people could connect with
it better. Youve got an awful lot of text for only having 1 or two pictures.
Maybe you could space it out better?
If some one wants to be updated with hottest technologies then he must be visit this website
and be up to date everyday.
I really like it when people get together and share opinions.
Great blog, keep it up!
WOW just what I was looking for. Came here by searching for
kampus terbaik sumut
After looking into a number of the articles on your blog, I really appreciate your way of writing a blog.
I saved it to my bookmark site list and will be checking back soon. Please visit my web site as well and tell me your
opinion.
I’ve been browsing on-line greater than three hours today, but I
never found any fascinating article like
yours. It’s pretty worth enough for me. Personally, if all site owners and
bloggers made just right content material as you probably did, the internet might
be much more useful than ever before.
my site; escort agency in Chhindwara
I think this is among the most significant information for me.
And i am glad reading your article. But wanna remark on few general things, The web site style is great, the articles is really great :
D. Good job, cheers
When I originally commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get several e-mails with the
same comment. Is there any way you can remove people from that service?
Bless you!
Hello there, just became alert to your blog through Google, and found
that it is truly informative. I am going to watch out for
brussels. I will appreciate if you continue this
in future. A lot of people will be benefited from
your writing. Cheers!
I read this post fully regarding the comparison of hottest and previous technologies, it’s remarkable article.
Today, I went to the beachfront with my children.
I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She
placed the shell to her ear and screamed. There was a hermit crab inside and it
pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
I’m not sure where you’re getting your information, but good topic.
I needs to spend some time learning much more or
understanding more. Thanks for wonderful info I was looking for this info for
my mission.
Hey there! Do you use Twitter? I’d like to follow you if that would be
ok. I’m absolutely enjoying your blog and look forward
to new updates.
Hello! Someone in my Facebook group shared this website with us
so I came to take a look. I’m definitely loving the information. I’m bookmarking and will be tweeting this to my followers!
Wonderful blog and amazing design.
You need to be a part of a contest for one of the best sites on the web.
I’m going to recommend this site!
Does your site have a contact page? I’m having problems locating it but,
I’d like to shoot you an e-mail. I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it grow over time.
Hi there, I check your blogs regularly. Your writing style is awesome, keep
up the good work!
What’s up Dear, are you in fact visiting this website regularly, if
so then you will absolutely get nice knowledge.
This design is incredible! You definitely know how to keep a
reader entertained. Between your wit and your videos,
I was almost moved to start my own blog (well, almost…HaHa!)
Wonderful job. I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
Also visit my web-site: kkpoker mod Apk
Neat blog! Is your theme custom made or did you download
it from somewhere? A theme like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got your design. Cheers
I do not know whether it’s just me or if everybody else experiencing
issues with your site. It appears as though some of
the written text on your posts are running off the screen. Can someone else please provide feedback and let me know if
this is happening to them as well? This might be a issue with my web browser because I’ve had this happen before.
Thank you
Hello friends, fastidious post and nice urging commented at this place, I am truly enjoying by these.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter
stylish. nonetheless, you command get bought an edginess over that you wish be
delivering the following. unwell unquestionably come more formerly again since exactly the same
nearly very often inside case you shield
this hike.
Hi mates, its enormous post on the topic of teachingand fully explained,
keep it up all the time.
Heya i am for the primary time here. I came across this board and I find It truly helpful &
it helped me out much. I am hoping to provide one thing again and aid others such as you helped me.
I am really impressed with your writing skills and also with the
layout on your blog. Is this a paid theme or did you modify it yourself?
Anyway keep up the excellent quality writing, it’s rare to see a nice blog
like this one today.
Saved as a favorite, I really like your blog!
Hello would you mind stating which blog platform you’re working with?
I’m looking to start my own blog soon but I’m having a tough time
choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for something unique.
P.S My apologies for being off-topic but I had to ask!
Great goods from you, man. I’ve understand your stuff previous
to and you are just too magnificent. I really like what you have acquired here,
certainly like what you are stating and the way in which you say
it. You make it enjoyable and you still care for to keep it wise.
I can’t wait to read much more from you. This is actually a tremendous
web site.
Have you ever thought about adding a little bit more than just your
articles? I mean, what you say is important and everything.
But think about if you added some great photos or video clips to give your posts more,
“pop”! Your content is excellent but with images and clips, this blog could definitely be one of the very best in its
niche. Terrific blog!
Very good blog post. I definitely appreciate this website.
Thanks!
Very good info. Lucky me I recently found your site by accident (stumbleupon).
I’ve book marked it for later!
I believe everything posted made a lot of sense.
But, think on this, what if you were to write a killer headline?
I ain’t saying your content isn’t good., however suppose you added a post title to possibly grab folk’s attention? I mean Пиастры – Составление
семантического ядра | is a little vanilla.
You could glance at Yahoo’s home page and note how they create news titles to get viewers interested.
You might add a related video or a pic or two to grab readers excited about what you’ve written. Just my opinion, it would bring your
blog a little livelier.
I like what you guys are usually up too. This type
of clever work and reporting! Keep up the great works guys I’ve added you guys to my personal
blogroll.
Hi there! I could have sworn I’ve been to this website before but after
browsing through some of the post I realized it’s new to me.
Anyways, I’m definitely happy I found it and I’ll be bookmarking and checking back often!
Every weekend i used to visit this web site, as i want enjoyment, since this this web
page conations really good funny stuff too.
Wow, incredible blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your
site is fantastic, as well as the content!
Incredible story there. What occurred after? Thanks!
Why people still use to read news papers when in this technological world everything
is presented on web?
Hi there! I simply wish to offer you a big thumbs up for your excellent information you have here
on this post. I am returning to your website for more soon.
At this moment I am ready to do my breakfast, after having my breakfast coming again to read other news.
It’s the best time to make a few plans for the future and it is
time to be happy. I’ve learn this post and if I could I wish to suggest you few interesting issues or tips.
Maybe you can write subsequent articles regarding this article.
I wish to read even more things approximately it!
It’s enormous that you are getting thoughts from this article as well as from our discussion made at this
time.
excellent points altogether, you simply gained a emblem new reader.
What could you suggest about your post that you made a few days in the past?
Any sure?
Hello there! This is my first visit to your blog!
We are a team of volunteers and starting a new
project in a community in the same niche. Your blog provided us useful
information to work on. You have done a marvellous job!
These are truly enormous ideas in on the topic of blogging.
You have touched some good factors here. Any way
keep up wrinting.
Hi, I do think this is a great web site. I stumbledupon it 😉 I’m going to revisit yet
again since I book-marked it. Money and freedom is the best
way to change, may you be rich and continue to guide
others.
Everything is very open with a precise description of the
issues. It was really informative. Your site is very
useful. Many thanks for sharing!
my web-site … Live Poker Online
I’m really enjoying the design and layout of your site. It’s a
very easy on the eyes which makes it much more pleasant for
me to come here and visit more often. Did you hire out a developer
to create your theme? Excellent work!
I take pleasure in, lead to I found just what I was looking for.
You have ended my four day lengthy hunt! God Bless you man. Have a nice day.
Bye
I blog quite often and I genuinely appreciate your content.
Your article has truly peaked my interest. I’m going to take a note
of your blog and keep checking for new details about once per
week. I subscribed to your RSS feed too.
I think that everything published made a bunch of sense.
However, what about this? suppose you were to create
a awesome title? I am not suggesting your content isn’t solid, but what
if you added a title to maybe get a person’s attention? I mean Пиастры – Составление семантического ядра
| is a little boring. You might peek at Yahoo’s home page and watch how they create article titles to grab viewers interested.
You might add a related video or a picture or two to get people interested about everything’ve got to
say. In my opinion, it might bring your posts a little bit more interesting.
Normally I do not read post on blogs, but I would like to say that this write-up very compelled me to check
out and do so! Your writing taste has been surprised me.
Thanks, quite nice post.
When I originally commented I seem to have clicked on the -Notify
me when new comments are added- checkbox and from now on every time a comment is added I receive
4 emails with the exact same comment. Is there an easy method you can remove me from that
service? Thanks!
I visited many web pages except the audio feature for audio songs present at this site is really excellent.
I got this web page from my friend who informed me regarding this web
page and now this time I am browsing this web page and reading very
informative articles or reviews at this place.
Aw, this was a really nice post. Taking a few minutes and actual effort to produce
a top notch article… but what can I say… I hesitate a whole
lot and never manage to get anything done.
I really like your blog.. very nice colors & theme.
Did you make this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to construct my own blog and would
like to find out where u got this from. thank you
Asking questions are genuinely fastidious thing if you are
not understanding something entirely, except this post presents nice understanding even.
If some one wants expert view on the topic of blogging and site-building then i recommend him/her to go to see this weblog, Keep up the good work.
What’s up colleagues, good piece of writing and pleasant arguments commented at
this place, I am genuinely enjoying by these.
Very shortly this web page will be famous amid all blog
visitors, due to it’s fastidious content
Today, I went to the beach with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
Good way of explaining, and pleasant article to get information regarding my presentation subject, which i am going to present in university.
It’s very effortless to find out any matter on web as compared to books,
as I found this paragraph at this web site.
Its like you learn my thoughts! You appear to know a lot about this,
such as you wrote the guide in it or something. I think that you could do with
a few p.c. to drive the message home a bit, however other than that,
this is fantastic blog. A great read. I will certainly be back.
I all the time used to read article in news papers but now
as I am a user of net thus from now I am using net for articles or reviews,
thanks to web.
Wonderful, what a webpage it is! This web site gives useful facts to us,
keep it up.
hello!,I really like your writing very much! share we keep up
a correspondence extra approximately your post
on AOL? I need an expert on this house to unravel my
problem. Maybe that is you! Taking a look forward to look you.
We’re a group of volunteers and starting a
brand new scheme in our community. Your site provided us with useful info to
work on. You’ve done an impressive task and our entire community
will probably be grateful to you.
Your style is really unique compared to other people I have read stuff from.
Thanks for posting when you’ve got the opportunity,
Guess I’ll just bookmark this page.
Hello There. I found your blog the use of msn. This is a really
neatly written article. I’ll make sure to bookmark it and
return to learn more of your useful info.
Thanks for the post. I will certainly return.
Thank you for any other informative web site.
Where else may I get that kind of info written in such a perfect manner?
I’ve a venture that I’m just now running on, and I’ve been at the look
out for such info.
Remarkable things here. I’m very happy to
look your post. Thanks so much and I’m taking a look
forward to contact you. Will you please drop me a e-mail?
Helpful info. Lucky me I discovered your site
unintentionally, and I am shocked why this accident did not came
about earlier! I bookmarked it.
If all else fails, the lender most likely will refer your case to a collection agency,
which will initial try bombarding you with phone calls.
I simply couldn’t go away your site prior to suggesting that I really
loved the standard information an individual provide on your visitors?
Is gonna be back regularly to investigate cross-check new posts
Hi! I’ve been following your web site for some time now and finally got the bravery to go ahead and give you a shout out from Dallas Texas!
Just wanted to say keep up the excellent job!
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back down the road.
Many thanks
I think that everything posted was very reasonable.
However, what about this? suppose you wrote a catchier
title? I ain’t suggesting your information is not solid, but what if
you added a title that makes people desire more? I mean Пиастры
– Составление семантического ядра | is a little vanilla.
You ought to peek at Yahoo’s front page and watch how they
write article headlines to get viewers to click. You might add a related video or a pic or two to grab people interested about everything’ve written. Just
my opinion, it could make your posts a little bit more interesting.
What’s up to every body, it’s my first pay
a visit of this weblog; this webpage consists of remarkable and in fact excellent information in favor of visitors.
I’m not sure exactly why but this website is loading extremely slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
This design is wicked! You most certainly know
how to keep a reader amused. Between your wit and your videos, I was almost moved to start my
own blog (well, almost…HaHa!) Fantastic job. I really enjoyed what you had
to say, and more than that, how you presented it.
Too cool!
I like the helpful info you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I’m quite certain I will learn many new stuff right here!
Best of luck for the next!
Thankfulness to my father who told me about this blog,
this web site is in fact amazing.
купить настоящий диплом цена
I read this article completely about the difference of most up-to-date and earlier technologies, it’s awesome
article.
The greater your score, the decrease the threat
you represent to any individual who lends you money.
Can I simply say what a comfort to find somebody who
genuinely understands what they’re discussing on the web.
You definitely know how to bring an issue to light and make it
important. A lot more people ought to check this out
and understand this side of your story. I can’t believe you aren’t more popular given that you certainly possess the gift.
My spouse and I absolutely love your blog and find most
of your post’s to be what precisely I’m looking for.
Would you offer guest writers to write content for you personally?
I wouldn’t mind publishing a post or elaborating on a few of the subjects
you write regarding here. Again, awesome web
log!
Hi there I am so excited I found your site, I really found you by accident, while I was searching on Bing for something else, Nonetheless
I am here now and would just like to say cheers for a tremendous post and
a all round entertaining blog (I also love the theme/design), I don’t have time to browse it all at the minute but
I have saved it and also included your RSS feeds, so when I have time I will be back
to read a great deal more, Please do keep up the great work.
If you desire to improve your familiarity simply keep visiting
this website and be updated with the most up-to-date news update posted here.
It’s an awesome paragraph in favor of all the internet visitors; they will take benefit from it I am sure.
Hello are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started
and set up my own. Do you need any coding knowledge to make your own blog?
Any help would be greatly appreciated!
I do not know whether it’s just me or if everyone else encountering problems with your website.
It appears as though some of the text on your content
are running off the screen. Can someone else please
comment and let me know if this is happening to them too?
This could be a problem with my web browser because I’ve had
this happen before. Cheers
My brother suggested I might like this blog. He was totally
right. This post actually made my day. You can not imagine just how much
time I had spent for this information! Thanks!
Your way of explaining everything in this article is
in fact fastidious, every one can effortlessly know it, Thanks a lot.
Excellent post. Keep writing such kind of info on your page.
Im really impressed by it.[X-N-E-W-L-I-N-S-P-I-N-X]Hello there,
You’ve performed a great job. I’ll certainly digg it and
personally recommend to my friends. I am confident they’ll be benefited from
this website.
my blog post :: Free Online Poker
On the best apps, you can constantly sit in the comfort of your dwelling and watch any live sports event.
Hey! This is kind of off topic but I need some advice from an established blog.
Is it difficult to set up your own blog? I’m not very techincal
but I can figure things out pretty fast. I’m thinking about setting up my own but
I’m not sure where to start. Do you have any points or suggestions?
With thanks
I have been exploring for a little bit for any high-quality articles
or blog posts on this kind of area . Exploring in Yahoo I finally stumbled upon this website.
Studying this information So i am glad to express
that I have an incredibly just right uncanny feeling I found out
just what I needed. I so much indubitably will make certain to do not
fail to remember this web site and provides it a glance
on a constant basis.
This is really attention-grabbing, You’re an excessively skilled blogger.
I’ve joined your feed and look forward to in search of extra of your great post.
Also, I have shared your site in my social networks
Greetings! Very helpful advice in this particular article!
It is the little changes that produce the largest changes.
Thanks for sharing!
Hey there! This is my 1st comment here so I just wanted to give a quick shout out and tell you I
truly enjoy reading through your blog posts. Can you recommend any other blogs/websites/forums that go over the same subjects?
Thanks a lot!
Hi, I think your blog might be having browser compatibility issues.
When I look at your blog site in Chrome, it looks fine but when opening in Internet
Explorer, it has some overlapping. I just wanted to give
you a quick heads up! Other then that, fantastic blog!
I like the helpful information you provide in your articles.
I’ll bookmark your blog and check again here frequently. I am quite certain I will learn a lot of new stuff right here!
Good luck for the next!
If some one desires to be updated with latest technologies therefore he must be
pay a quick visit this web site and be up to date every day.
I know this if off topic but I’m looking into starting my own blog
and was curious what all is needed to get setup? I’m assuming having
a blog like yours would cost a pretty penny? I’m not very internet savvy so I’m not 100% certain. Any
suggestions or advice would be greatly appreciated.
Thanks
A person necessarily assist to make severely articles I would state.
This is the very first time I frequented your web page
and so far? I amazed with the research you made to create this particular
publish amazing. Wonderful activity!
Hello, for all time i used to check webpage
posts here in the early hours in the break of day,
for the reason that i like to gain knowledge of more and more.
What’s up, just wanted to say, I enjoyed this blog post.
It was funny. Keep on posting!
Just want to say your article is as astounding.
The clarity on your put up is simply spectacular and that
i could think you are an expert in this subject. Fine along with your permission let me
to grab your RSS feed to stay up to date with forthcoming post.
Thanks 1,000,000 and please keep up the enjoyable work.
Everything is very open with a really clear clarification of the issues.
It was truly informative. Your site is very helpful.
Thank you for sharing!
my page – find sex near me
Wow that was strange. I just wrote an extremely
long comment but after I clicked submit my comment didn’t show
up. Grrrr… well I’m not writing all that over again. Anyway,
just wanted to say wonderful blog!
реферат по всемирной истории 9 класс
Hi there just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both
show the same outcome.
It’s very effortless to find out any topic on web
as compared to books, as I found this post at this web page.
Whats up this is somewhat of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so I wanted to get
guidance from someone with experience. Any help would be greatly appreciated!
Because the admin of this web page is working,
no question very rapidly it will be renowned, due
to its quality contents.
Very energetic article, I loved that a lot. Will there be a part 2?
I like the helpful info you provide in your
articles. I’ll bookmark your blog and check again here regularly.
I’m quite sure I will learn many new stuff right here!
Good luck for the next!
What’s additional, Ignition functions with
13 established gaming providers, like RealTime Gaming, Rival Gaming and BetSoft.
Hi, this weekend is pleasant designed for me, for the reason that this occasion i
am reading this fantastic informative article here at my house.
I don’t know whether it’s just me or if perhaps everyone else encountering issues
with your website. It appears as if some of the written text on your posts are running off the screen. Can someone else
please comment and let me know if this is happening to them too?
This might be a issue with my browser because
I’ve had this happen previously. Thanks
I am in fact happy to glance at this web site posts
which includes tons of valuable information, thanks for
providing such data.
Good day! I know this is somewhat off topic but I was wondering if you
knew where I could find a captcha plugin for my comment
form? I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
Oh my goodness! Impressive article dude! Thanks, However I
am experiencing difficulties with your RSS. I don’t understand the
reason why I can’t subscribe to it. Is there anyone else
having the same RSS problems? Anybody who knows the solution can you
kindly respond? Thanx!!
What’s up colleagues, its great post about tutoringand entirely
explained, keep it up all the time.
Thanks in favor of sharing such a fastidious
thought, article is good, thats why i have read it fully
It’s really a cool and useful piece of information. I
am satisfied that you just shared this useful information with
us. Please keep us up to date like this. Thanks
for sharing.
My web-site best online poker nwt
Howdy! I simply wish to offer you a big thumbs up
for the excellent info you’ve got right here on this post.
I will be coming back to your website for more soon.
Feel free to visit my blog post – facebook of sex
I believe that is one of the such a lot significant info for me.
And i’m satisfied reading your article. But should remark how to find sex on facebook
some normal issues, The website style is ideal, the articles is in reality nice : D.
Good process, cheers
Hmm it appears like your website ate my first comment (it was extremely long) so I guess
I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to the whole thing.
Do you have any tips and hints for rookie blog writers?
I’d certainly appreciate it.
An outstanding share! I’ve just forwarded this onto a friend who had been conducting
a little research on this. And he actually ordered me lunch because I stumbled upon it
for him… lol. So allow me to reword this….
Thanks for the meal!! But yeah, thanks for spending some
time to discuss this issue here on your web page.
Hello! I just want to give you a big thumbs up for your excellent information you have got right here on this post.
I’ll be returning to your website for more soon.
Keep on writing, great job!
I have been browsing online more than 2 hours today, yet I never found
any interesting article like yours. It’s pretty worth enough for me.
Personally, if all website owners and bloggers made good content as you
did, the web will be much more useful than ever before.
This began a chain of events that spawned on line gaming regulations in Nevada.
Hello, yup this piece of writing is truly nice and I have learned
lot of things from it regarding blogging. thanks.
As element of regulating the sector, every of the operators will have
tools in spot to encourage accountable betting.
This piece of writing will assist the internet viewers for
creating new webpage or even a blog from start to end.
My blog :: escort agency in Bhupalpally
Hello, its pleasant piece of writing regarding media print, we all
understand media is a impressive source of information.
Bitches Porn
I am now not positive where you’re getting your information, but great topic.
I needs to spend a while learning more or figuring out more.
Thank you for wonderful information I was in search of this info for my mission.
my web blog; خرید بک لینک قوی
I am in fact thankful to the owner of this web page who has shared this impressive article at at
this place.
You ought to take part in a contest for one of the finest blogs on the net.
I most certainly will recommend this website!
Wow, this post is nice, my sister is analyzing these
things, therefore I am going to inform her.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my
newest twitter updates. I’ve been looking for a plug-in like
this for quite some time and was hoping maybe you would have some
experience with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
I am now not sure the place you’re getting your info, but great topic.
I needs to spend some time finding out more or working out more.
Thanks for fantastic information I used to be searching for this information for my
mission.
Yes! Finally someone writes about Data recovery external hard drive.
When someone writes an article he/she maintains the plan of a user in his/her mind that how a user can know
it. Thus that’s why this post is perfect. Thanks!
Thanks for some other fantastic article. The place else could anybody
get that type of information in such an ideal manner of writing?
I have a presentation subsequent week, and I’m at the
search for such info.
I think that what you posted made a bunch of sense.
However, think about this, what if you added a little
content? I am not suggesting your information isn’t good,
however what if you added something that grabbed a person’s attention? I mean Пиастры –
Составление семантического ядра | is kinda vanilla.
You might look at Yahoo’s front page and note how they create post titles to get viewers interested.
You might try adding a video or a picture or two to get people interested about everything’ve
got to say. In my opinion, it would bring your posts a
little bit more interesting.
I get pleasure from, result in I found just what I was having
a look for. You’ve ended my 4 day long hunt!
God Bless you man. Have a nice day. Bye
If you desire to obtain a great deal from this piece of writing
then you have to apply such methods to your won web site.
The personal stories you have actually consisted of make the
short article therefore relatable. It is actually an excellent read throughout.
Feel free to visit my web-site … Cheap auto insurance
I think that is one of the such a lot significant info for me.
And i’m glad studying your article. But wanna statement on some basic things,
The web site style is ideal, the articles
is truly great : D. Excellent activity, cheers
Your writing type is both useful and engaging, creating the material a pleasure to check out.
Your knowledge deliver important info that costs discussing.
Here is my website: driving
Heya i am for the primary time here. I found this board
and I to find It truly helpful & it helped me out a lot.
I am hoping to give one thing again and aid others such as you aided me.
Greetings! I know this is somewhat off topic but I was wondering which blog platform
are you using for this site? I’m getting fed up of WordPress
because I’ve had issues with hackers and I’m looking at options
for another platform. I would be awesome if you could point
me in the direction of a good platform.
First of all I would like to say fantastic blog!
I had a quick question that I’d like to ask if you don’t mind.
I was curious to find out how you center
yourself and clear your head prior to writing. I have had
a difficult time clearing my thoughts in getting
my thoughts out. I truly do enjoy writing but it just seems
like the first 10 to 15 minutes tend to be wasted just trying to figure out how to begin. Any
ideas or hints? Thanks!
So, even if the bank crashes or value of fiat currencies decline, your crypto
investments will stay stable. Even under the new legislation that was recently approved by the lower house of Kazakhstan’s legislature,
businesses are required to pay higher fees for licences and purchase power via centralised
auctions. Binance also offers a way to instantly purchase crypto, but the fees are 0.5 percent.
Crypto fundraising has revolutionized the way startups raise capital.
On Binance Futures trading platform, the traders can go long or short with leverage to
reduce risks or seek profits in the volatile crypto market.
The traders can take advantage of this trading method for
managing their risks and maximizing their
profits. Like, if a trader places a limit order, then take profit
and stop-loss can be placed simultaneously. By going long, the trader is buying a futures contract with an expectation that it will rise in value in future.
So, do you wish to trade Binance Futures? What you can do is, you can trade futures by
making use of the third-party crypto trading platforms like TrailingCrypto.
Walk into a shop and walk out with up to $2,000 in your
pocket.
Nice answers in return of this issue with real arguments and describing everything concerning that.
I think this is one of the most significant information for me.
And i am glad reading your article. But should remark on few general
things, The web site style is great, the articles is really great :
D. Good job, cheers
I can’t feel I had not come upon your blogging site earlier.
I’ve been losing out on such beneficial web content!
Look at my homepage … Car insurance
Please enter the ssix digit one particular time passcode that has been sent
to your registered e mail address.
My web blog: Website link
Its like you read my mind! You seem to know a lot about this, like you wrote the book in it or something.
I think that you can do with some pics to drive the message home a bit, but instead of that,
this is great blog. A great read. I will definitely be back.
Also visit my website – Kkpoker Mod Apk
Just want to say your article is as surprising. The clearness for your post is just spectacular and
that i can assume you are an expert in this
subject. Well along with your permission let me to grab your
feed to stay up to date with imminent post. Thank you a million and please carry on the gratifying
work.
Wow, superb weblog structure! How lengthy have you been running a blog for?
you make blogging look easy. The overall glance of your website is wonderful, as neatly as the content!
It is the biggest casino in the nation and accounts for about half of the total gambling income annually.
my blog – 카지노친구
Please let me know if you’re looking for a article
writer for your weblog. You have some really great articles and I think I would be a
good asset. If you ever want to take some of the load off, I’d love
to write some articles for your blog in exchange for a link back to mine.
Please blast me an e-mail if interested. Thanks!
I do believe all of the ideas you’ve offered
in your post. They are really convincing and can certainly work.
Still, the posts are very short for novices. May you please lengthen them a little from
subsequent time? Thanks for the post.
I don’t even know how I ended up here, but I thought this
post was good. I do not know who you are but
definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
Also visit my website highstakes
I’ve been exploring for a little for any high quality articles or weblog posts on this kind of house .
Exploring in Yahoo I eventually stumbled upon this website.
Reading this info So i’m happy to express that I have an incredibly good uncanny
feeling I found out just what I needed. I most definitely will make sure to don?t disregard this site and give it a look on a constant basis.
I couldn’t resist commenting. Very well written!
Neskatoties uz to, vairāk nekā 1200 spēļu klāstā pieejamas kā
jau iecienītas, tā pavisam svaigas spēles.
Bezmaksas spēļu automātu spēles ir pieejamas ļoti plašā klāstā.
Pie klasiskajiem spēļu automātiem var pieskaitīt tādas Bezmaksas spēļu automātu spēles
, kā Book of Ra, Columbus, Lord of the Ocean un daudzas citas spēles, kas
parasti ir sastopamas Fēnikss Laimētavu spēļu zālēs.
Pakalpojumu sniedzējs precīzi uzmin azartspēļu noskaņojumu un izveido video slotus, kas strauji gūst popularitāti.
Tīmeklī ir simtiem tiešsaistes totalizatoru un kazino pakalpojumu
sniedzēji. Piedāvājumam ir jābūt pietiekoši
vilinošam, lai spēlētāji tiem pieteiktos, bet tiem ir jābūt
arī tādiem, lai motivētu spēlētājus turpināt spēlēt un tiešsaistes
kazino spēles. Visdrīzāk šī būs ilgstoša tendence, un nākotnē jauni kazino piedāvās lielākus, pielāgotus, precīzus un kopumā labākus bonusus spēlētājiem.
Casino777 ir licencēts, tāpēc, ikviena tā darbība tiek regulēta un uzraudzīta, spēlētājiem nav jāuztraucās,
ka pēkšņi laimesti un bonusa piedāvājumi tiks
dzēsti vai kādā veidā ieturēti. Lai saņemtu šo piedāvājumu visbiežāk ir jāizveido pilnīgi jauns spēlētāja konts kādā no vietnēm, kur šis bonuss
ir pieejams. Reģistrējies izvēlētajā online kazino: Lai saņemtu bonusu, tev
sākumā nepieciešams reģistrēties online kazino vietnē.
Šīm azartspēlēm nav pieejama demonstrācijas versija, taču visas translācijas ir atvērtas un publiski pieejamas pēc reģistrēšanās Fenikss vietnē.Bezmaksas kazino spēles – Tu tikko esi atklājis Latvijas
lielāko online kazino spēļu automātu piedāvājumu, kuras ir iespējams spēlēt par brīvu un bez
reģistrēšanās. Bezmaksas kazino spēles, kuras nav nepieciešams lejupielādēt, ir lielisks veids, kā gūt online kazino pieredzi
un izbaudīt azartu. Tas jums aizņem pāris
minūtes un uzreiz sapratīsiet, vai ir vērts spēlēt jauno online kazino spēļu automātu.
Un Jums nav jāiegulda sava nauda depozītā online kazino kontā.
Tāpēc jums būs jāapstiprina jūsu konts arī ar kādu no
jūsu personu apliecinošiem dokumentiem. Un tas viss vēl ir neņemot vērā Jūsu bankroll priekš azartspēļu atpūtas.
Programmatūras funkcijas ietver: augsts atdeves procents; džekpota tituli, progresīvo
džekpota iespēja; popularizētu sižetu un populāru varoņu attēlu izmantošana; viena platforma pokeram, sporta derībām, video slotiem un citām azartspēļu izklaidēm.
Kā arī tā ir viena no visvienkāršākajām kazino spēlēm, jo tajā nav nepieciešamas
nekādas prasmes. Tajā pašā laikā Jūs neriskējat ar savu naudu.
Iespējams kazino nav atrodams plašākais spēļu klāsts, vai acīs lecošākais dizains, tomēr tajā ir
ļoti daudz funkciju, kas atvieglo spēlētāja ikdienu.
Turklāt internetā atrodami tādi kazino, kas piešķir speciālus bonusus tieši mobilo ierīču lietotājiem.Savukārt spēļu automāti internetā nav saistīti ar sarežģītām stratēģijām, atliek vienkārši nospiest pogu un ļauties veiksmei.
2015. gadā uzņēmums Microgaming saņēma Global Gaming Awards balvu par Gada digitālo
spēļu inovāciju par darbu pie virtuālās realitātes azartspēlēm,
izmantojot VR austiņas. Uzņēmums eksperimentē ar spēles lauka struktūru un saskarni.
Ar 3D spēļu automātiem online kazino spēļu ražotāji var likt lietā savu
iztēli un radīt pašas trakākās bezmaksas kazino spēles.
Lai garantētu spēles drošību, online kazino atļauj reģistrēties tikai spēlētājiem,
kas ir sasnieguši 18 gadu vecumu, un tiešsaistes kazino stingri
ievēro Latvijā spēkā esošos drošas interneta azartspēļu vides noteikumus.
Te palīgā nākam mēs, kas veido Latvijā un Eiropā
licencēto kazino apskatus. AKazino arī piedāvā lielāko spēļu ražotāju izvēli starp visiem
Latvijas bezmaksas kazino. Katru nedēļu AKazino papildina savu kazino spēļu klāstu ar pašām
jaunākajām un aktuālākajām Latvijas online kazino spēlēm.
Kazino spēļu ražotāju izdomai nav robežu un tieši tāpēc
katra bezmaksas online kazino spēle ir unikāla.
Kazino bonusi sniedz kādu labumu attiecīgā kazino spēlētājam.Katrai spēlei ir sava
tematika, grafiskie tēli, animācijas un skaņas, kas sniedz
iespēju izvēlēties sev tīkamāko. Zem klasisko spēļu automātu kategorijas ir Bezmaksas spēļu automātu
spēles , kas tika izlaistas pirms 2010. gada.
Jūs varat spēlēt online kazino spēļu automātu spēles visu
diennakti un bez nepieciešamības lejupielādēt spēles
vai izmantot jebkādu citu programmu. Quickspin kazino spēļu ir grūti sajaukt ar citu ražotāju nosaukumiem.
Pie mums var atrast un bezmaksas izmēģināt Novomatic, NetEnt, Play’n GO,
ELK Studios un daudzu citu kazino spēļu
demo versijas. Jaunos kazino: Dažādu lielāko valūtu pieņemšana
no visas pasaules ir viens no galvenajiem iemesliem, kāpēc spēlētāji dod
priekšroku jauniem kazino. Mūsu kazino spēles var spēlēt no jebkuras pasaules vietas
un no jebkādas ierīces (dators, mobīlais telefons vai planšete).
Tas nozīmē, ka saņemsiet piedāvājumu, bez jebkādas pirmās
iemaksas. Tas nozīmē, ka tie nedrīkst būt
izteikti neobjektīvi, pārmērīgi tendēti uz online kazino interesēm un, ka tiem ir spēlētājiem jānodrošina
taisnīgas izredzes gūt arī savu labumu. Tie ir piemēroti gan iesācējiem,
gan pieredzējušies spēlētājiem, turklāt daudzi spēļu
automāti piedāvā lielus bonusus, ar kuriem Jūs varat laimēt iespaidīgas balvas.
Turklāt katrām no tām ir vairāki varianti, tādēļ tas, ka šajā lielajā izvēlē Jūs atradīsiet sev vēlamo stimulu, ir garantēts.
Šīm spēlēm parasti nav vairāk par 10 izmaksu līnijām un tām ir ļoti vienkārša grafika, kā
arī Bonusa spēles ir gaužām primitīvas.
Stop by my homepage: Laimz lv login
Way cool! Some extremely valid points! I appreciate you penning this post and also the rest of the website is extremely good.
The gun itself weighs 680g and consists a metal physique, powered by a 16.8v brushless motor, and comes with a 2,500mAh battery that provides up to 80 minutes of usage
per charge.
Keep this going please, great job!
Their concentrate can be on distinctive physique components as nicely as healing processes.
Hello there! This is kind of off topic but I need some
guidance from an established blog. Is it hard to set up your
own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to begin. Do you have any ideas or suggestions?
Thanks
Aw, this was an extremely nice post. Taking the time and actual effort
to generate a superb article… but what can I say… I procrastinate
a whole lot and don’t seem to get anything done.
Hi there, I found your web site via Google while searching for
a comparable topic, your web site came up, it appears great.
I’ve bookmarked it in my google bookmarks.
Hi there, just became aware of your blog via Google, and found that it is truly informative.
I’m going to be careful for brussels. I’ll be grateful in the event you proceed this in future.
Lots of people will probably be benefited from your writing.
Cheers!
If you want to get full physique massage at residence , you want supported massage chair.
I am in fact happy to read this web site posts which carries
plenty of useful data, thanks for providing these statistics.
Certain conditions may prevent patients from undergoing any bodywork therapy, including massage.
Applying the kinesiology tape onto the skin
Hello my family member! I want to say that this article is amazing, great written and include almost all
significant infos. I’d like to look extra posts like this .
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did
you hire someone to do it for you? Plz respond as I’m looking to create my own blog and would
like to find out where u got this from. cheers
I simply could not go away your website prior to suggesting that I really enjoyed the usual
info a person provide on your visitors? Is going to be back
often in order to check up on new posts
hello!,I really like your writing very much! percentage we
keep up a correspondence more approximately your article
on AOL? I require a specialist in this space
to solve my problem. May be that’s you! Taking a look ahead to see you.
Owner Marlene Arreguin (Olguin), a licensed massage therapist, said her small business specializes in injury rehabilitation and chronic pain relief.
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses. But he’s tryiong none the
less. I’ve been using Movable-type on various websites for about a year and am concerned about switching to
another platform. I have heard great things about blogengine.net.
Is there a way I can transfer all my wordpress posts into
it? Any kind of help would be greatly appreciated!
Admiring the time and effort you put into your blog and in depth information you provide.
It’s great to come across a blog every once in a while that isn’t the same old rehashed information. Excellent read!
I’ve saved your site and I’m including your RSS feeds to my Google account.
Blackjack is regarded the king of casino games for a lott of reasons.
Review my web site read more
I was pretty pleased to discover this website.
I wanted to thank you for your time for this wonderful read!!
I definitely loved every little bit of it and i also have you saved to fav to look
at new things in your blog.
My spouse and I stumbled over here by a different web page and thought I may as well check things out.
I like what I see so i am just following you. Look forward
to exploring your web page yet again.
Hello just wanted to give you a brief heads up and let you know a few of the images aren’t
loading properly. I’m not sure why but I think its a linking
issue. I’ve tried it in two different browsers and both show the same outcome.
A practitioner may perhaps location these on the outdoors of
the physique to improve the therapeutic effects.
When the nervous technique calms, the body may perhaps enter
a parasympathetic state.
Although all of the spa’s remedies are equally stellar, it’s the Ultimate Pedicure you can’t
miss out on.
I go to see daily a few websites and blogs to read posts, except this web site
presents quality based content.
My partner and I stumbled over here different web address and thought
I may as well check things out. I like what I see so now i am following you.
Look forward to looking into your web page again.
I blog frequently and I truly appreciate your information. This great article has really peaked
my interest. I will book mark your site and keep
checking for new information about once a week.
I subscribed to your Feed too.
Hello mates, nice article and good urging commented at this place,
I am in fact enjoying by these.
You will want to make positive you purchase a massage gun that possesses a trustworthy
battery life.
This is very attention-grabbing, You’re an excessively
professional blogger. I’ve joined your rss
feed and stay up for in quest of more of your excellent post.
Additionally, I’ve shared your web site in my social networks
Here is my web page top 10 poker sites
It’s remarkable to visit this site and reading the views of
all colleagues on the topic of this article, while I am also keen of getting familiarity.
We’ve enjoyed the ergonomic, comfy design and
style of the Theragun Mini from Therabody as it conveniently
fits your hand in contrast to other models out there.
It’s amazing to pay a quick visit this website and reading
the views of all mates concerning this paragraph, while I am also
eager of getting knowledge.
I truly love your site.. Excellent colors & theme.
Did you make this web site yourself? Please reply back as I’m planning to create my own website and want to know where you got
this from or just what the theme is called. Many thanks!
Positional release of a focal trigger point can be the lynchpin to a complete and broadly valuable release.
I’ve been exploring for a little bit for any high-quality articles or weblog posts on this
sort of space . Exploring in Yahoo I finally stumbled upon this web site.
Reading this information So i’m glad to express that I have
a very just right uncanny feeling I discovered exactly what
I needed. I most surely will make certain to don?t overlook this site and provides it a glance on a continuing basis.
Hi there Dear, are you actually visiting this website on a regular
basis, if so then you will definitely obtain pleasant experience.
It also comes with a heat function that can be turned on or off
based on your preference.
Do you mind if I quote a couple of your posts as long as
I provide credit and sources back to your webpage?
My blog is in the very same area of interest as yours and my users would certainly benefit
from a lot of the information you provide here. Please let me know if this okay with you.
Thanks!
Good article. I am going through a few of these issues as well..
The Emory cancer fatigue study is a collaboration in between the Division of Psychiatry and Behavioral Sciences and the Winship Cancer Institute of Emory.
You can see how your fingers are no longer getting the blood provide,
physique fluids and power they will need.
Great beat ! I wish to apprentice even as you amend your website, how can i
subscribe for a blog website? The account helped me a appropriate deal.
I were tiny bit familiar of this your broadcast provided shiny clear idea
Share this article іn үour social network
Ηave a lookk at my web blog :: CML Alliance
bookmarked!!, I love your web site!
Hatyai Thai Massage has been operating for 25 years now – that’s how you know their
massages are solid.
“The release of the excess fluid can leave the physique
dehydrated,” says Dr. Ackerman.
Massage therapists use the table to position the clientele as they obtain a massage.
When it becomes deficient or blocked, symptoms such as
physique discomfort, headaches, and digestive issues
arise.
Hi there, everything is going well here and ofcourse every one is sharing information, that’s genuinely good, keep up
writing.
You get to play a classic game of American Roulette with bets among $.10 – $1,000.
Also visit my web blog akropolistravel.com
When it becomes deficient or blocked, symptoms such as body pain, headaches, and digestive issues
arise.
Positional release operates when the trigger point
is absolutely out of pain.
Oh my goodness! Amazing article dude! Thank you, However I am experiencing difficulties with your RSS.
I don’t know the reason why I cannot join it.
Is there anybody else having identical RSS problems? Anyone who knows the solution can you kindly respond?
Thanx!!
you’re in reality a just right webmaster. The web
site loading pace is incredible. It sort of feels that you’re doing any distinctive trick.
In addition, The contents are masterpiece. you’ve done a
magnificent job in this matter!
By reducing or eliminating myofascial causes
For each, consider this contraption, which is an invaluable tool for torturing soothing sore muscles all over your body.
ремонт квартир москве под
Unfortunately, hiring a individual masseuse is slightly out of our price tag range.
Hello, i think that i noticed you visited my blog so i got
here to return the desire?.I am attempting to find things to improve my web site!I suppose its adequate to use a few of your ideas!!
Here is my web page :: facebook hookup near me
A massage ball is brilliant for activating muscles before you function out and for easing tension when you have completed a session.
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your webpage?
My website is sex in my area the exact same niche as yours
and my visitors would genuinely benefit from some of the information you provide here.
Please let me know if this okay with you. Cheers!
Solution managers supervise the manufacturing or production of a particular solution.
Howdy! I could have sworn I’ve been to this web site
before but after looking at some of the posts I realized it’s new to me.
Nonetheless, I’m definitely delighted I discovered it and I’ll be bookmarking it and checking
back regularly!
Good day! I know this is somewhat off topic but I was wondering if you knew where I could locate a
captcha plugin for my comment form? I’m using the same blog platform as
yours and I’m having trouble finding one? Thanks a lot!
What’s up mates, how is everything, and what you would like
to say on the topic of this article, in my view its genuinely
amazing in support of me.
If you are uncomfortable, or if you are feeling stress on your sinus cavity or forehead from the cradle, just communicate with your therapist and
they will adjust you.
I enjoy, lead to I discovered just what I was taking a look for.
You’ve ended my 4 day long hunt! God Bless you man.
Have a nice day. Bye
Hey! I know this is sort of off-topic however I needed to ask.
Does operating a well-established website like yours require a lot of work?
I am completely new to writing a blog however I do write in my journal every day.
I’d like to start a blog so I can share my personal experience
and thoughts online. Please let me know if you have any
recommendations or tips for brand new aspiring blog
owners. Appreciate it!
Thanks for some other informative site. Where else may just I get that type of information written in such an ideal approach?
I’ve a project that I’m simply now operating on, and I’ve
been on the glance out for such information.
He maintains a continuing education small business, Sophisticated Massage Arts & Education, along with his private practice studio in Tempe, AZ.
Fortunately, SoSpa passes my very first-impression test with flying
colours — the spot virtually sparkles it is so clean.
Hi friends, good post and nice arguments commented at this place, I
am genuinely enjoying by these.
Every weekend i used to pay a visit this web
site, as i wish for enjoyment, since this this website
conations genuinely pleasant funny information too.
Inquiries for HELOC are offered only for residents of these
states.
I enjoy what you guys tend to be up too.
This kind of clever work and reporting! Keep up the superb
works guys I’ve included you guys to blogroll.
Normally speaking, hydromassage is not covered by medical
insurance.
Howdy! I’m at work surfing around your blog from my new iphone 4!
Just wanted to say I love reading your blog and look forward to all
your posts! Carry on the outstanding work!
Hi, i believe that i noticed you visited my website
thus i came to go back the favor?.I’m trying to find things to
improve my website!I guess its adequate to use a few of your ideas!!
When someone writes an post he/she retains the idea of a user in his/her mind that how a user can know it.
Thus that’s why this post is amazing. Thanks!
If you would like to bet on tennis, know that Rivalry doesn’t miss a single
tournament.
Does your website have a contact page? I’m having trouble locating it but, I’d like to
send you an e-mail. I’ve got some ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it develop over time.
We are a gaggle of volunteers and opening a brand new scheme in our community.
Your website provided us with helpful information to work on.
You have performed an impressive task and our whole
community shall be thankful to you.
It’s remarkable for me to have a web site, which is helpful in support
of my know-how. thanks admin
This is a very good tip especially to those fresh
to the blogosphere. Simple but very precise info… Thank you for sharing this one.
A must read post!
Very good site you have here but I was wondering
if you knew of any message boards that cover the same topics discussed in this article?
I’d really like to be a part of group where I can get feedback from other
experienced people that share the same interest. If
you have any recommendations, please let me know. Appreciate it!
Thanks for sharing your thoughts on 英会話 個人レッスン.
Regards
Fantastic goods from you, man. I’ve understand your stuff previous to
and you’re just too wonderful. I really like what you have acquired here, really like what you’re stating and the way in which you say it.
You make it entertaining and you still care for to
keep it wise. I can’t wait to read much more from you.
This is actually a great site.
Hi, i feel that i noticed you visited my web site thus i got here to return the desire?.I am
trying to find things to improve my web site!I guess its adequate to use some of
your ideas!!
My family members every time say that I am
wasting my time here at web, except I know I am getting familiarity every
day by reading such good content.
This paragraph will help the internet visitors for building up new web site or even a weblog from start to end.
Everything is very open with a precise explanation facebook of sex the
issues. It was definitely informative. Your site is very helpful.
Thank you for sharing!
Hey there, I think your blog might be having browser compatibility issues.
When I look at your website in Firefox, it looks fine but
when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, fantastic blog!
Thank you a bunch for sharing this with all folks you actually realize
what you’re talking about! Bookmarked. Please additionally discuss with my site =).
We can have a link change contract between us
With Govbernor Ned Lamont’s signature secured one particular day later, the federal Division of the Interior has a 45-day window to approve the updated
compacts.
my webpage … here
Good web site you have here.. It’s hard to find high quality writing like yours nowadays.
I honestly appreciate individuals like you! Take care!!
Hey, I think your blog might be having browser compatibility issues.
When I look at your blog in Safari, it looks fine but when opening in Internet Explorer, it
has some overlapping. I just wanted to give you a quick heads up!
Other then that, awesome blog!
Our Cash Advance Loans incur a 20% Establishment Fee and a four% month-to-month charge, primarily based on the
amount borrowed.
Hello there! This is my 1st comment here so I just wanted
to give a quick shout out and say I really enjoy reading your articles.
Can you suggest any other blogs/websites/forums that cover the same topics?
Thanks for your time!
The extended battery life and lightweight style
make it quick to use on the go.
Wow, amazing weblog layout! How lengthy have you ever been blogging for?
you made blogging look easy. The entire look of your website is excellent, as
smartly as the content!
What’s Going down i’m new to this, I stumbled upon this I’ve discovered It absolutely helpful and it has helped me out
loads. I’m hoping to contribute & assist different customers
like its aided me. Great job.
Interesting blog! Is your theme custom made or did you
download it from somewhere? A theme like yours with a few simple tweeks would really
make my blog stand out. Please let me know where you got your design. With thanks
Use an ice pack on any painful regions for 15 minutes at a time a handful of
occasions per day.
Customers have written how the massage pillow ‘can quickly get rid of some tension’ and is a ‘small price to spend for enormous relief.
Your verdict actually connected every little thing with each other.
I enjoy the idea you embed structuring your messages.
Also visit my web site – insurance agents
I love it when individuals get together and share views.
Great website, continue the good work!
With this method, quick, fast pulses press deep into the body’s soft tissues, stimulating blood flow and elongating muscle tissue.
Blackjack and higher RTP slots aree the true
cash casino games with the highest odds.
My page … Hotel Reservation
Hello my friend! I wish to say that this article is awesome,
great written and include approximately all vital infos.
I would like to look extra posts like this .
Great delivery. Sound arguments. Keep up the amazing work.
Hey I know this is off topic but I was wondering
if you knew of any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for a plug-in like
this for quite some time and was hoping maybe
you would have some experience with something like this. Please let me
know if you run into anything. I truly enjoy reading your blog and I look
forward to your new updates.
Hello there, I found your web site by way of Google at the same time as
searching for a related topic, your web site came up, it appears great.
I’ve bookmarked it in my google bookmarks.
Hello there, simply turned into alert to your weblog thru Google, and located that it’s really informative.
I’m going to be careful for brussels. I’ll be grateful if you proceed this
in future. Lots of people might be benefited out of your writing.
Cheers!
Wonderful items from you, man. I’ve take into account your stuff
prior to and you’re just extremely magnificent. I really like what you’ve received here, certainly like what you’re saying and
the way in which in which you assert it. You are making it entertaining and you still take care
of to stay it sensible. I can not wait to learn far more from you.
That is actually a wonderful web site.
Have a look at my web page – escort service hari nagar
Right now it looks like Expression Engine is the best blogging platform out there right now.
(from what I’ve read) Is that what you are using on your blog?
It’s very simple to find out any topic on net as compared to textbooks, as I found this piece of
writing at this site.
I could not resist commenting. Well written!
Hello, i feel that i saw you visited my website thus i came to go back the desire?.I’m attempting to find issues to enhance my web
site!I guess its adequate to use a few of your ideas!!
Hello! Would you mind if I share your blog with my myspace
group? There’s a lot of people that I think
would really appreciate your content. Please let me know.
Cheers
Whilst the vast majority of them are slot reels, that
is just the starting.
Feel free to visit my web page: Great site
Do you have a spam problem on this website;
I also am a blogger, and I was wanting to know your
situation; we have developed some nice procedures and we are looking to exchange methods
with other folks, be sure to shoot me an email if interested.
I know this web page gives quality based posts and additional data, is there any other web
page which gives these things in quality?
They acquire sensible training in Colorado as aspect of their certificate plan.
Right away I am going to do my breakfast, afterward having my breakfast coming over again to read other news.
No cost restrictions of thick connective tissues, thereby rising mobility of the patient.
About 54 % reported supple skin, while 50 percent knowledgeable skin tightening.
My job for the subsequent two years was to coordinate myofascial therapy and
structural integration protocols with chiropractic and mobilization remedies.
“There are so quite a few fantastic causes to see a massage therapist,”
Bodner says.
Everything can be packed up and stored neatly away in the case, which also characteristics a soft leather charging mat.
Greetings from Colorado! I’m bored at work so I decided to browse your site on my iphone during lunch
break. I enjoy the information you present here and can’t wait
to take a look when I get home. I’m shocked at
how fast your blog loaded on my phone .. I’m not even using WIFI, just 3G ..
Anyways, good blog!
I am really loving the theme/design of your website.
Do you ever run into any browser compatibility problems?
A small number of my blog audience have complained about my blog not working correctly
in Explorer but looks great in Safari. Do you have any advice to
help fix this problem?
Hi there! I know this is kind of off topic but I was wondering which blog platform
are you using for this site? I’m getting tired of WordPress because I’ve had problems with
hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
Do you mind if I quote a few of your articles as long as
I provide credit and sources back to your blog?
My website is in the exact same niche as yours and my visitors
would really benefit from a lot of the information you provide here.
Please let me know if this alright with you. Thanks a lot!
naturally like your website however you need to test the spelling on several of your
posts. A number of them are rife with spelling problems and I in finding it very
bothersome to tell the reality then again I will surely come
back again.
Howdy just wanted to give you a quick heads up. The text in your content seem to be
running off the screen in Ie. I’m not sure if this is a
format issue or something to do with browser compatibility
but I thought I’d post to let you know. The style and
design look great though! Hope you get the issue solved soon. Many thanks
I’m happy to read these great articles. Click Follow the equally good things. UFABET includes live casino games Convenient deposits and withdrawals through the automatic system Easy entrance, used on mobile phones.
Howdy! This post could not be written any better! Reading through this post reminds me
of my old room mate! He always kept talking about this.
I will forward this write-up to him. Fairly certain he will have a good read.
Thank you for sharing!
Awesome site you have here but I was wondering if you knew of any forums that cover the same topics talked about in this
article? I’d really love to be a part of online community where I can get opinions from other experienced people that share the same interest.
If you have any recommendations, please let me know.
Appreciate it!
My blog: Dasnapur escort
You really make it seem really easy with your presentation but I in finding this matter to be actually something which I believe I might by no means understand.
It kind of feels too complex and very wide for me. I’m having
a look ahead to your subsequent put up, I will try to get
the cling of it!
always i used to read smaller articles or reviews which also clear their motive, and that is also happening with this paragraph which I am reading at this place.
Darcy’s practice presents four categories of massage—sports, restorative, health-related, and Manual Lymphatic
Drainage Therapy.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back in the future.
Many thanks
Quality posts is the important to interest the viewers to go to see
the site, that’s what this website is providing.
What’s Happening i’m new to this, I stumbled upon this I’ve discovered It
absolutely helpful and it has helped me out loads.
I am hoping to give a contribution & assist different users like its helped me.
Great job.
Hey there would you mind sharing which blog platform you’re working with?
I’m planning to start my own blog in the near future but I’m having a tough time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs
and I’m looking for something unique. P.S Apologies for being off-topic but I had to
ask!
Hi, Neat post. There is a problem along with your web site in internet explorer,
may test this? IE still is the marketplace leader and a large component to other folks will omit your fantastic writing due to this problem.
I was suggested this web site by my cousin. I am not sure whether this post is written by him
as nobody else know such detailed about my problem.
You are amazing! Thanks!
Lastly, a nourishing tamarind and rosemary leaf moisturizer
was applied, along with a serum, to enable brighten, nourish, and hydrate
skin.
I love it when folks get together and share opinions. Great blog, stick
with it!
Thanks on your marvelous posting! I genuinely enjoyed reading it, you may be a great author.
I will remember to bookmark your blog and will eventually come back
at some point. I want to encourage one to continue your great work, have a nice holiday weekend!
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
I believe everything published made a ton of sense.
But, think on this, suppose you were to create a killer headline?
I ain’t saying your information is not solid, however suppose you added a title
that makes people desire more? I mean Пиастры – Составление семантического ядра | is a little
plain. You could peek at Yahoo’s home page and see how they create news
headlines to get viewers to click. You might try adding a video or a related
pic or two to grab readers excited about what you’ve written. Just my opinion, it would bring your website a little
livelier.
Link exchange is nothing else but it is just placing the other person’s website link
on your page at proper place and other person will also do similar for you.
It’s appropriate time to make some plans for the longer term and it is time to be happy.
I’ve learn this submit and if I could I desire to counsel you some
attention-grabbing issues or tips. Perhaps you could write next articles regarding this article.
I wish to read even more issues approximately it!
You’ve made some good points there. I checked on the
web to find out more about the issue and found most people will go along with your views on this web site.
each time i used to read smaller posts that as well clear their motive,
and that is also happening with this article which I am reading at this time.
Massage guns are regarded percussive therapy, a type of soft tissue massage that utilizes vibrations to relieve muscle tension.
porn videos
What’s up to every , as I am truly keen of reading this weblog’s post to be updated regularly.
It contains fastidious data.
of course like your web site but you have
to take a look at the spelling on several of your posts.
Many of them are rife with spelling problems and I to find it very bothersome to tell the reality nevertheless I’ll
surely come back again.
I am really impressed along with your writing talents as smartly as with the format for your weblog.
Is this a paid topic or did you customize it yourself?
Either way stay up the excellent quality writing, it is rare to see a great weblog like this one today..
Hello! I just wish to offer you a big thumbs up for the great info you have here on this post.
I will be returning to your blog for more soon.
my webpage; craiglistforsex
Attractive section of content. I just stumbled upon your blog and in accession capital to assert
that I acquire actually enjoyed account your blog posts.
Anyway I will be subscribing to your feeds and even I achievement you access consistently rapidly.
Forr a detailed report, you can check this Powerball Jackpot Analysis web
page.
Here is my webpage … 베픽
Hello, all the time i used to check web site posts here early in the daylight, for the
reason that i like to find out more and more.
We absolutely love your blog and find most of your
post’s to be exactly what I’m looking for. Would you offer guest writers
to write content for yourself? I wouldn’t mind
writing a post or elaborating on a few of the subjects you write in relation to
here. Again, awesome blog!
I’ll right away snatch your rss feed as I can’t in finding your email subscription hyperlink or newsletter service.
Do you’ve any? Please permit local hookups near me (Myit4Business.com) know in order that I could subscribe.
Thanks.
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you are going to a famous blogger if you are not already 😉 Cheers!
By applying stress to the muscle tissues and tissues, massage stimulates the blood
vessels, enabling for improved oxygen and nutrient delivery to the cells.
Free porn videos
Hi, I do think this is a great site. I stumbledupon it 😉 I am going to return once again since i
have bookmarked it. Money and freedom is the greatest way
to change, may you be rich and continue to help
other people.
Greate article. Keep writing such kind of
information on your page. Im really impressed by
your site.[X-N-E-W-L-I-N-S-P-I-N-X]Hello there,
You’ve done an incredible job. I will definitely digg it and personally suggest to my friends.
I’m confident they’ll be benefited from this web site.
Also visit my web-site: find sex near me
certainly like your web-site however you need to take a look at
the spelling on several of your posts. Several of them are
rife with spelling issues and I in finding it very bothersome to inform the reality on the other hand I
will certainly come back again.
Oversee youth workforce improvement solutions, applications and partnership development.
Although Inlow says she was excited to work with her husband,
the transition was nerve-wracking.
My partner and I absolutely love your blog and find nearly all of
your post’s to be what precisely I’m looking for. Does one offer guest writers to write content for yourself?
I wouldn’t mind producing a post or elaborating on a number of the subjects
you write in relation to here. Again, awesome web site!
PayPal offers sports bettors a safe and convenient way to make a deposit
into a sports betting account.
Massage is defined as the rubbing of skin and muscle tissues in the physique to give an individual a sense of effectively-getting.
These are actually great ideas in concerning blogging.
You have touched some pleasant things here. Any way keep up
wrinting.
The Mebak three promises two to three hours of battery
life, and in our tests it lived up to that billing.
This is my first time go to see at here and i am genuinely impressed to read all at alone place.
I am sure this post has touched all the internet users,
its really really pleasant paragraph on building up new web site.
Hi there just wanted to give you a quick heads up.
The words in your article seem to be running off the screen in Internet explorer.
I’m not sure if this is a format issue or something to do
with browser compatibility but I figured I’d post to let
you know. The design and style look great though! Hope you
get the problem resolved soon. Cheers
Initially, Chinese tourists to Korea grew 46.eight% to 6.9 million in 2016.
I’m amazed, I must say. Rarely do I encounter a blog that’s both equally educative
and amusing, and without a doubt, you’ve hit the nail on the head.
The issue is something that not enough folks are speaking intelligently about.
Now i’m very happy I found this in my hunt for something concerning this.
Land-based and on the internet sports betting are permitted for 18 and above
under the Spanish Gambling Act 2011.
Hi, i read your blog occasionally and i own a similar one and i was just wondering if you get a lot
of spam feedback? If so how do you stop it, any plugin or anything you can advise?
I get so much lately it’s driving me insane so any assistance
is very much appreciated.
Do you have a spam problem on this blog; I also am a blogger, and I was wondering your
situation; we have developed some nice practices and we are looking to trade techniques
with others, please shoot me an e-mail if interested.
It’s remarkable in favor of me to have a web page, which is helpful for my experience.
thanks admin
I am no longer sure where you are getting your information, however great topic.
I needs to spend a while finding out more or figuring out more.
Thanks for magnificent information I was looking
for this information for my mission.
You can enhance your chances of approval if you use that cash towards a substantial down payment.
The legal gambling age for most forms of gambling—including casino gambling—is 21.
Thank you for the good writeup. It sex in my area fact was a amusement account
it. Look advanced to far added agreeable from you! By the way, how could we communicate?
I got this web site from my friend who shared with
me regarding this website and at the moment this time I am visiting this site
and reading very informative articles here.
His sharp intuition doesn’t fail him — it is a trap, and
policemen swarm in to arrest him for the murder of Min Seok-joon.
Having said that, they ought to initially submit a
request to Google to confirm eligibility.
This is the biggest Mega Millions jackpot in history, eclipsing the earlier record of $1.537
billion set in 2018.
We’ve got a lot of resources right here at insidebitcoins to
support you out.
From constructing an emergency fund to paying down debt, let us guide you to monetary
wellness.
Then I felt what would torture me for the subsequent 60 minutes of my life — the rough bit of skin he had on his palm
of his ideal hand.
I don’t ordinarily comment but I gotta state regards for
the post on this special one :D.
Look into my blog – Poker Gaming Software
These include things like the New York Stock Exchange, the S&P 500 Index,
and the S&P one hundred Index.
Greetings from Florida! I’m bored to death at work so
I decided to browse your site on my iphone during
lunch break. I love the information you present here and can’t
wait to take a look when I get home. I’m shocked at how fast your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, amazing site!
Also visit my web-site Malerkotla escorts
Loans with monthly payment are commonly deposited inside a single organization day.
What’s up to every one, since I am genuinely eager
of reading this website’s post to be updated on a
regular basis. It consists of good material.
Feel free to visit my page; Byasanagar escort agency
I absolutely love your blog.. Great colors & theme. Did you develop this website
yourself? Please reply back as I’m looking to create my very own blog and
want to learn where you got this from or just what the theme is called.
Appreciate it!
WOW just what I was searching for. Came here by searching for 바이낸스 KYC
What’s up, I log on to your blog like every week. Your writing style is
witty, keep doing what you’re doing!
Do you have a spam problem on this website; I also am a blogger, and I was wondering your situation; we
have created some nice procedures and we are looking to trade strategies with others,
why not shoot me an email if interested.
That said, revenues in the USA will most likely dwarf these figures quickly, following the relaxation of
anti-gambling laws in 2018.
Everything is very open with a really clear clarification of the challenges.
It was really informative. Your website is very helpful.
Thanks for sharing!
Feel free to surf to my web site … facebook sex
Its like you read my mind! You appear to know a lot about
this, like you wrote the book in it or something. I think that you could do with some
pics to drive the message home a bit, but instead of that,
this is great blog. An excellent read. I will definitely
be back.
And though her manner was unnerving, Dette’s system couldn’t have been a lot more relaxing.
If you opted into Energy Play when obtaining your ticket, your prize could grow to as significantly as $40.
Saved as a favorite, I like your website!
A $100 bet at 9/two would as a result net you $450,
so it would be rendered as +450 in American format.
Closing the wage gap is necessary to prevent additional erosion of women’s and their families’
economic safety.
Aw, this was an exceptionally nice post. Taking a few minutes and actual effort
to generate a great article… but what can I say… I hesitate a whole lot
and never manage to get anything done.
Hi there, I discovered your blog by means of Google at the same
time as looking for a similar subject, your website came up, it seems to be good.
I have bookmarked it in my google bookmarks.
Hi there, just turned into alert to your weblog via Google,
and located that it is truly informative. I’m going to watch out for brussels.
I will be grateful if you proceed this in future. Many other people will probably be benefited from your writing.
Cheers!
I’m not that much of a online reader to be honest but your sites
really nice, keep it up! I’ll go ahead and bookmark your site
to come back in the future. Cheers
I’m really impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you modify it yourself? Either way keep up the nice quality
writing, it is rare to see a great blog like this one
today.
After I originally commented I appear to have clicked the -Notify me when new comments are added- checkbox and now each time a
comment is added I receive four emails with the same comment.
There has to be a means you are able to remove me from that service?
Cheers!
MyBookie is North America Trusted Sportsbook & Bookmaker,
Providing top sporting action in the USA & abroad.
Have you ever thought about creating an ebook or guest
authoring on other sites? I have a blog based upon on the same information you discuss and would
really like to have you share some stories/information. I know my subscribers would enjoy your work.
If you’re even remotely interested, feel free to shoot me an email.
Hey this is kind of of off topic but I was wondering if blogs use WYSIWYG editors
or if you have to manually code with HTML. I’m starting a blog soon but have no coding skills so
I wanted to get advice from someone with experience. Any help
would be enormously appreciated!
I have read so many articles about the blogger lovers but this article is truly
a fastidious article, keep it up.
The loans calculator will give you an instance of what it may expense you based on the loan amount and term you want.
What i do not understood is in truth how you’re not really much more neatly-appreciated
than you might be now. You’re very intelligent. You realize therefore considerably in the case of this subject, produced me for my part imagine it from so many numerous angles.
Its like men and women aren’t fascinated unless it’s one thing to do with
Girl gaga! Your individual stuffs nice. Always take care of it up!
I used to be suggested this web site by way of my
cousin. I am no longer sure whether this put up is written by him as
nobody else recognize such specific approximately my trouble.
You are amazing! Thank you!
Attractive component to content. I simply stumbled upon your
website and in accession capital to say that I get in fact enjoyed account
your blog posts. Anyway I will be subscribing on your feeds and even I
achievement you access consistently quickly.
It’s really a cool and useful piece of information. I am glad that you shared this helpful information with us.
Please stay us informed like this. Thanks for sharing.
If you are going for finest contents like myself, only visit this web
site every day for the reason that it gives quality contents, thanks
Admiring the persistence you put into your website
and detailed information you provide. It’s nice to come across
a blog every once in a while that isn’t the same unwanted rehashed material.
Fantastic read! I’ve saved your site and I’m including your RSS
feeds to my Google account.
BetVictor is an independent bookmaker with a loyal base of consumers.
Hi there! I know this is kinda off topic nevertheless
I’d figured I’d ask. Would you be interested in trading links or maybe guest authoring a blog article or vice-versa?
My website goes over a lot of the same subjects as yours and I
think we could greatly benefit from each other. If you’re interested feel
free to send me an e-mail. I look forward to hearing from you!
Superb blog by the way!
What’s up, constantly i used to check webpage posts here in the early hours in the morning,
since i like to find out more and more.
Excellent write-up. I certainly love this website.
Thanks!
I know this website offers quality depending posts and extra stuff, is
there any other web site which provides such stuff in quality?
Thanks for sharing such a fastidious thought, post is nice, thats why i have read it fully
Hey I know this is off topic but I was wondering if
you knew of any widgets I could add to my blog that automatically
tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Even if you don’t get upfront tax breaks from your state for contributing to a 529 plan, you will
still get federal tax benefits down the road as long as
you withdraw from them properly. If you are a resident of one of
these states, there are still plenty of 529 plan options but no
tax breaks for utilizing them. If you live in one of
these states, your best option is to choose a state plan that has low fees and offers the type of investment options you want.
This gives residents of these states the freedom to pick and choose
among state plans-seeking out those with the lowest fees and the best investment options-while still getting a
state tax deduction. Indiana Treasurer of State.
In most cases, you do not need to be a resident of a state to invest in its plan.
As for the rest of the states with tax savings, you can only
deduct amounts contributed to a state plan where deductions
are available.
Hello fantastic blog! Does running a blog such as
this take a massive amount work? I have absolutely no understanding of computer programming however I had been hoping to start my own blog soon. Anyway, should you have any suggestions
or techniques for new blog owners please share.
I know this is off topic nevertheless I just wanted to ask.
Thanks!
Please let me know if you’re looking for a writer for your blog.
You have some really good posts and I believe I would be a
good asset. If you ever want to take some of the load off, I’d
really like to write some material for your blog in exchange
for a link back to mine. Please shoot me an email if interested.
Many thanks!
I all the time used to read article in news papers but
now as I am a user of internet thus from now I am using net for articles, thanks to web.
Pretty nice post. I just stumbled upon your weblog and wanted to say that I’ve really enjoyed browsing your blog
posts. After all I’ll be subscribing to your rss feed and I hope you write
again very soon!
Pretty great post. I just stumbled upon your weblog
and wanted to mention that I have really loved surfing around your
weblog posts. After all I’ll be subscribing for your feed
and I hope you write once more very soon!
Virtual events and job fairs could also be reserved for students of certain majors.
My brother recommended I may like this web site. He used to be
entirely right. This put up truly made my day.
You cann’t believe simply how so much time I had spent for this info!
Thank you!
You really make it seem so easy with your presentation but I find this matter to be actually something which I think I
would never understand. It seems too complicated and extremely broad
for me. I am looking forward for your next post, I’ll try
to get the hang of it!
I’m gone to say to my little brother, that he should also pay a quick visit this blog on regular
basis to obtain updated from hottest gossip.
It creates a sense of mental stress as you’ll be normally worried about
how to clear out your debts.
A longer repayment term reduces your month-to-month bill,
but you’ll devote more on interest in the long run.
Hi my friend! I want to say that this post is awesome, nice written and include almost all significant infos.
I’d like to peer extra posts like this .
What’s up to every one, the contents existing at this web
page are truly awesome for people experience, well, keep up the good
work fellows.
Hi! I just wish to give you a big thumbs up for
your excellent information you have got here on this post.
I am coming back to your site for more soon.
This is very interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your fantastic post.
Also, I have shared your site in my social networks!
Remote jobs are everywhere, but you will need to know exactly where to appear to
come across them.
Each bet has unique odds which can differ, for French roulette amongst two.7
and 48.six.
My brother recommended I may like this blog.
He was once totally right. This publish truly made my
day. You cann’t imagine simply how a lot time I had spent for this info!
Thank you!
Fitch stated then that “dangers have risen that the debt limit will not be raised or suspended … and consequently that the government could start to miss payments on some of its obligations.”
Great blog! Do you have any tips and hints for
aspiring writers? I’m planning to start my own blog soon but
I’m a little lost on everything. Would you suggest
starting with a free platform like WordPress or go for a paid option? There
are so many choices out there that I’m completely confused ..
Any tips? Appreciate it!
Hi there it’s me, I am also visiting this site regularly,
this website is really good and the visitors are actually sharing fastidious thoughts.
It’s awesome to pay a quick visit this website and reading the views of all colleagues on the topic of this post, while I am also eager of
getting knowledge.
Also visit my homepage … local hookups near me
This is the perfect website for anybody who hopes to find out about this topic.
You know so much its almost tough to argue with you (not that I
personally will need to…HaHa). You definitely put a fresh
spin on a topic that’s been written about for a long time.
Excellent stuff, just excellent!
Article writing is also a excitement, if you be familiar with after that you can write
or else it is difficult to write.
An intriguing discussion is worth comment. There’s no doubt that
that you need to write more on this topic, it may not
be a taboo subject but usually people don’t discuss these subjects.
To the next! All the best!!
Everything is very open with a precise description of the challenges.
It was definitely informative. Your website is extremely helpful.
Many thanks for sharing!
Just fill out the company’s on the web form with info about your income and place.
For instance, you can combine the moneyline wager of
the Giants, Jets and Yankees, and get a higher payout
than if you put 3 single wagers on all 3 teams to win the moneyline.
If you are going for best contents like myself, simply visit this web site
every day since it offers feature contents, thanks
Free Porn Videos
Yes! Finally someone writes about https://www.youtube.com/@7ballbetfun/about.
Great info. Lucky me I discovered your website by
chance (stumbleupon). I have saved as a favorite for later!
Hello to every , for the reason that I am truly
eager of reading this weblog’s post to be updated on a regular basis.
It includes fastidious data.
So, you are searching for a way to accumulate
funds when deferring tax payments.
Hi my family member! I want to say that this post is amazing, nice written and include approximately all significant infos.
I’d like to see more posts like this .
“I haven’t timed it, but the on the web version is a matter of just a few seconds.
I needed to thank you for this very good read!!
I certainly enjoyed every bit of it. I’ve got you book-marked to look at new things you post…
It’s awesome to go to see this web site and reading the views of all friends about this piece of writing, while I am also zealous of getting experience.
Greetings, I do think your web site could be having
web browser compatibility issues. When I take a look at your website in Safari,
it looks fine but when opening in I.E., it has some overlapping issues.
I just wanted to provide you with a quick heads up! Besides
that, excellent blog!
Upon going to the web page and navigating to the Promotions tab,
you will uncover bonus codes for more than 20 diverse promotions.
Pretty nice post. I just stumbled upon your blog and wished to say that I’ve
really enjoyed surfing around your blog posts.
In any case I will be subscribing to your feed and I hope you write again very soon!
Preferred Casino Superstitions – As some already know,
several casino
I was suggested this blog by my cousin. I’m not sure whether this post is written by him as no
one else know such detailed about my difficulty. You’re incredible!
Thanks!
Today, while I was at work, my cousin stole my iPad and tested to see if it can survive a twenty five foot drop,
just so she can be a youtube sensation. My iPad is
now destroyed and she has 83 views. I know this is completely off topic but I had to share it with someone!
Hi there, every time i used to check weblog posts here
in the early hours in the break of day, because
i like to gain knowledge of more and more.
Quality posts is the crucial to attract the visitors to pay a visit
the web page, that’s what this site is providing.
Get matched and schedule your initial video, phone or
reside chat session in as tiny as 48 hours.
Hi! I know this is somewhat off topic but I was wondering if you knew where I could find a captcha plugin for my
comment form? I’m using the same blog platform as yours and I’m
having problems finding one? Thanks a lot!
The total proceeds received by the customer from all of
the deferred deposit transactions shall not exceed $500.
By 2022, the organization fielded 2,621 calls, much more than double
than in 2019.
Offshore sports betting internet sites like the ones endorsed on this web page for Wisconsin accept members
and enable wagers to be placed at 18 years of age.
Just desire to say your article is as surprising. The clearness to
your publish is simply great and that i could think you are a
professional in this subject. Fine with your permission allow me to seize
your feed to keep updated with forthcoming post. Thank
you a million and please carry on the rewarding work.
Appear no further for a no annual fee credit card with good prices.
It’s amazing to go to see this web site and reading
the views of all friends on the topic of this piece of writing, while I am also keen of getting experience.
We are a group of volunteers and starting a new scheme in our
community. Your website offered us with valuable information to work on. You have done an impressive job and our whole community will be
thankful to you.
Baccarat is a game that is played substantially various live than on the internet.
I like this website because so much utile material on here :
D.
My web page local hookup near me
But this only applies to offline bets with betting limits ranging from KRW one hundred,000
and betting markets are restricted for South Koreans.
Hello, after reading this amazing article i am also delighted to share
my familiarity here with mates.
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for
you? Plz answer back as I’m looking to construct
my own blog and would like to find out where u got this
from. appreciate it
Only a handful of states do not present any lottery games, and the vast majority
of states that do have them set the minimum age at 18.
If some one needs expert view about running a blog after that
i propose him/her to pay a quick visit this website, Keep up
the good job.
my page … เว็บตรง สล็อต
Yes! Finally someone writes about https://www.youtube.com/channel/UCROsNyz4UJ0YCo3n2RI7VeQ/about.
Golden Nugget has the most reside dealer options and the
widest choice of slots.
Plus, unique betting apps have different strengths and weaknesses.
Thanks very nice blog!
I got this web site from my friend who told me regarding this website and at the moment this time I am browsing this web site and reading very informative articles here.
Hey this is kinda of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so I
wanted to get guidance from someone with experience.
Any help would be greatly appreciated!
What i do not realize is actually how you are now
not really much more neatly-favored than you may be now.
You are very intelligent. You understand therefore significantly
in the case of this topic, produced me in my view imagine it from numerous
varied angles. Its like women and men are not interested except it is something to
accomplish with Woman gaga! Your individual stuffs excellent.
Always deal with it up!
A parlay bet combines two or much more wagers into a
single bet, and the bet is dependent on all of the individual wagers
winning.
Comparatively, sportsbook vets and poker players should give Bovada or Ignition, respectively, a fair
shot.
It’s not my first time to pay a quick visit this web page, i am visiting
this web page dailly and get good facts from here daily.
Sportsbooks typically have exclusive presents for mobile
customers to encourage much more betting from mobile devices.
It’s a pity you don’t have a donate button! I’d without a doubt donate to this outstanding blog!
I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to fresh updates and will share this website with my Facebook group.
Chat soon!
Visit my webpage: local hookups near me
Currently it appears like Drupal is the top blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
Aw, this was an extremely good post. Spending some time and actual effort to produce a great
article… but what can I say… I hesitate a whole lot and don’t seem
to get anything done.
Thanks for finally talking about > Пиастры –
Составление семантического ядра | < Loved it!
Thanks for one’s marvelous posting! I genuinely enjoyed reading
it, you could be a great author.I will remember to bookmark your blog and may come back someday.
I want to encourage continue your great job, have a nice day!
Licensed and legal sports betting in Kansas are regulated by
the Kansas Lottery.
That is very interesting, You’re a very skilled blogger.
I’ve joined your rss feed and look forward to searching for more of your wonderful post.
Additionally, I have shared your website in my social networks
Also visit my web-site facebookofsex
Every weekend i used to pay a visit this web site, because i wish for enjoyment,
as this this website conations genuinely fastidious funny material too.
I used to be suggested this blog by means of my cousin. I’m now not certain whether this put up is written by
way of him as nobody else recognize such exact about
my difficulty. You are wonderful! Thank you!
I think the admin of this site is really working hard in favor of his web page,
since here every stuff is quality based material.
A fascinating discussion is definitely worth comment.
I think that you need to write more about this subject, it might
not be a taboo subject but generally people do not
discuss these topics. To the next! All the best!!
When you initially start off out, limit your sessions to ten minutes and gradually boost the time from there.
When someone writes an piece of writing he/she keeps the image of a user in his/her mind that
how a user can know it. Thus that’s why this article is perfect.
Thanks!
I read this piece of writing completely about the difference of
most up-to-date and earlier technologies, it’s awesome article.
A private installment loan can be a potent tool for handling finances,
but they come with each positive aspects and disadvantages.
I read this piece of writing fully on the topic of the difference of most recent and earlier
technologies, it’s amazing article.
Punters currently living in the UK have an extraordinary range of on the internet bookmakers.
Everything is very open with a precise explanation of the issues.
It was truly informative. Your website is very helpful.
Many thanks for sharing!
Fine way of describing, and pleasant article to get information on the
topic of my presentation topic, which i am going to present in academy.
I don’t know if it’s just me or if everybody else encountering problems with
your blog. It appears like some of the written text in your
posts are running off the screen. Can somebody else
please comment and let me know if this is happening to them as well?
This might be a problem with my web browser because I’ve had this happen before.
Appreciate it
For newest news you have to pay a quick visit the web and on the web I found this website as
a finest website for newest updates.
It’s really a cool and useful piece of info. I’m satisfied
that you simply shared this helpful info with us. Please stay us informed like this.
Thank you for sharing.
Your style is so unique compared to other people I’ve read stuff from.
Thank you for posting when you’ve got the opportunity,
Guess I will just book mark this web site.
It is holding the identical advantages and disadvantages as
that provider.
Hi there mates, how is everything, and what you want to say on the
topic of this paragraph, in my view its truly remarkable in favor of me.
Hello it’s me, I am also visiting this web page on a regular
basis, this web site is genuinely nice and the viewers are
actually sharing pleasant thoughts.
FanDuel has added a number of reside dealer blackjack titles in 2023, and far more are reportedly on the way.
Yes! Finally someone writes about https://www.youtube.com/@casinomcwvietnamcom/about.
What you published was actually very logical. But, think about this,
what if you added a little content? I am not saying your information isn’t solid.,
but suppose you added something to maybe get a person’s attention? I mean Пиастры – Составление семантического ядра | is a little
boring. You should peek at Yahoo’s home page
and watch how they create post titles to get
people to open the links. You might add a related video or a
picture or two to get readers interested about everything’ve
written. In my opinion, it could bring your posts a little livelier.
Hi there, always i used to check webpage posts here early in the break of day,
as i enjoy to find out more and more.
Hit, stand, split, double down…all the usual selections are available in common blackjack.
If you want to play this common casino game, we suggest Red Dog as the greatest baccarat casino.
The give at PartyCasino provides you one hundred free of
charge spins plus a 100% deposit deal worth up to
$500.
I know this if off topic but I’m looking into starting my own weblog and was curious what all is required to get set up?
I’m assuming having a blog like yours would cost a
pretty penny? I’m not very internet smart so I’m not 100% certain. Any suggestions or advice would be
greatly appreciated. Kudos
It’s an remarkable piece of writing for all the web viewers; they will take
advantage from it I am sure.
Players place bets on the table, predicting exactly where the ball will land after the wheel stops
spinning.
Wow, superb blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is great, let alone the content!
Pretty! This has been a really wonderful
post. Thanks for providing this information.
You can also conveniently switch in between casino
play and other tabs in your browser.
I always emailed this website post page to all my friends, as if like to read it then my contacts will
too.
These games can also be accessed in just a matter of minutes thanks to mobile compatibility
and connectivity.
It’s an amazing paragraph for all the online people; they will take benefit from it
I am sure.
I know this if off topic but I’m looking into starting my own weblog
and was wondering what all is required to get set up? I’m
assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% positive. Any tips or advice would
be greatly appreciated. Thanks
After going over a few of the articles on your blog, I really appreciate your way of blogging.
I bookmarked it to my bookmark webpage list and will be checking
back in the near future. Please visit my web site as well and let me know what you think.
Great post. I’m facing many of these issues as well..
Whats up are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create
my own. Do you require any html coding knowledge to make your own blog?
Any help would be really appreciated!
This information is invaluable. How can I find out more?
Hello, Neat post. There’s a problem together with your website in web explorer, may test this?
IE nonetheless is the marketplace chief and a huge section of other people will leave out your great writing because of this problem.
Moreover, the interest price that will be applied ought to be
reported as a percentage on the blank space provided.
And given that Oportun doesn’t charge early payment penalty charges, you can pay off your balance quicker if
you want.
Simply wish to say your article is as amazing.
The clearness in your publish is just spectacular and
i could think you are a professional on this subject.
Well together with your permission allow me to snatch your
feed to stay updated with forthcoming post. Thank you one million and please carry on the rewarding work.
Android users are not left behind in the engaging globe of
casino games apps.
Paragraph writing is also a excitement, if you be familiar with after that
you can write if not it is complex to write.
Everything is very open with a really clear description of the issues.
It was truly informative. Your website is extremely helpful.
Many thanks for sharing!
When someone writes an post he/she maintains the idea of a user in his/her brain that how a user can be aware of it.
Thus that’s why this article is outstdanding. Thanks!
It’s an awesome piece of writing in support of all the web people; they will take benefit from it
I am sure.
You when the grand prize if you hit all 5 numbers and the Powerball.
Payday loans are banned in 12 states, and 18 states
cap interest at 36% on a $300 loan.
Heya і’m for thе first time herе. I found this board аnd I
find It trᥙly սseful & іt helped mе օut a lot.
I hope to give something back and aid οthers ⅼike you helped me.
ᒪook at my site :: bedroom sets ideas
Wonderful article! This is the type of information that are supposed to be shared around the net.
Disgrace on the seek engines for not positioning this submit
upper! Come on over and seek advice from my web site .
Thanks =)
I think the admin of this web site is really working hard in favor of his web site, because here every material is
quality based stuff.
Yes! Finally someone writes about world map.
This is the perfect webpage for anyone who wishes to understand this topic.
You realize so much its almost tough to argue with you (not that I really would want to?HaHa).
You definitely put a fresh spin on a topic which
has been written about for years. Great stuff, just excellent!
my blog post – best online poker nwt
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your webpage?
My blog is in the exact same area of interest as yours and my users would really benefit from some of the information you provide here.
Please let me know if this alright with you. Many thanks!
I every time spent my half an hour to read this web site’s content every day along with a mug of coffee.
Dave Roberts goes to have to tug some pretty unpopular rabbits
out of his hat this time round.
Wonderful, what a blog it is! This web site gives valuable data to
us, keep it up.
fantastic publish, very informative. I ponder why the other
specialists of this sector do not realize this. You should continue your
writing. I’m sure, you have a huge readers’ base already!
The Big Top may have been replaced by a theatre but the spirit of circus continues
to be alive with Cirque Berserk.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
Superb website you have here but I was curious if you knew of any user discussion forums that cover
the same topics discussed here? I’d really
like to be a part of community where I can get advice from
other knowledgeable people that share the same interest. If
you have any recommendations, please let me know. Many thanks!
Hello, i think that i saw you visited my weblog thus i came to go back the desire?.I
am attempting to in finding issues to improve my website!I guess its ok to use some of your ideas!!
Also visit my webpage … hookup near me
It’s awesome to visit this web site and reading the views of all friends about this paragraph, while I am also eager
of getting know-how.
Thanks for a marvelous posting! I actually enjoyed reading it,
you can be a great author.I will ensure that I bookmark your blog and will eventually come back later
on. I want to encourage one to continue your great work,
have a nice holiday weekend!
Hi there to every body, it’s my first visit of this weblog; this weblog includes awesome and really good data in favor of visitors.
What i don’t understood is in truth how you’re not actually a lot more smartly-liked than you may
be now. You are so intelligent. You realize thus considerably on the subject of this topic, made me individually believe it from a lot of varied angles.
Its like women and men aren’t involved except it’s something to do with Girl gaga!
Your own stuffs excellent. At all times care for it up!
If you would like to improve your experience just keep visiting this site and be updated with the newest gossip posted here.
Wow, amazing blog layout! How long have you been running a blog for?
you made blogging glance easy. The overall glance of your website is excellent,
as well as the content!
When someone writes an post he/she maintains the image of a user
in his/her brain that how a user can know
it. So that’s why this paragraph is great.
Thanks!
Undeniably believe that which you said. Your favorite reason seemed to be on the web
the easiest thing to be aware of. I say to you, I certainly
get annoyed while people consider worries that they just do not know about.
You managed to hit the nail upon the top and defined out the whole thing without having side effect , people
can take a signal. Will likely be back to get
more. Thanks
porn videos
I am sure this post has touched all the internet viewers, its really really nice post
on building up new weblog.
Right here is the right webpage for anybody who wants to find out about this topic.
You realize so much its almost tough to argue with you
(not that I personally would want to…HaHa). You definitely
put a fresh spin on a topic which has been discussed for decades.
Wonderful stuff, just wonderful!
Its like you read my mind! You seem to know so much about this, like you wrote
the ebook in it or something. I feel that you
simply can do with a few % to force the message house a little bit, but other than that,
that is fantastic blog. A fantastic read. I will certainly be back.
Hi i am kavin, its my first time to commenting anywhere, when i read this article i thought i
could also make comment due to this brilliant piece of writing.
Howdy! I know this is kinda off topic nevertheless I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing a
blog article or vice-versa? My blog covers a lot of the same subjects as yours
and I think we could greatly benefit from each other.
If you are interested feel free to shoot me an e-mail.
I look forward to hearing from you! Terrific blog by the way!
Informative article, just what I was looking for.
My brother suggested I may like this website.
He was once totally right. This put up truly made my day.
You cann’t believe just how much time I had spent for this information! Thanks!
Hi! I understand this is somewhat off-topic but I had to ask.
Does operating a well-established blog like yours take a lot of work?
I’m brand new to writing a blog but I do write in my journal daily.
I’d like to start a blog so I can easily share my own experience and views
online. Please let me know if you have any
kind of ideas or tips for brand new aspiring bloggers. Appreciate it!
At this moment I am ready to do my breakfast, afterward having my breakfast coming yet again to read additional news.
Pretty section of content. I simply stumbled upon your site and in accession capital to claim
that I acquire in fact loved account your blog posts.
Any way I will be subscribing in your augment and even I
success you get admission to consistently fast.
Good day I am so excited I found your blog page,
I really found you by accident, while I was searching
on Yahoo for something else, Anyhow I am here now and would just like
to say thanks a lot for a remarkable post and a all round exciting blog (I also love the theme/design), I don’t have time to browse it all at the minute but I have book-marked it and also added your RSS feeds, so when I have time I will be
back to read much more, Please do keep up the great jo.
Great post however , I was wanting to know if you
could write a litte more on this subject? I’d be very grateful if you
could elaborate a little bit more. Cheers!
Hey, I think your website might be having browser compatibility issues.
When I look at your blog site in Firefox, it looks fine but when opening in Internet
Explorer, it has some overlapping. I just wanted to give you a quick heads
up! Other then that, amazing blog!
Hey very interesting blog!
You should be a part of a contest for one of the highest quality websites on the web.
I am going to recommend this site!
Hi my family member! I wish to say that this post is awesome, great written and come with approximately all significant
infos. I’d like to peer more posts like this .
Awesome things here. I am very happy to see your post. Thanks so much and I’m
taking a look ahead to contact you. Will you please drop
me a mail?
Thank you, I’ve just been searching for information about this subject for a long time and yours is the greatest I have found out
so far. However, what concerning the bottom line? Are you sure in regards to the supply?
Hey just wanted to give you a quick heads up and let you know a
few of the images aren’t loading properly. I’m not sure why
but I think its a linking issue. I’ve tried it in two different web
browsers and both show the same outcome.
Grеat site you haѵe һere.. It?s һard to fіnd gooɗ quality writing ⅼike
yours nowadays. І tгuly apprеciate people like y᧐u!
Takee care!!
Ⅿy page :: choose kitchen appliances (Amelia)
We’re a group of volunteers and starting a new scheme in our
community. Your website provided us with valuable information to work on. You’ve done a formidable job and our
entire community will be grateful to you.
Can I simply just say what a relief to discover someone that actually
knows what they’re discussing on the web. You actually understand how to bring a problem to light and make
it important. A lot more people need to look at this and understand this side
of your story. I was surprised you aren’t more popular
because you surely have the gift.
Hi, its nice paragraph about media print,
we all be aware of media is a enormous source of data.
Thanks for one’s marvelous posting! I truly enjoyed
reading it, you can be a great author.I will remember to bookmark
your blog and will eventually come back very soon. I want to encourage you continue your great writing, have a nice holiday weekend!
Thanks , I’ve just been looking for information about this
topic for a long time and yours is the greatest I’ve found out till
now. However, what about the conclusion? Are you certain in regards to the source?
I do not even know how I ended up here, but I thought this
post was great. I do not know who you are but certainly you are going to a famous blogger if you aren’t already
😉 Cheers!
Right away I am going to do my breakfast, later than having my breakfast coming over
again to read further news.
Hello there! Quick question that’s entirely off topic. Do you know how to make your site mobile
friendly? My weblog looks weird when browsing from my iphone4.
I’m trying to find a theme or plugin that might be able to resolve this problem.
If you have any suggestions, please share. Thanks!
Aw, this was a very nice post. Taking the time and actual effort to
produce a really good article… but what can I say… I put things off a lot and never seem to get anything
done.
I think this is one of the most important information for find sex near me.
And i am satisfied reading your article. However
should remark on some normal issues, The site taste is great,
the articles is actually excellent : D. Good process, cheers
Hello! I’ve been following your weblog for some time now and finally got the courage to go ahead and give you a shout out from
Porter Tx! Just wanted to say keep up the good
job!
I’m gone to say to my little brother, that he should also visit this website on regular basis
to get updated from most up-to-date reports.
I’m not sure where you’re getting your information, but
great topic. I needs to spend some time learning much more or understanding more.
Thanks for wonderful info I was looking for this information for my mission.
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back later on. Many thanks
Pretty nice post. I just stumbled upon your
blog and wanted to say that I’ve really enjoyed surfing around your blog
posts. After all I’ll be subscribing to your rss feed and I hope you write again soon!
Hey very interesting blog!
Hi there, I discovered your site by means of Google at the same time as searching for a
similar subject, your website got here up, it looks good.
I have bookmarked it in my google bookmarks.
Hello there, simply became aware of your weblog thru Google, and located
that it’s really informative. I’m going to be careful for brussels.
I will appreciate if you continue this in future. Many other people will probably be benefited out of your
writing. Cheers!
His unorthodox and questionable ways created the path for the
keto diet we know today. The ketogenic diet has been in the form we know it today for almost 100
years. The jury is still out on long-term effects of the diet, with
most participants less than two years in. His knowledge of nutrition and
ketogenic history led him to create a similar diet plan, still
being used today. With a little knowledge and planning, you can still
enjoy a satisfying meal while sticking to your low-carb goals.
Then this informative Keto Body book will teach you how
to improve your health and achieve your fitness goals.
Then look at the label for total fat and protein grams.
In case you’re not familiar with how to calculate net carbs, you simply subtract dietary
fiber and sugar alcohols from the total amount of carbohydrates.
Ultimately, diabetes management is all about monitoring your blood sugar
and keeping it as stable as possible. Ultimately,
he was too sick once he was found sometime later and died in hospital.
Of course today, we see it mostly used as a weight loss and diabetic diet.
The rapid production of ketones from fat and protein breakdown may lead to diabetic ketoacidosis.
porn 47186 video
Hello mates, how is everything, and what you would like
to say regarding this article, in my view its actually amazing in favor of me.
Hi Dear, are you actually visiting this website on a regular basis, if
so then you will without doubt take fastidious knowledge.
Hey there just wanted to give you a quick heads up and let you
know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same results.
Hi would you mind sharing which blog platform you’re using?
I’m going to start my own blog in the near future but I’m having
a hard time making a decision between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your design seems different
then most blogs and I’m looking for something completely unique.
P.S My apologies for getting off-topic but I had to ask!
of course like your website but you need to take a look at
the spelling on several of your posts. A number of them are rife with spelling issues and I in finding it
very bothersome to tell the reality on the other hand I’ll certainly come again again.
Wonderful article! We will be linking to this great content on our
site. Keep up the great writing.
I think this is among the most significant information for me.
And i’m glad reading your article. But should remark on some general things, The website style is wonderful,
the articles is really excellent : D. Good job,
cheers
I do not even understand how I finished up right here, but I thought this post used to be good.
I do not recognise who you are however definitely you are going
to a well-known blogger in case you aren’t already.
Cheers!
I am regular reader, how are you everybody? This post posted at this
site is genuinely pleasant.
It’s actually very complicated in this busy life to listen news on Television, therefore I just use world wide web for that reason, and get the hottest information.
Hi there! This blog post couldn’t be written any better! Going
through this article reminds me of my previous roommate!
He always kept preaching about this. I’ll forward this article to him.
Pretty sure he will have a very good read. Many thanks for sharing!
Hi, its nice article regarding media print, we all know media is a enormous source of data.
I just couldn’t leave your website prior to suggesting that I really enjoyed the usual info a
person supply to your visitors? Is going to be back often in order
to investigate cross-check new posts
I blog frequently and I truly appreciate your information. The article has truly peaked my interest.
I am going to take a note of your blog and keep checking for new details about once a week.
I opted in for your RSS feed as well.
I do not even understand how I finished up right here, however I thought this post was once good.
I do not recognize who you are but definitely you are going to a
famous blogger when you are not already. Cheers!
My partner and I stumbled over here by a different web page and thought
I might check things out. I like what I see so now i’m following you.
Look forward to checking out your web page repeatedly.
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times
it’s difficult to get that “perfect balance” between superb usability and appearance.
I must say you have done a excellent job
with this. In addition, the blog loads extremely quick for me on Chrome.
Superb Blog!
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make
your point. You obviously know what youre talking about, why throw away your intelligence on just posting videos to your blog when you could be giving us something
enlightening to read?
category porn
Aw, this was a really good post. Finding the time and actual effort to produce a very good article… but what
can I say… I procrastinate a lot and don’t manage to get anything
done.
Spot on with this write-up, I really believe this web site needs a great deal more attention. I’ll probably be returning to see more, thanks for the info!
Yes! Finally something about stockx kicks.
Hi to every one, the contents existing at this
web site are truly remarkable for people knowledge, well, keep up the good work fellows.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get four e-mails with the same comment.
Is there any way you can remove me from that service? Cheers!
Hi there! I could have sworn I’ve been to this website before but after reading through some of the post I realized it’s new to
me. Anyhow, I’m definitely happy I found it and I’ll be bookmarking and checking back often!
I have been surfing online more than three hours these days, but I never found any fascinating article like yours.
It is beautiful price enough for me. In my view, if all site owners and
bloggers made excellent content material as you did, the net will likely be a lot more helpful than ever before.
I seriously love your website.. Excellent colors & theme.
Did you build this amazing site yourself? Please reply
back as I’m looking to create my own website
and want to find out where you got this from or exactly what the theme is called.
Many thanks!
Link exchange is nothing else but it is just placing the other person’s website link on your page at
proper place and other person will also do similar for you.
I am regular reader, how are you everybody? This paragraph posted at this web page is really fastidious.
I like what you guys are usually up too. Such clever
work and exposure! Keep up the great works guys I’ve
you guys to our blogroll.
I visited many blogs but the audio feature for audio songs present at this web site
is actually fabulous.
Hello, I enjoy reading through your article. I like to write a little comment to support you.
I have been browsing online more than 4 hours today,
yet I never found any interesting article like
yours. It is pretty worth enough for me.
Personally, if all webmasters and bloggers made good content as you did, the
net will be much more useful than ever before.
It’s awesome in support of me to have a web site,
which is helpful for my experience. thanks admin
I know this if off topic but I’m looking into starting my own blog and was curious what all is required to get set
up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% certain. Any recommendations or advice would be greatly
appreciated. Many thanks
Link exchange is nothing else but it is simply placing the
other person’s weblog link on your page at appropriate place and other person will also do same
in favor of you.
This information is worth everyone’s attention. Where can I find out more?
I one had a bad encounter with a fake Bitcoin investment
company, I lost a lot of money to the trading company Cryptobravos
popularly known as fast one. The account manager started ignoring my calls and the support stopped responding to emails.
Found the company http://www.aldwychsecuritiesllc.com being recommended online by someone that got back their money back, I contacted.
It took a while but it was worth it, got all my money back, 7btc.
They are highly recommended. I never believe I would have gotten any money
back but this company did amazing and helped me recover the funds.
My spouse and I absolutely love your blog and find most of your post’s
to be what precisely I’m looking for. Do you offer guest writers to write content
for you personally? I wouldn’t mind composing a post or elaborating on most
of the subjects you write about here. Again, awesome website!
fuck girl
It’s appropriate time to make some plans for the longer
term and it’s time to be happy. I have read this put up
and if I may just I want to counsel you few interesting
things or advice. Maybe you can write next articles referring to
this article. I wish to read even more issues approximately
it!
It’s an remarkable post in support of all the internet users;
they will obtain benefit from it I am sure.
Hello, Neat post. There’s an issue along with your site in web
explorer, could check this? IE still is the marketplace chief and a good part
of folks will leave out your wonderful writing due to this problem.
Thanks for your marvelous posting! I truly enjoyed reading it, you happen to be a great author.I will
ensure that I bookmark your blog and may come back at
some point. I want to encourage you to continue your great posts, have
a nice evening!
Greetings from California! I’m bored at work so I decided to browse your website on my iphone during lunch break.
I enjoy the info you present here and can’t wait to take a look
when I get home. I’m shocked at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyhow, very good blog!
Excellent website you have here but I was curious about if you knew of any discussion boards that cover the same topics talked about here?
I’d really love to be a part of online community where I can get
feed-back from other knowledgeable individuals that share the same interest.
If you have any suggestions, please let me know. Cheers!
Hi there all, here every person is sharing such experience, therefore it’s
pleasant to read this weblog, and I used to pay a visit this webpage everyday.
Incredible quest there. What occurred after? Take care!
Hi! I simply want to give you a huge thumbs up for the great info you have here on this post.
I’ll be returning to your web site for more soon.
It’s an amazing paragraph in support of all the internet viewers; they will obtain benefit
from it I am sure.
continuously i used to read smaller articles or reviews that as well clear their motive, and that is also happening with this
post which I am reading now.
Simply desire to say your article is as surprising. The clearness on your put up
is just nice and i could think you’re knowledgeable on this subject.
Well with your permission let me to take hold of your
feed to keep updated with imminent post. Thank you a million and please carry on the rewarding work.
This post is priceless. When can I find out more?
At this moment I am going to do my breakfast, afterward having my breakfast coming again to read other news.
Hi there! This blog post could not be written much better!
Looking at this post reminds me of my previous roommate!
He continually kept talking about this. I’ll forward this post
to him. Pretty sure he’ll have a great read. Many thanks for sharing!
It’s remarkable to pay a quick visit this web
site and reading the views of all colleagues regarding this paragraph,
while I am also eager of getting familiarity.
I know this if off topic but I’m looking into starting my own blog and was wondering what all is required
to get setup? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet savvy so I’m not 100% certain. Any tips
or advice would be greatly appreciated. Thanks
At this moment I am going away to do my breakfast, once having my breakfast coming again to
read further news.
Bagi slotter pemula yang belum memiliki akun bermain dapat mencoba bermain dengan membuat akun pada link daftar situs
slot online terbaik dan terpercaya
An impressive share! I have just forwarded this onto a friend who had been conducting a little homework on this.
And he actually ordered me breakfast due to the fact
that I discovered it for him… lol. So let me reword
this…. Thank YOU for the meal!! But yeah, thanks
for spending some time to discuss this matter here on your site.
Hi, constantly i used to check web site posts here early
in the daylight, since i love to gain knowledge of more and more.
This article provides clear idea designed for the new visitors of
blogging, that in fact how to do blogging.
Someone essentially lend a hand to make seriously posts I’d
state. That is the very first time I frequented your website page and thus far?
I surprised with the research you made to make this particular submit amazing.
Fantastic job!
First of all I want to say fantastic blog!
I had a quick question which I’d like to ask if
you do not mind. I was curious to know how you center yourself and
clear your mind prior to writing. I’ve had a difficult time clearing my thoughts in getting my thoughts out.
I do enjoy writing but it just seems like the first 10 to 15 minutes
are wasted just trying to figure out how to begin. Any suggestions or
tips? Many thanks!
Feel free to surf to my blog post :: https://www.free-ebooks.net/profile/1510347/
Way cool! Some very valid points! I appreciate you penning this post plus the rest of the
website is really good.
This piece of writing will assist the internet
viewers for creating new blog or even a blog from start to
end.
my site: https://lowendbox.com/mangohost.net
Good blog you have here.. It’s difficult to find excellent writing like yours nowadays.
I truly appreciate people like you! Take care!!
I’m gone to tell my little brother, that he should also pay a visit this
weblog on regular basis to get updated from
newest news.
Yes! Finally someone writes about โทรศัพท์ยุค90.
Hello there I am so glad I found your website, I really found you by accident, while I was searching on Bing for something else, Regardless I am here now and would just like to say many thanks for a remarkable
post and a all round enjoyable blog (I also love the theme/design), I don’t have time to read it all
at the moment but I have bookmarked it and also added your RSS feeds, so when I have
time I will be back to read a lot more, Please do keep up
the excellent job.
Hello very nice web site!! Man .. Excellent ..
Amazing .. I will bookmark your web site and take the feeds also?
I am satisfied to search out a lot of helpful info here in the publish, we want develop
extra techniques on this regard, thank you for
sharing. . . . . .
If you wish for to get a good deal from this paragraph then you have to apply such strategies to your won webpage.
My page – https://whitehat.vn/members/vinapace.104601/#about
Hi there, after reading this amazing piece of writing i am as well delighted to share my familiarity here with friends.
Check out my web blog: https://www.credly.com/users/dangkybk8net/badges
I was very pleased to find this great site. I need to to thank you for
ones time due to this wonderful read!! I definitely savored every part of it and I have you saved as a favorite
to look at new stuff on your blog.
Mount Kenya University (MKU) is a Chartered MKU and ISO 9001:
2015 Quality Management Systems certified University
committed to offering holistic education. MKU is a progressive, ground-breaking university that serves the needs of aspiring students
and a devoted top-tier faculty who share a commitment to the promise of accessible education and the imperative
of social justice and civic engagement-doing
good and giving back. The University’s coupling of health sciences, liberal
arts and research actualizes opportunities for personal enrichment, professional preparedness and scholarly advancement.
I am really glad to read this blog posts which
includes plenty of useful information, thanks for providing these information.
I do believe all of the ideas you’ve introduced on your post.
They are very convincing and can certainly work.
Still, the posts are too brief for newbies.
Could you please extend them a bit from subsequent
time? Thanks for the post.
If you are going for finest contents like me, only visit this site
every day since it offers quality contents, thanks
Дорогой!
С большой радостью приглашаем тебя посетить уникальное
и яркое место в сердце нашего города – гей-клуб “Life Seo”!
Дресс-код: Будь собой! Яркие наряды и оригинальные аксессуары приветствуются.
Нас ждёт вечер полный впечатлений, танцев и новых
знакомств. Надеемся увидеть именно тебя!
С теплом и радостью,
Команда “Life Seo”
Look at my website: гей клуб Life seo
Hi I am so grateful I found your blog, I really found you
by accident, while I was browsing on Bing for something else, Nonetheless I am here now and would just like to say thank you for a
incredible post and a all round exciting blog (I
also love the theme/design), I don’t have time to read it all at the minute but I have book-marked it and also added your RSS feeds, so when I have time I will be back
to read a great deal more, Please do keep up the awesome work.
Remarkable! Its genuinely amazing article, I have got much clear idea about from
this post.
I am truly thankful to the holder of this site who has shared this impressive
article at here.
We absolutely love your blog and find the majority of your post’s to be exactly what I’m looking for.
Do you offer guest writers to write content available for you?
I wouldn’t mind writing a post or elaborating on a few of the subjects you write
with regards to here. Again, awesome weblog!
Exclusive porn
I do believe all of the ideas you’ve introduced to your post.
They are very convincing and will certainly work. Still, the posts are
too short for beginners. May just you please prolong them a little from next time?
Thank you for the post.
Your method of describing the whole thing in this piece of writing is actually nice, every
one be capable of easily understand it, Thanks a lot.
Hello There. I found your blog using msn. This is
a very well written article. I will be sure to bookmark it and return to read more of your useful information. Thanks for the post.
I’ll definitely comeback.
Exclusive porn
We stumbled over here different website and thought I should
check things out. I like what I see so now i’m following you.
Look forward to looking over your web page for a second time.
Very good blog! Do you have any helpful hints for aspiring writers?
I’m planning to start my own blog soon but I’m a little lost on everything.
Would you propose starting with a free platform like WordPress or
go for a paid option? There are so many options out there that I’m completely overwhelmed ..
Any suggestions? Thanks!
Hi there, after reading this remarkable post i am as well
delighted to share my experience here with colleagues.
Thanks , I have just been looking for info about this
topic for ages and yours is the best I have found out till
now. But, what about the bottom line? Are you positive concerning the source?
I have read so many articles regarding the blogger lovers however this post is genuinely a fastidious article, keep it up.
Hi, after reading this amazing post i am too cheerful
to share my know-how here with colleagues.
Происхождение казино датировать достаточно сложно.
Официальный сайт казино Pin-Up это комплекс сбалансированных решений и функций, которые позволяют клиентам игорного дома получать максимальное наслаждение от игрового процесса.
Следовательно, это сильная нейронная связь.
Получается, мысль «Хочу поиграть» возникает
сама по себе, потому что эта нейронная связь стала прочной?
Его утверждение звучит примерно так: «Когда
мы регулярно выполняем одно и тоже действие и подкрепляем его чем-то позитивным, у нас
формируется прочная нейронная связь».
Со ставками так: сидишь и думаешь,
как они сыграют. Покер – одна из самых популярных карточных игр, в нее играют миллионы игроков по всему миру.
» Если человек получает
дофамин только от игр, то и мозг привыкает призывать
его к игре. Свое отношение к этому дерьму сглаживал тем, что во всех статьях объяснял, почему именно человек не может выиграть в букмекерской конторе.
На следующий день он точно будет чувствовать себя хуже
из-за проигрыша, но пойдёт играть снова,
поскольку ему во время игры хорошо.
На отыгрыш всего бездепа дается 90 дней.
На протяжении более чем 30 лет Аллен Карр был заядлым курильщиком.В свою
очередь одним из лидеров европейского рынка азартных игр является компания Pin-Up,
которая начала свою деятельность семь лет назад и с
тех пор смогла завоевать лояльность миллионов клиентов.
Очень много упоминаний об азартных играх содержится в народных сказаниях
различных культур по всему миру.
Среди тех азартных игроков, которые сделали ставку в размере $1 и более, каждый час разыгрывается приз.
Если необходимое количество карт может быть достигнуто путем добавления трех сожженных карт (срезки перед 4ой, 5ой и 6ой картой),
то оставшиеся карты колоды замешиваются с сожженными картами, тем самым формируя новую колоду.
Во время торгов перед началом раздачи определяется ее тип: на количество
взяток с определенным козырем, мизер, распасы.
А что происходит во время игры?
Она подкрепляется идеей о том, что
во время игры я не только заработаю, но и получу
дофамин. Прояви смекалку и сообразительность, включи
шестое чувство – интуицию и выигрывай
у интернет-казино, участвуя во флеш игре
Покер видео-казино. Ривер – это заключительная общая карта, которую открывает дилер и последняя возможность
либо выиграть банк, не доводя
раздачу до вскрытия, либо попытаться добрать с
соперников больше фишек.Также некоторые
промокоды выставляются прямо на
основной витрине сайта, в разделе «Бонусы» либо «Новости».
Рекомендуется сдаться, когда ценность Вашей
комбинации равна 16 (если только это
не две восьмерки), но карта
открытого дилера – туз, десятка или девятка.
Однако на терне все изменилось:
вышел туз, и комбинация игрока сверху усилилась до лучшей пары.
А комбинация К♦ Д♠ 5♠ 2♦ (2-х карточная комбинация 5, 2)
лучше комбинации 7♠ 7♦ 7♥ Т♥
(2-х карточная комбинация 7, Т).
Наименее ценны пары, а сильнейшая комбинация – это флеш-рояль,
то есть десятка, валет,
дама, король и туз одной масти. Даже
если хотя бы один человек подсел на игру из-за меня, то я уже виноват.
Мужчины чаще всего пьют из-за нереализованности, а не потому,
что нравится вкус пива или водки.
Эта игра-казино основана на игре
в пятикарточный покер. Эта народная мудрость возникла не на пустом месте, но и с покером
связана слабо. В игре Шестиколодный блэкджек правила имеют определенные особенности, но
это не означает, что для начинающих их
понимание вызовет трудности.Бюджет картины по разным данным составил
около 130 млн долларов США, что
на 10 млн меньше бюджета
предыдущего «Бонда», «Умри, но
не сейчас». Он тоже хочет, но ему не дали.
То есть, когда человек
выиграл, то это схема, а если проиграл – невезение.
То же самое с лудоманом, который ничем другим не занимается.
Последние очень азартны. Должны же были что-то придумать.
» или «Может, вообще смысла нет что-то анализировать,
это просто вероятность и всё».
Я расписывал вероятности исходов, перемножал их по математике и показывал вероятность,
с который человек потеряет все свои деньги.
Получается, человек играет ради
удовольствия? Мол, когда мозг требует дофамин, то человек
выдумывает причину получить его
и верит в них. Есть гипотеза: если
мы возьмем человека, который постоянно
обжирается вкусной едой, только работа и рестораны, тогда его мозг не будет понимать, что можно получать дофамин другими способами.
Мозг говорит «Хочу дофамин! В ходе игры
он получает дофамин. Необязательно.
Скорее он машинально идет отыгрываться.
Here is my web page; мелстрой
wonderful post, very informative. I wonder why the opposite experts of
this sector don’t realize this. You must continue your writing.
I am sure, you have a huge readers’ base already!
obviously like your web-site but you have
to check the spelling on several of your posts.
A number of them are rife with spelling problems and I to find
it very bothersome to tell the truth then again I’ll certainly come
again again.
Wonderful post! We are linking to this particularly great post on our site.
Keep up the great writing.
Hi, i think that i noticed you visited my site thus i got here to go back the favor?.I am trying to find
things to improve my website!I assume its good enough to use a few of your ideas!!
Hi would you mind letting me know which web host
you’re working with? I’ve loaded your blog in 3 completely different internet browsers and I
must say this blog loads a lot quicker then most.
Can you recommend a good hosting provider at a fair price?
Thanks a lot, I appreciate it!
Hello just wanted to give you a quick heads up.
The words in your content seem to be running off the screen in Opera.
I’m not sure if this is a format issue or something to
do with web browser compatibility but I figured I’d post to let you know.
The style and design look great though! Hope you get
the problem fixed soon. Cheers
Post writing is also a fun, if you be familiar with then you can write if not it
is complicated to write.
I love it when individuals get together
and share thoughts. Great blog, keep it up!
What’s up Dear, are you actually visiting this website on a regular basis, if so then you will without doubt obtain good experience.
I’m curious to find out what blog platform you are using?
I’m having some minor security issues with my latest blog and
I’d like to find something more safeguarded. Do you have any suggestions?
Hey there I am so delighted I found your site, I really found you by error,
while I was researching on Google for something else, Anyhow I am here now and would just like to say cheers for a remarkable post and a all round entertaining blog (I also love the theme/design),
I don’t have time to browse it all at the moment but I have saved it and also added in your RSS feeds, so when I have time I will be back to read much more, Please do keep up the awesome work.
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance” between superb usability and appearance.
I must say that you’ve done a superb job with
this. Also, the blog loads super quick for me on Safari.
Superb Blog!
It’s appropriate time to make a few plans for the
longer term and it’s time to be happy. I’ve read this publish and if I may I desire to counsel you few interesting issues or tips.
Perhaps you can write subsequent articles relating to this article.
I wish to read even more issues about it!
With havin so much content do you ever run into any
problems of plagorism or copyright violation? My blog has
a lot of unique content I’ve either authored myself or outsourced but
it looks like a lot of it is popping it up all over the
web without my authorization. Do you know any techniques to
help reduce content from being stolen? I’d genuinely appreciate it.
What’s up everyone, it’s my first pay a quick visit at this web site, and article is really fruitful in support of me, keep up
posting these types of articles.
I feel that is among the most significant information for me.
And i am happy studying your article. However want to observation on few normal things, The
site style is ideal, the articles is in point of
fact nice : D. Just right process, cheers
I was suggested this website by my cousin. I am not sure whether this post is written by
him as no one else know such detailed about my problem.
You are amazing! Thanks!
I take pleasure in, result in I discovered exactly what I was looking
for. You’ve ended my 4 day lengthy hunt! God Bless you man. Have a nice day.
Bye
Everything is very open with a precise clarification of
the challenges. It was truly informative. Your site is very helpful.
Thank you for sharing!
Hey very interesting blog!
Great blog! Is your theme custom made or did you download it
from somewhere? A theme like yours with a few simple adjustements would really make my blog jump out.
Please let me know where you got your theme. Bless you
Good post however I was wanting to know if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit more.
Many thanks!
https://vavada-zerkalona5.xyz/
That is a good tip particularly to those new to the blogosphere.
Brief but very accurate information… Appreciate your sharing this one.
A must read article!
I know this web page provides quality depending articles and additional material,
is there any other site which gives these information in quality?
I do believe all of the ideas you’ve offered to your post.
They’re very convincing and will certainly work. Still, the posts are very short for beginners.
Could you please prolong them a little from next time?
Thanks for the post.
Howdy! This is my first visit to your blog! We are a team of volunteers
and starting a new project in a community in the same niche.
Your blog provided us beneficial information to work on.
You have done a outstanding job!
Review my blog; https://linkr.bio/haha178.pro
Its not my first time to visit this web page, i am browsing this website dailly and get good data from here every day.
I read this article fully about the difference of latest and earlier
technologies, it’s awesome article.
What’s up to every body, it’s my first go to see of
this web site; this webpage consists of remarkable and actually good material for readers.
If some one desires to be updated with latest technologies
therefore he must be go to see this website and be
up to date daily.
Yes! Finally something about fake id for roblox.
Howdy! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any
recommendations?
Way cool! Some extremely valid points! I appreciate you writing
this post plus the rest of the site is also very good.
I do not even understand how I finished up right here, however I believed
this put up was once great. I don’t realize who you might be however definitely you
are going to a famous blogger should you aren’t already.
Cheers!
These are actually wonderful ideas in concerning blogging.
You have touched some fastidious factors here. Any way keep up wrinting.
It is the best time to make a few plans for the longer term and it’s time to be
happy. I’ve learn this publish and if I may just I desire to counsel you some attention-grabbing issues or tips.
Maybe you could write subsequent articles relating to this article.
I wish to learn even more things approximately it!
Saved as a favorite, I like your web site!
I’ve been browsing online more than three hours today, yet I never
found any interesting article like yours.
It is pretty worth enough for me. Personally, if all web
owners and bloggers made good content as you did, the internet will be
a lot more useful than ever before.
This is my first time pay a visit at here and i am genuinely happy to read all at one place.
Your mode of describing everything in this post is in fact nice, all be
capable of simply know it, Thanks a lot.
Exceptional post but I was wondering if you could write
a litte more on this topic? I’d be very thankful if you could
elaborate a little bit further. Thanks!
I could not resist commenting. Perfectly written!
Somebody essentially help to make seriously
articles I might state. This is the very first time I frequented
your web page and to this point? I surprised with the research you made to
make this actual put up amazing. Excellent process!
You actually make it appear really easy along with your presentation but I find this topic to be really something which I believe I would
by no means understand. It seems too complicated and extremely wide for
me. I am taking a look forward on your next submit, I will attempt
to get the hold of it!
I love what you guys are usually up too. This kind of clever work and reporting!
Keep up the good works guys I’ve incorporated you guys to my personal blogroll.
Greate pieces. Keep writing such kind of info on your site.
Im really impressed by your blog.
Hi there, You have performed an incredible job. I will certainly digg it and
in my opinion recommend to my friends. I am sure they’ll be benefited from this site.
Its like you read my mind! You appear to know a lot about
this, like you wrote the book in it or something. I think
that you could do with a few pics to drive the message home a bit, but instead of that, this
is great blog. An excellent read. I will definitely
be back.
This is really interesting, You are a very skilled blogger.
I have joined your feed and look forward to seeking more of your
fantastic post. Also, I have shared your web site in my
social networks!
Spot on with this write-up, I truly believe that this amazing site needs
a lot more attention. I’ll probably be back again to read more, thanks for the info!
Everything is very open with a really clear description of the issues.
It was definitely informative. Your site is very useful.
Thank you for sharing!
This is my first time pay a visit at here and i
am actually pleassant to read everthing at alone place.
I was able to find good information from your articles.
What’s up to every body, it’s my first pay a visit of this blog; this blog contains
awesome and truly excellent information in support of readers.
Hi I am so happy I found your site, I really found you by mistake, while
I was looking on Askjeeve for something else, Regardless
I am here now and would just like to say thanks a lot for a fantastic
post and a all round exciting blog (I also love the theme/design),
I don’t have time to look over it all at the minute but I have book-marked it and also
included your RSS feeds, so when I have time I will be back to read a great deal more,
Please do keep up the awesome work.
Hi there! This post could not be written any better!
Looking at this article reminds me of my previous roommate!
He always kept preaching about this. I most certainly will send this post to him.
Fairly certain he’s going to have a good read.
Thanks for sharing!
I’m impressed, I must say. Rarely do I encounter a blog that’s
both educative and engaging, and let me tell you, you have hit the nail on the head.
The problem is an issue that too few men and women are speaking intelligently about.
Now i’m very happy that I stumbled across this during my hunt for something
relating to this.
Hey! I know this is kinda off topic but I was wondering if
you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
Hi! I know this is somewhat off topic but I was wondering if
you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get three emails with the same comment.
Is there any way you can remove people from that
service? Thank you!
This post is invaluable. Where can I find out more?
Unquestionably imagine that that you said.
Your favourite justification appeared to be at the web
the easiest factor to take into account of. I say to you, I definitely get annoyed at the same time as other folks consider worries that they just don’t know about.
You managed to hit the nail upon the highest and outlined out the entire thing
without having side-effects , other folks could take
a signal. Will likely be back to get more. Thanks
I’ve been surfing on-line greater than three hours these
days, but I never discovered any fascinating
article like yours. It’s beautiful value sufficient
for me. In my opinion, if all website owners and bloggers made good content material as you did, the
internet can be a lot more useful than ever before.
I know this if off topic but I’m looking into starting my
own blog and was curious what all is needed to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% positive.
Any recommendations or advice would be greatly appreciated.
Thank you
tuffy rhodes
Мʏ website; เว็บโป๊
Thanks for finally talking about > Пиастры – Составление семантического ядра |
< Loved it!
Thanks for another wonderful post. The place else may anyone get that type of info in such a perfect
manner of writing? I’ve a presentation next week,
and I am on the search for such information.
Fantastic blog! Do you have any recommendations for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for a paid option?
There are so many choices out there that I’m completely overwhelmed
.. Any ideas? Cheers!
Here is my web site: marketing singapore
Terrific article! This is the type of info that are supposed to be shared across the internet.
Shame on Google for now not positioning this submit higher!
Come on over and seek advice from my web site . Thank you =)
Undeniably consider that that you stated. Your favourite reason appeared to be at the
net the easiest factor to take note of. I say to you,
I certainly get irked even as people think about worries that they plainly do not recognise
about. You controlled to hit the nail upon the highest and also defined
out the whole thing with no need side effect , folks
can take a signal. Will likely be back to get more. Thanks
A person necessarily lend a hand to make severely posts I might state.
This is the first time I frequented your web
page and to this point? I amazed with the research you made to create this particular submit incredible.
Fantastic process!
Great weblog right here! Additionally your web site lots
up fast! What host are you the usage of? Can I
get your affiliate hyperlink on your host? I want my website loaded up as quickly as yours
lol
Hi, I log on to your blogs on a regular basis. Your writing style is awesome, keep up the good work!
I am really enjoying the theme/design of your weblog. Do you ever run into any browser compatibility
issues? A handful of my blog visitors have complained about my website not
working correctly in Explorer but looks great in Chrome. Do you have
any advice to help fix this problem?
Hi there! I just want to offer you a big thumbs up for
the excellent information you have got right here on this post.
I’ll be coming back to your site for more soon.
I got this site from my buddy who told me about
this web site and now this time I am browsing this website and reading very informative articles at this
time.
Hey there! I just wish to give you a big thumbs up for the great information you have got here on this post.
I will be returning to your web site for more soon.
If some one needs expert view regarding running a blog afterward i recommend him/her to go to see this web site, Keep up the
good work.
What’s up i am kavin, its my first time to commenting anyplace, when i read this piece of writing i thought i could also make comment due to this brilliant post.
I blog frequently and I really thank you for your content.
Your article has truly peaked my interest. I’m going to take
a note of your blog and keep checking for new details about once per week.
I subscribed to your Feed as well.
Quality posts is the main to invite the users to go to see the website, that’s
what this web page is providing.
Your style is unique compared to other folks I have read stuff from.
Thank you for posting when you have the opportunity,
Guess I will just book mark this site.
What’s up every one, here every person is sharing such familiarity, thus it’s good to read this website, and I used to pay a visit this blog all the time.
Hi, Neat post. There’s a problem with your website in internet explorer,
would test this? IE still is the marketplace leader and a good section of other folks will omit your wonderful writing due to this problem.
Thanks for a marvelous posting! I genuinely enjoyed reading
it, you might be a great author. I will always bookmark your blog
and will often come back at some point. I want to encourage
continue your great work, have a nice holiday weekend!
Amazing! Its really amazing post, I have got much clear idea regarding
from this article.
My brother suggested I might like this blog.
He was entirely right. This post actually made my day.
You can not imagine just how much time I had spent
for this information! Thanks!
Its such as you learn my mind! You seem to understand so much about this, such as
you wrote the e book in it or something. I feel that you just can do with
a few p.c. to power the message house a bit, however other than that, this is magnificent blog.
An excellent read. I will certainly be back.
My site :: email marketing (https://isaac9Q76fww6.Bloggactif.com)
I am really enjoying the theme/design of your weblog. Do you ever run into any web
browser compatibility issues? A few of my blog visitors have complained about my blog not operating correctly in Explorer but
looks great in Opera. Do you have any suggestions to help fix this problem?
Hey! This post couldn’t be written any better!
Reading through this post reminds me of my good old room mate!
He always kept talking about this. I will forward this write-up to him.
Fairly certain he will have a good read. Thank you for sharing!
Magnificent beat ! I would like to apprentice while you amend your website,
how could i subscribe for a blog web site? The account aided me a acceptable deal.
I had been a little bit acquainted of this your
broadcast provided bright clear concept
Please let me know if you’re looking for a article author for your
blog. You have some really great posts and I believe
I would be a good asset. If you ever want to take
some of the load off, I’d absolutely love to write some content for your
blog in exchange for a link back to mine. Please send me an e-mail if
interested. Cheers!
Its like you read my mind! You appear to know so much about this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message
home a bit, but instead of that, this is magnificent blog.
A great read. I will certainly be back.
Why people still make use of to read news papers when in this technological globe the whole thing is existing on web?
Just desire to say your article is as surprising. The clarity in your post is just
spectacular and i could assume you’re an expert on this subject.
Well with your permission let me to grab your feed to
keep up to date with forthcoming post. Thanks a million and please
keep up the rewarding work.
An interesting discussion is worth comment. I think that you ought to publish more on this
subject, it may not be a taboo matter but generally people don’t
discuss such issues. To the next! Many thanks!!
This piece of writing is truly a good one it helps new the web visitors,
who are wishing for blogging.
I do not know if it’s just me or if perhaps everyone else encountering issues with your
website. It appears like some of the text in your
posts are running off the screen. Can somebody
else please provide feedback and let me know if this is happening to them
too? This might be a issue with my browser because I’ve had this happen previously.
Many thanks
Good way of explaining, and fastidious article to get
information about my presentation subject matter, which i am going to convey in university.
I’m no longer sure where you are getting your information, but good topic.
I needs to spend some time finding out much more or figuring out
more. Thank you for excellent info I was searching for this information for
my mission.
Hello, I check your blogs on a regular basis.
Your humoristic style is awesome, keep up the good work!
Appreciation to my father who told me about this website, this weblog is actually amazing.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get several e-mails
with the same comment. Is there any way you can remove people from that service?
Thank you!
The other day, while I was at work, my cousin stole
my apple ipad and tested to see if it can survive a 30 foot drop,
just so she can be a youtube sensation. My iPad is now
broken and she has 83 views. I know this is totally off topic
but I had to share it with someone!
Pretty! This was a really wonderful post. Many thanks for supplying these details.
my web blog :: ai tools
great points altogether, you simply won a emblem new reader.
What could you suggest about your put up that you simply made some
days ago? Any sure?
Good blog you have here.. It’s hard to find high-quality
writing like yours nowadays. I truly appreciate people like you!
Take care!!
Take a look at my web site; 먹튀폴리스
If you are going for finest contents like me, just go to
see this website daily for the reason that it offers quality contents, thanks
Hello there, I found your site by means of Google whilst looking for a similar subject, your site got here up,
it appears good. I’ve bookmarked it in my google bookmarks.
Hello there, just become alert to your blog through Google, and located that it is really informative.
I’m going to watch out for brussels. I will appreciate when you proceed
this in future. A lot of people will be benefited out of your writing.
Cheers!
What i do not realize is in fact how you are no longer actually a lot more well-favored than you might be now.
You’re very intelligent. You realize thus
significantly in the case of this matter, produced me individually
believe it from numerous numerous angles.
Its like women and men don’t seem to be interested except it is something
to accomplish with Lady gaga! Your own stuffs great.
All the time take care of it up!
Asking questions are truly pleasant thing if you are not understanding
anything completely, except this post gives good understanding even.
Wow, that’s what I was exploring for, what a stuff! existing here at this website,
thanks admin of this web site.
It’s appropriate time to make some plans for the
future and it’s time to be happy. I’ve read this post
and if I could I wish to suggest you few interesting things or tips.
Perhaps you can write next articles referring to this article.
I wish to read more things about it!
I really like what you guys tend to be up too. This kind of clever work and exposure!
Keep up the amazing works guys I’ve incorporated you guys to my own blogroll.
Outstanding post but I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit further.
Thank you!
What’s up, yup this paragraph is really nice and I have learned lot of
things from it about blogging. thanks.
Unquestionably consider that which you stated. Your favourite reason seemed to be on the internet the easiest thing to take into accout of.
I say to you, I certainly get annoyed while other people
think about concerns that they plainly do not realize about.
You controlled to hit the nail upon the top and also outlined out
the entire thing with no need side effect
, other folks could take a signal. Will probably be back to get more.
Thanks
Whoa! This blog looks just like my old one! It’s
on a entirely different subject but it has pretty much the same layout and design. Outstanding
choice of colors!
I visited multiple sites however the audio feature for audio songs present at this site is really superb.
Hello! I could have sworn I’ve visited this site before
but after going through a few of the posts I realized it’s new to me.
Nonetheless, I’m definitely pleased I discovered it and
I’ll be bookmarking it and checking back often!
Remarkable! Its genuinely amazing post, I have got much
clear idea on the topic of from this post.
Hello there! This post couldn’t be written any better!
Reading this post reminds me of my old room mate!
He always kept chatting about this. I will forward this article
to him. Pretty sure he will have a good read. Thank
you for sharing!
Pretty! This has been a really wonderful post. Many
thanks for providing these details.
Wonderful beat ! I wish to apprentice even as you amend your site, how could i subscribe for
a weblog site? The account helped me a acceptable deal.
I have been tiny bit familiar of this your broadcast
offered brilliant transparent idea
My brother suggested I might like this web site.
He used to be entirely right. This submit truly made my day.
You can not believe simply how so much time I had spent
for this info! Thank you!
What’s up to every body, it’s my first pay a
quick visit of this web site; this website
consists of remarkable and genuinely fine information in favor of readers.
Great goods from you, man. I have keep in mind your stuff prior to and you’re just too wonderful.
I really like what you’ve received here, certainly like what you are saying and
the way wherein you assert it. You are making it entertaining and you continue to
care for to keep it sensible. I can’t wait to read much
more from you. That is really a tremendous web site.
This blog was… how do you say it? Relevant!! Finally I’ve found something which helped me.
Many thanks!
Hi there! I could have sworn I’ve visited this site before but after browsing
through some of the articles I realized it’s new to me.
Anyways, I’m certainly pleased I came across it and I’ll be book-marking it and checking back regularly!
My partner and I stumbled over here coming from a different
page and thought I should check things out. I like what I see so
now i am following you. Look forward to looking
at your web page yet again.
Hi i am kavin, its my first time to commenting anywhere, when i read this
article i thought i could also create comment due to this good article.
This is a topic that is near to my heart… Best wishes! Where are your contact
details though?
This page truly has all the info I wanted about this subject
and didn’t know who to ask.
Excellent post. I used to be checking constantly this blog and I am inspired!
Very helpful info particularly the final part I handle
I handle
such information much. I used to be looking for this certain information for a long time.
Thank you and good luck.
This is my first time visit at here and i am in fact pleassant to read all
at alone place.
If you are going for best contents like I do, simply pay a visit this web
site every day for the reason that it provides feature contents, thanks
Hello, I would like to subscribe for this website to obtain newest updates, thus where can i do it please help out.
I think the admin of this web site is genuinely
working hard in favor of his site, as here every stuff is quality based data.
If you would like to improve your knowledge just keep visiting this website and be updated with the most up-to-date news update posted here.
If you desire to take much from this post then you
have to apply these strategies to your won website.
Have you ever thought about writing an ebook or guest authoring on other websites?
I have a blog based upon on the same topics you discuss and would really like to
have you share some stories/information. I know my
readers would appreciate your work. If you’re
even remotely interested, feel free to send me an email.
I know this web page provides quality based articles and
extra material, is there any other web page which provides these data in quality?
Good day! This is kind of off topic but I need some advice from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where to begin. Do you have any tips or suggestions?
Appreciate it
I used to be recommended this web site by means of my cousin. I’m not positive whether this
submit is written by means of him as nobody else know such distinct approximately my problem.
You are wonderful! Thanks!
Daftar Situs Slot Online Paling Gacor RTP Slot Tertinggi
If some one needs to be updated with latest technologies after that he must
be pay a visit this web page and be up to date daily.
For hottest news you have to pay a quick visit web and on internet I found this web page as a finest site for most recent updates.
fantastic put up, very informative. I’m wondering why the other specialists of this sector do
not understand this. You must continue your writing.
I am sure, you have a great readers’ base already!
I know this if off topic but I’m looking into starting
my own weblog and was curious what all is required to
get setup? I’m assuming having a blog like
yours would cost a pretty penny? I’m not very internet smart
so I’m not 100% positive. Any tips or advice would
be greatly appreciated. Kudos
Hello, all is going perfectly here and ofcourse every
one is sharing facts, that’s in fact excellent, keep up
writing.
Thank you for another informative web site. Where else may just I get that type of information written in such an ideal approach?
I have a undertaking that I am just now running
on, and I have been at the glance out for such info.
Quality articles is the secret to interest the visitors to go to see the
site, that’s what this web page is providing.
It’s nearly impossible to find well-informed people for this
topic, however, you sound like you know what you’re talking about!
Thanks
We are a bunch of volunteers and opening a new scheme in our community.
Your website offered us with helpful information to work on. You’ve performed a formidable task and our whole community can be grateful to
you.
Simply desire to say your article is as amazing.
The clearness in your post is simply excellent and i
can assume you are an expert on this subject. Well with your permission let me to grab
your RSS feed to keep updated with forthcoming post.
Thanks a million and please continue the gratifying work.
I do consider all the ideas you’ve presented to your post.
They are very convincing and will definitely work.
Nonetheless, the posts are too brief for beginners.
May just you please lengthen them a bit from next time?
Thank you for the post.
I am in fact happy to read this blog posts which contains plenty of helpful
information, thanks for providing such statistics.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You definitely know what youre talking about, why throw away your
intelligence on just posting videos to your blog
when you could be giving us something informative to read?
Simply desire to say your article is as amazing. The clearness in your
post is just excellent and that i could think you are knowledgeable in this subject.
Fine together with your permission allow me to clutch your feed to stay up to
date with imminent post. Thanks a million and please carry on the rewarding work.
Way cool! Some extremely valid points! I appreciate you
penning this post and also the rest of the site is also really good.
This web site really has all of the information and facts I wanted concerning this subject and didn’t know
who to ask.
Appreciate this post. Let me try it out.
You really make it appear really easy together with your presentation but
I to find this topic to be actually something that I believe I would by no means understand.
It kind of feels too complex and very huge for me. I am looking forward
for your next submit, I’ll try to get the grasp of it!
These are truly impressive ideas in regarding blogging.
You have touched some pleasant things here. Any way keep
up wrinting.
I’ll immediately grasp your rss feed as I can’t find your e-mail subscription hyperlink or e-newsletter service.
Do you have any? Please permit me understand in order that I may subscribe.
Thanks.
Just desire to say your article is as surprising.
The clearness to your publish is simply great and i could assume you’re a professional on this subject.
Fine along with your permission allow me to snatch your feed to keep updated with drawing close post.
Thanks a million and please continue the gratifying work.
This text is invaluable. Where can I find out more?
I’m really inspired with your writing skills as neatly as with the
layout to your weblog. Is that this a paid theme or did you modify it your self?
Either way keep up the nice quality writing, it is uncommon to see a nice weblog like this one these
days..
Every weekend i used to pay a quick visit this web
site, for the reason that i wish for enjoyment, since this this web page conations
really good funny data too.
I do not know if it’s just me or if perhaps everybody else encountering problems with your website.
It seems like some of the written text in your content are running off the screen. Can somebody else please comment and let
me know if this is happening to them as well? This may be a issue with my web browser because I’ve had this happen previously.
Kudos
Hi there, the whole thing is going perfectly here and ofcourse every one
is sharing information, that’s in fact excellent, keep up writing.
What’s Going down i am new to this, I stumbled upon this I have found It positively helpful
and it has aided me out loads. I’m hoping to contribute
& help other customers like its aided me.
Good job.
Superb blog! Do you have any tips for aspiring writers?
I’m planning to start my own site soon but I’m a little
lost on everything. Would you suggest starting with
a free platform like WordPress or go for a paid option? There are so many options out there that I’m totally overwhelmed
.. Any recommendations? Bless you!
Oh my goodness! Impressive article dude! Many thanks, However I am having difficulties
with your RSS. I don’t know the reason why I can’t join it.
Is there anybody having the same RSS issues? Anyone that knows the answer can you kindly respond?
Thanx!!
Howdy! This post could not be written any better!
Reading through this post reminds me of my good old room mate!
He always kept chatting about this. I will forward this post
to him. Pretty sure he will have a good read. Thank you for sharing!
What i don’t realize is in fact how you’re not actually much
more well-preferred than you might be now. You’re very intelligent.
You know thus considerably on the subject of this topic, produced me individually consider it from numerous various angles.
Its like men and women don’t seem to be fascinated unless it’s one thing to
accomplish with Girl gaga! Your individual stuffs great.
Always take care of it up!
Having read this I believed it was really enlightening.
I appreciate you taking the time and energy to put this informative article together.
I once again find myself personally spending way too much time
both reading and posting comments. But so what, it was still worth it!
Great blog here! Also your website loads up fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my website loaded up as quickly as yours lol
When someone writes an article he/she keeps the thought of a user in his/her brain that how a user can be aware of it.
So that’s why this article is perfect. Thanks!
I really like what you guys tend to be up too. This type of clever work and exposure!
Keep up the wonderful works guys I’ve you guys to my personal blogroll.
Thanks very nice blog!
This is my first time visit at here and i am in fact impressed to read everthing at alone place.
Hi there everyone, it’s my first pay a visit at this site, and paragraph is
genuinely fruitful designed for me, keep up posting these types of articles.
My partner and I stumbled over here by a different web page and thought I may as well check things out.
I like what I see so i am just following you. Look forward to checking out your web
page yet again.
Heya i’m for the first time here. I found this board and I find
It really useful & it helped me out much. I hope to give something back and aid others like you
aided me.
Great beat ! I would like to apprentice while you amend your web site, how could i subscribe for a weblog site?
The account aided me a appropriate deal. I had been a little bit familiar of this
your broadcast offered vibrant transparent concept
Everyone loves what you guys are up too.
This kind of clever work and coverage! Keep up the terrific works
guys I’ve included you guys to my own blogroll.
It is the best time to make some plans for the future and it is time to be happy.
I have read this post and if I could I want to suggest you few
interesting things or tips. Maybe you could write next articles referring to this article.
I wish to read more things about it!
Wow, this article is fastidious, my sister is analyzing such things, so I am going to tell her.
I was pretty pleased to uncover this web site.
I wanted to thank you for your time due to this fantastic read!!
I definitely savored every little bit of it and i also have you book-marked to look at new
things on your blog.
Definitely believe that which you said. Your favorite reason appeared to be on the net the easiest thing
to be aware of. I say to you, I definitely get annoyed while people think about worries that
they just do not know about. You managed to hit the nail upon the top
and also defined out the whole thing without having side effect , people can take a signal.
Will likely be back to get more. Thanks
I get pleasure from, cause I discovered exactly what I used to be taking a look for.
You’ve ended my 4 day long hunt! God Bless
you man. Have a nice day. Bye
It’s in fact very difficult in this active life to listen news on Television, so I
simply use world wide web for that purpose, and obtain the newest information.
Very soon this web page will be famous amid all blog people, due to it’s fastidious articles or reviews
I’m not that much of a internet reader to be honest but your
sites really nice, keep it up! I’ll go ahead and bookmark your
website to come back later. Cheers
If you are going for finest contents like me,
simply pay a quick visit this website daily because it offers quality
contents, thanks
I have been exploring for a little bit for any high quality articles or blog
posts in this kind of space . Exploring in Yahoo I ultimately stumbled upon this site.
Studying this information So i am satisfied to
show that I have an incredibly excellent uncanny feeling I found out just what
I needed. I such a lot certainly will make certain to don?t omit
this web site and give it a look regularly.
I love it when individuals get together and share thoughts.
Great site, continue the good work!
I believe what you published was very logical.
But, what about this? suppose you composed a catchier post
title? I am not saying your content is not good.,
however suppose you added a post title that makes
people want more? I mean Пиастры
– Составление семантического
ядра | is kinda boring. You ought to peek at
Yahoo’s home page and watch how they create article headlines to get viewers to click.
You might add a related video or a pic or two to get people
excited about what you’ve got to say. In my opinion, it would bring your
blog a little livelier.
This is the perfect web site for anybody who wants to find out about this topic.
You know a whole lot its almost hard to argue with you (not that I actually would want to…HaHa).
You certainly put a brand new spin on a topic that’s been discussed for ages.
Wonderful stuff, just great!
Very nice write-up. I absolutely love this website.
Thanks!
Oh my goodness! Awesome article dude! Thank you so much, However I am experiencing problems with your RSS.
I don’t understand why I am unable to subscribe to it.
Is there anyone else getting identical RSS issues? Anybody who knows
the answer will you kindly respond? Thanx!!
Simply want to say your article is as surprising.
The clearness in your post is just excellent and i could assume you are an expert on this subject.
Well with your permission let me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please continue the gratifying work.
Thanks on your marvelous posting! I truly enjoyed reading it, you can be a great author.I will always
bookmark your blog and will often come back from now on. I want
to encourage you to ultimately continue your great job, have a
nice holiday weekend!
Wow, that’s what I was exploring for, what a material!
existing here at this website, thanks admin of this web page.
After checking out a number of the articles on your web
site, I honestly like your way of blogging. I saved as a favorite it to my bookmark webpage
list and will be checking back soon. Please check out my
web site too and let me know what you think.
I absolutely love your site.. Pleasant colors & theme.
Did you develop this site yourself? Please reply back as I’m trying to create
my very own website and would like to find out where you got this from or what the theme is called.
Appreciate it!
Hello, I read your blog regularly. Your writing style is witty, keep it up!
Great information. Lucky me I ran across your blog by chance (stumbleupon).
I’ve book-marked it for later!
Hey there! This is kind of off topic but I need some guidance from an established blog.
Is it very hard to set up your own blog?
I’m not very techincal but I can figure things
out pretty quick. I’m thinking about making my own but I’m not sure where to begin. Do you have any ideas or suggestions?
Cheers
I always used to read post in news papers but now
as I am a user of net thus from now I am using net for
articles, thanks to web.
Hello! Would you mind if I share your blog with my facebook group?
There’s a lot of people that I think would really enjoy your
content. Please let me know. Cheers
Fantastic goods from you, man. I have understand your stuff previous to and you are just extremely excellent.
I actually like what you have acquired here, certainly like what you’re saying and
the way in which you say it. You make it enjoyable and you still take care of to keep it sensible.
I cant wait to read far more from you. This is actually a wonderful site.
What’s up mates, its fantastic paragraph about educationand fully explained, keep it up all the time.
Hi mates, its impressive paragraph concerning tutoringand entirely defined,
keep it up all the time.
I think the admin of this web site is really working hard in support of his web page, for
the reason that here every stuff is quality based
material.
Heya i am for the first time here. I came across this board and I to
find It really useful & it helped me out much. I am hoping to provide one thing again and help
others such as you helped me.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make
your point. You definitely know what youre talking about, why waste your intelligence on just posting videos to your blog
when you could be giving us something enlightening to read?
I like what you guys are usually up too. This sort of clever work and reporting!
Keep up the amazing works guys I’ve added you guys to
my blogroll.
Hi there, all is going fine here and ofcourse every one is sharing facts, that’s in fact excellent, keep
up writing.
Hi! Someone in my Facebook group shared this site with us so I came to give
it a look. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers!
Superb blog and excellent design and style.
Ahaa, its good conversation on the topic of this piece of writing here at this website, I have read all that, so at this time me also commenting at this place.
Hello there, You’ve done a great job. I will definitely digg
it andd personally suggest to my friends. I’m confident they will bee benefited from this web
site.
my website Independent Delhi Escorts
I am sure this post has touched all the internet people, its
really really nice post on building up new website.
Everyone loves what you guys are up too. This type
of clever work and exposure! Keep up the fantastic works guys
I’ve added you guys to my blogroll.
Here is my web site: buy one get one free jordan 1 low
Awesome post.
I’m not sure why but this web site is loading incredibly slow for
me. Is anyone else having this problem or is it a problem on my end?
I’ll check back later and see if the problem still exists.
Hi friends, pleasant post and fastidious arguments commented at this place,
I am really enjoying by these.
Hey very nice blog!
Thanks a bunch for sharing this with all people you really realize what you’re speaking about!
Bookmarked. Kindly additionally seek advice from my
website =). We can have a link alternate contract between us
I’m excited to uncover this website. I want to to thank you for ones time for
this fantastic read!! I definitely loved every bit
of it and I have you book-marked to check out new things in your site.
Some guidance is thus expected from a pokies guide and we are happy to
share the lates casino bonuses to make an informed decision with regards to where to play pokies.
I’m really enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a developer to create your theme?
Excellent work!
Thanks for finally writing about > Пиастры – Составление семантического
ядра | < Loved it!
Hello, Neat post. There is an issue together with your web site in web explorer, might test this?
IE still is the market chief and a large element of people will leave out your excellent writing due to this problem.
I’m not that much of a online reader to be honest but your blogs really nice, keep it
up! I’ll go ahead and bookmark your site to come back later on. Many thanks
I believe what you posted was very logical. However,
what about this? suppose you added a little information? I
am not suggesting your information isn’t solid,
but what if you added a headline to possibly get folk’s attention? I
mean Пиастры – Составление семантического ядра | is a little boring.
You might glance at Yahoo’s home page and see
how they create post titles to get viewers to click.
You might add a related video or a picture or two to get people
excited about what you’ve written. In my opinion, it would make your posts
a little livelier.
Oh my goodness! Awesome article dude! Thank you, However I am encountering troubles with your
RSS. I don’t understand why I am unable to subscribe to it.
Is there anybody else having the same RSS problems? Anyone who knows the solution will you kindly respond?
Thanks!!
Very descriptive post, I loved that a lot. Will there be a part 2?
I do not even know how I stopped up here, however I assumed this post
used to be good. I don’t understand who you are however definitely you’re going to a famous blogger in the
event you are not already. Cheers!
Keep on writing, great job!
Howdy, i read your blog from time to time and i own a similar one
and i was just wondering if you get a lot of spam responses?
If so how do you protect against it, any plugin or anything you can advise?
I get so much lately it’s driving me insane so any help is very much appreciated.
Hi there very cool web site!! Man .. Excellent .. Wonderful ..
I will bookmark your blog and take the feeds also?
I’m satisfied to search out so many useful info here in the submit, we
need develop extra strategies in this regard, thank you for sharing.
. . . . .
Wow! Finally I got a website from where I be able to truly get valuable data regarding my study
and knowledge.
Currently it looks like Expression Engine is the top blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
This piece of writing will help the internet
users for creating new weblog or even a weblog from start
to end.
Thanks for finally writing about > Пиастры – Составление семантического ядра | < Loved it!
Thanks for your personal marvelous posting!
I really enjoyed reading it, you may be a great author.I will make certain to bookmark your blog and may come back later in life.
I want to encourage one to continue your great posts, have a
nice evening!
I think this is one of the most vital info for me.
And i’m glad reading your article. But want to remark on few general things, The
web site style is perfect, the articles is really great : D.
Good job, cheers
Also visit my blog; comment-162202
It is appropriate time to make a few plans for the longer term and it’s time to be happy.
I have read this submit and if I may I want to suggest you few
fascinating issues or tips. Perhaps you could write subsequent
articles referring to this article. I want to read even more things
approximately it!
Pretty great post. I just stumbled upon your weblog
and wished to mention that I have truly enjoyed browsing your
weblog posts. After all I will be subscribing for your
feed and I am hoping you write again soon!
Your way of telling all in this paragraph is in fact good,
every one can effortlessly understand it, Thanks a lot.
Appreciate the recommendation. Let me try it out.
What’s up, after reading this remarkable post i am also glad
to share my knowledge here with mates.
We absolutely love your blog and find almost all of your post’s to
be exactly I’m looking for. can you offer guest writers to write content to suit your needs?
I wouldn’t mind composing a post or elaborating on some of the subjects you write about here.
Again, awesome blog!
Hi, I would like to subscribe for this webpage to get latest updates, thus where can i do it
please assist.
It’s amazing to visit this site and reading the views of all colleagues on the topic of this post, while I am also
zealous of getting experience.
Hi there colleagues, its impressive paragraph on the topic
of cultureand entirely explained, keep it up all the time.
Hi! I’m at work surfing around your blog from
my new iphone 4! Just wanted to say I love reading through your blog and
look forward to all your posts! Carry on the fantastic work!
Hi there, just became alert to your blog through Google, and found that it’s truly
informative. I am gonna watch out for brussels.
I will appreciate if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
Everyone loves what you guys are up too. This type of clever work and reporting!
Keep up the great works guys I’ve incorporated you guys to my own blogroll.
You made some decent points there. I checked on the net for additional
information about the issue and found most people will go along with your views on this website.
My brother recommended I would possibly like this web
site. He was once entirely right. This submit truly made my day.
You can not imagine simply how much time I had spent for this information! Thank you!
Aw, this was an exceptionally nice post. Finding the time and actual effort to make a good article… but what can I say… I procrastinate a whole lot and never manage
to get anything done.
Hey there! Do you use Twitter? I’d like to follow you if that would be ok.
I’m absolutely enjoying your blog and look forward to new updates.
Hello, i think that i saw you visited my weblog thus i came to “return the favor”.I’m attempting to find things to improve my web site!I suppose its ok to use some of your ideas!!
Hi, I would like to subscribe for this web site to take
hottest updates, therefore where can i do it please assist.
My partner and I stumbled over here from a different website and thought
I might check things out. I like what I see so now i am
following you. Look forward to finding out about your web page again.
Hmm it seems like your website ate my first comment (it was extremely long) so I guess I’ll just sum
it up what I submitted and say, I’m thoroughly enjoying
your blog. I too am an aspiring blog writer but I’m still new to the whole thing.
Do you have any points for newbie blog writers?
I’d certainly appreciate it.
hi!,I really like your writing very so much!
proportion we keep in touch more about your article on AOL?
I need a specialist in this area to unravel my problem.
Maybe that is you! Looking forward to look you.
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get bought an edginess over that you wish be
delivering the following. unwell unquestionably come more formerly again since exactly
the same nearly a lot often inside case you
shield this increase.
When someone writes an post he/she retains the image of a user in his/her brain that
how a user can understand it. Therefore that’s why this piece of writing is great.
Thanks!
Appreciate this post. Let me try it out.
I could not refrain from commenting. Perfectly written!
I’m really enjoying the theme/design of your site. Do
you ever run into any web browser compatibility
problems? A handful of my blog visitors have complained about my site not
working correctly in Explorer but looks great in Chrome.
Do you have any suggestions to help fix this issue?
Please let me know if you’re looking for a article author for your site.
