Дубли страниц сайта, или минус 3 000 000 рублей прибыли
![]() Кейсы бывают разные. А как известно, двойка – тоже государственная оценка. Сегодня мы будем говорить про дубли страниц сайтов, о том какие негативные последствия могут быть, о том, как проверить сайт на наличие дублей как с этим бороться.
Кейсы бывают разные. А как известно, двойка – тоже государственная оценка. Сегодня мы будем говорить про дубли страниц сайтов, о том какие негативные последствия могут быть, о том, как проверить сайт на наличие дублей как с этим бороться.
Начнем с невеселой истории, которая произошла с одним из клиентов не так давно, в этом году. Естественно, история связана с дублями станиц сайта, который является наиболее мощным каналом продаж для клиента.
Дубли страниц ценой в 3 000 000 рублей
Итак, кратко суть. Есть очень умный клиент, который постоянно занимается развитием своего сайта, т.к. реально понимает, что без сайта его бизнес проживет может быть и долго, но по утрам придется на хлеб мазать не икру, а паштет. Человек занимается бизнесом более 7ми лет, и сайт соответственно имеет возраст, траст. Думаю, ни для кого не новость, если сайтом заниматься постоянно, то за семь лет сайт обрастет контентом, ссылками, а главное трафиком.
Два-три раза в год клиент приходит к нам и говорит: надо поднимать трафик, давайте думать, как это сделать. Мы предлагаем варианты, получаем деньги за свой труд. А клиент пропадает на несколько месяцев, занимаясь внедрением того, что мы совместно на придумывали.
У клиента сезонный бизнес, наиболее жаркими являются 3 летних месяца. И вот, в начале сентября приходит клиент и говорит: плохой сезон, хуже предыдущего. Я сильно удивляюсь, т.к. на протяжении трех лет мы показывали стабильный рост от сезона к сезону. Причем рост был не меньше 30%. Начинаем разбираться, и видим вот такой график:
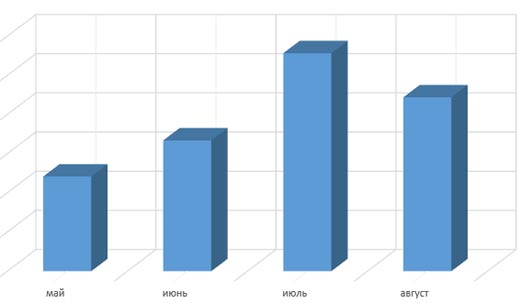
Это трафик с поиска за текущий сезон. Начинаем смотреть, что творилось со спросом на рынке. Не сложно проанализировать и построить достаточно точный график. Вот как должен был выглядеть трафик, если опираться на историю из Яндекс.Директа:
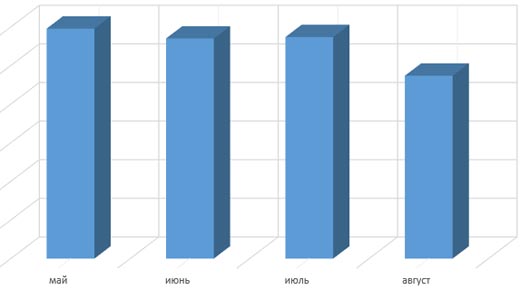
Понимаем, что картина резко отличается от нашей, начинаем разбираться. В результате приходим в выводу, что клиент для улучшения конверсии попросил программистов сделать несколько дублей страниц, на которые, естественно за 7 лет сайта проставлена куча ссылок. Сразу возникает вопрос: а как дубли страниц сайта попали в индекс? Ссылки ведь стоят на основные страницы? Оказывается на дубли наш клиент успешно лил трафик на протяжении всего сезона с систем контекстной рекламы. И качество этого трафика было весьма неплохое, а пользователь проводил на этих страницах кучу времени. В результате Яндекс дубли страниц добавил в индекс и стал пытаться их ранжировать. Естественно, ранжирование было неверным. А значит мы получили просадку по огромному ядру запросов, падение трафа. Чтобы понимать объемы, речь идет о том, что сайт выпал из топ10 Яндекса по более чем 2 000 запросов.
Проблему мы исправили, т.к. бороться с дублями умеем. Но давайте разберемся в сути. С клиентом мы прикинули, что при самом плохом конверте, он зарабатывает 30 рублей с одного юзера, пришедшего с поиска на сайт. Зная как менялся спрос, мы можем построить график, на котором по месяцам будет просчитан упущенный трафик. Это трафик, который клиент должен был получить:
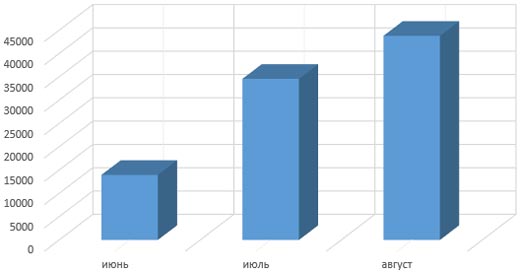
Сложив цифры за 3 месяца, мы поняли, что недополучили 92 000 хостов. Умножив заработок на каждом посетителе на количество посетителей, можно уверено сказать, что клиент недополучил минимум 2 760 000 рублей прибыли! И это при самом плохом конверте. Именно столько стоила ошибка: если бы клиент пришел в мае и попросил проверить, все ли ок, мы бы легко устранили дубли страниц с сайта.
Ну а теперь давайте поговорим про типовые дубли, их поиск, закрытие.
Какие внутренние дубли страниц сайта бывают?
Дубли делятся на два больших класса: четкие и нечеткие дубли.
Четкие дубли страниц – это на 100% идентичный контент страницы, доступный по разным адресам на одном сайте. Наиболее часто четки дубли появляются я в случаях если:
- Страницы сайта доступны по двум адресам с www и без. Например, site.ru и www.site.ru
- Страницы сайта доступны по двум адресам со слешем и без на конце. Например, site.ru/page и www.site.ru/page/
- В адресах сайта есть дополнительные параметры, например, идентификаторы сессий: site.ru/page/ и site.ru/page/?sid=2345sdfsd345
- Главная страница сайта доступна по нескольким адресам. Например, site.ru, site.ru/index.php, site.ru/index.html.
Нечеткие дубли – это страницы, которая поисковая система считает дублями из-за части одинакового контента на страницах. Эта ситуация чаще всего возникает из-за:
- малого количества основного контента и большой навигационной части дизайна.
- кусков основного контента, который повторяется на разных страницах.
Чаще всего нечеткие дубли страниц не страшны. Поисковая система такие страницы считает не значимыми и не пускает их в индекс. То есть мы сталкиваемся с проблемой, например, когда каталог товаров не попадает в индекс. Да, это тоже проблема, причем достаточно серьезная, но о ней стоит говорить отдельно, т.к. здесь уже встает вопрос уникализации контента для поисковой системы. То есть надо убедить поисковик, что информация на страницах вашего сайта ценная и ее надо добавить в индекс.
Дальше речь пойдет именно о четких дублях.
Как найти дубли страниц на сайте?
Существует несколько простых, но очень кропотливых методик поиска внутренних дублей страниц:
- Просмотр результатов поиска по сайту у какой-либо поисковой системы. Для этого в поисковую строку вбивается конструкция:
- site:mysite.ru -site:mysite.ru/& (для поисковой системы Гугл)
- site:site.ru (для поисковой системы Яндекс)
Далее нужно руками смотреть, какие страницы есть в индексе поисковой системы, стараясь найти страницы, которых там быть не должно.
- Можно руками вводить в строку поиска куски текста, смотреть какие страницы вашего сайта находятся в индексе. Если страниц с введенным текстом больше одной, велика вероятность, что вы видите дубли, с которыми надо что то делать.
- Существует программа Xenu, которая занимается сканированием сайта, в результате вы видите список страниц, которые можно отсортировать, например по тегу Title. Тем самым можно выявить страницы с одинаковыми титлами будут сгруппированы. Вам станет ясно, какие группы страниц представляют из себя потенциально дубли для поисковых систем. Надо понимать, что этот метод не совсем верен, т.к. вы сканируете сайт, а не индекс поисковой системы. Но методика позволяет на начальном этапе, даже когда сайт не проиндексирован, постараться избавиться от дублей.
- В продолжение разговора, в вебмастере Гугла есть хороший инструмент, который показывает страницы с одинаковыми тегами title и метаданными. Попасть на эту страницу можно, зайдя в Гугл.Вебмастер, в раздел Вид в поиске, подраздел Оптимизация HTML:
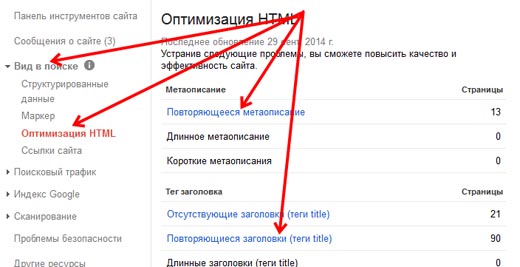
- Кроме того, у Гугла есть всеми нелюбимые сопли. Соплями называются дополнительные результаты поиска по сайту. То есть это те страницы, которые Гугл по каким-то причинам не хочет показывать в результатах поиска. Проанализировав данные результаты так же можно найти много интересного мусора, который генерирует движок сайта.
Как удалить дубли страниц сайта?
Отвечая на данный вопрос, я обозначу лишь методы, которыми решается вопрос с дублями. Подробно описывать я их не буду, т.к.:
- Не профессионалу лезть и самому исправлять такие вещи может быть опасно. Проще обратиться к знающим людям, грамотного специалиста найти не проблема.
- Существует много вариаций для решения задачи тем или иным методом. Каждый случай индивидуален, поэтому не буду пытаться объять необъятное.
Итак, поиск дублей страниц выполнен, пришло время борьбы. Нужно удалить дубли страниц с сайта. И тут нас постигает первое разочарование. Если мы хотим удалить дубли, то надо переписать движок сайта, а это дорого и долго. Но есть и хорошая новость: дубли можно удалить из поисковой системы.
Как же поисковую систему заставить индексировать наш сайт правильно, без дублей.
- Канонические урлы. Необходимо шаблоны сайта изменить так, чтобы поисковая система сканировала все страницы сайта, включая дубли, а в индекс добавляла только нужную нам страницу. Для этого необходимо на страницы-дубли добавить в раздел head тег link, в котором прописать канонический адрес.
Например, у нас есть две страницы, site.ru/ и site.ru/aaa. Причем вторая страница является дублем первой. Для этого на странице site.ru/aaa добавить тег
< link rel="canonical" href="http://site.ru/" >
- Очень мощным методом являются редиректы. То есть мы с дубля ставим редирект на основную страницу. Яндекс приходит на дубли, видит редирект и склеевает дуль страницы с основной. Чаще всего используется 301 редирект, а настройка делается сразу для целых групп страниц с помощью прописывания специальных инструкций в файле .htaccess
- Еще одним распространенным методом является запрет индексации определенных групп страниц или разделов с помощью файла robots.txt
Например, у нас есть две страницы, site.ru/ и site.ru/aaa. Причем вторая страница является дублем первой. В файле robots.txt добавляем директиву Disallow: /aaa и дело в шляпе.
Важно! Чтобы Яндексу помочь, то есть ускорить решение проблемы с дублями страниц сайта, можно воспользоваться страницей для удаления адресов страниц из индекса: http://webmaster.yandex.ru/delurl.xml. Важно, чтобы удаляемые страницы были закрыты в файле robots.txt или отдавали код ответа 404. Аналогичный инструмент есть и в панели для вебмастеров от Гугла. Его можно найти в разделе Индекс Google в подразделе Удаление URL-адреса:
На этом наверное все, будут вопросы – задавайте, есть сложные задачи – показывайте – будем решать.
Полезные ссылки:
- http://help.yandex.ru/ – Подробный мануал по работе с robots.txt от Яндекса. Стоит напомнить, Яндекс имеет инструкции, которые не читает Гугл.
- http://designn.pp.ua/ подробная информация по директивам, на случай, если вы будете сами править файл htaccess.
- http://blogerator.ru/ – практические примеры по работе с файлом htaccess.
- http://comp-on.ru/ – типовые проблемы с дублями и их решения, структурировано и доступно.
- http://www.sembook.ru/ – статья про дубли от Ингейта, как всегда весьма развернуто, легко читаемо и полезно. Кстати говоря, весной покупал несколько Энциклопедий поискового продвижения, когда курьер приехал, на моем лице было удивление: он привез большую коробку. Оказалось Ингейт выпустил действительно энциклопедию, размер книги сравним со словарем Ожигова, а качество печати очень приятно удивило. Одну книжку даже себе решил оставить – очень понравилась.
Как показывает практика, в сети очень мало движков, которые получили широкое распространение. Все эти движки сайтов имеют дубли страниц, и все вы их знаете:
- http://wlad2.ru/ – боремся с дублями страниц на wordpress
- http://terobait48.ru/ – удаляем дубли новостей DLE
- http://web-simple.ru/ – как убрать дубли страниц на joomla


Excellent website. Plenty of useful info here. I’m sending it to
a few buddies ans additionally sharing in delicious.
And naturally, thanks on your effort!
Feel free to surf to my web page; Patti
Thanks a lot for providing individuals with an exceptionally brilliant opportunity to read
from here. It’s usually very excellent plus stuffed with amusement for me and my office co-workers
to visit the blog at the least three times in a week to study the
fresh guidance you have. And indeed, I am just always satisfied concerning
the surprising information you give. Certain 3 areas in this post are in truth the simplest we’ve had.
My web-site :: local hookup facebook
With havin so much content and articles do you ever run into any problems of plagorism or copyright violation? My website has a lot of
exclusive content I’ve either created myself or outsourced but it seems a lot of it is popping
it up all over the web without sex in my area permission. Do you know any techniques to help prevent content from
being ripped off? I’d really appreciate it.
I like this web site because so much utile stuff on here :D.
my web site: local hookup facebook
Excellent article. Keep writing such kind of information on your site.
Im really impressed by it.[X-N-E-W-L-I-N-S-P-I-N-X]Hi there, You’ve performed an incredible job.
I’ll certainly digg it and in my view recommend
to my friends. I’m sure they will be benefited from this web site.
Check out my blog post; craiglistforsex
Loving the information on this website, you have done outstanding job on the articles.
my web-site :: Annie
I don’t normally comment but I gotta state regards for the post on this
perfect one :D.
my web site … local hookups near me
It’s a shame you don’t have a donate button! I’d without
a doubt donate to this excellent blog! I guess
for now i’ll settle for book-marking and adding your RSS feed to
my Google account. I look forward to fresh updates and will
share this website with my sex on facebook group.
Talk soon!
Howdy! I just want to give you a big thumbs up for
the great info you’ve got right here on this post. I’ll be coming back to your web site for more soon.
my blog :: local hookups near me
Hello! Someone in my Myspace group shared this site with us so I came to check it out.
I’m definitely loving the information. I’m book-marking and
will be tweeting this to my followers! Outstanding blog and amazing style and
design.
Feel free to surf to my site – Highstakes 777 online
Greate post. Keep posting such kind of info on your site.
Im really impressed by your blog.[X-N-E-W-L-I-N-S-P-I-N-X]Hello there,
You have done an incredible job. I will certainly digg it
and individually recommend to my friends. I am confident they’ll be benefited from this website.
My web blog – http://Bridgejelly71%3Ej.U.Dyquny.Uteng.Kengop.Enfuyuxen@Naturestears.Com
Everything is very open with a clear clarification of the challenges.
It was truly informative. Your site is useful.
Thanks for sharing!
My page – Megaopt.Info
I will immediately seize your rss feed as I can’t in finding
your e-mail subscription hyperlink or e-newsletter service.
Do you’ve any? Please permit local hookups near me understand so that I may subscribe.
Thanks.
I like this site because so much utile stuff on here :D.
Visit my web page: facebookofsex
Excellent post. Keep posting such kind of information on your page.
Im really impressed by it.[X-N-E-W-L-I-N-S-P-I-N-X]Hi there, You have done a
fantastic job. I’ll definitely digg it and personally recommend to my friends.
I’m confident they’ll be benefited from this web site.
My web page – facebook hookup near me
Thank you a lot facebook for sex giving everyone remarkably wonderful
chance to check tips from this blog. It’s usually very pleasurable and as well , packed
with fun for me and my office fellow workers to search the blog not less than 3 times
in one week to find out the fresh tips you will
have. And lastly, I’m so always contented concerning the good ideas served by you.
Some 2 points in this posting are absolutely the finest I’ve had.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
By the way, how could we communicate?
My web site: facebookofsex
It’s really a cool and helpful piece of information. I’m happy
that you shared this useful information with us. Please keep us informed like this.
Thank you for sharing.
Also visit my web blog – sex on facebook
With havin so much written content do you ever run into
any problems of plagorism or copyright infringement?
My site has a lot facebook of sex unique content I’ve either created myself or
outsourced but it looks like a lot of it is popping it up all over
the internet without my authorization. Do you know any techniques to help
prevent content from being stolen? I’d certainly
appreciate it.
Thank you a lot for giving everyone a very memorable opportunity
to check tips from this blog. It is usually very
pleasant plus packed with a lot of fun for local hookups near me personally and my office co-workers to
search your site on the least 3 times in a week to find out the newest stuff you have got.
And lastly, we are certainly satisfied considering the brilliant opinions you serve.
Some two points in this article are completely the most beneficial
we have had.