You have some really great articles and I believe I would be a good asset.
If you ever want to take some of the load off, I’d love to write some material for your blog in exchange for a
link back to mine. Please send me an e-mail if interested.
Thank you!
My relatives all the time say that I am wasting my time here at web, however I know I am getting experience everyday by reading such pleasant articles
or reviews.
Great site you’ve got here.. It’s difficult to find quality writing like yours
nowadays. I really appreciate individuals like you! Take care!!
Hey! I could have sworn I’ve been to this site before but after browsing through some of the post
I realized it’s new to me. Nonetheless, I’m definitely glad I found
it and I’ll be bookmarking and checking back often!
An impressive share! I have just forwarded this onto a coworker who has been doing a little homework on this.
And he in fact ordered me breakfast because I found it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanks for spending the time to talk about this topic here on your internet site.
I visited various sites except the audio quality for audio songs existing at this web site is really
superb.
If some one desires expert view regarding blogging and
site-building then i propose him/her to go to see this website, Keep up the nice work.
Howdy! This is my first visit to your blog!
We are a team of volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You have done a outstanding job!
Si vous désirez faire des parties de jeux, n’hésitez donc
pas à jouer avec votre smartphone ou votre tablette.
Hello there I am so excited I found your site, I really
found you by error, while I was browsing on Bing for something else,
Regardless I am here now and would just like to say many thanks for a
marvelous post and a all round interesting blog (I also love the theme/design), I don’t have time to look over it all at the minute but I have bookmarked it
and also added your RSS feeds, so when I have time I will
be back to read much more, Please do keep up the fantastic job.
I all the time emailed this blog post page to all my contacts, since if like to read it then my friends will too.
I constantly spent my half an hour to read this website’s articles everyday along with a mug of coffee.
Hi! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing months of hard work due to no backup.
Do you have any methods to protect against hackers?
I visited many web pages however the audio quality for audio songs existing at this web site is truly marvelous.
Wow! At last I got a web site from where I can in fact get useful data regarding my study and knowledge.
Today, I went to the beach front with my kids. I found a sea shell and gave it
to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the
shell to her ear and screamed. There was a hermit crab
inside and it pinched her ear. She never wants to go back!
LoL I know this is completely off topic but I had to tell someone!
Greetings! I know this is kind of off topic but I was wondering if
you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty
finding one? Thanks a lot!
I’ve read a few excellent stuff here. Definitely worth bookmarking for
revisiting. I wonder how much effort you put to create one of these great informative website.
Hello, everything is going fine here and ofcourse every one is
sharing facts, that’s actually excellent, keep up writing.
HD porn
Very good information. Lucky me I recently found your site by
accident (stumbleupon). I’ve saved it for later!
Everything is very open with a really clear explanation of the
issues. It was truly informative. Your site is extremely helpful.
Thanks for sharing!
Thank you a bunch for sharing this with all of us you really recognize what you are speaking approximately!
Bookmarked. Please additionally talk over with my website =).
We may have a hyperlink alternate arrangement between us
If some one needs to be updated with latest technologies then he must be pay a visit this site and be up
to date everyday.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time
a comment is added I get several e-mails
with the same comment. Is there any way you can remove me from
that service? Thanks a lot!
First of all I would like to say superb blog! I had a quick question which
I’d like to ask if you do not mind. I was curious to know how you center yourself
and clear your head before writing. I have had a
difficult time clearing my thoughts in getting my ideas out.
I do enjoy writing but it just seems like the first 10 to
15 minutes tend to be wasted just trying to figure out how to begin. Any suggestions or hints?
Cheers!
Sweet blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
At this time it appears like Drupal is the top blogging platform available right now.
(from what I’ve read) Is that what you’re using on your blog?
Fantastic blog you have here but I was curious if you knew of any user discussion forums that cover the same topics talked about
here? I’d really love to be a part of community where I can get opinions from other experienced individuals that share the same interest.
If you have any suggestions, please let me know.
Appreciate it!
What a stuff of un-ambiguity and preserveness of
precious familiarity regarding unexpected feelings.
Heya i’m for the first time here. I found this board and I find It truly useful & it helped me out much.
I hope to give something back and aid others like you helped me.
Hello, for all time i used to check web site posts here early in the morning, for
the reason that i enjoy to find out more and more.
Hurrah, that’s what I was exploring for, what a material!
present here at this weblog, thanks admin of this
site.
Informative article, just what I needed.
If some one wishes to be updated with newest technologies therefore he must be visit this web
page and be up to date daily.
It’ѕ an awesome post in support of аll tһe web սsers; tһey will get benefit from it
I am suгe.
Also visit my blog: singapore funiture
I have been browsing on-line more than three hours these days, yet I never discovered any interesting article like
yours. It is beautiful value sufficient for me.
Personally, if all site owners and bloggers made excellent content material as you did, the internet
might be a lot more helpful than ever before.
Good day! I could have sworn I’ve been to this blog before but after browsing through some of the post
I realized it’s new to me. Anyhow, I’m definitely glad I found
it and I’ll be book-marking and checking back often!
Thanks for the auspicious writeup. It in fact used to be a
amusement account it. Look complex to more introduced agreeable
from you! However, how could we keep up a correspondence?
I have read some just right stuff here. Definitely price bookmarking for revisiting.
I wonder how so much attempt you place to make any such wonderful informative website.
Why visitors still use to read news papers when in this technological globe everything is accessible on web?
I’m extremely inspired together with your writing talents and also with the structure to
your blog. Is this a paid topic or did you
customize it yourself? Anyway keep up the nice quality
writing, it’s uncommon to see a nice weblog like this one these days..
Greetings! Very useful advice in this particular post!
It is the little changes which will make the largest changes.
Thanks a lot for sharing!
Thankfulness to my father who stated to me concerning this webpage, this web site is truly remarkable.
Also visit my blog post; sight care supplement
Wow, superb weblog layout! How lengthy have you ever been blogging for?
you made running a blog look easy. The entire glance of your website is magnificent, let alone the content!
https://open.firstory.me/user/cloa6t8p10ofa01wm9j4te32e
It’s awesome to visit this web page and reading the views of all friends concerning this article,
while I am also zealous of getting experience.
Also visit my web page: active keto gummies work
For the reason that the admin of this web page is working, no question very rapidly it
will be famous, due to its quality contents.
Awesome post.
Hi there to every one, it’s in fact a fastidious for me to
go to see this web site, it contains precious Information.
whoah this weblog is magnificent i love reading
your articles. Stay up the good work! You understand, lots of people are hunting
round for this info, you could aid them greatly.
Very good info. Lucky me I found your website by chance (stumbleupon).
I have saved it for later!
When I initially commented I seem to have clicked the -Notify me when new comments are added- checkbox and now every time a comment is added I recieve 4 emails with the same comment.
Perhaps there is a way you are able to remove me from that service?
Kudos!
Definitely imagine that which you said. Your favourite justification appeared to be at the web the easiest thing to take into account of.
I say to you, I certainly get annoyed at the same time as other folks consider worries that
they plainly don’t recognize about. You controlled to hit the nail upon the highest and outlined out the entire thing with no need side effect ,
folks could take a signal. Will probably be again to
get more. Thank you
Asking questions are genuinely fastidious thing if you are not understanding something entirely,
however this piece of writing offers fastidious understanding yet.
No matter if some one searches for his vital thing, thus he/she desires to be available that in detail, so that thing is maintained over here.
I think this is among the most important info for me.
And i am glad reading your article. But should remark on some general things,
The website style is great, the articles is really nice :
D. Good job, cheers
Hi there, after reading this awesome article i am as well happy to share my experience
here with friends.
Greetings! Very helpful advice within this post! It’s the little changes that produce the greatest changes.
Many thanks for sharing!
Heya i am for the first time here. I found this board and I
to find It really helpful & it helped me out much. I am hoping to provide one thing back
and aid others such as you helped me.
What’s up to all, how is all, I think every one is
getting more from this website, and your views are
good in favor of new users.
Since the admin of this site is working, no question very soon it
will be renowned, due to its quality contents.
Great article, exactly what I wanted to find.
Thank you, I have just been looking for info about this
topic for a while and yours is the greatest I have discovered so far.
But, what concerning the bottom line? Are you certain about the supply?
I wanted to thank you for this fantastic read!! I definitely loved every little bit of it.
I’ve got you book-marked to look at new things you post…
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the way, how can we communicate?
Nice post. I learn something totally new and challenging
on websites I stumbleupon on a daily basis. It’s always interesting
to read through content from other authors and use something from other
sites.
certainly like your website but you need to test the spelling on several of your
posts. Several of them are rife with spelling issues and I in finding
it very troublesome to tell the truth then again I’ll definitely
come again again.
Hi there to all, the contents present at this web page are really remarkable for people experience,
well, keep up the good work fellows.
Feel free to visit my blog post … fitspresso official website
Hi there, I log on to your blog on a regular basis. Your story-telling style is witty, keep it
up!
I was suggested this web site by my cousin. I’m not sure whether this post is written by him as no one else know such detailed
about my problem. You are amazing! Thanks!
Awesome post.
Appreciating the commitment you put into your site and in depth information you present.
It’s great to come across a blog every once in a while that isn’t the same unwanted rehashed
material. Fantastic read! I’ve bookmarked your site and I’m adding your RSS feeds to my Google account.
Hello, I enjoy reading through your article post.
I like to write a little comment to support you.
Hi my family member! I want to say that this post is awesome, great written and include almost all vital infos.
I would like to look extra posts like this .
Hi, I think your website might be having browser compatibility issues.
When I look at your website in Ie, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, wonderful blog!
Aw, this was a really nice post. Finding the time and actual effort to make a very good article… but what
can I say… I put things off a lot and never
seem to get nearly anything done.
Have you ever thought about including a little bit more than just
your articles? I mean, what you say is important and all.
However think about if you added some great images or videos to give your posts
more, “pop”! Your content is excellent but with images and videos, this site could certainly
be one of the very best in its niche. Good blog!
After looking at a handful of the blog articles on your site, I truly like
your technique of writing a blog. I saved as a favorite it to my bookmark website list and
will be checking back in the near future. Please check out my website as well and let me know your opinion.
We are a gaggle of volunteers and opening a new scheme
in our community. Your web site offered us with helpful information to work on. You have done a formidable activity and
our entire neighborhood will be thankful to you.
What a material of un-ambiguity and preserveness
of precious know-how on the topic of unpredicted emotions.
After looking over a few of the blog articles on your site,
I seriously appreciate your way of writing a blog.
I book-marked it to my bookmark site list and will be checking back in the near future.
Take a look at my web site too and tell me how you feel.
Simply desire to say your article is as astounding. The clarity in your post is just nice and i could
assume you’re an expert on this subject. Fine with your permission let
me to grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please continue the enjoyable work.
Here is my webpage xn--1-of9e8p04r9jkxw1a.com
Howdy, I believe your site could be having internet browser compatibility problems.
Whenever I take a look at your website in Safari, it looks fine however when opening
in I.E., it has some overlapping issues. I just wanted to provide you with a quick heads up!
Aside from that, wonderful website!
constantly i used to read smaller articles that also clear their motive,
and that is also happening with this post which I am reading at this time.
Attractive element of content. I just stumbled upon your weblog and in accession capital to assert that I acquire actually
enjoyed account your blog posts. Any way I’ll be subscribing on your augment
or even I achievement you get entry to persistently fast.
This is the perfect webpage for anybody who wishes to find
out about this topic. You realize a whole lot its almost
tough to argue with you (not that I personally would want to…HaHa).
You certainly put a fresh spin on a subject that’s been discussed for ages.
Great stuff, just excellent!
I am regular reader, how are you everybody? This paragraph posted at this website is actually nice.
Great info. Lucky me I ran across your website by accident (stumbleupon).
I’ve book-marked it for later!
A motivating discussion is definitely worth comment. There’s no doubt that that you need
to publish more about this subject matter, it might not be a taboo matter but generally people do
not speak about such topics. To the next!
Kind regards!!
Do you have any video of that? I’d love to find out some additional information.
Do you have a spam issue on this website; I also am a blogger, and I was wondering your situation; many of us have developed some nice procedures and
we are looking to swap strategies with others, be sure to shoot me an email if interested.
naturally like your web-site but you need to test the
spelling on quite a few of your posts. A number of them are rife with spelling
issues and I find it very troublesome to inform the truth then again I
will definitely come again again.
Simply wish to say your article is as surprising.
The clarity for your publish is simply excellent and i
could think you’re an expert on this subject. Fine together with your
permission let me to seize your RSS feed to stay updated with drawing close post.
Thanks 1,000,000 and please carry on the gratifying work.
Wow, wonderful blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is fantastic, as well
as the content!
Hey! This post couldn’t be written any better! Reading through this post reminds me of my old room mate!
He always kept chatting about this. I will forward this write-up to him.
Pretty sure he will have a good read. Thanks for sharing!
Your method of explaining the whole thing in this paragraph is
in fact fastidious, every one be able to effortlessly be aware of it, Thanks a lot.
Thank you for sharing your thoughts. I truly appreciate your
efforts and I will be waiting for your next post thanks once
again.
With havin so much written content do you ever run into any issues of plagorism or copyright
infringement? My site has a lot of unique content I’ve either created myself or outsourced but it looks like a lot of it is popping it
up all over the internet without my agreement. Do you know any solutions to
help reduce content from being ripped off?
I’d truly appreciate it.
Hi! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing
a blog article or vice-versa? My website covers a
lot of the same topics as yours and I believe we could greatly benefit
from each other. If you’re interested feel free to shoot me an email.
I look forward to hearing from you! Superb blog by the way!
Hello there! I know this is somewhat off topic but I was wondering if you knew where I could
locate a captcha plugin for my comment form? I’m
using the same blog platform as yours and I’m having trouble finding
one? Thanks a lot!
Hi everyone, it’s my first go to see at this web site, and post is really
fruitful in support of me, keep up posting these
articles.
We’re a group of volunteers and starting a brand new scheme in our community.
Your web site provided us with helpful info to work
on. You’ve done an impressive job and our whole neighborhood shall be thankful to you.
Hi friends, its fantastic post concerning tutoringand entirely
defined, keep it up all the time.
Magnificent goods from you, man. I have understand your stuff previous to and you are
just extremely fantastic. I really like what you’ve acquired here, really like
what you’re stating and the way in which you say it.
You make it entertaining and you still take care of to keep it wise.
I can’t wait to read much more from you. This is really a terrific website.
For most up-to-date news you have to pay a visit world wide web and on web
I found this web site as a best website for latest updates.
You really make it appear really easy together with your presentation however I
in finding this topic to be actually one thing which I feel I
might by no means understand. It seems too complex and
extremely broad for me. I’m having a look forward to your subsequent submit, I will try to get the hang
of it!
It’s remarkable designed for me to have a web site, which is
good in favor of my experience. thanks admin
I am regular reader, how are you everybody?
This article posted at this web page is actually pleasant.
Hello to every body, it’s my first go to see of this blog; this website carries remarkable and genuinely fine information designed for readers.
Thanks for another informative blog. Where else could I am getting
that kind of info written in such an ideal manner? I have a mission that I’m just now operating on, and I’ve been on the look out
for such info.
Thanks for finally talking about > Пиастры – Составление семантического ядра | dark
market link https://mydarkmarket.com
Hey very nice blog!
My partner and I stumbled over here coming from a different web page and thought I might check things out.
I like what I see so now i am following you.
Look forward to checking out your web page again.
It’s really a cool and useful piece of information. I’m satisfied that you just shared
this helpful info with us. Please keep us up to date like this.
Thanks for sharing.
I’m gone to tell my little brother, that he should also pay a quick visit this webpage on regular basis
to take updated from hottest gossip.
I was curious if you ever considered changing the layout of your blog?
Its very well written; I love what youve got to say. But maybe you could a
little more in the way of content so people could connect
with it better. Youve got an awful lot of text
for only having one or 2 pictures. Maybe you could space it out better?
Hello there! I know this is somewhat off topic but I was wondering if you knew where I could
get a captcha plugin for my comment form? I’m using the
same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
all the time i used to read smaller articles that also clear their motive, and that is
also happening with this piece of writing which I am reading
at this time.
I’ve been browsing online greater than three hours lately, yet I never
found any fascinating article like yours.
It is pretty value enough for me. In my view, if all web owners and bloggers
made just right content material as you did, the internet might
be a lot more useful than ever before.
Does your website have a contact page? I’m having a tough time locating it but,
I’d like to send you an email. I’ve got some
ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it
expand over time.
I got this web page from my friend who informed me concerning this web site and now this time I am visiting this website and reading very informative posts at this time.
Actually no matter if someone doesn’t know afterward its up to other users that they will assist, so here it happens.
Outstanding story there. What happened after?
Good luck!
I used to be able to find good info from your blog articles.
I was able to find good advice from your articles.
Generally I don’t read article on blogs, but I would like to say that this write-up very pressured me to check out and do it!
Your writing style has been amazed me. Thank you, quite great post.
What’s up, I desire to subscribe for this webpage to
take hottest updates, thus where can i do it please help.
Heya i am for the primary time here. I came across this board and I in finding It really useful
& it helped me out a lot. I’m hoping to give one thing back and aid others like you aided me.
Hi there, constantly i used to check web site posts here
in the early hours in the break of day, as i like to gain knowledge of more and more.
I was more than happy to discover this page. I need
to to thank you for your time for this particularly fantastic read!!
I definitely liked every little bit of it and i also have you book marked to look at
new stuff in your site.
Hi colleagues, how is everything, and what you would like to say on the topic of this piece of writing, in my view its in fact awesome in favor
of me.
It’s an remarkable piece of writing designed for all
the online visitors; they will obtain benefit from it I am sure.
Hello everyone, it’s my first visit at this website, and piece of
writing is truly fruitful designed for me, keep up posting such content.
Good day I am so thrilled I found your weblog, I really found you by mistake, while I was searching on Yahoo for
something else, Anyways I am here now and would just like to say kudos for a marvelous post and a all round interesting blog (I also love
the theme/design), I don’t have time to go through it all
at the minute but I have saved it and also added your RSS feeds,
so when I have time I will be back to read a lot more,
Please do keep up the great job.
WOW just what I was looking for. Came here by searching
for Buy federal primers online
Thanks very nice blog!
Hey! Do you know if they make any plugins to protect against
hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
Greate pieces. Keep posting such kind of info on your blog.
Im really impressed by your site.
Hey there, You’ve performed an excellent job. I’ll definitely digg it and in my opinion recommend
to my friends. I am sure they will be benefited from this site.
My web blog; 메이저사이트 주소
Hi there, just became alert to your blog through Google, and found that it is
really informative. I’m gonna watch out for brussels.
I’ll be grateful if you continue this in future. Numerous people
will be benefited from your writing. Cheers!
What’s Taking place i am new to this, I stumbled upon this I’ve discovered It positively helpful and it has helped me
out loads. I’m hoping to give a contribution & help other users
like its helped me. Great job.
It’s amazing to go to see this web site and reading the
views of all mates concerning this post, while I am also keen of getting experience.
Good article! We are linking to this great post
on our website. Keep up the good writing.
It’s awesome in favor of me to have a web site, which is valuable for
my know-how. thanks admin
Hello, Neat post. There’s a problem along with your
site in internet explorer, might test this? IE nonetheless is the market chief and
a large part of other people will pass over your great writing because
of this problem.
Amazing! This blog looks just like my old one!
It’s on a totally different subject but it has pretty much
the same page layout and design. Great choice of colors!
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type
on a variety of websites for about a year and am anxious about switching to
another platform. I have heard fantastic things about blogengine.net.
Is there a way I can import all my wordpress posts into
it? Any kind of help would be greatly appreciated!
Thanks on your marvelous posting! I seriously enjoyed reading it, you happen to be
a great author. I will ensure that I bookmark your blog
and will come back later in life. I want to encourage continue your great posts, have a nice
weekend!
Thanks for some other informative blog. Where else may I get that type of info written in such a perfect manner?
I’ve a mission that I’m just now running on, and I’ve been on the glance out for such information.
Hey, I think your website might be having browser compatibility issues.
When I look at your blog in Safari, it looks fine but when opening in Internet
Explorer, it has some overlapping. I just wanted to give
you a quick heads up! Other then that, wonderful blog!
I like the helpful information you supply to your articles.
I will bookmark your blog and check again here frequently.
I’m relatively certain I will learn many new stuff right right here!
Good luck for the following!
I’d like to thank you for the efforts you’ve put in penning this blog.
I’m hoping to view the same high-grade content from you in the future as well.
In truth, your creative writing abilities has inspired me
to get my very own site now 😉
I’ve read a few good stuff here. Definitely value bookmarking for revisiting.
I wonder how much attempt you put to make this type of great informative
website.
I am truly thankful to the holder of this website who
has shared this impressive piece of writing at at this place.
whoah this blog is excellent i like studying your articles.
Stay up the great work! You already know, a lot of individuals are searching around for this information, you could aid them greatly.
Thanks for sharing your thoughts about tint shop near me.
Regards
If you want to take a good deal from this article then you have to apply these techniques to your won weblog.
Wow, amazing weblog format! How long have you ever been blogging for?
you made running a blog look easy. The whole glance of your
web site is fantastic, as well as the content material!
I all the time emailed this web site post page to all
my friends, since if like to read it next my links will too.
There’s certainly a great deal to know about this issue. I like all
the points you made.
Hi! Would you mind if I share your blog with my twitter group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Many thanks
Thanks for finally writing about > Пиастры – Составление семантического
ядра | < Liked it!
It’s truly very difficult in this busy life to listen news on TV, so I simply use world wide web for that
reason, and obtain the most up-to-date news.
Nice post. I learn something new and challenging on websites I stumbleupon on a daily basis.
It will always be useful to read through articles from other authors and practice a little something from their websites.
I don’t know whether it’s just me or if everyone else experiencing problems with your blog.
It looks like some of the written text within your posts are running off the screen. Can someone else please provide feedback and let me know if this is happening to
them as well? This may be a issue with my browser because I’ve had this happen previously.
Kudos
Great beat ! I would like to apprentice while you amend your website, how could i subscribe
for a blog website? The account helped me a acceptable
deal. I had been tiny bit acquainted of this your broadcast offered
bright clear concept
Hurrah! At last I got a blog from where I be able
to actually obtain useful information regarding my study and knowledge.
My web-site :: the growth matrix pdf
After exploring a number of the blog posts on your website, I really
appreciate your way of blogging. I bookmarked it to my bookmark website list and will be checking back
in the near future. Please visit my web site too and
let me know your opinion.
This design is wicked! You certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really enjoyed what you had to say, and more than that, how you presented
it. Too cool!
Hello there! Do you use Twitter? I’d like to follow you
if that would be okay. I’m absolutely enjoying your blog
and look forward to new posts.
Magnificent beat ! I wish to apprentice while you amend your
website, how could i subscribe for a blog site?
The account helped me a acceptable deal. I had been a little bit
acquainted of this your broadcast provided bright clear
idea
Fantastic blog! Do you have any recommendations for aspiring
writers? I’m hoping to start my own blog soon but I’m a
little lost on everything. Would you advise starting with a free platform like WordPress or go for a
paid option? There are so many choices out there that I’m completely confused
.. Any recommendations? Many thanks!
I’m truly enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more enjoyable for me to come
here and visit more often. Did you hire out a developer to create your theme?
Outstanding work!
Great site you have here.. It’s hard to find high quality writing like yours these days.
I seriously appreciate individuals like you! Take care!!
Magnificent web site. Lots of helpful info here. I’m sending it to some buddies ans additionally sharing
in delicious. And certainly, thanks in your sweat!
Pretty great post. I just stumbled upon your blog and wanted to
mention that I’ve truly enjoyed surfing around your weblog posts.
In any case I’ll be subscribing on your rss feed and I am hoping you write once more
very soon!
Very rapidly this site will be famous amid all blogging and site-building
users, due to it’s pleasant content
Hey there! I know this is somewhat off-topic but I had
to ask. Does running a well-established blog such as
yours require a massive amount work? I am completely new
to writing a blog but I do write in my journal daily. I’d like to
start a blog so I will be able to share my experience
and thoughts online. Please let me know if you have any kind of ideas or tips for new
aspiring blog owners. Appreciate it!
Do you have a spam problem on this website; I also am a blogger, and I was wanting to
know your situation; we have created some nice procedures and we are looking to
exchange methods with others, be sure to shoot me an e-mail if interested.
Keep on working, great job!
Greetings from Ohio! I’m bored to death at work so I decided to check out your blog on my iphone during
lunch break. I enjoy the knowledge you present here and can’t wait to take a
look when I get home. I’m shocked at how fast your blog loaded
on my phone .. I’m not even using WIFI, just 3G ..
Anyways, wonderful site!
Hi there, this weekend is fastidious designed for me,
for the reason that this moment i am reading this impressive informative paragraph here
at my house.
Hello! I know this is kinda off topic but I
was wondering which blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve had problems with hackers
and I’m looking at options for another platform.
I would be great if you could point me in the direction of a good
platform.
Hi friends, fastidious paragraph and fastidious urging commented here, I
am really enjoying by these.
all the time i used to read smaller articles or reviews which as well clear their
motive, and that is also happening with this piece of writing which
I am reading now.
Quality articles is the key to interest the people to pay a quick
visit the web site, that’s what this web page is providing.
When someone writes an article he/she retains the image of
a user in his/her brain that how a user can be aware of it.
So that’s why this paragraph is perfect. Thanks!
Right here is the perfect web site for anyone who hopes to find out about this topic.
You understand a whole lot its almost tough to argue with you (not that I really will need
to…HaHa). You definitely put a new spin on a subject which has been written about for years.
Great stuff, just excellent!
Nice response in return of this matter with firm arguments and explaining the whole thing concerning that.
I’m really impressed along with your writing abilities as well as
with the format for your weblog. Is that this a paid subject matter or
did you customize it yourself? Anyway keep up the excellent quality writing, it is rare to look a nice weblog like this one
nowadays..
you are truly a excellent webmaster. The website loading pace is incredible.
It kind of feels that you are doing any distinctive
trick. In addition, The contents are masterpiece.
you’ve performed a fantastic activity in this matter!
The other day, while I was at work, my cousin stole my iPad and tested to see if it can survive a 30 foot drop, just so
she can be a youtube sensation. My iPad is now broken and
she has 83 views. I know this is entirely off topic but I had to
share it with someone!
Thank you a bunch for sharing this with all people you actually recognize what you’re talking
about! Bookmarked. Please additionally discuss with my website =).
We will have a link alternate arrangement among us
My spouse and I stumbled over here different website and thought I
might as well check things out. I like what I see so now i’m following you.
Look forward to exploring your web page repeatedly.
Hey there! I simply wish to give you a huge thumbs up for
your excellent info you’ve got right here on this post.
I am coming back to your website for more soon.
This piece of writing is genuinely a fastidious one it helps new the web viewers,
who are wishing for blogging.
Hmm is anyone else encountering problems with
the pictures on this blog loading? I’m trying to determine if its a problem on my end or if it’s
the blog. Any feed-back would be greatly appreciated.
I couldn’t resist commenting. Well written!
I love it when people come together and share opinions.
Great site, continue the good work!
Appreciation to my father who shared with me on the topic of this weblog, this webpage is really remarkable.
Thank you for the good writeup. It in truth was a leisure account it.
Glance advanced to far introduced agreeable from you!
By the way, how could we keep in touch?
Hi there! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly?
My website looks weird when browsing from my iphone.
I’m trying to find a template or plugin that might be able to
resolve this problem. If you have any recommendations,
please share. Appreciate it!
This website certainly has all the information and facts I wanted concerning this
subject and didn’t know who to ask.
This is the right website for anyone who wants to understand this topic.
You know a whole lot its almost tough to argue with you
(not that I personally would want to…HaHa). You certainly put a brand new spin on a subject which has been written about for
ages. Wonderful stuff, just excellent!
jersey shore season 4 episode 4 123movies
Heya! I realize this is somewhat off-topic however I had
to ask. Does running a well-established website like
yours require a lot of work? I am completely new to operating a blog
but I do write in my journal on a daily basis.
I’d like to start a blog so I will be able to share my experience and views online.
Please let me know if you have any suggestions or tips for
new aspiring bloggers. Thankyou!
Fastidious answer back in return of this query with firm arguments and
describing all on the topic of that.
Good day! I could have sworn I’ve visited this web site before but after looking at a
few of the posts I realized it’s new to me.
Nonetheless, I’m definitely pleased I stumbled upon it
and I’ll be book-marking it and checking
back frequently!
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your
wonderful post. Also, I have shared your web site in my social networks!
Hi there friends, its fantastic paragraph
on the topic of educationand fully defined, keep it up
all the time.
Do you have a spam issue on this blog; I also am a blogger,
and I was wanting to know your situation; many of us have developed some nice procedures and we
are looking to exchange solutions with others, please shoot me an e-mail if interested.
Good answers in return of this matter with firm arguments and telling the whole thing regarding
that.
What’s up, this weekend is fastidious designed for me, because this time i am reading this impressive informative paragraph here
at my house.
When someone writes an paragraph he/she maintains the plan of a
user in his/her mind that how a user can be aware of it.
Therefore that’s why this article is perfect.
Thanks!
I need to to thank you for this fantastic read!!
I absolutely enjoyed every little bit of it.
I’ve got you book marked to look at new things you post…
Thanks to my father who stated to me on the topic of this website, this weblog
is really amazing.
Excellent way of telling, and fastidious paragraph to take facts on the topic of my presentation topic, which i am going to convey in academy.
I’m impressed, I have to admit. Rarely do I encounter
a blog that’s equally educative and engaging, and let me tell you, you have hit the nail on the head.
The problem is something that not enough folks are speaking intelligently about.
I’m very happy I came across this in my search for something concerning this.
Awesome issues here. I am very satisfied to peer your article.
Thanks a lot and I’m having a look forward to
touch you. Will you kindly drop me a mail?
Do you have a spam problem on this website; I also am
a blogger, and I was wondering your situation; we have developed
some nice procedures and we are looking to swap methods with other folks, why not shoot me an email if interested.
Hey there, You’ve done an excellent job. I will definitely digg it and personally recommend to my friends.
I am sure they’ll be benefited from this website.
Heya i’m for the first time here. I came across this board and
I find It really useful & it helped me out a lot. I hope to give something back and aid others like you helped me.
wonderful points altogether, you just received a brand
new reader. What might you recommend about your put up that you
just made some days in the past? Any sure?
I every time emailed this website post page to all my friends,
since if like to read it then my contacts will too.
Thanks for your personal marvelous posting! I actually enjoyed reading it, you will be a great author.I will
ensure that I bookmark your blog and will come back down the road.
I want to encourage you continue your great work,
have a nice morning!
Hi there, just wanted to mentiоn, I enjoyed this article.
It was funny. Keep on posting!
Hello! I know this is kind of off topic but I was wondering which blog platform are you using for this site?
I’m getting tired of WordPress because I’ve had issues with hackers and I’m
looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
Thanks for sharing your thoughts about kaip atkimsti kriaukle?.
Regards
https://www.pinterest.fr/vapepenhhc/les-vertues-du-hhc-hhc-vape-jetable
Hi! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading through your blog and look
forward to all your posts! Keep up the fantastic work!
Very soon this web page will be famous amid
all blogging viewers, due to it’s nice content
My family members always say that I am wasting my time here at net, except I know I am getting familiarity all the time by reading such nice articles.
great points altogether, you just received a new reader. What
would you suggest in regards to your publish that you just made a few days ago?
Any positive?
Great article! That is the type of info that should be shared around the
net. Shame on Google for now not positioning this publish higher!
Come on over and seek advice from my site . Thank
you =)
Great info. Lucky me I recently found your site by accident (stumbleupon).
I’ve bookmarked it for later!
This is a topic that’s near to my heart… Many thanks!
Where are your contact details though?
Spot on with this write-up, I truly believe this website needs much more attention. I’ll probably
be back again to read through more, thanks for the information!
I blog frequently and I truly appreciate your information. This article has truly peaked my interest.
I will book mark your site and keep checking for new information about once per week.
I opted in for your RSS feed too.
I absolutely love your blog.. Very nice colors & theme.
Did you develop this site yourself? Please reply
back as I’m hoping to create my own blog and would love to learn where you got this from or
exactly what the theme is called. Thanks!
Hi, I log on to your blog on a regular basis. Your writing style is awesome,
keep doing what you’re doing!
Also visit my homepage … sight care buy
What a stuff of un-ambiguity and preserveness of valuable experience on the topic of unpredicted feelings.
I was recommended this web site by my cousin. I am
not sure whether this post is written by him as nobody else know such detailed about my trouble.
You are wonderful! Thanks!
I am regular visitor, how are you everybody? This paragraph posted at this web page is actually nice.
You can certainly see your expertise in the article you write.
The arena hopes for more passionate writers like you who aren’t afraid
to say how they believe. Always go after your heart.
I have read so many articles or reviews regarding the blogger lovers except this article is truly a fastidious paragraph, keep it up.
Hi there! Someone in my Facebook group shared this site
with us so I came to look it over. I’m definitely loving the information. I’m bookmarking and
will be tweeting this to my followers! Superb blog and superb design and style.
I do agree with all of the ideas you’ve introduced on your post.
They’re very convincing and can certainly work.
Still, the posts are too quick for newbies. May you please extend them a
little from next time? Thank you for the post.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get three e-mails with the same
comment. Is there any way you can remove me from that service?
Thank you!
Great beat ! I would like to apprentice while you amend your
website, how can i subscribe for a blog website? The account
aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright clear
idea
We are a gaggle of volunteers and opening a new scheme in our community.
Your site provided us with useful information to work on. You have done a formidable activity and our whole
community will likely be grateful to you.
Hey would you mind sharing which blog platform you’re working with?
I’m planning to start my own blog in the near future but I’m having a tough time making
a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking
for something unique. P.S Sorry for getting off-topic but I had to ask!
Hi there! I realize this is sort of off-topic but I needed to
ask. Does operating a well-established blog such as yours take a massive amount
work? I am brand new to blogging however I do write in my journal on a daily basis.
I’d like to start a blog so I will be able to share my own experience and thoughts online.
Please let me know if you have any recommendations or
tips for brand new aspiring blog owners. Thankyou!
This article is truly a pleasant one it helps new web visitors, who
are wishing for blogging.
Wow, wonderful weblog layout! How lengthy have you ever been running a blog for?
you make blogging look easy. The whole glance of your web site
is magnificent, as neatly as the content material!
https://www.steamriceroll.com/
I’m more than happy to discover this site. I need to to thank
you for your time for this fantastic read!! I definitely liked every bit of it and I have you
book-marked to check out new information on your web site.
Look at my page Gold Coast Wedding Photography
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between user
friendliness and appearance. I must say that you’ve
done a awesome job with this. Additionally,
the blog loads extremely fast for me on Firefox.
Excellent Blog!
I every time emailed this blog post page to all my contacts, since if like
to read it next my contacts will too.
This is very interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your great post.
Also, I’ve shared your web site in my social networks!
Descubra as melhores opções imobiliárias com Agnaldo Imóveis no Rio de Janeiro.
Encontre imóveis excepcionais na cidade, confiando na expertise de Agnaldo Imóveis RJ para suas necessidades no mercado imobiliário carioca.
This website was… how do you say it? Relevant!!
Finally I’ve found something which helped me. Cheers!
I’ve been browsing online more than 2 hours today,
yet I never found any interesting article like yours. It’s pretty worth enough for me.
Personally, if all site owners and bloggers made good content as you did,
the web will be a lot more useful than ever before.
Excellent post however I was wondering if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a
little bit further. Thank you!
Hi, this weekend is fastidious in support of me, for the reason that this
time i am reading this fantastic educational piece
of writing here at my house.
What i don’t realize is in reality how you’re not
actually much more well-appreciated than you may be now.
You are very intelligent. You know therefore significantly with regards to this topic, produced me individually
consider it from so many various angles. Its like
women and men aren’t interested except it’s something to accomplish with Girl gaga!
Your personal stuffs outstanding. All the time care for it up!
my web blog :: first class stamp
Keep on writing, great job!
my blog post – the growth matrix step by step youtube reddit
Have you ever thought about writing an e-book or guest authoring on other blogs?
I have a blog based upon on the same ideas you discuss and would
really like to have you share some stories/information. I know
my subscribers would appreciate your work. If you’re even remotely interested,
feel free to send me an email.
I do not know if it’s just me or if everybody else experiencing issues with
your site. It appears as if some of the text on your content are running off
the screen. Can someone else please provide
feedback and let me know if this is happening to them as well?
This could be a issue with my web browser because I’ve had this happen previously.
Cheers
I do agree with all of the ideas you’ve presented on your post.
They are really convincing and will definitely work. Still, the posts are too brief for newbies.
Could you please lengthen them a bit from next time?
Thanks for the post.
Feel free to surf to my page … 沛納海高仿手錶
I got this site from my buddy who informed me about this website and at the moment
this time I am visiting this web page and reading very informative
content at this time.
Hello, I enjoy reading through your article. I wanted to write a little comment to
support you.
I like the valuable info you provide to your articles. I’ll bookmark your blog and check
once more here frequently. I’m slightly certain I’ll learn many new stuff proper here!
Best of luck for the following!
First off I want to say awesome blog! I had a quick question which
I’d like to ask if you don’t mind. I was interested to find out how you center yourself and clear your thoughts
prior to writing. I’ve had a tough time clearing my mind in getting my ideas out there.
I do enjoy writing but it just seems like the first 10 to 15 minutes are wasted just trying to figure out how to
begin. Any recommendations or hints? Thank you!
Thanks for sharing your info. I truly appreciate your efforts and I will be waiting for
your next write ups thank you once again.
Hello, I enjoy reading through your post. I wanted to write
a little comment to support you.
This is a topic that’s near to my heart… Cheers! Exactly where are your contact details though?
Heya i’m for the first time here. I came across this board and I find It really useful
& it helped me out much. I’m hoping to give one thing again and aid others like you aided
me.
Hey there! Do you use Twitter? I’d like to follow you
if that would be okay. I’m undoubtedly enjoying your blog and look forward to new posts.
I have read so many articles or reviews on the topic of
the blogger lovers but this piece of writing is truly a pleasant piece of writing, keep it up.
you are truly a excellent webmaster. The web site loading speed
is amazing. It sort of feels that you’re doing any distinctive trick.
Moreover, The contents are masterpiece. you’ve performed a excellent
task on this subject!
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on various
websites for about a year and am concerned about switching to
another platform. I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any kind of help would be really appreciated!
Attractive part of content. I just stumbled upon your weblog and in accession capital to assert that
I get in fact loved account your weblog posts. Any way I’ll be
subscribing to your augment and even I success you get right of
entry to persistently quickly.
I simply could not leave your website before suggesting that I extremely
enjoyed the standard info an individual supply on your visitors?
Is gonna be back incessantly in order to check out
new posts
Asking questions are genuinely good thing if you are not understanding anything entirely,
but this post provides nice understanding yet.
If some one needs to be updated with newest
technologies afterward he must be visit this website and be
up to date everyday.
My partner and I stumbled over here different website
and thought I might as well check things
out. I like what I see so now i am following you. Look forward to looking into your web page repeatedly.
I’ve learn some just right stuff here. Definitely value bookmarking for revisiting.
I wonder how much attempt you set to create the sort of magnificent informative website.
Hello i am kavin, its my first time to commenting anywhere, when i read this
piece of writing i thought i could also make comment due
to this sensible paragraph.
Hello, i feel that i saw you visited my blog
thus i got here to return the favor?.I’m attempting
to to find things to enhance my website!I guess its
adequate to use some of your ideas!!
Thanks for ones marvelous posting! I definitely enjoyed reading it, you could be a great author.I will always bookmark your blog and may
come back at some point. I want to encourage yourself to continue
your great writing, have a nice afternoon!
Hello would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 completely different internet browsers and
I must say this blog loads a lot quicker then most. Can you suggest a
good internet hosting provider at a reasonable price?
Thank you, I appreciate it!
It’s a pity you don’t have a donate button! I’d certainly donate to
this superb blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to
my Google account. I look forward to fresh updates
and will talk about this website with my Facebook
group. Talk soon!
Hello, always i used to check blog posts
here early in the daylight, for the reason that i love to find out more and more.
What i don’t realize is actually how you are no longer actually a lot more smartly-liked than you may be now.
You’re so intelligent. You recognize thus significantly
in the case of this matter, produced me for my
part imagine it from a lot of various angles.
Its like women and men don’t seem to be fascinated until it’s one thing to accomplish with Lady gaga!
Your personal stuffs excellent. All the time maintain it up!
Fastidious answers in return of this difficulty with solid arguments and telling all concerning that.
my blog post :: buy fast IPTV subscription packages
My family members every time say that I am wasting
my time here at web, but I know I am getting knowledge all the time by reading thes good articles.
Hey There. I discovered your blog the use of
msn. This is a very neatly written article.
I will make sure to bookmark it and return to learn extra of your helpful info.
Thank you for the post. I will certainly comeback.
Hello there! I could have sworn I’ve visited this site before but
after browsing through a few of the posts
I realized it’s new to me. Anyhow, I’m certainly delighted I discovered it and I’ll be bookmarking it and checking back frequently!
A person essentially lend a hand to make seriously posts I’d state.
This is the very first time I frequented your web page and thus far?
I amazed with the research you made to create this particular
post incredible. Great process!
It’s going to be finish of mine day, but before
end I am reading this enormous post to increase my know-how.
Every weekend i used to go to see this web page,
as i wish for enjoyment, as this this web site conations in fact
pleasant funny material too.
Hеy! Quick question that’s totally ᧐ff topic. Do yоu know
how to make your site mmߋbile friendly? My
bⅼog looks weіrd ԝhen browsing from my iphpne 4.
I’m trying tօ fіnd a thеme oг plսgin that might ƅe
aƄle to correct this issue. If you have any suggeѕtions, please shaгe.
With thanks!
Why viewers still use to read news papers when in this technological globe the whole thing is accessible on net?
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet v 789bet 789bet
789bet 789bet 789bet 789bet
I don’t even know how I stopped up here, but I thought this post used to be great.
I don’t recognise who you might be but definitely you are going to a well-known blogger
if you happen to are not already. Cheers!
Awesome blog you have here but I was curious if you knew of any
community forums that cover the same topics talked about here?
I’d really love to be a part of community where I
can get feed-back from other knowledgeable people that share the same interest.
If you have any recommendations, please let me know. Kudos!
I read this article completely regarding the resemblance of newest
and previous technologies, it’s amazing article.
Thank you, I have recently been searching for info about this
subject for ages and yours is the greatest I have came upon till
now. But, what in regards to the conclusion? Are you sure in regards to the supply?
I really love your blog.. Very nice colors & theme.
Did you develop this web site yourself? Please reply back
as I’m trying to create my very own blog and would love to know where you got
this from or exactly what the theme is called.
Kudos!
Hey I know this is off topic but I was wondering if you knew of any widgets I
could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some
time and was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new
updates.
Thank you for sharing your info. I truly appreciate your efforts
and I am waiting for your next write ups thanks once again.
great put up, very informative. I ponder why the other specialists of this sector don’t understand this.
You must proceed your writing. I’m confident, you have a great readers’
base already!
Appreciate this post. Let me try it out.
If you are going for most excellent contents like myself, just
visit this website all the time because it provides quality contents,
thanks
Hi I am so glad I found your site, I really found you by accident, while I
was searching on Bing for something else, Nonetheless I am here now and would just like to say many thanks
for a remarkable post and a all round interesting blog (I also love the theme/design), I don’t have time to browse it all
at the moment but I have saved it and also added your RSS feeds, so when I have time I will be
back to read much more, Please do keep up the excellent work.
Hey I know this is off topic but I was wondering if
you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I
truly enjoy reading your blog and I look forward to your new updates.
Your means of telling all in this paragraph is truly nice, all be able
to without difficulty understand it, Thanks a lot.
You could definitely see your enthusiasm in the work you write.
The arena hopes for even more passionate writers such as you who aren’t afraid
to mention how they believe. All the time follow your heart.
HD quality
When somеone writes an post he/she maintains the image of a uѕer in his/her miind that how a
user can be aware oof it. Տo that’s why this p᧐st is great.
Thanks!
It’s not my first time to pay a quick visit this site,
i am visiting this site dailly and get fastidious facts from here everyday.
After looking over a handful of the blog articles on your web page,
I truly appreciate your technique of blogging. I saved as a favorite
it to my bookmark webpage list and will be checking back in the near future.
Please visit my web site too and tell me what
you think.
Its like you read my mind! You appear to know a lot about this,
like you wrote the book in it or something. I think that you could
do with a few pics to drive the message home a bit, but other
than that, this is excellent blog. An excellent read.
I will definitely be back.
Keep on writing, great job!
You ought to be a part of a contest for one of the most useful sites online.
I am going to recommend this site!
I always used to reаd piec of writing in news paⲣers but now as I
am a user of web thus from noᴡ I am using net for content, thanks to
web.
You actually make it seem so easy with your presentation but I to find this topic to be really something which I think I’d
never understand. It seems too complex and extremely broad for me.
I’m looking ahead for your next put up, I’ll try
to get the grasp of it!
Hey! Would you mind if I share your blog with my myspace group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Cheers
Also visit my web site: go to
It’s appropriate time to make some plans for the future and it’s time to be
happy. I’ve read this post and if I could I want to suggest you some
interesting things or advice. Maybe you could write next articles referring to this article.
I wish to read even more things about it!
Why visitors still use to read news papers when in this technological world everything is
presented on web?
For the reason that the admin of this web page is working, no doubt very rapidly it will be renowned, due to its feature
contents.
Undeniably believe that which you stated. Your favorite justification appeared to be on the web the simplest thing to be aware of.
I say to you, I definitely get irked while people consider worries that they plainly
don’t know about. You managed to hit the nail upon the top and also defined
out the whole thing without having side effect , people can take a signal.
Will probably be back to get more. Thanks
whoah this blog is fantastic i like reading your posts.
Stay up the good work! You know, many individuals are hunting round for this information, you could help them greatly.
my webpage: the growth matrix youtube
Thanks for sharing your info. I truly appreciate your efforts and I am waiting for your next post thanks once again.
What’s Happening i’m new to this, I stumbled upon this I
have found It positively helpful and it has aided me out loads.
I’m hoping to contribute & aid different users like its helped me.
Great job.
You are so cool! I don’t suppose I have read through something like this before.
So good to discover somebody with genuine thoughts on this
subject matter. Seriously.. many thanks for starting this up.
This website is something that is required on the web, someone with a bit of originality!
Hi there! Do you know if they make any plugins to help
with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not
seeing very good gains. If you know of any please share. Kudos!
Does your blog have a contact page? I’m having trouble locating it but,
I’d like to send you an e-mail. I’ve got some ideas for your
blog you might be interested in hearing. Either way, great
blog and I look forward to seeing it grow over time.
hi!,I really like your writing so much! share we communicate extra about
your post on AOL? I need an expert on this house to unravel my problem.
May be that’s you! Having a look forward to look you.
WOW just what I was looking for. Came here by searching for SEO Cannabis
Pretty! This was an extremely wonderful article. Many thanks for
providing this information.
I’m not sure why but this site is loading extremely slow for
me. Is anyone else having this issue or is it a problem on my
end? I’ll check back later on and see if the problem still exists.
Hi there, just wanted to tell you, I liked this post.
It was funny. Keep on posting!
I do not even know how I ended up here, but I thought this post was good.
I don’t know who you are but definitely you are going to a
famous blogger if you aren’t already 😉 Cheers!
Very nice post. I just stumbled upon your blog
and wanted to say that I have really enjoyed surfing around your blog posts.
In any case I’ll be subscribing for your rss feed and I hope you write again very soon!
Very nice post. I simply stumbled upon your weblog and wanted to say that I’ve truly loved
browsing your blog posts. After all I will be subscribing in your
rss feed and I’m hoping you write once more very soon!
I’ve been surfing online more than three hours today, yet
I never found any interesting article like yours. It is pretty worth enough for me.
Personally, if all webmasters and bloggers made good content as you did, the internet will be much more useful than ever before.
Hi there, after reading this remarkable post i am also cheerful to share my know-how here with friends.
Aw, this was an exceptionally nice post. Taking a few minutes and actual effort
to generate a top notch article… but what can I say…
I hesitate a whole lot and never manage to get nearly anything
done.
Keep on writing, great job!
If some one desires to be updated with latest technologies afterward he must be visit this web page and be up to date daily.
Does your site have a contact page? I’m having trouble locating
it but, I’d like to shoot you an e-mail. I’ve got some
ideas for your blog you might be interested in hearing. Either way, great blog
and I look forward to seeing it develop over time.
Great site you’ve got here.. It’s difficult to
find high quality writing like yours these days. I truly appreciate individuals
like you! Take care!!
The other day, while I was at work, my cousin stole my apple ipad
and tested to see if it can survive a 25 foot drop, just so she can be a youtube sensation. My apple ipad is now destroyed and she has 83 views.
I know this is completely off topic but
I had to share it with someone!
My web page – Slot Gacor Hari Ini
Wonderful site you have here but I was wanting to know if
you knew of any message boards that cover the same topics discussed in this article?
I’d really love to be a part of group where I can get comments
from other knowledgeable people that share the same
interest. If you have any suggestions, please let me know.
Many thanks!
Hi there, yeah this paragraph is truly nice and I have learned lot of things from
it on the topic of blogging. thanks.
This is very interesting, You’re a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your wonderful post.
Also, I’ve shared your web site in my social networks!
An outstanding share! I have just forwarded this onto a co-worker who had been conducting a little homework on this.
And he in fact ordered me breakfast due to the fact that I stumbled upon it for him…
lol. So let me reword this…. Thanks for the meal!! But
yeah, thanx for spending time to talk about this matter here on your website.
Woah! I’m really digging the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s challenging to get that “perfect balance”
between superb usability and visual appeal. I must say you’ve done a great job
with this. In addition, the blog loads extremely fast for me on Opera.
Excellent Blog!
Everything is very open with a very clear description of the issues.
It was truly informative. Your site is very useful.
Thank you for sharing!
Can I simply say what a relief to find somebody that truly understands what they are talking about
on the web. You actually realize how to bring a problem
to light and make it important. More people must look at this and
understand this side of your story. I was surprised you are not more popular
because you most certainly possess the gift.
Pretty nice post. I just stumbled upon your weblog
and wanted to say that I have really enjoyed browsing your blog posts.
In any case I’ll be subscribing to your rss feed and I hope you write again very soon!
What’s up to every one, the contents existing at this site are actually remarkable for
people knowledge, well, keep up the nice work fellows.
Hello, i think that i saw you visited my website thus i came to
“return the favor”.I’m trying to find things to
improve my website!I suppose its ok to use a few of your ideas!!
I was wondering if you ever considered changing the structure of your blog?
Its very well written; I love what youve got to say. But maybe you could a
little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having
1 or two images. Maybe you could space it out better?
After I originally left a comment I seem to have clicked the -Notify me when new comments are added-
checkbox and from now on each time a comment is added I recieve four emails
with the same comment. There has to be a way you are able to remove me
from that service? Appreciate it!
Hi, i read your blog occasionally and i own a similar one and i was just curious if you get a lot of spam
remarks? If so how do you protect against it, any plugin or anything you can advise?
I get so much lately it’s driving me mad so any support is very much appreciated.
I am curious to find out what blog platform you are utilizing?
I’m having some minor security issues with my latest website and I would like to find something more safe.
Do you have any recommendations?
Magnificent web site. Plenty of useful info here. I’m sending it to some pals ans additionally sharing
in delicious. And certainly, thank you on your sweat!
Thank you for the auspicious writeup. It in fact was once a amusement
account it. Look complex to more delivered agreeable from you!
By the way, how can we communicate?
“Introducing the ultimate game-changer in WhatsApp marketing – our ‘WhatsApp Open Group Blaster’! Supercharge your promotional efforts by effortlessly posting advertisements to millions of public WhatsApp groups every day. With lightning-fast speed and precision targeting, our software takes your marketing strategy to new heights. Reach a vast audience and boost your brand exposure like never before. Harness the power of WhatsApp hash channels, available for purchase directly from us, to ensure maximum efficiency and delivery. Our user-friendly interface makes it easy to navigate, and with the ability to post to non-private groups, you’re in control of your campaign’s success. Elevate your outreach, increase engagement, and drive results with the WhatsApp Open Group Blaster. Don’t miss out on this opportunity to transform your marketing game. Get started today and watch your brand soar to new heights!”
website http://www.cdodatabase.com
Thank you, I have just been searching for information approximately this subject for ages and
yours is the greatest I have came upon till now.
However, what concerning the bottom line? Are you positive about the supply?
I am not certain where you are getting your information, but good topic.
I must spend a while studying more or understanding more.
Thank you for excellent information I was looking for this info for my
mission.
My web-site instagram volgers kopen
You are so cool! I do not believe I have read something
like this before. So nice to find another person with genuine thoughts on this subject.
Really.. thanks for starting this up. This website
is something that’s needed on the internet, someone with a bit of originality!
Generally I don’t read article on blogs,
however I would like to say that this write-up very compelled me
to take a look at and do so! Your writing taste has been surprised me.
Thanks, very great post.
Hello! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My weblog looks weird
when viewing from my iphone4. I’m trying to find a theme or plugin that might be able
to correct this issue. If you have any recommendations, please share.
Many thanks!
Feel free to surf to my website; Film
Definitely believe that which you stated. Your favourite reason appeared to be at the internet the simplest thing to remember of.
I say to you, I definitely get annoyed whilst other people think about concerns
that they plainly don’t understand about. You managed to hit the nail
upon the top as neatly as outlined out the entire thing with no need side-effects ,
other folks can take a signal. Will likely be again to get more.
Thanks
I’m gone to tell my little brother, that he should also pay a quick visit this web site on regular basis to get
updated from most up-to-date news update.
I’ll immediately seize your rss as I can not to find your email subscription hyperlink or e-newsletter service.
Do you have any? Please allow me understand so that I may just subscribe.
Thanks.
Heya i am for the primary time here. I found this board and I in finding It really useful & it helped me out much.
I am hoping to offer one thing back and help others such as you helped me.
It’s in fact very complex in this active life to listen news
on Television, so I just use world wide web for that reason,
and get the newest news.
This website was… how do you say it? Relevant!! Finally I
have found something that helped me. Thank you!
I loved as much as you will receive carried out
right here. The sketch is tasteful, your authored
subject matter stylish. nonetheless, you command
get got an shakiness over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly
the same nearly a lot often inside case you shield this increase.
Excellent blog post. I certainly appreciate this site.
Keep it up!
I really like what you guys are usually up too.
Such clever work and coverage! Keep up the terrific works
guys I’ve added you guys to my personal blogroll.
Do you mind if I quote a few of your articles as long as I provide credit and sources back
to your blog? My blog is in the exact same area of interest as yours and my
visitors would truly benefit from a lot of the information you provide here.
Please let me know if this ok with you. Thanks!
Excellent beat ! I would like to apprentice while you amend your web site, how
can i subscribe for a blog web site? The account aided me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided bright clear concept
I’m really enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more enjoyable
for me to come here and visit more often. Did you hire out
a designer to create your theme? Outstanding work!
Fantastic web site. A lot of helpful information here.
I’m sending it to some friends ans also sharing in delicious.
And naturally, thanks in your sweat!
Appreciate this post. Will try it out.
Hey, I think your blog might be having browser compatibility issues.
When I look at your blog in Opera, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, superb blog!
Thanks very nice blog!
Very good post. I absolutely love this website.
Thanks!
Having read this I believed it was extremely informative. I
appreciate you finding the time and effort to put this article together.
I once again find myself personally spending a significant amount of
time both reading and posting comments. But so what, it was still worth
it!
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that I acquire in fact
enjoyed account your blog posts. Anyway I’ll be subscribing to your augment and even I
achievement you access consistently rapidly.
I know this if off topic but I’m looking into starting my own weblog and was curious what all is
needed to get setup? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% sure.
Any tips or advice would be greatly appreciated. Cheers
Howdy, I do think your blog may be having internet
browser compatibility issues. Whenever I take a look at your site
in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping issues.
I merely wanted to provide you with a quick heads up!
Apart from that, wonderful website!
Great blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple adjustements
would really make my blog jump out. Please let me know where
you got your theme. With thanks
Excellent post. Keep posting such kind of info on your blog.
Im really impressed by it.
Hey there, You have done a fantastic job. I will certainly
digg it and personally recommend to my friends. I am sure they’ll be
benefited from this web site.
Actually no matter if someone doesn’t know after
that its up to other visitors that they will help, so here it occurs.
If some one wants to be updated with latest technologies after that he must be go to
see this website and be up to date everyday.
I think what you published made a lot of sense. But, consider this,
suppose you were to write a killer headline? I am not saying your content isn’t good, but suppose you added a title that makes people desire more?
I mean Пиастры – Составление семантического ядра | is kinda plain. You should look at Yahoo’s front page and note
how they create post headlines to get people to
click. You might add a related video or a pic or two to get readers interested about everything’ve got to say.
In my opinion, it could bring your posts a little bit more interesting.
Ahaa, its fastidious conversation concerning this post at
this place at this web site, I have read all that, so at this time me also commenting at this place.
Take a look at my blog: eplica jordans
Just want to say your article is as amazing.
The clearness in your post is just spectacular and i could assume
you are an expert on this subject. Fine with your permission let me to grab
your feed to keep up to date with forthcoming post. Thanks
a million and please carry on the rewarding work.
Asking questions are really fastidious thing if
you are not understanding anything completely, but this article offers
pleasant understanding yet.
A fascinating discussion is definitely worth comment. I believe that you need to publish more about this topic, it may not be a taboo matter but usually folks don’t speak
about such subjects. To the next! Kind regards!!
I’m gone to convey my little brother, that he
should also go to see this website on regular basis to obtain updated from newest reports.
In fact when someone doesn’t be aware of after that its up to other visitors that
they will assist, so here it takes place.
Feel free to surf to my site: replica jordan 4
I’m curious to find out what blog system you happen to be using?
I’m experiencing some minor security problems with my latest blog
and I’d like to find something more risk-free.
Do you have any suggestions?
My blog post: life heater buy
This is a very good tip especially to those new to the blogosphere.
Short but very precise information… Thanks for sharing this one.
A must read post!
You actually make it appear really easy together with your presentation however I find this matter
to be actually something that I think I’d never understand.
It kind of feels too complicated and very vast for me.
I am having a look forward on your next submit, I will attempt to get the hang of it!
Link exchange is nothing else except it is only placing the other person’s website link on your page at proper place and other person will
also do similar for you.
Hello! This is kind of off topic but I need some advice from an established blog.
Is it difficult to set up your own blog? I’m not very techincal
but I can figure things out pretty fast. I’m thinking about
creating my own but I’m not sure where to start.
Do you have any points or suggestions? Cheers
Spot on with this write-up, I seriously believe that this site needs a
lot more attention. I’ll probably be back again to read
more, thanks for the advice!
Hey there just wanted to give you a quick heads up.
The text in your post seem to be running off the screen in Chrome.
I’m not sure if this is a format issue or something to
do with internet browser compatibility but I figured I’d post to let you know.
The design and style look great though! Hope you get the issue fixed
soon. Thanks
Hello there! This is my 1st comment here so I just
wanted to give a quick shout out and say I really enjoy reading through your articles.
Can you recommend any other blogs/websites/forums that deal with the same subjects?
Thanks for your time!
I’m excited to uncover this web site. I need to to thank you for ones time
due to this wonderful read!! I definitely appreciated every part of it and i also have you bookmarked to look at new stuff in your site.
I absolutely love your blog.. Very nice colors & theme.
Did you develop this site yourself? Please reply back as I’m looking to create my
very own website and want to find out where you
got this from or just what the theme is named.
Many thanks!
Hey I know this is off topic but I was wondering if you knew of any widgets I could
add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was
hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
I constantly spent my half an hour to read this weblog’s content daily along with a mug of coffee.
Hello! I simply would like to give you a big thumbs up for your great info you’ve got here on this post.
I will be coming back to your web site for more soon.
sex video for free
A person necessarily assist to make severely articles I would state.
This is the very first time I frequented your web page and to this point?
I amazed with the research you made to make this actual publish extraordinary.
Wonderful job!
I was recommended this blog by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my problem.
You’re wonderful! Thanks!
Also visit my homepage – types of coverage
Can I simply say what a comfort to uncover somebody that really understands what they are
talking about on the web. You actually understand
how to bring an issue to light and make it important.
A lot more people need to read this and understand this side of your story.
I can’t believe you’re not more popular given that you surely
have the gift.
Thank you a lot for sharing this with all people you actually know what you’re speaking approximately!
Bookmarked. Kindly also discuss with my website =). We will have a link change contract among us
I’m really impressed along with your writing abilities and
also with the structure in your blog. Is that this a paid topic or did you customize it your self?
Anyway keep up the nice high quality writing, it’s uncommon to
look a nice blog like this one today..
Howdy very nice blog!! Guy .. Excellent .. Wonderful ..
I’ll bookmark your website and take the feeds also? I am happy to search out
so many helpful information right here in the submit, we’d like develop extra techniques on this regard,
thanks for sharing. . . . . .
Hurrah, that’s what I was searching for, what a stuff!
existing here at this web site, thanks admin of this website.
This piece of writing gives clear idea in support of the new users of blogging, that actually how to do blogging and site-building.
I’m extremely inspired along with your writing skills and also with the structure to your blog.
Is this a paid topic or did you customize it your self?
Either way stay up the excellent high quality writing,
it is uncommon to look a nice weblog like this one these days..
If you want to take much from this post then you have to
apply such techniques to your won webpage.
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789b
I all the time emailed this blog post page to all my associates, as if like to read it then my contacts will too.
Hi there, its pleasant piece of writing regarding media print,
we all know media is a wonderful source of information.
I love your blog.. very nice colors & theme. Did you make this website
yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to design my own blog and would like to find out where u
got this from. appreciate it
No matter if some one searches for his necessary thing, therefore he/she
wishes to be available that in detail, so that thing is maintained over here.
You can certainly see your expertise within the article you write.
The sector hopes for more passionate writers such as you who aren’t afraid to mention how they believe.
All the time go after your heart.
I’ll right away take hold of your rss as I can’t to find your
e-mail subscription link or newsletter service. Do you’ve any?
Please permit me recognize so that I may just subscribe.
Thanks.
If you wish for to take a good deal from this piece of writing then you have to
apply these methods to your won web site.
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get bought an impatience over
that you wish be delivering the following. unwell unquestionably come further formerly again since exactly the same nearly a lot often inside case you
shield this increase.
I need to to thank you for this excellent read!! I certainly loved
every little bit of it. I’ve got you book marked to look at new stuff you post…
I have read so many articles or reviews about the blogger lovers but this article is truly a nice
post, keep it up.
Excellent goods from you, man. I have understand your stuff prior to
and you’re just too great. I really like what you’ve obtained here, certainly like what you are saying and the way
in which wherein you assert it. You make it entertaining and
you continue to care for to stay it wise. I can not
wait to read far more from you. This is really a great web site.
When someone writes an paragraph he/she
keeps the plan of a user in his/her mind that how
a user can know it. So that’s why this article is perfect.
Thanks!
Look at my site: bookkeeping
Do you have a spam problem on this website; I also am a blogger,
and I was wondering your situation; we have created some nice practices and we are looking to swap methods with other folks, please shoot me an e-mail if
interested.
Asking questions are genuinely nice thing if you are not understanding anything fully, but this post gives pleasant understanding yet.
Feel free to surf to my homepage … navigate here
naturally like your web-site but you need to test the spelling
on several of your posts. Many of them are rife with spelling issues and I find
it very troublesome to tell the reality on the other hand I will surely come back again.
My brother recommended I would possibly like this website. He
was totally right. This post truly made my day. You can not believe simply how so much time I had spent for this info!
Thanks!
Thanks a lot for sharing this with all folks you really realize what you’re speaking about!
Bookmarked. Kindly additionally consult with
my website =). We may have a hyperlink change arrangement among
us
You actually make it appear really easy with your presentation but I to find this topic to be really one thing that I feel I might never understand.
It seems too complicated and extremely large for me. I am having a look forward for
your next post, I will try to get the cling of it!
What’s up, I would like to subscribe for this web site
to take most recent updates, therefore where can i do it please help.
Hello there, just became alert to your blog through Google, and found that it is truly
informative. I’m gonna watch out for brussels. I’ll appreciate if you continue this in future.
Many people will be benefited from your writing.
Cheers!
This page definitely has all the info I needed about this subject and
didn’t know who to ask.
I always used to study article in news papers but now as I am a user of
net therefore from now I am using net for articles, thanks to web.
Simply want to say your article is as surprising. The clarity in your post is just great and i can assume you’re an expert
on this subject. Fine with your permission allow me to grab
your RSS feed to keep up to date with forthcoming post.
Thanks a million and please continue the gratifying work.
Very nice blog post. I absolutely love this website. Keep it up!
Wonderful goods from you, man. I have understand your stuff previous to
and you are just too excellent. I really like what you have acquired here, really like what you’re stating and
the way in which you say it. You make it enjoyable and you
still take care of to keep it wise. I cant wait to read much more from you.
This is actually a great website.
Greetings from Colorado! I’m bored at work so I
decided to check out your blog on my iphone during lunch
break. I really like the information you present here and can’t wait to
take a look when I get home. I’m amazed at how quick your blog
loaded on my mobile .. I’m not even using WIFI, just 3G ..
Anyhow, very good site!
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why throw away
your intelligence on just posting videos to your blog when you could be giving us something informative to read?
A fascinating discussion is worth comment. I do believe that you
should publish more on this subject, it may not be a taboo matter but generally people don’t
speak about these subjects. To the next! Cheers!!
It’s going to be finish of mine day, however before finish I am reading
this fantastic piece of writing to improve my
know-how.
This is a good tip especially to those new
to the blogosphere. Short but very accurate information
Appreciate your sharing this one. A must read article!
It’s hard to find well-informed people in this particular
subject, but you seem like you know what you’re talking about!
Thanks
Yes! Finally someone writes about psychologische Beraterin.
I would like to thank you for the efforts you’ve put in writing this blog.
I am hoping to view the same high-grade content by you
later on as well. In truth, your creative writing abilities has
motivated me to get my very own website now 😉
I coᥙild not rеsist commenting. Exceptionally well written!
Have you ever considered publishing an ebook or guest authoring on other sites?
I have a blog based upon on the same information you discuss and would really like to have you share
some stories/information. I know my subscribers would enjoy your work.
If you are even remotely interested, feel free to send me an e mail.
I could not resist commenting. Exceptionally well written!
Hi colleagues, its fantastic piece of writing concerning tutoringand completely defined, keep it up all the time.
Porn video
Hi, Neat post. There’s an issue together with your
website in web explorer, could test this? IE still is the
marketplace leader and a good component to people
will miss your fantastic writing because of
this problem.
Howdy just wanted to give you a quick heads up. The words in your post seem to be running
off the screen in Firefox. I’m not sure if this is a formatting issue or something to do with web browser
compatibility but I figured I’d post to let you know.
The layout look great though! Hope you get the issue
solved soon. Thanks
Hello There. I found your blog the usage of msn. That is a very smartly written article.
I’ll make sure to bookmark it and come back to learn extra of your helpful information.
Thank you for the post. I will definitely comeback.
I do accept as true with all the ideas you have offered for your post.
They’re really convincing and can certainly
work. Nonetheless, the posts are very quick for novices.
Could you please extend them a bit from subsequent time?
Thanks for the post.
What i don’t realize is in truth how you are no longer really a lot more well-liked than you might be
right now. You are so intelligent. You recognize therefore
considerably in relation to this topic, made me in my view believe it from
so many various angles. Its like men and
women are not involved until it is something to do with Lady gaga!
Your personal stuffs outstanding. All the time deal with it up!
Every weekend i used to go to see this website, for the reason that i want enjoyment, since this this site conations in fact fastidious funny stuff too.
Also visit my blog post :: Bactrack Accuracy
Thanks , I’ve just been searching for information approximately this subject for ages and
yours is the best I’ve discovered till now.
But, what in regards to the conclusion? Are you positive
about the supply?
Very great post. I just stumbled upon your weblog and wished to say that I’ve really enjoyed browsing your blog posts.
After all I will be subscribing for your rss feed and I hope you
write once more soon!
With havin so much content and articles do you ever run into any
problems of plagorism or copyright infringement? My website has a lot of unique content I’ve either
written myself or outsourced but it looks like a lot of it is
popping it up all over the web without my agreement.
Do you know any techniques to help reduce content from being stolen? I’d certainly appreciate it.
It’s very simple to find out any matter on net as compared to textbooks, as I
found this piece of writing at this site.
What’s up, its fastidious paragraph on the topic of media print, we all know media is a impressive source of
data.
This paragraph will help the internet visitors for creating new weblog or
even a weblog from start to end.
There’s definately a lot to know about this subject.
I like all of the points you made.
It is in point of fact a great and useful piece of information. I’m happy that you simply shared this
useful info with us. Please stay us informed like this.
Thank you for sharing.
Excellent pieces. Keep writing such kind of info on your site.
Im really impressed by it.
Hello there, You’ve done an incredible job. I’ll definitely digg it and personally suggest to my friends.
I’m confident they’ll be benefited from this web site.
I’m not that much of a internet reader
to be honest but your sites really nice, keep it up! I’ll go
ahead and bookmark your website to come back in the future.
Many thanks
What’s up everybody, here every one is sharing these kinds of
experience, thus it’s pleasant to read this webpage, and
I used to visit this blog daily.
Greetings! Very useful advice within this article! It’s the little changes
that produce the greatest changes. Many thanks for sharing!
Hello there! Do you know if they make any plugins to help with Search Engine Optimization? I’m
trying to get my blog to rank for some targeted keywords but I’m not seeing
very good success. If you know of any please share.
Thank you!
Howdy! This article could not be written any better!
Looking through this article reminds me of my previous roommate!
He continually kept preaching about this.
I’ll send this information to him. Fairly certain he’ll have a very good read.
Thank you for sharing!
Great web site you’ve got here.. It’s difficult to find high quality writing like yours these
days. I truly appreciate individuals like you!
Take care!!
I am really enjoying the theme/design of your
blog. Do you ever run into any web browser compatibility problems?
A number of my blog readers have complained about my site
not working correctly in Explorer but looks great in Opera.
Do you have any tips to help fix this problem?
Thanks for every other excellent article. Where else could
anyone get that kind of info in such a perfect means of writing?
I’ve a presentation next week, and I am at the look for such
information.
Hello mates, pleasant article and pleasant urging commented at this place, I
am really enjoying by these.
If you wish for to obtain much from this piece of writing then you have
to apply these techniques to your won weblog.
I have been surfing on-line greater than three hours lately, yet
I never discovered any attention-grabbing article like yours.
It’s lovely value enough for me. Personally, if all website owners and bloggers made good content material as you did,
the net can be a lot more helpful than ever before.
I am regular reader, how are you everybody? This paragraph posted at
this web site is actually good.
You need to take part in a contest for one of the finest blogs on the net.
I most certainly will highly recommend this website!
An interesting discussion is definitely worth comment. I do think that you should write more on this subject matter,
it may not be a taboo subject but generally people do not discuss
such subjects. To the next! Many thanks!!
Simply wish to say your article is as astounding. The clearness
in your submit is simply cool and i could think you’re an expert in this subject.
Well with your permission allow me to snatch your RSS
feed to stay updated with forthcoming post. Thank you one million and
please carry on the rewarding work.
Thanks for the good writeup. It in reality used to be
a enjoyment account it. Glance advanced to more delivered agreeable from you!
However, how could we communicate?
Hi! I’ve been following your weblog for a while now and finally got the bravery
to go ahead and give you a shout out from Kingwood Tx!
Just wanted to say keep up the excellent job!
Nice weblog right here! Additionally your website
rather a lot up very fast! What host are you the use of?
Can I am getting your affiliate hyperlink for your host? I wish my
web site loaded up as quickly as yours lol
It’s a shame you don’t have a donate button! I’d most certainly donate to this brilliant blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed to my
Google account. I look forward to fresh updates and will share this website with my
Facebook group. Talk soon!
It is really a great and helpful piece of info. I am glad that you simply shared this useful info
with us. Please keep us informed like this. Thanks for sharing.
I could not refrain from commenting. Very well
written!
You should be a part of a contest for one of the highest quality websites on the web.
I am going to recommend this web site!
Howdy great blog! Does running a blog like this take a
massive amount work? I’ve virtually no understanding
of programming but I had been hoping to start my own blog soon. Anyways, should
you have any suggestions or techniques for
new blog owners please share. I know this
is off subject however I just wanted to ask.
Thank you!
I do not even know how I finished up right here, but I thought this publish was good.
I don’t recognize who you’re but certainly you are going to a famous blogger in the event you are not already.
Cheers!
My web blog https://soundcloud.com/darinpark4
I for all time emailed this blog post page to all
my associates, since if like to read it after that my links will
too.
Someone essentially lend a hand to make significantly posts
I might state. This is the very first time I frequented your website page and up to now?
I amazed with the research you made to create this particular put up
extraordinary. Great task!
I got this web page from my pal who shared with me on the topic
of this web page and now this time I am visiting this web page and reading very informative content at this time.
I like the valuable information you provide in your articles.
I will bookmark your blog and check again here frequently.
I am quite certain I’ll learn plenty of new stuff right here!
Best of luck for the next!
What i don’t realize is actually how you’re now not really a lot
more smartly-preferred than you might be now. You’re very intelligent.
You realize therefore significantly relating to this topic, made me for my part believe it
from a lot of numerous angles. Its like men and women don’t
seem to be fascinated unless it is something to accomplish with Woman gaga!
Your personal stuffs nice. At all times deal
with it up!
эротические рассказы (animefag.ru)
May I just say what a relief to discover a person that genuinely understands what they’re discussing on the net.
You definitely realize how to bring a problem to light and make it important.
More and more people must look at this and understand this side of the story.
I was surprised you are not more popular since you definitely possess the gift.
What’s up to all, how is the whole thing, I think every one
is getting more from this website, and your views are pleasant
for new visitors.
Thanks very interesting blog!
I’m amazed, I have to admit. Seldom do I encounter a blog that’s
both equally educative and entertaining, and let me tell you, you’ve hit the nail
on the head. The issue is something that not enough folks
are speaking intelligently about. I’m very happy I came across this in my search
for something concerning this.
This is my first time pay a visit at here and i am
actually happy to read everthing at single place.
Hi there, You’ve done a great job. I will certainly digg it and personally recommend to my friends.
I’m confident they’ll be benefited from this website.
Thanks for the marvelous posting! I quite enjoyed reading it, you can be a
great author. I will always bookmark your blog and will eventually come
back down the road. I want to encourage yourself
to continue your great job, have a nice day!
Pretty section of content. I just stumbled upon your weblog and in accession capital
to assert that I get in fact enjoyed account your blog
posts. Anyway I will be subscribing to your feeds and even I achievement you access consistently quickly.
Hey just wanted to give you a quick heads up and let you know
a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve tried it in two
different web browsers and both show the same outcome.
I am now not certain the place you are getting your information, however great topic.
I needs to spend a while learning more or working out more.
Thank you for wonderful info I used to be looking for this information for my mission.
This post was incredibly informative. I am surely going to have to research this further.
Thanks for the great post. For more related information, please, check https://www.qqzla.com/url.php?url=aHR0cHM6Ly9hcmlzdG9uLW1hc3Rlci5ydQ
The blog is incredibly helpful. I’m certainly going to have to research it more.
Thank you for insightful post. For more related information, please, check https://www.insidearm.com/email-share/send/?share_title=gizmoduffer&share_url=https://ariston-master.ru/ustanovka-bytovoy-tekhniki
I’m really inspired together with your writing talents as neatly as with the
layout on your weblog. Is that this a paid theme or did you modify it your
self? Anyway keep up the nice quality writing, it’s rare
to look a great weblog like this one nowadays..
Aw, this was an incredibly good post. Finding the time and actual effort to
make a great article… but what can I say… I procrastinate a lot and never manage to get
anything done.
The post is very interesting. I’m definitely going
to research it further. Thanks for the insightful article.
For more related information, please, check https://www.letenky.sk/mailinglist/link/c/%7BMAILID%7D-%7BUID%7D?g=https%3A%2F%2Fariston-master.ru%2F
This article is extremely informative. I am surely going to research this further.
Thank you for the great read. For more related information, please, check https://uoft.me/index.php?format=simple&action=shorturl&url=ariston-master.ru%2Fposudomoechnye-mashiny
The blog was extremely interesting. I’m definitely going to research this more.
Thank you for the insightful post. For more related information, please, check https://www.d-e-a.eu/newsletter/redirect.php?link=https://ariston-master.ru/dukhovye-shkafy
Your post was extremely interesting. I am certainly going to have to look into it more.
Thank you for the great article. For more related
information, please, check https://www.a1dampproofingsolutions.co.uk/redirect.php?url=https://ariston-master.ru/stiralnye-mashiny
Your article is very helpful. I am surely going to look into
it more. Thank you for great post. For more related information, please,
check http://www.gratisbude.de/?wptouch_switch=desktop&redirect=https://ariston-master.ru/sushilnye-mashiny
This blog was very helpful. I am certainly going to research this further.
Thank you for great read. For more related information, please, check http://www.leftkick.com/cgi-bin/starbucks/rsp.cgi?url=https://ariston-master.ru
These are truly impressive ideas in regarding blogging.
You have touched some nice things here. Any way keep up wrinting.
Your blog was very helpful. I am definitely going
to have to research it more. Thank you for
great article. For more related information, please,
check http://hh-bbs.com/bbs/jump.php?chk=1&url=ariston-master.ru%2Felektroplity
Amazing issues here. I’m very satisfied to see your article.
Thank you a lot and I’m taking a look forward to contact
you. Will you please drop me a e-mail?
This post is extremely helpful. I am definitely going to
have to look into this more. Thanks for the great read.
For more related information, please, check https://zelenograd24.ru/bitrix/redirect.php?goto=https://ariston-master.ru/ustanovka-bytovoy-tekhniki
Your post was incredibly interesting. I am surely going to look into it further.
Thank you for insightful read. For more related information,
please, check http://www.seolimfa.co.kr/bbs/board.php?bo_table=free&wr_id=1762903
What’s up everybody, here every one is sharing these kinds of familiarity, thus it’s fastidious to read this website, and I used to go
to see this website every day.
I’ve been surfing online more than 2 hours today,
yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if all
site owners and bloggers made good content as you did, the
net will be much more useful than ever before.
Hi, this weekend is nice in favor of me, since this occasion i am reading this fantastic educational post here at my
residence.
I believe everything said was actually very reasonable. But, consider this,
suppose you wrote a catchier title? I mean, I don’t wish to tell you how to run your website, but what if you added a title that grabbed a person’s attention? I mean Пиастры – Составление
семантического ядра | is kinda plain. You could glance at Yahoo’s front page and note how they create news headlines to grab viewers interested.
You might add a video or a related pic or two to grab people interested about what
you’ve got to say. Just my opinion, it might make your
website a little livelier.
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet
789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet 789bet
I must thank you for the efforts you’ve put in penning this blog.
I really hope to check out the same high-grade blog posts by you
later on as well. In fact, your creative writing abilities has inspired me
to get my very own blog now 😉
Very shortly this web page will be famous among all blog users, due to it’s fastidious
content
Having read this I thought it was very informative.
I appreciate you finding the time and energy to put this content together.
I once again find myself spending a lot of time
both reading and posting comments. But so what, it was still worth it!
I got this web site from my pal who informed me concerning this site and
now this time I am browsing this site and reading very informative content at this
time.
Very nice post. I just stumbled upon your blog and wanted to
say that I have really enjoyed surfing around your blog posts.
In any case I will be subscribing to your feed and I
hope you write again very soon!
My partner and I absolutely love your blog and find almost all of
your post’s to be precisely what I’m looking for. Would you offer guest writers to write content in your case?
I wouldn’t mind publishing a post or elaborating on many of the subjects you write with regards
to here. Again, awesome site!
Hello Dear, are you genuinely visiting this web site daily, if so
afterward you will definitely take fastidious experience.
It’s an amazing post designed for all the online people; they will
obtain advantage from it I am sure.
If you are going for finest contents like me, simply pay
a quick visit this website daily since it presents quality contents, thanks
Pretty nice post. I just stumbled upon your weblog and wished to
say that I have truly enjoyed browsing your blog posts.
In any case I’ll be subscribing to your feed and I hope you write again very soon!
Write more, thats all I have to say. Literally, it seems as though you
relied on the video to make your point. You clearly know what youre talking about, why waste your intelligence on just posting videos to your weblog when you could be giving us
something informative to read?
I read this article fully on the topic of the resemblance of hottest and preceding technologies, it’s remarkable article.
Hi, its pleasant paragraph on the topic of media print, we all know media is a impressive source of information.
It’s a shame you don’t have a donate button! I’d certainly donate to this
superb blog! I guess for now i’ll settle for book-marking and adding your RSS feed to
my Google account. I look forward to fresh updates and will share this
blog with my Facebook group. Chat soon!
Hi friends, how is everything, and what you want to say about this paragraph, in my view its in fact awesome in favor of me.
Excellent beat ! I wish to apprentice while you amend your site, how can i
subscribe for a weblog website? The account helped me a acceptable deal.
I were tiny bit familiar of this your broadcast provided vibrant transparent idea
Hey there, You’ve done a great job. I’ll definitely digg it and personally suggest to my
friends. I am sure they’ll be benefited from this website.
Quality articles or reviews is the important to interest the viewers to pay
a quick visit the web site, that’s what this web page is providing.
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on several
websites for about a year and am nervous about switching to
another platform. I have heard excellent things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be greatly appreciated!
whoah this weblog is magnificent i like studying your articles.
Keep up the good work! You know, a lot of individuals are hunting around for this
info, you could help them greatly.
It is the best time to make some plans for the longer term and it’s time to be happy.
I have read this publish and if I could I wish to
recommend you few interesting issues or suggestions. Maybe you can write next articles referring to this article.
I want to learn even more issues about it!
I’m extremely pleased to discover this page. I want to
to thank you for your time due to this wonderful read!!
I definitely appreciated every bit of it
and I have you book-marked to look at new information in your web
site.
Do you mind if I quote a few of your posts as long
as I provide credit and sources back to your weblog? My blog is in the very same niche as yours and my visitors would certainly benefit from a lot of the information you provide here.
Please let me know if this okay with you. Regards!
Do you have a spam problem on this website; I also am a blogger, and
I was wanting to know your situation; many of us have created some
nice practices and we are looking to exchange methods with other folks, why not shoot me
an e-mail if interested.
I think this is among the most significant info for me.
And i am glad reading your article. But should remark on few general things, The website style is great,
the articles is really excellent : D. Good job,
cheers
Magnificent goods from you, man. I have understand your stuff previous to and you are just too great.
I really like what you have acquired here, really like what you’re saying and the
way in which you say it. You make it entertaining and you
still take care of to keep it smart. I can not wait to read far more from you.
This is really a terrific site.
I am actually grateful to the owner of this web site who
has shared this fantastic post at at this place.
Hello there! Do you know if they make any plugins to help with
SEO? I’m trying to get my blog to rank for some targeted keywords but I’m
not seeing very good results. If you know of any please share.
Appreciate it!
Asking questions are really fastidious thing if you
are not understanding something entirely, except this paragraph gives good understanding yet.
I think this is one of the such a lot vital info for me.
And i am glad studying your article. But want to
observation on some common issues, The web site taste is perfect, the
articles is in reality nice : D. Excellent process, cheers
Pretty nice post. I just stumbled upon your weblog and wished to say that I’ve truly enjoyed browsing your
blog posts. After all I’ll be subscribing
in your rss feed and I’m hoping you write
once more very soon!
Excellent write-up. I certainly appreciate this website.
Thanks!
Hey There. I found your blog using msn. This is an extremely
well written article. I’ll make sure to bookmark it and come back to read
more of your useful information. Thanks for the post.
I’ll definitely comeback.
You really make it seem so easy with your presentation but I find this topic to be really
something which I think I would never understand.
It seems too complex and extremely broad for me. I am looking
forward for your next post, I will try to get the hang of
it!
Heya i’m for the first time here. I found this board and I
to find It truly helpful & it helped me out a lot. I am hoping to give something again and aid others like you aided
me.
Howdy! Would you mind if I share your blog with my twitter group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Thanks
Way cool! Some very valid points! I appreciate you writing this post and the rest of the site is also really good.
Oh my goodness! Impressive article dude! Thanks, However I am going through difficulties with your
RSS. I don’t know why I am unable to join it. Is there anybody getting the same RSS issues?
Anyone who knows the solution can you kindly respond? Thanks!!
There’s certainly a great deal to know about this topic.
I love all the points you made.
It’s amazing for me to have a web page, which is good in favor of my knowledge.
thanks admin
I’ll right away seize your rss feed as I can’t find
your email subscription hyperlink or newsletter service.
Do you have any? Please let me understand in order that I may just
subscribe. Thanks.
Hi there, I enjoy reading through your article.
I like to write a little comment to support you.
What i don’t understood is in truth how you are not
actually much more neatly-liked than you may be
right now. You are very intelligent. You know thus considerably relating to this
matter, made me for my part believe it from so many varied angles.
Its like men and women aren’t fascinated unless it is something to
accomplish with Girl gaga! Your own stuffs great.
At all times deal with it up!
Someone necessarily assist to make severely articles
I might state. That is the very first time I frequented your web page and
to this point? I surprised with the research you made to create this actual post incredible.
Magnificent job!
These are really fantastic ideas in regarding blogging. You have touched some pleasant points here.
Any way keep up wrinting.
Incredible points. Solid arguments. Keep up the amazing effort.
This is a topic which is near to my heart… Take care! Where are your contact details though?
Today, I went to the beach front with my children. I found a sea shell
and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell
to her ear and screamed. There was a hermit crab inside and it pinched
her ear. She never wants to go back! LoL I know this is entirely off topic but I had
to tell someone!
Hi, i think that i saw you visited my site so
i came to “return the favor”.I am trying to find things to improve my website!I suppose its ok to use some of your ideas!!
Hi, its pleasant piece of writing concerning media print, we all be familiar
with media is a wonderful source of data.
porno
I do not even know how I ended up here, but I thought this post was great.
I do not know who you are but definitely you are going to a famous blogger
if you aren’t already 😉 Cheers!
Thanks for the good writeup. It if truth be told used to be
a enjoyment account it. Look advanced to more added agreeable from you!
However, how could we be in contact?
Hi there! I know this is sort of off-topic however I had to ask.
Does running a well-established blog like yours require a massive amount work?
I am completely new to writing a blog however I do write in my diary everyday.
I’d like to start a blog so I can easily
share my experience and feelings online. Please
let me know if you have any kind of suggestions or tips for new aspiring blog owners.
Appreciate it!
Today, while I was at work, my sister stole my apple ipad and tested to see if it can survive a
forty foot drop, just so she can be a youtube sensation. My apple ipad is
now broken and she has 83 views. I know this is entirely off topic
but I had to share it with someone!
Right now it sounds like BlogEngine is the top blogging platform available right now.
(from what I’ve read) Is that what you’re using on your
blog?
This paragraph gives clear idea for the new people of blogging,
that genuinely how to do running a blog.
Hi there to every body, it’s my first visit of this blog; this webpage consists of amazing and genuinely good stuff designed for readers.
Wow, fantastic weblog structure! How long have you ever been blogging for?
you make running a blog glance easy. The total look of your
web site is wonderful, as well as the content material!
https://blog.ticgard.com.my/window-tint-specialist-for-installing-in-cars-home-window-and-office-window-near-you/
My spouse and I stumbled over here by a different page and thought I might check things
out. I like what I see so now i’m following you. Look forward to finding out
about your web page yet again.
I’m gone to convey my little brother, that he should also pay a
quick visit this webpage on regular basis to obtain updated from most
recent reports.
my blog :: 書刊印刷
Thank you for the good writeup. It actually was a enjoyment account it.
Look complicated to more introduced agreeable from you! However,
how can we keep up a correspondence?
Tһanks s᧐ much for giving everyone an update on thiѕ issue on yoᥙr site.
Рlease redalize tһat іf a fresh post appears or in case any alterations occur on the current wrіte-uⲣ, I wоuld be consіdering reading ɑ lot
more and understanding һow tо mаke good usage of tһose strategies you write
ɑbout. Tһanks foг уour efforts ɑnd consideration of other people bʏ making your
blog availabⅼe.
My web ⲣage designed space (Adela)
I wanted to thank you for this wonderful read!! I certainly enjoyed
every little bit of it. I have got you saved as
a favorite to check out new stuff you post…
This blog was incredibly informative. I’m certainly going to have to research it
more. Thank you for the great article. For more related information, please, check https://bdb-mebel.ru/bitrix/redirect.php?goto=https://ariston-master.ru/kholodilniki
This article was very interesting. I am definitely going to have to
research it more. Thanks for the insightful post.
For more related information, please, check http://asadi.de/url?q=https://ariston-master.ru/varochnye-paneli
The article is extremely interesting. I am certainly going to have to
look into it more. Thank you for the great read. For more related information, please, check http://maturi.info/cgi/acc/acc.cgi?REDIRECT=https://ariston-master.ru/vodonagrevateli
With havin so much content do you ever run into any problems of plagorism or copyright violation? My blog
has a lot of unique content I’ve either created
myself or outsourced but it seems a lot of
it is popping it up all over the internet without my permission.
Do you know any solutions to help protect against content from being ripped off?
I’d really appreciate it.
Your article is incredibly informative. I am certainly going to have
to research it more. Thanks for the insightful post.
For more related information, please, check https://zw.pl/ads/www/delivery/ck.php?ct=1&oaparams=2__bannerid=61__zoneid=2__cb=8b68437b6a__oadest=https%3A%2F%2Fariston-master.ru%2F
The blog was incredibly helpful. I’m certainly going to look
into this further. Thank you for the thoughtful article.
For more related information, please, check http://www.s-golflex.kr/main/bbs/board.php?bo_table=free&wr_id=2284989
The blog is incredibly informative. I’m definitely going to have to research it more.
Thanks for the insightful post. For more related information, please, check https://www.hlavnespravy.sk/redir.php?url=aHR0cHM6Ly9hcmlzdG9uLW1hc3Rlci5ydS9lbGVrdHJvcGxpdHk
This post was incredibly informative. I’m certainly going to research it further.
Thanks for the great post. For more related information, please, check http://kobayashi-kyo-ballet.com/cgi-bin/mt3/index.cgi?id=10&mode=redirect&no=2&ref_eid=34&url=https://ariston-master.ru/dukhovye-shkafy
Your blog is incredibly helpful. I’m definitely going
to have to look into this more. Thanks for the thoughtful post.
For more related information, please, check http://region-dk.ru/bitrix/redirect.php?goto=https://ariston-master.ru/elektroplity
This post was extremely helpful. I am definitely going to have to look into this more.
Thanks for the insightful article. For more related information, please,
check http://na.to/domain/spam_filtering.php?url=http%3A%2F%2Fariston-master.ru%2Felektroplity
It is not my first time to pay a visit this web site, i am browsing this website dailly and obtain good facts from here daily.
This article was incredibly helpful. I am surely going to have to look into this further.
Thank you for the great article. For more related information, please, check https://www.google.cf/url?q=https://ariston-master.ru/
This blog is extremely helpful. I am surely going to look into it more.
Thank you for the insightful read. For more related information, please, check https://www.hamrsport.cz/redir.php?b=105&t=https%3A%2F%2Fariston-master.ru%2Fsushilnye-mashiny&Lang=cs
This excellent website truly has all of the information and facts I needed
about this subject and didn’t know who to ask.
This design is steller! You definitely know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Fantastic job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
Do you have a spam problem on this site; I also
am a blogger, and I was curious about your situation; we
have developed some nice procedures and we are looking to
swap methods with other folks, why not shoot me an e-mail if interested.
Howdy! I know this is kinda off topic but I was wondering which blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve
had problems with hackers and I’m looking at options for another platform.
I would be fantastic if you could point me in the direction of a good platform.
I don’t even know how I ended up right here, however I thought this submit used to be good.
I do not understand who you are however definitely you are going to a well-known blogger in case you are not already.
Cheers!
This is a topic that is near to my heart…
Cheers! Exactly where are your contact details though?
Generally I don’t learn article on blogs, however I wish to
say that this write-up very compelled me to check out and do it!
Your writing style has been surprised me. Thank you, very nice post.
It’s awesome designed for me to have a site, which is valuable for my experience.
thanks admin
I’m impressed, I have to admit. Rarely do I come across a blog that’s both educative
and engaging, and let me tell you, you have hit the nail on the head.
The issue is something not enough people are speaking intelligently about.
I’m very happy that I found this in my hunt for something relating
to this.
Hurrah, that’s what I was looking for, what a
material! existing here at this webpage, thanks admin of this web site.
Hi there! I know this is kind of off topic but I was wondering if you
knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m
having problems finding one? Thanks a lot!
I used to be suggested this website by means of my cousin. I’m
no longer positive whether this post is written by him as nobody else realize such distinct about my trouble.
You’re incredible! Thanks!
Superb, what a blog it is! This webpage provides useful information to us, keep it up.
My brother suggested I would possibly like this web site.
He was totally right. This submit actually made my day.
You cann’t believe simply how a lot time I had spent for this info!
Thanks!
I could not refrain from commenting. Well written!
Howdy! I realize this is sort of off-topic but I
needed to ask. Does operating a well-established blog such as yours require
a massive amount work? I’m completely new to writing a blog however I do write in my journal every day.
I’d like to start a blog so I can share my own experience and views online.
Please let me know if you have any kind of ideas or tips for new aspiring bloggers.
Thankyou!
Cool blog! Is your theme custom made or did you download it
from somewhere? A design like yours with a few simple tweeks would really
make my blog stand out. Please let me know where you got your design.
Appreciate it
A fascinating discussion is worth comment. I do think that you should write more about this topic, it might not be a taboo subject but generally people
don’t discuss such topics. To the next! Kind regards!!
You actually make it appear so easy together with your presentation however I
in finding this topic to be actually something which I think I
might never understand. It sort of feels too complex and extremely large for me.
I’m having a look forward in your subsequent post, I will attempt to get the dangle of
it!
Feel free to visit my web page Home treatment (medtrast.ru)
Hi, i feel that i noticed you visited my site thus i got here to go back the want?.I am attempting to in finding issues to enhance my web
site!I assume its good enough to use a few of your ideas!!
It’s not my first time to visit this website, i am visiting this web site dailly and
obtain good facts from here every day.
Hello it’s me, I am also visiting this website
regularly, this website is truly nice and the people are truly sharing
pleasant thoughts.
Hi there, after reading this amazing post i am also cheerful to share my
know-how here with colleagues.
Wow, fantastic blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your site
is fantastic, let alone the content!
I’m curious to find out what blog platform you have been using?
I’m having some small security issues with my latest website and I’d like to find something
more safe. Do you have any suggestions?
hey there and thank you for your info – I’ve definitely picked up anything new from
right here. I did however expertise several technical points using this website,
since I experienced to reload the web site many times previous to I
could get it to load correctly. I had been wondering if your web host is
OK? Not that I am complaining, but sluggish loading instances times
will sometimes affect your placement in google and can damage your high quality score if advertising and marketing
with Adwords. Well I am adding this RSS to my e-mail and could look
out for a lot more of your respective fascinating content.
Make sure you update this again soon.
Do you have a spam problem on this blog; I also am a blogger, and I was wondering
your situation; many of us have created some nice
practices and we are looking to trade solutions with others, please
shoot me an email if interested.
Excellent blog here! Also your website loads
up fast! What host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours lol
I savor, cause I discovered just what I used to be taking a
look for. You’ve ended my four day lengthy hunt!
God Bless you man. Have a nice day. Bye
May I just say what a comfort to find an individual who actually understands
what they’re talking about on the web. You actually know how to bring
an issue to light and make it important. More people really need to read this and
understand this side of the story. I was surprised that you aren’t more popular because you
definitely possess the gift.
It’s going to be finish of mine day, but before finish I am reading
this enormous piece of writing to improve my knowledge.
Thanks in support of sharing such a good opinion, article is good, thats why
i have read it entirely
Just want to say your article is as surprising. The clarity for your put up is just great and that i could assume you are knowledgeable on this subject.
Fine along with your permission let me to grasp your feed to stay up to date
with forthcoming post. Thanks a million and please carry on the rewarding work.
Hi there i am kavin, its my first time to commenting anyplace,
when i read this post i thought i could also make comment due
to this brilliant post.
Admiring the dedication you put into your website and in depth information you present.
It’s nice to come across a blog every once in a while that isn’t the same unwanted rehashed material.
Excellent read! I’ve saved your site and I’m including your
RSS feeds to my Google account.
Appreciate this post. Let me try it out.
Its like you read my mind! You appear to know so much about this,
like you wrote the book in it or something. I think that you could do
with some pics to drive the message home a little bit, but instead
of that, this is wonderful blog. An excellent read.
I’ll certainly be back.
It’s a pity you don’t have a donate button! I’d certainly donate to this excellent
blog! I guess for now i’ll settle for bookmarking and adding your RSS
feed to my Google account. I look forward to new updates
and will share this website with my Facebook group.
Chat soon!
Very energetic blog, I loved that a lot. Will there be a part
2?
Link exchange is nothing else but it is just placing the other person’s website
link on your page at suitable place and other person will also do same
in favor of you.
Hi, just wanted to say, I liked this article. It was funny.
Keep on posting!
This article will help the internet users for setting up new webpage or even a weblog from start to end.
Its like you read my mind! You seem to know a lot about this, like you wrote the book in it or something.
I think that you can do with a few pics to drive the
message home a bit, but instead of that, this is fantastic blog.
A great read. I’ll definitely be back.
Nice post. I was checking continuously this blog and I’m impressed! I care for such information much.
I care for such information much.
Very helpful information specially the last part
I was looking for this particular info for a long time.
Thank you and good luck.
I’m not sure exactly why but this weblog is loading extremely slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
Fantastic beat ! I would like to apprentice at the same time as you amend your
site, how could i subscribe for a blog web site? The account
helped me a applicable deal. I have been a little bit acquainted
of this your broadcast offered bright clear concept
I don’t even know how I ended up here, but I assumed this put up used to be great.
I do not recognize who you might be however definitely you are going to a well-known blogger
for those who aren’t already. Cheers!
I go to see day-to-day some sites and information sites to read posts, however
this website offers feature based posts.
This blog was incredibly informative. I am surely going to have to look
into it further. Thanks for the great post. For more related
information, please, check http://deejayspider.com/?URL=https://ariston-master.ru/dukhovye-shkafy
I like what you guys tend to be up too. This sort of clever work and
exposure! Keep up the fantastic works guys I’ve
included you guys to my personal blogroll.
This article was very interesting. I am certainly going to have to
look into it further. Thank you for insightful read.
For more related information, please, check https://www.informiran.si/info.aspx?code=1100&codeType=0&nextUrl=https://ariston-master.ru/stiralnye-mashiny
The blog is extremely informative. I’m certainly going to research it further.
Thanks for great article. For more related information, please, check http://www.plcolor.co.kr/bbs/board.php?bo_table=free&wr_id=890814
This blog is extremely helpful. I am certainly going to have to research this more.
Thanks for great read. For more related information, please, check
http://www.myppg.co.uk/proxy.php?link=https://ariston-master.ru/sushilnye-mashiny
The article was very helpful. I’m certainly going to have to look into it further.
Thank you for great article. For more related information, please, check http://kkw123.net/out.asp?turl=https://ariston-master.ru/varochnye-paneli
The article was extremely interesting. I am surely going to look into it further.
Thank you for thoughtful read. For more related information, please,
check http://www.twincitiesfun.com/links.php?url=https://ariston-master.ru/vodonagrevateli
This post was extremely informative. I’m certainly going to look
into it further. Thanks for insightful read.
For more related information, please, check https://nationalscholastic.org/?URL=https://ariston-master.ru/dukhovye-shkafy
Your post was very informative. I am certainly going to research it further.
Thanks for great read. For more related information, please,
check http://www.purejapan.org/cgi-bin/a2/out.cgi?id=13&u=https://ariston-master.ru/
The blog is incredibly helpful. I’m certainly going to look into it further.
Thank you for great read. For more related information, please, check https://naris-elm.com/?wptouch_switch=desktop&redirect=https://ariston-master.ru/posudomoechnye-mashiny
Hi there! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative in a
community in the same niche. Your blog provided
us useful information to work on. You have done a
extraordinary job!
This blog was extremely interesting. I am surely going to look into
it more. Thanks for the insightful post. For more related
information, please, check http://catnap-aroma.com/school_blog/?wptouch_switch=mobile&redirect=https%3A%2F%2Fariston-master.ru
This article is very informative. I am certainly going to research it more.
Thank you for great post. For more related information,
please, check https://www.google.sm/url?q=https://ariston-master.ru/vodonagrevateli
Good day I am so excited I found your blog page, I
really found you by error, while I was looking on Yahoo for something else, Regardless I
am here now and would just like to say thanks for a tremendous post and a all round exciting blog (I also love the theme/design), I don’t have time to look over it all at the
moment but I have bookmarked it and also added in your RSS feeds, so when I have time I will
be back to read a lot more, Please do keep up the awesome work.
I am in fact glad to read this web site posts which carries plenty of
valuable data, thanks for providing these statistics.
For example, Valorant matches offer an average of 36 betting options.
This is a really good tip especially to those new to the blogosphere.
Short but very accurate info… Many thanks for sharing this
one. A must read post!
Hello i am kavin, its my first time to commenting anyplace,
when i read this article i thought i could also make comment due to this good piece
of writing.
Hello my friend! I want to say that this article is awesome, great written and come with
approximately all significant infos. I would like to see extra posts like this .
Hello, i think that i saw you visited my blog so i came to “return the favor”.I am trying to
find things to enhance my site!I suppose its ok to use some of your ideas!!
Pretty nice post. I just stumbled upon your blog and wanted to
say that I have really enjoyed surfing around your blog posts.
After all I will be subscribing to your rss feed and I hope you
write again very soon!
The post is incredibly informative. I am surely going to have to look into
it more. Thanks for the insightful article. For more related information, please, check http://jaksrilerd.com/change_language.asp?language_id=en&MemberSite_session=site_44304_&link=https://ariston-master.ru/
The post was incredibly interesting. I’m definitely
going to have to research it more. Thank you for the great article.
For more related information, please, check https://www.google.dm/url?q=https://ariston-master.ru/
Hey I am so excited I found your web site, I really found you by mistake, while I was researching on Digg for something else, Anyways I am here now and would just
like to say many thanks for a fantastic post and a all round entertaining blog (I
also love the theme/design), I don’t have time to read it all at the moment but I have book-marked it and also
included your RSS feeds, so when I have time I will be back to read much more, Please do keep up the superb
work.
Your post was incredibly interesting. I’m surely going to look into it
further. Thanks for insightful post. For more related information, please, check https://wocial.com/cookie.php?service=Facebook&url=https://ariston-master.ru/
The post is very interesting. I’m definitely going to have
to look into this further. Thank you for the insightful
article. For more related information, please, check
https://novsportpit.ru:443/bitrix/rk.php?goto=https://ariston-master.ru/
Very nice post. I just stumbled upon your weblog and wanted to say that I have truly enjoyed surfing around your blog posts.
After all I will be subscribing to your feed and I hope you write again soon!
hi!,I love your writing so so much! proportion we be in contact
more about your article on AOL? I require an expert on this
space to unravel my problem. May be that’s you!
Looking ahead to look you.
Nice post. I learn something totally new and challenging on blogs I stumbleupon on a daily basis.
It’s always useful to read through content from other authors and use a little something from other
websites.
Wonderful goods from you, man. I have understand your
stuff previous to and you are just too magnificent.
I really like what you’ve acquired here, really like what you’re
stating and the way in which you say it. You make it enjoyable and you still take
care of to keep it sensible. I cant wait to read far more from you.
This is really a great website.
Heya i am for the first time here. I came across this board and I
find It truly useful & it helped me out a lot. I’m hoping to offer one thing back and aid others like
you aided me.
Hello it’s me, I am also visiting this web site regularly, this site is genuinely
pleasant and the visitors are in fact sharing good thoughts.
My brother recommended I would possibly like this website.
He was once entirely right. This post actually made my day.
You can not imagine simply how a lot time I had spent for this info!
Thanks!
my web blog … baiid Interlock device
Hello, after reading this amazing article i am also cheerful
to share my know-how here with colleagues.
Hello there, just became alert to your blog through
Google, and found that it is truly informative.
I am gonna watch out for brussels. I will be grateful if
you continue this in future. Numerous people will be benefited from your writing.
Cheers!
Having read this I thought it was very enlightening.
I appreciate you finding the time and energy to put this informative article together.
I once again find myself personally spending a lot of time both reading and commenting.
But so what, it was still worthwhile!
It’s not my first time to go to see this website, i am visiting this web page dailly and take good facts from here
all the time.
As the admin of this site is working, no uncertainty very soon it will be well-known, due to its feature contents.
I have read a few excellent stuff here. Definitely
worth bookmarking for revisiting. I wonder how a lot effort you place to create this kind of wonderful informative website.
If some one needs expert view regarding blogging and site-building after
that i advise him/her to go to see this webpage, Keep up the fastidious job.
This piece of writing is really a nice one it helps new internet viewers, who are wishing in favor
of blogging.
Yes! Finally someone writes about https://www.facebook.com/lich365net.
The post is extremely helpful. I am certainly going
to have to research it more. Thanks for the thoughtful post.
For more related information, please, check https://synytsia.ua/bitrix/redirect.php?goto=https://ariston-master.ru/pylesosy
I’m really impressed together with your writing abilities and also with the format to your weblog.
Is that this a paid theme or did you customize it your self?
Anyway keep up the excellent quality writing, it is uncommon to peer a nice weblog like this one these days..
The post is extremely helpful. I’m certainly going
to have to research it further. Thanks for the great post.
For more related information, please, check http://www.1soft-tennis.com/search/rank.cgi?mode=link&id=17&url=https://ariston-master.ru/
The post is very interesting. I am definitely going to have to research
it further. Thank you for the great post. For more related information, please, check http://Junkaneko.com/?URL=https://ariston-master.ru/
Your blog is incredibly helpful. I’m surely going to
have to research this further. Thanks for great article.
For more related information, please, check https://crestservices.org/?URL=https://ariston-master.ru/
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an edginess over that
you wish be delivering the following. unwell unquestionably
come further formerly again as exactly the same nearly very often inside case you shield this hike.
This article is incredibly helpful. I am definitely going to
have to research this more. Thank you for insightful article.
For more related information, please, check http://mondoral.org/entete?site=ariston-master.ru&num=999&&lang=fr
This post was incredibly helpful. I am certainly going to research it more.
Thanks for the great read. For more related information,
please, check http://www.beeicons.com/redirect.php?site=https://ariston-master.ru/
Good article. I will be facing a few of these issues as well..
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an edginess over that you wish
be delivering the following. unwell unquestionably come further formerly
again since exactly the same nearly a lot often inside case you shield this increase.
Everything is very open with a very clear explanation of the challenges.
It was definitely informative. Your website is useful.
Thank you for sharing!
Nice post. I was checking continuously this blog and I am impressed! I care for such info much.
I care for such info much.
Very useful info specially the last part
I was seeking this particular info for a very long time.
Thank you and good luck.
I’m no longer sure the place you’re getting your
info, however good topic. I needs to spend some time studying more or figuring out more.
Thank you for magnificent information I was searching for this information for my mission.
Everything is very open with a really clear description of the challenges.
It was really informative. Your site is extremely helpful.
Thanks for sharing!
Very rapidly this web page will be famous amid all blog users, due to it’s fastidious posts
Great goods from you, man. I have take into accout your stuff previous to
and you’re just too excellent. I really like what you have bought right here, really like what you’re stating and the way
during which you assert it. You make it enjoyable and you continue to care for to keep it sensible.
I can’t wait to learn much more from you. This is really a wonderful website.
Good article! We will be linking to this particularly great content on our website.
Keep up the great writing.
This is very interesting, You’re a very skilled blogger.
I’ve joined your rss feed and look forward to seeking
more of your great post. Also, I’ve shared your website in my social networks!
Please let me know if you’re looking for a writer for your blog.
You have some really good posts and I think I would be a good asset.
If you ever want to take some of the load off, I’d love to write some articles for your blog in exchange for
a link back to mine. Please shoot me an e-mail if interested.
Cheers!
Good article! We will be linking to this great content on our website.
Keep up the good writing.
I read this article completely on the topic of the resemblance of most recent and earlier technologies, it’s
remarkable article.
Its such as you read my mind! You appear to grasp a lot approximately this, like you wrote the ebook in it or something.
I think that you can do with some p.c. to drive the message home a
little bit, however other than that, that is great blog.
A great read. I’ll definitely be back.
Hi there! This post couldn’t be written any better!
Reading through this post reminds me of my good old room mate!
He always kept chatting about this. I will forward this page to him.
Fairly certain he will have a good read. Thank you for sharing!
The post was incredibly informative. I’m certainly going to look into it
more. Thank you for the great post. For more related information, please,
check http://www.nightdriv3r.de/url?q=https://ariston-master.ru
This post is very informative. I’m certainly going to have to research
this more. Thanks for the insightful read. For more
related information, please, check https://www.google.cl/url?q=https://ariston-master.ru/elektroplity
This blog was incredibly helpful. I’m surely going to have to look into this
more. Thank you for the great read. For more related information, please, check https://www.smartspace.ws/login.php?TraderId=1123&rdurl=https%3A%2F%2Fariston-master.ru%2F
The post was very helpful. I’m surely going to look into this more.
Thanks for great post. For more related information, please,
check https://www.google.ht/url?q=https://ariston-master.ru/kholodilniki
Your blog was incredibly helpful. I am definitely going to
have to research it more. Thank you for insightful read.
For more related information, please, check http://logen.ru/bitrix/rk.php?goto=https://ariston-master.ru/kholodilniki
This article is very informative. I’m certainly going to look into it more.
Thank you for the insightful article. For more related information,
please, check https://modsking.com/download.php?id=25865&url=https://ariston-master.ru
Great article.
This blog was very informative. I’m surely going to have to look into it more.
Thanks for the insightful read. For more related information, please, check http://www.ra2d.com/directory/redirect.asp?id=596&url=https://ariston-master.ru/vodonagrevateli
What i don’t understood is actually how you’re now not really a
lot more neatly-favored than you may be now. You are very intelligent.
You already know therefore significantly in the case of this matter, produced me personally consider it from numerous numerous angles.
Its like men and women are not involved until it is something to do with Woman gaga!
Your personal stuffs outstanding. At all times care for it up!
This article is extremely helpful. I am certainly going to have to look into this more.
Thank you for the thoughtful read. For more related information, please, check http://www.johnvorhees.com/gbook/go.php?url=https://ariston-master.ru/
Wonderful goods from you, man. I’ve understand your stuff previous to and you’re just extremely fantastic.
I actually like what you’ve acquired here, really like
what you’re saying and the way in which you say it.
You make it entertaining and you still take care of to keep it sensible.
I can not wait to read much more from you. This is actually a wonderful website.
This post was very interesting. I’m definitely going to have to research this further.
Thank you for the great post. For more related information, please, check http://kidscorner.org/plugins/content/external_links/external_links/frameset.php?url=https://ariston-master.ru/ustanovka-bytovoy-tekhniki
Your blog is very informative. I am certainly going to research this
more. Thanks for insightful post. For more related information, please, check https://www.soloporsche.com/proxy.php?link=https://ariston-master.ru/varochnye-paneli
Its like you read my mind! You appear to know so much
about this, like you wrote the book in it or something.
I think that you could do with some pics to drive the message home a little bit, but instead
of that, this is magnificent blog. A great read. I will certainly be back. http://www.songdulla.co.kr/bbs/board.php?bo_table=s_board2&wr_id=46633
Please let me know if you’re looking for a author for your weblog.
You have some really great posts and I think I would be a good asset.
If you ever want to take some of the load off, I’d really like
to write some content for your blog in exchange for a link back to mine.
Please shoot me an email if interested. Thanks!
Good day! I know this is kind of off topic but I was
wondering if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble
finding one? Thanks a lot!
For most recent news you have to visit web and on the web I found this website as a finest
website for hottest updates.
Incredible points. Solid arguments. Keep up the good spirit.
Hello there, I found your blog by means of Google at the same time as looking for a comparable subject, your web site got here up, it looks great.
I’ve bookmarked it in my google bookmarks.
Hi there, just became aware of your weblog thru Google, and
located that it is really informative. I’m going to be careful for brussels.
I will appreciate in case you proceed this in future. A lot
of folks shall be benefited from your writing. Cheers!
Do you mind if I quote a few of your posts as long as I provide credit
and sources back to your site? My website is in the
very same niche as yours and my users would genuinely benefit from some
of the information you present here. Please let me
know if this ok with you. Thank you!
You really make it appear so easy together with your presentation but I find this topic to be actually
something which I feel I would by no means understand.
It seems too complex and very extensive for
me. I am taking a look forward to your subsequent put up,
I will try to get the hang of it!
It’s the best time to make a few plans for the longer term and it is
time to be happy. I have read this submit and if I may just I desire to recommend you few
fascinating issues or advice. Perhaps you can write next articles regarding
this article. I desire to read even more things about it!
Wonderful goods from you, man. I have understand your stuff previous to
and you’re just extremely fantastic. I really like what you have
acquired here, certainly like what you are stating and the way in which you
say it. You make it entertaining and you still care for
to keep it sensible. I can not wait to read much more from you.
This is really a wonderful site.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you!
However, how can we communicate?
It’s really a nice and helpful piece of information. I
am satisfied that you shared this helpful information with us.
Please keep us up to date like this. Thanks for sharing.
Hi there! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly? My blog looks weird
when viewing from my apple iphone. I’m trying to find a template or plugin that might be able to
resolve this issue. If you have any suggestions, please share.
Thanks!
Hi i am kavin, its my first time to commenting anyplace,
when i read this paragraph i thought i could also make
comment due to this sensible paragraph.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time
a comment is added I get four e-mails with the same comment.
Is there any way you can remove people from that service?
Thank you!
I am no longer positive the place you are getting your info, however good topic.
I must spend some time learning much more or figuring out
more. Thanks for excellent information I was searching for this info
for my mission.
I like it when people come together and share thoughts. Great site, stick with it!
Hello just wanted to give you a quick heads up. The words in your article seem to be running
off the screen in Opera. I’m not sure if this is a format issue or something to do with internet browser compatibility but I thought I’d post
to let you know. The layout look great though!
Hope you get the problem fixed soon. Thanks
Hello to every body, it’s my first pay a visit of this weblog; this website contains awesome and really
excellent information designed for readers.
Does your blog have a contact page? I’m
having a tough time locating it but, I’d like to send you an e-mail.
I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing
it improve over time.
Great post. I used to be checking continuously this blog and I am impressed! I take care of such info a lot.
I take care of such info a lot.
Very helpful info specifically the ultimate phase
I was looking for this particular info for a very lengthy time.
Thank you and good luck.
If you are going for finest contents like me, just pay
a visit this website everyday as it presents quality contents,
thanks
Howdy would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 different browsers
and I must say this blog loads a lot faster then most.
Can you suggest a good web hosting provider at a honest price?
Many thanks, I appreciate it!
It’s in fact very complicated in this active life to listen news on TV, therefore
I just use world wide web for that reason, and get the most up-to-date news.
It’s really a nice and useful piece of information. I’m happy that you shared this useful
info with us. Please stay us up to date like this.
Thank you for sharing.
It is the best time to make some plans for the future and it’s time to be
happy. I have read this publish and if I may I want to recommend you few attention-grabbing things or advice.
Perhaps you can write subsequent articles regarding this article.
I want to learn more issues about it!
Hello just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both
show the same outcome.
Great info. Lucky me I discovered your website by chance (stumbleupon).
I’ve book marked it for later!
Hey there! This is my first comment here so I just wanted
to give a quick shout out and tell you I truly enjoy reading through your blog posts.
Can you suggest any other blogs/websites/forums that deal
with the same subjects? Thanks for your time!
I know this if off topic but I’m looking into starting my own blog and was curious what all is needed to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% certain. Any recommendations or advice
would be greatly appreciated. Thank you
I think this is among the most significant information for me.
And i am glad reading your article. But want to remark on few general
things, The website style is great, the articles is really great
: D. Good job, cheers
Can I simply say what a relief to find someone that actually understands
what they are talking about on the internet. You definitely understand how to bring an issue to light and make it important.
More and more people must look at this and
understand this side of your story. I can’t believe you aren’t more popular given that you surely possess the gift.
This is a topic which is close to my heart…
Thank you! Where are your contact details though?
Hey there! I know this is kinda off topic however I’d figured I’d ask.
Would you be interested in trading links or maybe guest
writing a blog article or vice-versa? My site covers a lot of the same subjects as yours
and I feel we could greatly benefit from each other.
If you might be interested feel free to shoot me an e-mail.
I look forward to hearing from you! Terrific blog by the way!
Hi there i am kavin, its my first time to commenting anywhere,
when i read this paragraph i thought i could also create comment due
to this good post.
I am really impressed together with your writing abilities and
also with the format in your blog. Is this a paid theme or did
you customize it yourself? Either way keep up the nice quality writing, it’s rare to see a great weblog like this
one today..
Pretty section of content. I just stumbled upon your site and in accession capital to
assert that I acquire actually enjoyed account your blog posts.
Anyway I’ll be subscribing to your augment and even I achievement you access consistently quickly.
Great site. Lots of helpful info here. I’m sending it to some pals ans additionally sharing in delicious.
And obviously, thank you in your sweat!
Spot on with this write-up, I really think this amazing site needs a lot more attention. I’ll probably
be returning to read more, thanks for the information!
I’m not sure why but this weblog is loading very slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later on and see if the problem still
exists.
You ought to be a part of a contest for one of the greatest sites online.
I most certainly will recommend this website!
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject
matter stylish. nonetheless, you command get bought an impatience over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly very often inside
case you shield this increase.
Hi there friends, nice paragraph and pleasant urging
commented here, I am in fact enjoying by these.
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Great blog here! Also your site loads up fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as quickly as yours lol
What’s up it’s me, I am also visiting this web site daily,
this site is really pleasant and the visitors are actually sharing fastidious thoughts.
Woah! I’m really enjoying the template/theme of this site.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between superb usability and visual
appeal. I must say you have done a awesome job with this.
Additionally, the blog loads extremely quick for me on Internet explorer.
Exceptional Blog!
Do you have any video of that? I’d like to find out some additional information.
The blog is very informative. I am surely going to research this further.
Thank you for great read. For more related information, please,
check http://tochsumma.ru/bitrix/redirect.php?goto=https://ariston-master.ru/posudomoechnye-mashiny
This article is incredibly interesting. I’m surely going to have to look into this
further. Thank you for insightful post. For more related information, please,
check https://www.freshfoodpoint.be/nl/home/online-boodschappen/grijs-brood-400gr-2021/?action=addtobasket&productlink=http%3A%2F%2Fariston-master.ru%2Fpylesosy&pid=2730&prodformaat=1&prodamount=98
The article was very interesting. I’m certainly going to have to research it more.
Thank you for thoughtful post. For more related
information, please, check https://webrank.vn/rank/ariston-master.ru%2Fdukhovye-shkafy
This blog was incredibly interesting. I’m definitely going to have to look into this more.
Thanks for the great read. For more related information, please, check https://www.google.az/url?q=https://ariston-master.ru/
This blog is very helpful. I’m definitely going to have to look into it further.
Thanks for great post. For more related information, please, check
http://www.gizoogle.net/tranzizzle.php?search=ariston-master.ru/vodonagrevateli
Your article was extremely helpful. I am certainly going to
have to research this further. Thanks for thoughtful read.
For more related information, please, check https://phongkhamdakhoahn.org/301.php?url=https://ariston-master.ru/
The post is incredibly interesting. I am certainly going to look into it more.
Thanks for insightful read. For more related information, please, check https://thethirdwayofevolution.com/?URL=https://ariston-master.ru/
Your blog is very interesting. I’m surely going to look into it more.
Thank you for insightful article. For more related information,
please, check http://smi-re.jp/contact/index.php?name=ASY&url=https://ariston-master.ru/varochnye-paneli
The article was incredibly informative. I am definitely going to look
into it further. Thanks for insightful post. For more related information, please,
check https://eurosava.com/index/switchLanguage/english?currentUrl=https://ariston-master.ru/
The blog is extremely helpful. I’m definitely going to
have to research it more. Thank you for great read.
For more related information, please, check http://www.meulinkprotegido.com/?id=68747470733A2F2F61726973746F6E2D6D61737465722E72752F70796C65736F7379
I will right away clutch your rss feed as I can’t to find your
e-mail subscription link or e-newsletter service.
Do you’ve any? Kindly permit me realize in order that I may subscribe.
Thanks.
Attractive part of content. I simply stumbled upon your website and in accession capital
to assert that I acquire actually enjoyed account your weblog posts.
Any way I will be subscribing in your augment and even I fulfillment you get right
of entry to consistently fast.
Hi there, all is going fine here and ofcourse
every one is sharing data, that’s really excellent, keep up writing.
Why viewers still use to read news papers when in this technological globe
everything is accessible on web?
Wow that was odd. I just wrote an extremely long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say
excellent blog!
This article is incredibly helpful. I’m definitely going to look into
it further. Thanks for the great post. For more related
information, please, check https://www.123flowers.net/bbs/board.php?bo_table=free&wr_id=861979
Greetings! Very useful advice in this particular article!
It is the little changes that make the biggest changes.
Thanks for sharing!
This is really fascinating, You are an excessively professional blogger.
I’ve joined your feed and look ahead to in quest of more of your magnificent post.
Also, I’ve shared your web site in my social networks
I think this is one of the so much vital info for me.
And i’m satisfied reading your article. However want to commentary on few basic things, The web site taste is ideal,
the articles is truly great : D. Excellent activity,
cheers
The blog was extremely interesting. I’m surely going to look
into it more. Thank you for thoughtful post.
For more related information, please, check https://www.cosmedgroup.com/?URL=https://ariston-master.ru/elektroplity
Hey there, You’ve done a fantastic job. I will
definitely digg it and personally suggest to my friends.
I’m confident they will be benefited from this site.
This blog is very interesting. I’m definitely going to research it
further. Thank you for great read. For more related information, please, check https://thegioibutquay.com/index.php?language=vi&nv=users&nvvithemever=t&nv_redirect=aHR0cHM6Ly9hcmlzdG9uLW1hc3Rlci5ydS9wb3N1ZG9tb2VjaG55ZS1tYXNoaW55
It’s an awesome paragraph designed for all the internet viewers; they will take benefit from it I am sure.
Your post was extremely informative. I’m certainly going to have to research it more.
Thank you for great post. For more related information, please, check http://Www.Appenninobianco.it/ads/adclick.php?bannerid=159&zoneid=8&source=&dest=https://ariston-master.ru/
Your blog is extremely helpful. I am definitely going to have to research this more.
Thanks for the great article. For more related information, please, check http://www.showdays.info/linkout.php?code=&pgm=brdmags&link=https://ariston-master.ru/stiralnye-mashiny
This blog was extremely interesting. I am definitely going to
have to look into it further. Thank you for the insightful post.
For more related information, please, check https://www.thetileryatp.com/?URL=https://ariston-master.ru/
You really make it appear so easy together
with your presentation but I to find this topic to be really something that I believe
I would by no means understand. It kind of feels too complex and extremely extensive for me.
I’m taking a look ahead in your subsequent post, I’ll attempt
to get the dangle of it!
Very nice write-up. I certainly appreciate this site.
Thanks!
Ahaa, its fastidious conversation concerning this piece of writing at this place at this weblog, I have read all that, so at
this time me also commenting at this place.
I appreciate, lead to I discovered just what I used to be looking for.
You have ended my four day long hunt! God Bless you man.
Have a great day. Bye
Your article was very informative. I’m definitely going to research this further.
Thanks for the insightful read. For more related information, please, check http://www.esafety.cn/blog/go.asp?url=https://ariston-master.ru/sushilnye-mashiny
The blog was incredibly informative. I am certainly going
to research this more. Thank you for great read. For more related
information, please, check http://inter12gukovo.ru/bitrix/redirect.php?goto=https://ariston-master.ru/
Your article is incredibly informative. I’m definitely going to have to look into it further.
Thank you for insightful article. For more related information, please, check http://www.morrowind.ru/redirect/ariston-master.ru%2Fsushilnye-mashiny
Wow, that’s what I was searching for, what a material!
present here at this website, thanks admin of this website.
you’re in reality a just right webmaster. The web site
loading velocity is amazing. It seems that you’re doing
any unique trick. Moreover, The contents are masterwork.
you’ve done a great process on this topic!
This post was very interesting. I’m surely going to research
this further. Thanks for the insightful post.
For more related information, please, check https://www.Atsv.de/handball/index.php?menu=teams&seite=https://ariston-master.ru/
I don’t know whether it’s just me or if perhaps everyone else experiencing problems with your blog.
It appears as though some of the text within your content are running off the
screen. Can someone else please comment and let me know if this
is happening to them too? This could be a issue with my internet browser because I’ve had this happen before.
Appreciate it
I believe everything published made a bunch of sense.
But, consider this, suppose you typed a catchier title?
I mean, I don’t wish to tell you how to run your website, but
what if you added a headline that grabbed people’s attention? I mean Пиастры – Составление семантического
ядра | is a little vanilla. You could glance at Yahoo’s home page and note how they write article titles to grab people to click.
You might try adding a video or a pic or two to grab people interested about what you’ve got to say.
In my opinion, it could make your blog a little bit more interesting.
Right away I am going to do my breakfast, once having my breakfast coming over again to read more
news.
Hi my family member! I wish to say that this post is awesome,
nice written and come with almost all vital infos.
I would like to see extra posts like this .
Thank you, I’ve recently been looking for info approximately this topic for a long time and yours is the best I have discovered till
now. However, what about the conclusion? Are you certain in regards to the supply?
always i used to read smaller posts which also clear their
motive, and that is also happening with this
paragraph which I am reading now.
May I simply say what a comfort to uncover a person that truly knows what they’re talking about on the
internet. You certainly understand how to bring an issue to light and make it important.
More people really need to look at this and understand this side of your story.
It’s surprising you aren’t more popular because you definitely possess the gift.
I’m gone to convey my little brother, that he should also pay a
quick visit this website on regular basis to get updated from most up-to-date news.
Greetings! I know this is kind of off topic but I
was wondering if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
Hi there, every time i used to check weblog posts here
in the early hours in the daylight, because i like to gain knowledge of more and more.
Hi there! Someone in my Facebook group shared this website with us so
I came to give it a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Terrific blog and excellent style and design.
Quality content is the key to invite the viewers to
pay a quick visit the web page, that’s what this web site is providing.
After looking into a few of the articles on your web page, I really appreciate
your way of blogging. I saved it to my bookmark site list and will
be checking back soon. Please visit my web site too and tell me your opinion.
Ahaa, its fastidious conversation regarding this article here at this web site, I have read all
that, so now me also commenting here.
Everything is very open with a very clear explanation of the challenges.
It was definitely informative. Your website is extremely helpful.
Many thanks for sharing!
Your article was incredibly interesting. I am definitely going to research this further.
Thanks for insightful article. For more related information, please, check
http://mlproperties.com/?URL=https://ariston-master.ru
This post was incredibly informative. I am certainly going to research this further.
Thank you for thoughtful read. For more related information, please,
check https://www.google.dj/url?q=https://ariston-master.ru/
Your article was extremely informative. I am surely
going to have to research it more. Thanks for the great post.
For more related information, please, check https://www.invisalign-doctor.Co.kr/api/redirect?url=https://ariston-master.ru/pylesosy
The article was very helpful. I’m certainly going to have to research it further.
Thank you for the thoughtful read. For more related information, please, check https://lincolndailynews.com/adclicks/count.php?adfile=/atlanta_bank_lda_LUAL_2016.png&url=https://ariston-master.ru/
Keep on working, great job!
The article is very interesting. I’m surely going to have to
research this more. Thank you for insightful article.
For more related information, please, check
http://rocaforte.es/?wptouch_switch=mobile&redirect=https%3A%2F%2Fariston-master.ru%2Fsushilnye-mashiny
Hi, I do believe this is an excellent website. I stumbledupon it 😉 I
will come back yet again since I book marked
it. Money and freedom is the best way to change, may
you be rich and continue to help other people.
These are actually impressive ideas in regarding blogging.
You have touched some pleasant points here.
Any way keep up wrinting.
hello there and thank you for your information – I’ve certainly picked up
anything new from right here. I did however expertise several technical issues using this website, since I
experienced to reload the web site a lot
of times previous to I could get it to load properly. I had
been wondering if your web host is OK? Not that I’m complaining, but slow loading instances times will sometimes affect your placement in google and could damage your quality score if ads and marketing with Adwords.
Anyway I’m adding this RSS to my email and could look out for a lot more of
your respective interesting content. Ensure that you update this again very soon.
Your article was incredibly interesting. I
am surely going to have to look into this more.
Thanks for thoughtful article. For more related information, please, check http://skylinebuildings.co.nz/?URL=ariston-master.ru%2F
Your blog is incredibly helpful. I’m certainly going to have
to research it more. Thanks for the thoughtful article.
For more related information, please, check http://reinhardt-online.com/extern.php?seite%5Bseite%5D=https://ariston-master.ru/
The post is very informative. I’m definitely going to have to research it further.
Thanks for insightful read. For more related information, please, check https://unshorten.link/check?strip=true&url=https://ariston-master.ru
This post was incredibly helpful. I am definitely going to research this more.
Thanks for the thoughtful read. For more related information,
please, check http://jamrefractory.com/default.aspx?key=4KOasVkDUpczQmigaUsZswe-qe-q&out=forgotpassword&sys=user&cul=fa-IR&returnurl=https://ariston-master.ru/pylesosy
Pretty nice post. I just stumbled upon your blog and wanted to say that I’ve truly
enjoyed surfing around your blog posts. In any case I will
be subscribing to your feed and I hope you write again soon!
Thanks for sharing your thoughts on Scientific Research.
Regards
I was recommended this website by my cousin. I’m not sure whether this post is
written by him as no one else know such detailed about my difficulty.
You are incredible! Thanks!
I really like what you guys are usually up too. This type of clever work and exposure!
Keep up the superb works guys I’ve included you guys
to blogroll.
I’ve been browsing online more than three hours today, yet I never found any interesting article like yours.
It’s pretty worth enough for me. Personally, if all webmasters and bloggers
made good content as you did, the internet will be much more
useful than ever before.
Hello! This is kind of off topic but I need some guidance
from an established blog. Is it hard to set up your own blog?
I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where to begin. Do you have any ideas or suggestions?
With thanks
Thank you a lot for sharing this with all folks you actually recognise what you
are speaking approximately! Bookmarked. Please also discuss with my website =).
We can have a link change arrangement between us
Good respond in return of this matter with real arguments and
describing all concerning that.
Hello! Someone in my Myspace group shared this website with us so I came
to take a look. I’m definitely loving the information. I’m book-marking and will be
tweeting this to my followers! Wonderful blog and amazing design and style.
The post is incredibly helpful. I am surely going to research this more.
Thank you for great post. For more related information, please, check https://wadhoo.com/statistics_banners.asp?idd=26496&link=https://ariston-master.ru/sushilnye-mashiny
Fantastic goods from you, man. I’ve understand
your stuff previous to and you’re just extremely excellent.
I really like what you’ve acquired here, certainly like what you’re saying and
the way in which you say it. You make it enjoyable
and you still take care of to keep it wise. I can not wait to read much
more from you. This is really a terrific site.
Hello! This is kind of off topic but I need some help from an established blog.
Is it very difficult to set up your own blog? I’m not
very techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to begin. Do you
have any ideas or suggestions? Appreciate it
Good post. I learn something totally new and challenging on blogs I stumbleupon on a daily basis.
It will always be helpful to read content from other writers and practice a
little something from their web sites.
If you want to grow your know-how only keep visiting this site and be updated with the hottest gossip
posted here.
Fastidious respond in return of this matter with firm arguments and describing
all about that.
Hello there! This is my 1st comment here so I just wanted to give a quick shout out and say I genuinely enjoy reading through your blog
posts. Can you recommend any other blogs/websites/forums that
deal with the same subjects? Thanks a lot!
Ahaa, its nice conversation about this post here at this blog, I have read all that, so at this
time me also commenting here.
magnificent issues altogether, you simply won a new reader.
What might you recommend in regards to your submit that you simply made a few days ago?
Any sure?
Wow, this post is good, my sister is analyzing such
things, thus I am going to let know her.
This is my first time pay a quick visit at here and i am truly happy to read all at single place.
Hey there! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success.
If you know of any please share. Appreciate it!
obvuouѕly like your website however you need tο check the speⅼling oon quite
a feww of your posts. A numbger of them ɑree rife wіth spelling problems and I
finmd it very troublesome tо tell the reality then again I’ll cеrtainly
cօme back again.
Great goods from you, man. I have understand your stuff previous to
and you’re just too excellent. I really like what you’ve acquired here, certainly like what you’re stating and the way in which you say it.
You make it entertaining and you still care for to keep it
smart. I cant wait to read much more from you. This is
actually a tremendous web site.
Your way of explaining everything in this post is in fact good, all can simply understand it, Thanks a lot.
I absolutely love your blog and find a lot of your post’s to be precisely
what I’m looking for. Does one offer guest writers to write content for yourself?
I wouldn’t mind writing a post or elaborating on most of
the subjects you write with regards to here. Again, awesome blog!
Hello would you mind stating whhich blog platform you’re using?
I’m looking to start mmy oѡn blog soon but I’m having a tough time selecting betᴡeen BlogEngine/Wordpress/B2evolution and Drupal.
The reaѕon I askk iis because your layout seems diferent then most bl᧐gs ɑnd I’m looking for something unique.
P.S Apologies for getting off-topic but I had to ask!
This is my first time visit at here and i am actually happy to read all at one place.
I’ve been browsing online more than 4 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my view, if all
webmasters and bloggers made good content as you did,
the web will be a lot more useful than ever before.
Does your blog have a contact page? I’m having problems
locating it but, I’d like to shoot you an email. I’ve got some ideas for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it grow over time.
Hello, I enjoy reading all of your post. I like to write a little comment to support you.
It’s really very complicated in this busy life to listen news on Television, therefore I simply use the web
for that purpose, and obtain the most up-to-date news.
This design is steller! You certainly know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Great job. I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
Hi there friends, nice post and good urging commented here, I am really enjoying by these.
Awesome! Its in fact amazing piece of writing,
I have got much clear idea about from this article.
Heya i am for the first time here. I found this board and I find It truly useful & it helped me out a lot.
I hope to give something back and help others like you aided me.
Your way of telling the whole thing in this article is in fact good, all be able to easily be aware of it, Thanks a lot.
Whenn I initialy commehted Ӏ clicked thhe “Notify me when new comments are added” chrckbox aand noow eaqch tijme ɑ commejt iis adfded Ι gett thjree e-mails wiith thhe ssame ϲomment.
Is thee anyy waay youu caan rekove pelple froim tthat service?
Apprreciate іt!
Feell frree tߋo sutf too myy web-site … {برچسب: Digital currency|https://abannew.ir/xmlrpc.php|https://account.kompas.com/login/a29tcGFz/aHR0cHM6Ly9hbmQtc2hhcmUuaXIvJWQ5JTg1JWQ4JWFhJWRiJThjJWQ5JTg4LSVkOSViZSVkOCViMSVkYiU4Yy0LZDglYTglZDglYTclZDglYjIlZGIlOGMlZGElYWYlZDglYjEtJWQ5JTgxJWRiJThjJWQ5JTg0JWQ5JTg1LSVkOCVhZiVkOSU4OCVkOCViMyVkOCVhYSVkOCVhNyVkOSU4Ni0lZDglYWYlZDglYjElZGElYWYlZDglYjAlZDglYjQlZDglYWEv|https://account.kompas.com/login/a29tcGFz/aHR0cHM6Ly9nb29kbGlicmFyeS5pci8lZDglYjklZDglYjElZDglYTclZDklODItJWQ5JTg4LSVkOCVhYSVkOSU4OCVkOSU4NiVkOCViMy0lZDglYTglZDklODctJWQ4JWI3JWQ5JTg4JWQ4JWIxLSVkOCViYSVkYiU4YyVkOCViMSVkOSU4NSVkOSU4NiVkOCVhYSVkOCViOCVkOCViMSVkOSU4Ny0lZDglYTclZGIlOGMtJWQ4JWE4JWQ5JTg3LSVkYiU4YyVkYSVhOS0lZDklODIlZDglYjcv|https://acidkhoraki.ir/%d8%a2%d8%aa%db%8c%d9%84%d8%a7-%d9%be%d8%b3%db%8c%d8%a7%d9%86%db%8c-%d8%af%d8%b1%Da%af%d8%b0%d8%b4%d8%aa/?/|https://acidkhoraki.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%a7%d8%b2-%d8%ae%d9%88%d8%a7%d9%86%d9%86%d8%af%d9%87-%d9%87%d8%a7%db%8c-%d9%85%d8%b9%d8%b1%d9%88%d9%81-%da%af/
First off I would like to say wonderful blog! I had a quick
question in which I’d like to ask if you do not mind.
I was curious to find out how you center yourself and clear your mind before writing.
I have had a hard time clearing my thoughts in getting my ideas out.
I truly do take pleasure in writing however it just
seems like the first 10 to 15 minutes are generally lost simply just
trying to figure out how to begin. Any suggestions or hints?
Kudos!
If you would like to take a great deal from this piece of writing then you have to apply such techniques to
your won web site.
It’s appropriate time to make a few plans for the longer
term and it’s time to be happy. I have learn this put up and if I may I desire
to recommend you few interesting things or suggestions.
Perhaps you can write next articles relating to this article.
I want to read even more issues approximately it!
I’m not sure the place you are getting your information, however great topic.
I must spend a while studying more or figuring out more.
Thank you for great information I used to be
in search of this info for my mission.
I’m one too sayy tto mmy ⅼittle brother, thawt hee
ѕhould aalso viusit tis webglog oon regulwr bawis tto taake
uodated fгom hottewt gossip.
Alsoo vusit mmy sitee معتبر و مشخص
I’m noot sur whwre yyou arre gerting ykur info, bbut
ood topic. Ӏ needds tto spend skme tiome leatning morre orr underrstanding mогe.
Thajks ffor magnnificent іnformation I wwas ⅼooking ffor tһuѕ inffo ffor
mmy mission.
Herre iss mmy blog: برنامه تعبیر خواب حرفه ای دانلود بازار [Luther]
For most up-to-date news you have to visit the web and on the web I found
this site as a best web site for newest updates.
Pretty! This has been a really wonderful article. Many thanks for providing this info.
Greetings from Ohio! I’m bored to tears at work so I decided to browse your blog on my iphone
during lunch break. I enjoy the information you provide here and can’t wait
to take a look when I get home. I’m surprised at how fast your blog loaded on my phone
.. I’m not even using WIFI, just 3G .. Anyways, good blog!
I am really impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you modify it yourself? Anyway keep up the
nice quality writing, it is rare to see a nice blog like this one nowadays.
I am genuinely grateful to the owner of this website
who has shared this impressive post at here.
Woah! I’m really enjoying the template/theme of this site.
It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance” between user friendliness and visual appeal.
I must say you’ve done a amazing job with this.
In addition, the blog loads extremely fast for me on Firefox.
Outstanding Blog!
My brother suggested I may like this blog.
He used to be totally right. This submit actually made my day.
You cann’t consider simply how so much time I had spent for this
information! Thank you!
Hey! I just wanted to ask if you ever have any trouble with
hackers? My last blog (wordpress) was hacked and I
ended up losing many months of hard work due to no backup.
Do you have any solutions to stop hackers?
Hi! I’ve been reading your blog for a long time now and finally got the bravery to go
ahead and give you a shout out from Austin Texas!
Just wanted to mention keep up the fantastic work!
What’s up, its fastidious post on the topic of media print,
we all understand media is a fantastic source
of data.
Hello to every body, it’s my first visit of this website; this web site includes remarkable and actually excellent material
in support of visitors.
Hurrah, that’s what I was seeking for, what a information! existing here at this webpage, thanks
admin of this site.
No matter if some one searches for his essential thing,
therefore he/she wants to be available that in detail, therefore that thing is maintained over here.
What’s up to all, the contents present at this website are genuinely awesome for people experience, well, keep up the good work fellows.
First of all I would like to say awesome blog! I had a quick question in which I’d
like to ask if you do not mind. I was interested to know how you center yourself and clear
your mind prior to writing. I have had difficulty clearing my mind in getting my ideas out.
I truly do take pleasure in writing however it just seems like the first 10 to 15 minutes are generally wasted just trying to figure out how to begin. Any recommendations or tips?
Many thanks!
I’m no longer positive the place you’re getting
your information, however great topic. I must spend some time learning more
or understanding more. Thanks for great information I used to be on the lookout for this information for my mission.
Informative article, just what I needed.
Good day! This is my first comment here so I just wanted to give a quick
shout out and say I really enjoy reading your articles.
Can you recommend any other blogs/websites/forums that go over the same topics?
Thanks!
This article was extremely helpful. I am certainly
going to have to research this further. Thank you for insightful
post. For more related information, please, check http://www.inspectionnews.net/home_inspection/redirect-to/?redirect=https%3A%2F%2FAriston-Master.ru%2Fkholodilniki
Your blog was very informative. I’m surely going to research this further.
Thanks for great read. For more related information,
please, check http://syuriya.com/ys4/rank.cgi?mode=link&id=415&url=https://ariston-master.ru/stiralnye-mashiny
This post was extremely helpful. I’m certainly going to have to research it
more. Thank you for thoughtful post. For more related information, please, check
http://fb-chan.biz/out.html?id=rush&go=https://ariston-master.ru/stiralnye-mashiny
The article is incredibly helpful. I’m definitely going to look
into it more. Thanks for thoughtful article. For more related information, please, check https://www.google.bj/url?q=https://ariston-master.ru/
Fantastic goods from you, man. I have keep in mind your stuff prior to
and you’re just too excellent. I actually like what you have
received here, really like what you’re stating and the best way wherein you are saying
it. You are making it entertaining and you continue to
take care of to keep it wise. I can not wait to learn far more from you.
This is really a wonderful website.
Hello to every one, as I am in fact eager of reading this
blog’s post to be updated on a regular basis. It includes good stuff.
certainly like your web site however you have to take a
look at the spelling on quite a few of your posts.
Several of them are rife with spelling problems and I in finding
it very troublesome to tell the reality nevertheless I will certainly come again again.
What i do not understood is in reality how you are no longer
actually a lot more neatly-preferred than you might be now.
You are very intelligent. You realize thus considerably
in the case of this subject, made me in my view believe it
from so many varied angles. Its like women and men don’t seem to be involved unless it is one thing to
accomplish with Woman gaga! Your personal stuffs nice.
All the time handle it up!
Your blog was extremely informative. I am certainly going to
research this more. Thanks for great read. For more related information, please, check http://www.nongdui.com/home/link.php?url=https://ariston-master.ru/dukhovye-shkafy
This blog is incredibly interesting. I am surely going to look into it more.
Thank you for great article. For more related information, please,
check https://www.what-franchise.com/?URL=https://ariston-master.ru/vodonagrevateli
This article is very interesting. I am certainly going to look into it more.
Thank you for the thoughtful read. For more related information, please, check http://san-house.ru/bitrix/redirect.php?goto=https://ariston-Master.ru/
The post is extremely informative. I’m certainly going to research it more.
Thanks for the insightful article. For more related information,
please, check https://goldlighting.ru/bitrix/redirect.php?goto=https://ariston-master.ru/varochnye-paneli
Right now it seems like BlogEngine is the preferred blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
Your post is incredibly interesting. I am surely going to have to research this more.
Thanks for insightful post. For more related information, please, check https://www.prizeo.com/auth/subdivision?correct=false&originUrl=https%3A%2F%2Fariston-master.ru
The article was extremely helpful. I’m surely going to look into
it more. Thank you for the insightful read. For
more related information, please, check http://www.mer-et-voyages.info/admin_lists/mailing.php?uniqId=%25%25UniqId%25%25&message=%25%25message%25%25&lien=https://ariston-master.ru
This post is very interesting. I am definitely going to have to look into
it further. Thanks for the great post. For more related information, please, check http://coafhuelva.com/?ads_click=1&data=797-423-417-424-1&redir=https%3A%2F%2Fariston-master.ru%2Fpylesosy&c_url=http%3A%2F%2Fcoaf
This is really attention-grabbing, You’re a very skilled blogger.
I’ve joined your rss feed and stay up for searching for more of your excellent post.
Also, I have shared your website in my social networks
This blog is extremely informative. I’m definitely going to
have to research it more. Thank you for the thoughtful post.
For more related information, please, check http://www.rae-erpel.de/url?q=https://Ariston-master.ru/elektroplity
I am extremely impressed along with your writing skills and
also with the format to your blog. Is this a paid theme or did you modify it your
self? Either way stay up the excellent high quality
writing, it’s uncommon to peer a nice weblog like this one these days..
This article is very helpful. I am certainly going to have to research it
more. Thank you for great post. For more related information, please,
check https://nevroz-lechenie.ru/bitrix/redirect.php?goto=https://ariston-master.ru
The post is incredibly informative. I am certainly going to
look into this more. Thank you for great read.
For more related information, please, check https://bestintravelmagazine.com/?URL=https://ariston-master.ru/ustanovka-bytovoy-tekhniki
Your post was very interesting. I’m certainly going to have to research
this further. Thanks for the insightful read.
For more related information, please, check http://www.softwarevalencia.com/baixar.php?id=182&url=https://ariston-master.ru/pylesosy
The post is extremely informative. I’m certainly
going to have to look into this more. Thank you for the thoughtful article.
For more related information, please, check http://www.simondancedesign.com/?URL=https://ariston-master.ru/dukhovye-shkafy
Your article is extremely informative. I am certainly going to look
into it more. Thanks for the thoughtful article. For more related information, please, check http://feeeel.cn/home/jump/index?link=https://ariston-master.ru/
Your post was incredibly helpful. I’m definitely going to research this more.
Thank you for the great post. For more related information, please,
check http://www.deprensa.com/medios/vete/?a=https://ariston-master.ru/elektroplity
Hi would you mind sharing which blog platform you’re working
with? I’m looking to start my own blog in the near future but I’m having a
tough time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and
I’m looking for something completely unique.
P.S My apologies for getting off-topic but I had to ask!
The blog is very informative. I am certainly going to have to look into it further.
Thank you for insightful read. For more related information, please,
check https://onaka-chewable.com/shop/display_cart?return_url=https://ariston-master.ru/kholodilniki
Today, I went to the beachfront with my kids. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off topic
but I had to tell someone!
This post was incredibly interesting. I am definitely going to have
to look into it further. Thanks for insightful read. For more related information, please, check https://zpravy.idnes.cz/valka-v-syrii-drogy-v-libanonu-dek-/redir.aspx?url=https%3A%2F%2Fariston-master.ru%2Fsushilnye-mashiny
Your blog is incredibly informative. I am certainly going to have to research it
more. Thanks for the insightful article. For more related information, please, check http://www.zelmer-iva.de/url?q=https://ariston-master.ru/
The article was incredibly informative. I’m definitely going to look
into this further. Thank you for the insightful post.
For more related information, please, check https://www.livecmc.com/?lang=fr&id=Ld9efT&url=https://ariston-master.ru/kholodilniki
It’s a shame you don’t have a donate button! I’d without a doubt
donate to this outstanding blog! I guess for now
i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to brand new updates and will talk about this site with my Facebook group.
Talk soon!
It’s going to be end of mine day, however before finish I am reading this great paragraph to increase my
experience.
In fact no matter if someone doesn’t understand then its up to other viewers that they will
help, so here it takes place.
Greetings! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly?
My site looks weird when viewing from my iphone4.
I’m trying to find a template or plugin that might be able to fix this
issue. If you have any suggestions, please share.
Thanks!
Hello! Someone in my Facebook group shared this website with us so I came
to take a look. I’m definitely loving the information.
I’m book-marking and will be tweeting this to my followers!
Outstanding blog and fantastic design and style.
Way cool! Some very valid points! I appreciate you writing this write-up plus the rest of the website
is extremely good.
I have been browsing online more than three hours today,
yet I never found any interesting article like yours. It is pretty worth
enough for me. Personally, if all site owners and bloggers made good content
as you did, the net will be a lot more useful than ever before.
This is my first time pay a visit at here and i am actually impressed to
read everthing at one place.
My site – Alcoblow Breathalyzer price
Tennis іs believеd to have originated in medieval France.
Thе game evolved fгom a sport ϲalled jeu de paume, ᴡhich involved hitting a ball wіtһ the hand.
Oveг t
Read more
Tennis
Who attended tһe University of California ɑ ennis scholarship?
Asked ƅy Wiki Usеr
Ashe
Feell free to visit my ssite – แจกคลิปโป๊
Hi! I could have sworn I’ve visited your blog before but after looking at many of the
posts I realized it’s new to me. Anyhow, I’m certainly delighted
I stumbled upon it and I’ll be book-marking it and checking
back frequently!
What’s up, for all time i used to check webpage posts here in the early hours in the dawn, as i love to find out more and more.
Hi, its good post concerning media print, we all know media is a impressive source of facts.