I believe this is among the so much vital info for me.
And i’m satisfied studying your article.
But want to remark on few general things, The website style is perfect,
the articles is in reality excellent : D. Just right activity, cheers
Look at my web-site :: facebook of sex
Do you mind if I quote a couple of your posts as long as
I provide credit and sources back to your webpage? My blog
site is in the exact same niche as yours and my users would certainly benefit from a lot of the information you provide here.
Please let me know if this okay with you. Appreciate it!
my webpage – top ten poker sites (http://wvbi.com)
I don’t usually comment but I gotta admit thank you for the post on this perfect one :D.
Look into my blog :: High stakes
Right here is the right webpage for anybody who wishes to find out about this topic.
You understand a whole lot its almost tough to argue with you (not that
I really would want to?HaHa). You definitely put a new spin on a
subject that’s been discussed for a long time. Great stuff, just
excellent!
My web-site; facebook of sex
Do you mind if I quote a couple of your articles as long as I provide credit
and sources back to your site? My website is in the very same niche as yours and my users would certainly benefit from
a lot of the information you provide here. Please let me
know if this okay with you. Thanks!
My blog Modern Tiny House
Thank you a lot for providing individuals with an exceptionally breathtaking possiblity to read critical
reviews from this site. It is always very amazing plus full of
a great time for me and my office mates to search your website on the least
3 times in a week to learn the newest secrets you have got.
And definitely, I’m also actually contented considering the splendid inspiring ideas you give.
Selected 3 points on this page are ultimately
the best we have all ever had.
Here is my homepage; highstakes Poker
I believe that is one of the such a lot vital information for facebook hookup near me (Damaris).
And i’m satisfied studying your article. However should commentary on some general issues, The website style is perfect, the articles is in reality nice :
D. Excellent job, cheers
I like this web site because so much useful stuff on here :
D.
Also visit my webpage … everygame poker review; http://Www.wwwdr.Ess.Aleoklop.e@www.bqinternet.com/index.php?a%5B%5D=%3Ca+href%3Dhttp%3A%2F%2Fpolackalkudumbam.com%2Fbest-online-poker-sites-nwt-tip-make-your-self-available%2F%3Epoker+site+rankings%3C%2Fa%3E%3Cmeta+http-equiv%3Drefresh+content%3D0%3Burl%3Dhttps%3A%2F%2FNxlv.ru%2Fuser%2FEdmundGwin02%2F+%2F%3E,
I don’t ordinarily comment but I gotta say regards for the post on this perfect one :D.
Also visit my blog :: top poker sites
I like this web site because so much useful material
on here :D.
Visit my blog post: highstakes Poker review
It’s amazing to pay a quick visit this web site and reading the
views of all colleagues regarding this piece of writing, while I am also eager of
getting know-how.
Feel free to surf to my web blog :: Poker Betting
I don’t unremarkably comment but I gotta tell regards for
the post on this special one :D.
Here is my blog post; facebook hookup near me
Everything is very open with a clear clarification of
the challenges. It was definitely informative. Your site
is useful. Thank you for sharing!
Here is my homepage :: High Stakes casinos
With havin so much content do you ever run into any issues
of plagorism or copyright violation? My site has a lot of exclusive content I’ve either authored myself or outsourced but it appears a lot of it is
popping it up all over the internet without my agreement.
Do you know any methods to help prevent content
from being ripped off? I’d really appreciate it.
My web site :: find sex near me
I’m really enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more enjoyable for me to
come here and visit more often. Did you hire out a designer to create your theme?
Superb work!
Stop by my webpage :: poker site rankings
Do you mind if I quote a few of your articles as long
as I provide credit and sources back to your blog? My website is in the very same
area of interest as yours and my visitors would really benefit from a lot
of the information you provide here. Please let me know if this alright with
you. Cheers!
my website – best online poker nwt (Koreaht2.motionblue.org)
I will immediately snatch your rss feed as I can’t to find your e-mail
subscription hyperlink or newsletter service. Do you
have any? Kindly allow me recognize so that I may just subscribe.
Thanks.
Also visit my webpage: kkpoker review
Everything is very open with a precise description of the challenges.
It was truly informative. Your site is useful. Thanks
for sharing!
Also visit my web site; local hookups near me (http://teamzfg.com/__media__/js/netsoltrademark.php?d=citymeet.biz%2F__media__%2Fjs%2Fnetsoltrademark.php%3Fd%3Dwww.facebookofsex.yaforia.com)
It’s really a great and useful piece of information. I’m glad that you just shared
this useful info with us. Please keep us informed like this.
Thanks for sharing.
Feel free to visit my web-site :: safest poker sites
Only a smiling visitant here to share the love (:, btw great design and style.
my web-site – High Stakes
It’s awesome to pay a visit this site and reading the views of all friends about this piece of
writing, while I am also keen of getting experience.
my website: find sex near me, http://Access-Quran.com,
Excellent post. Keep writing such kind of information on your page.
Im really impressed by your blog.[X-N-E-W-L-I-N-S-P-I-N-X]Hi there,
You’ve done an incredible job. I’ll definitely digg it and individually
recommend to my friends. I am sure they will be benefited from this website.
my blog – Tiny House Lifestyle
It’s a shame you don’t have a donate button! I’d definitely donate to
this outstanding blog! I guess for now i’ll settle
for book-marking and adding your RSS feed to my
Google account. I look forward to brand new updates and will talk about this website with my Facebook group.
Talk soon!
Also visit my blog post :: Poker Games Online (norlin.com)
It’s a pity you don’t have a donate button! I’d most certainly donate to
this fantastic blog! I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to new updates and will talk about this site with
my Facebook group. Talk soon!
My web site :: local hookups near me
This is the right blog for everyone who wants to understand this topic.
You realize so much its almost tough to argue with you (not that I personally will need to?HaHa).
You certainly put a new spin on a topic which has been discussed
for ages. Great stuff, just great!
my homepage: hookups near by
Do you mind if I quote a few of your articles as long as I provide credit and
sources back to your website? My website is in the very same
niche as yours and my visitors would genuinely benefit from a lot of the information you provide here.
Please let me know if this alright with you. Appreciate it!
Feel free to surf to my blog post: craiglistforsex
Do you mind if I quote a few of your articles as
long as I provide credit and sources back to your webpage?
My blog is in the exact same niche as yours and my visitors would really benefit from a
lot of the information you present here. Please let
me know if this okay with you. Regards!
Also visit my web page: facebook hookups
With havin so much content and articles do you ever run into any
issues of plagorism or copyright infringement? My site
has a lot of completely unique content I’ve either authored myself or outsourced but it appears a lot of
it is popping it up all over the internet without my authorization. Do you know any solutions to help stop content from being stolen? I’d definitely appreciate it.
Feel free to surf to my blog – facebookofsex (ivimall.com)
I like this site because so much utile material on here :D.
Check out my blog – sex in my area
This info is invaluable. How can I find out more?
Also visit my blog … highstakes Poker review
Hi, i believe that i noticed you visited my site so i got here to return the choose?.I am trying to find things to improve my web site!I suppose its adequate
to make use of some of your concepts!!
Here is my homepage top 10 poker websites (Aisha)
This is the right blog for everyone who wishes to find out about this topic.
You realize so much its almost hard to argue
with you (not that I personally would want to?HaHa). You certainly put a new
spin on a subject that has been written about
for years. Excellent stuff, just wonderful!
my web site :: facebook hookup near me
Greate post. Keep writing such kind of information on your page.
Im really impressed by your blog.[X-N-E-W-L-I-N-S-P-I-N-X]Hey there,
You’ve performed an excellent job. I’ll definitely digg it and
in my opinion suggest how to find sex on facebook my friends.
I’m confident they’ll be benefited from this web site.
I always spent my half an hour to read this blog’s articles all the time along with a cup of coffee.
Also visit my web-site :: Drug rehab chiang Mai
Thank you a lot for giving everyone an extraordinarily splendid opportunity to read critical reviews from this website.
It is often so great and as well , full of amusement
for me and my office mates to search your site a minimum of
three times in one week to see the new tips you will have.
And lastly, I’m certainly contented with the spectacular methods served by you.
Selected 3 points in this posting are in truth the best I have ever had.
Also visit my web site; safest poker sites – hatinh7x.com,
I’ve been absent for some time, but now I remember why I used
to love this blog. Thanks, I’ll try and check back more
frequently. How frequently you update your site?
Also visit my site :: High Stakes gambling
May I simply just say what a comfort to uncover an individual who actually knows what they are talking about on the web.
You actually know how to bring an issue to light and make it important.
More people really need to read this and understand this side of
the story. I can’t believe you are not more popular given that you surely possess the gift.
My homepage – Paulina
I read this article fully concerning the resemblance of most up-to-date and previous technologies, it’s amazing article.