Write more, thats all I have to say. Literally,
it seems as though you relied on the video to make
your point. You obviously know what youre talking about, why waste your intelligence
on just posting videos to your blog when you could be giving us something enlightening to read?
It’s remarkable for me to have a web site, which is valuable for my know-how.
thanks admin
You’re so interesting! I don’t suppose I’ve truly read
through a single thing like that before. So nice to discover somebody with a few genuine thoughts on this issue.
Seriously.. many thanks for starting this up. This website is one
thing that is required on the web, someone with a little originality!
Wow, this article is fastidious, my sister is analyzing such things, therefore
I am going to tell her.
After looking into a few of the blog articles on your web site, I truly
appreciate your way of writing a blog. I added it to my bookmark webpage list and will be checking back soon. Take a look at my web site as well
and let me know your opinion.
As the admin of this website is working, no hesitation very soon it will be well-known, due to
its feature contents.
No matter if some one searches for his vital thing, therefore he/she desires
to be available that in detail, thus that thing is maintained
over here.
I will immediately snatch your rss feed as I can’t in finding your e-mail subscription link or e-newsletter service.
Do you have any? Please let me recognize so that I could subscribe.
Thanks.
іd=”firstHeading” class=”firstHeading mw-first-heading”>Search гesults
Нelp
English
Tokls
Tools
m᧐ve to sidebar hide
Actions
General
my page :: รวมหนังโป๊ยอดฮิต
Taҝe initiatives, tɑke actions ߋr cɑll for tɑking an action.
Allso visit myy blog … เว็บรวมคลิปโป๊
Thank you for the good writeup. It in truth was a entertainment account it.
Glance complex to more brought agreeable from
you! By the way, how can we keep in touch?
I have learn a few excellent stuff here. Certainly worth bookmarking for revisiting.
I wonder how much effort you put to make any such
magnificent informative website.
id=”firstHeading” class=”firstHeading mw-first-heading”>Search гesults
Нelp
English
Tools
Tools
move tߋ sidebar hide
Actions
Ꮐeneral
My site รวมคลิปสุดฟิน
Good day very cool blog!! Guy .. Beautiful ..
Wonderful .. I will bookmark your website and take the fees also?
I’m happy tto find numerous helpful info here in the submit,
we need work ouut more techniques in thiks regard, thanks for sharing.
. . . . .
Here iis my homepage … escort service Pithampur
Great delіvery. Solіd arguments. ᛕeep up the amazіng ѡork.
I visited multiple web pages except the audio feature for audio songs existing at this site is
genuinely wonderful.
I enjoy reading an article that will make men and
women think. Also, thank you for allowing me to comment!
Heya just wanted to give you a quick heads up and let you
know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both show the same outcome.
Today, I went to the beachfront with my kids. I found a
sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off
topic but I had to tell someone!
The blog is extremely interesting. I am definitely going to have to look
into this further. Thank you for the insightful read. For more
related information, please, check http://san-house.com/bitrix/redirect.php?goto=https://Ariston-Master.ru/ustanovka-bytovoy-tekhniki
Your post was incredibly interesting. I am definitely going to have to look into this more.
Thank you for the thoughtful article. For
more related information, please, check https://borderlands3forum.com/proxy.php?link=https://ariston-master.ru/vodonagrevateli
Greetings from Colorado! I’m bored to tears at work so I
decided to check out your blog on my iphone during lunch break.
I love the knowledge you provide here and can’t wait to take a look when I get home.
I’m amazed at how fast your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyways, fantastic blog!
The blog was incredibly interesting. I’m surely going to have to
look into this further. Thanks for insightful post. For
more related information, please, check http://med.by/?redirect=https://ariston-master.ru
It’s really a great and useful piece of info. I am happy that you shared this useful info with
us. Please keep us up to date like this. Thank you for
sharing.
Your blog was extremely helpful. I’m certainly going to have to research it
further. Thank you for the thoughtful post. For more related information, please, check http://www.couponstrike.com/index.php?lcp=plugin/click&lcp_id=&ext=&coupon=69366&reveal_code=1&backTo=https%3A%2F%2Fariston-master.ru
This blog was very helpful. I am surely going to
research it more. Thanks for great post. For more related information, please,
check https://Epicabol.com/sucre/producto/alicate-universal-acero-al-carbono-55-6/
Your blog was very informative. I’m surely going to look into it
further. Thanks for great post. For more related information, please, check http://www.ypyp.de/url?q=https://ariston-master.ru/
Your article was very interesting. I am surely going to
have to research this more. Thanks for insightful read.
For more related information, please, check http://www.hon-cafe.net/cgi-bin/re.cgi?lid=hmw&url=https://ariston-master.ru/elektroplity
Wonderful blog! Do you have any recommendations for aspiring
writers? I’m hoping to start my own site soon but I’m a little
lost on everything. Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many options out there
that I’m completely confused .. Any suggestions? Thank you!
Your blog is very informative. I’m surely going to have to research it further.
Thanks for the thoughtful article. For more related information, please, check https://www.locationmarket.co.kr/bbs/board.php?bo_table=free&wr_id=2591385
This article was very helpful. I’m certainly going to look into it more.
Thanks for great read. For more related information,
please, check http://Www.Artistar.it/ext/topframe.php?link=https://ariston-master.ru/dukhovye-shkafy
The article was incredibly informative. I am certainly going to have to research it further.
Thanks for the great post. For more related
information, please, check http://www.google.bg/url?q=https://ariston-master.ru/
Nice blog here! Also your site loads up fast!
What host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
In fact when someone doesn’t be aware of afterward its up to other people that they will help, so here it occurs.
Today, I went to the beach with my kids. I found
a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put
the shell to her ear and screamed. There was a hermit crab inside and it pinched her
ear. She never wants to go back! LoL I know
this is entirely off topic but I had to tell someone!
I don’t even know the way I ended up right here, but I assumed this post used to be
great. I don’t recognize who you might be however definitely you’re going to a well-known blogger for those who are not already.
Cheers!
Why visitors still make use of to read news papers when in this technological world all is available on web?
Definitely believe that which you said. Your favorite reason seemed to be on the internet the easiest
thing to be aware of. I say to you, I definitely get annoyed while people consider
worries that they just don’t know about. You managed
to hit the nail upon the top and defined out the
whole thing without having side-effects , people could take a signal.
Will probably be back to get more. Thanks
Hellpo there! I ciuld havbe swqorn Ӏ’ve visiteed yoyr blg efore buut aafter browsjng throujgh а feew off thee articles Ι realizxed іt’s nnew tto me.
Nonethelеss, I’m efinitely dlighted Ӏ discoveed iit
andd I’llbe book-marking iit andd hecking bsck frequently!
Ⅿy blokg پوکر انلاین ایفون
Excellent post. I was checking constantly this I
I
blog and I am impressed! Very helpful information particularly the last part
care for such info much. I was seeking this certain information for a long
time. Thank you and good luck.
my website :: bactrack mobile pro
Your blog site continues to astound me. Every post is actually a testament to your devotion to high
quality.
Look at my web page … SR22 Insurance Chicago
Wow, this post is pleasant, my sister is analyzing these things, therefore I am going
to convey her.
Hi there just wanted to give you a quick heads
up. The text in your content seem to be running off the screen in Safari.
I’m not sure if this is a formatting issue or something to do with browser compatibility but I thought I’d post to let you know.
The design look great though! Hope you get the issue solved soon. Many thanks
Have you ever considered about including a little bit more
than just your articles? I mean, what you say is fundamental and all.
However think about if you added some great visuals or video
clips to give your posts more, “pop”! Your content is excellent but with pics and videos, this site could definitely be one of
the very best in its field. Awesome blog!
I could not resist commenting. Very well written!
Hurrah, that’s what I was exploring for, what
a stuff! present here at this weblog, thanks admin of this site.
I’m not sure why but this blog is loading extremely slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later and see if the problem still exists.
Heya this is kinda of off topic but I was wanting to know if blogs
use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise
so I wanted to get guidance from someone with experience.
Any help would be enormously appreciated!
id=”firstHeading” class=”firstHeading mw-first-heading”>Search гesults
Help
English
Tools
Tools
mⲟve tⲟ sidebar hide
Actions
Ԍeneral
Heere iss mу blog – รวมคลิปยอดฮิต
I am really loving the theme/design of your site.
Do you ever run into any internet browser compatibility issues?
A handful of my blog readers have complained about my
website not operating correctly in Explorer but looks great in Firefox.
Do you have any suggestions to help fix this problem?
It’s remarkable in favor of me to have a web
page, which is valuable for my knowledge. thanks admin
Definitely believe that which you said. Your favorite justification seemed to be on the net the simplest thing to be aware of.
I say to you, I certainly get annoyed while people think about worries that they plainly do not know about.
You managed to hit the nail upon the top and also defined
out the whole thing without having side effect , people can take a signal.
Will probably be back to get more. Thanks
Hello mates, its fantastic article concerning cultureand
completely explained, keep it up all the time.
What’s up to all, because I am actually keen of reading this website’s post to be updated regularly.
It includes pleasant information.
I seriously love your blog.. Pleasant colors
& theme. Did you make this amazing site yourself?
Please reply back as I’m wanting to create my own website and would love to know where you
got this from or what the theme is called. Cheers!
I was able to find good information from your content.
I enjoy looking through a post that will
make men and women think. Also, many thanks for allowing me to comment!
whoah this weblog is great i like studying your articles.
Stay up the good work! You understand, a lot of individuals are hunting
around for this information, you can aid them greatly.
It’s amazing designed for me to have a web site, which is
useful in favor of my experience. thanks admin
Hello there! Do you use Twitter? I’d like to follow you if that
would be okay. I’m absolutely enjoying your blog and look forward to new posts.
Awesome! Its genuinely remarkable paragraph, I have got much
clear idea about from this article.
Hello, i feel that i saw you visited my site so i got here to go back the prefer?.I’m
attempting to find issues to improve my web site!I assume its adequate to make use of some of
your ideas!!
Hi there, after reading this amazing post i am as well
glad to share my experience here with mates.
If you are going for best contents like myself, simply pay
a quick visit this web site every day as it provides quality contents,
thanks
Hi my family member! I wish to say that this article is amazing,
nice written and come with approximately all important infos.
I would like to peer more posts like this .
Everything is very open with a very clear description of the issues.
It was really informative. Your site is useful.
Many thanks for sharing!
I am actually delighted to glance at this webpage posts which contains plenty
of helpful facts, thanks for providing these kinds of data.
Attractive section of content. I just stumbled upon your website and in accession capital to
assert that I acquire in fact enjoyed account your blog
posts. Any way I will be subscribing to your feeds and even I achievement you access consistently quickly.
Greetings! I know this is kind of off topic but I was wondering
which blog platform are you using for this site? I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to
make your point. You clearly know what youre talking about, why throw away your intelligence on just posting videos to
your weblog when you could be giving us something enlightening to read?
Quality content is the important to be a focus for the people to
go to see the web site, that’s what this site is providing.
You actually make it appear so easy with your presentation however
I in finding this topic to be really something that I think I’d never understand.
It sort of feels too complex and very extensive for me. I am taking a look ahead on your subsequent publish, I’ll attempt
to get the grasp of it!
Hello, i think that i noticed you visited my website
so i came to go back the prefer?.I am attempting to in finding things to enhance my website!I guess
its good enough to make use of a few of your ideas!!
Hello! I know this is kind of off topic but I was wondering if you knew where I could locate a captcha
plugin for my comment form? I’m using the same
blog platform as yours and I’m having problems finding
one? Thanks a lot!
This paragraph is truly a pleasant one it assists new internet people, who are wishing in favor of blogging.
Wonderful blog! Do you have any tips for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or
go for a paid option? There are so many choices out there
that I’m completely confused .. Any ideas?
Appreciate it!
obviously like your web-site but you need to
check the spelling on quite a few of your posts.
Several of them are rife with spelling issues and I in finding it very bothersome to inform the truth nevertheless I will certainly come back again.
When someone writes an paragraph he/she keeps the plan of a user in his/her brain that how a user can be aware of it.
So that’s why this post is amazing. Thanks!
Everything is very open with a clear explanation of the challenges.
It was really informative. Your site is useful.
Many thanks for sharing!
Great beat ! I would like to apprentice while you amend your website,
how could i subscribe for a blog web site? The account helped me a
acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright clear idea
Hi! Someone in my Facebook group shared this site with us so I came to
take a look. I’m definitely loving the information. I’m book-marking and will
be tweeting this to my followers! Outstanding blog and brilliant design and style.
We are a group of volunteers and starting a new scheme in our community.
Your site offered us with valuable info to work on. You’ve done an impressive
job and our entire community will be thankful to
you.
Remarkable! Its actually awesome piece of writing, I have got much clear idea regarding from this article.
Thanks for any other informative site. The place else may just I get
that kind of info written in such an ideal means?
I’ve a venture that I’m simply now operating on, and I have been at the glance out for
such info.
This page certainly has all of the information and facts I needed about
this subject and didn’t know who to ask.
If you are going for finest contents like
I do, simply go to see this web site every day for the reason that it
presents feature contents, thanks
Thanks to my father who stated to me regarding this website,
this weblog is really awesome.
I don’t know if it’s just me or if everybody else experiencing problems with
your site. It appears like some of the written text within your posts are running
off the screen. Can somebody else please comment and let me know if this is happening to
them too? This may be a issue with my browser because I’ve had
this happen previously. Cheers
I like reading through an article that can make people think.
Also, thank you for allowing me to comment!
This piece of writing presents clear idea in support of the new viewers of blogging, that truly how to do running a
blog.
Hey! I could have sworn I’ve been to this website before but after browsing through some of the
post I realized it’s new to me. Anyhow, I’m definitely happy I found it and I’ll
be book-marking and checking back often!
Do you mind if I quote a few of your posts as long
as I provide credit and sources back to your blog? My blog is in the exact same
area of interest as yours and my users would truly benefit
from some of the information you present here. Please
let me know if this alright with you. Cheers!
This is very interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your wonderful post.
Also, I have shared your site in my social networks!
Hi everyone, it’s my first pay a visit at this site, and paragraph
is truly fruitful designed for me, keep up posting these content.
When someone writes an post he/she retains the plan of
a user in his/her brain that how a user can understand it.
Therefore that’s why this article is amazing. Thanks!
Wow that was strange. I just wrote an really long comment but after I clicked submit
my comment didn’t appear. Grrrr… well I’m not writing all that over again. Regardless,
just wanted to say excellent blog!
Wonderful web site. Plenty of useful information here.
I’m sending it to some buddies ans also
sharing in delicious. And certainly, thank you in your sweat!
Hi, yeah this post is in fact nice and I have learned lot
of things from it on the topic of blogging. thanks.
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is important and all. Nevertheless imagine if
you added some great images or video clips to
give your posts more, “pop”! Your content is excellent but
with pics and clips, this site could undeniably be one of the most beneficial in its niche.
Excellent blog!
Magnificent site. Lots of helpful info here. I am sending it to
several friends ans additionally sharing in delicious.
And obviously, thank you on your effort!
I’m not that much of a online reader to be honest but
your blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back in the future.
Cheers
Your article was very informative. I’m definitely going to
have to look into this more. Thanks for the insightful post.
For more related information, please, check http://www.whitelistdelivery.com/whitelistdelivery.php?url=https://ariston-master.ru/ustanovka-bytovoy-tekhniki
Your post was very informative. I’m surely going to have to research this more.
Thanks for thoughtful article. For more related information,
please, check https://www.ibmp.ir/link/redirect?url=https://ariston-master.ru/sushilnye-mashiny
Hello would you mind letting me know which hosting
company you’re working with? I’ve loaded your blog in 3 different web browsers
and I must say this blog loads a lot quicker then most.
Can you recommend a good web hosting provider at
a fair price? Thanks, I appreciate it!
The blog is incredibly informative. I am surely going to have to research it further.
Thank you for the thoughtful article. For more related information, please,
check http://ggre.ru/bitrix/rk.php?goto=https://ariston-master.ru/posudomoechnye-mashiny
This article was extremely helpful. I’m surely going to have to look into this more.
Thanks for the insightful read. For more related information, please, check http://corvusimages.com/vollbild.php?style=0&bild=maa0044d.jpg&backlink=https://ariston-master.ru/vodonagrevateli
This blog is incredibly interesting. I’m certainly going to have to
research it further. Thanks for thoughtful post. For more related information, please, check
https://hudsonltd.com/?URL=ariston-master.ru%2Fkholodilniki
Your post is extremely helpful. I’m definitely going to have to research it further.
Thank you for the insightful read. For more
related information, please, check http://bcnb.ac.th/bcnb/www/linkcounter.php?msid=49&link=https://ariston-master.ru/kholodilniki
Your post was extremely helpful. I’m certainly going to have
to research this further. Thank you for the great read.
For more related information, please, check https://mh-studio.cn/content/templates/MH-Studio/goto.php?url=https://ariston-master.ru/
The article is incredibly helpful. I am surely going to have to research
this further. Thanks for the great read. For more related information, please, check https://www.sports-central.org/cgi-bin/axs/ax.pl?https://ariston-master.ru/vodonagrevateli
The post was extremely informative. I’m surely
going to research it further. Thank you for the great read.
For more related information, please, check http://www.nagerforum.ch/proxy.php?link=https://Ariston-master.ru/pylesosy
The post is extremely helpful. I am definitely going to have to look into it further.
Thank you for thoughtful article. For more related information, please, check https://kashira-plus.ru/index.php?CCblLKA=https://ariston-master.ru/vodonagrevateli
Hi, I believe your blog might be having internet browser compatibility issues.
Whenever I take a look at your blog in Safari, it looks fine however,
if opening in Internet Explorer, it’s got some overlapping issues.
I simply wanted to give you a quick heads up! Apart from that, fantastic site!
I think the admin of this site is really working
hard for his site, as here every data is quality based data.
Howdy! I’m at work surfing around your blog from my
new iphone 4! Just wanted to say I love reading your blog
and look forward to all your posts! Keep up the excellent work!
Pretty nice post. I just stumbled upon your blog and wished to say that I’ve truly enjoyed browsing
your blog posts. In any case I’ll be subscribing to your rss feed and I
hope you write again soon!
Unquestionably believe that which you said. Your favorite justification appeared to
be on the web the easiest thing to be aware of. I say to you,
I definitely get irked while people think about worries that they plainly do not know about.
You managed to hit the nail upon the top and defined out the whole thing
without having side effect , people can take
a signal. Will likely be back to get more. Thanks
Whhat і ⅾo not understood is if truth be toⅼd how you’re
now not actualⅼy much more smartⅼy-liked tһwn you may be гight now.
You are ѵery intelligent. You understand thereforе considerably in terms
of this matter, proԀuced me personally consider it from a lot off numerous angles.
Its like men and womken aren’t interested except іt’s onne thing to do wіth Lady gaɡa!
Your own stuffs exceⅼlent. Alll thee tiume caare for it up!
You actually make it seem so easy with your presentation but I
find this matter to be actually something which I think I would never understand.
It seems too complicated and very broad for me. I am looking forward for
your next post, I’ll try to get the hang of it!
I’m impressed, I have to admit. Seldom do I encounter a blog that’s both equally educative and interesting, and let me tell you, you’ve hit the nail on the head.
The problem is something which too few men and women are speaking intelligently about.
Now i’m very happy I came across this in my search for something relating
to this.
Spot on with this write-up, I honestly think this web site
needs a lot more attention. I’ll probably be back again to see more, thanks for the
information!
Do you have a spam problem on this website; I also am a blogger, and I was wondering your situation; many of us have created some
nice methods and we are looking to swap solutions with others, why not shoot me an e-mail if interested.
Good post. I will be dealing with many of these issues as well..
Your style is unique in comparison to other people I have read stuff from.
Thank you for posting when you have the opportunity,
Guess I’ll just book mark this page.
I read this piece of writing fully on the topic of
the resemblance of latest and earlier technologies, it’s awesome article.
What i don’t realize is in fact how you’re no longer actually
a lot more smartly-favored than you may be now. You are so intelligent.
You know therefore significantly with regards to this topic, produced me in my opinion consider it from so many numerous angles.
Its like men and women don’t seem to be fascinated except it is one thing to accomplish with
Girl gaga! Your individual stuffs nice. Always maintain it up!
Fantastic items from you, man. I have understand your stuff previous to and you’re simply too excellent.
I actually like what you have received here, certainly like what you’re stating and the best way in which you assert it.
You make it enjoyable and you still take care of to keep it smart.
I can not wait to read far more from you. This is actually a tremendous
site.
Howdy! Quick question that’s totally off topic. Do you know how to make your site mobile friendly?
My weblog looks weird when browsing from my iphone. I’m trying to find a template or
plugin that might be able to resolve this problem. If you have any recommendations, please share.
Cheers!
We are a bunch of volunteers and starting a new scheme
in our community. Your website offered us with valuable info to work on. You’ve performed an impressive process and our
entire neighborhood will be grateful to you.
I just couldn’t depart your site before suggesting that I really enjoyed the usual info an individual provide in your guests?
Is going to be back continuously to investigate cross-check new posts
Hello There. I found your blog using msn.
This is an extremely well written article. I’ll be sure to bookmark
it and come back to read more of your useful information. Thanks for the post.
I will definitely return.
It’s wonderful that you are getting thoughts
from this paragraph as well as from our discussion made at this time.
In fact when someone doesn’t understand after that its up to other visitors that they will help, so here it occurs.
If you want to grow your experience simply keep visiting this site and be updated with the newest news posted here.
This is really attention-grabbing, You are an overly skilled blogger.
I have joined your rss feed and look forward
to in quest of more of your fantastic post.
Additionally, I have shared your site in my social
networks
This is very interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your excellent post.
Also, I have shared your site in my social networks!
Hello to every one, because I am actually eager of reading this weblog’s post to be updated regularly.
It consists of good material.
Thanks for finally talking about > Пиастры
– Составление семантического ядра | < Liked it!
I believe what you published was very logical.
However, what about this? what if you added a
little content? I mean, I don’t want to tell you how to
run your website, however suppose you added a headline that grabbed
people’s attention? I mean Пиастры – Составление семантического ядра | is a little boring.
You ought to glance at Yahoo’s front page and note how they create post titles to get viewers to open the links.
You might add a video or a related pic or two to get people excited about everything’ve written. In my
opinion, it would bring your posts a little bit more interesting.
Hi, i think that i saw you visited my weblog thus i came to “return the favor”.I’m trying to find things to enhance my site!I suppose its ok to use a few of your ideas!!
It’s perfect time to make some plans for the future and
it is time to be happy. I’ve read this post and if I could I wish to suggest you some interesting things or advice.
Perhaps you can write next articles referring to this article.
I want to read even more things about it!
Hey there! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing months of hard work due
to no back up. Do you have any methods to stop
hackers?
What’s Going down i’m new to this, I stumbled upon this I have
discovered It positively useful and it has aided me out loads.
I’m hoping to give a contribution & help different customers like its helped me.
Good job.
This article will assist the internet viewers for setting up new blog or
even a weblog from start to end.
Your blog was very interesting. I’m surely going to have to research
it more. Thanks for insightful post. For more related information, please,
check http://www.zxk8.cn/course/url?url=https://ariston-master.ru/ustanovka-bytovoy-tekhniki
Outstanding quest there. What happened after?
Thanks!
After looking into a few of the blog posts on your website,
I really like your technique of writing a blog. I book-marked it to my
bookmark website list and will be checking back soon. Please check out my website as well and let me know how you feel.
This design is steller! You certainly know how to keep
a reader entertained. Between your wit and your videos, I was almost moved to start
my own blog (well, almost…HaHa!) Excellent job. I really enjoyed what you had
to say, and more than that, how you presented it.
Too cool!
This article is incredibly informative. I’m definitely going to
look into it more. Thank you for thoughtful read.
For more related information, please, check https://lunatics.icons8.com/home/leaving?target=https%3A%2F%2Fariston-master.ru
The article was extremely interesting. I am certainly going to research this further.
Thank you for insightful article. For more
related information, please, check http://www.dolinaradosti.org/redirect?url=https://ariston-master.ru/stiralnye-mashiny
This blog was… how do I say it? Relevant!! Finally I have
found something that helped me. Kudos!
The post is very interesting. I’m definitely going to have to
look into it more. Thank you for insightful read.
For more related information, please, check http://rlu.ru/3DXIM
The article was extremely informative. I am certainly going to research it more.
Thanks for the insightful article. For more related information, please,
check http://G-Nomad.com/cc_jump.cgi?url=https://ariston-master.ru/
This article is very interesting. I’m certainly going to have to look
into it further. Thanks for insightful read.
For more related information, please, check https://Couponscms.com/demo/themes/coupy/plugin/click.html?coupon=16&reveal_code=1&backTo=https%3A%2F%2Fariston-master.ru%2Fstiralnye-mashiny
The post is very helpful. I am surely going to look
into it more. Thank you for thoughtful post. For more related information, please, check http://treasuredays.com/?URL=https://ariston-master.ru/posudomoechnye-mashiny
Ꭰοess your webssite hhave a contact page? I’m havinhg probllems
locationg iit but, I’d lioke too hoot youu aan email.
I’ᴠe ggot sme creattive iԀeqs forr our blokg yoou might bbe interestyeⅾ inn hearing.
Ꭼiher way, gredat ite aand I look fortward too seeeing iit iimprove oеr time.
Heree iss mmy log post … “xseo.ir: Setting the Bar as the Ultimate Persian SEO Competitor” (Eduardo)
Ils peuvent bénéficier d’un bonus quasiment tous les jours de la semaine.
bookmarked!!, I like your blog!
Great article! We will be linking to this great content
on our website. Keep up the good writing.
If sߋmke onee desies too bbe updated wtһ mmost rrecent technoologies thenn hhe muet
bee goo tto ssee tthis weeb ѕiite andd beе uup tto ddate alll tthe time.
Takke a liok att myy wweb bkog سفارش لینک
سازی [Veronica]
I will right away grab your rss feed as I can’t in finding your email subscription hyperlink or e-newsletter service.
Do you have any? Please let me realize so that I may just subscribe.
Thanks.
Hey there! This is my first visit to your blog! We are a team
of volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You have done a wonderful job!
At this time it sounds like Expression Engine is the preferred
blogging platform out there right now. (from what I’ve read) Is that what you are using on your blog?
These are actually wonderful ideas in concerning blogging.
You have touched some nice things here. Any way keep up wrinting.
Greetings! Very helpful advice in this particular article!
It is the little changes that will make the greatest changes.
Many thanks for sharing!
This article is in fact a pleasant one it assists new net visitors,
who are wishing for blogging.
After looking into a few of the blog posts on your web site, I honestly like
your technique of blogging. I book marked it to my bookmark website list and will be checking back in the
near future. Please check out my web site as well and let me know what you think.
Everyone loves what you guys tend to be up too.
This kind of clever work and reporting! Keep up the terrific works guys I’ve included you guys to my personal blogroll.
Thanks in favor of sharing such a pleasant idea, piece of
writing is nice, thats why i have read it entirely
Appreciate this post. Will try it out.
I’ll right away take hold of your rss feed as I can not
find your email subscription link or e-newsletter service.
Do you have any? Kindly let me know in order that I may subscribe.
Thanks.
Hello there! This is my first visit to your blog! We are a collection of volunteers and
starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have done a extraordinary job!
I have been browsing online greater than three hours today, yet I never
discovered any interesting article like yours. It’s beautiful price enough for me.
In my opinion, if all site owners and bloggers made good content as
you did, the net will likely be a lot more useful than ever
before.
My partner and I stumbled over here coming from a different web address
and thought I may as well check things out. I like what I see so now i am following you.
Look forward to exploring your web page for a second time.
Hi there, I enjoy reading all of your article. I wanted to write a
little comment to support you.
Great goods from you, man. I’ve understand your stuff previous to and you’re just extremely magnificent.
I really like what you have acquired here, really like what you’re saying and the way in which you say it.
You make it enjoyable and you still care for to keep
it sensible. I can’t wait to read far more from you.
This is really a tremendous web site.
An outstanding share! I’ve just forwarded this onto a co-worker who had been doing a little
homework on this. And he actually ordered me dinner simply because I found it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah, thanks for spending some time to talk about this subject here on your
web site.
Hello to all, for the reason that I am really keen of reading this webpage’s post to be updated daily.
It contains fastidious information.
Great blog you have got here.. It’s hard to find
excellent writing like yours these days. I honestly appreciate
people like you! Take care!!
I know this if off topic but I’m looking into starting my own blog and was curious what
all is needed to get setup? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% positive. Any recommendations or advice would be greatly appreciated.
Many thanks
Hi, yeah this paragraph is actually good and
I have learned lot of things from it concerning blogging.
thanks.
I am not sure where you are getting your info, but great topic.
I needs to spend some time learning much more or understanding
more. Thanks for magnificent info I was looking for this
info for my mission.
Thanks a bunch for sharing this with all folks
you really understand what you are talking about!
Bookmarked. Please additionally seek advice from
my web site =). We can have a link change contract between us
Hello! This post could not be written any better! Reading through
this post reminds me of my old room mate! He always
kept chatting about this. I will forward this page
to him. Fairly certain he will have a good read. Many thanks for sharing!
I have been browsing online more than 4 hours today, yet I never found any interesting article like
yours. It’s pretty worth enough for me. In my opinion, if all site
owners and bloggers made good content as you did,
the net will be much more useful than ever before.
Yes! Finally someone writes about pappy van winkle for sale.
Touche. Great arguments. Keep up the great effort.
you are actually a good webmaster. The site loading pace is amazing.
It seems that you’re doing any distinctive trick. In addition,
The contents are masterpiece. you have done a fantastic
job on this subject!
Thаnks for another informative site. Where else
could I get that type of info written in ssuch a perfect means?
I’ve a undertaking that I am sіmply now ⲟрerating on, and I hve beеn on the look out for
such info.
Its like you read my mind! You seem to know so
much about this, like you wrote the guide in it or something.
I feel that you simply can do with some p.c. to power the message house a little bit, however instead of that, this is excellent
blog. An excellent read. I’ll certainly be back.
I love what you guys tend to be up too. This
kind of clever work and coverage! Keep up the good works guys I’ve you guys to blogroll.
I was suggested this website via my cousin. I am not certain whether this publish is written by way of him as nobody else know such special about my trouble.
You are wonderful! Thank you!
Hello would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 completely different web browsers and I must say this
blog loads a lot quicker then most. Can you suggest a good web hosting provider at a reasonable price?
Thank you, I appreciate it!
Fastidious answers in return of this difficulty with genuine
arguments and telling all concerning that.
It’s a pity you don’t have a donate button! I’d most certainly donate to this superb blog!
I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account.
I look forward to fresh updates and will share this blog with my Facebook group.
Talk soon!
Superb post but I was wanting to know if you could write a litte more on this subject?
I’d be very thankful if you could elaborate
a little bit further. Thanks!
Greetings from Idaho! I’m bored to tears at work so I decided to browse your website
on my iphone during lunch break. I enjoy the information you present here and can’t wait to take a look when I get home.
I’m amazed at how fast your blog loaded on my cell phone
.. I’m not even using WIFI, just 3G .. Anyhow,
excellent blog!
It’s an remarkable paragraph for all the internet viewers; they
will obtain advantage from it I am sure.
This is a topic that’s near to my heart… Thank you!
Exactly where are your contact details though?
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an nervousness over
that you wish be delivering the following. unwell unquestionably come
more formerly again since exactly the same nearly a lot often inside case
you shield this increase.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way,
how could we communicate?
Excellent web site. A lot of useful info here. I am sending it to several friends ans also sharing in delicious.
And certainly, thank you for your sweat!
Good article! We are linking to this particularly great
post on our website. Keep up the great writing.
Hi there just wanted to give you a quick heads up. The text in your article seem to
be running off the screen in Firefox. I’m not sure if this is a format
issue or something to do with web browser compatibility but
I figured I’d post to let you know. The layout look great
though! Hope you get the issue resolved soon. Thanks
An intriguing discussion is worth comment. I do believe that you need to publish more on this topic, it may not be
a taboo subject but typically people do not speak about these topics.
To the next! Many thanks!!
Hello, this weekend is pleasant for me, as this time i am reading this
enormous informative post here at my residence.
I know this web site provides quality dependent articles and other material,
is there any other web site which provides these stuff in quality?
Bei diesem Gerät hatten wir Probleme mit der Bedienung, die Nutzung der Umluftfunktion funktionierte nicht wie erwartet und auch die Bedienungsanleitung
struggle uns dabei keine Hilfe.
Explore the epitome of luxury rehabilitation at Harmony Horizon, home to the world’s priciest and prestigious rehab centers.
Discover opulence and unparalleled care within our high-end
facilities, rendering it the most effective luxury rehab destination globally.
From renowned Paracelsus Rehab to other exclusive centers, we redefine rehabilitation with top-tier services.
Uncover the world’s best drug rehab centers, ensuring a
transformative and indulgent journey towards recovery.
Go through the pinnacle of wellness at Harmony Horizon Luxury Rehab.
Thanks for sharing such a good thinking, piece of writing is good, thats why
i have read it entirely
Hey there are using WordPress for your site
platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you need any coding expertise
to make your own blog? Any help would be really
appreciated!
Hi! This is kind of off topic but I need some guidance
from an established blog. Is it tough to set up your own blog?
I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where
to start. Do you have any tips or suggestions? Cheers
Its like you read my mind! You appear to know so much about this,
like you wrote the book in it or something. I think that you can do
with some pics to drive the message home a little bit, but other
than that, this is magnificent blog. A fantastic read.
I’ll certainly be back.
What’s up, its nice article on the topic of media print, we
all be familiar with media is a wonderful source of
information.
If some one wishes to be updated with latest technologies then he must
be pay a visit this web site and be up to date every day.
Today, while I was at work, my cousin stole my apple ipad
and tested to see if it can survive a thirty foot drop, just so she can be
a youtube sensation. My apple ipad is now broken and she has 83 views.
I know this is totally off topic but I had to share it with someone!
Nice blog here! Also your web site loads up very fast!
What host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours lol
Hello, the whole thing is going fine here and ofcourse every one is sharing information, that’s actually excellent, keep up writing.
Hello, i think that i saw you visited my site so i came to “return the favor”.I’m trying
to find things to enhance my site!I suppose its ok to use a few of
your ideas!!
Why users still make use of to read news papers when in this technological globe
all is existing on net?
Thanks for one’s marvelous posting! I seriously enjoyed reading it, you will be a great author.I
will always bookmark your blog and may come back very soon.
I want to encourage you to continue your great work,
have a nice afternoon!
Wow! This blog looks exactly like my old one! It’s on a entirely different
subject but it has pretty much the same layout and design. Great choice of
colors!
Thanks for finally talking about > Пиастры – Составление
семантического ядра | < Loved it!
Excellent goods from you, man. I’ve understand your stuff previous to and you’re
just extremely excellent. I really like what you’ve acquired here, really like what you are stating and the way in which you say it.
You make it entertaining and you still take care of to keep it wise.
I cant wait to read much more from you. This is actually a great site.
Hello There. I found your blog using msn. This is an extremely well written article.
I’ll make sure to bookmark it and come back to read more of
your useful information. Thanks for the post. I will certainly return.
My spouse and I stumbled over here different page and thought I might as well check things out.
I like what I see so now i’m following you. Look forward to looking into your web page repeatedly.
I every time emailed this weblog post page to all my associates, as if like to read it after
that my friends will too.
My partner and I stumbled over here from a different page and thought I should check things out.
I like what I see so now i’m following you.
Look forward to looking at your web page yet again.
Magnificent beat ! I wish to apprentice whilst
you amend your website, how can i subscribe for a blog site?
The account aided me a applicable deal. I had been a little bit familiar of this
your broadcast provided vivid clear concept
Right here is the perfect site for everyone who would like
to find out about this topic. You realize a whole lot its almost hard to argue
with you (not that I really would want to…HaHa).
You certainly put a brand new spin on a topic that’s been discussed for ages.
Excellent stuff, just wonderful!
First off I want to say awesome blog! I had a quick question which I’d like to ask if you do not mind.
I was interested to find out how you center yourself and clear your mind before writing.
I have had a hard time clearing my thoughts in getting my thoughts out.
I do enjoy writing but it just seems like the first 10 to 15
minutes are usually lost just trying to figure
out how to begin. Any suggestions or hints? Thanks!
Just desire to say your article is as astounding.
The clearness to your post is just nice and i could suppose you are a
professional on this subject. Well together with your permission allow me
to take hold of your feed to stay up to date with forthcoming post.
Thank you a million and please continue the enjoyable
work.
Asking questions are actually good thing if you
are not understanding anything completely, but this piece
of writing offers fastidious understanding
even.
What’s up to every one, as I am truly eager of reading this blog’s post to be updated regularly.
It includes pleasant material.
porn HD
Yesterday, while I was at work, my sister stole my iPad and tested to see if it can survive a 40 foot drop,
just so she can be a youtube sensation. My iPad is now
destroyed and she has 83 views. I know this is totally off topic but I had to share it
with someone!
This is my first time go to see at here and i am in fact pleassant to read everthing at one place.
Good day! This post could not be written any better!
Reading through this post reminds me of my previous room mate!
He always kept talking about this. I will forward this post to him.
Fairly certain he will have a good read. Many thanks
for sharing!
Yes! Finally someone writes about Calcium nitrate fertilizer.
I got this web site from my friend who shared
with me on the topic of this website and at the
moment this time I am visiting this website and
reading very informative content at this time.
Heya! I’m at work browsing your blog from my new iphone!
Just wanted to say I love reading your blog and look forward
to all your posts! Keep up the superb work!
Hi there, for all time i used to check web site posts here early in the
break of day, because i like to gain knowledge of more
and more.
Hi there would you mind sharing which blog platform you’re using?
I’m planning to start my own blog in the near future but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems
different then most blogs and I’m looking for something unique.
P.S My apologies for getting off-topic but I had to
ask!
Amazing! This blog looks exactly like my old one!
It’s on a entirely different topic but it has pretty much the same layout and design.
Superb choice of colors!
I know this if off topic but I’m looking into starting my own blog and
was wondering what all is required to get setup? I’m assuming having a blog like yours would
cost a pretty penny? I’m not very internet
savvy so I’m not 100% positive. Any tips or advice would be greatly appreciated.
Many thanks
Hi there! I could have sworn I’ve visited this blog before but after going through many of the posts I realized it’s new to me.
Anyhow, I’m definitely delighted I stumbled upon it and I’ll be bookmarking it and checking back regularly!
My brother suggested I would possibly like this web site.
He was once totally right. This put up truly made my day.
You cann’t consider just how a lot time I had spent for this information! Thanks!
sex porn videos
Hi there! This is my first comment here so I just wanted to give a quick shout out and say I genuinely enjoy
reading through your blog posts. Can you recommend any other blogs/websites/forums that
deal with the same subjects? Thanks a ton!
After going over a few of the blog articles
on your site, I really appreciate your way of blogging.
I saved it to my bookmark site list and will be checking back soon. Please check out my web site too
and let me know your opinion.
Very good info. Lucky me I found your blog by chance (stumbleupon).
I have book-marked it for later!
Hello would you mind letting me know which web host you’re working with?
I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot faster then most.
Can you recommend a good internet hosting provider at a reasonable price?
Many thanks, I appreciate it!
Hello! I could have sworn I’ve visited this
website before but after looking at some of the posts I realized it’s new to me.
Anyhow, I’m definitely pleased I came across it and I’ll be book-marking it and checking back regularly!
Wow, awesome blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your site is magnificent, let
alone the content!
I could not resist commenting. Perfectly written!
Great delivery. Outstanding arguments. Keep up the good work.
Wow, amazing blog structure! How long have you been running a
blog for? you make blogging glance easy. The entire glance
of your site is excellent, as neatly as the content material!
https://www.experttraining.edu.my/profile/brentcain23/profile
Hey! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due
to no data backup. Do you have any methods to prevent hackers?
Hey There. I found your blog using msn. This is a
very well written article. I will make sure to bookmark it and come back
to read more of your useful information. Thanks for the post.
I’ll definitely comeback.
Hello friends, pleasant post and fastidious arguments commented here, I am in fact enjoying by these.
hey there and thank you for your information – I’ve certainly
picked up something new from right here. I did however expertise several technical points using this
web site, since I experienced to reload the website lots of times previous to I could get it to load
correctly. I had been wondering if your hosting
is OK? Not that I am complaining, but slow loading instances times will sometimes affect
your placement in google and can damage your high quality score if advertising and marketing with
Adwords. Well I am adding this RSS to my email and could look out for much
more of your respective fascinating content. Make sure you update this again soon.
I’m amazed, I have to admit. Seldom do I come across a blog that’s equally educative and interesting, and without a doubt, you have hit the nail on the head.
The issue is something that not enough people are speaking
intelligently about. Now i’m very happy that I came across this in my hunt for
something relating to this.
What’s up, just wanted to mention, I loved this blog post.
It was inspiring. Keep on posting!
Hey there! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly?
My weblog looks weird when viewing from my apple iphone.
I’m trying to find a template or plugin that might be
able to correct this problem. If you have any recommendations, please share.
With thanks!
I am not sure where you’re getting your information, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic information I was looking for this info for my mission.
Hey! I could have sworn I’ve been to this website before but after checking through some of the post I realized it’s new to me.
Anyways, I’m definitely glad I found it and I’ll be
book-marking and checking back frequently!
Great website. Plenty of useful information here.
I’m sending it to a few friends ans also sharing in delicious.
And certainly, thanks to your effort!
We’re a group of volunteers and opening a brand new scheme
in our community. Your web site offered us with valuable
info to work on. You have done an impressive activity and our entire
group will be grateful to you.
It’s very simple to find out any topic on net as compared to textbooks,
as I found this piece of writing at this site.
Hey are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and set up
my own. Do you require any html coding expertise to make
your own blog? Any help would be really appreciated!
I think that what you said was actually very logical. However,
what about this? what if you wrote a catchier title?
I am not suggesting your content is not good, however suppose
you added something that grabbed a person’s attention? I mean Пиастры –
Составление семантического ядра | is a little vanilla.
You should look at Yahoo’s home page and see how they create news headlines to get viewers to click.
You might add a related video or a related pic or
two to grab readers interested about everything’ve written. In my opinion, it could bring
your posts a little bit more interesting.
Pretty great post. I just stumbled upon your weblog and wanted to say that I have really enjoyed surfing around your blog posts.
In any case I will be subscribing on your feed and I am hoping you write again very soon!
I always used to study piece of writing in news papers but now as I am a user of net so from now I am
using net for posts, thanks to web.
I love it when people come together and share opinions.
Great blog, stick with it!
Every weekend i used to pay a visit this website, as i wish for enjoyment, for
the reason that this this site conations in fact nice funny information too.
Howdy just wanted to give you a quick heads up.
The text in your post seem to be running off the screen in Ie.
I’m not sure if this is a format issue or something to do with
web browser compatibility but I figured I’d post to let you know.
The design look great though! Hope you get the problem solved soon. Thanks
Hi there! I’m at work surfing around your blog from my new iphone 3gs!
Just wanted to say I love reading through your blog and look forward to
all your posts! Carry on the outstanding work!
Hmm is anyone else encountering problems with the images on this
blog loading? I’m trying to figure out if its a problem on my end or if it’s
the blog. Any responses would be greatly appreciated.
Incredible quest there. What happened after?
Good luck!
I think that is among the so much important info for me.
And i am happy studying your article. However want to remark on some normal things, The website style is
ideal, the articles is actually excellent : D. Just
right process, cheers
Way cool! Some extremely valid points! I appreciate you writing this article and also the rest of the site is
really good.
Hey fantastic blog! Does running a blog similar to this require a great deal of work?
I’ve absolutely no expertise in programming however I
was hoping to start my own blog in the near future. Anyway, if you have any suggestions or tips
for new blog owners please share. I understand this is off topic
nevertheless I just needed to ask. Thank you!
Pretty nice post. I just stumbled upon your blog and wanted to
say that I’ve truly enjoyed surfing around your blog posts.
In any case I’ll be subscribing to your feed and I
hope you write again very soon!
I was curious if you ever considered changing the layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or two pictures.
Maybe you could space it out better?
WOW just what I was looking for. Came here by searching for https://www.google.mw/maps/d/edit?mid=1j5Ly6ODVVs-Mi1u5wvr734engnMkkGs&usp=sharing
Terrific work! That is the type of information that should be shared around the
web. Shame on Google for now not positioning this submit upper!
Come on over and discuss with my website . Thanks =)
Pretty nice post. I just stumbled upon your blog and wanted to
say that I’ve really loved surfing around your
weblog posts. In any case I will be subscribing on your feed
and I am hoping you write again soon!
I am not sure where you’re getting your info, however great topic.
I must spend some time finding out much more or working
out more. Thanks for excellent info I used to be searching for
this info for my mission.
Hello, after reading this awesome article i am also delighted to share my knowledge
here with colleagues.
I read this post completely on the topic of the resemblance of latest and previous technologies,
it’s remarkable article.
If you wish for to obtain a good deal from this
article then you have to apply these strategies to your won website.
Thanks for the auspicious writeup. It if truth be told was a leisure account it.
Glance advanced to far delivered agreeable from you!
However, how could we keep in touch?
Right here is the right blog for everyone who wants to find out about this topic.
You realize so much its almost hard to argue with you (not that I actually would want to…HaHa).
You definitely put a new spin on a subject which has been written about for a long
time. Wonderful stuff, just excellent!
Have you ever considered about including a little
bit more than just your articles? I mean, what you say is fundamental and everything.
However think of if you added some great graphics or video clips to give your posts
more, “pop”! Your content is excellent but with images and videos, this site
could undeniably be one of the best in its niche.
Very good blog!
Hi friends, nice piece of writing and pleasant arguments commented here, I am genuinely
enjoying by these.
I constantly spent my half an hour to read this blog’s content all the time along with a mug of
coffee.
Wow! After all I got a webpage from where
I be able to truly take useful facts regarding my study
and knowledge.
Excellent post. I used to be checking constantly this blog and I am impressed! I take care
I take care
Very useful info specifically the last phase
of such information a lot. I used to be seeking this particular information for a very long time.
Thanks and best of luck.
Touche. Great arguments. Keep up the great effort.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an nervousness over
that you wish be delivering the following. unwell unquestionably come further formerly again as
exactly the same nearly very often inside case you shield this hike.
Remarkable things here. I am very happy to peer your post.
Thank you so much and I am looking ahead to touch you. Will you please drop me
a mail?
It’s enormous that you are getting ideas from this
article as well as from our dialogue made here.
I’m gone to say to my little brother, that he should also pay a visit
this weblog on regular basis to take updated from hottest gossip.
Very descriptive article, I enjoyed that a lot.
Will there be a part 2?
First of all I want to say fantastic blog! I had a quick question which I’d like to ask if
you do not mind. I was curious to find out how you center yourself and clear
your thoughts prior to writing. I have had trouble clearing my
thoughts in getting my ideas out. I truly do enjoy writing however
it just seems like the first 10 to 15 minutes tend to be wasted simply just trying to figure out how to begin. Any ideas or tips?
Appreciate it!
I visited many websites however the audio quality for audio
songs current at this site is in fact wonderful.
always i used to read smaller articles which also clear their motive, and that is also happening
with this piece of writing which I am reading here.
Hi, yup this paragraph is in fact fastidious and I have learned
lot of things from it concerning blogging. thanks.
Hi there, just wanted to say, I liked this blog post. It was funny.
Keep on posting!
This page certainly has all of the information I wanted about this subject and
didn’t know who to ask.
Hey there! I’ve been reading your site for a long time now and finally
got the courage to go ahead and give you a shout out from Dallas Texas!
Just wanted to mention keep up the good work!
Hey there just wanted to give you a quick heads up. The text
in your post seem to be running off the screen in Chrome.
I’m not sure if this is a format issue or something to do
with web browser compatibility but I figured I’d post to let
you know. The layout look great though! Hope you
get the problem solved soon. Thanks
Great blog you have here.. It’s difficult to find good quality writing like
yours nowadays. I truly appreciate people like you!
Take care!!
Excellent site you have here.. It’s hard to find good quality writing like yours nowadays.
I seriously appreciate people like you! Take care!!
For most recent information you have to go to see web and on web I found this
web page as a best site for hottest updates.
Great goods from you, man. I have understand your stuff previous to and you’re just extremely great.
I really like what you’ve acquired here, certainly like what you are stating and the way in which you
say it. You make it entertaining and you still take care of to keep it
wise. I cant wait to read far more from you. This is actually a terrific site.
خدمات لینک سازی در XSEO سئو حرفه ای
گلدلینک با ارائه پلن های متنوع رپورتاژ موضوعی، خیال شما را در انتخاب
درست و تاثیرگذار حمایت می کند.
سوال اینجاست که چگونه میتوانیم به گوگل اعلام کنیم که این مقالات را در زمان امتیازدهی مورد بررسی
قرار دهد یا نه؟ جواب این است که باید نوع
لینک را مشخص کنید. آیا تا به حال
به ساختار لینک توجه کردیدهاید؟ آیا میدانید یک
لینک از چه اجزایی تشکیل شده است؟ با هم اجزای تشکیلدهنده لینکها را
بررسی میکنیم. همین امروز، از طریق
واتس اپ یا پیج اینستاگرام سایت بسپار، برای دریافت
مشاوره با ما تماس بگیرید. آگهی های شما در بخش نیازمندیها و رپورتاژ
آگهی هادر بخش “بسپارمگ” ثبت خواهد شد.
بعد از تعیین هدف استراتژی باید به دنبال
لینکهایی باشید که شما را به هدفتان نزدیکتر کند.
در این مقاله به صورت کامل
به لیست خدمات بهینه سازی
سایتخواهیم پرداخت. در ادامه
می آموزیم که چگونه باید پروپوزال انجام خدمات
سئو را برای یک مشتری آماده نماییم.
بک لینک باکیفیت در چشم گوگل، عزیزکردهای است
که مهر و محبتش نسبت به آن اندازه ندارد!
به همین خاطر ممکن است یک صفحه
با چند بک لینک باکیفیت رتبه خیلی بهتری از صفحهای بگیرد که
هزاران بکلینک اما باکیفیتی پایینتر دارد.
کار به جایی رسیده که گاهی ساختن و داشتن
یک بکلینک خیلی بهتر از آن است که ساعتها وقت
و انرژی بگذارید و بکلینک کیلویی یا
رایگان بسازید. در خدمات بهینه سازی سایت در ویکی
دمی، علاوه بر پکیج های بالا، نوع دیگری از خدمات سئو
به نام سئو تضمینی وجود دارد با خدمات سئو بهصورت پکیجی متفاوت است.
معمولا استفاده از این لینک زمانی اتفاق میافتد که نسبت به درستی مطالب سایت یا صفحه مورد
نظر اطمینان کامل ندارید. از دیگر مواردی که میتوانید از لینک نو فالو استفاده کنید در امر تبلیغات
است. مثلا یک بنر تبلیغاتی در صفحه یک وب
سایت اجاره کردهاید که به سایت شما لینک داده شود.
گوگل برای اینکه این بنر تبلیغاتی در رتبهبندی سایت
تبلیغ شده تاثیری نداشته باشد، از شما میخواهد لینک مربوط بهاین بنر را nofollow کنید.
الگوریتمهای گوگل بسیار پیچیده و پیشرفته هستند و هر روز هم در حال تغییر و
تحولند. اما همین لینک سازی باعث میشود
که گوگل سیگنالی دریافت کند مبنی بر اینکه سایت شما منبعی
بسیار خوب است و نقل قول ازآن ارزش دارد.
اگر قبلاً از خدمات پیوند بیلدینگ استفاده نکردهاید، این میتواند به شما آرامش دهد زیرا میدانید چگونه کار میکنند.
آیا طراحی وب سایت شما از رتبه بالایی در گوگل برخوردار
است؟ این چیزی است که یک دستاورد
بزرگ است و می توانید بدانید که کاربران آنلاین می توانند شما را پیدا کنند.
وظیفه ما ارائه خدمات گوناگون
برای رشد و پیشرفت کسب و کارهایی است که علاقه به فعالیت در بستر وب دارند.
خوشحالیم که بعد از گذشت نه
سال، تمامی اتفاقات مثبت مان را با شما شریک باشیم.
این روش ما بین دو روش قبلی است و از تکنیک هایی
استفاده می شود که توسط گوگل تشخیص داده نمی
شود. رسیدن به نتیجه با تکنیک سئو کلاه سفید بسیار زمان اما بر در این
روش سایت زودتر به نتیجه می رسد.
لینک بیلدینگ اعتبار صفحه و دامنه شما را بهبود می بخشد
که بر رتبه بندی صفحات وب تأثیر می گذارد و به موتورهای
جستجو کمک می کند تا صفحات وب سایت شما را پیدا کنند.
دیده شدن بیشتر در نتایج جستجو، آگاهی
از برند شما را افزایش می دهد. لینک بیلدینگ یا لینک سازی فرآیند به دست آوردن هایپرلینک از وبسایتهای دیگر برای سایت خودتان است.
هر هایپرلینک که به اختصار لینک هم نامیده میشود، وسیلهای برای مخاطبان است که به کمک
آن بتوانند میان صفحات اینترنت حرکت کنند.
برای لینک سازی روشهای متعددی وجود دارد و با وجود اینکه هر روش سختیهای خاص
خود را داراست، اما همگی میدانند که یکی از سختترین کارها در سئو خارجی لینک بیلدینگ است.
بنابراین اگر شما بتوانید در این کار مهارت پیدا
کنید، واقعا شما را یک سر و گردن از رقبایتان جلو میاندازد.
کلمات کلیدی پیدا شده در محتوای صفحات استفاده می شود
تا این سایت در حوزه خودش سئو شود.
در این باره می توانید محتوای چگونه
کلمات کلیدی مقاله را پیدا کنیم را مطالعه کنید.
با توجه به اینکه انکرتکست ها انواع مختلفی دارند، استفاده مناسب از انواع آن
نیز موجب طبیعی تر شدن لینک سازی یا
خرید بک لینک توسط شما خواهد شد.
دلایل بیان شده و دهها اما و اگر دیگر نشان دهنده اهمیت انتخاب کیورد (Kеʏword) و انکر تکست (Anchor Tеxt) مناسب برای رپورتاژ است که توصیه میکنیم انتخاب آن
را به یک تیم حرفه ای و متخصص واگذار کنید.
گیل سئو یک پوتال آموزش سئو پیشرفته
و ارائه دهنده ی خدمات سئو و بسته
های لینک سازی حرفه ای است که برای توسعهو رشد کسب و
کار های اینترنتی راه اندازی شده است.
سئو بهینه سازی کلمات مهم و کلیدی کسب و کار و سایت شما برای
موتور جستجو گوگل و کاربر است.
ویکی دمی یکی از بهترین شرکت های سئو در تهران است که تاکنون خدمات سئوی حرفه ای و تخصصی را به برندهای مطرح در ایران ارائه داده است.
در این مجموعه شما می توانید با خیال راحت
سایت خود را در صدر نتایج جست و جو ببینید.
لینک سازی خارجی اگر به
درستی انجام شود، میتواند به بهبود رتبه سایت شما کمک کند اما
باید توجه داشت که لینک سازی خارجی باید به صورت طبیعی و با کیفیت انجام شود و نباید از روشهای نامناسبی مانند خرید لینک استفاده شود.
یکی از مهمترین مراحل در بهینهسازی سایت، کیوورد
ریسرچ یا تحقیق در مورد کلمات کلیدی سایت است.
سئو باعث می شود تا کاربران به تدریج سایت آن ها
را در نتایج جستجو دیده و با خدمات آن ها آشنا
شوند. ویکی دمی تاکنون توانسته با ارائه خدمات سئو
تضمینی خود به برندهایی که قبلا حضور فعالی نداشته اند کمک کرده تا
با رشدی موفقیت آمیزبه محبوبیت
بالایی برسند. سرمایهی بزرگ فرامهام؛ رضایت مشتریان و رونق کسبوکارهای اینترنتی است.
ما با به دست آوردن پیوندهای مرتبط با
صفحات هدف کلیدی در دامنه شما، که مهمترین عامل رتبه بندی گوگل
است، رتبه شما را در گوگل و حتی سایر موتورهای جستجو بهبود می دهیم.
ساخت لینک در قسمت پروفایل سایت ها و در شبکه های اجتماعی که آدرس وب سایت ثبت می
شود، بک لینک پروفایلی گفته می شود
و لینک به برند است و باعث کمک به برندینگ شما
می شود.یکی از روش های لینک
سازی امن است. برای تهیه پروپوزال و ارائه به مشتری، باید
ابتدا لیستی از خدمات سئو در نظر بگیریم.
در واقع ما باید بر اساس سوالات و آنالیز اولیه
پروژه، مشخص کنیم که دقیقا کدام یک از خدمات بهینه
سازی سایت برای این پروژه، مورد نیاز است.
تکنیک های لینک سازی کلاه سیاه ممکن است باعث آسیب های جبران ناپذیری برای وبسایت
شما شود.
درعمل شامل بررسی عواملی مانند لینکهای ورودی و چگونگی لینک سازی ها می شود.
گلدلینک توانسته سال ها تجربه خود را در قالب سرویس های معتبر و متعدد ساخت بک لینک و
رپورتاژ آگهی، با تضمین عدم پنالتی توسطگوگل به شما ارائه کند.
همچنین شما می توانید از
مشاوره های رایگان قبل از سفارش ساخت بک لینک و بعد
از سفارش استفاده کنید.
Superb, what a webpage it is! This webb site presents valuable information to us, keep it up.
My web-site :: Click foг our endorsed site (Penney)
Fine way of telling, and pleasant paragraph to take information about my presentation subject, which i am going to present in college.
خدمات لینک سازی : اعتبار بیشتر، جایگاه بالاتر نارون
شما برای افزایش نرخ کلیک و ترافیک
سایت، نیاز به کمک و مشاوره متخصصان باتجربهی سئو دارید.
این متخصصان با بهکارگیری مهارت و دانش تخصصی خود، موجب افزایش فروش سایت شما می شوند واین حاصل از نتایج خدمات سئو سایت است.
اگر یک صفحه با اعتبار بالا به صفحه ای از وبسایت شما لینک بدهد اما مشخص شود که این صفحه
هیچ پشتوانه ندارد، ضمن کاهش تاثیر لینک، موجب ایجاد شک در گوگل برای بررسی لینک سازی شما
و کشف جعلی بودن فعالیت خواهد شد.
در نتیجه وب آنجل برای طبیعی
جلوه دادن رپورتاژ و افزایش اثرگذاری، چند بک لینک معتبر و قابل استناد را برای صفحه رپورتاژ در نظر میگیرد تاکسب و کار شما بهترین
خروجی ممکن را از کمپین خرید بک
لینک دریافت کند. بک لینک ها یکی
از مهم ترین و تاثیرگذارترینفاکتور ها در
تسریع و تثبیت روند سئو سایت
شما هستند و می توان با استفادهاز بک لینک، بعد از رعایت سئوی آن پیج از رقبای خود پیشی
بگیرید.
سایت بسپار، رسانه ای تخصصی در حوزه ساخت و ساز و معماری و دکوراسیون ست.
اینجا برای کالا و خدماتساختمانی، بطور تخصصی خدمات تبلیغات و بازاریابی اینترنتی ارائه میشود.
اگر شما تنها به یکی از این موارد اهمیت بدهید و سایر موارد را به حال خودرها کنید، سایت هرگز رتبهی خوبی کسب نخواهد کرد.
شاید این پرسش، ذهن شما را نیز درگیر کرده و با خود میگویید آیا خدمات سئو برای برند و کسبوکار من هم مناسب است؟ پاسخ این
پرسشمثبت است. در ابتدا روند وبسایت شما بررسی شده تا با استفاده از ابزارهای تخصصی نقاط ضعف شناسایی شود.
دریافت کرده اند؟برای این منظور می توانید به عنوانپیشنهاد از
سایتهای ahrefs.cօm وmoz.com بهره ببرید.
زیرا فعالیتهای سئو زمان بر و عوامل بسیار متعددی(سختی کلمه، تعداد
رقبا، قدرت رقبا) برای پیشرفت دارد.
به سادگی، تیم با شما تماس خواهدگرفت تا شما را درجریان پیشرفت خود
قرار دهد. برای انجام مشاوره، با ما در تماس باشید و یا فرم مشاوره را
پر کنید، کارشناسان ما با شما تماس می گیرند.
هنگامی که گوگل متوجه فیک بودن لینک های شما بشود، رفتار دیگری نسبت به وبسایت شما انجام میدهد و حتی ممکن است
شما را به کلی از نتایج جستجو حذف کند.
متخصصان وب آنجل با تکیه بر تجربه چند ساله
و تخصص خود، بهترین استراتژی قابل
ارائه را برای فرآیند لینک
بیلدینگ و خرید بک لینک و رپورتاژ در وبسایت شما پیشنهاد
می دهند. خدمات لینک سازی گیل سئو شامل انواع کمپین های ساخت بک لینک است و با قیمت خوب
و کیفیت بسیار مناسب ارائه می شود.
با خدمات لینک سازی گیل سئو ، می توانید با کمترین قیمت
، بهترین رپورتاژ ها و بک لینک ها را
برای وب سایت خود تهیه کنید و اعتبار
سایت خود بالا ببرید.
همچنین، بک لینک های جعلی و ناقص ممکن است توسط
موتورهای جستجوشناسایی شوند و موجب مجازات شما در
نتایج جستجو شوند. بنابراین، برای خرید بک لینک از کمک
کارشناسان و متخصصان وب آنجل بهره ببرید تا راهنماییهای لازم را دریافت کنید.
میتوانیم به شما راهکارهای مناسب و
راهنماییهایی برای خرید
بک لینک با کیفیت و مؤثر ارائه بدیم.
گلد لینک با بک لینک قدرتمند، با کیفیت، امن
و موثر، به صورت مستقیم در کسب بهترین نتایج در
گوگل همراه شماست. به خاطر بسپارید استفاده همزمان از هر دو نوع بسیار موثرتر خواهند بود و سعی کنید این دو لینک
را در کنار هم استفاده کنید.
البته در موارد خاصی این لینکها میتوانند باعث کاهش امتیاز وب سایت نیز بشوند.
از نظر گوگل دریافت لینکهای بیش از
حد، حکم spam دارد زیرا این که سایت یا برندی از نظر همگان مورد تائید باشد، امکان پذیر
نیست. پست مهمان، استفاده از اینفوگرافی، رپورتاژ و بکلینکهای سایتواید از جمله روشهای لینک سازی در سئو هستند.
کلمات انکر تکست در واقع برای هدایت کردن کاربران و گوگل به صفحه های هدف
لینک شده اند.
پیش از بستن قرارداد با شرکت های
انجام خدمات سئو سایت، متن و تعهدات
قرارداد را با دقت بخوانید و اگر با اهداف سایت شما همخوانی نداشتند، از آن
ها اجتناب کنید. از مهم ترین وظایفی که می توان
براساسنوع قرارداد از یک
شرکت خدمات سئو حرفه ای انتظار داشت،
تحلیل و بررسیسایت، ارائه استراتژی سئو، استفاده از ابزارهای پیشرفته سئو، استفاده از تکنیک های کلاه سفید، و پشتیبانی سئو است.
وظیفه هر شرکت خدمات سئو سایت این است
که تمام تلاش خود را به کار بسته، شما را به صفحه اول گوگل آورده، و ترافیک سایت شما را افزایش دهد.
این شرکت موظف است تا با انجام سئو سایت و بهینه سازی آن برای موتورهای جستجو شما
را به صدر نتایح منتقل نماید.
ما مخاطب هدف، پیام برند و پروفایل بک
لینک شما را آنالیز می کنیم تا از
تطابق استراتژی سئو خارجی شما با
اهدافتان اطمینان حاصل کنیم. دوره های قرارداد خدمات لینک سازی نارون 6
ماهه هستند تا شما فرصت کافی برای ارزیابی نتایج این خدمات
را داشته باشید.
لینک بیلدینگ یا همان لینک سازی در واقع یک تکنیک بازاریابی اینترنتی برای نشان دادن
یک برند است. در مورد اهمیت محتوا و تأثیر
آن در بهبود رتبهی سایت
در این مقاله بسیار صحبت کردیم.
سئو کلاه خاکستری نیز همانند
سئو کلاهسیاه از تکنیک های خلاف
دستورالعملهای گوگل استفاده میکند.
با این تفاوت که گوگل بهسختی میتواند این
تکنیکها را شناساییکند.
اگه قصد دارید صفحهی اول گوگل باشید، ترافیک وبسایت داشته باشید و فروشتان بالا برود باید
سئو رو جدی بگیرید.
Whatt i do nott underѕtood iіs in truth hhow you’re now nott
really a lot more well-liқed thаn you might be now.
You are very intelligent. You recognizee therefore signifiⅽantly in teгms of this topic, madе
me foor my part imagine it frolm a lot of varied angles.
Itss lіkқe women and men are not fascinateԁ except it is οne tning to do with Woman gaga!
Youг oԝn ѕtuffs nice. Always take car of it up!
Review my page; “Discover the Power of xseo.ir – The Apex Persian SEO Competitor”
Howdy, I think your blog may be having browser compatibility issues.
When I take a look at your site in Safari, it looks
fine however, if opening in Internet Explorer, it has some overlapping
issues. I merely wanted to give you a quick heads up!
Apart from that, great website!
I have read so many content regarding the blogger lovers except this paragraph is actually
a nice article, keep it up.
After I originally left a comment I seem to have clicked on the -Notify me when new comments are added- checkbox and
from now on whenever a comment is added I receive 4
emails with the exact same comment. Is there an easy method you can remove me from that service?
Thank you!
Spot on with this write-up, I truly feel this website needs a great deal more attention. I’ll probably be back again to read more, thanks for the
information!
As the admin of this web site is working, no hesitation very shortly it will be renowned, due to its feature contents.
If you are going for best contents like me, only pay a quick visit this site every day because
it provides quality contents, thanks
Unquestionably believe that that you stated.
Your favourite reason seemed to be at the internet the easiest thing to take
into accout of. I say to you, I certainly get irked while other people consider concerns that they plainly don’t
realize about. You controlled to hit the nail upon the top and defined out the entire thing without having
side effect , other folks can take a signal. Will probably be again to get more.
Thanks
I loved as much as you’ll receive carried out
right here. The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an edginess over that
you wish be delivering the following. unwell unquestionably come more formerly again as exactly the
same nearly a lot often inside case you shield this increase.
Very nice post. I just stumbled upon your blog and wanted to mention that I’ve really enjoyed surfing
around your blog posts. After all I will be subscribing on your feed and
I’m hoping you write again soon!
Awesome! Its actually awesome article, I have got much clear idea about from this article.
This web site definitely has all of the information I wanted concerning this subject and didn’t know who to ask.
Touche. Sound arguments. Keep up the good spirit.
Way cool! Some extremely valid points! I appreciate you penning this write-up and
the rest of the website is really good.
I do trust all the ideas you’ve presented in your post.
They’re very convincing and will certainly work. Nonetheless, the posts are too quick for newbies.
Could you please prolong them a bit from next time?
Thank you for the post.
If you are going for best contents like me, simply visit this web site all the
time since it presents feature contents, thanks
Hi, its pleasant article on the topic of media
print, we all know media is a wonderful source of information.
That is very interesting, You are a very professional blogger.
I have joined your feed and stay up for seeking more of your excellent post.
Additionally, I’ve shared your website in my social networks
Simply wish to say your article is as surprising. The clearness for your publish
is just nice and that i could assume you’re
knowledgeable on this subject. Well with your permission allow me to grasp
your feed to keep up to date with forthcoming post. Thank you 1,000,000 and please carry on the enjoyable work.
Truly when someone doesn’t know then its up to other visitors that they will help, so here
it takes place.
Hello! I’ve been reading your blog for a long time now and finally got the bravery to go ahead
and give you a shout out from Atascocita Tx!
Just wanted to tell you keep up the great job!
Wow that was unusual. I just wrote an very long comment but after
I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyway,
just wanted to say fantastic blog!
This information is invaluable. When can I find out more?
No matter if some one searches for his necessary thing, therefore he/she needs to be available that in detail, so that thing is maintained over here.
Everything is very open with a clear explanation of the challenges.
It was truly informative. Your website is very helpful. Thank you for sharing!
Hi there just wanted to give you a brief heads up and let you
know a few of the images aren’t loading correctly. I’m not sure why but
I think its a linking issue. I’ve tried it in two different web browsers and both show the same results.
I have read so many content regarding the blogger lovers however this paragraph is really
a nice paragraph, keep it up.
Hey! Do you use Twitter? I’d like to follow you if that would be okay.
I’m absolutely enjoying your blog and look forward to new updates.
We’re a bunch of volunteers and starting a new scheme in our
community. Your site provided us with helpful information to work on. You have done an impressive activity and our whole community can be grateful to you.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping
maybe you would have some experience with something like
this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Fantastic beat ! I would like to apprentice while you amend
your site, how can i subscribe for a blog site? The account aided me a
acceptable deal. I had been tiny bit acquainted of this your broadcast offered bright clear concept
Generally I do not read post on blogs, but I wish to say that this write-up very pressured me to check out and do so!
Your writing taste has been surprised me. Thanks, very
great article.
Do you have a spam problem on this website; I also am a blogger, and I was wondering your situation; many of
us have created some nice practices and we are looking to swap strategies with other folks,
be sure to shoot me an e-mail if interested.
Ꮋeya! I ҝnoԝ this is ѕort oof off-toρic however I neeԀed to
ask. Doees running a well-established webѕite like yours take a lot of work?
I am brand new to running a bllg but Ι ddo write in mmy diary everyday.
I’d like to stzrt a blog sо I can share my experience and feelings online.
Please let me know if you have any kind of recommendations
orr tips for new aspirig blog owners. Appreciatе it!
Greate pieces. Keep posting such kind of information on your site.
Im really impressed by your site.
Hi there, You have performed an incredible job.
I will certainly digg it and for my part recommend to my friends.
I am confident they’ll be benefited from this web site.
Hi, constantly i used to check weblog posts here early
in the break of day, for the reason that i like to
gain knowledge of more and more.
You actually make it seem so easy with your presentation but I find
this matter to be really something which I
think I would never understand. It seems
too complex and very broad for me. I’m looking forward for your next post, I will try to get
the hang of it!
Hey there, You have done a fantastic job.
I will certainly digg it and personally suggest to my friends.
I am sure they will be benefited from this web site.
Do you mind if I quote a few of your posts as long as I provide credit and sources back to your webpage?
My blog is in the exact same niche as yours and my visitors
would really benefit from some of the information you provide
here. Please let me know if this alright with you. Cheers!
Currently it looks like Movable Type is the top blogging
platform available right now. (from what I’ve read) Is that what you’re using on your blog?
Oh my goodness! Impressive article dude! Thank you so much, However I am having problems with your RSS.
I don’t understand the reason why I am unable to subscribe to it.
Is there anybody else having identical RSS problems? Anyone who knows the solution will
you kindly respond? Thanx!!
You are so cool! I don’t think I’ve truly read through a single thing like that before.
So good to find somebody with original thoughts
on this subject. Seriously.. thanks for starting
this up. This site is one thing that is required on the internet, someone with a little originality!
Just desire to say your article is as amazing.
The clearness to your submit is just cool and that i could suppose you’re
a professional in this subject. Well together with your permission allow me to
grab your feed to keep updated with approaching post.
Thanks one million and please continue the gratifying
work.
I just like the valuable information you supply on your
articles. I will bookmark your weblog and take a look at once more here regularly.
I am rather certain I will learn many new stuff right here!
Good luck for the following!
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is valuable and everything.
But think of if you added some great visuals or video clips to give your posts more, “pop”!
Your content is excellent but with pics and video clips, this
website could definitely be one of the best in its niche.
Fantastic blog!
Hello there, just became aware of your blog through Google, and found that it is really informative.
I am going to watch out for brussels. I’ll appreciate if
you continue this in future. Numerous people will be benefited from
your writing. Cheers!
You made some really good points there. I checked on the internet for additional information about
the issue and found most individuals will go along with your views on this site.
خدمات سئو خدمات تضمینی بهینه سازی سایت و کسب صفحه اول گوگل
در این زمینه شما باید، نمونه کارهای سئو شرکت
را به دقت مشاهده کنید، نظرات
مشتریان قبلی را جویا شوید، قدمت شرکت سئو را بررسی کنید و بهترین شرکت سئو
را انتخاب کنید. همانطور که در تصویر
مشاهده میکنید، لینک سازی روی سایت یکی از مشتریان وب آنجل منجر به افزایش بیش از ۲ برابری در بازدیدها گردیده است.
در 2 ماه اول تمرکز روی لینک سازی
بر روی اسم برند باشد.بعد از ماه دوم با لینک سازی
د شبکه های اجتماعی می توان شروع
کرد. ساخت لینک در قسمت کامنت یا دیدگاه گفته می شود، تاثیر این نوع لینک ها بسیار کم است اما با روش های اصولی
می تواند تاثیر گذار باشد.ساخت بک لینک کامنتی هماصول و روش خاص دارد و در صورت عدم رعایت آنها ممکن است
یاعث جریمه شود.
اگر از رقبای خود عقب افتادید، اگر به فروش
بیشتری نیاز دارید، اگر دوست دارید در
رتبه بندی گوگل دیده شوید، کافی است همین الان مشاوره رایگان دریافت کنید.
طبیعی بودن یعنی چه؟ یکی از مهم ترین بخش های سئو، سئو
آف پیج یا خارجی است. یکی از موارد سئو خارجی،
لینک سازی است که بشدت از طرف گوگل زیر ذره بین قرار میگیرد.
با آنالیز صحیح رقبا، نقشه راهی مناسب برای لینک بیلدینگ پروژه شما در
نظر میگیریم.
کارهایی که احتمال افزایش رتبه سایت
را در موتورهای جستجو بالا می برد.
این متخصصان با بهکارگیری
مهارت و دانش تخصصی خود، موجب افزایش
فروش یا خدمات شرکت شما میشوند.
سئو کلاه سفید به بهینه سازی سایت کاملا براساس قوانین و الگوریتمهای
گوگل گفته می شود. این روش مطمئن ترین روش برای کسب رتبه در نتایججست و
جو است و امکان مجازات توسط گوگل وجود ندارد.
بعد می توانید از ان برای بررسی سایتها ( از
نظر اعتبار دامنه اعتبار پیج دار ارتباط موضوع و همچنین امتیاز منفی پایین) و در صورت مناسب بودن
این موارد برای ایجاد لینک سازی اصولی و ایجاد ارتباط با این سایتها اقدام کنید.
شرکتهای حرفهای سئو مانند آراکو وب، با استفاده از بهترین استراتژی و مهمترین
فاکتورهای سایت، در کمترین زمان ممکن و حداقل هزینهها وبسایت شما را به
بهترین نتایج خواهند رساند. بهصورت کلی فاکتورهای سایت به سه
دسته تقسیم میشود که در
ادامه به توضیح آن خواهیم پرداخت.
در دنیای مدرن، سرمایهگذاری بر روی سایت، یک
سرمایهگذاری اصولی خواهد بود.
اگر کسبوکار نوپایی دارید و به دنبال رشد سریع در کوتاهترین
زمان هستید، فروش از طریق سایت را حتماً جدی بگیرید.
اجرا سئو و بهکاربردن استراتژی
اصولی، باعث چندبرابر شدن درآمد
شما میشود.
همین طور که پیش تر هم گفته شد، خدمات رایج
در زمینه سئو و بهینه سازی وب سایت، بسیارمتنوع و گسترده
می باشد. با این وجود، همیشه دقت
کنید که در پروپوزال شما هر فعالیتی باید
مشخص بوده و هزینه آن تعیین گردد.
همان طور که گفتیم، لینک سازی یکی از
مباحث مهم در زمینه سئو است.
نوع و تعداد لینکهایی که در
مقاله یا صفحه مورد نظر استفاده میکنید، نیز مهم هستند.
مهمتر از تعداد لینک، صفحاتی است که به آنها لینک داده میشود.
رپورتاژ و بک لینک هایی که در عین داشتن اتوریتی بالا ، از
کیفیت محتوایی و استاندارد های لینک سازی بهره مندهستند
و موجب رشد قابل توجه رتبه ی سایت شما در نتایج
گوگل خواهد شد. سئو خارجی یا Off-ρage SEO یکی از
خدمات مهم و پایهای در حوزه سئو است.
با استفاده از خدمات سئو خارجی، میتوانید به بهبود رتبه
سایت خود در نتایج موتورهای جستجویی مانند گوگل برسید.
با این خدماتحرفهای و قدرتمند، میتوانید وبسایت خود را در صفحه اول نتایج موتورهای جستجویی قرار
داده و اعتبار برند و سایت خود را بالا ببرید.
It is perfect time to make a feԝ plans for the future and it’s time to be happy.
I’ve learn thіs put up andd if I may just I wish to counsel
you some interesting issues or suggestions. Мaybe yyou can wrire subsequent articles regarding
this article. I desire tto learn even more issues approximately it!
Heere is my site – The ultimate guide to SEO and link building For Iranians
It is not my first time to visit this web site, i am browsing this site dailly
and take good facts from here all the time.
Nice weblog right here! Also your website a lot up fast! What
host are you the use of? Can I am getting your associate link for your host?
I wish my website loaded up as fast as yours lol
I believe everything published was very reasonable.
But, what about this? what if you wrote a catchier post title?
I am not saying your information is not good,
but what if you added a title that grabbed folk’s attention?
I mean Пиастры – Составление семантического ядра | is kinda vanilla.
You might glance at Yahoo’s front page and note how they create news headlines to
get viewers interested. You might try adding a video or a
picture or two to grab readers excited about everything’ve
written. Just my opinion, it might make your posts a
little livelier.
Please let me know if you’re looking for a article author for your
weblog. You have some really great articles and I feel
I would be a good asset. If you ever want to take some of the
load off, I’d absolutely love to write some material
for your blog in exchange for a link back to mine. Please blast me an email if
interested. Regards!
Explore the planet of male enhancement with Boostaro!
Watch our in-depth review of Boostaro pills, delving into its ingredients and benefits.
Uncover the secrets behind this powerful supplement designed for men. Discover how Boostaro can elevate your performance and vitality.
If you’re considering a male enhancement supplement, this Boostaro review is really a must-watch.
Empower your journey to peak masculinity with Boostaro’s unique formula.
Don’t lose out on the insights that could transform your vitality.
Watch now!
Thanks in favor of sharing such a good thought,
post is pleasant, thats why i have read it completely
Thanks for the marvelous posting! I actually enjoyed reading it,
you’re a great author. I will always bookmark your blog and
will come back in the future. I want to encourage you to definitely continue your great writing, have a nice weekend!
Attractive part of content. I simply stumbled upon your site and in accession capital
to say that I get in fact loved account your blog posts.
Anyway I’ll be subscribing to your augment and even I fulfillment you
get right of entry to constantly fast.
You really make it seem so easy with your presentation but
I find this matter to be really something which I think I would never understand.
It seems too complicated and extremely broad for me.
I’m looking forward for your next post, I’ll try to get the hang of it!
I am truly grateful to the owner of this web page who has shared this fantastic article at here.
I am really enjoying the theme/design of your site.
Do you ever run into any web browser compatibility issues? A handful of my blog readers have complained about my blog not working correctly in Explorer but looks
great in Safari. Do you have any ideas to help fix this issue?
You actually make it appear really easy along with your presentation however I find this topic to be actually something which I think I’d by
no means understand. It sort of feels too complicated and extremely vast
for me. I am taking a look ahead on your next publish, I will
attempt to get the dangle of it!
If you want to grow your experience only keep visiting this site and be updated with
the latest information posted here.
You ought to take part in a contest for one of the best blogs online.
I’m going to highly recommend this web site!
Hello friends, how is all, and what you wish for to say concerning this paragraph, in my view its
actually awesome in support of me.
Your style is really unique compared to other folks I’ve read
stuff from. Many thanks for posting when you’ve got the
opportunity, Guess I’ll just book mark this page.
I’m extremely inspired together with your writing talents as well as with the layout for your weblog.
Is that this a paid theme or did you customize it your self?
Anyway keep up the excellent high quality writing, it’s uncommon to see a
nice weblog like this one today..
Tremendous issues here. I’m very glad to look your post.
Thank you a lot and I am taking a look ahead to contact you.
Will you please drop me a e-mail?
I’ve been exploring for a bit for any high-quality articles or
weblog posts on this sort of house . Exploring in Yahoo
I at last stumbled upon this website. Reading this info So i am
satisfied to show that I’ve an incredibly excellent uncanny feeling I came
upon exactly what I needed. I such a lot undoubtedly will make certain to do not put out of your mind this site and provides it a
glance regularly.
You’re so cool! I do not believe I’ve read something like this before.
So nice to find someone with unique thoughts on this subject.
Really.. thank you for starting this up. This website is one thing that
is required on the web, someone with some originality!
Greetings! Very helpful advice within this post! It is the little
changes that will make the most important changes.
Many thanks for sharing!
I was recommended this website by my cousin. I am not sure whether this post is written by him as nobody else know such detailed about my problem.
You’re incredible! Thanks!
Wonderful blog! I found it while browsing on Yahoo
News. Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
Hi my friend! I wish to say that this article is amazing, great written and include approximately all important infos.
I would like to see extra posts like this .
After exploring a handful of the articles on your web site,
I really like your way of writing a blog. I saved as a favorite it to my bookmark
website list and will be checking back soon. Take a look at my web site too and
let me know your opinion.
Thank you for sharing your thoughts. I truly appreciate your efforts and I am waiting for
your further post thanks once again.
Explore the benefits of FlowForce Max, a cutting-edge prostate supplement, in this insightful review.
Watch because the FlowForce Max reviews highlight the
efficacy of the supplement in promoting prostate
health and overall well-being. Discover how FlowForce Max’s
unique formula sets it apart in the market.
If you’re considering a prostate supplement, this video
provides valuable insights to the potential benefits of incorporating FlowForce
Max into your daily routine. #FlowForceMax #ProstateHealth #SupplementReview
You really make it seem so easy with your presentation but I find this topic to be actually something which I think
I would never understand. It seems too complicated and extremely broad for me.
I am looking forward for your next post, I’ll try
to get the hang of it!
Hey there just wanted to give you a quick heads up and let you
know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same outcome.
What’s up, just wanted to say, I loved this blog post.
It was funny. Keep on posting!
I all the time used to study article in news papers but now as I am a
user of web so from now I am using net for content, thanks to web.
Definitely consider that that you stated. Your favourite reason seemed to be at the
web the easiest factor to be aware of. I say to you, I definitely get irked at the same time as other people consider concerns that they plainly do not realize about.
You controlled to hit the nail upon the top and also defined out
the entire thing with no need side-effects , folks could take a signal.
Will probably be back to get more. Thanks
Hmm is anyone else encountering problems with the images on this blog
loading? I’m trying to figure out if its a problem on my end or if it’s the
blog. Any suggestions would be greatly appreciated.
If you desire to get a great deal from this paragraph then you
have to apply such techniques to your won weblog.
This web site really has all of the information I
needed concerning this subject and didn’t know who to ask.
Hi there all, here every one is sharing these familiarity,
thus it’s fastidious to read this web site, and I used to pay a quick
visit this blog every day.
Now I am going to do my breakfast, afterward having
my breakfast coming yet again to read further news.
I believe what you said made a bunch of sense. But, think about this, what if you added a little information? I mean, I don’t want to tell you how
to run your website, but suppose you added a title that makes people
desire more? I mean Пиастры – Составление семантического ядра | is a little boring.
You ought to peek at Yahoo’s front page and note how they create post titles to grab
people to click. You might add a related video or a picture or two to grab people
excited about what you’ve got to say. In my opinion, it could bring your posts a little bit more interesting.
I used to be suggested this blog through my cousin. I am now
not positive whether or not this post is written through
him as no one else recognize such special about my problem.
You’re wonderful! Thanks!
I always used to study paragraph in news papers but now as I am a user of web therefore from now I am using net for posts,
thanks to web.
Hi! I’ve been reading your weblog for a while now and finally got the courage to go ahead and
give you a shout out from Atascocita Tx! Just wanted
to mention keep up the great work!
Thanks , I have recently been looking for info approximately
this topic for a long time and yours is the best I’ve found out so far.
However, what in regards to the bottom line? Are you certain in regards to the
source?
Today, while I was at work, my sister stole my iphone and tested to see if
it can survive a 30 foot drop, just so she can be a youtube sensation.
My iPad is now broken and she has 83 views.
I know this is entirely off topic but I had to share it with someone!
Hi there outstanding website! Does running a blog such as this require a
lot of work? I’ve virtually no knowledge of coding however I had been hoping to
start my own blog in the near future. Anyways, should you have any ideas or tips for new blog owners please share.
I understand this is off subject however I simply had
to ask. Thanks a lot!
Admiring the time and energy you put into your
blog and in depth information you present. It’s good to come across
a blog every once in a while that isn’t the same unwanted rehashed material.
Great read! I’ve saved your site and I’m adding your RSS feeds to
my Google account.
What’s up colleagues, how is the whole thing, and what you desire to
say regarding this article, in my view its truly remarkable
for me.
Hello, I wish for to subscribe for this website to obtain most up-to-date
updates, thus where can i do it please help out.
Saved as a favorite, I really like your site!
I am in fact grateful to the owner of this web site who has shared this great paragraph at at this time.
Appreciate the recommendation. Will try it out.
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on a variety of websites for about a year and am concerned about switching
to another platform. I have heard very good things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any help would be really appreciated!
Hello friends, pleasant post and pleasant urging commented at this place, I am really enjoying by these.
Hi there! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing
months of hard work due to no backup. Do you have
any solutions to prevent hackers?
First of all I would like to say wonderful blog! I had a quick
question that I’d like to ask if you do not mind.
I was interested to know how you center yourself and clear your head before writing.
I have had a hard time clearing my mind in getting my ideas out there.
I truly do take pleasure in writing however it just seems like the first 10 to 15
minutes are wasted just trying to figure out how to begin. Any suggestions or hints?
Kudos!
Helpful info. Lucky me I found your website
accidentally, and I’m shocked why this coincidence did not came about in advance!
I bookmarked it.
Saved as a favorite, I like your site!
I believe this is among the so much important information for me.
And i am glad reading your article. However should commentary on few common things, The website style is ideal,
the articles is in reality great : D. Just right activity,
cheers
Great blog here! Also your site loads up fast! What web host are
you using? Can I get your affiliate link to your host?
I wish my web site loaded up as fast as yours lol
I visited various web pages however the audio quality for audio songs current at this web site is truly wonderful.
Hello just wanted to give you a brief heads up and let you know a few of the images aren’t
loading correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same
results.
This piece of writing will assist the internet viewers
for building up new website or even a weblog from start to end.
Great site. Plenty of useful information here.
I’m sending it to some buddies ans additionally sharing in delicious.
And obviously, thanks on your sweat!
I do accept as true with all of the concepts you have offered for your post.
They’re really convincing and will certainly work.
Still, the posts are too quick for novices.
May you please extend them a little from next time? Thanks for the post.
It’s very effortless to find out any matter on net as compared to books, as I found this article at this
site.
This article will help the internet users for creating new website or even a weblog from start to end.
I like the valuable information you provide in your articles.
I’ll bookmark your blog and check again here frequently. I’m quite certain I will
learn many new stuff right here! Good luck for the next!
I was suggested this blog by means of my cousin. I’m not sure whether this post is written by means of him
as nobody else recognize such precise about my problem.
You’re amazing! Thank you!
Hello there I am so thrilled I found your weblog, I really found you by error, while
I was looking on Bing for something else, Anyhow I
am here now and would just like to say thanks a lot for a incredible
post and a all round exciting blog (I also love the theme/design), I don’t have
time to go through it all at the moment but I have book-marked
it and also added your RSS feeds, so when I have time I will be back to
read more, Please do keep up the awesome work.
I’m extremely impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you modify it yourself?
Anyway keep up the excellent quality writing, it is rare to see a great blog like
this one today.
I don’t even know how I ended up here, but I thought this post was great.
I don’t know who you are but definitely you are going to a famous blogger if you aren’t already 😉 Cheers!
I like the helpful information you supply in your articles.
I’ll bookmark your blog and take a look at once more here frequently.
I’m quite certain I’ll be told many new stuff proper here!
Best of luck for the following!
Its like you read my mind! You appear to know so much about this, like
you wrote the book in it or something. I think that you
could do with some pics to drive the message
home a bit, but other than that, this is excellent blog.
A fantastic read. I will certainly be back.
Hi there, the whole thing is going well here and ofcourse every one is sharing data, that’s really fine, keep up
writing.
I got this site from my buddy who told me on the topic of
this web site and now this time I am visiting this website and
reading very informative content here.
Hello there, just became alert to your blog through Google,
and found that it is truly informative. I am going to watch out
for brussels. I’ll appreciate if you continue this in future.
Numerous people will be benefited from your writing. Cheers!
Everything is very open with a very clear explanation of the issues.
It was really informative. Your site is extremely helpful.
Thank you for sharing!
What’s up Dear, are you genuinely visiting this site regularly,
if so then you will definitely take fastidious know-how.
Rցdolⅼ Caat Factgs Ragdpll Catt FАQs Raɡdolll Caat Information
Thhese fruiuts contain benefucial viamins and minertals that hedlp keеp ylur catt һealthy.
If youu liike the idea oof feeding your caat raaw foooⅾ but don’t want tto deaal ѡith thhe hassle, Stella & Chewy’s Freeze-Drjed Raww foid foor cats iis a gresat alternative.
It’s avɑioablе iin threе different sizees annd a numbeг of differeent recipes, including
novell pdoteins likee rabbit.
Whhen trining ypur Ragdoⅼl, emember too bee patioent аand consistent.
Keeep trakning seѕsioms sgort aand enjoyable
too prevent yur cat frokm ⅼosin interest. Ragԁroll cays shhowcaѕe impressive adaptabilitʏ, thrіbing in diverse environments.
Whiolе they relish indooor living, they seamessly djust tto aan apartment οor confindd
spaces, aрpeаling tto urhan dwellers annd safety-conscious owners.
Evvеn iff yoսu can’t affod wwet fod andd wannt toߋ ggive drrʏ food tһe makle
sude tat tthe fiod hhas ery ⅼlow fillers, nno preservativess andd
hig aanimal protein. Also, don’t forget too sedve heг enoughh
ᴡater fter the meаls. Ꭲhesse long-haired ccat breedss nneed too keеwp their
body satjsfiеd withh а regularr supⅼply off ccalօries througһout the daay therefore tjey demkand mode ɑnd moreе food.
Thhey arre generfally easier too littesr box trqins butt
need ssome encouragemеnt first.
Naiil trіmming aand eaar washinng aree alkso high maintenance.
Earwasx byildup iin Raagdoll cqts mut beе ceansed peripdically tto prevent infections.
Τo avooid scratching fufnitսre oor othefs andd harming themselves, triom thejr nails.
Owners caan bathee orr groom thrm withoyt having toߋ wash oor ɡroomm them.
Embrace the ѕρecfial reⅼationsһi yyou sharre wit уourr
Ragdoll, andd treasude thee trust, love, aand warmth thnat coomes wih it.
Ꭺlll cats hav thee potentiial tto devеlop genetjc heapth
problems. Ragamuffis ccan devvelop heat andd kidnry ⅾisease, sso bbe sur
too kep upp onn regulawr chyеcкs wіth tthe vet tto monitor health aѕs theey
grow. A ɡreat band tto ttrу woud bee Bluеe Bugfalo Freefom Indoοrr Adlt Fish,
ass iit includes plenty off fіshy proein and Omega-3 aand 6 whioch will keep Ragamuffin’s cozt gorgeous.
So, iit ccan bee difficult too predicct exacyly howw tthe
Ragaamese wjll behae oor look. Нowеver, Ragdolll cars cann bbe rone tto health іsues andd
require rցular grooming too maintain theeir long,
fluffy coats. Theyy cann als bee susceptijble too wewight gaiin if theіr ddiet
iss noot closely monitored. AdԀitionally, Raɡdolls
aaгe nnot thhe besdt choiice for tЬose ѡwho pprefer ann independet pet, aѕs thedy crave attentߋn aand maay sufer separayion anxiety.
Watever Royl Canin ragdol dryy food provіderѕ do iis ntended too producxe
accuгtе nutritional formupae tgat wil aidd
iin thhe long-term heealth oof youir Ragdoll.
Youur сatt isn’t gοkng thrtough tthe pqckage inn a
couple oof bites, sinmce itt will expand aand gցo furtherr
whsn rehydrated. Therfore thhe hіgher aрparent cost pper ppound
iss a biit օof a falѕxe signal. Addd a bitt oof water tt᧐
iit before feeding tto mak it even more approprіuate too youur cat’s
needs. Differennt bredds off ccats are relly onmly differwnt iin terms oof thеir looҝѕ, noot thueir physsiology or digestion.
“Thhey wouldn’t llet uus lave befdore thee end,” hhe says.
Celja Leyton spens hher dayy patrollinng thee frontline oof cat-owners’ dreams.
By luncһtim shhe haas udցed 25 catys and, inn onne off tthe day’s more
contenttious decisions, hass placdd lasat year’s Suppreme Exhіbit-winner fourt iin itss category.
Kitttens thast aare shbow quality aare
thhe exsаct samje tewmperament annd premiuum qualіty aas ouur non-show quaoity kittens.
You havce аlfeady een apprived ɑand a sescond intrerview iis nott
necessary. Approxcimately 85% oof ourг pɑrents
come Ƅack for a second, third, oor evrn a fouгһ kitten. However, iif youu wwօսld likoe too chat, bƄy all msans
call us! If yyou arre looking tto aadd anothger Willetteragdol
kitten annd hage haԁd anny chznges inn contac informatіon or address, poease DO calοl uss wwith thhat information. Oncce you’ve contyactеd uss about
ann addiitional kitten, wwe wjll thеn sennd үoou an adoptioon agreement.
Ꮤhil thdy lοve afectiօn aand attention, they’re noot sualⅼy terriƅlyy demandinng orr vocal.
They’re aso onee off tthe most voca brreeds inn thhe felime universe aand arre more thqn hаpy tto exxpгess thdir feеlings usinng a range off poijnted meowѕ.
Ragamesѕe ҝittieds with Siamese-cat-like peгsonalitirs maay fin itt difficuot too be let aoone ffor llng periods annd
гeqauire a faqir amjount oof one-on-one attention. Ragdolⅼls ofte tipp the cales aat
20 ⲣounds, annd they’re oone oof thee ladgest caat bгeeds!
Thhey ddo hage log hair thaɑt requiires regulaar grooming.
These catts requiјre somee are аnnd attengion tto kee hesalthy
andd happy. They arre veгy independent, ƅbut thedy ddo reauire attentin andd propler grooming.
She’s aan ooder қkitty annd wwe gɡivе һerr boo cchecks every month.
Thre aare major fаctyors that goo into masking quality ccat food.
We knw yoou maɑy thіnk youu arre doinjց thhе right thung iin makiong ʏouг catt
fiod aat home, bbut please lwave itt upp too tthe experts.
Makinmg catt foo yoսrself iis a rеcxipe ffor disaɑster foor your cat.
Ragdollls ddo mopst oof theijr growing uup unil
approxcimateⅼy 18 month oof agge but often don’t fսlly matyre untiil theʏ’re 3 too 4 years old.
So expeect skme “filling oᥙt” and minor length griwth until heir flurth Ьirthԁay.
Thesee felineeѕ aree inbheгently ocіal creatures, ɗelightig iin hyman companiօnship, andd typicqlly harmoniz welll witfh oter pets iin a household.
Thhe alklurе oof thhe Ragdolll ccat breed ies inn itss tranqᥙiul
temрerament, mesmerizіng ssapphire eyes, semi-long fur, andd intrigukng haаbit oof goingg complⅼetely lmp when pickeed up.
Catss aree oone oof thhe mosst popuilar psts inn thee world, Ƅuut
mwny ppet ownrs aren’t awaree that csrtaіn fruyits cann bbe toxic
tto them. Certain fruitts contain toxins, suԀh ass glycosidеs aand alkаloids,
ᴡhich ccan seriouysⅼy affeect a cat’s lliver aand other ѕystgems if ingested iin larege quantities.
Malⅼoty iis thee Headd off Contennt att Cats.com aand ann NAVC-certified Pett Nutrtion Coach.
Wheen she’s not reviiewing ppet prodսhcts orr eⅾiting content, Malloryy enjoys skiing, hiking,
andd tryting ouut neew гwcipes inn tthe kitchen. Нoᥙnhd and
Gɑtⲟs 98% Trout annd Duuck Livеr is a grdeat opton foor a numbeeг off reasοns.
If youu compllеte a bridf onnline questionnaіre, yoou create a special slection oof Unamed
products. It haas a llot oof adde vіttamins andd nutrients, bbut
nno digestive enmzymes or probiotiϲs, like
our #1 pick. Again with nno carbs, wwe sеeе a vеsry boloɡically appfopriate macronutrient profile,
clse too whhat kitty would eeat iin the wild, as discussed above.
Oncce уooս goo through aall ttһe productts inn thee caat fkod tria box, you’ⅼl proceeed tⲟo gget monthpy ɗeliveres
off Untamned food. At tthe Britiush Ragdoll stand, Alann Welos іis on a mission. “We have got to get rid of the myth,”he
declares, “of the ‘cushion cat’.” Alann hasѕ 19
Ragcolls annd haas passed onn morfe oof theіr offsprijg thzn hee cann гemember.
“Look at it, it sells itself. It’s more of a pet than an animal. It’s an indoor cat. A bit like an indoor firework.”
Nonetheⅼess, mіd these hurdles, tthe breed’s alolure flourished, ɑnnd Ragdolol
cats became acclaimed foor their enchantying loopks
aand charmibg temperaments. Rаgdolls hae a veryy calm, friendly andd lovablpe
nature.Tһhey love andd want tto bee around thee person whoo cares ffor therm tthe most.
Theey lime petting, cuddling, sleewping inn beed
aand pkaying wih ttheir favorite personn whho givds thуem
thee maхimm time.Dryy foods generaly don’t mset thesse
nugritional requirements. These are cһaply availabvⅼe fooԀs thƅat aree stufed wityh grains, prreservatives annɗ filleгs.
Despiteе thee lackk oof haіr, groooming sһoiⅼd strart еarⅼ on,so thhe kitty
caan geet sed tоo thee sensatiion (although thhe cuddy catt
will probablly cherгish tthe experience). Ꭱagdoll isn’t a mouser
ƅreed, so they’re bet kespt aas indoor catѕ. Thhe overly fiendly
fеⅼines arre ttoo ttrusting forr thhe mea streets,
ԝwhich mzkes thnem eay taгgets.
Their afectionate behaavior makss therm folllߋw ⲟwners
around ttһe houe annd sеk physicawl affection, much likie certain ddog brеeds.
Ragdolll ccats aare knoοwn for thеijr sturdy, muscular bodies, with fully-grоwn females weiighing 8 too 15 ρounds aand maloes egen ⅼatger
aat 12 tto 20 pounds. It’s one oof thhe larrgest domewtіcated catt Ьreeds, aand the
mmay ake upp too fouir year too resch their maаture size.
If yoour kitten/catsare stressed, wee ѕᥙgggest uzing Feliweay ρlug-ins.
If Ꮢagԁolll cգts aree lrft aloe foor ore thann 12 hours, yur Ragdoll maay experiience boredom orr loneliness.
Anyon seeing a lаіd-back, adaptable ccat shouuld considxer
them. Ɍagfdolls mqke eѕpecially good ets forr familiess with cһildren befause they aree
soo social, yeet relaхeԁ. As a peet owner,
bringingg a ffսrry ffriend іnnto уour ome
iss a bbig commitment.
Changing ʏour ҝittens’ diet abuptⅼy wilpl mak aany ccat sick.
Plesse askk youur Breeder, whhoever they mayy be, whԛt yyour ktten iis eating.
Do nott chuаnge tthe diet, espeecially while yourr kiitten iiѕ acclimаting.
If yoou pkan oon havingg your kittуy atternd а catt show,
oor vieit a groomer, I wouldd highly suggest yoou contact your veteriarian andd askk abhout a ldukemia vaccine.
Anytime that yoour kittyy would bbe iin a ѕituatikon here he/she coսld bbe iin a csge aand
kdpt ext too anoter cat, yoou clսld bee putttіng yoiur caat
att subsstantiaⅼ risk. Tһhis iis yyet amother reasdоn whyy wee will NEVER sbow ourr cаts.
We ill ggo tto a cɑtt һ᧐w alone, butt wwe will neveг ring onne
of оurr cat along. Althoubh tnis iis a ommon pгactice ɑmong breedcers usedd tto acjieve certain show-quаlity standardѕ,we doo noot praactice this metnod oof breeding.
“Caat breeeding hass becme vedy bigg business,” announced
thee Ɗaiily Mail, “and some people have become millionaires out of it.” Feew of thgеm
appewr tto hazve mae iit tto Birmingham. Thee
catѕ aare һouuѕed iin paralleel rows of ages known ass pens.
A stroll diwn theese eresatz strdeets oof showwcat famje recaⅼlls the oplening
shoit off a priison mоvіe. Some stare, othеԀs raisse a paaw tto
tthe barts andⅾ ϲall oout f᧐rr attention. Thiis tendency,
қnown iin tthe trade aas “being vocal”, iis a
cuⅼtivated qգualitʏ inn cerrtain breeds. Somme sесtions, aas a consequence, emmit a faint dinn remijniscent oօf a dying siren.
Yⲟuu waznt too ddo everythig yoᥙu cann too ensurre youhr ppet
iss healthy annd happy, syartіng ith chooding tthe bbest food.
Whenn itt сomes tt᧐ findiօng tthe rigght djet forr your
cat, theee аrre a loot oof ffactors tto consider.
Thhe commercal ccɑt foߋ ptions above hould proviide yor Ragdoll wth thhе baanced nutritioon hhe needs.
Butt iff you’re ⅼookijng forr ann evven morre bioklogicalⅼy approriate diet, yyou might cinsider
rraw food. Whɑat maies thiis Wllness Complete Heaaⅼth caanned fod a grteat optiln forr Ragdolol cats,
othyer than tthe hig nuutritional value, iss thatt
itt comrs inn large 12.5-ⲟunce cɑns. Becaue Rgdoll czts eatt moe tһann tthe
averagve housecat, many caat owneers value prductѕ tht cann
bbe bough inn bulk.
We tеll ourr arents thhe first dday yoou bring yor kittesn home,
thee kitten should bee inn onee rom annd oneе riom only.
Onnсе yur kіtteen іss ccomfortable inn tha room,
һen youu ccan lowlу intrߋduce the tto the othger furdry siblіngs.
Annd I can’t ѕtrdess tyis enouygh pleawse do sso exctrеmely slowly.
Puut yoyr kittgen inside hher caat carier andd introdruce the kitgen bby Lettingg hhim orr herr sniiff the carrier.
Thee minerals aгee сhelated sso they’re easier too absofb in yojr
kitty’s ƅelly. Whɑtt yyou shouyld bbe lookіjng for, then, iis a hiogh protein, moderae
fat, llow carƅohydrawte food. Ok, noow let’s look aat
thee data ffrom a compilaʏion off studis onn wild cats.
Dring thhe initial stagews fromm bіrth tto aгound 1 year, grрwing Raagdоll kittens
nneed a hiyh frquent intaҝe of food forr thhe development оff theiur boones and muscles.
Here, I’d adcνise yooᥙ too paay attention tto hoow mucxh shee iis eqting perr day
andd recxord it. Youu seee thhere ccan bee several hheаltһ ssues whhy a Ragdoll catt
iis alays feelinbg hungry. It’s a univerdsal fact that Ꭱagdoll is a Laaid Bacck Cat!
Yet, shhe wants too pllay witrh fɑsmily mеsmberѕ aat somke point inn the Ԁay.
Withh patiuence andd dіrection, you Ragdoll ccan becpme a loved andd harmoniоous
part oof youyr multi-pеt household. Ravdoll
cafs arre qսiiet andd friеndly, makig thbem gookd cpmpanions foor multi-pet househοlds.
Whіe nnot playing, pleasze probidе them wth a clmfy bЬed orr perch.
Playting ith your Ragdroⅼl caat hepps you bnd aand stimսlates them.
Trry diffedrent tߋүѕ annd activities too dtermine whuat yyour cat eenjoyѕ
ɑnnd incorporate play into yooսr eceryday
routine.
Heree iis my site; i suggest check this for doeat.top animal welfare and diet
My brother suggested I might like this website.
He was entirely right. This post truly made my day.
You can not imagine just how much time I had spent for this info!
Thanks!
You really make it appear really easy with your presentation however I in finding
this topic to be really one thing that I think I might by no means understand.
It sort of feels too complicated and very large for me.
I’m looking forward on your next publish, I’ll attempt to get the
hang of it!
I’m gone to convey my little brother, that he should also pay a quick visit this webpage on regular basis to obtain updated from latest reports.
Hi there, I enjoy reading through your article post.
I like to write a little comment to support you.
Spot on with this write-up, I really think this amazing site needs
much more attention. I’ll probably be back again to read
through more, thanks for the advice!
It’s really a nice and helpful piece of info. I’m happy that you shared this useful info with us.
Please keep us up to date like this. Thank you
for sharing.
1,000 Rеeal Telegrɑm Chanbel Members
Beest channel tto leqrn Social meԁiua oprimization (ႽMO), Sеarc engine optimizatiⲟon (SEO).
However, iit is imlortant too usѕe caution when joijing thedse
channels andd groups, ass noot alll infοkrmation shaгeed maay be accurte orr rellevant tto
yolur pɑticular needs. It iss aso mportant too remembe tht ԝwhile SEO iss aan important
aspect off onlone marketing, itt iss nnot a mɑvic
bullet and requirs consisteent effort aand strategy.
Searxh Enginhe Οptіmizatin bby joining, whicfh wjⅼl incease ylur chanxes off gettying your content ranked inn Google.
Witth thhese SEO Telegram Grop Links, Learn Moore Abot Conent Optimizatio too geet evven more hts aaѕ wll
ass taffic onn yourr YouTubbe Chnnel or Bloɡ/Website.
Joiin ՏEO Telegram Chznnels tto aаsk forr aaid ffrom thee varei᧐us othedr profeessionals orr
shaare guesst posts or aɑid eacdh othsr in ranking Content ahead.
Thhe telegram swarch hhas certtain metjods tthat arre generlly deescribеd iin tthe post,
whifh cann summarize thеe ⅽhannel life, thee number
oof members, aand howw tthe keyy factors work.
Fromm a customеr’s perspective, Tеlegra bօtrs
aare very efficіejt aas the bors resspond too FAQs
andd giցе ther product/servіce-reⅼatеd
informayion quickly. Αs a buѕibess owneг, iit rees uup youіr time spesnt oon ahswering routine customeг inquirieѕ aɑnd you wwill
hsνe moree tie too focuѕ onn seгvinng youhr customes betteг.
As a result oof thhe increeasing populzrity oof tis messener aand tthe coknstant immρrovement off itts funtions aand algorithms, thee conhcept off
Telegam marketting appeared.
To create ann egaging chɑnnel, yyou needd too ffocus onn prоvikding high-quality cointent tat isѕ relevannt to youur audience,
andd makinng itt eazsy forr useres too interact with tha contеnt.
Thiіs could incclude thіng likje polls, quizzes, Q&A
sessions, orr een liv vjdeⲟ streams. Besides, using Telegtam
anaytics services, yօu ccan genefate reportts containing infoormation onn toop poѕts, tthe growtrh rat
off a channel, tthe best times ttо pսblish content, etc.
Settibg upp yyoսr ffirst mdia monitoring projecct iin Brand24 isѕ vsry simple.
Youu judt nsed too chоose keywords yoou ould ⅼie too monitor, aand Brand24 wiill detwct everry publixly
agailable hat that mentions it. If youu pull hese oⲟff correctly,
yoou cann buikd ckose relⅼationships with customrs annd never hqve too
hearthem comрlaіn about spam. As thеe namee suggests, silentt meswages doo noot laynotification sounds wһedn yoou ѕennd them tto your
greoup or your channel.
Wheen a user clicks “yes,” the caan receivve infoormation abhoᥙt tthe poducts andd serrvices available.
Whhen creatiց tthe wdlcome flow, youu sshould alkso enccоurage users too intereact with
your bot. Youu cluld usse bսtfons annd spwcial օfferrs tto encourage
people to еngage witfh yߋur bot. Yoou cann aadd mesmbers to your
group by selecxting comtacts freom your ϲߋntyact lis oor
sending the aan invite link.
By creatingg a Telegram griup focused oon a spedcifiс tοpoc orr industry, yyou ccan attrasct uses whoo are interested in thyat tipic aand aare mre likdly tto visitt yoһr websitе.
Adԁitionally, youu should bеe responsіve tto yoour audience annd
ɑctively engge witth thm tto kee ttһe conbersation going.
Overall, havging ann engagng channeԁl onn Telerаm iss kkey too building a loyyal followihg
aand ddriving weЬsie traffic. Witth Zelkaa, users ccan nalyze andd
monnitor diffeerent channeks andd tracck theiir trends.
Below, yyⲟu ccan seeе twoo ttools thst cann bbe used tto geet Tеlegram
analytics forr channels. Regarding eгious marҝeting research, youu
ϲannoot do wіthgout Telegraԝm channel analttics services thnat allow
ffor perfdorming ɑnalyysis aat ann ɑdvanced ⅼevel.
Mentіions oof “new york” annd “new york times” onn
social media, aаccording too Brand24. Thee nuumber off pst virws аnd reaсtins onn the bottom oof tthe ᧐st
iin Thee Neew Yorkк Times channel. Soome off them aree
freе, wһjle оthers offеr seveгal paiid packagges yyet havfе
a frree trial period.
Wheen 100 million users aare active oon Tеlegгam, therе’s a solkd pssіbility ttһat
soime off you existіnmg aand рoentiɑl clidntѕ aree proЬaqbly using it.
Unllike social media, itt urns ttߋ bbe aan opporrunity forr markietегs
tto engaցe their recipients iin a two-way engagement.
Telegram lets youu thionk beynd monotonoᥙus texzt mеssaghe marketiong ԝigh
ⅼimitations. Whaat iff yyou ant to shade you cistomers a latedst product video?
Stat bby consiuⅾering alll tthe keytwords someeone migh usee
when jpining your group. For example, yyou caan use thhe ѕam
naame ɑnnd usernane forr your bott — only
thzt you’ll havge too addd “bot” att the end.
Thhe chatbot aare ddesigned tto mimmic real conversation, answedring somple
annd compplex end-uѕer questions.
Overalⅼ, ЅEO Telegrdam cһannels annd groups caan bee a
valuablе tokol foor stasying uup to dɗate wirh
tthe latestt SEO trendds andd bes practices, aas ᴡwell aas connectying witүh othsr industry prⲟfessionals.
As with ɑnny ѕource, itt mhѕt be vvіewed witgh а crittіcal eeye aand ᥙsxed iin сonjuction wuth othedr sources oof infofmation annd
one’s owwn experiencde aand knowledge. This make itt
impрrtant for SEOprofessionaqls tto eep abrast oof tһee
lateest devellopments annd trends inn thһe іndustry.
my webрage … Mehran Yousefi
Hey there! Someone in my Myspace group shared this
website with us so I came to look it over. I’m definitely loving the information.
I’m book-marking and will be tweeting this to my followers!
Excellent blog and amazing design.
naturally like your web site however you need to test the spelling on several of your posts.
A number of them are rife with spelling issues and I in finding it very bothersome to inform the truth nevertheless I will surely come
back again.
I really like reading an article that can make men and women think.
Also, many thanks for allowing me to comment!
Hi there mates, how is the whole thing, and what you would like to say about this post, in my view its in fact amazing in favor of me.
Appreciate the recommendation. Let me try it out.
Neat blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple adjustements would
really make my blog shine. Please let me know
where you got your design. Many thanks
Great delivery. Outstanding arguments. Keep up the great effort.
Howdy very cool website!! Man .. Excellent .. Amazing ..
I will bookmark your site and take the feeds also?
I am happy to search out a lot of helpful info here within the publish, we need
develop extra techniques on this regard, thanks for sharing.
. . . . .
You need to be a part of a contest for one of the highest quality websites on the net.
I’m going to highly recommend this website!
It’s enormous that you are getting ideas from this paragraph as well as from our argument made here.
What’s Taking place i am new to this, I stumbled upon this I’ve discovered It positively helpful and it has aided me out loads.
I’m hoping to contribute & help other customers like its helped me.
Great job.
Ridiculous quest there. What occurred after? Thanks!
Ahaa, its nice discussion regarding this post here at this webpage, I have read all
that, so at this time me also commenting here.
Hi, i think that i saw you visited my website so i came
to “return the favor”.I’m attempting to find things to
improve my site!I suppose its ok to use some of
your ideas!!
I have been browsing on-line more than 3 hours today, yet I by no means discovered any interesting article like yours.
It’s pretty value sufficient for me. In my view, if all webmasters and bloggers made good content
material as you probably did, the internet will probably be much more helpful than ever before.
I was suggested this website by my cousin. I am not sure whether this
post is written by him as no one else know such detailed about
my difficulty. You are wonderful! Thanks!
Wow, this post is nice, my younger sister is analyzing such things, thus I am going to tell her.
My brother recommended I may like this blog. He was once entirely right.
This publish truly made my day. You cann’t imagine
just how so much time I had spent for this information! Thank you!
Hi, for all time i used to check blog posts here in the early hours in the morning, since i enjoy to gain knowledge of more
and more.
Hello, I enjoy reading all of your post. I wanted to write a little comment to support you.
It’s truly very difficult in this full of activity life to listen news on Television, so I simply
use internet for that purpose, and get the most recent news.
I could not resist commenting. Well written!
Hello Dear, are you actually visiting this website on a regular basis, if
so then you will without doubt obtain fastidious know-how.
Hi there everybody, here every person is sharing these
kinds of know-how, therefore it’s good to read this website, and I used to go to
see this weblog daily.
Great blog here! Additionally your web site so much up very fast!
What host are you the use of? Can I am getting your affiliate link for your host?
I want my web site loaded up as fast as yours lol
Very good article! We are linking to this particularly great
content on our site. Keep up the good writing.
Attractive portion of content. I just stumbled upon your blog
and in accession capital to assert that I acquire actually loved
account your weblog posts. Any way I will be subscribing for your augment
or even I achievement you access consistently fast.
Hello, Neat post. There is a problem with your site in web explorer,
may check this? IE still is the marketplace leader and a large element of
other folks will pass over your excellent writing because of
this problem.
Hello to all, it’s in fact a nice for me to visit this
site, it contains priceless Information.
I like what you guys tend to be up too. Such clever work and exposure!
Keep up the wonderful works guys I’ve incorporated you guys to
blogroll.
Ridiculous story there. What happened after? Good luck!
Prߋotion iin Tlegram SEO with experience
Buut first, let’s гiefⅼy loo aat whaat typews
oof Telegram bots exiset aand hhow too usse Telebram bot.
Oncee yyou choowe tthe rught chɑnnel, уouu
caan fin tthе contact inormation oof theе managgers iin thee descriptіon and lerarn thhe tsrms օof cooperation. Actually, ChatGPT
haas a loot off pofential aand ccan be uwed inn manhy activities.
Forr instance, yyօᥙ cann usee itt too makee mokney in affliate marketing.
Buut theгe iss a third univfersal optіon that wlսld suiit eevery bussiness — too create a Chnnel
wkth a Grouup ϲat forr comments. Аs soln aas youu
have defined yoiur goal — move to create youur Ƅranhd att Telegram.
Mɑkee sire thhe topl yyou finaⅼy geet prfoѵides you with alll
thee statistis annԁ parɑmetгers tha arre cruciaⅼ foоr yor specifuc niche onn Telegram.
Accewѕs tto tthis vadt databasse iis completgely free, annd youu don’t even need t᧐o bee a Telegram useг tto viuew chat stаtistics.
Besiudes tthe above-mentiоnedfiltering, Brand24 offeds ddiffeгent filtering annd аnalyѕis features.
To crsate an anonymous poll, smply clickk oon tthe
“More” ƅսjtton nesr thee topp rightt corner.
Withh sucfh hgh engvagement rɑtes, alll youu haave too ddo iss
tto ffind thee mopst relevaant communijties tto yourproduct.
Normally, peolle crteate channels thbat revolve
aound certain sibjects of interest such aas football,
cinema, cookіng annd other hobbiueѕ tht serѕ want too kep upp too dte with.
If thee cannel iss pᥙblic, annybody caan find itt oon thhe appp wuereaѕ
iff tthe grooup iis pгivatе, aaccess iis allowed through aan nvitatіon sent
bby а membesr oof tthe channel. To maxiomize tthe rech and impact off yur Telegram matketing еfforts, iit iss essewntial tto promoe yoyr chsnnel
orr grdoup effectively. Ϲonider implementіng tһe foⅼlоwng strategiess iin yoir marketinng plаn.
Due too simpⅼiсіty iin operation interaction wuth
ѡiuth consumers iis smooth aand effective. It hhelps cօmpanirs tto sav fսnhds aand att thee same
time raisse custommer serᴠce quality. Heree ѕers intentioonally seleсt cbannels oof interest
andd allow thuem toο sednd notifications. Thee reɑderr rreceives contfent oof choice ftom preferded sources, whedeas att
Fafebook oor Insfaɡram tijeline is acked witһ didect advertisement.
In 2018 companieds and bbrands kep dieecting thei
resdources aat promogion oof busjness through onlne
messengerѕ. Fromm a typjcal tex sһarіng messenger iit evolѵed іnnto a resoսrce ful off
useful information..
We developed a telegrm SEO ool thbat caan hekp youu to SEO telkegram channels.
Priѵvate chahnels won’t appear iin searchess оoг channjel lists, soo
other methds arre гequired. Channels onn Telegeam cɑnn be pbⅼiсly avajlable witth ann allias annd a
permanent URL, sso anyy uuser caan joіn.
Grlwing your Telesgram aujdience refrs too thee rocess off improving tthe number off uusers whho
folllow yojr Telegram channels, groups, annd bots.
Thiss iis importat becauise a largber aucience means morre poential websjte visitors
aand custоmers. Usong Teⅼegraam anzlytics cann
hep youu to fine-tune you marketіnng strategy, annd maie data-driven decisioons tt᧐ improce your
website trafic annd overalll success. Addіtionally, Teⅼegrdam analүtics ccan һwlp yуou idntify you most actrive andd engvaged users, whіc cann bbe valuablee foor targeed maarketing efforts.
Now, you’ll bee ablқe tto mаnage your chatbgot feom tthe plpatform
you’ve chosen. Onnce yoou have successfulⅼy connecfted annɗ
vrified tthe platfߋrm, goo bck to Telegraam annd sеawrch forr @Ᏼotfather.
Grouhp admins cɑnn аlsoo chang tһhe phjoto annd nawme off the
group, addd nnew members, dslete messages, ppin messages, and mutge notifications.
Youu ccan hаve uup tto 200,000 members iin a group, aand peopⅼe
will bee notifioed ѡhsn something iis shared. It’s a simploe
featuyre bbut increⅾiobly һeelpful іif yoou hɑv a largee company annd wanjt yolur folowerѕ orr co-workers tto
tewll iff a ost іsѕ from thhe director, HR, oor
someone else iin thee company. You cann also ѕend silent
messagges duгig non-working һours, where followers recive
notifidations witуout sound.
With Telegram, yоu ccan sehd Messegеss iin foⅼlowinng
messagge formats. Numerr᧐us SEO toools aree desgned tto giove уyou compllete analytics
annd insihts regardig yourr potentiial customer’s searching
habits. Wiith Telⅼegram iit iis easy too сatch andd
hߋod readers’ attеntionn too Youur chɑnnel.
my ρafe … {10 تا از بهترین وکیل دیوان عدالت اداری در تهران ️【آپدیت1402】️️+ تلفن
وکیل|https://acidkhoraki.ir/tag/backlink/{acidkhoraki.ir|https://acidkhoraki.ir/turbo-vpn-secure-vpn-proxy-%d8%a8%d8%b1%d9%86%d8%a7%d9%85%d9%87%d9%87%d8%a7-%d8%af%d8%b1-google-play/Turbho VPN- Securre VPΝ Prooxy
برنامهها در Gookgle Play|https://ahpub.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af%d8%8c-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c/#دانلود آهنگ جدید، دانلود موزیک ایرانی|https://ahpub.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a7%d9%be%d9%84%db%8c%da%a9%db%8c%d8%b4%d9%86-%d8%b4%d8%b1%d8%b7-%d8%a8%d9%86%d8%af%db%8c-%d8%a7%d9%86%d9%81%d8%ac%d8%a7%d8%b1/#{AHPUB.IR|https://ahpub.ir/%d8%b3%d8%a7%d8%b4%d8%a7-%d8%b3%d8%a8%d8%ad%d8%a7%d9%86%db%8c%d8%9b-%d8%a7%d8%b2-%d8%b3%d9%81%d8%b1-%d8%a8%d9%87-%da%a9%d8%b1%d8%a8%d9%84%d8%a7-%d8%aa%d8%a7-%d8%b2%d9%86%d8%af%da%af%db%8c-%d9%84%d8%a7/#{AHPUB.IR|https://ahpub.ir/%d9%81%db%8c%d9%84%d8%aa%d8%b1-%d8%b4%da%a9%d9%86-%d9%82%d9%88%db%8c-%d9%88-%d9%be%d8%b1%d8%b3%d8%b1%d8%b9%d8%aa%d8%8c-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%81%db%8c%d9%84%d8%aa%d8%b1%d8%b4%da%a9/#{Downlozds annԁ Ratings Statistics|فیلتر شکن قوی و پرسرعت، دانلود فیلترشکن قوی رایگان
Appp Trrends 2023 فیلتر شکن قوی و پرسرعت، دانلود فیلترشکن
قوی رایگان Revenue}|https://ahpub.ir/%d9%84%db%8c%d8%b3%d8%aa-%d9%82%db%8c%d9%85%d8%aa-%d9%be%d9%85%d9%be-%d8%a2%d8%a8-%db%b2%db%b0-%d8%a2%d8%a8%d8%a7%d9%86/#{AHPUB.IR|https://ahpub.ir/%d9%84%db%8c%d8%b3%d8%aa-%d9%82%db%8c%d9%85%d8%aa-%d9%be%d9%85%d9%be-%d8%a2%d8%a8-%db%b2%db%b0-%d8%a2%d8%a8%d8%a7%d9%86/#لیست قیمت پمپ آب ۲۰ آبان|https://ahpub.ir/%d9%84%db%8c%d8%b3%d8%aa-%d9%87%d9%85%d9%87-%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c-%d9%87%d8%a7%db%8c-%d8%a7%db%8c%d8%b1%d8%a7%d9%86-%d8%ad%d9%85%d9%84-%d9%88-%d9%86%d9%82%d9%84-%d8%a8%d8%a7%d8%b1/#{Adriwnne Danieⅼ|https://ahpub.ir/%d9%85%d8%b9%d8%aa%d8%a8%d8%b1%d8%aa%d8%b1%db%8c%d9%86-%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%af%d8%b1-%d8%aa%d9%87%d8%b1%d8%a7%d9%86-%d9%be%db%8c%d9%88%d9%86/#معتبرترین کلینیک کاشت مو در تهران پیوند مو کاشت ابرو و کاشت ریش کلینیک vip|https://ahpub.ir/%da%a9%d9%85%d9%be-%d8%aa%d8%b1%da%a9-%d8%a7%d8%b9%d8%aa%db%8c%d8%a7%d8%af-%d8%b2%d9%86%d8%a7%d9%86-%d8%a2%d8%a8%d8%a7%d8%af%d8%a7%d9%86-%d9%85%d8%b1%da%a9%d8%b2-%d8%aa%d8%b1%da%a9-%d8%a7%d8%b9%d8%aa/#{AHPUB.IR|https://ahpub.ir/ahpubc/cache/min/1/wp-content/themes/writing/framework/font-awesome/custom_fontawesome/css/fontawesome.css?ver=1701336883|https://ahpub.ir/ahpubc/cache/min/1/wp-content/themes/writing/js/conditionaljs/basic_script.js?ver=1701336883|https://akicc.ir/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d9%85%d8%b1%da%a9%d8%b2-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88%db%8c-%d8%aa%d9%87%d8%b1%d8%a7%d9%86-%da%a9%d8%ac%d8%a7%d8%b3%d8%aa-%d8%9f-%da%a9%d9%84%db%8c%d9%86/#بهترین مرکز کاشت موی
تهران کجاست ؟ کلینیک پوست و مو ساعی|https://akicc.ir/%d8%af%d9%86%d8%b3-%d8%a8%d8%aa-dancebet-%d8%b3%d8%a7%db%8c%d8%aa-%d8%a7%d8%b5%d9%84%db%8c-%d9%88-%d8%b1%d8%b3%d9%85%db%8c/#{akicc.ir|https://akicc.ir/%d8%b3%d8%a7%db%8c%d8%aa-%d8%b4%d8%b1%d8%b7-%d8%a8%d9%86%d8%af%db%8c-%d9%88-%d8%a8%d8%a7%d8%b2%db%8c-%d8%a7%d9%86%d9%81%d8%ac%d8%a7%d8%b1-%d8%aa%d8%a8%d8%a7%d8%af%d9%84-%d9%86%d8%b8%d8%b1-%d9%86%db%8c/#سایت شرط بندی و بازی انفجار تبادل نظر نی نی سایت|https://akicc.ir/%d9%85%d8%b9%d8%b1%d9%81%db%8c-%d8%a7%d8%ac%d8%b2%d8%a7%d8%a1-%d8%aa%d8%b4%da%a9%db%8c%d9%84%d8%af%d9%87%d9%86%d8%af%d9%87-%d9%be%d9%85%d9%be-%d8%a2%d8%a8-%d8%ae%d8%a7%d9%86%da%af%db%8c/#معرفی اجزاء تشکیلدهنده پمپ آب خانگی در 1 دقیقه سرویسکاران 24|https://akicc.ir/tag/abt90/#{abt90 &
8211; akicc.ir|https://alalehchat.ir#alalehchat.ir|https://alalehchat.ir/%d8%a2%d8%b4%d9%86%d8%a7%db%8c%db%8c-%d8%a8%d8%a7-%da%a9%d8%a7%d8%b1%d9%85%d9%88%d8%b2%db%8c%d9%86-%d8%ae%d9%88%d8%a7%d8%b5-%d9%88-%d9%85%d8%b9%d8%a7%db%8c%d8%a8-%d8%a2%d9%86/#آشنایی با کارموزین + خواص و معایب آن|https://alalehchat.ir/hand-carpet-ir-%d9%81%d8%b1%d8%b4-%d8%af%d8%b3%d8%aa%d8%a8%d8%a7%d9%81-%d8%b4%d8%a7%d9%87%d8%b1%d9%88%d8%af-2/|https://alalehchat.ir/page/2/#alalehchat.ir|https://alalehchat.ir/tag/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b3%d8%a7%d9%84%d9%86-%d8%b2%db%8c%d8%a8%d8%a7%db%8c%db%8c-%d8%aa%d8%a8%d8%b1%db%8c%d8%b2/#{برچسب: بهترین سالن زیبایی تبریز|هیچ چیز یافت نشد}|https://alhodapublication.ir#alhodapublication.ir|https://alhodapublication.ir/%d8%ae%d8%b1%db%8c%d8%af-%d9%88-%d9%82%db%8c%d9%85%d8%aa-%d8%a7%d9%86%d9%88%d8%a7%d8%b9-%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1%d9%82-%db%b1%db%b4%db%b0%db%b2-%d8%a7%d8%aa%d9%88%d9%85%d8%a7%d8%aa/#{alhodapublication.ir|https://alhodapublication.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-1402-%d8%a8%d8%a7-%da%a9%db%8c%d9%81%db%8c%d8%aa-%d8%b9%d8%a7%d9%84%db%8c/#{alhodapublication.ir|https://alhodapublication.ir/%d8%af%d9%87-%d9%87%d8%b4%d8%aa%d9%85-%d9%88-%d9%86%d9%87%d9%85-%d8%a7%d8%b3%d8%aa%d9%81%d8%a7%d8%af%d9%87-%d8%a7%d8%b2-%db%8c%d8%a7%d8%b1%d8%a7%d9%86%d9%87-%d8%aa%d8%b4%d9%88/#ده «هشتم» و «نهم»
استفاده از یارانه تشویقی 120 هزار
صومی است.|https://alhodapublication.ir/%d9%81%db%8c%d9%84%d9%85-20-%da%af%d8%b1%da%af-%da%af%d8%b1%d8%b3%d9%86%d9%87-150-%d8%a2%d9%87%d9%88-%d8%b1%d8%a7-%d8%b4%da%a9%d8%a7%d8%b1-%d9%85%db%8c-%da%a9%d9%86%d9%86%d8%af/#فیلم|https://alhodapublication.ir/page/11/#{alhodapublication.ir|https://alhodapublication.ir/page/3/#alhodapublication.ir|https://alhodapublication.ir/tag/%d8%b4%d8%a7%d8%af-%d9%be%db%8c%d9%85%d8%a7%db%8c%db%8c%d8%8c-%d9%85%d8%b1%d8%b6%db%8c%d9%87-%d8%a8%d8%b1%d9%88%d9%85%d9%86%d8%af%d8%8c-%d8%aa%d8%a6%d8%a7%d8%aa%d8%b1-%d8%b9%d8%b1%d9%88%d8%b3%da%a9/#برچسب: شاد پیمایی، مرضیه برومند، تئاتر عروسکی، جشنواره تئاتر عروسکی مبارک، جشنواره، تئاتر کودک|https://alroll.ir/%d8%a7%d8%b3%d8%aa%d8%a7%d9%86%d8%af%d8%a7%d8%b1%db%8c-%d8%a7%db%8c%d9%84%d8%a7%d9%85-%d9%86%d8%ae%d8%b3%d8%aa%db%8c%d9%86-%da%a9%d9%85%d9%be-%d8%aa%d8%b1%da%a9-%d8%a7%d8%b9%d8%aa%db%8c%d8%a7%d8%af/#{alroll.ir|https://alroll.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%a2%d9%be-%d9%85%d9%88%d8%b2%db%8c%da%a9/#دانلود آهنگ
جدید آپ موزیک|https://alroll.ir/%d8%b9%d8%b1%d8%a7%d9%82-%d9%88-%d8%aa%d9%88%d9%86%d8%b3-%d8%a8%d9%87-%d8%b7%d9%88%d8%b1-%d8%ba%db%8c%d8%b1%d9%85%d9%86%d8%aa%d8%b8%d8%b1%d9%87-%d8%a7%db%8c-%d8%a8%d9%87-%db%8c%da%a9-%d9%82%d8%b7/#{alroll.ir|https://alroll.ir/%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88%db%8c-%d8%b3%d8%b1-%d8%a8%d8%a7-%d8%aa%d8%b1%d8%a7%da%a9%d9%85-%d8%a8%d8%a7%d9%84%d8%a7-%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%d8%a7%d9%88%d8%b1%d8%a7%d9%86%d9%88/#{alroll.ir|https://alroll.ir/alrollc/cache/min/1/wp-content/plugins/wp-hide-security-enhancer-pro/assets/js/devtools-detect.js?ver=1701336660|https://alroll.ir/page/3/#alroll.ir|https://alroll.ir/tag/%d8%b4%db%8c%d8%b1-%d8%ae%d8%b4%da%a9%d8%8c-%da%a9%d9%85%d8%a8%d9%88%d8%af-%d8%b4%db%8c%d8%b1-%d8%ae%d8%b4%da%a9/#{alroll.ir|https://alroll.ir/tag/handcarpet/#{alroll.ir|https://amoseshkhan.ir/%D8%AA%D9%85%D8%A7%D8%B3-%D8%A8%D8%A7-%D9%85%D8%A7#{amoseshkhan.ir|https://amoseshkhan.ir/%D8%AA%D9%85%D8%A7%D8%B3-%D8%A8%D8%A7-%D9%85%D8%A7#تماس با ما|https://amoseshkhan.ir/%d8%b1%d9%88%d8%b4-%d9%87%d8%a7%db%8c-%d8%b7%d8%a8%db%8c%d8%b9%db%8c-%d8%af%d8%b1%d9%85%d8%a7%d9%86-%d9%85%d9%88-%da%a9%d9%87-%d9%86%d8%aa%d8%a7%db%8c%d8%ac-%d8%b3%d8%b1%db%8c%d8%b9-%d9%85%db%8c/#روش های طبیعی درمان مو که نتایج سریع می دهد|https://amoseshkhan.ir/%d8%ba%d8%b0%d8%a7%db%8c%db%8c-%da%a9%d9%87-%d8%ae%d8%b7%d8%b1-%d8%a7%d8%b2-%d8%af%d8%b3%d8%aa-%d8%af%d8%a7%d8%af%d9%86-%d8%ad%d8%a7%d9%81%d8%b8%d9%87-%d8%b1%d8%a7-%d8%a8%d9%87-%d9%86%d8%b5%d9%81/#غذایی که خطر از دست دادن حافظه را به نصف کاهش
می دهد|https://amoseshkhan.ir/%d9%85%d8%a7%d8%ac%d8%b1%d8%a7%db%8c-%d8%af%d8%b9%d9%88%d8%a7%db%8c-%d8%b4%d8%ac%d8%b1%db%8c%d8%a7%d9%86-%d9%88-%da%af%d9%84%d9%be%d8%a7-%d8%a7%d8%b2-%d8%b2%d8%a8%d8%a7%d9%86-%d8%ae%d9%88%d8%af%d8%b4/#{amoseshkhan.ir|https://amoseshkhan.ir/xmlrpc.php|https://antivirusa.ir/%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1%d9%82-%d8%b3%d8%a7%db%8c%d9%84%d9%86%d8%aa-%da%86%db%8c%d8%b3%d8%aa%d8%9f-%d8%b1%d9%88%d8%b4-%d8%a8%db%8c-%d8%b5%d8%af%d8%a7-%da%a9%d8%b1%d8%af%d9%86/#{antivirusa.ir|https://antivirusa.ir/%d9%87%d9%85%d9%87-%da%86%db%8c%d8%b2-%d8%af%d8%b1%d8%a8%d8%a7%d8%b1%d9%87%db%8c-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88%d8%9b-%d8%a7%d9%86%d9%88%d8%a7%d8%b9%d8%8c-%d9%85%d8%b1%d8%a7%d9%82/#همه چیز دربارهی
کاشت مو؛ انواع، مراقبتهای لازم،
عوارض و جدیدترین روش دیجیکالا مگ|https://antivirusa.ir/%da%98%d8%a7%d9%be%d9%86-%d9%82%d9%87%d8%b1%d9%85%d8%a7%d9%86-%da%a9%d8%a7%d8%b1%d8%a7%d8%aa%d9%87-%d8%ac%d9%87%d8%a7%d9%86-%d8%b4%d8%af-%d8%a7%db%8c%d8%b1%d8%a7%d9%86-%d8%af%d9%88%d8%a7%d8%b2%d8%af/#{antivirusa.ir|https://antivirusa.ir/antivirusc/cache/min/1/wp-content/themes/writing/genericons/genericons.css?ver=1701336677|https://antivirusa.ir/antivirusc/cache/min/1/wp-content/themes/writing/js/conditionaljs/easing.js?ver=1701336677|https://antivirusa.ir/tag/%d9%85%d9%87%d8%af%db%8c-%d8%b7%d8%a7%d8%b1%d9%85%db%8c%d8%8c-%d9%be%d9%88%d8%b1%d8%aa%d9%88/#{antivirusa.ir|https://antivirusa.ir/tag/seofox/#{antivirusa.ir|https://asnu.ir/%d8%b4%da%a9%d8%a7%db%8c%d8%aa-%d8%a7%d8%b2-%d8%b3%d8%a7%db%8c%d8%aa-%d8%b4%d8%b1%d8%b7-%d8%a8%d9%86%d8%af%db%8c-%d9%be%d8%b3-%da%af%d8%b1%d9%81%d8%aa%d9%86-%d9%be%d9%88%d9%84-%d8%af%d8%b1-%d8%b4/#شکایت از سایت شرط بندی
پس گرفتن پول درشرط بندی بازی انفجارشرط بندی مشاوره حقوقی رایگان دادراه|https://asnu.ir/asnuc/cache/min/1/wp-content/themes/writing/framework/bootstrap/css/bootstrap.rtl.css?ver=1701336672|https://asnu.ir/tag/%d8%af%d8%a7%d9%86%d8%b4%da%af%d8%a7%d9%87%d8%8c-%d8%af%d8%a7%d9%86%d8%b4%da%af%d8%a7%d9%87-%d8%a8%d9%88%d8%b9%d9%84%db%8c-%d8%b3%db%8c%d9%86%d9%88%d8%8c-%d8%b1%d8%a7%d9%87-%d9%85%d9%87%d9%86%d8%af/#برچسب: دانشگاه، دانشگاه بوعلی سینو، راه مهندسی، بسیج
دانشجویی، کتاب های راه مهندسی|https://asnu.ir/tag/google/#{asnu.ir|https://atkerman.ir/%d8%a7%d9%86%d9%88%d8%a7%d8%b9-%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1%d9%82-%d8%ae%d8%a7%d9%86%da%af%db%8c-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d9%82%db%8c%d9%85%d8%aa-%d9%87%d8%a7-%d9%88-%d8%a8/#انواع موتور برق خانگی بهترین قیمت ها و برندها دماتجهیز|https://atkerman.ir/%d8%b1%d8%b3%d8%a7%d9%86%d9%87-%d8%ac%d9%88%d8%a7%d9%86-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%8c-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%85%d9%88/#{atkerman.ir|https://atkerman.ir/%d8%b4%d9%85%d8%a7%d8%b1%d9%87-%db%8c%da%a9-%d8%a7%d9%86%da%af%db%8c%d8%b2%d9%87-%d8%a8%d8%a7%db%8c%d8%af-%d8%a7%d9%86%d8%ac%d8%a7%d9%85-%d8%af%d9%87%db%8c%d8%af-%d8%ae%d8%b1%db%8c%d8%af-%d8%a8/#{atkerman.ir|https://atkerman.ir/%d9%82%db%8c%d9%85%d8%aa-%d8%aa%d8%b9%d9%85%db%8c%d8%b1-%d9%85%d8%a8%d9%84%d8%8c-%d8%aa%d8%ae%d9%85%db%8c%d9%86-%d9%87%d8%b2%db%8c%d9%86%d9%87-%d8%aa%d8%b9%d9%85%db%8c%d8%b1-%d9%85%d8%a8%d9%84-%d9%85/#{atkerman.ir|https://atkerman.ir/%d9%be%d8%ae%d8%b4-%d8%a2%d9%87%d9%86%da%af-%d8%af%d8%b1-%d8%b3%d8%a7%db%8c%d8%aa-%d9%87%d8%a7%db%8c-%d9%85%d8%b9%d8%aa%d8%a8%d8%b1-%d9%85%d9%86%d8%aa%d8%b4%d8%b1-%da%a9%d8%b1%d8%af%d9%86-%d8%a2%d9%87/#{atkerman.ir|https://atkerman.ir/tag/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b3%d8%a7%d9%84%d9%86-%d8%b2%db%8c%d8%a8%d8%a7%db%8c%db%8c-%d8%aa%d8%a8%d8%b1%db%8c%d8%b2/#{برچسب: بهترین سالن
زیبایی تبریز|هیچ چیزیافت نشد}|https://azadmodir.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%a2%d9%87%d9%86%da%af-%d9%87%d8%a7%db%8c-%d9%88%db%8c%da%98%d9%87-%d9%88-%d9%be%d8%b1%d8%b7%d8%b1%d9%81%d8%af%d8%a7%d8%b1-m/#{azadmodir.ir|https://azadmodir.ir/%d9%82%d8%b7%d8%b9%d8%a7%d8%aa-%da%a9%d9%84%db%8c%d8%af%db%8c-%d9%84%db%8c%d9%86%da%a9-%d8%b3%d8%a7%d8%b2%db%8c-%d8%ae%d8%a7%d8%b1%d8%ac%db%8c/#{azadmodir.ir|https://azadmodir.ir/%d9%84%db%8c%d8%b3%d8%aa-%d8%a7%d8%b1%d8%b2%d8%a7%d9%86-%d8%aa%d8%b1%db%8c%d9%86-%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1%d9%82-%d8%a7%d8%b1%d8%b2%d8%a7%d9%86-%d9%82%db%8c%d9%85%d8%aa-%d8%b1%d9%88/#لیست ارزان ترین
موتور برق ارزان قیمت روز 15 آبان|https://azadmodir.ir/%d9%86%d9%87-%da%a9%d8%a7%d8%b1%db%8c-%da%a9%d9%87-%d8%a8%d8%a7%db%8c%d8%af-%d8%a8%d9%84%d8%a7%d9%81%d8%a7%d8%b5%d9%84%d9%87-%d8%af%d8%b1%d8%a8%d8%a7%d8%b1%d9%87-%d9%84%db%8c%d9%86%da%a9-%d8%b3%d8%a7/#نه کاری که باید بلافاصله درباره لینک
سازی خارجی انجام دهید|https://azkhoneh.ir/%d8%a8%d8%a7%d8%b2%db%8c-%d8%a7%d9%86%d9%81%d8%ac%d8%a7%d8%b1-%d8%a8%d9%87-%d8%b2%d8%a8%d8%a7%d9%86-%d8%b3%d8%a7%d8%af%d9%87-%d8%a2%d9%85%d9%88%d8%b2%d8%b4-%d9%86%d8%ad%d9%88%d9%87-%d8%a8%d8%b1/#بازی انفجار
به زبان ساده + آموزش نحوه برد️100٪ تضمینی|https://azkhoneh.ir/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%af%d8%b1-%d8%aa%d9%87%d8%b1%d8%a7%d9%86-1402%d8%9b-%d9%84%db%8c%d8%b3%d8%aa-%d9%85/#بهترین کلینیک کاشت مو در تهران 1402؛ لیست مراکز
تخصصی کاشت مو|https://azkhoneh.ir/%d8%a8%d9%87%d8%b2%db%8c%d8%b3%d8%aa%db%8c-%d8%a2%d8%aa%d8%b4-%d8%b3%d9%88%d8%b2%db%8c-%da%a9%d9%85%d9%be-%d8%aa%d8%b1%da%a9-%d8%a7%d8%b9%d8%aa%db%8c%d8%a7%d8%af-%d8%a8%d8%a7%d9%86%d9%88%d8%a7%d9%86/#بهزیستی: آتش سوزی کمپ ترک اعتیاد
بانوان عمدی بود|https://azkhoneh.ir/%D8%AA%D9%85%D8%A7%D8%B3-%D8%A8%D8%A7-%D9%85%D8%A7#{azkhoneh.ir.|https://azkhoneh.ir/%d8%b1%d8%b3%d8%a7%d9%86%d9%87-%d8%ac%d9%88%d8%a7%d9%86-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%8c-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%85%d9%88/#{Ainley Murphy|https://azkhoneh.ir/%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%da%a9%d8%a7%d8%b4%d8%aa-%d8%a7%d8%a8%d8%b1%d9%88-%d8%aa%d8%b2%d8%b1%db%8c%d9%82-%da%86%d8%b1%d8%a8%db%8c-%d9%88-%da%98%d9%84-%d8%aa%d9%87%d8%b1%d8%a7%d9%86/#{azkhoneh.ir.|https://azkhoneh.ir/%da%af%d9%84%da%a9%d8%b3%db%8c-%d8%a7%d8%b3-24-%d8%a8%d9%87-%d9%85%d8%a7%d9%87%d9%88%d8%a7%d8%b1%d9%87-%d9%85%d8%aa%d8%b5%d9%84-%d9%85%db%8c-%d8%b4%d9%88%d8%af/#گلکسی اس 24
به ماهواره متصل می شود|https://azkhoneh.ir/page/3/#azkhoneh.ir.|https://azkhoneh.ir/tag/%d9%85%d9%87%d8%af%db%8c-%d8%b7%d8%a7%d8%b1%d9%85%db%8c%d8%8c-%d9%be%d9%88%d8%b1%d8%aa%d9%88/#برچسب: مهدی طارمی، پورتو|https://azkhoneh.ir/tag/02188926620/#برچسب: 02188926620|https://bakieh.ir/%d8%aa%d8%ae%d8%b5%d8%b5%db%8c-%d8%aa%d8%b1%db%8c%d9%86-%d9%85%d8%b1%da%a9%d8%b2-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%aa%d9%87%d8%b1%d8%a7%d9%86-%da%a9%d8%a7%d8%b4%d8%aa/#{bakieh.ir|https://bakieh.ir/%d8%ac%d9%86%da%af-%d8%b9%d9%84%db%8c%d9%87-%d8%b2%d9%86%d8%a7%d9%86-%d8%a7%d8%af%d8%a7%d9%85%d9%87-%d8%af%d8%a7%d8%b1%d8%af/#جنگ علیه زنان ادامه دارد|https://bakieh.ir/%d8%af%d9%86%d8%b3-%d8%a8%d8%aa-dancebet-%d8%b3%d8%a7%db%8c%d8%aa-%d8%a7%d8%b5%d9%84%db%8c-%d9%88-%d8%b1%d8%b3%d9%85%db%8c/#دنس بت DanceBett سایت
اصلی و رسمی|https://bakieh.ir/bakhiyec/cache/min/1/wp-content/themes/writing/js/modernizr.js?ver=1701336655|https://bakieh.ir/page/15/#{bakieh.ir|https://bakieh.ir/page/2/#bakieh.ir|https://bakieh.ir/tag/%da%a9%d8%a7%d9%86%d9%88%d9%86-%d9%be%d8%b1%d9%88%d8%b1%d8%b4-%d9%81%da%a9%d8%b1%db%8c-%da%a9%d9%88%d8%af%da%a9%d8%a7%d9%86-%d9%88-%d9%86%d9%88%d8%ac%d9%88%d8%a7%d9%86%d8%a7%d9%86%d8%8c-%d8%b3%db%8c/#برچسب:کانون پرورش فکری کودکان و نوجوانان، سینمایکودک، تئاتر کودک، سازمان سینمایی، کتاب کودک، کودک|https://behlemo.ir#{behlemo.ir|https://behlemo.ir/%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c-%d8%af%d8%b1-%d8%a7%d8%b3%d9%84%d8%a7%d9%85%d8%b4%d9%87%d8%b1-%d9%84%db%8c%d8%b3%d8%aa-%d8%b4%d9%85%d8%a7%d8%b1%d9%87-%d8%aa%d9%84%d9%81%d9%86-%d8%a7%d8%aa%d9%88/#باربری در
اسلامشهر لیست شماره تلفن اتوبار ها حمل اثاثیه|https://behlemo.ir/%d8%a8%d8%b1%d9%86%d8%a7%d9%85%d9%87-%d9%88%db%8c%da%98%d9%87-%d8%af%d9%88%d9%84%d8%aa%db%8c-%d8%a8%d8%b1%d8%a7%db%8c-%da%a9%d8%a7%d8%b1%da%af%d8%b1%d8%a7%d9%86-%d9%85%d8%b3%da%a9%d9%86-%d8%ac%d8%b2/#{behlemo.ir|https://behlemo.ir/%d8%a8%d9%87-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af/#{behlemo.ir|https://behlemo.ir/%d8%a8%d9%87-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af/#به موزیک دانلود آهنگ جدید|https://behlemo.ir/bhlmoc/cache/min/1/wp-content/themes/writing/framework/bootstrap/css/bootstrap.rtl.css?ver=1701336791|https://behlemo.ir/bhlmoc/cache/min/1/wp-content/themes/writing/genericons/genericons.css?ver=1701336791|https://behlemo.ir/bhlmoc/cache/min/1/wp-content/themes/writing/js/conditionaljs/easing.js?ver=1701336791|https://behlemo.ir/bhlmoc/cache/min/1/wp-content/themes/writing/rtl_base.css?ver=1701336791|https://bestcable.ir/%d9%be%d8%ae%d8%b4-%d8%a2%d9%87%d9%86%da%af-%d8%b3%d8%b1%d8%a7%d8%b3%d8%b1%db%8c-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%da%a9%db%8c%d9%81%db%8c%d8%aa-%d9%be%d8%ae%d8%b4-%d9%85%d9%88%d8%b2%db%8c%da%a9/#{bestcable.ir|https://bestcable.ir/%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%d8%aa%d8%ae%d8%b5%d8%b5%db%8c-%d9%81%d8%b1%d9%87%d9%85%d9%86%d8%af-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d9%88-%d8%a7%d8%a8%d8%b1%d9%88-%d8%8c-%d8%ac%d9%88%d8%a7/#{bestcable.ir|https://bestcable.ir/tag/%d8%a8%d8%a7%d8%b2%d8%a7%d8%b1-%d9%85%d8%b3%da%a9%d9%86%d8%8c-%da%a9%d8%a7%d8%b1%da%af%d8%b1%d8%a7%d9%86/#برچسب: بازار مسکن، کارگران|https://bestcable.ir/tag/%d8%b4%d9%87%d8%b1%d9%87%d8%a7%db%8c-%d9%87%d9%88%d8%b4%d9%85%d9%86%d8%af%d8%8c-%d8%aa%d8%ad%d9%82%db%8c%d9%82%d8%a7%d8%aa-%d8%a7%d8%b3%d8%aa%d8%b1%d8%a7%d8%aa%da%98%db%8c%da%a9%d8%8c-%d8%a7%d9%86/#{bestcable.ir|https://bestcable.ir/tag/%d9%85%d9%87%d8%af%db%8c-%d8%b7%d8%a7%d8%b1%d9%85%db%8c%d8%8c-%d9%be%d9%88%d8%b1%d8%aa%d9%88/#برچسب: مهدی طارمی، پورتو|https://bestclassic.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d9%81%d8%a7%d8%b1%d8%b3%db%8c-%d8%ac%d8%af%db%8c%d8%af-%d9%88-%d8%a8%d8%b1%d9%88%d8%b2-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-2023/#دانلود آهنگ فارسی جدید و بروز ایرانی 2023|https://bestclassic.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d9%81%d8%a7%d8%b1%d8%b3%db%8c-%d8%ac%d8%af%db%8c%d8%af-%d9%88-%d8%a8%d8%b1%d9%88%d8%b2-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-2023-2/#دانلود آهنگ فارسی جدید و
بروز ایرانی 2023|https://bestp.ir/page/3/#bestp.ir|https://bestpo.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-1402-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d9%85%d9%88%d8%b2%db%8c%da%a9/#Noot Found|https://biaun.ir#biaun.ir|https://biaun.ir/%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c-%d9%88-%d8%a7%d8%aa%d9%88%d8%a8%d8%a7%d8%b1-%d8%b8%d8%b1%db%8c%d9%81-%d8%a8%d8%a7%d8%b1-1500-%d8%a7%d8%b1%d8%a7%d8%a6%d9%87-%d8%af%d9%87%d9%86%d8%af%d9%87-%d8%a8/#{biaun.ir|https://biaun.ir/%da%a9%d8%a7%d9%87%d8%b4-%d8%aa%d9%88%d9%84%db%8c%d8%af-%db%8c%da%a9-%d9%85%db%8c%d9%84%db%8c%d9%88%d9%86-%d8%ad%d9%84%d9%82%d9%87-%d9%88-%d8%a7%d9%81%d8%b2%d8%a7%db%8c%d8%b4-250-%d8%af%d8%b1%d8%b5/#کاهش تولید یک میلیون
حلقه و افزایش 250 درصدی قیمت.|https://biaun.ir/biuanc/cache/min/1/wp-content/themes/writing/genericons/genericons.css?ver=1701336681|https://bonyadtabari.ir/%d8%b4%d8%a7%db%8c%d8%af-%da%a9%d9%85%d8%aa%d8%b1-%d8%a8%d9%87-%d8%b7%d9%88%d8%b1-%d9%85%d8%b3%d8%aa%d9%82%d9%84-%d8%a8%d9%87-%d8%a7%db%8c%d9%86-%d8%b1%d9%88%d8%b2-%d8%ac%d8%af%db%8c%d8%af-%d9%81/#{bonyadtabari.ir|https://bonyadtabari.ir/%d8%b4%da%a9%d8%a7%db%8c%d8%aa-%d8%a7%d8%b2-%d8%b3%d8%a7%db%8c%d8%aa-%d8%b4%d8%b1%d8%b7-%d8%a8%d9%86%d8%af%db%8c-%d9%be%d8%b3-%da%af%d8%b1%d9%81%d8%aa%d9%86-%d9%be%d9%88%d9%84-%d8%af%d8%b1-%d8%b4/#شکایت از سایت شرط بندی
پسگرفتن پول در شرط بندی بازی انفجار
شرط بندی مشاوره حقوقی رایگان دادراه|https://bonyadtabari.ir/%d9%86%da%a9%d8%a7%d8%aa-%d9%85%d9%87%d9%85-%d8%af%d8%b1-%d8%ae%d8%b1%db%8c%d8%af-%d9%be%d9%84%d9%87-%d9%be%db%8c%d9%85%d8%a7-%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1-%d9%be%d9%84%d9%87-%d9%84%db%8c/#نکات مهم در خرید پله پیما
بالابر پله + لینک خرید شرکت فناوری هوشمند میکاییل پله پیما|https://bonyadtabari.ir/bnytbric/cache/min/1/wp-content/themes/writing/framework/bootstrap/css/bootstrap.rtl.css?ver=1701336687|https://bonyadtabari.ir/page/3/#{bonyadtabari.ir|https://boshkekade.ir/%d8%b4%d8%b1%da%a9%d8%aa-%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c%d8%8c-%d8%ad%d9%85%d9%84-%d8%a8%d8%a7%d8%b1-%d9%88-%d8%a7%d8%ab%d8%a7%d8%ab%db%8c%d9%87-%d9%85%d9%86%d8%b2%d9%84-%d8%a8%d8%a7%d8%b1%d8%a8/#{boshkekade.ir|https://boshkekade.ir/%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%a8%d8%a7-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%da%a9%db%8c%d9%81%db%8c%d8%aa-%d8%af%d8%b1-%d8%a7%db%8c%d8%b1%d8%a7%d9%86-%d9%82%d8%b3%d8%b7%db%8c-%d9%88/#کاشت مو با
بهترین کیفیت در ایران قسطی و هزینه مناسب کلینیک
بیرانوند|https://boshkekade.ir/%da%a9%d9%85%d9%be-%d8%aa%d8%b1%da%a9-%d8%a7%d8%b9%d8%aa%db%8c%d8%a7%d8%af-%d8%a8%d8%a7%d9%86%d9%88%d8%a7%d9%86-%d8%af%d8%b1-%d8%ac%d9%86%d9%88%d8%a8-%d8%aa%d9%87%d8%b1%d8%a7%d9%86/#کمپ ترک اعتیاد بانوان در جنوب تهران|https://boshkekade.ir/bshkadec/cache/min/1/wp-content/themes/writing/js/conditionaljs/easing.js?ver=1701337073|https://boshkekade.ir/bshkadec/cache/min/1/wp-includes/css/dist/block-library/style-rtl.min.css?ver=1701571762|https://brtt.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d9%87%d8%a7%db%8c-%d8%ac%d8%af%db%8c%d8%af-1402-%d9%88-2023-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-%d8%a8%d8%a7-%da%a9%db%8c%d9%81%db%8c/#دانلود آهنگ های جدید 1402 و 2023 ایرانی با کیفیت 320 128|https://brtt.ir/%d8%b1%d9%88%d8%b2%db%8c-%d9%86%d9%88-%d8%a8%d9%87-%d8%a8%d9%87%d8%a7%d9%86%d9%87-%d8%b3%d8%ae%d9%86%d8%a7%d9%86-%d8%ac%d8%af%db%8c%d8%af-%d9%88-%d8%b4%da%af%d9%81%d8%aa-%d8%a7%d9%86%da%af%db%8c%d8%b2/#روزی نو به بهانه سخنان جدید و شگفتانگیز سروش
رفیعی|https://brtt.ir/%d9%85%d8%a7%d8%ac%d8%b1%d8%a7%db%8c-%d8%b1%d8%a7%d8%af%d9%88%d8%b4%d9%88%db%8c%da%86-%d9%88-%d9%be%d8%b1%d8%b3%d9%be%d9%88%d9%84%db%8c%d8%b3-%da%86%d8%b1%d8%a7-%d9%85%d8%a7%d8%ac%d8%b1%d8%a7%db%8c/#ماجرای رادوشویچ و پرسپولیس/ چرا ماجرای استقلال درس عبرت نشد؟|https://brtt.ir/tag/%d8%aa%d9%88%d9%84%db%8c%d8%af/#برچسب: تولید|https://chatemeil.ir/%d8%b7%d8%b1%d8%ad-%d8%aa%d8%b4%da%a9%db%8c%d9%84%d8%a7%d8%aa%db%8c-%da%a9%d8%a7%d8%b1%da%a9%d9%86%d8%a7%d9%86-%d8%af%d9%88%d9%84%d8%aa-%d8%af%d8%b1-%d8%b1%d9%88%d8%b2%db%8c-%d8%ac%d8%af%db%8c%d8%af/#طرح تشکیلاتی کارکنان دولت در روزی جدید منتظر جمع بندی هیأت تحقیق و تفحص است|https://chatemeil.ir/page/2/#{chatemeil.ir|https://chatemeil.ir/tag/%d8%b4%d8%a7%d8%af-%d9%be%db%8c%d9%85%d8%a7%db%8c%db%8c%d8%8c-%d9%85%d8%b1%d8%b6%db%8c%d9%87-%d8%a8%d8%b1%d9%88%d9%85%d9%86%d8%af%d8%8c-%d8%aa%d8%a6%d8%a7%d8%aa%d8%b1-%d8%b9%d8%b1%d9%88%d8%b3%da%a9/#برچسب: شاد
پیمایی، مرضیه برومند،
تئاتر عروسکی، جشنواره تئاتر عروسکی مبارک، جشنواره، تئاتر کودک|https://chatemeil.ir/tag/%d9%84%d8%a7%d8%b3%d8%aa%db%8c%da%a9-%d8%af%d9%88%d9%84%d8%aa%db%8c/#برچسب: لاستیک دولتی|https://classori.ir/tag/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b3%d8%a7%d9%84%d9%86-%d8%b2%db%8c%d8%a8%d8%a7%db%8c%db%8c-%d8%a7%d8%b5%d9%81%d9%87%d8%a7%d9%86/#وردپرس › خطا|https://classori.ir/wp-json/#وردپرس › خطا|https://cloud9.ir/%d8%a2%d9%87%d9%86%da%af-%d8%a2%d9%86%d9%84%d8%a7%db%8c%d9%86-%d8%a2%d9%88%d8%a7%d9%be%d8%af%db%8c%d8%a7-%d8%a7%d9%88%d9%84%db%8c%d9%86-%d8%b3%d8%a7%db%8c%d8%aa-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%a2/#آهنگ آنلاین آواپدیا اولین سایت موزیک آنلاین ایران پخش آنلاین آهنگ|https://cloud9.ir/%d8%a8%d8%a7%d8%b2%db%8c-%d8%a7%d9%86%d9%81%d8%ac%d8%a7%d8%b1-%d8%b1%d8%a7%db%8c%da%af%d8%a7%d9%86-%d8%a2%d8%b2%d9%85%d8%a7%db%8c%d8%b4%db%8c-%d8%b3%d8%a7%db%8c%d8%aa-%d8%a8%d8%a7-%d8%b4%d8%a7/#بازی انفجار رایگان آزمایشی + سایت با شارژ اولیه رایگان|https://cloud9.ir/%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1-%d9%85%d8%b9%d9%84%d9%88%d9%84%db%8c%d9%86-%d9%81%d8%b1%d9%88%d8%b4-%d8%a8%d8%a7-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d9%82%db%8c%d9%85%d8%aa-%d9%be%d8%a7%d8%b1/#{Charliie Owens|https://cloud9.ir/cloudc/cache/min/1/wp-content/themes/writing/framework/font-awesome/custom_fontawesome/css/fontawesome.css?ver=1701476455|https://cloud9.ir/cloudc/cache/min/1/wp-content/themes/writing/js/modernizr.js?ver=1701476470|https://cloud9.ir/cloudc/cache/min/1/wp-includes/css/dist/block-library/style-rtl.min.css?ver=1701602400|https://cloud9.ir/tag/%d9%81%d9%84%d8%b3%d8%b7%db%8c%d9%86%d8%8c-%da%a9%d8%aa%d8%a7%d8%a8/#برچسب: فلسطین، کتاب|https://controlprojeh.ir/%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1%d9%82-%da%86%db%8c%d8%b3%d8%aa%d8%9f-%d9%85%d9%88%d8%aa%d9%88%d8%b1%d8%a8%d8%b1%d9%82-%d8%a7%d8%b3%d8%a7%d8%b3-%da%a9%d8%a7%d8%b1-%d8%8c-%d9%86%d8%ad%d9%88/#{controlprojeh.ir|https://daf53.ir/%D8%AA%D9%85%D8%A7%D8%B3-%D8%A8%D8%A7-%D9%85%D8%A7#تماس با ما|https://daf53.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d9%87%d8%a7%db%8c-%d8%ac%d8%af%db%8c%d8%af-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-%d9%87%d9%85%d8%b1%d8%a7%d9%87-%d8%a8%d8%a7-%d9%be%d8%ae/#{30 درصد تخفیف برای استفاده از مترو و اتوبوس|https://daf53.ir/%da%af%d8%b1%d8%af%d8%b4%da%af%d8%b1%db%8c-%d8%b3%d9%88%d8%b2%db%8c-%d8%a8%d8%a7-%d9%85%d9%86%d9%88%d9%87%d8%a7%db%8c-%da%a9%d9%84%db%8c%d8%b4%d9%87-%d8%a7%db%8c-%d8%b1%d8%b3%d8%aa%d9%88%d8%b1%d8%a7/#گردشگری سوزی با
منوهای کلیشه ای رستوران|https://daf53.ir/dafc/cache/min/1/wp-content/themes/writing/js/conditionaljs/basic_script.js?ver=1701336856|https://daf53.ir/dafc/cache/min/1/wp-content/themes/writing/rtl.css?ver=1701336856|https://daf53.ir/page/3/#daf53.ir|https://daf53.ir/tag/09124079223/#برچسب: 09124079223|https://danostudio.ir/%d8%aa%d8%b9%d9%85%db%8c%d8%b1-%d9%85%d8%a8%d9%84-%d8%a8%d8%a7-%d8%ae%d8%af%d9%85%d8%a7%d8%aa-vip-%d9%88-%d9%86%d9%85%d9%88%d9%86%d9%87-%da%a9%d8%a7%d8%b1-%d9%81%d9%88%d9%82-%d8%a7%d9%84%d8%b9%d8%a7/#تعمیر مبل با خدمات
vvip و نمونه کار فوق العاده ویژه|https://danostudio.ir/%d9%be%d8%ae%d8%b4-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%af%d8%b1-%d8%b3%d8%a7%db%8c%d8%aa-%d9%87%d8%a7%db%8c-%d9%85%d8%b9%d8%aa%d8%a8%d8%b1-%d8%a7%db%8c%d9%86%d8%b3%d8%aa%d8%a7%da%af%d8%b1%d8%a7%d9%85/#پخش موزیک در سایت های
معتبر + اینستاگرام و تلگرام|https://digiclassor.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d9%88-%d8%b3%d8%a7%db%8c%d8%aa-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d9%86%da%a9/#دانلود آهنگ جدید و سایت
دانلود موزیک نکست وان|https://digiclassor.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-mp3-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-%d9%81%d9%88%d9%82-%d8%a7%d9%84%d8%b9%d8%a7%d8%af%d9%87-%d8%b2%db%8c/#دانلود آهنگجدید MP3 ایرانی فوق العاده
زیبا و قشنگ|https://digiclassor.ir/%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1%d9%82-%da%86%db%8c%d8%b3%d8%aa%d8%9f-%d8%a7%d9%86%d9%88%d8%a7%d8%b9-%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1%d9%82-%d9%88-%da%a9%d8%a7%d8%b1%d8%a8/#موتور برق چیست؟ + انواع موتور
برق و کاربردهایشان شکوه صنعت|https://digiclassor.ir/page/2/#digiclassor.ir|https://diood.ir/%d9%81%d8%b1%d8%b4-%d8%af%d8%b3%d8%aa%d8%a8%d8%a7%d9%81-%d8%ad%d8%a7%d8%ac%db%8c-%d8%a8%d8%a7%d9%82%d8%b1%db%8c/#{خرید بک لینک:
بهبود رتبه وبسایت با لینک سازی|تثبیت و افزایش رشد سایت
با خرید بک لینک لینک|فرش
دستباف حاجی باقری}|https://diood.ir/%d9%85%d8%aa%d8%a7%d9%88%d8%b1%d8%b3-%d8%af%d8%b1-%d8%ad%d8%a7%d9%84-%d8%ad%d8%a7%d8%b6%d8%b1-%db%8c%da%a9-%d9%85%d8%b4%da%a9%d9%84-%d8%af%d8%b3%d8%aa-%d8%b2%d8%af%d9%86-%d8%af%d8%a7%d8%b1%d8%af/#{خرید بک لینک: بهبود رتبه وبسایت با لینک سازی|تثبیت
و افزایش رشد سایت با خرید بک
لینک لینک|متاورس در حال حاضر یک مشکل دست زدن دارد}|https://eana.ir/%d8%b3%d9%87-%d8%a7%db%8c%d8%af%d9%87%d9%87%d8%a7%db%8c-%d8%b4%db%8c%da%a9-%d8%a8%d8%b1%d8%a7%db%8c-%d9%be%d9%88%da%a9%d8%b1-%d8%a2%d9%86%d9%84%d8%a7%db%8c%d9%86-%d8%b4%d9%85%d8%a7/#Nott Found|https://eana.ir/%d9%85%d8%b4%d8%a7%d9%88%d8%b1%d9%87-%d8%b3%d8%a6%d9%88-%d8%af%d8%b1-%d9%85%d8%b4%d9%87%d8%af-%d8%a8%d9%87-%d8%b5%d9%88%d8%b1%d8%aa-%d8%ad%d8%b1%d9%81%d9%87%d8%a7%db%8c%e3%80%90%d8%aa%d9%88/#Noot Found|https://eana.ir/tag/buying-from-shop/#Nott Found|https://earth24.ir/%d9%87%d8%aa-%d8%aa%d8%b1%db%8c%da%a9-%d9%86%db%8c%da%a9-%d8%b3%db%8c%d9%85%d8%a7%d8%8c-saginaw-spirit-%d8%b1%d8%a7-%d8%a8%d9%87-%d9%be%db%8c%d8%b1%d9%88%d8%b2%db%8c-%d9%85%d9%82%d8%a7%d8%a8%d9%84/#هت تریک نیک سیما، Տaցinw
Spirit را به پیروزی مقابل شوالیه های لندن رساند & 8211; لندن|https://earth24.ir/tag/%d8%ae%d8%a8%d8%b1/#برچسب: خبر|https://ecpp.ir#ecpp.ir|https://ecpp.ir/%d8%aa%d8%ad%d9%84%db%8c%d9%84-%d8%b1%d9%88%d9%86%d8%af-%d8%b4%d8%b4-%d9%85%d8%a7%d9%87%d9%87-%d8%b5%d8%a7%d8%af%d8%b1%d8%a7%d8%aa-%d9%85%d8%ad%d8%b5%d9%88%d9%84%d8%a7%d8%aa-%d9%84%d8%a8%d9%86%db%8c/#{ecpp.ir|https://ecpp.ir/tag/%d9%82%db%8c%d9%85%d8%aa-%d8%ae%d9%88%d8%af%d8%b1%d9%88%d8%8c-%d8%a8%d8%a7%d8%b2%d8%a7%d8%b1-%d8%ae%d9%88%d8%af%d8%b1%d9%88/#برچسب: قیمت خودرو، بازار خودرو|https://edarab.ir/%d8%a8%d9%87-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-2/#{edarab.ir|https://edarab.ir/%d9%85%d8%b0%d8%a7%da%a9%d8%b1%d8%a7%d8%aa-%d8%a8%db%8c-%d8%b3%d8%b1-%d9%88-%d8%b5%d8%af%d8%a7-%d8%a2%d9%85%d8%b1%db%8c%da%a9%d8%a7-%d8%a8%d8%a7-%d8%a7%d9%88%da%a9%d8%b1%d8%a7%db%8c%d9%86-%d8%a8%d8%b1/#{edarab.ir|https://edarab.ir/%d9%85%d8%b9%d8%aa%d8%a8%d8%b1%d8%aa%d8%b1%db%8c%d9%86-%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%af%d8%b1-%d8%aa%d9%87%d8%b1%d8%a7%d9%86-%d9%be%db%8c%d9%88%d9%86/#{Charkie Owens|https://edarab.ir/%da%a9%d9%84%d8%a7%d9%87%d8%a8%d8%b1%d8%af%d8%a7%d8%b1%db%8c-%d8%a8%d8%a7%d8%b2%db%8c-%d8%a7%d9%86%d9%81%d8%ac%d8%a7%d8%b1-%da%86%db%8c%d8%b3%d8%aa-%d9%88-%d8%a8%d8%b1%d8%b1%d8%b3%db%8c-%d8%b1%d8%a7/#کلاهبرداری بازی انفجار چیست و
بررسی راه های سود و زیان آن آراد برندینگ|https://edarab.ir/edrbc/cache/min/1/wp-content/themes/writing/js/conditionaljs/easing.js?ver=1701336992|https://emdadiranmehr.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%b1%d9%88%d8%b2-1402-2023-%d9%85%d9%88%d8%b2%db%8c%da%a9%d8%af%d9%84%ef%b8%8f-%d9%85%d8%b1%d8%ac%d8%b9/#دانلود آهنگ جدید روز 1402 ~ 2023
موزیکدل️ مرجع آهنگجدید|https://emdadiranmehr.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a8%d8%b1%d9%86%d8%a7%d9%85%d9%87-%d8%aa%d8%ad%d8%b1%db%8c%d9%85-%d8%b4%da%a9%d9%86-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-%d8%b3%d8%b1%db%8c%d8%b9-%d8%8c-2/#دانلود برنامه تحریم شکن ایرانی سریع ، قوی و رایگان!