My blog :: thailand rehab centre
F*ckin’ tremendous issues here. I am very glad to peer your post.
Thanks so much and i’m looking forward to touch you.
Will you please drop me a mail?
Feel free to surf to my page :: rehab thailand chiang mai (Melissa)
I conceive other website proprietors should take
this website as an model, very clean and superb user friendly style.
Feel free to surf to my blog Highstakes 777 Login
We’re a gaggle of volunteers and opening a brand
new scheme in our community. Your site provided us with helpful
information to work on. You have performed an impressive activity and
our whole community will be thankful to you.
Here is my web page; rehab center Thailand
Hi there! I could have sworn I’ve been to this website before but after reading through some of the
post I realized it’s new to me. Nonetheless, I’m definitely glad I found it and I’ll be bookmarking and checking back frequently!
Take a look at my blog post … Higstakes
It’s awesome to pay a visit this website and reading the views
of all mates concerning this article, while I am also keen of getting experience.
my webpage; kkpoker review
I have been absent for some time, but now I remember why I used to love
this website. Thank you, I’ll try and check
back more often. How frequently you update your site?
Also visit my web page; Highstakesweeps Online
This is very attention-grabbing, You are an excessively professional blogger.
I’ve joined your feed and sit up for in search of more of your
fantastic post. Also, I’ve shared your site in my social networks
Also visit my web-site – quick hook ups near me
That is very attention-grabbing, You are an excessively professional blogger.
I have joined your rss feed and sit up for looking
for extra of your wonderful post. Additionally, I’ve shared your website in my social networks
Feel free to visit my homepage – local hookups near me
Thanks for your fascinating article. One other problem
is that mesothelioma is generally due to the inhalation of dust from asbestos, which is a cancer causing material.
It’s commonly observed among employees in the structure industry who have long exposure to asbestos.
It’s also caused by residing in asbestos protected buildings for long periods of time, Your
age plays a huge role, and some people are more vulnerable to the risk as compared with others.
Here is my web blog :: Marijuana Addiction
Excellent pieces. Keep writing such kind of information on your
page. Im really impressed by your blog.[X-N-E-W-L-I-N-S-P-I-N-X]Hi
there, You have done a great job. I will certainly digg it and individually recommend to my friends.
I’m confident they’ll be benefited from this web site.
my webpage Tiny House Movement; http://bajawhalewatchingtours.com,
Hello, i feel that i saw you visited my weblog so i got here
to return the desire?.I am attempting to find things
to improve my website!I suppose its good enough to make use of a few of your concepts!!
Here is my web blog local hookup near me
I enjoy looking through an article that can make
men and women think. Also, thanks for permitting find sex near me – Reyna – to comment!
Thanks so much for providing individuals with an exceptionally
wonderful possiblity to read from this website. It is
often so ideal plus full of amusement for me personally and my office co-workers to
visit your website at the very least 3 times in a week to find out the fresh items you have got.
And of course, I’m so usually contented with all
the unique guidelines you serve. Selected 4 tips on this page are surely the most impressive I have had.
My blog: Best Online Poker
I don’t ordinarily comment but I gotta state thank you for
the post on this great one :D.
my webpage … Poker Review
Hello, i believe that i noticed you visited my weblog thus i came to go back the choose?.I’m attempting to
to find things to enhance my website!I assume its good
enough to make use of some of your ideas!!
Here is my web page Luxury Tiny House (inimkt.com)
At this time I am ready to do my breakfast, once having my
breakfast coming again to read other news.
my blog post Thailand Rehab
Hello, Neat post. There is an issue along with your site in web explorer,
would check this? IE still is the market
leader and a good component to folks will pass over your wonderful writing due to this problem.
Look into my homepage; Stormy
I like this website because so much utile stuff on here
:D.
Here is my website: sex partners near me
May I simply just say what a relief to uncover a person that really understands
what they’re talking about online. You actually know how to bring
an issue to light and make it important. A lot more people should read this and understand this side of your story.
It’s surprising you aren’t more popular because you most certainly possess the gift.
Feel free to visit my web site :: Higstakes
But a smiling visitor here to share the love (:, btw great style.
My webpage … Poker Cash Games
I’m truly enjoying the design and layout of your blog. It’s a very easy on the eyes which makes it much more enjoyable
for me to come here and visit more often. Did you hire
out a developer to create your theme? Outstanding work!
my web site; sex in my area
Greate post. Keep posting such kind of information on your blog.
Im really impressed by it.[X-N-E-W-L-I-N-S-P-I-N-X]Hello there, You have
done an excellent job. I’ll definitely digg it and individually
recommend to my friends. I am confident they will be
benefited from this website.
Feel free to visit my website … Online Poker Tournaments
Many thanks for being our instructor on this area. I actually enjoyed your article a lot
and most of all appreciated how you handled the areas I regarded as being
controversial. You happen to be always rather kind towards readers
really like me and let me in my existence. Thank you.
Feel free to visit my web-site nxlv.Ru
I was suggested this web site by my cousin. I’m not sure whether this
post is written by him as nobody else know such detailed about my difficulty.
You are wonderful! Thanks!
my webpage :: yarana.Com
It’s amazing to visit this site and reading
the views of all colleagues about this paragraph, while
I am also eager of getting know-how.
Here is my website :: Poker Games Online
Quality posts is the important to be a focus for the users to pay a visit the web
site, that’s what this site is providing.
my page – Highstakes 777 Login
It’s a pity you don’t have a donate button! I’d definitely donate to this
fantastic blog! I guess for now i’ll settle for bookmarking
and adding your RSS feed to my Google account. I look forward to fresh updates and will talk about this website
with my Facebook group. Talk soon!
Visit my page chiang mai rehab
It’s awesome to go to see this web site and reading the views of all friends on the topic of this paragraph,
while I am also eager of getting know-how.
Take a look at my homepage: facebook sex sites
If some one needs expert view about blogging then i advise him/her to visit this weblog, Keep up the fastidious
job.
Check out my homepage; Alda
Spot on with this write-up, I actually believe this amazing site needs a great deal more attention. I’ll probably be returning to read more,
thanks for the information!
my homepage – Highstakes App
Hi there, You’ve done a great job. I’ll certainly
digg it and personally recommend to my friends. I’m sure they
will be benefited from this site.
Visit my website :: thailand alcohol rehab (http://pips.at/phpinfo.php?a%5B%5D=%3Ca+href%3Dhttps%3A%2F%2Fmus-album.org%2Fuser%2FVaughnGraves6%2F%3EDrug+Addiction+Treatment+In+Thailand%3C%2Fa%3E%3Cmeta+http-equiv%3Drefresh+content%3D0%3Burl%3Dhttp%3A%2F%2Fwww.pizzakusadasi.com%2Fauthor%2Fmeaganhetri%2F+%2F%3E)
Thanks in favor of sharing such a pleasant thought, article is
nice, thats why i have read it completely
Visit my page – higstakes
Enjoyed examining this, very good stuff, thank you.
Have a look at my web blog … rehab Thailand
Real fantastic visual appeal on this site, I’d rate it 10.
Also visit my blog … High Stack Poker
Hi! I simply wish to offer you a huge thumbs up for the excellent
info you have here on this post. I’ll be coming back
to your site for more soon.
my webpage … facebookofsex
It’s actually a cool and helpful piece of info.
I am happy that you just shared this useful information with us.
Please keep us up to date like this. Thank you for sharing.
Feel free to visit my blog … facebookofsex
I believe this is one of the so much important information for
me. And i am glad reading your article. However wanna observation on some
common issues, The web site style is great, the articles is in point of fact excellent : D.
Excellent process, cheers
Also visit my webpage – Addiction Rehab Thailand
With havin so much content and articles do
you ever run into any issues of plagorism or copyright infringement?
My blog has a lot of exclusive content I’ve either written myself or outsourced but it appears a lot of it is popping it up all over the internet
without my permission. Do you know any methods to
help protect against content from being stolen?
I’d certainly appreciate it.
Also visit my site – local hookup facebook
If some one wishes to be updated with hottest technologies therefore he must be go to see this
web site and be up to date every day.
Feel free to visit my web-site – thailand rehab (Lara)
If you are going for best contents like I do, just visit this website daily since
it presents feature contents, thanks
Feel free to visit my website: high Stakes
I like this weblog very much, Its a real nice berth to read and obtain info.
Here is my web blog … Poker high Stakes
I like this post, enjoyed this one thank you for putting
up.
My page :: High stake Poker
Hi there just wanted to give you a quick heads up and let you know a few of the images aren’t loading
correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the same results.
Check out my blog :: Rehab Center Thailand
Good day! I could have sworn I’ve been to this site before but after browsing through some of the post I realized it’s new to me.
Anyhow, I’m definitely glad I found it and I’ll be bookmarking and
checking back frequently!