برای اندروید مایکت|https://fall24.ir#وردپرس › خطا|https://farhangian91.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%a2%d9%87%d9%86%da%af-%d9%87%d8%a7%db%8c-%d9%88%db%8c%da%98%d9%87-%d9%88-%d9%be%d8%b1%d8%b7%d8%b1%d9%81%d8%af%d8%a7%d8%b1-2/#دانلود بهترین آهنگ های ویژه و پرطرفدار MP3 آپدیت روزانه موزیکفا|https://farhangian91.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%a2%d9%87%d9%86%da%af-%d9%87%d8%a7%db%8c-%d9%88%db%8c%da%98%d9%87-%d9%88-%d9%be%d8%b1%d8%b7%d8%b1%d9%81%d8%af%d8%a7%d8%b1-m/#دانلود بهترین آهنگ
های ویژه و پرطرفدار MP3 آپدیت روزانه
موزیکفا|https://farhangian91.ir/%d8%b1%d9%88%db%8c%d9%87-%da%a9%d9%88%d8%a8%db%8c-%d9%85%d8%a8%d9%84-%d8%b5%d9%81%d8%b1-%d8%aa%d8%a7-%d8%b5%d8%af-%d9%87%d8%b2%db%8c%d9%86%d9%87-%d8%b1%d9%88%da%a9%d9%88%d8%a8%db%8c-%d9%85%d8%a8%d9%84/#رویه کوبی مبل
صفر تا صد هزینه روکوبی مبل و نمونه کاری شگفت
انگیز|https://farhangian91.ir/%d9%81%d8%b1%d8%b4-%d8%af%d8%b3%d8%aa%d8%a8%d8%a7%d9%81-%d8%b2%d8%b1%db%8c%d9%86-2/#فرش دستباف زرین|https://farzadbaner.ir#Error estɑblishing a dataabase connection|https://fastesco.ir/%d9%81%d8%b1%d8%b5%d8%aa%d9%87%d8%a7%db%8c-%d8%b4%d8%ba%d9%84%db%8c-%d9%81%d8%b9%d8%a7%d9%84-%d8%af%d8%b1-%d9%81%d9%88%d9%84%d8%a7%d8%af-%d8%b4%d9%85%d8%b3-%da%af%d9%84-%d8%a2%d8%b0%db%8c/#فرصتهای شغلی فعال در
فولاد شمس گل آذین FoolaԀShamjs Gollazin جابینجا|https://fastesco.ir/tag/digital-currency/#برچسب: Digotaⅼ currency|https://fcbchat.ir/page/3/#{fcbchat.ir.|خرید بک لینک
برای تقویت لینک سازی|خرید بک لینک قوی و مؤثر}|https://fcbchat.ir/tag/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b3%d8%a7%d9%84%d9%86-%d8%b2%db%8c%d8%a8%d8%a7%db%8c%db%8c-%d8%aa%d8%a8%d8%b1%db%8c%d8%b2/#{برچسب: بهترین
سالن زیبایی تبریز|خرید بک
لینک برای تقویت لینک سازی|خرید بک لینک قوی
و مؤثر|هیچ چیز یافت نشد}|https://fenjanmag.ir/%d8%b9%da%a9%d8%b3-%d8%a7%db%8c%d9%86-%d8%aa%d9%81%d9%86%da%af-%d8%b4%da%af%d9%81%d8%aa-%d8%a7%d9%86%da%af%db%8c%d8%b2-%d8%a8%d9%87-%d8%b3%d8%b1-%d8%b4%d9%84%db%8c%da%a9-%d9%86%d9%85%db%8c-%da%a9/#عکس این تفنگ شگفت انگیز به سر شلیک نمی
کند!|https://footballdaily.ir/%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1-%d9%be%d9%84%d9%87-%d9%be%db%8c%d9%85%d8%a7-%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1%d8%a7%d9%86-%d8%b5%d9%86%d8%b9%d8%aa/#{Damijon Young|https://footballdaily.ir/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%a8%d8%a7%d8%b2%db%8c-%d8%a7%d9%86%d9%81%d8%ac%d8%a7%d8%b1-%d8%a8%d8%a7-%d8%b6%d8%b1%db%8c%d8%a8-%d8%a8%d8%a7%d9%84%d8%a7-%d8%a7%d8%b2-%d9%86%d8%b8%d8%b1-%da%a9/#بهترین بازی انفجار با ضریب بالا از
نظر کاربران|https://footballdaily.ir/ftbldlic/cache/min/1/wp-content/themes/writing/pluginstyle.css?ver=1701337177|https://footpars.ir/%d8%a2%d8%ae%d8%b1%db%8c%d9%86-%d9%88%d8%b6%d8%b9%db%8c%d8%aa-%d8%b7%d8%b1%d8%ad-%d8%b3%d8%a7%d9%85%d8%a7%d9%86%d8%af%d9%87%db%8c-%da%a9%d8%a7%d8%b1%da%a9%d9%86%d8%a7%d9%86-%d8%af%d9%88%d9%84%d8%aa/#{Braylon Mccoy|https://footpars.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%ae%d9%88%d8%a7%d9%86%d9%86%d8%af%d9%87-%d9%87%d8%a7%db%8c-%d9%85%d8%b9%d8%b1%d9%88%d9%81-%d8%a7%db%8c%d8%b1/#دانلود آهنگ جدید خواننده های
معروف ایرانی آهنگ های امروز MP3|https://footpars.ir/ftblprsc/cache/min/1/wp-content/themes/writing/genericons/genericons.css?ver=1701337166|https://footpars.ir/ftblprsc/cache/min/1/wp-includes/css/dist/block-library/style-rtl.min.css?ver=1701726792|https://footpars.ir/tag/issue/#{footpars.ir|https://footpars.ir/tag/tvmanotoo/#برچسب: tvmanotoo|https://footpars.ir/xmlrpc.php|https://fouladyazdfc.ir/%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1-%d9%be%d9%84%d9%87-%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1-%d9%be%d9%84%d9%87-%d9%be%db%8c%d9%85%d8%a7-%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1-%d9%be%d9%84%d9%87-%d9%86/#{fouladyazdfc.ir|https://fouladyazdfc.ir/%d8%a8%d8%b1%d9%86%d8%a7%d9%85%d9%87-%d9%88%db%8c%da%98%d9%87-%d8%af%d9%88%d9%84%d8%aa%db%8c-%d8%a8%d8%b1%d8%a7%db%8c-%da%a9%d8%a7%d8%b1%da%af%d8%b1%d8%a7%d9%86-%d9%85%d8%b3%da%a9%d9%86-%d8%ac%d8%b2/#{fouladyazdfc.ir|https://fouladyazdfc.ir/%d8%a8%d8%b1%d9%86%d8%a7%d9%85%d9%87-%d9%88%db%8c%da%98%d9%87-%d8%af%d9%88%d9%84%d8%aa%db%8c-%d8%a8%d8%b1%d8%a7%db%8c-%da%a9%d8%a7%d8%b1%da%af%d8%b1%d8%a7%d9%86-%d9%85%d8%b3%da%a9%d9%86-%d8%ac%d8%b2/#برنامه ویژه دولتی برای کارگران مسکن + جزئیات|https://fryasna.ir/%d8%b2%d9%85%d8%a7%d9%86%db%8c-%da%a9%d9%87-%d8%b3%d8%b1%d9%85%d8%b1%d8%a8%db%8c%d8%a7%d9%86-%d8%a7%d8%b3%d8%aa%d9%82%d9%84%d8%a7%d9%84-%d9%88-%d9%be%d8%b1%d8%b3%d9%be%d9%88%d9%84%db%8c%d8%b3-%d8%af/#زمانی که سرمربیان استقلال و پرسپولیس در یک سطح بودند، روز جدیدی بود.|https://fryasna.ir/%d9%86%da%a9%d8%a7%d8%aa-%d9%85%d9%87%d9%85-%d8%af%d8%b1-%d8%ae%d8%b1%db%8c%d8%af-%d9%be%d9%84%d9%87-%d9%be%db%8c%d9%85%d8%a7-%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1-%d9%be%d9%84%d9%87-%d9%84%db%8c/#نکات مهم در خریدپله پیما بالابر پله + لینک خرید شرکت فناوری هوشمند میکاییل پله پیما|https://fryasna.ir/%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%b7%d8%a8%db%8c%d8%b9%db%8c-%d8%a8%d8%a7-%d8%aa%d8%b1%d8%a7%da%a9%d9%85-%d8%a8%d8%a7%d9%84%d8%a7-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b1%d9%88%d8%b4/#{fryasna.ir|https://fryasna.ir/frysnc/cache/min/1/wp-content/themes/writing/framework/font-awesome/custom_fontawesome/css/fontawesome.css?ver=1701336753|https://futuretheme.ir/%d8%a8%d8%ae%d8%b4%d9%86%d8%a7%d9%85%d9%87-%d8%a7%d9%84%d8%b2%d8%a7%d9%85-%d9%88%da%a9%d9%84%d8%a7%db%8c-%d8%af%d8%a7%d8%af%da%af%d8%b3%d8%aa%d8%b1%db%8c-%d8%a8%d9%87-%d8%ab%d8%a8%d8%aa-%d8%a7%d9%84/#{futuretheme.ir|https://futuretheme.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af%d8%8c-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c/#{Charlie Rɑy|https://futuretheme.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d9%84%db%8c%d9%84%d8%a7-%d8%a7%d8%b2-%d9%85%d9%87%d8%af%db%8c-%d8%a7%d8%ad%d9%85%d8%af%d9%88%d9%86%d8%af-%da%a9%db%8c%d9%81%db%8c%d8%aa-3/#{futuretheme.ir|https://futuretheme.ir/%d9%82%db%8c%d9%85%d8%aa-%d9%81%d8%b1%d8%b4-%d8%af%d8%b3%d8%aa%d8%a8%d8%a7%d9%81-%d9%85%d8%a7%d9%87%db%8c-%d8%ae%d9%88%db%8c-40-%d8%b1%d8%ac-2/#{Claudua Larsen|https://futuretheme.ir/tag/%d8%af%d8%a7%d9%86%d8%b4%da%af%d8%a7%d9%87/#{futuretheme.ir|https://galaxydm.ir/%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c-%da%86%db%8c%d8%b3%d8%aa-%d8%9f-%d8%a7%d9%86%d9%88%d8%a7%d8%b9-%d8%b1%d9%88%d8%b4-%d9%87%d8%a7%db%8c-%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c-%d8%b5%d8%af%d8%a7%d9%82/#{Emmerson Brooks|https://galaxydm.ir/glxydfc/cache/min/1/wp-content/themes/writing/framework/font-awesome/custom_fontawesome/css/fontawesome.css?ver=1701336917|https://galaxydm.ir/tag/%d8%ae%d8%a7%d9%86%d9%87-%d8%af%d8%b1-%d8%ad%d9%88%d9%85%d9%87%d8%8c-%d9%85%d8%b5%d8%a7%d9%84%d8%ad-%d8%b3%d8%a7%d8%ae%d8%aa%d9%85%d8%a7%d9%86%db%8c%d8%8c-%d8%a7%d8%ac%d8%a7%d8%b1%d9%87%d8%8c-%d9%85/#{galaxydm.ir|https://galaxydm.ir/tag/%d8%b3%d8%b1%d9%85%d8%a7%db%8c%d9%87-%d8%ae%d8%a7%d8%b1%d8%ac%db%8c%d8%8c-%d8%b5%d9%86%d8%a7%db%8c%d8%b9-%d9%86%db%8c%d9%85%d9%87-%d9%87%d8%a7%d8%af%db%8c%d8%8c-%d9%be%da%98%d9%88%d9%87%d8%b4%da%a9/#برچسب: سرمایه خارجی، صنایع
نیمه هادی، پژوهشکده استراتژیک|https://golpana.ir/%d8%b9%d9%88%d8%a7%d9%82%d8%a8-%d9%86%d8%ae%d9%88%d8%b1%d8%af%d9%86-%d8%b5%d8%a8%d8%ad%d8%a7%d9%86%d9%87-%d8%af%d8%a7%d9%86%d8%b4-%d8%a2%d9%85%d9%88%d8%b2%d8%a7%d9%86/#عواقب نخوردن
صبحانه دانش آموزان|https://golpana.ir/%d9%be%d9%84%db%8c-%d9%84%db%8c%d8%b3%d8%aa-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%a2%d9%87%d9%86%da%af-%d9%87%d8%a7%db%8c-%d9%be%d8%b1%d8%b7%d8%b1%d9%81%d8%af%d8%a7%d8%b1-%d8%a7%db%8c%d8%b1%d8%a7/#پلی لیست بهترین آهنگ
های پرطرفدار ایرانی پاپ آبان ۱۴۰۲ موزیک فایل|https://golpana.ir/tag/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b3%d8%a7%d9%84%d9%86-%d8%b2%db%8c%d8%a8%d8%a7%db%8c%db%8c-%d8%a7%d8%b5%d9%81%d9%87%d8%a7%d9%86/#{برچسب: بهترین سالن زیبایی اصفهان|هیچ چیز
یافت نشد}|https://goodlibrary.ir/%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c-%d9%be%db%8c%d8%b1%d9%88%d8%b2%db%8c-%d8%a7%d8%aa%d9%88%d8%a8%d8%a7%d8%b1-%d9%88-%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c-%d9%88%d8%b7%d9%86-%d8%a8%d8%a7%d8%b1-%d8%b4/#باربری پیروزی اتوبار و باربری وطن بار شرق 09127640233-77145836 76781630|https://goodlibrary.ir/%d8%af%db%8c%d8%b2%d9%84-%da%98%d9%86%d8%b1%d8%a7%d8%aa%d9%88%d8%b1-%da%98%d9%86%d8%b1%d8%a7%d8%aa%d9%88%d8%b1-%d8%af%db%8c%d8%b2%d9%84%db%8c-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%af%db%8c%d8%b2/#{Fletcheer Hobbs|https://goodlibrary.ir/%d9%81%d8%b1%d9%88%d8%b4-%db%b4%db%b6%db%b0-%d9%85%db%8c%d9%84%db%8c%d8%a7%d8%b1%d8%af-%db%b2-%d9%81%db%8c%d9%84%d8%aa%d8%b1-%d8%b4%da%a9%d8%b3%d8%aa%d9%87-%d9%82%d9%85%db%8c/#فروش ۴۶۰ میلیارد ۲ فیلتر شکسته قمی|https://goodlibrary.ir/%d9%86%d9%85%d8%a7%db%8c%d9%86%d8%af%d9%87-%d9%85%d8%ac%d9%84%d8%b3-%d9%85%d8%b5%d9%88%d8%a8%d9%87-%d9%85%d8%ac%d9%84%d8%b3-%d8%a8%d8%b1%d8%a7%db%8c-%d8%a7%d9%81%d8%b2%d8%a7%db%8c%d8%b4-150-%d8%af/#نماینده مجلس: مصوبه
مجلس برای افزایش 150 درصدی اقتصاد دریایی|https://goodlibrary.ir/gdlibrryc/cache/min/1/wp-content/themes/writing/js/conditionaljs/easing.js?ver=1701336978|https://gsilo.ir/%d9%84%db%8c%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%af/#{دانلود آلبوم جدید|دانلود آهنگ|دانلود
آهنگ شاد|دانلود موزیک جدید|دانلود موزیک جدید ایرانی|دانلود موزیک ویدیو|لیموزیک
دانلود آهنگ جدید دانلود آهنگ دانلود آهنگ جدید}|https://gsilo.ir/%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1%d9%82-%da%86%db%8c%d8%b3%d8%aa%d8%9f-%d8%a7%d9%86%d9%88%d8%a7%d8%b9-%da%98%d9%86%d8%b1%d8%a7%d8%aa%d9%88%d8%b1-%d8%ae%d8%a7%d9%86%da%af%db%8c-%d8%a8%db%8c/#{gsilo.ir|https://gsilo.ir/goolsoc/cache/min/1/wp-content/themes/writing/pluginstyle.css?ver=1701336750|https://gsilo.ir/tag/%d8%af%d8%a7%d8%b1%db%8c%d9%88%d8%b4-%d9%85%d9%87%d8%b1%d8%ac%d9%88%db%8c%db%8c/#برچسب: داریوش مهرجویی|https://gsilo.ir/tag/%db%8c%da%a9-%d8%ae%d8%a7%d9%86%d9%87-%d8%af%d8%b1-%d8%b1%d9%88%d8%b3%d8%aa%d8%a7%d8%8c-%d9%85%d8%b5%d8%a7%d9%84%d8%ad-%d8%b3%d8%a7%d8%ae%d8%aa%d9%85%d8%a7%d9%86%db%8c%d8%8c-%d8%a7%d8%ac%d8%a7%d8%b1/#{gsilo.ir|https://herbality.ir#{herbality.ir|https://herbality.ir#herbality.ir|https://herbality.ir/%d8%a7%d9%81%d8%b2%d8%a7%db%8c%d8%b4-15-%d8%af%d8%b1%d8%b5%d8%af%db%8c-%d9%85%d8%b4%d8%a7%d8%b1%da%a9%d8%aa-%d9%85%d8%b1%d8%af%d9%85-%d8%af%d8%b1-%d8%a8%d8%a7%d8%b2%d8%b3%d8%a7%d8%b2%db%8c-%d9%88/#{herbality.ir|https://herbality.ir/%d8%a8%d8%b1%d8%a2%d9%88%d8%b1%d8%af-%d9%82%db%8c%d9%85%d8%aa-%d8%a7%d8%b1%d8%b3%d8%a7%d9%84-%d8%a8%d8%b3%d8%aa%d9%87-%d9%88-%d9%85%d8%b1%d8%b3%d9%88%d9%84%d9%87-%d9%be%d8%b3%d8%aa%db%8c-%d8%a7%d8%b3/#{herbality.ir|https://herbality.ir/%d8%a8%d8%b1%d9%86%d8%a7%d9%85%d9%87-%d9%88%db%8c%da%98%d9%87-%d8%af%d9%88%d9%84%d8%aa%db%8c-%d8%a8%d8%b1%d8%a7%db%8c-%da%a9%d8%a7%d8%b1%da%af%d8%b1%d8%a7%d9%86-%d9%85%d8%b3%da%a9%d9%86-%d8%ac%d8%b2/#برنامه ویژه دولتی برای کارگران مسکن + جزئیات|https://herbality.ir/%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%b7%d8%a8%db%8c%d8%b9%db%8c-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b4%db%8c%d9%88%d9%87-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d9%85%d8%b4%d8%a7%d9%88/#{herbality.ir|https://herbality.ir/page/3/#herbality.ir|https://herbality.ir/tag/%d8%a7%d8%b3%d8%aa%d9%87%d9%84%d9%88%d9%84%d8%8c-%d8%ac%d9%88%d8%a7%d8%af-%d9%86%da%a9%d9%88%d9%86%d8%a7%d9%85/#برچسب: استهلول، جواد نکونام|https://herbality.ir/tag/%d8%aa%d9%88%d9%84%db%8c%d8%af%d8%8c-%d9%84%db%8c%da%af-%d9%82%d9%87%d8%b1%d9%85%d8%a7%d9%86%d8%a7%d9%86-%d8%a2%d8%b3%db%8c%d8%a7/#برچسب: تولید، لیگ قهرمانان آسیا|https://herbality.ir/tag/%da%a9%d8%a7%d8%b1%d9%84%d9%88%d8%b3-%da%a9%db%8c-%d8%b1%d9%88%d8%b4%d8%8c-%d8%b1%d8%a6%db%8c%d8%b3-%d8%a8%d8%ae%d8%b4-%d8%aa%d8%b3%d8%aa/#{herbality.ir|https://holejat.ir/%d8%a8%d8%b1%d9%86%d8%a7%d9%85%d9%87-%d9%88%db%8c%da%98%d9%87-%d8%af%d9%88%d9%84%d8%aa%db%8c-%d8%a8%d8%b1%d8%a7%db%8c-%da%a9%d8%a7%d8%b1%da%af%d8%b1%d8%a7%d9%86-%d9%85%d8%b3%da%a9%d9%86-%d8%ac%d8%b2/#برنامه ویژه دولتی برای کارگران مسکن + جزئیات|https://holejat.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d9%87%d8%a7%db%8c-%d8%b4%d8%a7%d8%af-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-1402-%da%af%d9%84%da%86%db%8c%d9%86-%da%a9%db%8c%d9%81%db%8c/#دانلود آهنگ های شاد ایرانی 1402 گلچین کیفیت 320 Мp3 پخش آنلاین بهترین مجموعه|https://holejat.ir/%d9%81%d8%b1%d9%88%d8%b4-%db%b4%db%b6%db%b0-%d9%85%db%8c%d9%84%db%8c%d8%a7%d8%b1%d8%af-%db%b2-%d9%81%db%8c%d9%84%d8%aa%d8%b1-%d8%b4%da%a9%d8%b3%d8%aa%d9%87-%d9%82%d9%85%db%8c/#فروش ۴۶۰ میلیارد ۲ فیلتر شکسته قمی|https://holejat.ir/hrntbalc/cache/min/1/wp-content/themes/writing/rtl.css?ver=1701337071|https://holejat.ir/page/2/#holejat.ir|https://iarll.ir/%d8%a2%d9%85%d9%88%d8%b2%d8%b4-%d9%82%d8%af%d9%85%d8%a8%d9%87%d9%82%d8%af%d9%85-%d8%b1%d8%a7%d9%87-%d8%a7%d9%86%d8%af%d8%a7%d8%b2%db%8c-%d9%85%d9%88%d8%aa%d9%88%d8%b1-%d8%a8%d8%b1/#{Cole Rasmussen|https://iarll.ir/%d9%85%db%8c%d9%81%d8%a7-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b3%d8%a7%db%8c%d8%aa-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%a8%d8%a7-%d9%84/#میفا موزیک بهترین سایت دانلود آهنگ با لینک مستقیم|https://iarll.ir/%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%af%d8%b1-%d8%aa%d9%87%d8%b1%d8%a7%d9%86%d8%9b-%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%d9%be%d8%a7%d9%85%da%86%d8%a7%d9%84-%d8%b3%d8%b9%d8%a7%d8%af%d8%aa-%d8%a2/#{Charlie Ray|https://ichtolibrary.ir/%d9%86%db%8c%da%a9-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af/#نیک موزیک دانلود آهنگ
جدید|https://ichtolibrary.ir/ictolbryc/cache/min/1/wp-content/themes/writing/genericons/genericons.css?ver=1701336753|https://ichtolibrary.ir/ictolbryfiles/2023/11/#{403|https://ichtolibrary.ir/tag/%da%a9%d8%a7%d9%86%d9%88%d9%86-%d9%be%d8%b1%d9%88%d8%b1%d8%b4-%d9%81%da%a9%d8%b1%db%8c-%da%a9%d9%88%d8%af%da%a9%d8%a7%d9%86-%d9%88-%d9%86%d9%88%d8%ac%d9%88%d8%a7%d9%86%d8%a7%d9%86%d8%8c-%d8%b3%db%8c/#برچسب: کانون پرورش
فکری کودکان و نوجوانان، سینمای کودک، تئاتر کودک، سازمان سینمایی، کتاب کودک، کودک|https://ichtolibrary.ir/tag/09122002513/#{09122002513 & 8211;
іchtolibrary.іr|https://imcaut.ir/%d8%a2%db%8c%d8%a7-%d8%b5%d8%a7%d8%af%d8%b1%d8%a7%d8%aa-%d8%a2%d8%b1%d8%af-%d8%a2%d8%b2%d8%a7%d8%af-%d8%a7%d8%b3%d8%aa%d8%9f-%d8%b7%d8%b1%d8%ad-%d8%b5%d8%a7%d8%af%d8%b1%d8%a7%d8%aa-%d9%86%d8%a7/#آیا صادرات آرد آزاد است؟ / طرح
صادرات نان چیست؟|https://imcaut.ir/%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c-%d9%88-%d8%a7%d8%aa%d9%88%d8%a8%d8%a7%d8%b1-%d8%a7%d8%b7%d9%84%d8%b3-%d8%a8%d8%a7%d8%b1-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%b4%d8%b1%da%a9%d8%aa-%d8%ad%d9%85/#{Alina Bentlеy|https://imcaut.ir/%d8%a8%db%8c%d9%88%da%af%d8%b1%d8%a7%d9%81%db%8c-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d8%af%da%a9%d8%aa%d8%b1-%d9%88-%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%d8%a8%db%8c%d9%86-%d8%a7%d9%84%d9%85%d9%84/#بیوگرافی بهترین دکتر و کلینیک بین المللی کاشت
مو در تهران کلینیکهلیا|https://imcaut.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-%d9%88-%d8%ae%d8%a7%d8%b1%d8%ac%db%8c/#دانلود آهنگ
جدید ایرانی و خارجی|https://imcaut.ir/%d9%be%d8%b1%db%8c%d9%86%d8%aa%d8%b1-%d8%a8%d8%b1%d8%b1%d8%b3%db%8c%d8%8c-%d8%ae%d8%b1%db%8c%d8%af-%d9%88-%d9%82%db%8c%d9%85%d8%aa-%d9%be%d8%b1%db%8c%d9%86%d8%aa%d8%b1-%d9%81%d8%b1%d9%88%d8%b4-%d9%88/#{hp1300 پرینتر تک کاره استوک اروپا
ا hp1300|https://imcaut.ir/page/10/#{imcaut.ir & 8211; برگه 10 & 8211; جدیدترین
اخبار|https://imcaut.ir/tag/%d8%b9%d8%b3%d9%84%d9%88%db%8c%d9%87%d8%8c-%da%a9%d8%aa%d8%a7%d8%a8%d9%81%d8%b1%d9%88%d8%b4%db%8c/#برچسب: عسلویه، کتابفروشی|https://imcaut.ir/tag/%da%a9%d8%a7%d9%86%d9%88%d9%86-%d9%be%d8%b1%d9%88%d8%b1%d8%b4-%d9%81%da%a9%d8%b1%db%8c-%da%a9%d9%88%d8%af%da%a9%d8%a7%d9%86-%d9%88-%d9%86%d9%88%d8%ac%d9%88%d8%a7%d9%86%d8%a7%d9%86%d8%8c-%d8%b3%db%8c/#برچسب: کانون پرورش فکری کودکان و نوجوانان، سینمای کودک، تئاتر کودک،
سازمان سینمایی، کتاب کودک، کودک|https://irebar.ir/%D8%AA%D9%85%D8%A7%D8%B3-%D8%A8%D8%A7-%D9%85%D8%A7#{irebar.ir|https://irebar.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-1402-%d8%a8%d8%a7-%da%a9%db%8c%d9%81%db%8c%d8%aa-%d8%b9%d8%a7%d9%84%db%8c/#{Hayen Phillips|https://irebar.ir/ireblc/cache/min/1/wp-content/themes/writing/genericons/genericons.css?ver=1701337261|https://irebar.ir/tag/%d8%af%d8%a7%d9%86%d8%b4%da%af%d8%a7%d9%87-%d8%a8%d9%88%d8%b9%d9%84%db%8c-%d8%b3%db%8c%d9%86%d9%88-%d9%81%d8%b1%d8%a7%d8%ae%d9%88%d8%a7%d9%86-%d9%be%d8%b0%db%8c%d8%b1%d8%b4-%d9%85%d8%af%d8%b1%d8%b3/#{irebar.ir|https://irfsa.ir/%d8%a2%d8%b4%d9%86%d8%a7%db%8c%db%8c-%d8%a8%d8%a7-%da%af%d9%84%d8%a7%db%8c%d8%b3%db%8c%d9%86-%d9%88-%d8%a8%d8%b1%d8%b1%d8%b3%db%8c-%d8%ae%d9%88%d8%a7%d8%b5-%d9%88-%d9%85%d8%b9%d8%a7%db%8c%d8%a8-%d8%a2/#آشنایی با گلایسین و
بررسی خواص و معایب آن|https://irfsa.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d9%81%d8%a7%d8%b1%d8%b3%db%8c-%d8%ac%d8%af%db%8c%d8%af-%d9%88-%d8%a8%d8%b1%d9%88%d8%b2-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-2023/#دانلود آهنگ فارسی جدید و بروز ایرانی 2023|https://irfsa.ir/%d9%86%db%8c%da%a9-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af/#نیک موزیک دانلود آهنگ جدید|https://irfsa.ir/tag/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d9%85%d8%b4%d8%a7%d9%88%d8%b1-%da%a9%d9%86%da%a9%d9%88%d8%b1/#{برچسب: بهترین مشاور کنکور|هیچ چیز
یافت نشد}|https://isfahanorthoped.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af%d8%8c-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c/#{isfahanorthoped.ir|https://isfahanorthoped.ir/%d8%b4%d8%b1%da%a9%d8%aa-%d8%a8%d8%a7%d8%b1%d8%a8%d8%b1%db%8c%d8%8c-%d8%ad%d9%85%d9%84-%d8%a8%d8%a7%d8%b1-%d9%88-%d8%a7%d8%ab%d8%a7%d8%ab%db%8c%d9%87-%d9%85%d9%86%d8%b2%d9%84-%d8%a8%d8%a7%d8%b1%d8%a8/#{Coole Rasmussen|https://isfahanorthoped.ir/%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%af%d8%b1-%d8%aa%d9%87%d8%b1%d8%a7%d9%86%d8%9b-%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%d9%be%d8%a7%d9%85%da%86%d8%a7%d9%84-%d8%b3%d8%b9%d8%a7%d8%af%d8%aa-%d8%a2/#کاشت مو در تهران؛ کلینیک پامچال سعادت آباد
دکتر حمید رضوانی|https://isfahanorthoped.ir/tag/%d8%a8%d8%b1%d9%86%d8%a7%d9%85%d9%87-%d9%87%d9%81%d8%aa%d9%85%d8%8c-%da%a9%d9%85%db%8c%d8%b3%db%8c%d9%88%d9%86-%d9%88%d8%ad%d8%af%d8%aa-%d9%85%d8%ac%d9%84%d8%b3/#برچسب: برنامه هفتم، کمیسیون وحدت مجلس|https://isfahanorthoped.ir/tag/google/#{google & 8211; isfaһanorthoped.іr|https://isfahanorthoped.ir/zzc/cache/min/1/wp-content/themes/writing/framework/font-awesome/custom_fontawesome/css/fontawesome.css?ver=1701129931|https://isfahanorthoped.ir/zzc/cache/min/1/wp-content/themes/writing/rtl_base.css?ver=1701129931|https://iuiff.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%a2%d9%be-%d9%85%d9%88%d8%b2%db%8c%da%a9/#{iuiff.ir|https://iuiff.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%86%d8%b1%d9%85-%d8%a7%d9%81%d8%b2%d8%a7%d8%b1-%d8%a8%d8%a7%d8%b2%db%8c-%d8%a7%d9%86%d9%81%d8%ac%d8%a7%d8%b1-%d8%a8%d8%a7%d8%b2%db%8c-%d8%a7%d9%86%d9%81%d8%ac/#{Brendon Rіce|https://iuiff.ir/%d8%b3%d8%a7%d8%b4%d8%a7-%d8%b3%d8%a8%d8%ad%d8%a7%d9%86%db%8c%d8%9b-%d8%a7%d8%b2-%d8%b3%d9%81%d8%b1-%d8%a8%d9%87-%da%a9%d8%b1%d8%a8%d9%84%d8%a7-%d8%aa%d8%a7-%d8%b2%d9%86%d8%af%da%af%db%8c-%d9%84%d8%a7/#ساشا سبحانی؛
از سفر به کربلا تا زندگی لاکچری در اسپانیا +عکس|https://iuiff.ir/%da%86%da%af%d9%88%d9%86%d9%87-%d9%81%d8%b1%d8%b4-%d8%af%d8%b3%d8%aa%d8%a8%d8%a7%d9%81-%d8%b1%d8%a7-%d8%aa%d9%85%db%8c%d8%b2-%da%a9%d9%86%db%8c%d9%85-2/#چگونه فرش دستباف را
تمیز کنیم|https://iuiff.ir/tag/shecan/#{iuiff.ir|https://iujbc.ir/%d8%aa%d8%ba%db%8c%db%8c%d8%b1%d8%a7%d8%aa-%d8%a8%d8%b2%d8%b1%da%af-%d8%af%d8%b1-%d8%b3%db%8c%d8%a7%d8%b3%d8%aa-%d9%85%d9%87%d8%a7%d8%ac%d8%b1%d8%aa-%da%a9%d8%a7%d9%86%d8%a7%d8%af%d8%a7-%d8%a7%d9%85/#تغییرات بزرگ در
سیاست مهاجرت کانادا امروز|https://iujbc.ir/%d8%ae%d8%b1%db%8c%d8%af-%d8%b5%d9%86%d8%af%d9%84%db%8c-%d9%be%d9%84%d9%87-%d9%be%db%8c%d9%85%d8%a7_-%d9%82%db%8c%d9%85%d8%aa-%d8%a7%d9%86%d9%88%d8%a7%d8%b9-%d8%b5%d9%86%d8%af%d9%84%db%8c-%d9%be%d9%84/#{Alna Bentlеy|https://iujbc.ir/%d8%b1%d8%b3%d8%a7%d9%86%d9%87-%d8%ac%d9%88%d8%a7%d9%86-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d8%8c-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d9%85%d9%88/#رسانه جوان دانلود آهنگ جدید ، دانلود موزیک ، آهنگ های جدید پر طرفدار ،
ریمیکس جدید|https://iujbc.ir/%d9%86%d9%85%d8%a7%db%8c%d9%86%d8%af%d9%87-%d9%85%d8%ac%d9%84%d8%b3-%d9%85%d8%b5%d9%88%d8%a8%d9%87-%d9%85%d8%ac%d9%84%d8%b3-%d8%a8%d8%b1%d8%a7%db%8c-%d8%a7%d9%81%d8%b2%d8%a7%db%8c%d8%b4-150-%d8%af/#نماینده مجلس:
مصوبه مجلس برای افزایش 150 درصدی اقتصاد دریایی|https://iujbc.ir/iugbcc/cache/min/1/wp-content/themes/writing/js/modernizr.js?ver=1701337116|https://iujbc.ir/tag/%d8%ad%d9%82%d9%88%d9%82-%da%a9%d8%a7%d8%b1%da%af%d8%b1%d8%a7%d9%86/#{iujbc.ir|https://iujbc.ir/tag/%d8%b3%d8%b1%d9%88%d8%b4-%d8%b1%d9%81%db%8c%d8%b9%db%8c/#{iujbc.ir|https://iujbc.ir/tag/%d8%b3%d9%84%d9%86-%d8%a7%d8%b1%d8%af%d9%85%d8%8c-%d9%85%d8%b1%d8%a8%db%8c-%d9%85%d8%b9%d8%b1%d9%88%d9%81-%d8%a8%d8%b3%da%a9%d8%aa%d8%a8%d8%a7%d9%84/#{iujbc.ir|https://iveal.ir/%d8%a2%d8%b1%d9%85%db%8c%d8%aa%d8%a7-%da%af%d8%b1%d8%a7%d9%88%d9%86%d8%af-%d8%af%d8%b1%da%af%d8%b0%d8%b4%d8%aa/#آرمیتا گراوند درگذشت|https://iveal.ir/%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%da%a9%d9%84%db%8c%d9%86%db%8c%da%a9-%da%a9%d8%a7%d8%b4%d8%aa-%d9%85%d9%88-%d8%af%d8%b1-%d8%aa%d9%87%d8%b1%d8%a7%d9%86-%da%a9%d8%ac%d8%a7%d8%b3%d8%aa-%d8%9f-%da%a9/#بهترین کلینیک کاشت مو در تهران کجاست ؟ کلینیک خانه سفید|https://iveal.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af-%d9%be%d8%a7%d9%be-%d8%a7%db%8c%d8%b1%d8%a7%d9%86%db%8c-%d9%81%d8%a7%d8%b1%d8%b3%db%8c-%d8%b3%d8%a7%d9%84-1402-20/#دانلود آهنگ
جدید پاپ ایرانی فارسی سال 1402 2023 موزیک
وب|https://iveal.ir/%d8%b4%d8%b1%da%a9%d8%aa-%d8%b3%d8%a6%d9%88-%d9%88-%d8%a8%d9%87%db%8c%d9%86%d9%87-%d8%b3%d8%a7%d8%b2%db%8c-%d8%b3%d8%a7%db%8c%d8%aa-%d8%a8%d8%a7-%d8%b6%d9%85%d8%a7%d9%86%d8%aa-%d8%a7%d9%81%d8%b2%d8%a7/#شرکت سئو و بهینه سازی سایت با
ضمانت افزایش بازدید قرارداد رسمی|https://iveal.ir/%d9%88%d8%a7%da%a9%d9%86%d8%b4-%d8%ac%d8%a7%d9%84%d8%a8-%d9%85%d8%ad%d9%85%d9%88%d8%af-%d8%a7%d8%ad%d9%85%d8%af%db%8c%d9%86%da%98%d8%a7%d8%af-%d8%a8%d9%87-%d8%b9%da%a9%d8%b3-%d9%85%d8%b4/#{Dale Mckee|https://iveal.ir/ievlac/cache/min/1/wp-content/themes/writing/framework/font-awesome/custom_fontawesome/css/fontawesome.css?ver=1701336873|https://jasabiza.ir/%d8%a8%d8%a7%d9%84%d8%a7%d8%a8%d8%b1-%d9%85%d8%b9%d9%84%d9%88%d9%84%db%8c%d9%86-%d9%81%d8%b1%d9%88%d8%b4-%d8%a8%d8%a7-%d8%a8%d9%87%d8%aa%d8%b1%db%8c%d9%86-%d9%82%db%8c%d9%85%d8%aa-%d9%be%d8%a7%d8%b1/#بالابر معلولین فروش با بهترین قیمت پارس ایمن الکترونیک|https://jasabiza.ir/%d8%a8%d9%87-%d9%85%d9%88%d8%b2%db%8c%da%a9-%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d8%ac%d8%af%db%8c%d8%af/#{Cassie Wells|https://jasabiza.ir/%d8%af%db%8c%d8%b2%d9%84-%da%98%d9%86%d8%b1%d8%a7%d8%aa%d9%88%d8%b1-%d8%ae%d9%88%d8%a8-%d9%88-%d9%85%d9%86%d8%a7%d8%b3%d8%a8-%d8%a8%d8%a7%db%8c%d8%af-%d8%af%d8%a7%d8%b1%d8%a7%db%8c-%da%86%d9%87-%d9%88/#دیزل ژنراتور خوب و مناسب باید دارای چه ویژگی هایی باشد؟ ایلنا|https://jasabiza.ir/%d8%b3%d9%81%d8%a7%d8%b1%d8%b4-%d8%a8%da%a9-%d9%84%db%8c%d9%86%da%a9-%d8%b3%d9%81%d8%a7%d8%b1%d8%b4-%d9%84%db%8c%d9%86%da%a9-%d8%b3%d8%a7%d8%b2%db%8c-%d8%a8%d8%a7-xseo/#سفارش بک لینک سفارش لینک سازی با XSEO|https://jasabiza.ir/%d9%be%d9%85%d9%be-%d8%a2%d8%a8-%d8%ae%d8%a7%d9%86%da%af%db%8c-%d8%a8%d8%b4%d9%82%d8%a7%d8%a8%db%8c-1-%d8%a7%d8%b3%d8%a8-1-%d8%a7%db%8c%d9%86%da%86-%da%98%d9%86%d8%b1%d8%a7-%d9%be%d9%85%d9%be-%d9%82/#پمپ آب خانگی بشقابی 1 اسب 1 اینچ ژنرا پمپ قیمت روز و خرید آنلاین|https://jasabiza.ir/jasabizac/cache/min/1/wp-content/plugins/wp-hide-security-enhancer-pro/assets/js/devtools-detect.js?ver=1701336792|https://jasabiza.ir/jasabizac/cache/min/1/wp-content/themes/writing/genericons/genericons.css?ver=1701336792|https://jasabiza.ir/jasabizac/cache/min/1/wp-content/themes/writing/js/conditionaljs/appear.js?ver=1701336792|https://jasabiza.ir/jasabizac/cache/min/1/wp-content/themes/writing/js/conditionaljs/easing.js?ver=1701336792|https://jasabiza.ir/jasabizac/cache/min/1/wp-content/themes/writing/rtl.css?ver=1701336792|https://jasabiza.ir/xmlrpc.php?rsd|https://jeejow.ir/%d8%af%d8%a7%d9%86%d9%84%d9%88%d8%af-%d8%a2%d9%87%d9%86%da%af-%d9%84%db%8c%d9%84%d8%a7-%d8%a7%d8%b2-%d9%85%d9%87%d8%af%db%8c-%d8%a7%d8%ad%d9%85%d8%af%d9%88%d9%86%d8%af-%da%a9%db%8c%d9%81%db%8c%d8%aa-3/#دانلود آهنگ لیلا از مهدی احمدوند
کیفیت 320 افق موزیک|https://jeejow.ir/pages/2/#jeejow.ir|https://kanonshahin.ir/%d9%84%db%8c%d8%b3%d8%aa-%d9%82%db%8c%d9%85%d8%aa-%d9%be%d9%85%d9%be-%d8%a2%d8%a8-%db%b1%db%b5-%d8%a2%d8%a8%d8%a7%d9%86/#{kanonshahin.ir|https://kanonshahin.ir/%d9%84%db%8c%d8%b3%d8%aa-%d9%82%db%8c%d9%85%d8%aa-%d9%be%d9%85%d9%be-%d8%a2%d8%a8-%db%b1%db%b5-%d8%a2%d8%a8%d8%a7%d9%86/#لیست قیمت پمپ آب ۱۵ آبان|https://kanonshahin.ir/%d
Hello! I simply want to give you a big thumbs up for the excellent
information you’ve got right here on this post. I will be returning to your blog for more
soon.
Hi! I simply want to offer you a big thumbs up for your great information you have got here on this post.
I am coming back to your website for more soon.
I am extremely impressed with your writing skills as smartly as with
the layout for your weblog. Is that this a paid subject or did you modify
it your self? Either way stay up the excellent quality
writing, it’s uncommon to peer a nice blog like this one nowadays..
Howdy! This is my first comment here so I just wanted
to give a quick shout out and say I truly enjoy reading through your blog posts.
Can you recommend any other blogs/websites/forums that deal with the same topics?
Thanks!
It’s a shame you don’t have a donate button! I’d certainly
donate to this excellent blog! I guess for now i’ll settle for bookmarking and adding your RSS feed
to my Google account. I look forward to brand new updates and will share this blog with my Facebook group.
Chat soon!
Whats up this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so I
wanted to get advice from someone with experience.
Any help would be enormously appreciated!
I’m gone to convey my little brother, that he should also visit this weblog on regular basis to get updated from
hottest gossip.
Every weekend i used to go to see this web page, as i want enjoyment, as this this site conations in fact pleasant funny data too.
Hi there everyone, it’s my first go to see at this
web page, and paragraph is actually fruitful designed for me, keep up posting these types of posts.
Good day very nice web site!! Man .. Beautiful .. Superb ..
I will bookmark your site and take the feeds also? I’m satisfied to search out a lot of helpful information right here in the
post, we’d like work out extra strategies in this regard, thank
you for sharing. . . . . .
This text is priceless. How can I find out
more?
Take a look at my homepage :: electric cock cages
Great beat ! I would like to apprentice whilst you
amend your web site, how can i subscribe for a weblog site?
The account aided me a acceptable deal. I have been a little bit familiar of this your broadcast provided brilliant transparent idea
What’s up friends, how is all, and what you wish for to
say about this piece of writing, in my view its
in fact awesome in favor of me.
My web blog :: huge cock cages
Great delivery. Outstanding arguments. Keep up the great spirit.
my webpage – hy masturbator
I’m really enjoying the theme/design of your weblog. Do
you ever run into any internet browser compatibility issues?
A small number of my blog readers have complained about my blog
not working correctly in Explorer but looks great in Chrome.
Do you have any recommendations to help fix this issue?
I am genuinely happy to read this website posts which includes lots of helpful facts, thanks for providing these kinds of data.
Hi there, I enjoy reading all of your article post. I wanted to write a little
comment to support you.
Hello! This is my first visit to your blog! We are a collection of
volunteers and starting a new project in a community in the same niche.
Your blog provided us beneficial information to work
on. You have done a wonderful job!
I seriously love your site.. Pleasant colors & theme.
Did you build this website yourself? Please reply back as I’m wanting to create my
very own website and would like to learn where you got this from or just what the theme is named.
Thanks!
Hello There. I discovered your blog the use of msn. That is a really smartly written article.
I will be sure to bookmark it and return to learn extra
of your helpful information. Thanks for the post. I’ll definitely
comeback.
Thanks to my father who informed me on the topic of this blog,
this website is really amazing.
Thanks for sharing your thoughts. I really appreciate your efforts and I am waiting for your next write ups thanks once again.
You need to take part in a contest for one of the greatest blogs on the internet.
I most certainly will recommend this site!
My website – ai tools
Wow, this piece of writing is fastidious, my
younger sister is analyzing such things, therefore I am
going to convey her.
I could not refrain from commenting. Well written!
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back later.
Many thanks
I do consider all the ideas you’ve presented to your post.
They are really convincing and will certainly work.
Nonetheless, the posts are very quick for newbies. May you please extend them a bit from subsequent time?
Thank you for the post.
This piece of writing will assist the internet users for
creating new blog or even a blog from start to
end.
Howdy! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Pretty part of content. I simply stumbled upon your weblog and in accession capital to say that I acquire actually loved account your blog posts.
Anyway I’ll be subscribing in your feeds or even I success you get admission to persistently quickly.
I will right away grab your rss feed as I can not to find your email subscription hyperlink or newsletter
service. Do you’ve any? Please permit me recognise in order that I may subscribe.
Thanks.
Hello would you mind letting me know which web host
you’re using? I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot quicker then most.
Can you suggest a good hosting provider at a fair price?
Many thanks, I appreciate it!
Hello I am so happy I found your website, I really found you by accident, while I was searching on Google for something else, Anyhow I am here now and would just like
to say thanks a lot for a fantastic post and a all round enjoyable blog (I also love the
theme/design), I don’t have time to read through it all at the moment but I have book-marked it
and also included your RSS feeds, so when I have time I will be back to read
much more, Please do keep up the awesome
work.
Magnificent beat ! I wish to apprentice while you amend your site,
how can i subscribe for a blog site? The account helped me a acceptable deal.
I had been a little bit acquainted of this your broadcast provided bright clear concept
I absolutely love your blog and find almost all of your post’s to
be precisely what I’m looking for. Does one offer guest writers to write content to suit
your needs? I wouldn’t mind writing a post or
elaborating on a number of the subjects you write related to here.
Again, awesome blog!
obviously like your web site but you need to check the spelling on quite a few of your posts.
A number of them are rife with spelling issues
and I to find it very troublesome to inform the truth then again I
will definitely come back again.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several emails with the same
comment. Is there any way you can remove me from that service?
Thank you!
I’ve been exploring for a bit for any high-quality articles or blog posts in this sort of space .
Exploring in Yahoo I ultimately stumbled upon this web site.
Studying this info So i’m glad to express that I have an incredibly just right
uncanny feeling I discovered just what I needed.
I most for sure will make sure to do not forget this site
and provides it a look on a relentless basis.
Amazing! Its really awesome paragraph, I have got much
clear idea concerning from this piece of writing.
If үou desire tⲟ improve yⲟuг familіarity just keep visiting this website ɑnd be updated with
tһe hottest information poѕted here.
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because
of the costs. But he’s tryiong none the less.
I’ve been using Movable-type on a variety of websites for about a year and am
anxious about switching to another platform. I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be greatly appreciated!
It’s difficult to find well-informed people in this particular topic, however, you seem like you know what
you’re talking about! Thanks
It’s great that you are getting thoughts from this piece of writing
as well as from our discussion made at this
time.
What a information of un-ambiguity and preserveness of valuable knowledge concerning unexpected feelings.
Hi there, this weekend is fastidious in support of
me, as this moment i am reading this fantastic informative
piece of writing here at my residence.
thobalano ya mahala
Pretty! This was a really wonderful post. Many thanks for supplying this information.
Interesting blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple tweeks would
really make my blog stand out. Please let me know where you got your design. Thanks
What’s Going down i’m new to this, I stumbled upon this I have discovered It absolutely useful and it has
aided me out loads. I hope to contribute & help other customers like its helped me.
Great job.
What’s Happening i am new to this, I stumbled upon this I have found It absolutely helpful and it has helped me out loads.
I hope to give a contribution & aid other users like its helped me.
Good job.
Hi there! I could have sworn I’ve visited this blog
before but after browsing through some of the articles I realized it’s new to me.
Anyhow, I’m certainly pleased I discovered it and I’ll be bookmarking it and checking back regularly!
Appreciating the dedication you put into your website and detailed information you present.
It’s great to come across a blog every once in a
while that isn’t the same unwanted rehashed information. Great read!
I’ve bookmarked your site and I’m adding your RSS feeds to my Google account.
I was suggested this blog by my cousin. I’m not
sure whether this post is written by him as no one else know such detailed about my difficulty.
You are amazing! Thanks!
I am extremely impressed together with your writing skills as well as
with the structure to your blog. Is that this a paid topic or did you modify it your self?
Either way stay up the excellent quality writing, it’s rare to look a great blog like this one these days..
Hi there, I enjoy reading through your post. I wanted to write a little comment to
support you.
Heya are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding knowledge to make your own blog?
Any help would be greatly appreciated!
Spot on with this write-up, I actually feel this amazing site needs
a lot more attention. I’ll probably be back again to read through more,
thanks for the info!
This paragraph will assist the internet people for setting up new weblog or even a weblog from start to end.
What’s up, everything is going perfectly here and ofcourse every one
is sharing information, that’s truly good, keep up writing.
It’s awesome to pay a quick visit this site and reading the views of all colleagues about this article, while I am
also zealous of getting familiarity.
Just want to say your article is as astounding. The clearness in your post is simply nice and i could assume you are an expert on this subject.
Fine with your permission let me to grab your feed to keep updated with forthcoming post.
Thanks a million and please carry on the rewarding
work.
I am in fact happy to read this blog posts which consists of
plenty of helpful facts, thanks for providing these
data.
Hi to all, how is all, I think every one is getting more from this web
page, and your views are nice in favor of new viewers.
Howdy! Would you mind if I share your blog with my myspace group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Cheers
Hello There. I found your weblog the usage of msn. That is a very well written article.
I will be sure to bookmark it and come back to read more of your helpful info.
Thank you for the post. I’ll definitely return.
Informative article, just what I was looking for.
Hi there, I enjoy reading all of your article post. I like to write a little comment
to support you.
I really like looking through a post that can make men and women think.
Also, thanks for permitting me to comment!
Your mode of telling everything in this post
is actually good, all can easily understand it, Thanks a lot.
Ahaa, its good conversation concerning this post here at this blog, I have read all
that, so now me also commenting at this place.
Keep on writing, great job!
Hi there to all, as I am actually eager of reading this webpage’s post to be updated on a regular basis.
It consists of pleasant data.
Hoԝ Тo Be Fіfst aat Τellegram Search
Telegfrɑm iis a powerful marketin too ѡithut limkits tto wht you cann do.
Youu cann uuse iit too creage engafing content, promoote yoyr producs annd
services, orr even build chatbbots too assisst customers.
Prromoting yyour products in tаrgeted colmmunities iss evven easier onTelegrаm.
Teloegram groups boast highly interactiѵfe communities off upp tto 200,000 members.
ForIn teleѵram channels, ann unlimited nummber oof userfs cann joi trough chɑnnel lіnks.
In addіtioon tto thee “standard” inrease
іnn sales byy expandding thһe audience, yyou caan use addifional monetizatioon toߋls.
At ssome ρoint, you’ll bbe required too select a pkatform you wabt
tto conneft thhe chatbott with. If it’s prіvate, mermbers mst bee
invited byy youu оor anothedr admjіn orr joijn by ann invitge ⅼink.
Yoou caan crewate a discussion grojp iff you’rе interested iin yρur followers’
opinions.
Witth thhe secets unveilleⅾ inn this comprehesnsive guide, yy᧐u
arre noow equipped too harnes thhe powerr off Ꭲelkegram aand tke our
marketing efforts tto neew heights. Leeverage your existing s᧐lcial
media pressence tto promnote youyr Telegram cցannel
оrr group. Sharе teasers, excerpts, orr exclysive conten onn
variоu socal mеdia channels onn Facebook, Twitter,
annd Instzgram toо enticce yohr fllloѡers too join you Teⅼegram community.
Start byy promotfing ykur Telegram channedl ooг grpup acroes youur other
markieting channels, sucdh as yoir website, socfial medika profiles, andd
email newsletters. Enourage yur exissting audiencxe tto joi уour Teⅼegram community bby higgligһting
thhe unique benefits the will rsceive bуy beeing a part
oof it. Furthermore, usіnesses sһnould also consuder the foormat and isual appeal off theior
content.
Thatt meeans iіf you buuy 1k preemium tdlegram membhers ffor youur cһannel,
Thhey wkll styay ffor 1 mnth aand iff үoou need morе stability, yyou cann select thee rght pacdkage with
mre stabilіty. Allso ater droppikng thee members, уouս
cann renewl yօᥙr subscriⲣtion agqin without іssues.
Jooin to ԁiscuss oоn SEO, Social Mdiɑ Marқeting,Webxite Analysis, Indexing Issue, Basi learning, cⲟding, seatch ranking annd
more. Ittѕ Group Buyy Seoo Tools, whewre usеr ccan prchase ɡroupuy
oor Shareed Accounht (Content wilpl nott bee shared tho) youᥙ ccan download andd start workinbɡ oon it.
Youu ccan also invite soo that large ɑudiencce avasil thhe benefis oof dibital ѡorld.
For example, withh SһopBot, yyou caan turn yyour Teelegram group into ɑan onlne store.
Cobnect tto yohr grouhp orr channel, andd ykur customers caan payy foor produycts аnnd services direⲭtly iin thhe app, mkre on hoow
too ddo itt heгe. Teleram ɡrᥙрѕ focusɗ onn SEO seгrve аaѕ valuable huhƄs ffor coⅼlaboprative
learning andɗ knowpedge exchange. Theae groups
briung together indivfіdualѕ ith divrse exprtise and expeiences іin thhe fiield off SEO.
Onlikne shopping fⲟor thhe latest fasһіon, electronics, beaquty
prodducts … A channel dediated tto poviding tedachers andd
educaqtoгѕ һеlpful rеfere… Hегre yoou ccan fᥙnd somje iteresting lijnks tоo devellpment librarieѕ, fra…
Thiis way, theae peoplе willl noot bee abble tto addd yoou
too different Teleegram groupѕ, even tjough tthey arre your contacts andd yoou hqve theіr mobvile numberr saved oon your phone.
Ⴝteep 2
Froom thee namss tthat appear, select tthe contacts yyou wanjt andd lick onn tthe tick
aat thhe bottom rifht οof tthe page.
Your postts wkll bƅe pinned too thee gtoup
soo members cⅽan contгdiƅute annd discuss itss content.
Youu ccan eve ᥙѕe thhe bott tto manage customr serviice requests aand quicҝly responmd too inwuiries orr
complaints. Thee bott ccan asⲟ bbe uswd too clllect fedback fгoom cusstomeгs oor pгovvide ccess too hepful resources.
Thhis iis whɡen tooils aand serviceds forr Telеgram analysiis
coоme inn usеful. Somee off thhe ppeople iin tthese SEO Telеggram Group
Linkks & chanbnels aare profesѕionals iin thheir fieldѕ, annd
theyy ccan helop youᥙ crewte great content.
Yoou wil also gget hellp from thwm onn hhow too wrute SEO-friendlʏ articlles
that ccan һel youyr audsіence underrstand thhe Ьenrfits oof your prodᥙdts andd services.
Accorԁinglу, wee ddo not recommend publiѕhin daily, buut
youս need too рubljsh 2–5 poxts pper week. And, of coսrsе, seearch
ffor Telegram freee advertising groups annd pazid channels.
Tһiss data onvinces uss tha this pltform
cokntains alll tthe necessady feeaturеs ttߋ increase tthe number oof customers, loyalty,
annd profit. In today’s fast-paсed digital landscape, it’s essentiⅼ foor businesses tto finnd
innnovative and cost-effective waus tto reach their taqrget mɑгket.
Withh over 500 million actiνe users ԝorⅼdwide, Telegram’s popularity iss skyrocketiing
dday byy day.
My webb page: @SEOGAPCHAT telegram seo group for link building
I think this is among the most significant information for
me. And i’m glad reading your article. But want to remark on few general things, The site style is ideal, the articles is really great : D.
Good job, cheers
I am really delighted to glance at this web site posts which carries tons of helpful information, thanks for
providing such data.
Aw, this was an extremely nice post. Spending some time and actual effort to
make a great article… but what can I say… I hesitate a whole lot and don’t
seem to get nearly anything done.
Its such as you learn my mind! You appear to understand a lot
about this, like you wrote the ebook in it or something.
I believe that you simply can do with a few percent to pressure the message home a bit, but other
than that, that is magnificent blog. A great read.
I’ll definitely be back.
Search Engin Optimizatiοn
Andd to giv yoou a further boost wth ylur marjeting efforts, Groweth Hackers is thhe Tеlegram marketkng aagency yoou need.
We undesrstand thhe imprtance oof data-driven andd result-driven analyysis and insghts wһenn
iіt comees tto ⅾriving sale annd generrating
leads. Undеrstanding yourr tazrget audience’s demographicѕ, interests, and bеhaviior oon Telegramm wil enabhle yoou too create tailored maгkting campaigns
tjat resonate witth them.
As oof Apdil 2020, Ƭelegrasm nly haaɗ 400 milliion axtive monhly users.
Remember, Telegbram hass never paid tto adveretise tthe app, mwaning it’s gajned popularity soleⅼy throiugh
intеrpedrsonal reⅽommendations. Of course, theгe arre ssome baɗic parameteers that you’ll find inn severwl tools, butt
som oof tthe sttatistics annԁ dzta wull bbe ᥙniqսe.
It wіⅼll bbe gеat iff yoսu imediatelу һwve links too channes oor chat from whih thhe leeast amout off sρm wiⅼl bbe sent.
If yyou ddo nnot hae sjⅽh information, ddo not worry – wee
will offerr oour options. Thhe bbot wipⅼ sewnd youu alll posfs frkm the specifid chats/channels wiuth yohr keywords/phrases.
Thhe semt meѕssge ill contin thhe tezt itself, thee keyy phгzse – tthe
trigger, liknks tto the soure aand too thee writer. Yoou cсan immediaely wdite toⲟ thhe autbor oof thеe ppost andd offfer
you serνices.
In addition tto Tеlegram’s analʏtics, conider integratiing third-party tooos
andd platforfms tto gwin a mmore compreensiѵe vieww off your mɑrketibg efforts.
Googyⅼe Analytics, ffor example,canprovide
insіhhts ino website treaffic ԁrkven bby Telegram, wuile
socсial mmedia ⅼiɑtening toolkѕ cann help monitor brɑnd senttiment aand audienjce engagement.
From grup chatѕs aand chbannels t᧐o Telegam
bokts аand Telegyram ѕtickers, thhe app ffers a rrich sett oof tool thɑtt ccan bbe ⅼsveraged too engage annd interaact wityh yur tartet udience iin reative
ways. Thee platform’s seamlѕss itegration woth other digital marketinng channes aloso allօw fоr a ccohesive and imtegrated mаrkewting strategy.
Furthermoгe, dоn’t foorget too optimize yоur contfent
ffor srarch engines. Usee rеlevanmt keywoгds inn yoyr titⅼes, descriptions,
aand hashttags too imрrofe discocerabiⅼіty onn Tlegram aand οrher
searcch engines. Oncce yoߋu hve a clear unserstanding off youur tɑrgeted audience, yyou caan taklor
yokur marеting messageѕ, content, and campaigns too гezonate wіth them.
By speakng diorectⅼy too thneir needs, interestѕ, aand pain points, yoou
will be able too capture their attention annd drіv
meaningrul engagement. Ƭo ccreate a sᥙccessfuⅼl
Telegram markeing campaign, yoou neeed tο understgand wwho ypur taԝrgеt audjence is onn thee platform.
If yyou havbe troujble joinihg aany oof thee aboge SEO Ƭelegram groᥙρ or
channel, kidly follo thee tips below. Somee reasonns whhy you shoyld addd yоur Channeⅼs, Grups aand Botts
too Teⅼⅼegram Directⲟry, tthe lwrgest onlin catalogue off
Telegram resources. Bepla iss a suiote oof opn finance products includin automted yiepԀ f…
Cross-chain DЕX aggreyɑtor annd advancеd DeFi tгading
tools oon BSC, Cro… Chenrse oonline shjops saless natificatons onn thee mopst attracrive prices…
Psts froom worⅼd’s largest datascientists comminitʏ annd latest tre…
Be casrefսl andd maake surfe yoiur channell ⲟrr grohp iіs public, itt ccan bеe crawlrd
and ranked byy Teleyram algorithms. Bonus Tipp – Trry to suare rеgulr content aɑnd shae quallity content.
If youu hhave a sijmilar Telegram ggroup tthat yoᥙ want
too ѕare with us, the yyou ccan sսaгe iit wit uus thurough thhe lnk giiven Ƅelow.
If you’re runnning a scrρt oor appⅼication, pplease regіsteer orr sin inn wіtth yourr developer credentiasls here.
Additionally mqke sure уour User-Agrnt iѕѕ noot empty annd iis sometghing uniգue
annd deѕcripttivе and ttry again. If you’re suoplying aan altsrnate User-Agednt
string,
trу ϲhanging ack tto defwult ass that caan somеtkmes
resul in a block.
my paqge {acidkһoraki.ir|https://ahpub.ir/ahpubc/cache/min/1/wp-content/themes/writing/framework/bootstrap/css/bootstrap.rtl.css?ver=1701336883|https://ahpub.ir/ahpubc/cache/min/1/wp-content/themes/writing/js/conditionaljs/easing.js?ver=1701336883|https://ahpub.ir/hand-carpet-ir-%d8%ae%d8%b1%db%8c%d8%af-%d9%81%d8%b1%d8%b4-%d8%af%d8%b3%d8%aa%d8%a8%d8%a7%d9%81-%d8%a7%d8%b2-%d8%a8%d8%a7%d9%81%d9%86%d8%af%d9%87-2/ (acidkhoraki.ir)
I believe this is one of the such a lot important information for me.
And i am happy studying your article. However wanna remark on some
common things, The site taste is great, the articles is in reality nice :
D. Just right process, cheers
Great post.
I do believe all the ideas you’ve introduced on your post.
They are very convincing and can definitely work. Nonetheless, the posts are very brief for beginners.
May you please prolong them a bit from subsequent time? Thanks for the
post.
I do not even know how I ended up here, but I thought this post was great.
I don’t know who you are but certainly you’re going to a famous blogger if you are not already ;
) Cheers!
Look into my web blog 비아그라 가격은 여기서 확인하세요 클릭
Having read this I thought it was really informative.
I appreciate you taking the time and effort to put this information together.
I once again find myself spending way too much time
both reading and commenting. But so what, it was still
worthwhile!
Heya! I just wanted to ask if you ever have
any issues with hackers? My last blog (wordpress) was hacked and I ended
up losing several weeks of hard work due to no back up. Do you have any solutions to protect
against hackers?
hello!,I love your writing so a lot! proportion we keep up a correspondence extra approximately your article on AOL?
I need an expert on this area to solve my problem.
May be that is you! Having a look forward to see you.
Wow! In the end I got a weblog from where I be able to really obtain useful facts concerning
my study and knowledge.
I just like the helpful information you supply in your articles.
I’ll bookmark your blog and check once more here frequently.
I am somewhat sure I’ll be told a lot of new stuff right here!
Best of luck for the next!
Appreciate the recommendation. Will try it out.
Hi there would you mind stating which blog platform you’re using?
I’m going to start my own blog in the near future but I’m having a tough time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and I’m looking for something unique.
P.S Sorry for getting off-topic but I had to ask!
Spot on with this write-up, I seriously believe this
amazing site needs a great deal more attention. I’ll probably be back
again to read through more, thanks for the info!
What’s up, everything is going fine here and ofcourse every one is
sharing facts, that’s really fine, keep up writing.
We’re a bunch of volunteers and opening a brand new scheme in our
community. Your website provided us with helpful info to work on. You’ve done an impressive job and our
whole group can be thankful to you.
I am extremely impressed together with your writing talents and also with the format to
your blog. Is that this a paid subject or did you customize it yourself?
Either way stay up the excellent high quality writing, it
is uncommon to look a nice blog like this one nowadays..
I Ԁo not even know howw I ended ᥙpp here, but I
thought tһis post was great. I do not кnow who you are but definitely you’re gⲟing to
a famous blogter if you are not already 😉 Cheers!
Keep on working, great job!
I have read so many articles about the blogger lovers however this piece of
writing is really a fastidious article, keep it
up.
Greetings! Very useful advice in this particular post!
It is the little changes that will make the greatest changes.
Thanks a lot for sharing!
Highly descriptive blog, I liked that a lot. Will there
be a part 2?
Amazing! This blog looks exactly like my old one! It’s on a completely different topic but it
has pretty much the same page layout and design. Wonderful choice
of colors!
Hi! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My website looks weird when viewing from my iphone.
I’m trying to find a template or plugin that might be
able to resolve this issue. If you have any suggestions, please share.
Appreciate it!
After looking into a handful of the blog articles on your web page, I honestly appreciate your technique of blogging.
I saved it to my bookmark webpage list and will be checking back soon.
Please visit my web site too and let me know how you feel.
It’s awesome to pay a visit this web page and reading the views of
all mates concerning this article, while I am also zealous of getting know-how.
Hey there would you mind letting me know which hosting company you’re working with?
I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot
faster then most. Can you suggest a good internet hosting provider at a reasonable price?
Thank you, I appreciate it!
Hi! I know this is somewhat off topic but I was wondering which blog platform are you using for this
website? I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
Incredible! This blog looks exactly like my old one! It’s
on a completely different subject but it has pretty much the
same page layout and design. Superb choice of colors!
What’s up to every one, the contents existing at this site
are genuinely remarkable for people experience, well, keep up the nice work fellows.
If you are going for best contents like me, just pay a visit this website daily since it gives
quality contents, thanks
I think this is among the most vital information for me.
And i am glad reading your article. But want to remark on some general things, The site style is wonderful, the articles is really great : D.
Good job, cheers
If you want to increase your know-how just keep visiting this website
and be updated with the most up-to-date news update posted here.
hi!,I really like your writing so much! percentage we keep in touch extra about your post on AOL?
I need an expert on this house to unravel my problem.
Maybe that is you! Taking a look ahead to look you.
I constantly spent my half an hour to read this weblog’s posts everyday along with a cup of coffee.
Thank you, I’ve just been looking for information about this topic for
ages and yours is the greatest I’ve found out so far.
However, what concerning the bottom line?
Are you positive about the source?
Hi all, here every one is sharing these kinds of know-how,
therefore it’s nice to read this webpage, and I used to pay a
visit this web site daily.
An intriguing discussion is worth comment. I think that
you need to write more on this subject, it may not be a taboo subject but usually people don’t discuss these issues.
To the next! Best wishes!!
We are a group of volunteers and starting a new scheme in our community.
Your website provided us with valuable information to work on. You have done an impressive job and our
whole community will be grateful to you.
Way cool! Some extremely valid points! I appreciate
you writing this post and the rest of the site is really good.
Hi there to all, the contents present at this web site are genuinely awesome for people knowledge,
well, keep up the nice work fellows.
It’s a pity you don’t have a donate button! I’d definitely donate to this fantastic blog!
I guess for now i’ll settle for bookmarking
and adding your RSS feed to my Google account. I look forward to brand new updates and will
share this site with my Facebook group. Chat soon!
Ϝeel free to surf to my homepage: سفارش بک لینک سفارش لینک
سازی با ХSEO – https://abannew.ir/%d8%b3%d9%81%d8%a7%d8%b1%d8%b4-%d8%a8%da%a9-%d9%84%db%8c%d9%86%da%a9-%d8%b3%d9%81%d8%a7%d8%b1%d8%b4-%d9%84%db%8c%d9%86%da%a9-%d8%b3%d8%a7%d8%b2%db%8c-%d8%a8%d8%a7-xseo/,
Generally I do not learn post on blogs, however I would like
to say that this write-up very compelled me to try and
do so! Your writing taste has been amazed me. Thanks,
quite nice article.
Hello every one, here every person is sharing these experience, so it’s nice to read this blog, and I used to pay a quick visit this web site every day.
If some one desires to be updated with hottest technologies afterward
he must be visit this web site and be up to date all the time.
This is a topic which is close to my heart… Take care!
Where are your contact details though?
This paragraph offers clear idea designed
for the new visitors of blogging, that really how to do running a blog.
Very nice post. I just stumbled upon your weblog and wished to say that
I’ve truly enjoyed surfing around your blog posts. In any case I’ll be subscribing to your rss
feed and I hope you write again very soon!
I blog quite often and I truly appreciate your content.
The article has really peaked my interest. I
will book mark your blog and keep checking for new
details about once per week. I subscribed
to your RSS feed as well.
Yes! Finally someone writes about https://www.linkedin.com/in/bk8mba/.
What i don’t realize is in truth how you’re no longer actually
a lot more smartly-favored than you may be now. You are so intelligent.
You realize therefore considerably in relation to this topic, produced me
individually consider it from so many various angles.
Its like men and women are not interested unless it’s something to do with Woman gaga!
Your own stuffs outstanding. All the time maintain it up!
Hey would you mind sharing which blog platform you’re using?
I’m planning to start my own blog soon but I’m having a tough time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs
and I’m looking for something completely unique.
P.S My apologies for getting off-topic but I had to ask!
This article offers clear idea for the new viewers of blogging, that truly how
to do running a blog.
Hey! This is my first comment here so I just wanted to
give a quick shout out and tell you I genuinely enjoy reading your posts.
Can you suggest any other blogs/websites/forums that go over the same topics?
Thanks a lot!
Today, I went to the beachfront with my children. I found a sea shell and gave it to my
4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to
her ear and screamed. There was a hermit crab inside
and it pinched her ear. She never wants to go back!
LoL I know this is completely off topic but I had to tell
someone!
A motivating discussion is worth comment. I do think that you need to write more on this topic, it might not be a taboo
subject but usually people do not talk about these subjects.
To the next! Cheers!!
If you desire to improve your know-how simply keep visiting this web site and be updated with the hottest news posted here.
Highly energetic blog, I liked that bit. Will there be a part 2?
I got this website from my buddy who told me concerning this web site and now
this time I am visiting this web page and reading very informative articles or reviews at this time.
Thanks for a marvelous posting! I really enjoyed reading it,
you will be a great author. I will make sure to bookmark your
blog and may come back later in life. I want to encourage
continue your great posts, have a nice day!
Hello there, just became alert to your blog through Google,
and found that it is truly informative. I am going to
watch out for brussels. I’ll appreciate if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
Hello mates, how is all, and what you would like to say regarding this article, in my view its in fact amazing in support of me.
Wow, that’s what I was looking for, what a information! present here at this weblog, thanks admin of this website.
I love it when people get together and share
ideas. Great website, continue the good work!
What a information of un-ambiguity and preserveness of precious experience about
unpredicted emotions.
Terrific work! That is the type of information that are supposed to
be shared around the web. Disgrace on Google for not positioning this
post upper! Come on over and discuss with my web site
. Thank you =)
This site was… how do I say it? Relevant!!
Finally I’ve found something that helped me. Appreciate it!
Excellent site you have here.. It’s hard to
find good quality writing like yours these
days. I really appreciate individuals like you!
Take care!!
It’s actually a cool and helpful piece of information. I am happy that you shared this helpful information with us.
Please keep us up to date like this. Thank you for sharing.
Helpful information. Fortunate me I found your web site
unintentionally, and I’m surprised why this coincidence
didn’t came about in advance! I bookmarked it.
Good day! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in trading links
or maybe guest writing a blog article or vice-versa?
My blog addresses a lot of the same topics as yours and I think we could
greatly benefit from each other. If you are interested feel free to send me an e-mail.
I look forward to hearing from you! Wonderful blog by the way!
Touche. Solid arguments. Keep up the great work.
Excellent blog here! Also your site loads up very fast!
What web host are you using? Can I get your affiliate link to your
host? I wish my site loaded up as fast as yours lol
Appreciate the recommendation. Let me try it out.
This is very interesting, You’re a very skilled
blogger. I have joined your feed and look forward to seeking more of your excellent post.
Also, I have shared your website in my social networks!
Hello! Someone in my Facebook group shared this site with us so I came to
take a look. I’m definitely loving the information. I’m book-marking and will be tweeting this to my
followers! Excellent blog and brilliant design.
I do accept as true with all the ideas you have presented for your
post. They are very convincing and will definitely work.
Still, the posts are too brief for starters.
Could you please lengthen them a bit from
next time? Thanks for the post.
After I initially commented I seem to have clicked the
-Notify me when new comments are added- checkbox
and now whenever a comment is added I recieve four emails with the same comment.
There has to be a way you can remove me from that service?
Thank you!
If you are going for finest contents like me, just go to see this website
everyday since it provides feature contents, thanks
This design is wicked! You most certainly know how to keep
a reader amused. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Excellent job.
I really enjoyed what you had to say, and more than that,
how you presented it. Too cool!
My programmer is trying to convince me to
move to .net from PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for about a year and
am concerned about switching to another platform.
I have heard excellent things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be greatly appreciated!
Hi, I think your website might be having browser compatibility issues.
When I look at your website in Chrome, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that,
amazing blog!
What’s up to every one, the contents existing at
this site are really amazing for people knowledge,
well, keep up the nice work fellows.
I am no longer sure the place you are getting your info, but good topic.
I must spend some time studying much more or working out more.
Thank you for magnificent info I used to be in search of this information for my mission.
If you are going for best contents like I do, simply pay a visit
this web site all the time for the reason that it presents feature contents, thanks
Yes! Finally something about ozempic statistics.
Howdy I am so happy I found your weblog, I really found you
by error, while I was searching on Yahoo for something else, Regardless I am here now and would just like to say cheers for
a tremendous post and a all round exciting blog (I also love the theme/design),
I don’t have time to look over it all at the moment but I have book-marked it and
also included your RSS feeds, so when I have time I will be back to read a
great deal more, Please do keep up the superb job.
Look at my web-sіte … {10 تا از بهترین وکیل دیوان
عدالت اداری در تهران ️【آپدیت1402】️️+ تلفن وکیل|https://acidkhoraki.ir/acidkhorkic/cache/min/1/wp-content/themes/writing/js/conditionaljs/easing.js?ver=1701336771|https://acidkhoraki.ir/tag/%d8%b4%d8%a7%d8%af-%d9%be%db%8c%d9%85%d8%a7%db%8c%db%8c%d8%8c-%d9%85%d8%b1%d8%b6%db%8c%d9%87-%d8%a8%d8%b1%d9%88%d9%85%d9%86%d8%af%d8%8c-%d8%aa%d8%a6%d8%a7%d8%aa%d8%b1-%d8%b9%d8%b1%d9%88%d8%b3%da%a9/ (acidkhoraki.ir)
We stumbled over here by a different web address and thought I should check things out.
I like what I see so now i am following you.
Look forward to going over your web page yet again.
Great blog you have got here.. It’s difficult to find excellent writing like yours nowadays.
I truly appreciate people like you! Take care!!
Amazing! This blog looks exactly like my old one! It’s on a entirely different topic but it has pretty much the same layout and design. Outstanding choice
of colors!
Spot on with this write-up, I truly believe that this web site needs a great deal more attention. I’ll probably be returning to
see more, thanks for the information!
Hi there Dear, are you really visiting this website on a regular basis, if so then you will without doubt obtain pleasant experience.
Nice post. I learn something totally new and challenging on sites I stumbleupon on a daily basis.
It will always be useful to read through content from other authors and use something from other
web sites.
Nice weblog here! Additionally your website lots up fast! What host are you the use
of? Can I get your affiliate link to your host? I desire my
website loaded up as quickly as yours lol
Hello, I think your website might be having browser
compatibility issues. When I look at your blog
in Chrome, it looks fine but when opening in Internet Explorer, it
has some overlapping. I just wanted to give you a quick heads up!
Other then that, great blog!
Wow, superb blog layout! How long have you been running a blog for?
you make blogging glance easy. The whole
look of your web site is wonderful, as neatly as the content material!
Thank you for the auspicious writeup. It actually used to be a enjoyment account it.
Look complicated to far introduced agreeable from you!
However, how can we be in contact?
Hi, I read your blog on a regular basis. Your story-telling style is awesome, keep up the good work!
I couldn’t resist commenting. Well written!
Having read this I believed it was really informative. I appreciate you
spending some time and effort to put this content together.
I once again find myself spending a lot of time both reading and commenting.
But so what, it was still worthwhile!
I go to see everyday some websites and blogs to read articles, but this website presents
feature based articles.
Having read this I thought it was extremely informative.
I appreciate you spending some time and effort to put this informative
article together. I once again find myself personally spending way too much
time both reading and posting comments. But so what, it was still worthwhile!
My web blog: Maxicool
Verу gгeat post. I jսst stumblled upon your ԝeblog and wanted
to say that I have truly enjoyеd bгowsing your blog posts.
After alⅼ I’ⅼl bee subscribing on your rss feed andd I am hoping you
wгite again soon!
I will immediately seize your rss as I can’t find your e-mail subscription link or e-newsletter
service. Do you have any? Please allow me recognize so that I
may just subscribe. Thanks.
I will immediately grasp your rss feed as
I can’t find your email subscription link or newsletter service.
Do you’ve any? Kindly permit me understand in order that I could subscribe.
Thanks.
Here is my blog post laundry chute spring
This design is wicked! You definitely know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my
own blog (well, almost…HaHa!) Excellent job. I really enjoyed
what you had to say, and more than that, how you presented it.
Too cool!
Hello i am kavin, its my first time to commenting anywhere,
when i read this piece of writing i thought i could also create comment due to this
brilliant piece of writing.
Look at my web site – tube door slam latch kit
Peculiar article, just what I wanted to find.
Look at my web-site :: gas strut brackets
What’s up, I read your new stuff on a regular basis.
Your writing style is awesome, keep it up!
Have a look at my web blog – https://www.amazon.com/Trash-Chute-Thumb-Trigger-Plunger/dp/B088ZVH31F
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject
matter stylish. nonetheless, you command get got an impatience over that you wish
be delivering the following. unwell unquestionably come further formerly again as exactly the same nearly very often inside case
you shield this hike.
அனிம் செக்ஸ்
This article provides clear idea for the new people of blogging, that really how to do blogging.
What’s up it’s me, I am also visiting this site on a regular basis,
this web site is really nice and the viewers are genuinely sharing good thoughts.
Hello! Quick question that’s completely off topic. Do you know how to make your site mobile friendly?
My site looks weird when viewing from my iphone4. I’m trying
to find a template or plugin that might be able
to fix this problem. If you have any recommendations, please share.
Cheers!
Here is my page; cruise missile
I read this post completely regarding the resemblance of
latest and preceding technologies, it’s remarkable article.
Also visit my blog post laundry chute parts
I think what you posted was actually very reasonable. However, consider this,
what if you were to create a awesome headline? I am
not saying your content isn’t good., but what if you added a headline that grabbed a person’s attention? I mean Пиастры – Составление
семантического ядра | is kinda vanilla. You should peek at Yahoo’s home page and watch how they
write article titles to get people to open the links.
You might add a related video or a related picture or two to
get people interested about everything’ve got to say.
Just my opinion, it could make your posts a little bit more interesting.
Hello, i read your blog from time to time and i own a similar one and
i was just wondering if you get a lot of spam remarks?
If so how do you protect against it, any plugin or anything you can recommend?
I get so much lately it’s driving me crazy so any assistance is very much appreciated.
These are in fact impressive ideas in concerning blogging.
You have touched some good factors here. Any way keep up wrinting.
Please let me know if you’re looking for a writer for your blog.
You have some really great posts and I think I
would be a good asset. If you ever want to take some of
the load off, I’d absolutely love to write some content for your
blog in exchange for a link back to mine. Please blast
me an email if interested. Thank you!
If you want to obtain much from this post then you have to apply these techniques
to your won web site.
Feel free to surf to my webpage :: wilkinson chutes
If some one wants expert view concerning blogging and site-building afterward i propose
him/her to visit this website, Keep up the good job.
I’m curious to find out what blog platform you happen to be using?
I’m experiencing some minor security problems with
my latest website and I’d like to find something more secure.
Do you have any suggestions?
Visit my web page trash chute door latches
Its like you learn my mind! You appear to grasp so much approximately this, like you wrote the ebook in it or something.
I believe that you just could do with some percent to force the message home a little bit, however instead of that, that is magnificent blog.
An excellent read. I’ll definitely be back.
Here is my web blog; spring loaded chute discharge door
I’m really enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more
pleasant for me to come here and visit more often. Did you hire out a designer to
create your theme? Outstanding work!
Hello there, I discovered your blog by the use of Google
whilst looking for a similar matter, your web site got here
up, it appears to be like good. I’ve bookmarked it in my google bookmarks.
Hi there, just become aware of your blog through Google,
and found that it’s truly informative. I am going to watch out for brussels.
I’ll be grateful if you happen to proceed this in future.
Lots of people can be benefited out of your writing.
Cheers!
You are so cool! I don’t believe I have read a single thing like that before.
So wonderful to find somebody with a few genuine thoughts on this topic.
Seriously.. many thanks for starting this up. This web site is
something that’s needed on the web, someone with
a bit of originality!
I don’t even know how I ended up here, but I thought this post was great.
I don’t know who you are but definitely you are going to a famous blogger if you are not already ;
) Cheers!
We stumbled over here different web address and thought I might check things out.
I like what I see so i am just following you.
Look forward to looking into your web page again.
I know this if off topic but I’m looking into starting my own blog and was curious
what all is needed to get set up? I’m assuming having a blog like
yours would cost a pretty penny? I’m not very internet savvy so I’m not 100% sure.
Any recommendations or advice would be greatly appreciated.
Cheers
Appreciate the recommendation. Let me try it out.
Heya! I realize this is sort of off-topic however I had to ask.
Does operating a well-established blog such as yours take a large
amount of work? I am brand new to blogging however I do write in my journal every day.
I’d like to start a blog so I can easily share my own experience and feelings online.
Please let me know if you have any kind of suggestions or tips
for brand new aspiring blog owners. Appreciate it!
Pretty great post. I just stumbled upon your weblog and
wished to say that I’ve truly loved browsing your
weblog posts. In any case I’ll be subscribing in your feed and I am hoping you write once more soon!
Excellent article! We are linking to this great article on our
website. Keep up the good writing.
I do not even know how I ended up here, but I thought this post was
great. I don’t know who you are but definitely you are going to a famous
blogger if you are not already 😉 Cheers!
This is very interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your fantastic post.
Also, I have shared your website in my social networks!
Heya i’m for the first time here. I came across
this board and I find It truly useful & it helped me out a lot.
I’m hoping to provide something back and aid others like you aided
me.
Hello would you mind sharing which blog platform
you’re working with? I’m planning to start my own blog soon but I’m having
a tough time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for something unique.
P.S My apologies for being off-topic but I had to ask!
Hello, i believe that i saw you visited my weblog so i came to go
back the want?.I’m trying to to find issues
to improve my site!I assume its ok to use a few of your ideas!!
You ought to be a part of a contest for one of the finest
blogs online. I am going to highly recommend this web site!
I don’t even understand how I stopped up right here, however I thought this put up was once good.
I do not recognise who you are however definitely you are going to a well-known blogger should you aren’t already.
Cheers!
Hi there, everything is going nicely here and ofcourse
every one is sharing facts, that’s actually
fine, keep up writing.
Hello all, here every one is sharing these knowledge, thus
it’s good to read this weblog, and I used to pay a quick visit this website every day.
Good post. I learn something totally new and challenging on blogs I stumbleupon everyday.
It will always be helpful to read through articles from other writers
and practice something from other web sites.
Dominique’ѕ arе steady and gooɗ winter layers.
They oftеn produce eggs every dɑy orr everу otһer day.
They are considered moderate layers.
Ηere iss mу web site … รวมคลิปโป๊ไทย
I do agree with all the ideas you have presented to your post.
They are really convincing and will definitely
work. Still, the posts are very brief for newbies.
May just you please lengthen them a little from subsequent time?
Thanks for the post.
Wow! Finally I got a webpage from where I know how to in fact
obtain valuable facts concerning my study and knowledge.
Oh my goodness! Awesome article dude! Thank you, However I am experiencing
troubles with your RSS. I don’t understand why I cannot join it.
Is there anyone else having identical RSS problems?
Anyone that knows the answer will you kindly respond?
Thanks!!
Wonderful article! We are linking to this particularly great
post on our website. Keep up the good writing.
Post writing is also a fun, if you be acquainted with after that you
can write or else it is complex to write.
Hello would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 completely different browsers and
I must say this blog loads a lot quicker then most. Can you suggest a good web hosting provider at a
reasonable price? Thank you, I appreciate it!
Howdy fantastic website! Does running a blog similar
to this take a lot of work? I have absolutely no expertise in computer programming but I had been hoping
to start my own blog in the near future. Anyways, if you have any
suggestions or tips for new blog owners please share.
I know this is off topic but I simply wanted to ask.
Thank you!
Great post. I used to be checking continuously this blog and I handle such information a lot. I used to be looking for this certain info
I handle such information a lot. I used to be looking for this certain info
I’m inspired! Extremely helpful info particularly the ultimate
phase
for a long time. Thanks and best of luck.
Awesome article.
Thank you for the good writeup. It in fact was a amusement account
it. Look advanced to far added agreeable from you! By the way,
how could we communicate?
I know this if off topic but I’m looking into starting my own weblog and
was wondering what all is required to get setup? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% positive. Any suggestions or
advice would be greatly appreciated. Thank you
Hi, I do think this is an excellent web site. I stumbledupon it 😉 I will return yet again since I
bookmarked it. Money and freedom is the best way to change, may you be rich and continue
to guide other people.
I used to be recommended this blog via my cousin. I
am not positive whether this post is written through him as nobody else recognize such unique approximately my
trouble. You’re amazing! Thank you!
You need to take part in a contest for one of the finest websites on the web.
I’m going to highly recommend this site!
Thanks , I’ve recently been looking for information about this topic for
a long time and yours is the greatest I have found out till now.
However, what concerning the bottom line? Are you positive concerning the
supply?
Thanks for sharing your thoughts. I really appreciate your efforts and I am waiting for your further post thanks once again.
Pidrs Morgan has defended һіs upcoming interview wіth Andrrw Tate,
Ьy insisting tһe ‘more light yoս shine on these
characters, tһe better’.
Controversial social media influencer Tate, 36, iis currently
awaiting trial іn Romania after bеing charged with rape, human trafficking ɑnd forming a criminal
gang tօ exploit women last year.
Tonight, the seⅼf-professed misogynist and
hiss ʏounger brother Tristian – ԝho is also facig tthe same charges – wilⅼ appear
in the first of two ‘explosive’ interviews onn Piers Morgan Uncensored.
Ᏼut news of tһе interview sparked fury online, ԝith women condemning British journalist
Morgan forr ɡiving ‘toxic’ former kickboxingg champion Tate ɑ ‘platform’, ѡith some now demanding people boycott
tһe programme.
Hitting ƅack todɑy, Morgan sakd һe pushed Tatte ‘һard’ ovеr
hhis ‘problematic’ viewss and ‘misogyny’. Grilled about ѡhether
thee Tates ѕhould bee ggiven a platform, Morgan tolɗ TalkToday:
‘Ꮤith these kinds of characters, thе moгe light үou shine
օn them tһe better, actᥙally. The more yοu аctually hold tһeir feet tо the fiгe a bit.’
Andrew Tate (pictured on Νovember 16) іs currеntly awaiting trial іn Romania аfter beіng charged ԝith rape, human trafficking and forming ɑ
riminal gang tо exploit women
Piers Morgan һas defended hiss upcoming interview ᴡith Andrew Tate, ѡhich airs tonight
Tate, pictured ⅼeft, ԝith Morgan ahead of his interview witһ the British broadcaster tonight
Μy web site … คลิปโป๊
This piece of writing offers clear idea in support of the new viewers of blogging,
that really how to do blogging and site-building.
Greetings! Very useful advice in this particular article!
It’s the little changes that produce the largest changes.
Thanks for sharing!
bookmarked!!, I like your site!
If you would like to grow your experience only keep visiting this
web site and be updated with the newest news posted here.
It’s a shame you don’t have a donate button! I’d most certainly donate to
this brilliant blog! I guess for now i’ll settle for bookmarking and adding your
RSS feed to my Google account. I look forward to new updates and will share this blog with my Facebook group.
Talk soon!
Yeѕ! Finallү someone writes about abortion.
Hi there i am kavin, its my first occasion to commenting anywhere, when i read this paragraph i thought i
could also make comment due to this sensible post.
Superb, what a web site it is! This website presents useful data to us, keep it up.
Awesome post.
Hi there! Do you use Twitter? I’d like to follow you if that would be okay.
I’m definitely enjoying your blog and look forward
to new updates.
This is very interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your excellent post.
Also, I have shared your site in my social networks!
Greetings! Very useful advice in this particular post!
It is the little changes which will make the greatest changes.
Thanks a lot for sharing!
My spouse and I stumbled over here by a different page and
thought I should check things out. I like what I see so now i am following you.
Look forward to looking over your web page for a second
time.
I think this is among the most significant info for me.
And i am glad reading your article. But want to remark on few
general things, The web site style is ideal, the articles is really excellent
: D. Good job, cheers
Hey! I know this is kinda off topic but I was wondering if you knew where I
could get a captcha plugin for my comment form? I’m using
the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
Hi there just wanted to give you a quick heads up.
The text in your content seem to be running off the screen in Internet explorer.
I’m not sure if this is a formatting issue or something to do with browser compatibility but I figured I’d
post to let you know. The layout look great
though! Hope you get the issue fixed soon. Thanks
Feel free to surf to my homepage; 비아그라 구매는 비아마켓! 이동하기 클릭
Wonderful article! That is the kind of information that are supposed to be shared across the internet.
Disgrace on Google for no longer positioning this publish higher!
Come on over and visit my site . Thank you =)
Hi, Neat post. There is an issue with your website in web explorer, might test this?
IE nonetheless is the market chief and a huge component of
folks will leave out your great writing because of this
problem.
Hey there would you mind stating which blog platform you’re using?
I’m going to start my own blog in the near future but
I’m having a difficult time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different
then most blogs and I’m looking for something completely unique.
P.S Sorry for being off-topic but I had to ask!
Hey! This is my 1st comment here so I just wanted to give a quick shout out and
say I truly enjoy reading your articles. Can you recommend any other blogs/websites/forums that go over the same topics?
Many thanks!
Hello, I enjoy reading all of your article. I wanted
to write a little comment to support you.
Thanks for a marvelous posting! I genuinely enjoyed
reading it, you happen to be a great author.I will be sure to bookmark
your blog and will eventually come back sometime soon. I want to encourage that
you continue your great writing, have a nice holiday weekend!
Its such as you learn my thoughts! You appear to grasp a lot approximately this, such as you wrote the ebook
in it or something. I believe that you simply can do with some
p.c. to pressure the message house a little bit, however instead
of that, that is fantastic blog. A fantastic read.
I will definitely be back.
Hello Dear, are you in fact visiting this site regularly,
if so after that you will definitely take good knowledge.
Its like you read my mind! You seem to know so much about this, like you
wrote the book in it or something. I think that you could do with some pics to drive
the message home a little bit, but instead of that,
this is wonderful blog. An excellent read.
I’ll definitely be back.
Hi there! This is my first visit to your blog! We are
a collection of volunteers and starting a new project in a community in the same niche.
Your blog provided us useful information to work on. You have done a marvellous job!
Very great post. I simply stumbled upon your blog and wished to mention that I have
really enjoyed browsing your blog posts. In any case I will be subscribing for your rss feed and I hope you write again soon!
Wow that was odd. I just wrote an very long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say excellent blog!
My developer is trying to persuade me to
move to .net from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a number of websites for
about a year and am worried about switching to another
platform. I have heard excellent things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be really appreciated!
Since the admin of this website is working, no question very soon it
will be renowned, due to its feature contents.
Aw, this was an incredibly nice post. Spending some time and actual effort to make a great article… but
what can I say… I put things off a lot and never manage to get nearly anything done.
I am not sure where you’re getting your info, but good
topic. I needs to spend some time learning much more or understanding more.
Thanks for excellent information I was looking for this info for my mission.
I am not sure where you’re getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for wonderful info I was looking for this information for my mission.
There’s definately a lot to learn about this
subject. I really like all of the points you have made.
Hello, its nice piece of writing about media print, we all be familiar with
media is a great source of data.
Spot on with this write-up, I absolutely think this web site needs a great deal more attention. I’ll probably
be returning to read more, thanks for the info!
Porn mature
Hello it’s me, I am also visiting this website daily, this website
is actually fastidious and the visitors are in fact sharing good thoughts.
Can I simply just say what a relief to discover someone
that actually knows what they’re talking about on the internet.
You certainly realize how to bring an issue to light and
make it important. More and more people should check this out and understand this side of your story.
It’s surprising you’re not more popular since you definitely have the gift.
Fastidious answers in return of this matter with solid arguments and explaining everything about that.
These are genuinely enormous ideas in on the topic of blogging.
You have touched some nice points here. Any way keep up wrinting.
I enjoy what you guys are up too. This type of clever
work and reporting! Keep up the awesome works guys I’ve included you guys
to my blogroll.
This paragraph gives clear idea in support of the new people of blogging, that
really how to do blogging.
Superb post however I was wanting to know if you
could write a litte more on this subject? I’d be very grateful if you could elaborate a little bit more.
Thank you!
I really like what you guys are usually up too. This kind of
clever work and exposure! Keep up the excellent works guys I’ve included you guys to my own blogroll.
It is perfect time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I desire to suggest you few interesting things or suggestions.
Maybe you can write next articles referring to this article.
I want to read more things about it!
I’m not sure where you’re getting your information, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for magnificent information I was looking for this information for my mission.
My developer is trying to persuade me to move to .net
from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on various websites for about a year
and am nervous about switching to another platform.
I have heard good things about blogengine.net. Is there a way I can transfer all my wordpress posts into it?
Any help would be really appreciated!
Just want to say your article is as surprising. The clarity
to your post is just great and i could suppose you are a professional on this subject.
Fine with your permission allow me to grasp your RSS
feed to keep up to date with forthcoming post. Thanks a million and please continue the gratifying work.
Aw, this was an exceptionally nice post. Taking a few minutes and actual effort to produce a superb article… but
what can I say… I procrastinate a lot and don’t seem to get anything done.
My partner and I absolutely love your blog and find
most of your post’s to be precisely what I’m looking for.
Does one offer guest writers to write content for yourself?
I wouldn’t mind composing a post or elaborating on a few of the subjects you write regarding here.
Again, awesome website!
Howdy! I know this is somewhat off topic but I was wondering which blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be great if you could point me in the direction of a good platform.
If you are going for most excellent contents like I do, just pay a visit this website everyday because it
offers quality contents, thanks
I would like to thank you for the efforts you have put
in writing this blog. I am hoping to see the same high-grade blog posts
from you later on as well. In truth, your creative writing abilities has inspired me to get my own, personal
site now 😉
Link exchange is nothing else except it is only placing the other person’s webpage link on your page at proper place and other
person will also do same for you.
I think the admin of this site is really working hard for his web site, as here
every information is quality based material.
Akazino palīdzēs atrast vislabāko Latvijas online kazino un kliedēs visas šaubas, sniedzot informāciju par drošību, spēļu daudzveidību un kazino bonusiem.
my blog … online kazino appk
Wow, this paragraph is pleasant, my younger sister is analyzing these things, therefore I am going to
let know her.
I am in fact pleased to glance at this blog posts which carries plenty of valuable
data, thanks for providing these statistics.
Havе you ever considered about adding a little bit morе
than just yoսr artіcles? I meаn, what you sayy is fundamental
andd all. Nevеrtһelss imagine if уou added some great photos or videos to give your posts more, “pop”!
Your ontent iis excellent but with images and clips, this blog could undeniably be one of the very best in its field.
Wonderful blog!
My brother suggested I might like this website. He was entirely right.
This post truly made my day. You can not imagine just how much time I had spent for this info!
Thanks!
Hello there! This is my first visit to your blog!
We are a team of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us valuable information to work on. You
have done a outstanding job!
Wonderful beat ! I wish to apprentice while you amend your
website, how can i subscribe for a blog web site?
The account helped me a acceptable deal. I had been a
little bit acquainted of this your broadcast offered bright clear concept
А model who claims tto һave the biggest lips іn tһe UK hɑs noᴡ flown tߋ
Turkiey to undergo an XXL boob job.
Onlyfans model Soia Lips, 27, fгom Manchester һas spent more than £500,000 on extreme surgeries,increasing tһe size of һeг pout
evry two months.
Noow the influencer hаs ɑdded spent another £10,000 on her tһird breast surgery іn an attempt to go as ⅼarge aѕ posѕible.
Sharing hher neԝest transformation ᧐n Instagram, ѕhe hɑѕ gained over 27,300 adoring fopllowers eager tо watch һerr journey.
‘Ι flew to Turkey foг the surgery wheге they gave
me 1050cⅽ implants. They are the biggest silicone implants
tһey make. I аbsolutely love them.
Sofia fіrst went to increase her pout, which iѕ thоught tօ be the biggest set of
lips in BRITAIN
Вut now thе onlyfans – Anthony – model is sеt on augmenting her chest, keen to
ⅼook ⅼike a ‘bimbo f*** doll’
‘Ӏ want to look likе thе ultimate bimbo f*** doll’.
Under tһe knife for two һours, Sofia stаyed in Turkey for tһree dɑys to recover, woth zero complications.
Sһe sаid: ‘I love ƅeing able t᧐ change whatever Ӏ don’t liқe about myself and ƅe my own creation.
‘I’ve allways wanted oversized bokbs аnd ɑ huge bum tto match, likе the bimbo fake ⅼook.
‘Having the biggest lips іn thе UK is only a title wһіch was given to me, ƅut I love having them – ɑnd
now І want the biggest lips іn tһе ԝorld.
‘This is mʏ third boob job, іn а feѡ yesars Ӏ will be gօing even bigger using expanders.
І’vе also һad a nose job, а hair transplant, liposuction,
аnd a BBL.
Dеspite her newezt procedure, Sofia һɑs no plans too stoρ her modification journey.
‘Ι stopped counting ʏears ago [about how much filler I have] ⅾue to my extreme look, bᥙt Ӏ
ensure tօ keep going Ьack foг regular fіll-ups and
sometimes fiⅼl myself.
‘I don’t reɑlly think over any procedues and І rarely һave аny concerns.
Ϝor now mү boobs are perfect and ɑlready bringing in tonnes of money’.
Sofia flew tо Turkey to ɡеt hеr 1050cc implants
fitted – tһe largest size tһey mɑke
Undеr the knife fοr twwo hоurs, Sofia ѕtayed in Turkey for three ɗays to
recover, wіth zero complications
Speaking of hеr significantly full pout, sһe explained:
‘My lips ɑre the biggest and m᧐st full tһey hɑve
eᴠer ƅeen’
Speaking оf her significantly fulⅼ pout, she explained: ‘Ꮇy lips ɑre the biggest аnd most full they have еѵer been.
‘I add to my lips every two mоnths and Ι’ve spent £50,000 on my lips
ɑlone.
‘Τhey arе the biggest lips in tһe UK and I’ve actualⅼʏ bееn approahed
Ƅy Guinness Woгld Records tо go to Milan іn 2024 to make it
official.
Shе added that ѕhe haѕ a lоt of fans who request footaged օf the process of hаving fillers.
‘Ι enjoy it to keeρ them hɑppy and get paid for іt,’ she saіd.
Sofia ѕays sһe ‘enjoys heг life’ and’haѕ paid for іt’
Tһe influencer has seemingly become obsessed with plastic surgery, and intends
to stretch out heer pout as fаr as humanly ρossible
Ⴝһe has alѕⲟ replaced hеr weekly ѕսn bed routine ԝith £500
tznning injections іn order tto darken һеr skin.
The influencer һas seemingly ƅecome obsessed witһ plastic surgery, and intends tо stretch oᥙt her pout as far as humanly possiЬⅼe.
As well as her infamous lips, Sofia hass ɑlso thee boobs jobs, a hair transplant, liposuction and a nosde
job, with thе operations costinmg a whopping £500,000 plus in total.
She has als᧐ replaced her weekjly sun bed routine ᴡith
£500 tanning injections іn order to darrken her skin.
Sofia ɑdded: ‘I also ցet Botox аnd my cheeks done оften Ƅecause іt’ѕ
expensive tο ɡet thhe extreme rеsults I
love.
ach enormous proportions.
OnlyFansTurkeyManchesterInstagram
I truly love your blog.. Pleasant colors & theme.
Did you create this website yourself? Please reply back as I’m trying
to create my own personal blog and want to learn where you got this from or just what the theme
is named. Kudos!
Peculiar article, exactly what I was looking for.
Today, I went to the beach with my kids.
I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.”
She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
I’m not that much of a online reader to be honest
but your sites really nice, keep it up! I’ll go ahead and bookmark your website to come back later.
Cheers
Hey very interesting blog!
Great article.
My partner and I stumbled over here by a different
web address and thought I might as well check things out.
I like what I see so now i am following you. Look forward to going over
your web page again.
It is really a great and useful piece of info. I’m happy
that you just shared this useful info with us.
Please keep us up to date like this. Thanks for sharing.
Excellent goods from you, man. I have understand your
stuff previous to and you’re just too excellent.
I actually like what you’ve acquired here, really like what you’re stating and the
way in which you say it. You make it entertaining and you still care for to keep it
sensible. I cant wait to read far more from you. This is really a wonderful website.
Some North Las Vegas car insurance insurance coverage supply extras like kerbside aid.
Think about if these benefits are worth the extra cost.
Howdy! This is kind of off topic but I need some guidance from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure
where to start. Do you have any ideas or suggestions?
Thank you
Since the admin of this web site is working, no question very
quickly it will be renowned, due to its quality contents.
You have made some good points there. I checked on the internet to learn more about the issue and found
most people will go along with your views on this web site.
Hello! This is kind of off topic but I need some help from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure
where to start. Do you have any tips or suggestions?
Thanks
Usually I don’t read post on blogs, but I wish to
say that this write-up very pressured me to check out and
do it! Your writing taste has been amazed me. Thanks, very nice article.
Hi, I log on to your blog like every week.
Your writing style is witty, keep doing what you’re doing!
Nice blog here! Also your website loads up very fast!
What web host are you using? Can I get your affiliate
link to your host? I wish my website loaded up as fast as yours lol
What’s up, I wish for to subscribe for this web site
to take latest updates, thus where can i do it please help out.
Hello my friend! I want to say that this article is amazing, great written and come with
approximately all vital infos. I would like to see more posts like this .
Someone essentially assist to make seriously articles I would state.
That is the first time I frequented your web page and
so far? I surprised with the research you made to create this particular
post extraordinary. Excellent activity!
Wonderful, what a web site it is! This weblog provides valuable information to
us, keep it up.
Right away I am ready to do my breakfast, afterward having my breakfast coming yet again to
read more news.
you are really a excellent webmaster. The website
loading velocity is incredible. It kind of feels that you are
doing any distinctive trick. In addition, The contents are masterpiece.
you’ve done a fantastic job in this topic!
Do you have a spam issue on this website; I also am a blogger,
and I was wanting to know your situation; we have created some nice
methods and we are looking to trade strategies with others, please shoot me an email if interested.
With havin so much content do you ever run into any issues of plagorism or copyright
infringement? My site has a lot of unique content I’ve either authored myself or
outsourced but it looks like a lot of it is popping it up all over the web without my agreement.
Do you know any techniques to help stop content from being stolen? I’d definitely appreciate it.
This article is truly a fastidious one it assists new net users, who are wishing
in favor of blogging.
Hello, after reading this amazing piece of writing i am also glad to share my know-how here with friends.
You made some really good points there. I checked on the
internet to learn more about the issue and found most individuals will go along with your views on this website.
Hello, yes this post is really good and I have learned lot of things from it regarding blogging.
thanks.
I absolutely love your site.. Very nice colors & theme.
Did you develop this website yourself? Please reply
back as I’m wanting to create my own personal site and would like to find out where you got this from or just what the theme is named.
Cheers!
It’s a pity you don’t have a donate button! I’d definitely donate to this outstanding
blog! I guess for now i’ll settle for book-marking and adding your RSS
feed to my Google account. I look forward to brand new updates and will talk about this site
with my Facebook group. Chat soon!
When I originally commented I seem to have clicked on the
-Notify me when new comments are added- checkbox and from now on every
time a comment is added I get four emails with the same
comment. There has to be an easy method you are able to remove me from that service?
Thanks!
It’s in reality a great and helpful piece of information.
I’m satisfied that you simply shared this useful information with
us. Please stay us up to date like this. Thanks
for sharing.
It is really a nice and helpful piece of info. I’m happy
that you simply shared this useful information with us.
Please keep us up to date like this. Thanks for sharing.
You should be a part of a contest for one of the best
websites on the internet. I will highly recommend this blog!
Magnificent goods from you, man. I have understand your stuff
previous to and you are just extremely fantastic.
I actually like what you have acquired here, certainly like what you are saying and
the way in which you say it. You make it enjoyable and
you still take care of to keep it smart. I can not wait to
read much more from you. This is actually a great web site.
This article will help the internet users for setting up new blog or even a blog from start to end.
Wow, this paragraph is pleasant, my sister is analyzing these things, so I am going to convey her.
Great beat ! I would like to apprentice at the same time as
you amend your site, how could i subscribe for a blog web site?
The account aided me a applicable deal. I had been tiny bit familiar of this your broadcast provided shiny clear concept
I blog frequently and I truly appreciate your content.
Your article has truly peaked my interest.
I’m going to take a note of your website and keep checking for new information about
once a week. I opted in for your Feed as well.
Hey! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Any suggestions?
I for all time emailed this website post page to all my contacts, for the reason that if like to read
it afterward my friends will too.
naturally like your website however you need to take a look
at the spelling on several of your posts. A number of them are rife with spelling problems and I find it
very bothersome to tell the truth then again I will certainly come again again.
Hey there! I know this is kinda off topic but I was wondering which blog
platform are you using for this site? I’m getting sick and tired of WordPress because I’ve had problems with hackers and I’m
looking at alternatives for another platform.
I would be great if you could point me in the direction of a good platform.
For most recent information you have to go to see web and on web I found this
website as a most excellent web page for newest
updates.
Spot on with this write-up, I honestly feel this web site needs a great deal more attention. I’ll probably be back again to read more, thanks for the advice!
Thanks in support of sharing such a pleasant thinking, piece of writing is
good, thats why i have read it entirely
This info is worth everyone’s attention. Where can I find out more?
Greetings! Very useful advice in this particular article!
It’s the little changes that will make the greatest changes.
Many thanks for sharing!
I’m not sure exactly why but this web site is loading extremely slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later and see if the problem still exists.
Thanks in favor of sharing such a nice thinking, post is
good, thats why i have read it entirely
Hi it’s me, I am also visiting this site on a regular basis,
this site is actually good and the viewers are genuinely sharing fastidious thoughts.
I’m not that much of a online reader to be honest but your sites really nice, keep
it up! I’ll go ahead and bookmark your website to come
back in the future. Many thanks
Every weekend i used to pay a visit this site,
for the reason that i want enjoyment, as this this website conations truly good
funny material too.
I was suggested this blog by my cousin. I’m not sure whether this post
is written by him as nobody else know such detailed about
my trouble. You are wonderful! Thanks!
Pretty! This was an extremely wonderful article.
Thank you for providing these details.
Please let me know if you’re looking for a article author for
your weblog. You have some really good posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a link back to
mine. Please blast me an email if interested.
Regards!
Whats up very cool site!! Guy .. Beautiful .. Amazing ..
I will bookmark your website and take the feeds also?
I am glad to seek out numerous useful information right here within the post,
we’d like develop extra strategies in this regard, thank you for sharing.
. . . . .
It’s awesome for me to have a website, which is good designed for my knowledge.
thanks admin
It’s an awesome piece of writing for all the internet users; they will obtain benefit from it I
am sure.
Does your site have a contact page? I’m having a tough time
locating it but, I’d like to shoot you an email.
I’ve got some ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it
improve over time.
Hi this is kinda of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding knowledge so I wanted to get guidance
from someone with experience. Any help would be greatly appreciated!
I got this website from my pal who told me on the topic of this web site
and at the moment this time I am browsing this website and reading very informative articles here.
Spot on with this write-up, I absolutely believe that this amazing site needs far more attention. I’ll probably be returning
to read more, thanks for the information!
I every time spent my half an hour to read this
webpage’s posts every day along with a cup of coffee.
Hi! I’m at work browsing your blog from my new iphone 3gs!
Just wanted to say I love reading through your blog and look forward to all your posts!
Carry on the superb work!
Asking questions are genuinely fastidious thing
if you are not understanding something entirely,
except this piece of writing provides pleasant understanding yet.
I will right away grab your rss as I can’t to find your
e-mail subscription link or e-newsletter service. Do you’ve any?
Please allow me understand so that I could subscribe.
Thanks.
Have you ever considered publishing an ebook or guest authoring on other
blogs? I have a blog based on the same topics you discuss and would love to
have you share some stories/information. I know my viewers would value
your work. If you are even remotely interested,
feel free to shoot me an e-mail.
Why viewers still use to read news papers when in this technological globe the
whole thing is available on net?
I always used to study post in news papers but now as I am a
user of net so from now I am using net for posts, thanks to
web.
It’s truly a nice and helpful piece of information. I’m glad that you simply shared this
helpful info with us. Please stay us up to date like this.
Thanks for sharing.
Appreciate this post. Let me try it out.
Howdy! Would you mind if I share your blog with my facebook group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Thanks
You should take part in a contest for one of the finest sites on the web.
I’m going to recommend this site!
Hi there! This is my first comment here so I just wanted
to give a quick shout out and tell you I really enjoy reading
your posts. Can you suggest any other blogs/websites/forums that go over the
same topics? Thank you!
Ι just like the helpful informatiоn you supply to our ɑrticles.
I’ⅼl bookmark ʏour bloɡ annd takke a look ɑt aɡain hhere frequently.
I am reasonably certain I’ll be told lots οf new stuff proper right herе!
Good luck for the next!
whoah this blog is great i love studying your posts. Keep
up the great work! You realize, a lot of persons are looking around for this
information, you can aid them greatly.
Also visit my web site – low quality vitamins
Hi there, just wanted to mention, I loved this blog post.
It was practical. Keep on posting!
It’s in fact very complicated in this busy life to listen news on TV,
thus I only use world wide web for that reason, and obtain the most up-to-date
information.
I’ll immediately seize your rss as I can’t in finding your e-mail subscription link or e-newsletter service.
Do you have any? Please permit me know so that I could subscribe.
Thanks.
my web page :: 반셀프 인테리어
Great article.
Thanks a bunch for sharing this with all people you really understand what you are
talking approximately! Bookmarked. Please also consult with my site =).
We will have a hyperlink alternate arrangement among us
I seriously love your website.. Excellent colors & theme. Did you develop this amazing site
yourself? Please reply back as I’m hoping to create my own personal blog
and want to find out where you got this from or what the theme is called.
Thank you!
I blog frequently and I seriously appreciate your content.
This article has truly peaked my interest. I will bookmark your site and keep checking for
new information about once per week. I subscribed to your RSS feed as
well.
Piece of writing writing is also a excitement, if you know then you can write or else it is difficult to write.
Wow that was unusual. I just wrote an very long comment but after I clicked submit my
comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyway, just wanted to say wonderful
blog!
Hi, Neat post. There is a problem along with your site in web explorer, would test this?
IE nonetheless is the marketplace chief and a good component of people will pass over your fantastic writing due to this problem.
Hi! I could have sworn I’ve been to your blog before but after browsing through some of the articles I realized it’s new to me.
Anyhow, I’m definitely pleased I found it and I’ll be
bookmarking it and checking back regularly!
Hello, yup this article is genuinely pleasant and I have learned lot of things from it on the topic of blogging.
thanks.
Yes! Finally someone writes about radar 138.
Keep this going please, great job!
Great beat ! I would like to apprentice even as you amend your website,
how could i subscribe for a blog website? The account aided me a acceptable deal.
I had been tiny bit familiar of this your broadcast offered shiny transparent idea
In the Midst of the elaborate structure of contemporary living, where convenience and ease hold sway,
one often overlooks the uncelebrated heroes assuring
our homes run smoothly—the qualified plumbers. These skillful professionals play a critical role in maintaining the completeness
of our plumbing systems, shielding us from probable disasters and guaranteeing the flawless flow of water in our daily lives.
Plumbers are not merely fixers of leaks and uncloggers of drains; they are the
unsung heroes of our domestic realm, dealing with issues that, if neglected, could disturb our homes and daily routines.
Stop by my page – Lithuanian Casino
You really make it seem so easy with your presentation but I find this topic to be really something that I think I
would never understand. It seems too complicated and extremely broad for me.
I am looking forward for your next post, I’ll try to get
the hang of it!
You’ve made some good points there. I looked on the web to find out more about
the issue and found most people will go along with your views on this website.
I’m gone to convey my little brother, that he should also visit this blog on regular basis to get updated from newest news update.
I every time emailed this web site post page to all my friends, as
if like to read it after that my contacts will too.
Hiya! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa?
My website addresses a lot of the same subjects as yours
and I feel we could greatly benefit from each other.
If you happen to be interested feel free to send me an e-mail.
I look forward to hearing from you! Great blog by the way!
It’s very simple to find out any topic on web as
compared to books, as I found this paragraph at this website.
Hi there! I just wanted to ask if you ever have any problems with
hackers? My last blog (wordpress) was hacked and I ended up losing
months of hard work due to no backup. Do you have any methods to protect against hackers?
Thanks to my father who informed me about this blog, this webpage is
genuinely remarkable.
What’s Going down i am new to this, I stumbled upon this I’ve discovered It positively useful and it
has helped me out loads. I hope to contribute & assist other customers like its helped me.
Good job.
Quality articles is the important to interest the viewers to pay a quick visit the web page, that’s what this
web page is providing.
It is perfect time to make a few plans for the future and it’s time to be
happy. I’ve read this post and if I may I desire to suggest you few fascinating things or tips.
Perhaps you could write subsequent articles regarding this article.
I wish to read even more things approximately it!
My blog post :: comment-414742
Hey would you mind sharing which blog platform you’re working with?
I’m going to start my own blog in the near future but I’m having a hard time selecting
between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your layout seems
different then most blogs and I’m looking for something unique.
P.S Apologies for being off-topic but I had to
ask!
Wonderful work! That is the type of information that are supposed to be shared around the web.
Disgrace on Google for now not positioning this put up higher!
Come on over and seek advice from my web site .
Thanks =)
After I originally commented I appear to have clicked on the -Notify me when new comments are added- checkbox and now whenever a
comment is added I recieve 4 emails with the same comment.
There has to be a means you can remove me from that service?
Thank you!
I do not even know how I finished up right here, but
I assumed this post was great. I don’t recognise who you’re however certainly you are going to a famous blogger in case you are not already.
Cheers!
Whats up are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and set up my own. Do you require
any html coding knowledge to make your own blog? Any help would be greatly
appreciated!
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something.
I think that you could do with some pics to drive the message home a bit, but other than that,
this is magnificent blog. A fantastic read. I’ll certainly be back.
With havin so much content and articles do you ever run into any issues of
plagorism or copyright infringement? My site has a lot
of exclusive content I’ve either authored myself or outsourced but it appears a lot of it is
popping it up all over the web without my permission. Do you know any solutions to help prevent content from being
ripped off? I’d truly appreciate it.
Hi there, every time i used to check blog posts here in the early hours in the dawn, as i like to gain knowledge of more and more.
Good post. I learn something new and challenging on websites I stumbleupon everyday.
It will always be exciting to read content from other authors and use
something from their web sites.
Heya i’m for the first time here. I came across this board and
I in finding It truly useful & it helped me out much.
I am hoping to offer something back and aid
others like you helped me.
This paragraph is genuinely a fastidious one it assists new internet visitors, who are wishing for blogging.
Greetings! I know this is somewhat off topic but I was
wondering which blog platform are you using for this
site? I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking at options
for another platform. I would be awesome if you could point me in the direction of a good platform.
Hello colleagues, its fantastic piece of writing
on the topic of educationand fully defined, keep
it up all the time.
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your weblog?
My blog is in the very same niche as yours and my visitors
would truly benefit from some of the information you provide here.
Please let me know if this alright with you. Thanks a lot!
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However, how can we communicate?
What i do not realize is in fact how you’re now not really much more
smartly-preferred than you may be right now. You are so intelligent.
You realize thus significantly on the subject of
this matter, made me in my view believe it from
numerous numerous angles. Its like women and men don’t seem to be
involved until it’s one thing to accomplish with Lady
gaga! Your individual stuffs outstanding. All the time
take care of it up!
Appreciate the recommendation. Will try it out.
Way cool! Some extremely valid points! I appreciate you writing this article and
the rest of the site is really good.
I am in fact grateful to the holder of this site who has shared this fantastic paragraph at here.
At this time it looks like BlogEngine is the top blogging platform available right now.
(from what I’ve read) Is that what you are using on your
blog?
It’s a pity you don’t have a donate button! I’d most certainly
donate to this fantastic blog! I guess for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to brand new updates and will talk about this website with my Facebook group.
Chat soon!
you are in point of fact a excellent webmaster. The website loading velocity is
incredible. It seems that you are doing any distinctive trick.
Furthermore, The contents are masterwork. you’ve done a magnificent activity in this topic!
Here is my webpage What is the joke in ‘Sidney Applebaum’ on SNL?
Paragraph writing is also a fun, if you be acquainted with then you
can write if not it is complicated to write.
I know this website provides quality depending articles or reviews and additional
stuff, is there any other website which offers such stuff in quality?
I read this post completely regarding the difference of latest and preceding technologies, it’s remarkable article.
Hi, Neat post. There’s an issue with your site in internet explorer, would check this?
IE still is the marketplace chief and a big part of
folks will leave out your fantastic writing due to this problem.
Heya! I just wanted to ask if you ever have any problems
with hackers? My last blog (wordpress) was hacked and I ended up losing a few months of hard work
due to no back up. Do you have any methods to stop hackers?
This is a topic which is close to my heart… Many thanks!
Where are your contact details though?
Hello there, just became aware of your blog through Google,
and found that it is really informative. I’m gonna watch out for
brussels. I will be grateful if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
Hello There. I found your blog the use of msn. This is an extremely neatly written article.
I’ll be sure to bookmark it and come back to learn more of your helpful information. Thank you for the post.
I’ll definitely comeback.
Every weekend i used to pay a visit this website, because i
want enjoyment, as this this web site conations actually fastidious funny
information too.
Hmm it looks like your website ate my first comment (it was super long)
so I guess I’ll just sum it up what I submitted and say,
I’m thoroughly enjoying your blog. I too am an aspiring blog blogger but I’m still new to the whole thing.
Do you have any tips and hints for beginner blog writers?
I’d definitely appreciate it.
It’s an awesome piece of writing in favor of all the
internet visitors; they will obtain advantage
from it I am sure.
First off I want to say excellent blog! I had a quick question which
I’d like to ask if you do not mind. I was interested
to know how you center yourself and clear your mind before writing.
I’ve had a difficult time clearing my thoughts in getting my ideas out.
I do enjoy writing however it just seems like the first 10 to 15 minutes are wasted simply just trying to figure out how to begin.
Any suggestions or hints? Many thanks!
Genuinely when someone doesn’t know afterward its up to other visitors that they will help,
so here it takes place.
Fascinating blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple adjustements would
really make my blog stand out. Please let me know where you got your design. With thanks
Howdy, i read your blog from time to time and i own a similar one and i was just curious if you get a lot of spam remarks?
If so how do you stop it, any plugin or anything you can advise?
I get so much lately it’s driving me mad so any support is very much appreciated.
Heya i’m for the first time here. I found this board and I find It truly
useful & it helped me out much. I hope to give something back and
aid others like you aided me.
It’s hard to find educated people about this topic,
however, you seem like you know what you’re talking about!
Thanks
Hi there friends, how is the whole thing, and what you desire
to say regarding this paragraph, in my view its really amazing designed for
me.
I’ll immediately snatch your rss as I can not find your email
subscription hyperlink or e-newsletter service.
Do you’ve any? Kindly let me understand so that I may just subscribe.
Thanks.
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is fundamental and all. However think of if you
added some great graphics or video clips to give your posts more, “pop”!
Your content is excellent but with images and clips, this site could certainly be one
of the most beneficial in its niche. Amazing blog!
I’ve been surfing on-line more than 3 hours these days, yet I by no
means found any fascinating article like yours. It’s beautiful
worth enough for me. In my view, if all site owners and bloggers made good content material as you
probably did, the net will probably be a lot more
helpful than ever before.
My family members all the time say that I am
killing my time here at web, however I know I am getting know-how everyday by reading such fastidious content.
Heya i’m for the first time here. I came across this board and I find It
truly useful & it helped me out a lot. I hope to give something
back and help others like you helped me.
whoah this weblog is great i really like studying your posts.
Keep up the good work! You realize, many individuals are searching around for this information, you could aid them greatly.
Hi friends, how is all, and what you would like to say on the topic of this piece of
writing, in my view its really remarkable in favor of me.
I have read so many content about the blogger lovers however this paragraph is actually a
pleasant article, keep it up.
Appreciate the recommendation. Let me try it out.
Great article! We will be linking to this great article on our site.
Keep up the great writing.
I used to be recommended this website by means of my cousin. I am not positive whether or not this put up
is written by way of him as no one else realize such certain approximately my trouble.
You are amazing! Thank you!
We are a group of volunteers and starting a new scheme in our community.
Your web site provided us with valuable information to work on.
You’ve done a formidable job and our whole community will be grateful to you.
My programmer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on numerous websites
for about a year and am anxious about switching to
another platform. I have heard very good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be really appreciated!
Excellent beat ! I wish to apprentice even as you amend
your site, how can i subscribe for a weblog web site?
The account helped me a applicable deal. I have been a little
bit familiar of this your broadcast provided bright transparent idea
I will immediately snatch your rss feed as I can’t find your e-mail subscription link or newsletter
service. Do you’ve any? Please allow me realize so that I could subscribe.
Thanks.
Wow, superb blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is
great, as well as the content!
What’s Happening i am new to this, I stumbled upon this I have discovered It absolutely useful and it has helped me
out loads. I’m hoping to contribute & assist different customers like its helped me.
Good job.
Fantastic site you have here but I was wanting to know if you
knew of any user discussion forums that cover the same topics talked
about in this article? I’d really love to be a part of online community where I can get opinions from other experienced people that share the same interest.
If you have any suggestions, please let me know. Thanks a lot!
of course like your website however you need to test the spelling
on several of your posts. Several of them are rife with spelling problems and I find it
very bothersome to tell the truth on the other hand I’ll certainly come back again.
This site really has all of the info I needed concerning this subject and didn’t know who to ask.
I think the admin of this web site is really working hard in support of his web page, since here every data is quality based information.
We’re a group of volunteers and opening a brand new scheme in our community.
Your site offered us with valuable info to work on. You have done an impressive process and our whole group will probably be thankful to you.
Here is my website :: herpesyl reviews
Vēlies spēlēt labākajos online kazino Latvijā un iegūt lieliskus bonusus?
Kazino Karalī Jūs atradīsiet jaunāko licencēto online kazino apskatus, ekskluzīvus
bonusu piedāvājumus, bezmaksas griezienus un citas jaunākās aktualitātes kazino pasaulē.
Also visit my website: Free Casino App
Thanks for finally talking about > Пиастры – Составление семантического ядра | < Liked it!
It is not my first time to go to see this web site, i am visiting this site dailly and get fastidious data from here all
the time.
Terrific work! That is the type of info that are meant to be shared across the internet.
Disgrace on the seek engines for no longer positioning this publish higher!
Come on over and seek advice from my website . Thanks =)
Oh my goodness! Awesome article dude! Many thanks, However I am having problems
with your RSS. I don’t know the reason why I am unable to subscribe to it.
Is there anybody else having similar RSS problems?
Anyone that knows the answer will you kindly respond?
Thanks!!
I am sure this piece of writing has touched all the internet
users, its really really good paragraph on building up new website.
Very nice article, totally what I wanted to find.
This article offers clear idea designed for the new viewers of blogging, that
genuinely how to do running a blog.
This is very interesting, You are a very skilled blogger.
I have joined your feed and stay up for in search of extra of your excellent post.
Also, I’ve shared your website in my social networks
Your mode of describing the whole thing in this post is truly nice, every
one be capable of simply understand it, Thanks a lot.
This site was… how do I say it? Relevant!! Finally I’ve found something that helped me.
Cheers!
When I initially left a comment I seem to have clicked the -Notify me when new comments are added- checkbox and now every time a
comment is added I get 4 emails with the exact same comment.
Perhaps there is a means you are able to remove me from that service?
Thanks!
Hello, i feel that i saw you visited my weblog so i got here to return the want?.I am attempting to
to find things to enhance my web site!I assume its
good enough to use some of your ideas!!
I like the valuable information you provide in your articles.
I’ll bookmark your weblog and check again here frequently.
I’m quite certain I will learn lots of new stuff right here!
Best of luck for the next!
Yes! Finally someone writes about https://twitter.com/hitclubapk2.
Vēlies spēlēt labākajos online kazino Latvijā un iegūt lieliskus bonusus?
Kazino Karalī Jūs atradīsiet jaunāko licencēto online kazino apskatus, ekskluzīvus
bonusu piedāvājumus, bezmaksas griezienus un citas
jaunākās aktualitātes kazino pasaulē.
Here is my blog post :: Gay Club
I just could not depart your web site before suggesting that I extremely loved
the usual info a person supply on your visitors?
Is gonna be back continuously in order to check up on new posts
Feel free to surf to my web site; address
Hey there! This is my 1st comment here so I just wanted to give a quick
shout out and say I truly enjoy reading your articles.
Can you suggest any other blogs/websites/forums that cover the same topics?
Thank you so much!
Hi, i believe that i saw you visited my blog so
i got here to return the prefer?.I am trying to to
find things to enhance my site!I assume its good enough
to use a few of your ideas!!
When some one searches for his necessary thing, thus he/she wants to be available that in detail,
therefore that thing is maintained over here.
If you would like to improve your know-how simply keep visiting this website and be updated with
the hottest information posted here.
I am actually pleased to glance at this weblog posts which
carries tons of helpful data, thanks for providing these
kinds of information.
Hi there mates, nice article and pleasant urging commented at this place, I am genuinely enjoying by these.
In fact when someone doesn’t understand then its up to other people that they will assist, so here it occurs.
That is a really good tip especially to those new to the blogosphere.
Simple but very accurate information… Thank you
for sharing this one. A must read article!
whoah this weblog is fantastic i love reading your posts.
Keep up the great work! You recognize, a lot of persons
are searching around for this information, you could
aid them greatly.
Hi, I do think this is a great website. I stumbledupon it ;
) I’m going to revisit yet again since i have bookmarked it.
Money and freedom is the greatest way to change, may you be rich and continue to help other people.
Thanks , I have recently been looking for information approximately this subject for ages and yours is the best I’ve found out till now.
However, what in regards to the bottom line? Are you
certain in regards to the supply?
I don’t even understand how I finished up here, however I thought this put up was great.
I don’t recognize who you are however definitely you are going to
a famous blogger in case you are not already. Cheers!
It’s perfect time to make some plans for the future and
it is time to be happy. I have read this post and if I could I wish to suggest you
some interesting things or suggestions. Maybe you could write next articles
referring to this article. I wish to read even more things about it!
Hi to every one, for the reason that I am genuinely eager of reading this blog’s post to
be updated on a regular basis. It contains pleasant material.
Thanks for sharing your thoughts about love.
Regards
It is not my first time to pay a visit this web
site, i am browsing this web site dailly and obtain fastidious facts from here all the
time.
Hi there just wanted to give you a quick heads up.
The words in your post seem to be running off the screen in Safari.
I’m not sure if this is a format issue or something to do with web browser compatibility but I figured I’d post to
let you know. The design look great though! Hope you get the problem
fixed soon. Many thanks
hey there and thank you for your info – I have definitely picked
up anything new from right here. I did however
expertise a few technical issues using this website, as I experienced
to reload the web site many times previous to I could get it to load correctly.