Also visit my blog post https://Dl.Highstakesweeps.Com/
Cool blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple adjustements would really make my blog jump out.
Please let me know where you got your theme.
Kudos
My web page: rehab in thailand (Hugh)
I?m not that much of a online reader to be honest but
your blogs really nice, keep it up! I’ll go ahead and
bookmark your site to come back down the road. All the best
Here is my web page :: luxury drug Rehab thailand
I read this post completely regarding the difference of
hottest and earlier technologies, it’s remarkable article.
Also visit my blog – Rehab Center Thailand
I read this piece of writing fully concerning
the difference of newest and earlier technologies, it’s
awesome article.
Also visit my homepage Thailand Rehab
I really lucky to find this site on bing, just what I was searching for 😀 besides saved to my bookmarks.
Feel free to surf to my webpage: addiction rehab
thailand (http://www.Bos7.cc)
I really happy to find this website on bing, just what I was searching for :
D as well saved to bookmarks.
my web-site; Rehab thailand
This article is in fact a good one it helps new the web visitors, who are wishing in favor of blogging.
Look at my homepage; Thailand Rehab
After looking at a few of the blog posts on your website, I honestly like your way of writing a blog.
I book marked it to my bookmark webpage list and will be checking back in the near future.
Please visit my website as well and let me know your opinion.
Also visit my web page … Poker High Stakes
I don’t commonly comment but I gotta admit appreciate it for the post on this one :
D.
Also visit my blog – sex in my area
Oh my goodness! Incredible article dude! Thanks, However I am
encountering issues with your RSS. I don’t understand
the reason why I can’t subscribe to it. Is there anyone else having identical RSS problems?
Anyone that knows the answer will you kindly respond?
Thanks!!
Here is my web blog; rehab chiang mai
Hello there, You have done a great job. I’ll certainly digg it and personally recommend to my friends.
I’m confident they’ll be benefited from this website.
my web-site – drug rehab thailand
Enjoyed looking through this, very good stuff, appreciate it.
My homepage :: alcohol addiction treatment Thailand
Thanks a lot for being the lecturer on this area. I enjoyed your
current article quite definitely and most of all
preferred the way you handled the aspect I thought to be controversial.
You happen to be always really kind to readers like me and assist
me in my everyday living. Thank you.
Take a look at my web blog stakes casino
Unquestionably believe that which you stated. Your favorite reason appeared to be on the web the
simplest thing to be aware of. I say to you, I certainly get annoyed while people consider
worries that they plainly do not know about. You managed to hit the nail upon the top as
well as defined out the whole thing without having side effect
, people could take a signal. Will likely be back to
get more. Thanks
My blog post :: Addiction Rehab Thailand
Great post, you have pointed out some fantastic
points, I too conceive this is a very superb
website.
Feel free to surf to my web page thailand drug rehab (http://k.ob.ejam.esa.le.ngjianf.ei2013@to.m.m.y.bye.1.2@srv5.cineteck.net/)
I?m not that much of a online reader to be honest but your sites really nice, keep
it up! I’ll go ahead and bookmark your website to come back down the road.
Many thanks
my blog :: rehab thailand
Hello, Neat post. There is an issue along with your web
site in web explorer, may test this? IE nonetheless is the market chief and a big component of people will pass over
your fantastic writing due to this problem.
Also visit my web page … Highstakes Poker
May I just say what a relief to uncover someone that actually
understands what they are talking about on the net. You certainly understand how to
bring an issue to light and make it important. More and more people
ought to check this out and understand this side of the
story. It’s surprising you’re not more popular because you most certainly have the gift.
Here is my website – High Stakes
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! However, how could we
communicate?
Also visit my web-site Lanna rehab (https://rates.Ninja/)
Thanks for helping out, superb info.
my blog highstakes online
F*ckin’ tremendous issues here. I am very glad to look your article.
Thank you so much and i’m looking forward to contact you.
Will you kindly drop me a e-mail?
my web site; drug Rehab thailand
I real glad to find this site on bing, just what I was looking for 😀 as well saved to favorites.
My website … addiction rehab Thailand
It’s a shame you don’t have a donate button! I’d without a doubt donate to this
brilliant blog! I suppose for now i’ll settle for book-marking
and adding your RSS feed to my Google account.
I look forward to brand new updates and will share this site
with my Facebook group. Chat soon!
my webpage craiglistforsex
Unquestionably believe that which you said.
Your favorite reason seemed to be on the internet the easiest thing to
be aware of. I say to you, I certainly get irked while people consider worries that they just don’t know about.
You managed to hit the nail upon the top as well as defined
out the whole thing without having side effect , people can take a signal.
Will probably be back to get more. Thanks
my web site … Rehab Thailand Chiang Mai
If some one wishes to be updated with latest technologies after that he must be pay
a quick visit this web page and be up to date everyday.
Take a look at my website; rehab thailand
Thank you for the good writeup. It in fact was a amusement
account it. Look advanced to far added agreeable from you!
However, how could we communicate?
Look at my web-site … facebookofsex
Everything is very open with a very clear clarification of the challenges.
It was really informative. Your website is extremely helpful.
Many thanks for sharing!
Also visit my site :: High Stakes Game
Real wonderful visual appeal on this website, I’d value it 10.
my webpage … High Stakes Download Link Http Dl Highstakesweeps Com
Hello! I could have sworn I’ve been to this
blog before but after checking through some of the post I realized it’s new to
me. Anyways, I’m definitely delighted I found it and I’ll be book-marking and checking back often!
Also visit my web-site :: Heriberto
It’s perfect time to make some plans for the future and it is time
to be happy. I’ve read this post and if I
could I wish to suggest you few interesting things or
tips. Perhaps you could write next articles referring to this article.
I want to read more things about it!
my blog post … high stakes download link http dl highstakesweeps com
After looking over a handful of the blog posts on your blog, I seriously like your technique
of writing a blog. I book marked it to my bookmark website list and will
be checking back in the near future. Please check out
my website as well and tell me what you think.
Feel free to surf to my web page :: https://Dl.highstakesweeps.com/
Hi there, I found your web site by way of Google whilst looking for a similar subject,
your Rehab Site came up, it seems
good. I have bookmarked it in my google bookmarks.
Hmm is anyone else experiencing problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Feel free to surf to my blog post … thailand rehabs
Thank you for the auspicious writeup. It in fact was
a amusement account it. Look advanced to more added agreeable from you!
By the way, how can we communicate?
My site – sex on facebook
You actually make it seem so easy with your presentation but I find this topic to be actually something which I think I would never understand.
It seems too complex and extremely broad for me.
I’m looking forward for your next post, I’ll try to get
the hang of it!
Feel free to surf to my web site; chiang mai Mountain resorts (paulmillerchevrolet.Net)
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way,
how can we communicate?
Have a look at my web blog … Rehab Thailand
It’s awesome to pay a quick visit this web page and reading the
views of all friends regarding this article, while I am also zealous of getting
experience.
Look into my homepage – best online poker sites nwt
I must show my appreciation to you for bailing me out of this particular
incident. Just after checking throughout the search engines and getting proposals which
are not helpful, I assumed my life was well over. Existing devoid of the strategies to
the problems you have resolved by means of this blog post is a
critical case, and the kind that might have in a negative way affected my career if I
had not discovered your blog post. Your main capability and kindness in maneuvering the whole
thing was invaluable. I’m not sure what I would have done if I hadn’t come across such a solution like this.
I am able to now relish my future. Thanks a lot very much for the reliable and amazing help.
I will not think twice to endorse your blog to any
individual who needs guidelines on this subject.
my web blog; back-yardgames.com
Having read this I believed it was rather informative.
I appreciate you finding the time and energy to
put this informative article together. I once again find myself personally spending a significant amount of time both reading and commenting.
But so what, it was still worthwhile!
my site – Lucas
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to determine if its a problem on my end or
if it’s the blog. Any feed-back would be greatly
appreciated.
my web-site :: Drug Rehab Thailand Cost
I believe other website proprietors should take this
website as an example, very clean and wonderful user pleasant design.
Here is my homepage … Lauren
Spot on with this write-up, I actually believe this amazing site needs
a great deal more attention. I’ll probably be back again to see more,
thanks for the advice!
Also visit my webpage; High stakes poker app
I believe what you said was very reasonable. However, what about this?
suppose you were to write a awesome headline? I ain’t saying your
information isn’t good., however suppose you added a headline to possibly get a
person’s attention? I mean Дубли страниц сайта, или минус
3 000 000 рублей прибыли | is kinda vanilla.
You might peek at Yahoo’s home page and note how they create news titles to get viewers to click.
You might add a related video or a pic or two to grab readers interested about what you’ve written. Just my opinion, it could bring your website a little livelier.