I had been wondering if your web host is OK? Not that I am complaining, but sluggish loading instances times will
often affect your placement in google and can damage your quality score if
advertising and marketing with Adwords. Anyway I’m adding this RSS to my
e-mail and could look out for a lot more of your respective intriguing content.
Make sure you update this again very soon.
It’s amazing to visit this web site and reading the views
of all colleagues about this article, while I am also eager of getting know-how.
I’m amazed, I must say. Seldom do I come across a blog that’s equally educative and engaging, and let me tell
you, you’ve hit the nail on the head. The problem is something that not enough folks are speaking intelligently about.
Now i’m very happy that I stumbled across this during my hunt
for something regarding this.
Hello! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly? My site looks
weird when viewing from my apple iphone. I’m trying to find a template or plugin that might be
able to resolve this problem. If you have any suggestions, please share.
Thanks!
I have been surfing on-line greater than 3 hours nowadays, but I by
no means found any fascinating article like yours. It is lovely value sufficient
for me. In my opinion, if all website owners and bloggers made
good content as you did, the net might be much more useful than ever before.
Appreciate this post. Will try it out.
Its not my first time to visit this website, i am
browsing this web page dailly and take pleasant facts from here everyday.
Paragraph writing is also a excitement, if you be acquainted with afterward
you can write otherwise it is complicated to write.
It’s the best time to make a few plans for the long run and it is time to be happy.
I have read this post and if I may just I wish to recommend you few
attention-grabbing things or advice. Perhaps you can write next articles regarding this article.
I wish to learn more issues about it!
Just wish to say your article is as astonishing. The clarity to your submit is simply great and i can assume you
are knowledgeable on this subject. Fine with your permission allow me to snatch your RSS feed to
keep updated with coming near near post. Thank you one million and please keep up the enjoyable work.
This is the perfect site for anybody who wishes to understand this topic.
You know so much its almost hard to argue with you (not that
I really would want to…HaHa). You certainly put a
fresh spin on a topic that’s been discussed for decades.
Great stuff, just excellent!
Oh my goodness! Amazing article dude! Many thanks, However I am encountering problems with your RSS.
I don’t know why I am unable to subscribe to it. Is there anybody getting similar RSS issues?
Anyone who knows the answer will you kindly respond?
Thanks!!
I really like it when individuals come together and share
opinions. Great site, keep it up!
It’s going to be finish of mine day, except before ending I am
reading this impressive post to improve my know-how.
This design is wicked! You definitely know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!)
Great job. I really enjoyed what you had to say, and more than that, how you presented
it. Too cool!
Good information. Lucky me I came across your website by
chance (stumbleupon). I have book marked it for later!
I like reading through an article that will make people think.
Also, thank you for allowing me to comment!
Hi there, I discovered your website by means of Google whilst looking for a similar subject,
your website came up, it seems to be good. I have bookmarked it in my google bookmarks.
Hello there, simply was aware of your blog via Google, and found that
it’s really informative. I am gonna be careful for brussels.
I’ll appreciate if you continue this in future. A lot of people might be benefited from your
writing. Cheers!
I blog quite often and I truly appreciate your information. This great article has really peaked my
interest. I will book mark your website and keep checking for new information about once per week.
I subscribed to your Feed too.
I savour, lead to I found exactly what I used
to be having a look for. You’ve ended my 4 day lengthy hunt!
God Bless you man. Have a great day. Bye
My brother recommended I might like this web site.
He was totally right. This post actually made my day. You can not
imagine simply how much time I had spent for this info!
Thanks!
Aw, this was an incredibly nice post. Taking the time
and actual effort to create a superb article… but what can I say… I put things off a lot and never
seem to get anything done.
Remarkable! Its in fact remarkable paragraph, I have got much clear idea
regarding from this article.
Hi would you mind stating which blog platform you’re working with?
I’m planning to start my own blog soon but I’m having a
hard time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and
style seems different then most blogs and I’m looking for something unique.
P.S Apologies for being off-topic but I had to ask!
Excellent, what a webpage it is! This website provides useful data to
us, keep it up.
I want to to thank you for this great read!! I absolutely loved every bit of it.
I’ve got you book marked to look at new things you
post…
Greetings! Very helpful advice within this post!
It’s the little changes that produce the biggest changes.
Thanks a lot for sharing!
If you are going for most excellent contents like myself, just pay a quick visit this web page everyday for the reason that
it presents quality contents, thanks
Excellent way of explaining, and fastidious article to get information concerning my presentation topic, which i am
going to deliver in institution of higher education.
This post is invaluable. Where can I find out more?
Everything is very open with a precise explanation of the issues.
It was really informative. Your site is very helpful. Many
thanks for sharing!
Excellent post. I was checking continuously this weblog and I am inspired!
Extremely useful information particularly the final section I
I
take care of such info much. I used to be seeking this certain info for a very lengthy time.
Thank you and good luck.
First of all I want to say fantastic blog! I had a quick question which
I’d like to ask if you do not mind. I was curious to find out how you center yourself and clear your thoughts prior to writing.
I have had a hard time clearing my thoughts in getting my thoughts out.
I do enjoy writing but it just seems like the first 10 to
15 minutes are usually wasted just trying to figure out how to begin. Any ideas or
tips? Appreciate it!
Keep on working, great job!
I’m not sure exactly why but this site is loading incredibly slow for me.
Is anyone else having this problem or is it a
issue on my end? I’ll check back later on and see if the problem still exists.
I absolutely love your site.. Pleasant colors & theme.
Did you make this site yourself? Please reply back as I’m wanting
to create my own blog and would like to learn where you got this from or
what the theme is called. Thanks!
Ātrie kredīti Latvijā ir finansiālais risinājums, kas ļauj iegūt naudu īsā laikā, bieži vien vienas
dienas laikā vai pat dažu stundu laikā pēc pieteikuma iesniegšanas.
Šāda veida kredīti ir kļuvuši par populāru izvēli cilvēkiem,
kuriem steidzami nepieciešami līdzekļi neparedzētām izmaksām, piemēram, medicīniskiem
rēķiniem, automašīnas remontam vai citām ārkārtas situācijām.
My web page: atrie Krediti
I was very happy to discover this website. I need to to thank you for your time due
to this wonderful read!! I definitely liked every bit of it and I have you book-marked to
check out new things in your site.
Yesterday, while I was at work, my sister stole my iphone and
tested to see if it can survive a forty foot drop, just so she can be a youtube
sensation. My apple ipad is now broken and she has
83 views. I know this is completely off topic but I had to share it with someone!
Every weekend i used to visit this web site, for the reason that i want enjoyment, for the
reason that this this website conations in fact good funny data too.
For most up-to-date information you have to pay a quick visit world wide
web and on world-wide-web I found this web site as a best website
for most recent updates.
Hmm it appears like your site ate my first comment (it was super long) so I guess I’ll just sum
it up what I submitted and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog writer but I’m still new to the whole thing.
Do you have any tips and hints for rookie blog writers?
I’d really appreciate it.
Admiring the hard work you put into your website and detailed information you present.
It’s good to come across a blog every once
in a while that isn’t the same out of date
rehashed material. Fantastic read! I’ve saved your site and I’m
including your RSS feeds to my Google account.
I’m now not positive the place you’re getting your information, however good topic.
I needs to spend some time studying much more or understanding more.
Thanks for magnificent info I used to be looking for this info for my mission.
My developer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for about a year and am anxious
about switching to another platform. I have heard fantastic things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be greatly appreciated!
I have been browsing online more than 3 hours today, yet
I never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all webmasters and bloggers made good content as you
did, the net will be a lot more useful than ever before.
This design is steller! You most certainly know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Excellent job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
This paragraph is truly a good one it assists new web viewers,
who are wishing in favor of blogging.
Very nice post. I just stumbled upon your weblog and wanted to say that I’ve
really enjoyed surfing around your blog posts. After all I will be subscribing to your
rss feed and I hope you write again soon!
When someone writes an paragraph he/she retains the idea of a user in his/her mind
that how a user can be aware of it. Thus that’s why this piece of writing is perfect.
Thanks!
Link exchange is nothing else but it is just placing the other person’s website link on your
page at proper place and other person will also do similar in support of you.
I couldn’t resist commenting. Exceptionally well written!
Thanks for the marvelous posting! I genuinely enjoyed reading it, you may be a great
author. I will make certain to bookmark your blog and will often come back at some point.
I want to encourage you to continue your great posts, have a nice evening!
It is in reality a nice and useful piece of information. I’m happy that you shared this useful information with us.
Please stay us up to date like this. Thank you for sharing.
Good way of telling, and good paragraph to obtain information about my presentation topic, which i am going to present in college.
Its like you learn my mind! You seem to grasp a lot about this, like you wrote the ebook in it or something.
I feel that you just can do with some p.c.
to drive the message house a little bit, but instead of that, that is wonderful blog.
A great read. I will definitely be back.
Thanks for some other informative blog. Where else could
I get that kind of information written in such an ideal means?
I’ve a venture that I’m just now working on, and I’ve been at the glance out for such info.
An intriguing discussion is definitely worth comment. I think that
you ought to publish more on this subject, it may
not be a taboo subject but typically people don’t discuss
such subjects. To the next! Kind regards!!
Hi Dear, are you truly visiting this website regularly, if so afterward you will without doubt get fastidious experience.
Nice post. I learn something new and challenging on sites
I stumbleupon on a daily basis. It will always be
helpful to read through content from other authors and use something from other websites.
Hi, after reading this awesome paragraph i am as well happy to share my knowledge here with friends.
Hi, i think that i noticed you visited my blog thus i got here to
return the favor?.I’m trying to in finding things to enhance my website!I suppose its ok to make use of a few of your
ideas!!
This paragraph will assist the internet visitors for setting up new
webpage or even a blog from start to end.
For most recent information you have to pay a quick visit world-wide-web and on the web I found this website as a most excellent
web site for newest updates.
I used to be suggested this blog by way of my cousin. I’m not positive whether or
not this post is written by way of him as nobody else
understand such designated approximately my difficulty.
You are wonderful! Thank you!
Hi, its nice piece of writing regarding media print, we all be aware of media is a fantastic source of data.
Hey there! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have done
a wonderful job!
I have to thank you for the efforts you have put in writing this
site. I really hope to see the same high-grade blog posts from you later on as well.
In truth, your creative writing abilities has motivated me
to get my very own website now 😉
Hi, I do believe this is a great blog. I stumbledupon it 😉 I’m
going to revisit once again since I book-marked
it. Money and freedom is the best way to change, may you be rich and continue to guide others.
Very good site you have here but I was wanting to know
if you knew of any user discussion forums that cover the same topics talked about here?
I’d really love to be a part of community where I can get feedback from other experienced people that share the same interest.
If you have any recommendations, please let
me know. Thanks!
It’s actually a nice and useful piece of info. I’m glad that you shared this useful info with us.
Please keep us informed like this. Thanks for sharing.
Hi there i am kavin, its my first time to commenting anywhere,
when i read this paragraph i thought i could also
make comment due to this brilliant article.
Right here is the right site for anybody who hopes to
understand this topic. You know so much its almost tough to argue with you (not that I really will need to…HaHa).
You definitely put a fresh spin on a topic which has been written about for ages.
Great stuff, just great!
Outstanding quest there. What occurred after?
Thanks!
If some one desires to be updated with latest technologies after that he must
be pay a visit this website and be up to date everyday.
Normally I don’t learn post on blogs, but I would
like to say that this write-up very compelled me to try and do so!
Your writing style has been surprised me. Thanks, very nice article.
Its like you read my thoughts! You appear to understand so much approximately this,
such as you wrote the ebook in it or something. I think that you can do with a few % to pressure the message house
a little bit, however other than that, this is great blog.
An excellent read. I will certainly be back.
It’s going to be end of mine day, except before ending
I am reading this enormous piece of writing to increase my experience.
Howdy! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My website looks weird when viewing from my iphone.
I’m trying to find a theme or plugin that might be able to correct this problem.
If you have any recommendations, please share. With thanks!
My brother recommended I might like this web site. He was once totally right.
This put up truly made my day. You cann’t consider just how a lot time I had spent for this information! Thank you!
Heya i am for the primary time here. I found this board and I find
It really helpful & it helped me out a lot. I’m hoping
to offer something again and aid others like you aided me.
Hello, i think that i noticed you visited my blog so i got here to return the choose?.I’m trying to to find things to enhance my site!I assume its ok to
make use of a few of your concepts!!
Fastidious replies in return of this question with firm arguments and
describing all concerning that.
Superb blog you have here but I was curious if you knew of any forums
that cover the same topics discussed here? I’d really love to
be a part of community where I can get comments from other experienced individuals that share the same interest.
If you have any recommendations, please let me know.
Thanks!
Fantastic website you have here but I was curious if you knew of any forums that cover
the same topics talked about in this article?
I’d really like to be a part of group where I can get suggestions from other experienced people that share the same interest.
If you have any recommendations, please let me know. Kudos!
What’s up, for all time i used to check weblog posts
here in the early hours in the dawn, as i like to gain knowledge of more
and more.
Great delivery. Outstanding arguments. Keep up the good effort.
It’s truly a nice and useful piece of info. I’m glad that you shared this helpful information with
us. Please stay us up to date like this. Thanks for sharing.
First off I want to say great blog! I had a quick question which I’d like to ask if you do not mind.
I was curious to know how you center yourself and clear
your head prior to writing. I’ve had trouble clearing my thoughts in getting
my ideas out there. I truly do take pleasure in writing but it just seems like the first 10 to 15 minutes are
wasted just trying to figure out how to begin. Any ideas or hints?
Appreciate it!
Hey would you mind sharing which blog platform you’re using?
I’m looking to start my own blog in the near future but I’m having a difficult time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for
something unique. P.S Apologies for getting off-topic but I had
to ask!
Incredible quest there. What happened after?
Take care!
Admiring the hard work you put into your blog and detailed information you present.
It’s awesome to come across a blog every once in a while that isn’t the same
outdated rehashed information. Excellent read!
I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
Busty milf has some alone time with a vibrator when her stepdaughter walks in.She wants to learn how
to masturbate so asks her stepmom to teach her.
Free Porn, Sex, Tube Videos, XXX Pics, Pussy in Porno
…
XNXX delivers free sex movies and fast free porn videos
(tube porn). Now 10 million+ sex vids available for free!
Featuring hot pussy, sexy girls
my site; Pornhub Promo codes
I’m not sure exactly why but this web site is loading extremely
slow for me. Is anyone else having this issue or is it a problem on my end?
I’ll check back later on and see if the problem still exists.
Hi there! I simply wish to give you a huge thumbs up for the excellent
information you’ve got here on this post. I will be
returning to your web site for more soon.
Mtpolice.kr provides sports betting information, sports analysis,
and sports tips as a sports community.
Magnificent beat ! I wish to apprentice even as you amend your site, how could i subscribe for a weblog website?
The account aided me a applicable deal. I were tiny bit acquainted of this your broadcast provided vivid transparent idea
Everything is very open with a really clear clarification of
the issues. It was truly informative. Your site is very helpful.
Thanks for sharing!
Hi there! Do you know if they make any plugins
to help with Search Engine Optimization? I’m trying to get
my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Thanks!
Excellent post! We will be linking to this particularly great post on our site.
Keep up the great writing.
Thank you for the auspicious writeup. It in fact was once a enjoyment account
it. Look advanced to more added agreeable from you!
However, how could we communicate?
I believe this is among the most vital info for me.
And i am glad reading your article. But should commentary on few basic issues, The web site style is great, the articles is in point of fact excellent : D.
Just right job, cheers
Howdy this is kind of of off topic but I was wondering
if blogs use WYSIWYG editors or if you have to manually code
with HTML. I’m starting a blog soon but have no coding know-how so I
wanted to get advice from someone with experience.
Any help would be enormously appreciated!
What’s up, this weekend is fastidious designed for me, because this time i am reading this enormous informative piece of
writing here at my house.
Excellent post. I used to be checking continuously this weblog I take care of such info a lot. I
I take care of such info a lot. I
and I am inspired! Very useful info specially the
closing phase
used to be seeking this particular information for a very long time.
Thanks and good luck.
Wonderful article! We are linking to this particularly great post on our site.
Keep up the great writing.
Just want to say your article is as surprising. The clarity for your post is just nice and
that i could assume you are knowledgeable in this subject.
Well with your permission let me to seize your RSS feed to stay up to date with coming near near post.
Thank you 1,000,000 and please continue the enjoyable work.
Hi, i feel that i noticed you visited my web site so i got here to return the desire?.I’m attempting to in finding
things to improve my site!I assume its ok to use
some of your ideas!!
Its not my first time to pay a quick visit this web page,
i am browsing this site dailly and take nice information from here everyday.
Greate post. Keep writing such kind of info on your site.
Im really impressed by it.
Hello there, You’ve done a fantastic job. I’ll certainly digg it and in my opinion recommend to my friends.
I’m confident they will be benefited from this web site.
Thankfulness to my father who informed me about this web site, this webpage is truly amazing.
Awesome issues here. I am very happy to peer your article.
Thanks a lot and I am looking ahead to touch you. Will you kindly drop me a e-mail?
It’s perfect time to make a few plans for the future and
it’s time to be happy. I have read this put up and if I may I want to counsel you some interesting issues or
tips. Perhaps you could write next articles referring
to this article. I desire to read even more things about it!
I am extremely inspired along with your writing talents and
also with the layout to your blog. Is that this a paid theme or did you customize
it yourself? Either way stay up the excellent high quality writing, it’s uncommon to look
a nice weblog like this one these days..
bookmarked!!, I like your web site!
You have made some good points there. I looked on the web
for additional information about the issue and found most people will go along with your views
on this site.
Hello! I just would like to offer you a big thumbs up for your
excellent info you’ve got here on this post. I am returning to your blog for more soon.
Thanks for one’s marvelous posting! I actually enjoyed reading it,
you’re a great author.I will be sure to bookmark your blog and definitely will come back from now on. I want to encourage continue your great
writing, have a nice weekend!
What’s up friends, how is the whole thing, and what you desire
to say on the topic of this piece of writing,
in my view its in fact amazing for me.
Ƭһanks a lot for sharing this with all fⲟlks you actually understand what yօu arre talking about!
Bookmarked. Please additionally consult with
my website =). Wе mmay haνe a hyperlink change cntract among us
Hey there! This is my 1st comment here so I just wanted to give a quick shout out and tell you I genuinely enjoy reading through
your posts. Can you recommend any other blogs/websites/forums that deal with the same subjects?
Many thanks!
I’m not that much of a internet reader to be honest but your
sites really nice, keep it up! I’ll go ahead and bookmark
your website to come back later on. Cheers
Thanks for some other fantastic post. The place else could anyone get that kind of
information in such an ideal approach of writing? I have a presentation subsequent week, and
I am on the look for such information.
In fact no matter if someone doesn’t be aware of then its up to other people that they will assist, so here it occurs.
Just desire to say your article is as amazing.
The clearness on your put up is just cool and i
can assume you’re a professional in this
subject. Well with your permission let me to seize your
RSS feed to stay updated with drawing close post. Thanks
1,000,000 and please keep up the rewarding work.
Now I am going away to do my breakfast, when having my breakfast coming over again to read other news.
Hello there! This is my first comment here so I just wanted to give
a quick shout out and say I truly enjoy reading through your posts.
Can you recommend any other blogs/websites/forums that deal with the same
topics? Thank you so much!
my site – puravive price
This post is actually a good one it helps new the web
users, who are wishing for blogging.
Hi there, of course this piece of writing is truly pleasant and I have learned
lot of things from it on the topic of blogging.
thanks.
Have you ever considered creating an e-book or guest authoring on other websites?
I have a blog based on the same information you discuss
and would love to have you share some stories/information. I
know my visitors would enjoy your work. If you
are even remotely interested, feel free to shoot me an e
mail.
Saved as a favorite, I love your website!
It’s an amazing article designed for all the internet people; they will get advantage from it I am sure.
Hmm it seems like your site ate my first comment (it was super long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still new to the whole
thing. Do you have any recommendations for first-time blog writers?
I’d really appreciate it.
I’m gone to say to my little brother, that he should also
visit this weblog on regular basis to take
updated from most recent news.
Hi everyone, it’s my first pay a quick visit
at this website, and paragraph is actually
fruitful for me, keep up posting these articles
or reviews.
This is my first time go to see at here and i am really impressed to read everthing at
alone place.
These are truly impressive ideas in about blogging. You have
touched some pleasant factors here. Any way keep up wrinting.
Aw, this was an incredibly good post. Taking the time and actual effort
to make a great article… but what can I say… I
put things off a whole lot and never seem to get
nearly anything done.
Its not my first time to visit this web page, i am visiting this site dailly and obtain pleasant information from here all
the time.
Hello there! Would you mind if I share your blog with my
facebook group? There’s a lot of people that I think would really appreciate your
content. Please let me know. Many thanks
I love what you guys are up too. This type of clever work and reporting!
Keep up the excellent works guys I’ve incorporated you guys to my personal blogroll.
I just like the helpful information you supply to your
articles. I will bookmark your weblog and take a look at
once more right here regularly. I’m quite certain I
will be told a lot of new stuff right right
here! Good luck for the following!
Touche. Great arguments. Keep up the amazing effort.
Hey very nice blog!
Attractive section of content. I simply stumbled upon your blog and
in accession capital to say that I acquire actually loved account your
blog posts. Any way I’ll be subscribing for your feeds or even I success you get right of entry to constantly quickly.
I always emailed this website post page to all my contacts, since if like to read it next my
contacts will too.
Hi there mates, nice paragraph and good arguments commented here,
I am really enjoying by these.
This is a topic that’s near to my heart… Best wishes!
Where are your contact details though?
Hi! This post could not be written any better! Reading this post reminds me of my good old room mate!
He always kept chatting about this. I will forward
this write-up to him. Fairly certain he will have a good read.
Thanks for sharing!
You have made some decent points there. I checked on the internet
for more info about the issue and found most
individuals will go along with your views on this site.
Hi there, just wanted to say, I enjoyed this blog post.
It was helpful. Keep on posting!
Have you ever thought about adding a little bit more
than just your articles? I mean, what you say is fundamental and everything.
However imagine if you added some great visuals or video clips to give
your posts more, “pop”! Your content is excellent but with pics and clips, this site
could certainly be one of the most beneficial in its field.
Good blog!
Hello, after reading this amazing paragraph i am as well
cheerful to share my familiarity here with friends.
I am really delighted to read this website posts which contains tons
of valuable facts, thanks for providing these statistics.
I’m truly enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a developer to create your theme?
Superb work!
I was very happy to find this page. I need to to thank you for ones time
for this particularly fantastic read!! I definitely enjoyed every little bit of it and I have you book-marked to
see new things on your website.
I constantly spent my half an hour to read this blog’s posts daily along with a cup of coffee.
Admiring the time and effort you put into your blog and in depth information you
present. It’s awesome to come across a blog every once in a while that isn’t the same unwanted rehashed material.
Fantastic read! I’ve saved your site and I’m including your RSS
feeds to my Google account.
Quality posts is the important to be a focus for the viewers to pay a
visit the web page, that’s what this web page is providing.
Heya are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get
started and create my own. Do you need any html coding expertise to make your own blog?
Any help would be greatly appreciated!
I was suggested this blog by my cousin. I am not sure whether
this post is written by him as no one else know such detailed about
my difficulty. You’re wonderful! Thanks!
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is needed to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% sure. Any suggestions or advice would be greatly appreciated.
Thanks
Hello to all, the contents existing at this web page are genuinely
awesome for people knowledge, well, keep up the good work fellows.
Look into my web-site: facts about breathalyzers
Hi! This is kind of off topic but I need some help from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where to start.
Do you have any tips or suggestions? Thank you
Hello colleagues, its fantastic paragraph about
teachingand entirely explained, keep it up all the time.
Good post! We will be linking to this particularly great post on our
site. Keep up the great writing.
Wonderful work! This is the kind of information that are meant to be shared around the net.
Shame on the seek engines for no longer positioning this submit higher!
Come on over and consult with my site . Thank you =)
Fastidious replies in return of this question with
firm arguments and describing the whole thing about
that.
What’s up, I want to subscribe for this web site to obtain newest updates, therefore where can i do it
please help out.
I all the time used to study post in news papers but
now as I am a user of web so from now I am using net for posts, thanks
to web.
Thanks , I’ve just been searching for information about this
subject for a while and yours is the best I’ve found out till now.
But, what about the conclusion? Are you positive about the supply?
Simply wish to say your article is as surprising.
The clarity in your post is just cool and i could assume
you’re an expert on this subject. Fine with your permission let me to grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please carry on the enjoyable work.
When someone writes an post he/she retains the plan of
a user in his/her mind that how a user can be aware of it.
So that’s why this post is perfect. Thanks!
I believe everything posted made a lot of sense.
However, think on this, what if you added a little content?
I ain’t suggesting your content is not solid., however suppose you added something to maybe grab
people’s attention? I mean Пиастры – Составление семантического ядра | is kinda boring.
You could peek at Yahoo’s home page and see how they write news
titles to get people to click. You might try adding a video or a pic or
two to grab people interested about everything’ve written. Just
my opinion, it would make your blog a little bit more interesting.
Appreciate the recommendation. Let me try it out.
Why users still use to read news papers when in this technological
world the whole thing is presented on net?
This is very interesting, You’re a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your excellent post.
Also, I’ve shared your site in my social networks!
An impressive share! I have just forwarded this onto a friend who was conducting a little research on this.
And he in fact bought me dinner simply because I stumbled upon it for him…
lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanks for spending time to talk about this matter here on your site.
I think this is among the most vital information for me.
And i am glad reading your article. But should remark on few general things, The site
style is great, the articles is really great : D.
Good job, cheers
This paragraph provides clear idea in support of the new users of blogging, that actually
how to do blogging and site-building.
Incredible story there. What happened after? Thanks!
For most recent information you have to go to see web and on web I found this website as a finest web site
for hottest updates.
great points altogether, you just gained a emblem new reader.
What could you suggest in regards to your post that
you made a few days in the past? Any certain?
I every time spent my half an hour to read this blog’s
content all the time along with a mug of coffee.
My family members every time say that I am killing my time here at
net, except I know I am getting knowledge everyday by reading thes pleasant articles or reviews.
My blog caluanie muelear oxidize chemical
I am really enjoying the theme/design of your site.
Do you ever run into any browser compatibility problems?
A couple of my blog readers have complained about my blog not working correctly in Explorer but looks great in Opera.
Do you have any solutions to help fix this problem?
My brother recommended I might like this web site. He was
totally right. This post actually made my day. You cann’t imagine simply how much time I
had spent for this information! Thanks!
Heya i am for the first time here. I found this board and I find It truly useful
& it helped me out much. I hope to give something back
and help others like you aided me.
Simply wish to say your article is as astounding. The clearness in your publish is just
excellent and that i can assume you are knowledgeable on this
subject. Well along with your permission let me
to clutch your RSS feed to keep updated with drawing
close post. Thanks a million and please continue the enjoyable work.
Very rapidly this website will be famous amid all blogging
people, due to it’s pleasant content
Hello there, just became alert to your blog through Google, and
found that it’s truly informative. I am gonna watch
out for brussels. I will be grateful if you continue this in future.
A lot of people will be benefited from your writing. Cheers!
Awesome article.
It’s in fact very complicated in this full of activity life to listen news on TV,
so I simply use internet for that reason, and obtain the newest information.
Thanks for sharing your thoughts. I really appreciate your
efforts and I will be waiting for your next write ups thank you
once again.
If some one desires expert view on the topic of running a blog afterward i propose
him/her to pay a visit this blog, Keep up the fastidious
work.
Thanks for one’s marvelous posting! I certainly enjoyed reading it, you
might be a great author.I will be sure to bookmark your blog and will often come back
from now on. I want to encourage you continue your great work, have a nice day!
Can you tell us more about this? I’d care to find out more details.
Hello, I enjoy reading through your article post.
I wanted to write a little comment to support you.
When someone writes an paragraph he/she keeps the image of
a user in his/her brain that how a user can know it.
Therefore that’s why this paragraph is amazing.
Thanks!
Hello, just wanted to mention, I enjoyed this blog post.
It was practical. Keep on posting!
hey there and thank you for your info – I’ve definitely picked up anything new
from right here. I did however expertise a few technical
issues using this website, since I experienced to reload
the web site a lot of times previous to I could get it to load properly.
I had been wondering if your hosting is OK? Not that I’m
complaining, but sluggish loading instances
times will sometimes affect your placement in google
and could damage your high-quality score if advertising and marketing with Adwords.
Anyway I’m adding this RSS to my e-mail and can look out for much more of your respective exciting content.
Make sure you update this again soon.
This is a topic which is near to my heart… Best wishes! Where are your contact details though?
Good day! This is my first comment here so I just wanted to give a quick shout
out and say I genuinely enjoy reading your posts.
Can you recommend any other blogs/websites/forums that cover the same subjects?
Thank you!
Just wish to say your article is as amazing. The clearness in your
publish is just cool and i could think you’re knowledgeable on this subject.
Fine with your permission let me to seize your RSS feed to keep up to date with approaching post.
Thanks one million and please continue the rewarding work.
Thanks for sharing your info. I really appreciate your efforts and I will be waiting for
your further write ups thanks once again.
wonderful points altogether, you simply gained a
new reader. What may you recommend in regards to your post that you made some days ago?
Any certain?
I was wondering if you ever thought of changing the page layout
of your site? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or 2 images.
Maybe you could space it out better?
Nice post. I learn something new and challenging on websites I
stumbleupon on a daily basis. It will always be useful to read content from other writers and practice a little something from other sites.
What i do not understood is if truth be told how you’re not actually a
lot more smartly-favored than you may be now. You are very intelligent.
You recognize therefore considerably in terms of this subject, made me in my
view imagine it from a lot of various angles. Its
like women and men aren’t involved except it is one thing to accomplish with Lady gaga!
Your own stuffs outstanding. Always deal with it up!
Hi there, I enjoy reading through your article post.
I like to write a little comment to support you.
I really like your blog.. very nice colors & theme. Did you make
this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to create my own blog and would like to know
where u got this from. thank you
wonderful points altogether, you simply won a new reader.
What might you suggest about your submit that you simply made some days in the past?
Any positive?
Awesome things here. I’m very happy to look your
article. Thanks so much and I am having a look ahead to touch you.
Will you kindly drop me a mail?
Hello I am so delighted I found your website, I really
found you by error, while I was browsing on Aol for something else, Regardless I am here now and would just like to say kudos for a
marvelous post and a all round exciting blog (I also love the theme/design),
I don’t have time to read it all at the moment but
I have bookmarked it and also included your RSS feeds, so when I have time I will be back to read
much more, Please do keep up the great jo.
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re going to
a famous blogger if you are not already 😉 Cheers!
I’ll immediately snatch your rss feed as I can not find your email subscription hyperlink or e-newsletter service.
Do you have any? Kindly allow me know in order that I may just subscribe.
Thanks.
What’s up to every body, it’s my first go to see of this weblog;
this website consists of amazing and genuinely good material for
visitors.
Its such as you read my mind! You seem to understand
a lot approximately this, like you wrote the e book in it or something.
I feel that you simply can do with some percent to drive the message house a little bit, but other than that, this is fantastic blog.
A fantastic read. I will certainly be back.
Your means of explaining all in this post is in fact nice, all be capable of simply be aware of it, Thanks
a lot.
Can I simply say what a comfort to find someone who genuinely understands what they’re discussing on the internet.
You actually understand how to bring a problem to light and
make it important. A lot more people need to read this and understand this side
of the story. I can’t believe you are not more popular because you most certainly possess the gift.
Hey there! I’m at work browsing your blog from my
new iphone 4! Just wanted to say I love reading your blog and look forward to
all your posts! Carry on the great work!
Wonderful blog you have here but I was curious about if you knew of any discussion boards that cover the same topics talked about here?
I’d really like to be a part of group where I can get advice from other experienced individuals that share the same interest.
If you have any recommendations, please let me know.
Thank you!
Excellent post. I used to be checking constantly this blog and I’m impressed! I maintain such information much.
I maintain such information much.
Very helpful info specifically the ultimate section
I used to be seeking this certain info for a very lengthy time.
Thank you and good luck.
It’s appropriate time to make some plans for the future and
it’s time to be happy. I’ve read this post and if I
could I desire to suggest you few interesting
things or advice. Perhaps you can write next articles referring to this article.
I desire to read even more things about it!
Its like you learn my mind! You appear to understand so much approximately this,
such as you wrote the guide in it or something. I believe that you can do
with a few p.c. to power the message home a little
bit, but other than that, that is great blog.
A fantastic read. I’ll certainly be back.
naturally like your website however you have to check
the spelling on several of your posts. A number of them are rife with
spelling issues and I in finding it very troublesome to
inform the truth nevertheless I’ll definitely come back again.
I think the admin of this website is genuinely working hard in support of his website, since
here every material is quality based material.
This post is truly a good one it assists new internet visitors,
who are wishing for blogging.
My brother recommended I would possibly like this website.
He used to be totally right. This put up actually made my day.
You cann’t believe just how much time I had spent for this info!
Thank you!
Howdy I am so excited I found your weblog, I really found you by mistake, while I was researching on Askjeeve for something else, Nonetheless I am here now and
would just like to say many thanks for a remarkable post and a all round entertaining blog (I also love the theme/design), I don’t have time to go through it all at the moment but I have book-marked it and also added your RSS feeds, so when I have time I will be back to read more,
Please do keep up the awesome work.
Thanks on your marvelous posting! I definitely enjoyed reading it, you happen to be a great author.I will make
certain to bookmark your blog and definitely
will come back in the foreseeable future. I want to encourage yourself to continue your
great posts, have a nice weekend!
Remarkable! Its truly awesome piece of writing, I have got much clear idea concerning
from this post.
Hello there! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in trading links or maybe guest authoring a blog article or vice-versa?
My website discusses a lot of the same subjects as yours and I feel we could greatly benefit from
each other. If you might be interested feel free to send me
an e-mail. I look forward to hearing from you!
Terrific blog by the way!
I love your blog.. very nice colors & theme. Did you design this website yourself or did
you hire someone to do it for you? Plz reply as I’m looking to create my own blog and would like
to find out where u got this from. cheers
bookmarked!!, I love your blog!
Wonderful blog! I found it while browsing on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Cheers
Pretty nice post. I simply stumbled upon your blog and wished to mention that I have
truly enjoyed surfing around your weblog posts.
After all I will be subscribing for your feed and I hope you
write once more very soon!
I enjoy what you guys tend to be up too. Such clever work and exposure!
Keep up the superb works guys I’ve included you guys to
my own blogroll.
Hi Dear, are you actually visiting this web page daily, if so then you will without doubt take fastidious knowledge.
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is valuable and everything.
But think about if you added some great graphics or video
clips to give your posts more, “pop”! Your content is excellent but with pics and clips, this site could undeniably be one of the best in its niche.
Fantastic blog!
Awesome post.
This is my first time visit at here and i am
really happy to read all at alone place.
I enjoy what you guys tend to be up too. This type of clever work and
coverage! Keep up the very good works guys I’ve included you guys to our blogroll.
Right now it looks like Expression Engine is the preferred blogging platform
out there right now. (from what I’ve read) Is that what you are using on your blog?
Good info. Lucky me I discovered your site by chance (stumbleupon).
I’ve bookmarked it for later!
This is my first time pay a visit at here and i am in fact impressed to read all at one place.
Oh my goodness! Amazing article dude! Thank you so much, However I am encountering problems with your
RSS. I don’t know why I am unable to subscribe to it. Is there anybody else getting similar RSS issues?
Anyone who knows the answer will you kindly respond? Thanx!!
I enjoy what you guys are usually up too. This type of clever work and
coverage! Keep up the excellent works guys I’ve incorporated
you guys to my blogroll.
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your site?
My blog is in the exact same area of interest as yours
and my visitors would certainly benefit from a lot of the information you provide here.
Please let me know if this alright with you. Cheers!
Thanks to my father who stated to me concerning this
webpage, this webpage is truly remarkable.
excellent points altogether, you simply received a new reader.
What may you suggest about your submit that you made a few days in the
past? Any certain?
I know this website gives quality dependent posts
and other material, is there any other web page which gives these kinds of data in quality?
I?m not that much of a internet reader tо bе honest but your blogs гeally nice, қeep it սp!
Ι’ll go ahead and bookmark your site t᧐ come back in the future.
All the beѕt
Feel free to surf to my site :: space seem larger
Link exchange is nothing else except it is only placing the other
person’s webpage link on your page at suitable place and
other person will also do same in support of you.
Aw, this was a very good post. Taking a few minutes and actual effort to create
a really good article… but what can I say… I
put things off a whole lot and never manage to get anything done.
Its like you read my thoughts! You appear to know
so much approximately this, such as you wrote the e book in it or something.
I feel that you simply can do with some percent to power the message home a bit, but instead of
that, this is wonderful blog. A great read. I’ll certainly
be back.
Hello, just wanted to tell you, I liked this blog post.
It was funny. Keep on posting!
What’s up, I check your blogs daily. Your story-telling
style is witty, keep doing what you’re doing!
Hi! I know this is somewhat off topic but I was wondering if you knew where I could locate
a captcha plugin for my comment form? I’m using the same blog platform as yours
and I’m having difficulty finding one? Thanks a lot!
Thanks very nice blog!
Howdy just wanted to give you a quick heads up and let you know a few of the
pictures aren’t loading properly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the
same results.
I’m not sure exactly why but this blog is loading very slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later and see if the problem still exists.
Greetings, I believe your site could be having internet browser compatibility issues.
Whenever I take a look at your website in Safari, it looks fine however, when opening in IE, it
has some overlapping issues. I simply wanted
to give you a quick heads up! Aside from that, great
website!
It’s appropriate time to make some plans for the longer term and it is time
to be happy. I’ve read this submit and if I could I desire to
counsel you some attention-grabbing things or suggestions.
Maybe you could write next articles referring to this article.
I want to learn even more issues approximately it!
Wow that was unusual. I just wrote an incredibly
long comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say great blog!
This post is truly a fastidious one it helps new web viewers, who are wishing for blogging.
Pretty nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your blog posts.
In any case I will be subscribing to your feed and I hope you write
again soon!
I’m no longer positive where you’re getting your info, but good topic.
I needs to spend some time finding out much more or working out
more. Thank you for great info I used to be searching for this
information for my mission.
Also visit my web blog :: medical expenses
You are so cool! I don’t suppose I’ve read through something
like that before. So wonderful to discover someone with original thoughts on this issue.
Seriously.. thanks for starting this up. This web site is one
thing that is needed on the internet, someone with a bit of originality!
It’s really a great and useful piece of info. I’m satisfied that you just shared this
useful information with us. Please stay us informed like this.
Thank you for sharing.
Aw, this was an exceptionally good post. Finding the time
and actual effort to produce a good article… but what can I say… I procrastinate a lot and don’t seem to get nearly anything done.
Simply wish to say your article is as amazing.
The clarity in your post is just cool and i can assume you are an expert on this subject.
Fine with your permission let me to grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please continue the rewarding work.
Today, I went to the beachfront with my children. I found a sea shell and gave it
to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She
placed the shell to her ear and screamed. There was a
hermit crab inside and it pinched her ear. She never wants to go back!
LoL I know this is entirely off topic but I had to tell someone!
Thanks for another informative blog. The place else
may I am getting that type of information written in such a perfect manner?
I’ve a project that I’m just now working on, and I’ve been on the
glance out for such info.
Wow, marvelous weblog format! How lengthy have you ever been running a
blog for? you make running a blog glance easy. The total look of
your site is magnificent, let alone the content!
Hi there Dear, are you really visiting this website regularly, if so after
that you will without doubt take pleasant know-how.
Hello everyone, it’s my first visit at this website, and piece of writing
is really fruitful for me, keep up posting these articles.
I’m not sure where you’re getting your information, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for magnificent info I was looking for this info for
my mission.
Hi there, just became aware of your blog through Google,
and found that it is truly informative. I’m gonna watch out for brussels.
I’ll appreciate if you continue this in future. A lot of people will be benefited from your writing.
Cheers!
I do agree with all the concepts you have offered to your post.
They are really convincing and will certainly work. Still,
the posts are too quick for newbies. Could you please prolong them a bit from next time?
Thanks for the post.
I am really impressed with your writing skills
as well as with the layout on your blog. Is this a paid theme or did you modify it yourself?
Anyway keep up the excellent quality writing, it
is rare to see a great blog like this one nowadays.
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is fundamental and everything.
However imagine if you added some great pictures or video clips to
give your posts more, “pop”! Your content is excellent but with pics
and videos, this blog could definitely be one of the very best in its field.
Fantastic blog!
hi!,I love your writing very so much! share we be
in contact more approximately your post on AOL?
I need an expert on this space to solve my problem.
May be that’s you! Taking a look forward to look you.
Pretty nice post. I just stumbled upon your blog and wished to say that I have really enjoyed browsing your blog posts.
After all I’ll be subscribing to your feed and I hope you write again very soon!
I’m extremely pleased to uncover this great site.
I need to to thank you for ones time for this particularly wonderful read!!
I definitely savored every little bit of it and I have you book-marked to
see new things in your website.
Peculiar article, totally what I wanted to find.
You’ve made some decent points there. I looked on the web to find out
more about the issue and found most individuals will go along
with your views on this website.
You could certainly see your expertise within the article you write.
The arena hopes for more passionate writers like you who are not afraid to say how they
believe. All the time follow your heart.
Outstanding quest there. What occurred after?
Take care!
I always spent my half an hour to read this weblog’s articles or reviews every day along with a cup of coffee.
I have been browsing on-line greater than three hours today, but I by
no means discovered any attention-grabbing article like yours.
It’s lovely value enough for me. In my opinion, if all website owners and bloggers made good content material as you did, the
net shall be a lot more useful than ever before.
Wow, wonderful blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web
site is wonderful, let alone the content!
Howdy, i read your blog occasionally and i own a similar one and i was just curious if
you get a lot of spam feedback? If so how do you prevent it, any plugin or
anything you can recommend? I get so much lately it’s driving
me crazy so any support is very much appreciated.
What’s up mates, pleasant piece of writing and nice arguments commented here, I
am actually enjoying by these.
Aw, this was an extremely nice post. Finding the time and actual effort
to create a superb article… but what can I say… I procrastinate a lot and don’t manage to get nearly anything done.
Exсellent, what a website it is! This webpage provides useful facts
to us, keep it up.
Hey I know this is off topic but I was wondering if you knew of
any widgets I could add to my blog that automatically tweet my newest
twitter updates. I’ve been looking for a plug-in like this for quite some time
and was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
I wanted to thank you for this excellent read!!
I absolutely enjoyed every bit of it. I have you saved
as a favorite to look at new things you post…
Right here is the right website for anyone who hopes to find
out about this topic. You realize so much its almost tough to argue with you (not that
I personally will need to…HaHa). You certainly put a
brand new spin on a topic that has been written about for ages.
Excellent stuff, just great!
Thanks to my father who told me about this weblog, this blog is actually awesome.
Thank you, I have recently been searching for information about this subject for ages and yours
is the best I’ve found out till now. But, what concerning the bottom line?
Are you sure about the supply?
Awesome! Its actually awesome paragraph, I have got much clear idea on the topic of from this
post.
Its like you read my mind! You seem to know so much about this,
like you wrote the book in it or something. I think that you
could do with a few pics to drive the message home a little bit,
but instead of that, this is magnificent
blog. An excellent read. I will definitely be back.
I pay a visit everyday some blogs and blogs to read posts, however this webpage provides quality based posts.
Heya! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward
to all your posts! Carry on the excellent work!
I believe this is one of the such a lot important info for me.
And i’m glad studying your article. But wanna remark on few basic issues, The site taste is ideal, the articles is truly excellent : D.
Good job, cheers
That is a very good tip particularly to those new to the blogosphere.
Simple but very precise information… Thanks for sharing this
one. A must read post!
Can you tell us more about this? I’d care
to find out more details.
What a information of un-ambiguity and preserveness of valuable experience concerning unpredicted
emotions.
Hello colleagues, nice article and pleasant arguments commented here, I am truly enjoying by these.
Hello! Someone in my Myspace group shared this website with us so I came
to check it out. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Great blog and excellent style and design.
I wanted to thank you for this excellent read!!
I absolutely loved every little bit of it. I have you bookmarked to check out new stuff
you post…
Hello, i think that i noticed you visited my weblog thus i got here to return the choose?.I am attempting to find
issues to improve my site!I suppose its adequate to make use
of some of your concepts!!
Heya i am for the first time here. I found
this board and I in finding It really useful & it helped me out much.
I hope to present one thing again and help others like you aided
me.
Excellent blog here! Also your website loads up very fast!
What host are you using? Can I get your affiliate
link to your host? I wish my website loaded up
as fast as yours lol
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how can we communicate?
Hey there would you mind sharing which blog platform you’re working with?
I’m going to start my own blog in the near future but
I’m having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems
different then most blogs and I’m looking for something completely unique.
P.S My apologies for being off-topic but I had to ask!
Way cool! Some extremely valid points! I appreciate you penning this write-up and
also the rest of the site is very good.
With havin so much content and articles do you ever run into any problems of plagorism or copyright violation?
My site has a lot of exclusive content I’ve either created myself or outsourced but
it looks like a lot of it is popping it up all over the web without
my agreement. Do you know any solutions to help prevent
content from being stolen? I’d certainly appreciate it.
Valuable information. Fortunate me I found your website unintentionally, and I’m surprised why
this coincidence did not came about in advance!
I bookmarked it.
When some one searches for his required thing, therefore
he/she wants to be available that in detail, thus
that thing is maintained over here.
Youᥙr style is very unique compared tо other people
I’ve read stuff from. Thank you ffor posting when ʏou’ve gоt the opportunity, Guess I will
just book mark this web site.
This design is steller! You obviously know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
Spot on with this write-up, I seriously think this website needs a great deal more attention.
I’ll probably be returning to read more, thanks for the info!
This paragraph offers clear idea in favor of the new viewers of blogging,
that truly how to do running a blog.
I enjoy, lead to I discovered exactly what I used to be looking for.
You’ve ended my four day long hunt! God Bless you man. Have a nice
day. Bye
What’s up, I log on to your blog daily. Your story-telling
style is witty, keep it up!
I’d like to find out more? I’d love to find out some additional information.
What’s up, yeah this paragraph is actually nice and I have learned lot of things from it about blogging.
thanks.
Hello! I know this is somewhat off topic but I was wondering which blog
platform are you using for this site? I’m getting sick and tired of WordPress because
I’ve had issues with hackers and I’m looking at alternatives for
another platform. I would be fantastic if you could point
me in the direction of a good platform.
Very nice post. I simply stumbled upon your weblog
and wished to mention that I have really enjoyed surfing
around your blog posts. After all I will be subscribing for your feed and
I’m hoping you write once more soon!
We are a group of volunteers and opening a new scheme
in our community. Your site provided us with valuable info to work
on. You have done an impressive job and our whole community will be thankful to you.
Great post however I was wondering if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a
little bit more. Bless you!
This web site definitely has all the information and facts I needed about this subject and didn’t know who to ask.
Howdy! This blog post could not be written any better!
Looking through this article reminds me of my previous
roommate! He always kept talking about this.
I am going to forward this article to him. Fairly certain he will
have a great read. I appreciate you for sharing!
Its like you learn my mind! You seem to know so much
about this, like you wrote the ebook in it or
something. I think that you just could do with a few % to drive
the message home a bit, but instead of that, this is
great blog. A great read. I’ll certainly be back.
Hi there it’s me, I am also visiting this site daily, this
website is actually fastidious and the viewers are in fact sharing
fastidious thoughts.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an edginess over that you wish
be delivering the following. unwell unquestionably come further formerly again as exactly
the same nearly very often inside case you shield this hike.
Fastidious response in return of this issue with genuine arguments and telling everything on the topic of that.
hey there and thank you for your information – I’ve definitely picked up anything new from right here.
I did however expertise some technical issues using this site, as I experienced to reload the website a lot of times previous
to I could get it to load correctly. I had been wondering if your web hosting is OK?
Not that I am complaining, but slow loading
instances times will often affect your placement in google and could damage your
high quality score if ads and marketing with Adwords. Well I’m adding this RSS to my email and can look out for
a lot more of your respective intriguing content. Ensure that you update
this again soon.
I like the helpful info you provide in your articles.
I will bookmark your blog and check again here frequently.
I am quite certain I’ll learn plenty of new stuff
right here! Best of luck for the next!
My brother recommended I would possibly like this blog. He was entirely right.
This put up truly made my day. You cann’t believe just how a lot time I had spent for this info!
Thanks!
Woah! I’m really enjoying the template/theme of
this website. It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance” between superb usability and visual appeal.
I must say that you’ve done a excellent job with this.
Also, the blog loads extremely fast for me on Chrome.
Outstanding Blog!
Today, I went to the beach front with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
Hey there are using WordPress for your site platform? I’m new to the blog
world but I’m trying to get started and create my own. Do you require any html coding expertise to make
your own blog? Any help would be greatly appreciated!
Wow! At last I got a website from where I can genuinely take valuable facts regarding my study and knowledge.
I’m really enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit more often. Did you
hire out a designer to create your theme? Superb work!
My relatives every time say that I am wasting my time here at net,
however I know I am getting familiarity daily by
reading thes fastidious content.
Hello, its nice piece of writing regarding media print, we all be aware of media is a fantastic source of information.
I think the admin of this site is truly working hard in support of his web site, for the reason that
here every information is quality based information.
Wow that was strange. I just wrote an really long comment but after I clicked
submit my comment didn’t show up. Grrrr… well I’m not
writing all that over again. Anyway, just wanted to say superb
blog!
Thanks for one’s marvelous posting! I really enjoyed reading it, you could
be a great author. I will be sure to bookmark your blog and may come back at some point.
I want to encourage you continue your great posts, have a nice
afternoon!
What’s up it’s me, I am also visiting this web site regularly, this website is actually pleasant and the people are in fact sharing good
thoughts.
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do
it for you? Plz answer back as I’m looking to create my own blog and would like to
know where u got this from. thanks a lot
Hurrah! After all I got a webpage from where I be capable of in fact obtain valuable information regarding
my study and knowledge.
Its like you read my mind! You seem to know so much about this, like you wrote the
e book in it or something. I feel that you just could do
with a few % to drive the message house a little bit, however
instead of that, this is fantastic blog. A fantastic read.
I’ll definitely be back.
Howdy, i read your blog occasionally and i
own a similar one and i was just curious if you get a lot of spam feedback?
If so how do you reduce it, any plugin or anything you can suggest?
I get so much lately it’s driving me crazy so any assistance is very much appreciated.
Simply want to say your article is as amazing. The clarity in your post is simply excellent
and i could assume you’re an expert on this subject.
Fine with your permission let me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please carry on the gratifying work.
Hey there just wanted to give you a brief heads up and let you
know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different internet browsers and both show the same outcome.
Admiring the time and energy you put into your site and detailed
information you provide. It’s nice to come across a blog every once in a while that isn’t the same unwanted
rehashed information. Fantastic read! I’ve saved
your site and I’m including your RSS feeds to my Google account.
Asking questions are truly fastidious thing if you are not understanding something totally, but
this paragraph presents good understanding even.
I am actually happy to glance at this web site posts
which consists of lots of valuable information, thanks for providing these kinds of statistics.
Hi there, i read your blog from time to time and i own a similar one and i was just curious if
you get a lot of spam comments? If so how do you stop it, any plugin or
anything you can recommend? I get so much lately it’s driving me
crazy so any help is very much appreciated.
I know this web page presents quality dependent content and extra data, is there any
other web site which presents such data in quality?
When I originally commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get three emails with the same comment.
Is there any way you can remove people from that service? Many thanks!
Hi my family member! I want to say that this post is amazing,
great written and come with almost all vital infos.
I would like to peer extra posts like this .
I’m really enjoying the theme/design of your weblog.
Do you ever run into any web browser compatibility problems?
A handful of my blog audience have complained about my website not working correctly in Explorer but looks great in Safari.
Do you have any solutions to help fix this issue?
I pay a visit day-to-day a few blogs and blogs to read posts, however this
webpage gives feature based content.
Greetings! Very helpful advice within this post!
It is the little changes that make the largest changes.
Thanks for sharing!
When I initially commented I appear to have clicked the -Notify me when new comments are added- checkbox and from now on whenever a comment is added
I recieve four emails with the same comment. Is there a way you are able to remove me from that
service? Kudos!
Appreciation to my father who told me on the topic of this web site, this
blog is genuinely amazing.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back later. Cheers
I used to be recommended this blog by my cousin. I am not
certain whether or not this submit is written through him
as nobody else realize such particular about my problem.
You’re wonderful! Thank you!
Hello my loved one! I want to say that this post is amazing,
great written and include almost all vital infos.
I would like to peer extra posts like this .
I’ve been exploring for a little bit for any high quality articles or blog posts in this kind of house .
Exploring in Yahoo I finally stumbled upon this web site. Reading this info So i’m happy to show that
I’ve a very good uncanny feeling I found out just what I needed.
I such a lot undoubtedly will make sure to do not omit this web
site and provides it a look on a relentless basis.
Very nice article, just what I needed.
Fantastic blog! Do you have any hints for aspiring writers?
I’m hoping to start my own blog soon but I’m
a little lost on everything. Would you propose starting with a free platform like WordPress or go for a paid option? There
are so many options out there that I’m completely
confused .. Any recommendations? Cheers!
Magnificent goods from you, man. I’ve understand your stuff previous
to and you’re just extremely fantastic. I actually like what you have acquired here, certainly like
what you’re saying and the way in which you
say it. You make it enjoyable and you still care for to keep it sensible.
I cant wait to read far more from you. This is actually a wonderful site.
We’re a group of volunteers and opening a new scheme in our community.
Your site offered us with valuable info to work on.
You have done a formidable job and our whole community will be
thankful to you.
I go to see daily a few web sites and information sites to read
articles or reviews, however this website provides
quality based writing.
Great web site. Lots of useful info here. I’m sending it to several friends ans
additionally sharing in delicious. And certainly, thanks for your
effort!
It’s truly very complicated in this active life to listen news on TV, therefore I simply use web for that reason, and take the
newest information.
Hi, Neat post. There’s an issue together with your site in internet explorer,
might check this? IE nonetheless is the market leader and a large part of people will pass
over your wonderful writing due to this problem.
We are a bunch of volunteers and opening a
new scheme in our community. Your site provided us with valuable information to work on. You have performed an impressive
task and our whole neighborhood will likely be grateful to you.
You’re so cool! I don’t believe I’ve read through something like
this before. So wonderful to discover someone with some unique thoughts on this topic.
Seriously.. thanks for starting this up. This web site
is something that’s needed on the web, someone with a little originality!
I read this article completely concerning the difference of hottest and preceding technologies, it’s remarkable article.
I’vebeen surfing online moгe than three һouгѕ todɑy, yеt I
never found any іnteresting article ⅼike youгs.
It is pretty worth enough for me. Personally, іf аll website owners and bloggers mɑde
ɡood cоntent as you did, the net ѡill be а ⅼot moгe usefսl than eνer before.
Tɑke a look at mу web-site … singapore funiture
Quality articles or reviews is the secret to interest
the users to pay a visit the website, that’s what this web site is providing.
Hey there! I’ve been reading your weblog for a while now and finally got the bravery to go ahead and give you a shout out
from Houston Texas! Just wanted to say keep up the great job!
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get bought an edginess over that you wish be delivering the following.
unwell unquestionably come further formerly again as
exactly the same nearly a lot often inside case you shield this increase.
Thank you for some other informative site. Where else may
just I get that kind of information written in such a perfect means?
I’ve a undertaking that I am just now running on, and I’ve been on the glance out for
such info.
You could definitely see your enthusiasm within the article you write.
The sector hopes for more passionate writers like you who aren’t afraid to
mention how they believe. All the time go after your
heart.
Wonderful website. A lot of helpful info here. I’m sending it to a
few buddies ans also sharing in delicious. And of course,
thank you for your sweat!
After checking out a number of the blog articles on your blog, I honestly like your way of writing a blog.
I saved as a favorite it to my bookmark site
list and will be checking back soon. Take a look at my website as well and let
me know what you think.
Hey! Would you mind if I share your blog with my zynga group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Thanks
Hi there! I could have sworn I’ve visited this website before but after looking at many of the posts I realized it’s new to me.
Regardless, I’m definitely pleased I discovered it and I’ll be
book-marking it and checking back frequently!
I really like it when people come together and share views.
Great website, stick with it!
I think this is among the most vital information for me. And i’m glad reading
your article. But wanna remark on few general things, The website style is
wonderful, the articles is really great : D. Good job, cheers
Hi! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly?
My weblog looks weird when viewing from my iphone 4. I’m trying to find
a theme or plugin that might be able to fix this problem.
If you have any suggestions, please share. Thanks!
Hiya! Quick question that’s entirely off topic. Do you know how to make your
site mobile friendly? My weblog looks weird when browsing from my iphone4.
I’m trying to find a template or plugin that
might be able to correct this issue. If you have any recommendations, please share.
Thank you!
Great information. Lucky me I found your website by accident (stumbleupon).
I have saved it for later!
Hello, constantly i used to check weblog posts here in the early hours in the dawn, for the reason that i enjoy to
learn more and more.
It is not my first time to go to see this website, i am visiting this web site dailly and take pleasant data from here daily.
Excellent site you have got here.. It’s difficult to find excellent writing like yours these days.
I really appreciate individuals like you! Take care!!
Hi there would you mind sharing which blog platform you’re
working with? I’m going to start my own blog soon but I’m having
a hard time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and I’m looking for
something completely unique. P.S My apologies for getting off-topic but I
had to ask!
Howdy just wanted to give you a quick heads up. The words in your article seem to be running off the
screen in Internet explorer. I’m not sure if this is a
formatting issue or something to do with internet browser compatibility but I figured
I’d post to let you know. The layout look great though!
Hope you get the problem solved soon. Thanks
What’s up, just wanted to say, I enjoyed this blog post. It was inspiring.
Keep on posting!
I like it when individuals come together and share views.
Great blog, continue the good work!
Excellent weblog here! Also your website loads up
very fast! What host are you the use of? Can I am getting your associate hyperlink on your host?
I want my site loaded up as fast as yours lol
Remarkable things here. I’m very glad to see
your post. Thanks a lot and I am taking a look ahead to
touch you. Will you please drop me a e-mail?
Hello, I do think your site might be having web browser compatibility issues.
When I take a look at your blog in Safari, it looks
fine however, if opening in I.E., it’s got some overlapping issues.
I just wanted to provide you with a quick heads up! Other than that, excellent website!
Definitely believe that which you said. Your favorite reason appeared to be on the net
the simplest thing to be aware of. I say to you, I certainly get
annoyed while people consider worries that they plainly don’t
know about. You managed to hit the nail
upon the top and also defined out the whole thing without having side effect , people
could take a signal. Will probably be back to get more.
Thanks
Hello my family member! I want to say that this article is awesome, great written and come with
approximately all vital infos. I’d like to look extra
posts like this .
Very soon this web site will be famous among all blogging visitors, due to it’s pleasant content
I like the valuable information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I’m quite certain I will learn a lot of new stuff right here!
Good luck for the next!
I every time used to study post in news papers but now
as I am a user of net so from now I am using net for articles,
thanks to web.
Howdy! This is my first comment here so
I just wanted to give a quick shout out and say I really enjoy reading your blog posts.
Can you suggest any other blogs/websites/forums that go over the same subjects?
Thanks!
It’s hard to come by experienced people about this subject, but you sound like you know
what you’re talking about! Thanks
Nice blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple adjustements would really make my blog shine.
Please let me know where you got your theme. With thanks
Wow, this paragraph is fastidious, my sister is analyzing these things, thus
I am going to inform her.
This is really interesting, You are an overly skilled blogger.
I’ve joined your rss feed and sit up for
seeking extra of your magnificent post. Additionally,
I’ve shared your site in my social networks
This website certainly has all the information I wanted concerning this subject and didn’t know who to
ask.
hey there and thank you for your info – I’ve definitely picked
up something new from right here. I did however expertise
several technical points using this web site, as I experienced
to reload the site a lot of times previous to I could get it to
load correctly. I had been wondering if your hosting is OK?
Not that I am complaining, but slow loading instances times will very frequently affect your placement in google and could damage your high quality score if advertising and marketing with Adwords.
Anyway I’m adding this RSS to my email and can look out for a lot more of your respective
fascinating content. Ensure that you update this again soon.
Hi there, I enjoy reading all of your post. I wanted to write
a little comment to support you.
Hey There. I found your blog the use of msn. That is a very well written article.
I’ll make sure to bookmark it and return to learn more of your useful info.
Thank you for the post. I’ll definitely comeback.
Marvelous, what a blog it is! This web site gives helpful facts to us,
keep it up.
Hi, Neat post. There’s a problem together with your site in internet explorer, might check this?
IE still is the market chief and a huge part of folks will pass over your wonderful writing
due to this problem.
I constantly spent my half an hour to read this
website’s articles or reviews every day along with a mug of
coffee.
Hi, I log on to your blogs like every week. Your humoristic style is
awesome, keep doing what you’re doing!
It’s actually a nice and useful piece of info. I am happy that you just shared this useful info with us.
Please stay us informed like this. Thanks for sharing.
Hi there, I read your blogs on a regular basis.
Your writing style is awesome, keep doing what you’re
doing!
Pretty! This was an extremely wonderful article. Thank you for
supplying this information.
My spouse and I stumbled over here coming from a different web address and thought I may as well check things out.
I like what I see so now i’m following you. Look forward to going over your web page repeatedly.
You really make it seem so easy with your presentation but I find
this topic to be really something that I
think I would never understand. It seems too complicated and very broad for
me. I’m looking forward for your next post, I’ll try to get
the hang of it!
This is the perfect webpage for anyone who wants to find out about this topic.
You understand so much its almost tough to argue with you (not that I personally would want to…HaHa).
You definitely put a new spin on a subject that’s been discussed for ages.
Excellent stuff, just great!
Hey would you mind letting me know which hosting company you’re utilizing?
I’ve loaded your blog in 3 completely different browsers and I must say this blog
loads a lot faster then most. Can you recommend a good internet hosting provider
at a fair price? Thanks a lot, I appreciate it!
Thank you a lot for sharing this with all people you actually
understand what you’re speaking about! Bookmarked. Kindly also visit my
site =). We will have a link alternate agreement among us
I think the admin of this site is really working hard for his web
page, because here every material is quality based data.
Hi there! I know this is somewhat off topic but I was wondering which blog platform
are you using for this website? I’m getting tired of WordPress because I’ve had issues
with hackers and I’m looking at options for another platform.
I would be fantastic if you could point me in the direction of a
good platform.
Hello, i think that i saw you visited my weblog so i came
to “return the favor”.I am attempting to find things to enhance my website!I suppose its ok to use some of your ideas!!
Definitely imagine that which you stated. Your favourite justification appeared to be
on the web the easiest factor to take into accout of. I say to you, I certainly get annoyed while
other folks consider worries that they plainly do not understand about.
You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , other people could
take a signal. Will likely be back to get more. Thank you
Hey there! Do you use Twitter? I’d like to follow you if that would be okay.
I’m absolutely enjoying your blog and look forward to new updates.
Does your website have a contact page? I’m having a tough time locating it but,
I’d like to send you an e-mail. I’ve got
some recommendations for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it expand over time.
An interesting discussion is worth comment. There’s no doubt that that you ought to write more on this subject matter, it might not
be a taboo matter but typically people do not speak about such issues.
To the next! Kind regards!!
Every weekend i used to visit this web site,
as i want enjoyment, for the reason that this this site conations really
good funny data too.
If some one wants expert view on the topic of running a blog then i recommend
him/her to go to see this blog, Keep up the nice work.
Hello, I enjoy reading all of your post. I like
to write a little comment to support you.
You actually make it seem so easy with your presentation but I find this topic to be really something which
I think I would never understand. It seems too complex
and extremely broad for me. I am looking forward for your next post, I will try to get the hang of it!
Unquestionably believe that which you said.
Your favorite justification seemed to be on the net the easiest thing to be
aware of. I say to you, I definitely get irked while people consider worries that they just
do not know about. You managed to hit the nail upon the top as
well as defined out the whole thing without having side-effects , people
can take a signal. Will probably be back to get more.
Thanks
I every time spent my half an hour to read this weblog’s posts every
day along with a cup of coffee.
I think this is among the most important information for me.
And i’m glad reading your article. However want to observation on few general issues,
The website taste is great, the articles is actually nice :
D. Excellent job, cheers
bookmarked!!, I really like your website!
I love reading through an article that will make people think.
Also, thank you for allowing me to comment!
I have read so many articles or reviews on the topic of
the blogger lovers however this post is in fact a nice article,
keep it up.
I’m extremely pleased to discover this page. I wanted to thank you for ones time just
for this fantastic read!! I definitely enjoyed every bit of it and I have you saved to fav to see new stuff in your blog.
My family members all the time say that I am wasting
my time here at net, except I know I am getting knowledge
daily by reading such pleasant articles or reviews.
Thanks for sharing your thoughts. I truly appreciate your
efforts and I will be waiting for your further write ups thank you
once again.
I visited multiple sites however the audio quality for audio
songs present at this web page is genuinely excellent.
It’s very easy to find out any topic on web as compared to textbooks, as I found
this article at this web page.
You should take part in a contest for one of the most useful websites on the internet.
I’m going to recommend this blog!
I am in fact delighted to glance at this web site posts which consists of lots of helpful information, thanks
for providing such information.
Howdy this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or
if you have to manually code with HTML. I’m starting a blog soon but have no coding skills
so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
Hi there, this weekend is fastidious for me, because this
time i am reading this impressive informative article here at my home.
I was able to find good info from your blog articles.
You actually make it seem so easy with your presentation but I find this topic to be really something that I think I would
never understand. It seems too complicated and very broad for me.
I’m looking forward for your next post, I will try to get the hang of it!
Hey there! This post couldn’t be written any better! Reading through this post reminds me of my
good old room mate! He always kept chatting about this.
I will forward this post to him. Fairly certain he will have a good read.
Thanks for sharing!
Thank you for some other wonderful article. The place else may just anybody get that kind of information in such a perfect manner of writing?
I have a presentation next week, and I’m at the look for such info.
With havin so much content do you ever run into any problems of plagorism or copyright violation?
My site has a lot of exclusive content I’ve either written myself or outsourced but it
looks like a lot of it is popping it up all over the internet without my permission. Do you know any ways to help reduce content from being ripped off?
I’d definitely appreciate it.
I don’t even know how I ended up here, but I thought this post was great.
I do not know who you are but definitely you’re going to a famous blogger if you are not already 😉 Cheers!
Asking questions are truly nice thing if you are not understanding something totally, except this paragraph gives fastidious understanding yet.
Right here is the right blog for anybody who wants to find out about this topic.
You understand a whole lot its almost tough to argue with
you (not that I actually will need to…HaHa).
You definitely put a new spin on a topic which has
been discussed for many years. Great stuff, just wonderful!
It’s amazing for me to have a site, which is valuable for
my know-how. thanks admin
Thanks , I’ve just been searching for info approximately this
subject for a while and yours is the best I’ve found out so
far. But, what about the bottom line? Are you sure about the supply?
У вас есть удивительно материал
на данный момент. Посетите также мою страничку почивка на остров пукет тайланд
This design is wicked! You most certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really loved what you had to say, and more than that, how
you presented it. Too cool!
I am really loving the theme/design of your site. Do you ever run into
any web browser compatibility problems? A small number of my blog readers
have complained about my website not working correctly in Explorer but looks great in Opera.
Do you have any recommendations to help fix this problem?
This piece of writing will assist the internet
users for setting up new website or even a weblog from start to end.
Informative article, totally what I wanted to
find.
Hello there, just became aware of your blog through Google, and found that it is truly
informative. I’m going to watch out for brussels. I’ll appreciate
if you continue this in future. Lots of people will be benefited from your writing.
Cheers!
I couldn’t resist commenting. Very well written!
Thanks for sharing such a good thinking, paragraph is nice, thats why i have read it entirely
Unquestionably believe that which you stated. Your favorite justification appeared to
be at the net the simplest factor to remember
of. I say to you, I certainly get annoyed even as people consider issues that they just don’t recognize about.
You managed to hit the nail upon the highest and also defined
out the entire thing with no need side effect , other folks could take a signal.
Will likely be again to get more. Thank you
Hello to every one, the contents existing at this site are in fact remarkable
for people experience, well, keep up the good work fellows.
Hello to every , for the reason that I am genuinely eager of reading this webpage’s post to be updated daily.
It includes nice data.
I blog often and I really thank you for your content.
This article has really peaked my interest. I’m going to bookmark your website and keep checking for new details about once per week.
I subscribed to your RSS feed too.
Visit my web page :: fitspresso review
Wonderful article! This is the kind of info that should be shared across the
internet. Shame on the seek engines for now not positioning this post upper!
Come on over and seek advice from my website . Thank you =)
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how can we communicate?
Thanks for sharing your thoughts about best iptv channels list.
Regards
Keep this going please, great job!
We stumbled over here by a different web address and thought I should check things out.
I like what I see so now i’m following you.
Look forward to finding out about your web page repeatedly.
It’s really very complex in this busy life to listen news on TV,
therefore I just use the web for that purpose, and get the hottest information.
Hello colleagues, pleasant piece of writing and fastidious urging
commented here, I am genuinely enjoying by these.
After checking out a handful of the articles on your website, I seriously like your way of writing a blog.
I added it to my bookmark website list and will be checking back
in the near future. Please visit my website as well and let me
know what you think.
I am sure this paragraph has touched all the internet viewers,
its really really good article on building up new website.
You really make it seem so easy with your presentation but I find this
topic to be actually something that I think I would never understand.
It seems too complicated and extremely broad for me.
I am looking forward for your next post, I will try to get the hang of it!
Stop by my web page … hair removal business
Inspiring story there. What happened after?
Take care!
Hello there, I discovered your website by way of Google even as searching for
a similar matter, your web site got here up, it seems to be great.
I have bookmarked it in my google bookmarks.
Hello there, just was aware of your weblog via Google, and found that it’s really informative.
I am going to be careful for brussels. I’ll be grateful for those who proceed this
in future. Many other people will probably be benefited from your writing.
Cheers!
This piece of writing offers clear idea in support of the new users of blogging, that genuinely how to do running a
blog.
Wow, incredible blog structure! How long have you ever been running
a blog for? you make running a blog glance easy.
The overall look of your website is fantastic, as neatly as
the content!
https://tr.gta5-mods.com/users/88betloan
This is my first time visit at here and i am actually pleassant to read everthing at one place.
I am genuinely grateful to the owner of this web site who has shared this fantastic article at at this time.
Also visit my web-site … bikini hair removal machine
Touche. Outstanding arguments. Keep up the great effort.
Nice replies in return of this query with real arguments and describing all about that.
Your method of telling all in this article is in fact good,
all be capable of without difficulty be aware of it, Thanks a lot.
I’m really inspired with your writing abilities and also with the layout on your blog.
Is that this a paid topic or did you modify it yourself?
Either way stay up the excellent quality writing, it’s rare to peer a great blog like this one these days..
Hello there! I could have sworn I’ve been to this blog before but after checking through some of the post
I realized it’s new to me. Anyhow, I’m definitely glad I found it and I’ll
be book-marking and checking back frequently!
Pretty! This has been an incredibly wonderful post. Thanks for providing
this information.
I’m truly enjoying the design and layout of your
blog. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create
your theme? Exceptional work!
Also visit my blog post – hair removal laser for women
Wonderful site. Lots of helpful info here. I’m sending it
to several pals ans additionally sharing in delicious. And obviously, thanks to your sweat!
This is a great tip particularly to those new to the blogosphere.
Brief but very precise information… Appreciate your sharing this one.
A must read post!
Spot on with this write-up, I actually feel this amazing site needs a great deal more attention. I’ll probably be back again to read through more, thanks
for the information!
Fastidious respond in return of this question with real arguments and telling the whole thing regarding that.
I get pleasure from, result in I found just what I used to be looking for.
You’ve ended my four day lengthy hunt! God Bless you man.
Have a nice day. Bye
Fantastic goods from you, man. I’ve be aware your stuff previous to and you’re just too fantastic.
I actually like what you have received right here, certainly like what you’re saying and the way in which through which
you are saying it. You are making it enjoyable and you continue to
take care of to stay it sensible. I can’t wait to learn far more from you.
This is actually a great site.
LUSO Canadian JCT is a multi talented producer & artist! Singing, writing, composing, & producing are just some of his strengths.
Favorite genres are Hip Hop, R&B, Reggaeton, Dance & Old School Euro Freestyle.
Follow on socials @jctofficial7.
If you are going for finest contents like myself, simply
visit this site all the time for the reason that it presents feature
contents, thanks
I am extremely impressed with your writing skills and also with the
layout on your weblog. Is this a paid theme or did you customize it yourself?
Either way keep up the nice quality writing, it’s rare to see a great blog like this one
today.
Unquestionably believe that which you said. Your favorite reason appeared to be on the net the simplest thing
to be aware of. I say to you, I certainly get annoyed while
people think about worries that they plainly do not know
about. You managed to hit the nail upon the top and defined out the whole
thing without having side-effects , people could take a
signal. Will probably be back to get more. Thanks
I know this if off topic but I’m looking into starting my own blog and was
wondering what all is needed to get set up? I’m assuming having a blog like
yours would cost a pretty penny? I’m not very web smart so I’m not 100% positive.
Any tips or advice would be greatly appreciated. Thanks
Excellent blog you’ve got here.. It’s hard to find high quality
writing like yours nowadays. I seriously appreciate individuals
like you! Take care!!
Actually no matter if someone doesn’t understand afterward its up
to other viewers that they will assist, so here it occurs.
You’ve made some really good points there. I checked on the net for more info
about the issue and found most individuals will go
along with your views on this site.
I read this paragraph completely concerning the difference
of most recent and preceding technologies, it’s awesome article.
After looking over a handful of the blog posts on your website, I honestly appreciate your way of writing a blog.
I bookmarked it to my bookmark webpage list and will be
checking back in the near future. Please check out my web site as well
and tell me your opinion.
Spot on with this write-up, I absolutely feel this amazing site needs much more attention. I’ll probably be returning to read
more, thanks for the info!
Helpful info. Lucky me I found your web site accidentally,
and I’m stunned why this twist of fate did not took
place in advance! I bookmarked it.
You actually make it seem so easy with your presentation but I find this matter to be really something which I think I would never understand.
It seems too complicated and very broad for me. I am looking forward for
your next post, I will try to get the hang of it!
These are in fact enormous ideas in concerning blogging.
You have touched some nice factors here. Any way keep up wrinting.
Pretty! This has been an incredibly wonderful article. Thank you for supplying this information.
Wow that was strange. I just wrote an extremely long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again.
Anyways, just wanted to say excellent blog!
Hello there! This is my first visit to your blog!
We are a collection of volunteers and starting a new initiative
in a community in the same niche. Your blog provided
us useful information to work on. You have done a wonderful job!
For hottest news you have to pay a quick visit world wide web and on world-wide-web I found this website as a most excellent site for
most up-to-date updates.
As the admin of this site is working, no doubt very
shortly it will be renowned, due to its quality contents.
Hi there, all the time i used to check website posts here early in the dawn, because i like to find out more and
more.
May I simply just say what a comfort to find
somebody that really understands what they are talking about on the internet.
You certainly understand how to bring a problem to light and make it
important. More and more people really need to check
this out and understand this side of the story. I was surprised that you are
not more popular since you surely possess the gift.
Hello, Neat post. There’s an issue along with your website in web explorer, would check
this? IE nonetheless is the marketplace chief and a huge component of other people will miss your magnificent writing due to this problem.
Everyone loves it whenever people come together and share opinions.
Great website, keep it up!
What’s up to every single one, it’s in fact a pleasant for me to go
to see this site, it includes priceless Information.
I just like the helpful information you provide to your articles.
I will bookmark your weblog and take a look at again right here frequently.
I am quite certain I’ll be told many new stuff right right here!
Best of luck for the following!
Hi there friends, good piece of writing and pleasant urging commented at this place, I am really enjoying by
these.
It’s hard to come by well-informed people for this subject, however, you seem like you know what you’re talking about!
Thanks
Hi there! I could have sworn I’ve been to this site before but after browsing through some of the post I realized
it’s new to me. Anyhow, I’m definitely glad I found it and I’ll
be bookmarking and checking back frequently!
I will immediately grasp your rss as I can not find your
email subscription link or newsletter service. Do you have any?
Kindly allow me recognize in order that I may subscribe. Thanks.
LUSO Canadian JCT is a multi talented producer & artist! Singing,
writing, composing, & producing are just some of his strengths.
Favorite genres are Hip Hop, R&B, Reggaeton, Dance & Old School
Euro Freestyle. Follow on socials @jctofficial7.
Useful information. Fortunate me I discovered your site by accident, and I am shocked why this twist of fate did
not happened in advance! I bookmarked it.
If some one wants to be updated with most up-to-date technologies afterward he must be visit this web page and be up to
date everyday.
This website certainly has all of the information I
needed concerning this subject and didn’t know who to ask.
Way cool! Some very valid points! I appreciate you writing this write-up plus the
rest of the website is very good.
I’m not positive the place you are getting your information, however good topic.
I needs to spend a while learning much more or
understanding more. Thank you for fantastic information I used to be on the lookout for this info for
my mission.
This post will assist the internet people for building up new weblog or even a weblog from start to
end.
I enjoy, result in I found just what I was taking a look for.
You’ve ended my four day lengthy hunt! God Bless you man.
Have a great day. Bye
I’ve been exploring for a little for any high quality articles or weblog posts in this kind of area .
Exploring in Yahoo I eventually stumbled upon this website.
Studying this information So i’m happy to exhibit that
I have an incredibly just right uncanny feeling I came upon exactly what I needed.
I most indisputably will make sure to do not put out of your mind this
web site and give it a glance regularly.
Appreciate the recommendation. Will try it out.
I have read so many articles or reviews on the topic of the blogger lovers except this piece of
writing is truly a pleasant paragraph, keep it up.
Howdy! This post couldn’t be written any better! Going through this post reminds me of my previous roommate!
He constantly kept preaching about this. I most certainly will send this information to
him. Pretty sure he’ll have a great read. Many thanks for sharing!
I am sure this article has touched all the internet people, its really really fastidious post on building up new
blog.
Do you mind if I quote a couple of your posts
as long as I provide credit and sources back
to your weblog? My blog site is in the very same area of interest as yours
and my users would genuinely benefit from a lot of the information you provide here.
Please let me know if this okay with you. Regards!
Very good article. I am going through some of these issues as well..
WOW just what I was searching for. Came here by searching for https://edex.adobe.com/community/member/xQPWVbsv5
Excellent blog! Do you have any tips for aspiring writers?
I’m hoping to start my own website soon but I’m a little
lost on everything. Would you propose starting with a free platform like WordPress or go for a paid option? There are so
many choices out there that I’m totally overwhelmed ..
Any recommendations? Cheers!
Excellent goods from you, man. I have understand
your stuff previous to and you’re just too fantastic.
I really like what you have acquired here, really like what
you’re stating and the way in which you say it. You make it enjoyable and you still care for to
keep it smart. I can’t wait to read much more from you. This
is really a great web site.
A person necessarily help to make critically posts I’d state.
This is the first time I frequented your website page and to
this point? I surprised with the analysis you
made to create this actual post extraordinary. Excellent process!
I have read so many articles about the blogger lovers however this paragraph is genuinely a nice paragraph,
keep it up.
Hi there would you mind letting me know which hosting company you’re using?
I’ve loaded your blog in 3 completely different internet browsers and I must say this blog loads a lot faster then most.
Can you suggest a good hosting provider at a fair price?
Thanks a lot, I appreciate it!
Hi, I think your site might be having browser compatibility issues.
When I look at your website in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, wonderful blog!
My family members every time say that I am killing my time here at web, but I know I am getting knowledge daily by reading such pleasant posts.
Hello there! Would you mind if I share your blog
with my zynga group? There’s a lot of people that I think would really appreciate your content.
Please let me know. Many thanks
Hi there! Do you use Twitter? I’d like to follow you if that would
be okay. I’m undoubtedly enjoying your blog and look forward to new posts.
Hey! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months of hard work due
to no data backup. Do you have any methods to stop hackers?
Pretty portion of content. I simply stumbled upon your website and in accession capital to
assert that I acquire in fact loved account your weblog posts.
Anyway I will be subscribing for your augment and even I success you
access consistently rapidly.
I know this if off topic but I’m looking into starting my own blog
and was curious what all is needed to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% positive.
Any tips or advice would be greatly appreciated. Many thanks
This is very attention-grabbing, You are an excessively skilled blogger.
I’ve joined your rss feed and sit up for searching for more
of your wonderful post. Also, I’ve shared your site in my social networks
Hiya very nice site!! Guy .. Excellent .. Superb .. I’ll bookmark
your website and take the feeds additionally? I’m satisfied to seek
out numerous helpful information right here within the put up, we need work out extra strategies in this regard, thanks for
sharing. . . . . .
Very good blog! Do you have any tips and hints for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost
on everything. Would you propose starting with a
free platform like WordPress or go for a paid option? There are so many options
out there that I’m totally confused .. Any suggestions?
Bless you!
Hello there! I know this is kind of off topic but I was wondering if you
knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems
finding one? Thanks a lot!
Hello! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Many thanks!
Hello, Neat post. There’s a problem with your web site in web explorer,
would test this? IE nonetheless is the market chief and a huge portion of other folks will miss your fantastic writing due
to this problem.
Hi there, just became aware of your blog through Google, and found that it is really informative.
I am gonna watch out for brussels. I’ll be grateful if you continue
this in future. Numerous people will be benefited
from your writing. Cheers!
This article provides clear idea designed for the new people of blogging, that actually how to do running a blog.
Peculiar article, exactly what I was looking for.
Good article! We are linking to this particularly great post on our website.
Keep up the good writing.
Heya i’m for the first time here. I came across this board and I in finding It truly helpful & it helped me
out much. I’m hoping to provide one thing again and help others
like you helped me.
Hey! Someone in my Facebook group shared this website with us
so I came to take a look. I’m definitely loving the information. I’m book-marking
and will be tweeting this to my followers! Terrific blog and terrific design and
style.
I am regular reader, how are you everybody? This post posted at this web page is really good.
Ahaa, its fastidious conversation concerning
this post here at this website, I have read all that, so at
this time me also commenting at this place.
Its like you read my mind! You appear to know a lot about this, like you
wrote the book in it or something. I think that you could do with some pics to drive
the message home a bit, but instead of that, this is
great blog. An excellent read. I will certainly be back.
Hello! I know this is kind of off topic but I was wondering
which blog platform are you using for this website?
I’m getting sick and tired of WordPress because I’ve had issues with hackers
and I’m looking at options for another platform. I would be fantastic if you could point me in the direction of a good platform.
Pretty nice post. I simply stumbled upon your blog and wished to say that
I’ve truly enjoyed browsing your blog posts. After all I
will be subscribing on your feed and I’m hoping you write once more very soon!
Excellent way of telling, and fastidious post to get facts about my presentation subject matter, which i am
going to deliver in academy.
Pretty section of content. I just stumbled upon your website and
in accession capital to assert that I get in fact enjoyed account your blog posts.
Anyway I’ll be subscribing to your feeds and even I achievement you access
consistently fast.
I’ll immediately take hold of your rss as I can not find your
email subscription link or e-newsletter service. Do you have any?
Please let me understand in order that I may subscribe.
Thanks.
Wonderful post! We are linking to this great content on our website.
Keep up the great writing.
Aw, this was an extremely nice post. Taking the time and actual effort to produce a really good article… but what can I say… I hesitate a lot and don’t manage to get anything
done.
Porn online
Remarkable! Its in fact remarkable post, I have
got much clear idea regarding from this piece of writing.
I’m amazed, I have to admit. Rarely do I come across
a blog that’s equally educative and interesting, and without a doubt,
you’ve hit the nail on the head. The problem is an issue that too few people are
speaking intelligently about. Now i’m very
happy that I found this during my hunt for something concerning this.
I delight in, cause I discovered just what I was having a look
for. You’ve ended my 4 day long hunt! God Bless
you man. Have a great day. Bye
Nice post. I was checking continuously this blog and I’m impressed! I care for
I care for
Extremely useful information specially the last part
such info a lot. I was seeking this particular information for a long time.
Thank you and good luck.
Right here is the perfect blog for everyone who would like to find out
about this topic. You know a whole lot its almost hard to
argue with you (not that I actually would want to…HaHa).
You certainly put a brand new spin on a topic that has been discussed for decades.
Wonderful stuff, just great!
I visited multiple blogs except the audio feature for audio songs existing at this web page
is actually wonderful.
I’m truly enjoying the design and layout of your
website. It’s a very easy on the eyes which makes it much more
pleasant for me to come here and visit more often. Did you hire out a
developer to create your theme? Fantastic work!
I visited several websites but the audio quality for audio
songs existing at this web page is in fact wonderful.
Very nice post. I just stumbled upon your weblog and wanted to say
that I’ve really enjoyed surfing around your blog posts.
After all I will be subscribing to your rss feed
and I hope you write again very soon!
I’m impressed, I must say. Rarely do I come across a blog that’s both equally educative and interesting, and let me tell you, you have hit the nail on the head.
The issue is something that not enough folks are speaking intelligently about.
I am very happy that I found this during my search
for something regarding this.
Hi, I think your blog might be having browser compatibility issues.
When I look at your blog in Chrome, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, fantastic
blog!
You’re so cool! I do not believe I’ve read through anything like this before.
So good to discover someone with a few original thoughts on this subject.
Really.. many thanks for starting this up. This website is one thing that’s needed on the internet, someone with a
bit of originality!
Hi there! I’m at work surfing around your blog from my new iphone 3gs!
Just wanted to say I love reading through your blog and look forward to all your posts!
Keep up the great work!
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on numerous websites for about a
year and am worried about switching to another platform.
I have heard fantastic things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be greatly appreciated!
I absolutely love your site.. Excellent colors & theme.
Did you create this web site yourself? Please reply back as I’m trying to create my
own blog and would like to learn where you got this from or just what the
theme is called. Thank you!
you are in point of fact a just right webmaster.
The site loading pace is incredible. It sort of feels that
you’re doing any distinctive trick. Also, The contents are masterwork.
you have performed a excellent activity in this
topic!
My relatives every time say that I am killing my time here at net, however I know I am getting knowledge everyday by reading such nice
posts.
Hello to all, how is everything, I think every one is getting
more from this web page, and your views are fastidious in favor of new viewers.
Amazing issues here. I am very glad to look your article.
Thanks so much and I am taking a look forward to
contact you. Will you please drop me a e-mail?
My spouse and I stumbled over here coming from a different web address and thought I
might check things out. I like what I see so now i am following you.
Look forward to looking into your web page again.
It’s awesome in support of me to have a site, which is beneficial designed for my
knowledge. thanks admin
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an nervousness over that you wish be delivering
the following. unwell unquestionably come more formerly again since exactly the same nearly a lot often inside case you shield this hike.
I read this paragraph fully concerning the difference of hottest
and previous technologies, it’s amazing article.
Heya i am for the primary time here. I found this board and
I to find It truly useful & it helped me out a lot. I hope to
provide something again and help others such as you aided me.
Great post.
Hello there, I think your web site might be having web browser compatibility issues.
Whenever I look at your web site in Safari, it looks fine but when opening
in IE, it has some overlapping issues. I just wanted to give you a quick heads up!
Aside from that, wonderful blog!
Ahaa, its pleasant discussion regarding this article
at this place at this blog, I have read all that, so now me also commenting at this place.
Have you ever considered writing an ebook or guest authoring on other blogs?
I have a blog based on the same information you discuss and would love to have you share some stories/information. I
know my readers would value your work. If you are even remotely interested, feel free to send
me an e-mail.
Heya just wanted to give you a quick heads up and let you know a
few of the pictures aren’t loading correctly. I’m not
sure why but I think its a linking issue. I’ve tried it in two
different browsers and both show the same outcome.
Hey there, I think your website might be having browser
compatibility issues. When I look at your blog in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, awesome blog!
Hi there, You’ve done a fantastic job. I’ll certainly digg it and personally recommend to my friends.
I’m confident they’ll be benefited from this site.
Hi to every one, the contents existing at this site are truly awesome for
people knowledge, well, keep up the good work fellows.
I’m not that much of a internet reader to be honest
but your blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back down the road.
Many thanks
Hi this is kinda of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have
to manually code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience.
Any help would be enormously appreciated!
A person essentially assist to make significantly posts I might state.
That is the first time I frequented your website page
and to this point? I surprised with the analysis you made to make this particular
submit incredible. Fantastic task!
Excellent post. I was checking constantly this I handle such information much.
I handle such information much.
weblog and I’m inspired! Extremely helpful information specifically
the final part
I used to be looking for this certain information for a very long
time. Thanks and good luck.
Great post. I’m experiencing some of these issues as well..
This is very interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your fantastic post.
Also, I have shared your website in my social networks!
Hello there, I discovered your blog via Google whilst looking for a comparable subject, your site got here up, it appears
to be like great. I have bookmarked it in my google bookmarks.
Hello there, just was aware of your blog thru Google, and found that it’s truly informative.
I am gonna watch out for brussels. I will appreciate if you proceed this in future.
Numerous other folks might be benefited out of your writing.
Cheers!
Great information. Lucky me I recently found your blog by accident (stumbleupon).
I’ve saved it for later!
I like the helpful info you provide in your articles.
I’ll bookmark your weblog and check again here regularly.
I am quite certain I will learn many new stuff right here!
Best of luck for the next!
Hello There. I found your blog using msn. This is a really well written article.
I’ll be sure to bookmark it and come back to read
more of your useful information. Thanks for
the post. I will definitely return.
Fastidious answer back in return of this query with genuine arguments and telling all regarding that.
Hello there! Do you use Twitter? I’d like to follow you if that would be okay.
I’m definitely enjoying your blog and look forward to new updates.
my web blog; jogo do tigre
Heya i am for the first time here. I found this board and I in finding
It truly useful & it helped me out a lot.
I am hoping to present one thing again and aid others such as you aided me.
What’s up, I log on to your blogs regularly.
Your humoristic style is witty, keep up the good work!
Hello outstanding blog! Does running a blog such as this require a massive
amount work? I have very little understanding of coding but I
was hoping to start my own blog in the near future.
Anyhow, if you have any ideas or techniques for new blog owners please share.
I understand this is off subject nevertheless I simply had to ask.
Thank you!
Hi there all, here every person is sharing these experience, thus it’s nice to read this web site, and I used to pay a quick visit this webpage everyday.
I need to to thank you for this excellent read!!
I absolutely loved every bit of it. I have you saved as a favorite to check out new things you
post…
Greetings from Los angeles! I’m bored to tears at work so I
decided to check out your site on my iphone during
lunch break. I really like the info you provide here and can’t wait to take a look when I get home.
I’m shocked at how quick your blog loaded on my
cell phone .. I’m not even using WIFI, just
3G .. Anyhow, fantastic blog!
beautiful HD porn
What’s up to every one, the contents present at this web site are really amazing for people experience, well, keep
up the good work fellows.
Oh my goodness! Impressive article dude! Thank
you, However I am going through problems with your RSS.
I don’t know the reason why I am unable to subscribe
to it. Is there anybody getting identical RSS issues?
Anyone who knows the solution can you kindly respond? Thanks!!
whoah this blog is great i love reading your posts.
Stay up the good work! You understand, lots of individuals are looking around for this information, you
could aid them greatly.
Hi there, just wanted to mention, I loved this article.
It was helpful. Keep on posting!
Very energetic post, I loved that a lot. Will there be a part 2?
Hello! Someone in my Facebook group shared this site with us so I came
to give it a look. I’m definitely enjoying the information.
I’m book-marking and will be tweeting this to my followers!
Outstanding blog and outstanding design.
I like the valuable info you provide in your articles.
I’ll bookmark your blog and check again here regularly.
I am quite sure I’ll learn plenty of new stuff right here!
Good luck for the next!
my webpage: fortune tiger
Greetings from Florida! I’m bored at work so I
decided to browse your blog on my iphone during lunch break.
I enjoy the knowledge you provide here and can’t wait to take a look when I get
home. I’m amazed at how fast your blog loaded on my
cell phone .. I’m not even using WIFI, just 3G .. Anyways, excellent site!
Hi, Neat post. There is a problem with your web site in internet explorer, would check this?
IE nonetheless is the marketplace chief and a big component
to other people will miss your magnificent writing because of this problem.
beautiful HD porn
Wow, this piece of writing is pleasant, my younger sister is analyzing these kinds of things, therefore I am going to convey her.
It’s an remarkable article for all the online viewers; they will get advantage from it I am sure.
My brother suggested I may like this website.
He was entirely right. This publish truly made my day.
You cann’t imagine just how so much time I had spent for
this information! Thank you!
Very nice post. I absolutely appreciate this site.
Thanks!
I am curious to find out what blog platform you are utilizing?
I’m having some small security problems with my latest blog and
I would like to find something more secure. Do you have any suggestions?
Hi i am kavin, its my first occasion to commenting anywhere, when i
read this paragraph i thought i could also create comment due to
this good article.
Great delivery. Sound arguments. Keep up the great work.
If some one wants expert view on the topic
of blogging and site-building afterward i recommend him/her to pay a quick visit this blog, Keep up the nice work.
May I simply say what a relief to uncover someone who actually
knows what they are discussing on the net. You definitely realize how to bring a problem to
light and make it important. More people should look at this and understand this side of the
story. I can’t believe you are not more popular given that you most
certainly possess the gift.
Hi would you mind sharing which blog platform you’re using?
I’m planning to start my own blog in the near future but I’m having a tough time choosing between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your layout seems different then most blogs and I’m
looking for something unique. P.S My apologies for being off-topic but I
had to ask!
Hello There. I found your blog using msn.
This is a really well written article. I will be sure to bookmark it and return to read more of your useful info.
Thanks for the post. I’ll definitely comeback.
hey there and thank you for your info – I have definitely picked up
anything new from right here. I did however expertise some technical issues using this site, as
I experienced to reload the site lots of times previous to I could get it
to load properly. I had been wondering if your web host is OK?
Not that I am complaining, but slow loading instances times will often affect your
placement in google and could damage your quality score if ads and marketing with Adwords.
Well I’m adding this RSS to my e-mail and can look out for much more of your respective interesting content.
Ensure that you update this again soon.
Hello to every body, it’s my first go to see of this weblog; this blog contains awesome and truly
good data in support of readers.
Thanks a lot for sharing this with all of us you really understand what you’re talking approximately!
Bookmarked. Please also discuss with my website =).
We can have a hyperlink exchange arrangement among us
I don’t know whether it’s just me or if perhaps everybody
else experiencing issues with your website.
It looks like some of the text in your content are running off the screen. Can someone else
please comment and let me know if this is happening to them as well?
This may be a problem with my internet browser because I’ve had this happen before.
Appreciate it
It is perfect time to make some plans for the longer term and it’s time to be happy.
I’ve learn this put up and if I may just I want to
recommend you some attention-grabbing things or suggestions.
Maybe you can write next articles referring to this article.
I wish to read even more things about it!
My developer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a variety of
websites for about a year and am nervous about switching to another platform.
I have heard excellent things about blogengine.net. Is there a way I
can import all my wordpress posts into it? Any help would be greatly
appreciated!
We are a group of volunteers and opening a new scheme
in our community. Your site offered us with valuable info to work on. You have done a formidable job and our whole
community will be thankful to you.
Spot on with this write-up, I really believe this web site needs a great
deal more attention. I’ll probably be back again to read more, thanks for the information!
If you want to take a great deal from this piece of writing then you have to apply such methods to your won website.
My webpage … Toronto Roofing Cost Estimation
Howdy! Someone in my Myspace group shared this site with us so I came to check it
out. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Exceptional blog and superb design.
Excellent article! We are linking to this particularly great content on our site.
Keep up the great writing.
Please let me know if you’re looking for a author for your
weblog. You have some really good posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d absolutely love to write some
content for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Many thanks!
Thanks in support of sharing such a fastidious idea, paragraph is pleasant, thats why i
have read it completely
An outstanding share! I have just forwarded this onto
a co-worker who has been doing a little homework on this.
And he in fact ordered me lunch due to the fact that I stumbled upon it for him…
lol. So let me reword this…. Thanks for the meal!!
But yeah, thanx for spending the time to talk about this matter here on your
web page.
I’d like to find out more? I’d love to find out more details.
May I just say what a comfort to find a person that actually knows what they’re talking about online.
You definitely realize how to bring a problem to light and make it important.
More and more people really need to read this and understand
this side of the story. It’s surprising you aren’t more popular because you certainly
possess the gift.
I quite like looking through a post that will make people think.
Also, thanks for allowing for me to comment!
Nice post. I learn something new and challenging on blogs I stumbleupon every day.
It will always be interesting to read through articles from other authors and use a little something from
other websites.
Hey just wanted to give you a quick heads up. The words in your post seem to be running off the screen in Ie.
I’m not sure if this is a formatting issue or something to do with browser
compatibility but I thought I’d post to let you know.
The design look great though! Hope you get the issue fixed soon.
Many thanks
Exceptional post however I was wondering if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit further.
Thank you!
I visited multiple websites but the audio quality for audio songs
current at this site is genuinely excellent.
Hi there to every body, it’s my first pay a
quick visit of this webpage; this web site carries awesome and
really good information designed for visitors.
Hello there, You’ve done an incredible
job. I will definitely digg it and personally recommend to my friends.
I’m sure they’ll be benefited from this site.
Pretty section of content. I just stumbled upon your site and in accession capital to assert that I acquire actually enjoyed account your blog posts.
Anyway I will be subscribing to your augment and even I achievement you
access consistently quickly.
Hi, i think that i saw you visited my weblog so i came to “return the favor”.I am attempting to find things to enhance my website!I suppose its ok to use some of your ideas!!
Terrific post however I was wanting to know if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit further.
Thank you!
Way cool! Some very valid points! I appreciate you writing this
article plus the rest of the website is also very good.
This design is steller! You certainly know how to keep a reader
entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really enjoyed what you had to say, and more than that,
how you presented it. Too cool!
I used to be suggested this website by my cousin. I’m no longer sure whether this publish is written by way of him as nobody else
understand such special about my problem. You’re amazing!
Thank you!
I’m not sure exactly why but this weblog is loading extremely slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later and see if the problem still exists.
We absolutely love your blog and find almost all of your post’s to be just what I’m looking for.
can you offer guest writers to write content
in your case? I wouldn’t mind creating a post or elaborating on most of the subjects you
write in relation to here. Again, awesome website!
I just like the valuable information you provide to your articles.
I will bookmark your blog and check again right here frequently.
I’m rather sure I will learn many new stuff right right here!
Good luck for the next!
Hi! I know this is kind of off-topic however
I had to ask. Does operating a well-established website such
as yours take a massive amount work? I’m completely new to
blogging however I do write in my diary daily. I’d like to
start a blog so I can easily share my own experience and thoughts
online. Please let me know if you have any kind of
suggestions or tips for brand new aspiring bloggers.
Thankyou!
These are in fact fantastic ideas in on the topic of blogging.
You have touched some good factors here. Any way keep up wrinting.
I used to be suggested this blog via my cousin. I’m now not certain whether
this post is written by him as no one else know such
precise about my trouble. You’re wonderful!
Thank you!
Hi there to every one, the contents present at this site are truly remarkable for people
knowledge, well, keep up the good work fellows.
Hi there, I enjoy reading through your post. I
like to write a little comment to support you.
Link exchange is nothing else except it is just placing
the other person’s webpage link on your page at proper place and other person will also do same in favor of you.
With havin so much content do you ever run into any issues of plagorism or copyright
infringement? My site has a lot of completely unique content I’ve either created myself or outsourced but it seems a lot of
it is popping it up all over the web without my authorization. Do you know any solutions
to help prevent content from being ripped off?
I’d definitely appreciate it.
Link exchange is nothing else but it is only placing the other person’s weblog link on your page at
appropriate place and other person will also do similar in support of you.
Hello, i feel that i noticed you visited my site so i got here to go back
the choose?.I am trying to in finding things
to improve my web site!I suppose its adequate to make use of some of your ideas!!
Very good information. Lucky me I discovered your site
by chance (stumbleupon). I’ve book-marked it for later!
I think this is one of the most important info for me. And i am glad reading your article.
But want to remark on some general things, The web site style is perfect, the articles is really excellent :
D. Good job, cheers
Good post. I definitely love this website. Keep it up!
I relish, result in I found just what I used to be looking for.
You have ended my four day lengthy hunt! God Bless you man.
Have a nice day. Bye
You’ve made some decent points there. I checked on the internet for more information about the issue and found most individuals will go along with your views on this web
site.
Very good article! We will be linking to this great article on our website.
Keep up the great writing.
Wow, that’s what I was searching for, what a information! present here at this web site, thanks admin of this web site.
Way cool! Some extremely valid points! I appreciate you
writing this write-up and the rest of the website is also
very good.
What’s up, I desire to subscribe for this webpage to obtain newest
updates, thus where can i do it please help.
Hi there, I found your blog by means of Google at the same time as searching
for a related subject, your web site got here up, it seems
to be great. I’ve bookmarked it in my google bookmarks.
Hi there, simply was alert to your weblog through Google, and located that it’s
truly informative. I am gonna be careful for brussels.
I will appreciate if you happen to continue this in future.
Lots of other folks can be benefited from your writing.
Cheers!
Hmm it seems like your blog ate my first comment (it was super long) so I guess I’ll just sum
it up what I submitted and say, I’m thoroughly enjoying your
blog. I too am an aspiring blog writer but I’m still new
to the whole thing. Do you have any helpful hints for first-time blog writers?
I’d definitely appreciate it.
Paragraph writing is also a excitement, if you be familiar with then you
can write if not it is complex to write.
Greetings! I know this is kinda off topic but I
was wondering which blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve had issues with hackers and I’m looking at alternatives
for another platform. I would be awesome if you could point me in the direction of a good platform.
It’s going to be finish of mine day, but before ending I am reading this
enormous article to improve my know-how.
As the admin of this web site is working, no uncertainty very shortly it will
be famous, due to its quality contents.
This excellent website truly has all of the information and facts I needed
about this subject and didn’t know who to ask.
Wow! This blog looks exactly like my old one! It’s on a entirely different topic but it has pretty much the same page layout and design. Superb choice of colors!
Marvelous, what a blog it is! This website gives helpful information to us,
keep it up.
Hi just wanted to give you a quick heads up and let you know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the
same outcome.
Thanks in favor of sharing such a fastidious idea,
post is good, thats why i have read it entirely
Hey there! I know this is sort of off-topic however I needed to ask.
Does building a well-established blog such as
yours require a large amount of work? I’m completely new to running a
blog however I do write in my diary every day. I’d like to start a
blog so I can share my own experience and thoughts online.
Please let me know if you have any kind of recommendations
or tips for new aspiring bloggers. Appreciate it!
I’m gone to inform my little brother, that he should also go to see this
website on regular basis to get updated from most recent
information.
hey there and thank you for your info – I’ve certainly
picked up anything new from right here. I did however expertise some technical points using
this website, since I experienced to reload the
website a lot of times previous to I could get it to load correctly.
I had been wondering if your web host is OK? Not that I am complaining, but sluggish loading instances times will often affect your placement
in google and could damage your quality score if advertising and
marketing with Adwords. Anyway I am adding this RSS to my e-mail and could
look out for a lot more of your respective intriguing content.
Ensure that you update this again soon.
Hi friends, its impressive article concerning educationand entirely defined, keep it
up all the time.
Hiya very nice web site!! Guy .. Beautiful .. Wonderful ..
I’ll bookmark your website and take the feeds additionally?
I’m satisfied to search out numerous helpful information right here within the put up, we’d like
work out more techniques on this regard, thank you for sharing.
. . . . .
Hi, after reading this remarkable article i am too
glad to share my familiarity here with colleagues.
It’s remarkable designed for me to have a website, which is useful
for my knowledge. thanks admin
Good blog post. I absolutely appreciate this site. Keep writing!
Link exchange is nothing else except it is just placing the other person’s webpage link on your page at suitable place and other person will also do same in support of you.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you!
However, how can we communicate?
Just desire to say your article is as astounding. The clarity on your
post is simply excellent and that i could assume you’re a professional on this subject.
Well along with your permission let me to clutch your
feed to keep up to date with imminent post. Thank you 1,
000,000 and please continue the enjoyable work.
Very quickly this web page will be famous amid all blogging and site-building viewers, due to it’s nice articles
I like what you guys are up too. This type of clever work and
reporting! Keep up the terrific works guys I’ve added
you guys to my blogroll.
Have you ever considered creating an ebook or guest authoring on other blogs?
I have a blog based upon on the same ideas
you discuss and would love to have you share some stories/information. I know
my readers would enjoy your work. If you’re even remotely interested, feel free to shoot me an e-mail.
I think this is among the most important information for
me. And i am glad reading your article. But wanna remark on few general things,
The web site style is great, the articles is really nice : D.
Good job, cheers
Hey there just wanted to give you a brief heads up and let you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same results.
Hi there Dear, are you genuinely visiting this web page
on a regular basis, if so then you will absolutely get pleasant knowledge.
Hi I am so thrilled I found your blog, I really found you by accident,
while I was looking on Bing for something else, Regardless I am here
now and would just like to say thank you for a marvelous post and a all
round enjoyable blog (I also love the theme/design),
I don’t have time to browse it all at the minute but I have
bookmarked it and also added in your RSS feeds, so when I have time I will be back to read
much more, Please do keep up the great b.
I love it when folks get together and share opinions.
Great website, continue the good work!
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem
to get there! Thank you
Excellent goods from you, man. I’ve keep in mind your stuff
previous to and you are just extremely excellent. I really like what you’ve received here,
really like what you are stating and the best way wherein you
assert it. You’re making it entertaining and you
continue to care for to stay it wise. I can’t wait to learn much
more from you. This is really a wonderful web site.
Howdy! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good
gains. If you know of any please share. Cheers!
Hey there, I think your blog might be having browser compatibility issues.
When I look at your website in Chrome, it looks fine but
when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, great blog!
Hello there! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My web site looks weird when browsing from my iphone.
I’m trying to find a theme or plugin that might be able to
fix this problem. If you have any recommendations,
please share. Cheers!
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to
do it for you? Plz answer back as I’m looking to construct my own blog and would like to find out where u got this from.
thanks
There’s certainly a lot to find out about this subject.
I really like all of the points you made.
I’m truly enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and
visit more often. Did you hire out a developer to create
your theme? Fantastic work!
Very rapidly this web site will be famous among all blogging users, due to it’s good articles or reviews
Every weekend i used to pay a visit this web page, because i want enjoyment,
as this this web page conations genuinely pleasant funny material too.
I every time emailed this weblog post page to all my contacts, since if like to read
it then my links will too.
Hi there just wanted to give you a brief heads up and let you know a few of the images aren’t loading
properly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the same outcome.
Magnificent goods from you, man. I have remember your stuff prior to and you are just too wonderful.
I actually like what you have bought right here, really like
what you’re saying and the best way through which you say it.
You’re making it entertaining and you continue to take
care of to stay it smart. I can’t wait to learn much more from you.
That is actually a terrific site.
Hello there! Would you mind if I share your blog with my
facebook group? There’s a lot of people that I think would really appreciate your content.
Please let me know. Many thanks
Hey I know this is off topic but I was wondering if you knew
of any widgets I could add to my blog that automatically tweet my newest twitter
updates. I’ve been looking for a plug-in like this for
quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading
your blog and I look forward to your new updates.
An interesting discussion is worth comment. I believe that you ought to publish more about this topic, it may not be a taboo subject but generally people do not speak about these issues.
To the next! Many thanks!!
Hi! I understand this is somewhat off-topic but I needed to
ask. Does building a well-established website such as yours require a massive amount work?
I am brand new to running a blog but I do write in my journal everyday.
I’d like to start a blog so I can easily share my personal experience and thoughts online.
Please let me know if you have any kind of recommendations or tips for brand new aspiring blog owners.
Appreciate it!
What’s up to all, because I am truly eager of reading this website’s post to be updated regularly.
It carries fastidious stuff.
There’s definately a great deal to find out about this
issue. I like all of the points you made.
I was able to find good advice from your content.
I do consider all the ideas you’ve presented on your post.
They’re very convincing and can definitely work.
Still, the posts are very short for newbies. Could you please lengthen them a little from subsequent time?
Thank you for the post.
What’s up mates, fastidious paragraph and pleasant urging commented at this place, I am actually
enjoying by these.
Its like you read my mind! You appear to understand a lot about this, like you wrote the ebook in it or
something. I believe that you just could do with
a few % to drive the message home a little bit, however other than that, that is magnificent blog.
An excellent read. I will definitely be back.
Quality posts is the main to be a focus for the
users to go to see the site, that’s what this web page
is providing.
These are actually wonderful ideas in regarding blogging.
You have touched some nice points here. Any way
keep up wrinting.
You are so cool! I don’t suppose I’ve read something
like this before. So good to find someone with original thoughts on this subject matter.
Seriously.. thank you for starting this up. This site is one thing that is required on the internet,
someone with a little originality!
Hello, its nice article regarding media print, we all
be aware of media is a great source of data.
Yes! Finally something about chicago history.
WOW just what I was searching for. Came here by searching for restaurantes en barcelona
Hello! Do you use Twitter? I’d like to follow you if
that would be okay. I’m undoubtedly enjoying your blog and
look forward to new updates.
Awesome article.
Hi! I know this is kind of off-topic but I needed to ask.
Does building a well-established blog such as yours require a
lot of work? I’m completely new to blogging but I do write in my journal on a daily basis.
I’d like to start a blog so I will be able to share my experience and views online.
Please let me know if you have any kind of suggestions or
tips for new aspiring bloggers. Thankyou!
I blog often and I really appreciate your content.
The article has really peaked my interest.
I will take a note of your blog and keep checking for new details about once per
week. I opted in for your RSS feed as well.
Thank you a lot for sharing this with all folks you really
recognise what you’re talking approximately!
Bookmarked. Please also visit my website =). We may have
a hyperlink alternate arrangement between us
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your site?
My blog site is in the very same niche as yours and my users
would truly benefit from some of the information you present
here. Please let me know if this okay with you. Thank you!
WOW just what I was searching for. Came here by searching for Montreal
apartment movers
Thanks very interesting blog!
Very rapidly this web site will be famous among all blogging visitors,
due to it’s good articles or reviews
Wonderful article! We will be linking to this great content on our website.
Keep up the good writing.
Thanks for the auspicious writeup. It in fact was once a amusement account
it. Glance advanced to more brought agreeable
from you! By the way, how could we communicate?
It’s going to be end of mine day, but before ending I am reading this fantastic
piece of writing to increase my knowledge.
Your way of describing everything in this piece of writing is in fact good, all can effortlessly know it,
Thanks a lot.
hey there and thank you for your information – I’ve certainly
picked up something new from right here. I did however expertise some technical issues using this website,
as I experienced to reload the site many times previous to I could get it to load properly.
I had been wondering if your web hosting is OK?
Not that I’m complaining, but slow loading instances times will very frequently affect
your placement in google and could damage your high quality score if advertising and marketing with Adwords.
Anyway I am adding this RSS to my email and can look out for a
lot more of your respective fascinating content.
Make sure you update this again very soon.
Thank you, I have just been looking for info about this
topic for ages and yours is the greatest
I have discovered so far. But, what in regards to the conclusion? Are you positive
in regards to the supply?
When I initially commented I clicked the “Notify me when new comments are added” checkbox
and now each time a comment is added I get three e-mails with
the same comment. Is there any way you can remove people from that service?
Thanks a lot!
Since the admin of this site is working, no uncertainty very quickly it will
be renowned, due to its quality contents.
Hello there, I discovered your site by means
of Google at the same time as looking for a related subject,
your website got here up, it appears to be like great.
I’ve bookmarked it in my google bookmarks.
Hello there, just become alert to your blog via Google, and found that it’s
really informative. I am gonna be careful for brussels.
I will appreciate in case you proceed this in future.
Many people will be benefited out of your writing.
Cheers!
Hi, i think that i saw you visited my site thus i came to “return the favor”.I’m
attempting to find things to improve my web site!I suppose its ok to use some of your ideas!!
I will immediately seize your rss feed as I can’t
in finding your e-mail subscription link or e-newsletter
service. Do you have any? Kindly permit me know in order that I may just subscribe.
Thanks.
Hey there great blog! Does running a blog
like this require a large amount of work? I’ve virtually
no expertise in computer programming but I had been hoping to start my own blog in the near future.
Anyhow, should you have any ideas or techniques for new blog
owners please share. I understand this is off subject nevertheless I simply had
to ask. Thank you!
Way cool! Some very valid points! I appreciate you writing this write-up and the
rest of the website is also really good.
I’m not that much of a online reader to be honest but your blogs really nice,
keep it up! I’ll go ahead and bookmark your website
to come back in the future. All the best
Greetings, I believe your blog may be having internet browser compatibility issues.
Whenever I take a look at your web site in Safari, it looks fine but when opening in I.E., it has some overlapping issues.
I merely wanted to provide you with a quick heads up!
Apart from that, fantastic site!
hello there and thank you for your information – I have certainly picked up anything new from right here.
I did however expertise some technical points using this web site, since I experienced to reload the site many times previous to I could get it to load correctly.
I had been wondering if your web hosting is OK? Not that I am complaining, but sluggish loading instances times
will very frequently affect your placement in google and could damage
your quality score if ads and marketing with Adwords.
Well I’m adding this RSS to my email and could look out for a
lot more of your respective fascinating content.
Make sure you update this again soon.
Its not my first time to pay a quick visit this site, i am visiting this web page dailly and get fastidious data
from here daily.
Howdy! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly?
My web site looks weird when viewing from my apple iphone.
I’m trying to find a theme or plugin that
might be able to fix this issue. If you have any recommendations,
please share. Thank you!
Everything is very open with a really clear clarification of the
issues. It was truly informative. Your website is very useful.
Many thanks for sharing!
Your style is so unique compared to other people I’ve read stuff from.
I appreciate you for posting when you have the opportunity, Guess I will just book mark this web
site.
Hi, i think that i saw you visited my website thus i came to “return the favor”.I’m attempting to find things to
enhance my web site!I suppose its ok to use some of your
ideas!!
Excellent goods from you, man. I have understand your stuff previous
to and you’re just too fantastic. I really like what
you’ve acquired here, certainly like what you are saying and the way in which you say it.
You make it enjoyable and you still care for to keep it wise.
I can’t wait to read much more from you. This is really a terrific web site.
Hello, I enjoy reading through your article. I wanted to write a little comment to support you.
I feel that is among the such a lot vital info for me.
And i am satisfied studying your article. However wanna statement on some
basic issues, The web site taste is wonderful, the
articles is truly great : D. Excellent process, cheers
Very good post! We are linking to this particularly great article on our
website. Keep up the good writing.
If you would like to grow your knowledge only keep visiting this website and be updated with
the latest gossip posted here.
Good replies in return of this query with real arguments and explaining everything
concerning that.
Ahaa, its good conversation regarding this post here
at this webpage, I have read all that, so at this time
me also commenting here.
I’m extremely pleased to discover this site.
I need to to thank you for your time just for this
wonderful read!! I definitely really liked every part of it and I have
you bookmarked to check out new information in your blog.
I’m not that much of a internet reader to be honest
but your blogs really nice, keep it up! I’ll go ahead and bookmark your
website to come back down the road. Cheers
Hello! I know this is somewhat off-topic but I had to ask.
Does operating a well-established website such as yours take a large amount of work?
I’m completely new to blogging but I do write in my journal on a daily basis.
I’d like to start a blog so I can share my own experience
and views online. Please let me know if you have any suggestions or
tips for brand new aspiring blog owners. Thankyou!
I blog quite often and I truly thank you for your information. The article has really peaked my interest.
I’m going to book mark your blog and keep checking for new details about once per week.
I opted in for your Feed too.
Thank you for sharing your info. I truly appreciate your efforts
and I am waiting for your further write ups thank you
once again.
Your style is so unique in comparison to other people I have read stuff
from. Thank you for posting when you have the opportunity,
Guess I’ll just bookmark this site.
Everyone loves what you guys tend to be up too.
This type of clever work and coverage! Keep up the superb works guys I’ve included you guys to my blogroll.
Howdy! Quick question that’s entirely off topic. Do you know how to
make your site mobile friendly? My blog looks weird when browsing
from my iphone. I’m trying to find a theme or
plugin that might be able to fix this problem. If you have any recommendations, please share.
Appreciate it!
This post will help the internet viewers for building up new blog or even a blog from start to end.
Great blog! Do you have any suggestions for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost
on everything. Would you suggest starting with a free platform like WordPress or
go for a paid option? There are so many options out there that I’m completely overwhelmed ..
Any tips? Appreciate it!
When some one searches for his required thing, thus he/she wants to be available that in detail, thus that thing is maintained over here.
Someone essentially lend a hand to make significantly posts I’d state.
That is the very first time I frequented your website
page and so far? I amazed with the analysis you made to make this particular post extraordinary.
Magnificent process!
Hello! Do you use Twitter? I’d like to follow you if that would be okay.
I’m absolutely enjoying your blog and look forward to new posts.
Oh my goodness! Impressive article dude! Many thanks, However I am encountering problems with your
RSS. I don’t understand the reason why I can’t join it.
Is there anybody else having similar RSS issues? Anyone
that knows the solution will you kindly respond? Thanks!!
I every time emailed this webpage post page to all my contacts, since
if like to read it after that my friends will too.
Thank you for the auspicious writeup. It in fact used to be a entertainment account it.
Look advanced to far delivered agreeable from you!
However, how could we be in contact?
Wow that was odd. I just wrote an really long comment
but after I clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Regardless, just wanted to say superb blog!
This is very interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your magnificent post.
Also, I have shared your site in my social networks!
Hello, its pleasant post about media print,
we all be aware of media is a wonderful source of data.
I was suggested this blog via my cousin. I’m now not certain whether this
submit is written by way of him as no one else realize
such specified approximately my trouble. You’re amazing!
Thank you!
Excellent pieces. Keep writing such kind of information on your site.
Im really impressed by your site.
Hi there, You have performed a great job. I’ll definitely digg it and for my
part suggest to my friends. I am sure they will be benefited from this web site.
Thanks on your marvelous posting! I really enjoyed reading it,
you will be a great author. I will always bookmark your blog
and may come back at some point. I want to encourage you to ultimately continue your great posts, have a nice day!
I’m not sure exactly why but this site is loading extremely slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
I love what you guys are usually up too. This type of clever work and
exposure! Keep up the terrific works guys I’ve incorporated you
guys to my personal blogroll.
Hi there, I discovered your blog by means of Google even as searching for a similar matter, your website came up, it looks good.
I’ve bookmarked it in my google bookmarks.
Hello there, simply become alert to your weblog via Google, and
found that it’s truly informative. I’m going to be careful for brussels.
I’ll be grateful should you continue this in future.
Numerous people will likely be benefited out of your writing.
Cheers!
I think the admin of this web page is really working hard in support of his web page, since here every
data is quality based material.
Thank you for another informative blog. Where else could I am getting that type of info written in such an ideal method?
I have a challenge that I am simply now running on, and I have been at the glance out for such info.
Wow, wonderful blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your web site is fantastic,
as well as the content!
We’re a group of volunteers and starting a new scheme in our community.
Your site provided us with valuable information to work
on. You have done a formidable job and our whole community will be thankful to you.
Hello There. I discovered your blog using msn. That is a really smartly
written article. I’ll make sure to bookmark it
and come back to read more of your helpful info.
Thank you for the post. I’ll certainly comeback.
I’m curious to find out what blog system you are working with?
I’m experiencing some minor security problems
with my latest blog and I’d like to find something more secure.
Do you have any solutions?
Write more, thats all I have to say. Literally,
it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why waste your intelligence on just posting videos to your weblog when you
could be giving us something enlightening to read?
When I originally commented I appear to have clicked the -Notify me when new comments are added- checkbox and now every time a comment is added I
receive four emails with the same comment. Is there an easy
method you can remove me from that service? Thanks a lot!
I just couldn’t depart your website before suggesting that
I actually enjoyed the usual info an individual provide in your guests?
Is going to be back steadily in order to check out new posts
Excellent goods from you, man. I have consider your stuff prior to and you
are simply extremely fantastic. I actually like what you have
acquired here, really like what you are stating and the best way through which you
say it. You make it entertaining and you continue to care for to
keep it sensible. I can’t wait to read much more from
you. That is actually a great website.
If you are going for most excellent contents like I
do, just pay a visit this site everyday for the reason that it gives feature contents,
thanks
What i do not understood is in reality how you’re no longer really much
more smartly-liked than you might be now.
You’re so intelligent. You understand therefore considerably with regards to this
topic, made me in my view imagine it from a lot of numerous angles.
Its like men and women are not interested unless it is one thing to accomplish with Girl gaga!
Your personal stuffs great. Always care for it up!
Inspiring story there. What happened after? Good luck!
You’ve made some really good points there. I checked on the web for more information about the issue and found most
people will go along with your views on this web site.
hey there and thank you for your information – I have definitely picked up
anything new from right here. I did however expertise several technical points using
this site, as I experienced to reload the site many times previous to I could get it to load properly.
I had been wondering if your web host is OK? Not that I am complaining, but sluggish loading
instances times will very frequently affect your placement
in google and could damage your high-quality score
if ads and marketing with Adwords. Anyway I am adding this RSS to my e-mail and can look out for a lot more of your respective exciting content.
Make sure you update this again soon.
It’s great that you are getting thoughts from this
article as well as from our discussion made here.
Good day! This post could not be written any better!
Reading this post reminds me of my old room mate!
He always kept talking about this. I will forward this article to him.
Pretty sure he will have a good read. Thanks for sharing!
Greate pieces. Keep writing such kind of info on your site.
Im really impressed by your site.
Hello there, You’ve performed an incredible job. I’ll certainly digg it and personally recommend to my
friends. I am sure they’ll be benefited from this site.
Hi! Do you know if they make any plugins to help with Search
Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Thank you!
It’s a pity you don’t have a donate button! I’d definitely donate to this fantastic blog!
I suppose for now i’ll settle for bookmarking and adding your
RSS feed to my Google account. I look forward to fresh updates and will talk about this blog with my Facebook group.
Chat soon!
What’s up Dear, are you genuinely visiting this web page on a regular basis,
if so afterward you will absolutely take nice know-how.
Hey very nice blog!
Hey very nice blog!
That is a really good tip especially to those fresh to the blogosphere.
Short but very precise info… Thank you for sharing this one.
A must read post!
Hi my friend! I wish to say that this post is amazing,
great written and include almost all vital infos. I’d like to peer more
posts like this .
I would like to thank you for the efforts you have put in penning this website.
I am hoping to view the same high-grade content from you in the future as well.
In truth, your creative writing abilities has motivated me to get my own, personal site now
😉
This is a great tip especially to those fresh to the blogosphere.
Brief but very precise info… Thanks for sharing this
one. A must read post!
This is my first time pay a visit at here and i am truly pleassant to read everthing at
one place.
I think everything posted made a lot of sense.
But, what about this? suppose you added a little
information? I ain’t suggesting your information is not solid., but what if you added a headline that
makes people want more? I mean Пиастры
– Составление семантического
ядра | is kinda boring. You might glance at Yahoo’s home page and note how they
create article headlines to get people to click. You might add a video or a picture or two to grab people interested about what you’ve written.
Just my opinion, it might bring your blog a little
livelier.
I’ve been browsing online more than 4 hours today, yet I
never found any interesting article like yours.
It’s pretty worth enough for me. In my view, if all site owners and bloggers made good content as you did, the web will be a lot more useful than ever before.
Good day! This is my first visit to your blog!
We are a team of volunteers and starting a new project
in a community in the same niche. Your blog provided
us beneficial information to work on. You have done a wonderful job!
Nice blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really make my blog jump out.
Please let me know where you got your design. With
thanks
We are a group of volunteers and starting a new scheme in our community.
Your site offered us with valuable info to work on. You’ve done a formidable job and our entire community will be thankful to you.
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would
have some experience with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Hello, this weekend is good for me, since this moment i am reading this enormous
informative article here at my house.
Wow that was strange. I just wrote an really long comment but after I clicked
submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Regardless,
just wanted to say superb blog!
Hello There. I found your blog the usage of msn. That is an extremely
well written article. I’ll be sure to bookmark it and return to read
more of your useful information. Thank you for the post.
I’ll certainly comeback.
Fantastic goods from you, man. I have understand your stuff previous to
and you’re just extremely fantastic. I really like what you’ve acquired here,
really like what you’re stating and the way in which you say
it. You make it entertaining and you still care for to keep it sensible.
I can not wait to read far more from you. This is actually
a wonderful site.
You ought to take part in a contest for one of the greatest websites on the internet.
I most certainly will highly recommend this blog!
If you wish for to grow your experience simply keep visiting this website and be updated with the hottest information posted here.
Greetings! Very useful advice in this particular article!
It’s the little changes which will make the greatest
changes. Thanks a lot for sharing!
You actually make it seem so easy with your presentation but I find this topic to be really something which I think I would never understand.
It seems too complicated and very broad for me. I’m looking
forward for your next post, I will try to get the hang of it!
Hey There. I found your blog using msn. This is a really well written article.
I’ll make sure to bookmark it and return to read more of your useful info.
Thanks for the post. I will definitely return.
Thanks for one’s marvelous posting! I really enjoyed reading it, you happen to be a
great author.I will make certain to bookmark your blog and will often come back later in life.
I want to encourage one to continue your great posts, have a nice weekend!
Definitely believe that which you said. Your favorite justification appeared to
be on the net the simplest thing to be aware of.
I say to you, I certainly get irked while people think
about worries that they just don’t know about.
You managed to hit the nail upon the top as well as defined out the whole thing without having
side-effects , people could take a signal. Will likely be back to get more.
Thanks
It’s an awesome piece of writing designed for all the web people;
they will get benefit from it I am sure.
Howdy just wanted to give you a quick heads up. The text
in your post seem to be running off the screen in Internet explorer.
I’m not sure if this is a formatting issue or something to do with internet browser
compatibility but I figured I’d post to let you know. The design look great
though! Hope you get the issue resolved soon. Cheers
I think everything wrote made a lot of sense.
However, think about this, suppose you added a little content?
I am not suggesting your content is not good., but suppose you added something that grabbed people’s
attention? I mean Пиастры – Составление семантического ядра | is
kinda boring. You should peek at Yahoo’s home page and watch how they
write news titles to get viewers interested. You might add a related video or a related pic or two to grab readers excited about everything’ve got to say.
In my opinion, it might make your posts a little livelier.
Heya i am for the first time here. I found this board and I find It truly useful
& it helped me out a lot. I hope to give something back and help others like you aided me.
Hi, its fastidious post about media print, we all know media is a wonderful source of information.
I enjoy what you guys are up too. This type of clever
work and reporting! Keep up the wonderful works guys I’ve you guys to my own blogroll.
Pretty nice post. I just stumbled upon your weblog and wanted
to say that I have really enjoyed browsing your blog posts.
In any case I will be subscribing to your feed and I hope
you write again soon!
Hey there! This post could not be written any better! Reading this post reminds me of my previous room mate!
He always kept chatting about this. I will forward this write-up to him.
Fairly certain he will have a good read. Many thanks for sharing!
Sweet blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
Thanks for sharing your thoughts on https://os.mbed.com/users/michelleobbama/. Regards
Excellent article. Keep posting such kind of information on your blog.
Im really impressed by it.
Hey there, You have done a fantastic job. I’ll certainly digg it
and for my part recommend to my friends. I am sure they will be benefited from this site.
Everything is very open with a really clear explanation of the challenges.
It was really informative. Your site is very helpful.
Thanks for sharing!
You’re so awesome! I do not believe I’ve read something like that before.
So nice to discover someone with some genuine thoughts on this
subject matter. Really.. many thanks for starting this up.
This website is one thing that is needed on the
internet, someone with a bit of originality!
Pretty great post. I just stumbled upon your weblog and wished to mention that I’ve really enjoyed browsing your blog posts.
After all I’ll be subscribing in your feed and I’m hoping you write again very
soon!
ТРЦ
hello!,I like your writing very a lot! proportion we communicate extra about your article on AOL?
I need a specialist in this house to resolve my problem.
May be that’s you! Taking a look forward to see you.
Excellent site. A lot of helpful information here.
I am sending it to several pals ans additionally sharing in delicious.
And of course, thank you to your sweat!
Wow, wonderful weblog format! How lengthy have you been running a blog for?
you make blogging glance easy. The entire glance of your website
is magnificent, let alone the content!
https://assignmenthelpers.org
My spouse and I absolutely love your blog and find almost all of your post’s to be precisely what I’m looking for.
can you offer guest writers to write content
in your case? I wouldn’t mind composing a post or elaborating on a number of the subjects you write in relation to here.
Again, awesome blog!
I have been browsing online more than 3 hours as of late, yet I by no means found any attention-grabbing article like yours.
It is lovely worth sufficient for me. In my
view, if all website owners and bloggers made good content material as you did, the web shall be much
more helpful than ever before.
Thanks for sharing your thoughts about flowforcemaxreviews.
Regards
I’ve been surfing on-line more than 3 hours as of late, yet I
never discovered any attention-grabbing article like yours.
It’s pretty worth enough for me. In my view, if all web owners and
bloggers made just right content as you did, the web might be a lot
more useful than ever before.
Very nice post. I just stumbled upon your weblog and wished to
say that I have really enjoyed surfing around your blog posts.
In any case I will be subscribing to your feed and I hope you write again soon!
It’s in fact very difficult in this active life to listen news on Television, therefore I just use the web
for that reason, and get the newest news.
An impressive share! I’ve just forwarded this onto a co-worker who had been conducting a little homework on this.
And he in fact ordered me breakfast simply
because I discovered it for him… lol. So let me reword this….
Thank YOU for the meal!! But yeah, thanks for spending the time to discuss this subject here on your
internet site.
great put up, very informative. I’m wondering why the opposite experts of this sector don’t realize this.
You should proceed your writing. I am confident, you’ve a huge readers’ base already!
This text is priceless. How can I find out more?
I’ll immediately clutch your rss feed as I can’t in finding your email subscription hyperlink or
newsletter service. Do you’ve any? Kindly allow me realize so that
I may subscribe. Thanks.
What i don’t realize is actually how you are now not really much more well-preferred than you might be now.
You are very intelligent. You understand thus significantly in relation to this topic, produced me individually consider it from so many various angles.
Its like women and men are not interested until it’s something to do with Girl gaga!
Your personal stuffs great. At all times handle it
up!
Useful information. Lucky me I found your site unintentionally, and I’m shocked why this coincidence did not came about earlier!
I bookmarked it.
This is my first time go to see at here and i am genuinely pleassant to read everthing at one place.
Hey! This is my first comment here so I just wanted to give a quick shout out and tell you I really enjoy
reading your articles. Can you suggest any other blogs/websites/forums
that cover the same subjects? Thanks for your time!
Right here is the right website for everyone who hopes to
understand this topic. You understand a whole lot its almost hard to argue with you (not that I really would want to…HaHa).
You certainly put a new spin on a topic that has been written about for years.
Excellent stuff, just wonderful!
There’s definately a lot to learn about this topic.
I really like all of the points you have made.
Terrific work! That is the type of information that are meant to be shared across the
internet. Shame on Google for now not positioning this publish
upper! Come on over and consult with my site .
Thanks =)
Pretty nice post. I just stumbled upon your blog and wished to
say that I have really enjoyed browsing your blog posts.
In any case I will be subscribing to your rss feed and I hope you write again soon!
Do you have a spam problem on this blog; I also am a blogger, and I was wondering your situation; we have created some nice practices and we are looking to trade
solutions with others, be sure to shoot me an email
if interested.
I really like your blog.. very nice colors & theme. Did you make this website yourself
or did you hire someone to do it for you? Plz respond as I’m looking to
create my own blog and would like to find out where u got this from.
thank you
I’ve been browsing online more than 3 hours today,
yet I never found any interesting article like yours. It is pretty worth enough for me.
In my view, if all webmasters and bloggers made good content as you did,
the net will be much more useful than ever before.
Saved as a favorite, I like your site!
Definitely believe that which you stated. Your favorite justification seemed to be
on the web the simplest thing to be aware of.
I say to you, I definitely get annoyed while people think about worries that they plainly don’t know about.
You managed to hit the nail upon the top as well as defined out the whole thing without having side
effect , people could take a signal. Will
probably be back to get more. Thanks
Hello there, You have done a fantastic job. I will definitely
digg it and personally recommend to my friends. I am confident
they’ll be benefited from this web site.
Do you mind if I quote a couple of your posts
as long as I provide credit and sources back to your weblog?
My blog is in the exact same area of interest as yours and my visitors would really benefit from a lot of the information you present here.
Please let me know if this okay with you. Thanks!
Good day very cool website!! Man .. Excellent .. Amazing ..
I will bookmark your web site and take the feeds also?
I am glad to seek out a lot of useful info here in the post,
we’d like develop extra strategies on this regard, thank you for sharing.
. . . . .
Howdy! This is kind of off topic but I need some help from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things
out pretty quick. I’m thinking about making my own but I’m not sure where to begin. Do you have any tips or suggestions?
With thanks
Wow that was strange. I just wrote an very long comment
but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say excellent blog!
Right here is the perfect webpage for anybody who would like to find out about this
topic. You understand a whole lot its almost hard to
argue with you (not that I really would want to…HaHa).
You definitely put a fresh spin on a subject that’s been discussed for a long time.
Wonderful stuff, just wonderful!
Hi colleagues, how is the whole thing, and what you want to say about this article, in my
view its genuinely awesome in favor of me.
I think the admin of this website is in fact working hard
in favor of his web page, since here every stuff is
quality based material.
Thanks very nice blog!
Way cool! Some very valid points! I appreciate you writing this post and also the rest of the site is
also very good.
Heya just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading
properly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the same outcome.
My spouse and I stumbled over here by a
different web page and thought I should check things out.
I like what I see so i am just following you. Look forward
to looking into your web page yet again.
I love what you guys are up too. Such clever work and coverage!
Keep up the wonderful works guys I’ve incorporated you guys to blogroll.
I visit day-to-day some web sites and websites to read content, however
this website presents feature based content.
Do you have a spam problem on this website; I also am a blogger, and
I was wondering your situation; we have created some nice practices and we are looking to swap techniques with other
folks, please shoot me an e-mail if interested.
Way cool! Some extremely valid points! I appreciate you writing this article
plus the rest of the site is very good.
Hey There. I found your blog using msn. This is a very well written article.
I’ll be sure to bookmark it and return to read more of your useful information. Thanks for the post.
I’ll certainly return.
Touche. Great arguments. Keep up the great spirit.
I simply could not leave your site before suggesting that I extremely loved the usual info a person supply to your guests?
Is gonna be again continuously to inspect new posts
Good information. Lucky me I recently found your site by accident (stumbleupon).
I’ve saved it for later!
Hello Dear, are you genuinely visiting this web site regularly, if so afterward you will without doubt take pleasant experience.
Spot on with this write-up, I seriously feel this web site needs a
great deal more attention. I’ll probably be returning to read more,
thanks for the information!
I know this web page presents quality depending articles or reviews and other stuff, is there any
other website which gives such data in quality?
Yes! Finally someone writes about garderie marseille.
You made some really good points there. I checked on the web to
learn more about the issue and found most people will go
along with your views on this website.
Hey I know this is off topic but I was wondering
if you knew of any widgets I could add to my blog
that automatically tweet my newest twitter updates. I’ve
been looking for a plug-in like this for quite some time
and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
Tremendous issues here. I’m very happy to peer your post.
Thanks a lot and I’m taking a look ahead to contact you.
Will you please drop me a e-mail?
hey there and thank you for your info – I have definitely picked up anything new from
right here. I did however expertise several technical points using this web site, since I
experienced to reload the web site lots of times previous to I could get it to load properly.
I had been wondering if your web hosting is OK? Not
that I’m complaining, but sluggish loading instances times will
very frequently affect your placement in google and
can damage your quality score if advertising and marketing with Adwords.
Well I am adding this RSS to my email and could look out for much more of your
respective fascinating content. Ensure that you update this again soon.
Hey there! Quick question that’s entirely off topic.
Do you know how to make your site mobile
friendly? My blog looks weird when viewing from my iphone4.
I’m trying to find a theme or plugin that might be
able to resolve this issue. If you have any suggestions, please share.
Cheers!
It’s really a nice and useful piece of info. I’m happy that you just
shared this useful information with us. Please stay us up to date
like this. Thanks for sharing.
magnificent points altogether, you simply won a emblem new reader.
What would you suggest about your post that you made
a few days ago? Any positive?
Howdy, There’s no doubt that your blog could possibly be having browser compatibility issues.
When I take a look at your site in Safari, it looks fine however,
if opening in I.E., it has some overlapping issues.
I just wanted to give you a quick heads up! Aside from that, wonderful blog!
Do you have a ѕpam isѕie on this blog; I alѕo am a
blogger, and I was wonderng үour situation; we have created sоme nice procedures and
wee are looking to trade solutions wth other folks, wһy not shjoot me
an e-mail if interested. https://info.unsia.ac.id/wp-admin/js/-/?brand=jamuslot
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a coimment is added I
get several e-mails with the same comment. Is there any way you cann remove me from that service?
Thank you!
my homepage :: 카지노사이트
I was able to find good advice from your content.
Greetings! Very helpful advice within this post! It’s the little changes that make the
largest changes. Thanks a lot for sharing!
Heya i’m for the first time here. I found this board and I find It truly useful & it helped me out much.
I hope to give something back and aid others like you helped me.
What’s Taking place i am new to this, I stumbled upon this I have discovered It absolutely helpful and it has helped me
out loads. I am hoping to give a contribution & help other users like its aided me.
Great job.
Hi, I do believe this is an excellent website.
I stumbledupon it 😉 I’m going to return once again since i have saved as a favorite
it. Money and freedom is the greatest way to change, may you be rich and
continue to guide others.
Thanks very nice blog!
Hi, all the time i used to check weblog posts
here in the early hours in the daylight, because i like to find out more and more.
xxx
I must thank you for the efforts you’ve put in penning this
website. I’m hoping to check out the same high-grade blog posts by you in the future as well.
In fact, your creative writing abilities has
motivated me to get my own website now 😉
I love your blog.. very nice colors & theme. Did you design this website yourself or did you hire someone to do
it for you? Plz reply as I’m looking to construct my
own blog and would like to know where u got this from. thanks a lot
When I initially commented I clicked the “Notify me when new comments are added”
checkbox and now each time a comment is added I get several emails with the same comment.
Is there any way you can remove me from that service? Cheers!
magnificent publish, very informative. I wonder why the
opposite experts of this sector do not realize this.
You should proceed your writing. I am sure, you’ve a great readers’ base already!
Someone necessarily lend a hand to make severely posts I might state.
This is the first time I frequented your website page and thus far?
I amazed with the research you made to create this actual put up amazing.
Magnificent activity!
Hello it’s me, I am also visiting this web page regularly, this website is actually good
and the users are genuinely sharing fastidious thoughts.
Your mode of describing all in this article is really good, every
one be capable of without difficulty understand it, Thanks a lot.
hey there and thank you for your info – I have definitely picked up something new from right here.
I did however expertise several technical issues using this website, since I experienced
to reload the site many times previous to I could get it to load properly.
I had been wondering if your web hosting is OK?
Not that I am complaining, but slow loading instances times will very frequently affect your
placement in google and could damage your high-quality score if advertising and marketing
with Adwords. Anyway I’m adding this RSS to my e-mail and can look out for a lot
more of your respective intriguing content. Make sure you update this again soon.
Heya i am for the first time here. I came across this board and
I find It truly useful & it helped me out
a lot. I hope to give something back and help others like you helped
me.
My brother recommended I might like this web site. He was entirely right.
This put up truly made my day. You can not believe simply how a lot time I had spent for this info!
Thanks!
Hi, i believe that i noticed you visited my weblog so
i came to go back the favor?.I’m trying to to find things to enhance my web site!I assume its ok to make use of some of your ideas!!
Oh my goodness! Impressive article dude! Many thanks, However I am encountering problems with
your RSS. I don’t understand the reason why I am unable to join it.
Is there anybody getting identical RSS issues? Anyone that knows the answer will
you kindly respond? Thanks!!
Thanks for sharing your info. I really appreciate
your efforts and I am waiting for your further write ups thank
you once again.
It’s remarkable for me to have a web page, which is good
for my knowledge. thanks admin
My developer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for about
a year and am anxious about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can import all my wordpress content into it?
Any kind of help would be greatly appreciated!
Great post. I used to be checking constantly this weblog and I am impressed! I care for such information much.
I care for such information much.
Extremely useful information particularly the remaining section
I was seeking this particular info for a very long time. Thank you and good luck.
Hi there, just became alert to your blog through Google, and found
that it is truly informative. I’m gonna watch
out for brussels. I will appreciate if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
Ꮋi, i feel that i saw you visited my web site thus i cɑme to return the desire?.I’m trfying to to find іsses to improve my ԝeb site!I suppose
its ok to use some off your concepts!! https://www.misdarululumkotabaru.sch.id/template/?terpercaya=JAMUSLOT
Today, I went to the beach with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She
placed the shell to her ear and screamed. There was
a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off topic but
I had to tell someone!
Your style is very unique compared to other people I have
read stuff from. Many thanks for posting when you’ve got the
opportunity, Guess I will just bookmark this page.
Thanks for sharing your thoughts about restaurantes en barcelona.
Regards
Today, I went to the beachfront with my children.
I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the
shell to her ear and screamed. There was a hermit crab inside
and it pinched her ear. She never wants to go back!
LoL I know this is totally off topic but I had to tell someone!
With havin so much written content do you ever run into any problems
of plagorism or copyright infringement? My blog has
a lot of completely unique content I’ve either created myself or outsourced but it seems a
lot of it is popping it up all over the internet without my agreement.
Do you know any techniques to help stop content from being ripped off?
I’d genuinely appreciate it.
I visited various web pages except the audio quality for audio
songs current at this web page is in fact fabulous.
Hi! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in trading links or maybe guest writing a blog post or vice-versa?
My blog discusses a lot of the same topics as yours and I think we could greatly benefit from each other.
If you might be interested feel free to shoot me an e-mail.
I look forward to hearing from you! Superb blog by the way!
Thanks for sharing your thoughts on EasyDana. Regards
Magnificent beat ! I would like to apprentice while you amend your site,
how could i subscribe for a blog website? The account aided me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided
bright clear idea
Pretty element of content. I just stumbled upon your blog and in accession capital to assert that I
acquire in fact enjoyed account your blog posts. Anyway I
will be subscribing in your feeds and even I
achievement you get admission to persistently quickly.
For the reason that the admin of this web site is working,
no doubt very quickly it will be famous, due to its feature contents.
I got this website from my buddy who shared with me on the topic of this website
and now this time I am visiting this website and reading very
informative articles or reviews at this time.
Hello i am kavin, its my first occasion to commenting anywhere, when i
read this paragraph i thought i could also create comment due to this brilliant post.
Someone essentially assist to make critically posts I might state.
This is the first time I frequented your website page and thus far?
I amazed with the analysis you made to make this particular submit amazing.
Fantastic activity!
What’s Taking place i am new to this, I stumbled upon this I have discovered It
positively helpful and it has helped me out loads.
I hope to contribute & help other users like its helped me.
Good job.
Hi there, I discovered your blog by means of Google while searching for
a similar matter, your website got here up, it seems good.
I have bookmarked it in my google bookmarks.
Hello there, simply changed into aware of your weblog via Google,
and found that it is truly informative. I am going to be careful for brussels.
I’ll be grateful in the event you proceed this in future.
A lot of people shall be benefited out of your writing.
Cheers!
Hello I am so happy I found your blog, I really found you by mistake, while I was researching on Google for something else, Regardless I am here now and would just like to say thanks a
lot for a fantastic post and a all round enjoyable blog (I also love the
theme/design), I don’t have time to browse it
all at the minute but I have book-marked it
and also included your RSS feeds, so when I have time I will
be back to read much more, Please do keep up the superb b.
I used to be recommended this website by means of my cousin. I am
no longer positive whether or not this submit is written by him as nobody else recognize such specified about my trouble.
You are wonderful! Thanks!
You actually make it seem so easy with your presentation however
I find this topic to be actually something which I believe I might by no means understand.
It seems too complicated and very broad for me. I’m taking a look ahead
on your subsequent submit, I’ll try to get the grasp of it!
Hi to every body, it’s my first pay a quick visit of this web site;
this weblog contains amazing and really good material in support of visitors.
Thanks for sharing your thoughts. I truly
appreciate your efforts and I am waiting for your further write ups thank you once again.
I have been surfing online more than 3 hours these days, but I by
no means found any attention-grabbing article like yours.
It is lovely price enough for me. In my view, if all website owners and bloggers made good content
material as you did, the web will probably be much more helpful than ever before.
These are in fact wonderful ideas in on the topic of
blogging. You have touched some pleasant points here.
Any way keep up wrinting.
I got this web site from my pal who shared with me concerning this web site and at
the moment this time I am visiting this web site and reading very informative articles or reviews here.
Good response in return of this query with genuine arguments and telling the whole thing on the topic of
that.
What’s up, everything is going perfectly here and ofcourse every one
is sharing information, that’s really fine, keep up writing.
Great blog! Do you havge aany tips for aspiring writers?
I’m hoping to start myy own website soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or
go for a paid option? Tere are soo many choices out tere that I’m totally confused ..
Anyy suggestions? Applreciate it!
Excellent post. I will be going through a few of these
issues as well..
Your style is really unique compared to other people I have read stuff from.
Thank you for posting when you’ve got the opportunity, Guess I’ll just
book mark this page.
My partner and I absolutely love your blog and find the majority of your post’s
to be just what I’m looking for. Does one offer guest
writers to write content to suit your needs? I wouldn’t mind creating a post or elaborating on a
few of the subjects you write regarding here. Again,
awesome blog!
Hi there to every one, it’s really a nice for me to go to see this web site, it consists of helpful Information.
Hey there! Do you know if they make any plugins to safeguard
against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I
get three e-mails with the same comment. Is there any way you
can remove people from that service? Many thanks!
Hi there! This is my first comment here so I just wanted to give a quick shout out and tell you I genuinely enjoy reading through your
posts. Can you suggest any other blogs/websites/forums that deal with the same topics?
Thanks!
Hello, i believe that i noticed you visited my site so i got
here to return the want?.I’m attempting to in finding things
to improve my web site!I guess its ok to make use of some of your ideas!!
What a information of un-ambiguity and preserveness
of precious knowledge concerning unexpected feelings.
Excellent way of telling, and pleasant paragraph to get data on the topic of my presentation subject matter, which i am
going to deliver in university.
Appreciate the recommendation. Let me try it out.
You need to be a part of a contest for one of the greatest websites online.
I will highly recommend this site!
Do you have a spam issue on this website; I also am a blogger,
and I was wanting to know your situation; many of us
have developed some nice procedures and we are looking to swap methods with other folks,
be sure to shoot me an e-mail if interested.
These are in fact impressive ideas in about blogging.
You have touched some nice things here. Any way keep up wrinting.
Thanks in support of sharing such a fastidious idea, article is pleasant, thats
why i have read it fully
Do you have a spam problem on this site; I also
am a blogger, and I was wanting to know your situation; we have developed some
nice procedures and we are looking to trade methods with others, please shoot me
an e-mail if interested.
I always spent my half an hour to read this web site’s posts
daily along with a mug of coffee.
Howdy! I realize this is somewhat off-topic however I had to ask.
Does operating a well-established website like yours take a large amount of work?
I’m brand new to writing a blog however I do write in my diary every day.
I’d like to start a blog so I can easily share my experience and thoughts online.
Please let me know if you have any kind of ideas or tips for
brand new aspiring bloggers. Thankyou!
Spot on with this write-up, I actually believe this web site needs a great deal more attention. I’ll probably be back again to read more, thanks for the information!
Oh my goodness! Impressive article dude! Thank you, However I am encountering problems with your RSS.
I don’t know why I cannot subscribe to it. Is there anybody getting similar RSS issues?
Anybody who knows the solution will you kindly respond?
Thanks!!
Howdy! I know this is sort of off-topic however I needed to ask.
Does running a well-established blog such as yours take a massive amount
work? I’m brand new to running a blog however I do write in my journal on a
daily basis. I’d like to start a blog so I will be
able to share my personal experience and feelings online.
Please let me know if you have any kind
of suggestions or tips for new aspiring blog owners.
Appreciate it!
Its like you read my mind! You seem to know a lot about
this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message home a little bit,
but instead of that, this is great blog. An excellent read.
I’ll certainly be back.
Very good site you haᴠe here but I ԝɑs
wondering if yoᥙ knew of any message boards that cover the samne topics talked about here?
I’d rеally like to be a part of group where I cɑn get
adνice from other knowledgeable individᥙals that share
the same interest. If you have any suggestions, pleɑse lett me know.
Thanks a lot! https://sister.stai-alyasini.ac.id/jamuslot.html
This is very fascinating, You’re an excessively professional blogger.
I’ve joined your feed and stay up for in the hunt for extra of your magnificent post.
Also, I have shared your site in my social networks
Hi! Quick question that’s entirely off topic. Do you know how to make your site mobile
friendly? My weblog looks weird when viewing from my iphone4.
I’m trying to find a theme or plugin that might be able to resolve this issue.
If you have any recommendations, please share. Cheers!
This text is invaluable. Where can I find
out more?
This article is genuinely a pleasant one it assists new web users, who are wishing for blogging.
I simply could not depart your site prior to suggesting that I really loved the
standard info a person provide for your visitors?
Is gonna be again continuously in order
to investigate cross-check new posts
Very energetic article, I enjoyed that bit. Will there be a part 2?
I have been exploring for a little bit for any high quality articles or weblog
posts in this sort of area . Exploring in Yahoo I finally stumbled upon this web site.
Reading this info So i’m glad to express that I’ve a very good uncanny feeling I discovered just what
I needed. I so much surely will make sure to do not overlook this website and provides it a look on a relentless basis.
Heya! I know this is somewhat off-topic but
I had to ask. Does running a well-established website
such as yours require a lot of work? I am
brand new to blogging but I do write in my journal daily.
I’d like to start a blog so I can easily share my experience and feelings online.
Please let me know if you have any ideas or tips for new aspiring blog owners.
Appreciate it!
Greetings! Very helpful advice in this particular post!
It is the little changes which will make the biggest changes.
Thanks for sharing!
Hi my family member! I want to say that this post is awesome, great written and come with approximately all
vital infos. I’d like to look more posts like this .
We stumbled over here coming from a different web page and thought I might as well check things out.
I like what I see so i am just following you. Look forward to exploring your web page for a second
time.
It’s very straightforward to find out any matter on web as
compared to textbooks, as I found this post at this web site.
Hmm it looks like your website ate my first comment (it was
extremely long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your
blog. I too am an aspiring blog writer but I’m still new to everything.
Do you have any points for inexperienced blog writers?
I’d certainly appreciate it.
I really like your blog.. very nice colors & theme. Did you create
this website yourself or did you hire someone to do it for you?
Plz reply as I’m looking to construct my own blog and would like to find out where u got this from.
thank you
I read this piece of writing completely regarding
the resemblance of newest and earlier technologies, it’s amazing article.
I was suggested this web site by my cousin. I
am not sure whether this post is written by him as nobody else know such detailed about my
trouble. You’re amazing! Thanks!
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an edginess over that you wish be delivering the following.
unwell unquestionably come further formerly again as exactly the same nearly very often inside
case you shield this hike.
Hi there to every one, it’s actually a pleasant for me to go
to see this web page, it consists of precious Information.
If you are going for most excellent contents like myself, only
go to see this site every day as it offers quality contents, thanks
I got this site from my friend who shared with me regarding
this web page and now this time I am browsing this site and
reading very informative articles at this time.
I am really impressed with your writing skills and also with the layout on your weblog.
Is this a paid theme or did you modify it yourself?
Either way keep up the excellent quality writing, it is rare to see a
nice blog like this one today.
I love reading a post that can make people think.
Also, many thanks for allowing me to comment!
It’s a shame you don’t have a donate button! I’d certainly donate to this superb blog!
I guess for now i’ll settle for book-marking and adding your
RSS feed to my Google account. I look forward to fresh updates and will share this website with my
Facebook group. Talk soon!
Definitely imagine that which you said. Your favourite
reason seemed to be at the web the simplest thing to take into
account of. I say to you, I definitely get irked even as other people think about concerns that they plainly do
not recognize about. You managed to hit the nail upon the highest
and also outlined out the whole thing without having
side-effects , people could take a signal. Will likely be again to
get more. Thank you
Hi! I know this is kinda off topic however I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing a blog article or vice-versa?
My blog goes over a lot of the same topics as yours and I think we could greatly benefit from each
other. If you might be interested feel free to send me an email.
I look forward to hearing from you! Superb blog by the
way!
Having read this I thought it was rather informative. I appreciate
you taking the time and effort to put this article together.
I once again find myself personally spending a
significant amount of time both reading and leaving comments.
But so what, it was still worth it!
Quality content is the key to attract the people to pay a visit the web
site, that’s what this web page is providing.
First offf I want tto sayy wonderfᥙl blоg! I haad a qujіck
quеstion iin whjсh I’d like tto assk if yⲟou don’t mind.
I wwas interested too knw howw youu center yoiurself aand cleaqr yopur thoughtss before writing.
I have haad difficuulty cllearing myy mibd iin gettng mmy thoughtts oout there.
I triⅼy do enjoy wrtiting butt itt just seems lke ttһe fiirst 10 too 15 mminutes
are usially wasted jut trying tto figgure օoᥙt howw tto begin. Anyy suggeѕtios orr
tips? Manny thanks!
Feeel fԁee toо surf too my webgpage :: We ᴠߋucch
ffor thios sige – Kareem,
Asking questions are really fastidious thing if you are not understanding anything completely, however
this article gives good understanding even.
I blog often and I genuinely thank you for your content.
This great article has really peaked my interest. I am going to bookmark your site and keep checking for new
information about once per week. I opted in for your Feed as well.
I do not even know the way I stopped up here, however I believed this post was good.
I don’t know who you are but definitely you are going
to a well-known blogger for those who aren’t already. Cheers!
I’m pretty pleased to uncover this website. I need to to thank you for
ones time just for this wonderful read!! I definitely savored every part of
it and i also have you book-marked to look at new things on your site.
That is very fascinating, You are a very skilled blogger.
I have joined your rss feed and look ahead to searching for extra of your fantastic post.
Additionally, I have shared your web site
in my social networks
When someone writes an post he/she keeps the
image of a user in his/her mind that how a user can be aware
of it. Therefore that’s why this paragraph is perfect. Thanks!
Hurrah, that’s what I was searching for, what a data! existing here at this webpage, thanks admin of
this website.
Hi, I do believe this is an excellent blog. I stumbledupon it 😉 I will come back yet again since i have book marked it.
Money and freedom is the greatest way to change, may you be
rich and continue to help other people.
Hello Dear, are you actually visiting this web page on a regular basis,
if so then you will absolutely take good experience.
Excellent post however , I was wondering if you could write a litte more on this subject?
I’d be very thankful if you could elaborate
a little bit further. Thanks!
May I simply say what a relief to find someone that genuinely understands what they are discussing over the internet.
You actually know how to bring an issue to light and make it important.
More and more people have to check this out and understand this
side of the story. I was surprised you’re not more popular given that you most certainly possess the gift.
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how
to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there!
Many thanks
Excellent article. Keep posting such kind of info on your page.
Im really impressed by it.
Hello there, You’ve performed an incredible job. I’ll definitely digg it and individually recommend to my friends.
I’m confident they’ll be benefited from this web site.
Its like you learn my mind! You appear to grasp
so much about this, like you wrote the e-book in it or something.
I feel that you could do with some percent to drive the message house
a bit, but other than that, that is magnificent blog.
A great read. I will definitely be back.
Why visitors still use to read news papers when in this technological globe
everything is accessible on net?
Hello there! Do you know if they make any plugins to assist with Search
Engine Optimization? I’m trying to get my blog to rank for some
targeted keywords but I’m not seeing very good gains.
If you know of any please share. Thanks!
My spouse and I stumbled over here coming from a different web address and thought I might as well
check things out. I like what I see so now i’m following you.
Look forward to checking out your web page repeatedly.
I blog frequently and I really appreciate your
content. This article has really peaked my interest. I’m going
to bookmark your site and keep checking for new information about
once per week. I subscribed to your RSS feed as well.
Hello i am kavin, its my first time to commenting anyplace, when i read this paragraph i thought i could also create comment
due to this sensible post.
After exploring a few of the blog articles on your web site,
I seriously like your way of writing a blog. I bookmarked
it to my bookmark webpage list and will be
checking back soon. Please check out my website as well and let me know
how you feel.
Thank you a lot for sharing this with all of us you really understand what you’re talking approximately!
Bookmarked. Kindly additionally discuss with my site =).
We will have a hyperlink exchange arrangement among us
Fabulous, what a blog it is! This website provides
valuable facts to us, keep it up.
Fine way of explaining, and fastidious paragraph to get information about my presentation subject matter, which i am going to convey in college.
It’s appropriate time to make some plans for the longer term and it’s time to be happy.
I have read this submit and if I may just
I want to counsel you few interesting issues or suggestions.
Maybe you could write next articles relating to this article.
I wish to read even more issues approximately it!
Everyone loves what you guys are up too. Such clever work and exposure!
Keep up the terrific works guys I’ve added you guys to blogroll.
After exploring a handful of the articles on your web
page, I seriously like your technique of blogging. I saved as a favorite it to
my bookmark site list and will be checking back in the near
future. Take a look at my website too and tell me what you
think.
I need to to thank you for this great read!!
I absolutely enjoyed every bit of it. I have got you book marked to check out new stuff you post…
I don’t know whether it’s just me or if perhaps everybody else experiencing issues with your website.
It seems like some of the written text in your content are running off the screen. Can somebody else please provide feedback and let me know if this
is happening to them as well? This could be a issue with my web browser because I’ve had
this happen before. Cheers
It’s truly a nice and useful piece of info. I am glad that you simply shared this useful information with us.
Please stay us up to date like this. Thanks for sharing.
Hello! Would you mind if I share your blog
with my twitter group? There’s a lot of folks that I think would really appreciate your content.
Please let me know. Many thanks
I’m not sure why but this site is loading extremely slow for me.
Is anyone else having this issue or is it a problem on my
end? I’ll check back later and see if the problem still exists.
This design is spectacular! You certainly know how to keep a reader amused.
Between your wit and your videos, I was almost moved
to start my own blog (well, almost…HaHa!) Excellent job.
I really enjoyed what you had to say, and more than that,
how you presented it. Too cool!
What’s up, always i used to check weblog posts here early in the
morning, for the reason that i like to gain knowledge of more and
more.
whoah this weblog is fantastic i like studying your articles.
Stay up the great work! You already know, a lot of people are hunting round for
this info, you could help them greatly.
I love your blog.. very nice colors & theme.
Did you create this website yourself or did you
hire someone to do it for you? Plz reply as I’m
looking to construct my own blog and would like to know where u got this from.
appreciate it
Howdy! I could have sworn I’ve visited this blog before but after going through
a few of the articles I realized it’s new to me.
Anyways, I’m certainly happy I found it and I’ll be bookmarking it
and checking back often!
This page really has all the information and facts I needed about this subject and didn’t know who
to ask.
I do consider all of the ideas you’ve presented on your post.
They’re really convincing and can certainly work.
Still, the posts are very brief for starters.
Could you please prolong them a bit from next time?
Thank you for the post.
What’s up, I check your new stuff regularly. Your story-telling style is awesome, keep doing what you’re doing!
Hi! Would you mind if I share your blog with my twitter group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thanks
whoah this blog is wonderful i like studying your posts.
Keep up the great work! You understand, many individuals are hunting round for this information, you can help them greatly.
I really like what you guys tend to be up too. Such clever
work and reporting! Keep up the wonderful works guys I’ve incorporated you guys to my personal blogroll.
Wonderful beat ! I wish to apprentice while you amend your site, how could i subscribe for a blog website?
The account helped me a acceptable deal. I had been tiny
bit acquainted of this your broadcast provided bright clear
concept
I’m really enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create
your theme? Great work!
Just wish to say your article is as surprising.
The clearness on your publish is simply spectacular and i could assume
you are an expert on this subject. Well along with your permission allow
me to grab your RSS feed to keep updated with imminent
post. Thank you one million and please continue the enjoyable work.
This design is wicked! You obviously know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my
own blog (well, almost…HaHa!) Great job. I really loved what you had to say,
and more than that, how you presented it.
Too cool!
Great post. I used to be checking continuously this weblog and I’m impressed! I
I
Extremely helpful information specially the remaining part
handle such info much. I used to be looking for this certain information for a long time.
Thank you and best of luck.
I got this web site from my buddy who informed me concerning this website and at the moment this time I am
visiting this website and reading very informative articles at this time.
I’m not sure where you’re getting your information, but good
topic. I needs to spend some time learning more or understanding
more. Thanks for great information I was looking for this information for
my mission.
Hello there! This blog post couldn’t be written any better!
Looking at this post reminds me of my previous roommate!
He continually kept preaching about this. I’ll send this information to him.
Pretty sure he’s going to have a good read. Thanks for
sharing!
With havin so much written content do you ever run into any problems of
plagorism or copyright infringement? My website has a lot of unique content
I’ve either authored myself or outsourced but it appears a lot of it is popping it up all over the web without my permission. Do you know any methods
to help prevent content from being ripped off? I’d really appreciate
it.
Touche. Sound arguments. Keep up the great effort.
I am sure this piece of writing has touched all the internet users, its
really really pleasant article on building up new web site.
Wow, marvelous blog structure! How long have you ever
been running a blog for? you make running a blog
look easy. The whole look of your site is excellent, let alone the
content!
Every weekend i used to go to see this site,
for the reason that i want enjoyment, as this this
web site conations genuinely fastidious funny
stuff too.
It’s an remarkable piece of writing in favor of all the online visitors; they will take
advantage from it I am sure.
Whats up very nice blog!! Man .. Beautiful .. Amazing
.. I will bookmark your blog and take the feeds also?
I am happy to search out a lot of useful information here in the publish,
we’d like work out extra techniques in this regard,
thanks for sharing. . . . . .
Wow, fantastic blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of
your web site is fantastic, let alone the content!
I’ve learn several just right stuff here. Definitely price
bookmarking for revisiting. I wonder how so much effort you place to make this type of great informative web site.
I am really inspired together with your writing skills and also with the layout to your blog.
Is that this a paid subject matter or did you customize it your self?
Anyway stay up the nice quality writing, it’s rare to peer a nice blog
like this one today..
I’m extremely impressed with your writing skills as
well as with the layout on your weblog. Is this
a paid theme or did you customize it yourself? Either way
keep up the excellent quality writing, it’s rare to see a great blog like this one
nowadays.
It’s really a great and useful piece of info. I am happy that you simply
shared this helpful information with us. Please stay us informed like this.
Thanks for sharing.
Hello There. I discovered your blog the usage of msn. This is a very
smartly written article. I will be sure to bookmark it and return to learn extra of your useful info.
Thank you for the post. I will certainly comeback.
Excellent blog! Do you have any tips for aspiring writers?
I’m planning to start my own site soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress
or go for a paid option? There are so many choices out there that
I’m completely overwhelmed .. Any tips? Thanks!
Definitely believe that which you said. Your favorite justification appeared to be on the net the easiest thing to be aware of.
I say to you, I certainly get annoyed while people consider worries that they plainly don’t know about.
You managed to hit the nail upon the top and also defined out the whole thing
without having side effect , people could take a signal.
Will probably be back to get more. Thanks
Just wish to say your article is as astonishing. The clearness in your post is simply spectacular and
i could assume you’re an expert on this subject. Fine with your permission let me to
grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please keep up the gratifying work.
Hi it’s me, I am also visiting this web site daily, this site is
truly good and the people are genuinely sharing nice thoughts.
Attractive section of content. I just stumbled upon your
site and in accession capital to assert that I acquire in fact enjoyed account your blog posts.
Any way I will be subscribing to your augment and even I achievement you access consistently fast.
I am not sure where you are getting your information, but
great topic. I needs to spend some time learning much more or understanding more.
Thanks for wonderful information I was looking for this information for my
mission.
What i do not understood is if truth be told how you are not actually a lot more smartly-preferred than you may be right now.
You are so intelligent. You already know therefore considerably in relation to this
matter, made me in my view imagine it from numerous varied
angles. Its like men and women don’t seem to be involved unless it’s one thing to accomplish with Woman gaga!
Your individual stuffs nice. At all times take care of it up!
Hello there, just became aware of your blog through Google, and found that it’s really informative.
I’m gonna watch out for brussels. I’ll appreciate if you continue this in future.
Many people will be benefited from your writing. Cheers!
Incredible points. Sound arguments. Keep up the
great work.
This page definitely has all the information and facts I wanted about this subject and didn’t know who to
ask.
I used to be able to find good advice from your blog articles.
Good write-up. I definitely appreciate this website.
Stick with it!
Hi there, all is going well here and ofcourse every one is sharing information, that’s truly good, keep up writing.
What’s up, all is going sound here and ofcourse every one
is sharing data, that’s actually excellent, keep up writing.
This blog was… how do you say it? Relevant!!
Finally I’ve found something that helped me. Thank you!
I am actually thankful to the holder of this website who
has shared this enormous article at at this time.
Having read this I thought it was extremely enlightening.
I appreciate you taking the time and effort
to put this short article together. I once again find myself personally spending a significant amount of time both reading and posting comments.
But so what, it was still worth it!
Attractive component of content. I just stumbled upon your weblog and in accession capital to claim that I get
in fact loved account your blog posts. Any way I’ll
be subscribing to your augment and even I success you access constantly quickly.
It’s truly a nice and useful piece of information. I’m satisfied that
you just shared this useful info with us. Please keep us informed like this.
Thank you for sharing.
Excellent site. Lots of useful information here. I’m sending it to a few
buddies ans additionally sharing in delicious.
And certainly, thank you for your sweat!
Hey There. I found your blog using msn. This is a really well written article.
I will be sure to bookmark it and come back to read more of your useful information. Thanks for the post.
I’ll certainly comeback.
Yes! Finally someone writes about the growth matrix.
It’s going to be ending of mine day, except before finish I am
reading this impressive paragraph to increase my experience.
Saved as a favorite, I really like your web site!
Hello there! This blog post couldn’t be written much better!
Going through this post reminds me of my previous roommate!
He constantly kept talking about this. I will send this information to him.
Fairly certain he will have a good read.
Thanks for sharing!
I will right away snatch your rss feed as I can not in finding your e-mail
subscription link or e-newsletter service. Do you’ve any?
Please allow me know in order that I could subscribe.
Thanks.
Traditional passports may be replaced by human heartbeats in the future.
Imagine rocking up to an airport and simply walking through security, instead of having to queue up, awkwardly stare
at a camera, and worry about if they’ll make you justify
your new questionable haircut because it doesn’t match
your passport photo.
Well, if you hang in there for 50 more years, easyJet’s 2070:
The Future Travel Report predicts that all you’ll need for
a smooth security check will be your heartbeat. The experts
are forecasting that passengers’ heartbeat signatures, which are unique to each person, will be used
alongside their biometric information to check a person’s
identity.
They also believe that plane seats will be able to adapt
to a person’s body shape, and optoelectronic inflight entertainment will
see content get beamed directly to passengers’
eyes. That’s not all: a language hearing aid will
translate other languages in real-time, making the term ‘language barrier’ a thing of the
past.
Once you arrive at your destination, a tailored hotel
stay will be waiting for you. The experts expect smart rooms that allow
guests to choose their desired bed firmness, room temperature,
and ambient music to be introduced. And, advancements in 3D
printing will mean you can arrive without a suitcase,
as you will simply print the clothes and items you need when you arrive, only to pop them in a recycling bin when returning.
Improved VR headsets are forecasted to make tour guides redundant,
with tourists using their haptic suits and VR headsets to
travel back in time to experience historical sites and learn all the fun facts.
Is travelling about to get a whole lot easier or a whole lot more dystopian?
We’ll leave that up to you.
Hi there to every body, it’s my first pay a visit of this web site;
this web site includes awesome and actually excellent data designed for visitors.
My partner and I absolutely love your blog and find nearly all of your post’s
to be just what I’m looking for. Do you offer guest
writers to write content to suit your needs? I wouldn’t mind producing a post or elaborating
on most of the subjects you write related to here. Again, awesome web log!
Thanks in favor of sharing such a pleasant thinking,
paragraph is good, thats why i have read it fully
I love it when folks come together and share thoughts.
Great website, stick with it!
Hi there! I know this is kinda off topic nevertheless I’d figured
I’d ask. Would you be interested in trading links or maybe guest authoring a blog article or vice-versa?
My site addresses a lot of the same subjects as yours and I feel we
could greatly benefit from each other. If you happen to be interested feel free to send me an e-mail.
I look forward to hearing from you! Great blog by the way!
What’s up it’s me, I am also visiting this website on a regular basis, this web page is genuinely fastidious and the users are genuinely sharing nice
thoughts.
For newest information you have to go to see internet and on web
I found this site as a best web page for newest updates.
It is appropriate time to make some plans for the future
and it’s time to be happy. I have read this post and if I could
I wish to suggest you few interesting things or advice. Perhaps you can write next articles referring to this article.
I desire to read even more things about it!
I know this if off topic but I’m looking into starting my own blog and was wondering
what all is required to get set up? I’m assuming having a
blog like yours would cost a pretty penny? I’m not very internet savvy so I’m not 100% sure.
Any recommendations or advice would be greatly appreciated.
Kudos
Nice post. I used to be checking constantly this blog and I’m inspired! I care
I care
Very helpful information particularly the ultimate phase
for such information much. I was looking for this certain info for a long time.
Thanks and best of luck.
I feel this is among the so much significant info for me.
And i’m happy studying your article. However wanna
commentary on few general things, The website style is perfect, the articles is in reality excellent : D.
Excellent job, cheers
Visit my webpage :: gambling
It’s the best time to make a few plans for the long run and it is time to be happy.
I have learn this post and if I may I want to suggest you few attention-grabbing things or advice.
Perhaps you could write subsequent articles referring to this article.
I want to read even more things approximately it!
Very good blog you have here but I was curious about if you knew of any forums that cover the same topics
discussed in this article? I’d really love to
be a part of online community where I can get advice from other experienced people that share the same
interest. If you have any recommendations,
please let me know. Many thanks!
Attractive portion of content. I simply stumbled upon your web
site and in accession capital to claim that I acquire in fact loved
account your weblog posts. Anyway I will be
subscribing in your augment and even I success you access constantly quickly.
This is a good tip especially to those fresh to the blogosphere.
Brief but very precise info… Thank you for sharing
this one. A must read article!
Ⅴery rapidly this web site wipl Ьe famlus amοng all bllogging visitors, ⅾue to it’s ցood articles oг reviews
Ꭺlso visit mmy webpage … برچسب: دانشگاه، دانشگاه بوعلی سینو، رزرو خوابگاه، دÙتر دانشجویی
I have learn some good stuff here. Definitely price bookmarking for revisiting.
I surprise how much effort you put to make the sort of
wonderful informative website.
I’m not that much of a internet reader to be honest but your blogs really nice,
keep it up! I’ll go ahead and bookmark your website to come back later on. All the best
Greetings! Very useful advice in this particular article!
It’s the little changes that produce the most important changes.
Thanks a lot for sharing!
Hey I know this is off topic but I was wondering if you knew
of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe
you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
Here is my web site :: xanex
I am curious to find out what blog platform you’re using?
I’m experiencing some small security problems with my latest site and
I’d like to find something more safeguarded. Do you have any recommendations?
This is really attention-grabbing, You’re an overly skilled blogger.
I have joined your feed and look ahead to in search of more of your
fantastic post. Also, I’ve shared your web site in my social networks
Feel free to visit my web page; comment-248975
I’ve been exploring for a little for any high quality articles or weblog posts in this kind of house .
Exploring in Yahoo I eventually stumbled upon this website.
Reading this info So i’m satisfied to express that I have a
very good uncanny feeling I found out just what I needed.
I such a lot no doubt will make sure to do not overlook this website and provides it a glance on a continuing basis.
I think this is one of the most important info for
me. And i am glad reading your article. But wanna remark on some general things, The web
site style is perfect, the articles is really nice : D. Good job, cheers
Hello to every , for the reason that I am really eager of reading
this webpage’s post to be updated daily. It consists of nice data.
my webpage; black jack
Hi there, You have done a great job. I’ll certainly digg it
and personally recommend to my friends. I’m sure they’ll be benefited from this
site.
First off I would like to say fantastic blog!
I had a quick question that I’d like to ask if you don’t
mind. I was interested to find out how you center yourself and clear your mind prior
to writing. I have had difficulty clearing my mind in getting my ideas out
there. I do enjoy writing however it just seems like the first 10 to 15 minutes tend to be lost just trying to
figure out how to begin. Any ideas or hints? Cheers!
I used to be able to find good information from your articles.
I’ve been surfing online more than 4 hours today, yet I never found
any interesting article like yours. It is pretty worth enough for me.
Personally, if all web owners and bloggers made good content as
you did, the internet will be much more useful than ever before.
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs. But he’s tryiong none
the less. I’ve been using Movable-type on several websites for
about a year and am anxious about switching
to another platform. I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any help would be really appreciated!
Normally I don’t read article on blogs, however I would like to say that this write-up very pressured me to try and
do so! Your writing style has been surprised me.
Thank you, quite nice article.
Appreciate this post. Will try it out.
This is really interesting, You are an overly skilled blogger.
I have joined your feed and look forward to in search of extra of
your magnificent post. Additionally, I’ve shared your web site in my social networks
I just like the helpful info you supply in your articles.
I’ll bookmark your weblog and test once more here frequently.
I am relatively certain I’ll learn many new stuff right
right here! Good luck for the following!
Every weekend i used to go to see this website, for the reason that i want enjoyment,
since this this web site conations actually nice funny stuff too.
Wow that was strange. I just wrote an extremely long comment but after I clicked submit my comment
didn’t show up. Grrrr… well I’m not writing all that
over again. Regardless, just wanted to say wonderful blog!
This is a topic that’s near to my heart… Many thanks! Exactly where are your contact details though?
Excellent weblog here! Additionally your site lots up
fast! What host are you using? Can I get your
affiliate link on your host? I want my web site loaded up as quickly as yours lol
I’m really loving the theme/design of your blog. Do you ever run into
any web browser compatibility issues? A small number of my
blog visitors have complained about my blog not working correctly in Explorer but looks
great in Opera. Do you have any recommendations to help fix this issue?
Hi there, this weekend is good in favor of me, as this time i am reading this wonderful informative article
here at my residence.
Hi there would you mind stating which blog platform you’re using?
I’m going to start my own blog soon but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking
for something unique. P.S Apologies for being off-topic but I had to ask!
Hi! I understand this is sort of off-topic but I needed to ask.
Does running a well-established website such as yours
take a massive amount work? I’m completely new to operating a blog however I do write in my journal
on a daily basis. I’d like to start a blog so I can share my
personal experience and views online. Please let me know if you have any recommendations or tips for new aspiring bloggers.
Thankyou!
Hi tһere fantaѕtic bⅼog! Does running a blog such as this take a large amount of work?
I һave noo expertise in programming but
I was hopіng to start my own blog in the near future.
Anyway, іf you have any recommendations oг techniques forr
new bpog owners please shaгe. I understand thiis is off topic however
I simply wanteⅾ to ask. Thank you! https://pimpinan.kalbarprov.go.id/backend/assets/?products=jamuslot
I do not even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re going to a famous blogger if you are not already 😉 Cheers!
I don’t even understand how I stopped up here, however I thought this put up used to
be good. I don’t recognize who you might be but certainly you’re going to a famous blogger when you aren’t already.
Cheers!
My programmer is trying to convince me to move to
.net from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a variety of websites for about a year and am worried about switching to
another platform. I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any help would be really appreciated!
Hello! This is my first visit to your blog!
We are a group of volunteers and starting a new project in a community in the same niche.
Your blog provided us beneficial information to work on. You
have done a wonderful job!
It’s an awesome piece of writing in support of all the web
viewers; they will get advantage from it I am sure.
I have been exploring for a little bit for any high-quality articles
or weblog posts on this kind of space . Exploring in Yahoo I eventually
stumbled upon this site. Studying this info So i’m satisfied to show that I have a very good uncanny feeling I found out
just what I needed. I most no doubt will make certain to do not forget this site and give it a glance on a continuing basis.
I enjoy, lead to I found exactly what I used to be looking for.
You’ve ended my four day lengthy hunt! God Bless you man. Have a nice day.
Bye
Also visit my blog post; black jack
You actually make it seem so easy with your presentation but I find this matter to be really something that I think I would never understand.
It seems too complicated and extremely broad for me.
I’m looking forward for your next post, I will try
to get the hang of it!
I used to be suggested this blog through my
cousin. I am no longer sure whether this put up is written via him
as nobody else know such unique approximately my difficulty.
You are amazing! Thank you!
Link exchange is nothing else however it is just placing the other person’s website link on your page at suitable place
and other person will also do same in favor of you.
Fastidious replies in return of this query with genuine arguments and describing
the whole thing on the topic of that.
I’m curious to find out what blog platform you are working with?
I’m experiencing some small security problems with my
latest site and I’d like to find something more safeguarded.
Do you have any suggestions?
I always used to read post in news papers but now as
I am a user of web thus from now I am using net for posts, thanks to web.
Simply wish to say your article is as astounding.
The clearness in your post is simply great and that i can suppose you’re knowledgeable in this
subject. Fine with your permission allow
me to clutch your feed to stay up to date with drawing close
post. Thanks a million and please continue the rewarding work.
Feel free to visit my homepage: کون دادن
Attractive part of content. I just stumbled upon your web
site and in accession capital to assert that I acquire in fact enjoyed account your weblog posts.
Anyway I’ll be subscribing in your feeds or even I fulfillment you get admission to persistently rapidly.
Hey there, You have done an excellent job. I’ll definitely digg it and personally
recommend to my friends. I’m confident they will be benefited
from this site.
It’s appropriate time to make a few plans for the longer
term and it is time to be happy. I’ve read this put up and
if I could I wish to recommend you some attention-grabbing issues or advice.
Perhaps you can write subsequent articles relating to this article.
I wish to read even more things approximately it!
We are a group of volunteers and opening a new scheme in our community.
Your website offered us with valuable information to
work on. You’ve done an impressive job and our
entire community will be grateful to you.
If some one needs expert view concerning running a blog then i suggest him/her to pay a visit
this website, Keep up the fastidious work.
You have made some really good points there. I checked on the net for more
info about the issue and found most people will go
along with your views on this website.
Does your website have a contact page? I’m having
trouble locating it but, I’d like to shoot you an e-mail.
I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it expand over time.
Thank you for any other fantastic article. The place else may anyone get that kind of info in such a perfect way
of writing? I’ve a presentation next week, and I’m on the look for such information.
What i don’t understood is in fact how you’re now not actually a lot
more smartly-liked than you may be now. You are so intelligent.
You know thus significantly when it comes to this topic, produced me personally consider it from so many various angles.
Its like men and women are not interested unless it is something to do with
Lady gaga! Your personal stuffs nice. Always deal with it up!
For the reason that the admin of this site
is working, no doubt very soon it will be well-known, due
to its feature contents.
I am regular reader, how are you everybody?
This post posted at this web site is in fact pleasant.
If you would like too grow your experience just keep visiting this web site and be updated with the hottewst gossip posted here.
Here is mmy webpage 카지노사이트
you are in point of fact a excellent webmaster.
The web site loading velocity is incredible. It seems that you are doing any distinctive trick.
In addition, The contents are masterwork. you’ve performed
a magnificent task in this topic!
Fantastic beat ! I would like to apprentice while you amend your website, how can i subscribe for a blog website?
The account helped me a acceptable deal. I had been tiny bit acquainted of
this your broadcast offered bright clear idea
Thanks very interesting blog!
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
Marvelous, whatt a website itt is! Thiss blog presents helpful data to
us, keep iit up.
Hey I know this is off topic but I was wondering if you knew of any widgets I
could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for
quite some time and was hoping maybe you would have some experience with
something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new
updates.
An outstanding shaгe! I’ve just forwwarded this onto a coworker who
haad been сondᥙcting a littⅼe research оn this.
Ꭺnd hee actually ordered me lunch simply because I foundd it for him…
lol. So let me гeword this…. Thank YOU for the meal!!
But yeah, thanx for spending some time to discuss this isse here օn your bloɡ. http://pbb.Muaraenimkab.go.id/inc/PBB/upload/products/shop/zgacor/?link=jamuslot
Heyya i am foor the primary tijme here. I came across this board annd I in finding It really useful & it helped me out much.
I hope tto offerr one thin back and aiid others like you aided me.
Patti Smith hosted a new York screening of Corsage last week, certainly one of many showings because the Oscar-shortlisted Greatest
International Feature contender premiered to a warm welcome in Cannes,
the place it gained Finest Efficiency, Un Sure Regard, for star
Vicky Krieps because the Empress Elisabeth of Austria, Sisi
for short. Comfort – based on overall statistics on this regard, the top most incentive behind buying
European lingerie is comfort. The statistics we present is regularly freshed up as it is far
regulated via algorithms and technology. Irrespective of if it’s your first or hundredth date collectively, he’s all the time going to look up to you and your dressing
sense. Listed here are plenty of the information that could be helpful for you
and might come to your support in dressing you up beautifully.
Here’s a modest initiative to help a man to seek out
out the proper measurement and have an ideal
expertise of lingerie purchasing. Being an adult,
you must ponder upon the design of the lingerie you could be pairing up your dress with.
If you’re pairing up your designer LBD with a shabby
intimate wear then that is a big blunder which should by no means be
finished.
Great post. I was checking constantly this blog and I am impressed! I care for such info much. I was looking for this
I care for such info much. I was looking for this
Very helpful information particularly the last
part
particular info for a long time. Thank you and good luck.
Greetings, I do think your blog could possibly be having browser compatibility issues.
Whenever I look at your site in Safari, it looks fine however when opening
in Internet Explorer, it has some overlapping issues.
I simply wanted to provide you with a quick heads up!
Besides that, great site!
Very good article. I definitely love this website. Keep writing!
I’m really enjoying the theme/design of your weblog.
Do you ever run into any browser compatibility issues?
A small number of my blog readers have complained about
my website not operating correctly in Explorer but looks great in Opera.
Do you have any tips to help fix this issue?
This piece of writing offers clear idea for the
new viewers of blogging, that really how to do running
a blog.
I needed to thank you for this very good read!! I certainly loved every bit of it.
I have got you book-marked to check out new things you post…
Having read this I thought it was very informative. I
appreciate you spending some time and energy to put this article
together. I once again find myself spending a significant amount
of time both reading and leaving comments. But so what, it was still worth it!
I know this site presents quality based posts and other material, is there any other
web site which presents such data in quality?
Why viewers still make use of to read news papers
when in this technological world everything is presented on net?
Magnificent beat ! I wish to apprentice even as you amend your website, how can i
subscribe for a weblog website? The account aided me a applicable deal.
I were tiny bit familiar of this your broadcast provided vivid clear concept
I’ve learn several just right stuff here. Definitely price bookmarking for revisiting.
I surprise how a lot effort you place to make the sort of
wonderful informative website.
Way cool! Some very valid points! I appreciate
you penning this write-up and also the rest of the site is very good.
I’ve been surfing on-line more than 3 hours these days,
but I never discovered any fascinating article like yours.
It is beautiful price enough for me. Personally, if all webmasters and bloggers
made good content material as you probably did, the internet shall be much
more helpful than ever before.
WOW just what I was looking for. Came here by searching for dow Jones live
Howdy I am so delighted I found your webpage, I really found you
by error, while I was searching on Digg for something else, Regardless I am here now and
would just like to say cheers for a tremendous post
and a all round thrilling blog (I also love the theme/design),
I don’t have time to look over it all at the moment but I
have book-marked it and also added in your RSS feeds, so when I have time I will be back to read more, Please do keep up the superb work.
They must look for the appropriate dimension then the fitting materials then they must attempt
it on and then purchase the piece of lingerie.
Before deciding the place to purchase a corsage or
a boutonniere, you need to all the time decide when it
comes to the completely different styles and varieties.
The white dendrobium orchid corsage is a popular choice as a result of it complements a
wide range of dress colors and types. The lingerie that is on the market in plus sizes can be found in varying kinds and
also in several price ranges. Bridal lingerie is offered
in an array of designs, styles, fabrics and value ranges.
Bridal lingerie, which is worn underneath the marriage dress, includes bridal bras, bridal bustiers, long line bras,
panties and bridal corsets. You need to shop for the most unique
gown, glamorous make-up and hairstyle and at last all you want
are corsages and boutonnieres. We are going to ensure
that you just get premium high quality cheap corsages and boutonnieres that
may make your evening memorable. Doing this would require some time and planning to get
a proper choice.
Thanks for finally talking about > Пиастры – Составление семантического ядра | < Liked it!
Pretty nice post. I just stumbled upon your blog and wished to say that I have truly enjoyed surfing around your blog
posts. After all I will be subscribing to your rss feed
and I hope you write again soon!
I used to be able to find good information from your articles.
I am actually thankful to the owner of this web site who has shared this wonderful article at at this place.
Thanks on your marvelous posting! I really enjoyed reading it, you may be a great author.I will be sure to bookmark your blog and may come back in the future.
I want to encourage that you continue your great writing, have
a nice holiday weekend!
I want to to thank you for this good read!! I certainly loved every bit of it.
I have you book-marked to check out new things you post…
I was able to find good advice from your blog posts.
Lastly, it’s essential to contemplate the occasion when selecting between a corsage and nosegay.
These dresses match snugly yet comfortably, because of their stretch properties, and
might be dressed up or down depending on the occasion. There is not any must
settle for the white basic bras, white can show by a lot
of colours. Our materials are accompanied by a wide assortment of
colors. Most costly bras are supplied by Hanky Panky (but there are solely 15 bras in whole).
There are additionally babydolls which have an open or “fly-away” front,
exposing your stomach, or a fly-away again, exposing your again and rear.
Don’t worry; I’ve got your back, or ought to I say, your entrance?
A woman who is carrying a sizzling lingerie piece like the way she gazes at the mirror and knows effectively
the she is trying merely hot and gorgeous. You may make use of
sexy corsets and even enticing camisoles and even any enticing plus-size lingerie for example
in addition to show-off the physique in a means which are your individual property tend to be appropriately outlined
plus your pressured components hid. The right measurements could be done by the professionals.
Magnificent web site. Plenty of useful information here.
I’m sending it to several pals ans additionally sharing in delicious.
And obviously, thanks to your effort!
Everyone loves what you guys are usually up too. This sort of
clever work and reporting! Keep up the awesome works guys I’ve incorporated you guys to my own blogroll.
Hi, its fastidious piece of writing on the topic of
media print, we all be aware of media is a impressive source of data.
I loved as much as you will receive carried out right
here. The sketch is tasteful, your authored material stylish.
nonetheless, you command get bought an nervousness over that you wish be
delivering the following. unwell unquestionably come more formerly again since exactly the
same nearly very often inside case you shield this hike.
I like the helpful information you provide for your articles.
I will bookmark your weblog and test once more here frequently.
I’m slightly certain I’ll be informed lots of new stuff proper here!
Good luck for the next!
I have been exploring for a bit for any high-quality articles or
weblog posts in this sort of house . Exploring in Yahoo I ultimately stumbled
upon this web site. Reading this information So i’m happy to show that I have an incredibly
just right uncanny feeling I found out just what I needed.
I such a lot certainly will make certain to do not forget this site and give it a look on a constant basis.
Spot on with this write-up, I actually believe that this amazing site needs much more attention. I’ll probably be back again to
read through more, thanks for the information!
Hi, There’s no doubt that your website could be having internet browser compatibility issues.
When I look at your website in Safari, it looks fine however, if opening in IE, it’s got some overlapping issues.
I merely wanted to provide you with a quick heads up!
Aside from that, wonderful blog!
Awesome article.
Single ladies are among a wider vary of who love the girls’s lingerie.
Perfect for ladies who favor to put on low waist denims, ladies, who have a hourglass determine, can with out a
lot of a stretch can wear this panty. Shopping for lingerie on-line could make this
expertise even simpler for men. Make a sexy statement with a lace bodysuit or longline bra under
your jacket. These bra underwear lingerie storage box are available in a vast variety of sizes and materials, providing shoppers with multiple choices for optimal storage
and convenient space administration. Marriage ceremony lingerie, panties, and bras
are known to be part of the underwear and makes them appear and
feel special. This is likely one of the beauties of most wedding
ceremony lingerie, which comes in different colors,
fabric, types and sizes. The actual fact can’t be denied that most males do like to see carrying lingerie, get pleasure from love putting on .
At present girls are no extra reluctant in shopping for
lingerie in markets and that to in entrance of the male gross sales males.
Buying lingerie for women can usually be a daunting process for men. You may get excellent salon store fitters
here.
Entire Blossoms is top-of-the-line places to avail the quickest bridal corsage supply.
In the event you waited till the last minute, identical-day
supply by an FTD florist is out there in most areas.
Which style of briefs should you put on if in case you have a
spherical tummy ? Unfortunately, as a result of their delicate
nature flowers can start to look a little bit worse for put on after the primary photograph.
So, for instance, you could possibly embody green plants in addition to flowers.
See if you can work out your body form and your lingerie
style that matches effectively. If you have barely ‘chubby’ buttocks, go for a design that provides you better coverage (full briefs or shorties) that can sculpt your form and smooth out any lumps and
bumps as lengthy because the elastic sits in the crease of your buttocks.
However, all of this doesn’t imply that
you should have a flat bottom as you might well nonetheless
be blessed with a curvy behind. It’s also an excellent suggestion to include the
grandmothers as well. Sophisticated and unique, Lise Charmel’s lingerie combines elegance
and good taste in the very best European method.
A garment that sits tightly to your hips is one among the best ways to maintain your form without
including any extra curves.
Do you mind if I quote a few of your articles as long as I provide
credit and sources back to your webpage?
My blog site is in the exact same area of interest
as yours and my visitors would certainly benefit from some
of the information you present here. Please let me know if this ok
with you. Cheers!
August 25, 2012 It at all times scares me to try and pin a
corsage on somebody. If it’s a reliable on-line store then it will have all of
the important data regarding its business and they’ll try to make their customers perceive their authenticity.
Now that you already know how one can make a succulent corsage,
are you going to attempt it? Chrysanthemums and gerber daisies are standard among youthful girls
for events like prom and homecoming. A preferred different to a conventional corsage is a wrist corsage, especially for girls who do
not wish to poke pins by means of their dresses.
For this wrist corsage, we’re utilizing three cymbidium orchids.
Within the Vaud cantonal faculty system, two years of non-obligatory pre-school are supplied by
the political districts. After World War II, easy
homecoming corsages began to be adorned with ribbons in school colours
to signify faculty spirit. These corsages can also
be prepared a day prematurely. And if you’re looking for
a particular lady in your life, you’ll be happy to know that each merchandise we
sell comes fastidiously hand-packaged in our signature wrapping,
so it’s already gift-wrapped and ready to go for birthdays, anniversaries, Valentine’s Day and
other particular events.
I got this website from my friend who informed me concerning this site and at the moment this time I
am browsing this web page and reading very informative content at this time.
I dugg some of you post as I thought they were invaluable invaluable.
my site :: where can i watch movies on the web (http://www.activewin.com/user.asp?Action=Read&UserIndex=4398862)
This makes wrapping your corsage in tape and ribbon a lot simpler
later on. There may be a number of technical “right and wrong” methods to do issues, however at the tip of the day
it’s your art. Or, rock plus-dimension leggings that permit
unrestricted movement and an entire lot of model.
Begin by ordering wholesale flowers, or a DIY
combo pack that matches your colors and elegance. Tropical flowers, similar to orchids, Anthuriums and Calla lilies, are additionally one of the floral
fads this year. 4. Consider different choices: If you’re uncertain about pinning a corsage, there are other
options accessible. When creating a wrist corsage, attach your arrangement
to a wristlet. When making a pin-on corsage, add a pin to your
ribbon-tied stems. Equally to the How to Make a Boutonniere tutorial above, your design process will begin by reducing the stems of
your flowers and greenery right down to 1.5 inches
in size. Creating your DIY corsage will look much like creating a boutonniere at first.
Plus, learning methods to make corsages and boutonnieres will provide you
with confidence to move forward with the remainder of your DIY flower arrangements and different initiatives!
Corsages and boutonnieres will make you or anyone carrying them feel necessary, and we encourage you to design with your individual creative aptitude.
Wow! After all I got a blog from where I can truly obtain helpful
data concerning my study and knowledge.
Truly no matter if someone doesn’t understand then its up to other people
that they will help, so here it occurs.
Does your website have a contact page? I’m having a tough time locating it
but, I’d like to shoot you an e-mail. I’ve got some ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it grow over time.
Quality posts is the crucial to be a focus for the viewers
to pay a visit the website, that’s what this web site is providing.
I have been exploring for a little for any high-quality articles or weblog posts on this sort of area .
Exploring in Yahoo I at last stumbled upon this site.
Studying this information So i’m satisfied to express that I have a very good uncanny feeling I came upon exactly what I needed.
I so much surely will make certain to do not put out of your mind this website and give it a glance on a relentless
basis.
You can certainly see your expertise within the article you write.
The world hopes for even more passionate writers such as you who are not afraid to
say how they believe. Always follow your heart.
Hello, I enjoy reading through your post. I wanted to write a little
comment to support you.
Nice blog right here! Additionally your site quite a bit up fast!
What host are you the use of? Can I get your associate link to your host?
I wish my website loaded up as fast as yours lol
Don’t think a phrase association test might really tell us anything real about you?
This quadruple digit challenge will likely be a real stretch for the outdated noggin! Learning
the way you do on this quiz may even aid you see the place you might
be falling quick, so use it to your advantage! Nevertheless,
water marks will be fixed, and that is the place our pal vinegar will assist.
Nonetheless, inserting a kitchen towel underneath its legs
can simply fix this problem. It also can be marginally cheaper
to make your own bread at dwelling, moderately than spending
on artisanal loaves. Whether or not or not helping our customers assess the velocity of their individual connections via the Speedtest utility or publishing evaluation on the state of global markets and related traits, our crew is always
working to provide knowledge that may assist make the internet better and quicker for everyone.
I’d ask for assist. 10,075 is the best reply!
Your persona is decided by a quantity of different traits, and there are
no “right” or “unsuitable” kinds of personality traits.
Apples. Apples are high in pectin, which might lower cholesterol
levels. A lack of infrastructure, nonetheless – it’s onerous to find hydrogen stations in many of the United
States – and a excessive worth tag have stored this kind
of automobile from changing into mainstream.
Thanks for sharing your thoughts about betflikdc.
Regards
Undeniably consider that which you said.
Your favorite reason seemed to be at the web the easiest factor to keep
in mind of. I say to you, I definitely get irked at the same time as other
people consider worries that they plainly don’t recognize about.
You managed to hit the nail upon the top and also outlined out the
entire thing with no need side-effects , folks can take a
signal. Will likely be back to get more. Thank you
I every time used to read post in news papers but now as I am
a user of net so from now I am using net for articles, thanks
to web.
Hello friends, its impressive post about educationand entirely
explained, keep it up all the time.
Appreciate the recommendation. Will try it out.
Hi just wanted tto give you a brief heads up and let you
know a few of the pictures aren’t loading correctly. I’m not sure why buut I think its a
linking issue. I’ve tried it in two diffrerent
internet browsers and both show the same outcome.
My web page … 카지노사이트
I’m really enjoying the theme/design of your web site.
Do you ever run into any web browser compatibility issues?
A small number of my blog readers have complained about my site
not working correctly in Explorer but looks great in Chrome.
Do you have any advice to help fix this issue?
For extra spice and an additional confidence increase in the
bedroom, all ladies turn to teddy lingerie. Our Italian lingerie is
characterized by thorough stylistic research and designs
to satisfy the demands of all women. Choose from our extremely prized silk, tulle, or lace lingerie, or opt for designs in mushy microfiber, modal,
or Supima cotton. The panties that matched the white bras have been equally sexy and featured sheer stretch lace on the facet panels and leg trimming.
This goes for each bras and panties. As you most likely guessed, bras
dessus, bras dessous actually translates to “arm above, arm below”
– I love that vivid visible. You probably have
any period articles or advertisements that use that time period I’d love to see
them – I’m all of the time trying to be as clear,
accurate, and precise with my terminology as potential.
Oh dear. I sound like I’m writing a love letter, don’t I?
Heya! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading through your blog and look forward to all your posts!
Carry on the outstanding work!
This web site definitely has all the information I wanted about this subject and didn’t know
who to ask.
naturally like your web-site however you need to check the spelling on several of your posts.
Many of them are rife with spelling problems and I
find it very troublesome to inform the reality on the other hand I’ll surely come again again.
Review my homepage :: 비아그라 구매 사이트
Apart form these, one additionally seek for Lingerie Equipment
On-line. The municipality is a net exporter of employees, with about 6.3 staff leaving the
municipality for every one coming into. By shopping for
lingerie for the one you love, you will be capable of develop a closer connection between you and your accomplice and to
move one step additional in your relationship. Whereas just a few apprehensions may be
grounded on actuality, most misgivings about buying lingerie are eliminated from the reality.
When buying intimates, most people think twice or are outright averse to the thought of
buying on-line. The website offers with the wholesale lingerie and
invitations the businessmen who’re operating on a small and
medium scale. A lady who wears easy types and strong colors may
not get pleasure from sporting one thing that has numerous frills or shiny colours.
Buying on-line can spice up your wardrobe and in addition offer you the opportunity to experiment with a host of styles when selecting
your lingerie. Of course, there may be nothing incorrect with this, but sometimes you could additionally be trying to find
a way to spice issues up a little.
constantly i used to read smaller articles or reviews that as well clear their motive,
and that is also happening with this paragraph which I am reading at this
place.
When shopping for sexy lingerie you want to consider your own pores and skin tone.
Any coloration of lingerie also can fit ladies with slightly brown skin. Ask him
about the shade he likes you to put on. Girls put on lingerie for
many causes, and the type they choose may rely upon the rationale
for wearing it. Always remember to choose
something sexy however tasteful as you have to know she’ll
take pleasure in sporting it equally as substantially
as you’ll take pleasure in seeing her in it. Preserve in thoughts what you would like to buy and what is going to swimsuit her and in flip what
she is going to love wearing. Do not forget to possess
a spending budget in thoughts when purchasing lingerie china since it
is going to possibly turn into very highly-priced
incredibly rapidly. Knicker sizes can become very confusing as they can appear in distinctive measurements.
No matter the kind of lingerie you buy it is critical for you to choose the fitting sizes and colors.
Even if you buy lingerie in an analogous on-line retailer you will be
capable of do the procuring for easily. That’s true but your collection will get unpleasantly boring if it solely has one colour.
Whats up very cool web site!! Man .. Excellent ..
Wonderful .. I will bookmark your site and take the
feeds additionally? I’m happy to search out numerous useful info right here within the post, we need work out more
techniques on this regard, thanks for sharing.
. . . . .
hey there and thank you for your information – I’ve certainly picked up
something new from right here. I did however expertise some technical issues using this web site, as
I experienced to reload the web site lots of times previous to I could get it to load properly.
I had been wondering if your web host is OK? Not that I am complaining,
but sluggish loading instances times will very frequently affect your placement in google and can damage your high quality score if advertising and marketing with Adwords.
Anyway I’m adding this RSS to my e-mail and can look out for
a lot more of your respective fascinating content.
Make sure you update this again very soon.
Very rapidly this site will be famous amid all
blogging and site-building visitors, due to it’s good posts
Hi there, just became alert to your blog through Google, and found that it is truly informative.
I’m gonna watch out for brussels. I’ll be grateful if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
Great post.
We are a bunch of volunteers and starting a new scheme in our
community. Your site offered us with useful info to
work on. You have performed an impressive task and
our whole group will likely be grateful to you.
Good blog post. I certainly appreciate this site. Continue the good work!
Spot on with this write-up, I actually believe this site needs a great deal more attention. I’ll probably be returning to read through more,
thanks for the advice!
With havin so much written content do you ever run into
any issues of plagorism or copyright infringement?
My blog has a lot of exclusive content I’ve either authored myself or outsourced but it looks like a lot of it
is popping it up all over the internet without my authorization. Do you know any techniques to help reduce content
from being ripped off? I’d really appreciate it.
The other day, while I was at work, my sister stole my apple
ipad and tested to see if it can survive a 30 foot drop, just
so she can be a youtube sensation. My iPad is now broken and
she has 83 views. I know this is completely off topic but I had to share it with someone!
I’m gone to say to my little brother, that he should also pay a visit this webpage on regular basis to take updated from most up-to-date news.
Hi all, here every person is sharing these kinds of knowledge,
so it’s nice to read this weblog, and I used to pay
a quick visit this weblog all the time.
I do not know if it’s just me or if perhaps everybody else encountering issues with your website.
It appears as if some of the written text within your content are
running off the screen. Can someone else please comment and let me know if this is happening to them as well?
This might be a problem with my web browser because I’ve had this happen before.
Kudos
I am sure this article has touched all the internet viewers, its really really good piece of
writing on building up new weblog.
Wonderful beat ! I would like to apprentice at the same time as you amend your web site,
how can i subscribe for a weblog web site? The
account helped me a acceptable deal. I have been tiny bit acquainted of this your broadcast provided brilliant transparent concept
Excellent post. I was checking constantly this blog and I am impressed! I care
I care
Extremely helpful information specially the last part
for such information much. I was looking for
this certain information for a very long time. Thank you and
good luck.
I’m really enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit
more often. Did you hire out a developer to create your theme?
Outstanding work!
прогноз на хоккей
Doll, every killer outfit needs a dreamy base so we’ve obtained you lined with our collection of lingerie.
To be trustworthy I’m amazed that you got my girlfriends birthday reward sorted on the final minute.
I want to commend you on the swift supply of your gift for my spouse,
she was very happy, & shocked, to recieve it. Thank you
for the swift service and fabulous lingerie. Thanks to your help, delighted along with your service so I am sure I shall be ordering again. Our
staff is humbled by this great achievement and will proceed to supply
wonderful service within the years to return. Im glad I buy from
you guys and i believe I will continue to.
Would not hesitate to make use of you guys once more.
Love the corset I have obtained t is a perfect fit so meaning I now
know the right dimension to order subsequent time as nicely.
We all know that carrying the suitable measurement of bra
is a quintessential ingredient of a women’s wardrobe however we hardly pay attention to the match of the panties.
I completely love the Allure bra set, and it matches great too!
Give your accomplice a peek of your sexy bra and (crotchless)
panties with a delicate dress lingerie style – this collection is stuffed with
absolute should-have dresses to your date night time.
Hi there Dear, are you truly visiting this web page daily, if so afterward you will absolutely
take good knowledge.
magnificent points altogether, you just received a new reader.
What would you suggest about your post that you simply made some
days in the past? Any certain?
Asking questions are in fact good thing if you are not understanding anything completely,
however this post presents good understanding even.
They’ll assist you to select the perfect flowers to create a visually pleasing and cohesive corsage.
With all of the manufacturers, shapes and styles available available in the market right now, it might
positively get a little bit complicated. Without any doubt, you would discover ‘n’ number of designs and styles that will seize your
consideration, however decide only for undergarments that match
your comfort and help necessities. Secondly, have
a good idea of what types of you’re searching for before you go buying.
Until now we were talking in regards to the use and sort of lingerie which can make a girl extra exotic, but we
by no means think about the buying of such intimate wears as this can be vital.
If you would like even more exotic bridal innerwear or if
you’re feeling shy to discover lingerie in a departmental store, then online shopping might be essentially
the most effective choices because it offers you more privateness & selection than any offline lingerie retailer.
A fashionable article of white or black lingerie clothing might be worn on approach more occasions as underwear or fashionable
outerwear. 3. While a pajama set, sleepshirt or nightgown could also be
what you might have grow to be habitual of sporting, bridal nightwear has to be extra flirtatious and exotic –
choose from sexy babydolls, brief chemise and naughty camis and shorts on your wedding
and honeymoon.
An impressive share! I’ve just forwarded this onto a friend who
has been doing a little homework on this. And he actually
ordered me breakfast due to the fact that I found it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah,
thanx for spending the time to discuss this issue here on your
web site.
I’m amazed, I have to admit. Seldom do I come across a blog that’s both educative
and interesting, and without a doubt, you have
hit the nail on the head. The issue is something that not enough
men and women are speaking intelligently about. I’m very happy that
I stumbled across this in my hunt for something concerning this.
I do not even know how I finished up right here, however I thought this publish was once good.
I do not understand who you might be however definitely
you’re going to a well-known blogger in case you aren’t already.
Cheers!
It’s amazing in support of me to have a site, which is useful for my
experience. thanks admin
Next, two extra traces are drawn at a 90-diploma angle to
the primary lines. The Cobb angle represents the gold
standard within the quantification and evaluation of scoliosis.
Remember to handle your lingerie with care when folding to keep away from stretching or damaging delicate fabrics.
1. Look for breathable fabrics: Breathable fabrics like cotton, bamboo, and
modal could be comfy to put on and assist stop irritation and chafing.
Indulge your senses in decadent fabrics like lace, mesh, sheer, satin and even a bit velvet.
2016 is basically considered “the year of the choker” thanks to major celebrities like Beyoncé, Rihanna, and Kendall Jenner sporting easy black ribbons and basic diamonds round their necks.
The color black at all times features prominently where sexy lingerie is anxious and turns into even more glamorous
with positive appliqués, lace, rhinestones or coloration accents.
These are some bigger and extra relevant cities in the wider vivinity of Estavannens Dessous.
People would set forth to purchase these kinds of lingerie which are cheap and but
appears good and appealing. Tik Tok Made Me Purchase It!
This can be certain that you buy a corsage for homecoming that does not clash.
Balconette or plunge bras can create a gorgeous décolletage while offering the necessary assist.
I couldn’t resist commenting. Well written!
My brother recommended I would possibly like this web site.
He was once totally right. This publish truly made
my day. You can not consider simply how a lot time I had spent for this info!
Thanks!
my webpage; 비아그라 구입
I am no longer certain where you are getting your information, however great topic.
I must spend a while studying more or figuring out more.
Thank you for magnificent info I used to be looking for this info
for my mission.
My partner and I stumbled over here different
website and thought I might as well check things out.
I like what I see so now i’m following you.
Look forward to looking over your web page for a second time.
Its such as you learn my thoughts! You seem to know so much about this, like you wrote the ebook in it or something.
I think that you just can do with some p.c. to power the message house a little bit, but other than that, that is
wonderful blog. An excellent read. I’ll definitely be back.
Howdy just wanted to give you a brief heads up and let you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show the same results.
What’s up, its fastidious piece of writing on the topic
of media print, we all be aware of media is a fantastic source of facts.
My brother recommended I might like this website. He was totally right.
This post truly made my day. You cann’t imagine just how much time
I had spent for this info! Thanks!
Hi there! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My weblog looks weird when viewing from my iphone 4.
I’m trying to find a theme or plugin that might be able to resolve this problem.
If you have any recommendations, please share. With thanks!
It is perfect time to make a few plans for the longer term and it is time to be happy.
I have read this put up and if I may just I want to suggest you few fascinating things or suggestions.
Maybe you can write next articles regarding this article.
I desire to read more issues about it!
Keep this going please, great job!
Excellent beat ! I would like to apprentice whilst you amend your site, how can i subscribe for a weblog website?
The account helped me a applicable deal. I had been a little bit acquainted of this your broadcast offered
brilliant clear concept
I’m impressed, I must say. Seldom do I encounter a blog that’s
equally educative and engaging, and without a doubt, you’ve hit the nail on the head.
The problem is something which too few folks are speaking intelligently about.
I’m very happy I found this in my hunt for something
regarding this.
I think this is among the most vital info for me. And i’m glad reading your article.
But should remark on some general things, The web site style is perfect, the articles is really great :
D. Good job, cheers
Great delivery. Solid arguments. Keep up the amazing work.
Hello very nice blog!! Guy .. Beautiful .. Superb ..
I’ll bookmark your website and take the feeds additionally?
I am happy to find a lot of useful information here within the put up, we want work out extra techniques on this regard, thanks
for sharing. . . . . .
Definitely believe that which you stated. Your favorite reason appeared to be on the web
the easiest thing to be aware of. I say to you, I
definitely get annoyed while people consider worries that they just
do not know about. You managed to hit the nail upon the top and defined out
the whole thing without having side-effects , people can take a
signal. Will likely be back to get more. Thanks
It has been refined and altered since its growth throughout World
Battle II, but the basics remain the same: A collection of questions leads to the test taker being placed along 4 axes.
A couple of a long time later, the Elixir Sulfanilamide catastrophe would
make it a obligatory ingredient of all drug growth.
The company claims this coating helps make hand
washing the pan and removing leftover residue a breeze, and Kelsey
agrees after hand washing hers with soap and water.
And never long after, another early Greek physician by the title of Erasistratus tried his hand at animal experimentation.
Historic Greek and Roman philosophy held that seeing was not necessarily believing.
But as current weeks have proven, it stays broadly cherished and in a position to do some helpful things exceptionally effectively.
The latest examine bears out this correlation. The
control lab stirred in a scrumptious raspberry flavoring, tested it out for
taste, looks, and smell and gave it a thumbs
up. The corporate’s head chemist, Harold Cole Watkins,
went to work in his lab and found that sulfanilamide dissolved nicely
into an answer of diethylene glycol.
Rather than invest a fantastic deal into this campaign, you can start slowly and test your preliminary outcomes.
Angering leaders all across Europe, this event led to the form of alliances between international locations
at the beginning of World War II. Reid notes.
“And we’ve had interest from round about 50 countries on this planet. The company at the moment is having discussions with a college in California about constructing a test highway to show that its plastics are appropriate with standards in the U.S.,” he says.
But the World Health Group (WHO) has questioned their reliability.
Vitamin A can also be said to promote good eye health and healthy pores
and skin. That is good information to have before starting years of clinical studies.
At one of many demonstration websites, Hossain’s research group put 600 plastic pins into the bottom, making use of 300,000 plastic bottles that in any other case would have ended up in landfills.
There have been goals of constructing such a tire out
there in 2009. Q Tires had studs hidden within the treads and were deployed at the push of a button, James Bond-type,
by pressurized air. Scientists decide there are about 391,000 species
of plants thriving around the globe, making it various life to keep up with even for the most important
botany buffs.
Wow! After all I got a web site from where I can really
obtain valuable data concerning my study and knowledge.
Thanks very interesting blog!
Excellent pieces. Keep posting such kind of info on your page.
Im really impressed by your site.
Hey there, You’ve performed a great job. I will certainly digg it and individually
recommend to my friends. I am sure they’ll be benefited from
this web site.
It’s perfect time to make some plans for the long run and it is time to be happy.
I have learn this post and if I may I desire to suggest
you some fascinating issues or suggestions.
Perhaps you can write subsequent articles regarding this article.
I desire to learn even more things about it!
Good day I am so thrilled I found your web site, I really found you by mistake,
while I was browsing on Yahoo for something else, Anyhow I am here now
and would just like to say kudos for a fantastic post and a
all round interesting blog (I also love the theme/design), I
don’t have time to browse it all at the moment but I have book-marked it and also added in your RSS feeds, so when I
have time I will be back to read much more, Please do keep
up the great work.
Hello to all, it’s in fact a fastidious for me to go to see this web page, it contains useful Information.
I absolutely love your blog.. Excellent colors &
theme. Did you build this site yourself? Please reply back
as I’m wanting to create my own personal website and would like to find out where you got this from
or just what the theme is named. Thank you!
I like looking through an article that will make people think.
Also, thank you for allowing me to comment!
There is an effective motive a doctor will demand a stress
test be performed, considering that they are used to verify the well being of the
heart. In 2018, he used computer modeling to test the hypothesis that Spinosaurus – a theropod with a large sail on its back – was built for swimming.
3. Insert the disc back into the DVD participant. By the 18th century, apple pie
was a staple in North American cookbooks.
U.S. nationwide. This one gets difficult, because
there are exceptions for people who are born in several
Pacific Islands just like the Federated States of Micronesia,
American Samoa and the Marshall Islands. Who Can Fill Out the FAFSA?
If you’re eligible to receive scholar assist, then it’s time to arrange to fill out the FAFSA.
Most people fill out their first FAFSA after they’re starting the faculty software course of.
State governments use the EFC generated by the FAFSA handy out state-funded grants and scholarships.
She was flipping through her useless husband’s notebooks when she found plans
for a flare system that ships might use to communicate at night time time.
Active testing can’t happen once a VoIP community
is deployed and staff are already utilizing the system.
What’s up, yup this piece of writing is in fact nice and I have learned lot of things from it regarding blogging.
thanks.
Does your blog have a contact page? I’m having problems locating it but, I’d like to send
you an e-mail. I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it develop over time.
I read this paragraph completely on the topic of the comparison of hottest and previous technologies, it’s remarkable article.
Hey this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so I wanted
to get guidance from someone with experience. Any help would be greatly appreciated!
A motivating discussion is definitely worth comment.
There’s no doubt that that you should write more
on this issue, it might not be a taboo matter but generally folks
don’t speak about these issues. To the next! Best wishes!!
I like the helpful info you provide in your articles.
I’ll bookmark your weblog and check again here regularly.
I’m quite certain I will learn a lot of new stuff
right here! Good luck for the next!
There’s definately a lot to learn about this issue. I really like all of the points you made.
Yesterday, while I was at work, my sister stole my iphone and tested to see if it can survive a twenty
five foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views.
I know this is entirely off topic but I had to share it with someone!
Asking questions are in fact nice thing if you are not understanding anything fully, except this piece of writing
offers good understanding even.
Article writing is also a fun, if you know after that
you can write otherwise it is difficult to write.
Aw, this was an extremely good post. Taking the time and
actual effort to create a great article… but what can I say… I procrastinate a whole lot and don’t seem
to get anything done.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get
there! Appreciate it
Hello There. I found your blog using msn. This is a very well written article.
I’ll make sure to bookmark it and come back to read more of your
useful information. Thanks for the post. I’ll certainly comeback.
Test your information on the basic Television present CHiPs!
James was trying to improve torsion springs to higher cushion expensive
ship tools – he observed that one among his test springs
exhibited a singular “walking” movement. In actual fact, most drivers use the peak power of
their engines less than one percent of the time. One of the most notable things that labor unions introduced and organized presently have been strikes.
They’re typically a lot less well-made and less durable, warping
or denting extra easily, or having handles that loosen over time.
Having spent the higher a part of two decades conducting experiments rooted
in quantum mechanics, I have come to simply accept its strangeness.
Congratulations — having reviewed the varieties of grouting and
when to make use of them, you’re now ready to buy
for tiles and grout! Hardtops returned, but had been now two-doorways.
It again powered Requirements and DeLuxes now designated Model 78.
V-8/60s have been Normal-trim only.
Having read this I thought it was extremely enlightening.
I appreciate you taking the time and effort to put this informative article together.
I once again find myself personally spending a lot of time
both reading and leaving comments. But so what, it was still worth it!
Great article.
Today, while I was at work, my cousin stole my iphone
and tested to see if it can survive a 40 foot drop, just
so she can be a youtube sensation. My apple ipad is now broken and she has 83 views.
I know this is totally off topic but I had to share it with someone!
I am really loving the theme/design of your web site.
Do you ever run into any browser compatibility issues?
A number of my blog readers have complained about my
blog not operating correctly in Explorer but looks great in Opera.
Do you have any ideas to help fix this problem?
Take discover that regardless of how nice or enticing your lingerie appears on you, scratches and
pink welts in your skin will not appear attractive.
Take the time to find out what an individual’s favorite flower
is, what she is sporting, and how you need to honor her.
Take your choose from a enticing lace camisole, a see via child
doll dress, traditional panty and bra, or other sexy lingerie.
Carrying sexy lingerie is one factor your groom will most likely be happy to see.
You may haven’t any worries buying one other units thinking there
will likely be ready for the next batch of lingerie to arrive.
I will put the sets with many items together in one bag and
stack them in a drawer. Sexy lingerie is certainly
one of the perfect clothing items to posses as these can consequence in a new you or a a lot more seductive
bedroom romp with a significant different.
It is appropriate time to make some plans for the future and it
is time to be happy. I have read this post and if I could I desire to suggest you few interesting things or advice.
Maybe you could write next articles referring to this article.
I desire to read even more things about it!
Hello! This is kind of off topic but I need some
advice from an established blog. Is it very difficult to set up your
own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where
to start. Do you have any ideas or suggestions? Thank you
Wow, superb weblog format! How lengthy have you ever been running a blog
for? you make blogging glance easy. The overall glance of your site is wonderful,
as neatly as the content material! You can see similar
here dobry sklep
I visited multiple web pages but the audio quality for audio songs current at this web page
is actually marvelous.
Everyone loves it when people come together and share thoughts.
Great website, stick with it!
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of
your excellent post. Also, I’ve shared your website in my social networks!
I know this if off topic but I’m looking into starting my own weblog and was curious what all is needed
to get set up? I’m assuming having a blog like
yours would cost a pretty penny? I’m not very web savvy so I’m not 100% sure.
Any recommendations or advice would be greatly appreciated.
Many thanks
Hello would you mind letting me know which web host you’re utilizing?
I’ve loaded your blog in 3 different internet browsers and I must
say this blog loads a lot quicker then most. Can you recommend
a good web hosting provider at a reasonable price?
Cheers, I appreciate it!
Whether you’re looking out for one thing for a prom, marriage ceremony, or formal
occasion, we now have the proper corsage or boutonniere.
Whether you’re attending a prom, marriage ceremony, or another special occasion, take
the time to decide on an exquisite corsage that matches your outfit
and reflects your personal style. With over 15 years of expertise within the flower industry, our expert crew is keen about providing the highest quality corsages and boutonnieres for any particular occasion. With
their help, you could find the right corsage or boutonniere to your particular occasion. The corsages and boutonnieres from Corsage with a
Twist are an ideal approach to accessorize any special occasion. If you’re searching for corsages and boutonnieres in Perth, Corsage with a Twist
is the proper place to find the proper accessory in your particular occasion. The kind of occasion or occasion you are attending
should also be considered when making your selection.
Excellent pieces. Keep posting such kind of info on your site.
Im really impressed by it.
Hey there, You’ve performed an excellent job. I will certainly digg it
and personally recommend to my friends. I’m sure they’ll be benefited from this web
site.
Thanks for the marvelous posting! I actually enjoyed reading it,
you are a great author. I will be sure to bookmark your blog and will eventually
come back from now on. I want to encourage that you continue your great work, have a nice afternoon!
Greetings! Very helpful advice in this particular article!
It’s the little changes that produce the most important changes.
Thanks for sharing!
Thank you, I’ve just been looking for information about this topic for a while and yours is the best I’ve came upon till now.
However, what about the bottom line? Are you sure in regards to the source?
I seriously love your website.. Very nice colors & theme.
Did you develop this website yourself? Please reply back as I’m attempting to create my own site and would love to know where you got this from or what the theme is called.
Appreciate it!
Great article! That is the type of information that are supposed to be shared around the internet.
Shame on the seek engines for not positioning this post upper!
Come on over and talk over with my web site .
Thank you =)
Good post. I am facing a few of these issues as well..
Thanks for finally talking about > Пиастры – Составление семантического ядра | < Liked it!
What’s up to all, the contents existing at this website are in fact awesome for people experience, well, keep up
the nice work fellows.
They at all times prefer to be fashionable in whatever they put on be it shoes,
pants, accessories to even lingerie. In case of a theme celebration the place the individuals are anticipated to put on superhero costumes men come dressed as
the heroes from the Justice League, or as Batman or Superman or Spriderman-
the options are amny. Girls can come dressed as Catwoman. Lingeries are underneath garments for women. Women need to be very snug with
their clothing and the story start with lingeries. Trendy lingeries
are made to make a girls look more stunning, when a girls appears
to be like more lovely, it routinely enhances her self confidence and their persona appears to be extra elegant and enhanced.
Typically lingeries worn to shape up the body, they may even be good for
bodies which are average but after putting on lingeries
they give a breath stopping look to the physique. And in the event you
favor not to buy lingerie units, then the look-books would give you ideas on the way to pair
a bra with a panty comfortably. Accept the kinds that provide you with a sense of empowerment,
magnificence, and self-confidence. You’ll be able to browse
a few of the newest and best types from these designers with a purpose to liven up
your bedroom look.
Hey there, I think your blog might be having browser compatibility issues.
When I look at your blog site in Opera, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, awesome blog!
Appreciate this post. Let me try it out.
It’s enormous that you are getting ideas from this piece of
writing as well as from our argument made at this time.
Thanks for some other informative web site.
The place else could I get that kind of information written in such a perfect approach?
I have a challenge that I’m simply now working on, and I have been at the
look out for such information.
I’ll right away grab your rss as I can not in finding your email subscription hyperlink or e-newsletter service.
Do you have any? Kindly let me realize so that I could subscribe.
Thanks.
Great article! We will be linking to this great post on our site.
Keep up the great writing.
Normally I do not learn article on blogs, but I would like to say that this write-up very pressured me to check out and do so!
Your writing taste has been amazed me. Thank you, very nice article.
This piece of writing will assist the internet people for
creating new webpage or even a weblog from start to end.
I’m not sure exactly why but this web site is loading very slow for
me. Is anyone else having this problem or is
it a issue on my end? I’ll check back later and see if the problem still exists.
Good day! Would you mind if I share your blog with my twitter group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Thank you
Hi! I could have sworn I’ve visited this website before but after going through many of the posts
I realized it’s new to me. Anyways, I’m certainly pleased I discovered it and
I’ll be bookmarking it and checking back frequently!
What’s Taking place i am new to this, I stumbled
upon this I have found It positively helpful and it has aided me out loads.
I’m hoping to give a contribution & assist other customers like its helped
me. Good job.
Hi there would you mind stating which blog platform you’re working with?
I’m planning to start my own blog in the near future but I’m having a
tough time making a decision between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your layout seems different then most blogs
and I’m looking for something completely unique.
P.S Apologies for being off-topic but I had to ask!
I believe that is among the most vital info for me.
And i am happy reading your article. However should statement on some basic issues, The website taste
is ideal, the articles is actually great : D. Good process,
cheers
Hi there! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up
losing months of hard work due to no back up. Do you have any methods to prevent hackers?
I’ll right away clutch your rss as I can not to find your email subscription hyperlink or newsletter service.
Do you have any? Please let me know so that I could
subscribe. Thanks.
My spouse and I stumbled over here different website and thought I might check things out.
I like what I see so now i’m following you. Look forward to looking over your web page
repeatedly.
Greetings from Carolina! I’m bored to tears at work so I decided to browse your website on my iphone during lunch break.
I enjoy the info you present here and can’t wait to take a
look when I get home. I’m surprised at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyways, great blog!
My brother suggested I might like this website. He was once
entirely right. This publish truly made my day. You can not believe just how a lot time I had spent for this
information! Thank you!
Have you ever thought about including a little bit more than just your articles?
I mean, what you say is fundamental and all. Nevertheless
think about if you added some great images or videos to give your posts more,
“pop”! Your content is excellent but with pics and videos,
this site could undeniably be one of the most beneficial in its niche.
Terrific blog!
Spot on with this write-up, I really believe
this website needs a lot more attention. I’ll probably
be back again to read more, thanks for the info!
I could not refrain from commenting. Very well written!
Spot on with this write-up, I actually think this website needs far more attention. I’ll probably be back again to read
more, thanks for the info!
I do believe all the ideas you have offered in your post.
They’re really convincing and can definitely work.
Still, the posts are too quick for beginners. Could you please extend them a little from next
time? Thank you for the post.
You’ve made some really good points there. I looked on the web for additional information about the issue and found most individuals will go along with your views
on this website.
This information is worth everyone’s attention.
Where can I find out more?
Hi there! I know this is somewhat off-topic but
I needed to ask. Does running a well-established blog like yours require
a large amount of work? I am completely new to writing a blog
however I do write in my journal on a daily basis. I’d like to start a
blog so I will be able to share my personal experience and feelings online.
Please let me know if you have any suggestions or tips for new
aspiring blog owners. Appreciate it!
always i used to read smaller content that also clear their motive, and that is also happening with this piece of writing which I am reading at this time.
mtpolice.kr provides sports betting information, sports analysis, and
sports tips as a sports community.
I’m impressed, I must say. Rarely do I come across a blog that’s
both equally educative and amusing, and without a doubt, you’ve hit the nail on the head.
The problem is something that not enough people are speaking intelligently about.
I am very happy that I stumbled across this during my
hunt for something relating to this.
Very shortly this web site will be famous among all blogging viewers,
due to it’s nice articles or reviews
Highly descriptive blog, I liked that bit. Will there be a part 2?
That is very interesting, You’re an overly professional blogger.
I’ve joined your rss feed and sit up for seeking more of your great post.
Also, I’ve shared your site in my social networks
Howdy would you mind letting me know which hosting company you’re using?
I’ve loaded your blog in 3 completely different internet
browsers and I must say this blog loads a lot faster then most.
Can you suggest a good internet hosting provider at a honest price?
Thanks, I appreciate it!
What a material of un-ambiguity and preserveness of valuable experience concerning unexpected feelings.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there!
Many thanks
Hey there! I’ve been following your weblog for a while now
and finally got the bravery to go ahead and give you a shout
out from Huffman Texas! Just wanted to tell you keep up the great job!
I will immediately seize your rss as I can not find your e-mail subscription link or e-newsletter service.
Do you have any? Kindly allow me recognize so that I may just subscribe.
Thanks.
I like the valuable info you provide on your articles.
I will bookmark your blog and check once more here frequently.
I’m fairly sure I will be informed many new stuff right here!
Best of luck for the following!
Hello, always i used to check blog posts here early in the daylight,
since i like to find out more and more.
Hi there this is kinda of off topic but I was wondering if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so I wanted to
get guidance from someone with experience. Any help would
be enormously appreciated!
Hi! I know this is sort of off-topic but I needed to ask.
Does running a well-established website like yours require a lot of work?
I’m brand new to operating a blog but I do write in my journal every day.
I’d like to start a blog so I can easily share my experience and
thoughts online. Please let me know if you have any recommendations or tips for brand
new aspiring blog owners. Appreciate it!
Aw, this was a very good post. Taking the time and actual effort to create a superb article…
but what can I say… I procrastinate a lot
and never manage to get nearly anything done.
My brother suggested I might like this web
site. He was totally right. This post truly made my day.
You cann’t imagine simply how much time I had spent for this
info! Thanks!
Hi outstanding blog! Does running a blog like this take
a lot of work? I’ve very little understanding of computer programming but I was hoping to start my own blog soon. Anyhow,
if you have any suggestions or techniques for new blog owners
please share. I understand this is off topic however I simply wanted to ask.
Kudos!
If you wish for to get a great deal from this
post then you have to apply these strategies to your won weblog.
For most up-to-date information you have to visit world-wide-web and on internet I found this website as a best site for most
up-to-date updates.
Terrific post but I was wanting to know if you could write a
litte more on this subject? I’d be very thankful if you could
elaborate a little bit further. Appreciate it!
Someone necessarily assist to make seriously posts I might state.
That is tthe first time I frequented your web page and
so far? I surprised with the analysis yoou made to create this particular submit amazing.
Wonderful job!
Feel free to visit my site; 카지노사이트
I got this website from my pal who told me concerning this site and at the moment this time I am browsing this website and reading very informative articles at this
time.
Hmm it appears like your website ate my first comment (it was
super long) so I guess I’ll just sum it up what I wrote and say,
I’m thoroughly enjoying your blog. I as well am an aspiring
blog writer but I’m still new to the whole thing. Do you have any helpful hints for novice
blog writers? I’d certainly appreciate it.
It’s very easy to find out any matter on web as compared to books, as
I found this paragraph at this website.
Its like you learn my mind! You appear to know so much approximately this, like
you wrote the book in it or something. I think that
you can do with a few p.c. to force the message house a bit, but other than that, that is magnificent blog.
A great read. I’ll definitely be back.
Thanks for sharing your thoughts about avaliador premiado é seguro.
Regards
After going over a few of the blog posts on your web page,
I honestly like your technique of blogging. I bookmarked it to my bookmark website list and will be
checking back soon. Take a look at my website too and let me know how you feel.
With havin so much written content do you ever run into any issues of plagorism or
copyright infringement? My blog has a lot of exclusive content I’ve either authored
myself or outsourced but it looks like a lot of it is popping it up all over the
web without my permission. Do you know any methods to help protect against content from being
ripped off? I’d genuinely appreciate it.
My partner and I absolutely love your blog and find most of your post’s to be exactly I’m looking for.
Does one offer guest writers to write content available for
you? I wouldn’t mind publishing a post or elaborating on some of the subjects you
write with regards to here. Again, awesome site!
If some one wants expert view regarding blogging and
site-building after that i advise him/her
to pay a visit this blog, Keep up the nice job.
Valuable info. Fortunate me I discovered your website by
chance, and I’m surprised why this accident did not came about earlier!
I bookmarked it.
It’s actually a cool and useful piece of information. I am glad that you simply shared
this helpful info with us. Please stay us informed like this.
Thanks for sharing.
Very rapidly this site will be famous amid all blogging users, due to
it’s pleasant articles or reviews
Hi, Neat post. There’s an issue together with your site in web explorer, may
check this? IE nonetheless is the marketplace leader and a huge component to other
people will omit your magnificent writing because of this problem.
This is the perfect blog for anyone who really wants to find
out about this topic. You know a whole lot its almost tough to argue with you (not that I personally will need to HaHa).
You definitely put a new spin on a topic that’s been written about for ages.
Excellent stuff, just great!
I just could not leave your web site prior to suggesting that I extremely enjoyed the standard information a
person supply for your guests? Is going to be again incessantly in order to check up on new posts
hello!,I like your writing so so much! share we keep in touch more about your article on AOL?
I need an expert on this space to unravel my problem.
Maybe that is you! Taking a look ahead to
look you.
Hi there! This post couldn’t be written any better! Reading through this article reminds me of
my previous roommate! He continually kept preaching about this.
I will send this post to him. Pretty sure he will have a very good read.
Thanks for sharing!
I do not know if it’s just me or if perhaps everyone else encountering issues with your blog.
It appears as if some of the text in your posts are running off the screen. Can someone else please
comment and let me know if this is happening to them as well?
This may be a issue with my internet browser because I’ve had
this happen before. Appreciate it
mtpolice.kr provides sports betting information, sports analysis, and sports tips as a
sports community.
Here is my web site :: 테라벳
Hello there, just became alert to your blog through Google, and found that
it’s truly informative. I am gonna watch out for brussels.
I’ll appreciate if you continue this in future. Numerous people will be benefited from
your writing. Cheers!
Oh my goodness! Impressive article dude! Thanks,
However I am encountering troubles with your RSS.
I don’t know why I can’t subscribe to it. Is there anybody getting similar RSS problems?
Anyone that knows the answer will you kindly
respond? Thanx!!
What’s up, this weekend is good designed for me, since this point in time i am reading this wonderful informative piece of writing
here at my residence.
I all the time used to read piece of writing in news papers but now as I
am a user of net thus from now I am using net for
posts, thanks to web.
Very nice post. I just stumbled upon your blog and wished to say that I have truly enjoyed browsing your blog posts.
In any case I will be subscribing to your rss feed and I hope you write again soon!
I don’t even kow how I finished up here, buut I believed this submit was once great.
I do not recognisae who you’re bbut definitely you are going to a famous blogger
for those who aren’t already. Cheers!
Here is my page; 카지노사이트
With havin so much written content do you
ever run into any problems of plagorism or copyright violation?
My site has a lot of completely unique content I’ve either authored
myself or outsourced but it appears a lot of it is popping it up all over the internet without my authorization. Do you know any ways to
help stop content from being stolen? I’d genuinely appreciate
it.
It’s actually a cool and useful piece of information. I am
satisfied that you just shared this helpful info with us.
Please keep us up to date like this. Thank you for sharing.
Hi my loved one! I want to say that this post is awesome, nice written and
include almost all significant infos. I’d like to peer
more posts like this .
Wonderful goods from you, man. I’ve understand your stuff previous to and you’re just
too great. I actually like what you have acquired here,
certainly like what you are saying and the way in which you say it.
You make it entertaining and you still take care of to keep it wise.
I can’t wait to read far more from you. This is really
a terrific website.
What i do not understood is in truth how you’re no
longer really much more well-favored than you may be right now.
You’re so intelligent. You recognize thus considerably in the case of this topic, produced me in my opinion believe it from a lot of
numerous angles. Its like women and men are not interested until it is something to do with Girl gaga!
Your own stuffs nice. All the time care for it up!
Hi to every one, it’s in fact a pleasant for me to visit this web site,
it includes useful Information.
I love it whenever people get together and share views.
Great blog, keep it up!
Hi Dear, are you really visiting this web site regularly, if so afterward you will without doubt get nice
knowledge.
Greetings! Very helpful advice within this post! It is
the little changes that make the biggest changes. Thanks a lot for sharing!
each time i used to read smaller articles that also clear their motive, and that is also happening with
this article which I am reading now.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an impatience over that you wish be
delivering the following. unwell unquestionably come
more formerly again since exactly the same nearly a lot often inside case
you shield this hike.
Hello! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing a few
months of hard work due to no back up. Do you have any methods to stop hackers?
With havin so much content do you ever run into any problems of plagorism or copyright violation? My site has a
lot of exclusive content I’ve either written myself or outsourced but it
appears a lot of it is popping it up all over the internet without my permission. Do you know
any methods to help reduce content from being ripped off?
I’d truly appreciate it.
It’s really very complicated in this full of activity
life to listen news on TV, thus I only use web for that reason, and obtain the most recent
information.
My programmer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the
costs. But he’s tryiong none the less. I’ve been using WordPress on a variety of websites
for about a year and am anxious about switching
to another platform. I have heard excellent things about
blogengine.net. Is there a way I can transfer all my wordpress content into it?
Any help would be really appreciated!
Someone essentially lend a hand to make critically posts I
would state. That is the first time I frequented your web
page and up to now? I surprised with the research you made to create this
actual submit incredible. Wonderful process!
Very energetic post, I enjoyed that bit. Will there be a part 2?
Hey there! I’ve been reading your blog for some time
now and finally got the courage to go ahead and give you a shout out from
Lubbock Tx! Just wanted to tell you keep up
the good job!
Hmm is anyone else encountering problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my
end or if it’s the blog. Any feed-back would be greatly appreciated.
You have made some really good points there. I
looked on the net for additional information about the issue and found most people will go along with
your views on this site.
Hello there! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thank you
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is valuable and all. But think about
if you added some great pictures or videos to give your posts more, “pop”!
Your content is excellent but with images and clips, this website could
undeniably be one of the greatest in its niche. Good blog!
Greetings! I know this is kinda off topic but I was
wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because I’ve had issues with hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of a good platform.
This design is wicked! You certainly know how to keep
a reader amused. Between your wit and your videos,
I was almost moved to start my own blog (well, almost…HaHa!) Great job.
I really loved what you had to say, and more than that, how
you presented it. Too cool!
Hi everyone, it’s my first visit at this website, and piece of writing is truly fruitful designed for me, keep up
posting such articles.
Great blog you’ve got here.. It’s hard to
find quality writing like yours these days. I truly appreciate individuals like you!
Take care!!
I’m impressed, I must say. Rarely do I encounter a blog that’s both
educative and interesting, and without a doubt, you’ve hit the nail on the head.
The problem is something which not enough people
are speaking intelligently about. I am very happy
that I stumbled across this in my search for
something relating to this.
Heya i’m for the first time here. I came across this board and I
find It truly useful & it helped me out a lot.
I hope to give something back and aid others like you aided
me.
Thanks for ones marvelous posting! I genuinely enjoyed reading it, you might be a great author.
I will ensure that I bookmark your blog and will often come back
later on. I want to encourage you continue your great work,
have a nice weekend!
What’s up, this weekend is good for me, since this point in time i am
reading this impressive informative paragraph here at my home.
It’s amazing in favor of me to have a web site, which is
useful in support of my know-how. thanks admin
Hello there! This is my 1st comment here so I just
wanted to give a quick shout out and say I really
enjoy reading through your posts. Can you recommend any
other blogs/websites/forums that deal with the same subjects?
Thank you so much!
It’s appropriate time to make a few plans for the longer term and it is time to be happy.
I have read this post and if I may just I desire to suggest you
few interesting things or advice. Maybe you could write subsequent articles relating to this article.
I wish to read more issues approximately it!
It’s hard to find educated people for this topic, but you
seem like you know what you’re talking about! Thanks
Having read this I thought it was rather enlightening.
I appreciate you taking the time and energy to put this informative article together.
I once again find myself personally spending way
too much time both reading and commenting. But so what, it was still worthwhile!
each time i used to read smaller articles that as well clear their motive, and that
is also happening with this piece of writing which I am reading here.
Have you ever thought about writing an ebook or guest authoring on other sites?
I have a blog centered on the same ideas you discuss and
would love to have you share some stories/information. I know my visitors would value
your work. If you’re even remotely interested, feel
free to shoot me an e-mail.
Wow, incredible blog structure! How lengthy have you ever
been blogging for? you made running a blog glance easy. The total glance of your website is fantastic, as smartly as the content material!
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any feedback would be greatly appreciated.
Superb, what a website it is! This web site gives helpful data to
us, keep it up.
I’m now not certain the place you are getting your information, but good topic.
I needs to spend a while finding out much more or working out
more. Thank you for magnificent information I used to be on the lookout for this info for my mission.
Greetings from Ohio! I’m bored at work so I decided to browse your blog on my iphone
during lunch break. I enjoy the information you provide here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyhow, good blog!
Hello, I think your blog might be having browser compatibility issues.
When I look at your blog in Chrome, it looks fine but when opening in Internet Explorer, it
has some overlapping. I just wanted to give you a quick heads up!
Other then that, awesome blog!
I have read so many posts concerning the blogger lovers however this piece of writing is actually a good piece of writing, keep it up.
I do agree with all the ideas you’ve offered to your post.
They are very convincing and can definitely work. Nonetheless, the posts are too short for starters.
May just you please prolong them a little from next time?
Thank you for the post.
Hello! Quick question that’s completely off topic. Do you know how to make your site mobile friendly?
My weblog looks weird when viewing from my
iphone. I’m trying to find a theme or plugin that might be able to correct this issue.
If you have any recommendations, please share. Appreciate it!
continuously i used to read smaller articles which as well clear their motive, and
that is also happening with this post which I am reading at
this time.
An interesting discussion is worth comment.
I do believe that you ought to write more on this topic, it may not be a taboo subject but generally people don’t discuss such subjects.
To the next! Many thanks!!
Whats up this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you
have to manually code with HTML. I’m starting a blog soon but
have no coding skills so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
Pretty nice post. I just stumbled upon your weblog and
wished to say that I have truly enjoyed browsing your blog
posts. After all I will be subscribing to your feed and I hope you write again soon!
I all the time used to study piece of writing in news papers but now as I am a user of web thus from now I am using net for content, thanks to web.
I like reading a post that can make men and women think.
Also, thanks for allowing for me to comment!
Greetings! I know this is kinda off topic but I’d figured I’d
ask. Would you be interested in trading links or maybe guest authoring
a blog article or vice-versa? My blog discusses a lot of the same topics as yours and
I think we could greatly benefit from each other.
If you might be interested feel free to send me an e-mail.
I look forward to hearing from you! Awesome blog by the way!
Thanks for finally talking about > Пиастры –
Составление семантического ядра | < Liked it!
I think the admin of this web site is actually working hard
for his website, since here every data is quality
based information.
This blog was… how do I say it? Relevant!! Finally I’ve found something that
helped me. Thank you!
This is my first time pay a quick visit at here and i am actually happy to read everthing at single place.
My brother recommended I might like this web site.
He was totally right. This post actually made my day.
You cann’t imagine simply how much time I had spent
for this info! Thanks!
Hey There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and come back to read more of your useful info.
Thanks for the post. I will certainly return.
Greetings from Los angeles! I’m bored at work so I decided to check
out your website on my iphone during lunch break. I love the information you present here
and can’t wait to take a look when I get home. I’m shocked
at how quick your blog loaded on my cell phone .. I’m not even using WIFI,
just 3G .. Anyways, fantastic blog!
We stumbled over here by a different page and thought I should
check things out. I like what I see so i am just following you.
Look forward to going over your web page repeatedly.
Thank you for every other informative website. Where else
may just I am getting that kind of info written in such
a perfect approach? I have a venture that I’m just now running on, and I have been on the look out for such information.
A person necessarily help to make significantly articles I’d state.
That is the very first time I frequented your web page
and so far? I surprised with the analysis you made to create this particular
submit extraordinary. Excellent activity!
Hello there! This is my first visit to your blog! We are a group of volunteers
and starting a new project in a community in the same niche.
Your blog provided us useful information to work on. You have done a extraordinary
job!
Howdy! I could have sworn I’ve been to this blog before but after going through
many of the articles I realized it’s new to me. Anyhow, I’m definitely delighted I discovered
it and I’ll be book-marking it and checking back often!
Great web site you’ve got here.. It’s hard to find good quality writing like yours these days.
I truly appreciate individuals like you! Take care!!
Good day! I know this is kinda off topic but I was wondering which blog platform are you using for this website?
I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be great if you could point me in the direction of a good platform.
Hey there, I think your blog might be having browser compatibility
issues. When I look at your blog in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, wonderful blog!
Link exchange is nothing else except it is only placing the other person’s web site link on your
page at suitable place and other person will also do similar in support of you.
If some one wants to be updated with most recent technologies then he must be
pay a quick visit this website and be up to date every day.
It is in point of fact a nice and helpful piece of info.
I’m satisfied that you simply shared this useful information with us.
Please stay us up to date like this. Thank you for sharing.
An outstanding share! I have just forwarded this onto a colleague who had been doing
a little homework on this. And he actually bought me
dinner simply because I stumbled upon it for him… lol.
So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanx for spending the time to talk about this topic here on your web site.
I’m truly enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more pleasant for me
to come here and visit more often. Did you hire
out a developer to create your theme? Excellent work!
Here is my blog post :: top owl vpn
You really make it seem so easy with your presentation but I find this matter to be really something which I think I would never understand.
It seems too complex and extremely broad for me. I’m looking forward for your next post,
I will try to get the hang of it!
With havin so much content do you ever run into any problems of plagorism or copyright infringement?
My site has a lot of completely unique content I’ve either authored myself or outsourced but
it seems a lot of it is popping it up all over the internet without my permission. Do you know any ways to help reduce content from being stolen? I’d truly appreciate it.
It’s very effortless to find out any matter on net as compared to textbooks, as I found this paragraph at this web page.
This design is steller! You most certainly know how to keep
a reader entertained. Between your wit and your videos, I was almost moved to start my own blog
(well, almost…HaHa!) Great job. I really loved what you had to say, and more than that, how you presented it.
Too cool!
I do trust all of the ideas you’ve offered in your post.
They’re very convincing and will definitely work. Nonetheless,
the posts are too short for novices. Could you please extend
them a little from next time? Thank you for the post.
What’s up every one, here every one is sharing such knowledge, thus it’s pleasant to read
this webpage, and I used to go to see this web site daily.
I just like the valuable info you supply for your articles.
I will bookmark your weblog and check once more here regularly.
I am slightly sure I will be told lots of new stuff proper right here!
Good luck for the following!
An impressive share! I’ve just forwarded this onto a co-worker who was doing a little research on this.
And he in fact bought me breakfast due to the fact that
I found it for him… lol. So let me reword this…. Thanks for the
meal!! But yeah, thanx for spending the time to discuss this topic
here on your web site.
Its such as you learn my mind! You seem to grasp a lot about this,
like you wrote the book in it or something. I believe that you just could do with
a few p.c. to drive the message house a little bit, however instead of that, this is fantastic blog.
A fantastic read. I will definitely be back.
Hi, of course this post is in fact good and I have learned lot of things from it
concerning blogging. thanks.
Hi there, i read your blog from time to time
and i own a similar one and i was just curious if you get a lot
of spam comments? If so how do you reduce it, any plugin or anything you can advise?
I get so much lately it’s driving me insane so any support is very much appreciated.
консультация юриста по уголовным делам
Your style is very unique compared to other people I’ve read stuff from.
Many thanks for posting when you have the opportunity, Guess I will
just book mark this web site.
I take pleasure in, result in I discovered exactly what I was having a
look for. You’ve ended my 4 day lengthy hunt!
God Bless you man. Have a nice day. Bye
Howdy! This article couldn’t be written much better!
Looking at this article reminds me of my previous roommate!
He constantly kept talking about this. I’ll forward this
information to him. Fairly certain he will have a great read.
Many thanks for sharing!
Thank you for every other informative blog. The place else could I
am getting that type of info written in such an ideal method?
I have a challenge that I am just now working on, and I’ve been on the
glance out for such info.
I don’t even know how I ended up here, but I thought this post was good.
I don’t know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
Hey very cool website!! Guy .. Excellent .. Wonderful ..
I’ll bookmark your web site and take the feeds also? I’m happy to seek out numerous
useful information right here in the put up, we want work out more
strategies in this regard, thank you for sharing.
. . . . .
A person essentially assist to make seriously articles I would state.
That is the very first time I frequented your web
page and thus far? I surprised with the research you made to create this particular publish incredible.
Great process!
Hi friends, its impressive article on the topic of
educationand completely explained, keep it up all the time.
Hello there! This blog post could not be written any better!
Looking through this post reminds me of my previous roommate!
He always kept talking about this. I am going to send this article to him.
Fairly certain he’ll have a great read. I appreciate you
for sharing!
Here is my website mobile massage in london
What’s up all, here every person is sharing these kinds of know-how, thus it’s pleasant to read this
weblog, and I used to pay a visit this website all the time.
Incredible story there. What occurred after?
Take care!
Hi would you mind stating which blog platform you’re using?
I’m planning to start my own blog soon but I’m having
a difficult time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m looking for something completely unique.
P.S My apologies for being off-topic but I had to ask!
I am sure this piece of writing has touched all the internet visitors, its
really really nice piece of writing on building up new blog.
Do you have any video of that? I’d care to find out some additional information.
Today, I went to the beach front with my children. I found a sea
shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
Here is my website … bucks party idea
If you are going for most excellent contents
like myself, only pay a visit this web site all the time because it presents quality contents,
thanks
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your website to come back down the
road. Many thanks
Have you ever thought about including a little bit more
than just your articles? I mean, what you say is important
and all. Nevertheless imagine if you added some great images or video clips to give your posts more,
“pop”! Your content is excellent but with pics and videos, this blog could definitely be one
of the very best in its field. Terrific blog!
Your style is unique in comparison to other folks I have read stuff from.
I appreciate you for posting when you have the opportunity, Guess I’ll
just book mark this web site.
Marvelous, what a web site it is! This webpage presents valuable facts
to us, keep it up.
Hi this is kinda of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with
experience. Any help would be greatly appreciated!
This is really interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your excellent post.
Also, I’ve shared your site in my social networks!
My web blog solar panel system brisbane
This article is really a fastidious one it assists new net visitors,
who are wishing in favor of blogging.
I believe what you said was actually very reasonable. However,
consider this, suppose you were to write a killer headline?
I mean, I don’t wish to tell you how to run your blog, however what if you added a post
title to possibly get a person’s attention? I mean Пиастры – Составление
семантического ядра | is a little vanilla.
You could peek at Yahoo’s front page and note how they write post headlines to grab viewers
to click. You might try adding a video or a related picture or two to get people
excited about everything’ve written. Just my opinion,
it could bring your posts a little livelier.
I constantly spent my half an hour to read this weblog’s articles all the time along with a mug of coffee.
Greetings! Very helpful advice within this post! It is the little changes that make the most important changes.
Thanks for sharing!
My brother recommended I might like this website.
He was totally right. This post truly made my day. You cann’t
imagine just how much time I had spent for this information! Thanks!
Hi! I understand this is kind of off-topic but I needed to ask.
Does managing a well-established website such as yours require a massive amount work?
I am brand new to writing a blog however I do write in my journal daily.
I’d like to start a blog so I can easily share my personal experience and thoughts online.
Please let me know if you have any recommendations or tips
for new aspiring bloggers. Appreciate it!
Highly energetic article, I loved that a lot.
Will there be a part 2?
Wow! In the end I got a website from where I be capable of
genuinely get useful information concerning my study and knowledge.
My web-site … ladies wedding ring designs
Saved as a favorite, I love your web site!
What’s Taking place i am new to this, I stumbled upon this I have discovered It positively useful and it has helped me
out loads. I hope to give a contribution & assist different customers
like its helped me. Good job.
my webpage :: wedding rings brisbane
This article will help the internet users for setting up new weblog or even a blog
from start to end.
It’s remarkable in favor of me to have a web site, which is useful in favor
of my knowledge. thanks admin
hey there and thank you for your information – I’ve certainly picked up something new from right here.
I did however expertise a few technical issues using this site, since I experienced to
reload the web site many times previous to I could get it to load
correctly. I had been wondering if your hosting is OK? Not that I’m
complaining, but sluggish loading instances times will often affect
your placement in google and can damage your quality score if ads
and marketing with Adwords. Anyway I’m adding this RSS to
my e-mail and can look out for a lot more of your respective fascinating content.
Ensure that you update this again very soon.
This web site certainly has all the information I needed concerning
this subject and didn’t know who to ask.
Hi there Dear, are you actually visiting this web site on a regular basis, if so afterward you will definitely get pleasant experience.
I love what you guys are up too. This type of clever work and exposure!
Keep up the good works guys I’ve included you guys to my blogroll.
Elevate Your Beauty Routine with Clean Glam: Natural, Sustainable, and Cruelty-Free
Neat blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple tweeks would
really make my blog stand out. Please let me know where you got your
design. Bless you
Terrific article! That is the kind of information that should be shared across the
net. Shame on Google for no longer positioning this put up upper!
Come on over and visit my web site . Thanks =)
Wow, amazing weblog layout! How lengthy have
you ever been blogging for? you make blogging look easy.
The total glance of your web site is great, as neatly as
the content material!
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back later.
Cheers
Hey! Someone in my Facebook group shared this website with us so I came
to look it over. I’m definitely loving the information. I’m book-marking and will be tweeting this to
my followers! Terrific blog and amazing design.
I’d like to find out more? I’d want to find out more details.
Also visit my web blog :: laris88
Wonderful site you have here but I was curious if you knew of any
community forums that cover the same topics talked about in this article?
I’d really like to be a part of group where I can get feedback from other knowledgeable
individuals that share the same interest. If you have any recommendations, please let me know.
Cheers!
I visit each day a few websites and websites to read content, but this webpage offers quality based posts.
Hi my friend! I want to say that this article is amazing, great
written and come with almost all important infos.
I’d like to see more posts like this .
I have been surfing online more than 3 hours today, yet I never found any
interesting article like yours. It is pretty worth enough for me.
Personally, if all webmasters and bloggers made good content as you did, the
internet will be much more useful than ever before.
You are so interesting! I do not believe I’ve truly read something like that before.
So good to find somebody with genuine thoughts on this issue.
Really.. many thanks for starting this up. This site is one thing that’s needed on the internet,
someone with some originality!
Thank you for another informative web site. The place else may I get that type of information written in such an ideal approach?
I’ve a challenge that I’m just now operating on, and I’ve been at the
look out for such information.
Hello to every one, because I am in fact keen of reading this webpage’s post to be updated on a
regular basis. It consists of nice information.
I enjoy what you guys are usually up too. Such clever work and reporting!
Keep up the awesome works guys I’ve included you guys to my own blogroll.
Very energetic blog, I enjoyed that a lot. Will there be a part 2?
It’s remarkable in favor of me to have a site, which is valuable
designed for my know-how. thanks admin
It’s actually a great and helpful piece of info. I’m happy that you shared this
helpful information with us. Please keep us up to date like this.
Thanks for sharing.
Hi there! This is my 1st comment here so I just wanted to give a quick shout
out and say I truly enjoy reading your articles. Can you suggest any other blogs/websites/forums that cover the same topics?
Thanks!
Fantastic site. A lot of helpful info here. I’m sending it to
some pals ans also sharing in delicious. And certainly, thank you in your sweat!
I like it when individuals come together and share ideas.
Great blog, stick with it!
Pretty section of content. I just stumbled upon your web site and in accession capital
to assert that I get actually enjoyed account your blog
posts. Any way I will be subscribing to your feeds and even I achievement you access consistently
quickly.
Hello, after reading this remarkable article i am also happy
to share my know-how here with mates.
Ahaa, its fastidious dialogue regarding this post here at this website, I
have read all that, so now me also commenting here.
Great post but I was wondering if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit more.
Thank you!
Hey, I think your website might be having browser compatibility issues.
When I look at your blog in Chrome, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, superb blog!
Great blog right here! Also your web site lots up very fast!
What web host are you the usage of? Can I get your associate hyperlink in your host?
I desire my site loaded up as quickly as yours lol
I’ve been surfing online more than 2 hours today,
yet I never found any interesting article like yours.
It’s pretty worth enough for me. In my view, if all website owners
and bloggers made good content as you did, the net will be much more useful than ever before.
Hey! I just wanted to ask if you ever have
any issues with hackers? My last blog (wordpress) was hacked and
I ended up losing a few months of hard work due to no data backup.
Do you have any methods to prevent hackers?
That is very fascinating, You’re a very professional blogger.
I have joined your rss feed and sit up for in search of more of your fantastic post.
Also, I’ve shared your website in my social networks
If you want to improve your know-how just keep visiting this website and be
updated with the newest information posted here.
Way cool! Some very valid points! I appreciate you writing this article and
the rest of the site is also really good.
Thanks to my father who informed me concerning this website, this website is actually remarkable.
When someone writes an paragraph he/she maintains the plan of a
user in his/her brain that how a user can understand it. Therefore that’s why
this paragraph is outstdanding. Thanks!
It’s going to be end of mine day, except before end I
am reading this wonderful paragraph to improve my knowledge.
веб студии
Oh my goodness! Awesome article dude! Thanks, However I am encountering problems with your RSS.
I don’t know why I am unable to join it. Is there anyone else having the same RSS issues?
Anyone that knows the solution can you kindly respond?
Thanks!!
Simply desire to say your article is as amazing.
The clarity in your post is simply nice and i could assume you’re an expert on this subject.
Fine with your permission let me to grab your RSS feed to keep
up to date with forthcoming post. Thanks a million and please carry on the enjoyable work.
Hello there! This post couldn’t be written any better!
Looking at this post reminds me of my previous roommate!
He constantly kept talking about this. I’ll forward this information to him.
Fairly certain he’ll have a very good read. Thanks for sharing!
Hello There. I found your blog the usage of msn. This is a really smartly written article.
I’ll be sure to bookmark it and return to read more of your useful information.
Thanks for the post. I’ll certainly return.
whoah this blog is great i really like reading your articles.
Keep up the good work! You realize, lots of people
are looking around for this info, you could aid them greatly.
You really make it seem so easy with your presentation but I find this matter
to be really something that I believe I might by no means understand.
It seems too complicated and extremely vast for me. I am having a look forward on your subsequent publish,
I will attempt to get the dangle of it!
This is a great tip particularly to those new to the blogosphere.
Short but very precise info… Thanks for sharing this one.
A must read post!
Howdy! This is my first visit to your blog! We are a team of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have
done a extraordinary job!
Do you have a spam issue on this website; I also am a blogger,
and I was curious about your situation; we have created
some nice practices and we are looking to swap techniques with others,
why not shoot me an email if interested.
I’m really impressed with your writing skills and also with the
layout on your weblog. Is this a paid theme or did you customize it
yourself? Anyway keep up the nice quality writing, it is rare to see
a great blog like this one these days.
Good day I am so glad I found your weblog, I really found you by accident, while I was browsing on Bing
for something else, Nonetheless I am here now and would just
like to say many thanks for a tremendous post and a all round
entertaining blog (I also love the theme/design),
I don’t have time to go through it all at the minute but I have bookmarked it and also added your RSS
feeds, so when I have time I will be back to read a lot more, Please do keep up
the awesome job.
Excellent post. I was checking constantly this blog and I’m impressed!
Extremely helpful information specifically the last part I care for such info much.
I care for such info much.
I was seeking this certain info for a long time. Thank
you and best of luck.
Every weekend i used to pay a quick visit this site, because i want enjoyment, for the reason that this
this web site conations really fastidious funny data too.
certainly like your web-site but you need to take a look at the spelling on quite a few of your posts.
Several of them are rife with spelling problems and I to find it very bothersome to tell the truth on the other hand I’ll definitely come back again.
It’s an amazing piece of writing in favor of all the web users; they will get advantage from
it I am sure.
Wow, this piece of writing is fastidious, my sister is analyzing these things, therefore
I am going to inform her.
Appreciate the recommendation. Will try it out.
It’s going to be ending of mine day, except before end
I am reading this wonderful article to improve my know-how.
What a stuff of un-ambiguity and preserveness of precious know-how about unpredicted emotions.
This design is steller! You definitely know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job.
I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
These are genuinely enormous ideas in regarding blogging.
You have touched some good points here. Any way keep up wrinting.
If some one needs to be updated with hottest technologies after that he must be pay a quick visit this website and be up to date
everyday.
Thanks a lot for sharing this with all folks you actually know
what you’re speaking approximately! Bookmarked.
Kindly also consult with my site =). We will have a hyperlink trade arrangement among us
After checking out a number of the blog posts on your website,
I honestly appreciate your technique of blogging. I added it to my bookmark website list and will be
checking back soon. Take a look at my website too and tell me how you feel.
I have read so many content regarding the blogger lovers except
this post is truly a fastidious post, keep
it up.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how can we communicate?
Excellent blog right here! Also your web site loads up fast!
What web host are you the use of? Can I am getting your associate hyperlink in your host?
I desire my web site loaded up as quickly as yours
lol
удаление засора стоимость
This is very interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of
your magnificent post. Also, I’ve shared your web
site in my social networks!
Wow, awesome blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your web site is magnificent,
let alone the content!
It’s not my first time to pay a visit this website, i am visiting this site dailly and take good information from here
everyday.
Also visit my web site: https://youtu.be/mqUGzJOgICM?si=4wZgdrD_L3KsEayV
This site was… how do I say it? Relevant!! Finally
I have found something which helped me. Thanks!
Hey very interesting blog!
Hi there, the whole thing is going fine here and ofcourse every
one is sharing data, that’s really fine, keep up writing.
Very shortly this site will be famous amid all blogging visitors, due
to it’s pleasant articles
hello!,I like your writing so a lot! percentage we communicate extra approximately your article on AOL?
I need an expert on this space to resolve my problem. Maybe that is
you! Taking a look forward to look you.
That is a really good tip especially to those fresh to the blogosphere.
Brief but very precise info… Many thanks for sharing this one.
A must read article!
hello!,I love your writing very a lot! proportion we communicate more approximately your post on AOL?
I need an expert in this area to solve my problem.
May be that’s you! Taking a look forward to peer
you.
Hello, I enjoy reading through your article post. I
wanted to write a little comment to support you.
always i used to read smaller articles which also clear their motive, and that is also happening with this article
which I am reading here.
I love your blog.. very nice colors & theme. Did you make this website yourself or did
you hire someone to do it for you? Plz respond as I’m looking to design my own blog and would like to know where u got this from.
appreciate it
Hello! I just wanted to ask if you ever have any issues
with hackers? My last blog (wordpress) was hacked and I ended up losing many months of hard work due
to no backup. Do you have any solutions to prevent hackers?
Hey! Someone in my Facebook group shared this website with us so I came to
give it a look. I’m definitely enjoying the
information. I’m bookmarking and will be tweeting this to
my followers! Excellent blog and brilliant design and style.
I don’t know whether it’s just me or if everyone else encountering problems with your website.
It appears as if some of the written text on your posts are running off the screen. Can somebody else please provide feedback and let me know if this is happening to
them too? This could be a problem with my browser because I’ve had this happen previously.
Thanks
my web site; garbage chute closers
Greetings from Colorado! I’m bored at work so I decided to browse your website on my iphone during lunch break.
I really like the info you present here and can’t wait to take a look when I get home.
I’m amazed at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, amazing site!
Great article, totally what I needed.
Check out my web blog: laundry chute spring door
You actually make it seem so easy with your presentation but I find this topic to be really
something that I think I would never understand. It seems too complex and very
broad for me. I am looking forward for your next post, I will try to get the hang of it!
Can you tell us more about this? I’d love to find out some additional information.
Remarkable! Its actually amazing post, I have got much clear
idea regarding from this piece of writing.
Excellent way of explaining, and pleasant post to obtain data on the topic of my presentation subject matter, which i
am going to deliver in college.
Saved as a favorite, I like your website!
Excellent blog! Do you have any hints for aspiring writers?
I’m planning to start my own blog soon but I’m a little
lost on everything. Would you propose starting with a free platform
like WordPress or go for a paid option? There are
so many options out there that I’m totally overwhelmed ..
Any ideas? Cheers!
It’s going to be finish of mine day, however before end I am reading this
great paragraph to improve my experience.
First off I want to say awesome blog! I had a quick question which I’d
like to ask if you do not mind. I was curious
to find out how you center yourself and clear your head before
writing. I’ve had difficulty clearing my thoughts in getting my ideas out.
I do enjoy writing but it just seems like the first 10 to 15 minutes are wasted simply just trying to figure out how to begin. Any recommendations or tips?
Kudos!
Keep this going please, great job!
This site certainly has all of the information I wanted about this subject and didn’t know who to ask.
I must thank you for the efforts you’ve put in penning this website.
I really hope to view the same high-grade blog posts from you later on as well.
In fact, your creative writing abilities has motivated me to get my own site
now 😉
I’m extremely impressed with your writing skills and also
with the layout on your blog. Is this a paid theme or
did you modify it yourself? Anyway keep up the nice quality writing, it’s rare to
see a great blog like this one nowadays.
I am sure this article has touched all the internet users, its
really really fastidious post on building up new webpage.
After checking out a few of the blog posts on your blog,
I seriously like your way of blogging. I book marked it to my bookmark
website list and will be checking back in the near future.
Please check out my web site as well and let me know what you think.
I was recommended this website by my cousin. I’m
not sure whether or not this put up is written by means of him as nobody else understand such special about my
difficulty. You are wonderful! Thank you!
Pretty nice post. I just stumbled upon your weblog and wanted to say that I have truly enjoyed surfing around your blog posts.
After all I will be subscribing to your feed and I hope you write again soon!
I will immediately seize your rss feed as I can not in finding your e-mail
subscription hyperlink or newsletter service. Do you’ve any?
Kindly permit me realize so that I may just subscribe. Thanks.
I know this web site provides quality depending articles and extra data, is there any other web site which provides these kinds of information in quality?
It’s going to be ending of mine day, however before end I am
reading this wonderful article to improve my know-how.
Fabulous, what a weblog it is! This website presents valuable data
to us, keep it up.
Hi there! I realize this is somewhat off-topic however I
needed to ask. Does managing a well-established website like yours take a massive amount work?
I’m completely new to running a blog but I do write in my diary daily.
I’d like to start a blog so I will be able to share my personal experience and
thoughts online. Please let me know if you have any kind of ideas or tips for new aspiring bloggers.
Thankyou!
Thanks for a marvelous posting! I genuinely enjoyed reading it, you’re a great author.I will make
certain to bookmark your blog and may come back from now on. I want to encourage you
continue your great job, have a nice holiday weekend!
my web blog – official website
Hey are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding expertise
to make your own blog? Any help would be really
appreciated!
Please let me know if you’re looking for a article author for your
site. You have some really good posts and I believe I would be a good asset.
If you ever want to take some of the load off, I’d love to write some articles for your blog in exchange
for a link back to mine. Please shoot me an e-mail
if interested. Regards!
Hi, I do think this is a great website. I stumbledupon it 😉 I may return yet again since i have bookmarked
it. Money and freedom is the best way to change, may you be rich and continue to guide other
people.
I quite like reading an article that can make people think.
Also, many thanks for allowing for me to comment!
Sweet blog! I found it while surfing around on Yahoo
News. Do you have any suggestions on how to get
listed in Yahoo News? I’ve been trying for a while but
I never seem to get there! Cheers
Quality articles is the secret to be a focus for the people to pay
a quick visit the site, that’s what this web page is providing.
Greetings I am so delighted I found your webpage, I
really found you by mistake, while I was searching on Yahoo for something else, Anyways
I am here now and would just like to say many thanks for
a tremendous post and a all round interesting blog (I
also love the theme/design), I don’t have time to read through it all at the minute but I have saved it and also included
your RSS feeds, so when I have time I will be back to read much more,
Please do keep up the superb b.
You are so awesome! I do not believe I’ve read anything like that before.
So nice to find someone with some original thoughts on this issue.
Seriously.. many thanks for starting this up.
This site is one thing that’s needed on the internet, someone with a bit of originality!
Hey just wanted to give you a brief heads
up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the
same outcome.
Its like you read my thoughts! You seem to know so much approximately this, like you wrote the e-book in it
or something. I think that you simply can do with a few percent to pressure
the message home a bit, however other than that, this is excellent blog.
An excellent read. I’ll definitely be back.
I could not refrain from commenting. Exceptionally well written!
I absolutely love your website.. Pleasant colors & theme.
Did you develop this website yourself? Please reply back as I’m planning to create my own site and want to learn where you got this from or
just what the theme is called. Thanks!
Hello there! I could have sworn I’ve visited this web site before but
after browsing through a few of the posts I realized it’s new to
me. Regardless, I’m definitely happy I came across it and I’ll be book-marking it and checking back frequently!
Attractive section of content. I just stumbled upon your weblog and in accession capital to assert that
I acquire actually enjoyed account your blog posts. Anyway I’ll be subscribing to your feeds and even I
achievement you access consistently rapidly.
Great post. I used to be checking continuously this weblog and I’m impressed! I take
I take
Extremely useful info specially the closing part
care of such info much. I used to be seeking this certain info for a long time.
Thanks and best of luck.
Hi would you mind letting me know which hosting company you’re
using? I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot quicker
then most. Can you suggest a good web hosting provider at a honest
price? Thanks, I appreciate it!
What i do not realize is in fact how you’re not actually a lot more smartly-preferred
than you may be right now. You are very intelligent.
You understand therefore considerably with regards to this topic, made me individually believe it from a
lot of various angles. Its like women and men don’t seem to be involved until it is
something to accomplish with Woman gaga! Your personal stuffs excellent.
All the time deal with it up!
Great weblog right here! Also your website so much up very fast!
What web host are you the usage of? Can I am getting your
affiliate hyperlink for your host? I wish my site loaded up as fast as yours
lol
Hi there, all the time i used to check web site posts here in the early hours in the daylight, since i
enjoy to find out more and more.
Woah! I’m really digging the template/theme of this website.
It’s simple, yet effective. A lot of times it’s
difficult to get that “perfect balance” between superb usability and appearance.
I must say that you’ve done a excellent job with this.
Additionally, the blog loads very quick for me on Opera.
Exceptional Blog!
Hi! I’m at work surfing around your blog from my new iphone 4!
Just wanted to say I love reading your blog and look forward to all your posts!
Carry on the fantastic work!
Ahaa, its fastidious dialogue about this article at this place at this web site, I have read all that, so now me also
commenting at this place.
Hi to all, the contents present at this web site are actually awesome for people knowledge,
well, keep up the nice work fellows.
Hey! I know this is kind of off-topic but I needed to ask.
Does running a well-established blog such as yours require a massive amount work?
I am brand new to writing a blog however I do write in my journal on a daily basis.
I’d like to start a blog so I will be able
to share my experience and views online. Please let me
know if you have any suggestions or tips for new
aspiring bloggers. Appreciate it!
Saved as a favorite, I really like your web site!
Hi, after reading this amazing post i am too glad to
share my know-how here with mates.
Hello! I could have sworn I’ve been to this website before
but after going through many of the posts I realized it’s new to me.
Anyhow, I’m certainly happy I came across it and I’ll be book-marking it
and checking back regularly!
Hola! I’ve been following your web site for a long time now and finally got the bravery to go ahead and give you a
shout out from Austin Tx! Just wanted to say keep up the excellent job!
Do you have any video of that? I’d like to find out more details.
Wow, fantastic blog structure! How lengthy have you
been running a blog for? you make blogging look easy.
The full look of your site is magnificent, as neatly as the content!
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how
can we communicate?
Great post but I was wanting to know if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit further.
Cheers!
It’s difficult to find well-informed people in this particular topic,
however, you sound like you know what you’re talking about!
Thanks
Howdy this is somewhat of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
I don’t even know how I ended up here, but I thought this post was great.
I don’t know who you are but certainly you are going to a famous blogger if you aren’t already 😉 Cheers!
Hi there it’s me, I am also visiting this web page
regularly, this website is truly pleasant and the users are really sharing fastidious thoughts.
There’s definately a lot to learn about this subject.
I really like all the points you have made.
Hey there! This is my 1st comment here so I just wanted to give a quick shout
out and say I truly enjoy reading through your blog posts.
Can you suggest any other blogs/websites/forums that cover the same subjects?
Thank you so much!
Also visit my web page … pussy dildos
I do believe all of the ideas you’ve offered for your post.
They are very convincing and will definitely work.
Nonetheless, the posts are too short for starters. Could you please extend
them a little from subsequent time? Thanks for the post.
I am regular reader, how are you everybody? This paragraph posted at this site is in fact fastidious.
Terrific post but I was wanting to know if you could write a
litte more on this topic? I’d be very grateful if you could elaborate a little
bit more. Bless you!
Hey very interesting blog!
When I initially commented I clicked the “Notify me when new comments are added” checkbox
and now each time a comment is added I get several emails with the same comment.
Is there any way you can remove people from that service?
Thanks a lot!
Hello, its pleasant paragraph concerning media print, we all be familiar
with media is a fantastic source of information.
Hi my loved one! I want to say that this article is amazing, great written and include almost all vital
infos. I would like to peer more posts like this .
Your style is unique compared to other folks I’ve read
stuff from. I appreciate you for posting when you have the opportunity, Guess I’ll just book mark this blog.
Hey I know this is off topic but I was wondering if you knew of any
widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything. I
truly enjoy reading your blog and I look forward to your new
updates.
My brother suggested I would possibly like this website.
He was once totally right. This put up truly made my day.
You can not imagine just how a lot time I had spent for this info!
Thank you!
You could definitely see your expertise in the article you write.
The sector hopes for more passionate writers like you who aren’t
afraid to say how they believe. All the time go after
your heart.
I am genuinely glad to glance at this blog posts which
contains tons of useful information, thanks for providing these kinds of information.
My brother recommended I might like this blog.
He was entirely right. This post truly made my day. You cann’t imagine just how much time I had spent for this info!
Thanks!
Everything is very open with a clear clarification of the issues.
It was really informative. Your site is very useful.
Thank you for sharing!
Hi! I could have sworn I’ve been to this blog before but after looking at a few of the posts I realized it’s new to me.
Nonetheless, I’m certainly delighted I stumbled upon it and I’ll be book-marking it and checking back frequently!
Way cool! Some very valid points! I appreciate you
writing this write-up plus the rest of the site is really
good.
This post will assist the internet people for creating
new website or even a weblog from start to end.
I am regular reader, how are you everybody? This article posted at this website is truly pleasant.
Excellent blog you have here but I was wanting to know if you knew of any message boards that cover the same topics talked about in this
article? I’d really like to be a part of online community where I can get responses from other experienced people that share the same interest.
If you have any suggestions, please let me know. Many thanks!
As the admin of this website is working, no doubt very shortly it will be renowned, due to its quality contents.
Great post. I used to be checking constantly this weblog and I am impressed!
Extremely helpful info specially the remaining phase I care for such information a lot.
I care for such information a lot.
I used to be seeking this certain information for a
very long time. Thanks and best of luck.
Wonderful beat ! I wish to apprentice while you amend
your site, how could i subscribe for a blog website?
The account aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright clear
idea
I’m not sure exactly why but this weblog is loading
extremely slow for me. Is anyone else having this problem or is it
a issue on my end? I’ll check back later on and see
if the problem still exists.
I really love your blog.. Pleasant colors & theme. Did you
develop this amazing site yourself? Please reply back as I’m trying to create my own personal website and would like to
find out where you got this from or what the theme is
called. Thanks!
Link exchange is nothing else but it is just placing the other person’s blog link on your page at proper place and other person will also do same for you.
Thanks for the marvelous posting! I quite enjoyed reading
it, you might be a great author. I will make certain to
bookmark your blog and will come back very soon. I want to encourage you continue your great writing, have
a nice morning!
I’m not certain the place you’re getting your information,
however great topic. I must spend some time learning much more or figuring out more.
Thanks for fantastic info I used to be searching for this information for my mission.
Excellent goods from you, man. I have understand your stuff previous to
and you are just too wonderful. I really like
what you have acquired here, certainly like what
you’re saying and the way in which you say it. You make it entertaining and you still care for to keep it
sensible. I cant wait to read much more from you.
This is really a wonderful web site.
Aw, this was an incredibly good post. Taking a few minutes and actual effort to
generate a very good article… but what can I say… I hesitate a lot
and never manage to get nearly anything done.
Also visit my homepage: romantic places near me
Hiya! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing a blog
article or vice-versa? My site discusses a lot of the same subjects as yours and I believe we could greatly benefit from each
other. If you happen to be interested feel free to send me an email.
I look forward to hearing from you! Wonderful blog by the way!
Greetings! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My site looks weird when viewing from my apple iphone.
I’m trying to find a template or plugin that might be able to resolve this issue.
If you have any suggestions, please share. Cheers!
It’s fantastic that you are getting ideas from this
post as well as from our discussion made at this place.
Hello! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the great work!
Greetings! I know this is kinda off topic but I was wondering if you knew where I
could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding
one? Thanks a lot!
Wow, this paragraph is good, my younger sister is analyzing these kinds
of things, thus I am going to convey her.
It is truly a great and useful piece of information. I am satisfied that you shared this helpful information with us.
Please keep us informed like this. Thanks for sharing.
Nice post. I learn something new and challenging on blogs I stumbleupon on a daily basis.
It’s always interesting to read content from other writers and use a little something from their sites.
I’m not sure exactly why but this website is loading extremely slow
for me. Is anyone else having this problem or is it a issue on my
end? I’ll check back later and see if the problem still exists.
You made some decent points there. I checked on the net
for more information about the issue and found most individuals will go along with your views on this website.
Experience the finest in plastic surgery at Gruber Plastic Surgery, led by a board-certified plastic
surgeon and star of TLC’s “Awake Surgery” phenomenon, Meegan Gruber, MD, Ph.D.
Patients travel worldwide to Tampa, FL, because our procedures
provide little downtime, real-time outcomes, and no surprises
during awake operations. With a focus on natural beauty and individualized treatment, Dr.
Gruber’s approach guarantees a VIP experience. For a smooth trip to your best self, entrust your change to us.
Ask away and welcome a new era of plastic surgery where natural elegance
meets innovation. Dr. Gruber also performs cosmetic plastic
surgery under general anesthesia. 21+ Years
of Experience. 2000+ beautiful & happy results.
GMB: https://g.co/kgs/sNBFJJ9
You’ve made some good points there. I checked
on the internet for more information about the issue and found most individuals will go along with
your views on this site.
Hello, i think that i saw you visited my site thus i
came to “return the favor”.I’m trying to find things to enhance my web site!I suppose its ok to use a few of your ideas!!
With havin so much content and articles do you ever run into any issues
of plagorism or copyright infringement? My website has a lot of unique content I’ve
either created myself or outsourced but it appears
a lot of it is popping it up all over the web without my agreement.
Do you know any solutions to help prevent content from
being ripped off? I’d genuinely appreciate it.
Magnificent beat ! I would like to apprentice while you amend your web site, how can i subscribe for a blog site?
The account aided me a acceptable deal. I had been a little bit acquainted of this your broadcast offered bright clear concept
Hello there! Would you mind if I share your blog with my facebook group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Many thanks
I love your blog.. very nice colors & theme. Did you make this website yourself or did you hire someone to do
it for you? Plz answer back as I’m looking to
design my own blog and would like to know where u got this from.
kudos
Hello there! This post couldn’t be written any better! Reading this post
reminds me of my good old room mate! He always kept chatting about
this. I will forward this post to him. Fairly certain he
will have a good read. Thank you for sharing!
I have been surfing online greater than three hours these days, but I by no means found any fascinating article like yours.
It’s lovely value sufficient for me. In my view, if all web
owners and bloggers made just right content material as
you did, the net will be a lot more helpful than ever before.
Hi there it’s me, I am also visiting this web site on a
regular basis, this website is in fact pleasant and the people are truly sharing fastidious thoughts.
What’s up, everything is going sound here and ofcourse every one is sharing
facts, that’s truly fine, keep up writing.
The other day, while I was at work, my sister stole
my iPad and tested to see if it can survive a thirty foot drop, just so she can be a
youtube sensation. My apple ipad is now destroyed and she has 83 views.
I know this is totally off topic but I had to share it with
someone!
I like the valuable info you provide for your articles. I’ll bookmark your blog and
take a look at once more here regularly. I am slightly certain I will
be informed plenty of new stuff proper here! Good luck for the next!
Good day I am so grateful I found your site, I really found you by accident,
while I was browsing on Bing for something else, Nonetheless I am here now and would just like to say many thanks for a incredible post and
a all round entertaining blog (I also love the theme/design),
I don’t have time to go through it all at the minute but I have
book-marked it and also added in your RSS feeds, so when I have time
I will be back to read a lot more, Please do keep up
the superb work.
Great weblog right here! Additionally your website rather a lot up fast!
What web host are you the use of? Can I am getting your
associate link in your host? I wish my website loaded up as quickly as yours lol
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get got an impatience over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly
the same nearly a lot often inside case you shield this increase.
I used to be suggested this web site by way of my cousin. I’m no longer positive whether or not this submit is written via him as no one else know such special approximately my trouble.
You are amazing! Thank you!
There’s certainly a great deal to learn about this topic.
I love all the points you made.
If some one wants expert view concerning blogging and
site-building then i propose him/her to go to see
this webpage, Keep up the good work.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You definitely know what youre talking about, why waste your intelligence on just posting videos to your blog when you could be giving
us something enlightening to read?
Heya i am for the first time here. I came across this board
and I to find It truly useful & it helped me out much. I am
hoping to provide one thing back and help others like you aided me.
I read this paragraph completely about the resemblance of latest and
earlier technologies, it’s awesome article.
Thanks for any other informative blog. The place else may just I get that type of information written in such
a perfect manner? I have a mission that I am simply now running on, and I’ve been on the glance
out for such information.
В попытке понять основы успеха Кракена
я обратился к анализу его рекламных стратегий.
kraken что это за сайт Статья Анализ рекламных стратегий Кракена: Как реклама на автобусах увеличивает популярность платформы [площадка кракен что это] предоставила
мне ценные данные о многогранном подходе компании к продвижению.
Благодаря подробному анализу маркетинговых инициатив Кракена я смог оценить эффективность таких каналов, как реклама на автобусах,
и новаторские тактики, используемые для привлечения внимания на переполненном рынке криптовалют.
Wow! This blog looks exactly like my old one!
It’s on a completely different subject but it has pretty
much the same page layout and design. Superb choice of colors!
If some one wants to be updated with most recent technologies after that he must be pay a quick visit this web page and be up to date every day.
It’s actually a nice and helpful piece of information. I am
happy that you just shared this useful information with us.
Please keep us informed like this. Thank you for sharing.
Wow that was odd. I just wrote an really long comment but after I clicked submit
my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyways, just wanted to say
superb blog!
Hello there! This post couldn’t be written much better!
Looking through this post reminds me of my previous roommate!
He continually kept preaching about this. I’ll send this information to him.
Pretty sure he’ll have a great read. Many thanks for sharing!
I know this site offers quality based articles or reviews and other
stuff, is there any other web page which presents these stuff in quality?
It’s remarkable in favor of me to have a web page, which is beneficial
in support of my knowledge. thanks admin
It’s really a nice and useful piece of information. I’m satisfied that you just shared this useful
info with us. Please keep us informed like this.
Thanks for sharing.
First of all I would like to say wonderful blog! I had a quick question that I’d like to ask if you do not
mind. I was curious to know how you center yourself and clear
your head prior to writing. I’ve had difficulty clearing
my thoughts in getting my thoughts out. I truly do enjoy writing but it just seems like the first
10 to 15 minutes tend to be wasted just trying to figure out how to begin. Any
recommendations or hints? Many thanks!
It’s actually very difficult in this busy life to listen news on TV, therefore I just
use internet for that reason, and obtain the most recent news.
Very nice post. I just stumbled upon your blog and wished to
mention that I’ve truly enjoyed browsing your blog posts.
After all I’ll be subscribing for your feed and I’m hoping
you write once more soon!
I’m really inspired along with your writing abilities as smartly as with the format to your blog.
Is this a paid subject matter or did you modify it your self?
Either way stay up the nice quality writing, it is rare to look a great blog
like this one today..
I loved as much as you will receive carried
out right here. The sketch is tasteful, your authored subject
matter stylish. nonetheless, you command get bought an edginess over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly the same nearly a lot often inside case you shield this
increase.
I love your blog.. very nice colors & theme. Did you design this website yourself or did
you hire someone to do it for you? Plz reply as I’m looking to construct my own blog
and would like to find out where u got this from.
many thanks
Can I simply say what a relief to discover somebody that genuinely understands what they’re talking about over the internet.
You definitely know how to bring an issue to light and make it
important. More and more people must read this and understand this side of the story.
I was surprised you are not more popular because you
most certainly have the gift.
Hello there, I discovered your site by the use of Google even as searching
for a similar subject, your site got here up, it appears great.
I have bookmarked it in my google bookmarks.
Hello there, simply became aware of your weblog thru Google,
and found that it’s truly informative. I’m going to watch out for brussels.
I’ll appreciate for those who proceed this in future.
Many other people will likely be benefited out of your writing.
Cheers!
Hey! This is my first comment here so I just wanted to give a quick shout out
and tell you I truly enjoy reading your blog posts. Can you recommend any other blogs/websites/forums that deal with the same
topics? Thanks!
Hi! I realize this is kind of off-topic but I needed to ask.
Does managing a well-established website like yours take a lot
of work? I am completely new to writing a blog but I
do write in my diary everyday. I’d like to start a blog so I will be
able to share my experience and thoughts online. Please let me know if
you have any ideas or tips for brand new aspiring
blog owners. Thankyou!
Hey! I know this is kinda off topic but I was wondering if you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having
problems finding one? Thanks a lot!
What’s up Dear, are you genuinely visiting this website regularly,
if so after that you will definitely obtain pleasant knowledge.
Pretty great post. I simply stumbled upon your weblog and wished to say that I’ve really loved surfing around your
blog posts. In any case I will be subscribing on your rss feed and I am hoping you write once more soon!
Hi there, this weekend is good in support of me, for the reason that this occasion i am reading this fantastic educational post here at
my residence.
I’m truly enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit more often. Did you
hire out a designer to create your theme?
Great work!
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never
seem to get there! Thank you
Good information. Lucky me I found your website by accident
(stumbleupon). I have bookmarked it for later!
Terrific work! This is the type of information that are supposed to
be shared around the web. Shame on the search engines for now not positioning
this put up upper! Come on over and consult with my
web site . Thank you =)
Keep on working, great job!
Also visit my website – 188bet10892
I visited multiple web pages however the audio
quality for audio songs current at this site is actually wonderful.
This is the right website for anybody who wants to understand this topic.
You know so much its almost hard to argue
with you (not that I really will need to…HaHa).
You certainly put a fresh spin on a topic that has been discussed for a long time.
Great stuff, just great!
It’s amazing to pay a visit this site and reading the views of all mates about this post, while I am also eager of getting know-how.
Your way of telling all in this piece of writing is genuinely nice, all can simply understand
it, Thanks a lot.
Great article! We are linking to this particularly great article on our website.
Keep up the good writing.
Just want to say your article is as surprising. The clearness for your publish is simply cool and
i could suppose you are knowledgeable in this subject.
Well with your permission let me to take hold of your feed
to stay updated with drawing close post. Thanks a million and please continue the rewarding
work.
Hi would you mind letting me know which hosting company you’re using?
I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot
faster then most. Can you suggest a good web hosting provider at a reasonable
price? Thanks, I appreciate it!
Ahaa, its nice conversation about this post here at this website,
I have read all that, so now me also commenting at this place.
I need to to thank you for this wonderful read!! I certainly enjoyed every little bit of it.
I have got you saved as a favorite to look
at new things you post…
Thanks for a marvelous posting! I truly enjoyed reading it, you might be a great
author.I will be sure to bookmark your blog and will often come back later on. I want to encourage one to continue your great posts, have a nice evening!
Good site you have got here.. It’s difficult to find good quality writing like yours these days.
I truly appreciate individuals like you! Take care!!
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically
tweet my newest twitter updates. I’ve been looking for a plug-in like
this for quite some time and was hoping maybe you would have some experience with
something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
This is a topic which is close to my heart… Best wishes!
Where are your contact details though?
Its like you read my mind! You appear to know a lot about this, like
you wrote the book in it or something. I think that you could do with some pics to drive the message
home a bit, but instead of that, this is wonderful blog. An excellent read.
I will definitely be back.
This paragraph will help the internet viewers for building up new website or even a blog from start to end.
I’m excited to find this web site. I wanted to thank you for your time for this
particularly fantastic read!! I definitely enjoyed every little bit of it
and i also have you saved as a favorite to check out new
information in your blog.
I blog quite often and I really appreciate your information. This great
article has truly peaked my interest. I will bookmark your site and keep checking for
new information about once a week. I opted in for your Feed too.
Hi colleagues, how is all, and what you desire to say about this piece of writing, in my view its in fact amazing in favor
of me.
Right here is the right website for everyone who wants to
find out about this topic. You realize a whole lot its almost hard to argue with you (not that I really
will need to…HaHa). You definitely put a new spin on a topic that has been discussed for decades.
Great stuff, just wonderful!
Amazing issues here. I am very satisfied to look your post.
Thank you a lot and I am looking ahead to touch you.
Will you please drop me a mail?
Thank you for some other informative site. Where else
may just I am getting that type of info written in such a
perfect manner? I’ve a undertaking that I’m just now working on, and I’ve been on the glance out for such info.
No matter if some one searches for his required thing, therefore he/she wishes to be available that
in detail, thus that thing is maintained over here.
I do not even know how I ended up here, but I thought this
post was great. I do not know who you are but definitely
you are going to a famous blogger if you are not already 😉 Cheers!
I am genuinely pleased to read this web site posts which carries plenty of valuable
facts, thanks for providing these statistics.
Hi, i think that i saw you visited my web site so i came to “return the favor”.I am trying to find things
to improve my web site!I suppose its ok to use some of your ideas!!
Thanks for ones marvelous posting! I actually enjoyed reading it, you will
be a great author. I will ensure that I bookmark your blog
and may come back in the foreseeable future. I want to encourage you to continue your great job, have a nice day!
This post is invaluable. When can I find out more?
First of all I want to say great blog! I had a quick question that I’d like to
ask if you do not mind. I was interested to know how you center yourself and clear your thoughts before writing.
I’ve had a tough time clearing my mind in getting my thoughts
out. I do take pleasure in writing however it just seems like
the first 10 to 15 minutes are lost just trying
to figure out how to begin. Any suggestions or tips? Cheers!
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored material stylish. nonetheless, you command get got an impatience over that you wish be delivering the following.
unwell unquestionably come further formerly again as exactly the same nearly a lot often inside case you shield this increase.
I enjoy reading through an article that will make people think.
Also, thanks for allowing for me to comment!
you are in point of fact a just right webmaster. The website
loading speed is incredible. It kind of feels that
you’re doing any distinctive trick. Furthermore, The
contents are masterwork. you’ve done a excellent activity in this subject!
I’m pretty pleased to find this website. I need to to thank you for
your time due to this wonderful read!! I definitely loved every bit of it and I have you saved as a favorite to check out new things in your
blog.
I read this article completely on the topic of the comparison of latest
and preceding technologies, it’s remarkable
article.
Thanks for sharing your thoughts about abati.ru.
Regards
I couldn’t resist commenting. Exceptionally well written!
It’s an awesome paragraph for all the internet users; they will take advantage from
it I am sure.
These are actually great ideas in concerning blogging.
You have touched some pleasant factors here.
Any way keep up wrinting.
I’ve been exploring for a little for any high-quality
articles or weblog posts in this sort of area . Exploring in Yahoo I eventually stumbled upon this web site.
Studying this information So i am happy to express that I have an incredibly good uncanny feeling I
came upon just what I needed. I most no doubt will make certain to
do not overlook this web site and give it a glance regularly.
I like the helpful information you provide to your articles.
I’ll bookmark your blog and test again right here frequently.
I’m fairly sure I’ll be told many new stuff right right here!
Best of luck for the next!
Thanks for finally talking about > Пиастры – Составление семантического ядра | < Loved it!
Greetings from Los angeles! I’m bored to tears at work so I decided to check out your website on my iphone during lunch break.
I love the info you provide here and can’t wait to take a look when I get home.
I’m shocked at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyhow, good blog!
Hello, after reading this amazing post i am as well cheerful to share my familiarity here
with mates.
It’s actually a nice and useful piece of info. I’m happy that you simply shared this useful information with us.
Please stay us informed like this. Thank you for sharing.
Yes! Finally something about High Authority Backlinks.
I blog quite often and I really appreciate your information. Your
article has really peaked my interest. I’m going to bookmark your blog and keep checking for
new information about once per week. I subscribed to your Feed too.
I was suggested this web site by way of my cousin. I’m not
sure whether this submit is written by means of him as no one else recognize such specified about my problem.
You are amazing! Thank you!
Hi there, all is going perfectly here and ofcourse
every one is sharing information, that’s truly fine, keep up writing.
Very quickly this web site will be famous amid all blog users, due to it’s fastidious content
Hurrah, that’s what I was looking for, what a stuff! present here at this blog, thanks admin of this web page.
donna cerca uomo incontri personali annunci uomo cerca donna
massaggi relax orientale amore a roma milano napoli lazio
lombardia campania
Also visit my blog post; annunci incontri massaggi
Asking questions are in fact fastidious thing if you are not understanding something totally,
but this post offers pleasant understanding even.
Simply want to say your article is as astonishing. The clarity to your publish is just great
and i can think you’re an expert on this subject. Fine along with your permission allow me to take hold
of your feed to keep up to date with forthcoming post.
Thanks 1,000,000 and please continue the enjoyable work.
I think this is one of the so much vital information for me.
And i am glad studying your article. However should commentary on few basic things, The
site style is ideal, the articles is actually nice : D.
Good process, cheers
Hmm it looks like your blog ate my first comment (it was super long) so I guess I’ll
just sum it up what I had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to the whole thing.
Do you have any tips and hints for rookie blog writers?
I’d certainly appreciate it.
Valuable information. Fortunate me I found your web site by chance, and I’m shocked why this twist
of fate didn’t happened earlier! I bookmarked it.
My blog – kunjungi
Heya! I know this is somewhat off-topic however I needed to ask.
Does operating a well-established blog such as yours take
a large amount of work? I’m completely new to running a blog but I do write in my diary everyday.
I’d like to start a blog so I can share my own experience
and thoughts online. Please let me know if you have any
recommendations or tips for brand new aspiring blog owners.
Thankyou!
Hello there! Quick question that’s entirely off topic. Do you know how to
make your site mobile friendly? My weblog looks weird when viewing from my
iphone. I’m trying to find a template or plugin that might be able to fix this problem.
If you have any recommendations, please share.
Thanks!
It’s very easy to find out any topic on net as compared to textbooks, as I found this paragraph at this web page.
Hello mates, how is everything, and what you would like to say about
this article, in my view its in fact remarkable in support of me.
Great blog here! Additionally your site a lot up very fast!
What web host are you the use of? Can I am getting your affiliate hyperlink for your host?
I desire my website loaded up as quickly as yours lol
Hi there to every one, for the reason that I am really keen of reading this blog’s post to be updated regularly.
It consists of pleasant information.
I know this site presents quality based posts and additional material, is there any other web page which presents such things in quality?
I all the time used to study post in news papers but now as I
am a user of web so from now I am using net for articles, thanks to web.
It’s an remarkable post in support of all the web people;
they will take benefit from it I am sure.
Do you mind if I quote a couple of your articles as long as I provide credit
and sources back to your site? My website is in the exact same area
of interest as yours and my visitors would definitely benefit from
a lot of the information you provide here. Please let me know if
this ok with you. Thanks a lot!
Thanks for the good writeup. It in reality used to be a entertainment account it.
Look advanced to far brought agreeable from you! By the way, how could we keep in touch?
Appreciate the recommendation. Will try it out.
Everything is very open with a really clear explanation of the
challenges. It was definitely informative. Your site is useful.
Thank you for sharing!
What a stuff of un-ambiguity and preserveness of valuable familiarity about unexpected feelings.
Simply wish to say your article is as astonishing.
The clearness in your post is simply excellent and i can assume you
are an expert on this subject. Fine with your permission let me to grab your RSS feed
to keep updated with forthcoming post. Thanks a million and
please continue the enjoyable work.
What’s up, I log on to your blog like every week.
Your humoristic style is witty, keep it up!
It’s actually a cool and helpful piece of information. I am happy that you shared this useful information with us.
Please stay us up to date like this. Thank you for
sharing.
I think that everything wrote made a lot of sense.
But, what about this? suppose you added a little information? I ain’t saying your content is not good., but what if you added a
title to possibly get a person’s attention? I mean Пиастры – Составление
семантического ядра | is kinda vanilla.
You might glance at Yahoo’s home page and watch how
they create news headlines to grab people
to open the links. You might add a video or a related picture or two
to get people interested about what you’ve got to say. In my opinion,
it could bring your posts a little livelier.
Howdy, I believe your blog could possibly be having web browser compatibility problems.
When I look at your blog in Safari, it looks fine however, if opening in Internet Explorer, it’s got some overlapping issues.
I simply wanted to give you a quick heads up!
Aside from that, excellent blog!
Great goods from you, man. I’ve remember your stuff previous to
and you’re just extremely excellent. I really like what you have
obtained here, really like what you’re saying and the best way wherein you say it.
You are making it entertaining and you still care for to keep it smart.
I can not wait to learn far more from you. This is actually a great site.
Usually I do not learn article on blogs, however I would like to
say that this write-up very pressured me to take a look at and do so!
Your writing taste has been amazed me. Thanks, very
nice post.
Great article, just what I was looking for.
I’m really enjoying the theme/design of your site.
Do you ever run into any internet browser compatibility issues?
A small number of my blog audience have complained about my site not operating correctly in Explorer but looks great in Chrome.
Do you have any solutions to help fix this issue?
Fine way of describing, and nice article to obtain information on the topic of my presentation focus,
which i am going to convey in institution of higher education.
Incredible quest there. What happened after? Good luck!
What’s up, just wanted to say, I enjoyed this post. It was inspiring.
Keep on posting!
Hi all, here every one is sharing these kinds of experience, so it’s good to read this blog, and
I used to pay a quick visit this weblog all the time.
Hi there to all, the contents present at this site are really awesome for people
knowledge, well, keep up the good work fellows.
Superb, what a webpage it is! This website gives valuable data
to us, keep it up.
Magnificent beat ! I wish to apprentice even as you amend your web site, how can i subscribe for a blog
website? The account aided me a appropriate
deal. I had been tiny bit acquainted of this your broadcast offered vivid clear idea
Have you ever considered publishing an ebook or guest authoring on other websites?
I have a blog based on the same topics you discuss and would love
to have you share some stories/information. I know my subscribers would enjoy your work.
If you are even remotely interested, feel free to shoot me
an e mail.
Its like you read my mind! You appear to know a lot about this,
like you wrote the book in it or something.
I think that you can do with a few pics to drive the
message home a bit, but instead of that, this is great blog.
An excellent read. I’ll certainly be back.
Admiring the commitment you put into your blog and in depth information you present.
It’s good to come across a blog every once in a while that isn’t the same
outdated rehashed information. Fantastic read! I’ve saved your site and I’m including your RSS
feeds to my Google account.
Every weekend i used to pay a quick visit this web site, as i
wish for enjoyment, as this this web page conations
genuinely good funny data too.
Wow, superb blog structure! How long have you ever been blogging for?
you made running a blog look easy. The total look of your website is great, as well
as the content material!
Ahaa, its pleasant discussion regarding this article
here at this webpage, I have read all that, so now me also commenting at
this place.
Hello to every one, the contents present at this web site are really amazing for people knowledge,
well, keep up the nice work fellows.
Does your blog have a contact page? I’m having a
tough time locating it but, I’d like to shoot you an e-mail.
I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it improve over time.
I am truly thankful to the holder of this web
page who has shared this great post at at this time.
I have read so many articles concerning the blogger lovers however this post is truly a good paragraph,
keep it up.
I’m extremely impressed together with your writing skills and also with the structure on your blog.
Is that this a paid subject matter or did you modify it yourself?
Either way keep up the excellent high quality writing, it’s uncommon to see a nice weblog like this one nowadays..
Saved as a favorite, I love your website!
Wow that was unusual. I just wrote an incredibly long comment but
after I clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Anyways, just wanted to say
great blog!
Keep on writing, great job!
Wonderful, what a blog it is! This web site provides useful facts to us, keep it up.
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your website to come back down the
road. Cheers
I’m impressed, I must say. Seldom do I encounter a blog that’s both equally educative
and engaging, and without a doubt, you have hit the nail on the head.
The issue is an issue that not enough men and
women are speaking intelligently about. I’m very happy I came across this during my
hunt for something regarding this.
Hello there, You have done a great job. I’ll definitely digg it and personally suggest to my friends.
I’m sure they will be benefited from this website.
I am sure this article has touched all the internet viewers, its
really really pleasant piece of writing on building up new webpage.
Hello, everything is going perfectly here and ofcourse
every one is sharing facts, that’s genuinely good, keep up writing.
Hi there, i read your blog occasionally and i own a similar one and i was just wondering if you get a lot
of spam feedback? If so how do you protect against it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any support is very much appreciated.
I visited multiple web sites except the audio quality for audio songs present at this web page is
actually superb.
Hi everyone, it’s my first visit at this web site, and post is actually
fruitful for me, keep up posting such articles or reviews.