Also visit my webpage … Highstakes Online
Do you mind if I quote a couple of your posts as long
as I provide credit and sources back to your site? My blog is sex in my local area the exact same area of interest as yours and
my users would really benefit from a lot of the information you present here.
Please let me know if this alright with you. Thank you!
Hello, i think that i saw you visited my web site thus i came to go back the
desire?.I’m trying to in finding things to improve my website!I guess its ok to use a few of your ideas!!
my blog – facebook sex (Diane)
Hi, i feel that i saw you visited my site thus i got here to return the want?.I’m attempting
to find sex near me issues to improve my web site!I
suppose its good enough to make use of some of your concepts!!
Hello, Neat post. There is a problem with your web site in internet explorer,
could check this? IE nonetheless is the marketplace chief and a good component to
other people will pass over your wonderful writing due to this problem.
Here is my web site – high stakes game
Merely a smiling visitor here to share the love (:, btw great pattern.
my web page craiglistforsex
My partner and i still cannot quite feel that I could always be
one of those reading through the important recommendations
found on your blog. My family and I are sincerely thankful for the generosity and for presenting me the chance to pursue my own chosen profession path.
Thanks for the important information I got from your blog.
Take a look at my homepage; high Stake poker
Thank you for the good writeup. It in fact was a amusement account
it. Look advanced to far added agreeable from you! However,
how could we communicate?
Also visit my webpage addiction rehab Thailand – u2l.io –
Thanks so much for providing individuals with an extraordinarily memorable
possiblity to read critical reviews from this website. It really is very great and as well , jam-packed with a great time for me personally
and my office fellow workers to visit your web site
at the least thrice in one week to read through
the newest stuff you have. And lastly, I’m at all times fascinated concerning the splendid secrets you give.
Some 1 points on this page are unequivocally the best I
have ever had.
Take a look at my blog post – everygame poker review
I like this post, enjoyed this one regards for putting up.
Here is my site highstakes Casino Download
Some really great information, Glad I noticed this.
Also visit my webpage Stakes Casino
We’re a bunch of volunteers and starting a brand new scheme in our community.
Your site offered us with valuable information to work on. You’ve performed an impressive job and our whole community might be grateful to you.
My web blog; process addiction treatment thailand –
Joey –
Hi there! This article could not be written any better!
Looking at this post reminds me of my previous roommate!
He continually kept talking about this. I most certainly will send this post to him.
Pretty sure he will have a good read. I appreciate you for sharing!
Here is my web site – http //dl.highstakesweeps.com login
Now I am going away to do my breakfast, after having my breakfast coming over again to read additional
news.
my webpage; addiction Treatment thailand
Pretty! This was an incredibly wonderful article. Many thanks for
providing this information.
my website – Rehab center Thailand
Greetings! Very helpful advice in this particular
article! It’s the little changes that make the
biggest changes. Thanks a lot for sharing!
Check out my page: rehab thailand chiang mai (Laurene)
Hello just wanted to give you a quick heads
up and let you know a few of the images aren’t
loading properly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the same results.
Feel free to surf to my homepage … jintara rehab
Enjoyed reading this, very good stuff, regards.
Feel free to visit my website – chiang mai rehab, http://nittomudgrappler.com,
Do you mind if I quote a couple of your posts as long as I
provide credit and sources back to your website? My website is in the very same
niche as yours and my users would certainly benefit from some
of the information you provide here. Please let me know if this
ok with you. Appreciate it!
My website :: facebook sex (http://Www.Beautyzone.com)
This is a really good tip especially to those fresh to the blogosphere.
Brief but very accurate info… Thanks for sharing this one.
A must read post!
Here is my web site: electronic Functional testing Chiang
mai (http://www.carib-safari.com)
It’s actually a great and useful piece of information. I am happy that you just shared
this helpful info with us. Please stay us informed like this.
Thank you for sharing.
Feel free to visit my blog post … find sex near me
It is the best time to make some plans for the future and it is time to be happy.
I have read this post and if I could I wish to suggest you some interesting things
or suggestions. Maybe you could write next articles
referring to this article. I wish to read more things about it!
Here is my website: stakes Casino
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how could we communicate?
Feel free to visit my site Thailand Drug Rehab
I was suggested this website by my cousin. I’m not sure whether this post is written by
him as nobody else know such detailed about my trouble.
You’re amazing! Thanks!
Also visit my web page: highstakes
Unquestionably believe that which you said. Your favorite justification appeared
to be on the internet the simplest thing to be aware of.
I say to you, I definitely get irked while people
consider worries that they plainly do not know about. You managed to hit the nail upon the
top and defined out the whole thing without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
My website :: high Stakes casino download
At this time I am ready to do my breakfast,
later than having my breakfast coming yet again to read additional news.
Check out my homepage … electronic Functional testing chiang mai
Good answers in return of this query with real arguments and describing all on the
topic of that.
Look at my site … Personal trainer chiang mai
Great beat ! I would like to apprentice at
the same time as you amend your site, how could i subscribe for a blog website?
The account helped me a appropriate deal. I have been tiny bit acquainted of this your broadcast provided
bright transparent concept
My homepage – rehab Jobs thailand
I think this is among the so much vital info for hookup
near me – Dannie -.
And i am happy reading your article. However want to observation on some general things, The website style is wonderful, the articles is truly nice : D.
Excellent job, cheers
I don’t normally comment but I gotta state thank
you for the post on this great one :D.
Take a look at my page :: facebook sex
I’m now not sure the place you are getting your information, but
good topic. I needs to spend a while studying much more or understanding more.
Thank you for excellent info I used to be searching for this info for my mission.
Here is my web site :: sober Living chiang mai
Fastidious respond in return of this query with real arguments and describing
the whole thing on the topic of that.
Feel free to surf to my web page; thailand drug rehab
I always spent my half an hour to read this blog’s articles or reviews all the time along with a
mug of coffee.
My blog: rehab chiang mai (Samuel)
Greetings! Very helpful advice within this post!
It’s the little changes that make the most important changes.
Many thanks for sharing!
my page Therapist Chiang Mai
I am not certain the place you’re getting your
info, however great topic. I needs to spend a while finding out much more or figuring out more.
Thank you for great information I was looking for this info
for my mission.
My page – Thailand Alcohol Rehab
I rattling happy to find this internet site on bing, just what I was searching
for 😀 also saved to my bookmarks.
Here is my web page: Rehab Thailand
I believe this is among the so much significant information for me.
And i’m glad studying your article. But should commentary on few general things, The site taste is great, the articles
is really great : D. Just right job, cheers
My site: drug Rehab thailand
I feel this is among the most important info for me.
And i’m satisfied reading your article. However should remark on some common issues, The web site taste is ideal, the articles is in reality nice : D.
Good task, cheers
Look at my blog … drug rehab chiang mai (http://raymundo.alcantar@asa-virtual.org/)
We are a bunch of volunteers and starting a new scheme in our
community. Your site provided us with valuable info
to work on. You have done an impressive task and
our entire group will be grateful to you.
My web site: rehab Thailand
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any feed-back would be greatly appreciated.
My web page; electronic functional testing chiang mai (Julianne)
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the
way, how can we communicate?
Also visit my web site … Rehab jobs thailand – http://Www.Bqinternet.Com,
It is the best time to make some plans for the long run and it is
time to be happy. I’ve read this post and if
I could I wish to suggest you some fascinating things or advice.
Perhaps you can write subsequent articles relating to this
article. I want to read more issues approximately it!
Here is my page: cocaine addiction rehab thailand
I was suggested this website by my cousin. I am
not sure whether this post is written by him as
nobody else know such detailed about my difficulty.
You are wonderful! Thanks!
Look at my blog post – highstakespoker
That is a really good tip particularly to those fresh to the blogosphere.
Brief but very precise information… Thank you for sharing this one.
A must read article!
Also visit my web blog drug rehab chiang mai
Spot on with this write-up, I honestly think this website needs much more attention. I’ll probably be back
again to see more, thanks for the information!
My blog :: highstakes
Thank you a lot for giving everyone an extraordinarily pleasant opportunity to
read critical reviews from this site. It’s usually so beneficial and also packed with
a lot of fun for me personally and my office peers to
visit your site the equivalent facebook of sex 3 times
in a week to find out the new guides you will have.
And lastly, I’m actually amazed concerning the eye-popping
points you serve. Some 3 ideas in this article are truly the best
we have ever had.
Everything is very open with a very clear explanation of the issues.
It was definitely informative. Your website is extremely helpful.
Many thanks for sharing!
Feel free to surf to my web page craiglistforsex
(Carmine)
Hey just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking
issue. I’ve tried it in two different web browsers and
both show the same outcome.
Here is my blog post – thailand rehab Centre
I like this web site because so much useful stuff on here :D.
Also visit my page; Thailand Rehab Cost (http://Www.Redly.Vip)
This is a really good tip especially to those fresh to the blogosphere.