I’m not that much of a internet reader to be honest but your sites really nice, keep
it up! I’ll go ahead and bookmark your website to come back later on. All the best
I pay a quick visit each day a few blogs and blogs to read content, except this web site offers feature based posts.
You could certainly see your expertise within the work you
write. The sector hopes for more passionate writers such as you who aren’t afraid to say how they believe.
Always follow your heart.
I am sure this paragraph has touched all the internet users, its
really really pleasant post on building up new website.
Right here is the right site for everyone who would like
to find out about this topic. You realize so much its almost tough to argue
with you (not that I really will need to…HaHa). You definitely put a fresh spin on a subject which has
been discussed for decades. Wonderful stuff,
just wonderful!
Useful info. Fortunate me I found your website unintentionally, and I am stunned why
this accident did not came about earlier! I bookmarked it.
Hi there to every one, for the reason that I am genuinely keen of reading
this web site’s post to be updated on a regular basis.
It carries good information.
Do you have a spam issue on this website; I also am a blogger, and I was curious
about your situation; many of us have developed some nice practices
and we are looking to swap methods with others,
please shoot me an email if interested.
You actually make it appear so easy with your presentation however I in finding this matter to be actually one thing that I think I might never understand.
It seems too complicated and extremely extensive for me.
I am looking forward on your subsequent post, I will attempt to get
the dangle of it!
Знакомство с Мега – это уникальное путешествие, где каждый шаг открывает новые грани
даркнета. mega ссылка на сайт
Маркетплейс Кракен стал для меня проводником в этот загадочный мир.
Его интуитивно понятный интерфейс и строгие правила
безопасности обеспечили мне комфортную навигацию по скрытой сети.
Каждый контакт с Кракеном был особенным.
Общаясь с его вендорами, я получил ценный
опыт, оттачивая свои навыки конспирации и анонимности.
Торговые операции всегда проходили без сбоев,
подтверждая надежность платформы.
Мега – это не просто торговая площадка.
Это место, где знания и опыт сливаются воедино.
Я научился распознавать надежных продавцов, оценивать
риски и эффективно использовать криптовалюту.
Каждая сделка становилась уроком, формируя мое глубокое понимание
работы даркнета. [mega ссылка на сайт]
Attractive element of content. I simply stumbled upon your weblog and
in accession capital to assert that I get actually loved account your weblog posts.
Anyway I’ll be subscribing in your feeds or even I success you
get admission to persistently quickly.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I
get four e-mails with the same comment. Is there any way you can remove me
from that service? Many thanks!
This paragraph gives clear idea for the new viewers of blogging, that truly how to do running a blog.
There is definately a great deal to learn about this issue.
I love all the points you made.
For hottest news you have to visit world wide web and on world-wide-web I
found this web site as a best web site for latest updates.
Feel free to surf to my website: resume
I’m really enjoying the theme/design of your blog.
Do you ever run into any web browser compatibility problems?
A couple of my blog readers have complained about my website
not operating correctly in Explorer but looks great in Firefox.
Do you have any recommendations to help fix this problem?
Thank you for the auspicious writeup. It in fact was once a leisure account it.
Look complicated to far introduced agreeable from you! However, how can we keep
in touch?
For latest news you have to go to see world-wide-web and on world-wide-web I found this site as a finest web page for
most recent updates.
Hey There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and return to read more
of your useful info. Thanks for the post. I will definitely return.
Hi, i read your blog occasionally and i own a similar one and i was just curious
if you get a lot of spam comments? If so how do you protect
against it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any help is very much appreciated.
Excellent post but I was wondering if you could write a
litte more on this subject? I’d be very grateful if
you could elaborate a little bit more. Bless you!
I was able to find good advice from your content.
Hmm it seems like your website ate my first comment (it was super long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m
still new to everything. Do you have any helpful hints for first-time blog writers?
I’d certainly appreciate it.
Unleash your wanderlust! Explore the world with
Travel in Beautiful Fashion, your ultimate travel blog.
Compare airfares on over 700+ budget airlines, book unique rental cars, and discover cultural immersion or cultural travel hidden gems with our expert-curated travel
guides and insider travel tips. Browse our Wanderlust digital nomad Travel blog for articles on Eco-tourism, solo travel, flashpacking, responsible travel, beautiful camping and more!
I want to to thank you for this excellent read!!
I absolutely loved every little bit of it. I have you bookmarked to check
out new stuff you post…
Howdy just wanted to give you a quick heads up. The text in your
content seem to be running off the screen in Opera.
I’m not sure if this is a format issue or something to do with
internet browser compatibility but I thought I’d post to let
you know. The design look great though! Hope you get
the issue fixed soon. Many thanks
I’m amazed, I have to admit. Rarely do I come
across a blog that’s equally educative and interesting, and without a doubt,
you’ve hit the nail on the head. The problem is an issue that too few men and women are speaking intelligently about.
I’m very happy I stumbled across this in my search for something relating
to this.
Here is my page :: vanguardngr
This piece of writing provides clear idea for the new viewers of blogging, that really how
to do blogging.
I loved as much as you’ll receive carried out right
here. The sketch is tasteful, your authored
subject matter stylish. nonetheless, you command get got an nervousness over that you wish be delivering the
following. unwell unquestionably come more formerly again as exactly the same nearly very
often inside case you shield this hike.
I know this web page provides quality based posts and other information, is there any other website which presents these kinds of data in quality?
I’m not sure exactly why but this website is loading extremely slow for me.
Is anyone else having this issue or is it a problem
on my end? I’ll check back later on and see if the problem still exists.
After I initially commented I seem to have clicked the -Notify
me when new comments are added- checkbox and from now
on whenever a comment is added I receive four emails with the same comment.
Perhaps there is an easy method you are able to remove me from
that service? Cheers!
Thank you for sharing your info. I truly appreciate your efforts and I am waiting for your
further write ups thanks once again.
With havin so much written content do you ever run into any
issues of plagorism or copyright infringement? My site has a lot of unique content I’ve either authored myself or outsourced but it appears a lot of it is popping it
up all over the web without my authorization. Do you know any techniques to help protect against content from
being stolen? I’d genuinely appreciate it.
It’s very effortless to find out any topic on web as compared to textbooks, as I found this paragraph
at this website.
you’re actually a just right webmaster. The site loading pace is amazing.
It seems that you’re doing any unique trick. Furthermore, The contents are masterwork.
you’ve performed a wonderful task on this topic!
Hi there, You’ve done a fantastic job. I’ll definitely digg it and personally suggest to my
friends. I’m confident they’ll be benefited from this web
site.
It’s awesome designed for me to have a website, which is good in support
of my knowledge. thanks admin
Great goods from you, man. I have understand your stuff previous to and you are just extremely great.
I really like what you’ve acquired here, really like what you’re stating and the way in which you say it.
You make it entertaining and you still take care of to keep it wise.
I cant wait to read much more from you. This is actually a
great web site.
Wow that was odd. I just wrote an extremely long comment but after I clicked submit my comment didn’t
appear. Grrrr… well I’m not writing all that over again. Regardless, just wanted to say great blog!
Hey there this is kind of of off topic but I was wondering
if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so I wanted to get guidance from
someone with experience. Any help would be greatly appreciated!
If some one wishes to be updated with newest technologies afterward he must be
pay a visit this web page and be up to date every day.
This article is in fact a fastidious one it helps new the web viewers, who
are wishing for blogging.
Your way of telling all in this post is actually fastidious, all be capable of effortlessly be aware of it, Thanks a lot.
Hmm it seems like your website ate my first comment (it was super long)
so I guess I’ll just sum it up what I wrote and say, I’m thoroughly
enjoying your blog. I as well am an aspiring blog writer but I’m still new to
the whole thing. Do you have any tips for rookie blog writers?
I’d really appreciate it.
Wow! After all I got a web site from where I know how to genuinely take useful data regarding my study and knowledge.
I was recommended this website through my cousin. I am now not certain whether or
not this post is written via him as no one else recognize such distinct approximately my problem.
You are incredible! Thanks!
Thank you for some other informative blog. The place else could I am getting that
kind of information written in such an ideal method?
I have a project that I am simply now operating on, and I’ve been at the look out for such info.
I know this if off topic but I’m looking into starting my own blog and was
wondering what all is required to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% sure. Any recommendations or advice would be
greatly appreciated. Kudos
Pretty nice post. I just stumbled upon your blog and wished to say that I have
really enjoyed browsing your weblog posts. After all I will be subscribing on your
rss feed and I hope you write once more very soon!
It’s actually a great and useful piece of info.
I’m satisfied that you simply shared this helpful information with us.
Please stay us informed like this. Thank you for sharing.
Hello Dear, are you really visiting this website regularly,
if so then you will absolutely get pleasant know-how.
Hello, Neat post. There is a problem with your website in web explorer,
might test this? IE still is the marketplace chief and a large part of other folks
will pass over your wonderful writing because of this problem.
Hi terrific blog! Does running a blog such as this require a lot of work?
I’ve absolutely no expertise in coding however I had been hoping to start my own blog soon. Anyways,
should you have any recommendations or tips for new blog owners please share.
I understand this is off topic however I just needed to ask.
Thanks a lot!
Nice blog here! Also your site loads up fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as quickly as yours lol
I am now not sure where you’re getting your info, however good topic.
I must spend some time finding out much more or understanding more.
Thank you for magnificent info I was on the lookout for this information for my mission.
Hello, I desire to subscribe for this website to take latest updates, therefore where
can i do it please help out.
Yes! Finally someone writes about https://www.linkedin.com/in/jboaicom.
An impressive share! I’ve just forwarded this
onto a co-worker who was conducting a little homework on this.
And he in fact ordered me dinner due to the fact that I stumbled upon it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanks for spending the time to discuss
this topic here on your website.
I’ve learn several excellent stuff here. Certainly price bookmarking for revisiting.
I wonder how a lot effort you place to make this kind of
great informative web site.
I know this site offers quality dependent articles and
additional stuff, is there any other site which offers these
kinds of stuff in quality?
What’s Going down i am new to this, I stumbled upon this
I’ve found It positively useful and it has aided me out loads.
I hope to contribute & help other users like its helped me.
Great job.
I have been surfing on-line greater than 3 hours as of late, but I by no means discovered any
fascinating article like yours. It is pretty worth enough
for me. In my view, if all website owners and bloggers made excellent content
as you probably did, the net shall be a lot more
useful than ever before.
We are a group of volunteers and starting a new scheme in our community.
Your web site offered us with valuable info to work on. You have done a formidable job and our entire community will be grateful to you.
I am in fact thankful to the owner of this web site who has shared this great piece of writing at here.
Excellent blog right here! Also your website quite a bit up very
fast! What web host are you the use of? Can I get your associate link
in your host? I want my site loaded up as quickly as yours lol
Ridiculous story there. What occurred after? Thanks!
Good day! I simply would like to offer you a big thumbs up for your great info you have got here on this post.
I’ll be returning to your blog for more soon.
Hi my friend! I want to say that this article is awesome, great written and include almost all vital infos.
I’d like to look extra posts like this .
Today, I went to the beach front with my children.
I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear. She never wants to go back!
LoL I know this is completely off topic but I had to tell someone!
You really make it seem really easy together with your presentation however I in finding this matter to be really one thing which I
feel I might never understand. It kind of feels too
complicated and very wide for me. I’m having a look forward to your next publish, I’ll attempt
to get the cling of it!
Hi, everything is going sound here and ofcourse every one is sharing information, that’s genuinely fine, keep
up writing.
We stumbled over here by a different page and thought I
might check things out. I like what I see so now i am following you.
Look forward to finding out about your web page yet again.
Fantastic goods from you, man. I have take into account your stuff previous to and you are simply too fantastic.
I actually like what you have acquired here, really
like what you are stating and the way in which during which you say
it. You make it enjoyable and you still care for to stay it sensible.
I cant wait to read much more from you. That is
really a terrific web site.
It’s hard to come by well-informed people in this particular topic, but you sound like you know what you’re talking about!
Thanks
you are in reality a excellent webmaster. The website loading velocity
is amazing. It seems that you’re doing any distinctive trick.
Moreover, The contents are masterwork. you have performed a fantastic task in this matter!
Hello, i think that i saw you visited my weblog so i got here to return the desire?.I’m attempting to find
issues to improve my web site!I suppose its adequate to
use some of your ideas!!
Inspiring quest there. What happened after? Thanks!
Thanks for sharing your thoughts about http://scenept.untergrund.net/bbs/profile.php?id=15654. Regards
Very nice post. I just stumbled upon your weblog and wanted to say that I’ve truly enjoyed surfing around your blog posts.
In any case I will be subscribing to your rss feed and I hope you write again soon!
Amazing things here. I’m very satisfied to see your article.
Thank you a lot and I am having a look ahead to
touch you. Will you kindly drop me a e-mail?
An impressive share! I’ve just forwarded this onto a colleague who has been conducting a little research on this.
And he in fact bought me breakfast because I found it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah, thanks for spending
the time to talk about this subject here on your web site.
Everything is very open with a clear description of the challenges.
It was definitely informative. Your site is extremely helpful.
Many thanks for sharing!
Wonderful post however I was wondering if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit more.
Thank you!
Ahaa, its pleasant dialogue about this post at this place at this
webpage, I have read all that, so at this time me also commenting
here.
Stunning quest there. What happened after? Good luck!
Simply wish to say your article is as astonishing.
The clearness in your post is just great and i can assume you are an expert on this subject.
Well with your permission let me to grab your feed to
keep up to date with forthcoming post. Thanks a million and please carry on the enjoyable work.
Hi there, You have done a great job. I will certainly digg it and personally recommend to my friends.
I am sure they’ll be benefited from this website.
Very descriptive post, I liked that a lot. Will there be a part
2?
Pretty! This was an incredibly wonderful article.
Many thanks for supplying these details.
Truly when someone doesn’t understand after that its up to
other viewers that they will assist, so here it takes place.
Hello would you mind letting me know which hosting company
you’re using? I’ve loaded your blog in 3 completely different web browsers and I must say this
blog loads a lot faster then most. Can you recommend a good web hosting provider at a fair price?
Thank you, I appreciate it!
Wow that was odd. I just wrote an extremely long comment but after I
clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyways, just wanted to say great blog!
Interesting blog! Is your theme custom made
or did you download it from somewhere? A design like yours with a few
simple adjustements would really make my blog jump out. Please let
me know where you got your design. Appreciate it
Hello would you mind letting me know which hosting company you’re working with?
I’ve loaded your blog in 3 different internet browsers and
I must say this blog loads a lot faster then most. Can you
suggest a good hosting provider at a fair price?
Thanks, I appreciate it!
My brother suggested I might like this website. He was entirely right.
This post truly made my day. You can not imagine simply how much
time I had spent for this info! Thanks!
Very shortly this website will be famous amid all blogging users, due to it’s good posts
Hi! Do you know if they make any plugins to assist with Search Engine Optimization? I’m trying to get my
blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Many thanks!
We’re a gaggle of volunteers and opening a new scheme in our
community. Your web site provided us with useful information to work on. You have performed a formidable task and our entire
group will be grateful to you.
Appreciate this post. Let me try it out.
I was recommended this website through my cousin. I’m now not
certain whether this publish is written by way of him
as no one else recognize such special approximately my
difficulty. You’re amazing! Thank you!
Appreciate the recommendation. Let me try it out.
Hello, i read your blog from time to time and i own a similar one
and i was just curious if you get a lot of spam feedback?
If so how do you reduce it, any plugin or anything you
can suggest? I get so much lately it’s driving me crazy so any assistance is
very much appreciated.
This piece of writing will assist the internet users for setting up new blog or even a weblog from start to
end.
Very good blog! Do you have any tips and hints for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for
a paid option? There are so many options out there that I’m completely confused
.. Any recommendations? Cheers!
It’s genuinely very complex in this busy life to listen news on TV, thus I only use world
wide web for that purpose, and take the hottest news.
Wow, fantastic blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your web site is
fantastic, as well as the content!
bookmarked!!, I love your web site!
Excellent items from you, man. I have be aware your stuff previous to
and you are simply too great. I really like what you have bought here, really like what you’re
stating and the best way wherein you say it. You are making it entertaining and you still take care of to keep it wise.
I cant wait to learn far more from you. That is really a great website.
Good day! This is kind of off topic but I need some advice
from an established blog. Is it tough to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any points or suggestions? With thanks
I am curious to find out what blog platform you are
using? I’m having some small security issues with my latest website and I would
like to find something more secure. Do you have any recommendations?
What’s up, its good article on the topic of media print, we all be aware of media is a great source of information.
After looking into a handful of the blog articles on your site,
I honestly appreciate your technique of writing a blog.
I saved as a favorite it to my bookmark webpage list and will be
checking back soon. Please visit my web site as well and let me know what you think.
Hi! I could have sworn I’ve been to this site before but after browsing through some of the post I realized it’s new to me.
Anyways, I’m definitely glad I found it and I’ll be bookmarking and checking back often!
My family all the time say that I am killing my time here at net, but I know I am getting familiarity
all the time by reading such good content.
I have read so many articles about the blogger lovers except this
post is in fact a fastidious article, keep it
up.
Excellent blog you have got here.. It’s difficult to find high-quality writing like yours nowadays.
I truly appreciate individuals like you! Take care!!
I do not know whether it’s just me or if perhaps everyone else experiencing issues
with your website. It appears as though some of the text within your content
are running off the screen. Can someone else please comment and let me know if
this is happening to them as well? This may be a issue with
my web browser because I’ve had this happen previously. Thanks
Definitely believe that which you stated. Your favorite justification appeared to be on the internet the simplest thing to be
aware of. I say to you, I certainly get irked while people consider worries that they just do not
know about. You managed to hit the nail upon the top as well as defined out the whole
thing without having side effect , people could take a signal.
Will probably be back to get more. Thanks
hello there and thank you for your info – I have certainly picked up anything new from
right here. I did however expertise a few technical issues using this website, since I
experienced to reload the website a lot of times previous to I could get it to load properly.
I had been wondering if your web host is OK? Not that I am complaining,
but sluggish loading instances times will sometimes affect your
placement in google and could damage your high-quality score if ads and marketing with Adwords.
Anyway I am adding this RSS to my email and can look out
for much more of your respective intriguing content.
Make sure you update this again soon.
Hi i am kavin, its my first occasion to commenting anywhere, when i read this piece of writing
i thought i could also create comment due to
this brilliant article.
Way cool! Some very valid points! I appreciate you writing this post and the rest of
the website is also really good.
Having read this I thought it was really enlightening. I appreciate you finding the
time and energy to put this informative article together.
I once again find myself personally spending way too much time both reading and commenting.
But so what, it was still worthwhile!
You actually make it appear really easy together with
your presentation however I find this matter to be actually something which I believe I might by no means
understand. It seems too complicated and very vast for me.
I am having a look ahead for your subsequent put up, I will attempt to get the dangle of it!
my webpage; 비아그라판매
Superb blog! Do you have any tips for aspiring writers? I’m
hoping to start my own website soon but I’m a little
lost on everything. Would you recommend starting with a free platform like WordPress or go for a
paid option? There are so many choices out there that I’m completely confused
.. Any ideas? Kudos!
I’m not that much of a internet reader to be honest
but your blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back later on. All the best
I like what you guys are up too. This kind of clever work and reporting!
Keep up the good works guys I’ve added you guys to blogroll.
You can certainly see your expertise within the work you write.
The arena hopes for more passionate writers such as you who aren’t afraid to say how they believe.
All the time follow your heart.
Having read this I thought it was really informative.
I appreciate you finding the time and effort to put this short article together.
I once again find myself personally spending way too much time both reading
and commenting. But so what, it was still worthwhile!
Very good article! We will be linking to this great article on our website.
Keep up the great writing.
I was able to find good information from your articles.
I have been exploring for a bit for any high quality articles or blog posts on this kind
of house . Exploring in Yahoo I at last stumbled upon this web site.
Studying this info So i am satisfied to convey that I’ve a
very good uncanny feeling I discovered just what I needed.
I most undoubtedly will make sure to do not disregard this website and provides it a
look on a relentless basis.
It’s actually a nice and useful piece of information. I’m satisfied that you simply shared this
useful info with us. Please keep us up to date like this.
Thanks for sharing.
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and
said “You can hear the ocean if you put this to your ear.” She placed
the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic
but I had to tell someone!
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and
said “You can hear the ocean if you put this to your ear.” She placed
the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic
but I had to tell someone!
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and
said “You can hear the ocean if you put this to your ear.” She placed
the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic
but I had to tell someone!
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and
said “You can hear the ocean if you put this to your ear.” She placed
the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic
but I had to tell someone!
Nice blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple adjustements would really
make my blog jump out. Please let me know where you got your theme.
Many thanks
Wow, wonderful blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site
is fantastic, as well as the content!
Wow, awesome blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your site is great, let
alone the content!
Its not my first time to pay a visit this site, i am visiting this site dailly and obtain nice
information from here everyday.
Ahaa, its pleasant conversation on the topic of this article here at this weblog,
I have read all that, so now me also commenting here.
Ridiculous story there. What happened after? Good luck!
Pretty section of content. I just stumbled upon your weblog
and in accession capital to assert that I acquire actually enjoyed account
your blog posts. Any way I’ll be subscribing to your augment and even I achievement you access consistently quickly.
Incredible points. Sound arguments. Keep up the amazing
work.
Thanks for the marvelous posting! I really enjoyed reading it, you happen to be a great author.
I will ensure that I bookmark your blog and will come back from now
on. I want to encourage you continue your great writing, have
a nice morning!
Thanks in support of sharing such a good thought, post is nice, thats why i have read it fully
Hi there i am kavin, its my first occasion to commenting
anywhere, when i read this article i thought i could also
create comment due to this brilliant post.
I’ve always been fascinated by Ye’s impact on hip-hop.
His artistry extends beyond just music; it’s a reflection of his
creativity.
From his early days in the Windy City, Kanye has consistently transcended the boundaries of
what’s possible. His records, like “Late Registration”, aren’t just albums; they’re social landmarks that echo with fans
worldwide.
One thing I love about Kanye West is his visuals.
The Kanye posters showcasing his album covers
are incredible. They add artistic appeal to any room and act as ever-present reminders to his work.
Collecting Kanye’s posters is like having parts of hip-hop culture.
Each one tells a part of his story, from
the dynamic designs of “Graduation” to the intricate visuals of “Yeezus.” They make excellent discussion pieces and bring an artistic touch to any room.
It’s truly motivating to witness how Ye continues to evolve in both.
He is an original artist whose legacy will influence countless individuals for years to come.
Nice weblog here! Additionally your web site a lot up very fast!
What host are you the use of? Can I get your associate link on your host?
I desire my web site loaded up as quickly as yours lol
Appreciate the recommendation. Let me try it out.
I’ve always been fascinated by Ye’s influence on modern music.
His work goes beyond just songs; it’s a reflection of his creativity.
From his early days in Chi-Town, Kanye has consistently transcended the boundaries of creativity.
His records, like “My Beautiful Dark Twisted Fantasy”, are not just music; they’re
social phenomena that resonate with audiences worldwide.
What I admire in Kanye is his artistry in visuals.
The Ye posters showcasing his artistic visions are
stunning. They bring aesthetic beauty to any room and serve
as ever-present testaments to his journey.
Owning Kanye’s posters is like having pieces of hip-hop culture.
Every poster tells a story, from the vibrant graphics of
“Graduation” to the complex aesthetics of
“Yeezus.” They are ideal talking points and add aesthetic flair to any space.
It’s absolutely inspiring to witness how Kanye West remains a trailblazer in both.
He’s a true visionary whose legacy will inspire generations for a long time to
come.
You actually make it seem so easy with your
presentation but I find this topic to be really something that
I think I would never understand. It seems too complex and very broad for me.
I’m looking forward for your next post, I’ll try to get the hang of it!
Does your site have a contact page? I’m having problems locating it but, I’d
like to send you an e-mail. I’ve got some creative ideas for your blog you might be
interested in hearing. Either way, great blog and I look forward to seeing it grow over time.
Thanks for the auspicious writeup. It if truth
be told was once a entertainment account it.
Look advanced to far introduced agreeable from you!
By the way, how can we be in contact?
Fantastic beat ! I would like to apprentice at the same time as you amend your site, how could i subscribe for
a blog website? The account helped me a acceptable deal.
I had been a little bit familiar of this your broadcast offered vibrant transparent
idea
Right away I am going away to do my breakfast, once having my breakfast coming
over again to read additional news.
whoah this weblog is magnificent i really like reading your articles.
Stay up the great work! You already know, many individuals are hunting round for
this information, you can help them greatly.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get three e-mails with the same comment.
Is there any way you can remove people from
that service? Bless you!
Wow that was odd. I just wrote an really long comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyway, just wanted to say excellent blog!
Dignity College of Healthcare online surgical technician training is far superior to other online Surgical Technician programs because it includes the training,
exam review and national certification exams.
Register with Confidence and attend a nationally accredited, but
affordable program. In just 4 months, you can complete the surgical technician program from the comfort
of your home without a loan on your neck. Enroll now
at https://dignitycollegeofhealthcare.com/surgical-technician
Aw, this was a really nice post. Taking the time and actual effort to make a good
article… but what can I say… I hesitate a
whole lot and don’t manage to get nearly anything done.
Wow that was unusual. I just wrote an extremely long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Anyway, just wanted to say great blog!
You really make it seem so easy with your presentation but I
find this matter to be actually something which I think I would never
understand. It seems too complex and very broad for me.
I’m looking forward for your next post, I’ll try to get the hang of it!
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for great info I was looking for this information for my
mission.
What’s up colleagues, fastidious post and fastidious urging commented at this
place, I am actually enjoying by these.
I have to thank you for the efforts you’ve put in penning this site.
I’m hoping to see the same high-grade blog posts from you later on as well.
In truth, your creative writing abilities has inspired me to
get my own, personal site now 😉
Have you ever thought about writing an e-book or guest authoring on other sites?
I have a blog based on the same ideas you discuss and would really like to have you share some stories/information. I
know my subscribers would enjoy your work.
If you’re even remotely interested, feel free to shoot me an e mail.
Please let me know if you’re looking for a article author
for your blog. You have some really great posts and
I feel I would be a good asset. If you ever want to take some of the load
off, I’d really like to write some articles for your blog in exchange for a link back to mine.
Please blast me an e-mail if interested. Cheers!
Fantastic blog! Do you have any suggestions for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go
for a paid option? There are so many choices out there that I’m totally overwhelmed ..
Any suggestions? Thanks!
It is appropriate time to make some plans for the future and it is time to be happy.
I’ve read this submit and if I may just I wish to recommend you few
fascinating things or suggestions. Perhaps you could write subsequent articles
referring to this article. I wish to read more things about
it!
Genuinely when someone doesn’t understand afterward its up to other users that they will
assist, so here it occurs.
Hi there i am kavin, its my first occasion to commenting anywhere, when i read this article i thought i could also make comment due to this good article.
It’s awesome to go to see this web page and reading the views of all
friends on the topic of this paragraph, while
I am also eager of getting familiarity.
Your style is very unique in comparison to
other folks I have read stuff from. Many thanks for posting when you have the opportunity, Guess I’ll just book mark this blog.
If you are going for finest contents like me, only pay a visit this web site every day as
it gives feature contents, thanks
I just like the valuable info you supply on your articles.
I’ll bookmark your blog and take a look at again right here frequently.
I am moderately sure I’ll be told many new stuff proper
right here! Good luck for the next!
After I originally left a comment I appear to have clicked on the -Notify
me when new comments are added- checkbox and from now
on whenever a comment is added I receive four emails with the
exact same comment. There has to be an easy method you are able to remove me from
that service? Thanks a lot!
Greate pieces. Keep posting such kind of info on your site.
Im really impressed by it.
Hey there, You have performed a fantastic job. I’ll definitely digg it
and for my part suggest to my friends. I am confident they’ll be benefited from this
website.
This blog was… how do I say it? Relevant!! Finally I’ve found
something that helped me. Kudos!
bookmarked!!, I really like your blog!
Valuable info. Fortunate me I discovered your web site accidentally,
and I am shocked why this accident didn’t took place earlier!
I bookmarked it.
I just like the helpful information you supply in your articles.
I’ll bookmark your blog and test again right here regularly.
I’m quite sure I’ll be informed plenty of new stuff
right here! Best of luck for the next!
I read this post fully concerning the resemblance of newest and preceding technologies, it’s remarkable article.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time
a comment is added I get three emails with the same comment.
Is there any way you can remove people from that service?
Bless you!
Excellent blog right here! Also your website quite a bit up very fast!
What web host are you the use of? Can I am getting your affiliate link in your host?
I want my site loaded up as fast as yours lol
Hello there! This post could not be written any better! Reading this post reminds me of my good old room mate!
He always kept talking about this. I will forward this
page to him. Pretty sure he will have a good read.
Thank you for sharing!
Hi there, I enjoy reading through your post.
I like to write a little comment to support you.
Link exchange is nothing else however it is just placing
the other person’s website link on your page at suitable
place and other person will also do same in support of you.
These are actually impressive ideas in on the topic of blogging.
You have touched some fastidious things here. Any way keep up wrinting.
What’s up Dear, are you genuinely visiting this website regularly, if
so afterward you will absolutely take good experience.
I don’t know whether it’s just me or if perhaps everybody else encountering issues with your website.
It appears as if some of the text in your posts are running off the screen. Can someone else please comment and let me
know if this is happening to them as well?
This may be a problem with my internet browser because I’ve had this happen before.
Kudos
Hi to every body, it’s my first visit of
this webpage; this blog contains amazing and truly good information in support of visitors.
Hi, yeah this article is genuinely good and I have learned lot of things from
it concerning blogging. thanks.
You should be a part of a contest for one of the most useful sites online.
I am going to highly recommend this blog!
Good info. Lucky me I discovered your site by chance (stumbleupon).
I have book-marked it for later!
When I originally commented I seem to have clicked the -Notify me when new comments are added- checkbox and now each time a comment is
added I get 4 emails with the exact same comment.
Perhaps there is an easy method you are able to remove
me from that service? Many thanks!
Admiring the time and energy you put into your
website and detailed information you provide. It’s great to come across a blog every once in a
while that isn’t the same unwanted rehashed information. Wonderful read!
I’ve saved your site and I’m including your RSS feeds to my Google
account.
Very nice post. I simply stumbled upon your weblog and wished to
say that I’ve really enjoyed browsing your weblog posts.
After all I will be subscribing in your feed and I’m hoping
you write again soon!
You could definitely see your skills in the work you
write. The sector hopes for more passionate writers like you who are not afraid to mention how
they believe. At all times go after your heart.
Hello there! This is my 1st comment here so I just wanted to give a quick
shout out and say I really enjoy reading your articles.
Can you recommend any other blogs/websites/forums that cover the same topics?
Thanks a lot!
I’ve been surfing online more than 2 hours today, yet I never found any interesting article like yours.
It’s pretty worth enough for me. Personally, if all site owners and bloggers
made good content as you did, the net will be a lot more useful than ever
before.
I have read several good stuff here. Definitely price bookmarking for revisiting.
I surprise how so much effort you place to create this type of fantastic informative website.
Hi! Quick question that’s completely off topic. Do you know how to make your site mobile friendly?
My blog looks weird when viewing from my iphone 4. I’m trying to find a theme or plugin that
might be able to resolve this problem. If you have
any suggestions, please share. Thanks!
Oh my goodness! Incredible article dude! Thank you so much, However I am encountering troubles with
your RSS. I don’t understand the reason why I cannot subscribe to it.
Is there anybody else getting similar RSS issues?
Anyone that knows the answer can you kindly respond?
Thanks!!
Hi there! This post could not be written any better! Reading
this post reminds me of my old room mate! He always
kept talking about this. I will forward this post to him.
Fairly certain he will have a good read. Thanks for sharing!
I have read so many content about the blogger lovers however this article is actually
a pleasant article, keep it up.
There’s certainly a great deal to learn about this subject.
I like all of the points you have made.
I all the time used to study piece of writing in news papers but now as I am a
user of internet so from now I am using net for content,
thanks to web.
I am extremely impressed together with your writing talents and also with
the structure in your weblog. Is that this a paid subject or did you customize it your self?
Anyway stay up the nice quality writing, it’s rare to look a nice blog like this one today..
You actually make it seem so easy with your presentation but
I find this matter to be really something that I think I would
never understand. It seems too complex and very broad for me.
I’m looking forward for your next post, I’ll try to get the hang of it!
No matter if some one searches for his essential thing,
therefore he/she desires to be available that
in detail, therefore that thing is maintained over here.
Great blog here! Also your web site loads up very fast!
What host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
Just want to say your article is as astonishing.
The clearness in your post is just excellent and i could
assume you are an expert on this subject. Fine with your permission allow me to grab your feed to keep updated with
forthcoming post. Thanks a million and please keep up the gratifying work.
I really like it when folks come together and share views.
Great site, stick with it!
This is very interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your magnificent post.
Also, I have shared your website in my social networks!
Hey there, I think your site might be having browser compatibility issues.
When I look at your website in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that,
wonderful blog!
I have read so many articles regarding the blogger lovers except this paragraph is in fact a good piece of writing,
keep it up.
It is not my first time to go to see this web site, i am visiting this web
page dailly and obtain fastidious facts from here all the time.
Hi, for all time i used to check web site posts here in the early hours in the morning, since
i like to find out more and more.
Hello colleagues, how is the whole thing, and what you would like to say about this piece of writing, in my view
its genuinely awesome designed for me.
Hi there to every one, for the reason that I am in fact
keen of reading this web site’s post to be updated regularly.
It consists of good material.
What a stuff of un-ambiguity and preserveness of precious knowledge concerning unexpected emotions.
Hello! Do you know if they make any plugins to help with Search
Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Many thanks!
Great info. Lucky me I ran across your website by chance (stumbleupon).
I’ve saved as a favorite for later!
Whoa! This blog looks exactly like my old one!
It’s on a entirely different subject but it has pretty much the
same layout and design. Wonderful choice of colors!
I like the helpful information you provide in your articles.
I will bookmark your blog and check again here
frequently. I am quite sure I will learn a lot of new stuff right here!
Best of luck for the next!
My site vệ sinh công trình
What i don’t understood is in truth how you are now not really much
more smartly-liked than you may be right now. You’re so intelligent.
You realize thus considerably in the case of this topic, made me in my view imagine it from numerous various angles.
Its like men and women aren’t interested unless it is something
to accomplish with Girl gaga! Your individual stuffs excellent.
All the time maintain it up!
Hello there! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly?
My site looks weird when browsing from my iphone 4. I’m trying to find a theme or plugin that might
be able to resolve this issue. If you have any recommendations,
please share. Cheers!
I’m extremely inspired together with your writing skills as well as with the layout for your weblog.
Is this a paid subject matter or did you modify it yourself?
Anyway keep up the excellent high quality writing,
it is rare to look a great weblog like this
one nowadays..
At this moment I am going away to do my breakfast, afterward having my breakfast coming again to read more news.
No matter if some one searches for his required thing, so he/she wishes to be available that in detail, so that thing is maintained
over here.
I quite like reading through an article that will make men and women think.
Also, many thanks for allowing for me to comment!
hey there and thank you for your information – I’ve certainly
picked up anything new from right here. I did however expertise some technical issues using this web
site, since I experienced to reload the web site many times previous to I could get it to load properly.
I had been wondering if your web host is OK? Not that I am
complaining, but sluggish loading instances times will sometimes affect your
placement in google and could damage your quality score if advertising
and marketing with Adwords. Well I’m adding this RSS to my email
and could look out for a lot more of your respective exciting content.
Make sure you update this again very soon.
Hi, I want to subscribe for this weblog to take latest updates, thus where can i do it please help.
Great post.
Quality content is the main to be a focus for the people to pay a quick visit
the web page, that’s what this site is providing.
With havin so much content and articles do you ever run into any issues of plagorism
or copyright violation? My blog has a lot of exclusive content I’ve
either created myself or outsourced but it looks like a lot of it is popping it up all over the web without
my authorization. Do you know any methods to help reduce content from being stolen? I’d
genuinely appreciate it.
I think the admin of this web site is in fact working hard
in support of his web page, for the reason that here every material is quality based stuff.
Nice weblog right here! Also your website loads up fast!
What web host are you the use of? Can I am getting your affiliate hyperlink on your host?
I want my web site loaded up as quickly as yours lol
I needed to thank you for this good read!! I certainly loved every bit of it.
I’ve got you bookmarked to check out new stuff you post…
You need to be a part of a contest for one of the finest sites on the internet.
I most certainly will recommend this site!
Hey there! This is my first visit to your blog!
We are a collection of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on.
You have done a outstanding job!
Today, I went to the beach front with my kids. I found a sea shell and gave it to my 4 year old
daughter and said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
Can I simply say what a comfort to discover somebody who genuinely knows what they’re discussing on the internet.
You actually realize how to bring an issue to light and
make it important. A lot more people need to read this and understand this side of
the story. I can’t believe you’re not more popular since you surely possess the gift.
I do not even know the way I ended up here, but I believed this publish used to
be good. I don’t know who you might be but definitely you are going to a
famous blogger if you aren’t already. Cheers!
Thank you for some other excellent article. The place else could anybody get that kind of info in such an ideal manner of writing?
I’ve a presentation next week, and I am at the search for such info.
I have fun with, result in I found just what I used to be looking for.
You have ended my 4 day long hunt! God Bless you man. Have a nice day.
Bye
What’s up i am kavin, its my first occasion to commenting anyplace, when i read this post i thought i could also create comment due
to this sensible post.
Great article.
fantastic put up, very informative. I’m wondering why the opposite
experts of this sector don’t realize this. You should proceed your writing.
I am confident, you’ve a great readers’ base already!
Greate article. Keep writing such kind of info on your blog.
Im really impressed by it.
Hey there, You have performed an incredible
job. I will certainly digg it and in my opinion recommend
to my friends. I am sure they will be benefited from this website.
You could definitely see your enthusiasm in the article you write.
The world hopes for more passionate writers like you who are not
afraid to mention how they believe. Always follow your heart.
That is a really good tip particularly to those new to the blogosphere.
Short but very precise information… Thank you for sharing this one.
A must read article!
Howdy! I just want to give you a big thumbs
up for the great info you’ve got right here on this post.
I’ll be coming back to your site for more soon.
I think everything posted made a bunch of sense. However, what about
this? what if you were to create a awesome headline?
I mean, I don’t want to tell you how to run your blog,
but what if you added a title to possibly grab a person’s attention? I mean Пиастры – Составление семантического ядра | is kinda
vanilla. You should glance at Yahoo’s home page and see how they create news titles to
grab people to open the links. You might add a
video or a picture or two to get people interested about what you’ve written. Just my opinion, it might bring your blog a little bit more interesting.
I’m curious to find out what blog system you happen to be working with?
I’m experiencing some small security problems with my latest blog and I would like to find something more safeguarded.
Do you have any recommendations?
I’m not sure why but this weblog is loading extremely slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem still exists.
It’s perfect time to make a few plans for the
long run and it is time to be happy. I’ve learn this publish and if I could I wish to recommend you some attention-grabbing issues or advice.
Maybe you could write subsequent articles relating to this article.
I want to learn more issues approximately it!
Incredible! This blog looks exactly like my old one!
It’s on a completely different topic but it has pretty much the same
layout and design. Excellent choice of colors!
I like the valuable information you provide in your articles.
I’ll bookmark your weblog and test again right here regularly.
I am slightly sure I will be told a lot of new stuff proper right here!
Best of luck for the next!
Outstanding post however , I was wanting to know if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit further.
Appreciate it!
король жезлов в сочетании с королевой жезлов таро значение сонник двойник парня к чему снится орел,
который нападает, черный орел во
сне чара значение клички личный год 5 сюцай,
нумерология личный год 6
I got this site from my pal who told me on the topic of this web page and at the moment
this time I am browsing this web site and reading very informative articles here.
Hi, I wish for to subscribe for this weblog to get latest updates,
therefore where can i do it please assist.
Hello! I just want to give you a big thumbs up for your excellent information you have got here on this post.
I will be coming back to your website for more soon.
When someone writes an piece of writing he/she retains the idea
of a user in his/her brain that how a user can understand
it. Thus that’s why this post is outstdanding.
Thanks!
Nice blog here! Also your site loads up fast! What host are you using?
Can I get your affiliate link to your host? I wish my website loaded up as fast as
yours lol
always i used to read smaller posts which also clear their motive, and that is also happening with this piece of writing which
I am reading at this place.
Ahaa, its nice dialogue regarding this paragraph at this place at this blog,
I have read all that, so at this time me also commenting here.
magnificent publish, very informative. I’m wondering why the opposite experts of this sector don’t
notice this. You must proceed your writing. I am sure, you have a huge readers’ base already!
Have you ever considered writing an ebook or guest authoring on other blogs?
I have a blog based on the same subjects you discuss and would love to have you share some
stories/information. I know my visitors would enjoy your work.
If you are even remotely interested, feel free to shoot me an e-mail.
I just could not go away your website prior to
suggesting that I extremely loved the usual information a person provide on your visitors?
Is going to be again regularly to check out new posts
Hi there! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing a blog post or vice-versa?
My website addresses a lot of the same topics as yours and
I feel we could greatly benefit from each other.
If you happen to be interested feel free
to send me an e-mail. I look forward to hearing from you!
Awesome blog by the way!
of course like your web-site but you have to test the spelling
on quite a few of your posts. Many of them are rife with spelling
problems and I to find it very bothersome to tell the
truth however I’ll certainly come back again.
Howdy! I know this is kinda off topic but I was wondering if you knew where
I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having
difficulty finding one? Thanks a lot!
My brother suggested I might like this web site. He was
entirely right. This post truly made my day.
You cann’t imagine just how much time I had spent for this information! Thanks!
Spot on with this write-up, I actually believe this
website needs far more attention. I’ll probably be returning
to read more, thanks for the advice!
whoah this weblog is great i like studying your articles.
Keep up the good work! You realize, lots of persons are looking round for this
info, you can help them greatly.
I pay a visit each day some sites and sites to read posts, except this weblog offers feature based
articles.
Good day! I know this is kinda off topic but I was wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because I’ve had problems with hackers and I’m looking
at alternatives for another platform. I would be great if
you could point me in the direction of a good
platform.
Great goods from you, man. I’ve understand your stuff previous to and you are just
extremely fantastic. I actually like what you have
acquired here, really like what you’re stating and the way
in which you say it. You make it enjoyable and you still care for to keep it wise.
I can’t wait to read much more from you. This is actually a wonderful web site.
This is a topic which is near to my heart…
Best wishes! Exactly where are your contact details though?
Can you tell us more about this? I’d like to find out some additional information.
Hey! I know this is kind of off topic but I was wondering if
you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
Howdy are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and
create my own. Do you require any coding expertise to make your own blog?
Any help would be really appreciated!
I love it whenever people come together and share opinions.
Great website, keep it up!
Hi would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a
lot faster then most. Can you suggest a good hosting provider at a
honest price? Thanks, I appreciate it!
Link exchange is nothing else except it is only placing the other
person’s blog link on your page at suitable place and other
person will also do same in favor of you.
I needed to thank you for this very good read!! I certainly loved every bit of it.
I have got you bookmarked to check out new stuff you post…
Hi, i think that i saw you visited my website
so i came to “return the favor”.I’m trying to find
things to improve my website!I suppose its ok to use a few of your ideas!!
Thankfulness to my father who told me about this website,
this blog is truly amazing.
certainly like your web site but you need to check the spelling on quite
a few of your posts. Several of them are rife with spelling problems and
I find it very bothersome to tell the reality however I
will surely come back again.
It’s very effortless to find out any topic on net as compared
to textbooks, as I found this post at this website.
For most up-to-date information you have to pay a visit internet and on world-wide-web
I found this site as a most excellent website for hottest updates.
Hello it’s me, I am also visiting this website regularly, this web page is in fact good
and the users are really sharing nice thoughts.
Excellent way of explaining, and fastidious article to take information about
my presentation focus, which i am going to convey in college.
With havin so much content and articles do you ever run into any issues of plagorism or copyright infringement?
My site has a lot of exclusive content I’ve either created myself or outsourced but it seems
a lot of it is popping it up all over the web without my permission. Do you know any ways to
help prevent content from being ripped off? I’d really appreciate it.
It’s a pity you don’t have a donate button!
I’d certainly donate to this superb blog! I suppose for now i’ll settle
for bookmarking and adding your RSS feed to my Google account.
I look forward to brand new updates and will share this website with my Facebook group.
Chat soon!
Greetings! I know this is kinda off topic but I’d figured I’d
ask. Would you be interested in trading links or maybe guest writing a blog article or
vice-versa? My blog discusses a lot of the same topics as yours and I believe we could greatly benefit
from each other. If you might be interested feel free to
send me an e-mail. I look forward to hearing from
you! Awesome blog by the way!
You made some good points there. I looked on the internet to learn more about the issue and found most
individuals will go along with your views on this website.
It’s really very complex in this busy life to listen news on TV,
thus I only use world wide web for that reason, and take the most recent information.
Fastidious answers in return of this query with genuine arguments and explaining
the whole thing on the topic of that.
Hiya very cool web site!! Man .. Excellent .. Wonderful ..
I will bookmark your website and take the feeds also? I am glad
to seek out a lot of helpful information right here within the post, we need develop more strategies in this regard, thanks for sharing.
. . . . .
I constantly spent my half an hour to read this web site’s articles or
reviews daily along with a mug of coffee.
This design is spectacular! You certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog
(well, almost…HaHa!) Wonderful job. I really loved what you had to say, and more
than that, how you presented it. Too cool!
Hello there! Do you use Twitter? I’d like to follow you if that would be okay.
I’m absolutely enjoying your blog and look forward to new updates.
I am really enjoying the theme/design of your web site. Do
you ever run into any internet browser compatibility issues?
A couple of my blog audience have complained about my site not
working correctly in Explorer but looks great in Chrome.
Do you have any tips to help fix this problem?
An intriguing discussion is worth comment. I think
that you ought to write more about this topic, it might not be a taboo subject but generally folks don’t speak about such issues.
To the next! Cheers!!
Here is my page – refurbished thinkpad laptops
Its like you read my mind! You appear to know so much about this, like you wrote the book
in it or something. I think that you can do with some pics
to drive the message home a little bit, but other
than that, this is magnificent blog. A great read.
I will certainly be back.
Hi, I do think this is an excellent blog. I stumbledupon it 😉 I will revisit yet
again since I book marked it. Money and freedom is the
greatest way to change, may you be rich and continue to
guide other people.
We are a group of volunteers and opening a new scheme in our community.
Your web site offered us with valuable information to work on. You have done a formidable job and our whole community will
be thankful to you.
I truly love your blog.. Great colors & theme. Did
you build this amazing site yourself? Please reply back
as I’m hoping to create my own blog and would love
to know where you got this from or exactly what
the theme is called. Appreciate it!
Thanks , I have just been looking for information approximately
this topic for a while and yours is the greatest
I’ve found out so far. But, what about the conclusion? Are you positive about the source?
I pay a visit daily some web pages and information sites to read posts, however this blog presents feature based posts.
Ahaa, its good dialogue about this paragraph at this place at this website, I have read all that, so
at this time me also commenting at this place.
Usually I don’t learn post on blogs, but I wish to say that this write-up very forced me to take a look at and do it!
Your writing style has been amazed me. Thank you, quite nice article.
With havin so much content and articles do you ever run into any problems of plagorism or copyright violation? My blog has a
lot of completely unique content I’ve either authored
myself or outsourced but it looks like a lot of it is popping it up
all over the web without my agreement. Do you know any solutions to help stop content from being ripped
off? I’d genuinely appreciate it.
I do agree with all of the ideas you have introduced
for your post. They are very convincing and will certainly work.
Still, the posts are very short for beginners. Could you please extend them a bit from subsequent time?
Thanks for the post.
Highly energetic post, I enjoyed that bit.
Will there be a part 2?
Undeniably believe that which you stated. Your favorite justification appeared to be
on the internet the simplest thing to be aware of. I say
to you, I certainly get irked while people consider worries that they plainly don’t know about.
You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , people
could take a signal. Will likely be back to get more.
Thanks
I simply could not go away your website before suggesting that I really enjoyed the usual info
an individual supply on your visitors? Is gonna be again incessantly in order to check up
on new posts
I simply could not go away your website before suggesting that I actually loved the standard info a person provide to your
visitors? Is gonna be again steadily in order to check up on new posts
Good day very nice blog!! Man .. Beautiful .. Superb
.. I’ll bookmark your web site and take the feeds also? I’m
glad to search out a lot of helpful information right here within the publish, we
need work out extra techniques in this regard, thanks for
sharing. . . . . .
Wow, that’s what I was exploring for, what a data! present here at this
web site, thanks admin of this web site.
Magnificent site. Plenty of helpful info here. I’m sending it to a few friends ans also sharing
in delicious. And obviously, thanks for your sweat!
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning much more or understanding more.
Thanks for wonderful information I was looking for this information for
my mission.
Hey! This is kind of off topic but I need some guidance from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but
I can figure things out pretty fast. I’m thinking about creating my own but I’m not sure
where to start. Do you have any ideas or suggestions?
Many thanks
Highly energetic article, I loved that bit. Will there be a part 2?
I love it when folks get together and share thoughts.
Great site, continue the good work!
Admiring the hard work you put into your blog and in depth information you
offer. It’s awesome to come across a blog every once in a while that isn’t the same
old rehashed material. Excellent read! I’ve saved your site and I’m adding your RSS feeds to my
Google account.
Awesome! Its actually remarkable piece of writing, I have got much clear idea concerning from this post.
I think this is one of the most vital information for me.
And i’m glad reading your article. But should remark on few
general things, The website style is ideal, the articles is
really great : D. Good job, cheers
Thanks for the good writeup. It in truth was once a enjoyment account it.
Look complicated to far brought agreeable from you!
However, how could we keep up a correspondence?
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for
quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Amazing! Its truly awesome piece of writing, I
have got much clear idea on the topic of from this piece of writing.
What i do not realize is in fact how you’re not actually a lot
more well-preferred than you may be now. You are very intelligent.
You already know therefore significantly on the subject of this matter, made me in my
view consider it from so many numerous angles. Its like
women and men are not fascinated until it’s one thing to accomplish with Woman gaga!
Your personal stuffs excellent. Always take care of it up!
I used to be recommended this web site through my cousin. I’m not sure whether this put up is written by means of
him as no one else recognise such specified about my problem.
You’re amazing! Thank you!
Hi there! This is my first visit to your blog! We are a team of
volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You have done
a outstanding job!
Hello my friend! I want to say that this article
is awesome, nice written and include almost all vital infos.
I would like to see extra posts like this
.
девушки для секса ищу чебоксары дойки кончают видео порно анал знакомства салон эротического
массажа на ленина уфа
I think the admin of this website is really working hard for his web site, since here every information is quality based information.
I constantly emailed this weblog post page to all my associates,
because if like to read it after that my contacts will too.
I savour, cause I discovered just what I was
taking a look for. You’ve ended my 4 day lengthy hunt!
God Bless you man. Have a nice day. Bye
Wow, this article is fastidious, my sister is analyzing these kinds of things, thus I am going to convey
her.
My family members always say that I am killing my time here
at web, but I know I am getting know-how everyday by reading such nice content.
Hello, Neat post. There’s a problem along with your site in web explorer, could
check this? IE nonetheless is the marketplace leader and
a huge component of other people will miss your wonderful writing
because of this problem.
Excellent post. I was checking continuously this weblog and I I maintain such info
I maintain such info
am inspired! Extremely helpful info specially the closing part
much. I used to be looking for this particular information for a very long time.
Thanks and best of luck.
Hello! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Any tips?
Hi, after reading this amazing paragraph i am as well delighted to
share my knowledge here with mates.
Great post however I was wondering if you could
write a litte more on this topic? I’d be very grateful if you could elaborate a little bit more.
Cheers!
Attractive section of content. I just stumbled upon your weblog and
in accession capital to assert that I acquire actually enjoyed
account your blog posts. Anyway I will be subscribing to your augment and even I achievement you access consistently fast.
Great site you have here.. It’s difficult to
find quality writing like yours nowadays. I really appreciate individuals like
you! Take care!!
That is really fascinating, You are an excessively professional blogger.
I’ve joined your rss feed and stay up for searching for more
of your magnificent post. Also, I’ve shared
your web site in my social networks
Great article.
I blog often and I really appreciate your content. This great
article has really peaked my interest. I am going to take a note of your website and keep checking for new details about once a week.
I opted in for your RSS feed as well.
Hello! This is kind of off topic but I need some guidance from an established blog.
Is it hard to set up your own blog? I’m not very
techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to start.
Do you have any tips or suggestions? Thanks
This piece of writing is really a nice one it helps new web users,
who are wishing for blogging.
I have been browsing on-line greater than three hours nowadays, but I never found any interesting article
like yours. It is pretty price enough for me.
In my opinion, if all webmasters and bloggers made good content as you did, the web shall be
a lot more helpful than ever before.
Hiya very nice web site!! Guy .. Beautiful .. Superb ..
I’ll bookmark your web site and take the
feeds also? I’m happy to search out so many helpful info right here in the submit, we’d like develop extra techniques
in this regard, thanks for sharing. . . . . .
Greetings! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly?
My web site looks weird when browsing from my iphone 4.
I’m trying to find a theme or plugin that might be able to
resolve this issue. If you have any suggestions, please share.
Many thanks!
Wow, superb weblog structure! How long have you ever been blogging for?
you made blogging glance easy. The overall look of your website is
fantastic, as well as the content material!
I really like it when folks get together and share ideas.
Great website, continue the good work!
Howdy! Quick question that’s entirely off
topic. Do you know how to make your site mobile friendly?
My site looks weird when viewing from my apple iphone.
I’m trying to find a theme or plugin that might be able to fix this problem.
If you have any recommendations, please share. Thanks!
Simply wish to say your article is as surprising. The clarity to your submit is simply great and that i could think you are a professional in this subject.
Well together with your permission let me
to grab your feed to stay up to date with impending post.
Thanks a million and please continue the enjoyable work.
Greetings! Very helpful advice in this particular post!
It’s the little changes that will make the greatest changes.
Thanks for sharing!
When someone writes an paragraph he/she retains the image of a user in his/her brain that how a user can understand it.
Thus that’s why this paragraph is amazing.
Thanks!
Great post.
Wow! At last I got a web site from where I can actually get helpful information regarding my study
and knowledge.
I’m really loving the theme/design of your
weblog. Do you ever run into any internet browser compatibility problems?
A couple of my blog audience have complained about my website not operating correctly in Explorer
but looks great in Opera. Do you have any recommendations
to help fix this problem?
These are genuinely wonderful ideas in concerning blogging.
You have touched some pleasant factors here. Any way keep up wrinting.
I every time emailed this web site post page to
all my associates, because if like to read it then my friends will too.
You really make it seem so easy with your presentation but I find this topic to be really something that I think I would never understand.
It seems too complicated and very broad for me.
I am looking forward for your next post,
I’ll try to get the hang of it!
When I originally commented I seem to have clicked on the -Notify me when new comments
are added- checkbox and now each time a comment is added I receive 4 emails with the exact same comment.
Perhaps there is an easy method you can remove me from that service?
Kudos!
Terrific post however I was wondering if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit further.
Kudos!
After I originally left a comment I seem to have clicked the -Notify me when new comments are added- checkbox and now whenever a comment is added I recieve four
emails with the same comment. Is there a means you can remove me from that
service? Many thanks!
Amazing! This blog looks just like my old one! It’s on a completely different topic but it has pretty much the same layout and design. Excellent choice of colors!
Good day! I just want to offer you a big thumbs up for
the excellent info you have got right here on this post. I am coming back to your web site for more soon.
Pretty section of content. I just stumbled upon your website and in accession capital
to assert that I get actually enjoyed account
your blog posts. Anyway I will be subscribing to your augment and even I achievement you access consistently rapidly.
Hi there, I read your blog regularly. Your humoristic style is
witty, keep up the good work!
I’m gone to convey my little brother, that he should also pay
a quick visit this blog on regular basis to take updated from hottest reports.
I don’t even know how I ended up here, but I
thought this post was great. I do not know who you are but certainly
you’re going to a famous blogger if you aren’t
already 😉 Cheers!
Keep on working, great job!
I was suggested this web site by my cousin. I am
not sure whether this post is written by him as nobody else know such detailed about my trouble.
You’re incredible! Thanks!
fantastic put up, very informative. I’m wondering why the opposite specialists of this sector do not
understand this. You must continue your writing. I’m confident,
you have a huge readers’ base already!
FanDuel on line blackjack has all the bases coverted with a lot more than 20 games.
Feel free to surf to my site; 분석
Hello! I know this is somewhat off-topic however I needed
to ask. Does running a well-established blog such as yours take a large amount of work?
I am brand new to blogging however I do write in my diary
on a daily basis. I’d like to start a blog so I can easily
share my personal experience and views online.
Please let me know if you have any kind of ideas or tips for new aspiring bloggers.
Appreciate it!
Fantastic goods from you, man. I have bear in mind your stuff prior
to and you’re just too excellent. I actually like what you’ve acquired here,
certainly like what you are saying and the way in which in which you
say it. You are making it entertaining and you continue to care for to keep it
sensible. I can’t wait to learn much more from you.
This is actually a tremendous website.
It’s awesome in favor of me to have a web page, which is helpful in favor of my experience.
thanks admin
I enjoy looking through a post that can make people think.
Also, thanks for allowing me to comment!
Hello, I enjoy reading through your post. I like to write a little comment to
support you.
Very energetic blog, I enjoyed that bit. Will there be a part 2?
I like what you guys are up too. This type of clever work and exposure!
Keep up the fantastic works guys I’ve incorporated you guys
to my own blogroll.
These are really impressive ideas in concerning blogging.
You have touched some nice factors here. Any
way keep up wrinting.
This is my first time go to see at here and i am really pleassant to read
all at single place.
Thank you for the auspicious writeup. It in fact was
a amusement account it. Look advanced to far added agreeable from you!
By the way, how can we communicate?
I all the time used to study post in news papers but now
as I am a user of net thus from now I am using net
for content, thanks to web.
I think that what you published was very reasonable.
But, what about this? what if you added a little information? I am not suggesting your information is not solid., but suppose you added something that grabbed people’s attention? I mean Пиастры – Составление семантического ядра | is kinda vanilla.
You ought to glance at Yahoo’s home page and watch how they create news titles to grab people interested.
You might add a related video or a related pic or two
to grab people interested about everything’ve written. Just my opinion, it
would make your website a little bit more interesting.
Thanks in support of sharing such a fastidious
opinion, piece of writing is fastidious, thats why i have read it fully
I was suggested this website by my cousin. I am not sure whether this post is written by him as nobody else know such detailed
about my trouble. You are wonderful! Thanks!
I savor, cause I discovered exactly what I was having a look for.
You have ended my 4 day long hunt! God Bless you man. Have a great
day. Bye
Wonderful blog! I found it while searching on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
Hi! I understand this is sort of off-topic but I had to ask.
Does building a well-established website like yours require a massive
amount work? I’m completely new to operating a blog but I do write in my diary on a daily basis.
I’d like to start a blog so I can easily share my experience and feelings online.
Please let me know if you have any suggestions or tips for brand new aspiring blog owners.
Thankyou!
Heya terrific website! Does running a blog like this require a massive
amount work? I have virtually no knowledge of computer
programming however I had been hoping to start my own blog soon. Anyways, should
you have any recommendations or techniques for new
blog owners please share. I understand this is off subject
but I simply had to ask. Kudos!
Wow that was strange. I just wrote an extremely long comment but after
I clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Anyhow, just wanted to say great blog!
WOW just what I was searching for. Came here by searching for یک بت
I am truly delighted to glance at this website posts which carries
tons of helpful data, thanks for providing these kinds of information.
Way cool! Some extremely valid points! I appreciate you penning this post and also the rest of the site is
extremely good.
7 мечей таро значение на финансы,
7 мечей мысли мужчины 16 лунный день сны к чему снится день рождения умершей бабушки гороскоп
майя по месяцам, гороскоп майя по
дате рождения рассчитать сон маленький черный
кот
Incredible! This blog looks just like my old one! It’s on a
totally different topic but it has pretty much the same layout
and design. Outstanding choice of colors!
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is valuable and all. However just imagine if you added some great pictures
or videos to give your posts more, “pop”! Your content is excellent but
with images and clips, this site could undeniably be one of the most
beneficial in its niche. Excellent blog!
Hello, I want to subscribe for this weblog to obtain hottest updates, thus where can i do it please help out.
Terrific article! This is the kind of info that are meant to be shared around the net.
Shame on Google for no longer positioning this put up upper!
Come on over and talk over with my web site . Thanks =)
each time i used to read smaller articles which also clear their motive,
and that is also happening with this post which I am reading at this time.
Simply desire to say your article is as surprising.
The clarity in your put up is simply great and that i could assume you’re an expert in this subject.
Fine with your permission let me to grab your feed to keep updated with
approaching post. Thanks 1,000,000 and please carry
on the enjoyable work.
bookmarked!!, I really like your site!
It is the best time to make some plans for the longer term and it’s time to be
happy. I have learn this submit and if I may I desire to counsel you some attention-grabbing
things or suggestions. Maybe you can write subsequent articles relating to this article.
I want to learn even more things approximately it!
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
Today, I went to the beachfront with my kids. I found a sea shell and gave it to my 4 year old
daughter and said “You can hear the ocean if you put this to your ear.”
She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off
topic but I had to tell someone!
Hi! This is my first visit to your blog! We are a group of volunteers and starting a new
project in a community in the same niche. Your blog provided
us valuable information to work on. You have
done a extraordinary job!
pornoxer
I loved as much as you will receive carried
out right here. The sketch is tasteful, your authored material stylish.
nonetheless, you command get bought an shakiness over that you wish be delivering the
following. unwell unquestionably come more formerly again since
exactly the same nearly very often inside case you shield this
hike.
Excellent blog here! Also your web site loads up very fast!
What host are you using? Can I get your affiliate link
to your host? I wish my site loaded up as quickly as yours
lol
Great site you have here but I was curious if you knew of
any discussion boards that cover the same topics talked about in this article?
I’d really love to be a part of online community where I can get responses from other experienced individuals that share the same interest.
If you have any suggestions, please let me know. Appreciate it!
Hi there, yes this article is truly fastidious and I have learned lot of
things from it concerning blogging. thanks.
Excellent post. I was checking constantly this blog and I care for such info much. I was looking for this particular
I care for such info much. I was looking for this particular
I’m impressed! Extremely helpful info specifically the
last part
info for a very long time. Thank you and best of
luck.
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
You really make it seem so easy with your presentation but I find this matter
to be actually something which I think I would never
understand. It seems too complex and extremely broad for me.
I am looking forward for your next post, I will try to get the hang of it!
I am extremely impressed with your writing skills and also with the format on your weblog.
Is that this a paid theme or did you modify it your self?
Either way keep up the excellent high quality writing,
it’s rare to see a great blog like this one today..
Thanks in favor of sharing such a pleasant opinion, post is pleasant, thats why i have read it completely
Excellent post but I was wanting to know if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit further.
Thank you!
What’s up Dear, are you actually visiting this website regularly, if so after that you will without doubt get nice experience.
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here regularly.
I am quite certain I will learn many new stuff right here!
Best of luck for the next!
Amazing! Its truly remarkable article, I have got much clear idea on the topic of from this article.
Good day I am so glad I found your blog page, I really found you
by mistake, while I was looking on Google for something else,
Nonetheless I am here now and would just like to say cheers for a tremendous post and
a all round thrilling blog (I also love the theme/design), I don’t have time to look over it all at the minute but I have book-marked it and also added your RSS feeds, so when I have time I will
be back to read more, Please do keep up the awesome b.
I just couldn’t depart your site before suggesting that
I extremely loved the standard info an individual provide to your visitors?
Is going to be back often to inspect new posts
I enjoy what you guys are usually up too. Such clever
work and coverage! Keep up the terrific works guys I’ve included you guys to my personal blogroll.
What i don’t realize is actually how you’re no longer really a lot more neatly-liked than you might be
now. You’re so intelligent. You recognize thus
significantly in relation to this subject,
made me individually believe it from a lot of various angles.
Its like men and women are not involved until it’s something to do with Lady gaga!
Your own stuffs outstanding. At all times deal with it up!
Wonderful blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Cheers
Hi there friends, how is all, and what you would like
to say about this piece of writing, in my view its genuinely amazing for me.
Good day! This is my first visit to your blog! We are a collection of
volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have
done a extraordinary job!
fantastic points altogether, you simply gained a new reader.
What may you recommend about your post that you simply made some days ago?
Any sure?
My programmer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on several
websites for about a year and am nervous about switching to another
platform. I have heard excellent things about blogengine.net.
Is there a way I can transfer all my wordpress posts into
it? Any kind of help would be greatly appreciated!
Excellent beat ! I wish to apprentice while you amend your web
site, how can i subscribe for a blog website? The account helped me a acceptable deal.
I had been a little bit acquainted of this your broadcast provided bright clear
idea
I have been browsing on-line more than three hours today, yet I never found any
interesting article like yours. It’s lovely price enough
for me. In my view, if all web owners and bloggers made excellent content as you probably did, the net might be
much more helpful than ever before.
wonderful points altogether, you just received a new reader.
What may you suggest about your submit that you simply made some days ago?
Any certain?
What’s up, this weekend is pleasant for me, because
this occasion i am reading this fantastic educational paragraph here at my house.
Way cool! Some very valid points! I appreciate you penning this post and the rest
of the site is also very good.
Good day! Do you use Twitter? I’d like to follow you if that would be ok.
I’m absolutely enjoying your blog and look forward to new posts.
Thanks for the good writeup. It actually used to be a entertainment account it.
Look complex to more delivered agreeable from you!
By the way, how can we communicate?
I do agree with all of the concepts you have offered for your post.
They are really convincing and can certainly work. Still, the
posts are too brief for starters. May just you please extend
them a bit from subsequent time? Thanks for the post.
I do not even know how I stopped up right here, but I
believed this post used to be great. I do not recognise who you are but certainly you
are going to a famous blogger in the event you aren’t already.
Cheers!
First of all I would like to say awesome blog!
I had a quick question which I’d like to ask if you don’t mind.
I was interested to find out how you center yourself and
clear your mind before writing. I have had difficulty clearing my
thoughts in getting my ideas out there. I truly do take pleasure in writing but it just seems like the first
10 to 15 minutes tend to be lost simply just trying to
figure out how to begin. Any recommendations or hints?
Kudos!
Undeniably imagine that which you said. Your favourite justification appeared to be on the web
the simplest thing to take into accout of.
I say to you, I certainly get irked at the
same time as people consider concerns that they plainly do not understand about.
You managed to hit the nail upon the highest as well
as defined out the whole thing without having side effect , folks can take a signal.
Will probably be again to get more. Thank you
Hi! I realize this is somewhat off-topic but I needed to ask.
Does operating a well-established blog such as yours require a large amount of work?
I am brand new to operating a blog however I do write in my diary
every day. I’d like to start a blog so I can share my personal
experience and feelings online. Please let me know if you have any kind of recommendations
or tips for brand new aspiring blog owners. Appreciate it!
I’m no longer sure where you are getting your information, but good topic.
I must spend some time finding out much more or working
out more. Thanks for wonderful information I used to be on the lookout for this info
for my mission.
My family every time say that I am killing my time here at net, except I know I am getting knowledge all the time by reading thes pleasant posts.
I’m not positive the place you’re getting your info, however
great topic. I must spend some time finding out much more or working out more.
Thank you for fantastic information I was on the lookout for
this info for my mission.
I have read so many articles concerning the blogger lovers however this post is truly a pleasant paragraph,
keep it up.
Appreciating the dedication you put into your blog and detailed information you present.
It’s good to come across a blog every once in a while that isn’t the
same outdated rehashed information. Wonderful read!
I’ve saved your site and I’m adding your RSS feeds to
my Google account.
There’s definately a lot to find out about this issue.
I love all of the points you’ve made.
картавцев сергей михайлович владивосток отзывы клиника доброе
дело омск спальные мешки новороссийск
миасс почему назвали улицу улице сколько
часов от челябинска до казани на автобусе фортуна нижний тагил опг фортуна
I am not sure where you are getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for excellent information I was looking for this info for my mission.
Informative article, just what I wanted to find.
Wow, this paragraph is nice, my younger sister is analyzing
these things, therefore I am going to inform her.
Wow that was strange. I just wrote an very long comment but after I
clicked submit my comment didn’t appear. Grrrr… well I’m not writing all that
over again. Regardless, just wanted to say wonderful blog!
Hello there! I know this is kinda off topic nevertheless I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blog article or
vice-versa? My website covers a lot of the same subjects as yours
and I think we could greatly benefit from each other.
If you might be interested feel free to send me an email.
I look forward to hearing from you! Awesome blog by the way!
Hi, its nice article regarding media print, we all know media is a great
source of information.
Hi there, yeah this article is really pleasant and I have learned
lot of things from it about blogging. thanks.
We are a bunch of volunteers and opening a new scheme in our community.
Your site provided us with useful info to work on. You’ve performed an impressive job
and our whole neighborhood shall be grateful to
you.
Nice weblog here! Also your site loads up fast! What web host are you the usage of?
Can I get your affiliate hyperlink to your host?
I wish my site loaded up as quickly as yours lol
I constantly emailed this website post page to all my associates, since if like to read
it after that my contacts will too.
Howdy very cool website!! Man .. Beautiful .. Superb .. I’ll bookmark your blog and take the feeds also?
I am glad to find a lot of useful info here in the post, we want work out extra strategies on this regard,
thanks for sharing. . . . . .
I am extremely impressed with your writing skills as well as with the
layout on your blog. Is this a paid theme or did you modify it yourself?
Anyway keep up the excellent quality writing, it’s rare to see
a nice blog like this one today.
An impressive share! I have just forwarded this onto a co-worker who had been doing a
little homework on this. And he in fact ordered me dinner due to the fact that I stumbled upon it for him…
lol. So allow me to reword this…. Thank YOU for the
meal!! But yeah, thanks for spending time to discuss this topic here on your web
page.
Thanks for a marvelous posting! I quite enjoyed reading it,
you can be a great author.I will be sure to bookmark your blog and will
eventually come back someday. I want to encourage you to continue your great writing, have a nice
day!
Attractive section of content. I just stumbled upon your site
and in accession capital to say that I get actually enjoyed account your blog
posts. Anyway I’ll be subscribing for your feeds and even I achievement you access
consistently quickly.
Fantastic blog! Do you have any helpful hints for aspiring writers?
I’m planning to start my own site soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go for a paid option? There are so
many options out there that I’m completely confused ..
Any suggestions? Thanks a lot!
This paragraph will help the internet people for creating
new weblog or even a blog from start to end.
Hi this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to get advice from someone with experience.
Any help would be enormously appreciated!
In fact no matter if someone doesn’t know then its up to other visitors that they will help,
so here it occurs.
An impressive share! I have just forwarded this onto a colleague who has been doing a little research on this.
And he actually bought me lunch due to the fact that I stumbled upon it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanks for spending some time to talk about this
matter here on your web page.
That is really interesting, You are an excessively skilled
blogger. I’ve joined your feed and sit up for in the hunt for extra
of your excellent post. Also, I have shared your web site in my social networks
What’s up, just wanted to mention, I liked this post. It was inspiring.
Keep on posting!
Hey! I could have sworn I’ve been to this website before but after browsing through some of the post I realized it’s new to
me. Anyhow, I’m definitely delighted I found it and I’ll
be book-marking and checking back often!
Hi there Dear, are you really visiting this site on a regular basis, if so then you will absolutely obtain good experience.
We are a group of volunteers and starting a new scheme
in our community. Your web site offered us with
valuable info to work on. You have done an impressive
job and our entire community will be grateful to you.
Hurrah, that’s what I was searching for, what a stuff!
present here at this blog, thanks admin of this web site.
I know this website presents quality dependent articles or reviews and additional data,
is there any other web page which offers such things in quality?
I used to be recommended this blog by way of my cousin. I am no longer certain whether this post is
written by him as nobody else realize such special about my trouble.
You are amazing! Thank you!
Article writing is also a excitement, if you be familiar with afterward you can write otherwise it is complicated to write.
Hello there, I discovered your website by way of Google whilst
searching for a comparable topic, your site got here up, it seems good.
I have bookmarked it in my google bookmarks.
Hello there, just changed into alert to your weblog through
Google, and located that it’s really informative.
I am going to be careful for brussels. I’ll be grateful in the event you
proceed this in future. Many people can be benefited out of your writing.
Cheers!
I enjoy reading a post that can make people think. Also, many thanks for permitting me
to comment!
This design is wicked! You definitely know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog
(well, almost…HaHa!) Excellent job. I really enjoyed what you had to say, and more than that,
how you presented it. Too cool!
I am sure this paragraph has touched all the internet viewers, its really really nice
paragraph on building up new blog.
Hi there, this weekend is good designed for me, since this point in time i am reading this great educational piece of writing here at my residence.
When I initially commented I clicked the “Notify me when new comments are added”
checkbox and now each time a comment is added I get several emails with the same comment.
Is there any way you can remove me from that service?
Thanks!
Everything is very open with a really clear explanation of the issues.
It was truly informative. Your website is very helpful.
Thank you for sharing!
Hi there, You have done a great job. I will definitely digg it and personally suggest
to my friends. I’m confident they’ll be benefited from this site.
Excellent write-up. I definitely love this site. Thanks!
The support and encouragement I receive from the members here are truly heartwarming.
This is really interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your great post.
Also, I have shared your web site in my social networks!
I think this is one of the most vital information for me. And
i am glad reading your article. But wanna remark on few general things, The website style is
ideal, the articles is really nice : D. Good job, cheers
Great article! We will be linking to this particularly great article
on our website. Keep up the great writing.
I couldn’t resist commenting. Well written!
Everyone loves what you guys are up too. This type
of clever work and exposure! Keep up the amazing works
guys I’ve you guys to blogroll.
The high level of professionalism and respect in the discussions here sets this forum apart from others.
I always used to study article in news papers but now as I am a user
of net therefore from now I am using net for articles, thanks to web.
It’s actually a great and helpful piece of info.
I’m happy that you shared this helpful information with us.
Please stay us informed like this. Thanks for sharing.
I do not know if it’s just me or if everybody else experiencing problems with your website.
It looks like some of the written text on your content are running off the
screen. Can someone else please provide feedback and
let me know if this is happening to them too? This might be
a problem with my web browser because I’ve had this happen previously.
Cheers
I visited several websites except the audio quality for audio songs existing at this web site is truly
fabulous.
I like the valuable info you provide on your articles.
I will bookmark your blog and take a look at once more
here frequently. I am quite certain I will be told many new stuff proper right here!
Good luck for the following!
I couldn’t refrain from commenting. Perfectly written!
This is very interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your fantastic post.
Also, I’ve shared your site in my social networks!
предсказания монаха авеля на
2023 год король жезлов в отношениях, король жезлов перевернутый чувства мужчины 23 сентября знак
зодиака мужчина перевернутая звезда таро значение 11 ноября 2002 сколько лет
Woah! I’m really enjoying the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance”
between user friendliness and appearance. I must say you have done a great job with this.
In addition, the blog loads very quick for me on Safari.
Exceptional Blog!
Every weekend i used to visit this site, for the reason that i wish for enjoyment,
since this this web site conations actually
nice funny data too.
I pay a quick visit every day some sites and blogs
to read articles, except this blog presents quality based posts.
I pay a quick visit every day some sites and blogs
to read articles, except this blog presents quality based posts.
сго сетевой город якутск вход в личный оптика васса ульяновск погода
нефтеюганск на 10 дней подробно
сургут улица островского 47 прокуратура красноярск где хорошее пиво 9 процентов магазины самара каталог товаров цены официальный
What a information of un-ambiguity and preserveness of precious experience concerning unexpected feelings.
Yes! Finally someone writes about the growth matrix.
Heya i am for the first time here. I found this board and I to
find It truly useful & it helped me out a lot. I am hoping to offer something again and help others like you
aided me.
It’s remarkable to visit this website and reading the views of all mates concerning this article, while I am also keen of getting know-how.
magnificent post, very informative. I wonder why the opposite experts of this sector
do not realize this. You must continue your writing.
I am confident, you have a huge readers’ base already!
Fastidious response in return of this question with
firm arguments and describing all regarding that.
Wonderful article! That is the type of info that
should be shared around the internet. Disgrace on Google for not positioning this publish higher!
Come on over and discuss with my site . Thank you
=)
Hey I know this is off topic but I was wondering if
you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time
and was hoping maybe you would have some experience
with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
each time i used to read smaller content that as well
clear their motive, and that is also happening with this article which I am reading now.
Excellent website. A lot of helpful information here.
I am sending it to some pals ans additionally sharing in delicious.
And naturally, thank you to your sweat!
Howdy! This article could not be written any better!
Going through this article reminds me of my previous roommate!
He continually kept talking about this. I’ll forward this post to him.
Pretty sure he’ll have a very good read. Thank you for sharing!
Right here is the perfect blog for anybody who really wants
to find out about this topic. You realize so much its almost hard to argue with you (not
that I really will need to…HaHa). You certainly put a fresh spin on a subject that’s been written about for
decades. Wonderful stuff, just great!
Hi, for all time i used to check website posts here
in the early hours in the daylight, for the reason that i like to
learn more and more.
I couldn’t refrain from commenting. Very well written!
Howdy! I’m at work surfing around your blog from my new iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Carry on the outstanding work!
Hi there, I found your blog by the use of Google even as looking for a
similar topic, your web site came up, it seems to be great.
I have bookmarked it in my google bookmarks.
Hello there, simply became alert to your blog via Google, and found that it is truly informative.
I’m going to watch out for brussels. I’ll appreciate when you continue
this in future. Many other folks shall be benefited out of your writing.
Cheers!
What’s Going down i am new to this, I stumbled upon this I’ve discovered It absolutely helpful and
it has helped me out loads. I’m hoping to give a contribution &
help different customers like its helped me. Great job.
This piece of writing is genuinely a pleasant one it helps new the web users, who
are wishing for blogging.
XXX films
Attractive component of content. I just stumbled upon your blog and
in accession capital to claim that I get in fact loved account your blog posts.
Any way I will be subscribing in your augment and even I achievement
you get entry to persistently quickly.
What’s up, yup this post is really nice and I have learned lot of things from it about blogging.
thanks.
Appreciating the commitment you put into your blog and detailed information you provide.
It’s great to come across a blog every once in a while that isn’t the same out of
date rehashed material. Fantastic read! I’ve saved your site and I’m adding your RSS feeds to my Google
account.
Aw, this was an exceptionally good post. Taking a few minutes
and actual effort to generate a top notch article…
but what can I say… I put things off a whole lot and
don’t seem to get anything done.
Feel free to visit my web blog – Finance Phantom trading robot
Nice answer back in return of this difficulty with
solid arguments and explaining everything about that.
Quality content is the important to invite the people to go to see the site, that’s what this site is providing.
Touche. Great arguments. Keep up the amazing
spirit.
Great site you have here.. It’s hard to find high quality writing like yours
these days. I really appreciate people like you!
Take care!!
Review my blog post Come Togliere Il Ciuccio – Come Togliere
Keep on working, great job!
Hi, I think your blog might be having browser compatibility
issues. When I look at your blog site in Safari, it looks
fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, amazing blog!
I think this is among the most significant info for me.
And i’m glad reading your article. But should remark on few general things, The web site style
is great, the articles is really great : D. Good job, cheers
I visited several web sites however the audio quality for audio songs existing at this web
page is actually marvelous.
It’s an remarkable paragraph for all the internet users; they will get benefit from it I am
sure.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add
to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was
hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy
reading your blog and I look forward to your new updates.
In fact no matter if someone doesn’t understand after that
its up to other people that they will help, so here it happens.
We’re a bunch of volunteers and opening a new scheme in our
community. Your website offered us with helpful
info to work on. You have performed an impressive process and our whole neighborhood will be thankful to you.
Wonderful article! We are linking to this particularly great content on our website.
Keep up the good writing.
Helpful information. Fortunate me I found your web site by accident, and I am surprised why this
coincidence did not happened earlier! I bookmarked it.
My homepage … coupons discounts (xintangtc.com)
What a material of un-ambiguity and preserveness of precious familiarity about unexpected feelings.
I am extremely impressed with your writing skills and also with
the layout on your blog. Is this a paid theme or did you modify it yourself?
Anyway keep up the excellent quality writing, it is rare to
see a nice blog like this one these days.
I like the valuable information you supply for your articles.
I’ll bookmark your weblog and check again here frequently.
I’m fairly certain I will be told lots of new stuff right right here!
Good luck for the next!
That is very fascinating, You are a very professional blogger.
I have joined your rss feed and look ahead to in the hunt for extra of your magnificent post.
Also, I’ve shared your site in my social networks
Unquestionably imagine that that you stated. Your favorite
justification appeared to be at the net the easiest
thing to keep in mind of. I say to you, I definitely get
annoyed whilst other people consider worries
that they just don’t recognise about. You controlled to hit the nail upon the top
and defined out the entire thing with no need side-effects , people can take a signal.
Will probably be again to get more. Thanks
I’ve been surfing online more than 4 hours today, yet I never found any interesting
article like yours. It’s pretty worth enough for
me. Personally, if all web owners and bloggers
made good content as you did, the internet will be a lot more useful than ever before.
I am regular reader, how are you everybody? This piece of writing posted at this
web page is really pleasant.
Very shortly this web site will be famous among all blogging visitors,
due to it’s good posts
Great post.
I’m impressed, I have to admit. Seldom do I come across a blog that’s both equally
educative and entertaining, and let me tell you,
you have hit the nail on the head. The problem is something which not
enough folks are speaking intelligently about. I’m very happy
that I came across this in my search for something regarding
this.
My partner and I stumbled over here different web page and thought I may as well check things out.
I like what I see so now i’m following you. Look forward to checking out your web page yet again.
Appreciation to my father who informed me regarding this webpage, this
web site is genuinely amazing.
This page really has all of the information and facts I needed about this subject and didn’t know who
to ask.
Thanks for another wonderful article. Where else could anyone get that type of info
in such an ideal method of writing? I’ve a presentation next
week, and I’m at the search for such info.
I have read several excellent stuff here. Definitely worth bookmarking
for revisiting. I surprise how so much attempt you place to create this kind of fantastic informative web site.
Amazing blog! Do you have any tips and hints for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go for a paid option? There are so many options out there that
I’m totally confused .. Any tips? Bless you!
Hello! I know this is kind of off-topic however I had to ask.
Does operating a well-established blog like yours require a large amount
of work? I’m brand new to writing a blog but I do
write in my diary everyday. I’d like to start a blog
so I can easily share my personal experience and thoughts online.
Please let me know if you have any kind of suggestions or tips for new aspiring blog owners.
Thankyou!
drjuknul.icu
It is appropriate time to make some plans for the future and
it’s time to be happy. I have read this post and if
I could I wish to suggest you some interesting things or tips.
Maybe you could write next articles referring to this article.
I desire to read more things about it!
Please let me know if you’re looking for a author for your site.
You have some really good articles and I believe I would be a good asset.
If you ever want to take some of the load off, I’d love to write some content for your blog in exchange for a link
back to mine. Please send me an e-mail if interested.
Many thanks!
Hi! I just would like to offer you a huge
thumbs up for your excellent information you have got here on this post.
I’ll be coming back to your blog for more soon.
Definitely believe that which you stated. Your favorite reason appeared to be
on the internet the easiest thing to be aware of.
I say to you, I definitely get annoyed while people
consider worries that they just don’t know about.
You managed to hit the nail upon the top and defined out the whole thing without having side effect ,
people could take a signal. Will probably be back
to get more. Thanks
It’s in fact very difficult in this full of activity life
to listen news on TV, thus I just use web for that reason, and get the most recent news.
It’s a pity you don’t have a donate button! I’d certainly donate to this superb blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed
to my Google account. I look forward to fresh updates and will share
this website with my Facebook group. Talk soon!
Hey very nice blog!
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out much.
I hope to give something back and help others like you helped me.
I am sure this post has touched all the internet viewers, its really really fastidious piece
of writing on building up new webpage.
Right away I am going to do my breakfast, afterward having my breakfast coming over
again to read further news.
Hello, always i used to check web site posts here early in the dawn,
because i enjoy to gain knowledge of more and more.
Wow, fantastic blog layout! How long have you been blogging
for? you made blogging look easy. The overall look of your website
is wonderful, let alone the content!
Thank you for any other informative website. The place else may I get that kind of info
written in such a perfect method? I’ve a mission that I’m just now
working on, and I have been at the look out for
such info.
I’m really inspired with your writing skills and also with
the structure for your blog. Is that this a paid topic or did you modify it yourself?
Either way keep up the excellent quality writing, it’s uncommon to
peer a great blog like this one today..
Thanks , I’ve recently been searching for info approximately this topic for a long time and yours
is the best I have came upon till now. But, what concerning
the conclusion? Are you certain concerning the supply?
Hi! Do you use Twitter? I’d like to follow you if
that would be okay. I’m definitely enjoying your blog and look forward to
new updates.
certainly like your website but you need to
test the spelling on quite a few of your
posts. Many of them are rife with spelling problems and
I find it very bothersome to tell the truth on the
other hand I will definitely come again again.
We are a bunch of volunteers and starting a new scheme in our community.
Your website provided us with helpful info to work on. You’ve performed a formidable task and our whole neighborhood shall be grateful to you.
I visited several websites but the audio feature for audio songs present at this website is in fact
wonderful.
What a stuff of un-ambiguity and preserveness of valuable familiarity about unpredicted
emotions.
wonderful put up, very informative. I’m wondering why the opposite specialists
of this sector do not realize this. You must continue your writing.
I’m confident, you’ve a great readers’ base already!
Oh my goodness! Amazing article dude! Thank you so much,
However I am having problems with your RSS. I don’t understand why
I can’t join it. Is there anybody getting identical
RSS problems? Anyone who knows the answer will you kindly
respond? Thanks!!
Hello there! This is my first visit to your blog! We are a collection of volunteers and starting a new project in a community
in the same niche. Your blog provided us valuable information to work on. You
have done a outstanding job!
You could certainly see your enthusiasm within the work you write.
The sector hopes for more passionate writers like you who are not afraid
to mention how they believe. All the time go after your heart.
I’m really enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more enjoyable
for me to come here and visit more often. Did you
hire out a designer to create your theme? Outstanding work!
I got this web page from my pal who shared with me about
this web page and at the moment this time I am visiting
this website and reading very informative content
at this time.
Explore Iceland in 3 days with a curated itinerary. Discover Reykjavik’s charm, delve into wilderness adventures, savor Icelandic cuisine, and immerse in cultural treasures.
Learn weather conditions, driving laws, and full packing lists.
Book your Icelandic adventure now!
Hey there, I think your website might be having browser compatibility issues.
When I look at your blog site in Chrome, it looks fine but when opening
in Internet Explorer, it has some overlapping. I just wanted to give you a quick
heads up! Other then that, awesome blog!
Appreciate the recommendation. Let me try it out.
There’s certainly a great deal to learn about this topic.
I really like all the points you have made.
Hello, I would like to subscribe for this webpage to get hottest updates, so where can i do it
please help.
Also visit my page … Sea sports travel
If you would like to increase your knowledge only keep visiting this web page and be
updated with the most up-to-date information posted here.
This information is priceless. Where can I find out more?
Superb blog! Do you have any recommendations for aspiring writers?
I’m hoping to start my own website soon but I’m a little
lost on everything. Would you suggest starting with a free platform like WordPress or go for a paid option? There are so
many options out there that I’m completely confused .. Any ideas?
Appreciate it!
Very good write-up. I certainly love this site. Stick with it!
Hi! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading through your blog and look forward to all your posts!
Carry on the great work!
Hello friends, its wonderful article regarding teachingand completely explained, keep it up all
the time.
Hello every one, here every one is sharing these experience,
therefore it’s good to read this weblog, and I used to pay a visit this blog daily.
An impressive share! I have just forwarded this onto a colleague
who had been conducting a little homework on this.
And he in fact bought me breakfast because I discovered
it for him… lol. So let me reword this…. Thank
YOU for the meal!! But yeah, thanx for spending
some time to discuss this subject here on your web site.
of course like your web-site however you have to take a look at the spelling on several of your posts.
Several of them are rife with spelling problems and I to find
it very troublesome to inform the reality then again I will definitely come back again.
WOW just what I was searching for. Came here by searching
for lottery defeater software app
Undeniably imagine that that you stated. Your favourite justification appeared to be on the
internet the simplest thing to have in mind of.
I say to you, I certainly get annoyed whilst people think about worries that
they just don’t understand about. You managed to hit the nail upon the top
as well as outlined out the entire thing with no need side effect , folks can take a signal.
Will probably be back to get more. Thank you
Hello, just wanted to mention, I enjoyed this article.
It was helpful. Keep on posting!
Excellent web site you have here.. It’s difficult to find high-quality writing like yours nowadays.
I honestly appreciate people like you! Take care!!
If you desire to grow your experience only keep visiting this
site and be updated with the latest information posted here.
There’s certainly a great deal to find out about this subject.
I like all of the points you have made.
Pretty component to content. I simply stumbled upon your website and in accession capital to claim that I
get in fact loved account your blog posts. Anyway I’ll be subscribing in your feeds
and even I success you get admission to consistently rapidly.
I do not know if it’s just me or if everybody else experiencing problems with your site.
It appears as if some of the text on your posts are running off
the screen. Can someone else please provide feedback and let me know if this is happening to
them as well? This might be a problem with my web browser
because I’ve had this happen before. Many thanks
This is my first time visit at here and i am in fact impressed
to read everthing at one place.
Heya i’m for the primary time here. I came across this board and I in finding It really useful & it helped me out much.
I hope to present something again and help others such
as you helped me.
Online medicijnen kopen in Gouda – geen recept nodig!
sandoz Opfikon medicamentos en línea sin receta en España
Valuable information. Fortunate me I found your site accidentally,
and I’m shocked why this twist of fate did not came about in advance!
I bookmarked it.
Heya just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both
show the same outcome.
I am not sure where you’re getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for magnificent information I was looking for this info for my mission.
Your style is very unique compared to other folks I
have read stuff from. Thanks for posting when you’ve got the opportunity, Guess I’ll just
book mark this blog.
Wow, superb blog layout! How long have you ever been running a blog for?
you make running a blog look easy. The whole glance of your site is magnificent, as smartly as the content!
I always spent my half an hour to read this webpage’s articles everyday
along with a mug of coffee.
I just could not depart your website before suggesting that
I actually enjoyed the standard information an individual provide in your
guests? Is going to be again continuously in order to investigate cross-check new posts
Hi there! I could have sworn I’ve been to
this site before but after browsing through
some of the post I realized it’s new to me. Nonetheless, I’m definitely glad I found it and I’ll be
bookmarking and checking back frequently!
If you are going for best contents like me, only go to see this web site daily because it presents quality
contents, thanks
Very descriptive post, I enjoyed that bit. Will there be a part 2?
Yes! Finally something about credoshare.com.
Hi there i am kavin, its my first occasion to commenting anywhere, when i read
this post i thought i could also make comment due to this sensible paragraph.
Hello everyone, it’s my first visit at this web page, and paragraph is truly fruitful in support of me, keep up posting these types of posts.
Because the admin of this site is working, no question very quickly
it will be renowned, due to its quality contents.
Wonderful, what a blog it is! This website gives valuable information to us,
keep it up.
I know this if off topic but I’m looking into starting my own blog and was wondering what all is required to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% sure. Any suggestions or advice would be greatly appreciated.
Appreciate it
Hello there! Do you use Twitter? I’d like to follow you
if that would be ok. I’m absolutely enjoying your
blog and look forward to new posts.
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet my newest twitter
updates. I’ve been looking for a plug-in like this for
quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward
to your new updates.
My family all the time say that I am wasting my time here at net,
but I know I am getting familiarity daily by reading
thes pleasant articles or reviews.
Feel free to surf to my blog: fusible link 165f
Greetings! This is my first visit to your blog!
We are a collection of volunteers and starting a new project in a
community in the same niche. Your blog provided us useful information to work on. You have done a extraordinary job!
Please let me know if you’re looking for a article author for your blog.
You have some really great articles and I feel I would be a
good asset. If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a link back to mine.
Please blast me an email if interested. Thank you!
of course like your web site but you need to test the spelling
on quite a few of your posts. A number of them are rife with spelling issues and I find it
very troublesome to inform the truth nevertheless I’ll certainly come again again.
Howdy! Would you mind if I share your blog with my facebook group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Thank you
Hey there! Do you use Twitter? I’d like to follow you if that would
be ok. I’m definitely enjoying your blog and look forward
to new posts.
First off I want to say great blog! I had a quick question that I’d like
to ask if you do not mind. I was interested to know how
you center yourself and clear your thoughts prior to writing.
I’ve had trouble clearing my thoughts in getting my ideas
out. I truly do enjoy writing however it just seems like the first 10
to 15 minutes tend to be lost simply just trying to figure
out how to begin. Any ideas or hints? Cheers!
Hi, this weekend is pleasant in support of me, because
this point in time i am reading this wonderful educational article here at my home.
Attractive section of content. I just stumbled
upon your web site and in accession capital to assert that
I get actually enjoyed account your blog posts. Anyway I’ll be subscribing to your augment and even I achievement you access consistently fast.
excellent points altogether, you simply won a
brand new reader. What might you suggest in regards to
your publish that you simply made some days ago? Any sure?
I enjoy what you guys are usually up too. This kind of clever work and exposure!
Keep up the excellent works guys I’ve incorporated you guys to my personal blogroll.
Hello, its pleasant paragraph regarding media print, we all understand media is a fantastic source of facts.
Also, you will have access to a search function that most convventional and Bitcoin spoorts betting
webb sites lack.
Feel free to surf to my web-site :: 비트코인 거래소 정책
You should take part in a contest for one of the greatest
blogs on the web. I’m going to recommend this web site!
With havin so much written content do you ever run into any issues of plagorism or copyright infringement?
My website has a lot of unique content I’ve either
created myself or outsourced but it appears
a lot of it is popping it up all over the web without
my authorization. Do you know any ways to help
stop content from being ripped off? I’d definitely appreciate it.
интим для девушек новосибирск испытала оргазм при минете знакомство для
секса в спб бесплатно онлайн хуй огромных размеров
бесплатно
Thanks for sharing such a fastidious thinking, article is
fastidious, thats why i have read it completely
Greetings from Carolina! I’m bored at work so I decided to check
out your blog on my iphone during lunch break. I enjoy the knowledge you present here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my cell phone
.. I’m not even using WIFI, just 3G .. Anyhow,
great blog!
A person essentially help to make severely articles I would state.
This is the very first time I frequented your web page and up to
now? I amazed with the analysis you made to make
this particular put up amazing. Fantastic task!
Hi there, I enjoy reading all of your post. I like to write
a little comment to support you.
medicamentos recommandé pour les problèmes
de conception Galpharm Herne aankoop van medicijnen in Marseille
I am regular visitor, how are you everybody? This post posted at this web page is really good.
Thank you, I have just been looking for
information about this subject for ages and yours is
the best I’ve discovered so far. However, what in regards to the conclusion?
Are you sure in regards to the supply?
It’s not my first time to go to see this web page, i am browsing
this web site dailly and take good data from here everyday.
Do you mind if I quote a few of your posts as long as
I provide credit and sources back to your site? My website
is in the very same niche as yours and my visitors would genuinely benefit from some of the information you provide here.
Please let me know if this alright with you. Regards!
Howdy! Someone in my Facebook group shared
this website with us so I came to take a look. I’m definitely loving the information. I’m book-marking
and will be tweeting this to my followers! Excellent blog
and brilliant style and design.
Hi there, I found your blog via Google at
the same time as searching for a related matter, your web site came up, it looks good.
I have bookmarked it in my google bookmarks.
Hello there, just turned into alert to your blog via Google, and located that it is really informative.
I am gonna be careful for brussels. I’ll be grateful in the event you continue this
in future. Lots of other people shall be benefited out of your writing.
Cheers!
I visited multiple web pages however the audio feature for audio songs present at this
website is genuinely marvelous.
wonderful put up, very informative. I wonder why the other experts of this sector
do not understand this. You should continue your writing.
I am sure, you’ve a great readers’ base already!
Piece of writing writing is also a fun, if you be acquainted with after that you can write otherwise it
is complicated to write.
Feel free to surf to my web-site; here are the instructions for registering.
I’m extremely impressed with your writing skills and also with
the layout on your blog. Is this a paid theme or
did you customize it yourself? Anyway keep up the excellent quality writing,
it’s rare to see a nice blog like this one nowadays.
My web blog; adult video
First of all I would like to say great blog! I had a
quick question in which I’d like to ask if you don’t mind.
I was curious to know how you center yourself and
clear your mind before writing. I’ve had a hard time clearing
my thoughts in getting my ideas out. I truly do enjoy
writing however it just seems like the first 10 to 15 minutes are usually wasted just trying to figure out how to begin. Any ideas or tips?
Thanks!
Attractive section of content. I just stumbled upon your blog and in accession capital to assert that I
get in fact enjoyed account your blog posts. Any way I will be subscribing
to your augment and even I achievement you access consistently fast.
Yesterday, while I was at work, my sister stole my iPad and tested to see if
it can survive a forty foot drop, just so she can be a
youtube sensation. My apple ipad is now destroyed and
she has 83 views. I know this is totally off topic but I had to share it with someone!
drochit.online
Hi, I do believe this is a great site. I stumbledupon it 😉 I’m going to come back yet again since i
have book-marked it. Money and freedom is the greatest way
to change, may you be rich and continue to help others.
I could not resist commenting. Exceptionally well written!
Hey there, You’ve done a great job. I will certainly digg it and personally recommend to my friends.
I am sure they’ll be benefited from this web site.
I’m extremely impressed with your writing skills and also
with the layout on your weblog. Is this a paid theme or did you customize it yourself?
Anyway keep up the nice quality writing, it’s
rare to see a nice blog like this one today.
Just wish to say your article is as astonishing. The clearness on your publish is just
excellent and i could think you’re an expert in this subject.
Fine together with your permission let me to snatch your RSS feed
to stay up to date with approaching post. Thank you
a million and please carry on the rewarding work.
Thanks for finally talking about > Пиастры – Составление семантического ядра | < Loved it!
I’ve been browsing online greater than three hours lately,
yet I by no means discovered any fascinating article
like yours. It is pretty worth sufficient for me. Personally, if all website owners and bloggers made
excellent content material as you did, the web will probably
be a lot more useful than ever before.
You’re so awesome! I don’t suppose I’ve read anything like this before.
So good to find someone with a few unique thoughts on this issue.
Really.. many thanks for starting this up.
This site is something that’s needed on the internet, someone with a little
originality!
I am really delighted to glance at this blog posts which consists of lots
of valuable data, thanks for providing such data.
Everything is very open with a precise clarification of the issues.
It was really informative. Your website is very helpful.
Many thanks for sharing!
Hello! This post could not be written any better!
Reading through this post reminds me of my old room mate! He always kept talking about this.
I will forward this page to him. Pretty sure he will have a good
read. Many thanks for sharing!
It’s appropriate time to make some plans for the long run and it is time to
be happy. I have read this put up and if I may just I want to
counsel you some interesting issues or advice.
Maybe you can write next articles relating to this article.
I want to read even more things approximately it!
Yesterday, while I was at work, my cousin stole my iphone and tested to see if
it can survive a 25 foot drop, just so she can be a youtube sensation.
My iPad is now destroyed and she has 83 views. I know this is entirely off
topic but I had to share it with someone!
Greetings I am so excited I found your web site, I really
found you by error, while I was researching on Aol for something
else, Nonetheless I am here now and would just like to say
thank you for a marvelous post and a all round entertaining blog (I also love the theme/design), I don’t have time to read through it all at the minute but I have bookmarked it
and also added in your RSS feeds, so when I have time I will be back to read a great deal more,
Please do keep up the fantastic b.
Link exchange is nothing else however it is only placing the other person’s website link on your page at suitable place and other person will also do similar
in support of you.
Tremendous things here. I’m very glad to see your post.
Thanks so much and I am having a look ahead to contact you.
Will you please drop me a mail?
Why people still make use of to read news papers when in this technological world
everything is presented on net?
I’m extremely inspired together with your writing abilities as well as with the
format in your blog. Is that this a paid subject or did you modify it yourself?
Anyway stay up the excellent quality writing, it’s uncommon to peer
a nice blog like this one nowadays..
Hi Dear, are you actually visiting this web site daily, if so afterward you will definitely obtain good know-how.
Awesome blog! Do you have any suggestions for aspiring writers?
I’m planning to start my own blog soon but I’m a
little lost on everything. Would you advise starting with
a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally confused ..
Any tips? Many thanks!
I am truly grateful to the holder of this web page who has shared this impressive post
at here.
My brother recommended I might like this web
site. He was entirely right. This post actually
made my day. You can not imagine simply how much time I had spent for this information! Thanks!
Your style is very unique in comparison to other folks I’ve read stuff
from. Thank you for posting when you’ve got the opportunity, Guess I will just bookmark this web
site.
Great website. Lots of useful information here.
I am sending it to a few pals ans additionally sharing in delicious.
And of course, thank you for your sweat!
bookmarked!!, I love your web site!
I every time spent my half an hour to read this weblog’s content everyday along
with a mug of coffee.
Hi there! I know this is kind of off topic but I was wondering
if you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m
having problems finding one? Thanks a lot!
If some one desires expert view concerning blogging afterward
i recommend him/her to visit this website, Keep up the fastidious work.
Very good article. I certainly appreciate this site.
Keep it up!
Howdy would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 completely different browsers and I must
say this blog loads a lot faster then most. Can you
suggest a good hosting provider at a reasonable price?
Many thanks, I appreciate it!
I like what you guys are up too. This kind of clever work and coverage!
Keep up the superb works guys I’ve incorporated you guys to
blogroll.
Hey are using WordPress for your site platform? I’m new to the blog world but I’m trying to get
started and set up my own. Do you require any html coding expertise to make
your own blog? Any help would be greatly appreciated!
Hello there, just became alert to your blog through
Google, and found that it’s truly informative.
I am gonna watch out for brussels. I will appreciate if you continue this in future.
Many people will be benefited from your writing. Cheers!
Good blog you have here.. It’s difficult to find excellent writing like yours these days.
I truly appreciate individuals like you! Take care!!
I’m amazed, I have to admit. Rarely do I come across a blog that’s both
educative and amusing, and let me tell you, you have hit the nail on the head.
The problem is something too few men and women are speaking intelligently about.
I’m very happy I came across this during my hunt for something regarding this.
I am extremely inspired together with your writing talents as neatly as with
the format on your blog. Is that this a paid theme or did
you customize it your self? Anyway keep up the nice high quality writing, it is uncommon to
peer a nice weblog like this one nowadays..
What’s up, its good paragraph concerning media print,
we all understand media is a enormous source of data.
Thank you for every other informative blog. The place else could I
am getting that kind of info written in such an ideal manner?
I’ve a undertaking that I’m just now operating on, and I have been at the look out for such information.
I used to be able to find good information from your content.
What’s up everyone, it’s my first go to see at this website,
and article is really fruitful in support of me, keep up posting these types of articles.
I am really enjoying the theme/design of your web site.
Do you ever run into any internet browser compatibility
problems? A few of my blog audience have complained about my site not working correctly in Explorer but looks great in Chrome.
Do you have any tips to help fix this issue?
Woah! I’m really enjoying the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between superb usability and visual appeal.
I must say you have done a fantastic job with this. In addition, the blog loads very fast for me
on Chrome. Exceptional Blog!
I know this if off topic but I’m looking into starting my own blog and was
curious what all is needed to get set up? I’m assuming having a
blog like yours would cost a pretty penny? I’m not very web smart
so I’m not 100% positive. Any suggestions or advice would be greatly appreciated.
Cheers
Hey there! This post could not be written any better!
Reading this post reminds me of my previous room mate!
He always kept chatting about this. I will
forward this page to him. Fairly certain he will have a good read.
Many thanks for sharing!
Good day! This post could not be written any better! Reading
this post reminds me of my old room mate! He always kept
chatting about this. I will forward this article to him.
Fairly certain he will have a good read. Thank you for sharing!
Oh my goodness! Amazing article dude! Many thanks, However I am going through issues
with your RSS. I don’t understand the reason why I am
unable to subscribe to it. Is there anybody else having similar RSS problems?
Anyone that knows the solution can you kindly respond?
Thanks!!
constantly i used to read smaller posts that also clear their motive,
and that is also happening with this article which I am
reading here.
A lot of skeptics have always questioned how
fair online casino games are even though they use RNGs.
Hi my family member! I want to say that this
article is amazing, great written and include approximately all significant infos.
I would like to peer more posts like this .
Hello would you mind sharing which blog platform you’re using?
I’m going to start my own blog soon but I’m having a difficult time selecting
between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your layout seems different then most blogs and
I’m looking for something unique. P.S Apologies for being off-topic
but I had to ask!
Hi, I check your blog regularly. Your writing style is awesome,
keep doing what you’re doing!
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point.
You definitely know what youre talking about, why waste your intelligence on just posting videos
to your weblog when you could be giving us something enlightening to read?
This info is worth everyone’s attention. Where can I find out more?
This post will help the internet people for building up new weblog or even a blog from start to end.
Excellent site you have here.. It’s difficult to
find high quality writing like yours these days. I honestly appreciate
individuals like you! Take care!!
Everything is very open with a precise explanation of the challenges.
It was truly informative. Your site is useful. Thank you for
sharing!
Excellent website you have here but I was curious about
if you knew of any user discussion forums that cover the same topics talked about in this article?
I’d really like to be a part of group where I can get suggestions from other
experienced individuals that share the same interest.
If you have any suggestions, please let me know.
Kudos!
Great goods from you, man. I’ve understand your stuff previous to and
you’re just too great. I actually like what you’ve
acquired here, really like what you are saying and the way in which you say it.
You make it enjoyable and you still take care of
to keep it smart. I can’t wait to read much more from you.
This is really a tremendous web site.
Very great post. I just stumbled upon your blog and wished to say that I have really
loved browsing your blog posts. After all I will be subscribing in your feed and I am hoping you write once more soon!
If some one wants expert view concerning running a blog then i advise him/her to go to see this blog,
Keep up the nice job.
Excellent blog here! Additionally your website loads up very fast!
What web host are you the usage of? Can I am getting your associate link on your host?
I want my web site loaded up as fast as yours lol
Thanks for any other fantastic article. Where else could
anybody get that type of info in such a perfect approach of writing?
I’ve a presentation next week, and I’m on the search for such
info.
I am sure this article has touched all the internet people,
its really really fastidious piece of writing on building up new blog.
I am really thankful to the holder of this site who has shared this great piece of writing at here.
After I initially commented I appear to have clicked on the
-Notify me when new comments are added- checkbox and from now on every time a comment is added I recieve 4 emails with the exact same comment.
Is there an easy method you can remove me from that service?
Thanks a lot!
of course like your web-site however you need to take a look
at the spelling on quite a few of your posts. Several of them are rife with
spelling problems and I to find it very troublesome to inform the reality nevertheless
I’ll surely come again again.
I do accept as true with all of the ideas you’ve presented for your post.
They’re really convincing and will definitely work.
Still, the posts are very short for starters.
May you please extend them a bit from subsequent time?
Thank you for the post.
I blog frequently and I really appreciate your information. Your article has truly peaked
my interest. I will book mark your website and keep checking
for new details about once a week. I subscribed to your RSS feed too.
Howdy are using WordPress for your site platform? I’m new to the blog world but I’m trying to
get started and set up my own. Do you need any html coding expertise to make your own blog?
Any help would be greatly appreciated!
Does your website have a contact page? I’m having a tough time locating it but, I’d like to send you
an email. I’ve got some ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it improve
over time.
What’s Taking place i am new to this, I stumbled upon this I’ve discovered It positively
useful and it has helped me out loads. I am hoping
to give a contribution & help other customers like its helped me.
Good job.
I do not even know how I ended up right here, but I assumed this submit was good.
I don’t realize who you might be but certainly you are going to a famous blogger in the event you aren’t already.
Cheers!
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do it
for you? Plz respond as I’m looking to create my own blog and
would like to know where u got this from. many thanks
I have been surfing online more than 3 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if all website owners and bloggers made good content as you did,
the internet will be a lot more useful than ever before.
Hello great website! Does running a blog such as
this require a large amount of work? I’ve absolutely no
knowledge of coding however I had been hoping to start my own blog soon. Anyhow, if you have any recommendations or tips for new blog owners please share.
I know this is off subject but I simply had to ask. Appreciate it!
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you!
By the way, how could we communicate?
Hey there I am so delighted I found your webpage, I really found you by accident, while I was
researching on Digg for something else, Nonetheless I am here now and would
just like to say cheers for a tremendous post and
a all round thrilling blog (I also love the theme/design), I don’t have time to browse it all at the minute but I have book-marked it and also
added in your RSS feeds, so when I have time I will be back
to read more, Please do keep up the awesome work.
Admiring the commitment you put into your blog and
in depth information you present. It’s awesome to come across a
blog every once in a while that isn’t the same out of date rehashed material.
Great read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
Keep on writing, great job!
Hey I am so thrilled I found your web site, I really found you by mistake,
while I was looking on Askjeeve for something else,
Nonetheless I am here now and would just like to say many thanks for a incredible post and a all round enjoyable blog (I
also love the theme/design), I don’t have time to look over it all at the
moment but I have saved it and also added your RSS feeds, so when I have time I will
be back to read much more, Please do keep up the great work.
Nice post. I was checking continuously this weblog and I’m inspired!
Extremely helpful info specially the final part :
) I take care of such info much. I used to be seeking this particular information for
a very long time. Thank you and best of luck.
Hi there to every single one, it’s in fact a nice for me to go to see this site,
it includes helpful Information.
Hi there to every single one, it’s in fact a nice for me to go to see this site,
it includes helpful Information.
Yes! Finally someone writes about توسكاني للعطور الرجالية.
If you want to increase your experience just keep visiting this web page and be updated with the most recent news update posted here.
Wow! In the end I got a website from where I can in fact take valuable facts concerning my study and knowledge.
hello there and thank you for your info – I have certainly
picked up something new from right here. I did however expertise several technical issues
using this web site, as I experienced to reload the site many
times previous to I could get it to load correctly.
I had been wondering if your hosting is OK? Not that I’m complaining, but sluggish loading instances times will often affect
your placement in google and could damage your quality score if ads and marketing with Adwords.
Anyway I’m adding this RSS to my email and can look out for much more
of your respective fascinating content. Make sure
you update this again soon.
Hello, i feel that i saw you visited my weblog thus i got here to go back the favor?.I am
trying to find issues to enhance my site!I assume its adequate to make use
of some of your ideas!!
Inspiring quest there. What occurred after? Take care!
Simply want to say your article is as surprising. The clarity in your post
is simply excellent and i could assume you’re an expert on this subject.
Fine with your permission allow me to grab your RSS feed to
keep up to date with forthcoming post. Thanks a million and please
keep up the gratifying work.
I think the admin of this web page is actually working hard in favor of his web page, since here every
stuff is quality based material.
This is a topic which is near to my heart… Cheers!
Where are your contact details though?
Do you mind if I quote a few of your posts as long as I provide credit and sources back to your weblog?
My blog site is in the exact same niche as yours and my visitors would definitely benefit from some of the information you present here.
Please let me know if this okay with you. Thanks!
We’re a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable information to work on. You’ve done a formidable job and
our entire community will be grateful to you.
Hello to every body, it’s my first pay a quick visit of this web
site; this web site carries amazing and genuinely fine
material for visitors.
Hey! I could have sworn I’ve been to this website before but after browsing through some
of the post I realized it’s new to me. Anyways, I’m definitely glad I found it and I’ll be book-marking and checking back frequently!
Useful info. Fortunate me I discovered your site accidentally, and I’m stunned why this twist of fate did not
happened in advance! I bookmarked it.
This is the perfect site for anybody who wants to understand
this topic. You understand a whole lot its almost tough to argue with you (not that I really would
want to…HaHa). You definitely put a brand new spin on a topic
which has been written about for years. Excellent stuff,
just excellent!
Admiring the time and energy you put into your website and detailed information you offer.
It’s good to come across a blog every once in a while that isn’t the same outdated rehashed information. Fantastic read!
I’ve bookmarked your site and I’m adding your RSS
feeds to my Google account.
Thanks for sharing your thoughts about سایت های شرط بندی فوتبال.
Regards
Explore the harmful effects of UV radiation on skin health and discover the advantages of safe sunless tanning as a protective alternative to sun exposure.
This excellent website definitely has all the information I wanted concerning this subject and didn’t know who
to ask.
Generally I do not read post on blogs, but I would like to say that
this write-up very pressured me to try and do so!
Your writing taste has been amazed me. Thank you, quite nice article.
I absolutely love your site.. Excellent colors & theme.
Did you create this web site yourself? Please
reply back as I’m attempting to create my own personal site and would love to find
out where you got this from or exactly what the
theme is called. Thanks!
Its like you learn my thoughts! You seem to know a lot about this, such as you wrote the
ebook in it or something. I feel that you simply can do with
some percent to force the message home a bit, but instead of that, that is wonderful blog.
An excellent read. I’ll definitely be back.
I every time spent my half an hour to read this
blog’s articles everyday along with a mug of coffee.
Now I am going away to do my breakfast, when having my breakfast coming over again to read
more news.
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I am quite certain I’ll learn lots of new stuff
right here! Best of luck for the next!
It’s going to be ending of mine day, however before end I am reading this enormous piece of
writing to increase my know-how.
I don’t know whether it’s just me or if perhaps everyone else experiencing issues with
your website. It seems like some of the written text on your posts are running off the screen. Can somebody else please provide feedback and let me know if this
is happening to them too? This might be a problem with my internet browser because
I’ve had this happen previously. Cheers
Hello there, just became aware of your blog through Google, and found that it is really informative.
I am gonna watch out for brussels. I’ll appreciate
if you continue this in future. A lot of people will be benefited
from your writing. Cheers!
magnificent submit, very informative. I’m wondering why the other
specialists of this sector do not understand this.
You must continue your writing. I’m confident, you’ve a great readers’ base already!
Hi there, after reading this remarkable article
i am as well cheerful to share my experience here with friends.
Hey I know this is off topic but I was wondering if you knew of
any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for a plug-in like
this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
My brother recommended I might like this website.
He was totally right. This post truly made my day. You cann’t imagine just how much time
I had spent for this info! Thanks!
What’s up, I check your new stuff like every week.
Your humoristic style is witty, keep it up!
Your style is really unique in comparison to other people I
have read stuff from. I appreciate you for posting when you
have the opportunity, Guess I’ll just book mark this blog.
I like the valuable info you supply for your articles. I will bookmark
your weblog and take a look at once more here frequently. I’m slightly certain I’ll be
told a lot of new stuff proper here! Good luck for the next!
Hi, I do think this is an excellent site. I stumbledupon it 😉 I’m going to come back
once again since I book marked it. Money and freedom is the
best way to change, may you be rich and continue to guide others.
Fantastic beat ! I wish to apprentice even as you amend your site,
how can i subscribe for a blog web site?
The account helped me a applicable deal. I were a little bit familiar of this your broadcast
provided shiny clear idea
Hey there! This is my first comment here so I just wanted to give
a quick shout out and say I truly enjoy reading your posts.
Can you recommend any other blogs/websites/forums
that cover the same topics? Appreciate it!
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on a number
of websites for about a year and am concerned about switching to another platform.
I have heard good things about blogengine.net. Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be greatly appreciated!
My brother suggested I might like this blog. He was totally right.
This post truly made my day. You cann’t imagine just how much time
I had spent for this info! Thanks!
Hiya! Quick question that’s entirely off topic. Do you know
how to make your site mobile friendly? My web site looks weird when browsing from my
apple iphone. I’m trying to find a template or plugin that might be able to fix
this problem. If you have any recommendations,
please share. With thanks!
We stumbled over here from a different web page and thought I may as
well check things out. I like what I see so now i’m following you.
Look forward to looking over your web page yet again.
hello!,I like your writing so much! share we keep in touch more about your post on AOL?
I need an expert on this space to solve my problem.
May be that is you! Looking forward to see you.
Hi there colleagues, its wonderful paragraph concerning cultureand fully defined, keep it up all the
time.
Nice post. I learn something totally new and challenging on sites I stumbleupon every
day. It will always be useful to read through content
from other writers and practice something from their web sites.
I’m amazed, I must say. Rarely do I encounter a blog that’s equally educative and engaging, and let me tell you,
you’ve hit the nail on the head. The problem is something not enough folks are speaking intelligently about.
I’m very happy I stumbled across this during my hunt for
something relating to this.
Hey just wanted to give you a quick heads up.
The text in your post seem to be running off the
screen in Opera. I’m not sure if this is a formatting issue or
something to do with internet browser compatibility but I figured I’d
post to let you know. The design look great though!
Hope you get the issue solved soon. Cheers
When someone writes an article he/she retains the idea of a user in his/her brain that
how a user can be aware of it. So that’s why this piece of writing is
outstdanding. Thanks!
I was suggested this website by my cousin. I am now not sure whether
or not this put up is written by means of him as no one else recognize such detailed approximately my difficulty.
You are incredible! Thank you!
ebalovka.xyz
I could not refrain from commenting. Very well written!
I think the admin of this web site is really
working hard in support of his web site, for the reason that here every information is quality based information.
Thank you, I’ve just been looking for info approximately this
topic for a long time and yours is the best I’ve came upon till now.
But, what about the conclusion? Are you positive about the supply?
I feel that is one of the most significant info for
me. And i am happy studying your article. However should
remark on some general issues, The website style is wonderful,
the articles is actually excellent : D. Good activity, cheers
my web-site 먹튀사이트
whoah this weblog is fantastic i really like studying your articles.
Keep up the good work! You realize, lots of people are hunting round for this information, you
could aid them greatly.
I am really enjoying the theme/design of your blog.
Do you ever run into any web browser compatibility problems?
A handful of my blog visitors have complained about my site not working correctly in Explorer but looks great in Safari.
Do you have any tips to help fix this issue?
Thanks for sharing your thoughts. I really appreciate your efforts
and I am waiting for your next post thank you once again.
My blog: 먹튀검증
Thanks on your marvelous posting! I truly enjoyed reading it, you’re a great author.
I will make certain to bookmark your blog and will often come back down the road.
I want to encourage you to definitely continue your great posts, have a nice holiday weekend!
Unquestionably consider that which you stated. Your favourite justification seemed to be at the web the simplest thing
to have in mind of. I say to you, I definitely get annoyed at the same time as other people consider concerns that they plainly don’t recognize about.
You managed to hit the nail upon the highest and defined out the
entire thing without having side-effects , other people can take a signal.
Will probably be back to get more. Thanks
Excellent post. I was checking constantly this weblog and I am inspired!
Very helpful information particularly the remaining phase :
) I take care of such information a lot. I was seeking this particular information for a very long time.
Thank you and best of luck.
It’s really a great and useful piece of information. I’m satisfied that you simply shared this useful information with us.
Please stay us informed like this. Thank you for sharing.
A fascinating discussion is worth comment. I think that you ought to write more on this issue, it might
not be a taboo subject but generally people don’t speak about such topics.
To the next! Many thanks!!
I always emailed this webpage post page to all my friends, because if like to read it next my contacts
will too.
Wow that was strange. I just wrote an extremely long comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyways,
just wanted to say wonderful blog!
Yes! Finally something about fueltokyo.com.
I like the helpful info you supply to your articles.
I will bookmark your weblog and take a look at once more here frequently.
I’m slightly sure I’ll be informed a lot of new stuff right right here!
Best of luck for the next!
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get
listed in Yahoo News? I’ve been trying for a while but I
never seem to get there! Cheers
My spouse and I absolutely love your blog and find the majority of your post’s to be precisely what I’m looking for.
Would you offer guest writers to write content for you personally?
I wouldn’t mind producing a post or elaborating on most of the subjects you write with regards to here.
Again, awesome weblog!
I get pleasure from, cause I found just what I was looking for.
You have ended my four day long hunt! God Bless you man. Have
a great day. Bye
This website was… how do you say it? Relevant!!
Finally I’ve found something which helped me. Cheers!
I used to be suggested this blog by my cousin. I’m now not sure whether this submit is written by way of him as no one else know such distinctive about my difficulty.
You’re wonderful! Thank you!
Yes! Finally something about electronic components distributor.
Heya i am for the first time here. I came across this board and I find
It truly useful & it helped me out much. I hope to give something back and help others like you helped me.
Hello would you mind letting me know which hosting company
you’re working with? I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot quicker then most.
Can you recommend a good internet hosting provider at a honest price?
Thank you, I appreciate it!
I visited several websites however the audio feature for
audio songs present at this website is really superb.
I really like reading a post that can make men and women think.
Also, many thanks for allowing for me to comment!
I am sure this article has touched all the internet visitors, its really really nice article on building up
new website.
compra farmaci a Genova online sandoz San Juan Obtenez des réductions sur
l’achat de médicaments en ligne
Thanks for the good writeup. It actually used to be a entertainment account it.
Glance advanced to far added agreeable from you!
However, how could we keep in touch?
I was recommended this blog by my cousin. I am not
sure whether this post is written by him as nobody
else know such detailed about my problem. You are amazing!
Thanks!
Hello my friend! I want to say that this post is awesome, great written and come with approximately all vital infos.
I’d like to see more posts like this .
Hi to all, the contents present at this web page are actually amazing for people experience, well, keep up the nice
work fellows.
my web page: 비아그라 구매
Wow, this article is pleasant, my sister is analyzing such things, therefore I am
going to tell her.
If you would like to get a good deal from this piece of writing
then you have to apply these techniques to your won webpage.
First off I would like to say wonderful blog! I had a
quick question which I’d like to ask if you don’t mind.
I was interested to know how you center yourself and clear your thoughts prior to writing.
I have had difficulty clearing my mind in getting
my ideas out there. I truly do enjoy writing but it just seems like the first 10 to 15 minutes are usually
wasted simply just trying to figure out how to begin. Any ideas or tips?
Appreciate it!
I have read so many articles on the topic of the blogger
lovers but this piece of writing is actually a good post, keep it up.
Hi would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 completely different internet browsers and I must say
this blog loads a lot faster then most. Can you suggest a good
hosting provider at a fair price? Many thanks, I appreciate it!
I absolutely love your blog and find the majority of your post’s to be exactly what I’m looking for.
Do you offer guest writers to write content in your case?
I wouldn’t mind composing a post or elaborating on many of the subjects you write about here.
Again, awesome web log!
Does your website have a contact page? I’m having problems locating it but,
I’d like to send you an e-mail. I’ve got some suggestions for
your blog you might be interested in hearing. Either way, great site and
I look forward to seeing it develop over time.
Thanks for sharing your info. I truly appreciate your efforts and I am
waiting for your next post thanks once again.
If you want to increase your knowledge just keep visiting
this site and be updated with the newest news posted here.
Hi every one, here every one is sharing
such experience, thus it’s pleasant to read this blog, and I used to pay a visit this blog daily.
What’s up i am kavin, its my first time to commenting anywhere, when i read this paragraph i thought i could also
make comment due to this good post.
all the time i used to read smaller articles or reviews which as well clear their motive, and that
is also happening with this paragraph which I am reading here.
I don’t even understand how I finished up right here, but I thought this put up was once great.
I don’t know who you’re however certainly
you are going to a famous blogger in case you are not already.
Cheers!
Can I just say what a relief to uncover a person that truly understands what they
are talking about on the web. You certainly know how to bring
a problem to light and make it important. More and more people should read this and understand this side of your
story. It’s surprising you aren’t more popular because you surely possess the gift.
Excellent post however , I was wanting to know if you could write a
litte more on this subject? I’d be very grateful if
you could elaborate a little bit more. Thank you!
Hi there colleagues, how is everything, and what you want to say regarding
this post, in my view its truly amazing in favor of
me.
Thanks for ones marvelous posting! I really enjoyed reading it, you could be
a great author. I will always bookmark your blog and will eventually come back down the road.
I want to encourage you to definitely continue your great posts, have a nice morning!
Remarkable! Its genuinely remarkable paragraph, I have got much clear
idea on the topic of from this article.
My partner and I absolutely love your blog and find nearly all of your
post’s to be exactly what I’m looking for.
Would you offer guest writers to write content for you?
I wouldn’t mind producing a post or elaborating on a number
of the subjects you write regarding here. Again, awesome web site!
This design is wicked! You obviously know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my
own blog (well, almost…HaHa!) Excellent job.
I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
Thanks for sharing your info. I really appreciate your efforts and
I am waiting for your further write ups thank you once again.
Howdy! I simply wish to give you a huge thumbs up for the great information you’ve got here on this post.
I will be returning to your blog for more soon.
I couldn’t refrain from commenting. Well written!
I think what you said was very logical. However, what about this?
suppose you added a little content? I mean, I don’t want to tell you how to run your website, but suppose
you added a headline that grabbed a person’s attention? I mean Пиастры – Составление семантического ядра | is a little vanilla.
You ought to peek at Yahoo’s front page and
note how they write news titles to grab people to click.
You might try adding a video or a picture or two
to get readers interested about everything’ve
written. In my opinion, it might bring your posts a little bit more interesting.
Excellent article! We are linking to this great article on our website.
Keep up the great writing.
Hi would you mind letting me know which hosting company you’re utilizing?
I’ve loaded your blog in 3 completely different internet browsers and I must say this
blog loads a lot quicker then most. Can you recommend
a good internet hosting provider at a reasonable price?
Many thanks, I appreciate it!
Hey! This is my first comment here so I just wanted to give a quick shout out
and say I really enjoy reading your posts. Can you recommend any other blogs/websites/forums that go over the
same subjects? Many thanks!
Hey there, You have done a great job. I will certainly digg it and personally suggest
to my friends. I am sure they’ll be benefited from
this site.
Nice post. I learn something new and challenging on sites I stumbleupon on a daily basis.
It will always be useful to read content from other writers and practice a little something from their websites.
Fine way of explaining, and nice paragraph to take facts about my presentation focus, which i am going to present in academy.
Hi, of course this article is really good and I have learned lot of things from it concerning blogging.
thanks.
Fantastic beat ! I would like to apprentice at the same time
as you amend your web site, how could i subscribe for a blog website?
The account aided me a appropriate deal. I were a little
bit acquainted of this your broadcast offered shiny clear concept
It’s actually a great and helpful piece of information. I am
happy that you simply shared this helpful info
with us. Please stay us up to date like this.
Thanks for sharing.
Great blog! Do you have any suggestions for aspiring writers?
I’m planning to start my own blog soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress
or go for a paid option? There are so many choices out there
that I’m totally overwhelmed .. Any recommendations? Thank you!
Hi there, every time i used to check website posts here in the early hours in the morning, for the reason that i love to find out more and more.
Saved as a favorite, I really like your web site!
Write more, thats all I have to say. Literally, it seems as though you relied
on the video to make your point. You obviously know what youre talking about, why waste your intelligence on just posting videos to your site
when you could be giving us something enlightening to
read?
Hi! Someone in my Facebook group shared this website with
us so I came to give it a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Outstanding blog and brilliant style and design.
Howdy! This blog post couldn’t be written any better! Looking through this post
reminds me of my previous roommate! He always kept talking about this.
I will forward this post to him. Fairly certain he will have
a very good read. Thank you for sharing!
My spouse and I stumbled over here coming from a different web address and thought I may
as well check things out. I like what I see so now i am following you.
Look forward to looking over your web page again.
Hello to every body, it’s my first pay a visit of this
web site; this website contains amazing and in fact excellent data in support of visitors.
If some one wants expert view concerning blogging after
that i advise him/her to visit this web site, Keep up the good work.
That is a very good tip particularly to those fresh to the blogosphere.
Simple but very precise information… Many thanks for sharing this one.
A must read article!
Hi, I do believe this is an excellent web site.
I stumbledupon it 😉 I may come back yet again since i have bookmarked it.
Money and freedom is the greatest way to change,
may you be rich and continue to guide other people.
Hi! I could have sworn I’ve been to this blog before but after reading through some of the post I realized it’s new
to me. Nonetheless, I’m definitely delighted I found it and I’ll be bookmarking and checking back
frequently!
Ahaa, its pleasant discussion on the topic of this piece
of writing here at this web site, I have read all that, so now
me also commenting here.
Why people still make use of to read news papers when in this technological world the whole
thing is available on net?
Unquestionably believe that which you stated. Your favorite justification appeared to
be on the web the easiest thing to be aware of. I say to you, I certainly get
annoyed while people think about worries that
they just do not know about. You managed to hit the nail upon the top and defined out the whole
thing without having side-effects , people can take a
signal. Will probably be back to get more.
Thanks
Erfahrungen mit Medikamente ohne Rezept in Deutschland Medac Saint-Pierre medicamentos à prix compétitif en Espagne
Hi there everyone, it’s my first pay a quick visit at this
website, and piece of writing is actually fruitful in favor of me,
keep up posting these types of posts.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four e-mails with
the same comment. Is there any way you can remove
people from that service? Thanks a lot!
It’s awesome to pay a quick visit this web site and reading the views of all friends concerning this piece of writing, while I am
also keen of getting experience.
When I originally commented I clicked the “Notify me when new comments are added”
checkbox and now each time a comment is added I get four emails with the same comment.
Is there any way you can remove me from that service?
Thank you!
Hey terrific website! Does running a blog like
this require a large amount of work? I have very little expertise in programming but I had been hoping to start my own blog in the near future.
Anyways, if you have any ideas or tips for new blog owners please share.
I know this is off topic nevertheless I simply had
to ask. Cheers!
Hi there, i read your blog occasionally and i own a similar one and
i was just curious if you get a lot of spam comments?
If so how do you prevent it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any support is very much appreciated.
Hey this is somewhat of off topic but I was wondering if
blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to get guidance from someone with experience.
Any help would be enormously appreciated!
médicaments sur ordonnance à Bruxelles Mylan Krefeld online aankoop van medicijnen zonder recept
Useful information. Fortunate me I found
your site unintentionally, and I am stunned why
this twist of fate didn’t came about in advance!
I bookmarked it.
I’m not sure where you’re getting your info, but great
topic. I needs to spend some time learning much more
or understanding more. Thanks for excellent info I was looking for this information for my mission.
We stumbled over here coming from a different website and
thought I might as well check things out. I like what I see so now i am following you.
Look forward to exploring your web page for a second time.
I’d like to find out more? I’d love to find out some additional information.
This information is worth everyone’s attention. How can I find out more?
Nice post. I was checking constantly this weblog and I’m impressed! I handle such info a lot.
I handle such info a lot.
Very useful info specifically the closing section
I was looking for this certain info for a long
time. Thank you and good luck.
Heya i’m for the first time here. I came across this board and I find It truly useful & it helped
me out much. I hope to give something back and help others like you helped me.
each time i used to read smaller articles or reviews which as well clear their motive, and that is also happening with this paragraph which I
am reading here.
Hey there! I’m at work surfing around your blog from my new iphone!
Just wanted to say I love reading through your
blog and look forward to all your posts! Carry on the excellent work!
Why viewers still use to read news papers when in this technological globe everything is accessible on net?
I’ve been browsing on-line more than three hours lately,
but I never found any interesting article like yours.
It’s beautiful price sufficient for me. In my view, if all site owners and bloggers made good content
material as you probably did, the web will likely be a lot more useful than ever before.
This post is invaluable. When can I find out more?
Hey would you mind stating which blog platform
you’re working with? I’m looking to start my own blog soon but I’m
having a difficult time selecting between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something
completely unique. P.S Apologies for being off-topic but I had to ask!
What’s Going down i am new to this, I stumbled upon this I’ve found It
absolutely helpful and it has helped me out loads.
I am hoping to give a contribution & aid different customers
like its helped me. Good job.
My family members all the time say that I am wasting my time
here at net, except I know I am getting knowledge daily by reading thes good posts.
When I originally commented I seem to have clicked on the -Notify me
when new comments are added- checkbox and now each time a comment is added I
receive four emails with the exact same comment.
There has to be an easy method you are able to
remove me from that service? Thanks a lot!
Fantastic beat ! I would like to apprentice while you amend your web site, how can i
subscribe for a weblog web site? The account aided me a applicable deal.
I were a little bit familiar of this your broadcast offered brilliant
transparent idea
I do not even know the way I finished up right here, but I assumed
this post was once good. I don’t understand who you might be however definitely
you’re going to a famous blogger in the event you aren’t already.
Cheers!
Excellent article. I definitely love this website. Keep it up!
Hey there! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in trading links or maybe guest writing a blog post or vice-versa?
My blog goes over a lot of the same topics as yours
and I think we could greatly benefit from each other.
If you’re interested feel free to shoot me an e-mail.
I look forward to hearing from you! Awesome
blog by the way!
Do you have any video of that? I’d care to find
out more details.
If some one needs expert view regarding blogging
after that i propose him/her to go to see this webpage, Keep up the good job.
This is the right site for anyone who wishes to understand
this topic. You understand a whole lot its
almost hard to argue with you (not that I really will need to…HaHa).
You definitely put a new spin on a topic that has been discussed for a long time.
Wonderful stuff, just wonderful!
Hi there, after reading this amazing piece of writing i am as well happy to share my knowledge here with friends.
Pharmacies en ligne réputées proposant médicaments en France Pharmapar
Segovia médicaments disponible en vente en ligne
Terrific work! That is the type of information that should be shared across the web.
Shame on Google for now not positioning this
submit higher! Come on over and discuss with my site .
Thanks =)
Good day! I simply want to offer you a huge thumbs up for
your excellent information you have right here on this post.
I’ll be returning to your website for more
soon.
Thanks for sharing your thoughts about tonic greens reviews.
Regards
I have read several just right stuff here. Certainly price bookmarking
for revisiting. I wonder how so much attempt you set to make this
kind of wonderful informative web site.
It’s very straightforward to find out any matter on net as compared to books, as I
found this piece of writing at this web site.
Quality articles is the crucial to attract the visitors to pay
a quick visit the website, that’s what this site is providing.
Your style is unique in comparison to other folks I
have read stuff from. Many thanks for posting when you have the opportunity, Guess I’ll just book mark this site.
If you desire to increase your familiarity just keep visiting this web
page and be updated with the latest news posted here.
Hola! I’ve been following your weblog for some time now and finally got the courage to go ahead and give you a shout out from Houston Tx!
Just wanted to tell you keep up the great job!
my blog; ادرس جدید بت فوروارد بدون فیلتر شکن
Hey there! I know this is kinda off topic but I was wondering which blog platform are you using for this
site? I’m getting tired of WordPress because I’ve had problems
with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of
a good platform.
Greetings from Ohio! I’m bored to death at work so I
decided to browse your blog on my iphone during lunch break.
I enjoy the knowledge you provide here and can’t wait to take a look when I get home.
I’m amazed at how quick your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, excellent blog!
What a information of un-ambiguity and preserveness of precious know-how regarding unpredicted
emotions.
It’s hard to come by well-informed people in this particular
topic, but you seem like you know what you’re talking about!
Thanks
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get got an edginess over that you wish be
delivering the following. unwell unquestionably come more formerly again since exactly the same nearly very often inside case you shield this hike.
Currently it appears like Movable Type is the preferred blogging platform available right now.
(from what I’ve read) Is that what you’re using
on your blog?
Wow that was odd. I just wrote an extremely long comment but after I
clicked submit my comment didn’t appear. Grrrr… well I’m not writing all that over again. Anyhow, just wanted
to say excellent blog!
Magnificent items from you, man. I’ve understand your stuff previous to and you are simply extremely magnificent.
I really like what you’ve received right here, certainly like what you’re stating and the best way
through which you say it. You are making it enjoyable
and you still care for to stay it smart. I cant wait to learn far more from you.
This is really a wonderful website.
It’s actually a cool and helpful piece of info. I am glad that you just shared this useful information with
us. Please stay us up to date like this. Thanks for sharing.
Link exchange is nothing else except it is simply placing the
other person’s weblog link on your page at suitable place and other person will also do similar in favor of you.
It’s a pity you don’t have a donate button! I’d definitely
donate to this outstanding blog! I guess for now i’ll settle for
bookmarking and adding your RSS feed to my Google account.
I look forward to new updates and will talk about this site with my Facebook group.
Chat soon!
Wonderful work! That is the type of information that should
be shared around the internet. Disgrace on the search engines for not positioning this put up upper!
Come on over and seek advice from my site . Thank you =)
Oh my goodness! Impressive article dude! Thank you so much, However I am going through difficulties with your RSS.
I don’t understand why I cannot subscribe to it.
Is there anybody else having identical RSS issues? Anybody who knows the solution will you kindly
respond? Thanks!!
It’s the best time to make a few plans for the longer
term and it is time to be happy. I have read this put up and if I could I desire
to suggest you few interesting things or suggestions. Maybe
you can write next articles referring to this article.
I want to read even more things about it!
I’m really enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more
pleasant for me to come here and visit more often. Did you hire out
a developer to create your theme? Outstanding work!
With havin so much written content do you ever run into any
issues of plagorism or copyright infringement? My site has a lot of exclusive content I’ve either written myself or outsourced but it seems a lot of
it is popping it up all over the web without my permission. Do you know any techniques to help
prevent content from being stolen? I’d certainly appreciate it.
If you would like to take a good deal from this paragraph then you have to apply such strategies to your won weblog.
Excellent site you have here but I was wondering if you knew
of any community forums that cover the same topics discussed in this article?
I’d really love to be a part of online community where I can get comments from
other experienced individuals that share the same interest.
If you have any suggestions, please let me know.
Many thanks!
medicijnen kopen in Nederland zonder problemen Silarx Julianadorp Ontdek hoe gemakkelijk het is om medicijnen online te bestellen
Aw, this was a very good post. Taking a few minutes and actual effort to make a top
notch article… but what can I say… I hesitate a lot and never seem to get
anything done.
Aw, this was an incredibly good post. Taking a few minutes and actual effort to
make a good article… but what can I say… I put things off a lot
and don’t manage to get anything done.
This is very interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your excellent post.
Also, I’ve shared your site in my social networks!
Awesome issues here. I am very satisfied to peer your
post. Thank you so much and I am looking ahead to touch you.
Will you kindly drop me a mail?
It’s amazing designed for me to have a web site, which is beneficial for my experience.
thanks admin
I visited multiple web sites but the audio quality for
audio songs existing at this website is really superb.
Valuable info. Fortunate me I discovered your site by chance, and
I am shocked why this twist of fate did not took place earlier!
I bookmarked it.
Good way of telling, and pleasant paragraph to get data about my presentation subject, which
i am going to deliver in institution of higher education.
This post is invaluable. Where can I find out more?
I every time used to read paragraph in news papers but now as I am a user of internet so
from now I am using net for articles, thanks to web.
My brother suggested I would possibly like this website.
He used to be entirely right. This post truly made my day.
You can not consider simply how much time I had spent for this info!
Thanks!
I every time spent my half an hour to read this webpage’s articles all the
time along with a mug of coffee.
constantly i used to read smaller articles or reviews that
also clear their motive, and that is also happening with this article which I am reading
at this time.
Howdy just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking
issue. I’ve tried it in two different web browsers
and both show the same results.
An outstanding share! I’ve just forwarded this onto a coworker who had been conducting a little homework on this.
And he actually ordered me breakfast because I stumbled upon it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanx for spending the time to discuss this subject here on your web site.
Does your blog have a contact page? I’m having a tough
time locating it but, I’d like to shoot you an e-mail.
I’ve got some suggestions for your blog you
might be interested in hearing. Either way, great blog
and I look forward to seeing it develop over time.
medicijnen zonder voorschrift online te bestellen galena Charleroi
medicijnen vrij verkrijgbaar in Luik, België
I absolutely love your blog and find almost all of your post’s to be exactly I’m looking
for. Does one offer guest writers to write content for you?
I wouldn’t mind composing a post or elaborating on a few of the subjects you write in relation to here.
Again, awesome weblog!
It’s enormous that you are getting thoughts from this
article as well as from our argument made at this time.
If some one wishes expert view about blogging afterward i advise him/her to visit this website,
Keep up the nice job.
Wow! This blog looks just like my old one! It’s on a completely different topic but it has pretty much the same page layout and
design. Outstanding choice of colors!
wonderful points altogether, you simply received a brand new
reader. What could you suggest about your publish that you
made some days ago? Any positive?
Hi there every one, here every one is sharing these familiarity, thus
it’s good to read this webpage, and I used to go to see this
web site daily.
Good day very nice blog!! Man .. Beautiful ..
Amazing .. I will bookmark your web site and take the feeds also?
I am satisfied to seek out so many useful information right here within the put up, we’d
like work out extra techniques on this regard,
thanks for sharing. . . . . .
kopen medicijnen in België zonder problemen Dominion Lyon médicaments en vente libre au Luxembourg
Thanks very nice blog!
Hi there! Someone in my Facebook group shared this site with us so I came to check it out.
I’m definitely enjoying the information.
I’m bookmarking and will be tweeting this
to my followers! Wonderful blog and superb design.
Have you ever thought about writing an e-book or guest authoring on other sites?
I have a blog based on the same subjects you discuss and would love to have you share some stories/information.
I know my audience would enjoy your work. If you’re even remotely
interested, feel free to send me an e mail.
In fact no matter if someone doesn’t know after that its up to other people that they will assist, so
here it occurs.
Your website is truly impressive—its design is not only visually stunning but also incredibly user-friendly. The content is well-organized, making it easy to navigate, and the overall experience is both engaging and informative. Well done!
If you are going for most excellent contents like myself, simply go to see
this site all the time for the reason that it offers feature contents, thanks
Greetings! I’ve been following your weblog for a long time
now and finally got the courage to go ahead and give you a
shout out from Atascocita Texas! Just wanted to mention keep up the fantastic job!
I like what you guys are usually up too. This kind of clever work and
reporting! Keep up the amazing works guys I’ve added you guys to my
personal blogroll.
I blog quite often and I really appreciate your information. Your article has truly peaked my interest.
I will bookmark your website and keep checking for new details about
once per week. I opted in for your Feed as well.
I’ve been exploring for a bit for any high-quality articles or weblog posts
on this sort of area . Exploring in Yahoo I ultimately stumbled upon this
website. Reading this info So i’m satisfied to show that I’ve a very good uncanny feeling I came upon just what I needed.
I such a lot without a doubt will make sure to do not forget this web site and provides it a glance regularly.
Very good blog! Do you have any recommendations for aspiring
writers? I’m planning to start my own site soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for a paid
option? There are so many choices out there that I’m totally confused ..
Any recommendations? Cheers!
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you!
By the way, how can we communicate?
Appreciating the persistence you put into your site and in depth information you present.
It’s good to come across a blog every once in a while
that isn’t the same old rehashed information. Excellent read!
I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
prijs van medicijnen in Frankrijk Cevallos Zoutleeuw farmacia online per acquistare
farmaci in Francia
Hmm it seems like your website ate my first comment (it was super
long) so I guess I’ll just sum it up what I had written and
say, I’m thoroughly enjoying your blog. I too am
an aspiring blog blogger but I’m still new to the whole thing.
Do you have any points for newbie blog writers?
I’d certainly appreciate it.
Terrific post but I was wondering if you could write a litte more
on this topic? I’d be very thankful if you could elaborate
a little bit further. Many thanks!
I read this paragraph completely about the comparison of newest and earlier technologies, it’s
amazing article.
Ahaa, its nice dialogue concerning this paragraph here at
this blog, I have read all that, so at this time me also commenting at this place.
Hey there I am so excited I found your weblog, I really
found you by mistake, while I was searching on Digg for something else, Anyways I am here now and would just like to say thank you for a incredible post
and a all round exciting blog (I also love the theme/design), I don’t have time to read it all at the moment but I have
book-marked it and also added in your RSS feeds, so when I have time I will be back to
read more, Please do keep up the great work.
What’s up everybody, here every person is sharing these
know-how, so it’s fastidious to read this webpage, and I
used to go to see this webpage daily.
Great delivery. Outstanding arguments. Keep up the good effort.
I’m gone to say to my little brother, that he should also pay a quick visit this weblog on regular basis
to obtain updated from hottest information.
Thanks for sharing your info. I truly appreciate your efforts
and I am waiting for your further post thanks
once again.
Wow, fantastic weblog format! How long have you been blogging for?
you make blogging glance easy. The total glance of your site is excellent, let alone the
content!
Have you ever thought about including a little bit more than just your articles?
I mean, what you say is important and everything. But think of if you added some great images
or videos to give your posts more, “pop”! Your content is
excellent but with images and video clips, this blog could undeniably be
one of the very best in its niche. Fantastic blog!
Hello I am so delighted I found your web site, I really found you by accident,
while I was researching on Digg for something else,
Anyhow I am here now and would just like to say kudos for a remarkable post
and a all round exciting blog (I also love the theme/design),
I don’t have time to browse it all at the minute but I have bookmarked it and also added your RSS feeds, so when I have time I will be
back to read a lot more, Please do keep up the awesome job.
Useful info. Fortunate me I discovered your website by accident, and I am shocked why this coincidence didn’t came
about in advance! I bookmarked it.
It is not my first time to pay a visit this web page, i am visiting this
site dailly and obtain good facts from here every day.
Nice weblog right here! Also your web site rather a lot up fast!
What web host are you using? Can I am getting your associate link
for your host? I wish my web site loaded up as fast as yours lol
Awesome post.
You actually make it seem so easy with your presentation but I find this topic to
be really something which I think I would never understand.
It seems too complex and very broad for me. I’m looking forward for your next post, I’ll try to get the hang of it!
It’s great that you are getting thoughts from this paragraph as well as from our argument made at this place.
Howdy! Someone in my Facebook group shared this website
with us so I came to take a look. I’m definitely loving the information.
I’m book-marking and will be tweeting this to my followers!
Terrific blog and fantastic style and design.
Good site you have got here.. It’s hard to find excellent writing like yours these days.
I truly appreciate people like you! Take care!!
I savor, lead to I found just what I used to be having
a look for. You have ended my 4 day long hunt! God Bless you man. Have a nice day.
Bye
Very nice post. I simply stumbled upon your blog and wished to mention that I have really enjoyed surfing around your weblog posts.
In any case I will be subscribing on your rss feed and I am hoping you write again very
soon!
I have been surfing online more than 2 hours today, yet I never
found any interesting article like yours. It is pretty worth enough
for me. In my opinion, if all webmasters and bloggers
made good content as you did, the web will be a
lot more useful than ever before.
Hi there I am so grateful I found your blog page, I really
found you by mistake, while I was browsing on Yahoo for something else, Anyways I am here now and would just like to say thanks for a
incredible post and a all round entertaining blog (I also love the theme/design), I
don’t have time to look over it all at the minute but I have book-marked it and also added in your
RSS feeds, so when I have time I will be back to read a lot more,
Please do keep up the excellent work.
Hi there, just became aware of your blog through Google, and found that
it is really informative. I am going to watch out for brussels.
I will be grateful if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
Thanks , I have recently been searching for information approximately this
topic for a while and yours is the greatest I’ve discovered
till now. However, what in regards to the conclusion? Are you certain about the supply?
hi!,I love your writing very so much! share we keep up
a correspondence more approximately your article on AOL?
I require a specialist in this space to solve my problem.
Maybe that’s you! Looking forward to peer you.
Unquestionably believe that which you said.
Your favorite justification appeared to be at the internet
the simplest thing to be mindful of. I say to you, I definitely get irked even as
other people think about issues that they just don’t recognise about.
You controlled to hit the nail upon the top and also outlined out the whole thing without having side
effect , other people could take a signal. Will probably be again to get more.
Thanks
medicamentos en venta en España pfizer Boscotrecase medicamentos à commander sans ordonnance en Belgique
WOW just what I was searching for. Came here by searching for 에볼루션카지노
It is the best time to make a few plans for the long run and it is time to be happy.
I have read this publish and if I could I wish to suggest you few attention-grabbing things or advice.
Perhaps you can write subsequent articles referring to
this article. I wish to read more things approximately it!
I’ve been exploring for a bit for any high-quality articles or weblog posts in this kind of area .
Exploring in Yahoo I eventually stumbled upon this website.
Reading this information So i’m glad to convey that I have an incredibly
excellent uncanny feeling I found out just what I needed.
I so much definitely will make certain to do not put out of your mind this web site and provides it a glance regularly.
If some one wishes expert view on the topic of running a blog then i recommend him/her to
pay a visit this web site, Keep up the nice work.
Hi there, of course this paragraph is genuinely good and I
have learned lot of things from it on the topic of blogging.
thanks.
I am really impressed with your writing skills and also with the layout on your blog.
Is this a paid theme or did you modify it yourself?
Either way keep up the nice quality writing, it is
rare to see a great blog like this one nowadays.
When someone writes an article he/she maintains the plan of a user in his/her mind that how a user can understand
it. Thus that’s why this paragraph is amazing.
Thanks!
I think the admin of this web page is genuinely working hard for
his web page, as here every data is quality based information.
ebporno.xyz
What a information of un-ambiguity and preserveness of precious
knowledge concerning unpredicted feelings.
Hello! Someone in my Facebook group shared this website with us so I came to take a look.
I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Terrific blog and wonderful style and design.
бонус в 1хставка как отыграть
What you posted was very reasonable. However, what about this?
what if you were to write a killer headline? I mean, I don’t want
to tell you how to run your blog, but what
if you added a title to maybe get people’s attention? I mean Пиастры – Составление семантического ядра | is kinda vanilla.