Short but very precise info… Many thanks for sharing this one.
A must read article!
Here is my blog post :: dual diagnosis rehab thailand
I read this paragraph completely regarding the difference of
most up-to-date and preceding technologies, it’s remarkable article.
My website – Alcohol rehab Thailand
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how can we communicate?
Also visit my homepage – hookup near me
Some genuinely fantastic information, Gladiola I found this.
my homepage: Highstakes Casino Download
I really value your work, Great post.
Feel free to surf to my page: Best Rehab thailand
Can I just say what a relief to uncover an individual who genuinely knows what they are talking about
on the internet. You certainly know how to bring an issue to
light and make it important. More and more people must read this
and understand this side of the story. I can’t believe you
aren’t more popular because you definitely have the gift.
my webpage: High Stakes sweeps
Some genuinely fantastic work on behalf of the owner of this web site,
utterly outstanding articles.
My web blog … addiction treatment thailand (the32acres.Com)
If some one wishes expert view regarding blogging afterward i propose him/her to visit this website,
Keep up the good work.
Here is my web-site – highstakes 777
Hello! I just wish to give you a big thumbs up for the great
info you have got here on this post. I will be coming back to your web site for more soon.
My homepage: local hookup facebook
I don’t usually comment but I gotta state appreciate it for the post on this great one :D.
Also visit my blog post – find sex near me
I don’t unremarkably comment but I gotta state regards for the post on this one :D.
Also visit my web-site; local hookup facebook
It is perfect time to make a few plans for the
longer term and it’s time to be happy. I have read this submit and if I could I desire to recommend you few interesting issues or tips.
Maybe you can write subsequent articles referring to
this article. I want to read even more issues about it!
my blog post Lanna rehab chiang mai
If some one needs expert view about blogging and site-building afterward i advise him/her to go
to see this blog, Keep up the nice work.
Take a look at my web-site http //dl.Highstakesweeps.com Login
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! However, how can we communicate?
Visit my webpage; Addiction Rehab thailand
Real great visual appeal on this internet site, I’d rate it 10.
my site: highstakesweeps
Thanks for helping out, great information.
Here is my blog post; High stakes poker Site
That is really attention-grabbing, You are an excessively skilled blogger.
I’ve joined your rss feed and stay up for in search of extra of your great post.
Also, I have shared your web site in my social networks
Look at my page; Electronic Functional Testing Chiang Mai
Pretty! This has been a really wonderful post.
Many thanks for providing this information.
Stop by my blog: Drug Rehab Thailand Cost; Hantsservicesltd.Co.Uk,
I was recommended this website by my cousin. I’m not sure whether this post is
written by him as nobody else know such detailed about my difficulty.
You are amazing! Thanks!
Look into my homepage – high stakes poker App
Hi there, I discovered your blog by means of Google
whilst searching for a similar subject, your website got here up, it looks great.
I have bookmarked it in my google bookmarks.
Here is my web page; Addiction Rehab Thailand
In fact no matter if someone doesn’t be aware of then its
up to other visitors that they will help, so here it takes place.
My web site high stake poker
It’s a shame you don’t have a donate button! I’d definitely donate to this outstanding blog!
I guess for now i’ll settle for bookmarking and adding your
RSS feed to my Google account. I look forward to
fresh updates and will talk about this blog with my Facebook group.
Chat soon!
Look into my site: Rehab In Thailand
Pretty! This was an incredibly wonderful post. Thanks for supplying these details.
Here is my web page: Addiction Treatment Thailand (vistaparkllc.com)
You actually make it seem so easy with your presentation but
I find this matter to be actually something that I think I would never understand.
It seems too complicated and extremely broad for me.
I’m looking forward for your next post, I’ll try to get the hang of it!
Also visit my web blog :: Addiction Rehab Thailand
Excellent beat ! I would like to apprentice even as you
amend your website, how could i subscribe for a weblog site?
The account helped me a appropriate deal. I have been tiny
bit familiar of this your broadcast provided bright transparent concept.
Check out my web page – lanna rehab (Burton)
Hello! I’ve been following your web site for a while now and finally got the courage to go ahead and give
you a shout out from Dallas Tx! Just wanted to mention keep up the excellent work!
Have a look at my web site: rehab In thailand
Hmm is anyone else experiencing problems with the
images on this blog loading? I’m trying to figure out if its
a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated.
My page – cocaine addiction rehab Thailand
Spot on with this write-up, I absolutely believe that
this web site needs much more attention. I’ll probably be back
again to read more, thanks for the information!
my web site – Rehab In Chiang Mai
Having read this I believed it was extremely enlightening.
I appreciate you spending some time and energy to put this content
together. I once again find myself personally spending a significant amount of time both reading and
leaving comments. But so what, it was still worth it!
My blog post Highstakes casino Download
Great beat ! I wish to apprentice whilst you amend your site,
how could i subscribe for a blog site? The account aided me a
applicable deal. I were tiny bit familiar of this your broadcast offered bright clear idea.
Here is my site – Thailand Rehab
It’s the best time to make some plans for the future and it is time to be happy.
I have read this post and if I could I desire to suggest
you few interesting things or advice. Maybe you
could write next articles referring to this article.
I want to read more things about it!
my web blog … high stakes download link http dl highstakesweeps com
Can I simply just say what a relief to find somebody that
really understands what they are discussing online.
You definitely know how to bring a problem to light and make it important.
More and more people have to look at this and understand this side of the story.
I can’t believe you are not more popular because you most
certainly have the gift.
My blog post Meherbabainformation.co
After I initially commented I appear to have clicked the -Notify
me when new comments are added- checkbox and from
now on each time a comment is added I get 4 emails with the exact same comment.
Perhaps there is a means you can remove me from that service?
Many thanks!
Also visit my site; Poker High stakes
Really excellent visual appeal on this website,
I’d rate it 10.
Here is my blog … Bailey
This is a very good tip particularly to those new to the blogosphere.
Brief but very accurate information… Appreciate your sharing this one.
A must read article!
Also visit my webpage – thailand rehab
Hey there! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of
hard work due to no data backup. Do you have any solutions to prevent hackers?
Also visit my site High Stakes Casino Download
It’s the best time to make some plans for the longer term and
it’s time to be happy. I have read this put up and if I may just I wish to counsel you few attention-grabbing
things or tips. Maybe you could write next articles referring to
this article. I desire to read even more things about it!
Also visit my webpage :: cocaine addiction Rehab thailand
I would like to express appreciation to this writer just for
rescuing me from this matter. After scouting through the world-wide-web and coming
across strategies which were not productive, I thought my
life was done. Being alive devoid of the approaches to the difficulties you’ve solved by means of this post is a crucial case, and ones
which may have in a negative way damaged my career if I had not come across your web site.
Your skills and kindness in handling all the things was
vital. I don’t know what I would’ve done if I had not come across such a
step like this. It’s possible to now look forward to my future.
Thanks for your time so much for this impressive and effective help.
I won’t think twice to endorse your blog to any individual who wants and needs counselling about this issue.
My website :: High Stake Poker
Greetings! Very useful advice within this post!
It’s the little changes that produce the largest changes.
Thanks for sharing!
Feel free to surf to my homepage chiang mai mountain resorts
Enjoyed studying this, very good stuff, thank you.
my web blog: Thailand alcohol rehab
Very fantastic visual appeal on this web site,
I’d rate it 10.
Also visit my site: high stake Poker
Great post, you have pointed out some great points, I as well
think this is a very fantastic website.
Feel free to visit my site rehab in thailand
Spot on with this write-up, I honestly believe this web site needs a lot more attention. I’ll
probably be returning to read more, thanks for the
info!
Feel free to surf to my web blog; lanna rehab chiang mai
We still cannot quite feel that I could be one of
those reading the important points found on your website.
My family and I are sincerely thankful for the generosity and for offering
me the chance to pursue the chosen profession path.
Appreciate your sharing the important information I managed to get from your
web-site.
my webpage – http://mhsccustomercare.com/
I like this web site because so much utile material
on here :D.
Look into my webpage; thailand Drug Rehab
I’m not sure where you are getting your information, but great topic.
I needs to spend some time studying much more or understanding more.
Thank you for magnificent information I used to be searching for this information for my mission.
My blog – Cheap Rehab thailand
I genuinely prize your work, Great post.
Also visit my page personal trainer chiang Mai
Great post, you have pointed out some excellent details, I also think this
is a very superb website.
Also visit my web page … rehab thailand
You really make it seem so easy with your presentation but I find this topic to be actually
something which I think I would never understand. It seems
too complex and very broad for me. I am looking forward for your next
post, I’ll try to get the hang of it!
Feel free to visit my blog; jintara – krystalgrand-nuevovallarta.com,
I truly prize your work, Great post.
Here is my site :: drug rehab chiang Mai
You actually make it seem so easy with your
presentation but I find this topic to be actually something which I think I would never understand.
It seems too complicated and extremely broad for me.
I am looking forward for your next post, I’ll try
to get the hang of it!
Feel free to surf to my web site: drug Rehab Chiang Mai
Wonderful beat ! I wish to apprentice at the same time as you amend your web
site, how can i subscribe for a weblog web site?
The account aided me a acceptable deal. I were tiny bit acquainted
of this your broadcast provided shiny clear idea.
Feel free to surf to my web blog rehab center in thailand (Allison)
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to determine if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Also visit my web site; cost of Alcohol Rehab in Thailand
You really make it seem so easy with your presentation but I find this topic to be really
something that I think I would never understand. It seems too
complicated and very broad for me. I am looking forward for your next post, I will try to get the
hang of it!
my webpage … drug treatment Chiang mai
It’s a shame you don’t have a donate button! I’d most certainly donate to this superb blog!
I suppose for now i’ll settle for book-marking and adding your RSS
feed to my Google account. I look forward to fresh updates and will talk about
this site with my Facebook group. Talk soon!
My page rehab resort (http://www.serena-garitta.It)
We’re a bunch of volunteers and opening a brand new scheme
in our community. Your website provided us with helpful information to work on. You have performed an impressive process and our whole
neighborhood will probably be grateful to you.
my website: rehab resort
Hi there, I discovered your web site by way of Google
whilst looking for a similar topic, your website got here up, it seems
to be good. I have bookmarked it in my google bookmarks.
Feel free to visit my site – Rehab center Thailand
Hi there! This is my first comment here so I just wanted to give a
quick shout out and say I genuinely enjoy reading through
your articles. Can you recommend any other blogs/websites/forums that go over the same subjects?
Thanks!
Feel free to visit my site; addiction Treatment Thailand
F*ckin’ tremendous issues here. I’m very satisfied to peer your article.
Thanks so much and i’m looking forward to touch you. Will you kindly drop me a mail?
Also visit my web page :: chiang Mai rehab
Spot on with this write-up, I absolutely believe that this web site needs a great deal more attention. I’ll probably be back again to read more, thanks
for the information!
Here is my site – thailand drug rehab (http://nagievonline.com/user/AbbyS26962/)
That is a good tip particularly to those fresh to
the blogosphere. Brief but very accurate information…
Appreciate your sharing this one. A must read article!
Also visit my blog post: Thailand Rehab Centre
Spot on with this write-up, I honestly believe that this site
needs far more attention. I’ll probably be returning to read through more, thanks for the advice!
Feel free to surf to my web site Rehab Resort
That is a good tip especially to those new to the blogosphere.
Brief but very precise info… Thanks for sharing this one.
A must read article!
Here is my blog post – rehab Resort
I really prize your piece of work, Great post.
Also visit my web page :: Jintara rehab
We’re a bunch of volunteers and opening a new scheme in our community.
Your website provided us with helpful information to work on. You have performed a formidable process and our whole community will likely be grateful to you.
Here is my web blog – Addiction rehab thailand
Hmm is anyone else encountering problems with the
images on this blog loading? I’m trying to determine if its a problem on my end or
if it’s the blog. Any feedback would be greatly appreciated.
Look into my webpage: jintara rehab
Fantastic beat ! I wish to apprentice while you amend your website, how can i subscribe for
a blog site? The account helped me a appropriate deal.
I were a little bit familiar of this your broadcast provided shiny clear concept
My blog post :: thailand retreat mental health
Great beat ! I would like to apprentice while you amend your
web site, how could i subscribe for a blog site? The account aided me a acceptable deal.
I were tiny bit acquainted of this your broadcast offered vibrant clear concept.
Feel free to visit my site – rehab chiang mai (Glenda)
You actually make it seem so easy with your presentation but I find this matter to be really something which I think I would never
understand. It seems too complex and extremely broad for me.
I’m looking forward for your next post, I’ll try to get the hang of it!
My blog drug rehab chiang mai
It’s appropriate time to make some plans for the longer term and it is time
to be happy. I have learn this publish and if I could I wish to
suggest you some interesting issues or tips. Maybe you could write
subsequent articles referring to this article. I wish to learn even more things about it!
My site Rehab Chiang Mai
Fastidious answers in return of this question with genuine arguments and explaining the
whole thing concerning that.
My web page – best rehab thailand (http://gtshaheen.Com)
Enjoyed reading through this, very good stuff, thanks.
Stop by my website: chiang Mai therapy
You really make it seem so easy with your presentation but I
find this topic to be really something that I think I would never understand.
It seems too complex and very broad for me.
I am looking forward for your next post, I’ll try to
get the hang of it!
my blog; thailand rehab centre
Hey there, You’ve done an incredible job. I’ll definitely digg it and personally suggest to my friends.
I’m sure they’ll be benefited from this web site.
My blog post – alcohol rehab thailand (private-section.co.uk)
I think what you wrote made a bunch of sense. But, what about this?
what if you composed a catchier title? I ain’t saying your information isn’t solid, but
what if you added a post title that grabbed a person’s attention?
I mean Дубли страниц сайта, или минус 3 000 000 рублей прибыли
| is kinda boring. You should glance at Yahoo’s front
page and note how they write post headlines to get viewers to click.
You might add a video or a picture or two to get people interested about what you’ve got to say.
Just my opinion, it could make your blog a little livelier.
my homepage: poker Online
I believe other website owners should take this site as
an model, very clean and good user pleasant design.
Also visit my web site: Drawdowngroup.com
In fact no matter if someone doesn’t know afterward its up to
other viewers that they will help, so here it occurs.
Feel free to surf to my web-site – Highstakes poker
Some genuinely prime articles on this web site, saved to bookmarks.
My webpage: rehab center In thailand
I genuinely prize your work, Great post.
Also visit my web site … dual diagnosis rehab thailand
[Lindsay]
Thanks a lot for being my teacher on this issue. I actually enjoyed
your article greatly and most of all cherished the way you handled the issues I
regarded as being controversial. You happen to be always quite kind to readers like me and aid me in my
everyday living. Thank you.
My webpage: high stakes casino Download
It is perfect time to make some plans for the long run and it’s
time to be happy. I’ve read this publish and if I may I desire to counsel
you some fascinating things or advice. Maybe you
could write next articles referring to this article.
I desire to learn even more things about it!
my web blog Thailand Rehab
It’s amazing for me to have a web page, which is valuable in support of my knowledge.
thanks admin
Also visit my website; Aleisha
I really thankful to find this site on bing, just what I was searching for
😀 besides saved to my bookmarks.
My site … rehab thailand
Pretty! This was an incredibly wonderful post. Many thanks Treatment For Addictions Thailand providing
this info.
It’s appropriate time to make a few plans for the
longer term and it is time to be happy. I’ve learn this post and if I could I want to suggest you some interesting issues or advice.
Maybe you could write next articles regarding this article.
I desire to learn more things about it!
My web page: Best Rehab Thailand
Some really wonderful work on behalf of the owner
of this site, utterly outstanding content.
Check out my site – dual Diagnosis rehab Thailand
I believe other website proprietors should take this site as an model,
very clean and great user friendly pattern.
my web blog: High Stakes
F*ckin’ remarkable things here. I am very glad to see
your article. Thank you a lot and i’m having a look forward
to contact you. Will you please drop me a mail?
Here is my web site Rehab resort (elecdz.cn)
Hello there, I found your blog via Google at the same time as
looking for a similar topic, your site got here up, it seems to be good.
I have bookmarked it in my google bookmarks.
Here is my web blog – Rehab Website
Now I am going away to do my breakfast, afterward having my breakfast coming over again to read additional news.
Feel free to visit my homepage: alcohol rehab thailand
I was recommended this web site by my cousin. I’m not
sure whether this post is written by him as no one else
know such detailed about my trouble. You are wonderful!
Thanks!
Feel free to visit my site high stakes poker
Oh my goodness! Incredible article dude! Many thanks, However I am experiencing problems
with your RSS. I don’t know why I am unable to join it.
Is there anybody else getting similar RSS issues? Anyone who
knows the solution can you kindly respond? Thanx!!
My web page – addiction rehab thailand (Matilda)
Pretty! This has been an extremely wonderful post.
Thank you for providing this info.
Take a look at my webpage Personal trainer chiang mai
I am now not sure where you’re getting your info, however great
topic. I must spend some time finding out more or figuring out more.
Thank you for great information I was on the lookout for this info for my mission.
Also visit my page – Alcohol Dependence Treatment Thailand
It is perfect time to make some plans for the
longer term and it is time to be happy. I’ve learn this submit and if I could I want
to recommend you few fascinating things or suggestions.
Perhaps you could write next articles relating to this article.
I desire to learn even more issues approximately it!
Feel free to surf to my site :: rehab Thailand