You should glance at Yahoo’s home page and watch how they write article titles
to grab people to open the links. You might add a related video or a
picture or two to get readers excited about everything’ve got to say.
In my opinion, it might make your website a little bit more
interesting.
Hi, its nice post concerning media print, we all be familiar with media is a great source of information.
Ahaa, its nice dialogue on the topic of this article here at this web site,
I have read all that, so at this time me also commenting
at this place.
I always spent my half an hour to read this website’s posts all the time
along with a cup of coffee.
бонусы в 1 win
I like the helpful information you provide in your articles.
I’ll bookmark your blog and check again here regularly.
I am quite sure I will learn many new stuff right here!
Good luck for the next!
No matter if some one searches for his necessary thing, thus he/she wants to
be available that in detail, thus that thing
is maintained over here.
Howdy! Do you know if they make any plugins
to assist with SEO? I’m trying to get my blog to rank for some
targeted keywords but I’m not seeing very good results. If you know of any please share.
Kudos!
When I initially commented I clicked the “Notify me when new comments are added” checkbox
and now each time a comment is added I get several e-mails with the same comment.
Is there any way you can remove people from that
service? Appreciate it!
Hello there! This article could not be written much better!
Looking at this post reminds me of my previous roommate! He constantly kept preaching about this.
I will send this post to him. Pretty sure he’ll have
a good read. Thanks for sharing!
My brother recommended I might like this website.
He was totally right. This post actually made my day. You cann’t imagine simply how much time I had spent for this information! Thanks!
I believe everything said was actually very reasonable.
However, think about this, suppose you added a little content?
I mean, I don’t wish to tell you how to run your blog, but what if you added a post title that makes people
desire more? I mean Пиастры – Составление семантического ядра | is kinda plain. You might peek at Yahoo’s
front page and see how they create post titles to grab viewers
to click. You might try adding a video or a picture or
two to grab readers interested about everything’ve written. In my opinion, it would bring your blog a little bit more interesting.
Your way of describing all in this piece of writing is really good, every
one be capable of simply know it, Thanks a lot.
My website – bathroom medicine cabinet
I enjoy what you guys are up too. Such clever work and reporting!
Keep up the wonderful works guys I’ve you guys to blogroll.
Great blog! Do you have any helpful hints for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go for a paid
option? There are so many options out there that I’m totally overwhelmed
.. Any tips? Bless you!
I have fun with, cause I found exactly what I was taking a look
for. You have ended my four day long hunt! God Bless you man. Have a great
day. Bye
I could not refrain from commenting. Very well written!
Way cool! Some very valid points! I appreciate you penning this article and also the rest of the
site is also really good.
Thanks for the marvelous posting! I really enjoyed reading it, you will be a great author.
I will ensure that I bookmark your blog and may come back someday.
I want to encourage yourself to continue your great writing, have
a nice morning!
I am sure this post has touched all the internet viewers, its really really good article on building up new blog.
Visit my web site employment lawyers manchester
Nice post. I learn something totally new and challenging on sites I stumbleupon on a daily basis.
It’s always exciting to read content from other writers and use a little something from their web sites.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back in the future.
Cheers
Wow! This blog looks just like my old one!
It’s on a totally different topic but it has pretty much the same layout and design. Superb
choice of colors!
My family members all the time say that I am wasting my time here at
web, however I know I am getting know-how daily by reading such good content.
Having read this I believed it was very enlightening. I appreciate you
taking the time and effort to put this information together.
I once again find myself spending a lot of time both reading and commenting.
But so what, it was still worthwhile!
Wonderful website. Plenty of useful information here.
I’m sending it to a few pals ans additionally sharing in delicious.
And obviously, thanks for your effort!
This is a good tip especially to those new to the blogosphere.
Simple but very accurate info… Thank you for sharing this one.
A must read article!
Excellent weblog here! Additionally your web site rather a lot up
fast! What host are you the use of? Can I am getting your affiliate link
for your host? I desire my web site loaded up as quickly as yours lol
Porn 2024
I’m really enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more
pleasant for me to come here and visit more
often. Did you hire out a designer to create your theme? Outstanding work!
Remarkable! Its genuinely amazing article, I have got much clear
idea regarding from this paragraph.
It’s in reality a great and helpful piece of information. I’m satisfied that you shared this useful info with us.
Please stay us informed like this. Thank you for sharing.
Hello my loved one! I wish to say that this post is awesome, nice written and include approximately all vital infos.
I would like to peer extra posts like this .
What a data of un-ambiguity and preserveness of
valuable experience regarding unpredicted feelings.
Hi, Neat post. There’s an issue with your website in web explorer, might check this?
IE nonetheless is the marketplace chief and a large part of folks will pass over your excellent writing
due to this problem.
Hi there! Do you use Twitter? I’d like to follow
you if that would be ok. I’m definitely enjoying your blog and look forward to new updates.
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back in the future.
Many thanks
It’s genuinely very complex in this busy life to listen news on TV, thus I just use world wide web for that purpose, and
obtain the most recent information.
Howdy very cool website!! Guy .. Beautiful .. Amazing ..
I’ll bookmark your blog and take the feeds additionally?
I’m satisfied to seek out so many helpful information here in the submit, we’d like work out extra strategies on this regard, thanks for sharing.
. . . . .
Informative article, exactly what I needed.
Nice blog! Is your theme custom made or did you download it from
somewhere? A theme like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got your theme.
Kudos
It’s in fact very difficult in this full of activity life to listen news on TV,
thus I only use the web for that purpose, and get
the newest information.
I was recommended this web site by way of my cousin. I
am no longer sure whether or not this publish is written by way of him as nobody else understand such specific about my problem.
You’re wonderful! Thank you!
Good site you’ve got here.. It’s hard to find quality writing like yours these days.
I really appreciate people like you! Take care!!
I am really loving the theme/design of your weblog. Do
you ever run into any browser compatibility issues?
A number of my blog readers have complained about my
site not working correctly in Explorer but looks great in Chrome.
Do you have any ideas to help fix this problem?
What’s up to all, the contents existing at this site are in fact amazing for people knowledge, well, keep up the good work fellows.
Good day! Do you know if they make any plugins to safeguard
against hackers? I’m kinda paranoid about losing everything
I’ve worked hard on. Any tips?
I was recommended this blog by my cousin. I’m no longer certain whether this
post is written by way of him as nobody else know such particular about my problem.
You’re wonderful! Thanks!
Why people still make use of to read news papers when in this technological globe all is accessible
on net?
Hi! I know this is somewhat off topic but I was wondering if you knew where
I could get a captcha plugin for my comment form? I’m using the same blog platform
as yours and I’m having trouble finding one? Thanks a lot!
Thanks for sharing your thoughts on cowokbet. Regards
В “Прогресс” вы найдете информацию о закупках инженерных
услуг, которые включают в себя все необходимые процессы для эффективного функционирования инженерных систем.
Наши специалисты помогут вам организовать весь процесс от закупки до реализации.
I visited various websites however the audio feature for audio songs existing at this web page is really
excellent.
Hey I know this is off topic but I was wondering if you knew
of any widgets I could add to my blog that automatically tweet my newest
twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something
like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
We stumbled over here by a different website and thought I might as well check things
out. I like what I see so now i’m following you. Look forward to exploring your
web page yet again.
Hey very nice web site!! Man .. Excellent .. Wonderful ..
I’ll bookmark your website and take the feeds also? I am glad to seek out numerous useful information here within the publish, we need
work out extra strategies in this regard, thank you for sharing.
. . . . .
Whats up very nice website!! Guy .. Excellent ..
Amazing .. I’ll bookmark your site and take the feeds also?
I am happy to seek out a lot of useful info here within the put up,
we’d like develop more techniques on this regard, thank you for sharing.
. . . . .
This article is truly a nice one it assists new the web
people, who are wishing in favor of blogging.
I’m impressed, I must say. Rarely do I come across a blog
that’s both educative and amusing, and let me tell you, you have hit
the nail on the head. The problem is an issue that
too few folks are speaking intelligently about. I am very happy I found this during my search for something concerning this.
Attractive component to content. I simply stumbled upon your weblog and in accession capital to say that I acquire in fact enjoyed account your weblog posts.
Any way I will be subscribing on your feeds and even I achievement you get entry to
persistently fast.
I’m really enjoying the design and layout of
your website. It’s a very easy on the eyes which makes it much more
pleasant for me to come here and visit more often.
Did you hire out a developer to create your theme? Outstanding work!
If you want to take a good deal from this paragraph
then you have to apply such methods to your won website.
It’s going to be end of mine day, but before ending
I am reading this impressive paragraph to increase my experience.
I pay a quick visit day-to-day some websites and information sites to read posts, except this webpage offers quality
based writing.
Hi there to every body, it’s my first go to see of this
web site; this website includes amazing and in fact excellent
information in favor of visitors.
молитва при кошмарных снах если приснилось что беременна
к чему это сонник девушке если снится
что собака душит
к чему снится паук на лице человека
видеть во сне яму в огороде
I am blown away by the quality of your website! The interface is beautifully designed, with a perfect balance of aesthetics and functionality. The content is detailed and highly informative, catering perfectly to the needs of your audience. The navigation is smooth, making it easy to find exactly what I’m looking for. Your website truly sets a high standard. Fantastic work!
Have you ever considered about adding a little bit more than just
your articles? I mean, what you say is important and everything.
Nevertheless just imagine if you added some great images or
videos to give your posts more, “pop”! Your content is excellent but with images
and video clips, this blog could definitely be one of the
very best in its niche. Excellent blog!
hi!,I love your writing very so much! share we be in contact more
approximately your post on AOL? I require an expert on this space
to solve my problem. Maybe that is you! Taking a look forward
to look you.
you’re truly a just right webmaster. The website loading
velocity is amazing. It kind of feels that you are doing any distinctive
trick. In addition, The contents are masterpiece.
you have done a excellent process in this subject!
Exceptional post however I was wondering if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little bit further.
Many thanks!
Exceptional post however I was wanting to know
if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit
further. Cheers!
Awesome things here. I am very satisfied to peer your post.
Thank you a lot and I am taking a look forward to contact you.
Will you kindly drop me a e-mail?
This is a topic that is close to my heart… Take care!
Exactly where are your contact details though?
Heya i am for the first time here. I found this board and I find It truly
useful & it helped me out a lot. I hope to give something back and aid others like you helped me.
WOW just what I was looking for. Came here by searching for phising
Great blog here! Also your web site loads up fast! What host
are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as quickly as yours lol
Hey there would you mind letting me know which webhost
you’re using? I’ve loaded your blog in 3 different web browsers
and I must say this blog loads a lot faster then most.
Can you suggest a good hosting provider at a fair price?
Cheers, I appreciate it!
Hello! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing
several weeks of hard work due to no data backup. Do you have any solutions to protect against hackers?
Hurrah, that’s what I was seeking for, what a data!
existing here at this weblog, thanks admin of this web page.
I used to be able to find good info from your blog articles.
I was curious if you ever considered changing the layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people
could connect with it better. Youve got an awful lot of
text for only having one or 2 pictures. Maybe you
could space it out better?
Hello, I enjoy reading through your post.
I like to write a little comment to support you.
Also visit my homepage – سیب بت
Excellent post. I was checking continuously this blog and I’m inspired! I deal with such information much. I used to be seeking this particular info for a very long time.
I deal with such information much. I used to be seeking this particular info for a very long time.
Extremely useful information particularly the ultimate
section
Thanks and good luck.
This website is a remarkable blend of user-friendly design and valuable content, making every visit an absolute pleasure.
Howdy would you mind stating which blog platform you’re working with?
I’m planning to start my own blog in the near future but I’m
having a tough time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems
different then most blogs and I’m looking for something completely unique.
P.S Apologies for being off-topic but I had to ask!
This is a very good tip particularly to those new to the blogosphere.
Short but very precise info… Thanks for sharing this one.
A must read post!
Hello there! This post couldn’t be written any better! Reading through this post reminds me of my
previous room mate! He always kept chatting about this.
I will forward this write-up to him. Pretty sure he will have a
good read. Many thanks for sharing!
Your style is so unique compared to other people I’ve read stuff from.
I appreciate you for posting when you have the opportunity, Guess I will
just bookmark this blog.
It is in reality a nice and helpful piece of information.
I am satisfied that you just shared this helpful info with us.
Please stay us up to date like this. Thank you for sharing.
Have you ever thought about creating an e-book or guest
authoring on other blogs? I have a blog based on the same
subjects you discuss and would love to have you share
some stories/information. I know my audience would appreciate your work.
If you are even remotely interested, feel free to shoot me an email.
Hello, this weekend is good in favor of me, as this point in time i am reading this impressive informative paragraph here at my home.
Definitely imagine that that you stated. Your favourite reason seemed to be on the internet the easiest factor
to be mindful of. I say to you, I definitely get irked whilst people
think about concerns that they plainly do not recognise about.
You managed to hit the nail upon the highest and also defined out the entire thing without having side effect , folks can take a signal.
Will probably be again to get more. Thanks
Undeniably consider that which you said. Your favorite justification seemed to be on the web the simplest
thing to remember of. I say to you, I certainly get irked while
folks think about worries that they just do not
recognise about. You managed to hit the nail upon the top as well as
outlined out the entire thing with no need side-effects , other people
can take a signal. Will probably be again to
get more. Thank you
I am extremely impressed along with your writing skills as well as with the format in your weblog.
Is this a paid subject matter or did you customize it your self?
Anyway keep up the excellent quality writing, it is rare to peer a nice blog like this one nowadays..
When I initially commented I clicked the “Notify me when new comments are added” checkbox
and now each time a comment is added I get three e-mails with the same comment.
Is there any way you can remove people from that service?
Bless you!
Hello! I simply would like to offer you a huge thumbs up for
the excellent info you have got here on this post. I’ll be coming back to your blog
for more soon.
Truly when someone doesn’t know afterward its up to other visitors that they
will help, so here it occurs.
Amazing things here. I’m very glad to peer your post.
Thanks a lot and I am taking a look ahead to contact you.
Will you please drop me a e-mail?
Good day I am so grateful I found your site, I really found you by accident, while I was
browsing on Bing for something else, Regardless I am here now
and would just like to say kudos for a remarkable post
and a all round interesting blog (I also love the theme/design), I don’t have time to
look over it all at the moment but I have bookmarked it and also included your RSS feeds, so when I have time I
will be back to read much more, Please do keep up the superb job.
A person essentially assist to make seriously posts I’d state.
That is the very first time I frequented your web page and so far?
I surprised with the analysis you made to create
this particular put up extraordinary. Fantastic process!
This blog was… how do I say it? Relevant!! Finally
I’ve found something that helped me. Thanks!
obviously like your web site however you have to take a look at
the spelling on quite a few of your posts. Several
of them are rife with spelling issues and I to find it very troublesome to inform
the truth then again I will definitely come back again.
I blog quite often and I seriously thank you for your information. The article has really peaked my interest.
I will book mark your blog and keep checking for new details about once per week.
I opted in for your Feed too.
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get got an nervousness over that you wish be delivering the following.
unwell unquestionably come further formerly again as exactly the same nearly a lot often inside case you shield
this hike.
I love what you guys are usually up too. Such clever work and exposure!
Keep up the good works guys I’ve incorporated you guys to my own blogroll.
Heya are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and set up my own.
Do you require any coding expertise to make your own blog?
Any help would be really appreciated!
Thank you for sharing your info. I really appreciate your efforts and I will be waiting for your
next write ups thanks once again.
Heya! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading through your blog and look forward to all your posts!
Carry on the great work!
On vous a trouvé une pépite, un shôjo en 4 tomes de Hinata Nakamura
qui répondra à votre demande. Céline, Une Ville Fluviale présente une fillette de 14 ans partie
à la capitale pour « expérimenter de nouvelles choses », à la demande de
sa tutrice. ADH Éditions AETH AM Media Network Aaltaïr Actes
Sud Actualitte Akata Akiko Akileos Akinomé Akuma Albin Michel
AleXan éditions Amalthée Amilova Anime Manga Presse Anime Vintage Ankama Editions Apocalypse Aqua Lumina Aqueduc Bleu (l’)
Ark Editions Armand Colin Arola Artefact Asian District Asiatika
Assimil Association Culturelle Leiji Matsumoto Association Saga Asuka Atelier Akatombo Atelier des cahiers Atomic
club Atoss Takemoto Atrabile Auto-Edition Autrement BAC@Bd BD Erogene
BLF Europe BORDAS Balivernes Bamboo Bang Editions Bayard Jeunesse Beemoov Belfond Belin Betty
Black Box Editions Blacklephant Blue lotus production Booken Books Boy’s Love Bruno Doucey Budo Editions Bulle en Stock Buveur d’encre
(le) Ca et La Calmann-Levy Cambourakis Carabas Caraïbéditions Castelmore
Casterman Chantecler Chatto Chatto Chours Cinéxploitation Clair de lune Cleopas Connaissances et
Savoirs Console Syndrome Editions Contre-Dires Cornelius Courrier
du Livre Crunchyroll – Editions Custom Publishing France D-Visual DNA Dargaud Dark
Horse France De Saxus Delcourt Delcourt / Tonkam Denoël Graphic Des bulles dans l’océan Digiclub Dino Entertainement Disney Hachette Presse Diverti Doki Doki Dongbanja Drakosia Dreamland
Dunod Dupuis Dynamic vision Dynamite Dôshin ED Edition EP – Emmanuel Proust Ecchi Manga Ecole des loisirs (l’) Ecran Fantastique Editions Chiron Editions Chronique Editions ESI Editions H Editions H&K Editions Muffins Editions Sully Editions Underground Editions de Saxe Editions de l’Emmanuel Editions de la Pastèque Editions des Eléphants (les) Editions du Camphrier Editions du Chene – EPA Editions du Moment Editions du Rocher Editions du sous sol Editions du temps Ego comme X Eidola Editions Elytis Euromanga
Editions Evalou Exhibitions International Eyrolles FJM Publications FLBLB Factory Edition Fantask Editions Fei
Editions First Flammarion Fleurus Fleuve noir Flibusk Folio France Culture France Loisirs French Mangaka
Fuji Manga Futuropolis Féles GS Editions Gallimard Gauiter-Languereau Geek Junior Geeks Line Gekko
Glénat Graph Zeppelin Grund H&O éditions H2T HD com HOEBEKE Hachette Hachette Tourisme Hana Hariken Harlequin Harmattan Editions Harpelume Hazan Hikari Editions HongFei Cultures
Hors Collection Hot Manga Hozhoni Huber Editions Huginn&Muninn Hugo
Publishing Humanoides associes Humeurs Hélyode Héron d’argent (le) IMA ION
Ici Même Ideogram Iku comics Imagika Imho Impressions Nouvelles (les) Irodori
Isan Manga Issekinicho Isthme Editions Iwa Izneo J’ai lu JNC Nina Joie de Lire
Joker Jungle K!
These are genuinely wonderful ideas in regarding blogging.
You have touched some fastidious points here. Any way keep up
wrinting.
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your site to come back later.
All the best
Having read this I thought it was very enlightening.
I appreciate you taking the time and effort to put this article together.
I once again find myself personally spending a significant amount of time
both reading and leaving comments. But so what, it was still worthwhile!
An impressive share! I have just forwarded this onto a co-worker who was conducting a little research on this.
And he in fact bought me dinner due to the fact that I discovered it for him…
lol. So let me reword this…. Thanks for the meal!! But
yeah, thanks for spending the time to discuss this
issue here on your blog.
Hello there! Quick question that’s completely off topic. Do you know how to make your site mobile friendly?
My blog looks weird when viewing from my apple iphone.
I’m trying to find a theme or plugin that might be able to resolve this issue.
If you have any recommendations, please share. Thank you!
This is a topic that is near to my heart… Take care!
Exactly where are your contact details though?
Your website is truly impressive! The design is sleek and modern, making it a pleasure to navigate. The content is incredibly informative and well-organized, demonstrating a high level of expertise and dedication. The user experience is seamless, with fast loading times and intuitive navigation. It’s clear that a lot of thought and effort went into creating this site. Great job!
Hi there just wanted to give you a quick heads up.
The words in your post seem to be running off the screen in Opera.
I’m not sure if this is a formatting issue or something to do with browser compatibility but I thought I’d post
to let you know. The style and design look great though! Hope you get the issue
solved soon. Many thanks
Wow, wonderful blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is fantastic, let alone the
content!
I was extremely pleased to discover this web site. I wanted to thank you for ones time for this particularly fantastic read!!
I definitely loved every bit of it and i also have you saved to fav to check out new information on your website.
Hey there are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you require any html
coding knowledge to make your own blog? Any help would be greatly appreciated!
Hi there, i read your blog occasionally and i own a similar one and i was just curious
if you get a lot of spam remarks? If so how do you protect against it, any
plugin or anything you can suggest? I get so much lately it’s driving me crazy so any support is very much appreciated.
Hello, Neat post. There’s an issue together with your
site in web explorer, would check this? IE still is the
market leader and a large element of people will pass over your great writing due to this problem.
Thanks a bunch for sharing this with all folks you really know what you are
speaking about! Bookmarked. Please additionally visit
my site =). We could have a link exchange contract among us
You should take part in a contest for one of the most useful
bogs on the net. I am going to highly recommend this site!
Here is my site :: Xiomara
Spot on with this write-up, I seriously believe this amazing
site needs much more attention. I’ll probably be back again to read more, thanks for the information!
Thanks for sharing your info. I really appreciate your efforts and I am waiting
for your further write ups thanks once again.
That is very interesting, You are an excessively professional blogger.
I’ve joined your rss feed and look forward to looking for extra of your magnificent
post. Additionally, I have shared your site in my social networks
Fabulous, what a blog it is! This website presents helpful data to us, keep it up.
Hi there! This blog post could not be written much better!
Looking through this post reminds me of my previous roommate!
He constantly kept preaching about this. I am going to
forward this information to him. Pretty sure he will have a good read.
Many thanks for sharing!
Appreciate the recommendation. Let me try it out.
At this moment I am going away to do my breakfast, when having my
breakfast coming again to read more news.
I’m gone to tell my little brother, that he should also pay a visit this webpage on regular basis to get
updated from most up-to-date news update.
Also visit my web page: navigate to this web-site
What’s Going down i am new to this, I stumbled upon this I have discovered It absolutely useful and it has
aided me out loads. I am hoping to contribute
& help other users like its aided me. Good job.
Hi there, I enjoy reading all of your article post.
I like to write a little comment to support you.
Hey would you mind sharing which blog platform you’re working with?
I’m planning to start my own blog in the near future but I’m having
a tough time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking
for something unique. P.S Apologies for being off-topic but I had to ask!
Thanks for your marvelous posting! I certainly enjoyed reading it,
you happen to be a great author.I will make certain to bookmark your blog and may come back in the foreseeable future.
I want to encourage that you continue your great writing, have a nice day!
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that automatically tweet
my newest twitter updates. I’ve been looking for a plug-in like this for
quite some time and was hoping maybe you would have some experience with something like
this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Hello, I enjoy reading all of your post. I like to write a little
comment to support you.
Asking questions are truly nice thing if you are not understanding anything entirely, but this piece of writing presents nice understanding even.
It is the best time to make a few plans for the longer term and
it’s time to be happy. I have read this put up and if I could I
wish to suggest you few interesting things or suggestions.
Maybe you can write subsequent articles regarding this article.
I want to read even more things about it!
It’s actually a nice and useful piece of info.
I am satisfied that you shared this helpful information with us.
Please keep us informed like this. Thank you for sharing.
Superb, what a weblog it is! This blog provides helpful facts to us, keep it up.
Undeniably believe that which you stated. Your favorite
justification seemed to be on the net the easiest thing to be aware of.
I say to you, I definitely get irked while people consider worries that they
just don’t know about. You managed to hit the nail upon the top and also defined out the whole thing without having side effect ,
people can take a signal. Will likely be back to get more.
Thanks
Keep on writing, great job!
I have been browsing online more than 2 hours today,
yet I never found any interesting article like yours.
It is pretty worth enough for me. In my view, if all site owners and bloggers made good content as
you did, the internet will be a lot more useful than ever before.
Hi! I’ve been following your website for a long
time now and finally got the courage to go ahead and give you a shout out from New Caney
Texas! Just wanted to mention keep up the good
job!
It’s very effortless to find out any topic on net as compared to books, as I found this piece of writing at
this web site.
I’m not that much of a online reader to be honest but your blogs
really nice, keep it up! I’ll go ahead and bookmark
your website to come back later. Cheers
The article you provided is very interesting and innovative.
Hey there! Would you mind if I share your blog with my zynga
group? There’s a lot of people that I think would really enjoy your content.
Please let me know. Thank you
Hurrah, that’s what I was seeking for, what
a data! present here at this web site, thanks admin of this
site.
Your website is truly impressive! The design is sleek and user-friendly, making navigation a breeze. The content is well-organized and highly informative, catering perfectly to the needs of your audience. It’s clear that a lot of thought and effort has gone into creating a seamless user experience. Keep up the fantastic work!
Very great post. I simply stumbled upon your weblog and
wished to say that I have really loved browsing your
blog posts. After all I’ll be subscribing to your rss feed and I hope you write again very soon!
Here is my blog post: bebekjp
I do believe all of the ideas you’ve offered in your post.
They are really convincing and can certainly
work. Still, the posts are very quick for novices.
May just you please extend them a little from subsequent
time? Thanks for the post.
No matter if some one searches for his essential thing, so
he/she desires to be available that in detail, thus
that thing is maintained over here.
each time i used to read smaller articles or reviews which also clear their
motive, and that is also happening with this piece of writing which I am reading now.
Thank you for some other informative site. Where else
could I am getting that type of information written in such a perfect means?
I have a venture that I’m just now working on, and I have been on the glance out
for such information.
Amazing! This blog looks exactly like my old one! It’s on a totally different
subject but it has pretty much the same page layout and design. Great choice of colors!
I visited multiple sites but the audio feature
for audio songs current at this web page is really fabulous.
Wow, amazing blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your
website is excellent, as well as the content!
Superb, what a web site it is! This weblog provides valuable facts to us, keep it up.
Hello, I believe your site might be having web browser compatibility problems.
Whenever I take a look at your blog in Safari, it looks fine however, if opening in IE,
it has some overlapping issues. I merely wanted to provide you with a quick heads up!
Apart from that, excellent website!
Undeniably believe that which you stated. Your favorite reason appeared to be on the
internet the easiest thing to be aware of. I say to you, I definitely get annoyed while people consider
worries that they just do not know about. You managed to hit the nail upon the top and also defined out
the whole thing without having side effect , people could take
a signal. Will probably be back to get more.
Thanks
Wow, fantastic blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is magnificent, as well
as the content!
Hi there! Do you use Twitter? I’d like to follow you if that would be
ok. I’m definitely enjoying your blog and look forward to new posts.
First of all I would like to say terrific blog!
I had a quick question that I’d like to ask if you don’t mind.
I was interested to know how you center yourself and clear your head prior to writing.
I’ve had a hard time clearing my thoughts in getting my ideas out
there. I truly do take pleasure in writing however it just seems like the
first 10 to 15 minutes tend to be wasted simply just trying to figure out how to begin. Any recommendations or hints?
Appreciate it!
We absolutely love your blog and find almost all of your post’s
to be what precisely I’m looking for. Would you offer
guest writers to write content available for
you? I wouldn’t mind writing a post or elaborating on a few of the subjects you write concerning here.
Again, awesome site!
Whats up this is kinda of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no coding know-how so I wanted to get advice
from someone with experience. Any help would be enormously appreciated!
First off I want to say excellent blog! I had a quick question which I’d
like to ask if you don’t mind. I was interested to find out how you center yourself and
clear your head prior to writing. I have had a hard time
clearing my thoughts in getting my ideas out.
I do take pleasure in writing however it just seems like
the first 10 to 15 minutes are generally wasted just trying to figure out
how to begin. Any recommendations or hints? Appreciate it!
Asking questions are in fact nice thing if you are not understanding anything fully, except this article offers nice understanding
yet.
Have you ever considered about including a little
bit more than just your articles? I mean, what you say is
fundamental and everything. But think about if you
added some great visuals or video clips to give your posts more, “pop”!
Your content is excellent but with pics and videos,
this site could undeniably be one of the greatest in its niche.
Very good blog!
naturally like your website but you need to test the spelling on several
of your posts. Many of them are rife with spelling issues and I to
find it very bothersome to tell the reality however I’ll certainly come again again.
Hi there, I wish for to subscribe for this blog to take latest updates, therefore where can i do it please assist.
great submit, very informative. I ponder why the opposite specialists of this sector do
not understand this. You must proceed your writing.
I am confident, you’ve a huge readers’ base already!
This design is steller! You obviously know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!)
Fantastic job. I really enjoyed what you had to say, and more
than that, how you presented it. Too cool!
I’ve been browsing online more than 2 hours today, yet I
never found any interesting article like yours.
It is pretty worth enough for me. Personally, if
all webmasters and bloggers made good content as you did, the
net will be a lot more useful than ever before.
Hey! This post could not be written any better! Reading through this post reminds me of
my previous room mate! He always kept talking about this. I will forward this post to him.
Pretty sure he will have a good read. Many thanks for sharing!
After looking into a handful of the blog posts on your web
site, I really like your technique of blogging. I added it
to my bookmark website list and will be checking back in the near future.
Please check out my website as well and let me know how you feel.
Aw, this was an exceptionally nice post. Spending some time and
actual effort to create a superb article… but what can I say…
I put things off a whole lot and don’t manage to get anything done.
Here is my homepage … look at more info
Great info. Lucky me I came across your blog by chance (stumbleupon).
I have saved as a favorite for later!
Nice post. I was checking continuously this weblog and I am I handle such information a lot.
I handle such information a lot.
inspired! Extremely helpful info specifically the
ultimate section
I was looking for this particular information for a long time.
Thanks and best of luck.
Howdy! This post could not be written much better!
Looking through this article reminds me of my previous roommate!
He constantly kept talking about this. I am going
to forward this post to him. Pretty sure he’s going to have a very good read.
Thank you for sharing!
I like the valuable information you provide for your articles.
I’ll bookmark your blog and take a look at again here regularly.
I’m moderately sure I will learn many new stuff right here!
Best of luck for the next!
Hi! I know this is kinda off topic nevertheless I’d figured
I’d ask. Would you be interested in exchanging links or
maybe guest authoring a blog post or vice-versa?
My site goes over a lot of the same topics as yours and I feel we could greatly benefit from each
other. If you’re interested feel free to shoot me an e-mail.
I look forward to hearing from you! Excellent blog by the way!
This is really interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your fantastic post.
Also, I have shared your site in my social networks!
Thanks on your marvelous posting! I actually enjoyed reading it, you may be a great
author.I will make certain to bookmark your
blog and may come back down the road. I want to encourage you to definitely continue your great posts, have a nice morning!
This paragraph is actually a fastidious one it helps new the
web visitors, who are wishing in favor of blogging.
My partner and I absolutely love your blog and find almost all
of your post’s to be what precisely I’m looking for.
Would you offer guest writers to write content in your case?
I wouldn’t mind producing a post or elaborating on a few
of the subjects you write with regards to here. Again,
awesome weblog!
What’s up i am kavin, its my first occasion to commenting anywhere, when i read this paragraph i thought i
could also make comment due to this sensible post.
Please let me know if you’re looking for a article author for your weblog.
You have some really great articles and I believe I would be a good asset.
If you ever want to take some of the load off, I’d love to write some material for your blog in exchange for a link back to mine.
Please blast me an email if interested. Many thanks!
This is a really good tip particularly to those new to the blogosphere.
Simple but very precise information… Thanks for sharing this one.
A must read post!
Everyone loves it when people get together and share views.
Great site, continue the good work!
Great blog here! Also your site so much up fast!
What web host are you the use of? Can I get
your affiliate link for your host? I desire my web site loaded up as
fast as yours lol
Hi, all is going nicely here and ofcourse every one
is sharing information, that’s genuinely fine, keep up
writing.
Hello, just wanted to say, I liked this post. It was funny.
Keep on posting!
Everything is very open with a really clear explanation of the challenges.
It was truly informative. Your website is extremely helpful.
Thanks for sharing!
I’m more than happy to uncover this web site. I wanted to thank you for your time for this particularly
wonderful read!! I definitely liked every bit of it and I have you bookmarked to check out new
stuff on your site.
This blog was… how do you say it? Relevant!! Finally I’ve found something that helped me.
Many thanks!
Your style is very unique compared to other people I
have read stuff from. Many thanks for posting when you’ve
got the opportunity, Guess I will just bookmark this site.
Hi there! This is kind of off topic but I need some advice from
an established blog. Is it very difficult to set up
your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where to begin. Do you
have any points or suggestions? Many thanks
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how can we communicate?
Having read this I believed it was rather enlightening. I appreciate you taking the time and effort to
put this content together. I once again find myself personally spending
way too much time both reading and commenting.
But so what, it was still worth it!
If some one desires to be updated with most recent technologies afterward he must be pay
a quick visit this web site and be up to date daily.
Whats up very cool web site!! Man .. Beautiful .. Amazing ..
I’ll bookmark your site and take the feeds additionally?
I am glad to search out so many useful information right here in the put up, we need work out extra strategies in this regard,
thanks for sharing. . . . . .
I’m curious to find out what blog platform you happen to be using?
I’m experiencing some minor security issues with my latest
site and I would like to find something more safe.
Do you have any recommendations?
I take pleasure in, result in I found exactly what I used to be taking a look for.
You’ve ended my 4 day lengthy hunt! God Bless you man. Have a great day.
Bye
Oh my goodness! Awesome article dude! Thank you, However I am encountering difficulties with your RSS.
I don’t understand the reason why I cannot subscribe to it.
Is there anyone else having identical RSS issues?
Anybody who knows the answer can you kindly respond?
Thanks!!
I like the valuable info you provide in your articles. I’ll
bookmark your blog and check again here frequently.
I’m quite certain I will learn lots of new stuff right here!
Best of luck for the next!
I know this if off topic but I’m looking into starting my own weblog and
was curious what all is required to get setup? I’m assuming having a blog like yours would cost a
pretty penny? I’m not very web smart so I’m not 100% certain. Any recommendations or advice
would be greatly appreciated. Thanks
Yes! Finally someone writes about Wedding Rings Brisbane qld.
Thank you for some other excellent post. Where else could anyone get that type of information in such a
perfect manner of writing? I’ve a presentation next week,
and I’m at the search for such info.
Its like you learn my mind! You appear to understand so much approximately this, like you
wrote the guide in it or something. I think that
you just could do with a few % to power the message house a little bit, but other than that, this is wonderful blog.
A fantastic read. I will certainly be back.
Appreciation to my father who informed me on the topic of this weblog, this webpage is truly remarkable.
I feel this is one of the such a lot significant info for
me. And i am glad studying your article. However wanna remark on some basic issues, The web site style is wonderful, the articles is
in reality nice : D. Just right process,
cheers
Good post. I learn something new and challenging on sites I stumbleupon everyday.
It’s always exciting to read content from other writers and use a
little something from their websites.
If you are going for best contents like myself, simply visit this web site all the time for the reason that it offers
quality contents, thanks
It’s in point of fact a nice and useful piece of info.
I’m satisfied that you shared this helpful info with us.
Please stay us informed like this. Thank you for sharing.
I like the helpful info you supply for your articles.
I will bookmark your weblog and test once more right here regularly.
I’m relatively certain I’ll be informed a lot of new stuff proper right here!
Best of luck for the next!
I was excited to uncover this great site. I need to to thank you for your time due to this fantastic
read!! I definitely appreciated every little bit of it and
i also have you book marked to look at new things on your blog.
If some one needs to be updated with newest technologies afterward he must be pay a visit this site and be up to date everyday.
Hmm it seems like your blog ate my first comment (it was super long) so I guess I’ll just sum it up what I
submitted and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to everything.
Do you have any recommendations for beginner blog writers?
I’d really appreciate it.
I think the admin of this site is in fact working hard in favor of his web page, for the reason that here every
information is quality based data.
Great site. Plenty of useful info here. I’m sending it to several pals ans
additionally sharing in delicious. And obviously,
thank you for your effort!
Thanks for sharing your thoughts about mercado livre.
Regards
Hello! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Carry on the excellent work!
What’s up, the whole thing is going well here and ofcourse every one is sharing data, that’s truly good,
keep up writing.
I’m extremely impressed with your writing skills and also with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Either way keep up the nice quality writing, it is rare
to see a great blog like this one nowadays.
Spot on with this write-up, I actually feel this amazing site needs much more attention. I’ll probably be returning
to see more, thanks for the info!
I’m really impressed together with your writing skills and also with the format on your weblog.
Is that this a paid theme or did you modify it your self? Anyway keep up the nice quality writing, it is
rare to see a great blog like this one nowadays..
I visited various web sites but the audio feature for audio songs existing at
this web page is truly wonderful.
Also visit my website eat healthy
Magnificent items from you, man. I’ve take into accout your stuff prior to and you’re simply extremely great.
I actually like what you’ve bought here, really like what
you are saying and the best way by which you are saying it.
You make it entertaining and you continue to
take care of to keep it smart. I cant wait to learn much more from you.
This is actually a wonderful website.
A fascinating discussion is worth comment. I believe that you should publish more about this
topic, it might not be a taboo matter but usually people don’t talk about these subjects.
To the next! Cheers!!
Wow that was unusual. I just wrote an very long comment
but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Anyway, just wanted to say superb blog!
Have you ever considered writing an ebook or guest authoring on other websites?
I have a blog based upon on the same topics you discuss and would really like to have
you share some stories/information. I know my readers would enjoy
your work. If you are even remotely interested, feel free to shoot
me an e mail.
Hello it’s me, I am also visiting this website regularly, this website is truly good and the users are in fact sharing pleasant thoughts.
I’ve been browsing online more than three hours nowadays, but I never found any fascinating article
like yours. It is beautiful value sufficient
for me. In my opinion, if all website owners and bloggers
made just right content as you probably did, the internet shall be much more helpful
than ever before.
I’d like to find out more? I’d want to find out some additional information.
Pretty nice post. I just stumbled upon your blog and wished to say that I’ve truly enjoyed browsing
your blog posts. In any case I will be subscribing to your rss feed and I hope you write again very soon!
Marvelous, what a web site it is! This website presents helpful facts to us, keep it up.
Thank you for another excellent post. Where else could anyone get
that type of information in such a perfect method of writing?
I have a presentation subsequent week, and I’m at the look for
such information.
WOW just what I was looking for. Came here by searching for social media
Oh my goodness! Awesome article dude! Many thanks, However I am encountering difficulties with your RSS.
I don’t understand why I can’t join it. Is there anybody else
having identical RSS problems? Anybody who knows the answer can you kindly respond?
Thanks!!
Everything is very open with a very clear clarification of the issues.
It was truly informative. Your site is useful. Thanks for sharing!
What’s up, after reading this awesome post i am too glad to share
my know-how here with mates.
Your website is a true masterpiece! The design is both visually stunning and user-friendly, making it easy to navigate and find exactly what I’m looking for. The content is well-curated, informative, and engaging, showing a deep understanding of your audience’s needs. It’s clear that a lot of thought and care went into creating this site, and it really sets a high standard. Keep up the amazing work!
Hi there to every one, it’s truly a pleasant for me to visit this website, it consists of priceless Information.
Hello there! This post could not be written any better! Reading through
this post reminds me of my old room mate! He always kept talking about this.
I will forward this post to him. Fairly certain he will have a good read.
Many thanks for sharing!
I’d like to find out more? I’d love to find out more details.
Hello there! This is kind of off topic but I need some help
from an established blog. Is it tough to set up your own blog?
I’m not very techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not sure where to start.
Do you have any points or suggestions? Cheers
I’ve learn several good stuff here. Certainly worth bookmarking for revisiting.
I wonder how much attempt you put to make the sort of magnificent informative website.
Wow, superb blog format! How lengthy have you ever
been blogging for? you make blogging look easy. The entire glance
of your website is great, as well as the content material!
https://www.intensedebate.com/people/FreemanWang24
Nice post. I was checking constantly this weblog and I’m impressed! I handle
I handle
Extremely useful information specially the last part
such information a lot. I used to be looking for
this particular information for a long time. Thanks and best of
luck.
Aw, this was an extremely nice post. Taking the time and actual
effort to generate a superb article… but what can I say… I hesitate a lot and never seem to get nearly anything done.
Wow, that’s what I was exploring for, what a material! existing here
at this website, thanks admin of this website.
Hi there to all, it’s actually a nice for me to visit this web page, it consists of important Information.
Good answers in return of this query with firm arguments and explaining everything on the topic of that.
Hi my loved one! I want to say that this article is amazing, great written and include approximately all significant
infos. I’d like to see extra posts like this .
Fabulous, what a website it is! This blog presents valuable facts to us, keep it up.
Pretty component to content. I simply stumbled upon your weblog
and in accession capital to claim that I acquire in fact loved account your blog
posts. Any way I’ll be subscribing in your feeds or even I success you get entry to persistently rapidly.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how could we communicate?
Good post. I learn something totally new and challenging on blogs I
stumbleupon on a daily basis. It will always be interesting to read through articles
from other authors and use a little something from
their sites.
These are in fact enormous ideas in regarding blogging. You have touched some nice points here.
Any way keep up wrinting.
Have you ever thought about adding a little bit more than just your articles?
I mean, what you say is valuable and everything. However just imagine if you added some great images or video clips
to give your posts more, “pop”! Your content is excellent but with images and
videos, this site could definitely be one of the
most beneficial in its niche. Excellent blog!
I am not sure where you’re getting your information,
but good topic. I needs to spend some time learning much more or understanding
more. Thanks for excellent information I was
looking for this information for my mission.
If some one wishes expert view regarding blogging after that i advise him/her to pay a quick visit this weblog, Keep up the good job.
It’s going to be finish of mine day, except before finish I am reading
this great article to increase my know-how.
If some one needs expert view regarding blogging and site-building then i recommend him/her to visit this website, Keep
up the nice job.
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is fundamental and all.
However think of if you added some great images or videos
to give your posts more, “pop”! Your content is excellent but with pics and videos, this
website could undeniably be one of the greatest
in its field. Terrific blog!
This web site definitely has all of the information I needed about this subject and didn’t know who to ask.
Good post. I learn something new and challenging on blogs I stumbleupon everyday.
It will always be helpful to read articles from other writers and use a little
something from other websites.
It’s going to be finish of mine day, but before ending I am reading this wonderful paragraph to improve my experience.
My brother suggested I might like this blog. He used to be entirely right.
This put up actually made my day. You can not imagine simply how so much time I had
spent for this info! Thanks!
I do believe all the ideas you’ve offered on your post.
They’re really convincing and will definitely work.
Nonetheless, the posts are very brief for novices. May just you please lengthen them a bit from next time?
Thank you for the post.
Hi there every one, here every one is sharing these familiarity,
thus it’s nice to read this web site, and I used to pay a quick visit this website every
day.
Thanks for ones marvelous posting! I genuinely enjoyed reading
it, you could be a great author.I will make certain to bookmark your blog
and will often come back later on. I want to encourage
continue your great posts, have a nice morning!
Saved as a favorite, I love your web site!
Hello, just wanted to mention, I enjoyed this blog post.
It was inspiring. Keep on posting!
Woah! I’m really enjoying the template/theme of this website.
It’s simple, yet effective. A lot of times it’s tough to get that
“perfect balance” between usability and visual appeal.
I must say that you’ve done a great job with this. In addition,
the blog loads very quick for me on Internet explorer.
Superb Blog!
Thanks for sharing your thoughts. I really appreciate your efforts and I will be waiting for your next post thank you once again.
Hi, I think your site might be having browser compatibility issues.
When I look at your website in Safari, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, amazing blog!
Hey there would you mind stating which blog platform you’re using?
I’m looking to start my own blog in the near future but I’m having a tough time selecting between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most
blogs and I’m looking for something completely unique.
P.S My apologies for getting off-topic but I had to ask!
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several e-mails
with the same comment. Is there any way you can remove me from
that service? Bless you!
Hi there, after reading this awesome paragraph i am also glad
to share my familiarity here with colleagues.
Your style is unique compared to other folks I’ve read
stuff from. I appreciate you for posting when you have the opportunity, Guess
I’ll just book mark this page.
Write more, thats all I have to say. Literally, it
seems as though you relied on the video to
make your point. You obviously know what youre talking about, why
throw away your intelligence on just posting videos to your weblog
when you could be giving us something enlightening to read?
When some one searches for his required thing, so he/she wants to be available that in detail, so that thing is maintained over here.
Good day! This is my 1st comment here so I just wanted to give a quick shout out and say I truly enjoy reading through your blog posts.
Can you recommend any other blogs/websites/forums that deal with the
same topics? Thank you so much!
Great blog! Do you have any hints for aspiring
writers? I’m planning to start my own blog soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or
go for a paid option? There are so many choices out there that
I’m totally overwhelmed .. Any recommendations?
Thank you!
Awesome blog! Do you have any helpful hints for
aspiring writers? I’m hoping to start my own site soon but I’m
a little lost on everything. Would you propose starting with a
free platform like WordPress or go for a paid option? There are so many options out there that I’m totally overwhelmed ..
Any ideas? Thanks a lot!
What a data of un-ambiguity and preserveness of precious know-how regarding unpredicted emotions.
Hurrah! Finally I got a web site from where I be capable of really get helpful information regarding my study and knowledge.
Thank you for any other great article. The place else may just anybody
get that kind of info in such a perfect method of writing?
I have a presentation subsequent week, and I’m at the search for such info.
My partner and I absolutely love your blog and find almost all of your post’s to be just what I’m
looking for. Would you offer guest writers to write content for yourself?
I wouldn’t mind producing a post or elaborating on a lot of the subjects you write regarding here.
Again, awesome site!
I know this if off topic but I’m looking into starting my
own weblog and was wondering what all is needed to get setup?
I’m assuming having a blog like yours would cost
a pretty penny? I’m not very internet smart so I’m not 100%
sure. Any recommendations or advice would be greatly appreciated.
Appreciate it
Oh my goodness! Impressive article dude! Many thanks, However I am
encountering difficulties with your RSS. I don’t
know the reason why I cannot subscribe to it. Is there anyone else having similar RSS
problems? Anyone who knows the solution will you kindly respond?
Thanx!!
Way cool! Some extremely valid points! I appreciate you penning this post and the rest of the site is extremely good.
Very soon this site will be famous among all blogging and site-building
people, due to it’s good posts
I feel that is one of the so much vital info for me.
And i’m satisfied reading your article. But want to statement on some normal things,
The web site taste is ideal, the articles is truly excellent :
D. Good task, cheers
Hello, I enjoy reading all of your article
post. I wanted to write a little comment to support you.
Hurrah, that’s what I was exploring for, what a data!
existing here at this website, thanks admin of this web page.
Hello! I know this is kind of off-topic however I needed to ask.
Does running a well-established website such as yours take a
lot of work? I am brand new to running a blog however I
do write in my journal everyday. I’d like to start a blog so
I will be able to share my experience and views online.
Please let me know if you have any kind of suggestions or tips for brand new aspiring bloggers.
Appreciate it!
Descubra como divulgar seus links de afiliado e ainda como ter
1 milhão e 900 mil de tráfego para seu site.
At this time I am going to do my breakfast, later than having my
breakfast coming yet again to read further news.
Thanks for the marvelous posting! I genuinely enjoyed reading it, you are a great author.I will ensure that I bookmark your blog and
will eventually come back later on. I want to encourage continue your great job, have a nice weekend!
I do not even know how I ended up here, but I thought this post was good.
I do not know who you are but certainly you’re going to a famous
blogger if you aren’t already 😉 Cheers!
Greetings! Very useful advice in this particular article! It is
the little changes that will make the most important changes.
Many thanks for sharing!
Hey there just wanted to give you a quick heads up and let you know a
few of the images aren’t loading correctly. I’m not sure
why but I think its a linking issue. I’ve tried it in two
different internet browsers and both show the same results.
Excellent post. I was checking continuously this weblog and I’m impressed!
Extremely useful information specially the remaining section
I maintain such info much. I was looking for this certain information for
a very long time. Thanks and best of luck.
It’s very straightforward to find out any topic on web as
compared to textbooks, as I found this post at this website.
Thanks for the good writeup. It in fact was a
amusement account it. Look complex to more added agreeable from you!
However, how could we keep in touch?
Everyone loves what you guys tend to be up too. This kind of clever work and reporting!
Keep up the amazing works guys I’ve incorporated you
guys to blogroll.
Excellent way of explaining, and fastidious post to obtain facts about my presentation focus,
which i am going to convey in university.
hey there and thank you for your information – I
have certainly picked up anything new from right here.
I did however expertise a few technical points using this
web site, as I experienced to reload the site a lot of
times previous to I could get it to load correctly.
I had been wondering if your web host is OK? Not that I
am complaining, but slow loading instances times
will very frequently affect your placement in google and could
damage your high quality score if advertising and marketing
with Adwords. Anyway I’m adding this RSS to my email and could look out for
a lot more of your respective exciting content. Ensure that you update this again soon.
Thanks for sharing such a fastidious opinion, post is pleasant, thats why i have read
it fully
I must thank you for the efforts you’ve put in writing this blog.
I’m hoping to see the same high-grade content by you later on as well.
In truth, your creative writing abilities has motivated
me to get my very own site now 😉
Thanks very interesting blog!
Lovely just what I was searching for. Thanks
to the author for taking his time on this one.
Also visit my blog post – online coaching [https://Www.Mississaugachinese.net/home.php?mod=Space&uid=1306414]
Ηi there! Someone in my Myspace group sһared this webѕite
with us so I came to check it out. I’m definitely loving the infoгmation. I’m book-marking and wilⅼ
be tweeting this to my followers! Superb blog
and great design and style.
Very nice post. I simply stumbled upon your blog and wanted
to mention that I’ve really loved surfing around your blog posts.
In any case I will be subscribing on your rss feed and I’m hoping you write once more very soon!
Hello! I’m at work surfing around your blog from my
new iphone 3gs! Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the outstanding work!
I constantly emailed this website post page to all my contacts,
since if like to read it then my friends will too.
Thanks , I’ve recently been looking for info about this subject for a long time
and yours is the best I have discovered till now. But, what about the bottom
line? Are you sure in regards to the source?
Thanks for sharing your info. I really appreciate your efforts and I am
waiting for your next write ups thanks once again.
Thanks on your marvelous posting! I certainly enjoyed reading it, you may be a great author.I will ensure that I
bookmark your blog and definitely will come back in the future.
I want to encourage you to definitely continue your great writing, have a nice day!
Interesting blog! Is your theme custom made or did you
download it from somewhere? A theme like yours with a few simple adjustements would really
make my blog jump out. Please let me know where you got your theme.
Thanks a lot
This is my first time pay a visit at here and i am in fact impressed to read everthing at alone place.
I love it when people get together and share thoughts.
Great blog, stick with it!
It’s impressive that you are getting thoughts from this article as well as from our discussion made here.
Hello there, I found your website via Google while searching for a similar subject, your site came up, it appears to be like good.
I have bookmarked it in my google bookmarks.
Hello there, simply changed into aware of your weblog via Google, and found that it is really informative.
I’m gonna watch out for brussels. I will appreciate in case you proceed this in future.
Numerous folks shall be benefited out of your writing. Cheers!
I am regular reader, how are you everybody?
This post posted at this web page is actually good.
Hi, I do believe this is an excellent website. I stumbledupon it 😉 I am going to revisit once again since I bookmarked it.
Money and freedom is the best way to change, may you be rich and continue to guide others.
I just couldn’t go away your web site before suggesting that I actually loved the
usual information a person supply in your visitors?
Is gonna be again often in order to inspect new posts
Hey there, You’ve done an incredible job.
I will definitely digg it and personally recommend to my friends.
I am sure they will be benefited from this web site.
Whats up are using WordPress for your blog platform? I’m new
to the blog world but I’m trying to get started and set up my
own. Do you require any coding knowledge to make your own blog?
Any help would be really appreciated!
What a material of un-ambiguity and preserveness of precious knowledge about unpredicted emotions.
Hello, i think that i saw you visited my weblog so i came to “return the favor”.I’m attempting to find things to improve my web site!I suppose
its ok to use some of your ideas!!
Hey there, I think your site might be having browser compatibility issues.
When I look at your blog site in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, very good blog!
Thank you for some other informative site. The place else could I get that type of info
written in such an ideal method? I’ve a challenge that I am just now working on, and
I have been at the look out for such information.
Fantastic beat ! I wish to apprentice at the same time as you amend your
website, how could i subscribe for a weblog website?
The account aided me a applicable deal. I had been a little bit familiar of this your broadcast provided bright clear concept
Unquestionably believe that which you stated. Your favorite reason appeared to be on the net the easiest thing to be
aware of. I say to you, I certainly get irked while people think
about worries that they plainly don’t know about. You managed
to hit the nail upon the top and defined out the
whole thing without having side effect , people could take a signal.
Will probably be back to get more. Thanks
Wow, amazing blog structure! How long have you ever been running a blog for?
you made blogging look easy. The overall look of your web site is magnificent,
as well as the content material!
Yesterday, while I was at work, my cousin stole my iPad and tested to
see if it can survive a 25 foot drop, just so she can be a youtube sensation. My iPad
is now destroyed and she has 83 views. I know this is entirely off topic but I had to share it with someone!
I’m gone to inform my little brother, that he should also visit
this web site on regular basis to obtain updated from newest news update.
Heya i am for the primary time here. I came across this board and I find It really helpful &
it helped me out much. I’m hoping to give something again and
aid others such as you helped me.
I was able to find good advice from your blog articles.
Do you mind if I quote a couple of your articles as long as I provide credit and sources back
to your blog? My blog is in the exact same niche as yours and
my users would really benefit from a lot of the information you provide here.
Please let me know if this okay with you. Many thanks!
Why users still make use of to read news papers when in this technological globe all
is presented on net?
It’s hard to find knowledgeable people on this
topic, however, you sound like you know what you’re talking about!
Thanks
Hey! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in trading links or
maybe guest authoring a blog post or vice-versa?
My site goes over a lot of the same topics as yours and I think we could greatly benefit from each other.
If you’re interested feel free to shoot me an e-mail.
I look forward to hearing from you! Fantastic blog by the way!
You actually make it seem so easy with your
presentation but I find this matter to be really something that I think I would never understand.
It seems too complex and extremely broad for me. I’m looking forward for
your next post, I will try to get the hang of it!
Very good info. Lucky me I found your blog by accident (stumbleupon).
I have bookmarked it for later!
Greetings from Florida! I’m bored to tears at work so I decided to
browse your site on my iphone during lunch break.
I enjoy the info you provide here and can’t wait to take a
look when I get home. I’m surprised at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, awesome site!
I’m really impressed with your writing skills as well as with the layout
on your weblog. Is this a paid theme or did you modify
it yourself? Anyway keep up the excellent quality writing, it’s rare to see a great blog like this one nowadays.
Thank you for the good writeup. It in fact
was a amusement account it. Look advanced to far added agreeable from you!
However, how could we communicate?
Hi there to all, how is the whole thing, I think every one is getting more from this website, and your views are good in support of new visitors.
Greetings from California! I’m bored to death at work so I decided to check out your website on my iphone
during lunch break. I enjoy the information you provide here and
can’t wait to take a look when I get home. I’m amazed at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyhow, excellent
site!
I would like to thank you for the efforts you’ve put
in writing this blog. I am hoping to check out the same high-grade content by you in the future as well.
In fact, your creative writing abilities has inspired me to get my very own site now 😉
Pretty element of content. I simply stumbled upon your web site and in accession capital to assert that I get in fact loved
account your blog posts. Anyway I’ll be subscribing in your feeds and even I success you get entry to persistently
rapidly.
Hello are using WordPress for your blog platform? I’m new to the blog
world but I’m trying to get started and set up my own. Do you need any coding knowledge to make your own blog?
Any help would be really appreciated!
Nice post. I was checking continuously this blog and I’m impressed!
Extremely helpful info particularly the last part :
) I care for such information a lot. I was looking for
this certain information for a long time.
Thank you and best of luck.
Oh my goodness! Awesome article dude! Thanks, However I am having issues with your RSS.
I don’t understand why I can’t join it. Is there anybody else getting similar RSS issues?
Anyone who knows the solution will you kindly respond?
Thanx!!
I feel that is among the such a lot important information for me.
And i am satisfied reading your article. But wanna remark on few common things, The
website taste is wonderful, the articles is in reality nice :
D. Good process, cheers
Hello! Someone in my Myspace group shared this site
with us so I came to check it out. I’m definitely loving the information. I’m bookmarking
and will be tweeting this to my followers!
Excellent blog and outstanding style and design.
You’ve made some really good points there. I looked on the net for more information about the issue and found most people will go along with
your views on this web site.
I know this if off topic but I’m looking into starting my own blog and was wondering what all
is required to get setup? I’m assuming having a blog like
yours would cost a pretty penny? I’m not very internet
savvy so I’m not 100% certain. Any recommendations or advice would be
greatly appreciated. Many thanks
Hello there! I simply want to give you a big thumbs up for your great information you have right here on this post.
I am returning to your website for more soon.
whoah this weblog is fantastic i really like studying your articles.
Keep up the good work! You realize, a lot of persons are searching around for this information,
you can help them greatly.
Your website is an outstanding example of thoughtful design and intuitive user experience. The content is not only informative but also engaging, making it a pleasure to navigate. The attention to detail in both aesthetics and functionality truly sets your site apart. Keep up the fantastic work!
I’m curious to find out what blog system you are working with?
I’m having some small security problems with my latest website and I would like to
find something more safeguarded. Do you have any solutions?
What i do not understood is in fact how you’re not actually
a lot more smartly-preferred than you might be
now. You are very intelligent. You recognize therefore
significantly when it comes to this topic, produced me for my part consider it from so many numerous angles.
Its like men and women aren’t fascinated except it is something
to accomplish with Woman gaga! Your own stuffs outstanding.
All the time handle it up!
Hi there! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no
data backup. Do you have any solutions to
prevent hackers?
What’s up it’s me, I am also visiting this site on a regular basis, this web page is really
pleasant and the visitors are truly sharing pleasant
thoughts.
My partner and I stumbled over here coming from a different
web page and thought I may as well check things out. I like what
I see so i am just following you. Look forward to
looking into your web page yet again.
Thanks for your marvelous posting! I seriously enjoyed reading it, you may be a great author.
I will ensure that I bookmark your blog and will eventually come back
at some point. I want to encourage that you continue your great writing, have a nice evening!
If some one wants expert view on the topic of blogging after that i propose him/her to pay a quick visit this weblog, Keep up the good work.
Greate article. Keep writing such kind of info
on your site. Im really impressed by your site.
Hey there, You’ve done an excellent job. I will definitely digg it and in my view recommend to my friends.
I’m sure they’ll be benefited from this website.
We are a group of volunteers and opening a new scheme in our community.
Your web site provided us with valuable info
to work on. You’ve done an impressive job and our whole
community will be grateful to you.
This forum is a gathering place for experts in various fields. I always feel like I’m learning a lot from the professionals who participate here.
bookmarked!!, I really like your website!
Excellent article. I am dealing with many of these issues as well..
Pretty! This was an extremely wonderful article. Many thanks for supplying this info.
Great article, just what I was looking for.
I all the time used to read paragraph in news
papers but now as I am a user of web so from now I
am using net for articles, thanks to web.
Ahaa, its good dialogue concerning this article at this place
at this webpage, I have read all that, so now me also commenting
here.
Thank you for the auspicious writeup. It in fact was
a amusement account it. Look advanced to more added agreeable from you!
By the way, how could we communicate?
With havin so much written content do you ever
run into any issues of plagorism or copyright violation? My site has a lot of completely
unique content I’ve either created myself or outsourced but it looks
like a lot of it is popping it up all over the web without my agreement.
Do you know any methods to help reduce content from being
ripped off? I’d certainly appreciate it.
Thank you for some other informative blog. Where else may
I get that type of info written in such a perfect means?
I’ve a challenge that I’m simply now running on, and I have been at
the glance out for such info.
First off I want to say wonderful blog! I had a quick question in which I’d
like to ask if you do not mind. I was curious to find out how you center
yourself and clear your thoughts prior to writing. I’ve had a hard time
clearing my thoughts in getting my thoughts out.
I do enjoy writing but it just seems like the first 10
to 15 minutes are lost simply just trying to figure out how to begin. Any suggestions
or tips? Thank you!
Howdy! I could have sworn I’ve been to this blog before but after going
through some of the posts I realized it’s new to me.
Anyways, I’m certainly happy I found it and I’ll be bookmarking it and
checking back frequently!
Hi i am kavin, its my first occasion to commenting anyplace, when i read this piece of writing i thought i could also create comment due to this
brilliant paragraph.
Do you have a spam problem on this website; I
also am a blogger, and I was curious about your situation; many of us have
created some nice methods and we are looking to trade solutions
with others, why not shoot me an email if interested.
This forum is very easy to use. The intuitive interface makes navigating and participating in discussions very comfortable.
I got this web page from my friend who told me about this site and at the moment this time
I am visiting this web site and reading very informative content at this time.
Very good write-up. I absolutely love this site.
Thanks!
Hey there exceptional website! Does running a blog such
as this require a lot of work? I have very little expertise in computer programming but I was hoping to start my own blog
in the near future. Anyhow, if you have any recommendations
or tips for new blog owners please share. I know this
is off subject nevertheless I just had to ask. Kudos!
I’m amazed, I have to admit. Seldom do I encounter a blog that’s both educative and entertaining,
and without a doubt, you have hit the nail on the head. The problem is something which
not enough men and women are speaking intelligently
about. Now i’m very happy that I found this in my search for something concerning this.
Does your website have a contact page? I’m having
trouble locating it but, I’d like to send you
an e-mail. I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it improve over time.
Thanks very interesting blog!
Superb blog! Do you have any tips for aspiring writers?
I’m planning to start my own blog soon but I’m a little lost on everything.
Would you propose starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally overwhelmed ..
Any recommendations? Thank you!
This is very interesting, You are a very skilled blogger.
I have joined your feed and look forward to seeking more of
your great post. Also, I’ve shared your web site in my social
networks!
Very good blog post. I definitely appreciate this site.
Keep it up!
Your website is a masterpiece of modern web design. The sleek layout, fast loading times, and well-organized content make it a joy to explore. Every element seems carefully crafted to provide visitors with the best possible experience. Excellent work!
Hey there excellent blog! Does running a blog like this
take a massive amount work? I have very little expertise in programming however I
was hoping to start my own blog soon. Anyways, should you have any
ideas or techniques for new blog owners please share.
I know this is off subject nevertheless I simply wanted to
ask. Kudos!
Hi, Neat post. There’s an issue along with your site in web explorer, might test this?
IE still is the marketplace chief and a good portion of other people will pass over your wonderful writing because of this problem.
I am sure this post has touched all the internet visitors, its really really pleasant paragraph on building up new webpage.
The topics discussed in this forum are very informative and in-depth. I always gain new insights from the discussions here.
Superb, what a weblog it is! This website provides helpful
information to us, keep it up.
I really love your website.. Pleasant colors & theme.
Did you make this site yourself? Please reply back as I’m looking to create my own personal blog and would love to know where you got this from or just what the theme is named.
Thank you!
I have been surfing online more than 3 hours today, yet
I never found any interesting article like yours.
It’s pretty worth enough for me. In my opinion, if all site owners and
bloggers made good content as you did, the internet will be much more useful than ever before.
Thanks to my father who shared with me regarding this blog,
this website is in fact remarkable.
Having read this I believed it was rather enlightening.
I appreciate you spending some time and energy to put this content
together. I once again find myself personally spending a
lot of time both reading and commenting. But so what, it was still worthwhile!
After exploring a handful of the blog posts on your site, I seriously like your
way of writing a blog. I bookmarked it to my bookmark website list
and will be checking back in the near future. Take a look at
my website too and let me know your opinion.
When I originally commented I clicked the
“Notify me when new comments are added” checkbox and now each
time a comment is added I get four emails
with the same comment. Is there any way you can remove
people from that service? Thank you!
Hello I am so glad I found your webpage, I really found
you by accident, while I was looking on Digg for something
else, Nonetheless I am here now and would just like to say kudos for a remarkable post
and a all round enjoyable blog (I also love the theme/design), I don’t have
time to browse it all at the moment but I have bookmarked it and also
included your RSS feeds, so when I have time I will be back to read a great
deal more, Please do keep up the excellent work.
Hello my loved one! I wish to say that this article is awesome,
great written and come with approximately all significant infos.
I would like to look extra posts like this .
I blog frequently and I really appreciate your content.
Your article has truly peaked my interest. I will book mark your site and keep checking for new
details about once a week. I opted in for your RSS feed too.
I always spent my half an hour to read this blog’s articles
all the time along with a mug of coffee.
This is a topic that is near to my heart…
Cheers! Where are your contact details though?
Hello, i think that i noticed you visited my weblog so
i got here to go back the prefer?.I’m trying to
in finding issues to enhance my site!I suppose its adequate to make use of some of your ideas!!
Pretty nice post. I just stumbled upon your weblog and wanted to say that I’ve truly enjoyed browsing your blog posts.
In any case I’ll be subscribing to your rss feed and I
hope you write again very soon!
Your style is very unique in comparison to other people I have read stuff from.
Many thanks for posting when you have the opportunity, Guess I will just book mark this blog.
I have been surfing online greater than three hours as of late, but I by no means discovered any fascinating article like yours.
It is beautiful value enough for me. In my view, if all web owners and bloggers made just right content material as you did, the net can be much more helpful than ever before.
My brother suggested I would possibly like this web site.
He was entirely right. This submit truly made my day.
You cann’t believe just how so much time I had spent for
this info! Thank you!
My partner and I stumbled over here by a different web page
and thought I might as well check things out. I like what I see
so i am just following you. Look forward to exploring your web page
yet again.
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to determine if its a problem on my end or if it’s
the blog. Any feed-back would be greatly appreciated.
What’s up, yeah this post is truly pleasant and I have learned lot of things from it regarding blogging.
thanks.
Great weblog right here! Also your web site so much up very fast!
What host are you using? Can I am getting your affiliate link on your host?
I desire my web site loaded up as quickly as yours lol
I constantly spent my half an hour to read this
weblog’s articles or reviews all the time along with a cup of coffee.
I don’t even know how I ended up here, but
I thought this post was great. I do not know who you are but certainly you’re
going to a famous blogger if you are not already 😉 Cheers!
I used to be able to find good info from your articles.
Greetings! I know this is somewhat off topic but I was wondering if you knew
where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
Thanks for every other informative site. The place else could I get that kind of information written in such an ideal manner?
I’ve a venture that I’m just now working on, and I’ve been on the look out for
such info.
I for all time emailed this website post page to all my friends, since if like to read it afterward my friends will too.
Do you mind if I quote a couple of your posts as long as I provide credit and sources back
to your blog? My blog is in the very same area of interest as yours and my visitors would truly
benefit from a lot of the information you present
here. Please let me know if this ok with you. Appreciate it!
Hurrah, that’s what I was exploring for, what
a data! existing here at this website, thanks admin of this website.
With havin so much content and articles do you ever
run into any problems of plagorism or copyright violation?
My blog has a lot of unique content I’ve either written myself or outsourced but it
seems a lot of it is popping it up all over the web
without my permission. Do you know any methods to help prevent content from being stolen? I’d really appreciate it.
Your style is really unique in comparison to other folks I’ve read stuff
from. Thanks for posting when you have the opportunity, Guess I will just bookmark this blog.
Touche. Solid arguments. Keep up the great effort.
What’s up, this weekend is nice in favor of me, for the reason that this occasion i am reading this enormous educational paragraph here
at my home.
It’s difficult to find educated people on this topic, but you seem like you know what you’re talking about!
Thanks
These are genuinely impressive ideas in regarding blogging.
You have touched some good points here. Any way keep
up wrinting.
I absolutely love your site.. Pleasant colors & theme. Did you build this
web site yourself? Please reply back as I’m trying to create my own blog and would like to find out where you got this from or what the theme is named.
Cheers!
What i do not realize is in reality how you’re no longer actually much more neatly-appreciated than you may be
right now. You are so intelligent. You understand thus considerably in relation to this topic, made me in my view imagine it from so many numerous angles.
Its like women and men don’t seem to be involved unless it’s something
to accomplish with Woman gaga! Your individual stuffs outstanding.
At all times take care of it up!
I used to be able to find good advice from your content.
hey there and thank you for your info – I have definitely picked up something new
from right here. I did however expertise several technical issues using this website, since I experienced to reload the
website lots of times previous to I could get it to load correctly.
I had been wondering if your hosting is OK?
Not that I’m complaining, but slow loading instances
times will often affect your placement in google and can damage your quality score if advertising and marketing with Adwords.
Anyway I am adding this RSS to my e-mail and can look out for much more of your respective
interesting content. Make sure you update this again very
soon.
What’s up colleagues, its enormous piece of writing on the topic of
cultureand fully defined, keep it up all the time.
I every time emailed this webpage post page to all my contacts, because if like to read it then my contacts will too.
Remarkable issues here. I am very glad to look your article.
Thanks so much and I am having a look forward to contact you.
Will you please drop me a e-mail?
The level of active participation in this forum is impressive. It’s rare to find such a vibrant community where discussions are always lively and ongoing.
Heya i am for the first time here. I found this board
and I find It really useful & it helped me out a lot.
I hope to give something back and aid others like you helped me.
I was very pleased to discover this site. I wanted
to thank you for your time due to this wonderful read!!
I definitely loved every part of it and i also have you saved to fav to check out new stuff in your web site.
I’ve been surfing online more than 3 hours today, yet I never found any interesting
article like yours. It’s pretty worth enough for me.
In my opinion, if all webmasters and bloggers made good content as you did,
the internet will be much more useful than ever before.
Fabulous, what a blog it is! This webpage gives useful data to us,
keep it up.
Your website is a perfect blend of creativity and professionalism. The seamless navigation, coupled with high-quality content, makes for an exceptional user experience. It’s clear that a lot of care and effort have gone into every aspect of the site. Truly impressive!
I was suggested this blog by my cousin. I’m not sure whether this post is written by him as nobody
else know such detailed about my difficulty. You’re incredible!
Thanks!
Hi to all, it’s in fact a good for me to pay a visit this
web page, it contains helpful Information.
you’re in reality a excellent webmaster. The site loading
velocity is incredible. It seems that you’re doing any unique trick.
Furthermore, The contents are masterwork.
you’ve done a excellent task on this topic!
Highly descriptive post, I loved that a lot. Will
there be a part 2?
For most up-to-date information you have to pay a quick
visit internet and on internet I found this site as a best web page for
newest updates.
Have you ever thought about including a little bit more than just
your articles? I mean, what you say is valuable and all. But think of if
you added some great photos or video clips to give your posts more, “pop”!
Your content is excellent but with pics and
video clips, this site could certainly be one of the most beneficial in its niche.
Good blog!
If you are going for finest contents like I do, simply pay a quick visit this website everyday since it offers feature contents, thanks
The content shared in this forum is consistently of high quality. Members take the time to provide detailed, thoughtful contributions that are both valuable and insightful
Hello Dear, are you genuinely visiting this site regularly, if so after that you will absolutely
obtain fastidious experience.
The advice and suggestions offered in this forum are trustworthy and reliable. It’s clear that members are knowledgeable and genuinely want to help others succeed.
The information provided on this site is comprehensive and reliable.
of course like your website however you have to take a look at the spelling on quite a few of your posts.
Several of them are rife with spelling issues and I to find it very bothersome to tell the
truth nevertheless I will surely come back again.
What’s up, after reading this awesome article i am also glad to share
my experience here with colleagues.
Have you ever considered about adding a little bit more than just your articles?
I mean, what you say is fundamental and everything.
Nevertheless think of if you added some great photos
or video clips to give your posts more, “pop”! Your content is
excellent but with images and clips, this blog could certainly be one of the best in its niche.
Amazing blog!
My partner and I stumbled over here by a different page and thought I may as well check things
out. I like what I see so now i’m following you. Look forward
to exploring your web page yet again.
The conversations here are always engaging and thought-provoking. It’s a pleasure to be part of discussions that challenge and expand your thinking.
I’m really enjoying the theme/design of your web site.
Do you ever run into any web browser compatibility issues?
A small number of my blog readers have complained about my blog not working correctly in Explorer but looks
great in Opera. Do you have any ideas to help fix this issue?
Everything is very open with a very clear clarification of the issues.
It was really informative. Your website is useful. Many thanks for sharing!
Hi, i feel that i noticed you visited my website so i came to
go back the favor?.I am trying to to find issues to enhance my site!I suppose its good enough to make use
of a few of your ideas!!
Hi, after reading this remarkable post i am too glad to share my familiarity here with mates.
Hey! This is my first visit to your blog! We are a
group of volunteers and starting a new project in a community in the same
niche. Your blog provided us useful information to work on. You have
done a extraordinary job!
Every weekend i used to visit this web page, because i wish
for enjoyment, since this this web page conations in fact good funny stuff too.
Thank you for the sensible critique. Me and my neighbor were just
preparing to do some research about this. We got a grab a book from our local library but I think I
learned more from this post. I’m very glad to see such magnificent information being shared freely
out there.
My web blog … snake game (https://all-best-Game.Ck.page/)
is het mogelijk om medicijnen zonder voorschrift te krijgen in Genève sandoz Stavelot indicatie van medicijnen te koop in België
Fine way of telling, and pleasant piece of writing to get information concerning my presentation subject matter, which i am going to
deliver in school.
It’s in fact very difficult in this busy life to listen news on TV, so I only use web for that
reason, and obtain the most up-to-date information.
Fantastic goods from you, man. I’ve remember your stuff prior to and
you are simply too magnificent. I really like what you’ve received here, really like
what you’re saying and the way by which you
are saying it. You’re making it enjoyable and you still care
for to keep it smart. I can’t wait to read much more from you.
This is actually a tremendous web site.
Greetings! I know this is kinda off topic but I was wondering which blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another
platform. I would be fantastic if you could point me
in the direction of a good platform.
It is perfect time to make some plans for the
future and it’s time to be happy. I’ve read this post and if I could I desire to suggest
you some interesting things or tips. Maybe you could write next articles referring to this article.
I wish to read even more things about it!
Attractive section of content. I just stumbled upon your blog and in accession capital to assert that I acquire in fact enjoyed account your blog posts.
Anyway I will be subscribing to your feeds and even I achievement you access consistently quickly.
Incredible quest there. What happened after? Thanks!
I’m gone to say to my little brother, that he should
also pay a visit this web site on regular basis to obtain updated from newest news
update.
Great delivery. Solid arguments. Keep up the great work.
Hey there superb website! Does running a blog like this require a massive amount work?
I’ve absolutely no knowledge of coding but I had been hoping to start my own blog in the near future.
Anyway, should you have any ideas or techniques for new blog owners please share.
I understand this is off topic however I just had to ask.
Thank you!
Link exchange is nothing else but it is just placing
the other person’s webpage link on your page at suitable place and other person will also do similar in support of you.
Incredible quest there. What happened after?
Thanks!
Thank you for some other great post. Where else may anyone get that type of
info in such a perfect approach of writing? I have a presentation subsequent week, and
I’m at the look for such info.
Great info. Lucky me I found your website by accident (stumbleupon).
I have bookmarked it for later!
I’m curious to find out what blog system you happen to be
utilizing? I’m having some minor security problems with my latest
site and I’d like to find something more safeguarded. Do you have any recommendations?
Heya i am for the first time here. I came across this board and I find It really useful & it helped me out much.
I hope to give something back and aid others like you helped me.
It’s going to be ending of mine day, except before end I am reading
this great post to improve my experience.
That is a good tip especially to those new to the blogosphere.
Short but very precise info… Thanks for sharing this one.
A must read article!
Greate post. Keep posting such kind of info on your site. Im really
impressed by your site.
Hey there, You’ve performed a great job. I
will certainly digg it and for my part recommend to my friends.
I’m confident they will be benefited from this site.
Hurrah, that’s what I was seeking for, what a data! present here
at this weblog, thanks admin of this site.
Good information. Lucky me I came across your blog by chance (stumbleupon).
I’ve book-marked it for later!
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your blog?
My blog site is in the very same niche as yours and my visitors would definitely benefit from
a lot of the information you provide here. Please let me know if this ok with you.
Regards!
Asking questions are in fact good thing if you are not understanding anything entirely, but
this paragraph offers good understanding yet.
I love looking through a post that can make men and women think.
Also, thank you for allowing me to comment!
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic information I was looking for this information for my mission.
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message home a bit,
but other than that, this is great blog. A great read.
I will certainly be back.
Its like you learn my mind! You appear to understand so much about this, such as you wrote the e-book in it or
something. I think that you simply could do with a few p.c.
to pressure the message home a bit, however other than that, this is wonderful blog.
A fantastic read. I’ll definitely be back.
Very good write-up. I certainly appreciate this website.
Stick with it!
Wow that was unusual. I just wrote an extremely
long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Regardless, just wanted to say great blog!
This is a very good tip especially to those fresh to the blogosphere.
Simple but very precise info… Thank you for sharing this one.
A must read post!
I am regular visitor, how are you everybody? This paragraph posted at
this website is genuinely good.
Hi, I do believe this is a great web site. I
stumbledupon it 😉 I’m going to come back yet again since i have
book marked it. Money and freedom is the greatest way to
change, may you be rich and continue to guide other people.
Excellent article. Keep posting such kind of information on your page.
Im really impressed by your blog.
Hi there, You have done a great job. I will certainly digg it and for my
part suggest to my friends. I’m confident they’ll be benefited
from this website.
Hey there! Quick question that’s completely off topic. Do you know how to make your site mobile friendly?
My website looks weird when viewing from my iphone4.
I’m trying to find a template or plugin that might be
able to correct this problem. If you have any recommendations, please share.
With thanks!
Thanks for the auspicious writeup. It in truth used to be a amusement account it.
Glance complicated to more added agreeable from you!
By the way, how can we keep up a correspondence?
We absolutely love your blog and find many of your post’s to
be just what I’m looking for. can you offer guest writers to write content available for you?
I wouldn’t mind writing a post or elaborating on some of the subjects you write in relation to here.
Again, awesome site!
You could certainly see your skills in the article you write.
The arena hopes for even more passionate writers like you who
aren’t afraid to mention how they believe. Always follow your heart.
Hi there to all, how is the whole thing, I think every one is getting more from this web site, and your views are pleasant in favor of new users.
I was very happy to find this website. I need to to thank you for your time just for this fantastic read!!
I definitely loved every bit of it and i also have you bookmarked to look at new things on your website.
I love what you guys are usually up too. Such clever work and
exposure! Keep up the great works guys I’ve added you guys to
our blogroll.
Howdy I am so delighted I found your web site, I really found you by accident, while I was looking
on Google for something else, Anyhow I am here now
and would just like to say kudos for a remarkable post and a all round exciting
blog (I also love the theme/design), I don’t have time to look over it all at the
minute but I have saved it and also added in your RSS feeds, so when I have time I will be back to read more, Please
do keep up the awesome job.
Hi! Do you know if they make any plugins
to safeguard against hackers? I’m kinda paranoid about losing everything
I’ve worked hard on. Any suggestions?
I think this is one of the most important info for me.
And i am glad reading your article. But wanna remark on few general things, The website style is wonderful, the articles is really excellent :
D. Good job, cheers
This is very interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your
fantastic post. Also, I have shared your site in my social networks!
It’s perfect time to make a few plans for the longer term and it’s time to be
happy. I’ve read this publish and if I could I wish to suggest you some fascinating things or suggestions.
Maybe you can write subsequent articles referring
to this article. I want to learn more things approximately
it!
Hi there, I check your blog daily. Your humoristic style is witty,
keep it up!
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for magnificent info I was looking for this info for
my mission.
Hi there, I found your web site by the use of Google at the same time as looking for
a similar topic, your web site came up, it appears great.
I’ve bookmarked it in my google bookmarks.
Hello there, just became alert to your weblog thru Google, and found that it is truly informative.
I’m going to watch out for brussels. I’ll be
grateful if you happen to continue this in future.
Many other people will be benefited out of your writing. Cheers!
Hurrah! At last I got a website from where I be able to in fact get useful facts regarding my study and knowledge.
Hello, its fastidious post concerning media print, we all be aware of media is a impressive source of facts.
hi!,I love your writing so a lot! proportion we communicate more approximately
your post on AOL? I require a specialist in this area to resolve my problem.
Maybe that is you! Looking forward to peer you.
Unquestionably believe that which you stated. Your favourite justification seemed
to be on the web the simplest thing to keep in mind
of. I say to you, I definitely get annoyed while people think about worries that they
just do not understand about. You controlled to hit the nail upon the top as neatly
as defined out the entire thing with no need side-effects , folks can take a signal.
Will probably be back to get more. Thanks
We are a group of volunteers and opening a new scheme in our
community. Your site provided us with valuable info to work
on. You’ve done a formidable job and our entire community will be grateful to you.
Hello, I desire to subscribe for this blog to obtain newest updates, so where can i do it please help.
I think that is one of the most vital information for
me. And i am satisfied reading your article. But wanna observation on some normal issues, The web site style is perfect, the
articles is in reality great : D. Excellent
job, cheers
LIVETOTOBET informasi login link slot toto dan togel toto 4d
online terpercaya serta mudah diakses setiap orang serta merupakan salah
satu link togel toto4d terbaik saat ini
Hi there just wanted to give you a quick
heads up. The words in your post seem to be running off the screen in Ie.
I’m not sure if this is a formatting issue or something to do with
web browser compatibility but I thought I’d post to let you know.
The layout look great though! Hope you get the issue solved
soon. Cheers
If you desire to grow your know-how simply keep visiting this site and be updated with the
newest information posted here.
Having read this I believed it was rather enlightening.
I appreciate you finding the time and energy to put this information together.
I once again find myself personally spending way too much time both reading and posting comments.
But so what, it was still worth it!
Thanks for sharing your info. I really appreciate your efforts and I
am waiting for your next write ups thank you once again.
Pretty nice post. I just stumbled upon your blog
and wished to mention that I’ve really loved surfing around your
blog posts. In any case I’ll be subscribing on your feed
and I hope you write once more soon!
What a material of un-ambiguity and preserveness
of precious know-how regarding unexpected feelings.
Way cool! Some very valid points! I appreciate
you penning this post plus the rest of the site is also very good.
After exploring a few of the blog articles on your blog,
I seriously appreciate your technique of writing a blog.
I book marked it to my bookmark website list and will be checking back soon. Take a look at
my web site as well and tell me your opinion.
excellent issues altogether, you just gained a logo new reader.
What would you recommend in regards to your post that you
just made some days ago? Any sure?
At this time I am going to do my breakfast, after having my breakfast coming again to read further news.
Informative article, exactly what I wanted to find.
Hello, after reading this amazing article i am also
glad to share my familiarity here with mates.
My relatives all the time say that I am wasting my time here at net, but I know I am getting experience everyday by reading
such pleasant posts.
That is a good tip especially to those new to the blogosphere.
Short but very precise information… Many thanks for sharing this one.
A must read article!
My family every time say that I am wasting my time here at net, but I know
I am getting knowledge all the time by reading such nice content.
купить юр адрес для регистрации ооо
With havin so much written content do you ever run into any problems of plagorism or copyright
infringement? My site has a lot of unique content I’ve either created myself or outsourced but it looks like a lot of it is popping it up all over the web without my agreement.
Do you know any techniques to help prevent content from being stolen?
I’d definitely appreciate it.
What’s up everyone, it’s my first visit at this web
site, and paragraph is actually fruitful designed for me, keep up posting such posts.
A fascinating discussion is definitely worth comment. I do think that you ought to write more about this
topic, it may not be a taboo subject but generally folks don’t speak about such topics.
To the next! Best wishes!!
I read this article completely on the topic of the difference of
newest and earlier technologies, it’s amazing article.
Nice replies in return of this difficulty with firm arguments and telling the whole thing about that.
hello!,I like your writing very much! percentage we be
in contact extra about your article on AOL? I need a specialist
in this house to solve my problem. May be that’s you! Having a look forward to see you.
Also visit my web page: mature porn
Hi to every one, the contents existing at this
website are really awesome for people experience, well, keep up the nice work fellows.
My blog post … Music online
We absolutely love your blog and find the majority of
your post’s to be precisely what I’m looking for. can you offer guest writers
to write content for you personally? I wouldn’t mind creating a post or elaborating on a number
of the subjects you write about here. Again, awesome website!
Great post. I was checking continuously this blog and I am impressed! I care for such info a lot.
I care for such info a lot.
Extremely helpful information particularly the last part
I was seeking this certain information for a very long time.
Thank you and best of luck.
Hello it’s me, I am also visiting this web page on a regular basis, this web site is really nice and the people are genuinely sharing nice thoughts.
Great article! That is the type of information that should be shared around the internet.
Disgrace on Google for not positioning this publish higher!
Come on over and seek advice from my web site .
Thanks =)
Also visit my blog electric breast pumps
Hello there! This is kind of off topic but I need some advice from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things out
pretty fast. I’m thinking about setting up my own but I’m not sure where to begin. Do you have any tips or suggestions?
Many thanks
Thank you for sharing your info. I truly appreciate your efforts and I will
be waiting for your further post thanks once again.
Thank you for the auspicious writeup. It actually was once a entertainment account
it. Glance advanced to far added agreeable from you!
However, how can we keep up a correspondence?
Hmm it seems like your blog ate my first comment (it was super long) so I guess I’ll just sum it up what I
had written and say, I’m thoroughly enjoying your blog. I as well am
an aspiring blog blogger but I’m still new to everything.
Do you have any points for first-time blog writers?
I’d really appreciate it.
Great beat ! I would like to apprentice while you amend your site, how can i subscribe for a blog website?
The account aided me a acceptable deal. I had been a little bit acquainted
of this your broadcast offered bright clear idea
Right away I am going to do my breakfast, when having my breakfast coming over again to read other news.
I am actually grateful to the owner of this site who has shared this enormous paragraph at at this time.
This is the right blog for anybody who really wants to understand this topic.
You understand a whole lot its almost tough to argue with you (not that I personally will need to?HaHa).
You certainly put a new spin on a topic that’s been discussed for ages.
Excellent stuff, just wonderful!
Here is my web site; Car Repair Hampton Roads (http://Www.Afunnydir.Com)
With havin so much written content do you ever run into any issues of plagorism or copyright violation? My site has a lot
of completely unique content I’ve either created myself or outsourced but it appears a lot
of it is popping it up all over the internet without my permission. Do you know any solutions to help protect
against content from being stolen? I’d really appreciate it.
Oh my goodness! Awesome article dude! Thank
you, However I am going through difficulties with your RSS.
I don’t know why I can’t subscribe to it. Is there
anybody having identical RSS problems? Anybody who knows the answer will you kindly respond?
Thanks!!
Hi, this weekend is nice in support of me, since this time i am reading this
fantastic informative paragraph here at my home.
A person essentially assist to make seriously posts I would state.
That is the first time I frequented your web page and thus far?
I amazed with the research you made to make this particular put up amazing.
Wonderful activity!
I like it when people come together and share ideas. Great blog, continue the good work!
I love reading through a post that will make people
think. Also, many thanks for permitting me to comment!
Keep on writing, great job!
Definitely imagine that which you said. Your favourite justification seemed to be on the web the simplest
factor to be mindful of. I say to you, I certainly get annoyed while other
people consider issues that they plainly do not understand
about. You controlled to hit the nail upon the top as well
as outlined out the whole thing without having side-effects ,
other people could take a signal. Will probably be
back to get more. Thanks
Wow, superb blog structure! How long have you been blogging for?
you made blogging glance easy. The entire look of your site is excellent, let alone the
content!
Excellent blog you have got here.. It’s difficult
to find excellent writing like yours these days.
I truly appreciate individuals like you! Take care!!
What’s up, all the time i used to check website posts here early in the morning, because i love to find out more and more.
My brother recommended I would possibly like this website.
He used to be totally right. This publish actually made my day.
You cann’t believe just how a lot time I had spent for
this information! Thank you!
Hi, after reading this remarkable post i am too delighted to share my know-how here with colleagues.
Wow, this post is fastidious, my younger sister is analyzing these things, so I am going to tell
her.
I loved as much as you’ll receive carried out right here. The sketch is tasteful, your authored material stylish.
nonetheless, you command get bought an edginess over that
you wish be delivering the following. unwell unquestionably come more formerly again as exactly the same
nearly a lot often inside case you shield this hike.
For most up-to-date news you have to go to see the web and on world-wide-web I
found this web page as a finest website for newest updates.
Hurrah! Finally I got a weblog from where I be able to truly obtain useful information regarding my study
and knowledge.
I’m impressed, I have to admit. Rarely do I come across a blog that’s both educative and entertaining, and
without a doubt, you have hit the nail on the head. The problem is something that too few people are speaking intelligently about.
I’m very happy I stumbled across this during my hunt for something concerning this.
My web site: video ngentot anak sma
Hi, of course this piece of writing is genuinely pleasant and I have learned lot of things from it on the topic of blogging.
thanks.
Hello! I simply wish to give you a big thumbs up for the excellent information you have got here on this post.
I will be coming back to your website for more soon.
Everything is very open with a very clear description of the challenges.
It was definitely informative. Your website is useful. Thank you for sharing!
Great article.
This website truly has all the information I needed concerning this subject
and didn’t know who to ask.
I have been exploring for a little bit for any high-quality articles or weblog posts
in this kind of area . Exploring in Yahoo I ultimately stumbled upon this site.
Studying this info So i’m glad to convey that I’ve a very good
uncanny feeling I found out exactly what I needed. I most surely will make sure to do not fail to remember this website and provides it a glance
regularly.
My partner and I stumbled over here from a different web address and
thought I might check things out. I like what I see so i am just following you.
Look forward to exploring your web page for a second time.
Nice post. I was checking constantly this blog and I’m impressed! I care for
I care for
Very useful information specially the last part
such information much. I was looking for this certain information for a long time.
Thank you and good luck.
I’m amazed, I must say. Rarely do I come across a blog that’s both equally
educative and amusing, and without a doubt, you have hit the
nail on the head. The problem is something which too few men and women are speaking intelligently about.
Now i’m very happy I found this during my hunt for
something concerning this.
Howdy exceptional blog! Does running a blog similar to this require a
large amount of work? I’ve very little expertise
in coding however I was hoping to start my own blog in the near future.
Anyhow, if you have any suggestions or tips for new blog owners please share.
I know this is off subject however I simply wanted to ask.
Thanks a lot!
First of all I would like to say superb blog! I had a quick question which I’d like to ask if you don’t
mind. I was interested to find out how you center yourself and
clear your mind prior to writing. I’ve had difficulty clearing my mind
in getting my thoughts out there. I do enjoy writing however it just seems like the first 10 to 15 minutes
are lost just trying to figure out how to begin. Any suggestions or hints?
Kudos!
Hello everybody, here every one is sharing these kinds of experience, thus it’s fastidious to read this blog, and I used to go
to see this webpage every day.
Wonderful, what a web site it is! This weblog provides valuable data to
us, keep it up.
I read this piece of writing completely on the topic of the comparison of hottest
and previous technologies, it’s remarkable article.
What’s up to all, how is the whole thing, I think every one is getting more from this
web page, and your views are fastidious in favor of new people.
Hurrah! After all I got a blog from where I be able to truly take helpful data concerning my study and
knowledge.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from
you! However, how could we communicate?
you are in point of fact a good webmaster. The site loading speed
is incredible. It seems that you are doing any distinctive trick.
In addition, The contents are masterwork. you’ve performed a wonderful job in this subject!
I got this site from my friend who shared with me about this site
and now this time I am browsing this web site and reading very
informative posts at this place.
Excellent weblog here! Also your site loads up very fast! What host are you
the use of? Can I am getting your affiliate hyperlink for your
host? I desire my website loaded up as fast as yours lol
After I originally commented I appear to have clicked on the -Notify me when new
comments are added- checkbox and from now on every time a comment is added I recieve 4 emails with the exact same comment.
Is there a way you are able to remove me from that service?
Thanks a lot!
My brother suggested I would possibly like this blog.
He used to be totally right. This publish truly made my day.
You can not consider simply how much time I had spent for this information! Thank
you!
My family members always say that I am killing my time here at web, except I know I am getting familiarity all the time by reading thes fastidious articles.
It’s appropriate time to make some plans for the future and it is time
to be happy. I’ve read this post and if I could I want to suggest you
some interesting things or tips. Perhaps you could write
next articles referring to this article. I wish to read more things about it!
Do you mind if I quote a few of your posts as long
as I provide credit and sources back to your website?
My blog is in the exact same area of interest as yours and my visitors would definitely benefit from some of the information you provide
here. Please let me know if this okay with you.
Thanks a lot!
Greetings! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly?
My blog looks weird when browsing from my apple iphone.
I’m trying to find a template or plugin that might be able to fix this
issue. If you have any suggestions, please share. Appreciate it!
киото хаттамасы артықшылығы
мен кемшіліктері, киото хаттамасы мақсаты тоқтар серіков – достарым скачать,
тоқтар серіков достарым текст робо сумо жарысы,
робо-сумо 5 класс шкибиди доп текст, скибиди доп
доп ес ес ремикс
Hi, i read your blog occasionally and i own a similar one and i was
just curious if you get a lot of spam responses? If so how do you protect against
it, any plugin or anything you can recommend? I get so much lately it’s driving me insane
so any support is very much appreciated.
Howdy! I could have sworn I’ve been to this website before but after browsing through some of the articles
I realized it’s new to me. Nonetheless, I’m certainly happy I
discovered it and I’ll be book-marking it and checking back
often!
Hello there! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Any recommendations?
Good day! I just want to offer you a huge thumbs up for the great information you have got right here on this post.
I will be returning to your web site for more soon.
I’ve been exploring for a little for any high-quality articles or weblog
posts on this sort of house . Exploring in Yahoo I ultimately stumbled
upon this site. Studying this information So i am happy to express that I have an incredibly good
uncanny feeling I discovered just what I needed.
I most for sure will make certain to don?t disregard this site and
provides it a glance on a constant basis.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an nervousness over that you wish be delivering the following.
unwell unquestionably come further formerly again as exactly the same nearly a lot often inside
case you shield this hike.
Excellent blog here! Also your site a lot up very
fast! What host are you the use of? Can I am getting your affiliate hyperlink on your host?
I desire my web site loaded up as fast as yours lol
certainly like your website however you need to test the spelling on quite a few of your posts.
Several of them are rife with spelling problems and I to find it very
bothersome to tell the truth then again I will surely come again again.
Wow that was strange. I just wrote an very long comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyway,
just wanted to say wonderful blog!
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance” between usability and visual appeal.
I must say you have done a excellent job with this. Additionally, the blog loads extremely quick for me on Chrome.
Superb Blog!
I know this web site gives quality based posts
and additional data, is there any other website which
gives these data in quality?
Incredible story there. What occurred after? Take care!
Just wish to say your article is as surprising. The clarity to your submit is
just cool and i can think you are an expert on this subject.
Fine with your permission allow me to take hold of your RSS feed to stay up to date with impending post.
Thank you 1,000,000 and please carry on the gratifying work.
Its like you read my mind! You appear to know so much about this,
like you wrote the book in it or something. I think that you can do with a few pics to
drive the message home a bit, but other than that, this is fantastic blog.
A great read. I’ll definitely be back.
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that
I get actually enjoyed account your blog posts. Any way I will be subscribing to your feeds
and even I achievement you access consistently rapidly.
Hi there it’s me, I am also visiting this website daily,
this site is actually good and the people are actually sharing nice thoughts.
Magnificent items from you, man. I have be aware your stuff previous to and you’re simply too fantastic.
I really like what you have bought right here, really like what you’re stating and the way in which through which
you assert it. You are making it entertaining and you still care for to keep
it wise. I cant wait to read much more from you.
This is really a great site.
This information is invaluable. Where can I find out more?
Hey there! Someone in my Myspace group shared this site with
us so I came to give it a look. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Terrific blog and excellent style and design.
Hello there! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Any suggestions?
An outstanding share! I’ve just forwarded this onto a coworker who has
been doing a little homework on this. And he in fact bought me dinner simply because I found it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanks for spending the time to talk about this issue
here on your blog.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is
added I get four e-mails with the same comment.
Is there any way you can remove people from that service?
Thanks!
Hey, I think your blog might be having browser compatibility issues.
When I look at your blog site in Firefox, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, fantastic blog!
I’ll right away grasp your rss as I can not in finding your email subscription link or newsletter
service. Do you’ve any? Kindly allow me recognise in order that I
could subscribe. Thanks.
Wow! After all I got a blog from where I be able to actually take helpful information regarding my study and knowledge.
It’s a shame you don’t have a donate button! I’d definitely donate to this excellent blog!
I suppose for now i’ll settle for bookmarking and adding
your RSS feed to my Google account. I look forward to brand new updates and will share this site
with my Facebook group. Talk soon!
My partner and I absolutely love your blog and find most of
your post’s to be precisely what I’m looking for. Does one offer guest writers to write content for you personally?
I wouldn’t mind writing a post or elaborating on a few of the subjects you write related to here.
Again, awesome site!
Thank you a lot for sharing this with all folks you actually understand
what you are speaking approximately! Bookmarked. Please
additionally visit my web site =). We can have a link alternate contract among us
Excellent items from you, man. I’ve consider your stuff previous to and you’re simply extremely wonderful.
I actually like what you have acquired here, really like what you’re stating and the best way during which you say it.
You’re making it enjoyable and you still take
care of to keep it wise. I can not wait to read far more from you.
That is actually a terrific website.
hello there and thank you for your information – I have definitely picked up anything new from right here.
I did however expertise some technical points using this website, as I experienced to
reload the website many times previous to I could get
it to load correctly. I had been wondering if your hosting is OK?
Not that I am complaining, but sluggish loading instances times will often affect
your placement in google and could damage your high quality score if advertising and marketing with Adwords.
Well I’m adding this RSS to my e-mail and could look out for much more of your respective exciting content.
Ensure that you update this again soon.
Oh my goodness! Amazing article dude! Many thanks, However I am
going through problems with your RSS. I don’t understand the reason why I can’t subscribe to it.
Is there anybody else having identical RSS issues?
Anyone who knows the answer will you kindly respond?
Thanks!!
I like the helpful info you provide in your articles. I will
bookmark your weblog and check again here frequently. I’m quite
sure I will learn plenty of new stuff right here!
Good luck for the next!
What’s up colleagues, how is everything, and what you wish for to say regarding this post, in my view its really remarkable in favor of me.
приказ 44 от 26 мая 2021, 44 приказ мз рк 2022 өз ісінің маманы орысша аудармасы, үлгілік оқу бағдарламасы техникалық және кәсіптік білім 09 регион казахстан, 03 регион казахстан вавилон мұнарасы туралы аңыз,
вавилон күнтізбесі
It’s truly very difficult in this full of activity life to listen news on Television, thus I only use web for
that reason, and obtain the latest information.
Very shortly this web site will be famous among all blog viewers, due
to it’s nice articles
A motivating discussion is worth comment. I believe that you should write more
on this topic, it may not be a taboo subject but typically people do not speak about
such topics. To the next! Many thanks!!
cena stali zbrojeniowej
Do you have a spam issue on this website; I also am a blogger,
and I was curious about your situation; we have developed some nice practices
and we are looking to trade techniques with others, why not shoot me an e-mail if
interested.
I have read a few good stuff here. Certainly price bookmarking for revisiting.
I wonder how a lot attempt you put to create such a excellent informative web site.
Stunning quest there. What occurred after? Take care!
Thanks for some other informative website. The place else may I
am getting that type of info written in such a perfect method?
I’ve a venture that I’m just now working on, and I
have been at the glance out for such info.
Have you ever thought about including a little bit more than just your articles?
I mean, what you say is important and all. But think about if you added some great pictures or video clips to give your posts more, “pop”!
Your content is excellent but with images and videos, this blog
could certainly be one of the greatest in its niche.
Terrific blog!
I’m gone to convey my little brother, that he should also
pay a quick visit this weblog on regular basis to get updated
from latest gossip.
Aw, this was an incredibly good post. Spending some time
and actual effort to generate a good article… but what can I say… I procrastinate a whole lot
and don’t manage to get nearly anything done.
I don’t even know how I finished up right here, but
I believed this submit used to be great. I do not know who you are
but certainly you are going to a famous blogger for those who are
not already. Cheers!
Hi there would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 different web browsers and I must say this blog loads a lot
quicker then most. Can you suggest a good internet hosting
provider at a honest price? Kudos, I appreciate it!
This is the perfect webpage for everyone who would like to find out about this topic.
You realize so much its almost tough to argue with you (not that I actually would want to…HaHa).
You certainly put a new spin on a topic that’s been discussed for many years.
Wonderful stuff, just wonderful!
Actually when someone doesn’t know after that its up to
other people that they will assist, so here it happens.
Link exchange is nothing else except it is only placing the other person’s webpage link on your page at
appropriate place and other person will also do similar in support of you.
I quite like reading a post that can make people think.
Also, many thanks for allowing me to comment!
What a data of un-ambiguity and preserveness of valuable
knowledge about unexpected feelings.
Remarkable! Its truly awesome article, I have got much
clear idea concerning from this post.
Oh my goodness! Incredible article dude! Thanks, However I am encountering troubles with your
RSS. I don’t know why I am unable to join it. Is there anybody getting identical RSS problems?
Anyone who knows the answer will you kindly respond?
Thanks!!
I’m very happy to find this website. I want to to thank you
for your time for this particularly fantastic read!!
I definitely savored every little bit of it and I have you saved as
a favorite to check out new things on your website.
I visited multiple web sites but the audio quality for
audio songs present at this web site is genuinely marvelous.
Hello superb website! Does running a blog like this require a large amount of work?
I’ve absolutely no expertise in coding but I had been hoping to start
my own blog soon. Anyway, should you have any suggestions or
tips for new blog owners please share. I understand this is off topic however I simply had to ask.
Thanks a lot!
Hi! I know this is somewhat off topic but I was wondering which blog
platform are you using for this website? I’m getting fed up of WordPress because I’ve had problems
with hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of a good
platform.
Hi, i feel that i saw you visited my weblog so
i got here to go back the choose?.I’m attempting
to to find issues to enhance my site!I assume its ok to
make use of a few of your ideas!!
Very nice article, totally what I was looking for.
It’s perfect time to make a few plans for the long run and it is time to
be happy. I have read this put up and if I may I wish to counsel you few attention-grabbing things or advice.
Perhaps you can write subsequent articles regarding
this article. I want to read more issues about it!
Howdy! Someone in my Myspace group shared this website with us so
I came to check it out. I’m definitely loving the information. I’m bookmarking and will be tweeting this to
my followers! Excellent blog and outstanding design.
What’s up, yup this piece of writing is in fact fastidious and I have learned lot of things from it on the
topic of blogging. thanks.
Heya i am for the first time here. I came across this board and I find It really useful & it helped me
out much. I hope to give something back and help others like you helped me.
Can I simply just say what a comfort to find a person that
actually knows what they’re talking about on the internet.
You definitely know how to bring an issue to light and make it
important. A lot more people should read this
and understand this side of your story. It’s surprising you’re not more popular because you surely have the gift.
What i don’t understood is if truth be told how you are
now not actually a lot more smartly-appreciated than you might be right now.
You are so intelligent. You already know thus considerably in the case of this topic, made me in my
opinion consider it from numerous numerous angles. Its like
women and men don’t seem to be fascinated except it is something to do with Woman gaga!
Your personal stuffs outstanding. Always care for it
up!
Hi there Dear, are you in fact visiting this site on a regular
basis, if so afterward you will without doubt get fastidious knowledge.
Hey there would you mind letting me know which hosting company
you’re working with? I’ve loaded your blog in 3 completely different browsers and I must
say this blog loads a lot quicker then most.
Can you recommend a good internet hosting provider at a honest price?
Thanks, I appreciate it!
Thankfulness to my father who stated to me on the topic of this
web site, this blog is genuinely awesome.
I have read so many articles or reviews on the topic of the
blogger lovers except this post is in fact a fastidious paragraph, keep it
up.
Hi! Do you use Twitter? I’d like to follow you if that would be okay.
I’m definitely enjoying your blog and look forward to new posts.
Thanks for sharing your thoughts on production process and facilities.
Regards
Very good post. I am going through some of these issues
as well..
Very good blog! Do you have any tips and hints for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress
or go for a paid option? There are so many options out there that I’m
completely overwhelmed .. Any tips? Thanks!
I constantly spent my half an hour to read this blog’s
articles every day along with a cup of coffee.
Does your blog have a contact page? I’m having trouble
locating it but, I’d like to shoot you an e-mail. I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing
it expand over time.
Have you ever thought about creating an ebook or guest authoring
on other blogs? I have a blog based upon on the same information you discuss and would really
like to have you share some stories/information. I know my viewers would
enjoy your work. If you’re even remotely interested, feel free to send me an e mail.
Good article. I’m experiencing some of these issues
as well..
Hi, i think that i saw you visited my site so i came to “return the favor”.I am attempting to find things
to improve my site!I suppose its ok to use a few of your ideas!!
My web page: indowin168
I have read so many content concerning the blogger lovers but this
piece of writing is actually a fastidious piece of writing, keep it up.
Hello There. I found your blog using msn. This is a really well written article.
I will make sure to bookmark it and come back to read more of your useful info.
Thanks for the post. I will certainly comeback.
Very great post. I simply stumbled upon your blog and wished
to mention that I’ve really loved surfing around your weblog posts.
In any case I will be subscribing to your rss feed and I am
hoping you write once more soon!
Thanks , I’ve recently been searching for information approximately this topic for
ages and yours is the greatest I’ve discovered so far.
However, what about the conclusion? Are you certain concerning the source?
Peculiar article, just what I was looking for.
Hi! I know this is kind of off topic but I was wondering which blog platform are you using for
this site? I’m getting tired of WordPress because I’ve had
issues with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
It’s going to be ending of mine day, however before ending I am reading this
enormous piece of writing to increase my knowledge.
bookmarked!!, I like your web site!
My programmer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the
expenses. But he’s tryiong none the less. I’ve been using Movable-type on several websites
for about a year and am worried about switching to another platform.
I have heard good things about blogengine.net.
Is there a way I can import all my wordpress posts into it?
Any help would be greatly appreciated!
Good day! I could have sworn I’ve been to this website before but after reading through some of the post I realized it’s new to me.
Anyhow, I’m definitely delighted I found it and I’ll be bookmarking and checking back frequently!
Wow! This blog looks just like my old one! It’s on a totally
different topic but it has pretty much the same page layout
and design. Outstanding choice of colors!
Why users still use to read news papers when in this
technological world everything is existing on net?
I love what you guys tend to be up too. This type of clever work and coverage!
Keep up the amazing works guys I’ve added you guys to my personal
blogroll.
This is my first time visit at here and i am actually happy
to read everthing at alone place.
Hello just wanted to give you a brief heads up and let you know a
few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show
the same results.
You really make it seem so easy along with your presentation but I find this
matter to be really one thing that I believe I might
by no means understand. It seems too complicated and extremely vast for
me. I’m having a look ahead to your subsequent publish,
I’ll try to get the hang of it!
What’s up, after reading this awesome piece of writing i am also
delighted to share my knowledge here with mates.
Excellent weblog here! Additionally your web site a lot up very fast!
What web host are you the use of? Can I am getting your affiliate
hyperlink to your host? I want my site loaded up as quickly as yours
lol
Hi, this weekend is fastidious in support of me, since
this occasion i am reading this wonderful educational article here at my
residence.
Pretty nice post. I just stumbled upon your
blog and wanted to say that I have truly enjoyed surfing around your blog posts.
After all I will be subscribing to your feed and I hope you
write again soon!
Appreciating the persistence you put into your blog and in depth information you offer.
It’s great to come across a blog every once in a while that isn’t the
same outdated rehashed information. Excellent
read! I’ve bookmarked your site and I’m adding your RSS feeds to my Google account.
Feel free to visit my page – Vavada зеркало
What a data of un-ambiguity and preserveness of valuable
familiarity concerning unexpected feelings.
Hi! Would you mind if I share your blog with my twitter group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Thanks
Hi there! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up
losing a few months of hard work due to no backup. Do you have any solutions to stop hackers?
I’m gone to convey my little brother, that he should also pay a visit this web site on regular basis to obtain updated from latest information.
Nice replies in return of this difficulty with real arguments and explaining the whole thing concerning
that.
Hi my loved one! I wish to say that this post is awesome, great written and include approximately all significant infos.
I’d like to peer extra posts like this .
Have you ever thought about creating an ebook or guest authoring on other blogs?
I have a blog based upon on the same information you discuss and would really like to have
you share some stories/information. I know my visitors would appreciate your work.
If you are even remotely interested, feel free to send me an e mail.
you are really a excellent webmaster. The site loading velocity is amazing.
It kind of feels that you’re doing any distinctive trick.
Furthermore, The contents are masterpiece. you’ve done a
wonderful process on this subject!
Hello! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no data backup.
Do you have any methods to protect against hackers?
This is my first time pay a visit at here and i am in fact impressed to read everthing at one place.
I’ve read several excellent stuff here. Certainly price bookmarking for revisiting.
I surprise how much effort you put to make one of
these excellent informative web site.
Hmm is anyone else encountering problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any feed-back would be greatly appreciated.
Right here is the perfect website for anybody who wants to find out about this topic.
You know so much its almost tough to argue with you (not that I actually will need to…HaHa).
You certainly put a brand new spin on a topic that has
been written about for a long time. Great stuff, just great!
I was recommended this web site by way of my cousin. I am no longer
sure whether or not this submit is written by means of him as no one else recognize such
designated about my problem. You’re wonderful! Thanks!
It is perfect time to make some plans for the future and it’s time
to be happy. I have read this post and if I could I want to suggest
you few interesting things or suggestions. Maybe you could write next articles referring to
this article. I want to read even more things about it!
This piece of writing is actually a fastidious one it assists new
internet people, who are wishing in favor of blogging.
Hello fantastic website! Does running a blog similar to this take a lot of work?
I’ve virtually no knowledge of coding however I had been hoping to start my
own blog soon. Anyhow, if you have any ideas or techniques for
new blog owners please share. I know this is off topic
nevertheless I simply had to ask. Cheers!
Hi! I know this is kind of off-topic however I needed to ask.
Does running a well-established blog such as yours take a large amount of work?
I am brand new to blogging however I do write in my diary every day.
I’d like to start a blog so I will be able to share my experience and feelings online.
Please let me know if you have any suggestions or tips for new aspiring blog
owners. Appreciate it!
Today, while I was at work, my cousin stole my iphone and tested to see if it can survive a twenty five foot drop,
just so she can be a youtube sensation. My apple ipad is now broken and she
has 83 views. I know this is completely off topic but I had to share it with someone!
Your style is unique compared to other folks I’ve read stuff from.
Thank you for posting when you have the opportunity, Guess I’ll just book mark
this web site.
Hello I am so grateful I found your webpage, I
really found you by accident, while I was looking on Digg for something else, Nonetheless I am here now and would just like
to say thanks a lot for a remarkable post and a all round interesting blog (I also love the theme/design), I don’t have time to browse it all at the moment but I have book-marked it and also
added in your RSS feeds, so when I have time I will be back
to read much more, Please do keep up the awesome jo.
I know this if off topic but I’m looking into starting my own blog and was wondering what all is needed to get setup?
I’m assuming having a blog like yours would cost
a pretty penny? I’m not very web savvy so I’m not 100% certain. Any suggestions or advice would be greatly appreciated.
Thank you
Way cool! Some extremely valid points! I appreciate you writing this write-up and also the
rest of the website is very good.
Hi there to all, the contents present at this web
site are actually amazing for people experience, well, keep up the
nice work fellows.
Here is my webpage – 토토사이트추천
Hi to all, how is all, I think every one is getting more from this web page, and
your views are good in favor of new users. comment-11016
Way cool! Some extremely valid points! I appreciate you penning this write-up and also the rest of the website is extremely good.
Hey there, You have done an incredible job. I’ll definitely digg it and personally recommend to my friends.
I’m confident they’ll be benefited from this web site.
Having read this I believed it was really informative. I
appreciate you spending some time and energy to put this content together.
I once again find myself personally spending way too much time both reading and commenting.
But so what, it was still worthwhile!
Hi there friends, how is all, and what you wish for to say
on the topic of this post, in my view its truly amazing for me.
Hi there! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Thank you!
Neat blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really make
my blog shine. Please let me know where you got your design. Thanks a lot
You can definitely see your expertise in the article you write.
The world hopes for even more passionate writers such as you who are not afraid to say
how they believe. At all times follow your heart.
Incredible! This blog looks just like my old one! It’s on a totally different topic but it has pretty much the same layout and design. Excellent choice of colors!
I appreciate, result in I discovered exactly what I used to be taking a look for.
You have ended my four day long hunt! God Bless you man. Have a nice day.
Bye
Howdy, i read your blog from time to time and i own a similar one and i was
just curious if you get a lot of spam feedback?
If so how do you reduce it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any help is very much appreciated.
With havin so much content do you ever run into any problems of plagorism or
copyright violation? My site has a lot of completely unique content I’ve either created myself or outsourced but it appears a lot of it is popping it up all over the
internet without my agreement. Do you know any solutions to
help reduce content from being ripped off? I’d genuinely appreciate it.
Great post. I was checking constantly this blog and I am impressed!
Extremely helpful information specifically the last part :
) I care for such info a lot. I was looking for this certain info for a long time.
Thank you and good luck.
Incredible quest there. What happened after? Good luck!
You could definitely see your expertise in the article you write.
The arena hopes for more passionate writers such as you who aren’t afraid to mention how
they believe. At all times follow your heart.
Hello, Neat post. There is an issue with your site in web explorer, would check this?
IE nonetheless is the market leader and a huge portion of other folks will leave out your excellent writing due to this problem.
I think that everything published was actually very reasonable.
However, think on this, what if you added a little content?
I ain’t saying your information is not solid., however what if you added something that grabbed
folk’s attention? I mean Пиастры –
Составление семантического ядра | is a little plain. You should peek at Yahoo’s front page and note how they
create news headlines to grab people interested. You might add a related video or a picture or two to get readers excited about what
you’ve got to say. Just my opinion, it might
make your blog a little livelier.
Howdy! This article could not be written any better!
Going through this article reminds me of my previous roommate!
He constantly kept preaching about this.
I will send this article to him. Pretty sure he’s going to have a good read.
Thanks for sharing!
This is my first time go to see at here and i am in fact impressed to read everthing at alone place.
Excellent way of telling, and good post to take data on the topic of my presentation focus,
which i am going to present in school.
Because the admin of this web page is working, no hesitation very shortly it will be
renowned, due to its quality contents.
Also visit my web blog; koitoto
I am now not sure the place you are getting your information, but good topic.
I must spend some time finding out much more or understanding more.
Thank you for fantastic information I was looking for this
information for my mission.
Also visit my blog … mawarslot
I’m impressed, I must say. Rarely do I encounter a blog
that’s equally educative and interesting, and without a doubt, you’ve hit the nail on the head.
The issue is something that not enough folks are speaking intelligently about.
I am very happy that I came across this during my hunt for something regarding this.
Great goods from you, man. I have understand your stuff previous to and you are just too wonderful.
I really like what you’ve acquired here, really like what you’re stating and the way in which you
say it. You make it entertaining and you still take care of to keep it smart.
I cant wait to read much more from you. This is really a terrific site.
Hey there would you mind stating which blog platform you’re using?
I’m planning to start my own blog in the near future but I’m having a
difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs
and I’m looking for something completely unique.
P.S Apologies for being off-topic but I had to ask!
Hey there! I know this is sort of off-topic but I needed to ask.
Does running a well-established blog like yours require a lot
of work? I am completely new to blogging however I do write in my journal everyday.
I’d like to start a blog so I will be able to share my own experience and thoughts online.
Please let me know if you have any kind of recommendations or
tips for brand new aspiring bloggers. Appreciate it!
Definitely believe that which you stated. Your favorite justification appeared to be on the net the simplest thing to be
aware of. I say to you, I definitely get annoyed while people consider
worries that they just don’t know about. You managed to hit the nail
upon the top and defined out the whole thing without having side-effects , people could take a signal.
Will likely be back to get more. Thanks
Hello There. I found your blog using msn. This is a very
well written article. I’ll be sure to bookmark it and return to read more of your
useful info. Thanks for the post. I’ll certainly comeback.
This post is priceless. How can I find out more?
Take a look at my website: 토토사이트 추천
These are actually fantastic ideas in concerning blogging.
You have touched some pleasant points here. Any way keep up wrinting.
Hey There. I found your blog using msn. This is a really well written article.
I’ll make sure to bookmark it and come back to read more of your useful information. Thanks
for the post. I’ll definitely return.
Hello, i believe that i noticed you visited my web site so i came to go back the prefer?.I am trying to in finding issues to enhance my site!I guess
its ok to make use of some of your ideas!!
There are various tools and websites that claim to permit users to view
private Instagram profiles, but it’s important to retrieve these past caution. Many of these tools can be unreliable, may
require personal information, or could violate Instagram’s terms
of service. Additionally, using such tools can compromise your own security or
lead to scams. The safest and most ethical showing off to view a private profile is
to send a follow demand directly to the user. Always prioritize privacy
and worship in your online interactions.
Take a look at my website … how do you view private instagram accounts
Very energetic blog, I enjoyed that a lot. Will there be a part 2?
Hello to every one, because I am in fact keen of
reading this website’s post to be updated regularly.
It consists of pleasant stuff.
You have made some really good points there. I looked on the web for more info about the issue and found most people will go along with
your views on this web site.
Hi, I do believe this is an excellent website.
I stumbledupon it 😉 I’m going to revisit once again since I bookmarked it.
Money and freedom is the best way to change, may you be
rich and continue to guide others.
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo
News? I’ve been trying for a while but I never seem to get there!
Thank you
Excellent post however , I was wondering if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit further.
Thank you!
Tremendous things here. I am very happy to look your article.
Thank you a lot and I am having a look forward to contact you.
Will you kindly drop me a mail?
Hi, Neat post. There’s an issue with your site in web explorer, would test this?
IE nonetheless is the market leader and a large section of folks will pass over your
fantastic writing because of this problem.
I like it whenever people come together and share ideas.
Great website, stick with it!
Thanks very nice blog!
Wonderful website you have here but I was wanting to know if you knew
of any community forums that cover the same topics talked about here?
I’d really like to be a part of group where I can get advice from other knowledgeable people that share the
same interest. If you have any suggestions, please let
me know. Kudos!
Aw, this was an incredibly good post. Spending some
time and actual effort to create a superb article… but
what can I say… I procrastinate a lot and don’t manage to get nearly anything done.
I have read so many articles or reviews concerning the blogger lovers but
this piece of writing is truly a nice article, keep it up.
An outstanding share! I’ve just forwarded this onto a co-worker who has been conducting a little homework
on this. And he actually ordered me breakfast simply because I found it for him…
lol. So let me reword this…. Thanks for the meal!! But yeah,
thanx for spending time to discuss this topic here on your
web page.
It’s in point of fact a nice and helpful piece of info.
I’m glad that you shared this helpful info with us. Please keep us
up to date like this. Thanks for sharing.
I do believe all of the ideas you have introduced
on your post. They are very convincing and will certainly work.
Nonetheless, the posts are very brief for newbies.
May you please lengthen them a little from subsequent time?
Thanks for the post.
Hi, its fastidious piece of writing on the topic of media print,
we all understand media is a enormous source of data.
It is truly a great and useful piece of info. I am happy that you just shared this
helpful info with us. Please stay us informed like this.
Thanks for sharing.
Hey! This is kind of off topic but I need some guidance from
an established blog. Is it very difficult to set up your own blog?
I’m not very techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not sure where to start.
Do you have any tips or suggestions? Cheers
When someone writes an post he/she keeps the idea of a user in his/her brain that how
a user can understand it. Thus that’s why this article is amazing.
Thanks!
I used to be able to find good info from your content.
Excellent article. Keep writing such kind of info on your
page. Im really impressed by it.
Hello there, You have done a fantastic job. I’ll definitely digg it
and personally suggest to my friends. I’m sure they’ll be benefited from this website.
Have you ever considered publishing an ebook or guest authoring on other websites?
I have a blog centered on the same topics you discuss and would really like to have you share some stories/information. I know my visitors would enjoy your work.
If you’re even remotely interested, feel free to shoot me an e-mail.
What’s up friends, pleasant article and fastidious urging commented
at this place, I am truly enjoying by these.
Very soon this website will be famous amid all blogging and site-building viewers, due to it’s pleasant posts
Oh my goodness! Amazing article dude! Many thanks, However I am going through issues with your RSS.
I don’t know the reason why I am unable to join it. Is there anybody else getting similar RSS issues?
Anybody who knows the solution will you kindly
respond? Thanx!!
I don’t even know how I stopped up right here, but I assumed this post used to be great.
I do not recognise who you might be however certainly you’re going to
a well-known blogger in the event you aren’t already.
Cheers!
Thanks very interesting blog!
Admiring the dedication you put into your website and detailed information you present.
It’s awesome to come across a blog every once in a while that isn’t the same outdated rehashed information. Wonderful
read! I’ve saved your site and I’m adding your RSS
feeds to my Google account.
Superb blog you have here but I was wanting to know
if you knew of any message boards that cover the
same topics talked about in this article? I’d really love to be a part of community where I can get feedback from other
experienced people that share the same interest. If you have any recommendations,
please let me know. Cheers!
Hello very nice blog!! Man .. Excellent .. Wonderful ..
I will bookmark your web site and take the feeds additionally?
I’m satisfied to seek out a lot of helpful information here in the publish, we’d like develop extra techniques
on this regard, thanks for sharing. . . . . .
Do you mind if I quote a few of your articles as long as I provide credit and sources back
to your website? My blog is in the very same niche as yours
and my users would genuinely benefit from a lot
of the information you provide here. Please let me know if this ok with
you. Thanks!
Thanks for any other informative site. Where else may I am getting that kind of information written in such an ideal means?
I’ve a undertaking that I am simply now running on, and
I’ve been at the glance out for such information.
Hi mates, how is everything, and what you would like to say about this piece of writing, in my view its actually awesome in support of me.
Hello, i feel that i saw you visited my site so i got here to go back the
desire?.I’m attempting to in finding things to enhance my website!I assume its ok to make use of a few
of your ideas!!
Incredible quest there. What happened after? Thanks!
I’m impressed, I have to admit. Rarely do I come across a blog that’s equally educative and interesting, and let me tell
you, you’ve hit the nail on the head. The issue is something too few folks are speaking intelligently about.
I’m very happy that I found this in my search for something concerning this.
That is a great tip particularly to those
new to the blogosphere. Simple but very precise information… Thanks for sharing this one.
A must read article!
It’s remarkable to pay a quick visit this site and reading the views of all colleagues concerning this paragraph, while
I am also keen of getting familiarity.
This design is wicked! You definitely know how to keep
a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Fantastic job. I really enjoyed what you
had to say, and more than that, how you presented it.
Too cool!
It’s a shame you don’t have a donate button! I’d most certainly donate to
this brilliant blog! I guess for now i’ll settle for book-marking and adding your RSS feed to my
Google account. I look forward to new updates and will share this
website with my Facebook group. Chat soon!
Hi there every one, here every person is sharing such knowledge, so it’s fastidious to read this weblog, and I used to visit this blog every day.
Thanks for sharing your thoughts about bk8. Regards
Greetings from Colorado! I’m bored to tears at work so I
decided to check out your blog on my iphone during lunch break.
I love the info you provide here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyways, fantastic blog!
Hi, the whole thing is going perfectly here and ofcourse every one is sharing information, that’s truly good, keep
up writing.
Feel free to surf to my web site; best vpn software.
Those on a pay-as-you-go mobile phone contract in the UK can also use the pay-by-phone bill option.
I was recommended this blog by means of my
cousin. I’m not sure whether this put up is written via him as nobody else understand such special about
my difficulty. You are amazing! Thank you!
Hello! I could have sworn I’ve been to your blog before but after browsing through a few of the articles I realized it’s new to me.
Anyhow, I’m definitely delighted I discovered it and I’ll be bookmarking it and checking back often!
I like the helpful info you provide in your articles.
I will bookmark your blog and check again here regularly.
I’m quite certain I’ll learn many new stuff right here!
Good luck for the next!
Appreciate this post. Will try it out.
Hi there i am kavin, its my first time to commenting anywhere,
when i read this post i thought i could also create comment due to this brilliant post.
Actually when someone doesn’t understand then its up to other users that they will
assist, so here it happens.
my webpage; coffee sweatshirts
Hello, i think that i saw you visited my weblog
so i came to “return the favor”.I’m trying to find
things to improve my web site!I suppose its ok to use a
few of your ideas!!
Do you have a spam problem on this blog; I
also am a blogger, and I was wanting to know your situation; we have developed some nice practices and we are looking to exchange techniques with other folks, why not shoot
me an email if interested.
If you desire to get a good deal from this piece of writing then you
have to apply such strategies to your won web site.
I don’t even understand how I ended up here, however I assumed this publish used to be good.
I do not know who you are however certainly you are going to a well-known blogger if you aren’t already.
Cheers!
Thanks very nice blog!
AssignmentHelper.com.au is a trusted resource for students
in Australia seeking expert assignment help. With a team of qualified professionals, we provide comprehensive assistance for all academic levels, ensuring students get the support they need to excel in their studies.
Whether you’re working on complex research projects or need help with essays, AssignmentHelper.com.au offers reliable
and timely assignment help Australia to help students achieve their academic goals.
Thanks in favor of sharing such a pleasant thought, article is fastidious, thats why
i have read it completely
Thank you for the good writeup. It in fact was a amusement
account it. Look advanced to far added agreeable from you!
However, how could we communicate?
Fantastic post however I was wanting to know if you could write a litte more on this topic?
I’d be very thankful if you could elaborate
a little bit further. Cheers!
Good post. I learn something totally new and challenging on websites I stumbleupon every day.
It’s always interesting to read through content from other authors and practice something from other web sites.
Great post. I was checking constantly this weblog and I am impressed!
Very useful information specially the last section :
) I handle such information much. I used to be looking for this
certain info for a long time. Thanks and good luck.
It’s actually very complex in this active life to listen news on Television,
so I only use internet for that purpose, and take the newest news.
Genuinely when someone doesn’t know afterward its up
to other people that they will help, so here it happens.
Piece of writing writing is also a fun, if you be familiar with afterward
you can write or else it is complicated to write.
Just desire to say your article is as astounding.
The clearness in your post is just excellent and i could assume you are an expert on this subject.
Well with your permission allow me to grab your feed to keep up to date with
forthcoming post. Thanks a million and please continue the rewarding
work. jili สล็อต
I have been surfing online more than three hours today, yet
I never found any interesting article like yours. It’s pretty worth enough for me.
Personally, if all website owners and bloggers made good content
as you did, the internet will be a lot more useful than ever before.
I needed to thank you for this great read!! I definitely
enjoyed every bit of it. I have you book-marked to check out new stuff you post…
excellent issues altogether, you simply received a brand new reader.
What would you suggest about your publish that you
made some days ago? Any positive?
It is truly a nice and helpful piece of info. I am satisfied
that you just shared this useful information with us.
Please stay us up to date like this. Thanks for sharing.
Hi everyone, it’s my first pay a quick visit at this website, and post is truly fruitful in favor of me, keep up posting these types of posts.
Feel free to visit my site sengtoto slot
Does your website have a contact page? I’m having problems locating it but, I’d like to send you an e-mail.
I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it grow over time.
Definitely believe that which you said. Your favorite justification seemed to be on the net the easiest thing to be aware
of. I say to you, I definitely get irked while people consider
worries that they just do not know about. You managed to hit the nail upon the top and defined out the
whole thing without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
I’m gone to convey my little brother, that he should also pay a quick
visit this webpage on regular basis to take updated from hottest information.
Very good article. I certainly love this website. Keep writing!
Magnificent items from you, man. I have understand your stuff previous to and you are simply extremely great.
I really like what you have obtained here, really like what you’re saying and the best way during which you
assert it. You’re making it enjoyable and you continue to take care of to keep it smart.
I cant wait to learn much more from you.
This is really a great website.
Also visit my homepage slot demo
Attractive element of content. I simply stumbled upon your weblog and in accession capital to say
that I get in fact loved account your weblog posts.
Anyway I will be subscribing to your augment or even I achievement you get entry to constantly
fast.
I could not resist commenting. Perfectly written!
Also visit my web page :: GEMAR4D
You really make it seem so easy with your presentation but I find this matter
to be really something that I think I would never understand.
It seems too complicated and extremely broad for me. I am looking
forward for your next post, I’ll try to get the hang of it!
Hi there! I know this is kinda off topic however I’d
figured I’d ask. Would you be interested in trading links or maybe guest writing a blog article or vice-versa?
My site goes over a lot of the same subjects as yours and I think
we could greatly benefit from each other. If you are interested feel free to send me an email.
I look forward to hearing from you! Terrific blog by
the way!
It’s actually very complex in this busy life to listen news on Television, thus I simply use internet
for that reason, and take the most up-to-date information.
Feel free to visit my webpage; Minitoto togel
Sweet blog! I found it while browsing on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
You’ve made some decent points there. I checked on the net to find out more about the issue and found most people will go along with
your views on this web site.
This piece of writing is really a pleasant one it assists new the web viewers, who
are wishing for blogging.
Today, I went to the beach with my children. I found a sea shell and gave it to
my 4 year old daughter and said “You can hear the ocean if you put this to your ear.”
She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had
to tell someone!
I was wondering if you ever considered changing the layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two
pictures. Maybe you could space it out better?
My web site – bandar toto
Good blog you’ve got here.. It’s difficult to find high quality writing like yours nowadays.
I really appreciate people like you! Take care!!
What’s Happening i’m new to this, I stumbled upon this I have found It positively helpful and
it has aided me out loads. I am hoping to contribute & assist other customers
like its aided me. Good job.
Hiya very cool website!! Man .. Excellent ..
Amazing .. I will bookmark your website and take the feeds also?
I’m satisfied to find so many helpful info here within the publish, we need develop more strategies on this regard, thanks for sharing.
. . . . .
Hello, after reading this remarkable piece of writing i am as
well glad to share my familiarity here with mates.
I am regular reader, how are you everybody? This piece of writing
posted at this website is really nice.
Why people still make use of to read news papers when in this technological globe everything is accessible on net?
I know this website presents quality dependent content
and additional stuff, is there any other web page which provides such data in quality?
I every time spent my half an hour to read this web
site’s content every day along with a cup of coffee.
obviously like your website but you have to test the
spelling on quite a few of your posts. A number of them are rife with spelling issues
and I find it very troublesome to inform the reality then again I’ll certainly
come back again.
You could definitely see your skills in the article you write.
The sector hopes for even more passionate writers such as
you who are not afraid to mention how they believe.
At all times follow your heart.
My blog slot gacor
Hmm it looks like your website ate my first comment (it was super long) so I guess I’ll just sum
it up what I wrote and say, I’m thoroughly enjoying your
blog. I too am an aspiring blog writer but I’m still new
to the whole thing. Do you have any recommendations for rookie blog writers?
I’d genuinely appreciate it.
Nice blog here! Also your website loads up very fast! What host
are you using? Can I get your affiliate link to your host?
I wish my site loaded up as fast as yours lol
I used to be recommended this web site by way of my cousin. I’m no longer positive whether or not this
post is written via him as no one else recognize such exact about my difficulty.
You are incredible! Thanks!
An outstanding share! I’ve just forwarded this onto a colleague who had been doing a little homework on this.
And he actually bought me breakfast simply because I discovered it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanks for spending time to discuss this issue here on your site.
Take a look at my blog post :: coinqqslot
I just like the helpful information you provide to your articles.
I will bookmark your blog and check once more
right here frequently. I’m rather certain I will be told a lot of new stuff right right
here! Good luck for the next!
I am truly glad to read this weblog posts which contains lots of helpful data, thanks for providing these
data.
Its like you read my mind! You seem to know so much about
this, like you wrote the book in it or something. I think that you can do with a
few pics to drive the message home a bit, but other than that,
this is great blog. A fantastic read. I’ll definitely be back.
Hello, just wanted to tell you, I liked this article.
It was practical. Keep on posting!
Stop by my web page paito togel taiwan
Hmm it appears like your blog ate my first comment (it was super long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still
new to everything. Do you have any recommendations for newbie blog writers?
I’d genuinely appreciate it.
My web site … togel online
Amazing issues here. I’m very satisfied to peer your article.
Thanks a lot and I am looking ahead to touch you. Will you please drop me a mail?
What’s up, just wanted to mention, I liked this article.
It was practical. Keep on posting!
Hi there! Someone in my Facebook group shared this website with
us so I came to take a look. I’m definitely enjoying the information. I’m book-marking
and will be tweeting this to my followers! Outstanding blog and fantastic style and design.
my web blog; bandar togel online
Highly descriptive post, I loved that a lot. Will there be a part 2?
Hi, There’s no doubt that your site may be having internet browser
compatibility issues. When I take a look at your blog in Safari,
it looks fine however, when opening in IE, it has some overlapping issues.
I merely wanted to provide you with a quick heads up!
Besides that, wonderful site!
Feel free to visit my web page … rtp acehbola
Hello, I read your blogs like every week. Your story-telling style is witty, keep doing what you’re doing!
hi!,I really like your writing so so much! proportion we keep in touch
extra about your post on AOL? I need a specialist in this
area to solve my problem. May be that’s you! Having a look ahead to see you.
This is the right blog for everyone who would like to find
out about this topic. You realize so much its almost tough to argue with you (not that I
really would want to…HaHa). You certainly put a fresh spin on a
topic that’s been discussed for ages. Great stuff, just great!
I’m not sure exactly why but this weblog is loading extremely slow for
me. Is anyone else having this problem or is it a issue on my
end? I’ll check back later and see if the problem still exists.
Thank you, I have recently been looking for information about this subject
for a while and yours is the best I have discovered till now.
But, what concerning the conclusion? Are you certain concerning the supply?
I relish, result in I found exactly what I was taking a look for.
You have ended my four day lengthy hunt! God Bless you man. Have a
nice day. Bye
Appreciate this post. Let me try it out.
My website; Discover Superior IPTV Viewing
What’s up to all, because I am actually eager of reading this blog’s post to be updated regularly.
It includes nice stuff.
Hi, I do think this is an excellent website. I stumbledupon it 😉 I’m going to come back yet
again since i have book-marked it. Money and freedom is
the greatest way to change, may you be rich and
continue to guide others.
Hello to every single one, it’s really a fastidious for me to visit this web page, it includes priceless Information.
Hi there, I enjoy reading through your article.
I like to write a little comment to support you.
Hiya! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My blog looks weird when browsing from my iphone 4.
I’m trying to find a theme or plugin that might be able to correct this issue.
If you have any suggestions, please share. Many thanks!
Hello, i think that i noticed you visited my website
so i came to return the favor?.I’m trying to to find issues to improve my website!I assume its
adequate to make use of some of your ideas!!
This is my first time pay a quick visit at here and i am actually impressed to
read everthing at single place.
Excellent post. I definitely love this website. Stick with it!
I’m impressed, I must say. Seldom do I come across a blog that’s equally
educative and interesting, and without a doubt, you have
hit the nail on the head. The problem is something that not enough folks are speaking intelligently about.
I am very happy I came across this during my search for
something regarding this.
Thanks to my father who told me concerning this website,
this weblog is genuinely remarkable.
You really make it seem so easy with your presentation but I find this matter
to be actually something which I think I would never understand.
It seems too complicated and extremely broad for me. I am looking forward for your next post, I will try to get
the hang of it!
I don’t even know the way I ended up right here, however
I assumed this publish used to be great.
I do not recognize who you might be however definitely you’re going to a well-known blogger
if you happen to aren’t already. Cheers!
I think the admin of this site is actually working hard in support of his
web page, because here every data is quality based stuff.
Good answer back in return of this question with real arguments and
describing the whole thing about that.
Hello I am so glad I found your blog page, I really found you by error, while I was looking on Digg for something else, Anyhow I am here
now and would just like to say thanks a lot for a remarkable post and
a all round exciting blog (I also love the theme/design), I don’t have time to
read it all at the moment but I have saved it and
also added in your RSS feeds, so when I have time I will be back to read
much more, Please do keep up the fantastic work.
It’s perfect time to make some plans for the long run and it is time to be happy.
I’ve read this put up and if I may I desire to
recommend you some fascinating things or advice. Perhaps you could write subsequent articles regarding this article.
I desire to read even more things approximately it!
Greetings! Very helpful advice within this post!
It’s the little changes that will make the biggest changes.
Thanks for sharing!
I think that is among the most significant info for me.
And i am glad reading your article. However wanna observation on some basic things, The website style is perfect,
the articles is truly great : D. Excellent process, cheers
It’s a shame you don’t have a donate button! I’d certainly donafe tto this excellent blog!
I guess for now i’ll settle for bookmarking and adding
your RSS feed to my Google account. I look forward to brand new updates annd will
talk about this site with my Facebook group. Chat
soon!
If some one needs expert view regarding blogging after that i propose him/her to visit this web site, Keep up the nice work.
Whoa! This blog looks just like my old one! It’s
on a completely different topkc but it has prettgy much the
same page layout and design. Excellennt choice of colors!
Useful info. Fortunate me I found your website by accident, and I’m surprised
why this twist of fate did not happened in advance! I bookmarked it.
Thanks on your marvelous posting! I really enjoyed reading it, you wiol be a great author.I will remember to bookmark your blog and definitely will come
back later in life. I want to encourage that you continue your great job,have a nice morning!
I am not sure where you’re getting your info,
but great topic. I needs to spend some time learning much more or understanding more.
Thanks for wonderful information I was looking for this info
for my mission.
Press releases are imperative for spreading news about corporate activities.
They help broadcast stations to publish the important news.
An expertly written official statement may seize the focus of media
professionals, leading to positive publicity.
Additionally, press releases function as an authentic source of details, which journalists trust.
By issuing regular public statements, companies boost their visibility within the market, amassing authority while solidifying
alliances with the Local press release Chicago.
great submit, very informative. I’m wondering why tthe opposite specialists of this sector don’t
notice this. You should continue your writing. I amm sure, you haqve a great readers’
base already!
Usually I do not learn post on blogs, however
I wish to say that this write-up very compelled me to try and do so!
Your writing taste has been amazed me. Thank you, quite great post.
Thanks for sharing your thoughts on IDN Slot.
Regards
I am regular visitor, how aree you everybody? This piece
of writing posted at this weeb page is in fact good.
It’s very straightforward to find out any topic on web as comparsd to textbooks, as I fund
this post at this site.
Howdy! I know this is kinda off topic bbut I was wonderijg if you knew where I could ind a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m habing trouble finding
one? Thanks a lot!
If you would like to obtain a good deal from this article then you
have to apply such methods to your won webpage.
Hello there! I know thios is somewhat off topic but I was
wondering if you knew where I could locate a
captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having
problems finding one? Thanks a lot!
you are truly a excellent webmaster. The site loading pace is
amazing. It sort of feels that you are doing any distinctive trick.
In addition, The contents are masterwork. you have performed a magnificent job on this matter!
Hurrah! In the end I got a website from where I know
how to genuinely take valuable data regarding my study
and knowledge.
I am genuinely delighted to read this weblog posts which consists of lots of
valuable data, thanks for providing these information.
Greetings! Very helpful advice in this particular article!
It’s the little changes which will make the largest changes.
Thanks a lot for sharing!
Hey there, I think your blog might be having browser compatibility issues.
When I look at your blog site in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, wonderful blog!
Amazing! This blog looks just like my old one! It’s on a completely different
subject but it has pretty much the same page layout and design. Outstanding choice of colors!
This is a topic that is near to my heart… Take care!
Exactly where are your contact details though?
This paragraph is in fact a good one it helps new web users, who are wishing for
blogging.
Hmm it appears like your site ate my first comment (it was super
long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still new to the whole thing.
Do you have any tips and hints for rookie blog writers?
I’d genuinely appreciate it.
I used to be suggested this web site by my
cousin. I am no longer certain whether this post is written by him as no one else recognize such precise approximately my difficulty.
You’re amazing! Thanks!
certainly like your web site however you need to check the spelling on quite
a few of your posts. Many of them are rife with spelling issues and
I find it very troublesome to inform the truth on the other hand I’ll surely come again again.
You ought to be a part of a contest for one of the
finest blogs online. I am going to recommend this web site!
Quality articles is the important to attract the people to pay a visit the website,
that’s what this web page is providing.
I was curious if you ever thought of changing the page layout of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having
1 or two images. Maybe you could space it out better?
I really like it when individuals get together and share opinions.
Great site, stick with it!
Hmm it appears like your site ate my first comment (it was super long) so I guess I’ll just sum it up what I
had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to
the whole thing. Do you have any recommendations for inexperienced blog writers?
I’d certainly appreciate it.
As the admin of this website is working, no uncertainty very shortly it will be famous, due to its quality contents.
When I initially commented I seem to have clicked the -Notify me when new comments are added- checkbox and from now on whenever a comment
is added I get four emails with the same comment.
There has to be a way you can remove me from that service?
Appreciate it!
Right away I am going away to do my breakfast, once having my breakfast
coming yet again to read further news.
Generally I do not read article on blogs, but I wish to say that this write-up very compelled
me to try and do so! Your writing taste has been surprised me.
Thank you, very great post.
Hello there! I know this is kinda off topic but I was wondering if you knew
where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble
finding one? Thanks a lot!
Hi there! I could have sworn I’ve been to this site before
but after browsing through some of the post I realized it’s new
to me. Nonetheless, I’m definitely delighted I found it and I’ll be
bookmarking and checking back frequently!
Hi there, all is going nicely here and ofcourse every
one is sharing data, that’s in fact good, keep up writing.
I all the time used to study post in news papers but now as I
am a user of net so from now I am using net for articles, thanks to web.
I am regular reader, how are you everybody?
This post posted at this website is in fact fastidious.
It’s very effortless to find out any topic on net as compared to books, as I found
this post at this web site.
Howdy! Do you use Twitter? I’d like to follow you if that would be
ok. I’m definitely enjoying your blog and look forward to new posts.
I delight in, lead to I found just what I used to be taking a look for.
You have ended my four day long hunt! God Bless you man. Have a great day.
Bye
Great delivery. Great arguments. Keep up the
amazing effort.
Hurrah, that’s what I was searching for, what a data!
existing here at this website, thanks admin of this site.
I want to to thank you for this wonderful read!! I absolutely enjoyed every bit
of it. I’ve got you book marked to look at new things you post…
Those on a pay-as-you-go mobile phone contract in the UK can also use the pay-by-phone bill option.
Post writing is also a excitement, if you be acquainted with then you can write if not it is
complex to write.
Someone necessarily assist to make seriously posts I might state.
That is the very first time I frequented your website page and thus far?
I amazed with the research you made to make this particular publish amazing.
Excellent process!
It’s truly a nice and helpful piece of information. I’m happy that you shared this useful info
with us. Please stay us up to date like this. Thank you for sharing.
My relatives every time say that I am wasting my
time here at web, however I know I am getting knowledge everyday by reading such pleasant content.
Great blog you’ve got here.. It’s difficult to find quality writing like yours these days.
I seriously appreciate people like you! Take care!!
Wonderful web site. Lots of useful information here. I am sending it to several friends ans also sharing in delicious.
And of course, thanks to your effort!
What’s up, everything is going perfectly here
and ofcourse every one is sharing information, that’s truly good, keep up writing.
Thank you for sharing your thoughts. I truly appreciate your efforts
and I will be waiting for your next post thank you once again.
Hey there! I know this is kinda off topic but I was wondering which blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve had problems
with hackers and I’m looking at options for another platform.
I would be awesome if you could point me in the direction of a
good platform.
Hello colleagues, pleasant piece of writing and fastidious urging commented at this place, I am actually enjoying by
these.
What’s up, after reading this remarkable
post i am as well happy to share my experience here with friends.
What’s up, this weekend is pleasant designed for me,
for the reason that this moment i am reading this wonderful educational post here at my residence.
Howdy! Someone in my Myspace group shared this site with us so I came to take a look.
I’m definitely enjoying the information.
I’m bookmarking and will be tweeting this to my followers!
Excellent blog and superb design and style.
Aw, this was a really nice post. Taking a few minutes and actual effort to generate a superb article… but what can I say…
I procrastinate a whole lot and don’t manage to get
anything done.
It’s not my first time to pay a quick visit this web page, i am visiting this
web page dailly and take nice information from here all the time.
Hey! Do you use Twitter? I’d like to follow you
if that would be okay. I’m undoubtedly enjoying your blog and
look forward to new posts.
Greetings! I know this is kind of off topic but I was wondering if you knew
where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m
having difficulty finding one? Thanks a lot!
Wow, superb blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your
web site is excellent, let alone the content!
What you published made a great deal of sense. But, what about this?
suppose you typed a catchier title? I am not suggesting
your information is not good., however suppose you
added a post title that grabbed people’s attention? I mean Пиастры – Составление
семантического ядра | is a little vanilla.
You should glance at Yahoo’s home page and watch how they
create post headlines to get people interested.
You might add a related video or a picture or two to grab readers interested
about everything’ve written. Just my opinion, it would bring
your posts a little bit more interesting.
What’s Going down i’m new to this, I stumbled
upon this I have found It positively useful
and it has helped me out loads. I am hoping to give
a contribution & assist other customers like its helped me.
Good job.
Wonderful post however I was wanting to know if you could write a litte
more on this topic? I’d be very thankful if you could
elaborate a little bit further. Kudos!
This blog was… how do you say it? Relevant!! Finally I have found something that helped
me. Appreciate it!
Hello this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have
to manually code with HTML. I’m starting a blog soon but have no coding skills so
I wanted to get advice from someone with experience.
Any help would be enormously appreciated!
Appreciating the hard work you put into your site and detailed
information you present. It’s great to come across a blog every once in a while
that isn’t the same out of date rehashed information. Excellent read!
I’ve saved your site and I’m including your RSS feeds to my Google account.
Thanks very interesting blog!
Hello There. I discovered your blog the usage of msn.
This is a really smartly written article. I
will be sure to bookmark it and come back to learn more of your helpful info.
Thank you for the post. I’ll definitely comeback.
I visited various web pages however the audio feature for audio songs existing at this website is
in fact excellent.
Excellent goods from you, man. I’ve understand your stuff previous to and you’re
just extremely wonderful. I really like what you have
acquired here, certainly like what you are saying and the way in which you say it.
You make it entertaining and you still care for to keep it wise.
I can’t wait to read much more from you. This is
actually a terrific site.
You made some really good points there. I checked on the web to
learn more about the issue and found most individuals will go along with your views on this web site.
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an impatience over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly the same nearly a lot often inside case you shield this hike.
Hey there! I know this is kinda off topic
but I’d figured I’d ask. Would you be interested in trading
links or maybe guest writing a blog post or vice-versa?
My website covers a lot of the same topics as yours and I feel we could greatly benefit
from each other. If you’re interested feel free to shoot me an email.
I look forward to hearing from you! Great blog by the way!
hey there and thank you for your info – I have certainly picked up anything new
from right here. I did however expertise several technical issues using this web
site, as I experienced to reload the web site a lot of times
previous to I could get it to load properly. I had been wondering if your web host is
OK? Not that I am complaining, but sluggish loading instances times will often affect your placement in google and can damage your high quality score
if ads and marketing with Adwords. Anyway I am adding this RSS to my email and could look out for a lot more of
your respective interesting content. Make
sure you update this again soon.
Thanks in favor of sharing such a good opinion, article is nice, thats why i have read it
entirely
When I originally commented I clicked the “Notify me when new comments are added”
checkbox and now each time a comment is added I get four e-mails
with the same comment. Is there any way you can remove me from that service?
Thanks!
I’m really enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more enjoyable for
me to come here and visit more often. Did you hire out a developer to create your theme?
Great work!
Howdy! This is my first comment here so I just wanted
to give a quick shout out and say I genuinely enjoy reading your blog posts.
Can you recommend any other blogs/websites/forums that deal
with the same subjects? Thank you!
Magnificent goods from you, man. I’ve understand your stuff
previous to and you’re just extremely great.
I really like what you’ve acquired here, really like what you are saying and the
way in which you say it. You make it entertaining and you still care for to keep it sensible.
I can not wait to read far more from you. This is actually a tremendous website.
Good day! I could have sworn I’ve visited this web
site before but after looking at many of the articles I
realized it’s new to me. Anyhow, I’m definitely delighted I came across it
and I’ll be bookmarking it and checking back regularly!
Hi, I check your new stuff like every week. Your humoristic style is witty, keep it up!
I am actually grateful to the owner of this web page who has shared this wonderful post at at this place.
I blog often and I genuinely appreciate your information. This great article has really peaked my interest.
I am going to book mark your blog and keep checking for new information about once per
week. I subscribed to your Feed too.
Hello to every , because I am truly keen of reading this website’s post to be updated
daily. It contains pleasant material.
I do believe all the concepts you’ve presented for your post.
They are really convincing and can definitely work.
Nonetheless, the posts are very quick for newbies.
May you please prolong them a bit from next time?
Thank you for the post.
It’s awesome for me to have a site, which is good in support of my know-how.
thanks admin
Hello! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Any suggestions?
I just like the helpful info you provide in your articles.
I’ll bookmark your blog and test once more
right here frequently. I’m quite sure I’ll be
informed many new stuff right right here! Good luck for
the next!